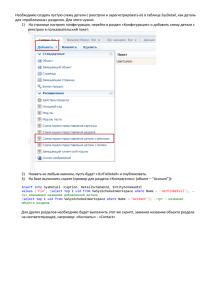
сЛабораторная работа № 1
Запускаем программу MySQL. Откроется окно, предлагающее ввести пароль.
Нажимаем Enter на клавиатуре, если вы не указывали пароль при настройке
сервера или указываем пароль, если вы его задавали. Ждем приглашения mysql>.
Нам надо создать базу данных, которую мы назовем forum. Для этого в SQL
существует оператор create database. Создание базы данных имеет следующий
синтаксис:
create database имя_базы_данных;
Максимальная длина имени БД составляет 64 знака и может включать буквы,
цифры, символ "_" и символ "$". Имя может начинаться с цифры, но не должно
полностью состоять из цифр. Любой запрос к БД заканчивается точкой с запятой
(этот символ называется разделителем - delimiter). Получив запрос, сервер
выполняет его и в случае успеха выдает сообщение "Query OK ..."
Итак, создадим БД forum:
Нажимаем Enter и видим ответ "Query OK ...", означающий, что БД была
создана:
Вот так все просто. Теперь в этой базе данных нам надо создать 3 таблицы:
темы, пользователи и сообщения. Но перед тем, как это делать, нам надо указать
серверу в какую именно БД мы создаем таблицы, т.е. надо выбрать БД для работы.
Для этого используется оператор use. Синтаксис выбора БД для работы следующий:
use имя_базы_данных;
Итак, выберем для работы нашу БД forum:
Нажимаем Enter и видим ответ "Database changed" - база данных выбрана.
Выбирать БД необходимо в каждом сеансе работы с MySQL.
Для создания таблиц в SQL существует оператор create table. Создание базы
данных имеет следующий синтаксис:
create table имя_таблицы (имя_первого_столбца тип, имя_второго_столбца
тип, ..., имя_последнего_столбца тип );
Требования к именам таблиц и столбцов такие же, как и для имен БД. К
каждому столбцу привязан определенный тип данных, который ограничивает
характер информации, которую можно хранить в столбце (например,
предотвращает ввод букв в числовое поле). MySQL поддерживает несколько
типов данных: числовые, строковые, календарные и специальный тип NULL,
обозначающий отсутствие информации. Подробно о типах данных мы будем
говорить в следующем уроке, а пока вернемся к нашим таблицам. В них у нас
всего два типа данных - целочисленные значения (int) и строки (text). Итак,
создадим первую таблицу - Темы:
Нажимаем Enter – таблица создана:
Итак, мы создали таблицу topics (темы) с тремя столбцами:
id_topic int - id темы (целочисленное значение),
topic_name text - имя темы (строка),
id_author int - id автора (целочисленное значение).
Аналогичным образом создадим оставшиеся две таблицы - users
(пользователи) и posts (сообщения):
Итак, мы создали БД forum и в ней три таблицы. Сейчас мы об этом
помним, но если наша БД будет очень большой, то удержать в голове названия
всех таблиц и столбцов просто невозможно. Поэтому надо иметь возможность
посмотреть, какие БД у нас существуют, какие таблицы в них присутствуют,
и какие столбцы эти таблицы содержат. Для этого в SQL существует несколько
операторов:
show databases - показать все имеющиеся БД,
show tables - показать список таблиц текущей БД (предварительно ее
надо выбрать с помощью оператора use),
describe имя_таблицы - показать описание столбцов указанной таблицы.
Давайте попробуем. Смотрим все имеющиеся базы данных (у вас она пока
одна - forum, у меня 30, и все они перечислены в столбик):
Теперь посмотрим список таблиц БД forum (для этого ее предварительно
надо выбрать), не забываем после каждого запроса нажимать Enter:
В ответе видим названия наших трех таблиц. Теперь посмотрим
описание столбцов, например, таблицы topics:
Первые два столбца нам знакомы - это имя и тип данных, значения
остальных нам еще предстоит узнать. Но прежде мы все-таки узнаем какие
типы данных бывают, какие и когда следует использовать.
А сегодня мы рассмотрим последний оператор - drop, он позволяет
удалять таблицы и БД. Например, давайте удалим таблицу topics. Так как мы
два шага назад выбирали БД forum для работы, то сейчас ее выбирать не надо,
можно просто написать:
drop table имя_таблицы;
и нажать Enter.
Теперь снова посмотрим список таблиц нашей БД:
Наша таблица действительно удалена. Теперь давайте удалим и саму БД
forum (удаляйте, не жалейте, ее все равно придется переделывать). Для этого
напишем:
drop database имя_базы данных;
и нажмем Enter.
И убедитесь в этом, сделав запрос на все имеющиеся БД:
У вас, наверно, нет ни одной БД, у меня их стало 29 вместо 30.
Лабораторная работа № 2.
Этот урок носит больше теоретический характер, но пропустить его нельзя. В
дальнейшем вы сможете возвращаться к нему, как к справочному уроку, сейчас же
просто ознакомьтесь. В прошлом уроке говорилось, что MySQL поддерживает
числовые, строковые, календарные данные и данные типа NULL. Рассмотрим их по
очереди.
Числовые типы данных
Тип данных
Объем
памяти
Диапазон
Описание
TINYINT (M) 1 байт
Целое число. Может быть объявлено
положительным с помощью ключевого слова
UNSIGNED, тогда элементам столбца нельзя будет
присвоить отрицательное значение.
Необязательный параметр М - количество
отводимых под число символов. Необязательный
атрибут ZEROFILL позволяет свободные позиции
по умолчанию заполнить нулями.
Примеры:
от -128 до 127 или от
TINYINT - хранит любое число в диапазоне от -128
0 до 255
до 127.
TINYINT UNSIGNED - хранит любое число в
диапазоне от 0 до 255.
TINYINT (2) - предполагается, что значения будут
двузначными, но по факту будет хранить и
трехзначные.
TINYINT (3) ZEROFILL - свободные позиции слева
заполнит нулями. Например, величина 2 будет
отображаться, как 002.
SMALLINT
(M)
Аналогично предыдущему, но с большим
диапазоном.
Примеры:
SMALLINT - хранит любое число в диапазоне от 32768 до 32767.
SMALLINT UNSIGNED - хранит любое число в
от -32768 до 32767
диапазоне от 0 до 65535.
или от 0 до 65535
SMALLINT (4) - предполагается, что значения
будут четырехзначные, но по факту будет хранить и
пятизначные.
SMALLINT (4) ZEROFILL - свободные позиции
слева заполнит нулями. Например, величина 2
будет отображаться, как 0002.
2
байта
MEDIUMINT 3
(M)
байта
Аналогично предыдущему, но с большим
диапазоном.
Примеры:
MEDIUMINT - хранит любое число в диапазоне от 8388608 до 8388608.
от -8388608 до
MEDIUMINT UNSIGNED - хранит любое число в
8388608 или от 0 до диапазоне от 0 до 16777215.
16777215
MEDIUMINT (4) - предполагается, что значения
будут четырехзначные, но по факту будет хранить и
семизначные.
MEDIUMINT (5) ZEROFILL - свободные позиции
слева заполнит нулями. Например, величина 2
будет отображаться, как 00002.
INT (M) или
4
INTEGER
байта
(M)
от -2147683648 до
2147683648 или от
0 до 4294967295
Аналогично предыдущему, но с большим
диапазоном.
Примеры:
INT - хранит любое число в диапазоне от 2147683648 до 2147683648.
INT UNSIGNED - хранит любое число в диапазоне
от 0 до 4294967295.
INT (4) - предполагается, что значения будут
четырехзначные, но по факту будет хранить
максимально возможные.
INT (5) ZEROFILL - свободные позиции слева
заполнит нулями. Например, величина 2 будет
отображаться, как 00002.
BIGINT (M)
8
байта
от -263 до 263-1 или
от 0 до 264
Аналогично предыдущему, но с большим
диапазоном.
Примеры:
BIGINT - хранит любое число в диапазоне от -263до
263-1.
BIGINT UNSIGNED - хранит любое число в
диапазоне от 0 до 264.
BIGINT (4) - предполагается, что значения будут
четырехзначные, но по факту будет хранить
максимально возможные.
BIGINT (7) ZEROFILL - свободные позиции слева
заполнит нулями. Например, величина 2 будет
отображаться, как 0000002.
BOOL или
BOOLEAN
1 байт
либо 0, либо 1
Булево значение. 0 - ложь (false), 1 - истина (true).
DECIMAL
(M,D) или
DEC (M,D)
или
NUMERIC
(M,D)
M + 2 зависят от
байта параметров M и D
Используются для величин повышенной точности,
например, для денежных данных. M - количество
отводимых под число символов (максимальное
значение - 64). D - количество знаков после запятой
(максимальное значение - 30).
Пример:
DECIMAL (5,2) - будет хранить числа от -99,99 до
99,99.
FLOAT
(M,D)
DOUBLE
(M,D)
4
байта
мин. значение +(-)
1.175494351 * 10-39
макс. значение +(-)
3. 402823466 * 1038
Вещественное число (с плавающей точкой). Может
иметь параметр UNSIGNED, запрещающий
отрицательные числа, но диапазон значений от
этого не изменится. M - количество отводимых под
число символов. D - количество символов дробной
части.
Пример:
FLOAT (5,2) - будет хранить числа из 5 символов, 2
из которых будут идти после запятой (например:
46,58).
8 байт
мин. значение +(-)
2.2250738585072015
* 10-308
макс. значение +(-)
1.797693134862315
* 10308
Аналогично предыдущему, но с большим
диапазоном.
Пример:
DOUBLE - будет хранить большие дробные числа.
Необходимо понимать, чем больше диапазон значений у типа данных, тем
больше памяти он занимает. Поэтому, если предполагается, что значения в
столбце не будут превышать 100, то используйте тип TINYINT. Если при этом
все значения будут положительными, то используйте атрибут UNSIGNED.
Правильный выбор типа данных позволяет сэкономить место для хранения этих
данных.
Строковые типы данных
Тип данных
CHAR (M)
VARCHAR (M)
Максимальный
размер
Описание
М символов
Позволяет хранить строку фиксированной
длины М. Значение М - от 0 до 65535.
Примеры:
CHAR (8) - хранит строки из 8 символов и
занимает 8 байтов. Например, любое из
следующих значений: '', 'Иван','Ирина', 'Сергей'
будет занимать по 8 байтов памяти. А при
попытке ввести значение 'Александра', оно
будет усечено до 'Александ', т.е. до 8 символов.
L+1 символов М символов
Позволяет хранить переменные строки длиной
L. Значение М - от 0 до 65535.
Примеры:
VARCHAR (3) - хранит строки максимум из 3
символов, но пустая строка '' занимает 1 байт
памяти, строка 'a' - 2 байта, строк 'aa' - 3 байта,
строка 'aaa' - 4 байта. Значение более 3
символов будет усечено до 3.
Объем памяти
M символов
L+2 символов 216-1 символов
BLOB, TEXT
Позволяют хранить большие объемы текста.
Причем тип TEXT используется для хранения
именно текста, а BLOB - для хранения
изображений, звука, электронных документов и
т.д.
MEDIUMBLOB,
L+3 символов 224-1 символов
MEDIUMTEXT
Аналогично предыдущему, но с большим
размером.
LONGBLOB,
LONGTEXT
Аналогично предыдущему, но с большим
размером.
L+4 символов 232-1 символов
ENUM ('value1',
'value2',
...,'valueN')
SET ('value1',
'value2',
...,'valueN')
1 или 2 байта
до 8 байт
65535
элементов
Строки этого типа могут принимать только
одно из значений указанного множества.
Пример:
ENUM ('да', 'нет') - в столбце с таким типом
может храниться только одно из имеющихся
значений. Удобно использовать, если
предусмотрено, что в столбце должен храниться
ответ на вопрос.
64 элемента
Строки этого типа могут принимать любой или
все элементы из значений указанного
множества.
Пример:
SET ('первый', 'второй') - в столбце с таким
типом может храниться одно из перечисленных
значений, оба сразу или значение может
отсутствовать вовсе.
Календарные типы данных
Тип данных
Объем
памяти
Диапазон
Описание
от '1000-01-01'
до '9999-12-31'
Предназначен для хранения даты. В качестве первого
значения указывается год в формате "YYYY", через
дефис - месяц в формате "ММ", а затем день в формате
"DD". В качестве разделителя может выступать не
только дефис, а любой символ отличный от цифры.
3 байта
от '-838:59:59'
до '838:59:59'
Предназначен для хранения времени суток. Значение
вводится и хранится в привычном формате - hh:mm:ss,
где hh - часы, mm - минуты, ss - секунды. В качестве
разделителя может выступать любой символ отличный
от цифры.
8 байт
от '1000-01-01
00:00:00' до
'9999-12-31
23:59:59'
Предназначен для хранения и даты и времени суток.
Значение вводится и хранится в формате - YYYY-MMDD hh:mm:ss. В качестве разделителей могут выступать
любые символы отличные от цифры.
TIMESTAMP 4 байта
от '1970-01-01
00:00:00' до
Предназначен для хранения даты и времени суток в виде
количества секунд, прошедших с полуночи 1 января
1970 года (начало эпохи UNIX).
DATE
TIME
DATATIME
3 байта
'2037-12-31
23:59:59'
YEAR (M)
1 байт
от 1970 до 2069
для М=2 и от
1901 до 2155
для М=4
Предназначен для хранения года. М - задает формат
года. Например, YEAR (2) - 70, а YEAR (4) - 1970. Если
параметр М не указан, то по умолчанию считается, что
он равен 4.
Тип данных NULL
Вообще-то это лишь условно можно назвать типом данных. По сути это скорее
указатель возможности отсутствия значения. Например, когда вы регистрируетесь
на каком-либо сайте, вам предлагается заполнить форму, в которой присутствуют,
как обязательные, так и необязательные поля. Понятно, что регистрация
пользователя невозможна без указания логина и пароля, а вот дату рождения и пол
пользователь может указать по желанию. Для того, чтобы хранить такую
информацию в БД и используют два значения: NOT NULL (значение не может
отсутствовать) для полей логин и пароль, NULL (значение может отсутствовать) для
полей дата рождения и пол. По умолчанию всем столбцам присваивается тип NOT
NULL, поэтому его можно явно не указывать.
Пример:
create
table
users
(login
varchar(20),
password
varchar(15),
floor enum('man', 'woman') NULL, date_birth date NULL);
Таким образом, мы создаем таблицу с 4 столбцами: логин (не более 20
символов) обязательное, пароль (не более 15 символов) обязательное, пол (мужской
или женский) не обязательное, дата рождения (тип дата) необязательное. Все, на
этом урок, посвященный типам данных, закончен. У вас, возможно, остались
вопросы, но они исчезнут по мере освоения дальнейшего материала, т.к. на практике
все становится более понятно, чем в теории.
