docx - Центр параллельных вычислительных технологий
advertisement

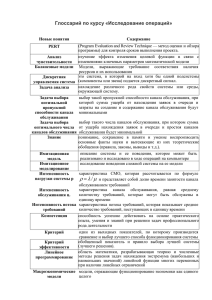
Федеральное агентство связи ФГОБУ ВПО «СибГУТИ» Кафедра вычислительных систем Практические задания по дисциплинам «Программирование» и «Языки программирования» семестр 2 2012/2013 учебный год Преподаватели: Доцент Кафедры ВС, к.т.н. – Поляков Артём Юрьевич Старший преподаватель Кафедры ВС – Перышкова Евгения Николаевна Лабораторная работа №4 Моделирование агрегированного канала передачи данных ЦЕЛЬ РАБОТЫ Применение программного обеспечения для моделирования и исследования реальных объектов. В качестве примера моделируемого объекта используется система передачи данных, основанная на агрегированном сетевом канале. Получаемые навыки: 1) изучение, реализация и практическое применение структуры данных «статическая очередь»; 2) изучение и реализация алгоритмов, применяемых в реальных системах передачи данных. МЕТОДИЧЕСКИЕ УКАЗАНИЯ 1. ОБЪЕКТ МОДЕЛИРОВАНИЯ 1.1. Введение Создание новой коммуникационной системы является дорогостоящим и длительным процессом. По этой причине необходимо максимально использовать уже существующие сетевые соединения. Одним из способов повысить скорость передачи данных за счет использования нескольких доступных линий связи является объединение каналов. Производительность физических линий зависит от многих параметров, в том числе: от длины кабеля и его физических и электромагнитных характеристик, от используемого стандарта передачи данных (Fast/Gigabit Ethernet, SHDSL, E1). По этой причине существует вероятность, что производительность доступных каналов будет различна. Рис. 1 – Агрегированный канал передачи данных 1 1.2. Стек протоколов TCP/IP В настоящее время для организации передачи данных наиболее часто используется стек протоколов TCP/IP (рис. 2). Это набор сетевых протоколов передачи данных, используемых в сетях, включая сеть интернет. Название TCP/IP происходит из двух наиболее важных протоколов семейства – Transmission Control Protocol (TCP) и Internet Protocol (IP), которые были разработаны и описаны первыми в данном стандарте. Прикладной уровень Telnet Транспортный уровень FTP TCP Сетевой уровень Канальный уровень SMTP DNS RIP UDP Internet Protocol (IP) Ethernet SNMP PPP Frame Relay ICMP ATM Рис. 2 – Стек протоколов TCP/IP Протокол IP – Internet protocol – (сетевой уровень) обеспечивает негарантированную доставку IP-датаграммы на узел-получатель, описываемый IP-адресом (рис. 3). Рис. 3 – Передача данных по сети с применением протокола IP Протокол TCP – Transmission Control Protocol – (транспортный уровень) обеспечивает: 1. Гарантированную доставку данных (повторная передача при потерях, рис. 4). 2. Регулировка нагрузки на сеть. 3. Восстановление исходного порядка следования сетевых пакетов. Рис. 4 – Гарантированная доставка данных, протокол TCP Передача информации с использованием стека протоколов TCP/IP выглядит следующим образом (рис. 5). Операционная система (ОС) принимает входные данные (порциями или единым буфером) от прикладной программы. Эти данные передаются для обработки программной реализации стека протоколов TCP/IP. Протокол TCP отвечает за разбиение входных данных на сегменты, размер которых определяется возможностями передающей аппаратуры. Каждый сегмент снабжается TCP заголовком, размер которого, обычно, составляет 32 байта. Заголовок содержит, в частности: 2 1) информацию о номере первого байта «полезной нагрузки» передаваемых данных; 2) номер последнего «подтвержденного байта» принимаемых данных. Таким образом, взаимодействующие стороны информируют друг друга о состоянии приема, что позволяет обеспечить гарантированную доставку сообщений и восстановление исходного порядка следования пакетов. Данную задачу решает алгоритм «скользящего окна», который будет долее подробно рассмотрен далее. Сформированные