Эффективность управления процессом
advertisement

А.Ю. Кручинин
Россия, Оренбург, Оренбургский государственный университет
ЭФФЕКТИВНОСТЬ УПРАВЛЕНИЯ ПРОЦЕССОМ РАСПОЗНАВАНИЯ
ОБРАЗОВ В РЕАЛЬНОМ ВРЕМЕНИ
Предложен подход к оценке производительности и
достоверности распознавания образов с использованием
однородной цепи Маркова
Распознавание образов является процессом, которым можно управлять,
изменяя поток поступающей информации или выбирая методы распознавания и
их характеристики [1]. Описанная в работе [1] модель системы управления
процессом распознавания в реальном времени показывает, что, изменяя
параметры управления, можно добиваться требуемых результатов системы
распознавания образов (СРО) по достоверности и производительности. В
качестве критерия эффективности при управлении процессом распознавания в
системах реального времени лучше использовать компромисс между уровнем
достоверности распознавания образов и производительностью работы,
определяющийся значением некоторых (например, стоимостных) затрат [1]:
(1)
E min Z ( D, P), t t , Dз D, Pз P ,
где ∆tω – интервал времени, потраченный на распознавание образа ω x; ∆t –
ограничивающий интервал времени; Dз, D – соответственно заданное и
фактическое значение достоверности распознавания; Pз, P – соответственно
заданная и фактическая производительность работы СРО реального времени.
В данной работе предлагается подход к расчёту эффективности СРО
реального времени путём оценки достоверности и производительности.
Рассмотрим некоторую вычислительную систему, на которой в реальном
времени одновременно распознаются 1 или более образов. Пусть условием к
работе системы является необходимость распознать эти образы с
достоверностью большей либо равной Dз за минимальное время. Различные
образы можно распознавать с уровнем Dз за разное время. В работе [1] показано,
что в зависимости от сложности распознавания образов можно выбирать
различное количество информации для обеспечения уровня Dз в каждом
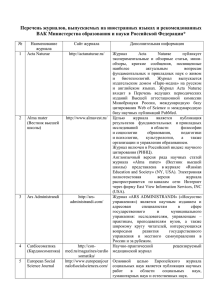
конкретном случае. На рисунке 1 изображены зависимости достоверности
результатов от сложности распознавания и репрезентативности данных для двух
образов с нормальными распределениями признаков.
Понятие сложности распознавания характеризует меру близости образов и
определяется, как вероятность ошибки распознавания [1] при объёме
характеризующих объект данных N равном 1.
Как видно из рисунка 1, для Dз = 0,9 образы с различной сложностью можно
распознать при разном объёме данных N. Зная сложность распознавания образов
можно выбирать такие режимы работы СРО, при которых Dз ≤ D и объём данных
для распознавания минимален.
Основным вопросом при применении описанного подхода к выбору режима
распознавания является определение значения сложности распознавания
конкретного образа. В идеале при решении задачи на вход должны поступать не
только признаки неизвестного образа, но и его сложность распознавания. На
практике это трудно осуществимо, т.к. обычно для того, чтобы оценить значение
сложности распознавания образа, необходимо его идентифицировать. Однако
можно использовать сложность распознавания предыдущего образа для
распознавания текущего образа. Данный подход применим в случае, когда на
СРО в потоке через интервал времени поступают порциями неизвестные образы,
причём изменение образов в потоке происходит постепенно. Такая ситуация
возможна, например, при анализе видеопотока с видеокамеры, геофизических
исследованиях скважин [2] и т.п. Негативным эффектом от описанного подхода
является то, что, при переходе от анализа образа с малой сложностью
распознавания к большей, может возникнуть ситуация, когда система работает в
режиме Dз > D. Поэтому необходимо оценить эффективность управления
процессом распознавания образов.
D
Sl=0,1;0,2;0,3;0,4;0,5;0,6;
1
Sl=0,7
0,9
Sl=0,8
0,8
Sl=0,9
0,7
0,6
N
0,5
1
11
21
31
41
51
61
71
81
91
Рисунок 1. – Зависимости достоверности результатов D от сложности
распознавания Sl и репрезентативности данных.
Допустим, что на СРО реального времени поступают неизвестные образы из
возможной группы образов:
(2)
1, 2 ,..., K ,0 Sl (1 ) Sl (2 ) ... Sl (K ) 1,
где K > 1 – количество классов образов, а вероятность их появления не
зависит от номера испытания. Тогда последовательность образов, поступающих
на СРО, можно описать однородной цепью Маркова [3]. Матрица переходов
последовательности на шаге 1 описывается следующим образом:
p11
p
M 1 21
...
p
K1
p12
...
p 22
...
...
...
pK 2
...
p1K
p2K
,
...
p KK
(3)
где pij – условная вероятность перехода из i-го состояния в j-ое. Номер
состояния характеризует режим СРО для анализа образа с тем же номером.