Лабораторная работа № 3.
Итак, мы познакомились с типами данных, теперь будем усовершенствовать
таблицы для нашего форума. Сначала разберем их. И начнем с таблицы users
(пользователи). В ней у нас 4 столбца:
id_user - целочисленные значения, значит будет тип int, ограничим его 10 символами
– int (10).
name - строковое значение varchar, ограничим его 20 символами - varchar(20).
email - строковое значение varchar, ограничим его 50 символами - varchar(50).
password - строковое значение varchar, ограничим его 15 символами - varchar(15).
Все значения полей обязательны для заполнения, значит надо добавить тип
NOT NULL.
id_user int (10) NOT NULL
name varchar(20) NOT NULL
email varchar(50) NOT NULL
password varchar(15) NOT NULL
Первый столбец, как вы помните из концептуальной модели нашей БД,
является первичным ключом (т.е. его значения уникальны, и они однозначно
идентифицируют запись). Следить за уникальностью самостоятельно можно, но не
рационально. Для этого в SQL есть специальный атрибут - AUTO_INCREMENT,
который при обращении к таблице на добавление данных высчитывает
максимальное значение этого столбца, полученное значение увеличивает на 1 и
заносит его в столбец. Таким образом, в этом столбце автоматически генерируется
уникальный номер, а следовательно тип NOT NULL излишен. Итак, присвоим
атрибут столбцу с первичным ключом:
id_user int (10) AUTO_INCREMENT
name varchar(20) NOT NULL
email varchar(50) NOT NULL
password varchar(15) NOT NULL
Теперь надо указать, что поле id_user является первичным ключом. Для этого
в SQL используется ключевое слово PRIMARY KEY (), в скобочках указывается имя
ключевого поля. Внесем изменения:
id_user int (10) AUTO_INCREMENT
name varchar(20) NOT NULL
email varchar(50) NOT NULL
password varchar(15) NOT NULL
PRIMARY KEY (id_user)
Итак, таблица готова, и ее окончательный вариант выглядит так:
create table users (
id_user int (10) AUTO_INCREMENT,
name varchar(20) NOT NULL,
email varchar(50) NOT NULL,
password varchar(15) NOT NULL,
PRIMARY KEY (id_user)
);
Теперь разберемся со второй таблицей - topics (темы). Рассуждая аналогично,
имеем следующие поля:
id_topic int (10) AUTO_INCREMENT
topic_name varchar(100) NOT NULL
id_author int (10) NOT NULL
PRIMARY KEY (id_topic)
Но в модели нашей БД поле id_author является внешним ключом, т.е. оно
может иметь только те значения, которые есть в поле id_user таблицы users. Для того,
чтобы указать это в SQL есть ключевое слово FOREIGN KEY (), которое имеет
следующий синтаксис:
FOREIGN KEY (имя_столбца_которое_является_внешним_ключом)
REFERENCES имя_таблицы_родителя (имя_столбца_родителя);
Укажем, что id_author – внешний ключ:
id_topic int (10) AUTO_INCREMENT
topic_name varchar(100) NOT NULL
id_author int (10) NOT NULL
PRIMARY KEY (id_topic)
FOREIGN KEY (id_author) REFERENCES users (id_user)
Таблица готова, и ее окончательный вариант выглядит так:
create table topics (
id_topic int (10) AUTO_INCREMENT,
topic_name varchar(100) NOT NULL,
id_author int (10) NOT NULL,
PRIMARY KEY (id_topic),
FOREIGN KEY (id_author) REFERENCES users (id_user)
);
Осталась последняя таблица - posts (сообщения). Здесь все аналогично, только
два внешних ключа:
create table posts (
id_post int (10) AUTO_INCREMENT,
message text NOT NULL,
id_author int (10) NOT NULL,
id_topic int (10) NOT NULL,
PRIMARY KEY (id_post),
FOREIGN KEY (id_author) REFERENCES users (id_user),
FOREIGN KEY (id_topic) REFERENCES topics (id_topic)
);
Обратите внимание, внешних ключей у таблицы может быть несколько, а
первичный ключ в MySQL может быть только один. В первом уроке мы удалили
нашу БД forum, пришло время создать ее вновь.
Запускаем сервер MySQL, вводим пароль, создаем БД forum (create database
forum;), выбираем ее для использования (use forum;) и создаем три наших таблицы:
Обратите внимание, одну команду можно писать в несколько строк,
используя клавишу Enter (MySQL автоматически подставляет символ новой строки
->), и только после разделителя (точки с запятой) нажатие клавиши Enter приводит
к выполнению запроса.
Помните, если вы сделали что-то не так, всегда можно удалить таблицу или
всю БД с помощью оператора DROP. Исправлять что-то в командной строке
крайне неудобно, поэтому иногда (особенно на начальном этапе) проще писать
запросы в каком-нибудь редакторе, например в Блокноте, а затем копировать и
вставлять их в черное окошко.
Итак, таблицы созданы, чтобы убедиться в этом вспомним о команде show
tables:
И, наконец, посмотрим структуру нашей последней таблицы posts:
Теперь становятся понятны значения всех полей структуры, кроме поля
DEFAULT. Это поле значений по умолчанию. Мы могли бы для какого-нибудь
столбца (или для всех) указать значение по умолчанию. Например, если бы у нас
было поле с названием "Женаты\Замужем" и типом ENUM ('да', 'нет'), то было бы
разумно сделать одно из значений значением по умолчанию. Синтаксис был бы
следующий:
married enum ('да', 'нет') NOT NULL default('да')
Т.е. это ключевое слово пишется через пробел после указания типа данных, а
в скобках указывается значение по умолчанию.
Но вернемся к нашим таблицам. Теперь нам необходимо внести данные в
наши таблицы. На сайтах, вы обычно вводите информацию в какие-нибудь htmlформы, затем сценарий на каком-либо языке (php, java...) извлекает эти данные из
формы и заносит их в БД. Делает он это посредством SQL-запроса на внесение
данных в базу. Писать сценарии на php мы пока не умеем, а вот отправлять SQLзапросы на внесение данных сейчас научимся.
Для этого используется оператор INSERT. Синтаксис можно использовать
двух видов. Первый вариант используется для внесения данных во все поля
таблицы:
INSERT INTO имя_таблицы VALUES
('значение_первого_столбца','значение_второго_столбца', ...,
'значение_последнего_столбца');
Давайте попробуем внести в нашу таблицу users следующие значения:
INSERT INTO users VALUES ('1','sergey', 'sergey@mail.ru', '1111');
Второй вариант используется для внесения данных в некоторые поля
таблицы:
INSERT
INTO
имя_таблицы
('имя_столбца',
'имя_столбца')
('значение_первого_столбца','значение_второго_столбца');
VALUES
В нашей таблице users все поля обязательны для заполнения, но наше первое
поле имеет ключевое слово - AUTO_INCREMENT (т.е. оно заполняется
автоматически), поэтому мы можем пропустить этот столбец:
INSERT INTO users (name, email, password) VALUES ('valera', 'valera@mail.ru',
'2222');
Если бы у нас были поля с типом NULL, т.е. необязательные для заполнения,
мы бы тоже могли их проигнорировать. А вот если попытаться оставить пустым поле
со значением NOT NULL, то сервер выдаст сообщение об ошибке и не выполнит
запрос. Кроме того, при внесении данных сервер проверяет связи между таблицами.
Поэтому вам не удастся внести в поле, являющееся внешним ключом, значение,
отсутствующее в связанной таблице. В этом вы убедитесь, внося данные в
оставшиеся две таблицы.
Но прежде внесем информацию еще о нескольких пользователях. Чтобы
добавить сразу несколько строк, надо просто перечислять скобки со значениями
через запятую:
Теперь внесем данные во вторую таблицу - topics (темы). Все тоже самое, но
надо помнить, что значения в поле id_author должны присутствовать в таблице users
(пользователи):
Теперь давайте попробуем внести еще одну тему, но с id_author, которого в
таблице users нет (т.к. мы внесли в таблицу users только 5 пользователей, то id=6 не
существует):
Сервер выдает ошибку и говорит, что не может внести такую строку, т.к. в
поле, являющемся внешним ключом, стоит значение, отсутствующее в связанной
таблице users.
Теперь внесем несколько строк в таблицу posts (сообщения), помня, что в ней
у нас 2 внешних ключа, т.е. id_author и id_topic, которые мы будем вносить должны
присутствовать в связанных с ними таблицах:
Итак, у нас есть 3 таблицы, в которых есть данные. Встает вопрос - как
посмотреть, какие данные хранятся в таблицах. Этим мы и займемся на следующем
уроке.
Лабораторная работа № 4.
Итак, в нашей БД forum есть три таблицы: users (пользователи), topics
(темы) и posts (сообщения). И мы хотим посмотреть, какие данные в них
содержатся. Для этого в SQL существует оператор SELECT. Синтаксис его
использования следующий:
SELECT что_выбрать FROM откуда_выбрать;
Вместо "что_выбрать" мы должны указать либо имя столбца, значения
которого хотим увидеть, либо имена нескольких столбцов через запятую, либо
символ звездочки (*), означающий выбор всех столбцов таблицы. Вместо
"откуда_выбрать" следует указать имя таблицы.
Давайте
сначала
посмотрим
все
столбцы
из
таблицы
users:
SELECT * FROM users;
Вот и все наши данные, которые мы вносили в эту таблицу. Но предположим,
что мы хотим посмотреть только столбец id_user (например, в прошлом уроке,
нам надо было для заполнения таблицы topics (темы) знать, какие id_user есть
в таблице users). Для этого в запросе мы укажем имя этого столбца:
SELECT id_user FROM users;
Ну, а если мы захотим посмотреть, например, имена и e-mail наших
пользователей, то мы перечислим интересующие столбцы через запятую:
SELECT name, email FROM users;
Аналогично, вы можете посмотреть, какие данные содержат и другие наши
таблицы. Давайте посмотрим, какие у нас существуют темы:
SELECT * FROM topics;
Сейчас у нас всего 4 темы, а если их будет 100? Хотелось бы, чтобы они
выводились, например, по алфавиту. Для этого в SQL существует ключевое
слово ORDER BY после которого указывается имя столбца по которому будет
происходить сортировка. Синтаксис следующий:
SELECT имя_столбца FROM имя_таблицы ORDER BY
имя_столбца_сортировки;
По умолчанию сортировка идет по возрастанию, но это можно изменить,
добавив ключевое слово DESC
Теперь наши данные отсортированы в порядке по убыванию.
Сортировку можно производить сразу по нескольким столбцам. Например,
следующий запрос отсортирует данные по столбцу topic_name, и если в этом
столбце будет несколько одинаковых строк, то в столбце id_author будет
осуществлена сортировка по убыванию:
Сравните результат с результатом предыдущего запроса.
Очень часто нам не нужна вся информация из таблицы. Например, мы хотим
узнать, какие темы были созданы пользователем sveta (id=4). Для этого в SQL есть
ключевое слово WHERE, синтаксис у такого запроса следующий:
SELECT имя_столбца FROM имя_таблицы WHERE условие;
Для нашего примера условием является идентификатор пользователя, т.е. нам
нужны только те строки, в столбце id_author которых стоит 4 (идентификатор
пользователя sveta):
SELECT * FROM topics WHERE id_author=4;
Или мы хотим узнать, кто создал тему "велосипеды":
Конечно, было бы удобнее, чтобы вместо id автора, выводилось его имя,
но имена хранятся в другой таблице. В последующих уроках мы узнаем, как
выбирать данные из нескольких таблиц. А пока узнаем, какие условия можно
задавать, используя ключевое слово WHERE.
Оператор
Описание
Отбираются значения равные указанному
Пример:
SELECT * FROM topics WHERE id_author=4;
Результат:
= (равно)
> (больше)
Отбираются значения больше указанного
Пример:
SELECT * FROM topics WHERE id_author>2;
Результат:
Отбираются значения меньше указанного
Пример:
SELECT * FROM topics WHERE id_author<3;
Результат:
< (меньше)
Отбираются значения большие и равные указанному
Пример:
SELECT * FROM topics WHERE id_author>=2;
Результат:
>=
(больше
или равно)
Отбираются значения меньшие и равные указанному
<= (меньше
Пример:
или равно)
SELECT * FROM topics WHERE id_author<=3;
Результат:
Отбираются значения не равные указанному
Пример:
SELECT * FROM topics WHERE id_author!=1;
Результат:
!= (не равно)
Отбираются строки, имеющие значения в указанном поле
Пример:
SELECT * FROM topics WHERE id_author IS NOT NULL;
Результат:
IS NOT NULL
IS NULL
Отбираются строки, не имеющие значения в указанном поле
Пример:
SELECT * FROM topics WHERE id_author IS NULL;
Результат:
Empty set - нет таких строк.
Отбираются значения, находящиеся между указанными
Пример:
SELECT * FROM topics WHERE id_author BETWEEN 1 AND 3;
Результат:
BETWEEN
(между)
Отбираются значения, соответствующие указанным
Пример:
SELECT * FROM topics WHERE id_author IN (1, 4);
Результат:
IN (значение
содержится)
NOT
IN Отбираются значения, кроме указанных
(значение не Пример:
содержится)
SELECT * FROM topics WHERE id_author NOT IN (1, 4);
Результат:
Отбираются значения, соответствующие образцу
Пример:
SELECT * FROM topics WHERE topic_name LIKE 'вел%';
Результат:
LIKE
(соответствие)
Возможные метасимволы оператора LIKE будут рассмотрены ниже.
Отбираются значения, не соответствующие образцу
Пример:
SELECT * FROM topics WHERE topic_name NOT LIKE 'вел%';
Результат:
NOT LIKE (не
соответствие)
Метасимволы оператора LIKE
Поиск с использованием метасимволов может осуществляться только в
текстовых полях.
Самый распространенный метасимвол - %. Он означает любые символы.
Например, если нам надо найти слова, начинающиеся с букв "вел", то мы напишем
LIKE 'вел%', а если мы хотим найти слова, которые содержат символы "клуб", то мы
напишем LIKE '%клуб%'. Например:
Еще один часто используемый метасимвол - _. В отличие от %, который
обозначает несколько или ни одного символа, нижнее подчеркивание обозначает
ровно один символ. Например:
Обратите внимание на пробел между метасимволом и "рыб", если его
пропустить, то запрос не сработает, т.к. метасимвол _ обозначает ровно один
символ, а пробел - это тоже символ.
