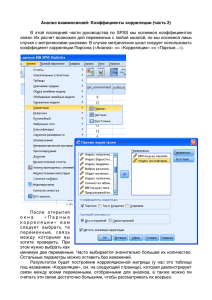
Статистика для тех, кто думает, что ненавидит статистику by Нил
advertisement

Что объединяет множество людей, начинающих изучать статистику? Большинство новичков считает, что она часто сложна и запутанна. Однако Нил Салкинд в результате множества проб и ошибок, а также учитывая многочисленные отзывы читателей, выпустил уже 6-е издание книги с целью научить статистике так, чтобы эта наука перестала пугать и стала для вас полезной! Вы узнаете все необходимое, чтобы понять, чем занимается и что изучает базовая статистика. В книге совсем немного теории (но кое-какая имеется) и доказательств. После прочтения вы сможете понять материал в научных статьях, интерпретировать результаты статистического анализа, а также выполнять основные статистические операции. В этой книге вы найдете: • чем занимается статистика; • вычисление и значение средних; • что такое дисперсия и стандартное отклонение, надежность и достоверность; • зачем нужно иллюстрировать данные; • какие существуют типы корреляции и что такое коэффициент корреляции; • определение вероятности и кривая нормального распределения; • как отличить ошибку первого рода от ошибки второго рода; • одновыборочный Z-критерий и t-критерий для независимых средних; • основы дисперсионного анализа, в т. ч. многофакторного; • линейная и множественная регрессия; • хи-квадрат и другие непараметрические критерии; • интеллектуальный анализ данных в SPSS. Интерактивная электронная книга (на английском) расширяет возможности обучения и содержит демонстрационные видеоролики, записанные автором. Узнайте больше на edge.sagepub.com/salkind6e. ISBN 978-5-97060-752-7 Интернет-магазин: www.dmkpress.com Оптовая продажа: КТК “Галактика” books@alians-kniga.ru www.дмк.рф 9 785970 607527 Статистика для тех, кто (думает, что) ненавидит статистику Преуспейте в статистике с этим простым для понимания иллюстрированным и содержательным руководством! Статистика для тех, кто (думает, что) ненавидит статистику Нил Дж. Салкинд Нил Дж. Салкинд Университет Канзаса Статистика для тех, кто (думает, что) ненавидит статистику Statistics for y) e h T People Who (Think Hate Statistics Neil J. Salkind University of Kansas Los Angeles | London | New Delhi Singapore | Washington DC | Melbourne Статистика о) т ч , ет а м у д для тех, кто ( ненавидит статистику Нил Дж. Салкинд Университет Канзаса Москва, 2020 УДК 311.1 ББК 60.6 С16 С16 Салкинд Н. Дж. Статистика для тех, кто (думает, что) ненавидит статистику / пер. с анг. М. В. Ермолиной. – М.: ДМК Пресс, 2020. – 502 с.: ил. ISBN 978-5-97060-752-7 Что объединяет множество людей, начинающих изучать статистику? Большинство новичков считает, что она часто сложна и запутана. Однако Нил Салкинд в результате множества проб и ошибок, а также учитывая многочисленные отзывы читателей, выпустил уже 6-е издание книги с целью научить статистике так, чтобы эта наука перестала пугать и стала для вас полезной! Вы узнаете все необходимое, чтобы понять, чем занимается и что изучает базовая статистика. В книге совсем немного теории (но кое-какая имеется) и доказательств. После прочтения вы сможете понять материал в научных статьях, интерпретировать результаты статистического анализа, в также выполнять основные статистические операции. УДК 311.1 ББК 60.6 Authorized Russian translation of the English edition of Statistics for People Who (Think They) Hate Statistics ISBN 9781506333830 © 2017 by SAGE Publications, Inc. This translation is published and sold by permission of SAGE Publishing, which owns or controls all rights to publish and sell the same. Все права защищены. Любая часть этой книги не может быть воспроизведена в какой бы то ни было форме и какими бы то ни было средствами без письменного разрешения владельцев авторских прав. ISBN 978-1-5063-3383-0 (анг.) ISBN 978-5-97060-752-7 (рус.) © 2017 by SAGE Publications, Inc. © Оформление, издание, перевод, ДМК Пресс, 2020 В честь и в память Шейна Джей Лопеса, и welcome to Bella Содержание Вступительное слово..................................................................... 17 Отзывы........................................................................................... 19 Обращение к студентам: почему я написал эту книгу.............. 26 Благодарности............................................................................... 29 А теперь о шестом издании…...................................................... 31 Предисловие от издательства...................................................... 33 Об авторе........................................................................................ 35 ЧАСТЬ I Ура! У меня статистика................................................................. 37 1 Статистика или садистика?...................................................... 41 6 Почему статистика?..........................................................................41 И почему SPSS?.............................................................................42 Пятиминутка истории статистики..................................................42 Чем (не) является статистика..........................................................44 Что такое описательная статистика?..........................................44 Что такое инференциальная статистика?...................................45 Другими словами….......................................................................46 Что я вообще делаю на курсе по статистике?.................................47 10 способов работы с этой книгой (и одновременного изучения статистики).......................................................................48 О пиктограммах................................................................................51 Ключ к маркерам сложности...........................................................52 Предметный указатель.....................................................................52 Реальная статистика.........................................................................52 Выводы по главе...............................................................................53 Время практики................................................................................53 Сайт с материалами для обучения..................................................54 Статистика для тех, кто (думает, что) ненавидит статистику ЧАСТЬ II ∑игма Фрейд и описательная статистика.................................. 55 2 Серединный мир....................................................................... 57 Вычисление среднего значения......................................................58 Вычисление взвешенной средней...............................................60 Вычисление медианы.......................................................................61 Вычисление моды.............................................................................64 Пирожок с двумя начинками.......................................................65 Как выбрать нужную меру центральной тенденции (и все, что вам нужно сейчас знать о шкалах измерения)........................66 Хоть розой назови ее, хоть нет: номинальная шкала измерения.....................................................................................67 Любой порядок подойдет: порядковая шкала измерения........67 1 + 1 = 2: интервальная шкала измерения..................................67 Можно ли не иметь ничего? Пропорциональная шкала измерения.....................................................................................67 Подводя итог…..............................................................................68 Вычисление описательных статистик при помощи компьютера.......................................................................................69 Выводы SPSS.................................................................................70 Реальная статистика.........................................................................72 Выводы по главе...............................................................................73 Время практики................................................................................73 Сайт с материалами для обучения..................................................77 3 Vive la Différence!....................................................................... 78 Почему важно понимать изменчивость?........................................78 Вычисление диапазона....................................................................79 Вычисление стандартного отклонения...........................................80 Почему n – 1? Что не так с просто n?...........................................83 И что такого?.................................................................................84 Вычисление дисперсии....................................................................85 Стандартное отклонение против дисперсии.............................85 Вычисление мер изменчивости при помощи компьютера...........86 Выводы SPSS.................................................................................87 Второй вывод SPSS.......................................................................88 Реальная статистика.........................................................................88 Выводы по главе...............................................................................89 Время практики................................................................................89 Сайт с материалами для обучения..................................................91 4 Лучше один раз увидеть........................................................... 92 Зачем нужно иллюстрировать данные?..........................................92 Десять способов сделать красивую картинку (не заваливать горизонт?).........................................................................................93 7 8 Статистика для тех, кто (думает, что) ненавидит статистику Обо всем по порядку: как создать распределение частот.............94 Самый классный интервал..........................................................94 Тени сгущаются: создание гистограммы........................................96 Метод подсчета.............................................................................98 Следующий шаг: полигон частот.....................................................98 Кумулятивная частота..................................................................99 Другие классные способы графического представления данных...........................................101 Столбиковые диаграммы...........................................................102 Линейчатые диаграммы............................................................103 Линейные графики.....................................................................103 Круговые диаграммы.................................................................104 Иллюстрация данных при помощи компьютера (т. е. SPSS)....................................................................................104 Создание гистограммы..............................................................105 Создание столбиковой диаграммы...........................................107 Создание линейного графика....................................................108 Создание круговой диаграммы.................................................109 Реальная статистика.......................................................................110 Выводы по главе.............................................................................111 Время практики..............................................................................111 Сайт с материалами для обучения................................................112 5 Мороженое и преступность.................................................... 113 О чем говорит корреляция?...........................................................113 Типы коэффициентов корреляции: вкус 1 и вкус 2.................114 Расчет простого коэффициента корреляции................................116 Визуальное представление корреляции: диаграмма рассеяния....................................................................................118 Кучи корреляций: матрица корреляции...................................122 Как понять, что значит коэффициент корреляции..................123 Эмпирический метод (оценим «на глазок»).............................123 Детерминируй это: квадрат коэффициента корреляции........124 Чем больше съедается мороженого, тем… выше преступность (или ассоциация против причинности)............125 Вычисление коэффициента корреляции при помощи SPSS.............................................................................................127 Создание диаграммы рассеяния...............................................129 Другие классные корреляции........................................................130 Делим на части: немного о частичной корреляции.....................131 Вычисление частичной корреляции при помощи SPSS..........133 Реальная статистика.......................................................................134 Выводы по главе.............................................................................135 Время практики..............................................................................135 Сайт с материалами для обучения................................................139 Статистика для тех, кто (думает, что) ненавидит статистику 6 Только правда.......................................................................... 140 Предисловие к надежности и достоверности...............................140 Так что там с этими измерениями?..........................................141 Надежность: повторяйте, пока не получится правильно............142 Оценки за тест: правда или действие?.....................................142 Наблюдаемая оценка = истинная оценка + оценка ошибки........................................................................................143 Виды надежности...........................................................................144 Ретестовая надежность..............................................................144 Надежность параллельных форм..............................................145 Надежность внутренней согласованности................................146 Взаимная надежность оценивающих........................................150 Много – это сколько? Наконец-то: интерпретация коэффициентов надежности.........................................................151 А если не получается установить надежность, что тогда?.......152 И еще одно..................................................................................152 Достоверность: в чем правда, брат?..............................................153 Виды достоверности...................................................................153 Содержательная достоверность.................................................153 Критериальная достоверность..................................................154 Конструктивная достоверность.................................................155 А если не получается установить достоверность – что тогда?...........................................................................................156 Дружественное напутствие............................................................157 Достоверность и надежность – очень близкие родственники..................................................................................158 Реальная статистика.......................................................................158 Выводы по главе.............................................................................159 Время практики..............................................................................159 Сайт с материалами для обучения................................................160 ЧАСТЬ III Карты, деньги, вероятности....................................................... 161 7 Гипотезы и вы.......................................................................... 163 Итак, вы хотите быть ученым….....................................................163 Выборка и генеральная совокупность..........................................164 Нулевая гипотеза............................................................................165 Назначение нулевой гипотезы..................................................165 Альтернативная гипотеза..............................................................167 Ненаправленная альтернативная гипотеза..............................168 Направленная альтернативная гипотеза..................................168 Различия между нулевой и альтернативной гипотезами.......170 Критерии качества хорошей гипотезы.........................................171 Реальная статистика.......................................................................174 Выводы по главе.............................................................................175 9 10 Статистика для тех, кто (думает, что) ненавидит статистику Время практики..............................................................................175 Сайт с материалами для обучения................................................176 8 Нормальны ли ваши кривые?................................................ 177 Почему вероятность?.....................................................................177 Кривая нормального распределения (также известная как «колокольчик»).........................................................................178 Эй, это ненормально!.................................................................179 Еще немного о нормальной кривой..........................................181 Наш любимый стандартный показатель: z-оценка.................184 Что показывает z-оценка?.........................................................187 Что на самом деле показывает z-оценка?................................190 Проверка гипотез и z-оценки: первый шаг..............................192 Вычисление z-оценок при помощи SPSS..................................193 Толстые и тощие распределения частот.......................................193 Среднее значение.......................................................................194 Изменчивость.............................................................................194 Асимметрия................................................................................194 Эксцесс........................................................................................196 Реальная статистика.......................................................................198 Выводы по главе.............................................................................198 Время практики..............................................................................199 Сайт с материалами для обучения................................................201 ЧАСТЬ IV Значимая разница: применение статистики вывода............. 203 9 Значимо значимый................................................................. 205 Концепция значимости..................................................................205 Если бы мы были идеальны.......................................................206 Самая важная таблица в мире (только для этого семестра)....209 Подробнее про таблицу 9.1........................................................209 Возвращаясь к ошибкам первого рода.....................................210 Значимость против осмысленности.............................................212 Предисловие к статистике вывода................................................214 Как работают выводы?...............................................................215 Как выбрать статистический критерий для проверки?...........215 Как пользоваться схемой?.........................................................216 Предисловие к проверке значимости...........................................216 Как работает проверка значимости: план................................217 Лучше один раз увидеть.............................................................219 Повысьте свое доверие...................................................................220 Реальная статистика.......................................................................221 Выводы по главе.............................................................................222 Время практики..............................................................................222 Сайт с материалами для обучения................................................223 Статистика для тех, кто (думает, что) ненавидит статистику 10 Строго по одному................................................................... 224 Предисловие к одновыборочному Z-критерию...........................224 Путь к мудрости и знанию.............................................................225 Вычисление Z-статистики.............................................................225 Так как мне интерпретировать z = 2,38, p < 0,05?.....................229 Расчет Z-критерия при помощи SPSS...........................................229 Спецэффекты: а эти различия настоящие?..................................231 Как понимать размер эффекта?................................................232 Реальная статистика.......................................................................233 Выводы по главе.............................................................................233 Время практики..............................................................................234 Сайт с материалами для обучения................................................235 11 (t)ет-а-тет............................................................................... 236 Предисловие к t-критерию для независимых выборок...............236 Путь к мудрости и знанию.............................................................237 Вычисление t-критерия.................................................................238 Время для примера.....................................................................239 Так как мне интерпретировать t(58) = −0,14, p > 0,05?................242 Размер эффекта и (t)ет-а-тет.........................................................242 Расчет и понимание размера эффекта.....................................243 Два очень классных калькулятора размера эффекта...............244 Расчет t-критерия при помощи SPSS............................................245 Реальная статистика.......................................................................247 Выводы по главе.............................................................................247 Время практики..............................................................................248 Сайт с материалами для обучения................................................250 12 (t)ет-а-тет (снова).................................................................. 251 Предисловие к t-критерию для зависимых средних...................251 Путь к мудрости и знаниям...........................................................252 Вычисление значения t-критерия.................................................253 Так как мне интерпретировать t(24) = 2,45, p < 0,05?.................256 Расчет t-критерия при помощи SPSS............................................256 Размер эффекта для (t)ет-а-тета (снова).......................................260 Реальная статистика.......................................................................260 Выводы по главе.............................................................................261 Время практики..............................................................................261 Сайт с материалами для обучения................................................264 13 Двух групп недостаточно?.................................................... 265 Предисловие к дисперсионному анализу.....................................265 Путь к мудрости и знанию.............................................................266 Разновидности дисперсионного анализа.....................................266 Вычисление статистического критерия Фишера.........................268 Так как мне интерпретировать F(2,27) = 8,80, p < 0,05?...............273 11 12 Статистика для тех, кто (думает, что) ненавидит статистику Вычисление F-отношения Фишера с помощью SPSS..................274 Размер эффекта для однонаправленного дисперсионного анализа............................................................................................277 Реальная статистика.......................................................................278 Выводы по главе.............................................................................279 Время практики..............................................................................279 14 Два лишних фактора............................................................. 281 Предисловие к многофакторному дисперсионному анализу............................................................................................281 Путь к мудрости и знанию.............................................................282 Новый сорт ANOVA.........................................................................283 Основное событие: главные эффекты в многофакторном дисперсионном анализе................................................................284 Еще интереснее: эффекты взаимодействия.................................286 Вычисление F-отношения с помощью SPSS.................................288 Расчет размера эффекта для многофакторного ANOVA..............292 Реальная статистика.......................................................................292 Выводы по главе.............................................................................293 Время практики..............................................................................293 15 Двоюродные или просто хорошие друзья? ........................ 295 Предисловие к проверке коэффициента корреляции.................295 Путь к мудрости и знанию.............................................................296 Расчет статистического критерия.................................................296 Так как мне интерпретировать r(28) = 0,437, p < 0,05?................300 Причины и связи (снова!)..........................................................300 Значимость против существенности (опять и снова!).............301 Вычисление коэффициента корреляции при помощи SPSS (снова).............................................................................................301 Реальная статистика.......................................................................303 Выводы по главе.............................................................................304 Время практики..............................................................................304 16 Как предсказать, кто выиграет Суперкубок........................ 307 Предисловие к линейной регрессии.............................................307 Вообще, что такое предсказание?.................................................308 Логика предсказания......................................................................309 Рисуем лучшую прямую в мире (по вашим данным)..................313 Насколько хороши ваши предсказания?.......................................315 Расчет прямой регрессии при помощи SPSS................................316 Чем больше предсказывающих переменных, тем лучше? Возможно........................................................................................320 Важные правила применения множественных независимых переменных.............................................................322 Реальная статистика.......................................................................323 Статистика для тех, кто (думает, что) ненавидит статистику Выводы по главе.............................................................................324 Время практики..............................................................................324 ЧАСТЬ V Больше статистики! Больше инструментов! Больше веселья!........................................................................... 329 17 Что делать с ненормальными.............................................. 331 Предисловие к непараметрическим критериям..........................331 Представляем критерий согласия хи-квадрат (одновыборочный).........................................................................332 Вычисление значения критерия согласия хи-квадрат................333 Так как мне интерпретировать χ2 = 20,6, p < 0,05?...................336 Предисловие к критерию независимости хи-квадрат.................336 Расчет значения критерия независимости хи-квадрат...............337 Расчет критерия хи-квадрат при помощи SPSS...........................339 Критерий согласия и SPSS..........................................................339 Критерий независимости и SPSS..............................................340 Другие непараметрические критерии, о которых вам нужно знать.....................................................................................343 Реальная статистика.......................................................................344 Выводы по главе.............................................................................345 Время практики..............................................................................345 18 Еще несколько (важных) статистических процедур, о которых вам стоит знать......................................................... 348 Многомерный дисперсионный анализ.........................................348 Дисперсионный анализ повторных измерений..........................349 Ковариационный анализ...............................................................350 Множественная регрессия.............................................................351 Метаанализ.....................................................................................351 Дискриминантный анализ.............................................................352 Факторный анализ..........................................................................353 Анализ пути....................................................................................353 Моделирование структурных уравнений.....................................354 Выводы по главе.............................................................................355 19 Интеллектуальный анализ данных...................................... 356 Наш подопытный набор данных – кто не любит младенцев?.....................................................................................359 Подсчет результатов.......................................................................360 Подсчет по частотам..................................................................360 Сводные таблицы и таблицы сопряженности: находим скрытые паттерны..........................................................................364 Создание сводной таблицы.......................................................364 Изменение сводной таблицы....................................................366 13 14 Статистика для тех, кто (думает, что) ненавидит статистику Выводы по главе.............................................................................369 Время практики..............................................................................369 20 Подборка программ для статистического анализа............ 371 Как выбрать идеальную программу для статистики?..................371 Что же у нас есть?...........................................................................374 Сначала о бесплатном................................................................374 Час расплаты...............................................................................377 Выводы по главе.............................................................................380 ЧАСТЬ VI Десять вещей (умножить на два), которые вы хотите узнать и запомнить.................................................................... 381 21 Десять (или более) лучших (и самых увлекательных) интернет-сайтов для статистики.............................................. 382 Не думали поучить статистику в Стокгольме?.............................383 Кто есть кто и что случилось?........................................................383 Все здесь..........................................................................................383 Hyperstat..........................................................................................384 Данные? Вам нужны данные?........................................................385 Больше и больше ресурсов.............................................................386 И конечно, YouTube….....................................................................386 Наконец…........................................................................................386 22 Десять заповедей сбора данных........................................... 387 Приложение A. SPSS Statistics меньше, чем за 30 мин............ 390 Запуск SPSS.....................................................................................391 Приветственное окно SPSS........................................................391 Панель инструментов и строка состояния SPSS...........................393 Использование справки SPSS........................................................393 Краткий тур по SPSS.......................................................................395 Открываем файл.........................................................................395 Простая таблица и диаграмма...................................................396 Простой анализ...........................................................................397 Создание и редактирование файла данных.................................397 Определение переменных.........................................................397 Настраиваемое определение переменных: использование представления переменных............................398 Определение значения меток данных......................................399 Изменение меток значений......................................................401 Как открыть файл данных..........................................................402 Печать из SPSS................................................................................402 Печать файла данных SPSS........................................................402 Печать выделения в файле данных SPSS..................................403 Статистика для тех, кто (думает, что) ненавидит статистику Создание диаграммы в SPSS..........................................................403 Создание простой диаграммы...................................................403 Создание столбиковой диаграммы...........................................403 Сохранение диаграммы.............................................................405 Улучшение диаграмм SPSS............................................................405 Редактирование диаграммы......................................................406 Работа с заголовками и подзаголовками..................................406 Работа со шрифтами...................................................................407 Работа с осями............................................................................407 Как изменить ось шкалы (y).......................................................408 Как изменить ось категорий (x).................................................408 Описание данных...........................................................................409 Частоты и сопряженные таблицы.............................................409 Применение t-критерия для независимых выборок...............411 Как рассчитать t-критерий для независимых выборок...........412 Выход из SPSS.................................................................................413 Приложение B. Таблицы............................................................. 414 Таблица B.1. Площади под кривой нормального распределения................................................................................414 Таблица B.2. Значения T, необходимые для отклонения нулевой гипотезы...........................................................................416 Таблица B.3. Критические значения для дисперсионного анализа, или F-критерия............................417 Таблица B.4. Значения коэффициента корреляции, необходимые для отклонения нулевой гипотезы........................421 Таблица B.5. Критические значения хи-квадрат..........................422 Приложение C. Наборы данных................................................. 424 Глава 2. Набор данных 1.............................................................424 Глава 2. Набор данных 2.............................................................425 Глава 2. Набор данных 3.............................................................425 Глава 2. Набор данных 4.............................................................425 Глава 3. Набор данных 1.............................................................425 Глава 3. Набор данных 2.............................................................426 Глава 3. Набор данных 3.............................................................426 Глава 3. Набор данных 4.............................................................426 Глава 4. Набор данных 1.............................................................427 Глава 4. Набор данных 2.............................................................427 Глава 4. Набор данных 3.............................................................427 Глава 5. Набор данных 1.............................................................428 Глава 5. Набор данных 2.............................................................428 Глава 5. Набор данных 3.............................................................428 Глава 5. Набор данных 4.............................................................428 Глава 5. Набор данных 5.............................................................429 Глава 5. Набор данных 6.............................................................429 15 16 Статистика для тех, кто (думает, что) ненавидит статистику Глава 6. Набор данных 1.............................................................429 Глава 6. Набор данных 2.............................................................430 Глава 11. Набор данных 1...........................................................431 Глава 11. Набор данных 2...........................................................431 Глава 11. Набор данных 3...........................................................432 Глава 11. Набор данных 4...........................................................432 Глава 11. Набор данных 5...........................................................433 Глава 11. Набор данных 6...........................................................433 Глава 12. Набор данных 1...........................................................434 Глава 12. Набор данных 2...........................................................434 Глава 12. Набор данных 3...........................................................434 Глава 12. Набор данных 4...........................................................435 Глава 12. Набор данных 5...........................................................435 Глава 13. Набор данных 1...........................................................436 Глава 13. Набор данных 2...........................................................436 Глава 13. Набор данных 3...........................................................437 Глава 13. Набор данных 4...........................................................437 Глава 14. Набор данных 1...........................................................438 Глава 14. Набор данных 2...........................................................438 Глава 14. Набор данных 3...........................................................439 Глава 14. Набор данных 4...........................................................440 Глава 15. Набор данных 1...........................................................441 Глава 15. Набор данных 2...........................................................441 Глава 15. Набор данных 3...........................................................442 Глава 15. Набор данных 4...........................................................442 Глава 15. Набор данных 5...........................................................442 Глава 16. Набор данных 1...........................................................443 Глава 16. Набор данных 2...........................................................443 Глава 16. Набор данных 3...........................................................443 Глава 17. Набор данных 1............................................................444 Глава 17. Набор данных 2............................................................444 Глава 17. Набор данных 3............................................................445 Глава 17. Набор данных 4............................................................446 Глава 17. Набор данных 5............................................................447 Глава 19. Набор данных 1 и Глава 19. Набор данных 2.............448 Набор данных. Пример..............................................................448 Приложение D. Ответы на задания........................................... 449 Приложение E. Математика: самые основы............................ 488 Большие правила: приветствуем СВД У ПМ.................................488 Маленькие правила........................................................................490 Приложение F. Бонус: рецепт брауни....................................... 492 Глоссарий..................................................................................... 494 Предметный указатель............................................................... 500 Вступительное слово С егодня, в эпоху цифровых технологий и огромного потока различных данных, возрождается интерес широкого круга спе­ циалистов к статистике. Статистический анализ позволяет получать из собираемых повсеместно данных новые знания о жизни людей, поведении потребителей, психологии принятия решений. Методы прикладной статистики активно применяются в технических исследованиях, экономике, теории и практике управления, социологии, медицине, геологии, истории. В то же время недостаточная образовательная подготовка, обилие различного рода манипуляций с данными, непонимание функций статистики в последние десятилетия во многом дискредитировали ее в глазах общества. В нашей стране недоверие к статистике тесно связано с непониманием ее основ: неумением «читать» данные и делать объективные выводы на их основе, неумением выявлять лжестатистику и отделять правду от спекуляций. Отдельная проб­лема – непрофессионализм журналистов в работе со статистическими данными, порой неверно интерпретируемыми ими в поисках ярких фактов и заголовков. Сегодня статистику изучают во многих учебных заведениях, она включена в программы подготовки различных специалистов, в том числе гуманитарного профиля. В то же время приходится констатировать, что подготовку сильных и востребованных на рынке социологов, маркетологов и аналитиков осуществ­ляет небольшое число российских вузов. И дело не только в педагогических кадрах, но и в учебных материалах. Сегодня преподавание статистики ослож­ няет серьезный дефицит ка­чественных учебных пособий, книг, электронных образовательных ресурсов. Российское исследовательское сообщество, представителем которого является Аналитический центр НАФИ, приветствует издание качественной и доступной для понимания широкого круга читате- 17 18 Статистика для тех, кто (думает, что) ненавидит статистику лей книги Нила Дж. Салкинда «Статистика для тех, кто (думает, что) ненавидит статистику». За многие годы совместной работы с крупнейшими вузами мы хорошо изучи­ли методические потребности студентов и можем смело сказать, что представляемая вашему вниманию книга отвечает им в полной мере. В 2022 г. будет отмечаться юбилей – 220 лет официальной российской статистике. Полагаем, что данная книга успеет к этому времени завоевать популярность у читателей и внести вклад в подготовку российских специалистов, имеющих дело со статистическим анализом. Данная книга относится к особому, не похожему ни на один из принятых в современной учебной литературе жанру. Это организованный курс с увлекательными примерами и доступными объяснениями. Книгу действительно легко и интересно читать. Желаем вам приятного погружения в интереснейший мир анализа данных! Тимур Аймалетдинов, кандидат социологических наук, заместитель генерального директора аналитического центра НАФИ, nafi.ru Отзывы Книга «Статистика для тех, кто (думает, что) ненавидит статистику» действительно заставляет студентов изучать эту область науки и наслаждаться ею и исследованиями в целом. Студентам особенно нравятся 10 заповедей и ссылки на интернет-сайты. – Валери Джейнсик (Valarie Janesick), профессор управления обучением, Университет Южной Флориды Я просто хотела сказать, что, проходя онлайн-обучение сестринскому делу в Университете штата Нью-Йорк, столкнулась с «Введением в статистику», и ваша книга спасла мою карьеру! Я бросила обучение из-за статистики, пару раз даже восстанавливалась и опять бросала. Я прочитала первые две главы книги и уже поняла суть. Я знаю, что дальше будет сложнее, но я так благодарна вам за простую для понимания методику. Прошлым вечером я сказала мужу, что вполне могу полюбить статистику. Отдельное спасибо вам за обзор основ математики. Никто еще не объяснял ее так понятно, как вы: в старшей школе я была в коррекционном классе по математике и все равно не понимала ее. Теперь я больше не боюсь ни математики, ни статистики. – Меган Уилер (Meghan Wheeler), дипломированная медсестра Очень признательна вам за помощь и отзывчивость. Я учусь использовать SPSS, пока готовлюсь к докторской программе, которая начнется осенью. Прошло уже двадцать лет с тех пор, как я изучала статистику. Спасибо этой доходчивой книге за то, что помогла мне освоиться с текущими трендами. – Сильвия Миллер-Мартин (Sylvia Miller-Martin) 19 20 Статистика для тех, кто (думает, что) ненавидит статистику Я полюбил статистику со времени получения второго высшего образования. Ваша книга «Статистика для тех, кто (думает, что) ненавидит статистику» прояснила запутанные и не до конца понятные вопросы, которые волновали меня много лет. Это обязательная для прочтения книга для всех начинающих или продолжающих свой путь в науке. Я обожаю ее и обязательно буду использовать в бу­ дущем. – Рональд А. Штраубе (Ronald A. Straube), Региональный медицинский центр, г. Мишен, Техас Д-р Салкинд, я чувствую себя просто обязанным поблагодарить Вас за такую отличную книгу. Два года назад я купил дом. Люди, жившие здесь раньше, оставили эту книгу. Я не выбросил ее, потому что я книжный маньяк. В общем, я начал учиться в магистратуре по курсу психологии и решил использовать Вашу книгу. Она оказалась для меня просто подарком. Это, определенно, лучшая книга по статистике, с которой я когда-либо имел дело, особенно учитывая простоту и доступность содержащихся в ней объяснений. Она точно стоила потраченных на дом ста тысяч! Благослови Вас бог! – Брайан Райт (Brian Wright) Проектная команда, состоявшая из Дениз, Рене, Шона и Триш, выбрала в качестве рабочей гипотезы утверждение, что брауни из обычной муки будет пользоваться большей популярностью, чем брауни без глютена. Они выбрали рецепт, приведенный в приложении F «Награда». Дениз испекла брауни без глютена, Рене сделала обычные, а выбор осуществляли наши сокурсники в колледже. Для оценки брауни мы использовали опрос с порядковой шкалой от 1 до 5, где 1 означало худший, а 5 – лучший брауни в вашей жизни. Брауни без глютена выиграли, тем самым опровергнув гипотезу исследования. Сравнение проводилось по среднему значению и по моде. У брауни без глютена среднее значение/мода составляло 4, а у обычных – 3. Широта распределения для брауни без глютена была больше, чем для обычных. Все участники опроса были без ума от брауни. Все это произошло, потому что я спросила преподавателя, будем ли мы как-то использовать информацию из приложения F. Ни преподаватель, ни сокурсники даже и не заглядывали в него. Преподаватель сказал, что я могу испечь брауни и принести их на занятия. Именно тогда я сказала, что у меня целиакия и в доме есть только мука без глютена. Из-за особой текстуры выпечка без глютена обычно нравится меньше. Преподаватель всегда хотел попробовать что-нибудь безглютеновое. Вот так и появился на свет наш учебный эксперимент. – Дениз Проске (Denise Proske), колледж Тускула Статистика для тех, кто (думает, что) ненавидит статистику Я просто хотел на минуту привлечь Ваше внимание, чтобы сообщить, что выбрал Вашу книгу, «Статистика для тех, кто (думает, что) ненавидит статистику», в качестве учебника по своему предмету. Я полностью согласен с курсом, которого Вы придерживаетесь в книге, и знаю, что наши студенты точно так же одобрят его. – Карл Р. Кравиц (Karl R. Krawitz), д-р педагогических наук, Университет Бейкера, Оверленд Парк, Канзас Я «нетрадиционная» (так милые ребята из Университета Дейтона называют пожилых) студентка магистратуры и получаю большое удовольствие от Вашей «Статистики для тех, кто (думает, что) ненавидит статистику». Несмотря на то что моя работа заключается в том, чтобы рассказывать об исследованиях, участие в них и статистических расчетах является для меня совершенно новой задачей. Так что считайте меня одной из множества тех, кто ценит Ваш подход к статистике и чувство юмора (оно, определенно, помогает уменьшить страх перед этим предметом). Еще раз спасибо за такое «человеческое» отношение к этой теме. С наилучшими пожеланиями, Памела Грегг (Pamela Gregg), администратор по коммуникациям, Исследовательский институт Университета Дейтона Я подумал, что нужно отправить Вам небольшой позитивный отзыв! Друг заставил меня купить Вашу книгу, когда я учился психологии в колледже. Предназначалась она не для курса по статистике, как Вы могли бы подумать. Он был у нас 2 года назад, и я не вынес из него НИЧЕГО! А приступив к дипломной работе, я стал ощущать легкое (а честно говоря, огромное) беспокойство по поводу анализа данных, который мне нужно было сделать. Именно тогда приятель и посоветовал купить Вашу книгу. Моя первая реакция? «Я не собираюсь покупать еще один учебник по статистике просто из любви к искусству!» Что ж, после множества напоминаний я все-таки купил эту книгу (в то время это было второе издание). Сейчас я снова изучаю статистику, но в этот раз, на третьем году аспирантуры, держу Вашу книгу при себе в качестве успокоительного средства! Спасибо за то, что все эти годы делали статистику сносной! – Эшли Шир (Ashley Shier), магистр педагогики, Университет Цинциннати, аспирант школы психологии Привет, д-р Салкинд! Просто хочу поблагодарить Вас за все вложенные в книгу усилия. Я использую ее в своем курсе «Количест­ венные методы исследований в антропологии» в Университете 21 22 Статистика для тех, кто (думает, что) ненавидит статистику Северной Аризоны. Мы по-доброму называем вашу книгу «ненавистной». Еще раз спасибо! – Бриттон Л. Шепардсон, PhD, преподаватель, ассистент кафедры антропологии, Университет Северной Аризоны Примеры Салкинда помогают понять, как правильно использовать ключевые концепции, и успешно сдать тесты. Книга легко читается благодаря разнообразной подаче информации, например блокам с техническими деталями и заметками на память, индексу сложности, различным спискам из «10 вещей», иконкам, рисункам и комиксам. Даже ее название вызывает у студентов смех, а юмор может быть отличным лекарством от стресса! – Мэри Бет Зени (Mary Beth Zeni), Школа сестринского дела, штат Флорида Привет, м-р Салкинд. Мне 19 лет, я работаю медсестрой на полную ставку и недавно приступила к обучению в бакалавриате по специальности «сестринское дело». Завтра у нас первое занятие по статистике. Я только что прочитала ваше обращение к студентам и хочу сказать, что вы описали все до единого мои симптомы. Мы с сокурсниками страшно переживаем по поводу изучения этого предмета и того, что нам предстоит в следующие три месяца. Прочитав эти две страницы, мне захотелось сказать, что вы уменьшили мои опасения. Я могу наконец перестать трястись перед неизвестностью и начать просто читать. Спасибо Вам за это! Сегодня я работаю в ночную смену. Надеюсь, у меня найдется время, чтобы прочитать заданные главы с меньшим волнением и на самом деле усвоить часть изучаемого материала. Спасибо еще раз. Я буду стараться и уже предвкушаю новые знания, которые получу из Вашей книги, от нашего отличного преподавателя и моих сокурсников. С уважением, Лори Вайда (Lori Vajda), медсестра Огромное количество статистической информации было поглощено. – Бельдар с планеты Ремулак Уважаемый проф. Салкинд, хочу поблагодарить Вас за удивительную книгу «Статистика для тех, кто (думает, что) ненавидит статистику». Я точно был одним из тех, кто ненавидит статистику, и до недавних пор игнорировал ее. Однако поскольку я почти заканчиваю аспирантуру, то подумал, что будет стыдно, если у меня не будет хотя бы минимальных знаний в статистике. Книга не только помогла понять предмет, но и вдох- Статистика для тех, кто (думает, что) ненавидит статистику новила меня на дальнейшее чтение. Я даже успел за два дня порекомендовать Вашу книгу нескольким людям! Большое Вам спасибо за такую замечательную работу! – Э. Дж. Пэдман (A. J. Padman) Хочу сказать Вам «спасибо» за то, что написали чрезвычайно дружелюбную по отношению к читателю книгу «Статистика для тех, кто (думает, что) ненавидит статистику». Я учусь на психфаке и на каникулах занимаюсь самостоятельно (у нас в Алверно, для того чтобы начать изучать экспериментальную психологию – предмет, который я хочу взять этой весной, нужно сдать статистику). Другими словами, я довольно много изучаю ее сама (с небольшой помощью от ментора), поэтому очень рада, что у меня есть книга, где весь материал изложен в простой, а порой даже юмористической манере. Могу лишь предложить написать еще один учебник по статистике более высокого уровня, чтобы я могла прочитать и его тоже! С искренним уважением, Дженни Сосерман (Jenny Saucerman) Мне понравился юмористический подход, который точно помогает снизить статистическую тревожность. Еще один плюс книги – это привлекательное и успокаивающее оформление. Стиль автора великолепен, а подача информации подходит моим студентам. Веселая и хорошо написанная книга, которую легко читать и использовать и которая доходчиво подает информацию о статистике. Несомненно, рекомендую ее. – Миньцзюань Ван (Minjuan Wang), Государственный университет Сан-Диего Позвольте поблагодарить Вас за удивительный учебник. Среди всех пособий, которые я использовала в эти годы, Вашему я бы присудила первое место за понятную и легко усваиваемую подачу материала. – Кэролин Летше (Carolyn Letsche), студентка магистратуры по социальной педагогике Книга Салкинда – единственная в своем роде. Ее с легкостью можно назвать лучшей книгой такого типа среди тех, которые мне встречались. С большим энтузиазмом рекомендую ее всем, кто интересуется предметом, и даже (в особенности) тем, кому он не интересен! – Расс Шафер-Ландау (Russ Shafer-Landau), Университет Висконсина «Статистика для тех, кто (думает, что) ненавидит статистику» – это, определенно, нужная книга для тех, кому приходится преодоле- 23 24 Статистика для тех, кто (думает, что) ненавидит статистику вать знакомое чувство тревоги, открывая обычную книгу по статис­ тике, и для тех, кто, преодолев его, все равно не может увидеть в ней никакого смысла. Книгу Салкинда легко и приятно читать, и вряд ли потребуется какое-то предварительное знание предмета, чтобы следовать за ходом мыслей автора. Салкинду удалось разъяснить ста­ тистику людям, которые ее ненавидят или думали так раньше. Из обзора в журнале «Статистические методы в медицинских исследованиях» (Statistical Methods in Medical Research). – Д-р Андреа Винклер (Dr. Andrea Winkler), Бетлемская королевская больница, Лондон, Великобритания Археологи раскапывают первое издание «Статистики для тех, кто (думает, что) ненавидит статистику» Обращение к студентам: почему я написал эту книгу С 26 помощью этого нового издания (теперь уже шестого по счету) я надеюсь обогатить ваш опыт обучения. Меня переполняет восторг от возможности продолжать дорабатывать эту книгу, и я надеюсь, что она принесет вам такое же удовольствие, какое приносит мне. Что объединяет множество людей, изучающих вводный курс в статистику (будь то новички в этой области или те, кто просто освежает в памяти материал)? Это, по крайней мере в начале обучения, довольно высокий уровень беспокойства, которое чаще всего основывается на услышанном от старших товарищей. Некоторая часть того, что они слышали, правдива. Ведь изучение статистики требует затрат времени и усилий (и иногда преподаватель оказывается сущим монстром). Но большая часть того, что они услышали (и что вызывает тревогу), не соответствует действительности. Так, нельзя согласиться с тем, что статистика невыносимо сложна и запутана. Тысячи напуганных студентов достигли успеха в том, в чем, по их мнению, должны были потерпеть поражение. Им это удалось, потому что они не спешили, последовательно изучали предмет, видели, как его основ­ные принципы применяются в реальной жизни, и даже получали некоторое удовольствие в процессе. Это то, чего я хотел добиться первыми пятью­изданиями «Статистики, для тех, кто…» и к чему я стремился еще сильнее, работая над текущим изданием. В результате большого количества проб и ошибок, нескольких удачных и множества неудачных попыток и многочисленных отзывов от студентов и преподавателей всех уровней образования я решил попробовать учить статистике так, чтобы она перестала, по моему (и множества моих студентов) мнению, пугать и стала полезной. Я сделал все, от меня зависящее, чтобы вложить весь этот опыт в данную книгу. Из нее вы узнаете все необходимое, чтобы понять, чем занимается и что изуча­ет базовая статистика. Вы познакомитесь с основ- Статистика для тех, кто (думает, что) ненавидит статистику 27 ными понятиями и наиболее часто применяемыми техниками организации и осмысления данных. В ней совсем немного теории (но кое-какая имеется) и доказательств или выводов, обосновывающих математические процедуры. Почему же в «Статистике для тех, кто…» нет теории и прочего? Очень просто. Прямо сейчас она вам не нужна. Дело даже не в том, что она неважна. Скорее, в данный момент обучения хочу предложить вам материал на том уровне, который, как я думаю, будет вам понятен и который вы сможете освоить, приложив разумные усилия. При этом он не отвратит вас от выбора дополнительных курсов по статистике в будущем. Мы с вашим преподавателем хотим, чтобы у вас все получилось. Так что, если вы ищете подробный разбор того, как выводится анализ отклонений по критерию Фишера, лучше найдите другую хорошую книгу от издательства SAGE (я с радостью посоветую вам, какую именно). Но если вы хотите узнать, почему и как статистика может быть полезной для вас, то вы попали, куда нужно. Эта книга поможет вам понять материал в научных статьях, объяснит, что означают результаты статистического анализа, и научит вас выполнять основные статистические операции. Если вы хотите поговорить о любом аспекте изучения статистики, не стесняйтесь обращаться ко мне. Это можно сделать по электронной почте: njs@ku.edu. Желаю удачи! И дайте мне знать, как еще можно улучшить эту книгу, чтобы она отвечала потребностям начинающего студента. А если вам нужны файлы с данными, которые помогут в изучении статистики, или сходите на сайт издательства SAGE edge.sagepub.com/salkind6e, или свяжитесь со мной по элект­ ронной почте и скажите, какое издание вы используете. И ( НЕБОЛЬШАЯ ) ЗАМЕТКА Д ЛЯ ПРЕПОДАВАТЕЛЯ Мне хотелось бы сказать вам две вещи. Во-первых, я аплодирую вашим усилиям по обучению основам статистики. Несмотря на то что для некоторых студентов предмет может быть очень простым, у большинства он вызывает существенные трудности. Ваше терпение и упорный труд заслуживают уважения. Если я могу что-то сделать, чтобы помочь вам, пожалуйста, дайте мне знать об этом. Во-вторых, «Статистика для тех, кто…» задумана не как упрощенная донельзя книга, каких вы, наверное, уже много видели. В ее названии нет ничего, кроме отображения того факта, что многие начинающие изучать предмет студенты очень беспокоятся, как все получится. Это не академическая или учебная версия пособий для начинающих. Я приложил все усилия, чтобы обращаться к студентам с уважением, которого они заслуживают, не покровительствовать им и сделать материал доступным для понимания. Насколько 28 Статистика для тех, кто (думает, что) ненавидит статистику я в этом преуспел, судить вам, но хочу еще раз подчеркнуть, что в этой книге содержится вся информация, необходимая для вводного курса. И даже если мой подход содержит в себе толику юмора, то в моих намерениях нет ничего несерьезного. Спасибо! Благодарности В се работники издательства SAGE заслуживают огромной благодарности за их поддержку и профессионализм. Существующую еще в зародыше идею (задолго до появления первого издания) они воплощают в книгу, подобную той, что вы сейчас читаете, а затем делают ее успешной. Эта книга была бы невозможна без тяжелой работы всех сотрудников издательства, начиная с Джонни Гарсиа (Johnny Garcia), который руководит распределительным центром, и заканчивая Ванессой Вондресса (Vanessa Vondressa), управляющей финансами. Однако некоторых людей необходимо поблагодарить отдельно за их особую заботу и упорный труд. Хелен Сэлмон (Helen Salmon), старший выпускающий редактор секции «Методы исследования и статис­ тика», пестовала это издание, оставаясь на постоянной связи для обсуждения новых идей и следя за тем, чтобы все было сделано вовремя и как следует. Она именно тот редактор, о котором мечтает каждый автор. С. Дебора Лафтон (C. Deborah Laughton), Лиза Куэвас Шоу (Lisa Cuevas Shaw) и Вики Найт (Vicki Knight) – все предыдущие редакторы – помогали этой книге на всем ее пути, и им я безмерно благодарен. Другие, заслуживающие отдельного упоминания, люди – это Кейти Анчета (Katie Ancheta), ответственный редактор; Челси Пирсон (Chelsea Pearson), помощник редактора; Либби Ларсон (Libby Larson), старший редактор по производству. Особую благодарность хочу выразить Пауле Флеминг (Paula Fleming) за острый взгляд и четкую корректуру, которые сделали этот материал таким легкочитаемым. Либби и Паула – лучшие во всей галактической империи. Отдельное спасибо д-ру Патрику Аменту (Dr. Patrick Ament) из Университета Цент­рального Миссури, который вместе с очень способными студентами выделил время и прислал мне подробный список опечаток, новых предложений и пр. Все это сделало данное издание более точным и полным, чем предыдущее. Спасибо Патрику и его студентам. Издательство SAGE хотело бы поблагодарить ряд рецензентов за их вклад в редактирование книги. Признательности заслуживают: 29 30 Статистика для тех, кто (думает, что) ненавидит статистику zz Чарльз Е. Баукал младший (Charles E. Baukal Jr.), Университет Оклахомы; zz Майкл Е. Кокс (Michael E. Cox), онлайн-преподаватель, мно­ жество университетов; zz Джонатан Аллен Кринген (Jonathan Allen Kringen), Университет Нью-Хейвена; zz Тим В. Фиклин (Tim W. Ficklin), Университет Шаминада в Гонолулу; zz Цинвэнь Дун (Qingwen Dong), Тихоокеанский университет; zz Шарль Ж. Фонтен (Charles J. Fountaine), Университет Миннесоты, Дулут; zz Де’Арно Де’Арман (De’Arno De’Armond), Техасский университет A&M; zz Лаура Андерсон (Laura Anderson), школа сестринского дела, Университет Баффало; zz Джордан К. Аквино (Jordan K. Aquino), Университет штата Калифорния, Фуллертон. А теперь о шестом издании… В се, что вы прочитали об этой книге выше, отражает мои мысли о том, почему я вообще написал эту книгу, но мало рассказывает о шестом ее издании. Работа над любой книгой не заканчивается никогда, и самое свежее издание «Статистики для тех, кто (думает, что) ненавидит статистику» не является исключением. За прошедшие 17 или около того лет одни люди говорили, как полезна эта книга, а другие советовали мне, что они хотели бы в ней изменить и почему. Работая над этим изданием, я старался пойти навстречу нуждам всех читателей. Некоторые вещи остались прежними, а другие действительно изменились. Всегда появляются новые моменты, на которые стоит обратить внимание, и новые способы подачи старых тем и идей. Вот список того нового, что вы найдете в шестом издании «Статистики для тех, кто (думает, что) ненавидит статистику»: zz информация об уровнях измерения была перенесена из главы 6 в главу 2, поскольку там она оказалась более к месту, а многие студенты и преподаватели согласились, что это хорошее решение; zz в главы 10–17 я добавил новый раздел «Понимаем результаты в SPSS», который, надеюсь, дает полезную информацию о пакете SPSS Statistics1 и результатах его работы; zz там, где необходимо, к описанию каждой статистики вывода был добавлен раздел о величине эффекта (начиная с главы 10). Это оказалось очень важной информацией даже для вводного уровня; zz в главу 5 добавилось обсуждение частичной корреляции; zz была написана новая глава (глава 19) в качестве введения в интеллектуальный анализ данных (data mining) с помощью SPSS. 1 SPSS – это зарегистрированный товарный знак корпорации IBM. 31 32 Статистика для тех, кто (думает, что) ненавидит статистику Это мини-подход к огромной теме, но он, по крайней мере, дает начинающим студентам представление о ее сущест­ вовании и помогает осознать ее важность для дальнейшего обучения; zz и наконец, в конце каждой главы стало примерно на 20 % больше дополнительных упражнений. Шестое издание опирается на SPSS 23, последнюю версию, доступную на данный момент. В большинстве случаев для работы можно использовать все версии SPSS, начиная с 11, и эти ранние версии могут читать файлы, созданные в более поздних. Если читателю нужна помощь с SPSS, то в приложении А предложен мини-курс, который также доступен онлайн. zz Возможно, самое интересное (и, наверное, крутое) в этом издании то, что оно доступно в виде интерактивной электронной книги. Интерактивная электронная версия включает в себя множество обучающих и содержательных функций, например ссылки на все: анимированные выводы по главам, обзоры книг, видеоролики с пошаговыми инструкциями для многих описанных здесь процедур, а также практические задания. Это не просто файл бумажного издания в формате .pdf, а насыщенная медийная версия с множеством интерактивных приемов, которые помогут вам извлечь максимум информации из учебника. Мы все надеемся, что вы будете от нее в таком же восторге, как и ее создатели, и что она поможет вам лучше понимать материал. В печатной и цифровой версиях текста вы увидите интерактивные иконки электронной книги. В последней все эти иконки являются ссылками на мультимедийный контент. Многие из этих ресурсов также доступны на открытом сайте издательства SAGE edge.sagepub. com/salkind6e. Ниже приведены обозначения иконок: Видео Интернет-сайт Статья в журнале SAGE Все опечатки и подобные им ошибки в этом издании являются полностью моей виной, поэтому приношу извинения преподавателям и студентам, которым они доставляют неудобство. Я очень ценю любые сообщения, звонки и электронные письма, указывающие на эти ошибки. Мы все очень старались исправить в этом издании предыдущие ошибки, и я надеюсь, что мы хорошо над этим поработали. Если у вас есть предложения, замечания, приятные пожелания и пр., дайте мне знать. Удачи! Нил Дж. Салкинд Университет Канзаса njs@ku.edu Предисловие от издательства ОТЗЫВЫ И ПОЖЕЛАНИЯ Мы всегда рады отзывам наших читателей. Расскажите нам, что вы думаете об этой книге – что понравилось или, может быть, не понравилось. Отзывы важны для нас, чтобы выпус­кать книги, которые будут для вас максимально полезны. Вы можете написать отзыв на нашем сайте www.dmkpress.com, зайдя на страницу книги и оставив комментарий в разделе «Отзывы и рецензии». Также можно послать письмо главному редактору по адресу dmkpress@gmail.com; при этом укажите название книги в теме письма. Если вы являетесь экспертом в какой-либо области и заинтересованы в написании новой книги, заполните форму на нашем сайте по адресу http://dmk­press.com/authors/publish_book/ или напишите в издательство по адресу dmkpress@gmail.com. СПИСОК ОПЕЧАТОК Хотя мы приняли все возможные меры для того, чтобы обеспечить высокое качество наших текстов, ошибки все равно случаются. Если вы найдете ошибку в одной из наших книг – возможно, ошибку в основном тексте или программном коде, – мы будем очень благодарны, если вы сообщите нам о ней. Сделав это, вы избавите других читателей от недопонимания и поможете нам улучшить последующие издания этой книги. Если вы найдете какие-либо ошибки в коде, пожалуйста, сообщите о них главному редактору по адресу dmkpress@gmail.com, и мы исправим это в следующих тиражах. 33 34 Статистика для тех, кто (думает, что) ненавидит статистику НАРУШЕНИЕ АВТОРСКИХ ПРАВ Пиратство в интернете по-прежнему остается насущной проблемой. Издательства «ДМК Пресс» и SAGE очень серь­езно относятся к вопросам защиты авторских прав и лицензирования. Если вы столкнетесь в интернете с незаконной публикацией какой-либо из наших книг, пожалуйста, пришлите нам ссылку на интернет-ресурс, чтобы мы могли применить санкции. Ссылку на подозрительные материалы можно прислать по адресу электронной поч­ты dmkpress@gmail.com. Мы высоко ценим любую помощь по защите наших авторов, благодаря которой мы можем предоставлять вам качественные материалы. Об авторе Нил Дж. Салкинд получил степень PhD в области развития человеческих ресурсов в Университете Мэрилэнда, и после 35 лет преподавания в Университете Канзаса он остается почетным профессором кафедры психологии и исследований в образовании, на которой продолжает сотрудничество с коллегами и ведет работу со студентами. Его ранние интересы лежали в сфере детского когнитивного развития, и после исследований в этой области (изучения того, что тогда было известно как гиперактивность) он стал постдокторантом по детской и семейной политике в Центре Буша в Университете Северной Каролины. Тогда направление его работы изменилось. Он сконцентрировался на детской и семейной политике, особенно на изучении влияния альтернативных форм общественной поддержки на различные перспективы развития детей и семьи. Нил Дж. Салкинд написал и подготовил более 150 профессиональных статей и презентаций, написал более 100 учебников и научно-популярных книг. Он является автором таких из них, как «Статистика для тех, кто (думает, что) ненавидит статистику» (издательство SAGE), «Теории человеческого развития» (издательство SAGE) и «Изучая исследования» (издательство Prentice Hall). Нил Дж. Салкинд был редактором нескольких энциклопедий, включая «Энцик­лопедию человеческого развития», «Энциклопедию измерений и статистики» и «Энциклопедию проектирования исследований». В течение 13 лет он работал редактором журнала «Child Development Abstracts and Bibliography» («Реферативного журнала по детскому развитию»). Сейчас автор проживает в Лоуренсе, штат Канзас, и любит читать, плавать с командой «River City Sharks», работать в качестве единственного сотрудника (и одновременно владельца) маленькой винтажной типографии, печь брауни (см. рецепт в приложении F) и ковыряться в старых вольво и старых домах. 35 ЧАСТЬ I Ура! У меня статистика Что же это, если не существенное подмножество нашей учебной группы?! 37 38 Статистика для тех, кто (думает, что) ненавидит статистику Х отите сказать, что нечему тут радоваться? Позвольте отвлечь вас на минутку и показать, как некоторые известные ученые используют этот широко применяемый набор инструментов под названием «статистика». zz Мишель Лампл (Michelle Lampl) – медик, профессор антропологии ка­фед­ры им. Самуэля Кандлера Доббса и содиректор Института предиктивной медицины Университета Эмори. Однажды за чашечкой кофе подруга Мишель заметила, как быстро растет ее младенец. На самом деле она сказала, будто ребенок «растет, как трава». Будучи любознательной (как и положено всем ученым), д-р Лампл подумала, что действительно может проверить скорость роста этого и других детей в период младенчества. Она начала ежедневно измерять рост группы детей и обнаружила, к своему огромному удивлению, что некоторые младенцы вырастали за ночь на целый дюйм. Вот уж точно скачок роста! Хотите узнать больше? Почему бы не обратиться к оригиналу? Узнать подробности можно в работе Lampl M., Veldhuis J. D. & Johnson M. L. Saltation and stasis: A model of human growth. Science, 1992. Р. 801–803. zz Сью Кемпер (Sue Kemper) – заслуженный профессор психологии в Университете Канзаса, работала над самыми интересными проектами. Вместе с другими исследователями она изучала группу монахинь и проверяла, как влияют их жизненный опыт, деятельность, характеристики личности и другие факторы на здоровье в пожилом возрасте. Особенно примечательно, что эта разномастная группа ученых (включая психологов, лингвистов, неврологов и др.) хотела узнать, насколько вся эта информация поможет предсказать вероятность болезни Альцгеймера. Кемпер и ее коллеги обнаружили, что то, насколько сложные тексты могли писать монахини в возрасте 20 лет, было связано с риском болезни Альцгеймера через 50, 60 и 70 лет. Хотите узнать больше? Почему бы не обратиться к оригиналу? Узнать подробности можно в работе Snowdon D. A., Kemper S. J., Mortimer J. A., Greiner L. H., Wekstein D. R. & Markesbery W. R. Linguistic ability in early life and cognitive function and Alzheimer’s disease in late life: Findings from the nun study. Journal of the American Medical Association, 1996. Р. 528–532. zz Алета Хьюстон (Aletha Huston) – заслуженный почетный профессор из Университета Техаса в Остине. Она посвятила большую часть своих трудов изучению влияния телевидения на психологическое развитие маленьких детей. Среди прочего она и ее ныне покойный муж Джон С. Райт (John C. Wright) проверяли, как может воздействовать количество просмотренных дошкольником образовательных телепрограмм на результаты Часть I Ура! У меня статистика обучения в старших классах. Профессор обнаружила убедительные доказательства того, что дети, смотревшие образовательные программы типа «Мистер Роджерс» и «Улица Сезам», успевали в школе лучше, чем те, кто их не смотрел. Хотите узнать больше? Почему бы не обратиться к оригиналу? Узнать подробности можно в работе: Collins P. A., Wright J. C., Anderson R., Hus­ton A. C., Schmitt K. & McElroy E. Effects of early childhood media use on adolescent achievement. Paper presented at the biennial meeting of the Society for Research in Child Deve­ lopment. Washington, DC, 1997. У всех этих исследователей был интересующий их вопрос, и они использовали интуицию, любопытство и отличное образование, чтобы найти на него ответ. В исследованиях они применяли набор инструментов, который мы называем статистикой, для того чтобы выявить закономерности в собранной ими информации. Без этих инструментов вся информация была бы просто набором разрозненных результатов. Они никак не помогли бы Мишель Лампл прийти к выводам о динамике роста детей, Сью Кемпер с их помощью не могла бы ничего узнать о старении и когнитивной функции (и, возможно, о болезни Альцгеймера), а Алета Хьюстон и Джон Райт не смогли бы на их основании понять влияние просмотра телепрограмм на достижения и социальное развитие детей. Статистика – наука об организации и анализе информации для облегчения ее понимания – сделала все эти задачи решаемыми. Причина, по которой любые результаты подобных исследований оказываются полезными, заключается в том, что с помощью статистики мы можем извлечь из них смысл. Именно в этом и состоит цель книги. Она предназначена для того, чтобы помочь вам понять эти базовые инструменты и принципы их применения и, конечно, научить пользоваться ими. В первой части «Статистики для тех, кто (думает, что) ненавидит статистику» вы узнаете, в чем состоит изучение статистики и почему стоит потратить усилия, чтобы освоить ее азы (важную терминологию и основополагающие идеи этой области). Эта часть даст вам надежную базу для изучения остальной книги. 