TCP-сегменты передаются на вход протоколу IP, который формирует IPдатаграммы, каждая из котороых также снабжается заголовком. Заголовок датаграммы содержит информацию об IP-адресе отправителя и получателя. Данная информация используется коммуникационным оборудованием, чтобы найти вычислительное устройство, которому адресована информация, в вычислительной сети. Размер стандартного заголовка датаграммы составляет 20 байт. IP-датаграмма передается канальному уровню стека протоколов TCP/IP. Наиболее распространенной реализацией канального и физического уровней TCP/IP является технология Ethernet. Канальный уровень оперирует Ethernet-кадрами, заголовки которых содержат MACадреса передающего узла и узла-адресата. Технология Ethernet позволяет организовать взаимодействие узлов только внутри локальной сети. Для организации межсетевого взаимодействия используется сетевой уровень и протокол IP, описанный выше. Размер заголовка Ethernet-кадра составляет 18 байт. Система 1 Программа Система 2 Входной поток байт Выходной поток байт TCP TCP/IP TCP/IP Поток пакетов Поток пакетов NIC driver IP Передаваемый буфер TCP сегменты 1 2 3 n ... IP датаграмы 1 2 3 ... n NIC driver Ethernet Ethernet кадры 1 2 3 ... n Среда передачи а б Рис. 5 – Функционирование стека протоколов TCP/IP, а – функциональная схема системы передачи данных б – процесс формирования сетевых пакетов 1.3. Агрегирование каналов В компьютерных сетях агрегирование каналов (link aggregation, channel bonding) – технологии объединения нескольких параллельных каналов передачи данных в один логический. Такой логический канал обладает потенциально большей пропускной способностью и надежностью. Для организации агрегирования каналов на канальном уровне стека протоколов TCP/IP вводится дополнительный компонент программного обеспечения, который выполняет следующие функции (рис. 6): 1) распределение потока Ethernet-кадров по N физическим каналам связи (на передающей стороне); 2) объединение потоков Ethernet-кадров, поступающих из N каналов связи, в единый выходной поток (на принимающей стороне). Распределение потока кадров осуществляется с целью обеспечения сбалансированной нагрузки на физические каналы связи. 3 Система 1 Система 2 Выходной поток байт TCP/IP TCP/IP Ethernet Ethernet driver NIC 1 driver NIC 2 … Канал 1 (b1 Мб/c) Канал 2 (b2 Мб/c) .. . Канал N (bN Мб/c) driver NIC N driver NIC 1 driver NIC 2 … driver NIC N Объединение Распределение Входной поток байт Рис. 6 – Функциональная схема агрегированного канала связи Далее рассмотрим существующие алгоритмы распределения нагрузки, считая, что имеется система из N физических (элементарных) каналов связи, для каждого из которых определена пропускная способность Bi, i[1,N]. 1. Циклический алгоритм (Round Robin) [1, 2] балансировки нагрузки между элементарными каналами связи. Данный алгоритм предусматривает отправку первого поступившего пакета по первому элементарному каналу, второго пакета – по второму каналу, Nго пакета – по N-тому каналу. Отправка (N+1)-го пакета производится опять по первому каналу, далее последовательность шагов повторяется. В общем случае пакет с номером n отправляется по каналу с номером i = (n – 1) % N + 1. Данный алгоритм применяется в драйвере bonding объединения каналов связи ядра Linux. 2. Адаптивный алгоритм (RateBalance) [3] балансировки нагрузки между элементарными каналами связи. Данный алгоритм основывается на принципе: «пакет передается по тому каналу, который доставит его раньше остальных». Для этого на передающей стороне для каждого канала i хранится и обновляется время Ti его освобождения для передачи новых кадров. При инициализации агрегированного канала Ti = 0 i[1,N]. При передаче нового пакета размера s выполняются следующие действия: 1) корректировка времени освобождения каждого из каналов по следующему правилу: Ti = max(Ti,T), где T – абсолютное время на момент передачи; 2) Определяется канал, по которому будет выполняться передача пакета, по правилу: i = argmin(Ti + s/Bi, i[1,N]), т.