На сегодня достаточно. В следующем уроке мы научимся составлять запросы
к двум и более таблицам. А пока попробуйте самостоятельно составить запросы к
таблице posts (сообщения).
Лабораторная работа № 5.
В прошлом уроке мы столкнулись с одним неудобством. Когда мы хотели
узнать,
кто
создал
тему
"велосипеды",
и
делали
соответствующий
запрос:
Вместо имени автора, мы получали его идентификатор. Это и понятно, ведь
мы делали запрос к одной таблице - Темы, а имена авторов тем хранятся в другой
таблице - Пользователи. Поэтому, узнав идентификатор автора темы, нам надо
сделать еще один запрос - к таблице Пользователи, чтобы узнать его
имя:
В SQL предусмотрена возможность объединять такие запросы в один путем
превращения одного из них в подзапрос (вложенный запрос). Итак, чтобы узнать,
кто создал тему "велосипеды", мы сделаем следующий запрос:
То есть, после ключевого слова WHERE, в условие мы записываем еще
один запрос. MySQL сначала обрабатывает подзапрос, возвращает id_author=2,
и это значение передается в предложение WHERE внешнего запроса.
В одном запросе может быть несколько подзапросов, синтаксис у такого
запроса следующий:
SELECT имя_столбца FROM имя_таблицы WHERE часть условия IN
(SELECT имя_столбца FROM имя_таблицы WHERE часть условия IN
(SELECT имя_столбца FROM имя_таблицы WHERE условие)
)
;
Обратите внимание, что подзапросы могут выбирать только один
столбец, значения которого они будут возвращать внешнему запросу. Попытка
выбрать несколько столбцов приведет к ошибке.
Давайте для закрепления составим еще один запрос, узнаем, какие
сообщения на форуме оставлял автор темы "велосипеды":
Теперь усложним задачу, узнаем, в каких темах оставлял сообщения
автор темы "велосипеды":
Давайте разберемся, как это работает.
1.
Сначала MySQL выполнит самый глубокий запрос:
SELECT id_author FROM topics WHERE topic_name='велосипеды'
2.
Полученный результат (id_author=2) передаст во внешний запрос,
который примет вид:
SELECT id_topic FROM posts WHERE id_author IN (2);
3.
Полученный результат (id_topic:4,1) передаст во внешний запрос,
который примет вид:
SELECT topic_name FROM topics WHERE id_topic IN (4,1);
4.
И выдаст окончательный результат (topic_name: о рыбалке, о
рыбалке). Т.е. автор темы "велосипеды" оставлял сообщения в теме "О
рыбалке", созданной Сергеем (id=1) и в теме "О рыбалке", созданной Светой
(id=4).
Вот собственно и все, что хотелось сказать о вложенных запросах. Хотя,
есть два момента, на которые стоит обратить внимание:
1.
Не рекомендуется создавать запросы со степенью вложения
больше трех. Это приводит к увеличению времени выполнения и к сложности
восприятия кода.
2.
Приведенный синтаксис вложенных запросов, скорее наиболее
употребительный, но вовсе не единственный. Например, мы могли бы вместо
запроса
SELECT name FROM users WHERE id_user IN
(SELECT id_author FROM topics WHERE topic_name='велосипеды');
написать
SELECT name FROM users WHERE id_user =
(SELECT id_author FROM topics WHERE topic_name='велосипеды');
Т.е. мы можем использовать любые операторы, используемые с
ключевым словом WHERE (их мы изучали в прошлом уроке).
Лабораторная работа № 6.
Предположим, мы хотим узнать, какие темы, и какими авторами были
созданы. Для этого проще всего обратиться к таблице Темы (topics):
Но, что если нам необходимо, чтобы в ответе на запрос были не
идентификаторы авторов, а их имена? Вложенные запросы нам не помогут,
т.к. в конечном итоге они выдают данные из одной таблицы. А нам надо
получить данные из двух таблиц (Темы и Пользователи) и объединить их в
одну.
Запросы,
которые
позволяют
это
сделать,
в
SQL
называются Объединениями.
Синтаксис самого простого объединения следующий:
SELECT
имена_столбцов_таблицы_1,
FROM имя_таблицы_1, имя_таблицы_2;
имена_столбцов_таблицы_2
Давайте создадим простое объединение:
Получилось не совсем то, что мы ожидали. Такое объединение научно
называется декартовым произведением, когда каждой строке первой таблицы
ставится в соответствие каждая строка второй таблицы. Возможно, бывают
случаи, когда такое объединение полезно, но это явно не наш случай.
Чтобы результирующая таблица выглядела так, как мы хотели,
необходимо указать условие объединения. Мы связываем наши таблицы по
идентификатору автора, это и будет нашим условием. Т.е. мы укажем в
запросе, что необходимо выводить только те строки, в которых значения поля
id_author таблицы topics совпадают со значениями поля id_user таблицы users:
На схеме будет понятнее:
Т.е. мы в запросе сделали следующее условие: если в обеих таблицах
есть одинаковые идентификаторы, то строки с этим идентификатором
необходимо объединить в одну результирующую строку. Обратите внимание
на две вещи:
Если в одной из объединяемых таблиц есть строка с идентификатором,
которого нет в другой объединяемой таблице, то в результирующей таблице
строки с таким идентификатором не будет. В нашем примере есть
пользователь Oleg (id=5), но он не создавал тем, поэтому в результате запроса
его нет.
При указании условия название столбца пишется после названия
таблицы, в которой этот столбец находится (через точку). Это сделано во
избежание путаницы, ведь столбцы в разных таблицах могут иметь
одинаковые названия, и MySQL может не понять, о каких конкретно столбцах
идет речь.
Вообще, корректный синтаксис объединения с условием выглядит так:
SELECT имя_таблицы_1.имя_столбца1_таблицы_1,
имя_таблицы_1.имя_столбца2_таблицы_1,
имя_таблицы_2.имя_столбца1_таблицы_2,
имя_таблицы_2.имя_столбца2_таблицы_2
FROM
имя_таблицы_1, имя_таблицы_2
WHERE
имя_таблицы_1.имя_столбца_по_которому_объединяем =
имя_таблицы_2.имя_столбца_по_которому_объединяем;
Если имя столбца уникально, то название таблицы можно опустить (как мы
делали в примере), но делать это не рекомендуется.
Как вы понимаете, объединения дают возможность выбирать любую
информацию из любых таблиц, причем объединяемых таблиц может быть и три, и
четыре, да и условие для объединения может быть не одно.
Для примера давайте создадим запрос, который покажет нам все сообщения, к
каким темам они относятся и авторов этих сообщений. Конечно, вся эта информация
хранится в таблице Сообщения (posts):
Но чтобы вместо идентификаторов отображались имена и названия, нам
придется сделать объединение трех таблиц:
Т.е.
мы
объединили
таблицы
posts.id_author=users.id_user,
а
Сообщения
таблицы
и
Сообщения
Пользователи
и
Темы
-
условием
условием
posts.id_topic=topics.id_topic
Объединения, которые мы сегодня рассматривали, называются Внутренними
объединениями. Такие объединения связывают строки одной таблицы со строками
другой таблицы (а может еще и третьей таблицы). Но бывают ситуации, когда
необходимо, чтобы в результат были включены строки, не имеющие связанных.
Например, когда мы создавали запрос, какие темы и какими авторами были созданы,
пользователь Oleg в результирующую таблицу не попал, т.к. тем не создавал, а
потому и связанной строки в объединяемой таблице не имел.
Поэтому, если нам потребуется составить несколько иной запрос - вывести
всех пользователей и темы, которые они создавали, если таковые имеются - то нам
придется воспользоваться Внешним объединением, позволяющим выводить все
строки одной таблицы и имеющиеся связанные с ними строки из другой таблицы. О
таких объединениях мы и будем говорить в следующем уроке.
Лабораторная работа № 7.
Итак, в продолжение прошлого урока, нам надо вывести всех
пользователей и темы, которые они создавали, если таковые имеются. Если мы
воспользуемся внутренним объединением, рассмотренным на прошлом уроке,
то получим в итоге следующее:
То есть в результирующей таблице есть только те пользователи, которые
создавали темы. А нам надо, чтобы выводились все имена. Для этого мы
немного изменим запрос:
SELECT users.name, topics.topic_name
FROM users LEFT OUTER JOIN topics
ON users.id_user=topics.id_author;
И получим желаемый результат - все пользователи и темы, ими
созданные. Если пользователь не создавал тему, но в соответствующем
столбце стоит значение NULL.
Итак, мы добавили в наш запрос ключевое слово - LEFT OUTER JOIN,
указав тем самым, что из таблицы слева надо взять все строки, и поменяли
ключевое слово WHERE на ON. Кроме ключевого слова LEFT OUTER
JOIN может быть использовано ключевое слово RIGHT OUTER JOIN. Тогда
будут выбираться все строки из правой таблицы и имеющиеся связанные с
ними из левой таблицы. И наконец, возможно полное внешнее объединение,
которое извлечет все строки из обеих таблиц и свяжет между собой те, которые
могут быть связаны. Ключевое слово для полного внешнего объединения
- FULL OUTER JOIN.
Давайте поменяем в нашем запросе левостороннее объединение на
правостороннее:
Как видите, теперь у нас есть все темы (все строки из правой таблицы),
а вот пользователи только те, которые темы создавали (т.е. из левой таблицы
выбираются только те строки, которые связаны с правой таблицей).
К сожалению полное объединение СУБД MySQL не поддерживает.
Подведем итог этого короткого урока. Синтаксис для внешнего объединения
следующий:
SELECT имя_таблицы_1.имя_столбца, имя_таблицы_2.имя_столбца
FROM имя_таблицы_1 ТИП ОБЪЕДИНЕНИЯ имя_таблицы_2
ON условие_объединения;
где ТИП ОБЪЕДИНЕНИЯ - либо LEFT OUTER JOIN, либо RIGHT OUTER
JOIN.
Лабораторная работа № 8.
Давайте вспомним, какие сообщения и в каких темах у нас имеются. Для
этого можно воспользоваться привычным запросом:
А что, если нам надо лишь узнать сколько сообщений на форуме
имеется. Для этого можно воспользоваться встроенной функцией COUNT().
Эта функция подсчитывает число строк. Причем, если в качестве аргумента
этой функции выступает *, то подсчитываются все строки таблицы. А если в
качестве аргумента указывается имя столбца, то подсчитываются только те
строки, которые имеют значение в указанном столбце.
В нашем примере оба аргумента дадут одинаковый результат, т.к. все
столбцы таблицы имеют тип NOT NULL. Давайте напишем запрос, используя
в качестве аргумента столбец id_topic:
SELECT COUNT(id_topic) FROM posts;
Итак, в наших темах имеется 4 сообщения. Но что, если мы хотим узнать
сколько сообщений имеется в каждой теме. Для этого нам понадобится
сгруппировать наши сообщения по темам и вычислить для каждой группы
количество сообщений. Для группировки в SQL используется оператор GROUP
BY. Наш запрос теперь будет выглядеть так:
SELECT id_topic, COUNT(id_topic) FROM posts
GROUP BY id_topic;
Оператор GROUP BY указывает СУБД сгруппировать данные по
столбцу id_topic (т.е. каждая тема - отдельная группа) и для каждой группы
подсчитать количество строк:
Ну вот, в теме с id=1 у нас 3 сообщения, а с id=4 - одно. Кстати, если бы
в поле id_topic были возможны отсутствия значений, то такие строки были бы
объединены в отдельную группу со значением NULL.
Предположим, что нас интересуют только те группы, в которых больше
двух сообщений. В обычном запросе мы указали бы условие с помощью
оператора WHERE, но этот оператор умеет работать только со строками, а для
групп те же функции выполняет оператор HAVING:
SELECT id_topic, COUNT(id_topic) FROM posts
GROUP BY id_topic
HAVING COUNT(id_topic) > 2;
В результате имеем:
В работе 4 мы рассматривали, какие условия можно задавать оператором
WHERE, те же условия можно задавать и оператором HAVING, только надо
запомнить, что WHERE фильтрует строки, а HAVING - группы.
Итак, сегодня мы узнали, как создавать группы и как подсчитать количество
строк в таблице и в группах. Вообще вместе с оператором GROUP BY можно
использовать и другие встроенные функции, но их мы будем изучать позже.
Лабораторная работа № 9.
Предположим, мы решили, что нашему форуму нужны модераторы. Для этого
в таблицу users надо добавить столбец с ролью пользователя. Для добавления
столбцов в таблицу используется оператор ALTER TABLE - ADD COLUMN. Его
синтаксис следующий:
ALTER TABLE имя_таблицы ADD COLUMN имя_столбца тип;
Давайте добавим столбец role в таблицу users:
ALTER TABLE users ADD COLUMN role varchar(20);
Столбец появился в конце таблицы:
Для того, чтобы указать местоположение столбца используются ключевые
слова: FIRST - новый столбец будет первым, и AFTER - указывает после какого
столбца поместить новый.
Давайте добавим еще два столбца: один - kol - количество оставленных
сообщений, а другой - rating - рейтинг пользователя. Оба столбца вставим после
поля password:
ALTER TABLE users ADD COLUMN kol int(10) AFTER password,
ADD COLUMN rating varchar(20) AFTER kol;
Теперь надо назначить роль модератора какому-нибудь пользователю, пусть
это будет sergey с id=1. Для обновления уже существующих данных служит
оператор UPDATE. Его синтаксис следующий:
UPDATE имя_таблицы SET имя_столбца=значение_столбца
WHERE условие;
Давайте сделаем Сергея модератором:
UPDATE users SET role='модератор'
WHERE id_user=1;
Изменять данные можно и сразу в нескольких строках и во всей таблице.
Например, мы решили давать рейтинг в зависимости от количества
оставленных пользователем сообщений. Давайте в нашу таблицу сначала
внесем
значения
столбца
kol
так,
как
мы
уже
умеем:
А теперь давайте зададим рейтинг Профи тем, у кого количество сообщений
больше 30:
UPDATE users SET rating='Профи'
WHERE kol>30;
Данные изменились в двух строках, согласно заданному условию.
Понятно, что если в запросе опустить условие, то данные будут обновлены во всех
строках таблицы.