39 1 Статистика или садистика? Вам решать Уровень сложности: (очень легко) В ЭТОЙ ГЛАВЕ ВЫ УЗНАЕТЕ: чем занимается статистика; почему вам стоит ей заняться; как успешно пройти этот курс. ПОЧЕМУ СТАТИСТИКА? Вы все это слышали раньше, верно? «Статистика – это сложно». «Невозможно понять всю эту математику». «Я не знаю, как пользоваться компьютером». «Зачем мне все это нужно?» «Что мне делать дальше?» И знаменитый крик слушателя начального курса статистики: «Я ничего не понимаю!» Не переживайте. Любой человек, начинающий изучать статистику, рано или поздно думает о чем-то подобном. Вполне возможно, он делится этими мыслями с сокурсниками, супругом, коллегой или друзьями. Если честно, некоторые курсы статистики легко можно назвать «садистикой». Это все оттого, что книжки бесконечно занудны, а у их авторов нет никакого воображения. Но это не ваш случай. Тот факт, что вы или ваш преподаватель выбрали эту книгу, означает, что вы готовы ступить на другой путь – тот, на котором нет места страхам, где все понятно, применимо на практике (и даже немного весело), и на котором вас пытаются нау- Введение в главу 1 41 Часть I 42 Вам решать чить тому, что нужно знать об использовании статистики в качестве ценного метода, каковым она и является. Если вы работаете с этим учебником на занятиях, это также означает, что преподаватель однозначно на вашей стороне. Он или она знает, что статистика может пугать, но они предприняли меры для того, чтобы эта наука не напугала вас. Собственно, могу поспорить, что есть большая вероятность (хотя в это и трудно поверить), что всего через несколько недель вам понравятся эти занятия. И почему SPSS? На протяжении всей книги вы будете наблюдать примеры анализа данных при помощи SPSS, специального инструмента статистического анализа. Не стоит волноваться: вы также увидите, как проводить тот же самый анализ вручную, чтобы наверняка понять оба способа. Почему SPSS? Очень просто. Это один из самых популярных и самых мощных аналитических инструментов, доступных сегодня. Он может принести бесценную пользу для изучения применения базовой и продвинутой статистики. Фактически многие вводные курсы по статистике используют SPSS в качестве основного средства расчетов, и вы можете заглянуть в приложение А, чтобы освежить свои знания об основных задачах SPSS. К тому же, учитывая скорость развития технологий, вероятно, почти во всех случаях, когда придется прибегнуть к статистике в исследованиях, управлении или ежедневной работе, вам потребуются и некоторые знания о том, как и когда нужно применять инструменты, подобные SPSS. Именно поэтому включаем его в эту книгу! Мы покажем, как можно пользоваться им, чтобы сделать ваше обучение еще лучше. ПЯТИМИНУТКА ИСТОРИИ СТАТИСТИКИ Почему статистика важна Прежде чем продолжить чтение, будет полезно взглянуть на историю того, что называется статистикой. В конце концов, почти каждый студент бакалавриата по социальным, поведенческим и биологическим наукам и каждый слушатель магистратуры по педагогике, сестринскому делу, психологии, социологии, социальной работе, антропологии и… (в общем, вы представляете) обязан изучить этот предмет. Разве не будет приятно получить некоторое представление о том, откуда он взялся? Конечно, будет. Давным-давно, как только человечество осознало, что умение считать является очень практичным (как в случае «Сколько вот этого нужно, чтобы обменять на одну штуку вон того?»), сбор информации стал очень полезным навыком. По отношению к счету это означало, что человек мог узнать, сколько раз взойдет солнце в течение одного Глава 1 Статистика или садистика? сезона, сколько еды нужно, чтобы пережить зиму, и какое количест­ во ресурсов кому принадлежит. Это было только начало. Как только цифры стали частью языка, оказалось, что следующим шагом можно привязать их к результатам. По-настоящему этим занялись в XVII в., когда были собраны первые наборы данных, относящихся к населению. В это время ученым (в основном математикам, а потом физикам и биологам) потребовалось разработать специальный инструментарий для того, чтобы отвечать на конкретные вопросы. Например, Фрэнсис Гальтон (Francis Galton) (кстати говоря, троюродный брат Чарльза Дарвина), живший в 1822–1911 гг., очень интересовался природой человеческого интеллекта. Он также предполагал, что причиной выпадения волос было интенсивное расходование энергии на размышления. Конечно, это не так. Однако вернемся к статистике. Для того чтобы изучить один из главных вопросов о сходстве интеллекта внутри семьи, он применил специальный статистический инструмент, называющийся коэффициентом корреляции и впервые разработанный математиками, а затем популяризовал его использование в поведенческих и социальных науках. Вы узнаете об этом инструменте в главе 5. На самом деле большинство базовых статистических процедур, которые вы изучите, было впервые разработано для применения в сельском хозяйстве, астрономии и даже политике. Использовать для изучения поведения человека их стали гораздо позже. За прошедшие 100 лет были предприняты шаги по изобретению новых способов применения старых идей. Простейшая проверка различия между средними величинами у двух групп впервые появилась в начале XX в. Десятилетия спустя были предложены методики, основанные на этой идее, а затем они были существенно улучшены. Появление персональных компьютеров и программ (например, Excel) открыло всем желающим возможность использовать сложные методы расчетов. Появление этих мощных персональных компьютеров было одновременно и благом, и злом. Благом это можно считать потому, что для большого количества статистических расчетов теперь не требуется доступ к огромному и дорогому суперкомпьютеру. Вместо этого простой персональный компьютер стоимостью меньше 250 долл. или облачное приложение может сделать 95 % того, что хотят 95 % людей. С другой стороны, недостаточно образованные студенты (вроде ваших сокурсников, которые отказались от этого курса) берут любые старые данные и думают, что, подвергнув их какому-нибудь сложному анализу, они получат надежные, достойные доверия и значимые результаты. А это не так. Как говорит ваш профессор: «Мусор на входе, мусор на выходе». Если вы начинаете работу с ненадежных и недостоверных данных, то после их анализа получите ненадежные и недостоверные результаты. 43 Часть I 44 Хорошие идеи и их источники Вам решать Сегодня статистики, работающие в разных областях – начиная от криминалистики, продолжая геофизикой и заканчивая психологией и выяснением того, действительно ли в NBA у кого-то есть «счастливая рука» (я не шучу – прочитайте статью в «Уолл Стрит Джорнал» по ссылке http://www.wsj.com/articles/SB10001424052702304071004579409071015 745370), – обнаруживают, что используют одни и те же фундаментальные методы, чтобы получить ответы на разные вопросы. Конечно, есть существенные различия в том, каким образом собираются данные, но в большинстве случаев следующая за сбором данных аналитическая работа оказывается практически одинаковой, даже если называется по-разному. Какой будет вывод? Этот курс даст вам инструменты для понимания и применения статистики в практически любой области. Довольно круто, и всего лишь за три или четыре кредита. Если вы хотите узнать больше об истории статистики и посмот­ реть на временную шкалу, то начать можно с сайтов колледжа св. Ансельма www.anselm.edu/homepage/jpitocch/biostatshist.html и Университета Калифорнии www.stat.ucla.edu/history. Что же, 5 мин истекли, и вы теперь знаете все необходимое об истории статистики. Давайте перейдем к тому, что же это такое. ЧЕМ ( НЕ ) ЯВЛЯЕТСЯ СТАТИСТИКА Статистика полезна «Статистика для тех, кто (думает, что) ненавидит статистику» – книга об основах статистики и их применении во множестве различных ситуаций, включая анализ и понимание информации. В более широком смысле статистика описывает набор инструментов и методов, которые применяются для описания, организации и интерпретации информации или данных. Такими данными могут быть баллы за тест, написанный учащимися специализированной математической школы, скорость решения проблем, количество случаев побочных эффектов у пациентов, получающих одно лекарство, количество ошибок в каждом периоде игры в первенстве по бейсболу или средняя стоимость ужина в люксовом ресторане в Санта-Фе, штат Нью-Мексико (не низкая). Во всех этих примерах и во множестве других, которые можно придумать, мы собираем, организуем, обобщаем, а затем интерпретируем данные. В этой книге вы узнаете о сборе, организации и обобщении данных в рамках описательной статистики. А затем, когда познакомитесь с приемами инференциальной статистики, вы научитесь интерпретировать данные. Что такое описательная статистика? Описательная статистика занимается организацией и описанием характеристик совокупности данных. Эта совокупность иногда называется набором данных или данными. Глава 1 Статистика или садистика? 45 Например, в списке ниже вы видите имена 22 студентов колледжа, их основную специальность и возраст. Если бы вам нужно было описать самую популярную специальность, вы могли бы воспользоваться неким количественным показателем, чтобы выделить наиболее часто встречающийся вариант (этот показатель называется модой). В нашем случае самая популярная специальность – это психология. А если бы вы хотели узнать средний возраст студентов, то легко бы рассчитали другой количественный показатель для данной переменной (этот показатель носит название «средняя»). Оба этих простых показателя описывают данные. Они отлично справляются со своей работой, позволяя нам увидеть характеристики больших наборов данных (например, состоящих из 22 элементов, как в нашем примере). Статистика вокруг нас Таблица 1.1 Список студентов колледжа Имя Ричард Сара Андреа Стивен Джордан Пэм Майкл Лиз Николь Майк Кент Специальность Педагогика Психология Педагогика Психология Педагогика Педагогика Психология Психология Химия Сестринское дело История Возраст 19 18 19 21 20 24 21 19 19 20 18 Имя Элизабет Билл Хэдли Баффи Чип Гомер Маргарет Кортни Леонард Джеффри Эмили Специальность Английский язык Психология Психология Педагогика Педагогика Психология Английский язык Психология Психология Химия Испанский язык Возраст 21 22 23 21 19 18 22 24 21 18 19 Так что смотрите, как все просто. Для того чтобы найти наиболее часто выбираемую специальность, просто определите ту, что встречается чаще всего. А для того, чтобы найти средний возраст, просто сложите все значения возраста и разделите их на 22. И вы окажетесь правы: самая выбираемая специальность – это психология, а средний возраст студентов – 20,3 (точнее, 20,27). Смотри, мам! Я уже настоящий статистик! Инференциальная статистика (или статистика вывода) часто (но не всегда) становится следующим методом, который требуется пос­ ле сбора и обобщения данных. Инференциальная статистика позволяет на основании небольшой группы данных (например, группы из 22 студентов) сделать выводы о возможно большей группе (например, обо всех учащихся в Колледже искусств и наук). Меньшая группа данных часто называется выборкой, и она является частью либо подмножеством генеральной совокупности, или может, лучше как можно большей??? Что такое инференциальная статистика? Часть I 46 Вам решать популяции. Например, все пятиклассники города Ньюарк (родного города автора книги), расположенного в штате Нью-Джерси, составят популяцию, т. е. все случаи с определенными характеристиками (в нашем примере это обучение в 5-м классе и посещение школы в Ньюарке), тогда как отобранные из них 150 учеников будут выборкой. Рассмотрим еще один пример. Маркетинговое агентство просит вас, недавно нанятого исследователя, определить, какое из предложенных названий картофельных чипсов будет наиболее привлекательным. «Чипстерс»? «ФанЧипс»? «Хрустики»? Будучи профи в статистике (да, мы немного забегаем вперед, но нужно верить в себя), вы знаете, что нужно найти небольшую группу потребителей картофельных чипсов, которые были бы похожи на весь подобный контингент, и спросить этих людей, какое из трех названий им нравится больше всего. Тогда, если вы все сделали правильно, можно будет с легкостью экстраполировать результаты на всю огромную совокупность чипсоедов. Или представим, что вас интересует, какое лечение лучше всего справляется с определенной болезнью. Возможно, вы предложите в качестве первого варианта новое лекарство, в качестве второго – плацебо (вещество, которое заведомо не окажет никакого эффекта), а в качестве третьего – отсутствие лечения, и посмотрите, что получится. Предположим, вы обнаружите, что больше всего пациентов выздоровело, когда не было никакого лечения, и что природа (а мы предполагаем, что это единственный фактор или набор факторов, по которым группы отличаются друг от друга) просто взяла свое! Новое лекарство не оказывает никакого эффекта. Зная это, вы сможете экстраполировать результаты своего эксперимента на большую группу всех пациентов, страдающих от этого заболевания. Другими словами… Статистика – это инструментарий, который помогает понять мир вокруг нас. Она структурирует собранную информацию и позволяет нам сделать определенные утверждения, насколько характеристики этих данных будут применимы в новых условиях. Описательная и инференциальная разновидности статистики работают рука об руку, а когда и какой набор инструментов применять, решаете вы в зависимости от вопроса, на который хотите найти ответ. Сегодня знание статистики важно как никогда, потому что она предоставляет нам инструменты для принятия решений, основанных на эмпирических (наблюдаемых) фактах, а не на собственных предубеждениях и верованиях. Хотите знать, работают ли программы раннего вмешательства для детей? Проверьте это экспериментально и предоставьте полученные доказательства, чтобы государство выделило деньги для финансирования этих программ. Глава 1 Статистика или садистика? 47 ЧТО Я ВООБЩЕ ДЕЛАЮ НА КУРСЕ ПО СТАТИСТИКЕ? У вас может быть множество причин для чтения этой книги. Возможно, вы выбрали вводный курс статистики в университете, или освежаете знания перед госэкзаменом, или, может быть, даже чи­ таете ее в период летних каникул (о ужас!), готовясь к более продвинутому курсу. В любом случае вы изучаете статистику независимо от того, придется вам сдавать итоговый экзамен в конце официального курса или нет. Но есть множество отличных причин для ее изучения: и смешных, и серьезных, и полусерьезных. Ниже представлен список некоторых из тех причин, о которых слышат мои студенты в начале вводного курса. 1.Название «Основы статистики» или «Введение в статистику» (или как бы она ни называлась в вашем учебном заведении) отлично выглядит во вкладыше к диплому. Если серьезно, то статистика может быть обязательным предметом в учебном плане, но даже если это не так, обладание статистическими навыками даст вам дополнительное преимущество, когда придет время искать работу или продолжать обучение на более высоком уровне. Если вы прослушаете более продвинутый курс, то ваше резюме будет еще более впечатляющим. 2.Если это необязательный предмет, то тот факт, что вы его пройдете, выделит вас среди остальных. Ваш выбор показывает, что вы готовы приняться за курс, сложность и трудоемкость которого выше среднего. По мере того как политический, экономический (и даже спортивный!) мир становится все более «просчитываемым», больше внимания уделяется аналитическим навыкам. Кто знает, возможно, этот курс станет вашей путевкой на работу! 3.Основы статистики представляют собой интеллектуальный вызов, возможно, непривычного вам типа. Здесь необходимо много думать, немножко считать, а также уметь соединять тео­рию и практику. Суть в том, что все эти действия дают вам в итоге вдохновляющий интеллектуальный опыт, потому что вы в целом узнаете о новой области или предмете. 4.Если вы изучаете социальные или поведенческие науки, то некоторые познания в статистике, несомненно, помогут вам лучше учиться, потому что вы будете лучше понимать не только то, что пишут в научных журналах, но и то, что обсуждают ваши преподаватели и коллеги во время и после занятий. Вы будете поражены, когда впервые скажете себе: «Я и в самом деле понимаю, о чем они говорят!» Это будет происходить снова и снова, потому что вы будете владеть базовыми навы- Карьерные возможности в статистике 48 Часть I Вам решать ками, необходимыми для понимания того, как именно ученые приходят к своим выводам. 5.Если вы планируете продолжать обучение в области педагогики, антропологии, экономики, сестринского дела, социологии или множества других социальных, поведенческих и биологических наук, этот курс даст вам базу, для того чтобы двигаться дальше. Немного статистического юмора 6.Есть множество различных способов для обдумывания и решения всевозможных типов задач. Набор инструментов, с которым вы познакомитесь в этой книге (и на этом курсе), поможет вам посмотреть на интересные задачи с нового ракурса. И хотя это может быть вовсе не очевидно сейчас, но этот новый способ мышления можно будет применять и в новых ситуациях. 7.И наконец, вы сможете хвастаться, что сдали предмет, который, по всеобщему мнению, равен по сложности постройке и запуску ядерного реактора. 10 СПОСОБОВ РАБОТЫ С ЭТОЙ КНИГОЙ ( И ОДНОВРЕМЕННОГО ИЗУЧЕНИЯ СТАТИСТИКИ ) Делайте успехи в статистике Ага. Именно это и нужно миру – еще одна книга по статистике. Но эта отличается от других. Она написана в интересах учащихся, без панибратства, содержит полезную информацию, которая подается максимально просто, к тому же не требует каких-то начальных знаний, а последовательное, пошаговое изложение материала позволяет не терять нити рассуждений. Однако статистика всегда считалась трудным для изучения предметом. И мы не отрицаем, что некоторые ее части вызывают сложность. С другой стороны, миллионы студентов справились с ней, и вы тоже сможете. Для этого в конце вводной главы, прежде чем двинуться дальше, мы предлагаем вам 10 советов. 1. В ы не тупица. Это действительно так. Если бы вы были тупым, то не доучились бы до нынешнего момента. Так что относитесь к статистике так же, как к любому новому курсу. Посещайте лекции, изучайте материалы, делайте упражнения, предлагаемые в учебнике и на занятиях, и у вас все получится. Ядерные физики знают статистику, но не нужно быть ядерным физиком, чтобы выучить ее. 2. С чего вы взяли, что статистика трудная? Сложна ли статистика? И да, и нет. Если вы послушаете друзей, у которых уже была статистика, но которые не особо ей занимались и не особо успевали, то они, конечно, с готовностью расскажут, как Глава 1 Статистика или садистика? им было сложно и что это был ужас всего семестра, а то и всей их жизни. Но не стоит забывать, что чаще всего мы слышим голоса недовольных. Поэтому мы бы предложили приступать к данному курсу с настроем, что вы подождете и посмотрите, каково это на самом деле, а затем будете судить на основании собственного опыта. А еще лучше – поговорите с несколькими людьми, прослушавшими курс данного предмета, и получите ясное представление от них. Не основывайте свои ожидания на опыте только одного жалобщика. 3. Н е пропускайте занятия – последовательно изучайте главу за главой. «Статистика для тех, кто (думает, что) ненавидит статистику» написана так, что каждая глава дает основу для следующей. Когда вы закончите курс, то, я надеюсь, продолжите пользоваться книгой в качестве справочника. Так, если вам потребуются значения конкретных величин, вы сможете обратиться к приложению B. Если вам будет нужно вспомнить, как рассчитывается стандартное отклонение, то можете заглянуть в главу 3. А сейчас читайте главы в том порядке, как они написаны. Это нормально – иногда заглядывать вперед, чтобы подсмотреть, что там дальше, просто не изучайте более поздние главы, прежде чем освоите предыдущие. 4. С оздайте учебную группу. Это отличный совет и один из самых простых способов добиться успеха в предмете. В начале семестра договоритесь с друзьями или сокурсниками о совместных занятиях. Если у вас нет друзей на этом потоке, заведите их или предложите позаниматься вместе тому, кто точно так же рад оказаться тут, как и вы. Совместные занятия позволят вам помочь другим, если вы знаете материал лучше них, или получить помощь от тех, кто знает больше вас. Назначьте конкретное время для еженедельного часового занятия и делайте упражнения в конце главы или задавайте друг другу вопросы. Занимайтесь так долго, как вам нужно. Совместные занятия – это бесценный способ для лучшего понимания и усвоения материала этого курса. 5. З адавайте вопросы преподавателю и друзьям. Если вы не понимаете, что вам говорят на занятии, попросите преподавателя объяснить еще раз. Не сомневайтесь: если вы не понимаете материал, то, скорее всего, и другие тоже. Чаще всего преподаватели рады вопросам, особенно в том случае, если вы уже прочитали материал перед занятием (при этом ваши вопросы будут хорошо обоснованы и помогут другим ученикам лучше понять предмет). 6. Д елайте упражнения в конце каждой главы. Они основаны на материале и примерах, приведенных в той главе, за которой 49 50 Часть I Вам решать они следуют. Их задача – помочь вам применить на практике понятия, описанные в главе, и почувствовать себя увереннее. Если вы можете дать ответы на задания в конце главы, тогда вы точно на пути к освоению материала, содержащегося в ней. Верные ответы к каждому заданию приведены в приложении D. 7. У пражнения, упражнения и упражнения. Да, это очень старая шутка: «Как попасть в Карнеги Холл? – Репетировать, репетировать и репетировать!» В статистике то же самое. Вы должны использовать то, что выучили, и использовать часто, чтобы овладеть различными понятиями и техниками. Это озна­чает делать задания в конце глав 1–17 и главы 19, а также пользоваться любыми возможностями, чтобы понять то, что вы изучаете. 8. И щите примеры практического применения, чтобы приблизить статистику к жизни. На других занятиях вам, наверное, приходится иногда читать научные статьи, говорить о результатах исследований и в целом обсуждать важность научного метода в вашей специализации. Все это позволяет увидеть, как изучение статистики может улучшить понимание тем для обсуждения вместе с началами статистики. Чем чаще вы применяете новые понятия, тем полнее будет ваше понимание. 9. Ч итайте. Сначала прочитайте заданную главу, потом вернитесь и прочитайте ее более внимательно. Не спеша, пролистайте «Статистику для тех, кто (думает, что) ненавидит статистику» и посмотрите, что там написано в разных главах. Не подгоняйте себя. Всегда интересно знать, какие темы будут дальше, а также полезно заранее ознакомиться с материалом, который будет разбираться на ближайшем занятии. 10. П олучайте удовольствие. Это может показаться странным пожеланием, но все сводится к тому, чтобы вы управляли предметом, вместо того чтобы предмет и его требования управляли вами. Создайте расписание занятий и следуйте ему, задавайте вопросы в классе, считая это интеллектуальное упражнение признаком своего роста. Усвоение нового материала всегда приносит восторг и удовлетворение, ведь это часть человеческой сущности. Вы можете почувствовать это удовлетворение и здесь – просто не запускайте учебу, прилежно выполняйте задания и усердно работайте. Глава 1 Статистика или садистика? 51 О ПИКТОГРАММАХ Пиктограмма – это символ. На страницах «Статистики для тех, кто…» вам встретятся разные пиктограммы. Вот описание того, что они означают. Эта пиктограмма обозначает дополнительную информацию. Иног­да нам может захотеться подробнее рассказать о чем-то или найти этот рассказ. Это гораздо проще делать за пределами основного потока учебного материала. Здесь мы обсуждаем технические вопросы, чтобы дать вам представление о темах, лежащих за границами данного курса. Они могут оказаться интересными и полезными для вас. На протяжении «Статистики для тех, кто…» вы увидите вот такую пиктограмму с лесенкой. Она показывает, что сейчас будет описана последовательность шагов, которая проведет вас по какому-то процессу. Иногда для их выполнения вы будете использовать SPSS. Эти шаги были протестированы и одобрены правительственной комиссией. Это очень симпатичная пиктограмма с бантиком на пальце, но ее основная задача – подчеркнуть наиболее важные моменты из того, что вы только что прочитали. Постарайтесь уделить им пристальное внимание, потому что обычно они являются основными для рассмат­риваемой темы. Приложение А содержит ознакомительный материал о SPSS. Прочитайте это приложение, и вы будете знать все, что вам необходимо, чтобы начать использовать SPSS. Если у вас стоят более ранние версии SPSS (или вы работаете на Mac), этот материал все равно будет вам полезен. Последние версии SPSS для Windows и для Mac почти идентичны и по дизайну, и по функциональности. Приложение B содержит важные таблицы, о которых вы узнаете и которые будете использовать на протяжении всей книги. Выполняя упражнения из этой книги, вы будете пользоваться наборами данных из приложения C. В упражнениях вы встретите ссылки на наборы данных, имеющие названия вроде «Глава 2. Набор данных 1». Все эти наборы приведены в приложении С. Можно или набрать все данные вручную, или скачать их с сайта издателя по адресу edge.sagepub.com/salkind6e, или получить напрямую от автора. Просто пришлите запрос на njs@ku.edu и не забудьте указать, для какого издания вам нужны данные. Приложение D содержит ответы на вопросы в конце каждой главы. В приложении E приведены базовые правила математики для тех, кому не помешает освежить их в памяти. В приложении F лежит тот самый, давно обещанный рецепт брауни (да, наконец-то вы нашли его). Часть I 52 Вам решать К ЛЮЧ К МАРКЕРАМ СЛОЖНОСТИ Для того чтобы немного помочь вам, мы разместили в начале каждой главы индекс сложности. Он немного поднимает настроение перед началом прочтения глав, а также служит полезным индикатором, предупреждающим о том, что вас ждет, и о том, насколько сложны главы по отношению друг к другу. (очень сложно) (сложно) (не очень сложно, но и не очень легко) (легко) (очень легко) ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ Термины, выделенные в тексте жирным, включены в предметный указатель в конце книги. РЕАЛЬНАЯ СТАТИСТИКА Реальная статистика В конце каждой главы, если это применимо, будет появляться реальная статистика, которая, как мы надеемся, проиллюстрирует, каким образом конкретный метод, тест, понятие или какой-то аспект ста­тис­тики применяется в ежедневной жизни ученых, врачей, политиков, чиновников и др. В качестве первого примера посмотрим на очень короткую статью, в которой автор делится информацией о том, что Национальная академия наук (основанная, кстати, в 1863 г.) «должна по запросу любого подразделения правительства проводить исследования, изучение, эксперименты и предоставлять отчеты по любому вопросу науки или искусства». Спустя 50 лет, в 1916 г., это положение привело к формированию Национального научно-исследовательского совета, еще одного федерального органа, который помогает законодателям получать информацию, необходимую для принятия взвешенного решения. Зачастую эта информация принимает форму количественных данных (также называемых статистикой), которые помогают людям оценить альтернативные решения проблем, имеющих широкое влияние на общество. Так что эта статья, так же как и учебник, и предмет, который вы изучаете, показывает, как важно мыслить ясно и полагаться на точные данные для достоверности своих доводов. Хотите узнать больше? Найдите в интернете или библиотеке статью... Cicerone R. The importance of federal statistics for advancing science and identifying policy options. The Annals of the American Acade­my of Political and Social Science, 2010. Р. 25–27. Глава 1 Статистика или садистика? 53 ВЫВОДЫ ПО ГЛАВЕ Было не так уж и плохо, верно? Мы хотим побудить вас продолжать чтение и не беспокоиться о том, что какая-то информация окажется трудной для восприятия, отнимающей время или сложной для применения. Просто читайте по одной главе за раз, как вы только что сделали. Выводы по главе ВРЕМЯ ПРАКТИКИ Поскольку ничто не заменит реальных действий, главы 1–17 и глава 19 будут заканчиваться набором упражнений, которые помогут вам разобрать материал, рассмотренный в главе. Как упоминалось выше, ответы к задачам можно найти в конце книги в приложении D. Например, вот первый набор упражнений (но не ищите на них ответы, т. к. у каждого ответ будет свой, ведь все эти вопросы тесно привязаны к вашему собственному опыту и интересам). 1.Проведите интервью с кем-то, кто использует статистику в своей ежедневной работе. Это может быть ваш советник, преподаватель, исследователь, живущий по соседству, аналитик здравоохранения, маркетолог какой-то компании, городской планировщик и т. д. Спросите его или ее, на что был похож их первый курс по статистике. Узнайте, что этому человеку понравилось, а что нет. Может быть, он может что-то вам посоветовать. И самое главное, спросите этого человека, как он или она использует эти новые для вас навыки в своей работе. 2.Мы надеемся, что вы являетесь участником учебной группы или, если это невозможно, у вас есть приятель по учебе (или даже несколько приятелей), с которым вы можете связаться по телефону, электронной почте, через мессенджер или вебкамеру. Конечно, у вас есть множество друзей на Фейсбуке. Поговорите со своей учебной группой или приятелями о том, что им нравится, не нравится, чего они боятся и т. д. по отношению к курсу статистики. Что у вас общего? В чем заключаются различия? Обсудите с сокурсниками стратегии для преодоления своих страхов. 3.Поищите в местной газете или других публикациях результаты опроса или исследования на любую тему. Обобщите результаты и постарайтесь, насколько можете, описать, как именно исследователи или авторы опроса пришли к своим выводам. Использованные ими методы и ход мысли могут быть очевидными или не очень. Когда вы получите представление о том, что именно они сделали, попробуйте предположить, какими 54 Часть I Вам решать другими способами можно было бы собрать, организовать и обобщить ту же самую информацию. 4.Посетите библиотеку (офлайн или онлайн) и найдите научную статью по своей специальности. Затем выделите в статье раздел (обычно это «Результаты»), где были использованы ста­ тистические процедуры для организации и анализа данных. Вы еще не очень много знаете об их особенностях, но сколько при этом статистических процедур (таких как t-критерий, средняя и расчет стандартного отклонения) вы можете выделить? Можете ли вы сделать следующий шаг и рассказать преподавателю, каким образом результаты соотносятся с исследуемым вопросом или основной темой исследования? 5.Найдите пять веб-сайтов с данными по любой теме и дайте краткое описание того, какой тип информации они предлагают и каким образом она организована. Например, если вы пойдете на сайт, являющийся прародителем всех сайтов с данными, Бюро переписи США (http://www.census.gov), то обнаружите ссылки на сотни баз данных, таблиц и других информативных источников. Попробуйте найти данные и информацию, которые относятся к вашей специальности. 6.Сложное задание на дополнительный балл – найти кого-то, кто использует SPSS для ежедневного анализа данных. Спросите, есть ли в SPSS что-то особенное, выделяющее его среди других инструментов для анализа данных. Вы можете найти таких людей практически везде, начиная с политологов, заканчивая медсестрами, так что не ограничивайте область поиска! 7.Наконец, в качестве последнего из этого набора упражнений придумайте пять самых интересных для вас вопросов в своей специализации или сфере интересов. Постарайтесь задать такие вопросы, для ответа на которые вам понадобилась бы реально существующая информация. Будьте ученым! ЧАСТЬ II ∑игма Фрейд и описательная статистика Да, все проясняется 55 Часть II 56 О ∑игма Фрейд и описательная статистика дна из вещей, которые основатель психоанализа Зигмунд Фрейд довольно хорошо умел делать, – это наблюдение за природой состояния своих пациентов и описание ее. Будучи проницательным наблюдателем, он разработал первую систематизированную и хорошо обоснованную теорию личности. Несмот­ря на то что вы можете сомневаться в правильности его идей, он был хорошим ученым. В начале XX в. курсы по статистике (подобные тому, какой вы сейчас изучае­те) не входили в учебные программы высшего образования. Эта область была относительно новой, а характер научных исследований не требовал той точности, которую набор статистических инструментов вывел на научную арену. Но все изменилось. Теперь цифры имеют значение почти в любой сфере деятельности (о чем также говорил и Фрэнсис Гальтон, изобре­ татель корреляции и троюродный брат Чарльза Дарвина). Этот раздел «Статистики для тех, кто (думает, что) ненавидит статистику» посвящен способам применения статистики для описания и лучшего понимания результатов, после того как информация о них будет сгруппирована. Глава 2 рассказывает о метриках средних значений и о том, как вычисление нескольких различных типов средних дает вам отличную точку данных, описывающую набор величин. Также благодаря этой главе можно узнать, когда какую среднюю применять. Глава 3 завершает рассказ об инструментах для описания наборов данных обсуждением изменчивости, включая стандартное отклонение и дисперсию. Когда вы перейдете к главе 4, то уже будете готовы узнать о том, чем распределения (или наборы данных) отличаются друг от друга и что эта разница означает. Глава 5 разбирается с природой отношений между переменными, а именно с корреляциями. И наконец, глава 6 расскажет вам о том, почему при описании некоторых характеристик эффективных методов измерения важны параметры надежности и обоснованности. Когда вы прочитаете раздел II, то будете отлично подготовлены к пониманию того, какую роль вероятность и предположения играют в социальных, поведенческих и других науках. 2 Серединный мир Вычисление и значение средних Уровень сложности: (довольно легко) В ЭТОЙ ГЛАВЕ ВЫ УЗНАЕТЕ: что такое меры центральной тенденции; как вычислить среднюю для набора данных; как вычислить медиану для набора данных; как вычислить моду для набора данных; что такое шкалы измерений и как они применяются; как выбрать меру центральной тенденции. В ы терпеливо ждали, и вот теперь пришло время начать наконец работу с настоящими живыми данными. Именно этим вы будете заниматься в данной главе. Когда данные собраны, обычно первым шагом становится их организация при помощи прос­тых показателей, описывающих эти данные. Самый простой способ сделать это – посчитать среднее значение, которое может быть нескольких видов. Среднее – это одна величина, которая лучше всего отражает целую группу величин. И не важно, описывает ли эта группа величин количество верных ответов на контрольной по правописанию у 30 пятиклашек, или процент подач у каждого игрока «Нью-Йорк Янки» (который, кстати, был не очень высок в сезоне 2015 г.), или количество людей, которые зарегистрировались как демократы или республиканцы для грядущих выборов. Во всех этих примерах можно обобщить группы данных при помощи среднего. Вы можете рассматривать среднюю как центральную точку или как ось вращения циркулярной пилы. Это точка, в которой все значения в наборе величин приходят в равновесие. Средние, которые также называются мерами центральной тенденции, представлены тремя видами: среднее значение, медиана и мода. Введение в главу 2 57 58 Часть II ∑игма Фрейд и описательная статистика ВЫЧИСЛЕНИЕ СРЕДНЕГО ЗНАЧЕНИЯ Вычисление среднего значения Среднее значение – самый распространенный тип вычисляемого среднего. Это просто сумма всех величин в группе, разделенная на количество этих величин. Да, если у вас есть оценки за контрольную у 30 пятиклашек, вы просто сложите все показатели, а затем разделите сумму на количество учеников, т. е. на 30. Формула для вычисления среднего значения представлена ниже (см. формулу 2.1). (2.1) где буква X с черточкой наверху (произносится как «икс с чертой») – это среднее значение группы величин, или просто среднее; ∑, или греческая буква «сигма» – это знак суммы, который указывает на необходимость сложить все, что следует за ним; x – это каждая отдельная величина в группе величин; n – это размер выборки, для которой вы вычисляете среднее. Для вычисления среднего значения сделайте следующие шаги: 1. Выпишите весь набор величин в один или несколько столбиков. Каждая величина – это x. 2. Вычислите сумму всех величин. 3. Разделите сумму на количество величин. Например, если вам нужно рассчитать среднее количество покупателей в трех магазинах, вы можете вычислить среднее значение. Таблица 2.1 Количество покупателей в магазинах Магазин Лэнхэм Парк Вильямсбург Центральный «Самые плохие» средние Годовое количество покупателей 2150 1534 3564 Среднее количество покупателей в каждом магазине равно 2416 чел. Формула 2.2 показывает, как эта величина была рассчитана при помощи формулы 2.1. (2.2) Если бы вам нужно было вычислить среднее количество учеников в классах с подготовительного по 6-й, вы бы делали то же самое. Глава 2 Серединный мир 59 Таблица 2.2 Количество детей в классе Класс Подготовительный 1 2 3 4 5 6 Количество детей 18 21 24 23 22 24 25 Среднее количество учеников в классе равно 22,43. Формула 2.3 показывает, как эта величина была рассчитана при помощи формулы 2.1. (2.3) Видите, мы же говорили, что это легко. Ничего сложного. zz Среднее значение иногда обозначается буквой M и называется также типичным (или центральным) значением. Если, читая книгу по статистике или отчет об исследовании, вы увидите что-то вроде М = 45,87, то, вероятно, это будет означать, что среднеарифметическое равно 45,87. zz В приведенной формуле маленькая n обозначает размер выборки, для которой рассчитывается среднее. Большая N будет означать размер генеральной совокупности. В некоторых книгах и научных статьях между ними не делают различия. zz Среднее значение выборки – это мера центральной тенденции, которая точнее прочих отражает среднюю всей генеральной совокупности. zz Среднее значение похоже на ось вращения циркулярной пилы. Это самая центральная точка, где сумма всех значений с одной стороны от нее равна сумме всех значений с другой. zz Наконец, плохо это или хорошо, но среднее значение очень чувствительно к экстремальным значениям величин. Экстремальное значение может сместить среднее в ту или иную сторону и сделать его менее репрезентативным для набора величин и менее ценным показателем центральной тенденции. Все это, конечно, зависит от величин, для которых рассчитывается среднее значение. Если у вас есть экстремальные величины, а среднее значение не работает так, как вам хотелось бы, у нас есть решение! Расскажем о нем позже. Часть II 60 ∑игма Фрейд и описательная статистика Среднюю также называют арифметической средней. Кроме нее, есть еще и другие виды средней, о которых вы можете прочитать в различных источниках, например гармоническая средняя. Они применяются в особых случаях и здесь вам не нужны. Если вы хотите быть технически подкованным, то знайте, что арифметическая средняя (та самая, которую мы все это время обсуждали) также определяется как точка, около которой сумма всех отклонений равна 0. Так, если у вас есть значения 3, 4 и 5, среднее для которых равно 4, сумма отклонений вокруг среднего (–1, 0 и +1) равна 0. Помните, что слово «средняя» означает только один показатель, который наилучшим образом представляет набор данных, и что есть еще много других типов средних значений. Какой тип среднего вам использовать, зависит от того, на какой вопрос вы отвечаете и какой тип данных пытаетесь обобщить. Это имеет отношение к шкалам измерения, о которых мы поговорим позже в данной главе. Вычисление взвешенной средней Вы только что увидели примеры расчетов обычной средней. Однако вы можете столкнуться с ситуацией, когда одно и то же значение встречается несколько раз, и тогда вам понадобится рассчитать взвешенную среднюю. Взвешенную среднюю легко посчитать, умножив значения на частоту их появления, сложив все произведения и затем поделив сумму на общее количество случаев. Это удобнее, чем складывать каждую величину по отдельности. Для вычисления взвешенной средней выполните следующие шаги: 1. Запишите все значения выборки, для которой рассчитывается средняя, в приведенную ниже таблицу. 2. Запишите частоту, с которой встречается каждое значение. 3. Перемножьте величины на частоту, как показано в третьем столбике. 4. Просуммируйте все значения в столбце «Значение × частота». 5. Разделите на сумму частот. Например, вот таблица, в которой сгруппированы результаты профессионального тестирования 100 пилотов гражданской авиации. Таблица 2.3 Результаты тестирования пилотов Значение оценки 97 94 92 Частота 4 11 12 Значение × частота 388 1034 1104 Продолжение ⇒ Глава 2 Серединный мир Значение оценки 91 90 89 78 60 (не летайте с этим парнем!) ИТОГО 61 Частота Значение × частота 21 30 12 9 1 100 1911 2700 1068 702 60 8967 Взвешенная средняя равна 8967/100, или 89,67. Вычислять среднюю таким способом гораздо легче, чем вводить 100 различных значений в калькулятор или специальную программу. В основах статистики проводится важное различие между величинами, относящимися к выборке (части генеральной совокупности) и ко всей генеральной совокупности (или популяции) в целом. Для этого статистики прибегают к следующим договоренностям. Для показателей выборки (таких как средняя по выборке) используются латинские буквы. Для параметров генеральной совокупности (таких как средняя по генеральной совокупности) берут греческие буквы. Так, например, среднее значение оценок _ за контрольную у 100 пятиклассников будет обозначаться X 5 , тогда как средняя оценка для генеральной совокупности всех пятиклассников будет обозначаться греческой буквой «мю» – µ5. ВЫЧИСЛЕНИЕ МЕДИАНЫ Медиана – это тоже средняя, только совсем другого рода. Медиана определяется как средняя точка в наборе величин. Это точка, в которой одна половина, или 50 %, значений лежит выше нее, а вторая половина, или 50 %, значений – ниже ее. У медианы есть особые свойства, о которых мы поговорим в этом разделе позже, а пока давайте сосредоточимся на том, как ее вычислить. Для вычисления медианы нет стандартной формулы. Для нахождения медианы выполните следующие шаги: 1. Запишите все величины в порядке от большего к меньшему или от меньшего к большему. 2. Найдите значение в самом центре списка. Это и есть медиана. Например, вот доходы пяти разных домохозяйств: $135 456 $25 500 $32 456 $54 365 $37 668 Вычисление медианы Часть II 62 ∑игма Фрейд и описательная статистика Вот упорядоченный список от большего к меньшему: $135 456 $54 365 $37 668 $32 456 $25 500 В списке пять величин, в самом центре стоит $37 668. Это и есть медиана. А что делать, если количество значений четное? Давайте добавим к нашему списку величину $34 500, чтобы теперь было 6 значений дохода. Вот они отсортированы по убыванию: $135 456 $54 365 $37 668 $34 500 $32 456 $25 500 Когда количество величин четное, медиана – это просто среднее между двумя центральными значениями. В данном случае два цент­ ральных значения – это $34 500 и $37 668. Их среднее значение равно $36 084, и это медиана для шести величин. Что, если два центральных значения одинаковы, как в следующем наборе данных? $45 678 $25 567 $25 567 $13 234 В этом случае медиана будет такая же, как обе эти центральные величины. В данном примере это $25 567. Если бы у нас был ряд значений, показывающий количество дней, затраченных на реабилитацию после спортивной травмы семью различными пациентами, то числа могли бы выглядеть так: 43 34 32 12 51 6 27 Как и раньше, мы можем отсортировать значения (51, 43, 34, 32, 27, 12, 6), а потом выбрать центральное значение в качестве медианы, которая в данном случае равна 32. Итак, медианное количество дней, затраченных на реабилитацию, равно 32. Глава 2 Серединный мир Если вы знаете о медианах, то должны знать и о процентильных точках. Процентильные точки используются, чтобы определить долю случаев, находящихся до определенной точки в распределении или наборе величин. Например, если величина находится на 75-м процентиле, это означает, что она равна или превышает 75 % других величин в распределении. Медиана также называется 50-м процентилем, потому что это точка, ниже которой находятся 50 % случаев в распределении. Другие процентили также весьма полезны, например 25-й процентиль, часто называемый Q1, и 75-й процентиль, называемый Q3. Что же такое Q2? Конечно, медиана. Вот и ответ на вопрос, который, вероятно, интересовал вас с тех пор, как мы начали говорить про медиану. Зачем использовать медиану вместо среднего? Это нужно делать по одной очень простой причине. Медиана вовсе не чувствительна к крайним значениям, на которые реагирует среднее значение. Когда у вас есть набор величин, в котором одно или несколько значений являются крайними (или экстремальными), медиана лучше обозначает самое центральное значение этого набора, чем любая другая мера центральной тенденции. Да, даже лучше, чем среднее значение. Что мы имеем в виду под «крайним»? Наверное, проще всего представить крайнюю величину как ту, которая очень отличается от группы, в которую она входит. Например, посмотрите на список пяти доходов, с которым мы уже работали раньше (вот он еще раз): $135 456 $54 365 $37 668 $32 456 $25 500 Значение $135 456 сильнее отличается от остальных четырех, чем любая другая величина в наборе. Мы будем считать ее крайней величиной. Лучшим способом проиллюстрировать полезность медианы в качестве меры центральной тенденции будет расчет и средней, и медианы для набора данных, содержащего одно или несколько крайних значений, а затем сравнение, какая из них лучше всего описывает группу. Приступим. Среднее значение пяти величин, приведенных выше, – это сумма всех величин, разделенная на 5, что дает в результате $57 089. С другой стороны, медиана для этого набора равна $37 668. Какое из этих значений лучше описывает группу? Это $37 668, потому что оно явно лежит ближе к центру группы, а мы предполагаем, что «среднее» (в данном случае мы используем медиану в качестве показателя среднего значения) показывает типичное значение или занимает центральное положение в наборе данных. В реальности среднее 63 Часть II 64 ∑игма Фрейд и описательная статистика значение $57 089 оказывается выше второго самого большого числа и не особо типично для этого распределения. Именно по этой причине определенные социальные и экономические показатели (зачастую имеющие отношение к доходу) публикуются с использованием медианы в качестве меры центральной тенденции (например, «Медианный доход средней американской семьи равен…»), вместо того чтобы обобщать данные через среднее значение. В этих данных слишком много крайних величин, которые скосят или существенно исказят то, что является настоящей цент­ ральной точкой в наборе или распределении данных. Вы уже узнали, _что иногда среднее обозначается заглавной буквой M вместо X. Для медианы тоже используются другие обозначения. Нам нравится буква M, но некоторые путаются, что она обозначает, поэтому используют для медианы сокращение Med или Mdn. Пусть это вас не смущает. Просто помните о том, что такое медиана и что она показывает, и вам будет несложно приспособиться к разным символам. Вот еще несколько интересных и важных фактов о медиане: zz в то время как среднее значение – это средняя точка совокупности значений, медиана – это центральная точка набора наблю­дений; zz из-за того что медиана принимает во внимание только количество наблюдений, а не их значения, экстремальные значения (иногда называемые выбросами) на нее не влияют. ВЫЧИСЛЕНИЕ МОДЫ Третья, и последняя, мера центральной тенденции, о которой мы поговорим, мода, является самой обобщенной и наименее точной. Однако она играет очень важную роль в понимании характеристик набора данных. Мода – это значение, которое встречается чаще всего. Для его вычисления нет никакой формулы. Для вычисления моды выполните следующие шаги: 1. Сделайте список всех значений, которые встречаются в распределении. 2. Укажите, сколько раз встречается каждое значение. 3. Определите самое частое значение (оно будет модой). Применение SPSS для описательной статистики Например, опрос 300 человек об их политических предпочтениях может показать следующие результаты (см. табл. 2.4). Мода – это наиболее часто встречаемое значение. В данном примере это «Независимые кандидаты». Это и есть мода этого распределения. Глава 2 Серединный мир 65 Таблица 2.4 Политические предпочтения 300 человек Предпочитаемая партия Демократы Республиканцы Независимые кандидаты Количество раз 90 70 140 Если бы посмотрели на ответы теста, состоящего из 100 вопросов, то мы могли бы обнаружить, что экзаменуемые чаще всего выбирают ответ «А». Данные могли бы выглядеть следующим образом (см. табл. 2.5): Таблица 2.5 Выбор ответов в тесте Выбранный вариант ответа Количество раз A 57 B 20 C 12 D 11 В этом тесте из 100 вопросов с множественным выбором из четырех вариантов (A, B, C и D) ответ А был выбран 57 раз. Этот ответ и есть мода. Хотите знать самую простую и часто совершаемую ошибку при вычислении моды? Она состоит в выборе частоты повторения категории вместо названия категории. Вместо определения того, что модой является категория «Независимые кандидаты» (в нашем первом примере), кто-нибудь может легко прийти к заключению, что модой является число 140. Почему? Потому что человек смотрит на то, сколько раз встречалось значение, а не на само часто встречающееся значение! Эту ошибку очень просто сделать, поэтому будьте начеку, когда вам зададут такой вопрос. Пирожок с двумя начинками Если каждое значение в распределении встречается одинаковое количество раз, то тогда в нем фактически нет ни одной моды. Но если с одинаковой частотой встречается более одного значения, то распределение будет мультимодальным. Например, набор величин может быть бимодальным (с двумя модами), как демонстрирует следующая совокупность данных (см. табл. 2.6): Таблица 2.6 Цвет волос Цвет волос Рыжий Блонд Черный Каштановый Количество случаев (или частота) 7 12 45 45 66 Часть II ∑игма Фрейд и описательная статистика Распределение в примере выше является бимодальным, поскольку частота значений «черный» и «каштановый» одинакова. У вас даже может быть бимодальное распределение, когда моды относительно близки друг к другу, но не совпадают полностью (например, 45 человек с черными волосами и 44 – с каштановыми). Вопрос в том, насколько одно количество случаев отличается от другого? Может ли распределение быть тримодальным? Конечно, это возможно в том случае, когда три значения имеют одну и ту же частоту. Это маловероятно, особенно когда вы имеете дело с большой совокупностью точек данных (или наблюдений), но, определенно, возможно. Настоящий ответ на выделенный выше вопрос состоит в том, что категории должны быть взаимоисключающими, т. е. у вас не может быть одновременно рыжих и черных волос (хотя если осмот­ реться сейчас в аудитории, то вы можете со мной не согласиться). Конечно, вы можете одновременно иметь волосы, выкрашенные в два цвета, но цвет волос каждого человека должен быть учтен только в одной категории. КАК ВЫБРАТЬ НУЖНУЮ МЕРУ ЦЕНТРАЛЬНОЙ ТЕНДЕНЦИИ ( И ВСЕ, ЧТО ВАМ НУЖНО СЕЙЧАС ЗНАТЬ О ШКАЛАХ ИЗМЕРЕНИЯ ) То, какую меру центральной тенденции использовать, зависит от определенных характеристик данных, с которыми вы работаете (особенно от шкалы измерения, в которой эти данные находятся). И эта шкала измерения будет диктовать, какую именно меру цент­ ральной тенденции нужно выбрать. Но давайте на минутку вернемся назад, чтобы убедиться, что мы говорим на одном языке, начиная с представления о том, что же такое измерение. Измерение – это присвоение значений результатам наблюдений в соответствии с набором правил, т. е. все очень просто. В итоге мы получаем разные шкалы, о которых пойдет речь далее, а результат наблюдений – это все то, что нам интересно было измерить, например цвет волос, пол, результаты тестирования или рост. Эти шкалы измерений, или правила, представляют собой определенные уровни, на которых мы наблюдаем результаты. У каждого уровня есть свой набор параметров, и шкалы измерения представлены в четырех видах: номинальная, порядковая, интервальная и пропорциональная. Давайте перейдем к краткому обсуждению всех четырех шкал измерения и приведем примеры, а затем поговорим, как эти шкалы соотносятся с разными мерами центральной тенденции. Глава 2 Серединный мир 67 Хоть розой назови ее, хоть нет: номинальная шкала измерения Номинальная шкала измерения определяется характеристиками результатов наблюдения, которые попадают в один и только один класс или категорию. Например, номинальной переменной может быть пол (женский или мужской), этническая принадлежность (европеец или афроамериканец), а также политические предпочтения (республиканец, демократ или независимый). Переменные номинального уровня – это «имена» (от лат. nominal), и номинальный уровень может быть наименее полным уровнем измерения. Номинальные шкалы измерения имеют взаимоисключающие категории. Например, политическая принадлежность не может быть одновременно республиканской и демократической. Любой порядок подойдет: порядковая шкала измерения Как следует из названия, порядковая шкала измерения имеет дело с порядком, и измеряемой характеристикой является то, в каком порядке находятся объекты. Отличным примером является ранжирование кандидатов на вакансию. Если мы знаем, что Расс – это кандидат № 1, Шелдон – № 2, а Ханна – № 3, то мы имеем дело с порядковой классификацией. Мы не знаем, намного ли выше на этой шкале стоит Расс по отношению к Шелдону, чем Шелдон по отношению к Ханне. Мы знаем только, что лучше быть № 1, чем № 2, а № 2 лучше, чем № 3, но не знаем, насколько. 1 + 1 = 2: интервальная шкала измерения Теперь мы кое к чему подходим. Когда мы говорим об интервальной шкале измерения, оценивание основывается на некотором непрерывном континууме, таком, что мы можем говорить о том, насколько именно высокий результат больше, чем низкий. Например, если в орфографическом тесте вы верно написали 10 слов, то это в 2 раза больше, чем пять правильно написанных слов. Отличительной характеристикой интервальной шкалы является то, что интервалы (или промежутки) между точками на шкале равны между собой. Десять правильных слов на два больше, чем 8, что на три больше, чем 5. Можно ли не иметь ничего? Пропорциональная шкала измерения Что ж, вот небольшая головоломка для вас. Критерии оценки в пропорциональной шкале измерения характеризуются наличием на шкале абсолютного нуля. Он означает отсутствие любого прояв- Часть II 68 ∑игма Фрейд и описательная статистика ления измеряемого признака. В чем состоит головоломка? Есть ли в наших наблюдениях возможность получить отсутствие того, что измеряется? В некоторых областях такое может быть. Например, в физике или биологии у вас может наблюдаться отсутствие характеристики, такое как абсолютный ноль (отсутствие движения молекул) или нулевая освещенность. В социальных и поведенческих науках немного сложнее. Даже если вы получите ноль в том орфографическом тестировании или не ответите ни на один вопрос IQ-теста (на китайском языке), означает ли это, что у вас полностью отсутствуют орфографические или интеллектуальные способности? Подводя итог… Шкалы (или правила) измерения представляют определенные уровни, на которых замеряются наблюдаемые результаты. Подводя итог, мы можем сказать следующее: zz любой результат наблюдения можно задать в одной из четырех шкал измерения; zz шкалы измерения можно расставить в порядке от наименее (номинальной) к наиболее тонко настроенной (пропорциональной); zz чем «выше» находится шкала измерения, тем точнее, детальнее и информативнее собираемые данные. Может быть достаточно того, чтобы знать, что некоторые люди богатые, а некоторые – бедные (и это номинальное, или категориальное, разграничение), но гораздо лучше знать точно, сколько денег они зарабатывают (пропорциональная шкала). Имея всю информацию, мы всегда сможем отделить богатых от бедных, если захотим; zz наконец, более тонко настроенные шкалы содержат все качест­ ва шкал, находящихся под ними. Например, интервальная шкала обладает характеристиками порядковой и номинальной. Если вы знаете, что средний уровень подачи у «Кабс» составляет 0,350, то вам известно, что это на 100 очков лучше, чем у «Тайгерс» (которые выбивают 0,250), но вы также знаете и то, что «Кабс» лучше, чем «Тайгерс» (но не знаете, насколько), и то, что «Кабс» отличаются от «Тайгерс» (но неизвестно, чем именно). Мы определили шкалы измерения и обсудили три меры центральной тенденции, приведя довольно понятные примеры каждой из них. Однако самый важный вопрос все еще остается без ответа: когда же и какую меру использовать? Вообще, выбор меры центральной тенденции зависит от типа описываемых вами данных, что, в свою очередь, означает уровень, на котором данные замеряются. Не вызывает вопросов, что цент­ ральную тенденцию для качественных, категориальных или номинальных данных (таких как расовая принадлежность, цвет глаз, Глава 2 Серединный мир 69 группа доходов, политические предпочтения и район проживания) можно описать только при помощи моды. Например, если вас интересует мера центральной тенденции, описывающая преобладающие политические предпочтения в группе, то вы не можете использовать среднее. Что вообще вы узнаете с его помощью? То, что каждый человек наполовину республиканец? А вот утверждение, что из 300 человек почти половина (140) предпочитает независимую партию, лучше всего опишет значение этой переменной. В общем, медиану и среднюю лучше всего использовать с количественными данными, такими как рост, размер дохода в долларах (не по категориям), возраст, результаты контрольной, время реакции и количество часов, прослушанных для получения диплома. Также будет справедливо сказать, что средняя точнее измеряет центральную тенденцию, чем медиана, а медиана – точнее, чем мода. Это означает, что при всех прочих равных лучше использовать среднюю. И она действительно применяется чаще всего. Однако бывают случаи, когда средняя не подходит в качестве меры центральной тенденции. Это возможно тогда, например, когда мы имеем дело с категориальными или номинальными данными, такими как пациенты на стационарном и амбулаторном лечении. Тогда мы используем моду. Итак, вот три инструкции, которые могут вам помочь. Помните, что всегда могут быть исключения. 1.Используйте моду, когда имеете дело с категориальными данными, чьи значения могут попадать только в один класс (такими как цвет волос, политические предпочтения, место жительства и религия). В подобных случаях эти категории называются взаимоисключающими. 2.Используйте медиану, когда имеете дело с крайними значениями и не хотите исказить средние показатели (как в обычной средней), например как в случае, когда интересующая вас переменная – это доход, выраженный в долларах. 3.Наконец, используйте среднюю, когда имеете дело с данными без крайних значений, которые при этом не являются категориальными (например, с числовой оценкой за тест или количеством секунд, за которое можно проплыть 50 ярдов). ВЫЧИСЛЕНИЕ ОПИСАТЕЛЬНЫХ СТАТИСТИК ПРИ ПОМОЩИ КОМПЬЮТЕРА Если вы этого еще не сделали, то сейчас самое время обратиться к приложению А и ознакомиться с основами работы в SPSS. Потом возвращайтесь сюда. Часть II 70 ∑игма Фрейд и описательная статистика Давайте посчитаем в SPSS некоторые описательные статистики. Набор данных, который мы будем использовать, называется «Глава 2. Набор данных 1» (Chapter 2 Data set 1) и состоит из 20 результатов тес­ тирования на предубеждения. Все наборы данных доступны в приложении C и на сайте издательства SAGE по адресу edge.sagepub.com/ salkind6e. Их также можно получить по запросу на почту автора: njs@ku.edu. В данном наборе используется только одна переменная: Таблица 2.7 Переменная набора данных «Глава 2. Набор данных 1» (Chapter 2. Data set 1) Переменная Определение Prejudice (Предубеждения) Результат тестирования на предубеждения в шкале от 1 до 100 Ниже приведены этапы вычисления мер центральной тенденции, которые обсуждались в этой главе. Попробуйте самостоятельно сделать это, строго соблюдая все этапы. В этом и других упражнениях предполагается, что набор данных уже открыт в SPSS (не важно, вводили вы их или скачали). 1. Выберите в меню Анализ (Analyze) ⇒ Описательные статистики (Descriptive Statistics) ⇒ Частоты (Frequencies). 2. Щелкните 2 раза по переменной «Prejudice», чтобы переместить ее в блок Переменные (Variable(s)). 3. Нажмите на Статистики (Statistics), Таблица, и вы увидите диалоговое окно Частоты: Статистики (Frequencies: Statistics), показанное на рис. 2.1. 4. В блоке Положение центра распределения (Central Tendency) поставьте галочки напротив Среднее значение (Mean), Медиана (Mediana) и Мода (Mode). 5. Нажмите Продолжить (Continue). 6. Нажмите ОК. Выводы SPSS На рис. 2.2 показаны выводы процедур SPSS для переменной Prejudice. В таблице Статистики (Statistics) вы можете увидеть рассчитанные значения среднего, медианы и моды вместе с указанием размера выборки и подтверждением, что ни одни данные не были пропущены. SPSS не использует в выводах такие символы, как X. В выводах также представлены частоты для каждого значения в количественном и процентном выражении, что тоже является полезной описательной информацией. Глава 2 Серединный мир Рис. 2.1 Диалоговое окно SPSS Частоты: Статистики (Frequencies: Statistics) Рис. 2.2 Описательные статистики из SPSS 71 Часть II 72 ∑игма Фрейд и описательная статистика Это немного странно, но если вы выберете в SPSS Анализ (Analyze) ⇒ Описательные статистики (Descriptive Statistics) ⇒ Описательные (Descriptives), вместо того чтобы пойти в Частоты (Frequencies), а затем нажмете Параметры (Options), то там не будет параметра медианы или моды, как можно было бы ожидать, поскольку они тоже являются базовыми описательными статистиками. Какой из этого вывод? Программы статистического анализа обычно отличаются друг от друга, используют разные названия для одних и тех же вещей и разные предположения о том, что где должно находиться. Если вы не можете найти то, что вам нужно, вероятно, оно там есть. Просто продолжайте искать. Не забывайте также пользоваться Помощью (Help) для навигации среди всей этой новой информации, пока не найдете то, что требуется. Читаем выводы SPSS Данный вывод довольно простой и понятный. Среднее значение для 20 переменных равно 84,70 (помните, что шкала возможных значений – от 0 до 100). Медиана, или точка, в которой 50 % всех переменных оказывается выше нее, а 50 % – ниже, равна 87 (что довольно близко к среднему значению), а наиболее час­то встречающийся результат, или мода, равен 87. Вывод SPSS может быть забит информацией или будет показывать только основное. Все зависит от типа выполняемого анализа. В примере выше мы получили только основное, и, честно говоря, именно это нам и требовалось. По мере чтения этой книги вы увидите разные выводы и узнаете, что они означают, но в некоторых случаях обсуждение полного набора информации в выводе совсем не входит в задачи книги. Мы сфокусируемся на выводах, которые имеют прямое отношение к тому, что вы изучаете в главе. РЕАЛЬНАЯ СТАТИСТИКА Больший смысл применение описательных статистик имеет при использовании их в опросах и голосованиях. Таких опросов уже буквально миллионы (как во время любых президентских выборов в США). В своей статье Роджер Моррелл (Roger Morrell) и его коллеги описывают особенности пользования интернетом 550 взрослых нескольких возрастных категорий, включая людей среднего (40–59 лет), раннего пожилого (60–74 лет) и глубоко пожилого возраста (75–92 лет). Получив 71 % откликов, что довольно хорошо, они обнаружили несколько очень интересных (хотя и не сказать, что неожиданных) результатов: zz пользователи интернета имеют явные возрастные и демографические различия; Глава 2 Серединный мир 73 zz пользователи среднего и раннего пожилого возраста схожи в своих интернет-привычках; zz два основных препятствия для пользования интернетом заключаются в отсутствии доступа к компьютеру и недостаточных знаниях об интернете; zz глубоко пожилые взрослые заинтересованы в использовании интернета меньше всех; zz основные вопросы при обучении использованию интернета – это работа с электронной почтой, доступ к медицинской информации и информации о путешествиях для удовольствия. Этот опрос, для обработки которого в основном использована описательная статистика, был проведен почти 20 лет назад, и с тех пор очень многое изменилось. Но причина, по которой мы включаем его в пример реальных данных, заключается в том, что он является хорошей иллюстрацией исторической узловой точки, которую можно использовать для сравнения в будущих исследованиях. Описательные статистики и подобные исследования часто применяются именно в таких целях. Хотите узнать больше? Найдите в интернете или библиотеке статью... Morrell R. W., Mayhorn C. B. & Bennett J. A survey of World Wide Web Use in middle-aged and older adults. Human Factors, 2010. Р. 175–182. Реальная статистика ВЫВОДЫ ПО ГЛАВЕ Независимо от того, насколько вы продвинуты в статистике, почти всегда начнете с простого описания того, что есть. Отсюда происходит важность понимания простой сущности центральной тенденции. Далее мы отправимся к другой важной описательной составляющей – изменчивости, т. е. тому, насколько данные отличаются друг от друга. Это мы изучим в главе 3! Выводы по главе ВРЕМЯ ПРАКТИКИ 1.Вручную посчитайте среднее значение, медиану и моду для следующего набора из 40 результатов контрольной по химии (табл. 2.8). Таблица 2.8 40 результатов контрольной работы по химии 93 94 95 85 99 99 99 86 97 77 76 84 Продолжение ⇒ Часть II 74 91 97 75 78 76 90 77 2. Проблема 2 ∑игма Фрейд и описательная статистика 89 83 94 92 94 79 86 77 80 81 89 96 80 83 87 98 85 94 94 92 81 ассчитайте среднее значение, медиану и моду для следующих Р трех наборов данных (табл. 2.9), приведенных также в файле «Глава 2. Набор данных 2» (Chapter 2. Data set 2). Сделайте это вручную или при помощи программы вроде SPSS. Покажите свои расчеты, а если вы используете SPSS, то распечатайте страницу выводов. Таблица 2.9 Три набора данных из файла «Глава 2. Набор данных 2» (Chapter 2. Data set 2) Набор 1 3 7 5 4 5 6 7 8 6 5 Набор 2 34 54 17 26 34 25 14 24 25 23 Набор 3 154 167 132 145 154 145 113 156 154 123 3.Рассчитайте средние для следующих наборов данных (табл. 2.10), сохраненных так же, как «Глава 2. Набор данных 3» (Chapter 2. Data set 3), при помощи SPSS. Распечатайте страницу выводов. Таблица 2.10 Данные по больнице Количество коек 234 214 165 436 432 342 276 187 512 553 Заболеваемость (на 1000 обратившихся) 1,7 2,4 3,1 5,6 4,9 5,3 5,6 1,2 3,3 4,1 Глава 2 Серединный мир 75 4.Вы менеджер ресторана быстрого питания. Одна из ваших задач – в конце каждого дня сообщать начальнику, какое блюдо продается лучше всего. Используйте свои глубокие знания описательных статистик и напишите один параграф, чтобы рассказать начальнику, что происходило сегодня. Вот данные. Не используйте SPSS для расчета важных величин, лучше сделайте это вручную. Не забудьте приложить к отчету копию ваших расчетов. Таблица 2.11 Продажи ресторана быстрого питания за один день Блюдо Огромный бургер Бэби-бургер Куриные малышки Свиной бургер Бургер «Вкусняшка» Хот-дог Продажи ИТОГО Количество продаж 20 18 25 19 17 20 119 Цена $2,95 $1,49 $3,50 $2,95 $1,99 $1,99 5.Представьте, что вы глава огромной корпорации и планируете расширение. Вам хотелось бы, чтобы новый магазин давал те же результаты, что и остальные три в вашей империи (см. табл. 2.12). Набросайте вручную, каких финансовых результатов вы хотите добиться от нового магазина. И помните: нужно решить, что использовать в качестве среднего: среднее значение, медиану или моду. Удачи, юный джедай! Таблица 2.12 Показатели розничных магазинов Среднее Продажи (тыс. долл.) Кол-во проданных штук Кол-во посетителей Магазин 1 323,6 3454 4534 Магазин 2 234,6 5645 6765 Магазин 3 308,3 4565 6654 Новый магазин 6.Ниже в табл. 2.13 приведены рейтинги (по шкале от 1 до 5) для угощений на вечеринке Суперкубка. Вам нужно решить, какая еда имеет самый высокий рейтинг (5 – победитель, 1 – проигравший). Определите, какой тип среднего использовать и почему. Сделайте это вручную или в SPSS. Таблица 2.13 Рейтинг предпочтений снеков Еда Фанаты Севера Фанаты Востока Фанаты Юга Начос с добавками 4 4 5 Фруктовая кружка 2 1 2 Фанаты Запада 4 1 Продолжение ⇒ Проблема 6 Часть II 76 Еда Острые крылышки Гигантская пицца с доп. начинкой Цыпленок в пиве ∑игма Фрейд и описательная статистика Фанаты Севера Фанаты Востока Фанаты Юга Фанаты Запада 4 3 3 4 3 4 3 5 5 5 5 4 7.При каких условиях вы скорее будете использовать медиану, чем среднее значение в качестве меры центральной тенденции? Почему? Приведите пример двух ситуаций, когда медиана может оказаться полезнее, чем среднее значение. 8.Предположим, вы работаете с набором данных, в котором встречаются сильно отличающиеся (очень большие или очень маленькие по сравнению с остальными) значения. Какой мерой центральной тенденции вы воспользуетесь и почему? 9.Для этого упражнения используйте набор из 16 отсортированных значений, представляющих уровни дохода от $50 000 до $200 000. Какая мера центральной тенденции подойдет лучше всего и почему? $199 999 $98 789 $90 878 $87 678 $87 245 $83 675 $77 876 $77 743 $76 564 $76 465 $75 643 $66 768 $65 654 $58 768 $54 678 $51 354 Проблема 11 10.Используйте данные файла «Глава 2. Набор данных 4» (Chapter 2. Data set 4) и вручную рассчитайте среднее отношение трех групп людей к опыту использования общественного городского транспорта (где 10 – очень положительное, а 1 – отрицательное отношение). 11. Взгляните на следующие цифры, характеризующие продажи пирогов в закусочной «Леди Берд» (табл. 2.14), и определите среднее количество заказов для каждой недели. Глава 2 Серединный мир 77 Таблица 2.14 Данные о продажах пирогов Неделя 1 2 3 4 Шоколадный шелк 12 14 18 27 Яблочный 21 15 14 12 Дуглас Каунти 7 12 21 15 3 Vive la Différence! Понимаем изменчивость Уровень сложности: (довольно легко, но не раз плюнуть) В ЭТОЙ ГЛАВЕ ВЫ УЗНАЕТЕ: что такое изменчивость; как рассчитать диапазон; как рассчитать стандартное отклонение; как рассчитать дисперсию; что общего у дисперсии и стандартного отклонения, а чем они различаются. ПОЧЕМУ ВАЖНО ПОНИМАТЬ ИЗМЕНЧИВОСТЬ? Введение в главу 3 78 В главе 2 вы узнали о разных типах средних показателей, их значении, о том, как их рассчитать и когда использовать. Но когда дело доходит до описания параметров распределения, то средние показатели дают только половину истории. Другая половина – это меры изменчивости. Говоря простыми словами, изменчивость показывает, насколько отдельные данные отличаются друг от друга. Например, следующий набор величин демонстрирует некоторую изменчивость: 7, 6, 3, 3, 1. У данного набора величин такое же среднее значение (4), но меньшая изменчивость, чем у предыдущего: 3, 4, 4, 5, 4. У следующего набора вообще нет изменчивости (значения не отличаются друг от друга), но у него такое же среднее значение, как и у двух других наборов выше: 4, 4, 4, 4, 4. Изменчивость (также называемая разбросом, или рассеянием) может быть представлена как показатель того, насколько различные величины отличаются друг от друга. Еще точнее (может быть, даже проще) изменчивость можно представить как разницу различных величин по отношению к какой-то конкретной величине. Как вы Глава 3 Vive la Différence! 79 думаете, что это может быть за величина? Вместо того чтобы сравнивать величины со всеми значениями в распределении, в качестве базы для сравнения можно взять одно значение. Как вы совершенно верно предположили, это среднее значение. Итак, изменчивость становится мерой того, насколько каждая величина в группе данных отличается от среднего значения. Ниже расскажем об этом подробнее. Помните, что вы уже знаете о вычислении средних: средняя (будь то среднее значение, медиана или мода) отображает величину набора величин. Теперь добавьте сюда новое знание об изменчивости: она показывает, насколько величины отличаются друг от друга. И то, и другое – важные описательные статистики. Вместе они (средняя и изменчивость) могут быть использованы для описания парамет­ ров распределения, показывая, насколько распределения отличаются друг от друга. Для отображения степени изменчивости, разброса или рассеяния в группе величин обычно используются три показателя: диапазон, стандартное отклонение и дисперсия. Давайте посмотрим внимательнее на каждый из них. На самом деле отличие точек данных друг от друга – это цент­ ральный вопрос для понимания и использования базовых статистик. Когда дело доходит до различий между индивидуумами и группами людей (что является основным предметом изучения большинства социальных и поведенческих наук), вся концепция изменчивости становится особенно важной. Иногда ее называют флуктуацией, или лабильностью, или ошибкой, или одним из множества других терминов, но факт в том, что разнообразие придает жизни вкус. То, что отличает одного человека от другого, также затрудняет понимание их поведения (и делает задачу более интересной). Без изменчивости внутри набора данных или между индивидуумами и группами все становится просто скучным. ВЫЧИСЛЕНИЕ ДИАПАЗОНА Диапазон – это самая общая мера изменчивости. Он дает вам представление о том, как далеко друг от друга отстоят величины. Диапазон вычисляется прос­то путем вычитания минимального значения распределения из максимального. В общем, формула для расчета диапазона такова (3.1): r = h – l, (3.1) где r – это диапазон; h – максимальное значение в наборе данных; l – минимальное значение в наборе данных. Возьмем следующий набор величин в качестве примера (расположим их в убывающем порядке): 80 Часть II ∑игма Фрейд и описательная статистика 98, 86, 77, 56, 48. В этом примере 98 − 48 = 50. Диапазон равен 50. В наборе из 500 чисел, максимальное из которых равно 98, а минимальное – 37, диапазон составляет 61. На самом деле есть два вида диапазонов. Один – это исключаю­ щий диа­пазон, который равен разнице между максимальным и минимальным значениями (или h – l) и которому мы только что дали определение. Второй вид диапазона – это включающий диапазон, который равен разнице между максимальным и минимальным значениями плюс 1 (или h – l + 1). Чаще всего в исследовательских статьях вы видите исключающий диапазон, но может применяться и включающий, если исследователю он нравится. Диапазон говорит вам о том, насколько различаются самое большое и самое маленькое значения в наборе данных, т. е. он показывает, насколько велик разброс между минимальной и максимальной точками в распределении. Так что, несмотря на то что диапазон подходит в качестве общего индикатора изменчивости, его не стоит использовать для каких-либо выводов об отличии друг от друга индивидуальных величин. И вы, вероятно, никогда не увидите, чтобы он применялся в качестве единственного параметра изменчивости, а только в ряду с несколькими другими. И это приводит нас к пункту… ВЫЧИСЛЕНИЕ СТАНДАРТНОГО ОТК ЛОНЕНИЯ Теперь мы подобрались к наиболее часто используемому показателю изменчивости – стандартному отклонению. Только задумайтесь о том, что подразумевает этот термин: это отклонение от чего-то (угадайте, чего именно?), которое еще и стандартно. Действительно, стандартное отклонение (обозначается как s или SD) отображает среднюю величину изменчивости в наборе данных. На практике это среднее расстояние от среднего значения. Чем больше стандартное отклонение, тем больше среднее расстояние каждой точки данных от среднего значения распределения, а также тем более изменчив этот набор величин. Итак, какова же логика вычисления стандартного отклонения? Возможно, вы уже предположили, что нужно рассчитать среднее значение набора величин, а затем вычесть из него каждую индивидуальную величину и посчитать среднее значение этих рас­ стояний. Это хорошая мысль. В итоге у вас получится среднее расстояние всех величин до среднего значения. Однако она не сработает (может быть, вы знаете, почему, а мы расскажем об этом чуть ниже). Глава 3 Vive la Différence! 81 Для начала приведем формулу для расчета стандартного отклонения: (3.2) где s – это стандартное отклонение; ∑ – сигма, знак суммы, означающий, что нужно сложить _ все, следующее за ним; X – каждое индивидуальное значение; X – среднее значение всех величин; n – размер выборки. Эта формула находит разницу между каждым индивидуальным _ значением и средней (X – X ), возводит ее в квадрат и складывает их все вместе. Затем сумма делится на размер выборки (минус 1), и из результата извлекается квадратный корень. Как видите (мы упоминали ранее), стандартное отклонение – это среднее отклонение от среднего значения. 1. Запишите все величины. Не важно, в каком порядке они будут записаны. 2. Вычислите среднее значение группы. 3. Вычтите среднее значение из каждой величины. _ 4. Возведите каждую разность в квадрат. Результат запишите в столбец (X – X )2. 5. Просуммируйте все квадраты отклонений от среднего. Как видите, итог равен 28. 6. Разделите сумму на n – 1, т. е. на 10 – 1 = 9, тогда 28/9 = 3,11. 7. Извлеките квадратный корень из 3,11, что равно 1,76. Это и есть стандартное отклонение для этого набора из 10 величин. Вот данные, которые мы используем для иллюстрации пошагового объяснения, как считать стандартное отклонение: 5, 8, 5, 4, 6, 7, 8, 8, 3, 6. _ То, что мы уже сделали, показано в табл. 3.1, где X – X обозначает разницу между данной величиной и средним значением всех величин, которое равно 6. Таблица 3.1 X 8 8 8 7 6 6 5 5 4 3 Расчет отклонения от среднего _ X 6 6 6 6 6 6 6 6 6 6 _ X–X 8 – 6 = +2 8 – 6 = +2 8 – 6 = +2 7 – 6 = +1 6–6 = 0 6–6 = 0 5 – 6 = –1 5 – 6 = –1 4 – 6 = –2 3 – 6 = –3 Со смещением и без Часть II 82 Таблица 3.2 X 8 8 8 7 6 6 5 5 4 3 Сумма ∑игма Фрейд и описательная статистика Расчет квадратов отклонения от среднего _ X–X 8 – 6 = +2 8 – 6 = +2 8 – 6 = +2 7 – 6 = +1 6–6 = 0 6–6 = 0 5 – 6 = –1 5 – 6 = –1 4 – 6 = –2 3 – 6 = –3 0 _ (X – X )2 4 4 4 1 0 0 1 1 4 9 28 Теперь в соответствии с результатами расчета нам известно, что каждая величина этого распределения отличается от среднего значения в среднем на 1,76. Давайте разберемся с тремя важными вопросами, которые улучшат понимание того, что собой представляет стандартное откло­ нение. Во-первых, почему мы просто не сложили все отклонения от среднего? Мы не сделали этого потому, что сумма всех отклонений от среднего всегда равна нулю. Попробуйте сложить отклонения (2 + 2 +2 + 1 + 0 + 0 − 1 − 1 − 2 − 3). Действительно, это лучший способ проверки того, что вы правильно рассчитали среднее значение. Есть еще один тип отклонения, о котором вы можете прочитать. Стоит знать, что оно означает. Среднее отклонение (также называемое средним абсолютным отклонением) – это сумма всех абсолютных отклонений от среднего значения, разделенная на количество значений. Вы уже знаете, что сумма всех отклонений от среднего должна равняться нулю (в противном случае среднее значение рассчитано неверно). Вместо этого возьмите абсо­ лютное значение каждого отклонения (т. е. значение без учета знака). Просуммируйте абсолютные величины и разделите их на количество точек данных. Вы получите среднее отклонение. Так что если у вас есть набор величин, таких как 3, 4, 5, 5, 8, и их арифметическое среднее равно 5, то среднее отклонение – это сумма чисел 2 (абсолютное значение для 5 – 3), 1, 0, 0 и 3, т. е. 6. Затем разделите это на 5 и получите результат 1,2. (Примечание: абсолютное значение числа обычно записывается как число с вертикальными чертами с обеих сторон от него: |5|. Например, абсолютное значение числа –6, или |–6|, равно 6.) Во-вторых, почему мы возводим отклонения в квадрат? Мы делаем это потому, что хотим избавиться от знаков «минус», чтобы при суммировании не получился ноль. Глава 3 Vive la Différence! 