е. канал выбирается так, чтобы время передачи пакета с учетом текущей загрузки было минимальным. Данный алгоритм является дополнением к драйверу bonding объединения каналов связи ядра Linux и используется в оборудовании Sigrand. 3. Алгоритм балансировки нагрузки, используемый в протоколе Point-to-Point Protocol Multilink (PPP ML) [4]. Данный алгоритм предусматривает разбиение входных пакетов на фрагменты, которые параллельно передаются по элементарным каналам. Размер фрагмента, предназначенного для передачи по i-му элементарному каналу, пропорционален его пропускной способности. Например, для пакета размера s по каналу i будет передан фрагмент размера si которого определяется по формуле: N B si i s, Bmax Bi Bmax i 1 При этом минимальный размер фрагмента не может быть менее 40 байт. Данный алгоритм предусматривает введение небольшого заголовка, содержащего информацию, необходимую, для реконструкции исходных кадров из фрагментов на принимающей стороне. 4. Алгоритм балансировки нагрузки, реализованный в Linux-драйвере EQL (Equalizer Load-balancer) [5], предназначен для объединения каналов, построенных на последовательных интерфейсах передачи данных. Для каждого физического канала i поддерживается уровень Li его 4 загрузки в байтах. Уровень загрузки выражается в объеме данных, поставленных в очередь отправки. Отправка пакета выполняется по менее нагруженному (на момент отправки) каналу. 2. СТРУКТУРА ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ 2.1. Имитационное моделирование Имитационное моделирование – это метод исследования, при котором изучаемая система заменяется моделью, с достаточной точностью описывающей реальную систему. С моделью проводятся эксперименты с целью получения информации об исходной системе. Экспериментирование с моделью называют имитацией. Имитационная модель — логико-математическое описание объекта, которое может быть использовано для экспериментирования на компьютере в целях проектирования, анализа и оценки функционирования объекта. 2.2. Основные программные компоненты разрабатываемой системы моделирования Таймер Канал 1 Узел1 Канал 2 ... Узел2 Канал N Рис. 7 – Функциональная схема системы моделирования На рис. 7 приведена функциональная схема разрабатываемой системы моделирования, она состоит из четырех видов объектов: 1) Узел1 – передающий узел; 2) Узел2 – принимающий узел; 3) Каналi – канал передачи данных; 4) Таймер – модельное время. Далее будут рассмотрены 3 варианта модели с различным уровнем детализации. Для каждой из этих моделей реализация функциональных элементов будет отличаться, однако их взаимодействие будет одинаковым. 2.3. Представление физического канала связи Отправка информации по реальным каналам связи происходит следующим образом (рис. 8, а): 1) прикладная программа (например, вэб-браузер) передает сообщение ОС; 2) ОС проводит сообщение через стек TCP/IP и на выходе получается набор сетевых кадров, подготовленных к отправке; 3) сетевые кадры по одному передаются драйверу сетевого устройства, для общения с сетевым устройством драйвер использует входную и выходную очереди, построенные на базе статических массивов в виде «кольцевых буферов»; 4) сетевые кадры помещаются во входную очередь до тех пор, пока очередь не заполнится (массив статический, следовательно, имеет фиксированный размер) или пока не закончится поток кадров. 5) сетевое устройство периодически проверяет входную очередь и, если она не пуста, осуществляет выборку и отправку кадров. Прием сетевых кадров осуществляется в обратном порядке и с использованием выходной очереди. 