Предположим, что нам не нравится название Рейтинг у нашего столбца,
и мы хотим переименовать столбец в Репутация - reputation. Для изменения имени
существующего столбца используется оператор CHANGE. Его синтаксис
следующий:
ALTER
TABLE
имя_таблицы
CHANGE
старое_имя_столбца
новое_имя_столбца тип;
Давайте поменяем rating на reputation:
ALTER TABLE users CHANGE rating reputation varchar(20);
Обратите внимание, что тип столбца надо указывать даже, если он не
меняется. Кстати, если нам понадобится изменить только тип столбца, то мы будем
использовать оператор MODIFY. Его синтаксис следующий:
ALTER TABLE имя_таблицы MODIFY имя_столбца новый_тип;
Последнее, что мы сегодня рассмотрим - оператор DELETE, который
позволяет удалять строки из таблицы. Его синтаксис следующий:
DELETE FROM имя_таблицы
WHERE условие;
Давайте из таблицы сообщений удалим те записи, которые оставлял
пользователь valera (id=2):
DELETE FROM posts
WHERE id_author='2';
Понятно, если опустить условие, то из таблицы будут удалены все данные.
Следует помнить, что данные СУБД даст удалить только в том случае, если они не
являются внешними ключами для данных из других таблиц (поддержка целостности
БД). Например, если мы захотим удалить из таблицы users пользователя, который
оставлял сообщения, то нам это не удастся.
Сначала надо удалить его сообщения, а уж потом и его самого.
Давайте подведем промежуточный итог. Мы умеем создавать таблицы и
связывать их между собой, обновлять, редактировать и удалять данные и извлекать
данные различным образом. В принципе - это можно назвать базовыми знаниями
SQL. Далее мы будем изучать встроенные функции и расширенные возможности
MySQL.
Лабораторная работа № 10.
Функции - это операции, позволяющие манипулировать данными. В
MySQL можно выделить несколько групп встроенных функций:
Строковые функции. Используются для управления текстовыми
строками, например, для обрезания или заполнения значений.
Числовые функции. Используются для выполнения математических
операций над числовыми данными. К числовым функциям относятся функции
возвращающие абсолютные значения, синусы и косинусы углов, квадратный
корень числа и т.д. Используются они только для алгебраических,
тригонометрических и геометрических вычислений. В общем, используются
редко, поэтому рассматривать их мы не будем. Но вы должны знать, что они
существуют, и в случае необходимости обратиться к документации MySQL.
Итоговые функции. Используются для получения итоговых данных по
таблицам, например, когда надо просуммировать какие-либо данные без их
выборки.
Функции даты и времени. Используются для управления значениями
даты и времени, например, для возвращения разницы между датами.
Системные функции. Возвращают служебную информацию СУБД.
Для того, чтобы рассмотреть основные встроенные функции нам
понадобится создать новую базу данных, чтобы в ней были числовые значения
и значения даты. В уроке 5 основ баз данных мы сделали реляционную модель
базы данных интернет-магазина. Пришло время реализовать ее в MySQL,
заодно закрепим пройденное. Итак, смотрим на последнюю схему урока 5 по
БД и создаем БД - shop.
create database shop;
Выбираем ее для работы:
use shop;
И создаем в ней 8 таблиц, как в схеме: Покупатели (customers),
Поставщики (vendors), Покупки (sale), Поставки (incoming), Журнал покупок
(magazine_sales), Журнал поставок (magazine_incoming), Товары (products),
Цены (prices). Один нюанс, наш магазин будет торговать книгами, поэтому в
таблицу Товары мы добавим еще один столбец - Автор (author), в принципе
это необязательно, но так как-то привычнее.
create table customers (
id_customer int NOT NULL AUTO_INCREMENT,
name char(50) NOT NULL,
email char(50) NOT NULL,
PRIMARY KEY (id_customer)
);
create table vendors (
id_vendor int NOT NULL AUTO_INCREMENT,
name char(50) NOT NULL,
city char(30) NOT NULL,
address char(100) NOT NULL,
PRIMARY KEY (id_vendor)
);
create table sale (
id_sale int NOT NULL AUTO_INCREMENT,
id_customer int NOT NULL,
date_sale date NOT NULL,
PRIMARY KEY (id_sale),
FOREIGN KEY (id_customer) REFERENCES customers (id_customer)
);
create table incoming (
id_incoming int NOT NULL AUTO_INCREMENT,
id_vendor int NOT NULL,
date_incoming date NOT NULL,
PRIMARY KEY (id_incoming),
FOREIGN KEY (id_vendor) REFERENCES vendors (id_vendor)
);
create table products (
id_product int NOT NULL AUTO_INCREMENT,
name char(100) NOT NULL,
author char(50) NOT NULL,
PRIMARY KEY (id_product)
);
create table prices (
id_product int NOT NULL,
date_price_changes date NOT NULL,
price double NOT NULL,
PRIMARY KEY (id_product, date_price_changes),
FOREIGN KEY (id_product) REFERENCES products (id_product)
);
create table magazine_sales (
id_sale int NOT NULL,
id_product int NOT NULL,
quantity int NOT NULL,
PRIMARY KEY (id_sale, id_product),
FOREIGN KEY (id_sale) REFERENCES sale (id_sale),
FOREIGN KEY (id_product) REFERENCES products (id_product)
);
create table magazine_incoming (
id_incoming int NOT NULL,
id_product int NOT NULL,
quantity int NOT NULL,
PRIMARY KEY (id_incoming, id_product),
FOREIGN KEY (id_incoming) REFERENCES incoming (id_incoming),
FOREIGN KEY (id_product) REFERENCES products (id_product)
);
Обратите внимание, что в таблицах Журнал покупок, Журнал поставок
и Цены первичные ключи - составные, т.е. их уникальные значения состоят из
пар значений (в таблице не может быть двух строк с одинаковыми парами
значений). Названия столбцов этих пар значений и указываются через запятую
после ключевого слова PRIMARY KEY. Остальное вы уже знаете.
В настоящем интернет-магазине данные в эти таблицы будут заноситься
посредством сценариев на каком-либо языке (типа php), нам же пока придется
внести их вручную. Можете внести любые данные, только помните, что
значения в одноименных столбцах связанных таблиц должны совпадать. Либо
скопируйте нижеприведенные данные:
INSERT INTO vendors (name, city, address) VALUES
('Вильямс', 'Москва', 'ул.Лесная, д.43'),
('Дом печати', 'Минск', 'пр.Ф.Скорины, д.18'),
('БХВ-Петербург', 'Санкт-Петербург', 'ул.Есенина, д.5');
INSERT INTO customers (name, email) VALUES
('Иванов Сергей', 'sergo@mail.ru'),
('Ленская Катя', 'lenskay@yandex.ru'),
('Демидов Олег', 'demidov@gmail.ru'),
('Афанасьев Виктор', 'victor@mail.ru'),
('Пажская Вера', 'verap@rambler.ru');
INSERT INTO products (name, author) VALUES
('Стихи о любви', 'Андрей Вознесенский'),
('Собрание сочинений, том 2', 'Андрей Вознесенский'),
('Собрание сочинений, том 3', 'Андрей Вознесенский'),
('Русская поэзия', 'Николай Заболоцкий'),
('Машенька', 'Владимир Набоков'),
('Доктор Живаго', 'Борис Пастернак'),
('Наши', 'Сергей Довлатов'),
('Приглашение на казнь', 'Владимир Набоков'),
('Лолита', 'Владимир Набоков'),
('Темные аллеи', 'Иван Бунин'),
('Дар', 'Владимир Набоков'),
('Сын вождя', 'Юлия Вознесенская'),
('Эмигранты', 'Алексей Толстой'),
('Горе от ума', 'Александр Грибоедов'),
('Анна Каренина', 'Лев Толстой'),
('Повести и рассказы', 'Николай Лесков'),
('Антоновские яблоки', 'Иван Бунин'),
('Мертвые души', 'Николай Гоголь'),
('Три сестры', 'Антон Чехов'),
('Беглянка', 'Владимир Даль'),
('Идиот', 'Федор Достоевский'),
('Братья Карамазовы', 'Федор Достоевский'),
('Ревизор', 'Николай Гоголь'),
('Гранатовый браслет', 'Александр Куприн');
INSERT INTO incoming (id_vendor, date_incoming) VALUES
('1', '2011-04-10'),
('2', '2011-04-11'),
('3', '2011-04-12');
INSERT INTO magazine_incoming
VALUES
('1', '1', '10'),
('1', '2', '5'),
('1', '3', '7'),
('1', '4', '10'),
('1', '5', '10'),
('1', '6', '8'),
('1', '18', '8'),
('1', '19', '8'),
('1', '20', '8'),
('2', '7', '10'),
('2', '8', '10'),
('2', '9', '6'),
('2', '10', '10'),
('2', '11', '10'),
('2', '21', '10'),
('2', '22', '10'),
('2', '23', '10'),
('2', '24', '10'),
('3', '12', '10'),
('3', '13', '10'),
('3', '14', '10'),
('3', '15', '10'),
('3', '16', '10'),
(id_incoming, id_product, quantity)
('3', '17', '10');
INSERT INTO prices (id_product, date_price_changes, price) VALUES
('1', '2011-04-10', '100'),
('2', '2011-04-10', '130'),
('3', '2011-04-10', '90'),
('4', '2011-04-10', '100'),
('5', '2011-04-10', '110'),
('6', '2011-04-10', '85'),
('7', '2011-04-11', '95'),
('8', '2011-04-11', '100'),
('9', '2011-04-11', '79'),
('10', '2011-04-11', '49'),
('11', '2011-04-11', '105'),
('12', '2011-04-12', '85'),
('13', '2011-04-12', '135'),
('14', '2011-04-12', '100'),
('15', '2011-04-12', '90'),
('16', '2011-04-12', '75'),
('17', '2011-04-12', '90'),
('18', '2011-04-10', '150'),
('19', '2011-04-10', '140'),
('20', '2011-04-10', '85'),
('21', '2011-04-11', '105'),
('22', '2011-04-11', '70'),
('23', '2011-04-11', '65'),
('24', '2011-04-11', '130');
INSERT INTO sale (id_customer, date_sale) VALUES
('2', '2011-04-11'),
('3', '2011-04-11'),
('5', '2011-04-11');
INSERT INTO magazine_sales (id_sale, id_product, quantity) VALUES
('1', '1', '1'),
('1', '5', '1'),
('1', '7', '1'),
('2', '2', '1'),
('3', '1', '1'),
('3', '7', '1');
Итак, в нашем магазине 24 наименования товара, привезенные в трех
поставках от трех поставщиков, и совершенно три продажи. Все готово, можем
приступать к изучению встроенных функций MySQL, чем и займемся в следующем
уроке.
Лабораторная работа № 11.
Итоговые функции еще называют статистическими, агрегатными или
суммирующими. Эти функции обрабатывают набор строк для подсчета и
возвращения одного значения. Таких функций всего пять:
AVG() Функция возвращает среднее значение столбца.
COUNT() Функция возвращает число строк в столбце.
MAX() Функция возвращает самое большое значение в столбце.
MIN() Функция возвращает самое маленькое значение в столбце.
SUM() Функция возвращает сумму значений столбца.
С одной из них - COUNT() - мы уже познакомились в уроке 8. Сейчас
познакомимся
с
остальными.
Предположим,
мы
захотели
узнать
минимальную, максимальную и среднюю цену на книги в нашем магазине.
Тогда из таблицы Цены (prices) надо взять минимальное, максимальное и
среднее значения по столбцу price. Запрос простой:
SELECT MIN(price), MAX(price), AVG(price) FROM prices;
Теперь, мы хотим узнать, на какую сумму нам привез товар поставщик "Дом
печати" (id=2). Составить такой запрос не так просто. Давайте поразмышляем,
как его составить:
1. Сначала надо из таблицы Поставки (incoming) выбрать идентификаторы
(id_incoming) тех поставок, которые осуществлялись поставщиком "Дом печати"
(id=2):
SELECT id_incoming FROM incoming
WHERE id_vendor=2;
2. Теперь из таблицы Журнал поставок (magazine_incoming) надо
выбрать
товары
(id_product)
и
их
количества
(quantity),
которые
осуществлялись в найденных в пункте 1 поставках. То есть запрос из пункта 1
становится вложенным:
SELECT id_product, quantity FROM magazine_incoming
WHERE id_incoming=(SELECT id_incoming FROM incoming WHERE
id_vendor=2);
3. Теперь нам надо добавить в результирующую таблицу цены на
найденные товары, которые хранятся в таблице Цены (prices). То есть нам
понадобится объединение таблиц Журнал поставок (magazine_incoming) и
Цены (prices) по столбцу id_product:
SELECT magazine_incoming.id_product, magazine_incoming.quantity,
prices.price FROM magazine_incoming, prices
WHERE
magazine_incoming.id_product=
prices.id_product
AND
id_incoming=
(SELECT id_incoming FROM incoming WHERE id_vendor=2);
4. В получившейся таблице явно не хватает столбца Сумма, то
есть вычисляемого
столбца.
Возможность
создания
таких
столбцов
предусмотрена в MySQL. Для этого надо лишь указать в запросе имя
вычисляемого столбца и что он должен вычислять. В нашем примере такой
столбец будет называться summa, а вычислять он будет произведение
столбцов quantity и price. Название нового столбца отделяется словом AS:
SELECT magazine_incoming.id_product, magazine_incoming.quantity,
prices.price,
magazine_incoming.quantity*prices.price AS summa
FROM magazine_incoming, prices
WHERE
magazine_incoming.id_product=
prices.id_product
AND
id_incoming=
(SELECT id_incoming FROM incoming WHERE id_vendor=2);
5. Отлично, нам осталось лишь просуммировать столбец summa и
наконец-то узнаем, на какую сумму нам привез товар поставщик "Дом
печати". Синтаксис для использования функции SUM() следущий:
SELECT SUM(имя_столбца) FROM имя_таблицы;
Имя столбца нам известно - summa, а вот имени таблицы у нас нет, так
как она является результатом запроса. Что же делать? Для таких случаев в
MySQL существуют Представления. Представление - это запрос на выборку,
которому присваивается уникальное имя и который можно сохранять в базе
данных, для последующего использования.
Синтаксис создания представления следующий:
CREATE VIEW имя_представления AS запрос;
Давайте
report_vendor:
сохраним
наш
запрос,
как
представление
с
именем
CREATE VIEW report_vendor AS
SELECT magazine_incoming.id_product, magazine_incoming.quantity,
prices.price,
magazine_incoming.quantity*prices.price AS summa
FROM magazine_incoming, prices
WHERE
magazine_incoming.id_product=
prices.id_product
AND
id_incoming=
(SELECT id_incoming FROM incoming WHERE id_vendor=2);
6. Вот теперь можно использовать итоговую функцию SUM():
SELECT SUM(summa) FROM report_vendor;
Вот мы и достигли результата, правда для этого нам пришлось
использовать вложенные запросы, объединения, вычисляемые столбцы и
представления. Да, иногда для получения результата приходится подумать,
без этого никуда. Зато мы коснулись двух очень важных тем - вычисляемые
столбцы и представления. Давайте поговорим о них поподробнее.
Вычисляемые поля (столбцы)
На примере мы рассмотрели сегодня математическое вычисляемое поле.
Здесь хотелось бы добавить, что использовать можно не только операцию
умножения (*), но и вычитание (-), и сложение (+), и деление (/). Синтаксис
следующий:
SELECT имя_столбца_1, имя_столбца_2, имя_столбца_1*имя_столбца_2 AS
имя_вычисляемого_столбца
FROM имя_таблицы;
Второй нюанс - ключевое слово AS, мы его использовали для задания
имени вычисляемого столбца. На самом деле с помощью этого ключевого
слова задаются псевдонимы для любых столбцов. Зачем это нужно? Для
сокращения и читаемости кода. Например, наше представление могло бы
выглядеть так:
CREATE VIEW report_vendor AS
SELECT A.id_product, A.quantity, B.price, A.quantity*B.price AS summa
FROM magazine_incoming AS A, prices AS B
WHERE A.id_product= B.id_product AND id_incoming=
(SELECT id_incoming FROM incoming WHERE id_vendor=2);
Согласитесь, что так гораздо короче и понятнее.
Представления
Синтаксис создания представлений мы уже рассматривали. После создания
представлений, их можно использовать так же, как таблицы. То есть выполнять
запросы к ним, фильтровать и сортировать данные, объединять одни представления
с другими. С одной стороны это очень удобный способ хранения часто применяемых
сложных запросов (как в нашем примере).
Но следует помнить, что представления - это не таблицы, то есть они не хранят
данные, а лишь извлекают их из других таблиц. Отсюда, во-первых, при изменении
данных в таблицах, результаты представления так же будут меняться. А во-вторых,
при запросе к представлению происходит поиск необходимых данных, то есть
производительность СУБД снижается. Поэтому злоупотреблять ими не стоит.
Лабораторная работа № 12.
Эта группа функций позволяет манипулировать текстом. Строковых
функций много, мы рассмотрим наиболее употребительные.
CONCAT(str1,str2...) Возвращает строку, созданную путем объединения
аргументов (аргументы указываются в скобках - str1,str2...). Например, в
нашей таблице Поставщики (vendors) есть столбец Город (city) и столбец
Адрес (address). Предположим, мы хотим, чтобы в результирующей таблице
Адрес и Город указывались в одном столбце, т.е. мы хотим объединить данные
из двух столбцов в один. Для этого мы будем использовать строковую
функцию CONCAT(), а в качестве аргументов укажем названия объединяемых
столбцов - city и address:
SELECT CONCAT(city, address) FROM vendors;
Обратите внимание, объединение произошло без разделения, что не
очень
читабельно.
Давайте
подправим
наш
запрос,
чтобы
объединяемыми столбцами был пробел:
SELECT CONCAT(city, ' ', address) FROM vendors;
между
Как видите, пробел считается тоже аргументом и указывается через
запятую. Если объединяемых столбцов было бы больше, то указывать каждый
раз пробелы было бы нерационально. В этом случае можно было бы
использовать строковую функцию CONCAT_WS(разделитель, str1,str2...),
которая помещает разделитель между объединяемыми строками (разделитель
указывается, как первый аргумент). Наш запрос тогда будет выглядеть так:
SELECT CONCAT_WS(' ', city, address) FROM vendors;
Результат внешне не изменился, но если бы мы объединяли 3 или 4
столбца, то код значительно бы сократился.
INSERT(str, pos, len, new_str) Возвращает строку str, в которой
подстрока, начинающаяся с позиции pos и имеющая длину len символов,
заменена подстрокой new_str. Предположим, мы решили в столбце Адрес
(address) не отображать первые 3 символа (сокращения ул., пр., и т.д.), тогда
мы заменим их на пробелы:
SELECT INSERT(address, 1, 3, ' ') FROM vendors;
То есть три символа, начиная с первого, заменены тремя пробелами.
LPAD(str, len, dop_str) Возвращает строку str, дополненную слева
строкой dop_str до длины len. Предположим, мы хотим, чтобы при выводе
городов поставщиков они располагались бы справа, а пустое пространство
заполнялось бы точками:
SELECT LPAD(city, 15, '.') FROM vendors;
Обратите внимание, значение len ограничивает количество выводимых
символов, т.е. если название города будет длиннее 15 символов, то оно будет
обрезано.
RPAD(str, len, dop_str) Возвращает строку str, дополненную справа
строкой dop_str до длины len. Предположим, мы хотим, чтобы при выводе
городов поставщиков они располагались бы слева, а пустое пространство
заполнялось бы точками:
SELECT RPAD(city, 15, '.') FROM vendors;
Обратите внимание, значение len ограничивает количество выводимых
символов, т.е. если название города будет длиннее 15 символов, то оно будет
обрезано.
LTRIM(str) Возвращает строку str, в которой удалены все начальные
пробелы. Эта строковая функция удобна для корректного отображения
информации в случаях, когда при вводе данных допускаются случайные
пробелы:
SELECT LTRIM(city) FROM vendors;
В нашем случае лишних пробелов не было, поэтому и результат
внешне мы не увидим.
RTRIM(str) Возвращает строку str, в которой удалены все конечные
пробелы:
SELECT RTRIM(city) FROM vendors;
В нашем случае лишних пробелов не было, поэтому и результат внешне
мы не увидим.
TRIM(str) Возвращает строку str, в которой удалены все начальные и
конечные пробелы:
SELECT TRIM(city) FROM vendors;
LOWER(str) Возвращает строку str, в которой все символы переведены
в нижний регистр. С русскими буквами работает некорректно, поэтому лучше
не применять. Например, давайте применим эту функцию к столбцу city:
SELECT city, LOWER(city) FROM vendors;
Видите, какая абракадабра получилась. А вот с латиницей все в порядке:
SELECT LOWER('CITY');
UPPER(str) Возвращает строку str, в которой все символы переведены в
верхний регистр. С русскими буквами так же лучше не применять. А вот с
латиницей все в порядке:
SELECT UPPER(email) FROM customers;
LENGTH(str) Возвращает длину строки str. Например, давайте узнаем
сколько символов в наших адресах поставщиков:
SELECT address, LENGTH(address) FROM vendors;
LEFT(str, len) Возвращает len левых символов строки str. Например,
пусть в городах поставщиков выводится только первые три символа:
SELECT name, LEFT(city, 3) FROM vendors;
RIGHT(str, len) Возвращает len правых символов строки str. Например,
пусть в городах поставщиков выводится только последние три символа:
SELECT name, RIGHT(city, 3) FROM vendors;
REPEAT(str, n) Возвращает строку str n-количество раз. Например:
SELECT REPEAT(city, 3) FROM vendors;
REPLACE(str, pod_str1, pod_str2) Возвращает строку str, в которой все
подстроки pod_str1 заменены подстроками pod_str2. Например, пусть мы
хотим, чтобы в городах поставщиков вместо длинного 'Санкт-Петербург'
выводилось короткое 'СПб':
SELECT REPLACE(city, 'Санкт-Петербург', 'СПб') FROM vendors;
REVERSE(str) Возвращает строку str, записанную в обратном порядке:
SELECT REVERSE(city) FROM vendors;
LOAD_FILE(file_name) Эта функция читает файл file_name и
возвращает его содержимое в виде строки. Например, создайте файл
proverka.txt, напишите в нем какой-нибудь текст (лучше латиницей, чтобы не
было проблем с кодировками), сохраните его на диске С и сделайте
следующий запрос:
SELECT LOAD_FILE("C:/proverka");
Обратите внимание, необходимо указывать абсолютный путь к файлу.
Как уже упоминалось строковых функций гораздо больше, но даже некоторые
рассмотренные здесь применяются крайне редко. Поэтому на этом закончим их
рассмотрение и перейдем к более используемым функциям даты и времени.
Лабораторная работа № 13.
Эти функции предназначены для работы с календарными типами
данных. Рассмотрим наиболее применимые.
CURDATE(), CURTIME() и NOW() Первая функция возвращает
текущую дату, вторая - текущее время, а третья - текущую дату и время.
Сравните:
SELECT CURDATE(), CURTIME(), NOW();
Функции CURDATE() и NOW() удобно использовать для добавления в
базу данных записей, использующих текущее время. В нашем магазине все
поставки и продажи используют текущее время. Поэтому для добавления
записей о поставах, и продажах удобно использовать функцию CURDATE().
Например, пусть в наш магазин пришел товар, давайте добавим информацию
об этом в таблицу Поставка (incoming):
INSERT INTO incoming (id_vendor, date_incoming) VALUES
('2', curdate());
Если бы мы хранили дату поставки с типом datatime, то нам больше
подошла бы функция NOW().
ADDDATE(date, INTERVAL value) Функция возвращает дату date, к
которой
прибавлено
значение
value.
Значение
value
может
быть
отрицательным, тогда итоговая дата уменьшится. Давайте посмотрим, когда
наши поставщики делали поставки товара:
SELECT id_vendor, date_incoming FROM incoming;
Предположим, мы ошиблись при вводе даты для первого поставщика,
давайте уменьшим его дату на одни сутки:
SELECT id_vendor, ADDDATE(date_incoming, INTERVAL -1 DAY)
FROM incoming
WHERE id_vendor=1;
В качестве значения value могут выступать не только дни, но и недели
(WEEK), месяцы (MONTH), кварталы (QUARTER) и годы (YEAR). Давайте
для пример уменьшим дату поставки для второго поставщика на 1 неделю:
SELECT id_vendor, ADDDATE(date_incoming, INTERVAL -1 WEEK)
FROM incoming
WHERE id_vendor=2;
В нашей таблице Поставки (incoming) мы использовали для столбца
Дата поставки (date_incoming) тип date. Как вы помните из урока 2, этот тип
данных предназначен для хранения только даты. А вот если бы мы
использовали тип datatime, то у нас отображалась бы не только дата, но и
время. Тогда мы могли бы использовать функцию ADDDATE и для времени.
В качестве значения value в этом случае могут выступать секунды (SECOND),
минуты (MINUTE), часы (HOUR) и их комбинации:
минуты и секунды (MINUTE_SECOND),
часы, минуты и секунды (HOUR_SECOND),
часы и минуты (HOUR_MINUTE),
дни, часы, минуты и секунды (DAY_SECOND),
дни, часы и минуты (DAY_MINUTE),
дни и часы (DAY_HOUR),
года и месяцы (YEAR_MONTH).
Например, давайте к дате 15 апреля 2011 года две минуты первого
прибавим 2 часа 45 минут:
SELECT ADDDATE('2011-04-15 00:02:00', INTERVAL '02:45'
HOUR_MINUTE);
SUBDATE(date, INTERVAL value) функция идентична предыдущей, но
производит операцию вычитания, а не сложения.
SELECT SUBDATE('2011-04-15 00:02:00', INTERVAL '23:53'
HOUR_MINUTE);
PERIOD_ADD(period, n) функция добавляет n месяцев к значению даты
period. Нюанс: значение даты должно быть представлено в формате
YYYYMM. Давайте к февралю 2011 (201102) прибавим 2 месяца:
SELECT PERIOD_ADD(201102, 2);
TIMESTAMPADD(interval, n, date) функция добавляет к дате date
временной интервал n, значения которого задаются параметром interval.
Возможные значения параметра interval:
FRAC_SECOND - микросекунды
SECOND - секунды
MINUTE - минуты
HOUR - часы
DAY - дни
WEEK - недели
MONTH - месяцы
QUARTER - кварталы
YEAR - годы
SELECT TIMESTAMPADD(DAY, 2, '2011-04-02');
TIMEDIFF(date1, date2) вычисляет разницу в часах, минутах и секундах
между двумя датами.
SELECT TIMEDIFF('2011-04-17 23:50:00', '2011_04-16 14:50:00');
DATEDIFF(date1, date2) вычисляет разницу в днях между двумя датами.
Например, мы хотим узнать, как давно поставщик 'Вильямс' (id=1) поставлял
нам товар:
SELECT date_incoming, CURDATE(), DATEDIFF(CURDATE(), date_incoming)
FROM incoming
WHERE id_vendor=1;
PERIOD_DIFF(period1, period2) функция вычисляет разницу в месяцах
между двумя датами, представленными в формате YYYYMM. Давайте узнаем
разницу между январем 2010 и августом 2011:
SELECT PERIOD_DIFF(201108, 201001);
TIMESTAMPDIFF(interval, date1, date2) функция вычисляет разницу
между датами date2 и date1 в единицах, указанных в параметре interval.