83 И наконец, почему в итоге мы извлекаем квадратный корень из результата на шаге 7? Мы делаем это потому, что хотим вернуться к тем же единицам измерения, с которых начинали. Мы возвели отклонения от среднего значения в квадрат на шаге 4 (чтобы избавиться от отрицательных величин), а затем извлекли квадратный корень из их суммы на шаге 7. Почему n – 1? Что не так с просто n? Возможно, вы догадались, почему мы возводим отклонения от среднего в квадрат и с какой целью затем извлекаем квадратный корень из их суммы. Но что насчет вычитания единицы из знаменателя в формуле? Почему мы делим на n – 1 вместо простой понятной n? Хороший вопрос. Ответ состоит в том, что s (стандартное отклонение) – это оценка стандартного отклонения генеральной совокупности, а добиться того, чтобы это была несмещенная оценка, можно только при условии вычитания 1 из n. Вычитая из знаменателя 1, мы искусственно делаем стандартное отклонение больше, чем оно могло бы быть. Зачем нам это нужно? Будучи хорошими учеными, мы являемся консервативными. Это проявляется в том, что если уж нам придется ошибиться (а всегда есть вероятность того, что мы ошибемся), лучше мы сделаем ошибку в сторону завышения стандартного отклонения генеральной совокупности. Деление на меньший знаменатель позволяет нам это сделать. Так что, вместо того чтобы делить на 10, мы делим на 9, или, вместо того чтобы делить на 100, мы делим на 99. Смещенные оценки пригодятся, если вы хотите только описать характеристики выборки. Но если вы собираетесь использовать выборку для оценки параметров генеральной совокупности, то лучше рассчитывать несмещенную статистику. Посмотрите на табл. 3.3, где показано, что происходит с увеличением размера выборки (и приближением ее к размеру генеральной совокупности). По мере роста размера выборки поправка на n – 1 оказывает гораздо меньшее влияние на разницу между смещенной и несмещенной оценками стандартного отклонения (последний столбец в таблице). Таблица 3.3 Смещенные и несмещенные оценки стандартного отклонения Значение числителя Смещенная оценка Несмещенная оценка Размер в формуле стандартного отклонения стандартного отклонения выборки стандартного генеральной совокупности генеральной совокупно­сти отклонения (при делении на n) (при делении на n – 1) 10 500 7,07 7,45 100 500 2,24 2,25 1000 500 0,7071 0,7075 Разница между смещенной и несмещенной оценками 0,38 0,01 0,0004 Часть II 84 ∑игма Фрейд и описательная статистика При всех прочих равных, чем больше размер выборки, тем меньше разница между смещенной и несмещенной оценками стандартного отклонения. Мораль сей басни? При вычислении стандартного отклонения для выборки, которое дает оценку генеральной совокупности, учитывайте: чем ближе размер выборки к размеру генеральной совокупности, тем точнее будет оценка. И что такого? Рассчитать стандартное отклонение очень просто. Но что оно означает? Как мера изменчивости все, о чем оно говорит, так это то, насколько каждая величина в наборе в среднем отклоняется от среднего значения. Но у него есть и практическое применение, которое вы обнаружите в главе 4. Для повышения интереса подумайте вот о чем: стандартное отклонение может помочь при сравнении величин из разных распределений, причем даже когда средние величины и стандартные отклонения различаются. Поразительно! Как вы увидите дальше, это может быть очень интересно. zz Стандартное отклонение рассчитывается как среднее расстояние от среднего значения. Значит, для начала вам нужно будет рассчитать среднее значение в качестве меры центральной тенденции. Не тратьте время, пытаясь рассчитать стандартное отклонение от медианы или моды. zz Чем больше стандартное отклонение, тем больше разбросаны данные, а также тем больше они отличаются друг от друга. zz Так же как и среднее значение, стандартное отклонение чувст­ вительно к экстремальным значениям. Если вы рассчитывае­ те стандартное отклонение выборки и видите экстремальные значения, отметьте этот факт в своем отчете и интерпретации значений данных. zz Если s = 0, в наборе величин нет совсем никакой изменчивости, т. е. все величины абсолютно идентичны по значению. Такое случается крайне редко. Так как же обстоят дела с изменчивостью и ее важностью? Как вы узнали выше, в качестве статистического понятия это показатель рассеивания или того, насколько величины отличаются друг от друга. Но разнообразие действительно придает жизни вкус. Как вы могли уже узнать на занятиях по биологии или психологии или из книг, изменчивость – это ключевой компонент эволюции, поскольку без изменений (которым всегда сопутствует изменчивость) организмы не могут приспосабливаться. Все очень круто. Глава 3 Vive la Différence! 85 ВЫЧИСЛЕНИЕ ДИСПЕРСИИ Встречайте еще одну меру изменчивости и приятный сюрприз. Если вы знаете стандартное отклонение набора величин и умеете возводить числа в квадрат, то можете легко высчитать дисперсию этого самого набора данных. Эта третья мера изменчивости, дисперсия, является просто стандартным отклонением в квадрате. Другими словами, это та же самая формула, которую вы видели раньше, но без квадратного корня (см. формулу 3.2): . (3.3) Если вы возьмете стандартное отклонение и не будете делать последний шаг (извлекать квадратный корень), то получите дисперсию. Другими словами, s2 = s × s, или дисперсия равна стандартному отклонению, умноженному само на себя (или возведенному в квадрат). В примере выше, где стандартное отклонение составляло 1,76 (пос­ ле округления), дисперсия равна 1,7622, или 3,11. В качестве другого примера давайте укажем, что стандартное отклонение набора из 150 величин равно 2,34. Тогда дисперсия будет равна 2,342, или 5,48. Вряд ли вы увидите отдельное упоминание дисперсии или встретите ее в качестве описательной статистики. Это связано с тем, что дисперсию трудно интерпретировать и применить к набору данных. В конце концов, она основана на расчете стандартного отклонения. Но дисперсия важна, поскольку применяется и как концепция, и как практический показатель изменчивости во многих статистических формулах и методах. Вы узнаете о них позже в «Статистике для тех, кто (думает, что) ненавидит статистику». Стандартное отклонение против дисперсии Чем похожи и чем различаются стандартное отклонение и дис­ персия? Они оба являются мерами изменчивости, рассеяния или размаха. Формулы для их расчета очень похожи. Вы всегда видите их в журнальных статьях в разделе «Результаты». В то же время они аболютно различны. Во-первых, что самое главное, стандартное отклонение (из-за того, что мы извлекаем квадратный корень из среднеквадратичного отклонения) измеряется в исходных единицах измерениях, для которых оно рассчитывалось. Дисперсия измеряется в единицах, возведенных в квадрат (из итогового результата квадратный корень не извлекается). Что это означает? Представим, что нам нужно узнать изменчивость для группы производственных рабочих, собирающих печатные платы. Скажем, что в среднем они собирают 8,6 платы за 1 ч, Вычисление стандартного отклонения Часть II 86 ∑игма Фрейд и описательная статистика а стандартное отклонение равно 1,59. Величина 1,59 означает, что в среднем за час собирают среднее количество плат, равное 1,59. Такого рода информация довольно полезна для понимания общей производительности группы. Давайте посмотрим на интерпретацию дисперсии, которая равна 1,592, или 2,53. Это может означать, что средняя разница между выработкой рабочих и средним значением равна примерно 2,53 печатной платы в квадрате. И какой из этих двух показателей более осмысленный? ВЫЧИСЛЕНИЕ МЕР ИЗМЕНЧИВОСТИ ПРИ ПОМОЩИ КОМПЬЮТЕРА Давайте посчитаем какие-нибудь меры изменчивости при помощи SPSS. Будем использовать файл «Глава 3. Набор данных 1» (Chapter 3. Data Set 1). В этом наборе данных одна переменная (табл. 3.4): Вычисление мер изменчивости Таблица 3.4 Определение переменных в файле «Глава 3. Набор данных 1» (Chapter 3. Data Set 1) Переменная ReactionTime (время реакции) Определение Время реакции на касание в секундах Вот шаги для вычисления мер изменчивости, которые мы обсуждали в данной главе. 1. Откройте файл «Глава 3. Набор данных 1» (Chapter 3. Data Set 1). 2. Выберите в меню Анализ (Analyze) ⇒ Описательные статистики (Descriptive Statistics) ⇒ Частоты (Frequencies). 3. Щелкните 2 раза по переменной Prejudice, чтобы переместить ее в блок Переменные (Variable(s)). 4. Нажмите на Статистики (Statistics), и вы увидите диалоговое окно Частоты: Статистики (Frequencies: Statistics). Оно используется для выбора переменных и процедур, которые вы хотите выполнить. 5. В разделе Разброс (Dispersion) отметьте галочкой Стандартное отклонение (Std. deviation). 6. В разделе Разброс (Dispersion) отметьте галочкой Дисперсию (Variance). 7. В разделе Разброс (Dispersion) отметьте галочкой Диапазон (Range). 8. Нажмите Продолжить (Continue). 9. Нажмите ОК. Глава 3 Vive la Différence! 87 Выводы SPSS На рис. 3.1 показаны некоторые выводы процедур SPSS для переменной ReactionTime. Рис. 3.1 Выводы SPSS для переменной ReactionTime Читаем выводы SPSS У нас 30 валидных данных, ничего не было пропущено, стандартное отклонение составляет 0,70255. Дисперсия (или s2) равна 0,494, а диапазон – 2,60. Как вы уже знаете, стандартное отклонение, дисперсия и диапазон – это показатели рассеяния или изменчивости. В случае данных 30 наблюдений стандартное отклонение (наиболее часто используемый показатель из всех) равно 0,703. Мы подробнее рассмотрим применение этой величины в главе 8, а сейчас значение 0,703 отображает среднее расстояние, на котором находится каждая величина от самой центральной точки значений, или среднее значение. Для данных о времени реакции это значит, что в среднем время реакции отклоняется от среднего значения примерно на 0,703 с. Давайте попробуем еще раз на данных под названием «Глава 3. Набор данных 2» (Chapter 3. Data Set 2). В этом наборе данных две переменные (табл. 3.5): Таблица 3.5 Определение переменных в файле «Глава 3. Набор данных 2» (Chapter 3. Data Set 2) Переменная Math_Score Reading_Score Определение Результаты теста по математике Результаты теста на чтение Следуйте тем же путем, что и до того, только на шаге 3 выберите обе переменные (или осуществив двойное нажатие на каждую из них, или выделив их и нажав на стрелочку «перенести»). Больше о мерах рассеяния Эти термины означают одно и то же? Часть II 88 ∑игма Фрейд и описательная статистика Второй вывод SPSS Этот вывод SPSS показан на рис. 3.2, где представлены результаты анализа для двух переменных. У нас 30 валидных данных, ничего не было пропущено, стандартное отклонение для теста по математике составляет 12,36, дисперсия – 152,70, диапазон – 43. Для результатов теста на чтение стандартное отклонение равно 18,70, дисперсия составляет 349,69 (это довольно много), диапазон – 76 (что тоже довольно много и соответствует такой же большой дисперсии). Рис. 3.2 Вывод для переменных Math_Score и Reading_Score Читаем выводы SPSS Как и в случае, показанном на рис. 3.1, интерпретация вывода SPSS довольно простая. В среднем отклонение от среднего для теста по математике равно 12,3. В среднем отклонение от среднего по чтению равно 18,70. Считать эти показатели изменчивости высокими или низкими? Это вопрос, ответить на который можно только с учетом множества факторов, включая объект измерения, количество наблюдений и диапазон возможных значений. Контекст – наше все. РЕАЛЬНАЯ СТАТИСТИКА Если бы вы были кем-то вроде мегафаната статистики, вас бы интересовали свойства мер изменчивости сами по себе. Это то, чем большую часть времени занимаются профессиональные статистики (они смотрят на характеристики, показатели и предположения (и их нарушения) для определенных статистик). Нас больше интересует, как применять эти инструменты, поэтому давайте посмотрим на одно из исследований, которое рассматривает изменчивость в качестве результата. Как вы уже прочитали ранее, изменчивость данных интересна сама по себе, но когда дело доходит до понимания причин изменчивости убедительных результатов и людей, то тема становится особенно интересной. Это именно то, чем занялись Николас Штапельберг (Nicholas Stapelberg) и его коллеги в Австралии, когда посмотрели на изменчи- Глава 3 Vive la Différence! 89 вость пульса в связи с коронарной болезнью сердца. То есть они не напрямую посмотрели на этот феномен, а ввели во множество элект­ ронных баз данных запросы «изменчивость частоты сердцебиения», «депрессия» и «заболевания сердца» и выяснили, что в связи с большинством депрессивных расстройств и коронарной болезнью сердца обнаруживается пониженная изменчивость частоты сердцебиения. Что может быть тому причиной? Исследователи полагают, что оба заболевания нарушают контроль контура обратной связи, который помогает сердцу эффективно работать. Это потрясающий пример того, как изучение изменчивости может быть ключевой точкой исследования, а не просто сопутствующей описательной статистикой. Хотите узнать больше? Найдите в интернете или библиотеке статью... Stapelberg N. J., Hamilton-Craig I., Neumann D. L., Shum D. H. & McCon­ nell, H. Mind and heart: Heart rate variability in major depressive disorder and coronary heart disease – a review and recommendations. The Australian and New Zealand Journal of Psychiatry, 2012. Р. 946–957. Реальная статистика ВЫВОДЫ ПО ГЛАВЕ Меры изменчивости помогают лучше понять, на что похоже распределение точек данных. Эти параметры можно использовать наряду с мерами центральной тенденции для определения различий между распределениями и полного описания того, на что похожа совокупность оценок за тесты, данных о росте или параметрах личности и что отобра­ жают эти отдельные значения. Теперь, когда мы можем думать и говорить о распределениях, давайте изучим способы их рассмотрения. Выводы по главе ВРЕМЯ ПРАКТИКИ 1.Почему диапазон является самым удобным показателем рассея­ ния, но при этом самой неточной мерой изменчивости? Когда бы вы использовали показатель диапазона? 2.Заполните включающие и исключающие диапазоны для сле­ дующих значений (табл. 3.6): Таблица 3.6 Расчет включающих и исключающих диапазонов Максимальное значение 12,1 92 42 7,5 27 Минимальное значение 3 51 42 6 26 Включающий диапазон Исключающий диапазон Часть II 90 ∑игма Фрейд и описательная статистика 3.Почему можно ожидать большей изменчивости при измерении личностных характеристик первокурсников колледжа, чем при измерении роста? 4.Почему стандартное отклонение становится меньше, по мере того как студенты в группе получают более похожие оценки за тест? И почему можно ожидать, что измеряемая изменчивость будет относительно ниже при большом количестве наблюдений, чем при малом? 5.Для следующего ряда данных рассчитайте диапазон, несмещенное и смещенное стандартные отклонения и дисперсию. Сделайте это вручную. 94, 86, 72, 69, 93, 79, 55, 88, 70, 93 Проблема 7 6.Почему в упражнении 5 несмещенная оценка выше, чем смещенная? 7. При помощи SPSS рассчитайте все описательные статистики для следую­щего набора оценок за три теста, написанных в течение семестра (табл. 3.7). У какого теста самая высокая средняя оценка? У какого теста самая маленькая изменчивость данных? Таблица 3.7 Тест 1 50 48 51 46 49 48 49 49 50 50 Оценки за тесты Тест 2 50 49 51 46 48 53 49 52 48 55 Тест 3 49 47 51 55 55 45 47 45 46 53 8.Для следующего набора данных рассчитайте вручную несмещенные оценки стандартного отклонения и дисперсии. 58 56 48 76 69 76 78 45 66 Глава 3 Vive la Différence! 91 9.Дисперсия для набора величин равна 36. Каковы стандартное отклонение и диапазон этого набора? 10.Найдите включающий диапазон, стандартное отклонение выборки и дисперсию выборки для каждого из следующего набора величин: 1) 5, 7, 9, 11; 2) 0,3, 0,5, 0,6, 0,9; 3) 6,1, 7,3, 4,5, 3,8; 4) 435, 456, 423, 546, 465. 11. В этом задании используются данные из файла «Глава 3. Набор данных 3» (Chapter 3. Data Set 3). В наборе данных присутствуют две переменные (см. табл. 3.8). Таблица 3.8 Определения переменных для файла «Глава 3. Набор данных 3» (Chapter 3. Data Set 3) Переменная Height Weight Определение Рост в дюймах Вес в фунтах При помощи SPSS рассчитайте все, какие сможете, параметры изменчивости для веса и роста. 12.Как вы можете узнать, рассчитывает SPSS смещенную или несмещенную оценку стандартного отклонения? 13.Рассчитайте смещенную и несмещенную оценки стандартного отклонения для набора данных о точности, представленного в файле «Глава 3. Набор данных 4» (Chapter 3. Data Set 4). Если можете, используйте SPSS. В противном случае сделайте это вручную. Какая оценка меньше и почему? 14.Стандартное отклонение результатов орфографического теста равно 0,94. Что это означает? Проблема 11 4 Лучше один раз увидеть Уровень сложности: (довольно легко, но не раз плюнуть) В ЭТОЙ ГЛАВЕ ВЫ УЗНАЕТЕ: почему лучше один раз увидеть картинку, чем сто раз услышать; как создать гистограмму и полигон; как понимать разные формы различных распределений; как создавать замечательные графики при помощи SPSS; как создавать разные типы графиков, понимать и применять их. ЗАЧЕМ НУЖНО ИЛЛЮСТРИРОВАТЬ ДАННЫЕ? Введение в главу 4 Интерактивные визуализации 92 В предыдущих главах вы узнали о двух важных типах дескриптивных статистик: мерах центральной тенденции и мерах изменчивости. Оба они предлагают наилучший показатель для описания группы данных (центральная тенденция) и степени различия или рассеяния данных друг от друга (изменчивости). Чего мы не делали ранее, но что будем делать сейчас, так это изучать­, каким образом различия в этих двух мерах приводят к тому, что распределения выглядят по-разному. Цифры (такие как M = 3 и s = 3) могут иметь значение, но визуальное представление гораздо более эффективно для изучения характеристик распределения и параметров любого набора данных. Итак, в этой главе мы узнаем, как визуально представлять распределения величин, а также как использовать разные виды диаграмм для представления разных типов данных. Глава 4 Лучше один раз увидеть 93 ДЕСЯТЬ СПОСОБОВ СДЕЛАТЬ КРАСИВУЮ КАРТИНКУ ( НЕ ЗАВАЛИВАТЬ ГОРИЗОНТ?) Не важно, создаете вы иллюстрации вручную или при помощи компью­терной программы, принципы приличного дизайна остаются одинаковыми. Вот десять из них, чтобы распечатать и повесить их над столом. 1.Минимизируйте графический мусор. «Графический мусор» (близкий родственник «словесного мусора») появляется, когда вы используете все функции, все диаграммы и все параметры компьютерной программы только для того, чтобы перегрузить свои картинки деталями и забить их под завязку ничего не говорящей информацией. Определенно, лучше меньше, да лучше. 2.Планируйте иллюстрации до того, как создавать итоговый документ. Используйте клетчатую бумагу даже в том случае, если вы будете рисовать диаграмму на компьютере. На самом деле просто создайте и распечатайте бумагу с координатной сеткой прямо на компьютере (попробуйте сайт www. printfreegraphpaper.com). 3.Говорите, что вы имеете в виду, и имейте в виду то, что говорите (не больше и не меньше). Ничто не сбивает читателя с толку лучше, чем захламленный (с большим количеством текста и замысловатыми вставками) график. 4.Давайте всему названия, чтобы аудитории все было понятно. 5. Один рисунок должен выражать только одну мысль. 6.Поддерживайте равновесие. При построении диаграммы центрируйте заголовки и обозначения осей. 7.Поддерживайте масштаб диаграммы. Под масштабом имеется в виду соотношение между горизонтальной и вертикальной осями. Оно должно составлять примерно 3 : 4, так что рисунок шириной в 3 дюйма будет иметь высоту, равную 4 дюймам. 8.Лучше проще и меньше. Не усложняйте картинку, но и не делайте ее упрощенной. Передавайте на диаграмме только одну мысль и так ясно, как только возможно, а отвлекающую информацию дайте в сопутствующем тексте. Помните, что график или диаграмма должны быть понятны читателю, даже если он увидит только их и больше ничего. 9.Ограничьте количество используемых слов. Слишком много слов или слишком длинные слова могут отвлечь от визуального сообщения, которое должен передавать ваш график. 10.График сам по себе должен передавать то, что вы хотите сказать. Если это не так, вернитесь к плану и попробуйте снова. Часть II 94 ∑игма Фрейд и описательная статистика ОБО ВСЕМ ПО ПОРЯДКУ: КАК СОЗДАТЬ РАСПРЕДЕЛЕНИЕ ЧАСТОТ Базовый способ визуализации данных состоит в построении распределения частот. Распределение частот – это метод подсчета и представления того, как часто встречаются определенные значения. При создании распределения частот значения обычно группируются в интервалы класса или диапазоны значений. Ниже в табл. 4.1 представлены оценки за проверку понимания текста, на которых будет основываться распределение частот. Таблица 4.1 47 2 44 41 7 6 35 38 35 36 Оценки за проверку понимания текста 10 11 14 14 30 30 32 33 34 32 31 31 15 16 17 16 15 19 18 16 25 25 26 26 27 29 29 28 29 27 20 21 21 21 24 24 23 20 21 20 А вот распределение частот (см. табл. 4.2). Как видите, для каждого диапазона значений подсчитана соответствующая частота. Таблица 4.2 Распределение частот Интервал класса 45–49 40–44 35–39 30–34 25–39 20–24 15–19 10–14 5–9 0–4 Частота 1 2 4 8 10 10 8 4 2 1 Самый классный интервал Как вы видите в табл. 4.2, интервал класса – это диапазон значений. Первый шаг в создании распределения частот состоит в том, чтобы Глава 4 Лучше один раз увидеть определить величину этого интервала. Как видно в созданном нами распределении, в каждый интервал входит 5 возможных оценок, таких как 5–9 (куда входят оценки 5, 6, 7, 8 и 9) и 40–44 (куда входят оценки 40, 41, 42, 43 и 44). Как мы решили, что в нашем интервале будет содержаться только 5 оценок? Почему бы не сделать 5 интервалов по 10 оценок в каждом или 2 интервала по 25? Вот несколько общих правил для создания интервала класса независимо от размера величин в данных, с которыми вы работаете. 1.Выбирайте интервал класса с диапазоном в 2, 5, 10, 15 или 20 точек данных. В нашем примере мы выбрали 5; 2.Выбирайте такой интервал класса, чтобы 10 или 20 подобных интервалов покрывали весь диапазон данных. Это удобно сделать, если вычислить диапазон, а затем разделить его на то количество интервалов, которое вы хотите использовать (между 10 и 20). В нашем примере 50 оценок, и мы хотели получить 10 интервалов: 50/10 = 5, что и стало размером каждого интервала класса. Если бы у вас был набор значений от 100 до 400, можно было бы начать с 20 интервалов и посмотреть, имеет ли получившийся диапазон интервала смысл на ваших данных: 300/20 = 15, так что интервал класса будет равен 15; 3.При записи начинайте указывать интервалы класса с нижней границы. В нашем распределении частот оценок за проверку понимания текста интервал класса равен 5, и мы начали самый нижний интервал с 0; 4.Наконец, самый большой интервал будет наверху распределения частот. Проще говоря, нет жестких правил для создания интервалов класса для распределения частот. Вот шесть общих правил: 1) 2) 3) 4) 5) 6) определите диапазон; определитесь с количеством интервалов; определитесь с размером интервала; определите начальную точку для первого класса; создайте интервалы класса; разместите данные в созданные интервалы. После того как будут созданы интервалы класса, нужно заполнить частоты или распределение частот. Для этого следует посчитать, сколько раз встречаются значения в исходных данных, и внести эти числа в каждый представленный для подсчета интервал. В нашем распределении частот, созданном для оценок за понимание текста, количество значений, попадающих между 30 и 34, а следовательно, и в интервал 30–34, равно 8. Значит, 8 записывается в колонку «Частота». Вот это и есть ваше распределение частот. 95 96 Часть II ∑игма Фрейд и описательная статистика Иногда бывает удобно сначала нарисовать все данные, а затем делать все необходимые расчеты и анализ. Посмотрев на данные, можно получить первое представление об отношениях между переменными, о том, какая дескриптивная статистика лучше всего подойдет для их описания и т. д. Этот дополнительный шаг может углубить ваше понимание и осознание ценности того, что вы делаете. ТЕНИ СГУЩАЮТСЯ: СОЗДАНИЕ ГИСТОГРАММЫ Теперь, когда у нас подсчитано, сколько величин попадает в каждый интервал класса, можно перейти к следующему шагу и создать так называемую гистограмму – визуальное представление распределения частот, в котором частоты показаны в виде столбиков. В зависимости от книги, статьи или отчета, которую вы читаете, и программного обеспечения, которым пользуетесь, визуальное представление данных может называться графиком (как в SPSS) или диаграммой (как Microsoft Excel). На самом деле разницы никакой. Все, что вам нужно знать, – это то, что график или диаграмма является визуальным представлением данных. Для того чтобы создать гистограмму, выполните следующие шаги. 1. На листе клетчатой бумаги на равном расстоянии друг от друга разместите значения по оси x, как показано на рис. 4.1. Теперь определите центр каждого интервала класса, который находится в точке посередине каждого интервала. Это довольно легко сделать на глаз, но можно и просто сложить верхнее и нижнее значения границ интервала и разделить их на 2. Например, центр интервала класса 0–4 – это средняя от 0 и 4, или 4/2 = 2. 2. Нарисуйте над каждым центром столбик, который будет отображать весь интервал класса, с высотой, представляющей частоту этого интервала. Например, на рис. 4.2 вы можете видеть, что первый интервал 0–4 представлен частотой 1 (что означает, что между 0 и 4 было только одно значение данных). Продолжайте рисовать столбики, пока не будут отображены все частоты для всех интервалов. Вот и получилась нарисованная вручную гистограмма для распределения частот 50 оценок, с которой мы все это время работали. Обратите внимание, что каждый интервал класса представлен диапазоном значений по оси x. Глава 4 Лучше один раз увидеть Рис. 4.1 Интервалы класса вдоль оси x Рис. 4.2 Вручную нарисованная гистограмма 97 Часть II 98 ∑игма Фрейд и описательная статистика Метод подсчета Как вы видели на примере простого распределения частот в начале этой главы, оно уже дает вам больше знаний о распределении величин, чем простое их перечисление. Вы видите, какие величины встречаются и с какой частотой. Помимо гистограммы, можно сделать еще одно графическое представление данных, используя счетные штрихи для каждого события, как показано на рис. 4.3. Рис. 4.3 Счетные палочки Мы использовали штрихи, которые соответствуют частоте значений, встречающихся в пределах каждого класса. Это дает даже лучшее визуальное представление о том, как часто по сравнению с другими встречаются определенные значения. СЛЕДУЮЩИЙ ШАГ: ПОЛИГОН ЧАСТОТ Создать гистограмму или подсчитать частоты было несложно, а следующий шаг (и следующий способ иллюстрации данных) еще проще. Мы будем использовать те же самые данные (и ту гистограмму, которая была создана на ваших глазах), для того чтобы создать полигон частот. Полигон частот – это непрерывная линия, которая отображает частоты значений внутри интервала класса, как показано на рис. 4.4. Глава 4 Рис. 4.4 Лучше один раз увидеть 99 Нарисованный от руки полигон частот Как его нарисовать? Вот так: 1) найдите центральную точку на вершине каждого столбика в гистограмме (см. рис. 4.2); 2) соедините точки линией, и полигон частот готов. Обратите внимание, что на рис. 4.4 гистограмма, на базе которой нарисован полигон частот, изображена горизонтальными и вертикальными чертами, а полигон нарисован как плавная линия. Это потому, что хотя мы и хотели показать вам, на основании чего строится полигон, не планировали открывать лежащую под ним гистограмму. Зачем использовать для представления данных полигон частот вместо гисто­граммы? Это больше дело вкуса, чем чего-то еще. Полигон частот выглядит более динамично, чем гистограмма (линия, показывающая изменения частоты, всегда выглядит опрятно), но в целом они передают одну и ту же информацию. Кумулятивная частота После того как вы сформировали распределение частот и представили эти данные визуально при помощи гистограммы или полигона частот, есть еще вариант создать графическое представление накоп­ 100 Данные, повсюду данные Часть II ∑игма Фрейд и описательная статистика ленной частоты случаев по интервалам классов. Оно называется кумулятивным распределением частот. Кумулятивное распределение частот строится на тех же данных, что и распределение частот, но с добавлением еще одного столбца (Накопленная частота), как показано ниже в табл. 4.3. Таблица 4.3 Кумулятивное распределение частот Интервал класса 45–49 40–44 35–39 30–34 25–39 20–24 15–19 10–14 5–9 0–4 Частота 1 2 4 8 10 10 8 4 2 1 Накопленная частота 50 49 47 43 35 25 15 7 3 1 Создание кумулятивного распределения начинается с добавления к таблице частот нового столбика под названием «Накопленная частота». Затем мы складываем частоту, соответствующую данному интервалу класса, со всеми частотами, находящимися ниже. Например, интервалу класса 0–4 соответствует только одно значение, и под ним ничего нет, так что накопленная (или кумулятивная) частота равна 1. В интервале класса 5–9 встречаются два значения данных, а под этим интервалом – еще одно, так что всего будет 3 (2 + 1) случая. Последний интервал класса (45–49) содержит всего одно значение, а в сумме в этом интервале или под ним находится 50 значений. После расчета кумулятивного распределения частот можно нанести данные на график точно так же, как мы делали это для гис­ тограммы или полигона частот. Только в этот раз мы пропустим предварительные шаги и назначим центру каждого интервала класса функцию накопленной частоты этого интервала. На рис. 4.5 вы можете видеть кривую кумулятивного распределения частот (кумулятивную кривую), построенную для 50 величин из начала этой главы. Глава 4 Рис. 4.5 Лучше один раз увидеть 101 Нарисованная вручную кривая кумулятивного распределения частот Другое название для полигона накопленных частот – огива. И если распределение данных является нормальным и похоже на колокол (см. подробности в главе 8), то огива представляет собой широко известную гауссову кривую, или кривую нормального распределения. SPSS рисует отличные огивы. Они называются графиками распределения вероятности, и их легко построить (см. введение в построение графиков в SPSS в приложении А, а также материалы в конце данной главы). ДРУГИЕ К ЛАССНЫЕ СПОСОБЫ ГРАФИЧЕСКОГО ПРЕДСТАВЛЕНИЯ ДАННЫХ До настоящего момента мы в этой главе брали какие-то данные и показывали, как можно визуально представлять их при помощи таких графиков, как гистограммы и полигоны. Но в поведенческих и социальных науках также используют несколько других типов диаграмм. И хотя вам необязательно досконально знать, как их создавать (вручную), вы должны быть знакомы с их названиями и тем, что они показывают. Так что вот несколько популярных диаграмм, их смысл и то, как они его передают. Часть II 102 Моменты ∑игма Фрейд и описательная статистика Есть несколько очень хороших приложений для ПК для создания диаграмм, среди которых находятся редактор электронных таблиц Microsoft Excel (отдельная любовь автора) и, конечно, SPSS. Диаграммы в параграфе «Иллюстрация данных при помощи компьютера» также были созданы с применением SPSS. Столбиковые диаграммы Столбиковые диаграммы нужно использовать, когда вы хотите сравнить частоты различных категорий между собой. Категории перечисляются по горизонтальной оси x, а значения показываются по вертикальной оси y. Вот несколько примеров случаев, когда вам может понадобиться столбиковая диаграмма: zz количество участников в различных видах водного спорта; zz продажи трех разных типов продуктов; zz количество детей в разных параллелях 6-го класса. На рис. 4.6 представлена диаграмма количества участников в различных видах водного спорта. Рис. 4.6 Столбиковая диаграмма, сравнивающая различные виды водного спорта Виды водного спорта по количеству участников 40 Количество 30 20 10 0 Профессиональное плавание Водное поло Плавание Синхронное на открытой воде плавание Виды водного спорта Глава 4 Лучше один раз увидеть 103 Линейчатые диаграммы Линейчатая диаграмма идентична столбиковой, но в ней категории располагаются по вертикальной оси y, а их значения показываются по горизонтальной оси x. Линейные графики Линейные графики нужно использовать, когда вы хотите показать тренд изменения данных на равных интервалах. Вот несколько примеров, когда вам может понадобиться линейный график: zz количество случаев мононуклеоза среди студентов трех государственных университетов по сезонам; zz продажи игрушек в компании «T&K» в четырех кварталах; zz количество путешествующих двумя разными авиалиниями по кварталам. На рис. 4.7 вы можете видеть линейный график продаж в штуках по четырем кварталам. Рис. 4.7 Применение линейного графика для демонстрации тренда в течение времени Продажи в штуках 7000 6000 5000 4000 3000 Первый Второй Квартал Третий Четвертый Часть II 104 ∑игма Фрейд и описательная статистика Круговые диаграммы Круговые диаграммы нужно использовать, когда вы хотите показать долю чего-то в серии точек данных. Вот несколько примеров, когда вам может понадобиться круговая диаграмма: zz доля детей, живущих за чертой бедности, по этнической принадлежности; zz доля студентов, поступивших на дневное и вечернее отделения; zz возраст участников с разделением по полу. Обратите внимание, что круговая диаграмма показывает коли­ чество только для номинальных классов (таких как национальность, вид обучения и пол), которые отображены на ней. На рис. 4.8 вы можете видеть круговую диаграмму предпочтений опрошенных. Мы включили несколько стильных штучек вроде разделения секторов и добавления значений прямо на них. Рис. 4.8 Круговая диаграмма показывает относительную долю категорий Предпочтения опрошенных Отличная куча-мала От безделья сойдет А оно мне надо? Иллюстрация данных при помощи компьютера (т. е. SPSS) Теперь давайте воспользуемся SPSS и пройдем по всем этапам создания некоторых диаграмм, изученных в данной главе. Для начала несколько общих рекомендаций по работе с графиками в SPSS. Глава 4 Лучше один раз увидеть 105 1. У более поздних версий SPSS в меню Графика (Graphs) есть Мастер диаграмм (Chart Builder). Это самый простой способ начать работу, и именно им мы будем пользоваться. 2. Нажмите на Графика (Graphs) ⇒ Мастер диаграмм (Chart Builder), и вы увидите диалоговое окно, в котором нужно выбрать, какой тип диаграммы хотите создать. 3. Щелкните по типу диаграммы, которую вы хотите создать, а затем выберите нужный дизайн этой диаграммы. 4. Перетащите названия переменных на оси, где они должны быть. 5. Нажмите ОК, и вы увидите готовую диаграмму. Давайте потренируемся. Создание гистограммы 1. Введите данные, для которых вы хотите построить диаграмму. 2. Нажмите на Графика (Graphs) ⇒ Мастер диаграмм (Chart Builder), и вы увидите диалоговое окно Мастера диаграмм, как показано на рис. 4.9. Если вы увидите какое-то другое окно, нажмите OK. 3. Щелкните по опции Гистограмма (Histogram) в списке вариантов и два раза щелкните по первому изображению. 4. Перетащите переменную под названием Score на надпись Ось x? (x-axis?) в предыдущем окне. 5. Нажмите ОК, и вы увидите гистограмму, как на рис. 4.10. Гистограмма на рис. 4.10 немного отличается от нарисованной вручную на рис. 4.2 в начале главы, которая отображает те же самые данные. Разница объясняется тем, что SPSS определяет интервалы классов на основании собственной специфической методики. SPSS берет в качестве центра интервала его нижнюю границу (например, 10), а не центральную точку (как 12,5). Следовательно, значения распределяются по разным группам. Какой можно извлечь из этого урок? То, как сгруппированы данные, сильно влияет на то, как они будут выглядеть на гистограмме. А когда вы хорошо узнаете SPSS, то сможете подкручивать любые тонкие настройки, чтобы диаграммы выглядели в точности, как вы того хотите. Создание гистограммы Часть II 106 Рис. 4.9 ∑игма Фрейд и описательная статистика Диалоговое окно Мастера диаграмм Рис. 4.10 Гистограмма, созданная в Мастере диаграмм 10 Количество 8 4 2 1 2 7 12 17 22 27 32 37 Предпочтения проголосовавших 42 47 Глава 4 Лучше один раз увидеть 107 Создание столбиковой диаграммы Для того чтобы создать столбиковую диаграмму, выполните следующие действия. 1. Введите данные, для которых вы хотите построить диаграмму. Мы использовали данные о среднем отношении избирателей к партиям, указанные в табл. 4.4. Таблица 4.4 Данные об отношении избирателей к партиям Республиканцы 54 Демократы 63 Независимые 19 2. Нажмите на Графика (Graphs) ⇒ Мастер диаграмм (Chart Buil­der), и вы увидите диалоговое окно Мастера диаграмм, как показано на рис. 4.11. Если вы увидите какое-то другое окно, нажмите OK. 3. Щелкните по опции Столбцы (Bar) в списке вариантов и 2 раза щелкните по первому изображению. 4. Перетащите переменную под названием Party надпись Ось x? (x-axis?) в предыдущем окне. 5. Перетащите переменную под названием Number на ось с подписью Коли­ чество (Count). 6. Нажмите ОК, и вы увидите гистограмму, как на рис. 4.12. Рис. 4.11 Диалоговое окно Мастера диаграмм Смысл средней величины Часть II 108 ∑игма Фрейд и описательная статистика Среднее значение Avg_Score Рис. 4.12 Столбиковая диаграмма, созданная при помощи Мастера диаграмм 60 40 20 0 Демократическая Независимая Республиканская Партия Создание линейного графика Для того чтобы создать столбиковую диаграмму, выполните следующие действия. 1. Введите данные, для которых вы хотите построить диаграмму. В этом примере мы использовали процент посещения студентов на протяжении 10-летней программы, указанный в табл. 4.5. Таблица 4.5 Создание линейного графика Год 1 2 3 4 5 6 7 8 9 10 Данные о посещаемости студентов Процент посещения 87 88 89 76 80 96 91 97 89 79 2. Нажмите на Графика (Graphs) ⇒ Мастер диаграмм (Chart Builder), и вы увидите диалоговое окно Мастера диаграмм, как показано на рис. 4.11. Если вы увидите какое-то другое окно, нажмите OK. 3. Щелкните по опции Линия (Line) в списке вариантов и 2 раза щелкните по первому изображению. Глава 4 Лучше один раз увидеть 109 4. Перетащите переменную Год на надпись Ось x? (x-axis?) в предыдущем окне. 5. Перетащите переменную Процент посещения на надпись Ось y? (y-axis?). 6. Нажмите ОК, и вы увидите линейный график, как на рис. 4.13. Мы воспользовались редактором графики SPSS, чтобы изменить минимальные и максимальные значения на оси y. Рис. 4.13 Линейный график, созданный при помощи Мастера диаграмм Процент посещения 100 90 80 70 1 2 3 4 5 6 7 8 9 10 Год Создание круговой диаграммы Для того чтобы создать столбиковую диаграмму, выполните следующие действия. 1. Введите данные, для которых вы хотите построить диаграмму. В этом примере круговая диаграмма показывает долю людей, покупающих разные бренды пончиков. Данные представлены в табл. 4.6. 2. Нажмите на Графика (Graphs) ⇒ Мастер диаграмм (Chart Builder), и вы увидите диалоговое окно Мастера диаграмм, как показано на рис. 4.11. Если вы увидите какое-то другое окно, нажмите OK. 3. Щелкните по опции Круговая/Полярная (Pie/Polar) в списке вариантов и 2 ра­ за щелкните по единственному изображению. 4. Перетащите переменную Бренд на надпись Секторы? (Slice by?). 5. Перетащите переменную Процент на надпись Переменная угла? (Angle Variable?). 6. Нажмите ОК, и вы увидите круговую диаграмму, как на рис. 4.14. 110 Часть II Таблица 4.6 ∑игма Фрейд и описательная статистика Любимые бренды пончиков Бренд Krispies Dunks Другие Процент 55 35 10 Рис. 4.14 Круговая диаграмма, созданная при помощи Мастера диаграмм Бренд Dunks Krispies Другие РЕАЛЬНАЯ СТАТИСТИКА Графики работают. Действительно, лучше один раз увидеть, чем сто раз услышать. В этой старой, но хорошей статье исследователи представили информацию, как люди воспринимают и обрабатывают статистические графики. Стивен Левандовски (Stephen Lewandowsky) и Иан Спенс (Ian Spence) провели обзор эмпирических исследований, выяснявших, насколько разные типы диаграмм отвечают своим задачам, а также каким образом наши знания о человеческом восприятии могут повлиять на дизайн и полезность этих графиков. Они сосредоточили внимание на нескольких теоретических объяснениях того, почему работают или не работают определенные элементы, на использовании пиктографических символов (вроде символов довольной рожицы, которые могут складываться в столбики в диаграмме) и на многовариантных представлениях, когда нужно показать более одного набора данных. И, как часто бывает со статья­ ми, они пришли к выводу, что данных пока недостаточно. Принимая во внимание все более визуальный мир, в котором мы живем (эмотиконы, да? ☹😊), можно сказать, что это интересное и полезное чтение для формирования исторического взгляда на то, каким образом обсуждалась и обсуждается информация в научной сфере. Глава 4 Лучше один раз увидеть 111 Хотите узнать больше? Найдите в интернете или библиотеке статью... Lewandowsky S. & Spence I. The perception of statistical graphs. Sociological Methods Research, 2010. Р. 200–242. Реальная статистика ВЫВОДЫ ПО ГЛАВЕ Несомненно, диаграммы весело рисовать. Они могут невероятно помочь пониманию того, что в противном случае могло казаться неорганизованным набором данных. Следуйте нашим инструкциям в главе и грамотно применяйте графики, но только в том случае, когда они действительно добавляют смысла тому, что уже имеется. Выводы по главе ВРЕМЯ ПРАКТИКИ 1.Найдите в приложении C или на веб-сайте набор данных из 50 оценок теста на понимание текста «Глава 4. Набор данных 1» (Chap­ter 4. Data Set 1). Ответьте на следующие вопросы и/или выполните задания: а) создайте распределение частот и гистограмму для этого на­ бора; б) почему вы использовали такой интервал класса? в) является ли данное распределение скошенным? Как вы это поняли? 2.Посмотрите на частотное распределение в табл. 4.7. Нарисуйте для него гистограмму – от руки или в SPSS. Таблица 4.7 Проблема 1 Частотное распределение Интервал класса 261–280 241–260 221–240 201–220 181–200 161–180 141–160 121–140 100–120 Частота 140 320 3380 600 500 410 315 300 200 3.Учительница 3-го класса хочет повысить уровень вовлеченности своих учеников в групповые обсуждения и инструктаж. В течение недели она ежедневно записывает количество ответов каждого из 15 третьеклассников. Эти данные доступны в файле «Глава 4. Проблема 3 112 Проблема 5 Часть II ∑игма Фрейд и описательная статистика Набор данных 2» (Chapter 4. Data Set 2). При помощи SPSS создайте столбиковую диаграмму, где каждый столбик соответствует одному дню (предупреждаем, что это может быть не так просто). 4.Используйте данные о предпочитаемых пирогах из файла «Глава 4. Набор данных 3» (Chapter 4. Data Set 3), чтобы создать круговую («пирожковую» ) диаграмму при помощи SPSS. 5.Определите для каждого случая, какой тип диаграммы (круговую, линейную или столбиковую) вы бы использовали и почему: а)доля студентов 1-го, 2-го, 3-го и 4-го курсов в данном университете; б) изменение температуры в течение 24 ч; в) количество претендентов на четыре разные вакансии; г)процент успешно сдавших экзамен среди всех экзаменующихся; д) количество данных в каждой из 10 категорий. 6. Приведите пример, когда мы бы могли использовать приведенные ниже типы диаграмм. Например, вы бы использовали круговую диаграмму, чтобы показать, какая доля учеников с 1-го по 6-й класс получает льготные обеды. Когда сделаете это, нарисуйте выдуманные графики от руки: а) линейная; б) столбиковая; в) точечная (на более высокую оценку). 7.Найдите в библиотеке научную статью по своей специальности, в которой содержатся эмпирические данные, но отсутствует какая-либо их визуализация. Сделайте график на основании этих данных. Объясните, какой тип диаграммы вы выбрали, а также почему. Можно рисовать вручную, при помощи SPSS или Excel. 8.Нарисуйте самую ужасно выглядящую диаграмму, какую только можете, забитую графическим и текстовым мусором. Ничто не запоминается так хорошо, как плохой пример. 9. Каково назначение графика или диаграммы? 5 Мороженое и преступность Рассчитываем коэффициенты корреляции Уровень сложности: (умеренно сложно) В ЭТОЙ ГЛАВЕ ВЫ УЗНАЕТЕ: что такое корреляция и как она работает; как рассчитать простой коэффициент корреляции; как интерпретировать значение коэффициента корреляции; какие еще существуют типы корреляции и когда они применяются. О ЧЕМ ГОВОРИТ КОРРЕЛЯЦИЯ? Меры центральной тенденции и показатели изменчивости не единственные описательные статистики, которые нас интересуют, чтобы получить полное представление о том, на что похож набор данных. Вы уже узнали, что для описания параметров распределения крайне важно знать показатели одного из наиболее типичных значений (центральную тенденцию) и меру размаха или рассеяния (изменчивости). Однако иногда нас также интересуют отношения между переменными, точнее то, как изменяется значение одной переменной при изменении значения другой. Для определения этого интереса мы рассчитываем простой коэффициент корреляции. Например, каково отношение между возрастом и силой, доходом и образованием, памятью и приемом наркотиков, политическими предпочтениями и взглядами на регулирование? Коэффициент корреляции – это числовой показатель, который показывает отношение между двумя переменными. Значение этой описательной статистики находится в пределах от –1,00 до +1,00. Введение в главу 5 113 114 Часть II ∑игма Фрейд и описательная статистика Корреляцию между двумя переменными иногда называют двумерной корреляцией. Еще точнее, тот тип корреляции, о котором мы будем говорить на протяжении почти всей этой главы, называется линейным коэффициентом корреляции Пирсона (в честь его изобретателя – Карла Пирсона). Коэффициент корреляции Пирсона оценивает отношение между двумя переменными, предполагая, что обе эти переменные непрерывны. Другими словами, они могут принять любое значение внутри некоторого заданного континуума. Примером может служить рост (вы действительно можете иметь рост 5 футов и 6,1938574673 дюйма), возраст, количество баллов за тест или доход. Но есть множество других переменных, которые не являются непрерывными. Они называются дискретными, или категориальными, переменными, а примерами могут служить раса (черная или белая), социальный класс (высокий или низкий) и политическая принадлежность (демократы или республиканцы). В этих случаях нужно использовать другие инструменты, такие, например, как точечно-бисериальная корреляция. Их изучают в более продвинутом курсе, но вы должны знать, что это допус­ тимые и очень полезные инструменты. Мы кратко упомянем их позже в этой главе. Типы коэффициентов корреляции: вкус 1 и вкус 2 Корреляция отражает динамическое качество отношений между переменными. Таким образом, она позволяет нам понять, склонны ли переменные при изменении двигаться в одном или противоположном направлении. Если переменные изменяются в одном и том же направлении, такое отношение называется прямой, или положительной, корреляцией. Если переменные изменяются в противоположных направлениях, такое отношение называется обратной, или отрицательной, корреляцией. В табл. 5.1 показана суть этих отношений. Имейте в виду, что примеры в таблице отображают общие случаи отношений (например, между временем, в течение которого был написан тест, и количеством верных ответов в нем). В общем случае чем меньше было времени, тем ниже будет оценка. Для такого заключения не требуется большого ума, потому что чем быстрее пытаешься отвечать, тем выше вероятность ошибок из-за невнимательности или из-за неверного понимания инструкций к заданиям. Но, конечно, некоторые люди могут отвечать очень быстро и очень хорошо, а другие будут писать очень медленно, при этом их результаты будут далеки от хороших. Смысл в том, что мы считаем корреляцию между двумя переменными для группы, а не для каждого отдельного человека. Глава 5 Мороженое и преступность Таблица 5.1 115 Типы корреляции Что происходит Что происходит Тип корреляции Значение Пример с переменной X с переменной Y X возрастает Y возрастает Прямая Положительное, Чем больше времени вы или положительная от 0 до +1 готовитесь, тем выше будет оценка за контрольную X убывает Y убывает Прямая Положительное, Чем меньше денег вы или положительная от 0 до +1 положите в банк, тем меньше заработаете на процентах X возрастает Y убывает Обратная Отрицательное, Чем больше вы тренируетесь, или отрицательная от –1 до 0 тем меньше вы весите X убывает Y возрастает Обратная Отрицательное, Чем меньше времени вы или отрицательная от –1 до 0 пишете тест, тем больше неверных ответов у вас будет Есть несколько простых (но важных) вещей, касающихся коэффициента корреляции, которые нужно запомнить: zz значение корреляции находится в пределах от –1,00 до +1,00; zz абсолютное значение коэффициента отображает силу корреляции. Так, корреляция с коэффициентом –0,70 сильнее, чем с коэффициентом +0,50. Одна из частых ошибок состоит в предположении студентов, что прямая (или положительная) корреляция всегда сильнее (т. е. лучше), чем обратная (или отрицательная), просто из-за ее знака; zz корреляция всегда описывает ситуацию, в которой присутствуют по меньшей мере два набора данных (или переменных) для каждого случая; zz еще одна частая ошибка состоит в оценочном суждении на основании знака корреляции. Многие студенты предполагают, что отрицательное отношение – это плохо, а положительное – хорошо. Поэтому вместо терминов отрицательная и положительная может быть предпочтительнее использовать термины обратная и прямая, чтобы точнее передавать смысл; zz линейный коэффициент корреляции Пирсона обозначается маленькой буквой r с нижним индексом, указывающим на то, между какими переменными рассчитано отношение. Например: rxy – корреляция между переменными X и Y; rвес-рост – корреляция между весом и ростом; rвступ.выпуск – корреляция между оценками за вступительный экзамен и средним выпускным баллом. 116 Часть II ∑игма Фрейд и описательная статистика Коэффициент корреляции отображает, насколько пересекается степень изменчивости двух переменных, а также что общего есть между ними. Например, вы можете ожидать, что рост человека будет связан с его весом, поскольку у этих двух переменных много общих одинаковых характеристик, таких как питание и перенесенные ранее болезни, общее состояние здоровья и генетика. Однако если значения одной переменной не изменяются, а следовательно, нет ничего общего с другой, тогда корреляция между ними равна 0. Например, если бы вы посчитали корреляцию между возрастом и количеством лет, проведенных в школе, и каждому из опрошенных было бы 25 лет, то между переменными не было бы корреляции, потому что у переменной возраста нет в буквальном смысле ничего (никакой изменчивости), что могло бы стать общим с годами обучения. Точно так же, если вы ограничите диапазон одной переменной, корреляция между ней и другой переменной будет меньше, чем в том случае, когда диапазон не ограничен. Например, если вы считаете корреляцию между пониманием текста и оценками в школе для очень одаренных детей, то обнаружите, что коэффициент будет ниже, чем если бы вы считали такую корреляцию для всех детей вообще. Это связано с тем, что оценки за понимание текста у отличников довольно высоки, но гораздо менее изменчивы, чем оценки всех детей. Какова тут мораль? Если вас интересуют отношения между двумя переменными, постарайтесь собрать достаточно разнородные данные. Таким образом вы получите действительно показательный результат. А как это сделать? Измерять переменную как можно точнее. РАСЧЕТ ПРОСТОГО КОЭФФИЦИЕНТА КОРРЕЛЯЦИИ Формула расчета для простого линейного коэффициента корреляции Пирсона между переменными X и Y приведена в формуле 5.1. Расчет простого коэффициента корреляции (5.1) где rxy – коэффициент корреляции между X и Y; n – размер выборки; xi – индивидуальные значения переменной X; yi – индивидуальные значения переменной Y; xi2 – индивидуальные значения переменной X в квадрате; yi2 – индивидуальные значения переменной Y в квадрате. Данные, которые мы будем использовать, приведены в табл. 5.2. Глава 5 Мороженое и преступность Таблица 5.2 117 Данные для расчета коэффициента корреляции Итого, сумма, или ∑ X 2 4 5 6 4 7 8 5 6 7 54 Y 3 2 6 5 3 6 5 4 4 5 43 X2 4 16 25 36 16 49 64 25 36 49 320 Y2 9 4 36 25 9 36 25 16 16 25 201 XY 6 8 30 30 12 42 40 20 24 35 247 Прежде чем приступать, давайте убедимся в вашем понимании того, что значит каждое обозначение: zz ∑xi, или сумма всех значений X, равна 54; zz ∑yi , или сумма всех значений Y, равна 43; zz ∑x 2, или сумма квадратов всех значений X, равна 320; zz ∑y 2, или сумма квадратов всех значений Y, равна 201; zz ∑(xi ×yi), или сумма всех произведений значений X и Y, равна 247. Легко перепутать сумму значений, возведенную в квадрат, и сумму квадратов значений. Сумма значений, возведенная в квадрат, означает, что мы взяли значения (например, 2 и 3), сложили их (получив 5), а затем возвели сумму в квадрат (что равно 25). Сумма квадратов значений означает, что мы взяли значения (например, 2 и 3), возвели их в квадрат (получив 4 и 9 соответственно), а затем сложили их (получив 13). Просто смотрите на скобки во время вычислений. Для вычисления коэффициента корреляции выполните следующие действия. 1. Напишите список из двух значений для каждой переменной. Это нужно сделать в столбик, чтобы не запутаться. Если вы считаете вручную, делайте это на бумаге в клеточку или используйте SPSS либо любую другую программу для анализа данных.; 2. Посчитайте сумму всех значений X, а затем сумму всех значений Y. 3. Возведите в квадрат все значения X и все значения Y. 4. Найдите сумму всех произведений X и Y. Подставим значения в формулы, как формуле 5.2: (5.2) Расчет корреляции 118 Часть II ∑игма Фрейд и описательная статистика Вы можете видеть ответ в формуле 5.3: (5.3) Что действительно интересно в корреляциях, так это то, что они измеряют расстояние, на котором одна переменная изменяется в соотношении с другой. Так, если обе переменные имеют высокую вариабельность, или изменчивость (у них много значений в широком диапазоне), то корреляция между ними будет скорее высокой, чем низкой. Нельзя утверждать, что большая изменчивость гарантирует высокую корреляцию, поскольку для этого нужно, чтобы изменения значений имели систематический характер. Но если изменчивость одной переменной ограничена, то тогда не важно, как сильно меняется другая (корреляция все равно будет ниже). Например, представим, что вы изучаете корреляцию между академическими успехами в старшей школе и оценками за первый год обучения в колледже и смотрите только на верхние 10 % группы. Что ж, эти верхние 10 %, вероятно, будут иметь похожие оценки, давая мало изменчивости и пространства для того, чтобы одна переменная изменялась как функция от другой. Угадайте, что вы получаете, когда соотносите одну переменную с другой, которая не меняется (т. е. не имеет вариабельности)? rxy = 0, вот что. Какой из этого можно извлечь урок? Изменчивость работает, и не следует искусственно ее ограничивать. Визуальное представление корреляции: диаграмма рассеяния Есть очень простой способ представить корреляцию визуально: создать то, что называется диаграммой рассеяния (на языке SPSS это называется графиком Рассеяния/Точки (Scatter/Dot)). Это просто графическое отображение каждого набора данных на отдельных осях. Вот какие шаги нужно сделать, чтобы получить диаграмму рассея­ ния, как на рис. 5.1, которая показывает 10 наборов значений, для которых мы ранее считали корреляцию: 1. Нарисуйте оси x и y. Обычно переменная X идет по горизонтальной оси, а переменная Y – по вертикальной. 2. Промаркируйте обе оси диапазоном значений, в котором, как вам известно, находятся данные. Например, в нашем случае значения переменной X находятся в диапазоне от 2 до 8, так что мы промаркировали ось x от 0 до 9. Когда обе оси одинаково промаркированы (и имеют одинаковый масштаб), это иног­ да облегчает понимание диаграммы рассеяния. 3. Наконец, для каждой пары значений (таких как 2 и 3, как показано на рис. 5.1) мы ставим на графике точку в месте, где ось x имеет значение 2, а ось y – значение 3. Эта точка представляет собой точку данных, которая является пересечением двух значений. Глава 5 Мороженое и преступность 119 Рис. 5.1 Простая диаграмма рассеяния 9 8 7 6 5 Y Точка данных (2,3) 4 3 2 1 0 0 1 2 3 4 5 6 7 8 9 X Что скажет нам иллюстрация об отношении между переменными, когда все точки данных будут нанесены? В первую очередь общая форма облака из точек данных показывает, является ли корреляция прямой (положительной) или обратной (отрицательной). Положительный наклон наблюдается, когда точки данных группируются в кластер, расположенный от нижнего левого угла между осями x и y и вверх до верхнего правого угла. Отрицательный наклон появляется, когда точки данных группируются в кластер, расположенный от верхнего левого угла между осями x и y и вниз до нижнего правого угла. Ниже приведено несколько диаграмм рассеяния для разных корреляций. На них вы сможете увидеть, каким образом группировка точек данных отражает знак и силу коэффициента корреляции. На рис. 5.2 показана идеальная прямая корреляция с rxy = 1, где все точки данных выстроились на прямой с положительным уклоном. Если бы корреляция была идеально обратной, то значение коэффициента корреляции было бы равно –1, а точки данных выстрои­ лись бы также вдоль прямой, но идущей от верхнего левого угла графика к нижнему правому. Иными словами, линия, соединяющая все точки данных, имела бы отрицательный наклон. Часть II 120 ∑игма Фрейд и описательная статистика Рис. 5.2 Идеальная прямая, или положительная, корреляция 10 9 8 7 6 Y 5 4 3 2 1 0 0 1 2 3 4 5 X 6 7 8 9 10 Даже и не ожидайте увидеть идеальную корреляцию между двумя переменными в поведенческих или социальных науках. Такая корреляция говорит о том, что переменные настолько тесно связаны, что у них все общее. Другими словами, если вы знаете одну из них, вам знакома и другая. Просто подумайте о своих одногруппниках. Как думаете, есть ли у них всех хотя бы одна общая черта, которая идеально определяет наличие каких-то других характеристик у столь разных людей? Вероятно, нет. На самом деле r, равный 0,7 или 0,8, – это максимум, который вы увидите. На рис. 5.3 вы можете увидеть диаграмму рассеяния для сильной (но не идеальной) прямой корреляции, где rxy = 0,70. Обратите внимание, что точки данных выстраиваются вдоль линии с положительным наклоном, хотя и не абсолютно точно. Теперь мы покажем вам сильную обратную, или отрицательную, корреляцию на рис. 5.4, где rxy = –0,82. Обратите внимание, что точки данных выстраиваются в примерную линию с отрицательным наклоном, идущую от верхнего левого угла графика к нижнему правому. Вот так выглядят различные типы корреляции, и вы действительно можете определить общую степень связи и ее направление, изучив­, каким образом группируются точки. Глава 5 Мороженое и преступность 121 Рис. 5.3 Сильная, хотя и не идеальная, прямая корреляция 10 9 8 7 6 Y 5 4 3 2 1 0 0 1 2 3 4 5 X 6 7 8 9 10 Не все корреляции отображаются в виде прямой, вдоль которой лежат значения X и Y, т. е. в виде линейной корреляции (см. главу 16, там много интересного об этом). Отношения могут быть нелинейными и не отображающимися в виде прямой линии. Возьмем корреляцию между возрастом и памятью. Для раннего возраста корреляция, вероятно, будет положительной: чем старше становятся дети, тем лучше память. В юности и зрелом возрасте нет особых изменений или какой-то корреляции, потому что большинство молодежи и людей среднего возраста обладает хорошей (но не обязательно все более изменчивой) памятью. Но к старости память начинает страдать, и появляется обратная зависимость между памятью и возрастом. Если все это сложить и посмотреть на данную связь на протяжении жизни, то окажется, что корреляция между памятью и возрастом больше похожа на кривую, на которой сила памяти возрастает, выравнивается, а затем убывает. Это криволинейное отношение, и иногда оно лучше всего описывает ситуацию. Часть II 122 ∑игма Фрейд и описательная статистика Рис. 5.4 Сильная, хотя и не идеальная, обратная корреляция 10 9 8 7 6 Y 5 4 3 2 1 0 0 1 2 3 4 5 X 6 7 8 9 10 Кучи корреляций: матрица корреляции Что будет, если у вас больше двух переменных? Как показать такие корреляции? Используйте для этого матрицу корреляции, похожую на ту, что показана в табл. 5.3, – это простое и элегантное решение. Таблица 5.3 Доход Образование Отношение Голосование Матрица корреляции Доход 1,00 0,574 –0,08 –0,291 Образование 0,574 1,00 –0,149 –0,199 Отношение –0,08 –0,149 1,00 –0,169 Голосование –0,291 –0,199 –0,169 1,00 Как видите, в матрице использованы 4 переменные: уровень дохода (Доход), уровень образования (Образование), отношение к выборам (Отношение) и участие в голосовании на последних выборах (Голосование). Для каждой пары переменных рассчитан коэффициент корреляции. Например, корреляция между уровнем дохода и образования равна 0,574. Аналогично корреляция между уровнем дохода и участием в последнем голосовании равна –0,291 (это значит, что чем выше уровень дохода, тем менее вероятно, что люди пойдут голосовать). Глава 5 Мороженое и преступность 123 В такой матрице с четырьмя переменными количество коэффициентов корреляции всегда равно 4!/(4 − 2)!2! – столько раз можно составить разные пары из четырех чисел – т. е. 6. Поскольку переменные идеально связаны сами с собой (это те единицы по диагонали), а корреляция между доходом и голосованием такая же, как между голосованием и доходом, то матрица отзеркаливает себя по диагонали. Для создания такой матрицы, что показана выше, можно воспользоваться SPSS или любой другой программой статистического анализа, например Excel. В приложениях вроде Excel можно обратиться к надстройке Пакет анализа (Data Analysis ToolPak). Вы увидите подобные матрицы в научных статьях, которые описывают связи между несколькими переменными. Как понять, что значит коэффициент корреляции Что ж, теперь у нас есть числовой коэффициент взаимосвязи между двумя переменными, и мы знаем, что чем он больше (независимо от знака), тем сильнее эта связь. Поскольку коэффициент корреляции – это величина, не связанная напрямую со значением выхода, то как можно его интерпретировать и сделать более значимым индикатором связи? Вот несколько вариантов интерпретации простого коэффициента rxy. Эмпирический метод (оценим «на глазок») Вероятно, самый простой (но не самый информативный) способ интерпретировать значение коэффициента корреляции состоит в том, чтобы пробежать по нему глазами и использовать информацию из табл. 5.4. Таблица 5.4 Интерпретация коэффициента корреляции Значение корреляции от 0,8 до 1,0 от 0,6 до 0,8 от 0,4 до 0,6 от 0,2 до 0,4 от 0 до 0,2 Общая интерпретация коэффициента Очень сильная связь Сильная связь Средняя связь Слабая связь Очень слабая или никакой связи Так, если корреляция между двумя переменными равна 0,5, то можно уверенно заключить, что связь между ними средняя, т. е. не сильная, но и, определенно, недостаточно слабая, чтобы сказать, что у этих переменных нет совсем ничего общего. 124 Часть II ∑игма Фрейд и описательная статистика Такая приблизительная оценка допустима для быстрой оценки силы связи между переменными (например, когда вы быстро оцениваете визуально представленные данные). Но поскольку такой эмпирический метод зависит от субъективного суждения о «сильной» и «слабой» связях, хотелось бы найти метод поточнее. Давайте посмотрим, что он собой представляет. Детерминируй это: квадрат коэффициента корреляции А вот гораздо более точный способ интерпретации коэффициента корреляции – через вычисление коэффициента детерминации. Коэффициент детерминации показывает, сколько процентов дисперсии в одной переменной связано с дисперсией другой переменной. Язык сломаешь, да? Ранее в этой главе мы показывали, что переменные, у которых есть что-то общее, имеют обыкновение коррелировать между собой. Если мы проверим оценки по математике и английскому языку у 100 пятиклассников, то обнаружим довольно сильную корреляцию между ними, потому что многие из причин, по которым дети хорошо (или плохо) успевают по математике, часто бывают причинами их хорошей (или плохой) успеваемости по английскому. Количество часов, которое они уделяют занятиям, то, насколько они сообразительны, в какой степени их родители интересуются домашними заданиями, сколько книг у них дома, – все это и многое другое имеет отношение к оценкам и по математике, и по английскому и отличает детей друг от друга (и именно здесь появляется вариабельность). Чем больше общего у двух переменных, тем больше они будут связаны. Эти две переменные имеют общую изменчивость, т. е. причину, по которой дети отличаются друг от друга. В целом более умный ребенок, который больше учится, будет успевать лучше. Для того чтобы определить, какой объем дисперсии одной переменной объясняется дисперсией значений у другой, рассчитывается коэффициент детерминации через возведение коэффициента корреляции в квадрат. Например, если корреляция между средним выпускным баллом и количеством учебных часов равна 0,70 (или rср.балл = 0,70), тогда ко2 эффициент детерминации, обозначаемый r ср.балл , равен 0,72, или 0,49. Это означает, что 49 % дисперсии среднего балла можно объяснить разницей во времени, уделяемом учебе. И чем сильнее корреляция, тем большая доля дисперсии этим объясняется (что вполне отвечает здравому смыслу). Чем больше общего имеют две переменные (например, хорошие навыки обучения, знание требований по предмету, отсутствие утомления), тем больше информация об оценках по одному предмету может сказать об оценках по другому. Однако если 49 % дисперсии могут быть объяснены, то это означает, что 51 % не могут. Так что даже при сильной корреляции в 0,70 Глава 5 Мороженое и преступность 125 множество причин, по которым значения переменных отличаются друг от друга, остается без объяснения. Этот объем необъясненной дисперсии называется коэффициентом алиенации (или коэффициентом неопределенности). Не волнуйтесь, это не как в «Секретных материалах», а всего лишь часть дисперсии в Y, которая не объясняется через X (а также, конечно, наоборот, поскольку отношение верно в обе стороны). Как насчет визуального представления этой идеи общей дисперсии? На рис. 5.6 вы видите коэффициент корреляции, соответствующий ему коэффициент детерминации и диаграмму, которая показывает долю общей дисперсии для двух переменных. Чем больше закрашенная часть диаграммы, т. е. доля дисперсии, которую переменные разделяют между собой, тем сильнее они взаимосвязаны, а именно: zz первая диаграмма на рис. 5.5 показывает два не соприкасающихся друг с другом круга. Они не соприкасаются, потому что у них нет ничего общего. Корреляция равна нулю; zz вторая диаграмма показывает два пересекающихся круга. При корреляции в 0,5 (и r 2xy = 0,25) у них есть примерно 25 % общей дисперсии; zz наконец, третья диаграмма показывает два почти полностью наложенных друг на друга круга. С почти идеальной корреляцией rxy = 0,9 (r 2xy = 0,81) они разделяют друг с другом около 81 % дисперсии. Рис. 5.5 Общая дисперсия и корреляция между переменными Корреляция Коэффициент детерминации rxy = 0 2 =0 r xy rxy = 0,5 2 r xy = 0,25, или 25 % rxy = 0,9 2 r xy = 0,81, или 81 % Переменная X Переменная Y 0 % общего 25 % общего 81 % общего Чем больше съедается мороженого, тем… выше преступность (или ассоциация против причинности) А теперь очень важный момент, когда нужно проявлять осторожность, рассчитывая, читая или интерпретируя коэффициенты корреляции. 126 Часть II ∑игма Фрейд и описательная статистика Вот представьте, что в маленьком городке на Среднем Западе произошел феноменальный случай, идущий вразрез с какой-либо логикой. Глава местной полиции обнаружил, что по мере роста потреб­ ления мороженого уровень преступности так же возрастает. Когда измерили и то, и другое, обнаружили, что взаимосвязь между ними была прямой, а это значило, что когда люди ели больше мороженого, уровень преступности рос. Как вы можете догадаться, когда они ели меньше мороженого, уровень преступности снижался. Начальник полиции был обескуражен, пока не припомнил «Основы статистики», которые читали им в колледже. Его удивление, как такое может быть, превратилось в понимание. «Очень просто, – подумал он. – У этих двух переменных должно быть что-то общее друг с другом». Важно, что это должно быть что-то, связанное и с потреблением мороженого, и с уровнем преступности. Можете догадаться, что это? Обе переменные связаны с температурой на улице. Когда становится тепло, например летом, совершается больше преступлений (световой день дольше, люди оставляют окна открытыми, плохие парни и девчонки больше гуляют и т. д.). Также при повышении температуры люди наслаждаются древним удовольствием – поеданием мороженого. Напротив, во время длинных и темных зимних месяцев потребляется меньше мороженого, а также совершается меньше преступлений. Джо, недавно избранный городским уполномоченным, узнает об этом соотношении. Ему в голову приходит отличная идея, которая, как он думает, понравится его избирателям. (Имейте в виду, что он отказался выбирать статистику в колледже.) Почему бы не ограничить потребление мороженого в летние месяцы, чтобы снизить уровень преступности? Отлично звучит, верно? При более детальном изучении это оказывается полной ерундой. Помните, что корреляция выражает ассоциацию, существующую между двумя или более переменными, при этом она никак не связана с причинностью. Другими словами, только то, что уровень потребления мороженого и уровень преступности вместе возрастают (а также вместе убывают), не означает, что изменение одного из них приведет к изменению другого. Например, если бы мы изъяли все мороженое из всех магазинов города и больше его было бы не достать, думаете, уровень преступности бы снизился? Конечно, нет, и было бы нелепо так думать. Но как ни странно, именно так часто и интерпретируют ассоциации (как будто они обладают причинно-следственной связью), а сложные вопросы социальных и поведенческих наук из-за этого недопонимания сводятся к пустой болтовне. Имели ли хиппи и длинные волосы какое-то отношение к войне во Вьетнаме? Конечно, нет. Имеет ли рост количества преступлений какое-то отношение к более экономичным и безопасным машинам? Конечно, нет. Но все эти явления происходят в одно и то же время, создавая иллюзию взаимосвязи. Глава 5 Мороженое и преступность 127 Вычисление коэффициента корреляции при помощи SPSS Давайте посчитаем коэффициент корреляции при помощи SPSS. Мы будем использовать набор данных под названием «Глава 5. Набор данных 1» (Chapter 5. Data Set 1). В этом наборе данных две переменные, представленные в табл. 5.5. Таблица 5.5 Переменные для файла «Глава 5. Набор данных 1» (Chapter 5. Data Set 1) Переменная Income Education Определение Годовой доход в тыс. долл. Уровень образования, измеряемый в годах Для того чтобы посчитать коэффициент корреляции Пирсона, выполните следую­ щие шаги. 1. Откройте файл «Глава 5. Набор данных 1» (Chapter 5. Data Set 1). 2. Нажмите Анализ (Analyze) ⇒ Корреляции (Correlate) ⇒ Парные (Biva­riate), и вы увидите диалоговое окно Парные корреляции (Bivariate Correlations), как показано на рис. 5.6. 3. Щелкните два раза по переменной Income, чтобы переместить ее в окошко Переменные: (Variables:). 4. Щелкните два раза по переменной Education, чтобы переместить ее в окошко Переменные: (Variables:). Вы также можете держать нажатой клавишу Ctrl, чтобы выбрать больше одной переменной за раз, а потом нажать на стрелку в центре диалогового окна, чтобы переместить их обе. 5. Нажмите ОК. Рис. 5.6 Диалоговое окно Парные корреляции Часть II 128 ∑игма Фрейд и описательная статистика Читаем выводы SPSS Вывод на рис. 5.7 показывает, что коэффициент корреляции равен 0,574. Также указаны размер выборки, 20, и мера статистической значимости коэффициента корреляции (мы раскроем тему статис­ тической значимости в главе 9). Рис. 5.7 Вывод SPSS для расчета коэффициента корреляции Вывод SPSS показывает, что две переменные связаны друг с другом и что по мере роста уровня дохода растет и уровень образования. Аналогично по мере снижения уровня дохода падает и уровень образования. Тот факт, что корреляция значима, означает, что эта взаимосвязь вовсе не случайна. Что касается содержания этой взаимосвязи, то коэффициент детерминации равен 0,5742, или 0,329, или 0,33. Это означает, что 33 % дисперсии одной переменной объясняется второй. По нашим примерным оценкам, это довольно слабое отношение. Еще раз повторим: помните, что низкий уровень дохода не является причиной низкого уровня образования, так же как только среднее образование не означает, что кто-то обречен на жизнь с низким доходом. Это описывается причинностью, а не ассоциацией, причем корреляция говорит только об ассоциации. Глава 5 Мороженое и преступность 129 Создание диаграммы рассеяния Вы можете нарисовать диаграмму рассеяния и от рубки, но также хорошо знать, как заставить SPSS сделать это за вас. Давайте возьмем те же самые данные, для которых мы создавали матрицу корреляции на рис. 5.8, и используем их для построения диаграммы рассеяния. Убедитесь, что перед вами на экране набор данных «Глава 5. Набор данных 1» (Chapter 5. Data Set 1). 1. Нажмите Графика (Graphs) ⇒ Мастер диаграмм (Chart Builder) ⇒ Рассеяния/ Точки (Scatter/Dot), и вы увидите диалоговое окно Мастера диаграмм, как на рис. 5.8. 2. Щелкните 2 раза по первому примеру Рассеяния/Точки (Scatter/Dot). 3. Выделите и перетащите переменную Income на ось y. 4. Выделите и перетащите переменную Education на ось x. 5. Нажмите ОК, и вы получите очень простую и понятную диаграмму рассеяния, похожую на ту, что вы видите на рис. 5.9. Рис. 5.8 Диалоговое окно Мастера диаграмм Вычисление диаграммы рассеяния Часть II 130 ∑игма Фрейд и описательная статистика Рис. 5.9 Простая диаграмма рассеяния $80 000 $70 000 Доход $60 000 $50 000 $40 000 $30 000 $20 000 $10 000 6 8 10 12 Образование 14 16 ДРУГИЕ К ЛАССНЫЕ КОРРЕЛЯЦИИ Другие важные коэффициенты корреляции Таблица 5.6 Переменные можно оценивать разными способами. Например, номинальные переменные описывают принадлежность к какой-либо категории. Так, это может быть раса (белая или черная) или политическая принадлежность (независимые или республиканцы). Если вы измеряете доход и возраст, то имеете дело с интервальными переменными, потому что множество значений, на которое они опираются, поделено на равные повторяющиеся интервалы. В процессе обучения вы, вероятно, столкнетесь с корреляциями между данными, которые относятся к разным статистическим шкалам. Для расчета таких корреляций вам потребуются специальные инструменты. В табл. 5.6 указаны эти инструменты и различия между ними. Кому каталог коэффициентов корреляции? Шкала измерения и примеры Переменная X Переменная Y Номинальная Номинальная (пол: (политические мужской или женский) предпочтения, например республиканец или демократ) Тип корреляции Фи-коэффициент Какая корреляция вычисляется Корреляция между политическими предпочтениями и полом Продолжение ⇒ Глава 5 Мороженое и преступность 131 Шкала измерения и примеры Переменная X Переменная Y Номинальная (политические предпочтения, например республиканец или демократ) Номинальная (социальный класс, например высокий, средний или низкий) Номинальная (тип семьи: полная или неполная) Порядковая (рост, приведенный к рангам) Интервальная (количество решенных проблем) Тип корреляции Какая корреляция вычисляется Корреляция между политическими предпочтениями и полом Номинальная (пол: мужской или женский) Фи-коэффициент Порядковая (ранг в выпускном классе старшей школы) Рангово-бисериальный коэффициент Корреляция между социальным классом и рангом в старшей школе Интервальная (средний выпускной балл) Порядковая (вес, приведенный к рангам) Интервальная (возраст в годах) Точечно-бисериальная Корреляция между типом семьи и средним выпускным баллом Корреляция между ростом и весом Ранговый коэффициент корреляции Спирмена Коэффициент корреляции Пирсона Корреляция между количеством решенных проблем и возрастом в годах ДЕЛИМ НА ЧАСТИ: НЕМНОГО О ЧАСТИЧНОЙ КОРРЕЛЯЦИИ Хорошо, теперь вы немного знакомы с простой корреляцией, но есть много других методов оценки корреляции для изучения отдельных отношений между переменными. Один из распространенных дополнительных методов называется частичной корреляцией. Здесь исследуется взаимосвязь между двумя переменными, но при этом убирается влияние третьей переменной. Иногда третью переменную называют опосредующим (или искажающим) фактором. Например, скажем, что мы изучаем связь между уровнем депрессии и частотой хронических заболеваний, обнаруживая при этом, что в целом связь положительна. Другими словами, чем больше хронических заболеваний проявляется у человека, тем больше вероятность, что у него также имеется депрессия (и наоборот, конечно). Напоминаем, что одна переменная не является причиной для другой, и наличие одной из них не означает, что другая также будет присутствовать. Положительная корреляция – это просто оценка связи между этими переменными, ключевая идея которой состоит в том, что у них есть некоторая одинаковая дисперсия. В этом-то и дело: именно то общее, что у них есть, нам и хотелось бы выделить, а в некоторых случаях и убрать из оценки связи. Например, что насчет уровня поддержки семьи, пищевых привычек, степени тяжести и длительности заболевания? Эти и мно­ Часть II 132 ∑игма Фрейд и описательная статистика жество других факторов могут отвечать за связь между переменными или, по крайней мере, они способны объяснять некоторую часть дисперсии. Немного напрягите память. Это тот самый аргумент, который мы приводили, рассуждая о взаимосвязи между потреблением мороженого и уровнем преступности. Как только температура воздуха на улице (опосредующая или искажающая переменная) была удалена из уравнения… бум! Взаимосвязь между потреблением мороженого и уровнем преступности улетела в трубу. Давайте посмотрим. Вот данные о потреблении мороженого и уровне преступности для 10 городов (табл. 5.7). Таблица 5.7 Коэффициенты корреляции между преступностью и потреблением мороженого Потребление мороженого Уровень преступности Потребление мороженого 1 Уровень преступности 0,743 1 Итак, корреляция между этими двумя переменными (потреблением мороженого и уровнем преступности) равна 0,743. Это довольно серьезная связь, отвечающая примерно за 50 % дисперсии между этими переменными (0,7432 = 0,55, или 55 %). Теперь добавим третью переменную – среднюю температуру на улице. Вот коэффициенты корреляции Пирсона для набора из трех переменных (табл. 5.8). Таблица 5.8 Корреляция между потреблением мороженого, преступностью и температурой воздуха Потребление мороженого Уровень преступности Потребление мороженого 1 Уровень преступности 0,743 1 Температура воздуха 0,704 0,655 1 Как видно из этой таблицы, существует довольно сильная связь между потреблением мороженого и температурой воздуха, а также между уровнем преступности и температурой. Нас интересует вопрос: какова будет корреляция между потреблением мороженого и уровнем преступности, если исключить влияние температуры воздуха на улице? Этим и занимается частичная корреляция. Она описывает связь между двумя переменными (потреблением мороженого и уровнем преступности), когда убрано влияние третьей (температуры на улице). Глава 5 Мороженое и преступность 133 Вычисление частичной корреляции при помощи SPSS Давайте возьмем какие-нибудь данные и SPSS, чтобы продемонст­ рировать расчет частичной корреляции. Вот исходные данные (табл. 5.9). Таблица 5.9 Город 1 2 3 4 5 6 7 8 9 10 Данные о потреблении мороженого, преступности и температуре воздуха Потребление мороженого 3,4 5,4 6,7 2,3 5,3 4,4 5,1 2,1 3,2 2,2 Уровень преступности 62 98 76 45 94 88 90 68 76 35 Температура воздуха (по Фаренгейту) 88 89 65 44 89 62 91 33 46 41 1. Нажмите Анализ (Analyze) ⇒ Корреляции (Correlate) ⇒ Частные (Partial), и вы увидите диалоговое окно Частные корреляции (Partial Correlations), как показано на рис. 5.10. 2. Переместите Потребление мороженого и Уровень преступности в окошко Переменные: (Variables:), перетащив их или дважды щелкнув по каждой. 3. Переместите переменную Температура воздуха в окошко Исключаемые: (Controlling for:). 4. Нажмите ОК, и вы увидите вывод SPSS, как на рис. 5.11. Рис. 5.10 Диалоговое окно Частные корреляции Часть II 134 ∑игма Фрейд и описательная статистика Рис. 5.11 Результаты анализа частичной корреляции Читаем выводы SPSS Как видно на рис. 5.12, корреляция между потреблением мороженого и уровнем преступности за вычетом влияния температуры на улице равна 0,525. Это меньше, чем простой коэффициент корреляции Пирсона между потреблением мороженого и уровнем преступности (равный 0,743), который не исключает влияния температуры. То, что, казалось, объясняет 55 % дисперсии значений (и является, как говорится, «значимым на уровне 0,05»), после исключения температуры воздуха в качестве опосредующей переменной теперь объясняет 0,5252 = 0,28 = 28 % дисперсии (и связь больше не является значимой). Наш вывод? Температура воздуха отвечала за достаточный объем общей дисперсии между потреблением мороженого и уровнем преступности, чтобы мы заключили, что связь между ними является значимой. Однако при исключении опосредующей или искажающей переменной в виде температуры связь перестала быть значимой. Нам не нужно запрещать продажу мороженого, чтобы попытаться снизить преступность. РЕАЛЬНАЯ СТАТИСТИКА Вот забавный материал, полностью соответствующий растущему интересу к разнообразному применению статистики в области спорта и дисциплине с неофициальным названием саберметрика. Термин был придуман Биллом Джеймсом (Bill James) и стал известен благодаря фильму «Человек, который изменил все». Стивен Холл (Stephen Hall) с коллегами исследовал связь между заработком команд и их конкурентоспособностью (в профессиональном бейсболе и футболе). Он был одним из первых, кто посмот­ рел на нее с эмпирической точки зрения. Другими словами, до того как были опубликованы эти данные, большинство людей принимало решения на основании разрозненного опыта, а не опираясь на ко- Глава 5 Мороженое и преступность 135 личественные оценки. Холл взял данные о заработной плате команд в Главной лиге бейсбола и в английском футболе за период 1980– 2000 гг. и использовал для их изучения модель, которая позволяла выявить причинно-следственные связи (а не только ассоциацию). За 1990-е гг. и оплата, и результаты бейсболистов существенно выросли, но нет доказательств, что причинная связь идет от оплаты к результативности. Для сравнения: исследователи показали, что для английского футбола более высокая оплата стала причиной лучших результатов. Здорово, правда, что можно исследовать ассоциацию при помощи специальных казуальных моделей? Хотите узнать больше? Найдите в интернете или библиотеке статью... Hall S., Szymanski S. & Zimbalist A. S. Testing causality between team performance and payroll: The cases of Major League Baseball and English soccer. Journal of Sports Economics, 2002. Р. 149–168. Реальная статистика ВЫВОДЫ ПО ГЛАВЕ Идея, что можно показать взаимосвязь вещей и то общее, что у них есть, очень притягательна, а коэффициент корреляции является очень полезной описательной статистикой (и используется также в статистике вывода, как мы покажем вам дальше). Имейте в виду, что корреляции выражают только ассоциативную, а не причинную связь. В этом случае вы сможете понять, как именно эта статистика дает нам бесценную информацию об отношениях между переменными, а также каким образом переменные изменяются или остаются прежними. В завершение части II обратимся к надежности и достоверности. Вам нужно знать, что включают в себя эти понятия, потому что они научат вас определять, о чем говорят различия в результатах (значениях или переменных). Выводы по главе ВРЕМЯ ПРАКТИКИ 1. И спользуйте данные из табл. 5.10, чтобы ответить на вопросы 1а и 1б. Эти же данные сохранены как файл «Глава 5. Набор данных 2» (Chapter 5. Data Set 2): а) рассчитайте коэффициент линейной корреляции Пирсона вручную и покажите все свои расчеты; б) вручную создайте диаграмму рассеяния для этих 10 пар значений. Можете ли вы на основании диаграммы определить, будет корреляция прямой или обратной? Почему? Проблема 1 Часть II 136 Таблица 5.10 ∑игма Фрейд и описательная статистика Данные из файла «Глава 5. Набор данных 2» (Chapter 5. Data Set 2) Количество верных ответов (из 20) 17 13 12 15 16 14 16 16 18 19 Проблема 2 Отношение (из 100 баллов) 94 73 59 80 93 85 66 79 77 91 2.Используйте данные из табл. 5.11, чтобы ответить на вопросы 2а и 2б. Эти же данные сохранены как «Глава 5. Набор данных 3» (Chapter 5. Data Set 3): а) рассчитайте на калькуляторе или компьютере коэффициент корреляции Пирсона; б) интерпретируйте эту корреляцию по общей шкале от «очень слабая» до «очень сильная». Рассчитайте также коэффициент детерминации. Сравните субъективный анализ со значением r2. Таблица 5.11 Данные из файла «Глава 5. Набор данных 3» (Chapter 5. Data Set 3) Скорость пловца (на дорожке в 50 ярдов) 21,6 23,4 26,5 25,5 20,8 19,5 20,9 18,7 29,8 29,7 Сила (количество отжимаемых фунтов) 135 213 243 167 120 134 209 176 156 177 3.Расположите следующие коэффициенты корреляции по степени демонст­рируемой ими связи (начните с самой слабой степени): 71 +0,36 −0,45 0,47 −0,62 Глава 5 Мороженое и преступность 137 4.Рассчитайте коэффициент корреляции для набора значений из табл. 5.12 и интерпретируйте результат. Эти же данные сохранены как «Глава 5. Набор данных 4» (Chapter 5. Data Set 4). Таблица 5.12 Данные из файла «Глава 5. Набор данных 4» (Chapter 5. Data Set 4) Прирост достижений за 12 месяцев 0,07 0,03 0,05 0,07 0,02 0,01 0,05 0,04 0,04 Прирост бюджета класса за 12 месяцев 0,11 0,14 0,13 0,26 0,08 0,03 0,06 0,12 0,11 5.Для следующего набора данных (табл. 5.13) рассчитайте корреляцию между количеством минут, затраченных на упражнения, и средним баллом. Какой вывод вы можете сделать с учетом своего анализа? Эти же данные сохранены как «Глава 5. Набор данных 5» (Chapter 5. Data Set 5). Таблица 5.13 Данные из файла «Глава 5. Набор данных 5» (Chapter 5. Data Set 5) Упражнения 25 30 20 60 45 90 60 0 15 10 Средний балл 3,6 4,0 3,8 3,0 3,7 3,9 3,5 2,8 3,0 2,5 6.При помощи SPSS определите корреляцию между количеством часов обучения и средним баллом в аттестате этих медалистов. Почему корреляция такая низкая? Таблица 5.14 Средний балл и часы подготовки Часы обучения 23 Средний балл 3,95 Продолжение ⇒ Проблема 6 Часть II 138 ∑игма Фрейд и описательная статистика Часы обучения Средний балл 12 15 14 16 21 14 11 18 9 3,90 4,00 3,46 3,97 3,89 3,66 3,91 3,80 3,89 7.Коэффициент детерминации между двумя переменными равен 0,64. Ответьте на следующие вопросы: а) чему равен коэффициент корреляции Пирсона? б) насколько сильна связь? в) какой объем дисперсии между этими двумя переменными не объясняется их связью? 8.В табл. 5.15 представлен набор из трех переменных для 20 участников исследования восстановления после травмы головы. Создайте простую мат­рицу, которая покажет корреляции между всеми переменными. Это можно сделать вручную (приготовьтесь потратить на это некоторое время), с помощью SPSS или любого другого приложения. Эти же данные сохранены как «Глава 5. Набор данных 6» (Chapter 5. Data Set 6). Таблица 5.15 Данные из файла «Глава 5. Набор данных 6» (Chapter 5. Data Set 6) Возраст получения травмы 25 16 8 23 31 19 15 31 21 26 24 25 36 45 16 23 31 Уровень лечения 1 2 2 3 4 4 4 5 1 1 5 5 4 4 4 1 2 Оценка годового лечения 78 66 78 89 87 90 98 76 56 72 84 87 69 87 88 92 97 Продолжение ⇒ Глава 5 Мороженое и преступность 139 Возраст получения травмы Уровень лечения Оценка годового лечения 53 11 33 2 3 2 69 79 69 9.Посмотрите на табл. 5.4 на стр. 120. Какой вид коэффициента корреляции вы бы использовали для изучения взаимосвязи между полом (определенным как мужской или женский) и политическими взглядами? Что насчет корреляции состава семьи (с одним или с двумя родителями) и высокого уровня среднего балла в школе? Объясните, почему вы выбрали именно эти ответы. 10.Когда между двумя переменными есть корреляция (как, например, между силой и скоростью бега), они ассоциированы друг с другом. Но если они ассоциированы, то почему одна из них не является причиной для другой? 11.Приведите три примера ассоциации между двумя переменными, где тео­ретически идеально подходит причинно-следственная связь, но, поскольку корреляции не предполагают причинности, после дополнительного изучения статистики эта связь не имеет смысла. 12.Почему нельзя использовать корреляции в качестве инструмента для доказательства причинной, а не ассоциативной связи между переменными? 13. Когда применяется частичная корреляция? 6 Только правда Подходим к пониманию надежности и достоверности Уровень сложности: (не очень сложно) В ЭТОЙ ГЛАВЕ ВЫ УЗНАЕТЕ: определения надежности и достоверности и поймете, почему они важны; зачем заниматься вопросами измерения на занятиях по статистике; что такое шкалы измерения; как вычислить и интерпретировать различные коэффициенты надежности; как вычислить и интерпретировать различные коэффициенты достоверности. ПРЕДИСЛОВИЕ К НАДЕЖНОСТИ И ДОСТОВЕРНОСТИ Введение в главу 6 140 Спросите любого родителя, учителя, педиатра или практически каждого человека по соседству, какие 5 причин заставляют больше всего волноваться о современных детях, и наверняка найдется группа тех, кто выделит ожирение в качестве одной из них. Сэнди Слейтер (Sandy Slater) и ее коллеги разработали и протестировали надежность и достоверность анкеты-самообследования о доступности мест для активных игр и физкультуры дома, в школе и районе для подростков, проживающих в малообеспеченных городских и сельских райо­ нах. В частности, исследователи смотрели на такие переменные, как информация о наличии электронного и игрового оборудования в спальнях и домах юных респондентов и данные об уличном игровом оборудовании в школах. Также они изучили, что думали о физической активности люди, окружающие этих детей. Всего выдавае­ мую на дом анкету, состоящую из 160 вопросов, заполнили 205 пар родитель + ребенок. Анкеты раздавались в двух разных случаях, что является отличной моделью для установления надежности повторного опроса. Исследователи обнаружили, что 90 % измерений имели хорошую надежность и достоверность. Можно надеяться, что это Глава 6 Только правда 141 исследование поможет выявить возможности опрашиваемых и разработать стратегии для поощрения физической активности в среде необеспеченных детей и подростков. Хотите узнать больше? Найдите в интернете или библиотеке статью… Sla­ter S., Full K., Fitzgibbon M. & Uskali A. Test/retest reliability and validity results of the Youth Physical Activity Supports Questionnaire, 2015. Так что там с этими измерениями? Отличный вопрос, и хорошо, что вы его задаете. В конце концов, вы изучаете статистику, и до сих пор именно ей и были посвящены все разбираемые материалы. А сейчас кажется, что вы столкнулись с вопросом, который относится к изучению контроля и измерений. Так что же этот материал делает в книге по статистике? Большая часть того, о чем мы уже рассказали в «Статистике для тех, кто (думает, что) ненавидит статистику», имеет отношение к сбору и описанию данных. Теперь мы стоим на пороге путешест­вия в анализ и интерпретацию данных. Но, прежде чем начнем изучать­ эти навыки, мы хотим убедиться, что данные действительно представляют именно то, о чем вы хотите знать. Другими словами, если вы изучаете бедность, то хотите убедиться, что инструмент измерения бедности работает, причем работает в каждом случае. Если вы изучае­те агрессию у мужчин среднего возраста, то хотите убедиться, что инструмент измерения агрессии работает, причем всегда. Еще одна хорошая новость: если вы продолжите свое образование и захотите изучать курс о контроле и измерениях, эта ознакомительная глава станет хорошим трамплином для понимания тем, которые вы будете изучать. Для того чтобы заставить работать весь процесс сбора и осмысления данных, вы должны сначала убедиться, что так же хорошо работает то, что вы используете для сбора данных. Базовыми вопросами, ответы на которые будут даны в этой главе, являются следующие: 1) откуда я узнаю, что тест, шкала, метод и т. д., которыми я пользуюсь, срабатывают при каждом использовании (это о надежности); 2) откуда я знаю, что тест, шкала, метод и т. д., которыми я пользуюсь, измеряют именно то, что предполагается (это о достоверности). Измерения 142 Часть II ∑игма Фрейд и описательная статистика Любой человек, занимающийся исследованиями, скажет вам, как важно установить надежность и достоверность вашего инструмента контроля, будь то простой метод наблюдения за поведением потребителей или тот, что измеряет сложный психологический аспект вроде привязанности. Однако есть еще одна важная причина. Если инструменты, при помощи которых вы собираете данные, ненадежны или недостоверны, тогда результаты любой проверки или любой гипотезы, а также выводы, к которым вы можете прийти на основании этих результатов, обязательно окажутся несостоятельными. Если вы не уверены, что замеры всякий раз были сделаны так, как предполагалось, то откуда вы знаете, что ваши результаты не являются следствием плохих инструментов измерения, а не опровержением нулевой гипотезы, когда она на самом деле верна (этот тип ошибки вы изучите в главе 9)? Хотите чистую проверку нулевой гипотезы? Сделайте надежность и достоверность важной частью своего исследования. Возможно, вы заметили термин зависимая переменная. В эксперименте это результирующая переменная или то, на что смотрит исследователь, чтобы увидеть, изменилось ли что-нибудь в зависимости от того, какое было оказано воздействие. И угадайте, что? У этого воздействия тоже есть название – независимая переменная. Например, если исследователь изучает влияние различных программ чтения на понимание, независимой переменной будет программа чтения, а зависимой (или результирующей) переменной станет оценка за понимание текста. Несмотря на то что эти термины не будут часто использоваться до конца этой книги, вероятно, вам следует все же их знать. НАДЕЖНОСТЬ: ПОВТОРЯЙТЕ, ПОКА НЕ ПОЛУЧИТСЯ ПРАВИЛЬНО Надежность Надежность довольно просто понять и обозначить. Она свидетельствует о том, насколько последовательно тест или то, что вы используете в качестве инструмента измерения, измеряет что-то. Если вы проводите тест на определение типа личности до того, как произойдет какое-то воздействие, будет ли проведение того же самого теста через четыре месяца надежным? Это, друг мой, один из вопросов. И это причина, по которой есть разные виды надежности, до каждого из которых мы доберемся после того, как немного точнее определим надежность. Оценки за тест: правда или действие? Когда вы пишете контрольную по этому предмету, то получаете оценку, такую как 89 (браво!) или 65 (возвращайтесь к учебникам!). Эта оценка состоит из нескольких элементов, включая наблюдае- Глава 6 Только правда 143 мую оценку (или то, что вы действительно получили за тест, например 89 или 65) или истинную оценку (истинное, на 100 % точное отражение того, что вы действительно знаете). Мы не можем напрямую измерить истинную оценку, потому что это теоретическое отражение действительного объема черт или характеристик, присущих индивидууму. Все, что относится к этим штукам про тесты и измерение, несколько туманно, и эта истинная оценка, определенно, тоже. Вот почему. Мы только что определили истинную оценку как настоящую величину, относящуюся к какой-то черте или свойству. Пока все нормально. Но есть также и еще одна точка зрения. Некоторые психометристы (люди, зарабатывающие тестированием и измерениями на жизнь) полагают, что истинная оценка не имеет ничего общего с тем, действительно ли она отображает предмет нашего интереса. Истинная оценка – это, скорее, средняя оценка, которую получит индивидуум, если пройдет тест бесконечное количество раз. Она отражает теоретический типичный уровень результатов для данного теста. Теперь-то можно надеяться, что типичный уровень результатов будет отражать предмет нашего интереса, но возникает еще один вопрос (в этот раз о достоверности). Отличие заключается в том, что тест считается надежным, если он постоянно выдает тот результат, который человек в среднем имеет, причем независимо от того, что именно измеряет тест. Фактически идеально надежный тест может и не выдавать оценку, которая имеет что-то общее с предметом интереса, таким как «что вы действительно знаете». Почему истинные и наблюдаемые оценки не совпадают? Они могут совпасть, если тест (и соответствующая ему наблюдаемая оценка) является идеальным (мы имеем в виду, абсолютно идеальным) отражением того, что измеряется. Но «Янки» («Yankees») не всегда выигрывают, хлеб иногда падает масляной стороной вниз, а законы Мерфи говорят нам, что мир не идеален. Так что, то, что вы видите в качестве наблюдаемой оценки, может приближаться к истинной, но они крайне редко совпадают. Вернее, разница между ними является величиной привносимой ошибки. Наблюдаемая оценка = истинная оценка + оценка ошибки Ошибка? Да, во всей своей красе. Например, давайте на секунду предположим, что кто-то получает на контрольной по статистике 89, но его или ее истинная оценка (которую мы никогда точно не узнаем, а можем только предполагать) равна 80. Это означает, что различие в 9 баллов (что и составляет величину ошибки) произошло из-за ошибки, т. е. той причины, по которой индивидуальные оценки отклоняются от 100 % истинности. Часть II 144 ∑игма Фрейд и описательная статистика Что может быть источником такой ошибки? Ну, возможно, в комнате, в которой проводилась контрольная, было так жарко, что некоторые студенты почти заснули. Это, определенно, сказалось бы на результатах теста. Или, может быть, студент не подготовился к тесту так хорошо, как ему или ей следовало бы. Тот же эффект. Оба эти примера описывают ситуации или условия тестирования, а не характеристики измеряемой способности, верно? Наша работа состоит в том, чтобы как можно больше сократить эти ошибки, создав, например, хорошие условия для проведения тес­та и удостоверившись, что все тестируемые постарались хорошенько выспаться. Сократите ошибку, и вы увеличите надежность, потому что наблюдаемая оценка будет ближе к истинной. Чем меньше ошибка, тем надежнее – все настолько просто. ВИДЫ НАДЕЖНОСТИ Надежность бывает нескольких видов, и в этой части мы осветим четыре самых важных и часто применяемых вида. Все они представлены в табл. 6.1. Таблица 6.1 Виды надежности и их условия применения, правила расчета и значения Вид надежности Когда применяется Ретестовая надежность Когда вы хотите знать, сохраняет ли тест надежность во времени Надежность параллельных форм Когда вы хотите знать, надежны ли или эквивалентны несколько разных форм одного теста Пример того, что вы можете сказать, когда посчитаете Посчитайте корреляцию Тест Бонзо на формирование между результатами теста, идентичности среди выданного в Момент 1, подростков надежен и результатами того же тес­та, при повторении выданного в Момент 2 Посчитайте корреляцию Две формы теста на хорошемежду оценками по одной го парня эквивалентны друг форме теста и оценками по другу и имеют хорошую второй форме теста с тем же надежность по методу содержанием (но не в точно­ параллельных форм сти с таким же тестом) Посчитайте корреляцию Все задания теста оценки за каждое тестовое на креативность оценивают задание с итоговой оценкой один и тот же компонент Как посчитать Надежность Когда вы хотите знать, внутренней действительно ли все согласованности задания теста оценивает одно измерение Взаимная Когда вы хотите знать, Посчитайте процентную надежность однородно ли оценивание долю согласия между оценивающих какого-то результата оценивающими Взаимная надежность оценок в конкурсе на самого стильного футболиста была равна 0,91, что указывает на высокую степень единодушия между судьями Ретестовая надежность Ретестовая надежность применяется, когда вы хотите проверить, надежен ли тест при повторении через какое-то время. Глава 6 Только правда 145 Допустим, что вы разрабатываете тест для изучения предпочтений при выборе различных программ среднего профессионального образования. Вы можете провести тестирование в сентябре, а затем дать тот же самый тест (и это важно, что он должен быть тем же самым) еще раз в июне. Затем два набора результатов (помните, что одни и те же люди проходили его дважды) следует проверить на корреляцию (как мы делали это в главе 5), после чего вы получите измерение надежности. Ретестовая надежность – обязательное условие, когда вы изучаете различия или изменения, происходящие с течением времени. Вы должны быть глубоко уверены: ваши измерения были выполнены с высокой надежностью, чтобы полученные вами значения как можно точнее раз за разом отражали индивидуальные результаты. Вычисление ретестовой надежности. В табл. 6.2 приведены результаты первичного и повторного тестов о выборе программы профтехобразования, которые находятся в процессе разработки. Наша задача – рассчитать коэффициент корреляции Пирсона в качестве показателя ретестовой надежности данного инструмента. Таблица 6.2 ID 1 2 3 4 5 6 7 8 9 10 Ретестовая надежность Результаты первичного и повторного тестирований Результаты первого теста 54 67 67 83 87 89 84 90 98 65 Результаты второго теста 56 77 87 89 89 90 87 92 99 76 Первый и последний шаг в этом процессе – расчет коэффициента корреляции Пирсона (см. главу 5, если нужно освежить память), который равен rтест1.тест2 = 0,90. Что означает 0,90 для ретестовой надежности? Мы займемся интерпретацией этого значения чуть позже. Надежность параллельных форм Надежность параллельных форм применяется, когда вы хотите проверить эквивалентность, или равнозначность, двух разных форм одного и того же теста. Допустим, вы изучаете память, и одно из заданий состоит в том, чтобы посмотреть на 10 разных слов, запомнить как можно больше из них, а затем назвать их после 20 с занятий и 10 с отдыха. По- Часть II 146 ∑игма Фрейд и описательная статистика скольку это исследование проводится в течение двух дней и включает в себя некоторую тренировку навыков памяти, вы хотите, чтобы у вас был еще и второй набор слов, абсолютно такой же, с точки зрения сложности выполнения задания, но, очевидно, не повторяющий первый по содержанию. Так что вы создаете еще один список слов в надежде, что он будет похож на первый. В данном примере вы хотите, чтобы формы соответствовали друг другу (проверяли одни и те же параметры, но при помощи разного содержания). Вычисление надежности параллельных форм. В табл. 6.3 приведены результаты теста памяти по форме А и Б. Наша задача – рассчитать коэффициент корреляции Пирсона в качестве показателя надежности параллельных форм для данного инструмента. Таблица 6.3 ID 1 2 3 4 5 6 7 8 9 10 Результаты тестирования памяти Результаты по форме А 4 5 3 6 7 5 6 4 3 3 Результаты по форме Б 5 6 5 6 7 6 7 8 7 7 Первый и последний шаги в этом процессе состоят в расчете коэффициента корреляции Пирсона (см. главу 5, если нужно освежить память), который равен rформа А.форма Б = 0,13. Мы займемся интерпретацией этого значения чуть позже. Надежность внутренней согласованности Надежность внутренней согласованности существенно отличается от двух ранее изученных типов надежности. Она применяются, когда вы хотите знать, согласованы ли между собой элементы теста в том, что они отражают одно (и только одно) измерение, компонент или интересующую область. Допустим, вы разрабатываете анкету для оценки отношения к различным типам здравоохранения и хотите удостовериться, что набор из пяти вопросов измеряет именно это и больше ничего. Вы возьмете ответы на каждый вопрос (принадлежащие группе ответивших) и посмотрите, коррелирует ли балл по каждому вопросу с общим баллом. Ожидается, что люди, которые дали высокую оценку определенным высказываниям (например, «мне нравится моя Глава 6 Только правда 147 медицинская организация»), низко оценят другие (например, «я не люблю тратить деньги на медицинское обслуживание»). Это будет верным для всех людей, ответивших на анкету. Альфа Кронбаха (или α) – это специальный показатель надежности внутренней согласованности. Чем более согласованно с общим результатом теста изменяются результаты по отдельным ответам, тем выше значение альфы Кронбаха. А чем выше значение, тем больше вы можете быть уверены в том, что ваш тест внутренне согласован, т. е. измеряет одно и то же, и объект измерения является суммой того, что оценивает каждый вопрос по отдельности. Например, вот тест из пяти заданий с большой внутренней согласованностью: 1. 4 + 4 = ? 2. 5 – ? = 3 3. 6 + 2 = ? 4. 8 – ? = 3 5. 1 + 1 = ? Похоже, что все задания измеряют одно и то же, независимо от того, что именно это может быть (это уже вопрос достоверности – оставайтесь с нами). А вот тест из пяти заданий, который не дотягивает до того, чтобы быть внут­ренне согласованным: 1. 4 + 4 = ? 2. Кто из трех поросят самый толстый? 3. 6 + 2 = ? 4. 8 – ? = 3 5. Так чего же хотел волк? Очевидно, почему так. Эти вопросы не соответствуют друг другу, а ведь именно это ключевой критерий для внутренней согласованности. Вычисление альфы Кронбаха В табл. 6.4 представлена выборка ответов 10 людей на вопросы об отношении к медучреждениям. Ответы могли находиться между 1 (полностью несогласен) и 5 (полностью согласен). При вычислении альфы Кронбаха (названной так в честь Ли Кронбаха (Lee Cronbach)) вы на самом деле считаете корреляцию между баллами каждого элемента и общей суммой баллов по каждому человеку, а затем сравниваете ее с дисперсией всех индивидуальных оценок за отдельные задания. Логика в этом такова, что любой тестируемый с высоким общим баллом должен иметь (более) высокий балл по каждому заданию (например, 5, 5, 3, 5, 3, 4, 4, 2, 4, 5 при общем балле 40), а каждый тестируемый с (более) низким общим баллом будет иметь (более) низкую оценку за каждое отдельное задание (например, 4, 1, 2, 1, 3, 2, 4, 1, 2, 1). Часть II 148 Таблица 6.4 ID 1 2 3 4 5 6 7 8 9 10 ∑игма Фрейд и описательная статистика Результаты опроса об отношении к медучреждениям Вопрос 1 3 4 3 3 3 4 2 3 3 3 Вопрос 2 5 4 4 3 4 5 5 4 5 3 Вопрос 3 1 3 4 5 5 5 5 4 4 2 Вопрос 4 4 5 4 2 4 3 3 2 4 3 Вопрос 5 1 3 4 1 3 2 4 4 3 2 А вот формула расчета альфы Кронбаха: (6.1) где k – количество вопросов; sy2 – дисперсия каждого наблюдаемого значения; ∑si2 – сумма всех дисперсий для каждого задания. Вот тот же самый набор данных со значениями, которые нужны для завершения приведенного выше уравнения Таблица 6.5 Промежуточные расчеты альфы Кронбаха ID 1 2 3 4 5 6 7 8 9 10 Вопрос 1 3 4 3 3 3 4 2 3 3 3 Вопрос 2 5 4 4 3 4 5 5 4 5 3 Вопрос 3 1 3 4 5 5 5 5 4 4 2 Вопрос 4 4 5 4 2 4 3 3 2 4 3 Вопрос 5 1 3 4 1 3 2 4 4 3 2 Дисперсия вопроса 0,32 0,62 1,96 0,93 1,34 ИТОГО 14 19 19 14 19 19 19 17 19 13 sy2 = 6,4 ∑si2 = 5,17 После подстановки этих чисел в уравнение мы получаем сле­ дующее: (6.2) Глава 6 Только правда 149 Вы нашли, что коэффициент альфа равен 0,24, и дело сделано (за исключением интерпретации, посколько этим мы займемся позже). Если бы мы сказали, что есть еще множество других типов проверки внутренней согласованности, вы не удивились бы, верно? И это действительно так. Используется не только коэффициент альфа, но и метод расщепления, формула Спирмена–Брауна, формулы Кудера–Ридчардсон KR20 и KR21 и многие другие, которые, по сути, делают одно и то же (проверяют одномерность теста), но только разными способами. Вычисление альфы Кронбаха при помощи SPSS Если вы знаете, как рассчитать альфу Кронбаха вручную и хотите перейти к расчетам в SPSS, сделать это очень просто. Мы будем использовать данные из набора выше, касающиеся ответов 10 людей на 5 вопросов. 1. Введите данные в Редактор данных (Data Editor). Убедитесь, что каждый вопрос теста имеет свою собственную колонку. 2. Нажмите Анализ (Analyze) ⇒ Шкалы (Scale) ⇒ Анализ надежности (Relia­bility Analysis), и вы увидите диалоговое окно, как на рис. 6.1. 3. Переместите каждую переменную (с вопроса 1 по вопрос 5) в область Элементы (Items), дважды щелкнув по каждой из них или выбрав и перетащив их все (используя клавишу Shift и мышь). Проверьте, что в выпадающем меню Модель (Model) выбрана Альфа (Alpha). 4. Нажмите ОК. SPSS проведет анализ и покажет выдачу, как на рис. 6.2. Рис. 6.1 Диалоговое окно анализа надежности Часть II 150 ∑игма Фрейд и описательная статистика Рис. 6.2 Вывод SPSS для анализа надежности Читаем выводы SPSS Вычисление оценки внутренней согласованности Для набора данных из табл. 6.4 для пяти вопросов, заданных 10 людям, значение альфы Кронбаха составило 0,239. Как видите, это действительно близко к тому, что было рассчитано вручную. Вывод не раскрывает нам особо много дополнительной информации. Как вы узнаете позже, это относительно низкий уровень надежности. Взаимная надежность оценивающих Взаимная надежность оценивающих – это показатель, который говорит о том, насколько двое оценивающих согласны в своих суждениях о каком-то результате. Допустим, вас интересует определенный тип социального взаимодействия во время транзакции между банковским работником и потенциальным клиентом банка. Вы наблюдаете за обоими людьми в режиме реального времени (через одностороннее зеркало), чтобы узнать, привел ли улучшенный курс по управлению отношениями с клиентами, который прошел работник, к увеличению количества улыбок и обходительности. Ваша задача – каждые 10 с делать пометки, демонстрирует ли банковский работник один из трех видов поведения, которым его обучали: улыбается, наклоняется вперед при сидении на стуле или подчеркивает смысл слов жестами. Каждый раз, когда видите проявления одного из этих видов поведения, вы ставите в своем оценочном листе Х. Если вы ничего не наблюдаете, то ставите минус (–). В рамках данного процесса, а также для того, чтобы убедиться, что ваши запи­си являются надежным показателем, вам захочется вы- Глава 6 Только правда 151 яснить, насколько же сходятся во мнении о проявлении этих типов поведения разные наблюдатели. Чем более похожи их оценки, тем выше уровень взаимной надежности оценивающих. Вычисление взаимной надежности оценивающих В данном примере очень важной переменной является то, произо­ шла ли демонстрация дружелюбного к клиенту поведения в течение 10-секундного промежутка в рамках 2-минутного наблюдения (или двенадцать 10-секундных периодов). Итак, в табл. 6.6 мы ищем согласованность оценок в течение 2-минутного периода, разбитого на двенадцать 10-секундных отрезков. Х в листе оценки означает, что поведение было продемонстрировано, а минус (–) – что не было. Из 12 отрезков времени (и 12 возможностей полного согласия) Дэйв и Морин 7 раз согласились, что дружелюбное действие было совершено (отрезки 1, 3, 4, 5, 7, 8 и 12), а 3 раза они согласились, что его не было (отрезки 2, 6 и 9), итого 10 случаев согласия и 2 случая разногласия. Таблица 6.6 Оценки демонстрации дружелюбия Отрезок времени Оценщик 1 Дэйв Оценщик 2 Морин 1 Х Х 2 – – 3 Х Х 4 Х Х 5 Х Х 6 – – 7 Х Х 8 Х Х 9 – – 10 – Х 11 Х – 12 Х Х Взаимная надежность оценивающих рассчитывается по следующей простой формуле: Взаимная надежность Количество согласий = . оценивающих Количество возможностей согласия При подстановке чисел мы увидим, что Взаимная надежность оценивающих = 10 12 = 0,833. Итоговый коэффициент взаимной надежности равен 0,833. МНОГО – ЭТО СКОЛЬКО? НАКОНЕЦ-ТО: ИНТЕРПРЕТАЦИЯ КОЭФФИЦИЕНТОВ НАДЕЖНОСТИ Помните, что вы узнали про интерпретацию значения коэффициента корреляции в главе 5? Практически то же самое верно для интерпретации коэффициентов надежности (с очень небольшой разницей). Часть II 152 ∑игма Фрейд и описательная статистика Требуется соблюдение только двух условий: zz коэффициенты надежности должны быть положительными, а не отрицательными; zz коэффициенты надежности должны быть как можно больше (в пределах между 0,00 и +1,00). Итак, интерпретация остается за вами. Коэффициент взаимной надежности оценивающих, который мы только что получили, 0,833, определенно, является высоким и отображает сильную степень согласия между двумя наборами наблюдений. Рассчитанное ранее значение альфы Кронбаха, равное 0,239, не особо велико. А если не получается установить надежность, что тогда? Пусть к установлению надежности теста совсем не усыпан розами – требуется хорошо потрудиться. Что, если опросник окажется ненадежным? Вот несколько моментов, которые стоит иметь в виду. Помните, что надежность зависит от того, насколько сильно ошибка воздействует на наблюдаемую оценку. Уменьшите эту ошибку, и вы увеличите надежность: zz убедитесь, что для всех мест, где проводится тест, используются стандартные и ясные инструкции; zz увеличьте количество вопросов или наблюдений, потому что чем больше выборка из множества вариантов исследуемого вами поведения, тем вероятнее, что она окажется репрезентативной и надежной. Это особенно верно для тестов, проверяющих уровень знаний и умений; zz удалите неоднозначные вопросы, потому что одни люди будут отвечать так, а другие – иначе независимо от их знаний, способностей или индивидуальных характеристик; zz для тестов на проверку знаний и умений (например, орфографических или контрольных по истории) усредняйте легкость и сложность теста. И слишком легкий, и слишком сложный тест не дает верного представления об уровне знаний тестируемого; zz минимизируйте влияние внешних событий и стандартизируйте указания. Например, если дата тестирования оказывается рядом с каким-то важным событием (например, масленицей или выпускным), то можно и отложить тестирование. И еще одно При создании инструмента с полноценными психометрическими (вас длинные слова не расстраивают?) свойствами сначала необходимо установить его надежность (мы только что потратили на это Глава 6 Только правда 153 некоторое время). Почему? Если тест или измерительный инструмент ненадежен, несогласован и не делает одно и то же раз за разом, то не имеет значения, что он измеряет (а это вопрос достоверности), верно? На первом орфографическом диктанте в первом классе первые три задания могут оказаться такими: 16 + 12 = ? 21 + 13 = ? 41 + 33 = ? Это, определенно, высоконадежный тест, но уж точно вовсе не достоверный. Теперь, когда мы хорошо разобрались с надежностью, давайте перейдем к достоверности. ДОСТОВЕРНОСТЬ: В ЧЕМ ПРАВДА, БРАТ? Простыми словами: достоверность, или валидность, – это свойство инструмента оценки, которое показывает: этот инструмент делает именно то, что он обещает сделать. Достоверный тест – это тест, который измеряет то, что планирует измерить. Если предполагается, что тест на интеллект измеряет то, что создатели теста понимают под интеллектом, то он делает именно это. Виды достоверности Точно так же, как и надежность, достоверность бывает разных видов, и мы рассмотрим в этой части три самые важные и часто применяемые категории. Все они кратко описаны в табл. 6.7. Содержательная достоверность Содержательная достоверность – это свойство теста, показывающее, насколько хорошо задания теста отображают понятийную область, для оценки которой разработан тест. Содержательная достоверность чаще всего применяется для тестирования знаний и навыков, т. е. везде, начиная с первой контрольной по правописанию и заканчивая экзаменом на выявление академических способностей. Как установить содержательную достоверность Установить содержательную достоверность на самом деле очень просто. Все, что вам нужно сделать, – это найти местного (и готового сотрудничать) эксперта по содержанию. Например, если бы я разрабатывал тест для вводного курса физики, то пошел к местному эксперту по физике (возможно, учителю в средней школе или профессору в университете) и сказал: «Привет, Альберт (или Альберта). Как Вы думаете, этот набор из ста вопросов множественного выбора Часть II 154 ∑игма Фрейд и описательная статистика точно отображает все возможные темы и идеи, которые должны понимать учащиеся на моем вводном курсе физики?» Вероятно, я бы сказал Альберту (или Альберте), какие разделы входят в курс, а затем он или она посмотрел(а) бы на задания и выразил(а) мнение о том, подходят ли они к заданному мной критерию – соответствуют ли понятийной области вводного курса физики. Если ответ «да», то мое дело сделано (по крайней мере, на данный момент). Если ответ «нет», то нужно все начать сначала и разработать новые вопросы или уточнить уже имеющиеся (до тех пор, пока содержание не покажется эксперту правильным). Таблица 6.7 Вид достоверности Виды достоверности и условия их применения, правила расчета и значения Когда применяется Содержательная Когда вы хотите знать, достоверность действительно ли набор вопросов соответствует выбранной теме Критериальная достоверность Когда вы хотите знать, действительно ли результаты теста систематически связаны с другими критериями, указывающими, что тестируемый обладает компетенциями в определенной области Конструктивная Когда вы хотите знать, достоверность измеряет ли тест какой-то базовый психологический конструкт Как посчитать Спросите у эксперта, действительно ли набор вопросов в тесте отображает понятийную область, которую вы хотите измерить Соотнесите результаты теста с каким-то другим показателем с доказанной достоверностью, который оценивает тот же самый набор способностей Соотнесите результаты теста с каким-то теоретическим представлением, которое описывает компонент, для которого был разработан тест Пример того, что вы можете сказать, когда посчитаете Мой еженедельный опрос на занятиях по статистике честно оценивает знание содержания этой главы Тест на кулинарные способности имеет корреляцию с двухлетним опытом работы в качестве шеф-повара после окончания кулинарной школы (пример предсказательной достоверности) И верно: мужчины, занимающиеся контактными и физически опасными видами спорта, имеют более высокие показатели при тестировании на агрессию Критериальная достоверность Критериальная достоверность оценивает, отображает ли тест соответствие свойств оцениваемых какому-то критерию в настоящем или будущем времени. Если критерий проявляется здесь и сейчас, мы говорим о текущей критериальной достоверности. Если критерий проявится в будущем, то мы говорим о предсказательной достоверности. Для обеспечения критериальной достоверности нет необходимости устанавливать и текущую, и предсказательную достоверность. Достаточно той, которая отвечает целям теста. Как установить текущую достоверность Например, вы были наняты Всеобщим кулинарным институтом для разработки инструмента для оценки кулинарных навыков. Некото- Глава 6 Только правда 155 рая часть обучения кулинарии относится к теории (например, что такое ру?). А это область применения тестов на знания. Итак, вы разрабатываете тест, который, по вашему мнению, хорошо измеряет кулинарные навыки. Сейчас вы хотите установить уровень текущей достоверности. Для того чтобы это сделать, вы разрабатываете шкалу оценок (для которой выбираете диапазон от 1 до 100) и набор заданий для оценки по нескольким критериям (таким, например, как подача, пищевая безопасность, чистота и т. д.), которыми будут пользоваться проверяющие. В качестве критерия (и это ключевой момент) вы возьмете оценки другой группы судей, которые присвоят каждому студенту ранг от 1 до 10 в зависимости от их кулинарных способностей. Затем вы просто посчитаете корреляцию между оценками по вашей шкале и оценками судей. Если коэффициент достоверности (простая корреляция) будет высок, то вы в деле, а если нет – начинайте все сначала. Как установить предсказательную достоверность Предположим, что кулинарная школа существует на рынке уже в течение 10 лет. Вас интересует не только то, насколько хорошо люди готовят (это имеет отношение к текущей достоверности, которую вы уже установили), но и предсказательная способность теста. Теперь критерий смещается от оценки текущего положения вещей (которую дают судьи) к той, что оценивает будущее. Здесь нас интересует разработка теста, который предсказывал бы успех повара через 10 лет после его прохождения. Для установки предсказательной достоверности вашего теста вы находите выпускников школы, которые занимаются готовкой уже 10 лет, и тестируете их. Используемый здесь критерий – это их уровень успеха. В качест­ ве показателя такового вы берете наличие у них собственного ресторана и время его существования, т. е. работает ли этот ресторан уже больше года (учитывая, что 80 % новых ресторанов закрываются в течение первого года). Суть в том, что если ресторан продержался на рынке более года, то, должно быть, шеф-повар делает все правильно. Для завершения задачи вы рассчитываете корреляцию между оценкой за тест, которую получили выпускники школы, владеющие рестораном, открытым более года назад, и их предыдущей оценкой за этот тест (10 лет назад). Высокий коэффициент корреляции указывает на предсказательную достоверность, а низкая корреляция – на ее отсутствие. Конструктивная достоверность Конструктивная достоверность – это самая интересная и самая сложная из всех видов достоверности, потому что она основана на каком-то базовом конструкте, или идее, стоящей за тестом или инст­рументом измерения. 156 Часть II ∑игма Фрейд и описательная статистика Возможно, вы помните из вводного курса психологии, что конструкт — это группа взаимосвязанных переменных. Например, агрессия — это конструкт (состоящий из таких переменных, как неуместные прикосновения, насилие, недостаток успешного социального взаимодействия и т. д.), точно так же, как и интеллект, материнско-детская привязанность и надежда. И помните, что эти конструкты возникают из некоторой теоретической позиции, которую занимает исследователь. Например, он или она может предполагать, что агрессивные мужчины имеют больше проблем с правоохранительными органами, чем неагрессивные. Как установить конструктивную достоверность Итак, у вас есть тест на агрессию – инструмент наблюдения, который состоит из нескольких компонентов. Это продукт ваших теоретических взглядов на то, из чего состоит конструкт агрессии. Вы знаете из литературы по криминологии, что агрессивные мужчины совершают некоторые поступки чаще, чем другие. Например, они больше участвуют в спорах, проявляют физическую агрессию (толкаются и т. п.), совершают насильственные преступления против других, при этом у них меньше успешных межличностных отношений. Ваша шкала агрессии включает в себя аспекты, которые описывают разные виды поведения, одни из которых теоретически относятся к агрессивному, а другие – нет. После завершения оценки агрессии по вашей шкале вы проверяе­ те результаты на предмет наличия корреляции между положительными оценками агрессии и действительным проявлением тех видов поведения, которые вы предсказываете в соответствии со своей теорией (таких как уровень вовлеченности в правонарушения, качество личных отношений и т. д.), и отсутствия корреляции с поведением, которое не должно иметь связи с агрессией (например, право- или леворукость, предпочтения определенной еды). Если корреляция окажется высокой для предсказанных вами аспектов и низкой для тех, у которых она и ожидалась таковой, тогда вы можете заключить, что в вашей шкале агрессии есть что-то здравое (возможно, разработанные вами компоненты для оценки элементов агрессии). Поздравляю! А если не получается установить достоверность – что тогда? Что ж, это сложный вопрос, особенно учитывая, как много видов достоверности существует. В общем, если у вас нет нужных вам доказательств достоверности, то это оттого, что ваш тест не делает того, что должен. Если это тест Глава 6 Только правда 157 знаний и умений и вы стремитесь к удовлетворительному уровню содержательной достоверности, тогда, вероятно, вам придется переписать вопросы своего теста, чтобы привести их в соответствие с мнением эксперта, который вас консультировал. Если вам важна критериальная достоверность, тогда, вероятно, нужно перепроверить суть заданий теста и спросить себя: «Насколько, по моим ожиданиям, ответы на эти вопросы должны соотноситься с выбранным критерием?» Конечно, это предполагает, что используемый вами критерий имеет смысл. Наконец, если вы ищете и не находите конструктивной достоверности, то лучше обратитесь к теоретическому обоснованию, на котором основывается разработанный вами тест. Возможно, ваши определение и модель агрессии неверны, а может быть, определение и представление об интеллекте нуждаются в критической доработке. Ваша задача – согласовать между собой теорию и задания теста, основанные на этой теории. ДРУЖЕСТВЕННОЕ НАПУТСТВИЕ Все эти измерения довольно крутые. Это развивает ум. К тому же в наше время индивидуальной ответственности все хотят знать о результатах развития студентов, брокеров, профессоров(!), программ социальной поддержки и т. д. Из-за такого сильного и постоянно растущего интереса к ответственности и измерению результатов у студентов, работающих над курсовым проектом, или выпускников, пишущих диплом либо диссертацию, появляется искушение разработать собственный инструмент для итогового проекта. Имейте в виду, то, что кажется хорошей идеей, может привести к катастрофе. Процесс установки надежности и достоверности любого инструмента может занять годы напряженной работы. А хуже всего, когда наивный или ничего не подозревающий человек хочет создать новый инструмент для проверки новой гипотезы. Это значит: помимо всего остального, что сопутствует тестированию новой гипотезы, возникает задача обеспечения правильной работы инструмента. Если вы занимаетесь собственным исследованием, например для диплома или диссертации, обязательно найдите показатель, который уже имеет хорошо обоснованные надежность и достоверность. Таким образом, вы сможете заняться основной работой по тестированию гипотез, а не возиться с труднейшей задачей разработки инструментария, которая сама по себе может стать делом жизни. 158 Часть II ∑игма Фрейд и описательная статистика ДОСТОВЕРНОСТЬ И НАДЕЖНОСТЬ – ОЧЕНЬ БЛИЗКИЕ РОДСТВЕННИКИ Давайте на минуту оглянемся назад и вспомним одну из причин, по которой вы вообще читаете эту главу. Вам сказали ее прочитать. Нет, в самом деле. Эта глава важна, потому что вам нужно что-то знать о надежности и достоверности инструментов, которые используете для измерения результатов. Почему? Если эти инструменты не являются надежными и достоверными, тогда результаты вашего эксперимента всегда будут подвергаться сомнениям. Как мы упоминали ранее в этой главе, у вас может быть надежный, но недостоверный тест. Однако ваш тест не может быть достоверным, если он изначально оказался ненадежным. Почему? Тест может делать то, что он делает, раз за разом (это надежность), но все же не выполнять того, что должен (это достоверность). Если тест делает то, что от него ожидается, то он должен делать это без сбоев. Вы уже прочитали в разных местах этой главы о взаимосвязи между надежностью и достоверностью, но между ними маячит еще одно важное отношение, о котором вы можете прочитать как-нибудь позже и о котором вам следует знать. Это отношение говорит, что максимальный уровень достоверности равен квад­ ратному корню из коэффициента надежности. Например, если коэффициент надежности для проверки технических способностей равен 0,87, то коэффициент достоверности не может быть выше, чем 0,93 (что является квадратным корнем из 0,87). На техническом языке это означает, что достоверность теста ограничена его надежностью. И это закономерно, если мы задумаемся, что прежде чем убедиться, что тест выполняет заявленное к выполнению, он должен бесперебойно делать то, что делает. И это тесная взаимосвязь. У вас не может быть достоверного инструмента, если он ненадежен. Для того чтобы что-то делало то, что должно делать, ему для начала следует делать это без перебоев, верно? Так что эти двое работают рука об руку. РЕАЛЬНАЯ СТАТИСТИКА Вот классический пример того, почему так важно понимать и обес­ печивать наличие достоверности при проведении любого исследования или при использовании результатов исследования для руководства действиями профессионалов. В данном случае исследование было посвящено оценке синдрома дефицита внимания и гиперактивности (СДВГ). Зачастую этот диагноз искажается из-за субъективной оценки симптомов и отчетов родителей и учителей. Относительно новая Глава 6 Только правда 159 практика применения тестов действия (которые измеряют устойчивое и выборочное внимание) пробудила ожидания, что диагностика СДВГ станет более стандартизированной и точной. Это качества любого надежного и достоверного теста. В этом исследовании Натанел Зелник (Nathanel Zelnik) со своими коллегами обратился к результатам теста вариабельности внимания, который выполнили 230 детей, получивших рекомендацию посетить клинику СДВГ. В группе критерия, состоявшей из 179 детей с диагностированным СДВГ, тест вариабельности внимания предположил наличие СДВГ у 163 человек (чувствительность 91,1 %), но он также предположил СДВГ у 78,4 % детей без данного синдрома. В результате этот тест оказался недостаточно надежным измерителем для точного различения этих двух групп. Хотите узнать больше? Найдите в интернете или библиотеке статью... Zelnik N., Bennett-Back O., Miari W., Geoz H. R. & Fattal-Valevski A. Is the test of variables of attention reliable for the diagnosis of attentiondeficit hyperactivity disorder (ADHD)? Journal of Child Neurology, 2012. Р. 703–707. Реальная статистика ВЫВОДЫ ПО ГЛАВЕ Да, это курс по статистике, так что же здесь делает материал про измерения? Напомним, что почти любое применение статистики вращается вокруг измерения какого-то результата. Точно так же, как вы читаете основы статистики с целью извлечения смысла из множества данных, вы должны получить базовую информацию про измерения, чтобы понять, каким образом оцениваются поведение, результаты тестов, ранжирование и рейтинги. Выводы по главе ВРЕМЯ ПРАКТИКИ 1.Сходите в библиотеку и найдите пять журнальных статей по своей специальности, в которых приведены данные о надежности и достоверности. Обсудите используемые показатели результатов. Определите, какой тип надежности и достоверности был установлен. Как вы думаете, приемлемы ли такие уровни? Если нет, как можно их улучшить? 2.Приведите пример, когда бы вам было нужно установить ретестовую надежность и надежность параллельных форм. 3.Вы разрабатываете инструмент, который измеряет профессиональные предпочтения (т. е. чем люди хотят зарабатывать себе на жизнь), и вам нужно несколько раз в течение одного года прове- 160 Часть II ∑игма Фрейд и описательная статистика сти тестирование студентов, посещающих программу профподготовки. Вам нужно оценить ретестовую надежность теста и данных от двух этапов тестирования (приведенных в файле «Глава 6. Набор данных 1» (Chapter 6. Data Set 1)): осеннего и весеннего. Можете ли вы назвать этот тест надежным? Почему? 4.Каким образом тест может быть надежным и при этом недостоверным? Приведите пример. Почему тест не может быть достоверным, если он ненадежен? 5.Представьте ситуацию. Вы возглавляете программу разработки тестов для офиса службы занятости. Вам необходимо выдать минимум два варианта одного и того же теста в один и тот же день. Какой вид надежности вы хотите установить? Используйте данные из файла «Глава 6. Набор данных 2» (Chapter 6. Data Set 2) для расчета коэффициента надежности между первым и вторым вариантами теста на базе 100 написавших его человек. Достигли ли вы своей цели? 6.Опишите общими словами, на что будет похож надежный, но недостоверный тест. Теперь сделайте то же самое для достоверного, но ненадежного теста. 7.Почему при проверке экспериментальной гипотезы важно, чтобы тест, используемый для измерения результатов, был одновременно и надежным, и достоверным? 8.Опишите различия между содержательной, предсказательной и конструктивной достоверностью. Приведите примеры того, как измеряется каждая из них. 9.Опишите шаги, которые необходимо предпринять для оценки конструктивной надежности наблюдательной письменной проверки, оценивающей «нестандартное мышление». ЧАСТЬ III Карты, деньги, вероятности «А это моя статистически значимая половина» 161 Часть III 162 Ч Карты, деньги, вероятности то вы уже знаете, и что будет дальше? У вас есть действительно крепкая база для понимания того, как можно описать характеристики набора величин или отличие одного распределения от другого. Это то, что вы узнали из глав 2, 3 и 4. Благодаря главе 5 вы изучили, как описать связи между переменными при помощи корреляции. А из главы 6 вы узнали о важности надежности и достоверности для оценки объективности результатов любого теста или любых других измерений. Пришла пора поднять ставки и начать серьезную игру. В части III «Статистики для тех, кто (думает, что) ненавидит статистику», а именно в главе 7, вы познакомитесь со значением и сущностью проверки гипотез, в том числе с подробным обсуждением того, что такое гипотеза, какие бывают типы гипотез, какова их функция, почему и как они проверяются. В главе 8 мы перейдем к немаловажной теме вероятности, представленной в обсуждении нормальной кривой и базовых принципов лежащей в ее основе вероятности. Это та часть статистики, которая помогает нам определить, насколько велика вероятность какого-то события (например, того, что тест выдаст определенный результат). Мы будем опираться в своих рассуждениях на нормальную кривую, и вы увидите, что каждому значению или событию в любом распределении соответствует связанная с ним вероятность. После упражнений с вероятностью и нормальной кривой мы будем готовы перейти в части IV к развернутому обсуждению того, как применить проверку гипотез и теорию вероятности к изучению конкретных вопросов об отношениях между переменными. Дальше будет только лучше! 7 Гипотезы и вы Проверяем свои вопросы Уровень сложности: ½ (ничего не планируйте на вечер) В ЭТОЙ ГЛАВЕ ВЫ УЗНАЕТЕ: в чем разница между выборкой и генеральной совокупностью; важность нулевой и альтернативной гипотез; по каким критериям определить хорошую гипотезу. ИТАК, ВЫ ХОТИТЕ БЫТЬ УЧЕНЫМ… Возможно, вы слышали термин гипотеза на занятиях по другим предметам. Возможно, вам даже пришлось формулировать свою гипотезу для исследовательского проекта. Может быть, вы встречали их в научных статьях. Если это так, то, вероятно, у вас есть неплохое представление о том, что такое гипотеза. Для тех, кто еще незнаком с этим часто используемым термином, скажем, что гипотеза – это, по сути, «догадка, основанная на фактах». Ее самая важная роль состоит в том, чтобы отражать общую постановку проблемы или вопроса, который послужил причиной для формулировки темы исследования. Именно поэтому так важно уделить время и внимание формулировке действительно точной и ясной темы исследования. Эта тема будет направлять вас при создании гипотезы, и, в свою очередь, гипотеза определит методики, которыми вы будете пользоваться, чтобы проверить ее и ответить на изначально выраженный в теме вопрос. Итак, хорошая гипотеза переводит постановку проблемы или тему исследования в форму, более подходящую для проверки. Эта форма и называется гипотезой. Позже в этой главе мы поговорим о том, что делает гипотезу хорошей. А до этого давайте обратим внимание на разницу между выборкой и генеральной совокупностью, или популяцией. Это различие имеет значение, поскольку при проверке ги- Введение в главу 7 163 164 Часть III Карты, деньги, вероятности потезы мы имеем дело с выборкой, а затем результаты распространяются на всю генеральную совокупность. Мы также рассмотрим два основных вида гипотез (нулевую и альтернативную). Но для начала давайте дадим формальные определения некоторым простым терминам, которые мы уже использовали ранее. ВЫБОРКА И ГЕНЕРАЛЬНАЯ СОВОКУПНОСТЬ В поисках ошибки выборки Хорошему ученому хочется иметь возможность сказать, что если Метод А лучше, чем Метод Б по результатам исследования, то это верно всегда, везде и для всех. Если вы проведете достаточно исследований относительно достоинств методов А и Б и протестируете необходимое количество людей, то однажды сможете так сказать. Учитывая ограничения в виде нехватки времени и постоянного дефицита финансирования для исследований, с которыми сталкиваются практически все ученые, лучшей альтернативой этому будет следующий вариант: взять часть от большой группы участников и изучить эту маленькую подгруппу. В этом контексте большая группа будет называться генеральной совокупностью, а маленькая, отобранная из этой совокупности, – выборкой. Показатель того, насколько хорошо выборка отображает свойства генеральной совокупности, называется ошибкой репрезентативности. Ошибка репрезентативности – это, по сути, разница между значениями статистики выборки и параметрами генеральной совокупности. Чем выше ошибка репрезентативности, тем больше погрешность вашей выборки, следовательно, тем сложнее будет доказать, что результаты, полученные для нее, действительно отображают то, что вы ожидали обнаружить в генеральной совокупности. И точно так же, как существуют меры изменчивости для распределений, есть и показатели изменчивости для этой разницы между выборкой и генеральной совокупностью. Она часто называется стандартной ошибкой – по сути, это стандартное отклонение для разницы между показателем выборки и генеральной совокупности. Выборки нужно формировать таким образом, чтобы они как можно точнее отображали характеристики генеральной совокупности. Задача – сделать так, чтобы выборка была как можно больше похожа на генеральную совокупность. Основной смысл обес­ печения сходства между ними состоит в том, что в этом случае результаты, полученные на выборке, можно будет обобщить для всей совокупности. Когда выборка точно отображает генеральную совокупность, говорят о высокой степени обобщаемости результатов исследования. Высокая степень обобщаемости является важным качеством для хорошего исследования, потому что она означает, что время, усилия Глава 7 Гипотезы и вы 165 и средства, затраченные на исследование, могут иметь значение для широких групп людей, а не только для его участников. Легко приравнять «большую» к «репрезентативной». Имейте в виду, что гораздо более важно иметь репрезентативную выборку, чем большую (люди часто думают, что чем больше, тем лучше, но это верно только для индейки в День благодарения). Толпы участников в выборке, может, и выглядят впечатляюще, но если они не отображают свойства большей генеральной совокупности, то исследование будет иметь мало ценности. НУЛЕВАЯ ГИПОТЕЗА Итак, у нас есть выборка участников, отобранных из генеральной совокупности. Для того чтобы начать проверку предположений нашего исследования, мы для начала сформулируем нулевую гипотезу. Нулевая гипотеза – очень интересная штука. Если бы она могла говорить, то сказала бы что-то вроде: «Я отражаю отсутствие связи между переменными, которые вы изучаете». Другими словами, нулевые гипотезы – это утверждения об отсутствии разницы, как в приведенных ниже реальных нулевых гипотезах, взятых из разных популярных журналов по социальным и поведенческим наукам (имена были изменены для защиты персональных данных): Нулевая гипотеза zz между учениками 9-го и 12-го классов не будет наблюдаться различий в средних результатах теста на память; zz в плане эффективности поощрения социальной активности пожилых людей при измерении по шкале Марголиса нет различий между длительным уходом на дому и длительным уходом в доме престарелых; zz отсутствует связь между временем реакции и способностями к решению задач; zz между белыми и черными семьями нет различий в объеме помощи, предлагаемой детям для выполнения школьных заданий. Что объединяет все эти четыре нулевые гипотезы, так это содержащееся в них утверждение, что два или более явлений равны или вовсе не взаимосвязаны друг с другом (та самая часть про «нет различий» и «отсутствует связь»). Назначение нулевой гипотезы Каково основное назначение нулевой гипотезы? Нулевая гипотеза выступает одновременно в качестве начальной точки и точки контроля, по которой можно оценить фактические результаты исследования. Давайте изучим каждую из этих задач более подробно. Во-первых, нулевая гипотеза выступает в качестве начальной точки, потому что это положение дел, которое принимается за истинное 166 Часть III Карты, деньги, вероятности при отсутствии любой другой информации. Например, давайте посмотрим на первую нулевую гипотезу из приведенных ранее: «Между учениками 9-го и 12-го классов не будет наблюдаться различий в средних результатах теста на память». При условии отсутствия любого знания о навыках памяти у учеников 9-го и 12-го классов у вас нет причин предполагать, что между этими двумя группами будут какие-то различия, верно? Если вы ничего не знаете об отношениях между этими переменными, лучшее, что вы можете сделать, – это предполагать. А это догадки на удачу. Вы можете, конечно, рассуждать, почему одна группа может показывать результаты лучше, чем другая, но если у вас нет никаких априорных (до получения фактов) доказательств, то какой еще выбор у вас есть, кроме как предположить, что они равны? Эта начальная точка в виде отсутствия связи является визитной карточкой всего этого подхода. Другими словами, до тех пор пока не докажете наличие разницы, вы должны полагать, что разница отсутствует. И утверждение об отсутствии различий или взаимосвязи – это именно то, из чего состоит нулевая гипотеза. Такое утверж­дение дает нам (как представителям научной общественности) уверенность, что мы начинаем с равных для всех условий, без каких-либо предубеждений о том, в чью пользу выльется проверка нашей гипотезы. Более того, если между двумя группами обнаружатся различия, вы должны предположить, что они объясняются самой привлекательной причиной различий между любыми группами переменных – случайностью! Именно так: при условии отсутствия другой информации случайность является самым вероятным и самым приемлемым объяснением наблюдаемых различий между группами или взаимосвязи между переменными. Случайность объясняет то, что не можем объяснить мы. Возможно, вы представили случайность как вероятность выиграть 5000 долл. в игровом автомате, но мы говорим о случайности, имея в виду все то, что затуманивает картину и еще больше затрудняет понимание «истинной» природы отношений между переменными. Например, вы можете взять группу игроков в английский и американский футбол и сравнить скорость их бега, размышляя, игра в какой футбол делает атлетов более быстрыми. Но посмотрите на все факторы, о которых мы не знаем и которые могут внести свой вклад в различия. Кто знает, может быть, некоторые игроки в английский футбол больше тренируются, или некоторые американские футболисты сильнее, или, возможно, обе группы имеют дополнительные тренировки? Более того, возможно, способ измерения их скорости оставляет место для случайности. Неисправный секундомер или ветреный день может привести к различиям, которые не имеют отношения к настоящей скорости бега. Работа хороших исследователей заключается в том, чтобы исключить фактор случайности из объяснений Глава 7 Гипотезы и вы 167 наблюдаемых различий и оценить другие факторы, способные повлиять на групповые результаты (например, специальные тренировки или программы питания), и проверить, как они воздействуют на скорость. Дело в том, что если мы обнаружим различия между группами и их причина не будет связана с тренировками, у нас не останется другого выбора, кроме как объявить эти различия случайными. Кстати, иногда полезно думать о случайности как о некоем эквиваленте ошибки. Когда есть возможность контролировать источники ошибок, возрастает вероятность того, что мы сможем предложить имеющее смысл объяснение какого-то результата. Вторая задача нулевой гипотезы состоит в обеспечении контрольной точки, с которой можно будет сравнить наблюдаемые результаты, чтобы увидеть, объясняются ли эти различия каким-то другим фактором. Нулевая гипотеза помогает определить диапазон, в рамках которого любые наблюдаемые различия между группами могут быть отнесены к случайным (что утверждает нулевая гипотеза) или возникшим по другим причинам (которые могут быть результатом манипуляций с какой-то переменной, как, например, в случае с тренировками игроков в английский и американский футбол). Большинство исследований подразумевает наличие нулевой гипотезы, и вы можете не найти ее в явном виде в отчете или научной статье. Вместо этого вы обнаружите явную формулировку альтернативной гипотезы, и именно на нее мы и переключим сейчас внимание. АЛЬТЕРНАТИВНАЯ ГИПОТЕЗА В то время как нулевая гипотеза утверждает отсутствие связи между переменными, альтернативная гипотеза является явным утверждением того, что между переменными существует связь. Например, для каждой из приведенных ранее нулевых гипотез существует какая-то соответствующая ей альтернативная. Обратите внимание, что мы сказали «какая-то», а не «единственная» альтернативная гипотеза, потому что, конечно, для одной нулевой гипотезы может быть сформулировано несколько альтернативных. Посмотрите на примеры: zz между учениками 9-го и 12-го классов имеются различия в средних результатах теста на память; zz в плане эффективности поощрения социальной активности пожилых людей при измерении по шкале Марголиса есть различия между длительным уходом на дому и длительным уходом в доме престарелых; zz существует положительная связь между временем реакции и способностями к решению задач; Альтернативная гипотеза 168 Часть III Карты, деньги, вероятности zz между белыми и черными семьями имеются различия в объеме помощи, предлагаемой детям для выполнения школьных заданий. Все четыре альтернативные гипотезы объединяет одно: они утверж­дают отсутствие равенства. Эти гипотезы постулируют взаи­ мосвязь между переменными, а не их независимость, как делает нулевая гипотеза. Суть этого неравенства может принять две разные формы: направленную или ненаправленную альтернативные гипотезы. Если альтернативная гипотеза не указывает на направление неравенства (как в формулировке «отличается от»), то это ненаправленная гипотеза. Если альтернативная гипотеза указывает на направление неравенства (как в формулировке «больше, чем» или «меньше, чем»), то это направленная гипотеза исследования. Ненаправленная альтернативная гипотеза Ненаправленная альтернативная гипотеза отображает различие между группами, но направление этого различия не уточняется. Например, альтернативная гипотеза «между учениками 9-го и 12-го классов имеются различия в средних результатах теста на память» является ненаправленной, поскольку не указывает на направление различий между двумя группами. Эта гипотеза является альтернативной, потому что она утверждает наличие различий. Она ненаправленная, потому что ничего не говорит о направлении различий. Ненаправленная альтернативная гипотеза вроде этой будет описываться следующим уравнением: _ _ (7.1) H1 : X9 ≠ X12, где H1 является обозначением _ первой (из, возможно, нескольких) альтернативной гипотезы; X9 обозначает средний балл по тесту па_ мяти для выборки из учеников 9-го класса; X12 обозначает средний балл по тесту памяти для выборки из учеников 9-го класса; ≠ означает «не равно». Направленная альтернативная гипотеза Направленная альтернативная гипотеза отображает различие между группами и уточняет направление этого различия. Например, альтернативная гипотеза «средние результаты теста на память у учеников 12-го класса выше, чем средние результаты у учеников 9-го класса» является направленной, потому что указывается направление различия между двумя группами. Одна из них предположительно будет больше (а не просто отличной от другой). Глава 7 Гипотезы и вы 169 Примеры направленных гипотез таковы: zz A больше, чем B (или A > B); zz B больше, чем A (или A < B). Обе они указывают на различия (больше или меньше, чем). Направленная альтернативная гипотеза вроде той, что приведена выше, где ученики 12-го класса предположительно имеют лучшие результаты, чем 9-го, будет описываться следующим уравнением: _ _ H1 : X12 > X9, (7.2) где H1 является обозначением _ первой (из, возможно, нескольких) альтернативной гипотезы; X9 обозначает средний балл по тесту па_ мяти для выборки из учеников 9-го класса; X12 обозначает средний балл по тесту памяти для выборки из учеников 9-го класса; > означает «больше, чем». Каково назначение альтернативной гипотезы? Важным этапом исследовательского процесса является ее проверка. Результаты этой проверки сравниваются с теми, которые могли бы быть вызваны только случайностью (и описаны в нулевой гипотезе), чтобы проверить, какая из двух гипотез предлагает лучшее объяснение наблюдаемым различиям между группами или переменными. В табл. 7.1 приведены четыре нулевые гипотезы и сопутствующие им направленные и ненаправленные альтернативные гипотезы. Таблица 7.1 Нулевые гипотезы и соответствующие им альтернативы Ненаправленная альтернативная гипотеза Между учениками 9-го Ученики 12-го и 9-го классов и 12-го классов не будет будут показывать разные наблюдаться различий в средних средние результаты результатах теста на память при тестировании памяти В плане эффективности Влияние длительного ухода поощрения социальной за пожилыми людьми на дому отактивности пожилых людей личается от влияния длительного при измерении по шкале Маргоухода в домах престарелых при лиса нет различий между длитель- измерении по шкале социальной ным уходом на дому и длительактивности Марголиса ным уходом в доме престарелых Нулевая гипотеза Отсутствует связь между временем реакции и способностями к решению задач Между белыми и черными семьями нет различий в объеме помощи, предлагаемой детям для выполнения школьных заданий Направленная альтернативная гипотеза Ученики 12-го класса будут иметь более высокие средние результаты теста на память, чем ученики 9-го Пожилые люди, длительный уход за которыми осуществляется на дому, показывают более высокие результаты по шкале социальной активности Марголиса, чем пожилые люди, получающие длительный уход в домах престарелых Существует связь между временем Существует положительная связь реакции и способностями между временем реакции к решению задач и способностями к решению задач Объем помощи, предлагаемой Объем помощи, предлагаемой детям для выполнения школьных детям для выполнения школьных заданий, в белых семьях заданий, в белых семьях больше, отличается от объема чем объем поддержки, поддержки, оказываемой детям оказываемой детям при выполнении школьных при выполнении школьных заданий, в черных семьях заданий, в черных семьях 170 Часть III Карты, деньги, вероятности Другим способом описания направленных и ненаправленных гипотез является применение одно- и двустороннего критерия проверки. Односторонний критерий (отображающий направленную гипотезу) постулирует различие в определенном направлении, такое как в гипотезе, что группа 1 покажет более высокие результаты, чем группа 2. Двусторонний критерий (отображающий ненаправленную гипотезу) постулирует различие без указания конкретного направления. Эта разница имеет значение, когда вы проверяете разные типы гипотез (одно- и двусторонние) и устанавливаете уровни вероятности для отклонения или принятия нулевой гипотезы. Больше об этом говорится в главе 9. Различия между нулевой и альтернативной гипотезами Вопросы о направлении проверки Помимо того что нулевая гипотеза представляет равенство, а альтернативная – отсутствие равенства, эти два вида гипотез имеют еще несколько важных различий. Во-первых, напоминаем, нулевая гипотеза утверждает, что между переменными нет связи (они равны), тогда как альтернативная гипотеза говорит, что между переменными есть взаимосвязь (они не равны). Это основное различие. Во-вторых, нулевая гипотеза всегда относится к генеральной совокупности, тогда как альтернативные гипотезы всегда относятся к выборке. Мы отбираем выборку участников из большей совокупности. Затем мы пытаемся обобщить результаты, полученные на выборке, на генеральную совокупность. Если вы помните основы философии и логики (вы же изучали эти предметы, верно?), то вспомните, что переход от малого (выборки) к большому (генеральной совокупности) – это процесс вывода. В-третьих, поскольку нельзя напрямую проверить всю генеральную совокупность (это непрактично, неэкономично и зачастую невозможно), вы не можете со 100%-ной уверенностью сказать, что нет действительных различий по какой-то переменной между сегментами генеральной совокупности. Скорее, вам придется вывести это (косвенно) из результатов проверки альтернативной гипотезы, которая основывается на выборке. Следовательно, нулевая гипотеза должна проверяться ненаправленно, а альтернативная гипотеза может быть проверена направленно. В-четвертых, нулевая гипотеза записывается со знаком равенства, тогда как альтернативная гипотеза записывается со знаками «не равно», «больше, чем» и «меньше, чем». В-пятых, нулевые гипотезы всегда записываются греческими буквами, а альтернативные – латинскими. Следовательно, нулевая гипотеза о том, что средний результат учеников 9-го класса равен среднему результату 12-го, записывается вот так: H0 : µ9 = µ12, (7.3) Глава 7 Гипотезы и вы где H0 обозначает нулевую гипотезу; µ9 обозначает теоретическое среднее значение для всей совокупности учеников 9-го класса; µ12 обозначает теоретическое среднее значение для всей совокупности учеников 12-го класса. Альтернативная гипотеза о том, что средний результат выборки учеников 12-го класса будет больше, чем средний результат выборки учеников 9-го, показана в формуле 7.2. Наконец, из-за того что нельзя напрямую проверить нулевую гипотезу, она подразумевается, тогда как альтернативная гипотеза явно выражена и сформулирована в качестве таковой. В том числе и поэтому в отчетах об исследованиях редко встречаются формулировки нулевых гипотез, но практически всегда есть прописанные словами или символами формулировки альтернативных гипотез. КРИТЕРИИ КАЧЕСТВА ХОРОШЕЙ ГИПОТЕЗЫ Теперь вы знаете, что гипотезы – это обоснованные догадки и начальная точка для гораздо большего. Как и в случае с любыми догадками, некоторые гипотезы оказываются лучше других с самого начала. Не устаем подчеркивать, как важно сформулировать вопрос, на который вы хотите получить ответ, и постоянно помнить, что любая выдвигаемая вами гипотеза должна являться прямым продолжением исходного заданного вопроса. Этот вопрос будет отражать ваши личные интересы и мотивы, а также понимание того, какие исследования проводились ранее. Имея все это в виду, предлагаем критерии, с помощью которых можно решить, насколько приемлема гипотеза, о которой вы читаете в статье или которую формулируете сами. В качестве примера будем использовать исследование, в котором изучается, как возможность отправить детей на занятия после уроков влияет на приспособленность их родителей к поздно заканчивающейся работе. Вот хорошо написанная прямая альтернативная гипотеза: «Родители, отдающие своих детей на программу продленного дня в школе, будут пропускать меньше рабочих дней в течение одного года и будут иметь более положительное отношение к работе, измеряемое по опроснику “Отношение к работе”, чем родители, не записавшие своих детей на такие программы». А вот критерии качества. Во-первых, хорошая гипотеза сформулирована как утверждение, а не как вопрос. Притом что приведенная выше гипотеза могла появиться в голове исследователя как вопрос: «Будут ли родители лучше относиться…?», она была переформулирована, потому что гипотезы работают лучше всего, когда в них есть четкое и прямое утверждение. 171 172 Часть III Карты, деньги, вероятности Во-вторых, хорошая гипотеза указывает на ожидаемую связь между переменными. Гипотеза в нашем примере явно описывает ожидаемые отношения между продленкой для детей, отношением родителей и количеством их отлучек с работы. Эти переменные изуча­ются на предмет того, влияет ли одна из них (посещение детьми группы продленного дня) на другие (количество отлучек и отношение к работе). Обратите внимание на слово «ожидаемую» в данном критерии. Определение ожидаемой связи помогает предотвратить беспорядочное выуживание любого отношения между переменными, которое может обнаружиться в исследовании (что называется «бессистемным подходом»). Это может быть очень заманчиво, но не очень продуктивно. Вы действительно можете куда-то попасть, пользуясь бессистемным подходом, но поскольку вы не знаете, откуда начнете, то у вас нет никакого о представления о том, где вы окажетесь. При «выуживании» взаимосвязей вы закидываете удочку и берете все, что на нее клюнет. Вы собираете данные обо всем, о чем только можете, не глядя на то, относятся ли они к интересующей вас теме, а также является ли вообще сбор данных разумной частью научного исследования. Или, если провести аналогию, вы заряжаете пулемет и палите во все, что движется, и, вероятно, во что-нибудь попадете. Но проблема в том, что вам может быть не нужно то, во что вы попали, и даже хуже, вы можете промахнуться мимо того, во что хотели попасть, а хуже всего (если это возможно) то, что вы можете даже не знать, во что же вы попали! Кому нужно больше данных и информации о техниках их обработки, читайте главу 17. Хорошие исследователи не хотят получить хоть что-нибудь, что они могут выловить или подстрелить. Им нужны конкретные результаты. Для их получения исследователям необходимы ясные, мощные и легко понимаемые начальные вопросы и гипотезы. В-третьих, гипотезы отображают теорию или источники, на которых они основаны. Как вы читали в главе 1, достижения ученых редко можно приписать исключительно их усердному труду. Ученые всегда в какой-то мере обязаны своим успехом множеству других исследователей, работавших ранее и заложивших фундамент для дальнейшего изучения. В хорошей гипотезе это проявляется в том, что в ней есть отсылка к существующей научной литературе и теории. Давайте предположим для приведенного выше примера, что существуют печатные работы, содержащие информацию, что родители чувствуют себя комфортнее, зная, что их дети находятся под присмотром в учебном заведении, и что в таком случае родители могут трудиться продуктивнее. Это знание позволяет выдвинуть гипотезу, что программа продленного дня может дать родителям нужное им чувство уверенности. В свою очередь, это чувство позволит Глава 7 Гипотезы и вы им сконцентрироваться на работе, вместо того чтобы звонить или слать смс с вопросами, действительно ли Рэйчел или Джорджи добрались до дома в полном порядке. В-четвертых, гипотеза должна быть краткой и целенаправленной. Нужно, чтобы она описывала отношения между переменными в утвердительной форме и была как можно более прямой и однозначной. Чем лучше она указывает на суть вопроса, тем легче будет другим (например, вашему научному руководителю или членам диссертационного совета) читать работу и в точности понимать, с какой целью выдвинута ваша гипотеза и каковы важные переменные в ней. На самом деле когда люди читают и оценивают научную работу (о чем вы узнаете больше в этой главе), первое, что многие из них делают, – это находят гипотезу, чтобы получить представление об общей цели исследования и о том, как оно будет проводиться. Хорошая гипотеза говорит вам об этих двух моментах. В-пятых, хорошие гипотезы – это проверяемые гипотезы, т. е. содержащие переменные, которые можно измерить. Это означает, что вы действительно можете исполнить намерение, заложенное в гипотезе. В приведенном примере гипотезы вы видите, что важно сравнить родителей, которые отдали своих детей на программу продленного дня, с теми, кто не сделал этого. Затем будут измерены такие показатели, как отношение и количество пропущенных рабочих дней. Выделение двух групп людей и измерение переменных отношения к работе и отгулов – вполне разумные задачи. Отношение к работе измеряется опросником «Отношение к работе» (название выдуманное, но вы понимаете суть), а количество неотработанных рабочих дней – это легко фиксируемая и однозначная метрика, почти всегда присутствующая в зарплатных ведомостях (предполагаем, что вам дали к ним доступ). Подумайте, насколько сложнее все было бы, если бы эта гипотеза была сформулирована так: «Родители, которые отдают своих детей на продленку, лучше относятся к работе». Хотя вы можете уловить тот же смысл, но в этом случае гораздо труднее интерпретировать результаты исследования, учитывая неоднозначную трактовку «лучшего отношения». Подводя итог, гипотезы должны: zz представлять собой утвердительное предложение; zz предполагать связь между переменными; zz отражать теорию или корпус печатных работ, на которых они основаны; zz быть краткими и по существу; zz быть проверяемыми. Когда гипотеза отвечает всем пяти критериям, вы понимаете, что она достаточно хороша, чтобы использовать ее в дальнейшем исследовании, которое тщательно проверит основной вопрос, из которого и возникла эта гипотеза. 173 Создание гипотез Часть III 174 Карты, деньги, вероятности РЕАЛЬНАЯ СТАТИСТИКА Реальная статистика Дополнительная реальная статистика Еще больше дополнительной реальной статистики Вам может показаться, что научный подход и применение нулевой и альтернативных гипотез – это обязательный атрибут в мире научных исследований. Что ж, вы ошибаетесь. Вот подборка некоторых статей, опубликованных в профессиональных журналах за последние годы, которые высказывают все больше беспокойства. Никто не готов отбросить научный метод в качестве лучшего подхода для проверки гипотез, но в целом неплохо иногда спросить себя, действительно ли данный метод подходит лучше всего везде и всегда. Хотите узнать больше? Найдите в интернете или библиотеке следующие статьи... zz Джефф Джилл (Jeff Gill) из Калифорнийского политехнического государственного университета указывает на множество моментов, ставящих под сомнение использование моделей проверки значимости нулевых гипотез в качестве лучшего способа оценки гипотез. Он делает упор на политологию (свою область знаний) и на то, каким образом часто неверно понимается применение данного инструментария. Вот данные статьи: Gill J. The insignificance of null hypothesis testing. Politics Research Quarterly, 1992. Р. 647–674. zz Говард Вайнер (Howard Wainer) и Даниель Робинсон (Daniel Robinson) развивают эту критику дальше и предполагают, что исторически применение таких процедур было оправданным, но модификация проверки значимости и интерпретаций выводов пошла бы на пользу современной науке. В сущности, они говорят, что для оценки результатов нужно использовать другие инструменты (например, размер эффекта, о котором мы поговорим в главе 11). Прочитайте об этом в статье: Wai­ ner H. & Robin­son D. H. Shaping up the practice of null hypothesis significance testing. Educational Researcher, 2003. Р. 22–30. zz Наконец, в действительно интересной статье «A Vast Graveyard of Undead Theories: Publication Bias and Psychological Science’s Aversion to the Null» Кристофер Фергюсон (Christopher Ferguson) и Мориц Хине (Moritz Heene) поднимают вопрос о том, что многие журналы отказываются пуб­ликовать результаты, подтверждающие нулевую гипотезу (например, об отсутствии различий между группами). Они полагают, что при отсутствии публикаций таких результатов ложные теории не проверяются и не тестируются на достоверность. Вследствие этого ставится под угрозу принцип воспроизводимости науки (очень важный аспект всего процесса научного познания). Узнать больше вы можете из статьи: Ferguson C. J. & Heene M. A vast graveyard of undead theories: Publication bias and psychological science’s aversion to the null. Perspectives on Psychological Science, 2012. Р. 555–561. Глава 7 Гипотезы и вы 175 Надеемся, благодаря приведенным примерам вы получили представление, что наука различает не только черное и белое и не придерживается шаблонов. Научное познание – это живой и динамический процесс, который всегда меняет объект своего внимания, методы и потенциальные результаты. ВЫВОДЫ ПО ГЛАВЕ Гипотеза является центральным компонентом любого научного исследования. Разные типы гипотез (нулевая и альтернативные) помогают сформировать план по поиску ответов на вопросы, заданные целью нашего исследования. Нулевая гипотеза является начальной точкой и мерилом исследования, и мы используем ее для сравнения, когда оцениваем приемлемость альтернативной гипотезы. А теперь давайте перейдем к тому, как же в самом деле проверяют гипотезы. Выводы по главе ВРЕМЯ ПРАКТИКИ 1.Сходите в библиотеку и выберите пять научных статей об эмпирических исследованиях (в которых содержатся реальные данные) в области ваших интересов. Для каждой статьи укажите следующее: а) какова нулевая гипотеза (выраженная явно или неявно); б) какова альтернативная гипотеза (выраженная явно или не­ явно); в) что насчет статей, где нет ни одной явно или неявно выраженной гипотезы? Выделите эти статьи и попробуйте написать альтернативную гипотезу для них. 2.Пока вы еще в библиотеке, выберите две другие статьи по интересующей вас теме и дайте краткое описание выборки и того, как она была отобрана из генеральной совокупности. Обязательно сделайте вывод о том, насколько ответственно исследователи подошли к отбору выборки. Будьте готовы обосновать свой ответ. 3.Для приведенных ниже вопросов исследования сформулируйте одну нулевую гипотезу, одну направленную альтернативную гипотезу и одну ненаправленную альтернативную гипотезу: а) какое влияние оказывает устойчивость внимания на усидчивость во время занятий в классе? б) какова связь между качеством брака и качеством отношений супругов со своими братьями и сестрами? в) как лучше всего лечить расстройство пищевого поведения? 4.Вернитесь к пяти гипотезам, выделенным в вопросе 1, и оцените каждую из них по пяти критериям, приведенным в конце этой главы. 176 Часть III Карты, деньги, вероятности 5.К какого рода проблемам может привести использование плохо написанной или неоднозначной альтернативной гипотезы? 6.Что такое нулевая гипотеза, и в чем состоит одно из ее важных назначений? Чем она отличается от альтернативной гипотезы? 7.Что такое случайность в контексте альтернативной гипотезы? Что мы делаем со случайностью в своих экспериментах? 8.Почему нулевая гипотеза предполагает отсутствие связи между переменными? 8 Нормальны ли ваши кривые? Вероятность и ее значение Уровень сложности: (не очень легко и не очень сложно, но очень важно) В ЭТОЙ ГЛАВЕ ВЫ УЗНАЕТЕ: что такое вероятность, и почему она лежит в основе понимания статис­тики; как использовать характеристики нормального распределения; как рассчитать и интерпретировать z-оценки. ПОЧЕМУ ВЕРОЯТНОСТЬ? А вы-то думали, что изучаете статистику! Ха! Что же, как вы узнаете из этой главы, вероятность лежит в основе кривой нормального распределения (подробнее об этом поговорим позже) и является базой для статистики вывода. Почему? Во-первых, кривая нормального распределения дает нам базу для понимания вероятности, связанной с любым возможным результатом (например, вероятности получить определенную оценку за тест или вероятности выкинуть орла при подбрасывании монеты). Во-вторых, изучение вероятности дает нам основание для определения степени уверенности, с которой мы утверждаем, что конкретный вывод или результат является истинным. Лучше сказать, что результат (вроде среднего значения) получился не только благодаря счастливой случайности. Например, давайте сравним группу А (которая каждую неделю дополнительно тренировалась в плавании по 3 ч) и группу Б (у которой не было дополнительных тренировок по плаванию). Мы обнаружили, что группа А показывает отличные от группы Б результаты при проверке физической формы, но можем ли мы сказать, что эта разница объясняется дополнительной прак- Введение в главу 8 Базовое введение в теорию вероятности 177 178 Часть III Карты, деньги, вероятности тикой? Может быть, на нее повлияло что-то еще? Инструменты теории вероятности позволяют нам определить точное математическое правдоподобие того, что причиной различия являются тренировки (и только они), а не что-либо иное (например, случайность). Время, потраченное на гипотезы в предыдущей главе, прошло не зря. Когда мы сведем воедино понимание сущности нулевой и альтернативной гипотез с основными понятиями теории вероятности, то будем в состоянии обсуждать, насколько вероятны определенные результаты (сформулированные в альтернативной гипотезе). КРИВАЯ НОРМАЛЬНОГО РАСПРЕДЕЛЕНИЯ ( ТАКЖЕ ИЗВЕСТНАЯ КАК « КОЛОКОЛЬЧИК ») Что такое нормальная кривая? Кривая нормального распределения (которую также называют колоколом распределения) – это визуальное представление распределения данных, которое описывается тремя признаками. Все эти признаки отражены на рис. 8.1. Рис. 8.1 Нормальная, или колоколообразная, кривая Симметричная Асимптотический хвост Средняя Медиана Мода Кривая нормального распределения показывает распределение значений, при котором средняя, медиана и мода равны друг другу. Возможно, вы помните из главы 4, что если медиана и среднее значение отличаются друг от друга, то распределение будет скошено в ту или иную сторону. Нормальная кривая не скошена. У нее есть симпатичный горбик (только один), и он находится ровно посередине. Глава 8 Нормальны ли ваши кривые? 179 Во-вторых, кривая нормального распределения абсолютно симметрична относительно среднего значения. Если вы сложите рисунок кривой вдоль ее центральной линии, обе части полностью совпадут друг с другом. Они идентичны. Одна половина является зеркальным отражением другой. И наконец (готовы потренировать произношение?), хвосты нормальной кривой являются асимптотическими. Это означает, что они приближаются к горизонтальной оси, но никогда ее не касаются. Подумайте (заранее, т. к. мы поговорим об этом позже), почему это так важно, ведь это на самом деле краеугольный камень всех моментов, связанных с вероятностью. Похожая на колокол форма нормальной кривой также дала графику еще одно название – колоколообразная кривая. Когда ваш покорный слуга был ростом не выше колена, ему всегда было интересно, каким образом хвост кривой нормального распределения может приближаться к горизонтальной оси x, но никогда не касаться ее. Попробуйте сделать так. Положите два карандаша на расстоянии 2 см друг от друга, затем сдвиньте их на половину разделяющего расстояния (до 1 см), а потом пере­ мес­тите ближе (на 0,5 см) и еще ближе (на 0,25 см) и совсем близко (на 0,125 см). Они непрерывно сближаются, верно? При этом они не касаются друг друга (и никогда не соприкоснутся). То же самое происходит с хвостами нормальной кривой. Хвост медленно приближается к оси, на которой он «покоится», но хвост и ось никогда не смогут коснуться друг друга. Почему это важно? Как вы узнаете позже из этой главы, тот факт, что хвосты никогда не касаются оси x, означает, что есть бесконечно маленькая вероятность получить очень отличающееся от всех других значение. Если бы хвосты смогли коснуться оси x, тогда вероятности получения подобного результата не сущест­ вовало бы. Эй, это ненормально! Надеемся, что ваш следующий вопрос – это: «Но ведь есть мно­ жество наборов данных, распределение которых не имеет нормальной, или колоколообразной, формы, верно?» Да (и также большое «но»). Когда имеем дело с большими наборами данных (более 30), то, по мере того как мы берем повторные выборки данных из генеральной совокупности, их значения распределяются все ближе к форме нормальной кривой. Это очень важно, потому что многое из того, что мы делаем, когда выводим результат по выборке и распространяем его на генеральную совокупность, основано на предположении, что выборка, взятая из совокупности, подчиняется нормальному распределению. А это просто еще один способ сказать, что характерис­ Часть III 180 Карты, деньги, вероятности тики выборки продолжают приближаться к параметрам генеральной совокупности. Оказывается, в природе вообще множество вещей имеет распределение, которое мы называем нормальным. То есть множество событий или случаев происходит точно по центру распределения, но относительно немногие оказываются по краям от центра, как вы можете видеть на рис. 8.2, который показывает распределение IQ и роста среди людей. Рис. 8.2 Как могут распределяться значения Количество людей Много людей Мало людей Не очень умные люди Умеренно умные люди Невысокие люди Люди среднего роста Умные люди Высокие люди Интересующие нас переменные Например, есть очень мало людей с выдающимся умом и очень мало тех, кто по интеллектуальным или когнитивным способностям находится на абсолютно нижней границе группы. Существует множество тех, кто находится прямо посередине, и это количество уменьшается, по мере того как мы движемся к хвостам распределения. Также в мире относительно мало очень высоких людей и относительно мало очень маленьких людей, но множество людей попадает как раз посередине. В обоих этих примерах распределение интеллекта и роста приближается к нормальному. Вследствие вышесказанного те события, которые тяготеют к хвос­ там нормальной кривой, связаны с меньшей вероятностью для каждого случая. Мы можем с большой долей уверенности сказать: вероятность того, что любой случайный человек (чей рост нам был заранее неизвестен) окажется очень высоким (или очень маленьким), не особо велика. Мы знаем: вероятность того, что человек окажется среднего роста, т. е. ровно посередине распределения, доволь- Глава 8 Нормальны ли ваши кривые? 181 но значительна. Те события, которые располагаются ближе к центру нормальной кривой, имеют более высокую вероятность возникновения, чем те, что находятся по краям. И это верно для роста, веса, общего интеллекта, способности поднимать вес, дохода, количества принадлежащих людям фигурок из «Звездных войн» и т. д. Еще немного о нормальной кривой Вы уже знаете три важных признака, по которым можно определить нормальную кривую, или «колокольчик», но их может быть гораздо больше. Посмотрите на кривую на рис. 8.3. Рис. 8.3 Кривая нормального распределения, поделенная на секции Исходные данные 70 80 90 Стандартные отклонения –3 –2 –1 100 (Среднее) 0 110 120 130 1 2 3 Среднее значение представленного здесь распределения равно 100, а стандартное отклонение – 10. Мы добавили на ось x числа, которые обозначают расстояния от среднего значения, данные в стандартных отклонениях. Как видите, шкала оси x, показывающая исходные данные, имеет обозначения от 70 до 130 с шагом в 10 (что равно стандартному отклонению распределения) или в 1 стандартное отклонение. Мы придумали эти числа (100 и 10), так что не ломайте голову, откуда мы их взяли. Итак, быстрый взгляд говорит нам, что среднее значение этого распределения равно 100, а стандартное отклонение – 10. Каждая вертикальная линия под кривой делит площадь под ней на секции, и каждая секция ограничена конкретными значениями. Например, первая секция справа от среднего значения ограничена значениями 100 и 110. Эта секция отображает 1 стандартное отклонение от среднего (которое равно 100). Нормальные кривые Часть III 182 Карты, деньги, вероятности Под каждым значением исходных данных (70, 80, 90, 100, 110, 120 и 130) вы обнаружите соответствующее им количество стандартных отклонений (−3, −2, −1, 0, +1, +2 и +3). Как вы, возможно, уже догадались, в нашем примере каждое стандартное отклонение равно 10. Так что 1 стандартное отклонение от среднего (равного 100) – это среднее плюс 10 или 110. Не так уж и сложно, да? Если мы продолжим эти рассуждения дальше, вы поймете, почему диапазон исходных данных, описываемых нормальным распределением со средним значением 100 и стандартным отклонением 10, находится в границах от 70 до 130 (или от –3 до +3 стандартных отклонений). А теперь важный факт, который всегда верен для нормального распределения, его среднего значения и стандартного отклонения. При любом распределении данных (независимо от величины среднего значения и стандартного отклонения), если они распределены нормально, почти 100 % всех значений попадут в промежуток от –3 до +3 стандартных отклонений от среднего значения. Это очень важно, потому что относится ко всем нормальным распределениям. Поскольку это правило всегда выполняется (независимо от величины среднего значения и стандартного отклонения), распределения можно сравнивать друг с другом. Мы вернемся к этому чуть позже. В связи с этим продолжим наши рассуждения дальше. Если распределение величин нормально, мы можем также сказать, что между разными точками на оси x (например, между средним значением и 1 стандартным отклонением) будет находиться определенная доля всех величин. Фактически между средним значением (которое в нашем случае равно 100 – вы уже запомнили?) и 1 стандартным отклонением (что дает 110) будет попадать около 34 % всех значений нашего распределения. Вы можете предъявить этот факт даже в банке, поскольку он всегда будет верен. Хотите пойти еще дальше? Посмотрите на рис. 8.4. Здесь вы можете видеть все ту же кривую нормального распределения во всей ее красе (со средним значением 100 и стандартным отклонением 10) и с процентами случаев, которые, как мы ожидаем, попадут в границы между средним значением и стандартным отклонением. Вот что мы можем отсюда извлечь: Таблица 8.1 Вероятность попадания значения справа от среднего или (если среднее = 100, а стандартное отклонение = 10) величины … средним значением и одним 34,13 % всех значений от 100 до 110 стандартным отклонением под кривой одним стандартным отклонением 13,59 % всех значений от 110 до 120 и двумя стандартными отклонениями под кривой двумя стандартными отклонениями 2,5 % всех значений от 120 до 130 и тремя стандартными отклонениями под кривой тремя стандартными отклонениями 0,13 % всех значений от 130 и больше и больше под кривой В расстояние между… попадает… Глава 8 Нормальны ли ваши кривые? 183 Рис. 8.4 Кривая нормального распределения, разделенная на секции 34,13 % 34,13 % 13,59 % 13,59 % 2,15 % 2,15 % 0,13 % 0,13 % Исходные данные 70 80 90 100 110 120 130 Стандартные отклонения –3 –2 –1 0 1 2 3 Если сложите все проценты для любой половины нормальной кривой, угадайте, что вы получите? Верно, почти 50 %. Почему? В площадь под кривой на расстоянии между средним значением и всеми величинами справа от него попадают 50 % всех величин. А поскольку кривая симметрична относительно своей центральной оси (каждая половина является зеркальным отражением другой), обе половины представляют 100 % всех значений. Не ядерная физика, но тем не менее стоящий вашего внимания факт. Теперь давайте применим ту же самую логику для значений слева от среднего. Таблица 8.2 Вероятность попадания значения слева от среднего или (если среднее = 100, а стандартное отклонение = 10) величины … средним значением 34,13 % всех значений от 90 до 100 и –1 стандартным отклонением под кривой –1 стандартным отклонением 13,59 % всех значений от 80 до 90 и –2 стандартными отклонениями под кривой –2 стандартными отклонениями 2,5 % всех значений от 70 до 80 и –3 стандартными отклонениями под кривой –3 стандартными отклонениями 0,13 % всех значений 70 и меньше и больше под кривой В расстояние между… попадает… Обратите внимание, что мы используем среднее значение, равное 100, и стандартное отклонение, равное 10, только в качестве примера. Очевидно, что не все распределения (и даже большинство из них!) имеют такие значения среднего и стандартного отклонения. 184 Часть III Карты, деньги, вероятности Все это довольно круто, особенно в том случае, когда вы осознаете, что 34,13 % и 13,59 % и т. д. совершенно не зависят от реальной величины среднего значения и стандартного отклонения. Эти проценты объясняются формой кривой и не зависят от значений данных распределения или величины среднего и стандартного отклонения. На самом деле вы можете нарисовать нормальную кривую на картоне и вырезать ее, чтобы у вас получился картонный «колокольчик». Тогда если вы вырежете область между средним значением и +1 стандартным отклонением и взвесите ее, то ее вес будет равен в точности 34,13 % от веса всего вашего картонного «колокольчика». (Попробуйте и убедитесь сами.) В нашем примере это означает, что (примерно) 68 % (2 раза по 34,13 %) величин попадают между значениями от 90 до 110. Что насчет оставшихся 32 %? Хороший вопрос. Половина из них (16 % или 13,59 % + 2,15 % + 0,13 %) окажется выше (или правее) 1 стандартного отклонения от среднего, а половина попадет ниже (или левее) –1 стандартного отклонения от среднего. Поскольку по мере удаления от средней кривая снижается и область под ней уменьшается, вовсе неудивительно, что вероятность того, что значение попадет в дальние области распределения, меньше, чем вероятность того, что оно окажется в середине. Именно поэтому у кривой есть горб в центре, она не скошена ни в одном направлении, а значения, находящиеся дальше от среднего, имеют меньшую вероятность возникновения, чем значения, близкие к среднему. Наш любимый стандартный показатель: z-оценка Вы неоднократно читали, что распределения отличаются по своим показателям центральной тенденции и изменчивости. Но в обычной практике применения статистики и использования ее в исследовательской работе мы сталкиваемся с очень разными распределениями, которые нам все-таки придется сравнивать друг с другом. Для того чтобы провести такое сравнение, нам нужен какой-то стандарт. Познакомьтесь со стандартными показателями. Это оценки, которые можно сравнивать, потому что они стандартизированы в единицах стандартного отклонения. Например, стандартный показатель 1 для распределения со средним значением 50 и стандартным отклонением 10 означает то же самое, что и стандартный показатель 1 для распределения со средним значением 100 и стандартным отклонением 5. Они оба представляют собой 1 стандартную оценку и являются эквивалентом расстояния от среднего значения каждого распределения. Кроме того, мы можем прибегнуть к нашим знаниям о нормальном распределении и рассчитать вероятность появления значения, которое находится на расстоянии 1 стандартного отклонения от среднего. Мы сделаем это позже. Глава 8 Нормальны ли ваши кривые? 185 Несмотря на то что есть и другие типы стандартных показателей, чаще всего при изучении статистики вы увидите тот, что называется z-оценкой. Это результат деления разницы между величиной и средним значением выборки на стандартное отклонение, как показано в формуле 8.1: (8.1) _ где z – это z-оценка; X – индивидуальное значение данных; X – среднее значение распределения; s – стандартное отклонение распределения. Например, в формуле 8.2 вы можете видеть, как рассчитывается z-оценка, если среднее значение равно 100, исходные данные – 110, а стандартное отклонение – 10. (8.2) Точно так же можно легко рассчитать исходное значение данных при заданной z-оценке. Вы уже знаете формулу z-оценки при известных значениях данных, среднего и стандартного отклонения. Если вы знаете только z-оценку, среднее значение и стандартное отклонение, то чему равно соответствующее им значение исходных_ данных? Это легко узнать, если использовать формулу X = z · s + X . Вы можете легко превращать значения исходных данных в z-оценку и обратно, если необходимо. Например, z-оценка –0,5 в распределении со средним значением 50 и стандартным отклонением 5 будет соответствовать исходному значению X = (–0,5) · 5 + 50, или 47,5. Как вы видите, в формуле 8.1 мы _ обозначаем среднее значение и стандартное отклонение как X и s соответственно. В некоторых книгах (и лекциях) среднее значение генеральной совокупности обозначается греческой буквой мю, или µ, а стандартное отклонение – греческой буквой сигма, или σ. Некоторые очень педантичны по поводу того, когда какие буквы использовать, но для наших целей будем пользоваться буквами латинского алфавита. Следующие данные показывают исходные сырые данные плюс z-оценки для выборки из 10 значений, среднее которой равно 12, а стандартное отклонение – 2. Любое значение данных выше среднего будет иметь положительную z-оценку, а любое значение данных ниже среднего – соответствующую ему отрицательную z-оценку. Например, исходное значение 15 имеет z-оценку +1,5, а исходному значению 8 соответствует z-оценка –2,0. Конечно, исходное значение 12 (или среднее) имеет z-оценку, равную 0 (потому что 12 никак не удалено от среднего). Часть III 186 Таблица 8.3 Карты, деньги, вероятности Данные выборки и их z-оценки _ X –X 0 3 –1 1 –4 2 0 1 0 –2 X 12 15 11 13 8 14 12 13 12 10 z-оценка 0,0 1,5 –0,5 0,5 –2,0 1,0 0,0 0,5 0,0 –1,0 Приведем некоторые наблюдения за этими данными в качестве небольшого обзора. Во-первых, данные меньше среднего (такие как 8 и 10) имеют отрицательные z-оценки, а данные больше среднего (такие как 13 и 14) – положительные z-оценки. Во-вторых, положительные z-оценки всегда попадают в область справа от среднего значения и находятся в верхней половине распределения. А отрицательные z-оценки всегда попадают в область слева от среднего и находятся в нижней половине распределения. В-третьих, когда мы говорим, что какое-то значение находится на 1 стандартное отклонение выше среднего, – это то же самое, что и сказать, что значение находится на одну z-оценку выше среднего. Для наших целей сравнения значений в распределениях z-оценки и стандартные отклонения эквивалентны. Другими словами, z-оценка – это просто количество стандартных отклонений от среднего значения. И наконец (и это очень важно), z-оценки разных распределений можно сравнивать между собой. Вот еще одна таблица, похожая на приведенную выше, которая иллюстрирует последнее утверждение. Эти 10 значений были выбраны из набора из 100 данных, среднее значение которых равно 59, а стандартное отклонение – 14,5. Таблица 8.4 Другая выборка и z-показатели Исходные данные 67 54 65 33 56 76 65 33 48 76 _ X –X 8 –5 6 –26 –3 17 6 –26 –11 17 z-оценка 0,55 –0,34 0,41 –1,79 –0,21 1,17 0,41 –1,79 –0,76 1,17 Глава 8 Нормальны ли ваши кривые? 187 В первом показанном вам распределении со средним значением 12 и стандартным отклонением 2 исходное значение 12,8 имеет соответствующую ему z-оценку +0,4, что означает: исходное значение 12,8 находится на расстоянии в 0,4 стандартных отклонения от среднего. Во втором распределении со средним значением 59 и стандартным отклонением 14,5 исходное значение 64,8 также имеет соответствующую ему z-оценку +0,4. Чудо? Нет, просто хорошая идея, которая дает огромное подспорье для сравнения значений из разных наборов данных или распределений. Оба исходных значения, 12,8 и 64,8, находятся относительно друг друга на равном расстоянии от среднего. Когда исходные данные представлены в виде стандартных показателей, их можно напрямую сравнивать друг с другом в терминах их относительного расположения в соответствующих им распределениях. Что показывает z-оценка? Вы уже знаете, что конкретная z-оценка не только соответствует исходному значению данных, но также указывает на конкретное положение в распределении по оси x. Чем экстремальнее значение z-оценки (например, –2,0 или +2,6), тем дальше оно от среднего. Поскольку вы уже знаете доли площади, которые приходятся на области между определенными точками на оси x (такие как 34 % между средним и стандартным отклонением +1, например, или около 14 % между стандартным отклонением +1 и стандартным отклонением +2), то можете также сделать следующие справедливые утверждения: zz 84 % всех значений данных оказываются ниже z-оценки +1 (50 % тех, что оказываются ниже среднего, плюс 34 % тех, что попадают между средним значением и +1 z-оценкой); zz 16 % всех значений данных оказываются выше z-оценки +1 (потому что общая площадь под кривой равна 100 %, а 84 % значений оказываются ниже z-оценки +1,0). Подумайте немного об этих фактах. Мы пытаемся сказать, что при условии нормального распределения разные области кривой сопровождает разное количество стандартных отклонений или z-оценок. Ладно, пришло ее время. Эти доли (или области) можно также легко представить как вероятности возникновения определенного значения. Например, вот образец вопроса, подобные которому вы теперь можете задавать и на который сумеете ответить (барабанная дробь, пожалуйста): «Какова вероятность того, что в распределении со средним значением 100 и стандартным отклонением 10 значение данных будет равно 110 или выше?» Какой ответ? Вероятность равна 16 %, или 16 из 100, или 0,16. Как мы это узнали? 188 Часть III Карты, деньги, вероятности Во-первых, мы рассчитали соответствующую z-оценку, которая равна +1 [(110 – 100)/10]. Благодаря тому, что уже изучили (см. рис. 8.4), мы знаем, что z-оценка 1 показывает точку на оси x, ниже которой находятся 84 % (50 % + 34 %) всех значений распределения. Выше нее находятся 16 % значений, или вероятность равна 0,16. Другими словами, поскольку мы уже знаем площадь области между средним значением и 1,2 или 3 стандартными отклонениями вверх или вниз от среднего, то можем легко прикинуть вероятность появления любой z-оценки. Что же, метод, который мы только что разобрали, отлично подходит для таких z-оценок, как 1, 2 или 3. Но что, если значение z-показателя не целое число вроде 2, а равно 1,23 или –2,01? Нам нужно найти способ давать более точный ответ. Как это сделать? Нужно выучить интегралы и применить их к кривой, чтобы рассчитать площадь под ней для практически любой возможной точки на оси x, или (этот вариант нам нравится гораздо больше) можно обратиться к таблице B.1 в приложении B (таблице нормального распределения). Это список всех значений (кроме очень больших) для площади под кривой, которые соответствуют разным z-оценкам. В табл. B.1 есть 2 столбца. Первый столбец («z-оценка») – это прос­ то рассчитанный вами z-показатель. Второй столбец («площадь между средним значением и z-оценкой») – точная площадь под кривой, которая находится между этими двумя точками. Например (вам нужно обратиться к таблице B.1 и воспользоваться ей во время чтения), если бы мы хотели узнать площадь между средним значением и z-оценкой +1, то нашли бы +1 в столбце «z-оценка» и прочитали бы значение во втором столбце, где обнаружили бы, что площадь области между средним значением и z-показателем 1,00 равна 34,13. Видели уже такое? Почему в этой таблице нет знаков плюс или минус (например, –1,00)? Поскольку кривая симметрична, то не важно, какой знак имеет z-оценка. Площадь области между средним значением и 1 стандартным отклонением в любом направлении всегда 34,13 %. А вот и следующий шаг. Скажем, вы хотите узнать вероятность, соответст­вующую z-оценке 1,38. Если вам нужно узнать долю площади между средним значением и z-оценкой 1,38, найдите в табл. B.1 соответствующую площадь напротив z-оценки 1,38, которая равна 41,62. Получается, что более 41 % всех случаев в распределении попадает между z-показателями 0 и 1,38. Следовательно, около 92 % (50 % + 41,62 %) случаев окажутся меньше или равны z-оценке 1,38. Вы, должно быть, заметили, что мы разобрали этот последний пример вообще без каких-либо исходных данных. Как только вы обращаетесь к этой таблице, они вам становятся больше не нужны. Но всегда ли нас интересует только площадь области между средним значением и каким-то другим z-показателем? Что насчет об- Глава 8 Нормальны ли ваши кривые? 189 ласти между двумя z-оценками, ни одна из которых не является средней? Например, что делать в случае, если нас интересует, какова площадь области между z-оценкой 1,5 и z-оценкой 2,5, что можно перевести как вероятность нахождения значения между двумя z-показателями? Как можно использовать таблицу для вычисления ответов на такие вопросы? Легко. Просто найдите соответствующие площади для каждой z-оценки и вычтите одну из другой. Зачастую помогает способ нарисовать картинку, как на рис. 8.5. Рис. 8.5 Вычисление разности площади между двумя z-оценками при помощи картинки 34,13 % 15,25 % 49,38 % z-оценки 0 +1 +2,5 Например, скажем, что мы хотим найти область между исходными значениями 110 и 125 в распределении со средним значением 100 и стандартным отклонением 10. Вот шаги, которые нам нужно будет предпринять. 1. Вычислить z-оценку для исходного значения 110, что равно (110 – 100)/10, или +1. 2. Вычислить z-оценку для исходного значения 125, что равно (120 – 100)/10, или +2,5. 3. В табл. B.1 приложения B найти площадь области между средним и z-оценкой +1, что равно 34,13 %. 4. В табл. B.1 приложения B найти площадь области между средним и z-оценкой +2,5, что равно 49,38 %. 5. Поскольку мы хотим знать расстояние между двумя показателями, вычтем меньшую область из большей: 49,38 – 34,13 = 15,25 %. И вот картинка, которая стоит тысячи слов, – рис. 8.5. Хорошо. Значит, мы можем с уверенностью утверждать, что для понимания вероятности возникновения определенного значения Как вычислить z-оценку 190 Часть III Карты, деньги, вероятности лучше всего проверить, куда это значение попадает относительно других величин в распределении. В данном примере вероятность возникновения значения между z-оценкой +1 и z-оценкой +2,5 составляет около 15 %. Вот еще один пример. В наборе величин со средним значением 100 и стандартным отклонением 10 исходное значение 117 имеет соответствующую ему z-оценку 1,70. Этой z-оценке соответствует 95,54 % (50 % + 45,54 %) площади под кривой нормального распределения, что означает: вероятность возникновения значения между z-показателем 0 и z-показателем 1,70 равна 95,54 %, или 95,5 из 100, или 0,955. Еще два факта о стандартных показателях. Во-первых, несмотря на то что мы сфокусировались на z-показателях, есть и другие виды стандартных оценок. Например, T-показатель – это вид стандартной оценки, которая вычисляется умножением z-показателя на 10 и прибавлением 50. Одним из его преимуществ является то, что вы редко получите отрицательный Т-показатель. Так же, как и z-оценки, Т-показатель позволяет сравнивать стандартные оценки разных распределений. Во-вторых, стандартный показатель – это не тот зверь, что стандартизованный. Стандартизованный показатель относится к распределению с заранее заданным средним значением и стандартным отклонением. Стандартизованные показатели таких тестов, как тесты на проверку академических способностей, используются для того, чтобы можно было легко сравнивать результаты разных форм проведения теста, все из которых имеют одинаковое значение средней и стандартного отклонения. Что на самом деле показывает z-оценка? Игра в статистику заключается в том, чтобы получить возможность оценить вероятность результата. Если мы возьмем все, о чем говорили и чем занимались в этой главе до настоящего момента, и чуть разовьем тему, то сможем определить вероятность возникновения какого-то события. Тогда мы используем какой-то критерий, чтобы определить, считаем ли мы это событие вероятным, более вероятным или менее вероятным, чем можно было бы ожидать от случайности. Альтернативная гипотеза представляет собой утверждение об ожидаемом событии, и мы при помощи статистических инструментов оцениваем, насколько это событие вероятно. Это 20-секундная версия сути инференциальной статистики (или статистики вывода), но и этого уже много. Давайте возьмем все сказанное в этом абзаце и разберем еще раз на конкретном примере. Представим, что ваш давний друг, заслуживающий доверия, Лью дает вам монету и просит определить, насколько она «честная», т. е. выйдет ли у вас 5 орлов и 5 решек, если вы подбросите ее 10 раз. Глава 8 Нормальны ли ваши кривые? 191 Мы ожидаем увидеть 5 орлов (или 5 решек), потому что для каждого броска вероятность выбросить орла или решку равна 0,5 (если это подлинная монета). При 10 независимых бросках (т. е. при том условии, что один бросок не влияет на другой) мы должны получить орла 5 раз и т. д. А теперь вопрос: «Сколько бросков с орлом требуется, чтобы забраковать монету как фальшивую или поддельную?» Допустим, что в качестве критерия подлинности мы будем использовать следующее: если при 10 подбрасываниях монеты мы получим орла меньше, чем в 5 % случаев, то скажем, что монета поддельная, и сдадим Лью полиции. Этот критерий 5 % – один из стандартов, которыми пользуются статистики. Если вероятность события (будь это количество бросков с выпадением орла, или баллы за тест, или разница между средними величинами у двух групп) попадает на дальние края распределения (а мы говорим, что край определяется как все, что меньше 5 % случаев), то это маловероятный или нечестный результат. Вернемся к монете и Лью. Поскольку есть два возможных результата (орел или решка) и мы подбрасываем монету 10 раз, то существует 210, или 1024, возможных результата, таких как 9 орлов и 1 решка, 7 орлов и 3 решки, 10 орлов и 0 решек и т. д. Вот распределение того, сколько орлов вы можете ожидать по чистой случайности при 10 бросках. Например, вероятность, относящаяся к выбрасыванию 6 орлов при 10 бросках, составляет около 21 %. Таблица 8.5 Вероятность результатов при подбрасывании монеты Количество орлов 0 1 2 3 4 5 Вероятность 0,00 0,01 0,04 0,12 0,21 0,25 Количество орлов 6 7 8 9 10 Вероятность 0,21 0,12 0,04 0,01 0,00 Итак, вероятность каждого конкретного результата нам известна. Какова вероятность выбросить 6 орлов при 10 бросках? Она составляет около 0,21, или 21 %. Пришло время решений. Сколько же орлов нужно получить при 10 брос­ках, чтобы решить, что монета сфальсифицирована, сломана или ненормальна? Как все хорошие статистики, мы определим критерий 5 %, о котором уже говорили. Если вероятность наблюдаемого результата (в данном случае результата всех наших бросков) меньше 5 %, мы заключим, что это настолько маловероятно, что что-то иное, кроме случайности, должно быть его причиной, и это что-то – фальшивая монета. 192 Часть III Карты, деньги, вероятности Если вы посмотрите на таблицу, то увидите, что 8, 9 или 10 орлов являются результатом, вероятность возникновения которого меньше 5 %. Так что если итогом 10 бросков монеты станут 8, 9 или 10 орлов, выводом будет то, что монета нечестная. (Да, вы правы: 0, 1 и 2 приводят к такому же выводу.) Такая же логика применима к нашим более ранним обсуждениям z-оценок. Насколько крайним должно быть значение z-оценки, чтобы мы могли утверждать, что результат не является случайным, но объясняется каким-то другим фактором? Если вы посмотрите на таб­лицу нормального распределения в приложении B, то увидите, что пороговая точка для z-оценки 1,65 включает в себя около 45 % площади под кривой. Если вы добавите это к оставшимся 50 % площади с другой стороны кривой, то получите 95 %. И только 5 % останется за этой точкой на оси x. Любое значение, представленное z-оценкой 1,65 (или больше), тогда будет, что называется, написано вилами на воде или, по меньшей мере, на области, которая имеет гораздо меньшую вероятность возникновения, чем другие. Проверка гипотез и z-оценки: первый шаг Проверка гипотез и z-оценки Мы показали, что у каждого события есть связанная с ним вероятность. Используем эти значения вероятности, чтобы решить, насколько вероятным, по нашему мнению, может быть какое-то событие. Например, выбросить только 1 орла и 9 решек при 10 бросках монеты очень маловероятно. Мы также сказали: если похоже, что событие возникает только 5 раз из 100 (5 %), то будем полагать такое событие довольно маловероятным по отношению ко всем другим событиям, которые могут случиться. Это во многом верно и для любого результата, относящегося к альтернативной гипотезе. Нулевая гипотеза, о которой вы узнали в главе 7, утверждает, что между группами (или переменными) нет никакой разницы, а вероятность не найти различия составляет 100 %. Мы пытаемся проверить броню нулевой гипотезы на любые щели, которые могут в ней быть. Другими словами, если при проверке альтернативной гипотезы мы обнаружим, что вероятность произошедшего события находится на краю нормального распределения, тогда альтернативная гипотеза будет более привлекательна, чем нулевая. Итак, если мы найдем z-оценку (а вы помните, что у z-оценок тоже есть связанные с ними вероятности возникновения), значение которой экстремально (вероятность появления меньше, чем 5 %), то мы говорим, что причина такого крайнего значения имеет какое-то отношение к применяемому лечению или взаимосвязи показателей, а не только к случайности. Мы рассмотрим этот момент более подробно в следующей главе. Глава 8 Нормальны ли ваши кривые? 193 Вычисление z-оценок при помощи SPSS SPSS делает множество реально интересных вещей, но именно моменты, которые вы сейчас увидите, позволяют экономить с ее помощью огромное количество времени. Теперь, когда вы знаете, как рассчитать z-оценки вручную, дадим SPSS сделать ее работу. Для того чтобы рассчитать в SPSS z-показатели для набора данных из первого столбца на рис. 8.6 (который вы также видели ранее в главе), выполните следующие шаги. Вычисление z-оценок при помощи SPSS 1. Введите данные в новое окно SPSS. 2. Нажмите Анализ (Analyze) ⇒ Описательные статистики (Descriptive Statistics) ⇒ Описательные (Descriptives). 3. Дважды щелкните по переменной Данные (Score), чтобы переместить ее в поле Переменные: (Variables:). 4. Отметьте Сохранить стандартизованные значения в переменных (Save standardized values as variables) в диалоговом окне. 5. Нажмите ОК. На рис. 8.6 вы можете увидеть, как SPSS рассчитала соответст­ вующие данным z-оценки. (Будьте внимательны – при завершении практически любого действия SPSS автоматически перебрасывает вас в окно выводов, где нет рассчитанных z-оценок! Чтобы увидеть их, нужно перейти обратно в окно редактора данных.) Рис. 8.6 SPSS рассчитала для вас z-оценки ТОЛСТЫЕ И ТОЩИЕ РАСПРЕДЕЛЕНИЯ ЧАСТОТ К настоящему моменту вы, определенно, догадываетесь, что распределения могут сильно отличаться друг от друга по множеству параметров. Фактически есть четыре параметра, по которым они различаются: среднее значение (средняя, медиана или мода), изменчивость (диапазон, дисперсия и стандартное отклонение), асимметричность (или скошенность) и эксцесс. Последние два термина Часть III 194 Карты, деньги, вероятности для вас новые, и мы дадим им определение, когда покажем, на что это похоже. Давайте обсудим каждую из четырех характеристик и проиллюстрируем их. Среднее значение Мы снова возвращаемся к мерам центральной тенденции. На рис. 8.7 вы можете видеть, как три распределения могут отличаться друг от друга по среднему значению. Обратите внимание, что среднее для Распределения C больше, чем среднее у Распределения B, которое, в свою очередь, больше, чем среднее значение Распределения A. Частота Рис. 8.7 Различия распределения по показателю среднего значения Низкие значения Среднее Среднее Среднее для Распределения A для Распределения В для Распределения С Высокие значения Изменчивость На рис. 8.8 вы можете увидеть три распределения с одинаковым средним значением, но разной изменчивостью. Изменчивость Распределения A меньше, чем у Распределения B, изменчивость которого, в свою очередь, меньше, чем у Распределения C. Другими словами, можно сказать, что у Распределения C наибольшая изменчивость из трех, а у Распределения A – наименьшая. Асимметрия Асимметрия – это мера отсутствия симметрии, или скошенности, распределения. Другими словами, один «хвост» распределения длиннее другого. Например, на рис. 8.9 правый хвост Распределения А длиннее, чем левый, что соответствует меньшему количеству случаев в высокой области распределения. Это распределение с положительной асимметрией. Оно может появиться, например, когда вы даете очень сложный тест, такой, что только несколько человек получают относительно высокие оценки за него, а основная часть получает относительно низкие оценки. Правый хвост Распределе- Глава 8 Нормальны ли ваши кривые? 195 Рис. 8.8 Различия распределений по изменчивости Частота Распределение А Распределение В Распределение С Низкие значения Среднее Высокие значения Рис. 8.9 Степень асимметрии у разных распределений Распределение В без асимметрии Распределение С с отрицательной асимметрией Частота Распределение А с положительной асимметрией Низкие значения Высокие значения Часть III 196 Карты, деньги, вероятности ния С короче, чем левый, что соответствует большему количеству случаев в высокой области распределения. Это распределение с отрицательной асимметрией, и оно может появиться в случае очень легкого теста (большое количество высоких оценок и относительно мало низких). А Распределение В является совершенно правильным: с одинаковыми хвостами и отсутствием асимметрии. Эксцесс Несмотря на сходство названия с медицинским термином, это последняя из четырех характеристик, по которым мы можем классифицировать различия распределений. Эксцесс имеет отношение к степени плоскости или крутизны распределения и описывается в относительных терминах. Например, плосковершинным называется более плоское, по сравнению с нормальным, колоколообразным, распределение. Крутовершинным называют распределение с более высокой вершиной в центре, по сравнению с нормальным, колоколообразным, распределением. На рис. 8.10 Распределение А плосковершинное по сравнению с Распределением В. Распределение С крутовершинное по сравнению с Распределением В. Рисунок 8.10 похож на рис. 8.8, и тому есть веская причина: плосковершинные распределения, например, имеют больший разброс, чем остальные. Аналогично этому крутовершинное распределение менее изменчиво по сравнению с другими. Рис. 8.10 Степень эксцесса у разных распределений Частота Распределение С Распределение В без эксцесса Распределение А Низкие значения Среднее Высокие значения Глава 8 Нормальны ли ваши кривые? 197 Хотя асимметрия и эксцесс чаще всего используются в качестве описательных характеристик (например, «это распределение имеет отрицательную асимметрию»), существуют математические показатели степени асимметрии и эксцесса для распределения. Например, асимметрия вычисляется путем вычитания значения медианы из среднего. Если среднее значение распределения равно 100, а медиа­на – 95, величина асимметрии равна 100 – 95 = 5, то данное распределение положительно скошенное. Если среднее значение распределения – 85, медиана – 90, показатель асимметрии равен 85 – 90 = –5, то распределение имеет отрицательную асимметрию. Есть даже еще более сложная формула, в которой используется стандартное отклонение распределения, так что показатели асимметрии можно сравнивать между собой (см. формулу 8.3): (8.3) где Sk – показатель асимметрии Пирсона (это _ тот парень с корреляцией, о котором вы узнали в главе 5); X – среднее значение; M – это медиана. Ниже приведем пример. Среднее значение Распределения А равно 100, медиана – 105, а стандартное отклонение – 10. У Распределения В среднее значение – 120, медиана – 116 и стандартное отклонение – 10. Используя формулу Пирсона, получаем показатель асимметрии для Распределения А – 1,5, а для Распределения В – 1,2. Распределение А имеет отрицательную асимметрию (отрицательно скошено), а Распределение В имеет положительную асимметрию. При этом Распределение А более асимметрично, чем Распределение В, независимо от направ­ ления. Не будем забывать об эксцессе. Его тоже можно рассчитать при помощи вот такой формулы: (8.4) где K – показатель эксцесса; ∑ – сумма; X – отдельное значение _ данных; X – среднее значение выборки; s – стандартное отклонение; n – размер выборки. Это довольно сложная формула, которая в основном показывает, насколько плоским или выпуклым является набор данных. Вы можете увидеть, что если все значения данных равны, то числитель будет равен 0 и K = 0, что говорит об отсутствии асимметрии. K = нулю, когда распределение является нормальным или средневершинным (введем еще одно новое слово). Если отдельные значения данных (представленные в формуле как X) сильно отличаются от среднего (и изменчивость очень велика), тогда кривая, вероятно, будет довольно плоской. Часть III 198 Карты, деньги, вероятности РЕАЛЬНАЯ СТАТИСТИКА Реальная статистика И об ожирении у детей… Вероятно, вы слышали о беспокойстве, вызванном детским ожирением. Исследователи изучили возможность снижения ожирения у детей при помощи введения дополнительной физической активности. Какое отношение это может иметь к z-оценкам? z-показатель был одним из основных результатов, или зависимых переменных: мы имеем в виду z-оценку индекса массы тела (ИМТ) = 3,24, стандартное отклонение = 0,49. Участников пригласили на 1 неделю в спортивный лагерь, пос­ ле чего тренер из местного спортивного клуба оказывал детям поддержку в выбранном ими виде спорта в течение 6 месяцев. До начала исследования и через 12 месяцев после были оценены вес, рост, состав тканей организма и стиль жизни. Результаты? Дети, участвовавшие в программе, имели существенное снижение z-оценки ИМТ. Почему исследователи использовали z-показатели? Вероятно, потому, что дети, которых сравнивали друг с другом, относились к разным распределениям значений (у них были разные ИМТ) и при помощи стандартного показателя эти различия (по меньшей мере, вариабельность значений) были нивелированы. Хотите узнать больше? Найдите в интернете или библиотеке статью... Nowicka P., Lanke J., Pietrobelli A., Apitzsch E. & Flodmark C. E. Sports camp with six months of support from a local sports club as a treatment for childhood obesity. Scandinavian Journal of Public Health, 2009. Р. 793–800. ВЫВОДЫ ПО ГЛАВЕ Выводы по главе Умение вычислять z-оценки и оценивать вероятность их возникновения в выборке данных является первостепенным и самым важным навыком, необходимым для понимания самой сущности статистики вывода. Когда мы знаем вероятность такой оценки за тест или появления такой разницы между группами, то можем сравнить эту вероятность с той, которая определяется чистой случайностью, а затем принимать обоснованные решения. Когда мы приступим к части IV «Статистики для тех, кто (думает, что) ненавидит статистику», мы применим эту модель к конкретным примерам проверки вопросов о различиях. Глава 8 Нормальны ли ваши кривые? 199 ВРЕМЯ ПРАКТИКИ 1.Каковы характеристики кривой нормального распределения? Почему, по вашему мнению, поведение, свойства или характеристики человека могут быть распределены нормально? Что заставляет вас думать, что они могут быть распределены нормально? 2.Какие три части данных вам необходимы для вычисления стандартного показателя? 3.Стандартные показатели, такие как z-оценка, позволяют нам сравнивать разные выборки. Почему? 4.Почему z-оценка является стандартным показателем, а также почему можно использовать стандартные показатели для сравнения величин из разных распределений между собой? 5.Среднее значение результатов тестирования равно 50, а стандартное отклонение – 5. Исходному значению данных 55 соответствует z-оценка +1. Чему будет равна эта z-оценка, если стандартное отклонение будет в 2 раза меньше, т. е. 2,5? Какой вывод вы можете сделать на основании этого примера о влиянии снижения изменчивости данных на стандартные показатели (при условии что все остальное остается прежним, включая исходное значение данных)? Почему это влияние имеет значение? 6.Заполните ячейки для следующего набора данных. Среднее значение равно 74,13, стандартное отклонение – 9,98. Исходные данные 68,0 ? 82,0 ? 69,0 ? 85,0 ? 72,0 z-оценка ? –1,6 ? 1,8 ? –0,5 ? 1,7 ? 7.Вычислите стандартные оценки для следующего набора значений. Сделайте это с помощью SPPS (легко) и вручную, чтобы проверить SPSS (не так легко, как в SPSS, но когда вы ухватите идею, то это будет сделать довольно просто). Заметили ли вы какую-то разницу? Проблема 7 200 Часть III Карты, деньги, вероятности 18 19 15 20 25 31 17 35 27 22 34 29 40 33 21 8.Вопросы от 8а до 8г основаны на распределении данных со средним значением 75 и стандартным отклонением – 6,38. Нарисуйте небольшую картинку, чтобы было проще понять, что именно требуется сделать: а)какова вероятность попадания значения данных между 70 и 80? б)какова вероятность того, что значение данных окажется выше 80? в)какова вероятность попадания значения данных между 81 и 83? г)какова вероятность того, что значение данных окажется ниже 63? 9.Джейку нужно оказаться в верхних 10 % класса, чтобы получить сертификат физической подготовки. Средний балл за физкультуру в классе – 78, стандартное отклонение – 5,5. Какой балл он должен набрать, чтобы получить этот ценный лист бумаги? 10.Представьте, что вы руководите программой, по завершении которой все участники будут оцениваться по 5 разным тестам. Почему не имеет смысла рассчитывать для проверки результативности программы среднее значение всех пяти оценок, вмес­ то того чтобы вычислить z-оценки по каждому тесту для каждого участника и посчитать среднюю уже по ним? 11.Кто из учеников лучше по сравнению с его (или ее) одноклассниками? Вот вся информация, которую вы хотели узнать… Глава 8 Нормальны ли ваши кривые? Математика 81 2 Чтение Среднее значение по классу 87 Стандартное отклонение по классу 10 Исходные баллы Математика Ноа 85 Талья 87 z-оценки Математика Ноа ________________ Талья ________________ 201 Среднее значение по классу Стандартное отклонение по классу Чтение 88 81 Среднее 86,5 84 Чтение ________________ ________________ Среднее ________________ ________________ 12.А вот интересный вопрос на дополнительную оценку. Как вы знаете, одна из определяющих характеристик кривой нормального распределения заключается в том, что ее хвосты никогда не касаются оси x. Почему так происходит? ЧАСТЬ IV Значимая разница: применение статистики вывода «Говори о сумме квадратов» 203 Часть IV 204 В Значимая разница: применение статистики вывода ы забрались уже так далеко, но все еще живы и здоровы, так что поздравьте себя. К настоящему времени вы должны уже хорошо понимать, чем занимается описательная статистика, какую роль играет случайность при принятии решений о результатах эксперимента, а также какова вероятность того, что результаты были получены благодаря случайности или же какому-то воздействию. Вы эксперт в выдвижении гипотез и понимании роли, которую они играют в социологических и поведенческих исследованиях. Пришло время проверить свои силы на практике. Посмотрим, из чего вы сделаны, и следующая часть «Статистики для тех, кто (думает, что) ненавидит статистику» нам в этом поможет. Приложенные вами усилия скоро окупятся благодаря пониманию прикладных задач! Эта часть книги посвящена исключительно пониманию и применению определенных видов статистик для ответов на определенные типы исследовательских вопросов. Мы рассмотрим самые распространенные статистические тесты. Затем, в части V, мы даже увидим несколько более сложных вариантов и покажем вам наиболее полезные программные пакеты, с помощью которых можно рассчитывать те значения, которые мы до этого считали на старом добром калькуляторе. Давайте начнем с короткого обсуждения концепции значимости и пройдемся по всем этапам тестирования выводов. Затем мы обратимся к примерам конкретных тестов. У нас просто гора работы, так что давайте начинать. 9 Значимо значимый Что это значит для вас и меня? Уровень сложности: (побуждает думать и дает ключ ко всему этому!) В ЭТОЙ ГЛАВЕ ВЫ УЗНАЕТЕ: что такое значимость, и почему она важна; как отличить ошибку первого рода от ошибки второго рода; как работает инференциальная статистика (статистика вывода); как выбрать подходящий для ваших целей статистический тест. КОНЦЕПЦИЯ ЗНАЧИМОСТИ Пожалуй, ни один термин или концепция не вызывает у начинающих изучать статистику больше растерянности, чем статистическая значимость. Но это не значит, что и с вами должно быть так же. Несмотря на свое влияние, это довольно простая идея. Ее может понять любой человек, изучающий базовый курс статистики. Для иллюстрации наших соображений нам понадобится пример исследования. Давайте возьмем работу Э. Дукетта (E. Duckett) и М. Ричардса (M. Richards) под названием «Maternal Employment and Young Adolescents’ Daily Experiences in Single Mother Families» (это статья, представленная в Обществе исследования развития детей в 1989 г., т. е. давным-давно в далекой галактике…). Эти два автора изучили отношение 436 подростков, учащихся с 5-го по 9-й класс, к рабочей занятости матерей. Несмотря на то что результаты были представлены много лет назад, статья является отличным примером для иллюстрации множества важных идей, лежащих в ее основе. В частности, два исследователя проверяли, есть ли разница в отношении к занятости матерей у подростков, чьи матери работают, и детей, чьи матери не работают. Они также изучили несколько других факторов, но для нашего примера мы остановимся только на группах «работающие матери» и «неработающие матери». Еще одно. Введение в главу 9 205 206 Часть IV Значимая разница: применение статистики вывода Давайте добавим слово значимый к обсуждению различий, и мы получим примерно такую альтернативную гипотезу: Существует значимая разница в отношении к рабочей занятости матерей между подростками, чьи матери работают, и подростками, чьи матери не работают, измеряемая тестом эмоционального состояния. Под словом «значимый» мы подразумеваем то, что любая разница в отношении между двумя группами объясняется каким-то систематическим влиянием, а не чистой случайностью. В нашем примере это влияние того, работают матери или нет. Мы предполагаем, что все другие факторы, которые могут отвечать за различия между группами, находились под контролем. Следовательно, единственное, что может определять различие между отношением подростков, – это то, работают их матери или нет. Верно? Да. На этом все? Не совсем. Если бы мы были идеальны Поскольку наш мир вовсе не идеален, мы должны оставить некоторые домыслы относительно своей уверенности в том, что только выделенные нами факторы могут вызывать различия между группами. Другими словами, вы должны иметь возможность сказать: хотя вы довольно уверены, что разница между двумя группами подростков объясняется занятостью матерей, вы не можете быть уверены в этом абсолютно, на 100 %, положительно, безоговорочно, бесспорно (уловили суть?). Всегда есть шанс, не важно, насколько маленький, что вы ошибаетесь. Невероятное вероятно, как говорил Аристотель, и он был прав. Не важно, насколько мала вероятность, она всегда есть. кстати говоря, сама идея о том, что хвосты нормального расИ пределения никогда в действительности не касаются оси x (как мы упоминали в предыдущей главе), имеет прямое отношение к нашему текущему обсуждению. Если бы хвосты касались оси, вероятность появления очень крайнего события на одном и другом хвосте была бы равна 0. Но поскольку они не касаются, то всегда есть шанс, не зависящий от нашей идеальности, что событие может произойти (при этом не важно, насколько мала и невероятна может быть эта вероятность). Почему? Для этого есть много причин. Например, вы можете прос­ то ошибаться. Возможно, во время именно этого эксперимента различия между отношением подростков объяснялись не тем, работают ли их матери, а каким-то другим фактором, который невольно был упущен из виду, например речью, произнесенной в местном клубе работающих матерей, который посещают несколько подростков. А что, если в одной группе оказались в основном подростки муж- Глава 9 Значимо значимый ского пола, а во второй – в основном женского? Это тоже могло быть причиной возникновения различий. Если вы хороший исследователь и тщательно готовите эксперимент, то учтете такие различия, но всегда существует вероятность, что вы этого не сделаете. Будучи хорошим исследователем, вы должны принять эту возможность во внимание. Так что же нам делать? В большинстве научных проектов, которые требуют проверки гипотез (таких как различия между группами), должна быть определенная доля ошибки. Ее нельзя проконтролировать – это фактор случайности, о котором мы говорили в предыдущих главах. Уровень случайности, или риска, который вы готовы взять на себя, выражается в виде уровня значимости, понятия, которое вызывает страх в сердцах даже сильных мужчин и женщин. Уровень значимости (вот примерное быстрое определение) – это риск, что вы не будете на 100 % уверены в том, что наблюдаемые результаты эксперимента являются следствием применяемого лечения или того, что вы проверяете (в нашем примере – факта наличия работы у матерей). Если вы видите, что представленные результаты имеют уровень значимости 0,05 (или p < 0,05, как вы это регулярно читаете в профессиональных журналах), это можно объяснить как наличие 1 шанса из 20 или 5 из 100 (или 0,05, или 5 %), что любые найденные различия объясняются не приведенной в гипотезе причиной (такой как наличие у мамы работы), а какой-то другой, неизвестной причиной или причинами (либо случайностью). Ваша работа состоит в том, чтобы как можно больше сократить эту вероятность, исключив все конкурирующие причины любых наблюдаемых вами различий. Поскольку вы не можете полностью исключить эту вероятность (потому что никто не может контролировать все потенциальные факторы), то определяете ей какой-то уровень и представляете свои результаты с таким вот предупреждением. В итоге (в том числе и на практике) исследователь определяет уровень рис­ка, который он готов взять на себя. Если результаты попадают в область, которая говорит: «Это не могло произойти по чистой случайности – что-то еще оказывает влияние», – то исследователь знает, что нулевая гипотеза (которая утверждает отсутствие различий) не является лучшим объяснением полученных результатов. Вместо нее предпочтительнее использовать объяснение альтернативной гипотезы (заключающееся в том, что существуют различия или неравенство). Давайте посмотрим на еще один пример, на этот раз гипотети­ ческий. Исследователю интересно посмотреть, есть ли разница между академическими успехами детей, которые участвовали в программе дошкольной подготовки, и теми, кто не участвовал. Нулевая гипотеза состоит в том, что обе группы равны друг другу по какому-то измеряемому показателю достижений в учебе. 207 208 Часть IV Значимая разница: применение статистики вывода Альтернативная гипотеза заключается в том, что среднее значение оценок в группе детей, ходивших на дошкольную подготовку, будет выше, чем среднее значение оценок в группе детей, не ходивших на такие занятия. Ваша задача в качестве хорошего исследователя – показать (насколько вы можете, ведь никто не идеален настолько, чтобы учесть все на свете), что любое различие, существующее между группами, объясняется только влиянием дошкольного опыта, а не каким-то другим фактором или их комбинацией. С помощью разнообразных методик (которые вы изучите в следующем курсе по статистике или по методам исследований) вы контролируете или исключаете все возможные источники различий, такие как влияние образования родителей, количество детей в семье и т. д. Как только другие потенциально влияющие переменные будут убраны, останется единственное альтернативное объяснение различий – собственно, влияние дошкольной подготовки. Но можете ли вы быть совершенно (вот прямо чертовски) уверены? Нет, не можете. Почему? Во-первых, потому что вы никогда не можете быть уверены, что протестировали выборку, которая полностью представляет профиль генеральной совокупности. И даже если выборка идеально отображает генеральную совокупность, то всегда есть другие причины, которые могли повлиять на результат и которые вы случайно пропустили при подготовке эксперимента. Всегда есть вероятность ошибки (это другое название для случайности). Делая вывод о том, что различия в оценках объясняются различиями в воздействии, вы принимаете на себя некоторый риск. Степень этого риска и есть фактически (барабанная дробь, пожалуйста) уровень статистической значимости, на котором вы готовы работать. Статистическая значимость (вот и формальное определение) – это степень принимаемого вами риска, что вы отклоните нулевую гипотезу, когда в действительности она будет справедлива. В нашем предыдущем примере нулевая гипотеза говорит, что нет никакой разницы между двумя группами выборки (помните, что нулевая гипотеза всегда утверждает равенство). В своих данных, однако, вы эту разницу нашли. То есть с учетом всех доказательств, которые у вас есть, принадлежность к той или иной группе, похоже, влияет на оценки. В реальности, однако, разница, возможно, отсутствует. Если вы отклоните нулевую гипотезу, то сделаете ошибку. Принимаемый вами риск совершить такую ошибку (или уровень значимости) также известен как ошибка первого рода, или ошибка типа I. Итак, следующий шаг состоит в том, чтобы разработать ряд действий для проверки того, действительно ли за различия в результатах отвечает эта ошибка или же они реально существуют. Глава 9 Значимо значимый 209 Самая важная таблица в мире (только для этого семестра) Вот к чему все это сводится. Нулевая гипотеза может быть истинной или ложной. Либо и в самом деле между группами нет различий, либо неравенство действительно и истинно существует (такое как различия между группами). Но помните, вы никогда не узнаете настоящего положения вещей, потому что нулевую гипотезу нельзя проверить напрямую (т. к. нулевая гипотеза применима только ко всей генеральной совокупности и по разнообразным причинам, о которых мы говорили, генеральные совокупности нельзя проверить напрямую). Таблица 9.1 Различные типы ошибок Ваши действия Принять нулевую гипотезу Отклонить нулевую гипотезу Истинная природа Нулевая гипотеза 1 2 нулевой гипотезы на самом деле Бинго! Вы приняли Упс! Вы совершили ошибку первого верна нулевую гипотезу, когда рода и отклонили нулевую гипотезу, она верна, и в действихотя на самом деле в реальности есть тельности между группами различия между группами. Ошибка нет различий первого рода (ошибка типа I) также часто обозначается греческой буквой альфа, α Нулевая гипотеза 3 4 на самом деле Ой! Вы совершили Хорошая работа, вы отклонили неверна ошибку второго рода нулевую гипотезу, когда и в самом и приняли ложную нулевую деле между двумя группами существуют гипотезу. Ошибки второго различия. Это также называется рода (или ошибки типа II) мощностью критерия и обозначается также обозначаются 1–β греческой буквой бета, β Как блестящий статистик, вы делаете выбор, отклонить или принять нулевую гипотезу. Так? Возникающие четыре ситуации формируют таблицу, которую вы видите (табл. 9.1). Давайте посмотрим на каждую ячейку. Подробнее про таблицу 9.1 В табл. 9.1 есть четыре важные ячейки, которые описывают отношения между сутью нулевой гипотезы (верна она или нет) и вашими действиями (принять или отклонить нулевую гипотезу). Как вы видите, нулевая гипотеза может быть истинной или ложной, а вы можете либо отклонить, либо принять ее. Самое важное для понимания этой таблицы – то, что исследователь никогда на самом деле не знает истинной природы нулевой гипотезы и того, есть ли в действительности разница между группами. Почему? Потому что генеральная совокупность (которую представ- Принятие или отклонение нулевой гипотезы 210 Часть IV Значимая разница: применение статистики вывода ляет нулевая гипотеза) никогда не тестируется напрямую. Это непрактично, и именно поэтому у нас есть статистика вывода: zz ячейка 1 в табл. 9.1 описывает ситуацию, в которой нулевая гипотеза действительно верна (между группами нет различий), а исследователь принял верное решение, согласившись с нулевой гипотезой. Здесь нет проблем. В нашем примере результаты могли бы показать, что между двумя группами детей нет различий, а мы поступили верно, приняв нулевую гипотезу об отсутствии различий; zz упс! Ячейка 2 описывает серьезную ошибку. Здесь мы отклонили нулевую гипотезу (о том, что различий нет), когда она в действительности верна (и между группами есть различия). Даже если между двумя группами детей нет разницы, мы пришли к выводу, что она есть, и это ошибка – очевидный промах под названием ошибка первого рода (или типа I), также известная как уровень значимости; zz ой! Еще один тип ошибки. Ячейка 3 также описывает серьезную ошибку. Здесь мы приняли нулевую гипотезу (об отсутствии различий), когда на самом деле она неверна (и в действительности между группами есть различия). Несмотря на то что на самом деле разница между двумя группами детей существует, мы пришли к выводу, что ее нет, – это тоже очевидный промах, в этот раз имеющий название ошибка второго рода (или ошибка типа II); zz ячейка 4 описывает ситуацию, когда нулевая гипотеза в действительности ошибочна и исследователь принял верное решение отклонить ее. Здесь нет никаких проблем. В нашем примере результаты показали, что между двумя группами детей есть различия, а мы поступили правильно, отклонив нулевую гипотезу, утверждающую, что различий нет. Итак, если 0,05 – это хорошо, а 0,01 – еще «лучше», почему бы не установить риск для ошибки первого рода на уровень 0,000001? По очень серьезной причине: тогда вы будете столь сурово отвергать ошибочные нулевые гипотезы, что можете отклонить нулевую гипотезу и в том случае, когда она на самом деле будет верна. Такой жесткий показатель уровня ошибок типа I дает очень мало допусков. Действительно, альтернативная гипотеза может быть верна, но ей может соответствовать вероятность 0,015 – все еще довольно редкая, но, возможно, очень полезная информация, которая была упущена из-за слишком жесткого уровня ошибки первого рода. Возвращаясь к ошибкам первого рода Оценка уровней значимости Давайте немного задержимся на ячейке 2, в которой была совершена ошибка первого рода, поскольку это тема нашего обсуждения. Эта ошибка первого рода, или уровень значимости, имеет привязанные к ней значения, которые определяют риск, принимаемый Глава 9 Значимо значимый вами при любой проверке нулевой гипотезы. Традиционно эти уровни устанавливаются между 0,01 и 0,05. Например, если уровень значимости равен 0,01, это означает, что при любой проверке нулевой гипотезы есть 1 % вероятности того, что вы отклоните нулевую гипотезу, когда она верна, и придете к выводу, что между группами есть различия, когда в действительности таковых между ними нет. Если уровень значимости равен 0,05, это означает, что при любой проверке нулевой гипотезы есть 5 % вероятности того, что вы отклоните ее (и решите, что между группами есть различия), когда нулевая гипотеза верна и в действительности никакого различия между группами нет. Обратите внимание, что уровень значимости связан с независимой проверкой нулевой гипотезы. Неправильно говорить, что «при 100 проверках нулевой гипотезы я ошибусь только 5 раз, или в 5 % случаев». В отчетах об исследовании статистическая значимость обычно записывается как p < 0,05, что читается как «вероятность наблюдения такого результата меньше, чем 0,05» и часто выражается в отчете или статье просто как «уровень значимости 0,05». С появлением продвинутых программ, таких как SPSS и Excel, которые могут выполнять статистический анализ, больше нет нужды волноваться о неопределенности таких выражений, как p < 0,05 или p < 0,01. Например, p < 0,05 может означать все, что угодно, от 0,000 до 0,49999, верно? Вместо этого такие программы, как SPSS и Excel, дают вам точную вероятность, например 0,013 или 0,158, возникновения того риска совершения ошибки первого рода, который вы готовы принять. Итак, когда вы видите в статье об исследовании утверждение, что p < 0,05, это означает, что значение p равно чему угодно от 0,00 до 4,9999999999… (ну, вы поняли). Аналогично, когда вы видите p > 0,05 или p = н. з. (не значимо), это означает, что вероятность отклонить правдивую нулевую гипотезу выше 0,05 и фактически может иметь любое значение от 0,0500001 до 1,00. Так что это действительно отлично, когда нам известна точная вероятность результата, потому что мы можем измерить риск, который готовы принять на себя. Но что делать, если значение p в точности равно 0,05? С учетом всего того, что уже прочитали, если вы хотите играть по правилам, то ваш результат незначителен. Он или есть, или его нет. Итак, 0,4999999999 означает, что у вас есть результат, а 0,05 – нет. Если SPSS или Excel (или любая другая программа) показывает значение 0,05, то увеличьте количество знаков после запятой, ведь оно действительно может быть равно 0,04999999999. Как мы обсуждали ранее, есть еще один вид ошибки, которую вы можете совершить. Она показана в табл. 9.1 вместе с ошибкой первого рода. Ошибка второго рода (или типа II), представленная в ячейке 3, возникает, когда вы по неосторожности принимаете ложную 211 212 Часть IV Значимая разница: применение статистики вывода нулевую гипотезу. Например, на самом деле могут быть различия между генеральными совокупностями, представленными группами выборок, но вы ошибочно заключаете, что их нет. При обсуждении значимости результатов вы можете услышать слово мощность. Мощность – это концепция, имеющая отношение к тому, насколько хорошо статистический критерий может выявлять и отклонять ложность нулевой гипотезы. Математически она вычисляется путем вычитания значения ошибки второго рода из ошибки первого рода. Более мощный критерий всегда предпочтительнее менее мощного, потому что он дает вам возможность добраться до сути того, что ложно, а что нет. В идеале вы хотите минимизировать ошибки и первого, и второго рода, но это не всегда легко и не всегда вам подконтрольно. Вы можете полностью контролировать уровень ошибки первого рода или объем риска, который вы готовы принять (потому что фактически сами устанавливаете этот уровень). Ошибки второго рода, однако, не напрямую зависят от вас, но связаны с такими факторами, как размер выборки. Ошибки второго рода особенно чувствительны к количеству предметов в выборке, и по мере возрастания их числа ошибки второго рода сокращаются. Другими словами, по мере приближения характеристик выборки к характеристикам генеральной совокупности (что достигается увеличением размера выборки) снижается вероятность того, что вы примете ложную нулевую гипотезу. ЗНАЧИМОСТЬ ПРОТИВ ОСМЫСЛЕННОСТИ Статистическая значимость против практической В какой интересной ситуации оказывается исследователь, когда он или она обнаруживает, что результаты эксперимента действительно статистически значимы! Вы знаете, что означает статистическая значимость с технической стороны: технически исследование было успешно, и нулевая гипотеза не является разумным объяснением тому, что наблюдалось в нем. Теперь, если вы хорошо позаботились о дизайне эксперимента и других важных факторах, статистически значимые результаты, несомненно, станут первым шагом для вклада в исследования в вашей области. Однако нужно трезво оценивать величину статистической значимости и ее важность или осмысленность. Давайте, например, возьмем случай, когда очень большая выборка неграмотных людей (скажем, 10 000 человек) разделена на две группы. Одна группа проходит интенсивное обучение чтению традиционными методами, а другая – при помощи компьютеров. Средний балл по тесту чтения для группы 1 (которая учится традиционно) составляет 75,6, и это зависимая переменная. Средний балл по тесту чтения для группы 2 (которая учится при помощи компьютера) ра- Глава 9 Значимо значимый вен 75,7. Величина дисперсии в обеих группах примерно одинакова. Как вы видите, разница в баллах составляет всего лишь десятую долю процента, или 0,1 (75,6 против 75,7), но после применения t-теста на значимость различий между независимыми средними результаты оказываются значимыми на уровне 0,01, указывая, что компьютеры работают лучше, чем традиционные методы обучения. (Применяемый в таких ситуациях t-тест обсуждается в главах 11 и 12.) Разница в 0,1 балла действительно статистически значима на уровне 0,01, но имеет ли она смысл? Дает ли улучшение результатов чтения (на такую малую долю балла) достаточно оснований для вложения 300 000 долл. в программу? Или же разница достаточно незначительна, чтобы ею можно было пренебречь, даже если она статистически значима? Вот несколько выводов о важности статистической значимости, к которым мы можем прийти с учетом этого и бессчетного множест­ ва других возможных примеров: zz статистическая значимость сама по себе еще не имеет особого смысла, если только проводимое исследование не имеет прочной концептуальной базы, которая придает какой-то смысл значимости результата; zz статистическую значимость нельзя интерпретировать вне зависимости от контекста, в котором были получены результаты. Например, если вы управляете образовательным учреждением, хотите ли вы оставить детей на второй год в первом классе, если повторное обучение значимо увеличивает их оценки за тесты на половину балла; zz несмотря на важность статистической значимости как концепции, она не является итогом всему и, определенно, не должна быть единственной целью научного исследования. Это причина, по которой мы намереваемся проверять гипотезы, а не доказывать их. Если наше исследование правильно спроектировано, тогда даже нулевые результаты скажут нам что-то важное. Если конкретное воздействие не работает, то это важная информация, о которой должны знать другие. Если ваше исследование хорошо спроектировано, тогда вы должны знать, почему это воздействие не работает, а затем следующий за вами человек сможет разработать собственное исследование с учетом предоставленной вами ценной информации. Исследователи по-разному подходят к указанию статистической значимости в своих письменных работах. Некоторые используют такие слова, как значимый (предполагая, что если что-то значимо, то именно статистически), или полное сочетание статистически значимый. Но некоторые также используют фразу ограниченно значимый, когда вероятность ошибки может быть равна 0,051 или 0,053. Что же делать? Решать вам – анализируете ли вы собственные данные или же смотрите на чужие. Поразмыслите и рассмотрите все аспекты 213 214 Часть IV Значимая разница: применение статистики вывода проделанной работы. Если 0,051 «достаточно хорошо» в контексте заданного вопроса, тогда пусть будет так. Согласятся ли с вами внешние рецензенты, это источник масштабных споров и хорошая тема для обсуждения в классе. Почти в каждой дисциплине есть иные термины для различения значимости и осмысленности, но в целом все крутится вокруг тех же самых элементов. Например, специалисты здравоохранения называют ту часть, которая имеет смысл, клинически значимой, а не осмысленной. Идея та же самая – они просто используют другой термин с учетом окружения, в котором получают свои результаты. Слышали когда-нибудь о предвзятости публикаций? Это когда заранее установленный уровень значимости 0,05 используется в качестве единственного критерия для серьезного рассмот­ рения и допуска статьи к публикации. Не то чтобы в точности требовалось 0,05 любой ценой, но раньше и даже сейчас некоторые редакции считают уровни значимости 0,05 или 0,01 святым Граалем, оправдывающим все. Если эти уровни не достигнуты, тогда, по мнению некоторых людей, результаты не могут быть значимыми, не говоря уже о том, чтобы иметь какой-то смысл. Можно много чего сказать о последовательности в этой области, но нынешние статистические инструменты вроде SPSS или Excel позволяют засекать точную вероятность, относящуюся к результату, вместо того чтобы пользоваться подходом «все или ничего», как с критерием 0,05, который ставит крест на имеющей смысл работе еще даже до начала ее обсуждения. Будьте мудрыми – принимайте собственные решения на основании всех доказательств. ПРЕДИСЛОВИЕ К СТАТИСТИКЕ ВЫВОДА Тогда как описательная статистика применяется для описания характеристик выборки, инференциальная статистика используется для формирования предположений о генеральной совокупности на основании этих характеристик. В первой половине «Статистики для тех, кто (думает, что) ненавидит статистику» мы в нескольких местах подчеркивали, что отличительным признаком хорошего научного исследования является формирование репрезентативной выборки, представляющей генеральную совокупность, из которой она отобрана. Затем вы переходите к инференциальному процессу, когда делаете по маленькой выборке выводы о большой генеральной совокупности на основании результатов тестов (и экспериментов), проведенных с этой выборкой. Глава 9 Значимо значимый 215 Давайте разберем логику работы инференциальных методов, прежде чем переходить к обсуждению конкретных критериев вывода. Как работают выводы? Вот несколько общих этапов исследовательского проекта, по которым можно судить о работе процесса вывода. В качестве примера возьмем все то же исследование отношения подростков к рабочей занятости матерей. Вот последовательность событий, которые могут произойти: 1)исследователь отбирает репрезентативные выборки подростков с работающими матерями и тех, чьи матери не работают. Отбор происходит таким образом, чтобы выборки отображали генеральные совокупности, из которых они сформированы; 2)каждый подросток проходит тестирование для оценки его или ее отношения. Для каждой группы рассчитываются средние значения и сравниваются при помощи какого-то критерия; 3)делается заключение, является ли различие между оценками следствием случайности (т. е. того, что какой-то другой фактор, помимо наличия у мам работы, отвечает за разницу) или же результатом «истинных» и статистически значимых различий между двумя группами (т. е. результаты связаны с тем, работают ли мамы); 4)делается заключение о связи между трудоустройством матерей и отношением к этому подростков в генеральной совокупности, из которой была отобрана выборка. Другими словами, на основании результатов анализа данных выборки делается вывод о генеральной совокупности всех подростков. Как выбрать статистический критерий для проверки? Шаг 3 из списка выше приводит нас к вопросу: «Как мне выбрать подходящий статистический критерий, чтобы определить, сущест­ вуют ли различия между группами?» Ей-богу, их множество, и вы должны решить, какой именно и когда использовать. Лучший способ узнать, какой критерий применить, – это стать опытным статистиком, который прошел множество курсов в этой области и принял участие в массе исследований. Опыт – все еще лучший учитель. На самом деле нет другого способа научиться выбирать, что и когда использовать, кроме как реальная, прикладная возможность действительно применить эти инструменты. В результате прохождения данного курса вы научитесь использовать эти самые инструменты. Итак, мы создали для наших целей и в качестве отправной точки отличную схему (шпаргалку), которую вы видите на рис. 9.1. У вас должно быть какое-то понимание того, что вы делаете, так что выбор 216 Часть IV Значимая разница: применение статистики вывода правильного статистического критерия не переключает остальную часть работы на автопилот, но, определенно, дает хороший старт. Даже и не думайте, что рис. 9.1 поможет определить, когда эти разные критерии подходят лучше всего. Эта схема нужна только для того, чтобы помочь вам начать работу. Это действительно важно. Мы только что написали, что выбор подходящего статистического критерия не обязан быть легким. Лучший способ научиться это делать – делать это, что означает практику и даже выбор дополнительных курсов по статистике. Приведенная здесь простая схема в целом работает, но использовать ее нужно с осторожностью. Когда придете к решению, проверьте его у своего профессора или кого-то другого, кто занимался всем этим и чувствует себя увереннее, чем вы (а также знает больше!). Как пользоваться схемой? 