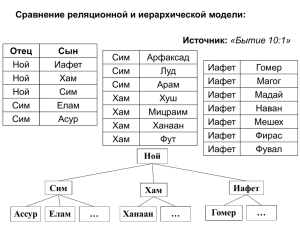
Язык преобразования XSLT
advertisement

Презентацию подготовила Шигаева Алена, гр.950б Это расширяемый язык таблиц стилей. Язык XSL фактически состоит из двух частей: языка преобразований и языка форматирования. Язык, предназначенный для выполнения преобразований, позволяет конвертировать структуры документов в различные формы (например, PDF,WML,HTML или иные типы схем), в то время как язык форматирования используется для оформления и определения стилей документов различными способами. Обе части языка XSL могут функционировать совершенно независимо одна от другой, поэтому их можно рассматривать в качестве независимых языков разметки. Язык XSLT применяется для обработки документов, внесения изменений и необходимых дополнений в разметку. Его можно применять для преобразования XMLкода в отформатированный HTML-код. Язык XSLT обеспечивает доступ к содержимому XML-документов, а также применяется для создания новых документов на их основе. Для выполнения XSLT-преобразований используется два документа: преобразуемый документ и таблица стилей, определяющая само преобразование. В данном случае речь идет об XML-документах. Ниже показан примерный вид таблицы стилей. В данном случае содержимое файла преобразуется в HTML-код: Документ можно преобразовать тремя способами: С помощью сервера – серверная программа, например JAVA или JAVA SERVER PAGE, применяет таблицу стилей для автоматического преобразования документа и представления его клиенту. С помощью клиента – клиентская программа, например браузер, выполняет преобразование путем чтения таблиц стилей, указанной с помощью инструкции по обработке <?xml-stylesheet?>. С помощью отдельной программы – некоторые программы, обычно основанные на JAVA, предназначены для выполнения XSLT-преобразования. Выполненного с помощью сервера Tomcat: Для создания программы воспользуемся классом TransformerFactory для формирования нового объекта из этого класса. МЕТОД ОПИСАНИЕ 1. Protected TransformerFactory() 2. Abstract Source 2. getAssociatedStylesheet(Source source, String media, String title, String charset) 3. Abstract object getAttribute (String name) 4. Abstract ErrorListener getErrorListener() 5. 1. Заданный по умолчанию конструктор Получает спецификации таблиц стилей 3. Возвращает определенные атрибуты 4. Возвращает обработчик ошибочного события для TransformerFactory Abstract boolean getFeature (String name) 5. Возвращает значение свойства 6. Abstract URIResolver getURIResilver() 6. Получает объект, используемый по умолчанию в процессе преобразования для разрешения URI-ссылок 7. Static TransformerFactory newInstance() 7. Получает новый объект TransformerFactory 8. Abstract Templates newTemplates (Source source) 8. Обрабатывает Source в объекте Templates 9. Abstract Transformer new Transformer() 9. Создает новый объект TransFormer, который использует источник для преобразований МЕТОД ОПИСАНИЕ newTransformer1. Создает новый объект TransFormer, который применяет Source для выполнения преобразований 1. Abstract Transformer (Source source) 2. Abstract void setAttribute (String name,2. Object value) Устанавливает определенные атрибуты 3. Abstract void (ErrorListener listener) Устанавливает слушатель связанных с ошибками JAVA 4. Abstract void setURIResolver (URIResolver4. resolver) setErrorListener3. событий, Устанавливает объект, применяемый по умолчанию во время преобразования для разрешения URI-ссылок МЕТОД 1. Protected Transformer() 2. Abstract void clearParameters() 3. Abstract ErrorListener getErrorListener() 4. Abstract Properties getOutputProperties() 5. Abstract String getOutputProperty (String name) 6. Abstract Object getParameter(String name) 7. Abstract URIResolver getURIResolver() 8. Abstract void setErrorListener (ErrorListener listener) 9. Abstract void setOutputProperties (Properties oformat) 10. Abstract void SetOutputProperty (String name, String value) ОПИСАНИЕ 1. Заданный по умолчанию конструктор 2. Очищает все параметры, установленные с помощью setParameter 3. Возвращает обработчик сообщения об ошибке 4. Возвращает копию выводимых свойств 5. Возвращает значение выводимого свойства 6. Возвращает параметр, с помощью setParameter либо setParameters 7. Возвращает объект, используемый для разрешения URI-ссылки 8. Устанавливает слушатель событий, связанных с ошибками JAVA 9. Устанавливает выводимые свойства 10. Устанавливает выводимое свойство МЕТОД ОПИСАНИЕ 1. Abstract void setParameter (String name, 1. Object value) Устанавливает параметр 