Возможные значения параметра interval:
FRAC_SECOND - микросекунды
SECOND - секунды
MINUTE - минуты
HOUR - часы
DAY - дни
WEEK - недели
MONTH - месяцы
QUARTER - кварталы
YEAR - годы
SELECT TIMESTAMPDIFF(DAY, '2011-04-02', '2011-04-17') AS days,
TIMESTAMPDIFF(HOUR, '2011-04-16 20:14:00', '2011-04-17 23:58:20') AS
houres;
SUBTIME(date, time) функция вычитает из времени date время time:
SELECT SUBTIME('2011-04-18 23:17:00', '02:15:30');
DATE(datetime) возвращает дату, отсекая время. Например:
SELECT DATE('2011-04-15 00:03:20');
TIME(datetime) возвращает время, отсекая дату. Например:
SELECT TIME('2011-04-15 00:03:20');
TIMESTAMP(date) функция принимает дату date и возвращает полный
вариант со временем. Например:
SELECT TIMESTAMP('2011-04-17');
DAY(date) и DAYOFMONTH(date) функции-синонимы, возвращают из
даты порядковый номер дня месяца:
SELECT DAY('2011-04-17'), DAYOFMONTH('2011-04-17');
DAYNAME(date), DAYOFWEEK(date) и WEEKDAY(date) функции
возвращают день недели, первая - его название, вторая - номер дня недели
(отсчет от 1 - воскресенье до 7 - суббота), третья - номер дня недели (отсчет от
0 - понедельник, до 6 - воскресенье:
SELECT DAYNAME('2011-04-17'), DAYOFWEEK('2011-04-17'),
WEEKDAY('2011-04-17');
WEEK(date), WEEKOFYEAR(datetime) обе функции возвращают номер
недели в году, первая для типа date, а вторая - для типа datetime, у первой
неделя начинается с воскресенья, у второй - с понедельника:
SELECT WEEK('2011-04-17'), WEEKOFYEAR('2011-04-17 23:40:00');
MONTH(date) и MONTHNAME(date) обе функции возвращают
значения месяца. Первая - его числовое значение (от 1 до 12), вторая - название
месяца:
SELECT MONTH('2011-04-17'), MONTHNAME('2011-04-17');
QUARTER(date) функция возвращает значение квартала года (от 1 до 4):
SELECT QUARTER('2011-04-17');
YEAR(date) функция возвращает значение года (от 1000 до 9999):
SELECT YEAR('2011-04-17');
DAYOFYEAR(date) возвращает порядковый номер дня в году (от 1 до
366):
SELECT DAYOFYEAR('2011-04-17');
HOUR(datetime) возвращает значение часа для времени (от 0 до 23):
SELECT HOUR('2011-04-17 18:20:03');
MINUTE(datetime) возвращает значение минут для времени (от 0 до 59):
SELECT MINUTE('2011-04-17 18:20:03');
SECOND(datetime) возвращает значение секунд для времени (от 0 до
59):
SELECT SECOND('2011-04-17 18:20:03');
EXTRACT(type FROM date) возвращает часть date определяемую
параметром type:
SELECT EXTRACT(YEAR FROM '2011-04-17 23:15:18') AS year,
EXTRACT(MONTH FROM '2011-04-17 23:15:18') AS mon,
EXTRACT(DAY FROM '2011-04-17 23:15:18') AS day,
EXTRACT(HOUR FROM '2011-04-17 23:15:18') AS hour,
EXTRACT(MINUTE FROM '2011-04-17 23:15:18') AS min,
EXTRACT(SECOND FROM '2011-04-17 23:15:18') AS sec;
TO_DAYS(date) и FROM_DAYS(n) взаимообратные функции. Первая
преобразует дату в количество дней, прошедших с нулевого года. Вторая,
наоборот, принимает число дней, прошедших с нулевого года и преобразует
их в дату:
SELECT TO_DAYS('2011-04-17'), FROM_DAYS(734420);
UNIX_TIMESTAMP(date) и FROM_UNIXTIME(n) взаимообратные
функции. Первая преобразует дату в количество секунд, прошедших с 1 января
1970 года. Вторая, наоборот, принимает число секунд, с 1 января 1970 года и
преобразует их в дату:
SELECT UNIX_TIMESTAMP('2011-04-17'), FROM_UNIXTIME(1302524000);
TIME_TO_SEC(time) и SEC_TO_TIME(n) взаимообратные функции.
Первая преобразует время в количество секунд, прошедших от начала суток.
Вторая, наоборот, принимает число секунд с начала суток и преобразует их во
время:
SELECT TIME_TO_SEC('22:10:30'), SEC_TO_TIME(45368);
MAKEDATE(year, n) функция принимает год и номер дня в году и
преобразует их в дату:
SELECT MAKEDATE(2011, 120);
В следующий раз рассмотрим функции, которые помогают переводить даты
из одного формата в другой.
Лабораторная работа № 14.
Эти функции также предназначены для работы с календарными типами
данных. Рассмотрим их подробнее.
DATE_FORMAT(date, format) форматирует дату date в соответствии с
выбранным форматом formate. Эта функция очень часто используется. Например, в
MySQL дата имеет формат представления YYYY-MM-DD (год-месяц-число), а нам
привычнее формат DD-MM-YYYY (число-месяц-год). Поэтому для привычного нам
отображения даты ее необходимо переформатировать. Давайте сначала приведем
запрос, а затем разберемся, как задавать формат:
SELECT DATE_FORMAT(CURDATE(), '%d.%m.%Y');
Теперь дата выглядит для нас привычно. Для задания формата даты
используются специальные определители. Для удобства перечислим их в таблице.
Опред Описание
%a
Сокращенное наименование дня недели (Mon - понедельник, Tue - вторник, Wed - среда,
Thu - четверг, Fri - пятница, Sat - суббота, Sun - воскресенье).
Пример:
SELECT DATE_FORMAT(CURDATE(), '%a');
Результат:
Сокращенное наименование месяцев (Jan - январь, Feb - февраль, Mar - март, Apr - апрель,
May - май, Jun - июнь, Jul - июль, Aug - август, Sep - сентябрь, Oct - октябрь, Nov - ноябрь,
Dec - декабрь).
Пример:
SELECT DATE_FORMAT(CURDATE(), '%b');
Результат:
%b
Месяц в числовой форме (1 - 12).
Пример:
SELECT DATE_FORMAT(CURDATE(), '%с');
Результат:
%c
%d
День месяца в числовой форме с нулем (01 - 31).
Пример:
SELECT DATE_FORMAT(CURDATE(), '%d');
Результат:
День месяца в английском варианте (1st, 2nd...).
Пример:
SELECT DATE_FORMAT(CURDATE(), '%D');
Результат:
%D
День месяца в числовой форме без нуля (1 - 31).
Пример:
SELECT DATE_FORMAT(CURDATE(), '%e');
Результат:
%e
%H
Часы с ведущим нулем от 00 до 23.
Пример:
SELECT DATE_FORMAT('2011-04-15 23:03:20', '%H');
Результат:
Часы с ведущим нулем от 00 до 12.
Пример:
SELECT DATE_FORMAT('2011-04-15 23:03:20', '%h');
Результат:
%h
Минуты от 00 до 59.
Пример:
SELECT DATE_FORMAT('2011-04-15 23:03:20', '%i');
Результат:
%i
%j
День года от 001 до 366.
Пример:
SELECT DATE_FORMAT('2011-04-15 23:03:20', '%j');
Результат:
Часы c ведущим нулем от 0 до 23.
Пример:
SELECT DATE_FORMAT('2011-12-31 01:03:20', '%k');
Результат:
%k
Часы без ведущим нуля от 1 до 12.
Пример:
SELECT DATE_FORMAT('2011-04-15 00:03:20', '%l');
Результат:
%l
%M
Название месяца без сокращения.
Пример:
SELECT DATE_FORMAT('2011-04-15 00:03:20', '%M');
Результат:
Название месяца без сокращения.
Пример:
SELECT DATE_FORMAT('2011-04-15 00:03:20', '%M');
Результат:
%M
Месяц в числовой форме с ведущим нулем (01 - 12).
Пример:
SELECT DATE_FORMAT('2011-04-15 00:03:20', '%m');
Результат:
%m
%p
АМ или РМ для 12-часового формата.
Пример:
SELECT DATE_FORMAT('2011-04-15 00:03:20', '%p');
Результат:
Время в 12-часовом формате.
Пример:
SELECT DATE_FORMAT('2011-04-15 00:03:20', '%r');
Результат:
%r
Секунды от 00 до 59.
Пример:
SELECT DATE_FORMAT('2011-04-15 00:03:20', '%s');
Результат:
%s
%T
Время в 24-часовом формате.
Пример:
SELECT DATE_FORMAT('2011-04-15 21:03:20', '%T');
Результат:
Неделя (00 - 52), где первым днем недели считается понедельник.
Пример:
SELECT DATE_FORMAT('2011-04-17 21:03:20', '%u');
Результат:
%u
Неделя (00 - 52), где первым днем недели считается воскресенье.
Пример:
SELECT DATE_FORMAT('2011-04-17 21:03:20', '%U');
Результат:
%U
%W
Название дня недели без сокращения.
Пример:
SELECT DATE_FORMAT('2011-04-17 21:03:20', '%W');
Результат:
Номер дня недели (0 - воскресенье, 6 - суббота).
Пример:
SELECT DATE_FORMAT('2011-04-17 21:03:20', '%w');
Результат:
%w
Год, 4 разряда.
Пример:
SELECT DATE_FORMAT('2011-04-17 21:03:20', '%Y');
Результат:
%Y
%y
Год, 2 разряда.
Пример:
SELECT DATE_FORMAT('2011-04-17 21:03:20', '%y');
Результат:
STR_TO_DATE(date, format) функция обратная предыдущей, она
принимает дату date в формате format, а возвращает дату в формате MySQL.
SELECT STR_TO_DATE('17.04.2011 23:50', '%d.%m.%Y %H:%i');
Как видите, сама функция GET_FORMAT() возвращает формат
представления, а вместе с функцией DATE_FORMAT() выдает дату в нужном
формате. Сделайте сами запросы со всеми пятью стандартами и посмотрите на
разницу.
TIME_FORMAT(time, format) функция аналогична функции
DATE_FORMAT(), но используется только для времени:
SELECT TIME_FORMAT('22:38:15', '%H-%i-%s');
GET_FORMAT(date, format) функция возвращает строку
форматирования, соответствующую одному из пяти форматов времени:
EUR – европейский стандарт
USA – американский стандарт
JIS – японский индустриальный стандарт
ISO – стандарт ISO (международная организация стандартов)
INTERNAL – интернациональный стандарт
Эту функцию хорошо использовать совместно с предыдущей DATE_FORMAT(). Посмотрим на примере:
SELECT
GET_FORMAT(DATE,
'EUR'),
DATE_FORMAT('2011-04-17',
GET_FORMAT(DATE, 'EUR'));
Как видите, сама функция GET_FORMAT() возвращает формат
представления, а вместе с функцией DATE_FORMAT() выдает дату в нужном
формате. Сделайте сами запросы со всеми пятью стандартами и посмотрите на
разницу.
Ну вот, теперь вы знаете о работе с датами и временем в MySQL
практически все. Это вам очень пригодится при разработке различных webприложений. Например, если пользователь в форму на сайте вводит дату в
привычном ему формате, вам не составит труда применить нужную функцию,
чтобы в БД дата попала в нужном формате.
Лабораторная работа № 15.
Как правило, мы в работе с БД используем одни и те же запросы, либо
набор
последовательных
запросов.
Хранимые
процедуры
позволяют
объединить последовательность запросов и сохранить их на сервере. Это
очень удобный инструмент, и сейчас вы в этом убедитесь. Начнем с
синтаксиса:
CREATE PROCEDURE имя_процедуры (параметры)
begin
операторы
end
Параметры это те данные, которые мы будем передавать процедуре при
ее вызове, а операторы - это собственно запросы. Давайте напишем свою
первую процедуру и убедимся в ее удобстве. В уроке 10, когда мы добавляли
новые записи в БД shop, мы использовали стандартный запрос на добавление
вида:
INSERT INTO customers (name, email) VALUE ('Иванов Сергей', 'sergo@mail.r
u');
Т.к. подобный запрос мы будем использовать каждый раз, когда нам
необходимо будет добавить нового покупателя, то вполне уместно оформить
его в виде процедуры:
CREATE PROCEDURE ins_cust(n CHAR(50), e CHAR(50))
begin
insert into customers (name, email) value (n, e);
end
Обратите внимание, как задаются параметры: необходимо дать имя
параметру и указать его тип, а в теле процедуры мы уже используем имена
параметров. Один нюанс. Как вы помните, точка с запятой означает конец
запроса и отправляет его на выполнение, что в данном случае неприемлемо.
Поэтому, прежде, чем написать процедуру необходимо переопределить
разделитель с ; на "//", чтобы запрос не отправлялся раньше времени. Делается
это с помощью оператора DELIMITER //:
DELIMITER //
Таким образом, мы указали СУБД, что выполнять команды теперь
следует после //. Следует помнить, что переопределение разделителя
осуществляется только на один сеанс работы, т.е. при следующем сеансе
работы с MySql разделитель снова станет точкой с запятой и при
необходимости его придется снова переопределять. Теперь можно разместить
процедуру:
CREATE PROCEDURE ins_cust(n CHAR(50), e CHAR(50))
begin
insert into customers (name, email) value (n, e);
end
//
Итак, процедура создана. Теперь, когда нам понадобится ввести нового
покупателя нам достаточно ее вызвать, указав необходимые параметры. Для
вызова хранимой процедуры используется оператор CALL, после которого
указывается имя процедуры и ее параметры. Давайте добавим нового
покупателя в нашу таблицу Покупатели (customers):
call ins_cust('Сычов Валерий', 'valera@gmail.ru')//
Согласитесь, что так гораздо проще, чем писать каждый раз полный запрос.
Проверим,
работает
ли
процедура,
посмотрев,
новыйпокупатель в таблице Покупатели (customers):
появился
ли
Появился, процедура работает, и будет работать всегда, пока мы ее не
удалим с помощью оператора DROP PROCEDURE название_процедуры.
Как было сказано в начале урока, процедуры позволяют объединить
последовательность запросов. Давайте посмотрим, как это делается. Помните
в уроке 11 мы хотели узнать, на какую сумму нам привез товар поставщик
"Дом печати"? Для этого нам пришлось использовать вложенные запросы,
объединения, вычисляемые столбцы и представления. А если мы захотим
узнать, на какую сумму нам привез товар другой поставщик? Придется
составлять новые запросы, объединения и т.д. Проще один раз написать
хранимую процедуру для этого действия.
Казалось бы, проще всего взять уже написанные в уроке 11
представление и запрос к нему, объединить в хранимую процедуру и сделать
идентификатор поставщика (id_vendor) входным параметром, вот так:
CREATE PROCEDURE sum_vendor(i INT)
begin
CREATE VIEW report_vendor AS SELECT magazine_incoming.id_product,
magazine_incoming.quantity,
prices.price, magazine_incoming.quantity*prices.price AS summa FROM
magazine_incoming, prices
WHERE magazine_incoming.id_product= prices.id_product AND id_incoming=
(SELECT id_incoming FROM incoming WHERE id_vendor=i);
SELECT SUM(summa) FROM report_vendor;
end
//
Но так процедура работать не будет. Все дело в том, что в
представлениях не могут использоваться параметры. Поэтому нам придется
несколько изменить последовательность запросов. Сначала мы создадим
представление,
которое
будет
выводить
идентификатор
поставщика
(id_vendor), идентификатор продукта (id_product), количество (quantity), цену
(price) и сумму (summa) из трех таблиц Поставки (incoming), Журнал поставок
(magazine_incoming), Цены (prices):
CREATE VIEW report_vendor AS SELECT incoming.id_vendor,
magazine_incoming.id_product, magazine_incoming.quantity,
prices.price, magazine_incoming.quantity*prices.price AS summa
FROM incoming, magazine_incoming, prices
WHERE magazine_incoming.id_product= prices.id_product AND
magazine_incoming.id_incoming= incoming.id_incoming;
А потом создадим запрос, который просуммирует суммы поставок
интересующего нас поставщика, например, с id_vendor=2:
SELECT SUM(summa) FROM report_vendor WHERE id_vendor=2;
Вот теперь мы можем объединить два этих запроса в хранимую
процедуру, где входным параметром будет идентификатор поставщика
(id_vendor), который будет подставляться во второй запрос, но не в
представление:
CREATE PROCEDURE sum_vendor(i INT)
begin
CREATE VIEW report_vendor AS SELECT incoming.id_vendor,
magazine_incoming.id_product, magazine_incoming.quantity,
prices.price, magazine_incoming.quantity*prices.price AS summa
FROM incoming, magazine_incoming, prices
WHERE magazine_incoming.id_product= prices.id_product AND
magazine_incoming.id_incoming= incoming.id_incoming;
SELECT SUM(summa) FROM report_vendor WHERE id_vendor=i;
end
//
Проверим работу процедуры, с разными входными параметрами:
call sum_vendor(1)//
call sum_vendor(2)//
call sum_vendor(3)//
Как видите, процедура срабатывает один раз, а затем выдает ошибку,
говоря нам, что представление report_vendor уже имеется в БД. Так
происходит потому, что при обращении к процедуре в первый раз, она создает
представление. При обращении во второй раз, она снова пытается создать
представление, но оно уже есть, поэтому и появляется ошибка. Чтобы
избежать этого возможно два варианта.