1. Предположим, что вы новичок во всех этих статистических делах (кем вы и являетесь на самом деле) и что у вас есть некоторое представление об этих критериях проверки значимости, но вы совершенно не знаете, как решить, какой из них и когда использовать. 2. Ответьте на вопрос, находящийся наверху блок-схемы. 3. Спускайтесь вниз по схеме, отвечая на каждый вопрос, пока не доберетесь до конца. Это статистический критерий, который вам нужно использовать. Это не ядерная физика, и после некоторой практики (которую получите в этой главе) вы сможете быстро и надежно выбирать подходящий тест. Все оставшиеся главы в этой час­ти учебника будут начинаться со схемы, как на рис. 9.1, и проведут вас по конкретным шагам к статистическому критерию, который нужно применить. Содержит ли схема на рис. 9.1 все существующие статистические критерии? Нет. Их сотни, но на рис. 9.1 указаны наиболее часто используемые. Если вы хотите ознакомиться с исследованиями в собственной области, то обязательно с ними столкнетесь. ПРЕДИСЛОВИЕ К ПРОВЕРКЕ ЗНАЧИМОСТИ Критерии значимости Что лучше всего делает статистика вывода, так это позволяет принимать решения о генеральной совокупности на основании информации о выборках. Одним из самых полезных инструментов для этого является проверка статистической значимости, которую можно применить к различным ситуациям (в зависимости от сути заданных вопросов и формы нулевой гипотезы). Например, вы хотите выявить различия между двумя группами, например: есть ли существенная разница между мальчиками и девочками по какому-то тесту? А может, вас интересуют отношения Глава 9 Значимо значимый 217 между двумя переменными, например количеством детей в семье и средним баллом в тестах на интеллект? Эти два случая требуют разных подходов, но оба закончатся проверкой нулевой гипотезы при помощи специального критерия статистической значимости. Рис. 9.1 Быстрая (но не всегда идеальная) инструкция для выбора применяемого статистического критерия Вы изучаете отношения между переменными или различия между группами из одной или нескольких переменных? Я изучаю отношения между переменными Я изучаю различия между группами из одной или нескольких переменных Одни и те же участники оцениваются несколько раз? Да С каким количеством переменных вы работаете? С каким количеством групп вы работаете? Нет С каким количеством групп вы работаете? Две переменные Более двух переменных Две группы Больше двух групп Две группы Больше двух групп t-критерий значимости коэффициента корреляции Регрессия, факторный анализ или канонический анализ t-критерий для зависимых выборок Дисперсионный анализ повторных измерений t-критерий для независимых выборок Простой дисперсионный анализ Как работает проверка значимости: план Проверка значимости основана на факте, что с каждым типом нулевой гипотезы связан определенный вид статистики, или статистический критерий. Для каждого статистического критерия известно его распределение, с которым вы сравниваете данные, полученные из выборки. Сравнение характеристик вашей выборки и параметров распределения критерия позволяет вам сделать вывод, отличаются ли характеристики выборки от того, что вы бы ожидали от случайных результатов. Вот общие шаги, которые нужно предпринять для статистической проверки любой нулевой гипотезы (эти шаги послужат моделью для всех остальных глав в части IV): 1)формулировка нулевой гипотезы. Вы помните, что нулевая гипотеза утверж­дает наличие равенства? Нулевая гипотеза – это «истинное» положение дел, при условии что нет другой информации, на основании которой можно вынести суждение; 218 Часть IV Значимая разница: применение статистики вывода 2)определение уровня риска (или уровня значимости, или ошибки первого рода), связанного с нулевой гипотезой. Каждая альтернативная гипотеза связана с определенной степенью рис­ ка, обусловленного тем, что вы ошибаетесь. Чем меньше эта ошибка (например, 0,01 в сравнении с 0,05), тем на меньший риск вы готовы пойти. Ни одна проверка гипотезы не избавлена от риска, потому что вы никогда не знаете «настоящего» отношения между переменными. Помните, что обычно уровень ошибки первого рода устанавливают как 0,01 или 0,05. SPSS, Excel и другие программы указывают точный уровень; 3)выбор соответствующего статистического критерия. Каждая нулевая гипотеза связана с определенным видом статистического критерия. В этой части учебника вы можете узнать, какой критерий какому типу вопроса соответствует; 4)вычисление значения критерия. Значение критерия (также называемое наблюдаемым значением) является результатом или продуктом применения конкретного статистического тес­ та. Например, есть критерии для значимости разницы между средними значениями двух групп, для значимости отличия коэффициента корреляции от нуля и для значимости разницы между двумя пропорциями. Вы в прямом смысле рассчитывае­ те значение критерия и получаете его числовую величину; 5)определение значения, необходимого для отклонения нулевой гипотезы, по соответствующей таблице критических значений для конкретного критерия. У каждого критерия (с учетом размера группы и риска, который вы готовы на себя взять) есть связанное с ним критическое значение. Это значение, которое, как вы ожидаете, примет критерий значимости, если нулевая гипотеза окажется верной; 6)сравнение наблюдаемого значения с критическим. Это самый важный этап. Здесь полученное вами значение критерия (то, которое вы рассчитали) сравнивается со значением (критическим значением), которое вы ожидаете увидеть при чисто случайных результатах; 7)если наблюдаемое значение оказывается более крайним, чем критическое, то нулевая гипотеза не может быть принята. То есть утверждение нулевой гипотезы о равенстве (обозначающее случайность) не является предпочтительным объяснением найденных различий. Именно здесь проявляется истинная красота инференциального метода. Только если ваше полученное значение будет более крайним, чем то, которое получилось бы случайно (это означает, что рассчитанный результат не является следствием какой-то случайной флуктуации), вы можете сказать, что найденные вами различия не объясняются случайностью и что утверждаемое нулевой гипотезой равенство не является самым привлекательным объяснением Глава 9 Значимо значимый 219 любых найденных вами различий. Наоборот, эти различия, должно быть, стали следствием воздействия. Что, если эти два значения равны (вы же хотели это спросить, да?)? Нет – это следствие случайности; 8)если полученное значение не превосходит критического, нулевая гипотеза является самым привлекательным объяснением. Если вы не можете показать, что полученные различия проистекают из чего-то иного, кроме случайности (например, из воздействия), тогда они, должно быть, объясняются случайностью или чем-то, чем вы не управляете. Другими словами, нулевая гипотеза и есть лучшее объяснение. Лучше один раз увидеть На рис. 9.2 представлены все восемь шагов, которые мы только что сделали. Это визуальное представление того, что происходит при сравнении наблюдаемого и критических значений. В этом примере установлен уровень значимости 0,05, или 5 %. Он мог бы быть равен и 0,01, или 1 %. Рис. 9.2 Сравнение наблюдаемых значений с критическими и решение об отклонении или принятии нулевой гипотезы 95 % всех значений Не отклонять нулевую гипотезу 5 % всех значений Отклонять нулевую гипотезу Критическое значение Глядя на рис. 9.2, обратите внимание на следующее: 1)кривая отображает все возможные результаты для конкретной нулевой гипотезы, такие как различия между двумя группами или значимость коэффициента корреляции; 220 Часть IV Значимая разница: применение статистики вывода 2)критическое значение – это точка, после которой наблюдаемые значения считаются такими редкими, что делается вывод: наблюдаемые значения возникли не случайно, а из-за влияния какого-то фактора. В данном примере под редким мы понимаем то, что имеет меньше 5 % вероятности возникновения; 3)если результат, представленный наблюдаемым значением, оказывается слева от критической точки, то делается вывод, что нулевая гипотеза является наиболее привлекательным объяснением для любых наблюдаемых различий. Другими словами, наблюдаемое значение попадает в область (95 % площади под кривой), в которой мы ожидаем появления только результатов, объясняемых случайностью; 4)если наблюдаемое значение оказывается справа от критической точки, то делается вывод, что альтернативная гипотеза является наиболее привлекательным объяснением для любых наблюдаемых различий. Другими словами, наблюдаемое значение попадает в область (5 % площади под кривой), в которой мы ожидаем появления только результатов, объясняемых чем-то иным, но не случайностью. ПОВЫСЬТЕ СВОЕ ДОВЕРИЕ Теперь вы знаете, что вероятности могут быть связаны с результатами (мы только об этом и говорим в последних двух главах). Сейчас мы собираемся сказать то же самое, но немного по-другому и представить новую идею под названием «доверительные интервалы». Доверительный интервал (или ДИ) – это лучшая оценка диапазона значений генеральной совокупности (или параметра генеральной совокупности), которую мы можем получить при заданном значении выборки (или показателя выборки, отображающего тот параметр генеральной совокупности). Скажем, нам известно среднее значение баллов за тест по правописанию у 20 третьеклассников (или у всех третьеклассников района). Насколько мы уверены в том, что среднее по генеральной совокупности окажется в промежутке между какими-то двумя величинами? 95%-ный доверительный интервал будет верен в 95 % всех случаев. Вы уже знаете, что вероятность попадания исходных данных в промежуток ±1,96 z-оценки или стандартных отклонений равна 95 %, верно? (Смотрите главу 8, если нужно освежить память.) Также вам известно, что вероятность попадания исходных данных в промежуток ±2,56 z-оценки или стандартных отклонений равна 99 %. Если мы подставим вместо z-оценки положительные и отрицательные значения исходных данных, то получим доверительный интервал. Давайте поиграем с реальными числами. Глава 9 Значимо значимый 221 Скажем, что среднее значение балла за правописание в случайной выборке из 100 шестиклассников равно 64 (из 75 слов), а стандартное отклонение – 5. Насколько мы можем доверять предсказанию о среднем значении балла за правописание у генеральной совокупности всех шестиклассников? 95%-ный доверительный интервал равен… 64 ± 1,96 × 5… или диапазону между 54,2 и 73,8, так что вы можете сказать с 95%-ной уверенностью, что среднее значение балла за правописание у генеральной совокупности всех шестиклассников попадет между двумя этими величинами. Хотите доверять себе еще больше? 99%-ный доверительный интервал будет рассчитываться как 64 ± 2,56 × 5, или будет равен диапазону от 51,2 до 76,8, так что вы можете заключить с 99%-ной уверенностью, что среднее генеральной совокупности окажется между этими двумя величинами. Имейте в виду, что некоторые люди используют для расчета доверительных интервалов стандартную ошибку среднего и что можно применять для расчета и стандартное отклонение, и стандартную ошибку среднего. Учитывайте, что вас просит делать преподаватель. В то время как мы пользуемся стандартным отклонением для расчета доверительных интервалов, многие люди предпочитают использовать стандартную ошибку среднего (см. главу 10). Стандартная ошибка среднего – это стандартное отклонение всех средних величин выборок, которые теоретически можно отобрать из генеральной совокупности. Помните, что и стандартное отклонение, и стандартная ошибка среднего – это «ошибки» в измерениях, окружающие определенную «истинную» точку (которая в нашем случае будет истинным средним, или истинным размером изменчивости). Использование стандартной ошибки среднего чуть сложнее, но это альтернативный способ расчета и понимания доверительных интервалов. Почему доверительный интервал увеличивается, по мере того как возрастает вероятность, что вы будете правы (например, с 95 % до 99 %)? Потому что больший диапазон доверительного интервала (в данном случае 19,6 [73,8 – 54,2] для 95%-го доверительного интервала против 25,6 [76,8 – 51,2] для 99%-го доверительного интервала) позволяет вам охватить большее количество возможных результатов, следовательно, вы можете быть более уверены. Ха! Ну не круто ли это? РЕАЛЬНАЯ СТАТИСТИКА Действительно, интересно, как разные дисциплины могут поучиться друг у друга, когда они делятся знаниями, и очень жаль, что это не происходит чаще. Это одна из причин, по которой так важны междисциплинарные исследования. Они создают среду, в которой 222 Реальная статистика Часть IV Значимая разница: применение статистики вывода новые и старые идеи могут найти применение в прежних и нынешних условиях. Одно из таких обсуждений наблюдалось в медицинском журнале, посвященном анестезии. Тема обсуждения касалась относительных достоинств статистической и клинической значимости, и доктора Тимоти Хоул (Timothy Houle) и Дэвид Стамп (David Stump) утверждали, что многие клинические испытания показывают высокий уровень статистической значимости с крошечными различиями между группами (точно как мы говорили ранее в этой главе), что делает результаты клинически бесполезными. Однако авторы сказали, что с соответствующим маркетингом на результатах с сомнительной клинической важностью можно сделать миллиарды. Вот уж действительно: «Пусть покупатель будет бдителен!» Очевидно, отсюда можно извлечь несколько очень хороших уроков, касающихся того, сколь велика значимость полученных результатов. Как это понять? Смотрите на то, что стоит за результатами, и на контекст, в котором они были получены. Хотите узнать больше? Найдите в интернете или библиотеке статью... Hou­le T. T. & Stump D. A. Statistical significance versus clinical significance. Seminars in Cardiothoracic and Vascular Anesthesia, 2008. Р. 5–6. ВЫВОДЫ ПО ГЛАВЕ Выводы по главе Итак, теперь вы точно знаете, как работает концепция значимости, остается только применить ее к разнообразным вопросам исследований. Именно этим мы начнем заниматься в следующей главе и продолжим до конца этой части книги. ВРЕМЯ ПРАКТИКИ 1.Почему значимость является важным понятием в изучении и применении статистики вывода? 2. Что такое статистическая значимость? 3. Что представляет собой критическое значение? 4.При следующих условиях и уровне значимости 0,05 вы решите принять или отклонить нулевую гипотезу? Объясните свои выводы: а) нулевая гипотеза об отсутствии связи между типом музыки, которую слушает человек, и его предрасположенностью к преступлениям (p < 0,05); б) нулевая гипотеза об отсутствии связи между количеством по- Глава 9 Значимо значимый требляемого кофе и средним баллом успеваемости (p = 0,62); в) альтернативная гипотеза о наличии отрицательной связи между количеством рабочих часов и удовлетворенностью работой (p = 0,51). 5. Что не так со следующими утверждениями: а) ошибка первого рода 0,05 означает, что в 5 случаях из 100 экспериментов мы отклоним верную нулевую гипотезу; б) вполне возможно установить ошибку первого рода на нулевом уровне; в) чем меньше ошибка первого рода, тем лучше результаты. 6.Почему оказывается труднее найти значимый результат (при всех прочих равных условиях), когда альтернативная гипотеза проверяется на уровне значимости 0,01, а не 0,05? 7.Почему мы должны думать о том, что не удалось отклонить нулевую гипотезу, вместо того чтобы просто принять ее? 8. В чем состоит разница между значимостью и существенностью? 9.Вот еще немного дебатов о разнице между значимостью и су­ щественностью: а) приведите пример выводов, которые могут быть одновременно статистически значимыми и осмысленными; б) теперь приведите пример выводов, которые могут быть статистически значимыми, но не осмысленными. 10.Какое отношение имеет случайность к проверке значимости альтернативных гипотез? 11.На рис. 9.2 есть заштрихованная область в правой части рисунка: а) что отображает эта заштрихованная область? б) если бы заштрихованной частью была большая область под кривой, что бы это означало? 223 Проблема 8 10 Строго по одному Одновыборочный Z-критерий Уровень сложности: (не слишком сложно – это первая такая глава, но ваших знаний достаточно, чтобы справиться с ней) В ЭТОЙ ГЛАВЕ ВЫ УЗНАЕТЕ, КАК: решить, когда можно использовать Z-критерий; рассчитать наблюдаемое значение z; интерпретировать значение z; понять, что означает значение z; определить величину эффекта и интерпретировать ее. ПРЕДИСЛОВИЕ К ОДНОВЫБОРОЧНОМУ Z - КРИТЕРИЮ Введение в главу 10 Одновыбо­ рочный Z-критерий 224 Недостаток сна может вызвать самые разные проблемы: от брезгливости до утомления и даже смерти. Так что вы можете представить, насколько медики заинтересованы в том, чтобы их пациенты достаточно спали. Особенно понятен их интерес, касающийся болеющих пациентов, которые действительно нуждаются в излечивающих и восстанавливающих свойствах сна. Д-р Джозеф Каппеллери (Joseph Cappelleri) и его коллеги изучили сложности со сном у пациентов с конкретным заболеванием, фибромиалгией, чтобы оценить полезность опросника со шкалой оценки сна для измерения проблем с ним. И хотя были проведены и другие типы анализа, включая сравнение контрольной и экспериментальной групп между собой, важной (для нашего обсуждения) частью работы было сравнение показателей сна пациентов с национальными нормами. Такое сравнение между показателем выборки (оценкой сна участников этого исследования) и значениями генеральной совокупности (нормами) обусловливает необходимость применения одновыборочного Глава 10 Строго по одному 225 Z-критерия. Каковы же были выводы исследователей? Показатели сна пациентов оказались статистически незначимыми (p < 0,05). Другими словами, нельзя было принять нулевую гипотезу о том, что среднее значение выборки и среднее по совокупности равны. Так зачем использовать одновыборочный Z-критерий? Каппеллери и его коллеги хотели узнать, отличаются ли измеренные одинаковым инструментом значения выборки от значений генеральной совокупности (по всей стране). Исследователи, по сути, сравнивали показатель выборки с параметром совокупности и проверяли, могут ли они заключить, что выборка является (или не является) репрезентативной. Хотите узнать больше? Обратитесь к… Cappelleri J. C., Bushmakin A. G., McDermott A. M., Dukes E., Sadosky A., Petrie C. D. & Martin S. Measurement properties of the Medical Outcomes Study Sleep Scale in patients with fibromyalgia. Sleep Medicine, 2009. Р. 766–770. ПУТЬ К МУДРОСТИ И ЗНАНИЮ А вот как вы можете использовать рис. 10.1 (схему, представленную вам в главе 9) для выбора подходящего статистического критерия, одновыборочного Z-критерия. Следуйте по выделенной очередности шагов на рис. 10.1. Сейчас это довольно легко (но так будет не всегда), потому что это единственная процедура вывода во всей части IV, где мы имеем дело только с одной группой. К тому же тут много того, что возвращает нас к главе 8 и стандартным показателям, а поскольку вы уже эксперт в них… Проведение одновыбо­ рочного Z-критерия 1. Мы изучаем различия между выборкой и генеральной совокуп­ностью. 2. Проверяется только одна группа. 3. Подходящий статистический критерий – это одновыборочный Z-кри­терий. ВЫЧИСЛЕНИЕ Z - СТАТИСТИКИ Расчет значения одновыборочного Z-критерия приведен в формуле 10.1. Помните, что мы проверяем, отображает ли среднее значение выборки среднюю _генеральной совокупности. Разница между выборочным средним X и средним генеральной совокупности (µ) находится в числителе значения Z-кри­терия. Знаменатель, отображающий ошибку, называется стандартной ошибкой среднего и представляет собой величину, которую мы ожидаем получить в результате случайности, при наличии всей той изменчивости, которая присуща набору средних значений всех возможных выборок из ге- Часть IV 226 Значимая разница: применение статистики вывода неральной совокупности. Применение стандартной ошибки среднего (и ключевое слово здесь – стандартная) позволяет нам еще раз (как было показано в главе 9) воспользоваться таблицей z-оценок для определения вероятности результата. (10.1) _ где X – среднее значение выборки; µ – среднее значение совокупности; SEM – стандартная ошибка среднего. А теперь для расчета стандартной ошибки среднего, которая нужна вам в формуле 10.1, воспользуйтесь формулой 10.2: (10.2) где σ – стандартное отклонение генеральной совокупности; n – размер вы­борки. Рис. 10.1 Проверка, что одновыборочный Z-критерий – то, что нам нужно Вы изучаете отношения между переменными или различия между группами из одной или нескольких переменных? Вы изучаете разницу между одной выборкой и генеральной совокупностью? Я изучаю отношения между переменными Я изучаю различия между группами из одной или нескольких переменных Одни и те же участники оцениваются несколько раз? Да С каким количеством переменных вы работаете? Одновыборочный Z-критерий Генеральные совокупности и выборки С каким количеством групп вы работаете? Нет С каким количеством групп вы работаете? Две переменные Более двух переменных Две группы Больше двух групп Две группы Больше двух групп t-критерий значимости коэффициента корреляции Регрессия, факторный анализ или канонический анализ t-критерий для зависимых выборок Дисперсионный анализ повторных измерений t-критерий для независимых выборок Простой дисперсионный анализ Стандартная ошибка среднего – это стандартное отклонение всех возможных средних, отобранных из генеральной совокупности. Это лучшая приблизительная оценка, которую мы можем получить, учитывая, что невозможно рассчитать все возможные выборочные средние. Если бы наша отобранная выборка была идеальна, разница между выборочной средней и средним значением совокупности была бы равна нулю, верно? Да. Однако если выборка из совокупности формируется некорректно (т. е. вовсе Глава 10 Строго по одному 227 не случайно и не репрезентативно), тогда стандартное отклонение всех средних величин этих выборок будет огромным, верно? Да. Так что мы стараемся отобрать идеальную выборку, но независимо от нашего усердия всегда будет существовать какая-то ошибка. Стандартная ошибка среднего показывает, чему было бы равно ее значение для всей генеральной совокупности всех средних значений. И да, Вирджиния, это стандартная ошибка среднего. Также могут быть (и есть) стандартные ошибки для других мер. Пора привести пример. Д-р МакДональд думает, что его группа студентов, изучающих нау­ку о Земле, исключительна (в хорошем смысле), и ему интересно знать, попадает ли средняя оценка его группы в границы средних оценок большей группы студентов, изучавших науку о Земле за прошедшие 20 лет. Поскольку он все записывал, то знает средние значения и стандартные отклонения как для своей группы из 36 человек, так и для большей группы из 1000 бывших учеников. Вот эти данные. Таблица 10.1 Показатели студентов Выборка Генеральная совокупность Размер 36 1000 Среднее 100 99 Стандартное отклонение 5,0 2,5 Вот знаменитые восемь шагов и вычисление значения Z-статистики. 1. Формулировка основной и альтернативной гипотез. Нулевая гипотеза утверждает, что среднее выборки равно среднему по генеральной совокупности. Если нулевая гипотеза не отклоняется, это означает, что выборка репрезентативна. Если нулевая гипотеза отклоняется в пользу альтернативной гипотезы, это означает, что среднее выборки отличается от среднего генеральной совокупности. Нулевая гипотеза: _ (10.3) H0: X = µ. Альтернативная гипотеза для данного примера: _ H1: X ≠ µ. (10.4) 2. Выбор уровня риска (или уровня значимости, или ошибки первого рода), связанного с нулевого гипотезой. Уровень риска, или ошибки первого уровня, или уровня значимости (еще какие-нибудь названия?), здесь 0,05, но это остается полностью на усмотрение исследователя. 3. Выбор подходящего статистического критерия. При помощи схемы, показанной на рис. 10.1, мы определили, что нам подходит одновыборочный Z-критерий. 228 Часть IV Значимая разница: применение статистики вывода 4. Расчет значения статистического критерия (наблюдаемого зна­чения). Это ваш шанс подставить в формулы значения и сделать какие-то вычисления. Формулой для значения z является 10.1. Подставляем значения (сначала рассчитываем SEM в формуле 10.5, а затем переходим к z в формуле 10.6). После подстановки получаем следующие результаты: (10.5) (10.6) Величина z для сравнения выборочного среднего со средним по совокупности на основании данных д-ра МакДональда равна 2,38. 5. Определение значения, необходимого для отклонения нулевой гипотезы, при помощи соответствующей таблицы критических значений для конкретного критерия. Здесь мы переходим к таблице B.1 в приложении B, в которой дан список вероятностей, связанных с конкретными z-оценками, которые и являются критическими значениями для отклонения нулевой гипотезы. Все то же самое мы делали в нескольких примерах в главе 9. По итогам работы в главе 9 мы знаем, что z-оценка +1,96 соотносится с вероятностью 0,025. Если мы полагаем, что среднее выборки может быть больше или меньше, чем среднее совокупности, нам нужно посмотреть на оба конца распределения (в диапазоне ±1,96) и на уровень ошибки первого рода 0,05. 6. Сравнение наблюдаемого значения с критическим. Наблюдаемое значение z = 2,38. Итак, критическое значение для проверки этой нулевой гипотезы на уровне значимости 0,05 с 36 участниками равно ±1,96. Это значение указывает на величину, при которой случайность является наиболее привлекательным объяснением того, почему различаются средние по выборке и по совокупности. Результат, превосходящий это критическое значение в любом направлении (помните, что наша альтернативная гипотеза ненаправленная, у критерия есть два хвоста), означает, что нам нужно будет предоставить объяснение тому, почему различаются средние по выборке и по совокупности. 7 и 8. Время решать! Если наблюдаемое значение оказывается более крайним, чем критическое (вспомните рис. 9.2), то нулевую гипотезу нельзя принять. Если наблюдаемое значение не превосходит критического, то нулевая гипотеза дает самое привлекательное объяснение. В данном случае наблюдаемое значение (2,38) действительно превосходит критическое (1,96), и оно достаточно крайнее, чтобы мы могли сказать, что выборка из 36 студентов в группе д-ра МакДональда отличается от предыдущих 1000 студентов, изучавших этот предмет. Если бы наблюдаемое значение было меньше, чем 1,96, это бы означало, что нет различий между оценками за контрольные у выборки и у тех 1000 студентов, которые изучали предмет в прошедшие 20 лет. В этом случае 36 студентов показывали бы в целом такие же результаты, как и предыдущие 1000 человек. И последний шаг? Ну, конечно! Нам же интересно, почему эта группа студентов отличается? Возможно, МакДональд прав, что они умнее, но также возможно, что они лучше используют технику или более мотивированы. Может быть, они просто усерднее учатся. Все это – вопросы для других проверок. Глава 10 Строго по одному 229 Так как мне интерпретировать z = 2,38, p < 0,05? zz z обозначает статистический критерий, который мы использовали. zz 2,38 – это наблюдаемое значение, рассчитанное при помощи формул, которые мы показали вам ранее в этой главе. zz p < 0,05 (действительно важная часть этого короткого выражения) обозначает, что для любой проверки нулевой гипотезы существует меньше 5 % вероятности, что средние значения выборки и генеральной совокупности будут различаться. Таблица Z-распре­ деления РАСЧЕТ Z - КРИТЕРИЯ ПРИ ПОМОЩИ SPSS Здесь мы немного сменим направление, поскольку SPSS не предлагает расчет одновыборочного Z-критерия, но в ней есть расчет одновыборочного t-крите­рия. Их работа, в принципе, одинакова, и пример расчета одновыборочного t-критерия продемонстрирует полезность SPSS, что и является нашей целью. Главное различие между t-критерием и Z-критерием состоит в том, что SPSS использует распределение t-показателя для оценки результата. Настоящее различие между Z- и t-критериями состоит в том, что для t-критерия стандартное отклонение неизвестно, тогда как для Z-критерия оно известно. Другое различие заключается в том, что тесты используют разные распределения критических значений для оценки результатов (что вполне разумно, учитывая, что они применяют разные статистические критерии). В следующем примере мы будем использовать одновыборочный t-критерий в SPSS для оценки того, является ли одно значение (13) характеристикой всей выборки. Вот состав всей выборки: 12 9 7 10 11 15 16 8 9 12 Часть IV 230 Значимая разница: применение статистики вывода 1. После ввода данных нажмите Анализ (Analyze) ⇒ Сравнение средних (Compare Means) ⇒ Одновыборочный t-критерий (One-Sample T test), и вы увидите диалоговое окно, как на рис. 10.2. 2. Дважды щелкните на имя переменной, чтобы переместить ее в поле Проверяемые переменные (Test Variable(s)). 3. Введите в поле Проверяемое значение (Test Value) 13. 4. Нажмите ОК, и вы увидите вывод, как на рис. 10.3. Рис. 10.2 Диалоговое окно Одновыборочный t-критерий Читаем выводы SPSS Рисунок 10.3 показывает вам следующее: 1)для выборки из 10 значений среднее значение – 10,9, стандартное отклонение – 2,92; 2)результирующее значение t-критерия –2,72 значимо на уровне 0,05 (едва-едва, но получилось!); 3)результаты указывают на то, что проверяемое значение 13 значимо отличается от величин в данной выборке. Рис. 10.3 Вывод SPSS для одновыборочного t-критерия Глава 10 Строго по одному 231 СПЕЦЭФФЕКТЫ: А ЭТИ РАЗЛИЧИЯ НАСТОЯЩИЕ? Ладно, пора вас занять совершенно новой идеей про размер эффекта и научить его применению, чтобы ваш анализ любого инференциального критерия стал более ценным и интересным. В общем, при помощи разных методик статистики вывода вы можете находить различия между выборками и генеральными совокупностями, между двумя или более выборками и т. д. Однако вопрос на 64 000 долл. не только в том, значима ли (статистически) эта разница, но и в том, имеет ли она смысл, т. е. достаточно ли разнесены между собой распределения, описывающие каждую выборку или группу, которую вы проверяете, чтобы эта разница действительно стоила того, чтобы ее обсуждать! Хмм… Добро пожаловать в мир размера эффекта. Размер эффекта – это мера того, насколько отличаются две группы друг от друга (мера величины воздействия). Это что-то вроде: насколько большое – большое? Что особенно интересно, при вычислении размера эффекта не учитывается размер выборки. Расчет размера эффекта и суждение о нем добавляют новое измерение к пониманию значимых результатов. Еще одним интересным фактом о размере эффекта является то, что много разных проверок выводов используют разные формулы для расчета размера эффекта (как вы увидите сами в следующих нескольких главах), но независимо от этого используется одна и та же единица измерения (под названием d Коэна). Это как в том случае, если бы вы использовали рулетку или линейку для замера двух бревен разного размера, но все равно получили результат в дюймах. Давайте возьмем в качестве примера данные д-ра МакДональда по оценкам, связанным с изучением науки о Земле. Вот еще раз эти средние значения и отклонения. Таблица 10.1 Показатели студентов Выборка Генеральная совокупность Размер 36 1000 Среднее 100 99 Стандартное отклонение 5,0 2,5 Вот формула для расчета d Коэна для размера эффекта одновыборочного Z-кри­терия: (10.7) _ где X – среднее значение выборки; µ – среднее значение генеральной совокупности; σ – стандартное отклонение генеральной совокупности. Если мы подставим в формулу 10.7 данные д-ра МакДональда, то получим это: Размер эффекта 232 Часть IV Значимая разница: применение статистики вывода Мы уже знаем из предыдущих расчетов, что наблюдаемое значение z-кри­терия 2,38 значимо. Это означает, что успехи группы д-ра МакДональда действительно отличаются от результатов генеральной совокупности. Теперь мы узнали, что размер эффекта равен 0,4, так давайте обратимся к тому, что же может означать этот статистически значимый результат в терминах размера его влияния. Как понимать размер эффекта? Великим гуру размера эффекта был Джейкоб Коэн (Jacob Cohen), который написал одни из самых внушительных статей на эту тему. Он был автором очень важной и авторитетной книги (у вашего преподавателя статистики она стоит на полке!), которая учит исследователей выявлять размер эффекта для множества разнообразных вопросов о различиях и отношениях между переменными. И эта книга также дает некоторые подсказки, что могут означать разные размеры эффекта для понимания различий. Как вы помните, в нашем примере размер эффекта – 0,4. Что это значит? Одна из самых классных штук, которые обнаружил Коэн и другие исследователи, – это границы маленького, среднего и большого размеров эффекта. Они использовали следующие указания: zz маленький размер эффекта находится в пределах от 0 до 0,2; zz средний размер эффекта находится в пределах от 0,2 до 0,5; zz большой размер эффекта – это любое значение больше 0,5. Наш пример с размером эффекта 0,4 относится к категории средних. Но что это действительно значит? Размер эффекта дает нам представление об относительном положении одной группы при сопоставлении с другой. Например, если размер эффекта нулевой, это означает, что обе группы очень похожи и полностью накладываются друг на друга, т. е. нет никакой разницы между двумя распределениями величин. С другой стороны, размер эффекта 1 означает, что две группы пересекаются примерно на 45 % (имеют столько общего). Как вы догадываетесь, чем больше становится размер эффекта, тем большее отсутствие пересечений двух групп он отображает. Книга Джейкоба Коэна «Statistical Power Analysis for the Behavioral Sciences», впервые опубликованная в 1967 г., обязательна к прочтению для любого, кто хочет выйти за рамки очень общей информации, представленной здесь. Глава 10 Строго по одному 233 РЕАЛЬНАЯ СТАТИСТИКА Посещали ли вы недавно врача? Объясняли ли вам результаты ваших анализов? Знаете ли вы что-нибудь о применении электронных карт пациентов? В этом исследовании Ноэль Бруэр (Noel Brewer) и его коллеги сравнивают полезность таблиц и столбиковых диаграмм для представления результатов медицинских анализов. При помощи Z-критерия исследователи обнаружили, что участникам требовалось меньше времени на просмотр, когда использовались столбиковые диаграммы вместо таблиц. Исследователи приписали эту разницу тому, что столбиковые диаграммы лучше передают основную информацию (и вы хорошо помните это из главы 4, где мы подчеркивали, что картинка, например столбиковая диаграмма, действительно стоит тысячи слов). Кроме того, не вызывает особого удивления тот факт, что когда участники рассматривали оба формата, те из них, у кого был опыт работы со столбиками, предпочитали столбиковые диаграммы, а те, у кого был опыт работы с таблицами, находили, что пользоваться столбиковыми диаграммами так же просто. В следующий раз, когда пойдете к своему врачу и он (или она) покажет вам таблицу, скажите, что вы хотите видеть результаты в виде столбиков. Вот это применение статистики в реальном мире на ежедневной основе! Хотите узнать больше? Найдите в интернете или библиотеке статью... Bre­wer N. T., Gilkey M. B., Lillie S. E., Hesse B. W. & Sheridan S. L. Tables or bar graphs? Presenting test results in electronic medical records. Medical Decision Making, 2012. Р. 545–553. Реальная статистика ВЫВОДЫ ПО ГЛАВЕ Одновыборочный Z-критерий является простым примером инференциальной проверки, и именно поэтому мы начали этот длинный раздел книги с объяснения того, что делает этот критерий и как его применять. Очень хорошие новости – то, что большинство (если не все) шагов, которые мы делаем на пути к более сложным аналитическим методикам, в точности повторяют те, что вы видите здесь. На самом деле в следующей главе мы переходим к очень распространенному статистическому критерию, который является продолжением Z-критерия, рассмотренного здесь, – к простому t-критерию для средних двух разных групп. Выводы по главе 234 Часть IV Значимая разница: применение статистики вывода ВРЕМЯ ПРАКТИКИ 1. Когда применим одновыборочный Z-критерий? 2.Что отображает z в Z-критерии? Какое сходство она имеет с прос­ то z, или стандартным показателем? 3.Запишите словами альтернативную гипотезу для следующих ситуаций: а) Боб хочет знать, отображает ли потеря веса в его группе приверженцев шоколадной диеты потерю веса в большей совокупности мужчин среднего возраста; б) департаменту здравоохранения поручили выяснить, сравнима ли заболеваемость гриппом на тысячу человек в прошедшем сезоне со средней заболеваемостью за 50 сезонов; в) Блэр почти уверен, что его ежемесячные расходы в прошлом году не похожи на среднемесячные расходы за прошедшие 20 лет. 4.В прошлом сезоне гриппа в школьной системе Ремулака (n = 500) наблюдалось 15 случаев гриппа в неделю. Во всем штате среднее количество случаев в неделю было равно 16, стандартное отклонение составляло 15,1. Болеют ли дети в Ремулаке так же, как и дети во всем штате? 5.Ночные работники в трех специализированных магазинах «Супер Бо» пересчитывают около 500 продуктов за 3 ч. Как эта скорость сопоставима с учетом других 97 магазинов сети, где в среднем за 3 ч пересчитывается 496 продуктов? Делают ли работники спе­циализированных магазинов свое дело лучше, чем в среднем? Вот информация, которая вам понадобится: Размер Специализированные магазины Все магазины 3 100 Среднее количество учтенных продуктов 500 496 Стандартное отклонение 12,56 22,13 6.Крупное исследование изучало, насколько репрезентативно было уменьшение симптомов болезни при приеме лекарства в экспериментальной группе по сравнению с откликом на нее во всей генеральной совокупности. Оказалось, что проверка альтернативной гипотезы дала значение Z-критерия, равное 1,67. К какому заключению, вероятно, пришли исследователи? Подсказка: обратите внимание, что уровень ошибки первого рода, или уровень значимости, не задан (как, наверное, полагалось бы). Какой вывод вы сделаете из этого? 7.Группа гольфа Миллмана играет блестяще для любителей. Готовы ли они стать профессионалами? Вот данные. (Подсказка: помните, что в гольфе чем ниже счет, тем лучше!) Глава 10 Строго по одному Группа Миллмана Профи Размер 9 500 235 Средний счет 82 71 Стандартное отклонение 2,6 3,1 8.Вот список количества игрушек, проданных магазином «T & K» за 12 месяцев 2015 г. Имеют ли продажи одного месяца 2016 г. в размере 31 456 шт. значимую разницу с месячными продажами 2015 г.? Шт., проданные в 2015 г. Январь 34 518 Февраль 29 540 Март 34 889 Апрель 26 764 Май 31 429 Июнь 29 962 Июль 31 084 Август 30 506 Сентябрь 28 546 Октябрь 29 560 Ноябрь 29 304 Декабрь 25 852 11 (t)ет-а-тет Проверки значимости для средних значений разных групп Уровень сложности: (немного длиннее, чем предыдущая глава, но в основном такие же процедуры и очень похожие вопросы. Не очень сложно, но вы должны быть внимательны) В ЭТОЙ ГЛАВЕ ВЫ УЗНАЕТЕ: когда использовать t-критерий для независимых средних; как рассчитать наблюдаемое значение t; как интерпретировать значение t и понять, что оно значит; как рассчитать размер эффекта для t-критерия независимых средних. ПРЕДИСЛОВИЕ К t- КРИТЕРИЮ Д ЛЯ НЕЗАВИСИМЫХ ВЫБОРОК Введение в главу 11 236 Несмотря на то что признается серьезность пищевых расстройств, было проведено мало исследований для сравнения распространенности и выраженности симптомов в разных культурах. Джон П. Сьйостед (John P. Sjostedt), Джон Ф. Шумакер (John F. Schumaker) и С. С. Натауот (S. S. Nathawat) предприняли свое исследование в группах из 297 австралийских и 249 индийских студентов университета. Каждый студент заполнял опросник об отношении к еде и оценивался по шкале боязни ожирения. Результаты групп сравнивались друг с другом. При сравнении средних значений индийских и австралийских участников оказалось, что индийские студенты имели более высокие баллы по обоим опросникам. Результаты опросника об отношении к еде были t(544) = −4,19, p < 0,0001, а результаты шкалы боязни ожирения оказались t(544) = –7,64, p < 0,0001. Так что же все это означает? Читайте дальше. Почему был использован t-критерий для независимых средних? Сьйостед и его коллеги хотели узнать, существует ли разница между Глава 11 (t)ет-а-тет 237 средними значениями одной (или нескольких) переменной, не зависящими друг от друга. Под независимыми мы имеем в виду, что обе группы никак не были связаны. Каждый участник исследования опрашивался только 1 раз. Исследователи применили t-критерий Стьюдента для независимых средних и пришли к заключению, что для каждой из результирующих переменных различия между группами были значимыми на уровне, равном или более низком, чем 0,0001. Такая маленькая ошибка первого рода означает очень маленькую вероятность того, что различия между группами являются следствием чего-то иного, чем принадлежности к группе, в данном случае представленной национальностью, культурой и этнической принадлежностью. Хотите узнать больше? Найдите в интернете или библиотеке статью… Sjos­tedt J. P., Schumaker J. F. & Nathawat S. S. Eating disorders among Indian and Australian university students. Journal of Social Psychology, 1998. Р. 351–357. ПУТЬ К МУДРОСТИ И ЗНАНИЮ Вот так вы можете использовать рис. 11.1, схему, представленную вам в главе 9, для выбора подходящего статистического критерия, t-критерия для независимых средних. Следуйте очередности шагов на рис. 11.1. 1. Изучаются различия между группами австралийских и индийских студентов. 2. Участники опрашиваются только один раз. 3. Есть две группы. 4. Подходящий статистический критерий – t-критерий для независимых средних. Почти все статистические критерии опираются на какие-то предположения, которые обусловливают их применение. Например, t-кри­терий основывается на предположении, что уровень изменчивости в каждой из двух групп одинаков. Это предположение о равенстве дисперсий. И хотя это предположение можно без особых последствий нарушить при достаточно большом размере выборки, невыполнение предположения на маленьких выборках может привести к спорным результатам и выводам. Не забивайте себе голову беспокойством об этих предположениях, потому что они не рассматриваются в данной книге. Однако вы должны знать, что хотя такие предположения и редко нарушаются, они все-таки существуют. Выбор зависимого t-критерия между средними Часть IV 238 Значимая разница: применение статистики вывода Рис. 11.1 Проверка, что t-критерий – это то, что нам нужно Вы изучаете отношения между переменными или различия между группами из одной или нескольких переменных? Вы изучаете разницу между одной выборкой и генеральной совокупностью? Я изучаю различия между группами из одной или нескольких переменных Я изучаю отношения между переменными Одни и те же участники оцениваются несколько раз? С каким количеством переменных вы работаете? Одновыборочный Z-критерий Да Нет С каким количеством групп вы работаете? С каким количеством групп вы работаете? Две переменные Более двух переменных Две группы Больше двух групп Две группы Больше двух групп t-критерий значимости коэффициента корреляции Регрессия, факторный анализ или канонический анализ t-критерий для зависимых выборок Дисперсионный анализ повторных измерений t-критерий для независимых выборок Простой дисперсионный анализ Как мы упоминали ранее, существуют сотни статистических критериев. В этой книге мы рассматриваем единственный инференциальный критерий для одной выборки – одновыборочный Z-критерий (см. главу 10). Но существует также и одновыброчный t-критерий, который сравнивает среднее значение выборки с другим значением. Иногда это значение действительно оказывается средним значением генеральной совокупности, так же как и в одновыборочном Z-критерии. В любом случае вы можете применять одновыборочный Z-критерий или одновыборочный t-критерий для проверки одной и той же гипотезы и придете к одним и тем же выводам (хотя и будете пользоваться для этого разными значениями и таблицами). Мы немного обсуждали это в главе 10, когда говорили о сравнении выборки с популяцией при помощи SPSS. ВЫЧИСЛЕНИЕ t- КРИТЕРИЯ Вычисление t-критерия для независимых выборок Вычисление значения t-критерия Стьюдента для независимых средних показано в формуле 11.1. Разница между средними записывается в числитель; размер вариации внутри групп и между двумя группами стоит в знаменателе. Глава 11 (t)ет-а-тет 239 (11.1) _ _ где X1 – среднее значение для группы 1; X2 – среднее значение для группы 2; n1 – количество участников в группе 1; n2 – количество участников в группе 2; s12 – дисперсия для группы 1; s22 – дисперсия для группы 2. Эта формула длиннее, чем те, что встречались нам раньше, но в ней нет ничего принципиально нового. Нужно просто подставить правильные значения. Нахождение критического значения t-критерия Время для примера Вот некоторые данные, отражающие количество запоминаемых слов по программе, разработанной для помощи пациентам с болезнью Альцгеймера. Группа 1 обучалась на визуальных примерах, а в группе 2 использовали ви­зуальные средства и интенсивное повторение слов. Мы используем эти данные в примере для расчета статистического критерия. Таблица 11.1 Количество запоминаемых слов 7 3 3 2 3 8 8 5 8 5 Группа 1 5 4 6 10 10 5 1 1 4 3 5 7 1 9 2 5 2 12 15 4 5 4 4 5 5 7 8 8 9 8 Группа 2 3 2 5 4 4 6 7 7 5 6 4 3 2 7 6 2 8 9 7 6 Вот те знаменитые восемь шагов и вычисление значения t-кри­ терия. 1. Формулировка основной и альтернативной гипотез. Как показано в формуле 11.2, нулевая гипотеза утверждает, что нет различий между средними значениями для группы 1 и группы 2. В нашем случае альтернативная гипотеза (показанная формулой 11.3) утверждает, что между средними значениями группы 1 и группы 2 существует разница. Альтернативная гипотеза является двусторонней и ненаправленной, поскольку она утверждает различие, но не указывает его конкретного направления. Вычисление t-статистики 240 Часть IV Значимая разница: применение статистики вывода Нулевая гипотеза: Альтернативная гипотеза: H0: µ1 = µ2. (11.2) (11.3) H1: µ1 ≠ µ2. 2.Выбор уровня риска (или уровня значимости, или ошибки первого рода), связанного с нулевого гипотезой. Уровень риска, или ошибки первого уровня, или уровня значимости (еще какие-нибудь названия?), здесь равен 0,05, но это остается полностью на усмот­ рение исследователя. 3. Выбор подходящего статистического критерия. При помощи схемы, показанной на рис. 11.1, мы определили, что нам подходит t-критерий Стьюдента для независимых средних. Это не t-критерий для зависимых средних (частая ошибка начинающих студентов), потому что наши группы не зависят друг от друга. 4.Расчет значения статистического критерия (наблюдаемого зна­чения). Это ваш шанс подставить в формулы значения и сделать какие-то вычисления. Формула для значения t была показана в формуле 11.1. После подстановки конкретных значений мы получаем уравнение, показанное в формуле 11.4. (Мы уже посчитали среднее значение и стандартное отклонение.) (11.4) После подстановки, как показывает нам формула 11.5, мы получаем итоговое значение –0,137. Значение отрицательно, т. к. большее значение (среднее для группы 2, равное 5,53) вычитается из меньшего (среднее для группы 1, равное 5,43). Однако помните, что поскольку альтернативная гипотеза ненаправленная (она утверждает, что существует любое различие), то знак этой разницы не имеет никакого значения. (11.5) При обсуждении ненаправленного статистического критерия вы можете увидеть, что значение t представляют как абсолютную величину вроде |t| или t = |0,137|, которая игнорирует знак показателя. Ваш преподаватель может записывать значение t именно таким образом, чтобы подчеркнуть, что для однонаправленного критерия знак имеет значение, но для ненаправленного он совершенно неважен; 5.Определение значения, необходимого для отклонения нулевой гипотезы, при помощи соответствующей таблицы критических значений для конкретного критерия. Здесь мы переходим к таблице B.2 в приложении B, в которой дан список критических значений для t-критерия. Глава 11 (t)ет-а-тет Мы можем использовать это распределение для проверки того, отличаются ли друг от друга две независимые средние, сравнив то, что мы ожидаем получить вследствие случайности (критическое значение из таблицы), с тем, что мы наблю­даем (наблюдаемым значением). Сначала мы должны определить степени свободы (df), которые приближаются к размеру выборки. Для данных из нашего примера количество степеней свободы равно n1 − 1+ n2 – 1, или n1 + n2 – 2 (перемена мест слагаемых дает одинаковый результат). Итак, для каждой группы сложите размеры двух выборок и вычтите 2. В данном примере 30 + 30 − 2 = 58. Это степени свободы именно для этого статистического критерия, у другого критерия они не обязаны быть такими же. Идея степеней свободы означает примерно одно и то же независимо от того, какой статистический критерий вы используете. Но способ вычисления степеней свободы для конкретного критерия может отличаться от преподавателя к преподавателю и от учебника к учебнику. Мы говорим, что правильно считать количество степеней свободы для критерия, приведенного выше, как n1 − 1+ n2 – 1. Однако некоторые преподаватели полагают, что вы должны использовать только меньшее из двух n (более консервативный подход, который вы, возможно, захотите рассмотреть). Взяв это количество (58), уровень риска, который вы готовы принять (ранее заданный как 0,05), и двусторонний критерий (поскольку альтернативная гипотеза ненаправленная), вы можете посмотреть в таблице t-критерия его критическое значение. На уровне 0,05 с 58 степенями свободы для двустороннего статистического критерия значение, необходимое для отклонения нулевой гипотезы, равно… Упс! В таблице нет 58 степеней свободы! Что же вам делать? Ну, если вы выберете значение, соответствующее 55, то будете консервативны в своей оценке, т. к. возьмете значение для меньшей выборки, чем ваша (и критическое значение t будет выше). Если вы обратитесь к 60 степеням свободы (ближайшее значение к вашим 58), то будете ближе к размеру выборки, но немного смягчите требования, т. к. 60 больше, чем 58. Несмотря на то что статистики расходятся во мнениях, что же делать в такой ситуации, давайте всегда придерживаться значения, более близкого к размеру выборки. Итак, значение, необходимое для того, чтобы отклонить нулевую гипотезу с 58 степенями свободы на 0,05-м уровне значимости, равно 2,001. 6. Сравнение наблюдаемого значения с критическим. Наблюдаемое значение равно –0,14 (–0,137, округленное до сотых), а критическое значение для отклонения нулевой гипотезы, что группа 1 и группа 2 показали одинаковые результаты, равно 2,001. Критическое значение 2,001 показывает величину, при которой самым привлекательным объяснением наблюдаемых различий между двумя группами является случайность, при условии 30 участ­ников в каждой группе и желании принять на себя 5 % риска; 241 242 Часть IV Значимая разница: применение статистики вывода 7 и 8. Время решать! А теперь нужно решать. Если наблюдаемое значение оказывается более крайним, чем критическое (вспомните рис. 9.2), то нулевую гипотезу нельзя принять. Если наблюдаемое значение не превосходит критического, то нулевая гипотеза дает самое привлекательное объяснение. В данном случае наблюдаемое значение (–0,14) недостаточно крайнее, чтобы мы могли сказать, что различия между группами 1 и 2 вызваны чем-то иным, чем случайностью. Если бы наблюдаемое значение было больше, чем 2,001, это было бы похоже на выбрасывание 8, 9 или 10 орлов при кидании монеты (слишком экстремальный результат, чтобы мы поверили, что это вызвано чистой случайностью). В случае с монетой причиной могло бы быть жульничество, а в данном примере это означало бы, что один способ обучения пожилых людей навыкам запоминания лучше другого. Так с чем же мы можем связать маленькую разницу между двумя группами? Если мы придерживаемся нашей аргументации, то можно сказать, что разница может объясняться всем, чем угодно, начиная с ошибки формирования выборки до ошибки округления или простой вариабельности результатов участников. Самое главное, мы вполне уверены (но, конечно, не на 100 %, ведь именно об этом говорят нам уровень значимости и ошибки первого рода, верно?), что разница не вызвана чем-то, повлиявшим на одну из групп и улучшившим ее результаты. Так как мне интерпретировать t(58) = −0,14, p > 0,05? zz t обозначает использованный статистический критерий. zz 58 – это количество степеней свободы. zz –0,14 – это наблюдаемое значение, рассчитанное по формуле, которую мы показывали ранее в этой главе. zz p > 0,05 (действительно важная часть этого короткого выражения) обозначает, что для любой проверки нулевой гипотезы существует больше 5 % вероятности, что две группы не будут различаться между собой из-за способа их обучения. Обратите внимание, что p > 0,05 может также быть записано как p = н. з. (незначимо). РАЗМЕР ЭФФЕКТА И (t) ЕТ-А-ТЕТ Вы узнали из главы 10, что размер эффекта – это мера того, насколько две группы отличаются друг от друга, т. е. это мера величины воздействия (что-то вроде «насколько большое действительно большое?»). Что особенно интересно, при вычислении размера эффекта не учитывается размер выборки. Расчет размера эффекта и суждение о нем добавляют целое новое измерение к пониманию значимых результатов. Глава 11 (t)ет-а-тет 243 Давайте посмотрим на следующий пример. Исследователь изуча­ет вопрос, повышает ли участие в общественных мероприятиях (таких как карточные игры, экскурсии и т. д.) качество жизни пожилых американцев (по шкале от 1 до 10). Исследователь в течение 6 месяцев организует воздействие и в конце этого периода измеряет качество жизни у двух групп (в каждой из которых по 50 участников старше 80 лет, где одна группа участвовала в мероприятиях, а другая – нет). Вот полученные результаты. Таблица 11.2 Качество жизни пожилых людей Среднее значение Стандартное отклонение Не было общественных мероприятий 6,90 1,03 Были мероприятия 7,46 1,53 Вердикт – различия значимы на уровне 0,034 (т. е. p < 0,05, верно?). Так что есть значимое различие, но что насчет его величины? Расчет и понимание размера эффекта Как мы показали вам в главе 10, самый простой и прямой способ вычислить размер эффекта – это просто разделить разность между средними на любое из стандартных отклонений. Опасность, Уилл Робинсон! Это действительно предполагает, что стандартные отклонения (и дисперсия) групп равны друг другу. В нашем примере мы сделаем следующее… (11.6) _ где _ ES – это размер эффекта; X1 – среднее значение для группы 1; X2 – среднее значение для группы 2; s – стандартное отклонение для любой группы. В нашем примере (11.7) Размер эффекта для этого примера равен 0,37. Вы видели в главе 10, что размер эффекта 0,37 относится к категории среднего размера. В дополнение к тому, что различия между двумя средними величинами являются статистически значимыми, можно заключить, что эта разница также существенна в том смысле, что размер эффекта не является незначительным. Ну а насколько существенный результат вам нужен, зависит от множества факторов, включая контекст, в котором ставится вопрос исследования. Часть IV 244 Значимая разница: применение статистики вывода Итак, вы действительно хотите разобраться с этим размером эффекта. Можно рассчитать его простым способом, как мы только что вам показали (вычитая средние друг из друга и деля их на стандартное отклонение), или можно поразить ту симпатичную одногруппницу (одногруппника), что сидит рядом с вами. В формуле размера эффекта для взрослых в знаменателе уравнения ES, который мы показали вам раньше, используется объединенная дисперсия. Объединенная дисперсия – это что-то вроде среднего дисперсии группы 1 и дисперсии группы 2. Вот формула: (11.8) _ где_ES – это размер эффекта; X 1 – среднее значение для группы 1; X2 – среднее значение для группы 2; σ12 – дисперсия для группы 1; σ22 – дисперсия для группы 2. Если применить эту формулу к тем же числам, что мы показали вам, то получится впечатляющий размер эффекта 0,43, но не очень отличающийся от 0,37, который мы получили при помощи более прямого метода ранее (и все еще в той же категории среднего размера). Но это более точный метод, и о нем стоит знать. Два очень классных калькулятора размера эффекта Калькулятор размера эффекта Почему бы не вскочить на поезд и не отправиться прямо на сайт http://www.uccs.edu/~lbecker/, на котором статистик Ли Бекер (Lee Becker) из Университета Калифорнии разработал калькулятор размера эффекта? Можно также зайти на сайт http://www.psychometrica.de/effect_size.html, созданный докторами Вольфгангом и Александрой Ленард (Wolfgang & Alexandra Lenhard)? Вам нужно только подставить данные в эти калькуляторы, нажать на Compute (Рассчитать), и программа сделает все остальное, как вы видите на рис. 11.2. Рис. 11.2 Очень классный калькулятор размера эффекта Источник: Ли Бекер, http://www.uccs.edu/~lbecker/ Глава 11 (t)ет-а-тет 245 РАСЧЕТ t- КРИТЕРИЯ ПРИ ПОМОЩИ SPSS SPSS с готовностью поможет вам рассчитать эти инференциальные критерии. Вот как можно сделать это с только что изученным критерием и интерпретировать результаты. Мы воспользуемся набором данных под названием «Глава 11. Набор данных 1» (Chapter 11. Data Set 1). Как вы видите, в наборе данных переменная принадлежности к группе (1 или 2) находится в столбце 1, а проверяемая переменная (Memory (Память)) – в столбце 2. 1. Введите данные в Редактор данных (Data Editor) или загрузите файл. Убедитесь, что обе группы указаны в одном столбце и что в этом столбце не больше двух групп. 2. Нажмите на Анализ (Analyze) ⇒ Сравнение средних (Compare Means) ⇒ T-кри­терий для независимых выборок (Independent-Samples T Test), и вы увидите диалоговое окно, как на рис. 11.3. 3. Щелкните по переменной Группа (Group) и перетащите ее в поле Группировать по (Grouping Variable(s)). 4. Щелкните по переменной Память (Memory) и перетащите ее в поле Прове­ ряемые переменные (Test Variable(s). 5. SPSS не позволит вам продолжить, пока вы не зададите группируемые переменные. Этим действием вы говорите SPSS, сколько уровней группируемых переменных у вас есть (вам не кажется, что такая умная программа могла бы и сама это понять?). В любом случае, нажмите Задать группы (Define Groups) и введите значение 1 для Группы 1 (Group 1) и значение 2 для Группы 2 (Group 2). Для того чтобы вы могли задать группируемые переменные, их название (в нашем случае – Group) должно быть подсвечено. 6. Нажмите Продолжить (Continue) и затем ОК, и SPSS проведет анализ и покажет окно вывода, как на рис. 11.5. Рис. 11.3 Диалоговое окно T-критерий для независимых выборок Часть IV 246 Значимая разница: применение статистики вывода Рис. 11.4 Диалоговое окно Задать группы Заметили, что SPSS использует заглавную букву Т для обозначения этого критерия, тогда как мы использовали строчную t? Дело исключительно в личных предпочтениях, и чаще всего выбор отображает то, к чему приучили людей во время их учебы. Вам важно знать, что разница только в написании буквы, а критерий остается тем же самым. Читаем выводы SPSS SPSS показывает множество выводов по итогам этого анализа, но для наших целей мы возьмем только избранные выводы, показанные на рис. 11.5. Здесь нужно обратить внимание на три момента: 1)наблюдаемое значение t – 0,137, в точности, как мы рассчитали его вручную ранее в этой главе (0,14, или округленное 0,1368); 2)количество степеней свободы – 58 (что, как вы уже знаете, было рассчитано по формуле n1 + n2 − 2); 3)значимость этих выводов – 0,891, или p = 0,891. Это означает, что при одной проверке этой нулевой гипотезы вероятность отклонить гипотезу, когда она верна, довольно высока (89 из 100)! Так что ошибка первого рода определенно выше, чем 0,05, и к такому же заключению мы пришли ранее, когда вручную выполнили весь процесс. Никакой разницы! Глава 11 (t)ет-а-тет 247 Рис. 11.5 Снимок вывода SPSS для T-критерия для независимых выборок РЕАЛЬНАЯ СТАТИСТИКА Нет ничего лучше, чем быть всегда готовыми, как говорят пионеры. Но как лучше всего учить готовности? В своем исследовании Серкан Селик (Serkan Celik) из Университета Кириккале в Турции сравнивал онлайн- и офлайн-курсы первой помощи, чтобы проверить эффективность моделей обучения. Интересно, что с одним и тем же инструктором, ведущим оба вида обучения, онлайн-форма показала более высокие оценки слушателей в конце курса. Что сделал Селик для этого анализа? Рассчитал независимый t-критерий, конечно. Фактически он использовал SPSS, чтобы получить итоговые значения t, показывающие, что имелась разница в результатах. Хотите узнать больше? Найдите в интернете или библиотеке статью... Celik S. A media comparison study on first aid instruction. Health Education Journal, 2013. Р. 95−101. Реальная статистика ВЫВОДЫ ПО ГЛАВЕ t-критерий Стьюдента – это ваш первый шаг в проведении настоящего статистического теста для двух групп, а также для того, чтобы понять прикладной смысл всего этого вопроса со значимостью. Убедитесь, что вы понимаете все в этой главе, прежде чем двигаться дальше, и что вы можете вручную делать расчеты, о которых мы просили. Дальше мы перейдем к применению другой формы того же критерия, только в этот раз вместо одного показателя, взятого из двух отдельных групп, мы возьмем два показателя из одной группы участников. Выводы по главе 248 Часть IV Значимая разница: применение статистики вывода ВРЕМЯ ПРАКТИКИ Проблема 1 Проблема 2 Проблема 5 1.На данных из файла «Глава 11. Набор данных 2» (Chapter 11. Data Set 2) проверьте на уровне значимости 0,05 альтернативную гипотезу о том, что мальчики чаще поднимают руку в классе, чем девочки. Решите эту практическую задачу вручную, при помощи калькулятора. Каково ваше заключение по поводу этой альтернативной гипотезы? Помните, что сначала нужно решить, будете ли вы использовать одно- или двусторонний критерий. 2.На том же наборе данных «Глава 11. Набор данных 2» (Chapter 11. Data Set 2) проверьте на уровне значимости 0,01 альтернативную гипотезу о том, что существует различие между мальчиками и девочками по количеству раз, когда они поднимали руку в классе. Решите эту практическую задачу вручную, при помощи калькулятора. Каково ваше заключение по поводу этой альтернативной гипотезы? Вы использовали те же данные, что и для вопроса 1, но гипотеза была другой (одна направленная, другая ненаправленная). Как отличаются друг от друга результаты и почему? 3.Перейдем к утомительной практике расчетов вручную, чтобы проверить, что вы можете работать с числами. На основании следующей информации вручную рассчитайте значение t-критерия: а) X1 = 62, X2 = 60, n1 = 10, n2 = 10, s1 = 2,45, s2 = 3,16; б) X1 = 158, X2 = 157,4, n1 = 22, n2 = 26, s1 = 2,06, s2 = 2,59; в) X1 = 200, X2 = 198, n1 = 17, n2 = 17, s1 = 2,45, s2 = 2,35. 4.Учитывая результаты, полученные из ответа на вопрос 3, и уровень значимости 0,05, ответьте на вопрос, чему равны двусторонние критические значения для каждого ответа? Будет ли отвергнута нулевая гипотеза? 5.Используйте приведенные ниже данные и SPSS или другую компью­терную программу вроде Excel или Google Sheets и напишите небольшой параграф о том, имеет ли психологическое консультирование на дому такую же эффективность, как и консультирование вне дома для двух независимых групп. Вот данные. Переменная в них показывает уровень тревожности после консультации по шкале от 1 до 10. Консультации на дому 3 4 1 1 1 3 3 Консультации вне дома 7 6 7 8 7 6 5 Продолжение ⇒ Глава 11 (t)ет-а-тет 249 Консультации на дому Консультации вне дома 6 5 1 4 5 4 4 3 6 7 7 7 8 6 4 2 5 4 3 6 7 5 4 3 8 7 6.На данных из файла «Глава 11. Набор данных 3» (Chapter 11. Data Set 3) проверьте нулевую гипотезу, что городские и сельские жители одинаково относятся к контролю за оружием. Для проведения анализа по этой проблеме воспользуйтесь SPSS. 7.Вот хороший вопрос, чтобы подумать. Исследователь общест­ вен­ного здравоохранения (д-р Л) проверил гипотезу, что предо­ ставление новым покупателям машин детских кресел будет также служить стимулом для родителей по обеспечению других мер безопасности для своих детей (например, более безопасной езды, организации безопасного для детей пространства дома и т. д.). Д-р Л посчитал все случаи безопасного поведения в машине и дома у родителей, которые получили кресла, и тех, кто не получил. Каковы результаты? Значимая разница на уровне 0,013. Другой исследователь (д-р Р) провел точно такое же исследование. Для наших целей предположим, что все в нем было таким же (такой же тип выборки, такие же показатели данных, такие же кресла и т. д.). Результаты д-ра Р были ограниченно значимы (помните это из главы 9?) на уровне 0,051. Чьим результатам вы доверяете больше и почему? 8.Ниже приведены результаты трех экспериментов, в которых средние значения сравниваемых групп не изменялись от эксперимента к эксперименту, но стандартное отклонение оказалось довольно разным. Рассчитайте размер эффекта по формуле 11.6, а затем обсудите, почему он меняется в зависимости от уровня изменчивости. Эксперимент 1 Среднее значение группы 1 Среднее значение группы 2 Стандартное отклонение 78,6 73,4 2,0 Размер эффекта _____________ Продолжение ⇒ 250 Часть IV Эксперимент 2 Эксперимент 3 Значимая разница: применение статистики вывода Среднее значение группы 1 Среднее значение группы 2 Стандартное отклонение Среднее значение группы 1 Среднее значение группы 2 Стандартное отклонение 78,6 73,4 4,0 78,6 73,4 8,0 Размер эффекта _____________ Размер эффекта _____________ 9.На данных из файла «Глава 11. Набор данных 4» (Chapter 11. Data Set 4) проверьте нулевую гипотезу, что нет разницы между средним количеством правильно написанных слов в двух группах четвероклассников. Каково ваше заключение? 10.Для ответа на этот вопрос вам нужно будет провести две проверки. На данных из файла «Глава 11. Набор данных 5» (Chapter 11. Data Set 5) рассчитайте значение t-критерия для различия между двумя группами по проверяемой переменной. Затем сделайте то же самое на данных из файла «Глава 11. Набор данных 6» (Chapter 11. Data Set 6). Обратите внимание, что значения t-критериев различны даже при том, что средние значения каждой группы одинаковы. Какова причина этого различия и почему при том же размере выборки t-критерии отличаются? 11.А вот интересная (гипотетическая) ситуация. Средний балл тес­ та на профпригодность у одной группы равен 89,5, а средний балл у другой группы – 89,2. Обе группы представляют собой выборки из примерно 1500 человек, и различие между средними статистически значимо, но размер эффекта очень мал (скажем, 0,1). Какой вывод вы сделаете из факта существования статис­ тически значимой разницы между группами при отсутствии сущест­венного размера эффекта? 12 (t)ет-а-тет (снова) Сравнение средних величин связанных групп Уровень сложности: (не очень сложно – это первая глава про такие вещи, но ваших знаний достаточно, чтобы справиться с нею) В ЭТОЙ ГЛАВЕ ВЫ УЗНАЕТЕ, КАК: понять, когда нужно использовать t-критерий для зависимых средних; рассчитать наблюдаемое значение t; интерпретировать значение t-критерия и понять, что оно значит; рассчитать размер эффекта для t-критерия для зависимых средних. ПРЕДИСЛОВИЕ К t- КРИТЕРИЮ Д ЛЯ ЗАВИСИМЫХ СРЕДНИХ Как лучше всего учить детей – это, определенно, один из самых раздражающих вопросов, с которым сталкивается любое общество. Поскольку дети очень отличаются друг от друга, необходимо находить баланс между удовлетворением базовых потребностей у всех и предоставлением нужных возможностей для особых детей (на любом конце континуума). Обучение чтению – это очевидная и важная часть образования. Три профессора из Университета Алабамы изучили влияние ресурсных классных комнат и обычных классов на успехи в чтении у детей с трудностями обучения. Ренитта Голдман (Renitta Goldman), Гэри Л. Сапп (Gary L. Sapp) и Энн Шумейт Фостер (Ann Shumate Foster) обнаружили, что в целом один год ежедневных занятий в обоих кабинетах не привел к различию общих показателей чтения. В результате одного из сравнений показателей до и после эксперимента для группы, обучающейся в ресурсном кабинете, они обнаружили, что t(34) = 1,23, p > 0,05. До начала программы показатели чтения у детей, обучающихся в ресурсном кабинете, составляли 85,8. По окончании программы их показатели чтения были равны 88,5 – различие наблюдалось, но было незначимым. Введение в главу 12 251 252 Вычисление t-критерия для зависимых средних Часть IV Значимая разница: применение статистики вывода Так зачем нужно сравнивать зависимые средние? t-критерий для зависимых средних указывает, что одна группа с одними и теми же участниками изучалась в разных условиях (в данном примере – в условиях до начала эксперимента и после его завершения). Главным образом t-критерий для зависимых средних был выбран потому, что одни и те же дети 2 раза проходили тестирование: до начала одногодичной программы и по ее окончании. Как вы можете видеть по упомянутым выше результатам, не было обнаружено различий в баллах до начала и после окончания программы. Относительно малое значение t (1,23) даже близко не подходит к границам области, за которыми мы бы отклонили нулевую гипотезу. Другими словами, изменение слишком мало, чтобы мы могли сказать, что различия произошли из-за чего-то, отличного от случайности. Небольшая разница в 2,7 балла (88,5 – 85,8), вероятно, является следствием ошибки выборки или изменчивости внутри групп. Хотите знать больше? Посмотрите статью… Goldman R., Sapp G. L. & Foster A. S. Reading achievement by learning disabled students in resource and regular classes. Perceptual and Motor Skills, 1998. Р. 192–194. ПУТЬ К МУДРОСТИ И ЗНАНИЯМ А вот так вы можете воспользоваться нашей схемой, чтобы выбрать подходящий статистический критерий, t-критерий для зависимых средних. Следуйте очередности шагов на рис. 12.1: 1)в центре внимания разница между результатами учеников до и после проведения эксперимента; 2) участники тестируются больше одного раза; 3) есть два набора показателей; 4)подходящий статистический критерий – это t-критерий для зависимых средних. Выбор t-критерия для зависимых средних Есть еще одно название, которым пользуются статистики для обозначения проверки зависимых групп, – повторные измерения. Результаты зависимых групп называются «повторными измерениями» и потому, что измерения повторяются через какое-то время, или в других условиях, или при влиянии другого фактора, а также потому потому, что они повторяются для тех же самых объектов (будь то человек, мес­то или предмет). Глава 12 (t)ет-а-тет (снова) 253 Рис. 12.1 Проверка, что нам подходит t-критерий для зависимых средних Вы изучаете отношения между переменными или различия между группами из одной или нескольких переменных? Вы изучаете разницу между одной выборкой и генеральной совокупностью? Я изучаю различия между группами из одной или нескольких переменных Я изучаю отношения между переменными Одни и те же участники оцениваются несколько раз? С каким количеством переменных вы работаете? Одновыборочный Z-критерий Да Нет С каким количеством групп вы работаете? С каким количеством групп вы работаете? Две переменные Более двух переменных Две группы Больше двух групп Две группы Больше двух групп t-критерий значимости коэффициента корреляции Регрессия, факторный анализ или канонический анализ t-критерий для зависимых выборок Дисперсионный анализ повторных измерений t-критерий для независимых выборок Простой дисперсионный анализ ВЫЧИСЛЕНИЕ ЗНАЧЕНИЯ t- КРИТЕРИЯ t-критерий для зависимых средних включает в себя сравнение средних величин каждой группы данных и фокусируется на различиях между данными. Как вы видите в формуле 12.1, сумма разностей между двумя значениями одного показателя стоит в числителе и отображает различия между группами данных. (12.1) где D – это разность значений конкретного показателя в точке 1 и точке 2; ∑D – это сумма всех разностей между группами значений; (∑D)2 – это сумма квадратов разностей между группами значений; n – это количество пар наблюдений. Скоро мы покажем вам данные для демонстрации расчета t-кри­ терия для зависимых средних. Как и в рассмотренном ранее в этой главе примере, мы имеем дело с группой значений до и после окончания эксперимента. Для целей демонстрации будем предполагать, что это данные об оценках за чтение до и после окончания программы. Степени свободы 254 Часть IV Значимая разница: применение статистики вывода Вот те знаменитые восемь шагов и вычисление значения t-кри­ терия: 1. Формулировка основной и альтернативной гипотез. Нулевая гипотеза утверждает, что нет различий между средними значениями оценок до и после проведения программы. Альтернативная гипотеза является односторонней и направленной, поскольку она утверждает, что оценка после окончания программы будет выше, чем до. Нулевая гипотеза: H0: µпосле программы = µдо программы. (12.2) Альтернативная гипотеза: _ _ H1: X после программы > X до программы. (12.3) Таблица 12.1 Оценки за чтение до и после программы Сумма Среднее значение До программы 3 5 4 6 5 5 4 5 3 6 7 8 7 6 7 8 8 9 9 8 7 7 6 7 8 158 6,32 После программы 7 8 6 7 8 9 6 6 7 8 8 7 9 10 9 9 8 8 4 4 5 6 9 8 12 188 7,52 Разность 4 3 2 1 3 4 2 1 4 2 1 –1 2 4 2 1 0 –1 –5 –4 –2 –1 3 1 4 30 1,2 D2 16 9 4 1 9 16 4 1 16 4 1 1 4 16 4 1 0 1 25 16 4 1 9 1 16 180 7,2 Глава 12 (t)ет-а-тет (снова) 255 2.Выбор уровня риска (или уровня значимости, или ошибки первого рода), связанного с нулевой гипотезой. Уровень риска, или ошибки первого уровня, или уровня значимости, здесь 0,05, но это остается полностью на усмотрение исследователя. 3. Выбор подходящего статистического критерия. При помощи схемы, показанной на рис. 12.1, мы определили, что нам подходит t-критерий для зависимых средних. Это не t-кри­те­рий для независимых средних, потому что наши группы зависимы друг от друга. На самом деле это даже не группы участников, а группы данных об одних и тех же участниках. Они зависят друг от друга. Другое название t-критерия для зависимых средних – t-критерий для парных выборок, или t-критерий для связанных выборок. Вы увидите в главе 15, что есть тесная связь между проверкой значимости корреляции между этими двумя наборами данных (до и после эксперимента) и вычисляемым здесь значением t-критерия. 