2. Abstract void setURIResolver (URIResolver resolver) 2. Устанавливает объект, применяемый для разрешения Uri-ссылки 3. Abstract void transform (Source xmlSource, Result outputTarget 3. Выполняет преобразование Для выполнения преобразования воспользуемся методом transform объекта TransFormer, передавая ему преобразованный XML-документ: В процессе XSLT-преобразований в качестве вводных данных используется дерево документа, в результате обработки которого формируется дерево результатов. В этом случае документы представляют собой деревья, построенные на основе узлов. Язык XSLT распознает семь типов XSLT-узлов. Эти узлы представлены в следующем списке, где также указан порядок их обработки XSLT-процессорами: Корень документа – начало документа; Атрибут - данный узел включает значение атрибута наравне с объектными ссылками, которые могут расширяться, и пропусками, которые могут удаляться; Комментарий – данный узел включает текст комментария без знаков <!– и -->; Элемент – этот узел содержит все символьные данные элемента, включая символьные данные любого дочернего элемента; Пространство имен – данный узел содержит URIпространства имен; Инструкция по обработке – этот узел включает текст инструкции по обработке, куда не входят символы <? и ?>; Текст – данный текст содержит текст узла. Для определения обрабатываемого узла XSLT предлагает различные способы, обеспечивающие установку соответствия с узлами или их выбора. Для начала разработаем небольшой пример, заменяющий корневой узел HTML-страницей. Таким образом начинает создаваться таблица стилей XSLT. Для обработки определенных узлов XMLдокумента XSLT использует шаблоны. В следующем примере требуется заменить корневой узел новым HTML-документом. Начнем с создания шаблона с помощью элемента <xsl:template>: При установлении соответствия с корневым узлом к нему применяется шаблон. В этом случае корневой узел заменяется HTML-документом, который непосредственным образом используется в качестве содержимого элемента <xsl:template>: Вот и все, что требуется выполнить в данной ситуации. С помощью элемента <xsl:template> в таблице стилей устанавливается правило. Когда XSL-процессор просматривает документ, в качестве первого узла выбирается корневой узел. Данное правило устанавливает соответствие с корневым узлом, поэтому XSL-процессор заменяет его HTML-документом. Результат: Шаблон описанный в предыдущем разделе, применяется только по отношению к корневому узлу. Выполняется тривиальное действие по замене полного XML-документа HTMLдокументом. Можно также применять шаблоны по отношению к дочерним элементам узла, с которым установлено соответствие. В этих целях применяется элемент <xsl:apply-templates>. Например, рассмотрим случай, когда элемент <PLANETS> можно заменить элементом <HTML>: Чтобы удостовериться, что дочерние элементы корректно преобразованы воспользуемся элементом <xsl:apply-templates>следующим образом: Теперь можно применить шаблоны для дочерних узлов: Например, если требуется заменить текст из элемента <NAME> в каждом элементе <PLANET> в результирующем документе, используется следующий код: В данном примере выбирается название каждой из планет, включаемое в результирующий документ. Для получения названия каждой планеты применяется элемент <xsl:value-of> из шаблона, выбранного в элементе <PLANET>. Элемент <NAME> выделяется с помощью атрибута select: Атрибут select выделяет только первый узел, соответствующий данному критерию. Но как быть, если требуется установить соответствие с несколькими узлами? Ответ: для выполнения цикла по всем возможным соответствиям можно воспользоваться элементом <xsl:for-each>: Атрибуту match элемента <xsl:template> присущ специфический синтаксис; еще в большей степени сказанное справедливо в отношении атрибута select элементов <xsl:apply-templates>, <xsl:value-of>, <xsl:copy-of>, <xsl:for-each> и <xsl:sort>. Начнем с match: Установка соответствия с корневым узлом Установка соответствия с элементами Установка соответствия с дочерними элементами Установка соответствия с потомками элементов Установка соответствия с атрибутами Теперь select: Атрибут select использует выражения XPath .