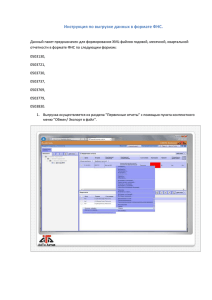
Полнотекстовый поиск в PostgreSQL за миллисекунды
advertisement

Полнотекстовый поиск в PostgreSQL
за миллисекунды
Коротков А.Е, Бартунов О.С.
Полнотекстовый поиск в базе
данных: задача
Найти документы, которые
удовлетворяют запросу
Вернуть результаты в порядке
релевантности
Полнотестовый поиск в базе
данных: требования
Интеграция с ядром СУБД
Поддержка транзакций
Конкуретность, recovery
Обновление индекса «online»
Поддержка языка
Расширяемость, масштабируемость
Что такое документ?
Произвольный текстовый атрибут
Комбинация текстовых атрибутов
Может быть полностью вирутальным.
Например, результатом SQL объединения
таблиц doc и autor
Title || Abstract || Keywords || Body || Author
Операторы полнотекстового поиска
Традиционные FTS операторы для
атрибутов LIKE, ILIKE, ~, ~*
Проблемы
– Отсутствие поддержки языка (стемминг, стоп
слова)
– Отсутствие ранжирования
– Последовательное сканирование документов
Решение
– Предварительная обработка документов
– Поддержка индексов
FTS в PostgreSQL
набор правил по преобразованию
документа в его FTS представление –
tsvector, tsquery
набор функций для получения tsvector,
tsquery из текста
FTS операторы и индексы
функции ранжирования, подсветки
результатов
FTS в PostgreSQL
=# select 'a fat cat sat on a mat and ate a fat rat'::tsvector
@@
'cat & rat':: tsquery;
– tsvector – представление документа,
оптимизированное для поиска
• отсортированный массив лексем
• позиции и вес лексем
– tsquery – тип данные для полнотекстового запроса
• булевы операторы - & | ! ()
– поисковый оператор
tsvector @@ tsquery
Возможности FTS
Полная интеграция PostgreSQL
27 встроенный конфигураций для 10 языков
Поддержка пользовательских конфигураций
Встраиваемые словари (ispell, snowball, thesaurus),
парсеры
Ранжирование по релевантности
GiST и GIN индексы с поддержкой concurrency и
recovery
Богатый язык запросов с поддержкой
перезаписывания запросов
FTS в PostgreSQL
OpenFTS — 2000, Pg как хранилище
GiST index — 2000, спасибо Rambler
Tsearch — 2001, contrib:без ранжирования
Tsearch2 — 2003, contrib:config
GIN —2006, спасибо JFG Networks
FTS — 2006, в ядре, спасибо EnterpriseDB
E-FTS — Enterprise FTS, спасибо???
Накладные расходы
на ACID велики
Внешние решения: Sphinx, Solr, Lucene....
Скачивание БД в «поисковый движок»
(задержка)
Затруднен доступ к атрибутам
Дополнительная сложность
НО: Очень быстро !
Можно ли ускорить встроенный FTS ?
Можно ли ускорить
встроенный FTS ?
1.Поиск релевантных документов: Index
scan — как правило, довольно быстро
2.Расчет релевантности: Heap scan —
как правило, медленно
3.Сортировка документов
Можно ли ускорить
встроенный FTS ?
156676 статей Wikipedia:
postgres=# explain analyze
SELECT docid, ts_rank(text_vector, to_tsquery('english', 'title')) AS rank
FROM ti2
WHERE text_vector @@ to_tsquery('english', 'title')
ORDER BY rank DESC
LIMIT 3;
Limit (cost=8087.40..8087.41 rows=3 width=282) (actual time=433.750..433.752 rows=
-> Sort (cost=8087.40..8206.63 rows=47692 width=282) (actual time=433.749..433.
Sort Key: (ts_rank(text_vector, '''titl'''::tsquery))
Sort Method: top-N heapsort Memory: 25kB
-> Bitmap Heap Scan on ti2 (cost=529.61..7470.99 rows=47692 width=282) (a
Recheck Cond: (text_vector @@ '''titl'''::tsquery)
-> Bitmap Index Scan on ti2_index (cost=0.00..517.69 rows=47692 wid
Index Cond: (text_vector @@ '''titl'''::tsquery)
Total runtime: 433.787 ms
Можно ли ускорить
встроенный FTS ?
156676 статей Wikipedia:
postgres=# explain analyze
SELECT docid, ts_rank(text_vector, to_tsquery('english', 'title')) AS rank
FROM ti2
WHERE text_vector @@ to_tsquery('english', 'title')
ORDER BY text_vector>< plainto_tsquery('english','title')
LIMIT 3;
Если бы был такой план
Limit
->
(cost=20.00..21.65 rows=3 width=282) (actual time=18.376..18.427 rows=3 loops
Index Scan using ti2_index on ti2 (cost=20.00..26256.30 rows=47692 width=282
Index Cond: (text_vector @@ '''titl'''::tsquery)
Order By: (text_vector >< '''titl'''::tsquery)
Total runtime: 18.511 ms
то было бы неплохо!
