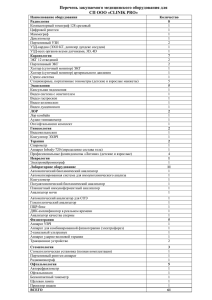
Общее устройство компиляторов. Использование LEX и YACC
advertisement

Общее устройство
компиляторов.
Использование Lex и Yacc
Сергей Нечаев,
аспирант МО ВВС ИВМиМГ
План лекции
•
•
•
•
Устройство компилятора
Лексический анализ. Генератор
лексических анализаторов Lex
Синтаксический анализ. Генератор
синтаксических анализаторов Yacc
Калькулятор.
Что такое компилятор
Компилятор – это программа, которая
считывает текст программы,
написанной на одном языке – исходном
и переводит его в текст эквивалентной
программы на другом языке – целевом.
Если в исходном тексте программы
имеются ошибки, компилятор сообщает
о них пользователю.
Фазы компиляции
Исходная
программа
Фаза анализа
Промежуточное
представление
Целевая
программа
Фаза синтеза
Компиляция состоит из двух этапов: анализ и синтез.
На этапе анализа программа разбивается на
составные части и создается ее промежуточное
представление.
На этапе синтеза по построенному внутреннему
представлению генерируется исполняемый код.
Устройство компилятора
Исходная программа
Лексический анализатор
Синтаксический анализатор
Семантический анализатор
Диспетчер таблицы
символов
Генератор промежуточного
кода
Оптимизатор кода
Генератор кода
Целевая программа
Обработчик ошибок
Устройство компилятора
Исходная программа
Лексический анализатор
Синтаксический анализатор
Семантический анализатор
Диспетчер таблицы
символов
Генератор промежуточного
кода
Оптимизатор кода
Генератор кода
Целевая программа
На этапе лексического
анализа из входной строки
выделяются лексемы –
единицы исходного языка.
'm', 'y', 'v', 'a', 'r' myvar
(идентификатор)
Обработчик ошибок
Устройство компилятора
Исходная программа
Лексический анализатор
Синтаксический анализатор
Семантический анализатор
Диспетчер таблицы
символов
Генератор промежуточного
кода
Оптимизатор кода
Генератор кода
Целевая программа
На фазе синтаксического
анализа и синтаксически
управляемой трансляции
анализируется иерархическая
структура программы
Если A, B – выражения, то
A+B – выражение.
Обработчик ошибок
Устройство компилятора
Исходная программа
Лексический анализатор
Синтаксический анализатор
Семантический анализатор
Диспетчер таблицы
символов
Генератор промежуточного
кода
Оптимизатор кода
Генератор кода
Целевая программа
На фазе семантического
анализа проверяется наличие
семантических (смысловых)
ошибок в исходной программе
и накапливается информация
о типах для следующей
стадии – генерации
промежуточного кода
Обработчик ошибок
Устройство компилятора
Таблица символов представляет
собой структуру данных,
содержащую записи о каждом
идентификаторе с полями для его
атрибутов. Эта структура
позволяет быстро найти, изменить
или добавить информацию о
любом идентификаторе
Исходная программа
Лексический анализатор
Синтаксический анализатор
Семантический анализатор
Диспетчер таблицы
символов
Генератор промежуточного
кода
Оптимизатор кода
Генератор кода
Целевая программа
Обработчик ошибок
Устройство компилятора
Исходная программа
Лексический анализатор
Синтаксический анализатор
Семантический анализатор
Диспетчер таблицы
символов
Генератор промежуточного
кода
Оптимизатор кода
Генератор кода
Целевая программа
На каждой фазе компиляции
могут встретиться ошибки. Но,
после их обнаружения,
необходимо предпринять
какие-то действия, чтобы
продолжить компиляцию и
выявить остальные ошибки
Обработчик ошибок
Устройство компилятора
Исходная программа
Лексический анализатор
Синтаксический анализатор
Семантический анализатор
Диспетчер таблицы
символов
Генератор промежуточного
кода
Оптимизатор кода
Генератор кода
Целевая программа
Обработчик ошибок
После синтаксического и
семантического анализа
некоторые компиляторы
генерируют явное промежуточное
представление исходной
программы, которое можно
рассматривать как программу для
абстрактной машины
Устройство компилятора
Исходная программа
Лексический анализатор
Синтаксический анализатор
Семантический анализатор
Диспетчер таблицы
символов
Генератор промежуточного
кода
Оптимизатор кода
Генератор кода
Целевая программа
Обработчик ошибок
При оптимизации кода
производятся попытки
улучшить промежуточный код,
чтобы получить более
эффективный машинный код.
Устройство компилятора
Исходная программа
Лексический анализатор
Синтаксический анализатор
Семантический анализатор
Диспетчер таблицы
символов
Генератор промежуточного
кода
Оптимизатор кода
Генератор кода
Целевая программа
Обработчик ошибок
Последняя фаза компиляции
состоит в генерации целевого
кода, обычно перемещаемого
машинного кода или
ассемблерного кода
Инструментарий для создания
компиляторов
• Генераторы синтаксических анализаторов. Эти генераторы
конструируют синтаксические анализаторы, обычно по входной
информации, основанной на контекстно-свободной грамматике.
• Генераторы сканеров. Этот инструментарий автоматически
генерирует лексические анализаторы.
• Средства синтаксически управляемой трансляции. С их
помощью создаются программы прохода по дереву разбора и
генерации промежуточного кода.
• Автоматические генераторы кода. Эти инструменты получают
на вход множество правил, по которым каждая операция
промежуточного кода транслируется в набор операций
конкретного машинного языка.
• Средства анализа потока данных. Для получения
оптимизированного кода требуется сбор и анализ информации о
том, каким образом значения передаются из одной части
программы в другую.
Лексический анализ
Во многих языках программирования
используются следующие правила
конструирования элементов языка.
Идентификатор – последовательность букв и
цифр, начинающаяся с буквы.
Числовая целочисленная константа –
последовательность цифр. Возможно наличие
минуса перед этой последовательностью
цифр.
Регулярные выражения
пусть - алфавит (множество символов), - пустая
строка. Тогда:
1. - регулярное выражение.
2. a - регулярное выражение.
3. Если R1 и R2 регулярные выражения, то (R1|R2),
R1 R2, R1* - регулярные выражения.
Здесь R1|R2 обозначает «R1 или R2», R1 R2
обозначает подряд записанные R1 и R2, (R1)*
обозначает «0 или более R1, записанных подряд»
Регулярные выражения
Идентификатор:
(БУКВА)(БУКВА|ЦИФРА)*
БУКВА=(A|B|…|Z|a|…|z)
Расширение регулярных
выражений в Lex
• X обозначает «символ Х»
• [A-Z] обозначает «любой символ от A
до Z».
• «строка символов» обозначает
«строка символов» буквально.
• R? «ноль или 1 R»
• R+ обозначает «один или более R»
• . (точка) обозначает любой символ,
кроме символа новой строки.
Лексемы калькулятора
1. Число:
?-{digit}+("."{digit}+|{digit}*)
Знак "." используется в записи
расширенных регулярных выражений,
поэтому он взят в кавычки.
2. Знак операции. Удобно записать их
отдельно:
"+", "-", "*","/".
3. Скобки (левая и правая). "(" и ")"
Структура программы на языке
Lex
Определения
%%
правила
%%
пользовательский код
Программа на языке Lex
В разделе «определения» содержатся объявления
вспомогательных регулярных выражений для
упрощения записи правил анализа. Эти объявления
имеют вид
имя выражение
Например,
digit [0-9]
Правая часть объявления может содержать
объявленные ранее имена. Например,
digit [0-9]
number -?{digit}+((”.”{digit}+)|{digit}*)
Программа на языке Lex
Раздел «правила» состоит из записей следующего вида
{Шаблон} {последовательность действий на С}
Шаблон представляет собой регулярное выражение, с
использованием объявленных в предыдущей секции имен.
Последовательность действий – это то, что лексический
анализатор будет делать при обнаружении подстроки,
соответствующей данному регулярному выражению.
Пример
{number} {yylval=atof(yytext);return NUMBER;}
yylval – семантическое значение найденной лексемы.
yytext - найденная подстрока, соответствующая шаблону
Третий раздел содержит различные вспомогательные процедуры
Совместная работа лексического
и синтаксического анализаторов
• Синтаксический анализатор вызывает лексический анализатор.
• Лексический анализатор просматривает оставшуюся часть
входной строки по одному символу до тех пор, пока не будет
найден самый длинный префикс, соответствующий одному из
регулярных выражений в разделе «правила». Если этот
префикс соответствует нескольким регулярным выражениям,
среди них выбирается первое в списке. Затем выполняются
действия, соответствующие данному выражению.
• Лексический анализатор возвращает синтаксическому
единственную величину – номер найденной лексемы.
Передача семантического значения осуществляется
посредством глобальной переменной yylval
Калькулятор – лексический
анализатор
delim
[ \t]
ws
{delim}+
digit
[0-9]
number
?-{digit}+(“.”{digit}+|{digit}*)
%%
{ws}
{}
{number}
{yylval=atof(yytext);return NUMBER;}
“-”
{return '-';}
“+”
{return '+';}
“*”
{return '*';}
“/”
{return '/';}
“(”
{return '(';}
“)”
{return ')';}
“\n”
{return '\n';}
.
{yyerror(“unknown character”);}
%%
void yyerror(char* msg)
{
printf(“Error: %s\n”, msg);
}
Синтаксический анализ.
Грамматики.
Грамматика – G =< , N, P, S>.
Здесь – множество терминальных символов или
терминалов.
N – множество нетерминальных символов или
нетерминалов.
N =
P – множество продукций – строк вида ( ), ,
(N )*, хотя бы один символ в - нетерминал.
(N )
S N – выделенный стартовый символ.
Грамматики
Грамматика называется контекстносвободной, если все продукции Pi P
имеют вид:
(A), A N, (N )*.
Если в грамматике присутствуют
несколько правил A1,…, An, то для
краткости записывается это так
A1|2|…|n
Грамматики
Строка называется непосредственно выводимой из
строки в грамматике G,
(Обозначается это ==>G )
если строка получается из строки заменой одного из
вхождений какой-либо левой части правила из P на
соответствующую правую часть.
Пример:
G=< , N, P, S>. ={'(', ')', 'a'}, N={S}, P={S (S)|SS|a}
Строка «(a)(S)» непосредственно выводима из строки
«(S)(S)»
Грамматики
Строка называется выводимой из строки в
грамматике G,
(Обозначается это ==>*G )
если 1…n 1=, n= i ==>G i+1
Говорят, что грамматика G порождает строку *,
если S ==>*G
Множество всех таких называется языком,
порождаемым грамматикой G (обозначается L(G)). Если
грамматика является контекстно-свободной, то
говорят, что язык, который она порождает, контекстносвободный.
Дерево вывода (дерево разбора).
•Корнем дерева является стартовый
символ грамматики.
•Внутренние узлы дерева помечены
нетерминалами, листья помечены
терминальными символами.
•Если существует продукция AXYZ
(А – нетерминал, X, Y, Z могут быть
как терминалами, так и
нетерминалами), то в дереве вывода
может встретиться узел, помеченный
А, с тремя потомками, помеченными
слева направо как X, Y, Z.
Пример: G=< , N, P, S>. ={'(', ')', 'a'},
N={S, A}, P={SA; A (A)|AA|a;}
S
A
A
(
)
a
Дерево вывода (дерево разбора).
Сечение – максимальное по включению
множество вершин, никакие две из
которых не лежат на одном пути из
корня.
Крона сечения – строка, полученная
конкатенацией вершин в порядке слева
направо.
Крона дерева – крона сечения,
состоящего из листьев.
Дерево вывода строки - дерево
вывода, крона которого есть .
S
A
A
(
)
a
Однозначные и неоднозначные
грамматики
Однозначная грамматика G – если L(G) ! дерево вывода. Если это не так,
грамматика называется неоднозначной.
Пример неоднозначной грамматики:
SS-S|NUMBER
NUMBER0|1|2|3|4|5|6|7|8|9
Рассмотрим строку 6-4-2. Для нее существует два дерева вывода:
S
S
S
S
-
S
S
-
S
-
S
2
6
S
-
6
(6-4)-2=0
4
4
6-(4-2)=4
S
2
Левоассоциативные и
правоассоциативные операторы
Определение: бинарный оператор op
называется левоассоциативным, если a
op b op c равно (a op b) op c,
правоасооциативным, если a op b op c
равно a op (b op c).
YACC - программа.
%{
Пролог
%}
Объявления
%%
Правила
%%
Эпилог
YACC- программа
• В прологе содержатся необходимые макроопределения и
объявления функций и процедур, подключаются необходимые
файлы заголовков.
• В секции объявлений содержатся объявления терминалов и
нетерминалов.Терминалы объявляются как %token <имя
терминала>. Если же терминал является левоассоциативным
оператором, для его объявления используется директива
%left, если же он является правоассоциативным оператором,
используется директива %right.
Считается, что операторы, объявленные в одной директиве
%left имеют одинаковый приоритет. Если есть несколько
объявлений вида %left ops1, %left opsn , то первые
имеют наиболее низкий приоритет, а последние – наиболее
высокий. Объявлять нетерминалы необходимо только в том
случае, когда определено более одного типа для
семантического значения, и необходимо явно указать, какой
нужно использовать.
YACC- программа
Секция «правила».
Это основная часть. Она состоит из строк вида
Правило
{Действия}
Правило – это правило грамматики языка. Записывается оно в виде:
A:1|…|n
Действия – это то, что анализатор будет делать при применении данного правила
во время вывода входной строки из стартового символа грамматики.
Семантические значения
Каждой лексеме и нетерминалу соответствуют некоторые семантические значения
Для правила A: alpha1…alphan переменная $$ соответствует семантическому
значению А, переменная $1 соответствует значению alpha1, $2 – alpha2, $n –
alphan
Пример: в правиле expr: (expr+expr) $$ - expr (слева), $1-скобка,
$2-expr, $3-знак плюс, $4-expr, $5-скобка закрывающая
Эпилог копируется дословно в конец сгенерированной программы –
синтаксического анализатора.
Yacc-программа калькулятора
%{
#include "lex.yy.c"
#define YYERROR_VERBOSE
%}
%token NUMBER
%left '-' '+'
/*Операторы + и - левоассоциативны*/
%left '*' '/' /*Операторы * и / левоассоциативны, приоритет у них выше, чем у сложения и
вычитания*/
%%
input: /* empty */
| input line
;
line: '\n'
| exp '\n' { printf ("The result is: \t%g\n", $1);};
exp: NUMBER
{ $$ = $1;
}
| exp '+' exp
{ $$ = $1 + $3; }
| exp '-' exp
{ $$ = $1 - $3; }
| exp '*' exp
{ $$ = $1 * $3; }
| exp '/' exp
{ $$ = $1 / $3; }
| '(' exp ')'
{ $$ = $2;
}
;
%%
void main()
{
while(1)
yyparse();
}