4. Расчет значения статистического критерия (наблюдаемого зна­чения). Это ваш шанс подставить в формулы значения и сделать какие-то вычисления. Формула для значения t была показана ранее. После подстановки конкретных значений мы получаем уравнение, показанное в формуле 12.4. (Мы уже посчитали средние значения и стандартные отклонения для наборов данных до и после программы.) (12.4) После подстановки, как показывает нам формула 12.5, мы получаем итоговое наблюдаемое значение 2,45. Среднее значение оценок до начала программы было равно 6,32, а после окончания программы – 7,52: (12.5) 5.Определение значения, необходимого для отклонения нулевой гипотезы, при помощи соответствующей таблицы критических значений для конкретного критерия. Здесь мы переходим к таблице B.2 в приложении B, в которой дан список критических значений для t-критерия. Мы снова имеем дело с t-критерием и будем пользоваться той же таблицей, что и в главе 11, чтобы найти критическое значение для отклонения нулевой гипотезы. Сначала мы должны определить степени свободы (df), которые приближаются к размеру выборки. Для данного статистического критерия количество степеней свободы равно n1 – 1, где n равно количеству пар наблюдений, или 25 – 1 = 24. Это степени свободы именно для этого статистического критерия, у другого критерия они не обязаны быть такими же. Взяв это количество (24), уровень риска, который вы готовы принять (ранее заданный как 0,05) и односторонний критерий (поскольку альтернативная гипотеза направленная – результаты после эксперимента будут выше, чем до него), находим значение, необходимое для того, чтобы отклонить нулевую гипотезу: 1,711. 256 Часть IV Значимая разница: применение статистики вывода 6. Сравнение наблюдаемого значения с критическим. Наблюдаемое значение равно 2,45, что больше, чем критическое значение, необходимое для отклонения нулевой гипотезы. 7 и 8. Время решать! А теперь нужно решать. Если наблюдаемое значение оказывается более крайним, чем критическое, то нулевую гипотезу нельзя принять. Если наблюдаемое значение не превосходит критического, то нулевая гипотеза дает самое привлекательное объяснение. В данном случае наблюдаемое значение действительно превосходит критическое. Оно является достаточно крайним, чтобы мы могли сказать, что различия в оценках до и после эксперимента являются следствием чего-то иного, чем случайность. Если мы правильно провели эксперимент, то какой фактор мог повлиять на результаты? Легко – введение программы ежедневного чтения. Мы знаем, что разница определяется конкретным фактором. Различия между данными до эксперимента и после него не могли появиться случайно. Они являются следствием нашего воздействия. Так как мне интерпретировать t(24) = 2,45, p < 0,05? Снова быстрые расчеты zz t обозначает использованный статистический критерий; zz 24 – это количество степеней свободы; zz 2,45 – это наблюдаемое значение, рассчитанное по формуле, которую мы показывали ранее в данной главе; zz p < 0,05 (действительно важная часть этого короткого выражения) обозначает, что для любой проверки нулевой гипотезы существует меньше 5 % вероятности, что средняя оценка после эксперимента окажется выше оценки до него только из-за влияния случайности (тут происходит что-то еще). Поскольку мы установили уровень 0,05 в качестве критерия для определения привлекательности альтернативной гипотезы по сравнению с нулевой, то приходим к выводу, что существует значимая разница между двумя наборами данных. Вот то, что происходит. РАСЧЕТ t- КРИТЕРИЯ ПРИ ПОМОЩИ SPSS SPSS с готовностью поможет вам рассчитать эти инференциальные критерии. Вот как можно сделать это с только что изученным критерием и интерпретировать результаты. Мы воспользуемся набором данных под названием «Глава 12. Набор данных 1» (Chapter 12. Data Set 1), который был рассмотрен в примере ранее. 1.Введите данные в Редактор данных (Data Editor) или загрузите файл. Убедитесь, что данные до и после эксперимента записаны в две разные колонки. В отличие от t-критерия для независимых средних, здесь нет групп, которые нужно задавать. Вы можете увидеть на рис. 12.2, что данные имеют заголовки «До эксперимента» (Pretest) и «После эксперимента» (Posttest). Глава 12 (t)ет-а-тет (снова) 2.Нажмите на Анализ (Analyze) ⇒ Сравнение средних (Compare Means) ⇒ T-кри­терий для парных выборок (Paired-Samples T Test), и вы увидите диалоговое окно, показанное на рис. 12.3. 3.Перетащите переменную После эксперимента (Posttest) в ячейку Переменная 1 (Variable1) в области Парные переменные (Paired Variables), как показано на рис. 12.4. 4.Перетащите переменную До эксперимента (Pretest) в ячейку Переменная 2 (Variable2) в области Парные переменные (Paired Variables). 5. Нажмите ОК. 6. SPSS проведет анализ и покажет вывод, как на рис. 12.5. Рис. 12.2 Данные из файла «Глава 12. Набор данных 1» (Chapter 12. Data Set 1) Рис. 12.3 Диалоговое окно T-критерий для парных выборок 257 258 Часть IV Значимая разница: применение статистики вывода Рис. 12.4 Перетаскивание переменных для анализа парного T-критерия Рис. 12.5 Вывод SPSS для T-критерия для парных выборок Расчет значения t Почему нужно сначала перетаскивать переменную После эксперимента? SPSS работает следующим образом: вычитает Переменную 2 из Переменной 1, потому что альтернативная гипотеза является направленной и говорит, что результаты после эксперимента будут выше, чем до него. Следовательно, поскольку мы хотим вычесть данные до эксперимента из данных после него, то постэкспериментальные данные должны быть обозначены как Переменная 1. Глава 12 (t)ет-а-тет (снова) 259 Более ранние версии SPSS могут не разрешить вам определить, какую среднюю нужно вычитать из другой. Если вы пользуетесь более старой версией SPSS, то можете получить отрицательное значение t, при условии что среднее значение первой переменной окажется меньше, чем среднее значение второй (в нашем случае мы бы получили t = –2,449 вместо 2,449). Но если при интерпретации результатов вы держите в голове формулировку своей альтернативной гипотезы, то это вам будет вовсе не страшно. Забавы ради добавим сюда еще одно предупреждение. Иногда (только иногда) исследователи используют критерий для зависимых средних, когда два измерения (которые обычно относятся к одному участнику) на самом деле снимаются с разных участников, имеющих очень сильное сходство по всем важным параметрам (будь то возраст, пол, со­циальный класс, уровень агрессии, скорость тренировок, предпочтения мороженого – ну, вы понимаете). В этом случае даже притом что это разные участники, данные считаются зависимыми, потому что они сочетаются друг с другом. Мы просто уточняем значение слова «зависимые», а также то, как оно относится к подобным ситуациям. Читаем выводы SPSS 1. Оценка после эксперимента (7,52) выше, чем результаты, показанные до него (6,32). По крайней мере, на этом этапе анализа видно, результаты поддерживают альтернативную гипотезу о том, что дети показывают лучшие успехи после программы, чем до нее. 2. Различие между средними значениями данных до и после эксперимента составляет 1,2, притом что значение до эксперимента вычиталось из значения после эксперимента. Точное значение вероятности того, что значение критерия t – 2,499 было получено случайно, равно 0,022 – очень маловероятно. 3. Но обратите также внимание, вывод на рис. 12.5 показывает, что эта вероятность относится к двустороннему (или ненаправленному) критерию. Мы же проводили одностороннюю проверку, так что же нам делать? Читайте дальше! При помощи табл. B.2 в приложении B мы находим, что для однонаправленного критерия с 24 степенями свободы и уровнем значимости 0,05 критическое значение для отклонения нулевой гипотезы равно 1,711. Итак, хотя SPSS и показывает нам рассчитанное наблюдаемое значение t, но не дает нам вероятности этого значения для одностороннего критерия. Программа рассчитывает вероятность только для двустороннего критерия. Для одностороннего мы должны полагаться на собственные навыки и пользоваться таблицей, как мы и сделали, или же можно использовать программу, которая может рассчитывать односторонние критерии (ищите больше информации об этом в главе 20). 260 Часть IV Значимая разница: применение статистики вывода Хотите верьте, хотите нет, но давным-давно, когда автор этой книги и, возможно, ваш преподаватель учились в университете, существовали только огромные вычислительные машины, не было ни намека на такие чудеса, как те, что стоят сейчас у нас на столах. Другими словами, все, что считалось на занятиях по ста­тис­тике, рассчитывалось вручную. Большое преимущество ручных расчетов состоит, во-первых, в том, что они помогают лучше понять процесс. Во-вторых, окажись вы без компьютера, все равно сможете провести анализ. Так что если компьютер не выдает вам все необходимое, примените смекалку. Пока вы знаете базовые формулы критических значений и имеете доступ к соответствующим таблицам, все будет в порядке. РАЗМЕР ЭФФЕКТА Д ЛЯ (t) ЕТ-А-ТЕТА ( СНОВА ) Ребята, знаете ли вы, что размер эффекта для критерия для зависимых средних рассчитывается по формуле, верной для расчета размера эффекта для критерия для независимых средних? Вы можете вернуться к главе 11 и вспомнить все подробности, а здесь у нас есть формула и размер эффекта. Как вы, должно быть, понимаете, мы получили эти значения из вывода на рис. 12.5. (12.6) Итак, для этого анализа размер эффекта (в соответствии с рекомендациями, предложенными Коэном и рассмотренными в главе 11) довольно большой (к нему относится все, что больше 0,5). Различие не только статистически значимо, но и довольно велико и, вероятно, существенно, с учетом контекста, в котором был поставлен вопрос исследования. РЕАЛЬНАЯ СТАТИСТИКА Вы можете принадлежать к «поколению бутерброда», в котором взрослые не только заботятся о своих престарелых родителях, но и растят детей. Эта ситуация (и старение населения, как это происходит в Соединенных Штатах) указывает на важность оценки пожилых людей (какое бы определение ни давали этой когорте) и требует использовать инструменты, которые мы только что обсудили. Целью данного исследования было определение зависимости удовлетворенности жизнью тайских пожилых людей от их ежедневных занятий. Были протестированы сопоставимые пары пожилых людей, чтобы определить, кто из них считает себя удовлетворенным или не удовлетворенным жизнью. В качестве критерия для опре- Глава 12 (t)ет-а-тет (снова) 261 деления удовлетворенных жизнью участников был выбран результат в 85 % и выше по использованной шкале оценки. Для проверки различий между средними значениями показателей по всем участникам исследования и каждой группе с ежедневными привычками был использован двусторонний зависимый t-критерий (поскольку участники были сопоставимы – в том смысле, что исследователи рассматривали парных участников как одного). Группа удовлетворенных жизнью пожилых людей имела статистически значимые более высокие результаты, чем не удовлетворенные жизнью участники. Один из самых интересных вопросов заключается в том, можно ли применить эти результаты к другим выборкам пожилых людей в разных культурах. Хотите узнать больше? Найдите в интернете или библиотеке статью... Othaganont P., Sinthuvorakan C. & Jensupakarn P. Daily living practice of the life-satisfied Thai elderly. Journal of Transcultural Nursing, 2002. Р. 24–29. Реальная статистика ВЫВОДЫ ПО ГЛАВЕ На этом со средними заканчиваем. Вы узнали, как сравнивать данные для независимых (глава 11) и зависимых (глава 12) групп. Пришло время перейти к другому классу проверок значимости, которые имеют дело с более чем двумя группами (как зависимыми, так и независимыми). Этот класс инструментов, называемых дисперсионным анализом, пользуется большим влиянием и популярностью и станет ценным вкладом в ваш резервный запас методик! Выводы по главе ВРЕМЯ ПРАКТИКИ 1.В чем состоит разница между критерием для независимых средних и критерием для зависимых средних, и когда применяется каждый из них? 2.Определите для следующих ситуаций, будете вы применять критерий для независимых или зависимых средних: а) две группы подвергались разному лечению растяжения голеностопа, вам нужно определить, какое лечение было более эффективным; б) исследователь сестринского дела хотел узнать, шло ли выздоровление пациентов быстрее, когда одни из них получали дополнительный уход на дому, тогда как другим был обеспечен стандартный объем ухода; 262 Проблема 3 Часть IV Значимая разница: применение статистики вывода в) группе юношей предложили консультации по навыкам межличностного общения, а затем протестировали их в сентяб­ ре и мае, чтобы проверить, оказало ли это влияние на гармонию в семье; г) одной группе взрослых мужчин были даны инструкции по снижению высокого артериального давления, тогда как другая не получила никаких инструкций; д) одной группе мужчин предоставили доступ к программе тренировок и дважды за 6 месяцев проверили состояние сердца. 3.Возьмите файл «Глава 12. Набор данных 2» (Chapter 12. Data Set 2), вручную рассчитайте t-критерий и напишите заключение, наблю­далось ли изменение в количестве тонн использованной бумаги в результате запуска программы переработки в 25 различных районах. (Подсказка: до и после становятся двумя уровнями воздействия.) Проверьте гипотезу на уровне значимости 0,01. 4.Ниже приведены данные из исследования, в котором подросткам предлагалось психологическое консультирование в начале учебного года, чтобы проверить, оказывает ли оно положительное влияние на толерантность по отношению к подросткам из других этнических групп. Замеры производились прямо перед консультированием и через 6 месяцев после этого. Сработала ли программа? Результирующая переменная – это значение, полученное по тесту отношения к другим с диапазоном возможных значений от 0 до 50; чем выше результат, тем выше толерантность. Используйте SPSS или другую компьютерную программу для проведения этого анализа. До воздействия 45 46 32 34 33 21 23 41 27 38 41 47 41 32 22 После воздействия 46 44 47 42 45 32 36 43 24 41 38 31 22 36 36 Глава 12 (t)ет-а-тет (снова) До воздействия 34 36 19 23 22 263 После воздействия 27 41 44 32 32 5.Рассчитайте для данных из «Глава 12. Набор данных 3» (Chapter 12. Data Set 3) значение t-критерия и напишите заключение, существуют ли различия между уровнем удовлетворенности семей, измеряемым по шкале от 1 до 15, при их пользовании возможностями центрами услуг после вмешательства социальных служб. Сделайте это задание при помощи SPSS и укажите точную вероятность результата. 6.Выполните это задание старым добрым способом – вручную. Производитель известного бренда хочет знать, какой бренд нравится людям больше: «Нибблз» или «Рибблз». Потребители получают возможность попробовать каждый вид крекера и указать, нравится он им или нет, на шкале от 1 до 10. Какой крекер им нравится больше всего? «Нибблз» 9 3 1 6 5 7 8 3 10 3 5 2 9 6 2 5 8 1 6 3 «Рибблз» 4 7 6 8 7 7 8 6 7 8 9 8 7 3 6 7 6 5 5 6 7.Посмотрите на данные из файла «Глава 12. Набор данных 4» (Chapter 12. Data Set 4). Влияет ли смена на стресс (чем выше показатель стресса, тем больше его ощущает рабочий)? Проблема 5 264 Проблема 8 Часть IV Значимая разница: применение статистики вывода 8.В файле «Глава 12. Набор данных 5» (Chapter 12. Data Set 5) представлены данные для двух групп взрослых людей, протестированных осенью и весной во время тренировки по тяжелой атлетике. Результирующая переменная – это плотность кости (чем выше показатель, тем плотнее кость) по шкале от 1 до 10. Работает ли тяжелая атлетика? Каков размер эффекта? 13 Двух групп недостаточно? Попробуйте дисперсионный анализ Уровень сложности: (длиннее и сложнее, чем остальные, но очень интересная и полезная методика – стоит всех усилий!) В ЭТОЙ ГЛАВЕ ВЫ УЗНАЕТЕ, КАК: решить, что вам нужно использовать дисперсионный анализ; рассчитать и интерпретировать F-статистику; провести дисперсионный анализ при помощи SPSS; рассчитать размер эффекта для одностороннего дисперсионного анализа. ПРЕДИСЛОВИЕ К ДИСПЕРСИОННОМУ АНАЛИЗУ Одним из перспективных разделов психологии является психология спорта. Несмотря на то что она фокусируется в основном на улучшении спортивных результатов, многие другие аспекты спорта тоже попадают в сферу ее внимания. Одна из изучаемых тем – какие психологические навыки необходимы для того, чтобы быть успешным атлетом. Пытаясь найти ответ этот вопрос, Мариус Гудас (Marious Goudas), Янис Теодоракис (Yiannis Theodorakis) и Георгий Карамусалидис (Georgios Karamousalidis) проверили полезность тес­та стрессоустойчивости спортсмена (Athletic Coping Skills Inventory). В рамках исследования они использовали простой дисперсионный анализ (или ANOVA) для проверки гипотезы, что количество лет занятий спортом связано со стрессоустойчивостью (или результатами атлета по тесту стрессоустойчивости). Выбор ANOVA объясняется тем, что проверялось более двух уровней одной и той же переменной, а затем эти группы сравнивались по своим средним результатам. В частности, в группу 1 входили спортсмены со спортивным опытом до 6 лет включительно, в группу 2 входили атлеты Введение в главу 13 265 266 Часть IV Значимая разница: применение статистики вывода со спортивным опытом от 7 до 10 лет, а в группу 3 вошли спортсмены с более чем 10-летним опытом. Статистическим критерием для ANOVA является F-критерий (названный в честь Р. А. Фишера, создателя этого критерия), и результаты этого исследования по подшкале теста «Достижения под давлением» показали, что F(2,110) = 13,08, p < 0,01. Это означает, что три группы результатов по этой подшкале отличались друг от друга. Иными словами, все отличия в результатах тестирования зависели больше от количества лет занятий спортом, чем от каких-то случайных событий. Хотите узнать больше? Найдите в интернете или библиотеке статью… Goudas M., Theodorakis Y. & Karamousalidis G. Psychological skills in basketball: Preliminary study for development of a Greek form of the Athletic Coping Skills Inventory-28. Perceptual and Motor Skills, 1998. Р. 59–65. ПУТЬ К МУДРОСТИ И ЗНАНИЮ Выбор одностороннего дисперсионного анализа Вот так вы можете при помощи схемы, показанной на рис. 13.1, выбрать ANOVA в качестве подходящего статистического критерия. Следуйте очередности выделенных шагов: 1.Мы проверяем различия между показателями разных групп (в данном случае – разницу в максимальных результатах спортсменов). 2. Спортсмены тестируются только один раз. 3.Выделяются три группы (меньше 6 лет опыта, 7–10 лет опыта, более 10 лет отпыта). 4.Подходящий статистический критерий – простой дисперсионный анализ. РАЗНОВИДНОСТИ ДИСПЕРСИОННОГО АНАЛИЗА Дисперсионный анализ имеет много разновидностей. Самый прос­ той, являющийся предметом изучения в этой главе, – это простой дисперсионный анализ, применяемый, когда изучается только один фактор или одно влияние на переменную (такое как принадлежность к конкретной группе), причем у этого фактора более двух уровней. Простой дисперсионный анализ также называют односторонним дисперсионным анализом, потому что применяется только один параметр для группировки. Методика называется «дисперсионным анализом», потому что дисперсия, возникающая из-за различий в результатах, подразделяется на (а) дисперсию, возника- Глава 13 Двух групп недостаточно? 267 ющую из-за различий между группами, и (б) дисперсию, возникающую из-за различий внутри групп. Затем два вида дисперсий сравниваются друг с другом. Дисперсия между группами объясняется разницей влияния, тогда как внутригрупповая дисперсия возникает из-за различий между отдельными представителями внутри каждой группы. Рис. 13.1 Проверка, что нам подходит дисперсионный анализ Вы изучаете отношения между переменными или различия между группами из одной или нескольких переменных? Вы изучаете разницу между одной выборкой и генеральной совокупностью? Я изучаю различия между группами из одной или нескольких переменных Я изучаю отношения между переменными Одни и те же участники оцениваются несколько раз? С каким количеством переменных вы работаете? Одновыборочный Z-критерий Да Нет С каким количеством групп вы работаете? С каким количеством групп вы работаете? Две переменные Более двух переменных Две группы Больше двух групп Две группы Больше двух групп t-критерий значимости коэффициента корреляции Регрессия, факторный анализ или канонический анализ t-критерий для зависимых выборок Дисперсионный анализ повторных измерений t-критерий для независимых выборок Простой дисперсионный анализ Фактически ANOVA во многих отношениях похож на проверку по t-кри­те­рию (дисперсионный анализ для двух групп и есть, по сути, проверка по t-кри­терию!). И в дисперсионном анализе, и при применеии t-критерия вычисляются различия между средними величинами. Но в случае ANOVA имеется больше двух средних значений. Например, представим, что мы изучаем, как влияет на развитие речи пребывание в дошкольных группах на протяжении 5, 10 или 20 ч в неделю. Группа, к которой относятся дети, является экспериментальной переменной (или группирующим, или межгрупповым фактором). Развитие речи является результирующей переменной. Проект эксперимента будет выглядеть примерно так, с тремя уровнями одной переменной (количества часов). Таблица 13.1 Дизайн эксперимента Группа 1 (5 ч в неделю) Результаты теста развития речи Группа 2 (10 ч в неделю) Результаты теста развития речи Группа 3 (20 ч в неделю) Результаты теста развития речи 268 Часть IV Значимая разница: применение статистики вывода Более сложный вид дисперсионного анализ, многофакторный анализ, применяется для изучения нескольких экспериментальных факторов. Ниже приведен пример для изучения влияния времени пребывания в дошкольных группах, при котором также исследуется влияние пола. Проект эксперимента может выглядеть как в табл. 13.2. Таблица 13.2 Дизайн многофакторного эксперимента Количество часов дошкольной подготовки Группа 1 (5 ч в неделю) Группа 2 (10 ч в неделю) Группа 3 (20 ч в неделю) Мужской Результаты теста развития речи Результаты теста развития речи Результаты теста развития речи Женский Результаты теста развития речи Результаты теста развития речи Результаты теста развития речи Пол Такой факторный дизайн называется факторным дизайном 3×2. Цифра 3 указывает, что у одного группирующего фактора выделяются три уровня (группа 1, группа 2 и группа 3). Цифра 2 указывает, что у другого группирующего фактора имеется два уровня (мужской или женский). Их комбинация дает шесть возможных вариантов (мальчики, которые 5 ч в неделю занимаются в дошкольных группах; девочки, которые 5 ч в неделю занимаются в дошкольных группах; мальчики, которые 10 ч в неделю занимаются в дошкольных группах, и т. д.). Такие факторные планы эксперимента следуют той же базовой логике, что и простой дисперсионный анализ. Просто они более масштабны в том плане, что могут проверять влияние нескольких факторов одновременно, а также комбинации факторов. Не переживайте – вы изучите факторный анализ в следующей главе. ВЫЧИСЛЕНИЕ СТАТИСТИЧЕСКОГО КРИТЕРИЯ ФИШЕРА ANOVA: вычисление F-критерия Простой дисперсионный анализ состоит в проверке различий между средними значениями более, чем двух групп, выделенных по одному фактору или измерению. Например, возможно, вы хотите узнать, отличаются ли четыре группы людей (возрастом в 20, 25, 30 и 35 лет) по своему отношению к государственной поддержке частных школ. Или, может быть, вас интересует, отличаются ли у пяти групп детей из разных параллелей (2-й, 4-й, 6-й, 8-й и 10-й классы) уровни вовлеченности их родителей в школьные мероприятия. Любой анализ, в котором: zz анализируется только одно измерение или влияние; zz группирующий фактор имеет более двух уровней (или гра­ даций); zz вы смотрите на различия между средними значениями групп, – требует применения дисперсионного анализа. Глава 13 Двух групп недостаточно? 269 Расчет значения F-критерия, показателя, необходимого для оценки гипотезы о существовании различий между группами, записан в формуле 13.1. Она выглядит просто, но для ее вычисления понадобится чуть больше арифметических действий, чем для статистических критериев, с которыми вы работали в предыдущих главах. (13.1) где MSмежгр – дисперсия между группами; MSвнутригр – дисперсия внут­ ри групп. За этой дробью стоит примерно такая логика. Если бы внутри каждой группы полностью отсутствовала изменчивость (все значения были бы одинаковыми), тогда любые различия между группами были бы существенными, верно? Вероятно, так. Формула дисперсионного анализа (т. е. наше соотношение) сравнивает степень вариабельности между группами (возникающую из-за группирующего фактора) со степенью вариабельности внутри групп (возникающую вследствие случайно­сти). Если это соотношение равно 1, тогда степень изменчивости, возникающей из-за внутригрупповых различий, равна изменчивости, возникающей из-за межгрупповых различий, а любые различия между группами не являются статистически значимыми. По мере увеличения средней разницы между группами (и возрастания числителя дроби) также возрастает и значение F-критерия. По мере возрастания значения F оно становится все более крайним по отношению к распределению всех значений F. При этом все больше вероятность того, что на него повлияло что-то еще, помимо случайности. Уф! Вот некоторые данные и предварительные расчеты, демонстрирующие вычисление значения F-критерия. Давайте предположим в нашем примере, что это три группы дошкольников и их показатели развития речи. Таблица 13.3 Показатели развития речи у дошкольников Показатели группы 1 87 86 76 56 78 98 77 66 75 67 Показатели группы 2 87 85 99 85 79 81 82 78 85 91 Показатели группы 3 89 91 96 87 89 90 89 96 96 93 Односторонний дисперсионный анализ 270 Часть IV Значимая разница: применение статистики вывода Вот те знаменитые восемь шагов и вычисление значения F-кри­ терия. F-критерий 1. Формулировка основной и альтернативной гипотез. Нулевая гипотеза, представленная в формуле 13.2, утверждает, что нет различий между средними показателями трех разных групп. Дисперсионный анализ, называемый также F-критерием Фишера (потому что в результате он дает значение F-критерия, или отношения Фишера), ищет общие различия между группами. Обратите внимание, что эта проверка не смотрит на парные различия, такие как различия между группой 1 и группой 2. Для этого нам придется воспользоваться еще одним инструментом, который мы обсудим позже в данной главе: H0: µ1 = µ2 = µ3. (13.2) Альтернативная гипотеза, представленная формулой 13.3, утверждает, что существует общее различие между средними величинами трех групп. Обратите внимание, что это различие не имеет направления, т. к. все F-критерии являются ненаправленными: H1: X1 ≠ X2 ≠ X3; (13.3) 2.Выбор уровня риска (или уровня значимости, или ошибки первого рода), связанного с нулевой гипотезой. Уровень риска, или ошибки первого уровня, или уровня значимости (нужны еще какие-то названия?), здесь 0,05. Еще раз повторим, что это остается полностью на усмотрение исследователя; 3. Выбор подходящего статистического критерия. При помощи схемы, показанной на рис. 13.1, мы определили, что нам подходит простой дисперсионный анализ; 4. Расчет значения статистического критерия (наблюдаемого значения). Это ваш шанс подставить в формулы значения и сделать какие-то вычисления. А вычислять здесь придется много: – отношение Фишера – это отношение вариабельности между группами к вариабельности внутри групп. Чтобы вычислить эти значения, сначала нужно рассчитать то, что называется суммой квадратов, для каждого источника изменчивости (между группами, внутри групп и в целом); – межгрупповая сумма квадратов равна сумме разностей между средними значениями всех данных и средним значением показателя каждой группы, которые затем возводятся в квадрат; – внутригрупповая сумма квадратов равна сумме разностей между каждым индивидуальным значением данных в группе и средним значением этой группы, которые затем возводятся в квадрат. Это дает нам представление о том, насколько отличается каждое значение в группе от среднего значения этой группы; – общая сумма квадратов равна сумме межгрупповой и внутригрупповой сумм квадратов. Давайте найдем эти значения. Глава 13 Двух групп недостаточно? 271 До этого момента мы говорили об одно- и двусторонних критериях. Но для дисперсионного анализа такого понятия не сущест­ вует! Поскольку проверяется больше двух групп и F-кри­терий является универсальным устойчивым критерием (следовательно, дисперсионный анализ любого вида проверяет общие различия между средними), обсуждение конкретного направления этих различий не имеет никакого смысла. На рис. 13.2 показаны данные, которые вы видели раньше, со всеми расчетами, которые необходимы для вычисления суммы межгрупповой, внутригрупповой и общей сумм квадратов. Вопервых, давайте посмотрим на обозначения в расширенной таб­ лице. Начнем с левого столбца: – n – это количество участников в каждой группей (например, 10); – ∑X _ – это сумма всех значений в каждой группе (например, 766); – X – это среднее значение для каждой группы (например, 76,60); – ∑(X 2) – это сумма квадратов каждого значения (например, 59964); – (∑X )2 – это сумма значений в каждой группе, возведенная в квад­рат и поделенная на размер группы (например, 58675,6). Рис. 13.2 Расчет важных величин для однофакторного дисперсионного анализа Группа Значение показателя X2 Группа Значение показателя X2 Группа Значение показателя X2 Во-вторых, давайте посмотрим на правый столбец: – n – это общее количество участников (например, 30); – ∑∑X – это сумма всех значений по всем группам; – (∑∑X)2/n – это сумма всех значений по всем группам, возведенная в квадрат и поделенная на количество участников; – ∑∑(X2) – это сумма всех сумм возведенных в квадрат значений; – ∑(∑X)2/n – это сумма сумм квадратов значений каждой группы, поделенная на количество участников. 272 Часть IV Значимая разница: применение статистики вывода Это целая куча вычислений, но мы почти закончили! Во-первых, рассчитаем сумму квадратов для каждого источника изменчивости. Вот эти вычисления (табл. 13.4). Таблица 13.4 Вычисление сумм квадратов ∑(∑X )2/n – (∑∑X )2/n, 1133,07 или 215 171,60 –214 038,53 Внутригрупповая сумма квадратов ∑∑(X 2) – ∑(∑X)2/n, или 216 910 – 215 171,6 1738,40 Общая сумма квадратов ∑∑(X 2) – (∑∑X)2/n, или 216 910 – 214 038,53 2871,47 Межгрупповая сумма квадратов Во-вторых, нам нужно рассчитать среднюю сумму квадратов, которая просто равная среднему значению всех сумм квадратов. Это оценки дисперсии, которые нам нужны для итогового вычисления столь важного отношения Фишера. Мы сделаем это путем деления каждой суммы квадратов на примерное количество степеней свободы (df ). Как вы помните, степени свободы приближаются к размеру выборки или группы. Нам нужно два набора степеней свободы для ANOVA. Для межгрупповой оценки это k – 1, где k равно количеству групп (в данном случае у нас три группы и две степени свободы). Для внутригрупповой оценки нам потребуется N – k, где N равно размеру всей выборки (что означает, что количество степеней свободы равно 30 – 3, или 27). Тогда отношение Фишера – это просто отношение средней суммы квадратов межгрупповых различий к средней сумме квадратов внутригрупповых различий, или 566,54/64,39, или 8,799. Это наблюдаемое значение F-критерия. Вот таблица оценок дисперсии, которые используются для вычисления F-кри­ терия. Именно так выглядит большинство таблиц для критерия Фишера в профессиональных журналах и рукописях. Таблица 13.5 Таблица для критерия Фишера (F-критерия) Источник вариабельности Между группами Внутри групп Всего Сумма квадратов df Средняя сумма квадратов F 1133,07 2 566,54 8,799 1738,40 27 64,39 2871,47 29 И все это ради одного маленького F-критерия? Да, но, как мы говорили ранее, крайне важно выполнить все эти расчеты хотя бы один раз вручную. Это даст вам важное понимание того, откуда берутся цифры, а также поможет получить некоторое представление о том, что они означают. Поскольку вы уже знаете про t-критерий Стьюдента, возможно, вам интересно, как соотносятся t-критерий (который всегда применяется для проверки различия средних величин у двух групп) и F-критерий (который всегда применяется для более чем двух групп). Довольно интересно, что F-критерий для двух групп будет равен квадрату t-критерия для двух групп, или F = t2. Подходящий вопрос для викторины, да? Также это полезная информация на случай, если вам известно одно значение и нужно узнать другое. Глава 13 Двух групп недостаточно? 5.Определение значения, необходимого для отклонения нулевой гипотезы, при помощи соответствующей таблицы критических значений для конкретного критерия. Как и раньше, нам нужно сравнить наблюдаемое и критическое значения. Теперь следует обратиться к таблице, в которой указаны критические значения для F-критерия, табл. B.3 в приложении B. Сначала мы должны определить степени свободы для числителя, что равно k – 1, или 3 – 1 = 2. Затем мы определим степени свободы для знаменателя, что равно N – k, или 30 – 3 = 27. Вместе они записываются как F(2,27). Наблюдаемое значение 8,80, или F(2,27) = 8,80. Критическое значение на уровне значимости 0,05 с двумя степенями свободы в числителе (что представлено столбцами табл. B.3) и 27 степенями свободы в знаменателе (что представлено строками табл. B.3) равно 3,36. Итак, на уровне значимости 0,05, с 2 и 27 степенями свободы для обобщенной проверки различия средних у трех групп, значение, необходимое для отклонения нулевой гипотезы, равно 3,36. 6. Сравнение наблюдаемого значения с критическим. Наблюдаемое значение равно 8,80, а критическое значение для отклонения на уровне значимости 0,05 нулевой гипотезы о том, что три группы не различаются между собой, равно 3,36. 7 и 8. Время решать! А теперь нужно решать. Если наблюдаемое значение оказывается более крайним, чем критическое, то нулевую гипотезу нельзя принять. Если наблюдаемое значение не превосходит критического, то нулевая гипотеза дает самое привлекательное объяснение. В данном случае наблюдаемое значение действительно превосходит критическое – оно является достаточно крайним, чтобы мы могли сказать: различия меду тремя группами появились не из-за случайности. И если мы правильно провели эксперимент, то какой фактор мог повлиять на результаты? Легко – количество часов дошкольной подготовки. Мы знаем, что разница определяется конкретным фактором, потому что различия между группами не могли появиться случайно, а стали следствием влияющего фактора. Так как мне интерпретировать F(2,27) = 8,80, p < 0,05? zz F обозначает использованный статистический критерий; zz 2 и 27 – это количество степеней свободы для межгрупповой и внутригрупповой оценок соответственно; zz 8,80 – это наблюдаемое значение, рассчитанное по формуле, которую мы показывали вам в этой главе; zz p < 0,05 (действительно важная часть этого короткого выражения) обозначает, что для любой проверки нулевой гипотезы сущест­ вует меньше 5 % вероятности, что средние значения развития речи для каждой группы будут различаться из-за случайности, а не влияющего фактора. Поскольку мы выбрали 0,05 в качестве критерия большей привлекательности альтернативной, а не нулевой гипотезы, то заключаем, что между тремя наборами данных есть значимые различия. 273 274 Часть IV Значимая разница: применение статистики вывода Действительно важные технические подробности Представьте такой сценарий. Вы влиятельный исследователь в компании, занимающейся рекламой, и хотите узнать, приводит ли использование цвета в рекламных сообщениях к изменению объема продаж. Вы решили проверить это на уровне значимости 0,05. Так что вы верстаете одну брошюру в полностью черно-белом варианте, другую – с 25 % цвета, следующую – с 50%, затем – с 75 % и, наконец, на 100 % цветную, т. е. получаете пять уровней фактора. Вы проводите дисперсионный анализ, чтобы выяснить наличие разницы в продажах. Но поскольку ANOVA является обобщенным критерием, то вы не знаете, где находится источник значимой разницы. Так что вы берете две группы (или пары) за один раз (например, 25 % цвета и 75 % цвета) и проверяете различия между ними. Фактически вы проверяете все парные комбинации по очереди. Дозволено ли это? Ни в коем случае. Это называется проведением множественных проверок t-критерия и действительно является противозаконным в некоторых юрисдикциях. Когда вы это делаете, ошибка первого рода (которую вы обозначили как 0,05) просто зашкаливает, в зависимости от количества проверок, которые вы хотите сделать. Существует 10 возможных вариантов попарного сравнения (черно-белый с 25 % цвета, черно-белый с 50 % цвета, черно-белый с 75 % цвета и т. д.). Действительная ошибка первого рода равна 1 – (1 – α)k, где α – это ошибка первого рода (в данном примере 0,05); k – это количество сравнений. Таким образом, вместо 0,05 действительная ошибка проверок каждого сравнения равна 1 – (1 – 0,05)10 = 0,40 (!!!!!). Это не имеет ничего общего с 0,05. ВЫЧИСЛЕНИЕ F - ОТНОШЕНИЯ ФИШЕРА С ПОМОЩЬЮ SPSS Вычисление F-отношения Фишера с помощью SPSS F­-отношение скучно рассчитывать вручную (это не трудно, но занимает много времени). О чем тут еще говорить? Считать на компьютере гораздо проще и точнее, потому что так исключаются ошибки в вычислениях. Так сказать, радуйтесь, что вы видели, как это значение рассчитывается вручную, потому что это важный навык, который помогает вам понять идеи, стоящие за процессом. Но радуйтесь также тому, что есть такие инструменты, как SPSS. Мы будем использовать данные из набора «Глава 13. Набор данных 1» (Chapter 13. Data Set 1). Это те же значения, которыми мы пользовались в примере о дошкольной подготовке. Глава 13 Двух групп недостаточно? 1.Внесите данные в Редактор данных (Data Editor). Проверьте, что у вас есть отдельный столбец для групп и что в этом столбце указаны все три группы. На рис. 13.3 вы можете увидеть, что столбцы данных называются Group (Группа) и Language_ Score (Показатель речи). Рис. 13.3 Данные из файла «Глава 13. Набор данных 1» (Chapter 13. Data Set 1) 2.Нажмите на Анализ (Analyze) ⇒ Сравнение средних (Compare Means) ⇒ Однофакторный дисперсионный анализ (One-Way ANOVA), и вы увидите диалоговое окно Однофакторный дисперсионный анализ (One-Way ANOVA), как показано на рис. 13.4. Рис. 13.4 Диалоговое окно Однофакторный дисперсионный анализ (One-Way ANOVA) 275 276 Часть IV Значимая разница: применение статистики вывода 3.Щелкните по переменной Группа (Group) и переместите ее в поле Фактор (Factor); 4.Щелкните по переменной Показатель речи (Language_Score) и переместите ее в поле Список зависимых переменных (Dependent List). 5.Нажмите на Параметры (Options), отметьте Описательные (Descriptives), нажмите на Продолжить (Continue). 6.Нажмите на ОК. SPSS проведет анализ и покажет вывод, как на рис. 13.5. Рис. 13.5 Вывод SPSS для однофакторного дисперсионного анализа Читаем выводы SPSS Этот вывод SPSS вовсе не сложен и в точности похож на таблицу, которую мы рисовали, чтобы показать вам, как рассчитывается F-от­но­ше­ ние, а также некоторые описательные статистики. Вот что у нас есть: 1)приведен отчет по описательным статистикам (размер выборки, средние значения и т. д.); 2)определены источники рассеяния данных, такие как «между группами», «внутри групп» и «всего»; 3)для каждого источника приведены соответствующие суммы квадратов; 4)за ними следуют степени свободы, а затем средние квадраты, что равно сумме квадратов, поделенной на степени свободы; 5)и наконец, наблюдаемое значение критерия и соответствующий ему уровень значимости. Имейте в виду, что эта гипотеза проверялась на уровне значимости 0,05. Вывод SPSS указывает точное значение вероятности результата, 0,001. Это гораздо более значимо, чем заданная p-величина, и в данном случае гораздо менее вероятно, чем 0,05. Глава 13 Двух групп недостаточно? РАЗМЕР ЭФФЕКТА Д ЛЯ ОДНОНАПРАВЛЕННОГО ДИСПЕРСИОННОГО АНАЛИЗА В предыдущих главах вы видели, что мы использовали d Коэна в качестве показателя размера эффекта. Здесь мы меняем направление и будем использовать величину под названием «эта в квадрате», или η2. Как и у d Коэна, у η2 есть шкала для оценки величины размера эффекта: zz маленький размер эффекта – около 0,01; zz средний размер эффекта – около 0,06; zz большой размер эффекта – около 0,14. А теперь перейдем к фактическому размеру эффекта. Формула для η2 выглядит так: и вы берете информацию прямо из таблицы дисперсий, сгенерированной в SPSS (или подготовленной вручную). В использованном ранее примере с тремя группами сумма квад­ ратов между группами равна 1133,07, а общая сумма квадратов равна 2871,27. Легкие вычисления: и в соответствии со шкалой маленького–среднего–большого размера η2, равное 0,39, – это большой эффект. Размер эффекта – это потрясающий инструмент, поддерживающий оценку F-критерия, как, впрочем, и почти любого другого статистического критерия. Вы провели дисперсионный анализ и теперь знаете, что между средними значениями трех, четырех или более групп имеются общие различия. Но где именно находится это различие? Вы уже знаете, что не нужно проводить множественные проверки t-кри­терия. Вам нужно выполнить то, что называется апостериорными сравнениями, или сравнениями после анализа. Вы будете сравнивать каждое среднее значение со всеми другими средними значениями и увидите, где находится различие, но важнее всего то, что ошибка первого рода для каждого сравнения будет контролируемой на том самом уровне, который вы зададите. Есть множество способов провести такие сравнения, например метод Бонферрони (любимый статистический термин автора этой книги). Для проведения этого анализа в SPSS нажмите на кнопку Апостериорные (Post hoc) в диалоговом окне Однофакторный дисперсионный анализ (One-Way ANOVA), показанном на рис. 13.4. Затем отметьте Бонферрони (Bonferroni), нажмите на Продолжить (Continue) и т. д., и вы увидите вывод вроде того, что показан на рис. 13.6. Очевидно, этот анализ говорит вам, что значимые 277 Часть IV 278 Значимая разница: применение статистики вывода парные различия, вносящие вклад в общие значимые различия между тремя группами, находятся между группами 1 и 3. Между группами 1 и 2 или между группами 2 и 3 парные различия отсутствуют. Это парное сравнение очень важно, т. к. позволяет вам определить источник различий между более чем двумя группами. Рис. 13.6 Апостериорные сравнения, выполняемые после получения значимого F-критерия РЕАЛЬНАЯ СТАТИСТИКА Интересные ли получаются результаты, когда исследователи объединяют знания из различных областей науки для поиска ответа на разные вопросы? Просто взгляните на журнал, в котором это происходит: «Музыка и медицина» («Music and Medicine»)! В исследовании, авторы которого изучали волнение среди выступающих музыкантов, были протестированы уровни возбуждения у пяти профессиональных певцов и четырех флейтистов. В дополнение они использовали пятиуровневую шкалу лайертовского типа для оценки нервозности участников. Каждый музыкант исполнил легкое и трудное произведения перед слушателями (как будто на концерте) и без слушателей (как будто на репетиции). Затем исследователи оценили частоту сердцебиения и вариабельность частоты сердцебиения при помощи дисперсионного анализа, который показал значимое различие между четырьмя ситуа­циями (легкое/ репетиция; трудное/репетиция; легкое/концерт; трудное/концерт). Более того, при проверке влияния других факторов не обнаружилось различий, связанных с возрастом, полом или инструментом (голос/флейта). Глава 13 Двух групп недостаточно? 279 Хотите узнать больше? Найдите в интернете или библиотеке статью... Harmat L. & Theorell T. Heart rate variability during singing and flute playing. Music and Medicine, 2010. Р. 10–17. Реальная статистика ВЫВОДЫ ПО ГЛАВЕ Дисперсионный анализ (ANOVA) является одним из самых сложных из всех проверок вывода, о которых вы узнаете в данной книге. Требуется большая сосредоточенность, чтобы выполнить все расчеты вручную, и даже когда вы пользуетесь SPSS, то необходимо быть крайне внимательным, чтобы понимать, что это обобщенный критерий (он не дает информации о различиях между парами). Если вы решите продолжить и провести апостериорный анализ, то только тогда сможете выполнить все задачи, сопутствующие этому мощному инструменту. Скоро мы узнаем еще об одном критерии проверки различий между средними – факторном дисперсионном анализе. Он, предел мечтаний дисперсионных анализов, может рассматривать два или более факторов. Мы остановимся на двух, и SPSS укажет нам путь. Выводы по главе ВРЕМЯ ПРАКТИКИ 1.Когда дисперсионный анализ является более подходящим критерием, чем проверка значимости различий между парами средних значений? 2.В чем заключается разница между однофакторным и многофакторным дисперсионным анализом? 3.При помощи следующей таблицы приведите три примера прос­ того однофакторного, два примера двухфакторного, один пример трехфакторного дисперсионного анализа. Мы покажем вам некоторые примеры, а вы подберите остальные. Обязательно определите группирующие и зависимые переменные, как мы делали это раньше. Таблица 13.6 Виды дисперсионного анализа Вид анализа Простой дисперсионный анализ Группирующая(ие) переменная(ые) 4 уровня (градации) часов тренировки: 2, 4, 6 и 8 ч Приведите здесь свой пример Приведите здесь свой пример Приведите здесь свой пример Зависимая переменная Точность печати Приведите здесь свой пример Приведите здесь свой пример Приведите здесь свой пример Продолжение ⇒ 280 Часть IV Вид анализа Двухфакторный дисперсионный анализ Трехфакторный дисперсионный анализ Проблема 4 Проблема 6 Значимая разница: применение статистики вывода Группирующая(ие) переменная(ые) Два уровня тренировки и пола (дизайн 2×2) Приведите здесь свой пример Приведите здесь свой пример Два уровня образования, два уровня пола и три уровня дохода Приведите здесь свой пример Зависимая переменная Точность печати Приведите здесь свой пример Приведите здесь свой пример Отношение к голосованию Приведите здесь свой пример 4.Для данных из набора «Глава 13. Набор данных 2» (Chapter 13 Data Set 2) рассчитайте при помощи SPSS F-отношение Фишера для сравнения трех уровней, представляющих количество времени, которое пловцы еженедельно затрачивают на тренировки (< 15, 15–25 и > 25 ч). В качестве зависимой переменной возьмите их время заплыва на 100 ярдов. Ответьте на вопрос, влияет ли объем тренировок на результаты. Не забудьте зайти в пункт Парамет­ ры (Options), чтобы получить средние значения для групп. 5.Данные, представленные в файле «Глава 13. Набор данных 3» (Chapter 13. Data Set 3), были собраны исследователем, который хочет знать, различается ли уровень стресса у трех групп сотрудников. Сотрудники в группе 1 работают в смену утро/день, в группе 2 – в смену день/вечер, в группе 3 – в ночную смену. Нулевая гипотеза состоит в том, что между группами нет различий по уровню стресса. Проверьте ее при помощи SPSS и предоставьте собственное заключение. 6.Компания «Лапшичка» хочет знать, какая толщина лапши кажется потребителям наиболее приятной на вкус (по шкале от 1 до 5, где 1 – самая приятная), так что производитель решает это проверить. Полученные данные представлены в файле «Глава 13. Набор данных 4» (Chapter 13. Data Set 4). Обнаружено значимое различие (F(2,57) = 19,398, p < 0,001) между группами, и больше всего потребители предпочитают тонкую лапшу. Но что насчет различий между тонкой, средней и толстой лапшой? Апостериорный анализ вам в помощь! 7.Почему допускается проведение апостериорного анализа только в том случае, если F-критерий оказывается значимым? 14 Два лишних фактора Краткое введение в многофакторный дисперсионный анализ Уровень сложности: (так же сложно, как понять прогрессивную мысль, но мы здесь затронем только основные положения) В ЭТОЙ ГЛАВЕ ВЫ УЗНАЕТЕ: как использовать дисперсионный анализ для более чем одного фактора; что такое основной эффект и эффект взаимодействия; как провести многофакторный дисперсионный анализ в SPSS; как рассчитать размер эффекта для многофакторного дисперсионного анализа. ПРЕДИСЛОВИЕ К МНОГОФАКТОРНОМУ ДИСПЕРСИОННОМУ АНАЛИЗУ Психологов десятилетия занимал вопрос, как люди принимают решения. Полученные из их исследований данные нашли применение в таких широких областях, как реклама, бизнес, планирование и даже теология. Милтиадес Пройос (Miltiades Proios) и Георг Доганис (George Doganis) исследовали, какое влияние на моральные суждения могут оказывать опыт активного участия в принятии решений и возраст. Выборка состояла из 148 рефери: 56 из них судили футбол, 55 – баскетбол и 37 занимались гандболом. Их возраст находился в диапазоне от 17 до 50 лет, а пол не рассматривался в качестве важной переменной. Около 8 % участников всей выборки не имели никакого опыта участия в процессе принятия решений в социальном, политическом или спортивном окружении; около 53 % принимали участие в решениях, но были полностью вовлечены в процесс; около 39 % были активными участниками процесса принятия реше- Введение в главу 14 281 282 Часть IV Значимая разница: применение статистики вывода ний внутри организации. Двухфакторный дисперсионный анализ показал наличие связи между комбинацией опыта и возраста и моральными суждениями и целями спортивных судей. Почему был выбран двухфакторный дисперсионный анализ? Все просто: присутствовали два независимых фактора, уровень опыта и возраст. Итого, как и в любой процедуре дисперсионного анализа, были проведены: а) проверка главного эффекта для возраста; б) проверка главного эффекта для опыта; в) проверка эффекта взаимодействия для опыта и возраста (которое оказалось значимым). Самое интересное в дисперсионном анализе для более чем одного фактора или независимой переменной – то, что исследователь может посмотреть не только на отдельные эффекты каждого фактора, но также и на одновременное влияние обоих, что и называется взаимо­действием. Мы еще поговорим об этом далее в главе. Хотите узнать больше? Найдите в интернете или библиотеке статью… Proios M. & Doganis G. Experiences from active membership and participation in decision-making processes and age in moral reasoning and goal orientation of referees. Perceptual and Motor Skills, 2003. Р. 113–126. ПУТЬ К МУДРОСТИ И ЗНАНИЮ Вот таким образом вы можете при помощи схемы, показанной на рис. 14.1, выбрать в качестве подходящего критерия дисперсионный анализ (но в этот раз для более чем одного фактора). Следуйте выделенной очередности шагов. 1.Мы проверяем различия в результатах у разных групп, в данном случае групп, отличающихся по уровню опыта и возрасту. 2. Участники тестируются только один раз. 3. У нас больше двух групп. 4. У нас больше одного фактора или независимой переменной. 5. Нам подходит многофакторный дисперсионный анализ. Выбор подходящего критерия Как и в главе 13, мы решили, что нам подойдет дисперсионный анализ (для изучения различий между более чем двумя группами или уровнями независимой переменной), но, поскольку мы имеем дело с более чем одним фактором, верным выбором станет многофакторный дисперсионный анализ. Глава 14 Два лишних фактора 283 Рис. 14.1 Проверка, что нам подходит дисперсионный анализ Вы изучаете отношения между переменными или различия между группами из одной или нескольких переменных? Я изучаю различия между группами из одной или нескольких переменных Я изучаю отношения между переменными Одни и те же участники оцениваются несколько раз? С каким количеством переменных вы работаете? Да Нет С каким количеством групп вы работаете? С каким количеством групп вы работаете? Две переменные Более двух переменных Две группы Больше двух групп Две группы Больше двух групп t-критерий значимости коэффициента корреляции Регрессия, факторный анализ или канонический анализ t-критерий для зависимых выборок Дисперсионный анализ повторных измерений t-критерий для независимых выборок Сколько у вас факторов? Один Больше одного Простой дисперсионный анализ Многофакторный дисперсионный анализ НОВЫЙ СОРТ ANOVA Вы уже знаете, что у дисперсионного анализа есть по меньшей мере одна разновидность – простой дисперсионный анализ, который мы обсуждали в главе 13. В простом дисперсионном анализе изучается только один фактор, или независимая переменная (например, принадлежность к группе), и для данного фактора, или независимой переменной, выделяется более двух групп или уровней. А теперь мы немного усилим эту методику, чтобы иметь возможность одновременного изучения более чем одного фактора. Это называется многофакторным дисперсионным анализом. Давайте посмотрим на простой пример, в котором изучаются два фактора: пол (мужской или женский), воздействие (сложная или простая программа тренировок) и зависимая переменная (потеря веса). Вот как будет выглядеть факторная таблица (см. табл. 14.1). Многофакторный дисперсионный анализ 284 Часть IV Значимая разница: применение статистики вывода Таблица 14.1 Факторный план Программа тренировок Сложная Простая Пол Мужской Женский Затем мы посмотрим, на что будут похожи главные эффекты и эффекты взаимодействия. Сейчас мы не увидим именно анализа данных – он появится позже в этой главе, сейчас это в основном режим «смотри и учись». Даже если в результатах анализа будут указаны точные значения вероятности ошибки первого рода (и нам не придется возиться с условиями вроде p < 0,05), мы будем использовать в качестве критерия отклонения (или отсутствия принятия) нулевой гипотезы уровень 0,05. При использовании данного типа анализа вы можете задать три вопроса и получить на них ответ: 1)есть ли различия во влиянии на потерю веса у двух уровней программы тренировок: сложной и простой; 2)есть ли различия во влиянии на потерю веса у двух градаций пола: мужского и женского; 3)различается ли влияние сложной и простой программы тренировок у мужчин и женщин. Вопросы 1 и 2 относятся к выявлению главных эффектов, тогда как вопрос 3 имеет дело со взаимодействием двух факторов. ОСНОВНОЕ СОБЫТИЕ: ГЛАВНЫЕ ЭФФЕКТЫ В МНОГОФАКТОРНОМ ДИСПЕРСИОННОМ АНАЛИЗЕ Вы, возможно, хорошо помните, что основной задачей дисперсионного анализа является проверка различий между двумя или более группами. Когда анализ данных выявляет различия между уровнями любого фактора, мы говорим о наличии главного эффекта. В нашем примере в каждую из четырех групп входит по 10 участников, что в сумме дает 40. И вот на что похожи результаты анализа (чтобы получить такую стильную табличку, мы воспользовались SPSS). Это другая форма таблицы дисперсионного анализа, которую мы представили в главе 13. Посмотрите только на столбцы «Источник» и «Значимость» (выделены жирным шрифтом). Мы можем прийти к заключению, что присутствует главный эффект для пола (p = 0,000), отсутствует главный эффект для программы (p = 0,091) и нет взаимодействия между двумя основными факторами (p = 0,665). Итак, по отношению к потере веса не имело значения, участвовал человек в простой или Глава 14 Два лишних фактора 285 сложной программе, но определенно имел значение пол участника. И поскольку отсутствовало взаимодействие между факторами программы и пола, внутри пола результаты не дифференцировались. Таблица 14.2 Таблица для многофакторного дисперсионного анализа Критерии межгрупповых эффектов Зависимая переменная: ПОТЕРЯ ВЕСА Источник Сумма квадратов типа III Скоррект. модель 3678,275 Прерывание 232 715,025 ПРОГРАММА 429,025 ПОЛ 3222,025 ПРОГРАММА* ПОЛ 27,225 Ошибка 5129,7 Общая 241 523,000 Скоррект. общая 8807,975 Ст. св. 3 1 1 1 Средний квадрат 1226,092 232 715,025 429,025 3222,025 1 36 40 39 27,225 142,492 F 8,605 1633,183 3,011 22,612 0,191 Если бы вы нанесли средние значения этих величин на график, то получили бы что-то вроде рис. 14.2. Рис. 14.2 Средние результаты программ для мужчин и женщин 90 85 Потеря веса 80 75 70 65 60 55 50 Сложная Программа Мужчины Простая Женщины Вы можете видеть большую разницу по оси «Потеря веса» между мужчинами и женщинами (среднее значение для всех мужчин равно 85,25, а для женщин 67,30), но обнаружите мало различий по оси «Программа» (если рассчитаете средние значения, которые равны для всех участников сложной программы 73,00, а для участников простой программы 79,55). Конечно же, мы проводим дисперсион- Значимость 0,000 0,000 0,091 0,000 0,665 286 Часть IV Значимая разница: применение статистики вывода ный анализ, и имеет значение еще и вариабельность внутри групп, но в данном примере вы можете видеть различия между группами (такими как мужчины и женщины) внутри каждого фактора (например, пола) и как они проявляются в результатах анализа. ЕЩЕ ИНТЕРЕСНЕЕ: ЭФФЕКТЫ ВЗАИМОДЕЙСТВИЯ Эффекты взаимодействия Хорошо, а теперь к взаимодействию. Давайте посмотрим на другую исходную таблицу, которая указывает на мужчин и женщин, получивших разные результаты в разных программах, что говорит о наличии эффекта взаимодействия. И конечно, вы увидите несколько очень классных результатов. Напоминаем, что самые важные части таблицы выделены. Здесь отсутствует главный эффект для программы или пола (p = 0,127 и 0,176 соответственно), но таки присутствует эффект взаимодействия между программой и полом (p = 0,004), из-за чего мы видим очень интересный результат. Фактически не имеет значения, участвуете вы в простой или сложной программе или являетесь мужчиной или женщиной, но имеет очень большое значение одновременное совпадение этих факторов, поскольку программа оказывает разное влияние на потерю веса у мужчин и у женщин. Таблица 14.3 Другая таблица для многофакторного дисперсионного анализа Критерии межгрупповых эффектов Зависимая переменная: ПОТЕРЯ ВЕСА Источник Сумма квадратов типа III Скоррект. модель 1522,875 Прерывание 218 892,025 ПРОГРАММА 265,225 ПОЛ 207,025 ПРОГРАММА* ПОЛ 1050,625 Ошибка 3906,100 Общая 224 321,000 Скоррект. общая 5428,975 Ст. св. 3 1 1 1 1 36 40 39 Средний квадрат 507,625 218 892,025 265,225 207,025 1050,625 108,503 F 4,678 2017,386 2,444 1,908 9,683 Значимость 0,007 0,000 0,127 0,176 0,004 На рис. 14.3 показаны графики средних значений для каждой из четырех групп. На что похожи сами значения средних (все благодарности SPSS), мы можем увидеть в табл. 14.4. Таблица 14.4 Средние значения потери веса Сложная программа Простая программа Мужчины 73,70 78,80 Женщины 79,40 64,00 Глава 14 Два лишних фактора 287 Рис. 14.3 Средние результаты программ для мужчин и женщин 90 85 Потеря веса 80 75 70 65 60 55 50 Сложная Программа Мужчины Простая Женщины Что мы можем из этого понять? Интерпретация здесь довольно прямолинейная. По сути, это ответы на три вопроса, перечисленных ранее: 1) отсутствует главный эффект для вида программы; 2) отсутствует главный эффект для пола; 3)существует явное взаимодействие между видом программы и полом. Это означает, что женщины теряют больше веса, чем мужчины, в условиях сложной программы тренировок, а мужчины теряют больше веса, чем женщины, при простой программе. Конечно, проще всего увидеть величину эффекта воздействия (или его отсутствие), если отметить средние на графике, как мы сделали на рис. 14.3. Линии могут не пересекаться столь явно, и общий вид графика будет зависеть от того, какая переменная отражается по оси x, но построение графика средних часто оказывается единственным способом понять, что происходит в плане главных эффектов и эффекта взаимодействия. Все это действительно впечатляет. Если бы вы не знали ничего лучшего (и никогда не читали бы эту главу), то подумали бы, что вам нужно лишь рассчитать простой t-критерий для средних значений у мужчин и женщин, а потом еще один простой t-критерий для средних значений участников сложной и участников простой программы, – и вы бы ничего не обнаружили. Но с помощью идеи взаимодействия главных факторов вы видите наличие дифференцированного эффекта (это результат, который бы в другом случае остался незамеченным). Если вы можете себе это позволить, взаимодействия являются самым интересным результатом многофакторного дисперсионного анализа. 288 Часть IV Значимая разница: применение статистики вывода ВЫЧИСЛЕНИЕ F - ОТНОШЕНИЯ С ПОМОЩЬЮ SPSS Вычисление F-отношения с помощью SPSS Вот что-то новенькое для вас. На протяжении всей «Статистики для тех, кто…», наряду с применением пакета статистического анализа вроде SPSS, мы показывали вам и примеры проведения расчетов по конкретной методике старым добрым способом (вручную, используя калькулятор). С появлением многофакторного дисперсионного анализа мы проиллюстрируем расчеты только при помощи SPSS. Не то чтобы требовались какие-то дополнительные интеллектуальные усилия для вычисления ANOVA на калькуляторе, но труда, определенно, нужно больше. По этой причине мы не будем рассказывать о расчетах вручную, а сразу перейдем к вычислениям в SPSS и посвятим больше времени интерпретации результатов. Мы воспользуемся данными, которые показали нам наличие значимого эффекта воздействия, из табл. 14.5. Таблица 14.5 Данные для примера расчета в SPSS Программа → Пол → Сложная Мужской 76 78 76 76 76 74 74 76 76 55 Сложная Женский 65 90 65 90 65 90 90 79 70 90 Простая Мужской 88 76 76 76 56 76 76 98 88 78 Простая Женский 65 67 67 87 78 56 54 56 54 56 И вот шаги для расчета статистического критерия F. Причиной отсутствия здесь «знаменитых восьми шагов» (ладно, у нас будет 10) является то, что в первый (и последний) раз в этой книге мы не делаем вычисления вручную, но используем компьютер. Этот анализ (как мы уже говорили) слишком трудоемкий для курса данного уровня сложности. 1. Формулировка основной и альтернативной гипотез. На самом деле здесь представлены три нулевые гипотезы (формулы 14.1а, 14.1б и 14.1в), которые утверждают, что не существует различий между средними значениями для каждого из двух факторов и что отсутствует эффект взаимодействия. Вот они. Сначала гипотеза для сложности программы: H0: µсложн = µпрост. (14.1а) Глава 14 Два лишних фактора 289 Теперь гипотеза для пола: H0: µмуж = µжен. (14.1б) И гипотеза для взаимодействия между программой и полом: H0: µсложн*муж = µсложн*жен = µпрост*муж = µпрост*жен. (14.1в) Альтернативные гипотезы, представленные формулами 14.2а, 14.2б и 14.2в, утверждают, что существует различие между средними значениями групп, а также присутствует эффект взаимодействия факторов. Вот они. Сначала гипотеза для сложности _программы: _ Теперь для пола: H1: Xсложн ≠ Xпрост. (14.2а) _ _ H1: Xмуж ≠ Xжен. (14.2б) И гипотеза для взаимодействия _ _ между программой _ _ и полом: H1: Xсложн*муж ≠ Xсложн*жен ≠ Xпрост*муж ≠ Xпрост*жен. (14.2в) 2.Выбор уровня риска (или уровня значимости, или ошибки первого рода), связанного с нулевой гипотезой. Уровень риска, или ошибки первого уровня, или уровня значимости, здесь равен 0,05. Еще раз повторим, что SPSS выдаст нам точное значение p, но используемый уровень значимости полностью зависит от решения исследователя; 3. Выбор подходящего статистического критерия. При помощи схемы, показанной на рис. 14.1, мы определили, что нам подходит многофакторный дисперсионный анализ. 4.Расчет значения статистического критерия (наблюдаемого зна­чения). Мы воспользуемся для этого SPSS. Ниже описан порядок действий для расчета. Мы возьмем приведенные выше данные, которые можно получить с вебсайта книги или из набора данных «Глава 14. Набор данных 1» (Chapter 14 Data Set 1) либо запросить их напрямую у меня по адресу: njs@ku.edu. Введите данные в Редактор данных (Data Editor) или откройте файл. Убедитесь, что каждый фактор записан в отдельном столбце, включая уровень программы, пол и потерю веса, как вы видите на рис. 14.4. 5.Нажмите Анализ (Analyze) ⇒ Общая линейная модель (General Linear Mo­ del) ⇒ ОЛМ-одномерная (Univariate), и вы увидите диалоговое окно, как на рис. 14.5. 6.Щелкните по переменной Потеря веса (Loss) и переместите ее в поле Зависимая переменная (Dependent Variable). 7.Щелкните по переменной Программа (Treatment) и переместите ее в поле Фиксированные факторы (Fixed Factor (s)). 8.Щелкните по переменной Пол (Gender) и переместите ее в поле Случайные факторы (Random Factor(s)). 9.Нажмите на Параметры (Options), отметьте галочкой Описательные статистики (Descriptive Statistics) и затем нажмите Продолжить (Continue). 10. Нажмите ОК. SPSS проведет анализ и покажет вывод, как на рис. 14.6 (вы уже видели его в этой главе). 290 Часть IV Значимая разница: применение статистики вывода Рис. 14.4 Данные из файла «Глава 14. Набор данных 1» (Chapter 14. Data Set 1) Рис. 14.5 Диалоговое окно многофакторного дисперсионного анализа Глава 14 Два лишних фактора 291 Рис. 14.6 Вывод SPSS для многофакторного дисперсионного анализа Задумались, почему вывод SPSS имеет название «Одномерный анализ дисперсии»? Мы так и знали. Ну, в терминах SPSS этот анализ смотрит только на одну зависимую, или результирующую, переменную (в данном случае потерю веса). Если бы в нашем вопросе исследования было больше одной переменной (например, еще отношение к еде), тогда это был бы «Многомерный анализ дисперсии», который не только показывает групповые различия по более чем одной зависимой переменной, но и контролирует отношения между зависимыми переменными. Подробнее об этом в главе 18. Читаем выводы SPSS Этот вывод SPSS довольно прямолинеен. Вот что у нас есть: 1)источник дисперсии (определены главные эффекты и эффект взаимодействия); 2)для каждого источника дана соответствующая сумма квадратов; 3)за ней следуют степени свободы, а затем средний квадрат, который равен сумме квадратов, поделенной на количество степеней свободы; 4)наконец, наблюдаемая величина критерия и точный уровень значимости; 5)для фактора пола результаты при печати в журнальной статье­ или рукописи будут выглядеть следующим образом: F(1,36) = 0,197, p = 0,734; 6)для фактора уровня программы результаты при печати в журнальной статье или рукописи будут выглядеть так: F(1,36) = 0,252, p = 0,704; 292 Часть IV Значимая разница: применение статистики вывода 7)для фактора взаимодействия результаты при печати в журнальной статье или рукописи будут выглядеть так: F(1,36) = 9,683, p = 0,004. Мы закончили! И единственным значимым результатом оказалось взаимодействие между полом и уровнем программы. РАСЧЕТ РАЗМЕРА ЭФФЕКТА Д ЛЯ МНОГОФАКТОРНОГО ANOVA Для расчета размера эффекта для многофакторного дисперсионного анализа применяется другая формула, но идея остается прежней. Мы все так же выносим суждение о величине наблюдаемых нами различий. Для многофакторного ANOVA этот показатель называется «омега в квадрате» и обозначается как ω2. Вот его формула: (14.3) где ω2 – это величина размера эффекта; SSмежгр – это сумма квадратов между группами; dfмежгр – это общее количество степеней свободы; MSвнутригр – это средняя сумма квадратов внутри групп; SSобщ – это скорректированная общая сумма квадратов. Пусть вас не пугает эта формула. Все термины вы уже видели в главе 13, а интерпретация полученного значения ω2 такая же, как и интерпретация других размеров эффекта, которые мы уже обсуждали. Для размера эффекта по фактору «пол» из нашего примера в самом начале главы предназначена следующая формула: В соответствии с нашими инструкциями размер эффекта, равный 0,34, указывает на большую связь. РЕАЛЬНАЯ СТАТИСТИКА Вы же видели новости: увеличивается частота определенных расстройств, возникающих в основном в детстве, таких как расстройства аутистического спектра или синдром дефицита внимания и гиперактивности (СДВГ). Это может происходить из-за изменений в критериях диагностики, а может отражать действительное увеличение количества случаев. В любом случае для рассмотрения такого диагноза необходимо тщательно оценивать определенные типы поведения и их результаты. Вот этому и посвящено данное исследо- Глава 14 Два лишних фактора 293 вание. Для изучения факторной валидности, экологической валидности и надежности пяти основанных на результатах показателей использовались меры торможения поведения в выборке из 70 трех-, четырех- и пятилетних детей. Дисперсионный анализ с 2×3 факторами, где независимыми переменными выступали пол и группа по возрасту (два фактора), показал значимые главные эффекты для пола и возраста и незначимый эффект воздействия. Некоторые показатели коррелировали с рейтингом учителя, а некоторые нет. Это позволило ученым сделать заключение, что некоторые меры торможения поведения могут быть полезны, а другие требуют дополнительного изучения. Хотите узнать больше? Найдите в интернете или библиотеке статью... Floyd R. G. & Kirby E. A. Psychometric properties of measures of behavioral inhibition with preschool-age children: Implications for assessment of children at risk for ADHD. Journal of Attention Disorders, 2001. Р. 79–91. Реальная статистика ВЫВОДЫ ПО ГЛАВЕ Теперь, когда мы закончили проверять различия между средними, приступим к изучению значимости корреляций, или отношений между двумя переменными. Выводы по главе ВРЕМЯ ПРАКТИКИ 1.В каком случае вы будете применять многофакторный, а не простой дисперсионный анализ для проверки различий между средними значениями двух или более групп? 2.Нарисуйте схему или проект факторного плана типа 2×3, для которого потребуется многофакторный дисперсионный анализ. Обязательно определите независимые и зависимые переменные. 3.На основании данных из файла «Глава 14. Набор данных 2» (Chapter 14. Data Set 2) и с помощью SPSS проведите анализ и интерпретируйте результаты для уровня выраженности боли и типа воздействия для ее облегчения. Это эксперимент типа 2×3, как тот, что вы создали в ответе на вопрос 2. 4.Используя данные из файла «Глава 14. Набор данных 3» (Chapter 14. Data Set 3), ответьте на следующие вопросы, относящиеся к анализу наличия влияния уровня стресса и пола на потребление кофеина (измеряемое количеством чашек кофе в день): а) есть ли различия в уровне потребления кофеина для групп с высоким, средним и низким уровнями стресса? Проблема 3 Проблема 4 294 Часть IV Значимая разница: применение статистики вывода б) есть ли различия между мужчинами и женщинами независимо от уровня стресса? в) есть ли какие-то эффекты взаимодействия? 5.Это вопрос на дополнительный балл. Судя по данным из файла «Глава 14. Набор данных 4» (Chapter 14. Data Set 4), можно ли сказать, что девочки показывают лучшие результаты (замеренные по шкале развития навыков от 1 до 10, где 10 – лучшее значение), чем мальчики? Если это так, то при каких условиях? 15 воюродные или Д просто хорошие друзья? Проверка отношений коэффициентом корреляции Уровень сложности: (легко – вам даже не нужно ничего считать!) В ЭТОЙ ГЛАВЕ ВЫ УЗНАЕТЕ, КАК: проверить значимость коэффициента корреляции; интерпретировать коэффициент корреляции; различить значимость и существенность (снова!); анализировать корреляционные данные и понимать результаты анализа. ПРЕДИСЛОВИЕ К ПРОВЕРКЕ КОЭФФИЦИЕНТА КОРРЕЛЯЦИИ В статье, посвященной исследованию отношения между качеством брака и качеством взаимоотношений между родителем и ребенком, Дэниел Шек (Daniel Shek) говорит нам, что есть по меньшей мере два варианта. Во-первых, плохой брак может усилить связь между родителем и ребенком. Это происходит из-за того, что не удовлетворенные своим браком родители могут замещать своими детьми отсутствие эмоционального вознаграждения в браке. Во-вторых, в соответствии с гипотезой побочного эффекта плохой брак может нарушить детскородительские отношения, создавая дополнительные сложности для воспитания детей. Шек в течение двух лет изучал связь между качеством брака и детско-родительскими отношениями в 378 китайских семейных парах. Он обнаружил, что более высокий уровень качества брака был связан с более высоким уровнем детско-родительских отношений. Это было выявлено как для параллельных (происходящих в одно время), так и для лонгитюдных (совершаемых через какое-то время) Введение в главу 15 Проверка коэффициента корреляции 295 296 Часть IV Значимая разница: применение статистики вывода измерений. Он также обнаружил, что прочность отношений между родителями и детьми была одинакова и для матерей, и для отцов. Это явный пример того, как применение коэффициента корреляции дает нам необходимую информацию о том, связаны ли наборы переменных между собой. Шек рассчитал целую кучу корреляций для матерей и отцов в период 1 и период 2, и все это с одной целью – проверить, есть ли значимая корреляция между переменными. Помните, что это ничего не говорит о причинности данной связи, а только о том, что переменные соотносятся друг с другом. Хотите узнать больше? Найдите в интернете или библиотеке статью… Shek D. T. L. Linkage between marital quality and parent-child relationship: A longitudinal study in the Chinese culture. Journal of Family Issues, 1998. Р. 687–704. ПУТЬ К МУДРОСТИ И ЗНАНИЮ Выбор подходящего статистического критерия Вот как вы можете использовать схему для выбора подходящего статистического критерия – проверки коэффициента корреляции. Следуйте выделенной очередности шагов на рис. 15.1. 1. Изучается связь между переменными, а не различия между группами. 2. Используются только две переменные. 3.Подходящий статистический критерий – это t-критерий для коэффициента корреляции. РАСЧЕТ СТАТИСТИЧЕСКОГО КРИТЕРИЯ Определение критического значения А вот то, что вам, наверное, будет приятно прочитать: коэффициент корреляции может выступать в качестве собственного критерия проверки. Это существенно все упрощает, потому что вам не нужно рассчитывать никакие критерии, а оценка значимости становится совсем простой. Давайте возьмем для примера данные из табл. 15.1, которые показывают связь между двумя переменными: качеством брака и качеством детско-родительских отношений. Эти гипотетические (придуманные) значения могут на ходиться в диапазоне от 0 до 100. Чем выше показатель, что брак счастливее, тем лучше отношения с детьми. Глава 15 Двоюродные или просто хорошие друзья? 297 Рис. 15.1 Проверка, что нам подходит проверка коэффициента корреляции по t-критерию Вы изучаете отношения между переменными или различия между группами из одной или нескольких переменных? Вы изучаете разницу между одной выборкой и генеральной совокупностью? Я изучаю отношения между переменными Я изучаю различия между группами из одной или нескольких переменных Одни и те же участники оцениваются несколько раз? С каким количеством переменных вы работаете? Одновыборочный Z-критерий Да Нет С каким количеством групп вы работаете? С каким количеством групп вы работаете? Две переменные Более двух переменных Две группы Больше двух групп Две группы Больше двух групп t-критерий значимости коэффициента корреляции Регрессия, факторный анализ или канонический анализ t-критерий для зависимых выборок Дисперсионный анализ повторных измерений t-критерий для независимых выборок Простой дисперсионный анализ Таблица 15.1 Качество брака и отношений с детьми Качество брака 76 81 78 76 76 78 76 78 98 88 76 66 44 67 65 59 87 77 79 85 68 Качество детско-родительских отношений 43 33 23 34 31 51 56 43 44 45 32 33 28 39 31 38 21 27 43 46 41 Продолжение ⇒ 298 Часть IV Значимая разница: применение статистики вывода Качество брака 76 77 98 98 99 98 87 67 78 Качество детско-родительских отношений 41 48 56 56 55 45 67 54 33 Вы можете применить формулу 5.1 из главы 5, чтобы рассчитать коэффициент корреляции Пирсона. Когда вы этого сделаете, то обнаружите, что r = 0,437. А теперь давайте пройдем по всем этапам настоящей проверки значимости и принятия решения о смысле этой величины. Если вам нужно освежить в памяти знания о корреляции, вернитесь к главе 5. Вот те знаменитые восемь шагов и вычисление значения t-кри­ терия: 1. Формулировка основной и альтернативной гипотез. Нулевая гипотеза утверждает отсутствие связи между качеством брака и качеством отношений между родителями и детьми. Альтернативная гипотеза является двусторонней и ненаправленной, потому что она утверждает наличие взаимосвязи между двумя переменными, но не направление этой связи. Помните, что корреляция может быть положительной (или прямой) и отрицательной (или обратной), и главной характеристикой коэффициента корреляции является его абсолютная величина или размер, а не знак (положительный или отрицательный). Нулевая гипотеза записана в формуле 15.1: H0: ρxy = 0. (15.1) H1: rxy ≠ 0. (15.2) Греческая буква ρ, или «ро», обозначает оценку коэффициента корреляции для генеральной совокупности. Альтернативная гипотеза (записанная в формуле 15.2) утверждает, что между двумя значениями существует связь и что коэффициент корреляции между ними отличается от 0: 2.Выбор уровня риска (или уровня значимости, или ошибки первого рода), связанного с нулевой гипотезой. Уровень риска, или ошибки первого уровня, или уровня значимости, равен 0,05. 3 и 4. Выбор подходящего статистического критерия. При помощи схемы, показанной на рис. 15.1, мы определили, что нам подходит t-критерий для коэффициента корреляции. В данном случае нам не нужно вычислять значение статистического критерия, потому что значение r для выборки (rxy = 0,437) и является для нас статистическим критерием. Глава 15 Двоюродные или просто хорошие друзья? 5.Определение значения, необходимого для отклонения нулевой гипотезы, при помощи соответствующей таблицы критических значений для конкретного критерия. В табл. B.4 даны критические значения для коэффициента корреляции. Сначала мы должны определить степени свободы (df ), которые приближаются к размеру выборки. Для данного статистического критерия количество степеней свободы равно n – 2, или 30 – 2 = 28, где n равно количеству пар, использованных для расчета коэффициента корреляции. Это степени свободы именно для этого статистического критерия, у другого критерия они не обязаны быть такими же. Взяв это количество (28), уровень риска, который вы готовы принять (0,05), и двусторонний критерий (поскольку у альтернативной гипотезы нет направления), находим критическое значение: 0,381 (используя df = 25, т. к. это более консервативный вариант, чем 30). Итак, на уровне значимости 0,05 и с 28 степенями свободы для двустороннего критерия значение, необходимое для отклонения нулевой гипотезы, равно 0,381; 6. Сравнение наблюдаемого значения с критическим. Наблюдаемое значение равно 0,437, а критическое значение для отклонения нулевой гипотезы о том, что 2 переменные не имеют связи, равно 0,381; 7 и 8. Время решать! Если наблюдаемое значение (или величина статистического критерия) оказывается более крайним, чем критическое (или табличное) значение, то нулевую гипотезу нельзя принять. Если наблюдаемое значение не превосходит критического, то нулевая гипотеза дает самое привлекательное объяснение. В данном случае наблюдаемое значение (0,437) действительно превосходит критическое (0,381) – оно является достаточно крайним, чтобы мы могли сказать, что связь между двумя переменными (качеством брака и качеством детско-родительских отношений) действительно возникла благодаря чемуто иному, чем случайность. Односторонний или двусторонний критерий? Довольно легко объяснить разницу между односторонней и двусторонней проверками, когда речь идет о различиях между средними. И возможно, вам будет легко понять смысл двусторонней проверки коэффициента корреляции (когда проверяется любое отклонение от нуля). Но что насчет одностороннего критерия? На самом деле это точно так же просто. Направленная альтернативная гипотеза здесь будет утверждать наличие связи, которая либо положительна (прямая), либо отрицательна (обратная). Так, например, если вы думаете, что есть положительная корреляция между двумя переменными, тогда критерий будет односторонним. Если вы выдвигаете гипотезу об отрицательной корреляции между двумя переменными, то критерий тоже будет односторонним. Только тогда, когда вы не предсказываете направления связи, критерий будет двусторонним. Понятно? 