Режим характеризуется объёмом данных для распознавания в соответствии с
выражением (2) и рисунком 1:
(4)
1 N1 N 2 ... N K .
При установившемся режиме СРО в одном состоянии D ~ Dз, поэтому
матрица статистического уровня достоверности при переходе из одного
состояния в другое имеет следующий вид:
Dз
D D21
MD з
...
D D
K1
з
D з D12
Dз
...
D з D K 2
... D з D1K D11
... D з D2 K D21
...
...
...
D
...
Dз
K1
D12
D22
...
DK 2
D1K
... D2 K
.
... ...
... DKK
...
(5)
Для того, чтобы вычислить безусловную вероятность появления каждого
образа достаточно рассчитать матрицу перехода за L шагов (где L ), которая
вычисляется согласно следующему выражению [3]:
(6)
M L M 1L .
Результирующая матрица будет содержать одинаковые строки с
безусловными вероятностями для каждого состояния p = {p1, p2, …, pK}:
(7)
p1 p2 ... p K 1 .
Согласно теореме умножения вероятностей [3] можно найти вероятность
каждого перехода в выражении (3), которая будет равна произведению
безусловной вероятности состояния на условную вероятность перехода в то же
или другое состояние. Данные вероятности необходимы для определения
среднего значения достоверности распознавания образов:
Dср ( D11 p1 p11 D12 p1 p12 ... D1K p1 p1K ) ( D21 p2 p21 D22 p2 p22 ...
D2 K p2 p2 K ) ... ( DK1 p K p K1 DK 2 p K p K 2 ... DKK p K p KK )
.
(8)
Производительность работы СРО напрямую связана с объёмом
анализируемых данных, поэтому достаточно вычислить средний объём данных
на распознавания одного образа для оценки производительности:
(9)
N ср N1 p1 N 2 p2 ... N K p K .
Далее
приведён
пример
расчета
средней
достоверности
и
репрезентативности данных. Имеются три класса образов с различной
сложностью Sl = {0,1; 0,3; 0,5}, для распознавания которых с Dз = 0,9 требуются
различные объёмы данных N = {1, 3, 6} соответственно. Матрица переходов и
матрицы статистической достоверности следующие:
0,5 0,4 0,1
0,9 0,8 0,6
M 1 0,4 0,4 0,2 , MD 0,95 0,9 0,8 .
0,1 0,3 0,6
0,97 0,92 0,9
(10)
Используя выражение (6) с L = 15, рассчитываются безусловные
вероятности p = {0,353; 0,373; 0,275}. Подставив полученные вероятности в
выражение (8) и (9) определяются средние значения достоверности и объёма
данных: Dср = 0,88; Nср = 3,617. В то время, как если бы СРО работала в одном
режиме (N = 6), то Dср = 0,933; Nср = 6. Не смотря на значительный прирост в
производительности (в 1,66 раза), СРО при управлении процессом распознавания
работает ниже уровня Dз. Однако эта проблема устраняется если немного
завысить Dз при построении матрицы MD или поменять режимы работы,
например, установив N = {3, 3, 6}, соответственно:
0,95 0,9 0,8
MD 0,95 0,9 0,8 .
0,97 0,92 0,9
(11)
В этом случае Dср = 0,91; Nср = 4,323, что в 1,388 раз быстрее работы СРО без
управления при сохранении достоверности большей Dз. Сравнительные
гистограммы всех трёх режимов представлены на рисунке 2.
0,94
7
D
N
6
0,92
5
0,9
4
0,88
3
2
0,86
Режим
0,84
1
2
3
1
Режим
0
1
2
3
Рисунок 2. – Достоверность распознавания и средний объём данных для режимов СРО:
без управления (1), управление N = {3, 3, 6} (2), управление N = {1, 3, 6} (3).
Зная показатели достоверности и производительности работы СРО не
сложно вычислить режим, удовлетворяющий (1), для этого необходимо знать
показатели функций затрат:
Z Z 0 Z1 ( N ) Z 2 (1 D) ,
(12)
где Z0 – затраты независящие от производительности и достоверности
распознавания СРО, Z1 – затраты, обусловленные производительностью, Z2 –
затраты обусловленные ошибками при распознавании образов.
Описанный подход позволяет оценить возможность применения методики
управления процессом распознавания образов в реальном времени и возможный
эффект от применения.
Литература
1. Кручинин, А.Ю. Управление процессом распознавания образов в реальном
времени / А.Ю. Кручинин // Автоматизация и современные технологии. –
2010. – №3. – С. 33-37.
2. Кручинин А.Ю., Аралбаев Т.З. Оптимизация геофизических исследований
скважин на основе многофакторной имитационной модели // Вестник
Самарского государственного университете, серия «Технические науки».
2007. № 2 (20).
3. Гмурман, В.Е. Теория вероятностей и математическая статистика / В.Е.
Гмурман. М. : Высш. шк., 2004. 479 с.