Первый - вынести представление из процедуры. То есть мы один раз
создадим представление, а процедура будет лишь к нему обращаться, но не
создавать его. Предварительно не забудет удалить уже созданную процедуру
и представление:
DROP PROCEDURE sum_vendor//
DROP VIEW report_vendor//
CREATE VIEW report_vendor AS SELECT incoming.id_vendor,
magazine_incoming.id_product, magazine_incoming.quantity,
prices.price, magazine_incoming.quantity*prices.price AS summa
FROM incoming, magazine_incoming, prices
WHERE magazine_incoming.id_product= prices.id_product AND
magazine_incoming.id_incoming= incoming.id_incoming//
CREATE PROCEDURE sum_vendor(i INT)
begin
SELECT SUM(summa) FROM report_vendor WHERE id_vendor=i;
end
//
Проверяем работу:
call sum_vendor(1)//
call sum_vendor(2)//
call sum_vendor(3)//
Второй вариант - прямо в процедуре дописать команду, которая будет
удалять представление, если оно существует:
CREATE PROCEDURE sum_vendor(i INT)
begin
DROP VIEW IF EXISTS report_vendor;
CREATE VIEW report_vendor AS SELECT incoming.id_vendor,
magazine_incoming.id_product, magazine_incoming.quantity,
prices.price, magazine_incoming.quantity*prices.price AS summa
FROM incoming, magazine_incoming, prices
WHERE magazine_incoming.id_product= prices.id_product AND
magazine_incoming.id_incoming= incoming.id_incoming;
SELECT SUM(summa) FROM report_vendor WHERE id_vendor=i;
end
//
Перед использованием этого варианта не забудьте удалить процедуру
sum_vendor, а затем проверить работу:
Как видите, сложные запросы или их последовательность действительно
проще один раз оформить в хранимую процедуру, а дальше просто обращаться
к ней, указывая необходимые параметры. Это значительно сокращает код и
делает работу с запросами более логичной.
Лабораторная работа № 16.
Теперь давайте узнаем, как можно посмотреть, какие хранимые
процедуры имеются у нас на сервере, и как они выглядят. Для этого
познакомимся с двумя операторами:
SHOW PROCEDURE STATUS - позволяет просмотреть список
имеющихся хранимых процедур. Правда просматривать этот список не очень
удобно, т.к. по каждой процедуре выдается информация об имени БД, к
которой процедура принадлежит, ее типе, учетной записи, от имени которой
была создана процедура, о дате создания и изменения процедуры и т.д. И всетаки, если вам необходимо посмотреть, какие процедуры у вас есть, то стоит
воспользоваться этим оператором.
SHOW CREATE PROCEDURE имя_процедуры - позволяет получить
информацию о конкретной процедуре, в частности просмотреть ее код. Вид
для просмотра также не очень удобный, но разобраться можно.
Попробуйте оба оператора в действии, чтобы знать, как это выглядит. А
теперь рассмотрим более удобный вариант получения подобной информации.
В системной базе данных MySQL есть таблица proc, где и хранится
информация о процедурах. Так вот мы может сделать SELECT-запрос к этой
таблице. Причем, если мы создадим привычный запрос:
SELECT * FROM mysql.proc//
То получим нечто такое же нечитабельное, как и при использовании
операторов SHOW. Поэтому мы будем создавать запросы с условиями.
Например, если мы создадим вот такой запрос:
SELECT name FROM mysql.proc//
То получим имена всех процедур всех баз данных, имеющихся на
сервере. Нас, например, на данный момент интересуют только процедуры
базы данных shop, поэтому изменим запрос:
SELECT name FROM mysql.proc WHERE db='shop'//
Вот теперь мы получили то, что хотели:
Если же мы хотим посмотреть только тело конкретной процедуры (т.е.
от begin до end), то мы напишем такой запрос:
SELECT body FROM mysql.proc WHERE name='sum_vendor'//
И увидим вполне читабельный вариант:
Вообще, чтобы извлекать из таблицы proc необходимую вам
информацию, надо просто знать, какие столбцы она содержит, а для этого
можно воспользоваться знакомым нам с первого урока оператором describe
имя_таблицы, в нашем случае describe mysql.proc. Правда, вид у нее тоже не
очень
читабельный,
поэтому
приведем
здесь
названия
наиболее
востребованных столбцов:
db - имя БД, в которую сохранена процедура.
name - имя процедуры.
param_list - список параметров процедуры.
body - тело процедуры.
comment - комментарий к хранимой процедуре.
Столбцы db, name и body мы уже использовали. Запрос, извлекающий
параметры процедуры sum_vendor составьте самостоятельно. А вот про
комментарии к хранимым процедурам мы сейчас поговорим подробнее.
Комментарии вещь крайне необходимая, ведь через какое-то время мы
может забыть, что делает та или иная процедура. Конечно, по ее коду можно
восстановить нашу память, но зачем? Гораздо проще сразу при создании
процедуры указать, что она делает, и тогда, даже по прошествии долгого
времени, обратившись к комментариям, мы сразу вспомним, зачем эта
процедура создавалась.
Создавать комментарии крайне просто. Для этого сразу после списка
параметров, но еще до начала тела хранимой процедуры указываем ключевое
слово COMMENT 'здесь комментарий'. Давайте удалим нашу процедуру
sum_vendor и создадим новую, с комментарием:
CREATE PROCEDURE sum_vendor(i INT)
COMMENT
'Возвращает
сумму
товара
по
идентификатору
поставщика.'
begin
DROP VIEW IF EXISTS report_vendor;
CREATE VIEW report_vendor AS SELECT incoming.id_vendor,
magazine_incoming.id_product, magazine_incoming.quantity,
prices.price, magazine_incoming.quantity*prices.price AS summa
FROM incoming, magazine_incoming, prices
WHERE magazine_incoming.id_product= prices.id_product AND
magazine_incoming.id_incoming= incoming.id_incoming;
SELECT SUM(summa) FROM report_vendor WHERE id_vendor=i;
end
//
А теперь сделаем запрос к комментарию процедуры:
SELECT comment FROM mysql.proc WHERE name='sum_vendor'//
Вообще-то, чтобы добавить комментарий, вовсе не обязательно было
удалять старую процедуру. Можно было отредактировать имеющуюся
хранимую процедуру с помощью оператора ALTER PROCEDURE. Давайте
посмотрим, как это сделать, на примере процедуры ins_cust из прошлого
урока. Эта процедура вводит информацию о новом покупателе в таблицу
Покупатели (customers). Давайте добавим комментарий к этой процедуре:
ALTER PROCEDURE ins_cust COMMENT 'Вводит информацию о
новом покупателе в таблицу Покупатели.'//
И сделаем запрос к комментарию, чтобы проверить:
SELECT comment FROM mysql.proc WHERE name='ins_cust'//
В нашей базе данных всего две процедуры, и комментарии к ним
кажутся излишними. Не ленитесь, обязательно пишите комментарии.
Представьте, что в нашей базе данных десятки или сотни процедур. Сделав
нужный запрос, вы без труда узнаете, какие процедуры есть и что они делают
и поймете, что комментарии - это не излишества, а экономия вашего времени
в будущем. Кстати, а вот и сам запрос:
SELECT name, comment FROM mysql.proc WHERE db='shop'//
Ну вот, теперь мы умеем извлекать любую информацию о наших
процедурах, что позволит нам ничего не забыть и не запутаться.
Лабораторная работа № 17.
Хранимые процедуры это не просто контейнера для групп запросов, как
может показаться. Хранимые процедуры могут в своей работе использовать
операторы ветвления. Вне хранимых процедур такие операторы использовать
нельзя.
Начнем
изучение
с
операторов IF...THEN...ELSE.
Если
вы
изучали уроки JavaScript или просто знакомы с каким-нибудь языком
программирования, то эта конструкция вам знакома. Напомним, что условный
оператор IF позволяет
организовать
ветвление
программы.
В
случае
хранимых процедур этот оператор позволяет выполнять разные запросы, в
зависимости от входных параметров. На примере, как всегда, будет понятнее.
Но для начала синтаксис:
CREATE PROCEDURE имя_процедуры (параметры)
begin
IF(условие) THEN
запрос 1;
ELSE
запрос 2;
END IF;
end
//
Логика работы проста: если условие истинно, то выполняется запрос 1,
в противном случае - запрос 2.
Предположим, каждый день мы устраиваем в нашем магазине
счастливые часы, т.е. делаем скидку 10% на все книги в последний час работы
магазина. Чтобы иметь возможность выбирать цену книги, нам необходимо
иметь два ее варианта - со скидкой и без. Для этого, нам понадобится создать
хранимую процедуру с оператором ветвления. Так как мы имеем всего два
варианта цены, то удобнее в качестве входящего параметра иметь булево
значение, которое, как вы помните, может принимать либо 0 - ложь, либо 1 истина. Код процедуры может быть таким:
CREATE PROCEDURE discount (dis BOOLEAN)
begin
IF(dis=1) THEN
SELECT id_product, price*0.9 AS price_discount FROM prices;
ELSE
SELECT id_product, price FROM prices;
END IF;
end
//
Т.е. на входе у нас параметр, который может являться, либо 1 (если
скидка есть), либо 0 (если скидки нет). В первом случае будет выполнен
первый запрос, во втором - второй. Давайте посмотрим, как работает наша
процедура в обоих вариантах:
call discount(1)//
call discount(0)//
Оператор IF позволяет выбирать и большее количество вариантов
запросов, в таком случае используется следующий синтаксис:
CREATE PROCEDURE имя_процедуры (параметры)
begin
IF(условие) THEN
запрос 1;
ELSEIF(условие) THEN
запрос 2;
ELSE
запрос 3;
END IF;
end
//
Причем блоков ELSEIF может быть несколько. Предположим, что мы
решили делать скидки нашим покупателям в зависимости от суммы покупки,
до 1000 рублей скидки нет, от 1000 до 2000 рублей - скидка 10%, более 2000
рублей - скидка 20%. Входным параметром для такой процедуры должна быть
сумма покупки. Поэтому сначала нам надо написать процедуру, которая будет
ее подсчитывать. Сделаем это по аналогии с процедурой sum_vendor,
созданной в уроке 15, которая подсчитывала сумму товара по идентификатору
поставщика.
Необходимые нам данные хранятся в двух таблицах Журнал покупок
(magazine_sales) и Цены (prices).
CREATE PROCEDURE sum_sale(IN i INT)
COMMENT 'Возвращает сумму покупки по ее идентификатору.'
begin
DROP VIEW IF EXISTS sum_sale;
CREATE VIEW sum_sale AS SELECT magazine_sales.id_sale,
magazine_sales.id_product, magazine_sales.quantity,
prices.price, magazine_sales.quantity*prices.price AS summa
FROM magazine_sales, prices
WHERE magazine_sales.id_product=prices.id_product;
SELECT SUM(summa) FROM sum_sale WHERE id_sale=i;
end
//
Здесь перед параметром у нас появилось новое ключевое слово IN. Дело
в том, что мы можем, как передавать данные в процедуру, так и передавать
данные из процедуры. По умолчанию, т.е. если опустить слово IN, параметры
считаются входными (поэтому раньше мы это слово и не использовали). Здесь
же мы явно указали, что параметр i является входным. Если же нам
понадобится извлечь какие-нибудь данные из хранимой процедуры, то мы
будем использовать ключевое слово OUT, но об этом чуть позже.
Итак, мы написали процедуру, которая создает представление, выбирая
идентификатор покупки, идентификатор товара, его количество, цену и
подсчитывает сумму по всем строчкам получившейся таблицы. Затем идет
запрос к этому представлению, где по входному параметру идентификатора
покупки подсчитывается итоговая сумма этой покупки.
Теперь нам надо написать процедуру, которая пересчитает итоговую
сумму с учетом предоставляемой скидки. Здесь нам и понадобится оператор
ветвления:
CREATE PROCEDURE sum_discount(IN sm INT, IN i INT)
COMMENT 'Возвращает сумму покупки с учетом скидки.'
begin
IF((sm>=1000) && (sm<2000)) THEN
SELECT SUM(summa)*0.9 FROM sum_sale WHERE id_sale=i;
ELSEIF(sm>=2000) THEN
SELECT SUM(summa)*0.8 FROM sum_sale WHERE id_sale=i;
ELSE
SELECT SUM(summa) FROM sum_sale WHERE id_sale=i;
END IF;
end
//
Т.е. мы передаем процедуре два входных параметра сумму (sm) и
идентификатор покупки (i) и в зависимости от того, какая это сумма,
выполняется запрос к представлению sum_sale на подсчет итоговой суммы
покупки, умноженной на нужный коэффициент.
Осталось только сделать так, чтобы сумма покупки автоматически
передавалась в эту процедуру. Для этого процедуру sum_discount хорошо бы
вызвать прямо из процедуры sum_sale. Выглядеть это будет примерно вот так:
CREATE PROCEDURE sum_sale(IN i INT)
COMMENT 'Возвращает сумму покупки по ее идентификатору.'
begin
DROP VIEW IF EXISTS sum_sale;
CREATE VIEW sum_sale AS SELECT magazine_sales.id_sale,
magazine_sales.id_product, magazine_sales.quantity,
prices.price, magazine_sales.quantity*prices.price AS summa
FROM magazine_sales, prices
WHERE magazine_sales.id_product=prices.id_product;
SELECT SUM(summa) FROM sum_sale WHERE id_sale=i;
CALL sum_discount(?, i);
end
//
Вопросительный знак при вызове процедуры sum_discount поставлен,
т.к. не понятно, как результат предыдущего запроса (т.е. итоговой суммы)
передать в процедуру sum_discount. Кроме того, не понятно, как процедура
sum_discount вернет результат своей работы. Вы, наверно, уже догадались, что
для решения второго вопроса нам как раз и понадобится параметр с ключевым
словом OUT, т.е. параметр, который будет возвращать данные из процедуры.
Давайте введем такой параметр ss, и так как сумма может быть и дробным
числом, зададим ему тип DOUBLE:
CREATE PROCEDURE sum_discount(IN sm INT, IN i INT, OUT ss
DOUBLE)
COMMENT 'Возвращает сумму покупки с учетом скидки.'
begin
IF((sm>=1000) && (sm<2000)) THEN
SELECT SUM(summa)*0.9 FROM sum_sale WHERE id_sale=i;
ELSEIF(sm>=2000) THEN
SELECT SUM(summa)*0.8 FROM sum_sale WHERE id_sale=i;
ELSE
SELECT SUM(summa) FROM sum_sale WHERE id_sale=i;
END IF;
end
//
CREATE PROCEDURE sum_sale(IN i INT, OUT ss DOUBLE)
COMMENT 'Возвращает сумму покупки по ее идентификатору.'
begin
DROP VIEW IF EXISTS sum_sale;
CREATE VIEW sum_sale AS SELECT magazine_sales.id_sale,
magazine_sales.id_product, magazine_sales.quantity,
prices.price, magazine_sales.quantity*prices.price AS summa
FROM magazine_sales, prices
WHERE magazine_sales.id_product=prices.id_product;
SELECT SUM(summa) FROM sum_sale WHERE id_sale=i;
CALL sum_discount(?, i, ss);
end
//
Итак, в обе процедуры мы ввели выходной параметр ss. Теперь вызов
процедуры CALL sum_discount(?, i, ss); означает, что передавая два первых
параметра, мы ждем возврата третьего параметра в процедуру sum_sale.
Осталось только понять, как внутри самой процедуры sum_discount присвоить
этому параметру какое-либо значение. Нам надо, чтобы в этот параметр
передавался результат одного из запросов. И, конечно, в MySQL предусмотрен
такой вариант, для этого используется ключевое слово INTO:
CREATE PROCEDURE sum_discount(IN sm INT, IN i INT, OUT ss
DOUBLE)
COMMENT 'Возвращает сумму покупки с учетом скидки.'
begin
IF((sm>=1000) && (sm<2000)) THEN
SELECT SUM(summa)*0.9 INTO ss FROM sum_sale WHERE
id_sale=i;
ELSEIF(sm>=2000) THEN
SELECT SUM(summa)*0.8 INTO ss FROM sum_sale WHERE
id_sale=i;
ELSE
SELECT SUM(summa) INTO ss FROM sum_sale WHERE id_sale=i;
END IF;
end
//
С помощью ключевого слова INTO, мы указали, что результат запроса
надо передать в параметр ss.
Теперь давайте разбираться с вопросительным знаком, вернее узнаем,
как передать в процедуру sum_discount результат работы предыдущих
запросов. Для этого мы познакомимся с таким понятием, как переменная.
Переменные позволяют сохранить результат текущего запроса для
использования в следующих запросах. Объявление переменной начинается с
символа собачки (@), за которой следует имя переменной. Объявляются они
при помощи оператора SET. Например, объявим переменную z и зададим ей
начальное значение 20.
SET @z='20'//
Переменная с таким значение теперь есть в нашей БД, можете
проверить, сделав соответствующий запрос:
SELECT @z//
Переменные действуют только в рамках одного сеанса соединения с
сервером MySQL. То есть после разъединения переменная перестанет
существовать.
Для
использования
переменных
в
процедурах
используется
оператор DECLARE, который имеет следующий синтаксис:
DECLARE имя_переменной тип
DEFAULT значение_по_умолчанию_если_есть
Итак, давайте в нашей процедуре объявим переменную s, в которую
будем сохранять значение суммы покупки с помощью ключевого слова INTO:
CREATE PROCEDURE sum_sale(IN i INT, OUT ss DOUBLE)
COMMENT 'Возвращает сумму покупки по ее идентификатору.'
begin
DECLARE s INT;
DROP VIEW IF EXISTS sum_sale;
CREATE VIEW sum_sale AS SELECT magazine_sales.id_sale,
magazine_sales.id_product, magazine_sales.quantity,
prices.price, magazine_sales.quantity*prices.price AS summa
FROM magazine_sales, prices
WHERE magazine_sales.id_product=prices.id_product;
SELECT SUM(summa) INTO s FROM sum_sale WHERE id_sale=i;
CALL sum_discount(s, i, ss);
end
//
Эта переменная и будет первым входным параметром для процедуры
sum_discount. Итак, окончательный вариант наших процедур выглядит так:
CREATE PROCEDURE sum_discount(IN sm INT, IN i INT, OUT ss
DOUBLE)
COMMENT 'Возвращает сумму покупки с учетом скидки.'
begin
IF((sm>=1000) && (sm<2000)) THEN
SELECT SUM(summa)*0.9 INTO ss FROM sum_sale WHERE
id_sale=i;
ELSEIF(sm>=2000) THEN
SELECT SUM(summa)*0.8 INTO ss FROM sum_sale WHERE
id_sale=i;
ELSE
SELECT SUM(summa) INTO ss FROM sum_sale WHERE id_sale=i;
END IF;
end
//
CREATE PROCEDURE sum_sale(IN i INT, OUT ss DOUBLE)
COMMENT 'Возвращает сумму покупки по ее идентификатору.'
begin
DECLARE s INT;
DROP VIEW IF EXISTS sum_sale;
CREATE VIEW sum_sale AS SELECT magazine_sales.id_sale,
magazine_sales.id_product, magazine_sales.quantity,
prices.price, magazine_sales.quantity*prices.price AS summa
FROM magazine_sales, prices
WHERE magazine_sales.id_product=prices.id_product;
SELECT SUM(summa) INTO s FROM sum_sale WHERE id_sale=i;
CALL sum_discount(s, i, ss);
end
//
На случай, если вы запутались, давайте посмотрим алгоритм работы
нашей процедуры sum_sale:
Мы вызываем процедуру sum_sale, указывая в качестве входного
параметра идентификатор интересующей нас покупки, например id=1, и
указывая, что второй параметр - выходной, переменный, являющийся
результатом работы процедуры sum_discount:
call sum_sale(1, @sum_discount)//
Процедура sum_sale создает представление, в котором собираются
данные обо всех покупках, товарах, их количестве, цене и сумме по каждой
строчке.
Затем выполняется запрос к этому представлению на итоговую сумму
по покупке с нужным идентификатором, и результат записывается в
переменную s.
Теперь вызывается процедура sum_discount, в которой в качестве
первого параметра выступает переменная s (сумма покупки), в качестве
второго - идентификатор покупки i, а в качестве третьего указывается
параметр ss, который выступает, как выходной, т.е. в него вернется результат
действия процедуры sum_discount.
В процедуре sum_discount проверяется, какому условию соответствует
входная
сумма,
и
выполняется
соответствующий
запрос,
результат
записывается в выходной параметр ss, который возвращается в процедуру
sum_sale.
Чтобы увидеть результат работы процедуры sum_sale нужно сделать
запрос:
select @sum_discount//
Давайте убедимся, что наша процедура работает:
Сумма наших обеих покупок меньше 1000 рублей, поэтому скидки нет.
Можете самостоятельно ввести покупки с разными суммами и посмотреть, как
будет работать наша процедура.
Возможно, этот урок показался вам достаточно трудным или
запутанным. Не расстраивайтесь. Во-первых, все приходит с опытом, а вовторых, справедливости ради, надо сказать, что и переменные, и операторы
ветвления в MySQL используются крайне редко. Предпочтение отдается
языкам типа PHP, Perl и т.д., с помощью которых и организуется ветвление, а
в саму БД посылаются простые процедуры.
Лабораторная работа № 18.
Сегодня узнаем, как работать с циклами, т.е. выполнять один и тот же
запрос несколько раз. В MySQL для работы с циклами применяются
операторы WHILE, REPEAT и LOOP.
Оператор цикла WHILE
Сначала синтаксис:
WHILE условие DO
запрос
END WHILE
Запрос будет выполняться до тех пор, пока условие истинно. Давайте
посмотрим на примере, как это работает. Предположим, мы хотим знать
названия, авторов и количество книг, которые поступили в различные
поставки. Интересующая нас информация хранится в двух таблицах - Журнал
Поставок (magazine_incoming) и Товар (products). Давайте напишим
интересующий нас запрос:
SELECT magazine_incoming.id_incoming, products.name, products.author,
magazine_incoming.quantity
FROM magazine_incoming, products
WHERE magazine_incoming.id_product=products.id_product;
А что, если нам необходимо, чтобы результат выводился не в одной
таблице, а по каждой поставке отдельно? Конечно, можно написать 3 разных
запроса, добавив в каждый еще одно условие:
SELECT magazine_incoming.id_incoming, products.name, products.author,
magazine_incoming.quantity
FROM magazine_incoming, products
WHERE magazine_incoming.id_product=products.id_product AND
magazine_incoming.id_incoming=1;
SELECT magazine_incoming.id_incoming, products.name, products.author,
magazine_incoming.quantity
FROM magazine_incoming, products
WHERE
magazine_incoming.id_product=products.id_product
magazine_incoming.id_incoming=2;
AND
SELECT magazine_incoming.id_incoming, products.name, products.author,
magazine_incoming.quantity
FROM magazine_incoming, products
WHERE
magazine_incoming.id_product=products.id_product
AND
magazine_incoming.id_incoming=3;
Но гораздо короче сделать это можно с помощью цикла WHILE:
DECLARE i INT DEFAULT 3;
WHILE i>0 DO
SELECT
magazine_incoming.id_incoming,
products.name,
products.author, magazine_incoming.quantity
FROM magazine_incoming, products
WHERE
magazine_incoming.id_product=products.id_product
AND
magazine_incoming.id_incoming=i;
SET i=i-1;
END WHILE;
Т.е. мы ввели переменную i, по умолчанию равную 3, сервер выполнит
запрос с id поставки равным 3, затем уменьшит i на единицу (SET i=i-1),
убедится, что новое значение переменной i положительно (i>0) и снова
выполнит запрос, но уже с новым значением id поставки равным 2. Так будет
происходить, пока переменная i не получит значение 0, условие станет
ложным, и цикл закончит свою работу.
Чтобы убедиться в работоспособности цикла создадим хранимую
процедуру books и поместим в нее цикл:
DELIMITER //
CREATE PROCEDURE books ()
begin
DECLARE i INT DEFAULT 3;
WHILE i>0 DO
SELECT magazine_incoming.id_incoming, products.name,
products.author,
magazine_incoming.quantity
FROM magazine_incoming, products
WHERE magazine_incoming.id_product=products.id_product
AND magazine_incoming.id_incoming=i;
SET i=i-1;
END WHILE;
end
//
Теперь вызовем процедуру:
CALL books ()//
Теперь у нас 3 отдельные таблицы (по каждой поставке). Согласитесь,
что код с циклом гораздо короче трех отдельных запросов. Но в нашей
процедуре есть одно неудобство, мы объявили количество выводимых таблиц
значением по умолчанию (DEFAULT 3), и нам придется с каждой новой
поставкой менять это значение, а значит код процедуры. Гораздо удобнее
сделать это число входным параметром. Давайте перепишем нашу процедуру,
добавив входной параметр num, и, учитывая, что он не должен быть равен 0:
CREATE PROCEDURE books (IN num INT)
begin
DECLARE i INT DEFAULT 0;
IF (num>0) THEN
WHILE i < num DO
SELECT
magazine_incoming.id_incoming,
products.name,
products.author, magazine_incoming.quantity
FROM magazine_incoming, products
WHERE magazine_incoming.id_product=products.id_product AND
magazine_incoming.id_incoming=i;
SET i=i+1;
END WHILE;
ELSE
SELECT
'Задайте правильный параметр';
END IF;
end
//
CALL books (0)//
Убедитесь, что с другими параметрами, мы по-прежнему получаем
таблицы по каждой поставке. У нашего цикла есть еще один недостаток - если
случайно задать слишком большое входное значение, то мы получим
псевдобесконечный цикл, который загрузит сервер бесполезной работой.
Такие ситуации предотвращаются с помощью снабжения цикла меткой и
использования оператора LEAVE, обозначающего досрочный выход из цикла.
CREATE PROCEDURE books (IN num INT)
begin
DECLARE i INT DEFAULT 0;
IF (num>0) THEN
wet : WHILE i < num DO
IF (i>10) THEN LEAVE wet;
ENF IF;
SELECT magazine_incoming.id_incoming, products.name,
products.author, magazine_incoming.quantity
FROM magazine_incoming, products
WHERE magazine_incoming.id_product=products.id_product AND
magazine_incoming.id_incoming=i;
SET i=i+1;
END WHILE wet;
ELSE
SELECT
'Задайте правильный параметр';
END IF;
end
//
Итак, мы снабдили наш цикл меткой wet вначале (wet:) и в конце, а также
добавили еще одно условие - если входной параметр больше 10 (число 10 взято
произвольно), то цикл с меткой wet следует закончить (IF (i>10) THEN LEAVE
wet). Таким образом, если мы случайно вызовем процедуру с большим
значением num, наш цикл прервется после 10 итераций (итерация - один
проход цикла).
Циклы в MySQL, так же как и операторы ветвления, на практике в webприложениях почти не используются. Поэтому для двух других видов циклов
приведем лишь синтаксис и отличия. Вряд ли вам доведется их использовать,
но знать об их существовании все-таки надо.
Оператор цикла REPEAT.
Условие цикла проверяется не в начале, как в цикле WHILE, а в конце,
т.е. хотя бы один раз, но цикл выполняется. Сам же цикл выполняется, пока
условие ложно. Синтаксис следующий:
REPEAT
запрос
UNTIL условие
END REPEAT
Оператор цикла LOOP.
Этот цикл вообще не имеет условий, поэтому обязательно должен иметь
оператор LEAVE. Синтаксис следующий:
LOOP
запрос
END LOOP
На этом мы заканчиваем уроки посвященные SQL. Конечно, мы
рассмотрели не все возможности этого языка запросов, но в реальной жизни
вам вряд ли придется столкнуться даже с тем, что вы уже знаете.
Напомню, на реальных сайтах, вы обычно вводите информацию в какиенибудь html-формы, затем сценарий на каком-либо языке (php, java...)
извлекает эти данные из формы и заносит их в БД. При необходимости
происходит обратный процесс, т.е. данные извлекаются из БД и выводятся на
страницы сайта. Оба процесса происходят посредством SQL-запросов. HTML
вы знаете, с базами данных разобрались, SQL-запросы писать научились,
осталось изучить PHP, чтобы ваши сайты превратились в полноправные webприложения.