5 NIC driver NIC driver а б Рис. 8 – Представление физического канала связи, а – функциональная схема реального канала связи б – упрощенная функциональная схема модельного канала В рамках данной лабораторной работы мы будем рассматривать соединение типа «точкаточка». Данный тип сетевых соединений предусматривает непосредственное соединение двух сетевых устройств. В этом случае пакеты могут поступать на один из узлов только со второго узла. Поэтому выходная очередь отправляющего узла будет работать синхронно со входной очередью принимающего узла. Для упрощения программной реализации эти очереди можно объединить (рис. 8, б). Рассмотрим реализацию очереди на базе статического массива («кольцевой буфер»). Пусть размер статического массива Q составляет n элементов. Тогда на его основе может быть организован кольцевой буфер вместимостью (n – 1) элемент. Для этого необходимы два вспомогательных индекса: head и tail. head хранит индекс головы очереди (элемента, размещенного первым), tail хранит индекс первого свободного элемента очереди, в который будет размещен следующий пришедший элемент. Если head = tail, то очередь пуста, если (tail + 1) mod (n + 1) = head, то очередь заполнена. Рассмотрим далее алгоритмы инициализации, включения и исключения элемента из очереди, а также алгоритмы проверки очереди на пустоту и проверки наличия свободного места в очереди. Листинг 1 Входные данные: q – структурный тип данных, описывающий очередь, в состав структуры входит массив (q.mas), атрибут, хранящий количество элементов в массиве (q.n), а также индексы q.head и q.tail. QINIT(q) q.head ← q.tail ← 1 Листинг 2 Входные данные: q – структурный тип данных, описывающий очередь, в состав структуры входит массив (q.mas), атрибут, хранящий количество элементов в массиве (q.n), а также индексы q.head и q.tail. x – элемент, включаемый в очередь ENQUEUE(q, x) q.mas[q.tail] ← x next ← (q.tail+1) mod (q.n + 1) if next ≠ q.head then q.tail ← next 6 Листинг 3 Входные данные: q – структурный тип данных, описывающий очередь, в состав структуры входит массив (q.mas), атрибут, хранящий количество элементов в массиве (q.n), а также индексы q.head и q.tail. DEQUEUE(q) x ← q.mas[q.head] if q.head ≠ q.tail then q.head ← (q.head+1) mod (q.n + 1) return x Листинг 4 Входные данные: q – структурный тип данных, описывающий очередь, в состав структуры входит массив (q.mas), атрибут, хранящий количество элементов в массиве (q.n), а также индексы q.head и q.tail. QEMPTY(q) return (q.head = q.tail) Листинг 5 Входные данные: q – структурный тип данных, описывающий очередь, в состав структуры входит массив (q.mas), атрибут, хранящий количество элементов в массиве (q.n), а также индексы q.head и q.tail. QSPACE(q) return (q.head ≠ (q.tail+1) mod (q.n + 1)) Для удобства использования кольцевого буфера применительно к рассматриваемой задачи введем функцию QFIRST, которая аналогична функции DEQUEUE, однако не удаляет первый элемент из очереди, а лишь возвращает его значение Листинг 6 Входные данные: q – структурный тип данных, описывающий очередь, в состав структуры входит массив (q.mas), атрибут, хранящий количество элементов в массиве (q.n), а также индексы q.head и q.tail. QFIRST(q, x) return q.mas[q.head] 2.4. Модельное время Имитационное моделирование, как правило, проводится с использованием средств вычислительной техники в соответствии с программой, реализующей последовательность возникающих в системе основных событий, т.е. соответствующий процесс функционирования системы. При этом несколько часов, суток, лет работы реальной системы моделируется за несколько секунд, минут, часов работы компьютера. При имитационном моделировании различают три вида времени. 1. Время реальной системы – это время, в котором функционирует моделируемая система. 2. Модельное время – это "искусственное" время, в котором "живет" модель или другими словами это время, которое является имитацией, прообразом (моделью) времени реальной системы. 