Было бы неплохо
Обучить индекс (GIN) считать
релевантность и возвращать документы
упорядоченно
Хранить позиции лексем в индесу —
больше не нужна колонка tsvecotr
Использовать компрессию
Изменить алгоритмы и интерфейсы
Оптимизировать случай
редкое_слово & частое_слово
Инвертированный индекс
Инвертированный индекс
QUERY: compensation accelerometers
INDEX: accelerometers
5,10,25,28,30,36,58,59,61,73,74
RESULT:
30
compensation
30,68
Инвертированный индекс в PostgreSQL
E
N
T
R
Y
Posting list
Posting tree
T
R
E
E
Нет позиционной информации в индексе !
Список изменений
• GIN
– способ хранения
– алгоритм поиска
– поддержка ORDER BY
– изменения интерфейса
• Планировщик
Изменение структуры GIN
Дополнительная информация
(позиции слов)
ItemPointer
typedef struct ItemPointerData
{
BlockIdData ip_blkid;
OffsetNumber ip_posid;
}
typedef struct BlockIdData
{
uint16
bi_hi;
uint16
bi_lo;
} BlockIdData;
6 bytes
WordEntryPos
/*
* Equivalent to
* typedef struct {
*
uint16
*
weight:2,
*
pos:14;
* }
*/
typedef uint16 WordEntryPos;
2 bytes
Varbyte сжатие BlockIdData
Varbyte сжатие OffsetNumber
O0-O15 – биты OffsetNumber
N – NULL бит дополнительной информаци
Varbyte сжатие WordEntryPos
P0-P13 – биты позиции
W0,W1 – биты веса
Пример
Top-N запросы
1. Сканирование + вычисление
релевантности
2. Сортировка
3. Возвращение результатов по
одному с помощью gingettuple
Быстрое сканирование
entry1 && entry2
Изменения интерфейса GIN
extractValue
Datum *extractValue
(
Datum itemValue,
int32 *nkeys,
bool **nullFlags,
Datum *addInfo,
bool *addInfoIsNull
)
extractQuery
Datum *extractValue
(
Datum query,
int32 *nkeys,
StrategyNumber n,
bool **pmatch,
Pointer **extra_data,
bool **nullFlags,
int32 *searchMode,
???bool **required???
)
consistent
bool consistent
(
bool check[],
StrategyNumber n,
Datum query,
int32 nkeys,
Pointer extra_data[],
bool *recheck,
Datum queryKeys[],
bool nullFlags[],
Datum addInfo[],
bool addInfoIsNull[]
)
calcRank
float8 calcRank
(
bool check[],
StrategyNumber n,
Datum query,
int32 nkeys,
Pointer extra_data[],
bool *recheck,
Datum queryKeys[],
bool nullFlags[],
Datum addInfo[],
bool addInfoIsNull[]
)
???joinAddInfo???
Datum joinAddInfo
(
Datum addInfos[]
)
Оптимзация для
планировщика
До
test=# EXPLAIN (ANALYZE, VERBOSE) SELECT * FROM test
ORDER BY slow_func(x,y) LIMIT 10;
---------------------------------------------------Limit (cost=0.00..3.09 rows=10 width=16) (actual t
Output: x, y, (slow_func(x, y))
-> Index Scan using test_idx on public.test (co
Output: x, y, slow_func(x, y)
Total runtime: 103.524 ms
(5 rows)
После
test=# EXPLAIN (ANALYZE, VERBOSE) SELECT * FROM test
ORDER BY slow_func(x,y) LIMIT 10;
---------------------------------------------------Limit (cost=0.00..3.09 rows=10 width=16) (actual t
Output: x, y
-> Index Scan using test_idx on public.test (co
Output: x, y
Total runtime: 0.164 ms
(5 rows)
Результаты тестирования
avito.ru: 6.7 млн. документов
С колонкой tsvector, без патча
SELECT
itemid, title
FROM
items
WHERE
fts @@ plainto_tsquery('russian',
'квартира')
ORDER BY
ts_rank(fts, plainto_tsquery('russian',
'квартира')) DESC
LIMIT
10;
С колонкой tsvector, без патча
Limit (cost=729272.24..729272.26 rows=10 width=398) (actu
Buffers: shared hit=696232
-> Sort (cost=729272.24..731294.81 rows=809028 width=3
Sort Key: (ts_rank(fts, '''квартир'''::tsquery))
Sort Method: top-N heapsort Memory: 26kB
Buffers: shared hit=696232
-> Bitmap Heap Scan on items (cost=8661.97..7117
Recheck Cond: (fts @@ '''квартир'''::tsquery
Buffers: shared hit=696232