Основы XPath : чтобы указать узел или набор узлов в Xpath, применяется путь локализации. Путь локализации, в свою очередь, состоит из одного или большего числа шагов локализации, которые разделяются / или //. Если путь локализации начинается с /, он называется абсолютным путем локализации, поскольку начинается от корневого узла; иначе, путь локализации является относительным, начинаясь от текущего узла, именуемого контекстным узлом. Шаг локализации состоит из оси, узла тестирования и нуля или других предикатов. Оси XPath Узлы тестирования Xpath Предикаты XPath Самое важное заданное по умолчанию правило применяется по отношению к элементам и может выражаться следующим образом: Это правило просто гарантирует то, что каждый элемент, от корневого и далее, обрабатывается с помощью <xsl:apply-templates/> в том случае, если не применяется никакое другое правило. Если же применить другое правило, это приведет к отмене соответствующего заданного по умолчанию правила. Заданное по умолчанию правило для текста может выражаться следующим образом: Аналогичное заданное по умолчанию правило применяется по отношению к атрибутам, Которые добавляются к результирующему документу с помощью заданного по умолчанию правила, например: По умолчанию инструкции по обработке не включаются в результирующий документ, поэтому соответствующее заданное по умолчанию правило можно выразить следующим образом: Аналогичное утверждение справедливо и для комментариев, для которых заданное по умолчанию правило можно выразить так: Если не применяются никакие правила, все анализируемые символьные данные из вводного документа включаются в результирующий документ. Ниже показано, какой имеет вид таблица стилей XSLT, где не используются явно определенные правила: Результат: Создание шаблонов атрибутов Результирующий документ: Создание новых элементов В случае, когда необходимо контролировать выбор названий элементов и содержимого, применяется элемент <xsl:attribute>. Пример: Получаем следующий результат: Генерирование текста с помощью xsl:text С помощью этого элемента можно создавать текстовые узлы, которые позволяют выполнить замену целых элементов текстом «на лету». Одно из преимуществ элемента заключается в сохранении пропусков. Пример: Элемент <xsl : copy> можно применять для копирования узлов, причем можно указывать отдельные копируемые части. Заданное по умолчанию правило для элементов состоит в том, что копируется только текст элемента. Но правило можно изменить, если воспользоваться элементом <xsl : copy> , который копирует целые элементы, текстовые узлы, атрибуты, инструкции по обработке и т.д. Рассмотрим соответствующий пример: Элемент <xsl : sort> используется для выполнения сортировки наборов узлов. Этот элемент используется внутри <xsl : apply-templates>, а атрибут select этого элемента применяется для указания объекта сортировки. Пример, в котором показано, как отсортировать планеты с учетом их плотности: С помощью элемента <xsl : if> можно выбирать варианты на базе вводного документа. Чтобы воспользоваться этим элементом, просто присвоить его атрибуту test выражение, оценивающее булевское значение. Пример: перечисляем планеты и в конце горизонтальная линия. Результат: Применение xsl : choose Элемент < xsl : choose>во многом схож с JAVA –конструкцией switch,которая позволяет сравнивать тестовое значение с несколькими возможными. Например, предположим, что атрибут COLOR добавляется к каждому элементу <PLANET>: Правило: если узлом документа для результирующего документа является <HTML>, XSLT-процессору известно, что типом результирующего документа является HTML-код, и документ записывается соответствующем образом. Можно указать три типа результирующих документов. XML задан по умолчанию, подобный документ начинается с объявления <?xml?>. Кроме того, объектные ссылки не заменяются в результирующем документе символами, например < либо &; в результате отображается реальная объектная ссылка. HTML – стандартный html 4.0, без XML-объявления, то есть не возникает необходимости закрывать элементы, которые обычно не имеют завершающего тега. Пустые элементы могут заканчиваться с помощью >, но не />. Кроме того, символы < и & в тексте не заключаются в соответствующие символы объектных ссылок. TEXT – этот тип результирующего документа представляет собой сплошной текст. В этом случае результирующий документ представляет собой просто текст дерева документа. Можно определить результирующий метод, присвоив атрибуту method элемента <xsl : output> значения “xml”, “html” либо “text”. Например если необходимо создать html-документ, даже если корневой элемент не является <HTML>, можно воспользоваться элементом <xsl : output>: Другим полезным атрибутом для <xsl : output> является indent,позволяющий XSLT-процессору включить пропуск для выделения результата: Атрибуты для <xsl : output> ,которые можнот использовать для создания или обновления XML-объявлений: