Версия для печати - Информационно
advertisement

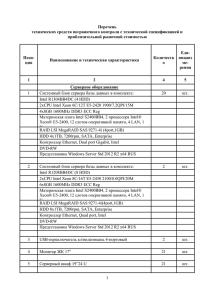
АНАЛИЗ ПРОИЗВОДИТЕЛЬНОСТИ ПАКЕТА GEANT4 НА АРХИТЕКТУРЕ HYBRILIT Максимов А.А. Санкт-Петербургский Государственный Университет, tolord95@gmail.com В данной статье представлены результаты анализа работы пакета Geant4 на примере TestEm12 (extended → electromagnetic) на объемах данных в 10 5, 106 и 107 событий. Для сборки инструментария были использованы компиляторы GCC и ICC с применением оптимизации и без. На основе времени работы получены сведения об ускорении и эффективности Geant4 в зависимости от количества задействованных потоков. Также проанализирована работа пакета на сопроцессоре Intel Xeon Phi в native-режиме. В дальнейшем полученные результаты помогут сэкономить ресурсы при высокопроизводительных и ресурсоёмких вычислениях Geant4 на кластере HybriLIT. Ключевые слова: компьютерные науки, информационные технологии, физика высоких энергий, вычислительная физика, Geant4, CERN, JINR, гетерогенный кластер HybriLIT. Введение Geant4 (акроним от «GEometry ANd Tracking» - с англ. «геометрия и трэкинг») – инструментарий для симуляции методами Монте-Карло прохождения элементарных частиц через различные вещества и взаимодействия с ними. Первая версия пакета была разработана ЦЕРНом в 1974 году. В середине 1990-ых годов началось создание Geant4 – на языке С++, в отличие от предыдущих версий, написанных на Fortran. Последняя стабильная версия на данный момент – Geant4.10.2 – выпущена 4 декабря 2015 года. В настоящее время Geant4 используется в различных областях науки: от электромагнитных полей и физики высоких энергий до брахитерапии (контактная лучевая терапия) и адронной терапии (2). Начиная с версии 10.0 в Geant4 добавлена поддержка многопоточного режима. Ввиду активного использования ОИЯИ данного пакета для вычислений, а также наличия гетерогенного кластера HybriLIT, возникла необходимость проверки эффективности работы Geant4 в многопоточном режиме. Описание вычислительных ресурсов Вычислительные эксперименты проводились на ресурсах Лаборатории информационных технологий ОИЯИ (г. Дубна). Вычислительный кластер HybriLIT был запущен в эксплуатацию в 2014 году, но досконально не протестирован, в связи с чем и был выбран в качестве объекта исследований. На данный момент кластер состоит из девяти вычислительных узлов, для тестирования использовались узлы с 4 по 7 (GPU partition) с установленными на них по два CPU Intel® Xeon® Processor E5-2695 v2 (30M Cache, 2.40 GHz) на каждом. На каждом процессоре 12 ядер, 24 потока – итого на одном вычислительном узле можно задействовать до 48 потоков. Также на каждом вычислительном узле установлено 128 Гб ОЗУ (1). Используемые компиляторы: GCC-4.9.1 и ICC (Intel Cluster Studio 2013.1.046). Используемая версия пакета Geant4 – 10.1.p02. Для тестирования выбран пример TestEm12 (examples → extended → electromagnetic). Результаты тестирования Время вычислений представлено как среднее арифметическое из показаний нескольких запусков (от 5 на некоторых затратных по времени до 20 на более быстрых). Ускорение (speed-up) на N потоках вычислено по следующей формуле: 𝑆𝑁 = Эффективность: 𝑇1 , где 𝑇𝑖 − время работы на 𝑖 потоках 𝑇𝑁 𝐸𝑁 = 𝑆𝑁 𝑁 (1) (2) Рис. 1. 105 событий. Сравнение сборок на GCC vs. GCC (-O3) vs. ICC vs. ICC (-O3). Рис. 2. 106 событий. Сравнение сборок на GCC vs. GCC (-O3) vs. ICC vs. ICC (-O3). Рис. 3. 107 событий. Сравнение сборок на GCC vs. GCC (-O3) vs. ICC vs. ICC (-O3). На рис. 1 можно увидеть значительные колебания по времени работы сборки на компиляторе GCC. Это можно объяснить тем, что процессоры Intel Xeon используют технологию Turbo Boost, увеличивающую при необходимости частоту ядер, и в ICC это учтено при инициализации потоков, в отличие от GCC. На рис. 2 и 3 видно, что с увеличением количества событий эти колебания сглаживаются. Также были проведены единичные тесты на Intel Xeon Phi. Рис. 4. 105 событий на Intel Xeon Phi. Как видно на рис. 1, эффективность Xeon Phi на мелких задачах довольно низка. Тестовые замеры показали, что почти половину времени при полной загрузке сопроцессора (240 потоков) занимает только инициализация потоков. На 103 событий время работы на 240 потоках составляет 76,494 с и 25,457 с на 10. Промежуточные значения распределены близко к линейной зависимости. С увеличением числа событий эффективность увеличивается, что доказывается на рис. 2. Тесты на размерностях порядками выше (3) показывают даже превосходство Xeon Phi над CPU Intel Xeon. Рис. 5. 106 событий на Intel Xeon Phi. Выводы Сборка компилятором ICC с оптимизацией (-О3) показал свою высокую стабильность и эффективность в сравнении с другими сборками на малом количестве событий (105), при этом с увеличением объёма вычислений время всех четырёх сборок сходится при большом количестве потоков. При этом наилучшую эффективность на трёх объёмах вычислений показывает именно сборка под ICC (-O3) на 35 потоках. В то же время Intel Xeon Phi показывает худшие результаты в сравнении с CPU. Так на 105 событий лучшее время Phi сравнимо с пятипоточной работой CPU, а на 106 – с десятипоточной, что вполне совместимо с результатами других испытаний (3). Литература 1. 2. Гетерогенный кластер ЛИТ/ОИЯИ - http://hybrilit.jinr.ru/resources/hardware. Introduction to Geant4 - http://geant4.web.cern.ch/geant4/UserDocumentation/UsersGuides/IntroductionToGeant4/html/index.html. 3. Schweitzer P. Performance Evaluation of Multithreaded Geant4 Simulations Using an Intel Xeon Phi Cluster - http://www.hindawi.com/journals/sp/2015/980752/. ANALYSIS OF PERFOMANCE OF GEANT4 TOOLKIT ON HYBRILIT ARCHITECTURE Maximov A.A. St. Petersburg State University, tolord95@gmail.com Here are results of analysis of Geant4 performance with example TestEm12 (extended → electromagnetic) on the number of events equal 10 5, 106 and 107. Used compilers – GCC and ICC with and without optimization. Basing on calculation time I get an information about Geant4 performance and efficiency in depence of number of threads. Also toolkit was tested on co-processor Inter Xeon Phi in native mode. In future these results will help to save resources computing in work on hard tasks. Key words: computer science, IT, physics of high energy, computational physics, Geant4, CERN, JINR, heterogenous cluster HybriLIT.