-> Bitmap Index Scan on fts_idx (cost=0.00
Index Cond: (fts @@ '''квартир'''::tsq
Buffers: shared hit=612
Total runtime: 1871.349 ms
С колонкой tsvector, с патчем
SELECT
itemid, title
FROM
items
WHERE
fts @@ plainto_tsquery('russian',
'квартира')
ORDER BY
fts >< plainto_tsquery('russian',
'квартира')
LIMIT
10;
С колонкой tsvector, с патчем
Limit (cost=20.00..59.46 rows=10 width=4
-> Index Scan using fts_idx on items
Index Cond: (fts @@ '''квартир'''
Order By: (fts >< '''квартир'''::
Total runtime: 143.952 ms
Без колонки tsvector, без патча
SELECT itemid, title
FROM items2
WHERE (setweight(to_tsvector('russian'::regconfig
ORDER BY ts_rank((setweight(to_tsvector('russian'
LIMIT 10;
Без колонки tsvector, без патча
Limit (cost=749132.39..749132.41 rows=10 width=372) (actu
Buffers: shared hit=485458
-> Sort (cost=749132.39..751145.79 rows=805360 width=3
Sort Key: (ts_rank((setweight(to_tsvector('russian
Sort Method: top-N heapsort Memory: 26kB
Buffers: shared hit=485458
-> Bitmap Heap Scan on items2 (cost=8625.55..731
Recheck Cond: ((setweight(to_tsvector('russi
Buffers: shared hit=485458
-> Bitmap Index Scan on fts_idx2 (cost=0.0
Index Cond: ((setweight(to_tsvector('r
Buffers: shared hit=612
Total runtime: 52685.595 ms
Без колонки tsvector, с патчем
SELECT itemid, title
FROM items2
WHERE (setweight(to_tsvector('russian'::re
ORDER BY (setweight(to_tsvector('russian':
LIMIT 10;
Без колонки tsvector, с патчем
Limit (cost=20.02..59.61 rows=10 width=373) (ac
Buffers: shared hit=1556
-> Index Scan using fts_idx2 on items2 (cost
Index Cond: ((setweight(to_tsvector('rus
Order By: ((setweight(to_tsvector('russi
Buffers: shared hit=1556
Total runtime: 143.639 ms
C колонкой tsvector, без патча
SELECT
itemid, title
FROM
items
WHERE
fts @@ plainto_tsquery('russian',
'квартира арбат')
ORDER BY
ts_rank(fts, plainto_tsquery('russian',
'квартира арбат')) DESC
LIMIT
10;
C колонкой tsvector, без патча
Limit (cost=6908.03..6908.05 rows=10 width=398) (actual t
Buffers: shared hit=1314
-> Sort (cost=6908.03..6912.44 rows=1766 width=398) (a
Sort Key: (ts_rank(fts, '''квартир'' & ''арбат''':
Sort Method: top-N heapsort Memory: 26kB
Buffers: shared hit=1314
-> Bitmap Heap Scan on items (cost=61.69..6869.8
Recheck Cond: (fts @@ '''квартир'' & ''арбат
Buffers: shared hit=1314
-> Bitmap Index Scan on fts_idx (cost=0.00
Index Cond: (fts @@ '''квартир'' & ''а
Buffers: shared hit=616
Total runtime: 92.069 ms
C колонкой tsvector, с патчем
SELECT
itemid, title
FROM
items
WHERE
fts @@ plainto_tsquery('russian',
'квартира арбат')
ORDER BY
fts >< plainto_tsquery('russian',
'квартира арбат')
LIMIT
10;
C колонкой tsvector, с патчем
Limit (cost=40.00..80.22 rows=10 width=400) (ac
Buffers: shared hit=1236
-> Index Scan using fts_idx on items (cost=4
Index Cond: (fts @@ '''квартир'' & ''арб
Order By: (fts >< '''квартир'' & ''арбат
Buffers: shared hit=1236
Total runtime: 1.579 ms
avito.ru: тесты
Без
патча
С патчем
С пачем
без
tsvector
Sphinx
Размер
таблицы
6.0 GB
6.0 GB
2.87 GB
-
Размер
индекса
1.29 GB
1.27 GB
1.27 GB
1.12 GB
216 с
303 с
718 с
180 с*
3,0 млн.
42.7 млн.
42.7 млн.
32.0 мн.
Время
созадания
индекса
Запросов за
8 часов
Анонимный источник:
18 млн. документов
Анонимный источник: тесты
Без
патча
С патчем
С патчем,
без
tsvector
Sphinx
Размер
таблицы
18.2 GB
18.2 GB
11.9 GB
-
Размер
индекса
2.28 GB
2.30 GB
2.30 GB
3.09 GB
258 с
684 с
1712 с
481 с*
2.67 млн. 38.7 млн.
38.7 млн.
26.7 млн.
Время
создания
индекса
Запросов за
8 чаос
Положение дел
2 из 4 планируемых патчей на
текущем commitfest
Спасибо за внимание!