7 3. Реальное время — это время, в котором живет исследователь, компьютер или другими словами это время необходимое для моделирования (затратное время). С точки зрения разработки программной системы моделирования наибольший интерес представляет модельное время. Для того, чтобы вести отсчет модельного времени и обеспечить правильную хронологическую последовательность наступления основных событий в имитационной модели используется так называемый таймер модельного времени (рис. 7), которая представляет собой переменную для хранения (фиксации) текущего значения модельного времени. Существуют два основных способа продвижения модельного времени. 1. Пошаговый, при котором применяются фиксированные интервалы изменения модельного времени. Такой способ не является эффективным с точки зрения использования машинного реального времени, затрачиваемого на моделирование. 2. По-событийный, при котором применяются переменные интервалы изменения модельного времени, при этом величина шага измеряется интервалом до следующего события. Время изменяется тогда, когда изменяется состояние системы. В по-событийных методах длина шага временного сдвига максимально возможная. Модельное время с текущего момента изменяется до ближайшего момента наступления следующего события. Применение пособытийного метода предпочтительнее в том случае, если частота наступления событий невелика. Тогда большая длина шага позволит ускорить ход модельного времени. На практике по-событийный метод получил наибольшее распространение. Работа агрегированного канала передачи данных управляется событиями. Будем считать, что время, необходимое для постановки сетевого кадра в очередь для отправки, ничтожно мало по сравнению со временем его передачи по агрегированному каналу связи (что близко к истине). Поэтому событиями, управляющими изменением модельного времени, будут поступления сетевых кадров из физических каналов. Рассмотрим следующий пример (табл. 1). Для передачи используется два канала производительностью 10 и 5 Б/с. Каждый из каналов представлен очередью, вместительность которой составляет 2 кадра. Требуется отправить последовательность кадров следующих размеров: 100 Б, 30 Б, 50 Б, 90 Б, 200 Б. Таблица 1 T – значение таймера всей системы, Ti – время приема предыдущего кадра из i-го канала vi – пропускная способность i-го канала Шаг Входные данные Состояние каналов Замечания T=0c 1 2 Исходное состояние 100, 30, 50, 90, 200 v1=10 Б/с, T1=0 c 200 v1=10 Б/с, T1=0 c (0c,100),(0c,50) v2=10 Б/с, T2=0 c (0c,30),(0c,90) v2=10 Б/с, T2=0 c T=0c T=0c 3 200 v1=10 Б/с, T1=0 c (0c,100),(0c,50) v2=10 Б/с, T2=0 c (0c,30),(0c,90) 8 Кадры распределены по алгоритму RoundRobin τi = si / vi + max(Ti,ti) τ1 = 100/10+max(0,0) = = 10 c τ2 = 30/5+max(0,0) = =6c τ2 < τ1 => Первым приходит кадр из 2-го канала Алгоритм RoundRobin ждет освобождения канала 1 T=6c 4 200 v1=10 Б/с, T1=0 c (0c,100),(0c,50) v2=10 Б/с, T2=6 c (0c,90) T = 10 c 5 v1=10 Б/с, T1=10 c (0c,50), (10c,200) v2=10 Б/с, T2=6 c (0c,90) T = 10 c 6 v1=10 Б/с, T1=10 c (0c,50), (10c,200) v2=10 Б/с, T2=6 c (0c,90) T = 15 c 7 v1=10 Б/с, T1=15 c (10c,200) v2=10 Б/с, T2=6 c (0c,90) T = 24 c 8 v1=10 Б/с, T1=15 c (10c,200) v2=10 Б/с, T2=24 c Пакет размером 200 байт распределяется алгоритмом RoundRobin на первый канал τi = si / vi + max(Ti,ti) τ1 = 50/10+max(10,0) = = 15 c τ2 = 90/5+max(6,0) = = 24 c τ1 < τ2 => Первым приходит кадр из 1-го канала τi = si / vi + max(Ti,ti) τ1 = 200/10+max(15,10) = = 35 c τ2 = 90/5+max(6,0) = = 24 c τ2 < τ1 => Первым приходит кадр из 2-го канала τi = si / vi + max(Ti,ti) τ1 = 200/10+max(15,10) = = 35 c Все каналы пусты, нет новых кадров для передачи. Общее время передачи – T = 35 c. T = 35 c 9 τi = si / vi + max(Ti,ti) τ1 = 100/10+max(0,0) = = 10 c τ2 = 90/5+max(6,0) = = 24 c τ1 < τ2 => Первым приходит кадр из 1-го канала v1=10 Б/с, T1=35 c v2=10 Б/с, T2=24 c 2.5. Высокоуровневый алгоритм моделирования Псевдокод алгоритма работы системы моделирования представлен в листинге 1. Листинг 7 Входные данные: bsize – размер передаваемого прикладного буфера hsize – суммарный размер сетевых заголовков, например, 32 (TCP) + 20 (IP) + 18 (Ethernet) = 70 байт fsize – максимальный размер сетевого кадра (включая сетевые заголовки), для отправки полезных данных в каждом кадре имеется (fsize – hsize) байт N – количество физических каналов, доступных для передачи B[1 ... N] – массив, содержащий значения пропускных способностей для каждого из каналов связи. SIMULATION(bsize, hsize, fsize, N, B[1 ... N]) // Инициализация модельного времени и моделируемых каналов и счетчиков кадров T←0 n ← rn ← 1 for i ← 2 to N do τ[i] ← 0 9 QINIT(channels[i]) // инициализация очереди типа «кольцевой буфер» // Инициализация алгоритма распределения кадров INIT_DISTRALGO(DistrData) while (bsize ≠ 0) ИЛИ (i: !QEMPTY(channels[i]) ) do // Вычислить размер следующего кадра nfsize ← min(fsize – hsize, bsize) nfsize ← nfsize + hsize // Получить номер канала для отправки очередного кадра index ← SCHEDULE(DistrData, nfsize) // Функция QSPACE(q) определяет можно ли разместить в очереди q как // минимум один элемент while QSPACE(channels[index]) И NOT_EMPTY(data) do // Сформировать следующий сетевой кадр frame.s ← nfsize frame.t ← T frame.sn ← n n←n+1 ENQUEUE(channels[index], frame) // разместить кадр в выбранном канале bsize ← bsize – nfsize // уменьшить объем не переданных данных // Вычислить размер следующего кадра nfsize ← min(fsize – hsize, bsize) nfsize ← nfsize + hsize // Получить номер канала для отправки очередного кадра index ← SCHEDULE(DistrData, nfsize) // Поиск следующего по номеру for i ← 1 to N do frame ← QFIRST(channels[i]) if frame.sn = rn then ind ← i // Извлечение следующего по номеру кадра и обновление модельного времени frame ← DEQUEUE(channels[index]) T ← τ[ind] ← (frame.s / B[ind]) + max(τ[ind], frame.t) // Вывод информации о приеме кадра в журнал моделирования LOG_OUT(frame, index) // Вывод информации о времени окончания передачи OUTPUT( T ) 2.6. Оценка эффективности алгоритма распределения нагрузки Эффективность K работы агрегированного канала связи определяется по формуле: N B bsize , Bmax B[i], B , Bmax T i 1 где Bmax – максимально достижимая пропускная способность виртуального канала связи, равная сумме составляющих его элементарных каналов передачи данных. B' – фактическая пропускная способность виртуального канала связи, равная отношению размера буфера прикладной программы к общему времени его передачи. K 10 ЗАДАНИЯ Номер варианта выбирается в соответствии с номером студента в журнале преподавателя (необходимо уточнить) согласно следующему выражению на языке СИ: ((n – 1) % S + 1), где n – номер студента по журналу, S – количество заданий. 1. Реализовать имитацию работы объединенного канала передачи данных. Сравнить эффективность работы циклического и адаптивного алгоритмов распределения нагрузки. 2. Реализовать имитацию работы объединенного канала передачи данных. Сравнить эффективность работы циклического алгоритма и алгоритма PPP ML распределения нагрузки. 3. Реализовать имитацию работы объединенного канала передачи данных. Сравнить эффективность работы циклического алгоритма и алгоритма EQL распределения нагрузки. 4. Реализовать имитацию работы объединенного канала передачи данных. Сравнить эффективность работы адаптивного алгоритма и алгоритма PPP ML распределения нагрузки. 5. Реализовать имитацию работы объединенного канала передачи данных. Сравнить эффективность работы адаптивного алгоритма и алгоритма EQL распределения нагрузки. 6. Реализовать имитацию работы объединенного канала передачи данных. Сравнить эффективность работы алгоритмов PPP ML и EQL распределения нагрузки. 11