299 300 Часть IV Значимая разница: применение статистики вывода Ладно, мы немного сжульничали. На самом деле можно рассчитать t-критерий (такой же, как для сравнения средних величин) для значимости коэффициента корреляции. Формула не сложнее тех, с которыми уже имели дело, но вы ее здесь не увидите. Дело в том, что какие-то умные статистики рассчитали критические значения r для разных размеров выборки (и, соответственно, степеней свободы) для одно- и двустороннего критерия с различным уровнем риска (0,01, 0,05), как вы видите в табл. B.4. Но если вы читаете научный журнал и видите, что корреляция была проверена с помощью t-критерия, то теперь вы будете знать, почему. Так как мне интерпретировать r(28) = 0,437, p < 0,05? zz r обозначает использованный статистический критерий; zz 28 – это количество степеней свободы; zz 0,437 – это наблюдаемое значение, рассчитанное по формуле, которую мы показывали вам в главе 5; zz p < 0,05 (действительно важная часть этого короткого выражения) обозначает: для любой проверки нулевой гипотезы существует меньше 5 % вероятности, что связь между двумя переменными возникла только из-за случайности. Поскольку мы выбрали 0,05 в качестве критерия большей привлекательности альтернативной, а не нулевой гипотезы, то заключаем, что между двумя переменными есть значимая взаимосвязь. Причины и связи (снова!) Поиграем в корреляцию! Основы корреляции Наверное, вы думаете, что уже достаточно об этом слышали, но это настолько важно, что мы не устаем это подчеркивать. Так что подчеркнем еще раз. То, что две переменные связаны друг с другом (как в предыдущем примере), никак не означает, что одна из них является причиной для другой. Другими словами, наличие потрясающего брака высочайшего качества никоим образом не гарантирует, что детско-родительские отношения также окажутся на высоте. Эти две переменные могут быть связаны, потому что какие-то черты характера, которые, возможно, делают человека хорошим супругом, также делают его хорошим родителем (терпение, понимание, готовность жертвовать своими интересами), но, конечно, возможно, что кто-то будет хорошим мужем или женой, но у него окажутся ужасные отношения с собственными детьми. Помните пример про преступность и мороженое из главы 5? Здесь то же самое. Просто факт того, что какие-то вещи связаны друг с другом и имеют что-то общее, не означает автоматического наличия причинно-следственной связи между ними. Глава 15 Двоюродные или просто хорошие друзья? 301 Коэффициенты корреляции применяются для различных целей, и вы, вероятно, наткнетесь на научные статьи, в которых они были использованы для оценки надежности теста. Но вы уже все это знаете, потому что прочитали главу 6 и освоили весь материал! В главе 6, как вы можете помнить, говорили о таких коэффициентах надежности, как ретестовая надежность (корреляция показателя, измеренного в разные моменты времени), надежность параллельных форм (корреляция между результатами, полученными при использовании разных форм тестирования) и надежность внутренней согласованности (корреляция между заданиями теста). Коэффициенты корреляции также стандартно используются в более продвинутых статистических методиках, например тех, которые мы обсудим в главе 18. Значимость против существенности (опять и снова!) В главе 5 мы рассмотрели важность применения коэффициента детерминации для понимания, имеет ли смысл коэффициент корреляции. Возможно, вы помните, что возводите коэффициент корреляции в квадрат, чтобы определить, сколько процентов дисперсии одной переменной связано с дисперсией другой переменной. В главе 9 мы также прошлись по общему вопросу сравнения значимости и существенности. Но мы должны затронуть и обсудить эту тему еще раз. Даже если коэффициент корреляции оказался значимым (как в примере в данной главе), это не означает, что доля рассеяния, за которую он отвечает, окажется существенной. Например, в данном случае коэффициент детерминации для простого значения корреляции Пирсона 0,437 равен 0,190. Это говорит о том, что 19 % дисперсии объясняется связью переменных, а подавляющие 81 % – нет. Это оставляет большой простор для сомнений, не так ли? Итак, даже если мы знаем, что существует положительная связь между качеством брака и качеством детско-родительских отношений и они склонны «идти рука об руку», относительно малая корреляция, равная 0,437, указывает, что в этой связи участвует множество других факторов, которые также могут быть важны. Так что в статис­ тике совы – это часто не то, чем они кажутся. ВЫЧИСЛЕНИЕ КОЭФФИЦИЕНТА КОРРЕЛЯЦИИ ПРИ ПОМОЩИ SPSS ( СНОВА ) Здесь мы воспользуемся данными из файла «Глава 15. Набор данных 1» (Chapter 15. Data Set 1), где приведены два показателя качества: один – для качества брака (время, проведенное вместе, где 1 – меньшая оценка качества, чем 3), другой – для детско-родитель- Применение SPSS 302 Часть IV Значимая разница: применение статистики вывода ских отношений (сила привязанности, где чем выше показатель, тем больше привязанность). 1.Введите данные Редактор данных (Data Editor) или просто откройте файл. Проверьте, что у вас в таблице два столбца, по одному для каждой переменной. На рис. 15.2 эти столбцы имеют названия Qual_Marriage (Качество брака) и Qual_PC (Ка­ чество детско-родительских отношений). Рис. 15.2 Данные из файла «Глава 15. Набор данных 1» (Chapter 15. Data Set 1) 2.Нажмите на Анализ (Analyze) ⇒ Корреляции (Correlate) ⇒ Парные (Bivariate), и вы увидите диалоговое окно Парные корреляции (Bivariate Correlations), как на рис. 15.3. Рис. 15.3 Диалоговое окно Парные корреляции (Bivariate Correlations) Глава 15 Двоюродные или просто хорошие друзья? 303 3.Дважды щелкните по переменной Qual_Marriage (Качество брака), чтобы переместить ее в поле Переменные (Variables), а затем дважды кликните по переменной Qual_PC (Качество детско-родительских отношений), чтобы сделать то же самое. 4.Поставьте галочку напротив Пирсона (Pearson) и Двусторонний (Two-tailed). 5.Нажмите ОК. Вывод SPSS показан на рис. 15.4. Рис. 15.4 Вывод SPSS для проверки значимости коэффициента корреляции Читаем выводы SPSS Этот вывод SPSS довольно простой и понятный. Корреляция между интересующими нас двумя переменными равна 0,081, что значимо на уровне 0,637. Или скажем еще (гораздо) точнее: вероятность совершить ошибку первого рода равна 0,637. Это означает, что вероятность отклонить нулевую гипотезу, когда она верна (о том, что две переменные не связаны), составляет 63,7 % – пугающе высокие и очень неприятные шансы! Похоже, что качество родительства и качество брака (по меньшей мере, для этого набора данных) не связаны между собой. РЕАЛЬНАЯ СТАТИСТИКА Учитывая внимание к социальным сетям, интересно посмотреть, как исследователи оценивают «социальное» благополучие студентов колледжа, которые живут и учатся за пределами Соединенных Штатов. Это исследование изучало связь между пятью параметрами личности и социальной успешностью у 236 студентов, поступивших в Университет Тегерана. Корреляции показали, что некоторые параметры личности, такие как невротизм, были отрицательно связаны с общественным признанием, общественным вкладом и соответствием обществу. Сознательность имела положительную связь с общественным вкладом. Открытость была положительно связана с общественным вкладом, а соответствие обществу и доброжелательность были связаны с общественным признанием и общест­ 304 Реальная статистика Часть IV Значимая разница: применение статистики вывода венным вкладом. Студенты мужского пола имели более высокие показатели благополучия, чем женщины-студентки. Исследователи обсудили эти результаты в свете культурных различий между странами и общей связи между чертами характера и благополучием. Интересная тема! Хотите узнать больше? Найдите в интернете или библиотеке статью... Joshanloo M., Rastegar P. & Bakhshi A. The Big Five personality domains as predictors of social wellbeing in Iranian university students. Journal of Social and Personal Relationships, 2012. Р. 639–660. ВЫВОДЫ ПО ГЛАВЕ Выводы по главе Корреляция – это мощный инструмент, указывающий на направленность связи и помогающий понять, что общего друг с другом имеют два разных результата. Помните, что корреляция работает только тогда, когда вы говорите о связи, но не о причинно-следственных отношениях. ВРЕМЯ ПРАКТИКИ Проблема 2 1.Используйте табл. B.4 в приложении B, чтобы определить значимость корреляции с учетом следующих данных. Как бы вы интерпретировали результаты: а) корреляция между скоростью и силой у 20 женщин равна 0,567. Проверьте эти результаты на уровне значимости 0,01 при помощи одностороннего критерия; б) корреляция между количеством правильных ответов на контрольной по математике и временем, которое потребовалось для ее написания, равна –0,45. Проверьте, значима ли эта корреляция для 80 детей на уровне значимости 0,05. Выберите одно- или двусторонний критерий и объясните свой выбор; в) корреляция между количеством друзей и средним баллом аттестата у 50 подростков равна 0,37. Значимо ли это на уровне 0,05 для двустороннего критерия? 2.Используйте данные из файла «Глава 15. Набор данных 2» (Chapter 15. Data Set 2) для ответа на вопросы ниже. Проведите анализ вручную или при помощи SPSS: а) рассчитайте корреляцию между мотивацией и средним баллом аттес­тата; б) проверьте значимость коэффициента корреляции на уровне 0,05 для двустороннего критерия; в) правда или ложь? Чем больше ваша мотивация, тем лучше вы будете учиться. Какой ответ вы выбрали и почему? Глава 15 Двоюродные или просто хорошие друзья? 3.Используйте данные из файла «Глава 15. Набор данных 3» (Chapter 15 Data Set 3) для ответа на вопросы ниже. Проведите анализ вручную или при помощи SPSS: а) рассчитайте корреляцию между доходом и уровнем образования; б) проверьте значимость этой корреляции; в) какие аргументы вы можете привести в поддержку утверждения, что «более низкий уровень образования приводит к более низким доходам»? 4.Используйте данные из файла «Глава 15. Набор данных 4» (Chapter 15. Data Set 4) для ответа на вопросы ниже. Проведите анализ вручную или при помощи SPSS: а) значимость коэффициента корреляции между количеством часов учебы и оценкой на уровне 0,05 для двустороннего критерия; б) интерпретируйте эту корреляцию. Что вы скажете о связи между количеством часов, потраченных на учебу, и оценкой за контрольную; в) какая доля дисперсии является общей для двух переменных; г) как вы интерпретируете результаты? 5.Было проведено исследование взаимосвязи между потреблением кофе и уровнем стресса в группе из 50 студентов старших курсов. Корреляция составила 0,373, значимость проверялась на уровне 0,01 для двустороннего критерия. Во-первых, значима ли корреляция? Во-вторых, что не так в следующем утверждении: «На основании собранных в исследовании данных и нашего тщательного анализа мы пришли к выводу, что чем меньше кофе вы пьете, тем меньше стресса будете испытывать»? 6.Используйте данные из табл. 15.2, чтобы ответить на вопросы ниже. Сделайте эти расчеты вручную: а) рассчитайте корреляцию между возрастом (в месяцах) и количеством известных ребенку слов; б) проверьте значимость корреляции на уровне 0,05; в) вернитесь к главе 5, чтобы вспомнить все, что вы узнали о корреляции, и интерпретируйте результаты. Таблица 15.2 Возраст детей и количество слов Возраст (мес.) 12 15 9 7 18 24 Кол-во известных слов 6 8 4 5 14 20 Продолжение ⇒ 305 Проблема 4 306 Часть IV Значимая разница: применение статистики вывода Возраст (мес.) Кол-во известных слов 15 16 21 15 7 6 18 17 7.Обсудите мысль о том, что факт наличия связи между двумя вещами не озна­чает, что одна из них обязательно вызывает другую. Приведите пример (отличный от мороженого и преступности!). 8.Файл «Глава 15. Набор данных 4» (Chapter 15. Data Set 4) содержит четыре переменные: zz возраст (лет); zz размер обуви (маленький, средний и большой в виде 1, 2 и 3); zz интеллект (измеренный стандартизованным тестом); zz уровень образования (в годах обучения). Какие переменные имеют значимую корреляцию, и, что более важно, какие корреляции имеют смысл? 16 Как предсказать, кто выиграет Суперкубок Применение линейной регрессии Уровень сложности: (сложно по максимуму!) В ЭТОЙ ГЛАВЕ ВЫ УЗНАЕТЕ: как работают предсказания и как можно их использовать в социальных и поведенческих науках; как и почему линейные регрессии предсказывают одну переменную на осно­вании другой; как оценить точность предсказаний; как работает множественная регрессия и зачем она нужна. ПРЕДИСЛОВИЕ К ЛИНЕЙНОЙ РЕГРЕССИИ В новостях вы нередко слышите об обеспокоенности проблемой ожирения и его влияния на работу и повседневную жизнь. Ряд исследователей из Швеции заинтересовался, насколько хорошо нарушение способности к передвижению и/или ожирение предсказывает напряжение на работе и может ли социальная поддержка на работе изменить эту связь. В исследовании участвовало более 35 000 человек, и различия в средних значениях напряжения на работе были оценены с помощью линейной регрессии, которая и находится в центре внимания этой главы. Результаты показали, что степень ограничения в передвижении действительно предсказывала напряжение на работе, а социальная поддержка на рабочем месте существенно изменила связь между напряжением на работе, нарушением способности к передвижению и ожирением. Введение в главу 16 307 308 Часть IV Значимая разница: применение статистики вывода Хотите узнать больше? Найдите в интернете или библиотеке статью: Norr­back M., De Munter J., Tynelius P., Ahlstrom G. and Rasmussen F. The association of mobility disability, weight status and job strain: A cross-sectional study. Scandinavian Journal of Public Health, 2016. Р. 311–319. ВООБЩЕ, ЧТО ТАКОЕ ПРЕДСКАЗАНИЕ? Вводим в курс дела. Вы можете не только рассчитать степень, в которой две переменные связаны между собой (путем вычисления коэффициента корреляции, как мы делали в главе 5), но и использовать эти корреляции для того, чтобы предсказать значение одной переменной на основании значения другой. Это очень частный случай применения корреляций и мощный инструмент для исследователей в области социальных и поведенческих наук. Основная идея состоит в том, чтобы взять набор ранее собранных данных (например, про переменные X и Y), рассчитать корреляцию этих переменных между собой, а затем использовать эту корреляцию и знания про X для предсказания Y. Звучит сложно? На самом деле нет, особенно тогда, когда вы увидите иллюстрации. Например, исследователь собирает данные о среднем балле в школьном аттестате и о среднем балле за первый курс колледжа у 400 студентов первого года обучения. Он рассчитывает корреляцию между двумя переменными. Затем использует методику, о которой вы узнаете дальше в этой главе, для того чтобы взять новый набор данных о среднем балле аттестата и (зная связь между средним баллом аттестата и средним баллом на первом курсе колледжа по предыдущей выборке студентов) предсказать, каким будет средний балл на первом курсе у новой группы из 400 студентов. Довольно находчиво, а? Вот еще один пример. Группа учителей хочет узнать, насколько хорошо работает практика оставления учеников на второй год, т. е. показывают ли дети, которых оставили еще на один год в детском саду (и не пустили в первый класс), лучшие результаты в первом классе, когда они туда попадают? Эти учителя знают корреляцию между дополнительным годом в саду и успеваемостью в первом классе из опыта прошлых лет. Они могут применить ее к новому набору учеников и предсказать результаты обучения в первом классе на основании достижений ребенка в садике. Как работает регрессия? Собираются данные о прошлых событиях (например, о существующей связи между двумя переменными), а затем они применяются к будущему событию при условии знания только одной переменной. Это легче, чем вы думаете. Глава 16 Как предсказать, кто выиграет Суперкубок 309 Чем выше абсолютное значение коэффициента корреляции, независимо от того, прямая она или обратная (положительная или отрицательная), тем точнее будет предсказание одной переменной по другой на основании корреляции. Это так, потому что чем больше общего у двух переменных, тем больше вы знаете о второй переменной, основываясь на первой. И вы можете уже догадаться, что когда корреляция идеальна (+1,0 или –1,0), то и предсказание тоже будет идеально. Если rxy = −1,0 или +1, то при условии знания значения X вам также известно и точное значение Y. Точно так же если rxy = −1,0 или +1, то при условии знания значения Y вам известно и точное значение X. Оно хорошо работает в обе стороны. ЛОГИКА ПРЕДСКАЗАНИЯ Прежде чем мы перейдем, собственно, к расчетам и покажем вам, как использовать корреляцию для предсказаний, давайте разберемся, как и почему это работает. Дальше мы будем рассматривать пример предсказания среднего балла в колледже на основании среднего балла аттестата. Предсказание – это расчет будущих результатов на основании знания имеющихся. Когда мы хотим предсказать одну переменную по другой, нам сначала нужно вычислить корреляцию между ними. В табл. 16.1 приведены данные, которыми мы будем пользоваться в этом примере. Рисунок 16.1 показывает диаграмму рассеяния (см. главу 5) двух переменных, для которых ведутся расчеты. Таблица 16.1 Средний балл в аттестате и на первом курсе колледжа Средний балл в аттестате 3,50 2,50 4,00 3,80 2,80 1,90 5,20 3,70 2,70 3,30 Средний балл на первом курсе 3,30 2,20 3,50 2,70 3,50 2,00 3,10 3,40 1,90 3,70 Корреляции и причинноследственная связь Корреляции и причинноследственная связь еще раз! Часть IV 310 Рис. 16.1 Значимая разница: применение статистики вывода Диаграмма рассеяния для среднего балла в школе и среднего балла в колледже Средний балл в колледже (Y) 4,0 3,5 3,0 2,5 2,0 1,5 1,5 2,0 2,5 3,0 3,5 4,0 Средний балл в школе (X) Для того чтобы предсказать средний балл в колледже по среднему баллу школьного аттестата, мы должны создать уравнение регрессии и нарисовать, опираясь на него, то, что называется прямая регрессии. Прямая регрессии отображает наши лучшие догадки о том, какое значение переменной Y (среднего балла в колледже) будет предсказано значением переменной X (средним баллом в школе). Для всех данных из табл. 16.1 прямая регрессии была нарисована так, чтобы получилась минимальная сумма расстояний между ней и каждой точкой для предсказываемой переменной (Y). Скоро вы узнае­те, как рисовать эту прямую, показанную на рис. 16.2. Что показывает прямая регрессии, которую вы видите на рис. 16.2? Во-первых, это регрессия переменной Y по переменной X. Другими словами, Y (средний балл в колледже) предсказывается по X (среднему баллу в аттестате). Эта линия регрессии называется также линией лучшего соответствия. Эта прямая соответствует данным, потому что она дает минимальное расстояние между линией регрессии и каждой отдельной точкой. Например, если вы возьмете все эти точки и попытаетесь найти прямую, которая лучше всего соответствовала бы им всем, то у вас получится линия, которую вы видите на рис. 16.2. Глава 16 Рис. 16.2 Как предсказать, кто выиграет Суперкубок 311 Прямая регрессии для среднего балла в колледже (Y) и среднего балла в школе (X) Средний балл в колледже (Y) 4,0 3,5 3,0 2,5 Прямая регрессии Y по X 2,0 1,5 1,5 2,0 2,5 3,0 3,5 4,0 Средний балл в школе (X) Во-вторых, это прямая, которая показывает нам наши лучшие догадки (о том, каким может быть средний балл в колледже при определенном среднем балле аттестата). Например, если средний балл аттестата – 3,0, тогда средний балл в колледже будет составлять примерно (помните, что это предсказание на глазок) 2,8. Посмотрите на рис. 16.3, чтобы понять, как мы это сделали. Мы нашли значение предсказывающей переменной (3,0) на оси x, построили перпендикуляр от оси x к прямой регрессии и провели горизонтальную линию к оси y, в результате чего оценили прогнозное значение для Y. В-третьих, расстояние между каждой точкой данных и прямой регрессии является ошибкой предсказания – прямым отражением корреляции между двумя переменными. Например, если вы посмот­рите на точку данных (3,3, 3,7), отмеченную на рис. 16.4, то увидите, что она находится над прямой регрессии. Расстояние между этой точкой и прямой и есть ошибка в предсказании, как указано на рис. 16.4, потому что если бы предсказание было идеальным, то где бы оказались все предсказанные значения? Прямо на прямой регрессии. Часть IV 312 Рис. 16.3 Значимая разница: применение статистики вывода Приближенная оценка среднего балла в колледже (Y) при заданном среднем балле в школе (X) Средний балл в колледже (Y) 4,0 3,5 3,0 Предсказание Y при X = 3,0 2,5 2,0 1,5 1,5 2,0 2,5 3,0 3,5 4,0 Средний балл в школе (X) Рис. 16.4 Предсказания редко бывают идеальны: оценка ошибки предсказания 4,0 Средний балл в колледже (Y) Х = 3,3; Y = 3,7 Ошибка в предсказании 3,5 3,0 2,5 2,0 1,5 1,5 2,0 2,5 3,0 Средний балл в школе (X) 3,5 4,0 Глава 16 Как предсказать, кто выиграет Суперкубок 313 В-четвертых, если бы корреляция была идеальная, все точки данных выстроились бы вдоль линии с наклоном 45°, при этом прямая регрессии проходила бы через каждую точку (о чем мы уже сказали в третьем пункте). При наличии прямой регрессии мы можем с ее помощью предсказывать любой будущий результат. Именно этим мы прямо сейчас и займемся – создадим прямую и затем сделаем некоторые предсказания. РИСУЕМ ЛУЧШУЮ ПРЯМУЮ В МИРЕ ( ПО ВАШИМ ДАННЫМ ) О предсказании проще всего думать как об определении значения одной переменной (которую мы будем называть Y – результирующей, или зависимой, переменной) на основании значения другой переменной (которую мы будем называть X – предсказывающей, или независимой, переменной). Мы определяем, насколько хорошо X может предсказывать Y, путем создания прямой регрессии, о которой только что упоминали. Эта прямая строится по уже собранным данным. Затем получившее­ ся уравнение используется для предсказания значений для новых значений X, независимой переменной. Формула 16.1 представляет собой общую формулу для прямой регрессии, которая может показаться вам знакомой. Вероятно, вы сталкивались с чем-то подобным на уроках математики в школе или колледже. Это формула для любой прямой: Y ′ = bX + a, (16.1) где Y ′ – это прогнозное значение Y, основанное на известном значении X; b – это наклон, или направление, прямой; a – это точка, в которой прямая пересекает ось Y. Давайте возьмем все те же данные из табл. 16.1 и добавим к ним некоторые расчеты, которые нам могут понадобиться. В этой таблице мы видим, что: zz ∑X, или сумма всех значений X, равна 31,4; zz ∑Y, или сумма всех значений Y, равна 29,3; zz ∑X 2, или сумма квадратов всех значений X, равна 102,5; zz ∑Y 2, или сумма квадратов всех значений Y, равна 89,99; zz ∑XY, или сумма произведений X и Y, равна 94,75. Для расчета наклона регрессии (коэффициента b в уравнении прямой) используется формула 16.2: (16.2) Рисуем прямую регрессии 314 Часть IV Значимая разница: применение статистики вывода Таблица 16.2 Данные для расчета уравнения регрессии ИТОГО X 3,50 2,50 4,00 3,80 2,80 1,90 5,20 3,70 2,70 3,30 31,4 Y 3,30 2,20 3,50 2,70 3,50 2,00 3,10 3,40 1,90 3,70 29,3 X2 12,25 6,25 16,00 14,44 7,84 3,61 10,25 13,69 7,29 10,89 102,50 Y2 10,89 4,84 12,25 7,29 12,25 4,00 9,61 11,56 3,61 13,69 89,99 XY 11,55 5,50 14,00 10,26 9,80 3,80 9,92 12,58 5,13 12,21 94,75 В формуле 16.3 вы можете видеть расчет значения b, наклона прямой: (16.3) Для расчета точки, в которой прямая пересекает ось y (коэффициента a в уравнении прямой), применяется формула 16.4: (16.4) В формуле 16.5 вы можете видеть расчет значения a, точки пересечения для прямой: (16.5) Если мы вернемся к уравнению прямой (Y = bX + a) и подставим в него значения a и b, то получим итоговое уравнение регрессии: Y ′ = 0,704X + 0,719. Почему Y ′, а не просто обычный Y? Как вы помните, мы используем X, чтобы предсказать значение Y, и Y ′, чтобы обозначить предсказываемое, а не фактическое значение Y. Теперь, когда у нас есть уравнение, что мы будем с ним делать? Предсказывать Y, конечно. Скажем, например, что средний школьный балл равен 2,8 (или X = 2,8). Если мы подставим 2,8 в уравнение, то получим следующий результат: Y ′ = 0,704×2,8 + 0,719 = 2,69. Глава 16 Как предсказать, кто выиграет Суперкубок Итак, 2,69 – это прогнозное значение Y (или Y ′), при условии что X равен 2,8. Теперь мы можем легко и быстро рассчитать предсказываемое значение Y для любого значения X. 315 Линейная регрессия Вы можете использовать эту формулу и известные значения, чтобы рассчитывать прогнозные значения. В основном именно об этом мы и говорили. Но вы также можете нарисовать прямую регрессии, чтобы посмотреть, насколько хорошо значения (которые вы пытаетесь предсказать) в самом деле соответствуют данным, на основании которых вы их предсказываете. Посмотрите еще раз на рис. 16.2 – диаграмму рассеяния для данных по оценкам в школе и колледже. Она включает в себя и линию регрессии, которую также называют линией тренда. Как мы получили эту прямую? Легко. Мы использовали навыки создания графиков из главы 5, чтобы нарисовать диаграмму, а затем выбрали Добавить линию аппроксимации (Add Fit Line) в Редакторе диаграмм (Chart Editor) в SPSS. Уф! Готово! Вы можете видеть, что тренд положителен (прямая имеет положительный наклон) и что корреляция равна 0,6835 (очень положительна). Вы также можете видеть, что точки данных не лежат на прямой, но находятся довольно близко к ней, что указывает на относительно небольшой размер ошибки. Не все линии, которые лучшим образом соответствуют множеству точек данных, являются прямыми. Скорее, они будут криволинейными, так же как вы можете иметь криволинейную связь между своими переменными, как мы обсуждали в главе 5. Например, соотношение между волнением и результатом таково, что когда люди совсем не волнуются или очень сильно волнуются, их результаты оказываются не самыми хорошими. Если уровень волнения у них средний, тогда результаты могут быть гораздо лучше. Отношение между этими двумя переменными криволинейно, и предсказание Y на основе X учитывает этот факт. НАСКОЛЬКО ХОРОШИ ВАШИ ПРЕДСКАЗАНИЯ? Как можно измерить качество проделанной нами работы по предсказанию одного результата на основании другого? Мы знаем, что чем выше абсолютная величина корреляции между двумя переменными, тем лучше предсказание. В теории это замечательно. Но на практике мы также можем посмотреть после расчета формулы регрессии на разницу между прогнозным значением (Y’) и фактическим значением (Y). Например, если формула регрессии Y ′ = 0,704X + 0,719, то предсказанное значение Y (или Y ′) для значения X = 2,8 – это 0,704×2,8 + 0,719, или 2,69. Мы знаем, что действительное значение Y, соответствую- 316 Часть IV Значимая разница: применение статистики вывода щее этому значению X, – это 3,5 (из набора данных в табл. 16.1). Разница между 3,5 и 2,39, или 0,81, называется ошибкой предсказания. Еще один показатель ошибки, которым вы можете пользоваться,– это коэффициент детерминации (см. главу 5), который показывает процент снижения ошибки в отношениях между переменными. Например, если корреляция между двумя переменными равна 0,4, а коэффициент детерминации – 16 % (или 0,42), то снижение ошибки равно 16 % (поскольку изначально мы подозреваем, что связь между двумя переменными начинается с ошибки в 0 или 100 % (полное отсутствие предсказательной ценности)). Если мы возьмем все эти разности, то сможем рассчитать среднюю величину, на которую каждая точка данных отличается от предсказанного значения, или стандартную ошибку оценки. Это что-то вроде стандартного отклонения, которое отражает вариабельность вдоль линии регрессии. Это значение говорит нам о размере неточности в наших оценках. Как вы можете ожидать, чем выше корреляция между двумя величинами (и чем лучше предсказание), тем ниже будет эта стандартная ошибка оценки. Фактически если корреляция между двумя переменными идеальна (равна или +1 или –1), стандартная ошибка оценки равна нулю. Почему? Потому что если предсказание идеально, то все фактические точки данных попадают на прямую регрессии, при этом нет никакой ошибки в оценке Y на основании X. Предсказываемая Y ′, или зависимая переменная, не всегда будет непрерывной, такой как рост, результаты теста или развитость навыков решения проблем. Она также может быть категориальной переменной, такой как «допуск/недопуск», «Уровень А / Уровень Б» или «Социальный класс 1 / Социальный класс 2». Значение, которое используется в предсказании, «кодируется» как 1 или 2, а затем применяется в том же самом уравнении. РАСЧЕТ ПРЯМОЙ РЕГРЕССИИ ПРИ ПОМОЩИ SPSS Давайте воспользуемся SPSS для расчета прямой регрессии, которая предсказывает Y ′ на основании X. Возьмем данные из файла «Глава 16. Набор данных 1» (Chapter 16. Data Set 1). Мы будем использовать количество часов тренировки для предсказания тяжести травм, которые может получить человек, играющий в футбол. В этом наборе данных две переменные (табл. 16.3). Глава 16 Как предсказать, кто выиграет Суперкубок Таблица 16.3 Переменная Тренировки (X) Травмы (Y) 317 Переменные из файла «Глава 16. Набор данных 1» (Chapter 16. Data Set 1) Определение Количество силовых тренировок в неделю, в часах Тяжесть травм по шкале от 1 до 10 Вот список действий для расчета регрессии, которую мы обсуждали в этой главе. Следуйте ему и сделайте это сами. 1. Откройте файл «Глава 16. Набор данных 1» (Chapter 16. Data Set 1). 2.Нажмите Анализ (Analyze) ⇒ Регрессия (Regression) ⇒ Линейная (Linear). Вы увидите диалоговое окно линейной регрессии, как на рис. 16.5. 3.Щелкните по переменной Травмы (Injuries), а затем переместите ее в поле Зависимая переменная (Dependent). Это зависимая переменная, потому что ее значение зависит от количества часов тренировок. Другими словами, это та переменная, которую мы будем предсказывать. 4.Щелкните по переменной Тренировки (Training), а затем перемес­тите ее в поле Независимые переменные (ndependent(s)). 5.Нажмите ОК, и вы увидите частичные результаты анализа, как на рис. 16.6. Мы перейдем к интерпретации этого вывода через минуту. Сначала давайте заставим SPSS наложить линию регрессии на диаграмму рассеяния для этих данных (как было показано на рис. 16.2). 6.Нажмите Графика (Graphs) ⇒ Устаревшие диалоговые окна (Le­gacy Dialogs) ⇒ Рассеяния/Точки (Scatter/Dot). 7.Щелкните по Простая диаграмма рассеяния (Simple Scatter), а затем нажмите Задать (Define). Вы увидите диалоговое окно простой диаграммы рассеяния. 8. Щелкните по Травмы (Injuries) и переместите на поле Ось Y (Y Axis). Помните, что зависимые переменные отражаются по оси y. 9.Щелкните по Тренировки (Training) и переместите на поле Ось X (X Axis). 10. Нажмите ОК, и вы увидите диаграмму рассеяния, как на рис. 16.7. А теперь давайте нарисуем прямую регрессии; 11. Если вы не находитесь в редакторе графики, дважды щелкните по диаграмме, чтобы начать редактирование. 12.Нажмите на кнопку Добавить линию аппроксимации к итогам (Add Fit Line at Total), которая выглядит похоже на . 13. Закройте окно Свойства (Properties), которое открылось, когда вы нажали кнопку Добавить линию аппроксимации к итогам (Add Fit Line at Total), а затем закройте окно редактора графики. Готовая диаграмма рассеяния с линией регрессии показана на рис. 16.8 вместе со значением множественной регрессии R2, которое равно 0,21. Как вы скоро узнаете, коэффициент корреляции для множественной регрессии – это регрессия всех значений X к предсказанному значению. Расчет регрессии 318 Часть IV Значимая разница: применение статистики вывода Рис. 16.5 Диалоговое окно Линейная регрессия (Linear Regression) Рис. 16.6 Результаты анализа SPSS Глава 16 Как предсказать, кто выиграет Суперкубок Рис. 16.7 Диаграмма рассеяния, созданная в SPSS Рис. 16.8 Диаграмма рассеяния с прямой регрессии 319 Часть IV 320 Значимая разница: применение статистики вывода Когда у вас откроется диалоговое окно Свойства (Properties) во время добавления линии регрессии, обратите внимание, что в нем есть набор опций Доверительные интервалы (Confidence Intervals). Если отметить их, то будут показаны границы, в пределах которых вероятность совпадения предсказаний и фактических значений будет одинаково задана. Например, если вы отметите Среднее (Mean) и зададите значение 95 %, график покажет вам границы вокруг прямой регрессии, внутри которых находится 95 % вероятности попадания предсказанных значений. Читаем выводы SPSS Этот вывод SPSS говорит нам о нескольких мо­ментах: 1)формула регрессии выводится из первого набора результатов, показанного на рис. 16.6: Y ′ = –0,125X + 6,847. Это уравнение можно использовать для предсказания тяжести травм при заданном количестве часов, потраченных на силовые тренировки; 2)как вы видите на рис. 16.8, прямая регрессии имеет отрицательный наклон, отображая отрицательную корреляцию (–0,458 – это то, что обозначено как «Бета» на рис. 16.6) между часами тренировок и тяжестью травм. Судя по данным, чем больше человек тренируется, тем менее тяжелые травмы он получает; 3)вы также можете видеть, что предсказание значимо. Другими словами, предсказывание Y по X основано на значимой связи между двумя переменными, так что критерий значимости для постоянной (Тренировки) и зависимой (Травмы) переменных значимо отличается от нуля (чему он был бы равен, если бы у X не было никакой прогнозной ценности в предсказании Y). Так насколько хорошо это предсказание? Ну, вывод SPSS (который мы вам не показали) указывает также, что стандартная ошибка оценки для Травмы (Injuries), зависимой переменной, равна 2,182. Это означает существование 95 % вероятности (помните, что это расстояние в одно стандартное отклонение от среднего), что прогнозные значения окажутся в области между средним значением всех травм (которое равно 4,33) и ±2,182. Так что, судя по коэффициенту корреляции, это довольное хорошее, хотя и не отличное предсказание. ЧЕМ БОЛЬШЕ ПРЕДСКАЗЫВАЮЩИХ ПЕРЕМЕННЫХ, ТЕМ ЛУЧШЕ? ВОЗМОЖНО Все примеры, рассмотренные до этого момента в данной главе, касались одного критерия, или результирующей переменной, и одной предсказывающей, или независимой, переменной. Существует Глава 16 Как предсказать, кто выиграет Суперкубок также регрессия, в которой для предсказания какого-то результата используется более одной предсказывающей, или независимой, переменной. Если одна переменная может предсказать результат с какой-то степенью точности, тогда почему бы двум не сделать это еще лучше? Может быть, и так, но есть важная оговорка. О ней прочитаете дальше. Например, если средний балл по школьному аттестату служит довольно хорошим индикатором среднего балла в колледже, то что насчет среднего школьного балла и количества часов участия в об­ щественной деятельности? В этом случае вместо Y ′ = bX + a модель уравнения регрессии становится Y ′ = bX1 + bX2 + a, где X1 – это значение первой независимой переменной; X2 – это значение второй независимой переменной; b – это вес регрессии для данной конкретной переменной; a – это точка отсечения линии регрессии, или точка, в которой линия регрессии пересекает ось y. Как вы, наверное, уже догадались, эта модель называется мно­ жественной регрессией (множество независимых переменных, да?). Так что, во всяком случае теоретически, вы предсказываете результат по двум независимым переменным вместо одной. Но вы захотите добавлять дополнительные независимые переменные только при определенных условиях. Читайте дальше. Любая добавляемая вами переменная должна вносить особенный вклад в понимание зависимой переменной. Иначе зачем ее использовать? Что мы имеем в виду под «особенным»? Дополнительная переменная должна объяснять различия в зависимой переменной, которые не объясняются первой независимой переменной, т. е. комбинация двух переменных должна предсказывать Y лучше, чем каждая из них сделала бы по отдельности. В нашем примере степень участия в общественных мероприятиях может внести особенный вклад. Но должны ли мы добавлять общее количество часов, потраченное на учебу в школе, в качестве третьей независимой переменной? Поскольку количество времени, затраченное на учебу, вероятно, сильно связано со средним баллом школьного аттестата (другой нашей независимой переменной, помните?), то суммарное время занятий, вероятно, не особо много добавит к предсказанию среднего балла в колледже. Наверное, нам лучше поискать другую переменную (такую как рейтинги, проставленные в рекомендательных письмах), а не собирать данные о времени, посвященном учебе. Посмотрите на рис. 16.9, где представлен результат анализа множественной регрессии, в которой к данным из табл. 16.1 было добавлено количество часов общественной деятельности. Вы видите, что 321 322 Часть IV Значимая разница: применение статистики вывода и высокий школьный балл, и количество часов общественной деятельности вносят значимый вклад в средний балл на первом курсе колледжа. Это впечатляющий способ проверки того, что именно дополнительные переменные вносят в предсказание другой переменной, и того, каким образом они это делают. Рис. 16.9 Анализ множественной регрессии ВАЖНЫЕ ПРАВИЛА ПРИМЕНЕНИЯ МНОЖЕСТВЕННЫХ НЕЗАВИСИМЫХ ПЕРЕМЕННЫХ Если вы используете более одной независимой переменной, постарайтесь держать в уме следующие два полезных правила: 1)выбирая независимую переменную для предсказания результата, отдавайте предпочтение такой (X), которая связана с зависимой переменной (Y). Таким образом, у них обеих будет что-то общее (помните, что между ними должна быть корреляция); 2)выбирая более одной независимой переменной (например, X1 и X2), постарайтесь отдавать предпочтение таким переменным, которые будут независимыми или не связанными друг с другом, но связанными с результирующей, или предсказываемой, переменной (Y). Фактически вам нужны только связанные с зависимой переменной, но не связанные друг с другом независимые переменные. Каждая из них вносит существенный вклад в предсказание зависимой, или предсказываемой, переменной. Глава 16 Как предсказать, кто выиграет Суперкубок 323 Когда независимых переменных становится слишком много? Если одна переменная предсказывает какой-то результат, а две делают это еще лучше, тогда почему не взять три, четыре или пять независимых переменных? В практическом смысле каждый раз, когда вы добавляете переменную, возрастают затраты. Кто-то должен пойти и собрать данные, а на это требуется время (которое равно деньгам из бюджета исследования) и т. д. В тео­ ретическом смысле существует фиксированный предел тому, сколько переменных может помочь понять то, что мы пытаемся предсказать. Помните, что лучше всего, когда предсказывающие, или независимые, переменные являются независимыми или не связанными друг с другом. Проблема в том, что когда вы берете три или четыре переменные, все меньшее их количество остается несвязанным. Лучше быть точным и осторожным, чем включить в анализ слишком много переменных и потратить впустую деньги и силу предсказания. РЕАЛЬНАЯ СТАТИСТИКА Отношение детей к тому, что они делают, зачастую очень тесно связано с тем, насколько хорошо они это делают. Цель данного исследования – проанализировать влияние эмоций во время выполнения письменного задания. В модели, которая лежит в основе этого исследования, мотивация и аффект (проживание эмоции) играют важную роль в процессе письма. Четырех- и пятиклассникам задали написать автобиографический текст без эмоционального содержимого, с положительным эмоциональным содержимым и с негативным эмо­ цио­нальным содержимым. Результаты показали отсутствие влия­ния этих заданий на долю орфографических ошибок, но обнаружили влияние на длину написанного детьми текста. Простой регрессионный анализ (точно такой же, как тот, что проводили и обсуждали в этой главе) показал наличие корреляции и некоторой предсказательной силы между мощностью рабочей памяти и количеством орфографических ошибок только в нейтральных условиях. Поскольку модель, на которой исследователи построили многие из предварительных предположений, утверждает, что эмоции могут увеличить когнитивную нагрузку или объем «работы», необходимой для письма, это стало центральной темой обсуждения в данной статье. Хотите узнать больше? Найдите в интернете или библиотеке статью... Fartoukh M., Chanquoy L. & Piolat A. Effects of emotion on writing processes in children. Written Communication, 2012. Р. 391–411. Реальная статистика 324 Часть IV Значимая разница: применение статистики вывода ВЫВОДЫ ПО ГЛАВЕ Выводы по главе Предсказания являются специальным случаем простой корреляции и очень мощным инструментом для изучения сложных отношений. Эта часть могла показаться вам чуть более сложной, чем другие, но то, что вы узнали, сослужит вам хорошую службу, особенно, если вы сможете применить это знание к научным статьям и отчетам, которые должны читать. Мы подходим к концу части, посвященной статистике вывода, и готовы перейти к следующей части этой книги, касающейся использования статистики, когда размер выборки очень мал или когда предположение о нормальном распределении величин не выполняется. ВРЕМЯ ПРАКТИКИ Проблема 2 1.В чем состоит отличие линейной регрессии от дисперсионного анализа? 2.Файл «Глава 16. Набор данных 2» (Chapter 16. Data Set 2) содержит данные по группе участников, выполнявших задание на время. Это среднее количество времени, которое потребовалось участникам для ответа на каждый вопрос (Время (Time)), и количество попыток, которое потребовалось для правильного ответа (Прав. отв. (Correct)): а) напишите уравнение регрессии для предсказания времени ответа на основании количества попыток; б) чему равно прогнозное время ответа, если количество попыток составляет 8; в) какова разница между предсказанным и фактическим коли­ чеством попыток для каждого из предсказанных значений времени ответа? 3.Бетси интересует, сколько из 75-летних людей заболеет болезнью Альцгеймера, и она использует для предсказания в качестве независимых переменных уровень образования и общее физическое здоровье, оцененное по шкале от 1 до 10. Но ей также интересно использовать и другие независимые переменные. Ответьте на следующие вопросы: а) по каким критериям она должна выбирать другие независимые переменные и почему; б) назовите еще две независимые переменные, которые, как вы думаете, могут быть связаны с развитием болезни Альцгеймера; в) напишите, на что будет похожа модель уравнения регрессии при использовании четырех независимых переменных: уровня образования, общего физического здоровья и двух новых, предложенных вами в ответе на вопрос «б». Глава 16 Как предсказать, кто выиграет Суперкубок 325 4.Сходите в библиотеку и найдите три различных исследования в вашей области интересов, в которых используется линейная регрессия. Ничего страшного, если они содержат более одной независимой переменной. Для каждого исследования ответьте на следующие вопросы: а) назовите одну независимую переменную. Какова зависимая переменная? б) если используется больше одной независимой переменной, как автор аргументирует, что они не зависят друг от друга? в) в каком из трех исследований приведено наименее убедительное доказательство того, что зависимая переменная предсказывается по независимой, и почему? 5.Здесь вы можете воспользоваться одной из подсказок в этой главе и получить шанс предсказать победителя Суперкубка! Тренеру Джо было любопытно узнать, предсказывает ли общее количест­ во выигранных игр результаты на Суперкубке (выигрыш или проигрыш). В качестве переменной X выступало среднее количество выигранных игр за прошедшие 10 сезонов. Переменная Y описывала, выигрывала ли команда Суперкубок хотя бы раз за прошедшие 10 сезонов. Данные приведены в табл. 16.4. Таблица 16.4 Результаты игр и Суперкубка Команда Акулы Саванны Пеликаны Питтсбурга Воины Вильямстоуна Вышибалы Беннингтона Ангелы Атланты Ужас Трентона Аспиды Вирджинии Мурлыки Чарльстона Варвары Харрисбурга Энерджайзеры Итона Среднее количество выигрышей за 10 лет 12 11 15 12 13 16 15 9 8 12 Суперкубок? (1 = да, 0 = нет) 1 0 0 1 1 0 1 0 0 1 а) Как бы вы оценили полезность среднего количества выигрышей в качестве предсказывающего фактора для выигрыша Суперкубка? б) В чем состоит преимущество возможности использовать категориальную переменную (такую как 1 или 0) в качестве зависимой? в) Какие еще переменные можно было бы использовать для предсказания зависимой переменной, и почему вы бы выбрали именно их? 6.Проверьте свои расчеты коэффициента корреляции между потреблением кофе и стрессом, выполненные в процессе ответа на Часть IV 326 Значимая разница: применение статистики вывода вопрос 5 к главе 15. Если бы вы хотели узнать, предсказывает ли потребление кофе уровень стресса: а) какова была бы ваша предсказывающая, или независимая, переменная; б) какова была бы ваша предсказываемая, или зависимая, переменная; в) есть ли у вас мысли о том, каково было бы значение R2? 7.Пора испытать множественные независимые переменные. Посмотрите на данные в табл. 16.5, где приведены результаты теста на должность главного шеф-повара. Мы подозреваем, что такие переменные, как количество лет кулинарного опыта, уровень официального кулинарного образования и количество ранее занимаемых позиций, влияют на результаты теста. Таблица 16.5 Результаты теста на должность главного шеф-повара Опыт, лет Уровень образования 5 6 12 21 7 9 13 16 21 11 15 15 1 17 26 11 18 31 27 1 2 3 3 2 1 2 2 2 1 2 3 3 2 2 2 3 3 2 Кол-во занимаемых позиций 5 4 9 8 5 8 8 9 9 4 7 7 3 6 8 6 7 12 16 Результат теста на главного шеф-повара 88 78 56 88 97 90 79 85 60 89 88 76 78 98 91 88 90 98 88 К настоящему моменту вы должны уже были освоиться с выводом уравнений из подобных данных, поэтому давайте перейдем к настоящим вопросам: а) какие переменные лучше всего предсказывают результаты теста? б) какой результат вы можете ожидать для человека с 12-летним опытом работы и уровнем образования 2, который ранее работал на пяти позициях? Глава 16 Как предсказать, кто выиграет Суперкубок 8.Посмотрите на табл. «Глава 16. Набор данных 3» (Chapter 16. Data Set 3), в которой предсказывается количество продаж домов (Number_Homes_Sold) по количеству лет в бизнесе (Years_In_Business) и уровню образования, выраженному в количестве лет обучения (Level_Of_Education). Почему уровень образования вносит такой незначительный вклад в общий результат предсказания количества проданных домов (на основании комбинации лет в бизнесе и уровня образования)? Какая независимая переменная предсказывает лучше всех? Как вы это поняли? (Подсказка: это вопрос с подвохом. Прежде чем бросаться анализировать данные, посмотрите на исходные данные в файле и проверьте известные вам важные характеристики, связанные с корреляцией одной переменной с другой.) 9.Какова должна быть сущность связи для любого сочетания зависимых и независимых переменных? 327 ЧАСТЬ V Больше статистики! Больше инструментов! Больше веселья! Дэн хвастается своей коллекцией данных 329 330 Часть V У Больше статистики! Больше инструментов! Больше веселья! х ты! Большая часть книги (и, вероятно, курса) уже позади, и вы готовы познакомиться с новыми идеями в этой части «Статистики для тех, кто (думает, что) ненавидит статистику». Цель части V состоит в том, чтобы дать вам обзор различных инструментов, которые применяются для множества целей. В главе 17 мы представим вам оборотную сторону статистики вывода – всегда интересные и полезные непараметрические критерии (в частности, хи-квадрат), применяемые, когда распределение величин, с которыми вы работаете, не является нормальным или нарушает некоторые другие важные предположения. Затем в главе 18 будет дан обзор более продвинутых статистических процедур, таких как факторный анализ и моделирование структурных уравнений. Вы точно услышите и о них, и о других статистических процедурах в своих изысканиях. Несмотря на то что глубокое изучение находится немного за пределами уровня вводного курса, мы кратко расскажем о каждой методике и приведем примеры. Эта глава даст вам представление о возможностях некоторых более сложных инструментов и принципах их работы. Глава 19, добавленная в этом издании, представляет быстро набирающий популярность подход к данным – глубинный анализ данных, или data mining. По мере нарастания объема данных и расширения технологических возможностей для работы с ними исследователи находят все больше и больше применения глубинному анализу данных. Здесь вы узнаете, как можно с помощью SPSS искать паттерны в очень больших наборах данных. Забавный факт, касающийся этой главы: для практики мы используем базу данных с именами более чем 52 000 новорожденных в Нью-Йорке, начиная с 2007 г., и вы можете скачать ее и пользоваться дальше. Наконец, последняя глава в этой части книги дает обзор некоторых программных продуктов, которые могут применяться для статистического анализа вместо SPSS. Некоторые из них бесплатны, некоторые нет, но все предлагают набор инструментов, который может вам пригодиться. Что же, вот все пять глав в части V, и вы неуклонно движетесь к тому, чтобы стать хорошо вооруженным знаниями экспертом по основам статистики. 17 Что делать с ненормальными Хи-квадрат и другие непараметрические критерии Уровень сложности: (легко) В ЭТОЙ ГЛАВЕ ВЫ УЗНАЕТЕ: что такое непараметрические критерии и как их использовать; как анализировать данные при помощи критерия согласия хи-квадрат; как анализировать данные при помощи критерия независимости хи-квадрат; когда и как нужно применять непараметрические критерии. ПРЕДИСЛОВИЕ К НЕПАРАМЕТРИЧЕСКИМ КРИТЕРИЯМ Почти все статистические критерии, о которых мы до сих пор говорили в «Статистике для тех, кто…», предполагают, что набор данных, с которыми вы работаете, имеет определенные характеристики. Например, лежащее в основе t-кри­терия предположение о значимости для средних значений (будь они зависимы или независимы) состоит в том, что дисперсии обеих групп гомогенны, или одинаковы. И это предположение можно проверить. Другое предположение множест­ ва параметрических критериев заключается в том, что выборка достаточно велика, чтобы быть репрезентативной для генеральной совокупности. Статистики обнаружили, что для удовлетворения этого условия необходима выборка из примерно 30 участников. Многие из рассмотренных нами критериев являются достаточно устойчивыми, мощными, чтобы работать даже в том случае, если одно из этих предположений нарушено. Но что делать, когда эти предположения нарушены? Исходные вопросы исследования, конечно, не теряют от этого своей актуальности. Именно здесь мы применяем непараметрические критерии. Эти критерии не следуют тем же «правилам» (т. е. не требу- Введение в главу 17 331 332 Часть V Больше статистики! Больше инструментов! Больше веселья! ют таких же, потенциально ограничительных предположений, как рассмотренные нами параметрические критерии), но оказываются такими же ценными для нас. Использование непараметрических критериев также позволяет нам анализировать данные в виде час­ тот (например, количество детей в разных классах или доля людей, получающих социальную помощь). И очень часто эти переменные измеряются на номинальном, или категориальном, уровне (см. главу 2 по вопросу о номинальной шкале измерения). Например, если бы мы хотели знать, соответствуют ли характеристики людей, голосовавших на последних выборах за введение школьных ваучеров, тем, что объясняются случайностью, или же там действительно присутствовал какой-то паттерн предпочтений в соответствии с одной или несколькими переменными, то мы бы использовали непараметрическую методику под названием хи-квадрат. В этой главе мы расскажем о методе хи-квадрат, одном из наиболее часто используемых критериев, и дадим краткий обзор некоторых других, так что вы сможете ознакомиться с дополнительными имеющимися критериями. ПРЕДСТАВЛЯЕМ КРИТЕРИЙ СОГЛАСИЯ ХИ - КВАДРАТ ( ОДНОВЫБОРОЧНЫЙ ) Хи-квадрат представляет собой интересный непараметрический критерий, который позволяет определить, является ли наблюдаемое вами распределение частот тем, что могло бы объясняться чистой случайностью. Одновыборочный хи-квадрат включает в себя только одно измерение, переменную или фактор, так же как в приведенном здесь примере, и обычно называется критерием согласия хи-квадрат (т. е. показывает, насколько собранные вами данные согласуются с паттерном, который вы ожидали увидеть). Двухвыборочный хи-квадрат включает в себя два измерения, фактора или две переменные и часто называется критерием независимости. Например, его можно использовать для проверки того, является ли предпочтение школьных ваучеров независимым от принадлежности к политической партии и пола. Мы рассмотрим оба типа процедур хи-квадрат. Для примера критерия согласия хи-квадрат мы возьмем данные по выборке, отобранной случайным образом из данных переписи населения от 1990 г. в округе Сонома, Калифорния. Как вы видите, в табл. 17.1 организованы данные об уровне образования (только один фактор). Таблица 17.1 Среднее 25 Уровень образования Уровень образования Высшее неоконченное 42 Высшее 17 Глава 17 Что делать с ненормальными 333 Нас интересует вопрос, равномерно ли распределяется количест­ во респондентов по всем трем уровням образования. Для ответа на этот вопрос было рассчитано значение хи-квадрат, а затем проверено на значимость. В данном примере хи-квадрат был равен 11,643, что значительно выходит за пределы уровня 0,05. Вывод состоит в том, что количество респондентов с разным уровнем образования в этой выборке распределено неравномерно. Другими словами, это не то, чего мы бы ожидали от чистой случайности. Принцип, лежащий в основе одновыборочного хи-квадрата (или критерия согласия хи-квадрат), состоит в том, что вы можете легко вычислить, что могли бы получить на основе случайности. Это делается путем деления общего количества случаев на количество классов или категорий. В примере с данными о переписи населения общее наблюдаемое количество случаев равно 84. Мы могли бы ожидать, что при случайном распределении 84/3 (84 – общее количество случаев, 3 – общее количество категорий), или 28, респонденты попали бы в каждую из трех категорий по уровню образования. Затем мы смотрим, как отличается то, чего мы ожидали бы от случайности, от того, что мы наблюдаем. Если между ожиданиями и наблю­дениями нет разницы, то значение хи-квадрат равно нулю. Давайте посмотрим подробнее на вычисление значения хи-квад­ рат. ВЫЧИСЛЕНИЕ ЗНАЧЕНИЯ КРИТЕРИЯ СОГЛАСИЯ ХИ - КВАДРАТ Одновыборочный критерий согласия хи-квадрат сравнивает то, что мы наблюдаем, с тем, что мы ожидали бы от случайности. Формула 17.1 показывает, как вычисляется значение хи-квадрат для одновыборочного критерия: Хи-квадрат (17.1) где χ2 – значение критерия хи-квадрат; ∑ – знак суммы; О – наблюдаемая час­тота; Е – ожидаемая частота. В табл. 17.2 приведены некоторые данные по выборке, для которой мы рассчитаем значение хи-квадрат для одномерного анализа. Таблица 17.2 Предпочтения по поводу школьных ваучеров Предпочтения по поводу школьных ваучеров За Возможно Против 23 17 50 Всего 90 Определение критического значения 334 Часть V Больше статистики! Больше инструментов! Больше веселья! А вот и знаменитые восемь шагов проверки данного критерия: 1. Формулировка основной и альтернативной гипотез. Нулевая гипотеза, записанная в формуле 17.2, утверждает, что нет различий в частоте или пропорции распределения случаев по каждой категории: H0: P1 = P2 = P3. (17.2) P в нулевой гипотезе обозначает процент случаев в любой категории. Нулевая гипотеза утверждает, что проценты случаев в Категории 1 (За), Категории 2 (Возможно) и Категории 3 (Против) равны. Мы используем только три категории, но их количество может расширяться в соответствии с ситуацией до тех пор, пока категории остаются взаимоисключающими. Это означает, что любое наблюдение не может относиться более чем к одной категории. Например, вы не можете одновременно быть в категории и мужчин, и женщин (перепись позволяет вам выбрать только одно значение). Вы не можете одновременной быть и за, и против плана школьных ваучеров. Альтернативная гипотеза, записанная в формуле 17.3, утверждает, что в частоте или пропорции распределения случаев по каждой категории есть различия: H1: P1 ≠ P2 ≠ P3; (17.3) 2.Выбор уровня риска (или уровня значимости, или ошибки первого рода), связанного с нулевой гипотезой. Уровень ошибки первого рода установлен на 0,05. Как мы решили, что будет именно это значение, а не другое, вроде 0,01 или 0,001? Как подчеркивалось в предыдущих главах, мы принимаем (в чем-то) произвольное решение о том, какой риск берем на себя; 3. Выбор подходящего статистического критерия. Любая проверка между частотой или пропорцией взаимоисключающих категорий (За, Возможно и Против) требует применения критерия хи-квадрат. Схема, которую мы использовали на протяжении глав 10–16 для выбора типа статистического критерия, не подходит для непараметрических процедур; 4.Расчет значения статистического критерия (наблюдаемого зна­чения). Давайте вернемся к данным о ваучерах и составим таблицу, которая поможет нам рассчитать значение хи-квадрат. Таблица 17.3 Категория За Возможно Против ИТОГО Расчеты для хи-квадрата О (наблюдаемая частота) 23 17 50 90 Е (ожидаемая частота) 30 30 30 90 D (разница) (О – Е )2 (О – Е )2/Е 7 13 20 49 169 400 1,63 5,63 13,33 20,6 Вот какие шаги мы предприняли для подготовки этой информации: 1) ввели категории (За, Возможно и Против) в первый столбец. Помните, что эти три категории взаимоисключающие. Любая точка данных может одновременно принадлежать только одной категории; Глава 17 Что делать с ненормальными 2) ввели наблюдаемую частоту (О), которая отражает собранные данные; 3) ввели ожидаемую частоту (Е), которая равна сумме всех наблюдаемых частот (90), разделенной на количество категорий (3), или 90/3 = 30; 4) для каждой ячейки вычли ожидаемую частоту из наблюдаемой, или наоборот. Не имеет значения, что из чего вычитать, т. к. на следующем шаге эти разности возводятся в квадрат; 5) возвели в квадрат разности между наблюдаемыми и ожидаемыми значениями. Вы видите результат в колонке (О – Е)2; 6) разделили квадрат разности между наблюдаемой и ожидаемой частотой на ожидаемую частоту. Вы видите получившиеся значения в колонке (О – Е)2/Е; 7) просуммировав эту последнюю колонку, получаем итоговое значение хи-квадрата, равное 20,6. 5.Определение значения, необходимого для отклонения нулевой гипотезы, при помощи соответствующей таблицы критических значений для конкретного критерия. Здесь мы переходим к таблице B.5 в приложении B, в которой дан список критических значений для критерия хи-квадрат. Сначала мы должны определить степени свободы (df), которые примерно равны количеству категорий, в которые попадают данные. Для данного статистического критерия количество степеней свободны равно r – 1, где r – коли­ чество рядов в табл. 17.3, или 3 – 1 = 2. Взяв это количество (2) и уровень риска, который вы готовы принять (ранее заданный как 0,05), вы можете посмотреть в таблице хи-квадрата критическое значение критерия. Оно равно 5,99. Итак, значение, необходимое для отклонения нулевой гипотезы на уровне значимости 0,05 с двумя степенями свободы, равно 5,99. 6. Сравнение наблюдаемого значения с критическим. Наблюдаемое значение равно 20,6, а критическое значение для отклонения нулевой гипотезы, что частота случаев в группе 1, группе 2 и группе 3 одинакова, равно 5,99. 7 и 8. Время решать! Если наблюдаемое значение оказывается более крайним, чем критическое, то нулевую гипотезу нельзя принять. Если наблюдаемое значение не превосходит критического, то нулевая гипотеза дает самое привлекательное объяснение. В данном случае наблюдаемое значение превосходит критическую величину. Оно достаточно крайнее, чтобы мы могли сказать, что распределение респондентов по группам неравномерно. Определенно, существуют различия в количестве людей, голосующих за, против или не определившихся по вопросу школьных ваучеров. 335 336 Часть V Больше статистики! Больше инструментов! Больше веселья! Почему «критерий согласия»? Название предполагает, что эта статистика отвечает на вопрос, насколько хорошо набор данных согласуется с существующим стандартом. Набор данных – это, конечно, то, что вы наблюдаете. Слово «согласуется» предполагает, что есть другой набор данных, с которым можно сравнить наблюдаемый. Этот стандарт является набором ожидаемых частот, которые рассчитываются в процессе вычисления значения χ2. Если набор данных согласуется с ним, то значение χ2 приближается к тому, что вы ожидаете увидеть при влиянии чистой случайности, и не имеет значимых отличий от него. Если наблюдаемые данные не согласуются, тогда то, что вы наблю­даете, отличается от того, что вы могли бы ожидать. Так как мне интерпретировать χ2 = 20,6, p < 0,05? Расчет вероятностей хи-квадрата при помощи программы zz χ2 – статистический критерий; zz 2 – это количество степеней свободы; zz 20,6 – это наблюдаемое значение, рассчитанное по формуле, которую мы показывали вам в данной главе; zz p < 0,05 (действительно важная часть этого короткого выражения) обозначает, что для любой проверки нулевой гипотезы сущест­ вует меньше 5 % вероятности, что частота голосов равномерно распределена по категориям только из-за случайности. Поскольку мы выбрали 0,05 в качестве критерия большей привлекательности альтернативной, а не нулевой гипотезы, то заключаем, что между тремя наборами данных существует значимое различие. ПРЕДИСЛОВИЕ К КРИТЕРИЮ НЕЗАВИСИМОСТИ ХИ - КВАДРАТ Мы в основном говорили о критерии согласия хи-квадрат, но другой – немного более сложный – критерий также достоин внимания. Речь идет о критерии независимости хи-квадрат. При его применении изучаются два разных измерения, почти всегда заданных в виде номинативных переменных, для проверки наличия связи между ними. Возьмем, к примеру, следующую таблицу, которая включает данные по мужчинами и женщинам, а также по участвовавшим в голосовании и не участвовавшим (табл. 17.4). Таблица 17.4 Пол Мужской Женский Данные по участию в голосовании Участие в голосовании Голосовали Не голосовали 50 20 40 10 Глава 17 Что делать с ненормальными 337 Вам нужно иметь в виду, что здесь даны две размерности (пол и участие в голосовании). Вопрос, задаваемый при проверке независимости по критерию хи-квадрат, состоит в том, являются ли в данном случае пол и участие в голосовании независимыми друг от друга переменными. Как и в случае с одноразмерным критерием хи-квадрат, чем ближе будут друг к другу наблюдаемое и ожидаемое значения, тем более вероятно, что размерности не зависят друг от друга. Чем сильнее отличаются друг от друга наблюдаемое и ожидаемое значения, тем менее вероятно, что две размерности не зависят друг от друга. Данный критерий рассчитывается таким же образом, как и критерий согласия (какой приятный сюрприз). Рассчитываются ожидаемые значения, затем они и наблюдаемые значения используются для вычисления значения хи-квадрат, которое затем проверяется на значимость. В отличие от одноразмерного критерия, ожидаемые значения критерия независимости рассчитываются по-другому, что мы разберем ниже. РАСЧЕТ ЗНАЧЕНИЯ КРИТЕРИЯ НЕЗАВИСИМОСТИ ХИ - КВАДРАТ Вот каков порядок действий, которые мы предприняли для проведения проверки независимости для данных о голосовании и поле, которые вы видели ранее. Мы следовали тем же путем, что вы видели при расчете критерия согласия, и использовали ту же формулу. Вот наша итоговая таблица (см. табл. 17.4). Голосовали Не голосовали Итого Мужчины 37 20 57 Женщины 32 31 63 Итого 69 51 120 Обратите внимание, что хотя формула та же самая, ожидаемые значения вычисляются по-другому. В частности, ожидаемое значение для любой ячейки – это произведение суммы всего ряда и суммы всего столбца, поделенное на общее количество всех наблюдений. Так, например, ожидаемое значение для голосовавших мужчин считается следующим образом: (69 × 57)/ 120 = 32,775. 1.Введите категории: мужчины голосовали, мужчины не голосовали, женщины голосовали, женщины не голосовали. Помните, что все эти категории взаимно исключают друг друга; любая точка данных может одновременно принадлежать только одной категории. 338 Часть V Больше статистики! Больше инструментов! Больше веселья! 2.Введите наблюдаемую частоту (О), которая отражает собранные данные. 3.Введите ожидаемую частоту (Е ), которая равна произведению суммы по строке и суммы по столбцу, поделенному на общее количество наблюдений. 4.Для каждой ячейки вычтите ожидаемую частоту из наблюдаемой, или наоборот. Не имеет значения, что из чего вычитать, т. к. на следующем шаге эти разности возводятся в квадрат. 5.Возведите в квадрат разности между наблюдаемыми и ожидаемыми значения­ ми. Вы видите результат в колонке (О – Е)2. 6.Разделите квадрат разности между наблюдаемой и ожидаемой час­тотами на ожидаемую частоту. Вы видите получившиеся значения в колонке (О – Е)2/Е. 7.Просуммировав эту последнюю колонку, вы получите итоговое значение хиквадрат, равное 2,441. В табл. 17.5 представлены значения наблюдаемых данных (O), ожидаемых значений (E), и квадратов разниц между ожидаемым и наблюдаемым значениями для каждой ячейки (О – Е)2. Таблица 17.5 Расчет значения хи-квадрат Голосовали Не голосовали Итого Голосовали Не голосовали Голосовали Не голосовали Промежуточные расчеты для значения хи-квадрат Наблюдаемые значения (О) Мужчины Женщины 37 32 20 31 57 63 Ожидаемые значения (Е ) Мужчины Женщины 32,78 36,23 24,23 26,78 (О – Е )2/Е Мужчины Женщины 0,54 0,49 0,74 0,67 Итого 69 51 120 Наблюдаемое значение хи-квадрат равно 0,54 + 0,49 + 0,74 + 0,64 = 2,44. Здесь мы переходим к табл. B.5 в приложении B, в которой дан список критических значений для критерия хи-квадрат. Сначала мы должны определить степени свободы (df ), которые примерно равны количеству категорий, в которые попадают данные. Для данного критерия независимости хи-квадрат количество степеней свободы равно (r – 1)×(c – 1), где r соответствует количеству рядов (2 – 1 = 1), а c равно количеству столбцов (2 – 1 = 1). Итак, (r – 1)×(c – 1) = 1 × 1, или 1. Взяв это количество (1) и уровень риска, который вы готовы принять (ранее заданный как 0,05), можете посмотреть в таблице хи-квадрата критическое значение критерия. Оно равно 3,84. Итак, значение, необходимое для отклонения нулевой гипотезы на уровне значимости 0,05 с одной степенью свободы, равно 3,84. Наблюдаемое значение – 2,44, а критическое значение, необходимое для отклонения нулевой гипотезы о том, что участие в голосовании и пол независимы, – 3,84. Глава 17 Что делать с ненормальными 339 8.Если наблюдаемое значение оказывается более крайним, чем критическое, то нулевую гипотезу нельзя принять. Если наблюдаемое значение не превосходит критического, то нулевая гипотеза дает самое привлекательное объяснение. В данном случае наблюдаемое значение не превосходит критической величины. Пол и участие в голосовании на самом деле не зависят друг от друга. РАСЧЕТ КРИТЕРИЯ ХИ-КВАДРАТ ПРИ ПОМОЩИ SPSS Критерий согласия и SPSS Вот так можно провести простой одновыборочный тест критерия хи-квадрат при помощи SPSS. Мы используем набор данных под названием «Глава 17. Набор данных 1» (Chapter 17. Data Set 1), который был приведен в нашем примере выше про школьные ваучеры: 1)откройте набор данных. Для одновыборочного критерия хиквадрат вам нужно только внести количество случаев в каждый столбец, используя разные значения для каждого возможного результата. В данном примере в столбце 1 будет находиться 90 точек данных: 23 единицы (или «За»), 17 двоек (или «Возможно») и 50 троек («Против»); 2)нажмите Анализ (Analyze) ⇒ Непараметрические критерии (Nonparametric Tests) ⇒ Устаревшие диалоговые окна (Legacy Dialogs) ⇒ Хи-квадрат (Chi-Square), и вы увидите диалоговое окно, как на рис. 17.1; Рис. 17.1 Диалоговое окно Хи-квадрат 340 Часть V Больше статистики! Больше инструментов! Больше веселья! 3) дважды щелкните по переменной Ваучер (Voucher); 4)нажмите ОК. SPSS проведет анализ и покажет вывод, который вы видите на рис. 17.2. Рис. 17.2 Вывод SPSS для анализа критерия хи-квадрат Читаем выводы SPSS Вывод SPSS для хи-квадрат показывает именно то, о чем вы ранее читали в этой главе: 1)перечислены категории «За» (закодировано как 1), «Возможно» (закодировано как 2) и «Против» (закодировано как 3) и их Наблюдаемые N (Observed N); 2)за ними следует Ожидаемое N (Expected N), которое в данном случае равно 90/3, или 30; 3)значение хи-квадрат – 20,600 и количество степеней свободы указаны в разделе под заголовком Статистические критерии (Test Statistics). Точный уровень значимости (на рисунке она обозначена как Асимптотическая значимость (Asymp. Sig.)) так мал (меньше, чем, например, 0,0001), что SPSS показывает его только как 0,000. Очень маловероятный результат! Крайне вероятно, что частоты этих трех категорий не равны. Критерий независимости и SPSS Критерии независимости А вот как нужно проводить проверку двумерного критерия независимости хи-квадрат при помощи SPSS. Мы используем набор данных под названием «Глава 17. Набор данных 2» (Chapter 17. Data Set 2), который вы видели в примере выше о соотношении пола Глава 17 Что делать с ненормальными и участия в голосовании. Как вы можете видеть на рис. 17.3, где показаны строки с 63 по 75, у нас есть одна переменная Пол (Gender), которая может принимать значения «Мужчина» или «Женщина», и одна переменная Голосование (Vote), которая может принимать значения «Да» или «Нет». Рис. 17.3 Две переменные из файла «Глава 17. Набор данных 2» 1.Для расчета критерия независимости хи-квадрат вам нужно в каждую колонку внести количество случаев, используя различные числа для каждого возможного результата. В данном примере будет всего 120 значений данных: в столбце, представляющем пол, в виде 1 или 2, а также в виде 1 или 2 в столбце, представляющем участие в голосовании. Мы использовали опцию Значения (Value) на вкладке Представление Переменные (Variable View), чтобы задать, что 1 означает «Мужчина» и «Да», а 2 – «Женщина» и «Нет», так что мы сможем увидеть в столбцах их заголовки. 2.Нажмите Анализ (Analyze) ⇒ Описательные статистики (Descriptive Statistics) ⇒ Таблицы сопряженности (Cross Tabs), и вы увидите диалоговое окно, как на рис. 17.4. 3.Дважды щелкните по переменной Пол (Gender), чтобы переместить ее в поле Строки (Row(s)). 4.Дважды щелкните по переменной Голосование (Vote), чтобы переместить ее в поле Столбцы (Column(s)). 5.Нажмите кнопку Статистики (Statistics) и в окошке Таблицы сопряженности: Статистики (Crosstabs: Statistics) отметьте Хи-квадрат (Chi-square). 6.Нажмите ОК. SPSS проведет анализ и покажет вывод, как тот, что вы видите на рис. 17.5. 341 342 Часть V Больше статистики! Больше инструментов! Больше веселья! Рис. 17.4 Диалоговое окно Таблицы сопряженности Рис. 17.5 Вывод SPSS для анализа хи-квадрат Глава 17 Что делать с ненормальными 343 Замечательный генератор значений хи-квадрат для обоих типов критерия хи-квадрат можно найти на сайте http://www.quantpsy.org/chisq/chisq.htm. Его создал для нас д-р Крис­тофер Джей Причер (Dr. Kris­topher J. Preacher) из Университета Вандербильт. После того как сделаете вычисления вручную и поймете, как получаются значения хи-квадрат, пользуйтесь этим инструментом наряду с SPSS, чтобы еще больше облегчить свою жизнь! Читаем выводы SPSS Вывод SPSS для критерия независимости хи-квадрат показывает следующее: 1)перечислены частоты для разных категорий, таких как Мужчины – Да (37), Мужчины – Нет (20), Женщины – Да (32), Женщины – Нет (31); 2)в разделе Критерии хи-квадрат (Chi-Square Tests) указано значение хи-квадрата Пирсона, равное 2.441, и количество степеней свободы (1). Мы видим в результатах те же значения, что получили при вычислениях вручную ранее в этой главе; 3)точный уровень значимости (на рисунке она обозначена как Асимптотическая значимость (Asymp. Sig.)) равен 0,118, так что результаты не значимы на уровне 0,05. Другими словами, пол и участие в голосовании не зависят друг от друга. Наша интерпретация? Участие в голосовании не является функцией, зависящей от пола, так же как и пол не связан с участием в голосовании. ДРУГИЕ НЕПАРАМЕТРИЧЕСКИЕ КРИТЕРИИ, О КОТОРЫХ ВАМ НУЖНО ЗНАТЬ Возможно, вам никогда и не понадобится использовать непарамет­ рический критерий для ответа на выдвигаемые вами вопросы исследования. С другой стороны, вы также можете обнаружить, что имеете дело с очень маленькими выборками (по меньшей мере, состоящими из менее чем 30 случаев) или с данными, которые нарушают некоторые важные предположения, лежащие в основе параметрических критериев. Основная причина, по которой вам могут понадобиться непара­ метрические критерии, связана с уровнем измерения переменной, которую вы оцениваете. Мы поговорим об этом еще в следую­ щей главе, но сейчас скажем, что большинство категориальных данных, которые разбиты на категории (такие как «Акулы» или «Факелы»), или порядковых данных, которые расположены по рангу (1-е, 2-е и 3-е место), требует применения непараметрических тестов вроде тех, что вы видите в табл. 17.6. Часть V 344 Больше статистики! Больше инструментов! Больше веселья! Если это ваш случай, попробуйте для разнообразия непарамет­ рические критерии. Таблица 17.6 предоставит вам все, что нужно знать о некоторых непараметрических критериях, включая их название, то, для чего они применяются, и вопрос исследования для иллюстрации этого применения. Имейте в виду, что в таблице представлены только некоторые из множества различных имеющихся критериев. Таблица 17.6 Непараметрические критерии для анализа категориальных и порядковых данных Название критерия Критерий значимости изменений МакНемара Когда он применяется Для изучения изменений «до и после» Точный критерий Фишера Одновыборочный критерий хи-квадрат (о котором мы говорили ранее в этой главе) Критерий Колмогорова–Смирнова Для расчета точной вероятности результатов в таблице 2×2 Для выявления того, является ли количество случаев по категориям случайным Для определения, относятся ли результаты выборки к заданной генеральной совокупности Знаковый, или медианный, критерий Для сравнения медиан у двух выборок U-критерий Манна–Уитни Для сравнения двух независимых выборок Ранговый критерий Уилкоксона Для сравнения величины и направления различий между двумя группами Односторонний дисперсионный анализ Краскела–Уоллиса Критерий Фридмана Для сравнения общих различий между двумя или более независимыми выборками Для сравнения общих различий между двумя или более независимыми выборками по более чем одному измерению Для вычисления корреляции между рангами Коэффициент ранговой корреляции Спирмана Пример вопроса исследования Насколько эффективны телефонные звонки неопределившимся избирателям для склонения их к голосованию определенным образом? Какова точная вероятность получить 6 орлов при подбрасывании 6 монет? Были ли продажи брендов «Фрутис», «Ваммис» и «Зиппис» равны во время недавней распродажи? Насколько репрезентативны суждения об определенных учениках начальной школы по отношению ко всем ученикам этой школы? Превышает ли медианный доход людей, проголосовавших за Кандидата А, медианный доход людей, проголосовавших за Кандидата Б? Происходила ли передача знания, измеряемая количеством правильных ответов, в группе А быстрее, чем в группе Б? Является ли дошкольное образование в два раза более эффективным для развития языковых навыков у детей, чем его отсутствие? Как различаются рейтинги супервизоров в четырех региональных офисах? Как различаются рейтинги супервизоров в четырех региональных офисах в зависимости от региона и пола? Какова корреляция между рейтингом ученика в конце выпускного старшего класса и его рейтингом в конце первого курса колледжа? Глава 17 Что делать с ненормальными 345 РЕАЛЬНАЯ СТАТИСТИКА Применение современных инструментов для исследования текста Библии действительно очень интересно (и разумно) и является отличной иллюстрацией к тому, как используется хи-квадрат в реальном мире. Профессор Хук (Houk) провел при помощи хи-квадрата то, что называется анализом паттерна частотности слов и слогов, чтобы выделить значимые различия в различных частях Книги Бытия. Вывод? Различные отрывки были написаны одним и тем же человеком. Анализ разных отрывков дал аргументы против утверждения, что истории были созданы отдельно друг от друга, поскольку нет значимой разницы в частоте использования определенных слов и т. п. Хотите узнать больше? Найдите в интернете или библиотеке статью... Houk C. B. Statistical analysis of Genesis sources. Journal for the Study of the Old Testament, 2002. Р. 75–105. Реальная статистика ВЫВОДЫ ПО ГЛАВЕ Хи-квадрат является одним из множества различных непараметрических критериев, которые помогают находить ответы на вопросы на основании данных, нарушающих основные предположения о нормальном распределении, или тогда, когда набор данных слишком мал для работы с другими статистическими методиками. Эти непараметрические критерии представляют собой очень ценный инструмент. Даже такое ограниченное знакомство с ними, как у нас, поможет вам понять их применение в исследованиях, о которых вы будете читать, и побудит вас продолжить самостоятельное изучение их возможностей. Выводы по главе ВРЕМЯ ПРАКТИКИ 1.Когда наблюдаемое значение хи-квадрат равно нулю? Приведите пример того, когда это может случиться. 2.На основании следующих данных проверьте, одинаковое ли количество демократов, республиканцев и независимых голосовало на прошедших выборах. Проверьте гипотезу на уровне значимости 0,05. Выполните расчеты вручную. Политическая принадлежность Республиканцы Демократы Независимые 800 700 900 346 Часть V Больше статистики! Больше инструментов! Больше веселья! 3.На основании следующих данных проверьте на уровне значимости 0,01, одинаковое ли количество мальчиков (код = 1) и девочек (код = 2) играет в начальной школе в футбол. (Эти данные также доступны в таблице в файле «Глава 17. Набор данных 3» (Chapter 17. Data Set 3).) Используйте SPSS или другую статистическую программу для вычисления точного значения вероятности хиквадрат. Каковы ваши выводы? Пол Мальчики = 1 Девочки = 2 45 55 4.Школьные работники, отвечающие за набор учеников, заметили изменение в распределении количества учеников по классам и сомневаются, является ли новое распределение тем, что они должны были бы ожидать. Проверьте следующие данные с помощью критерия согласия на уровне значимости 0,05. Класс Количество учащихся Проблема 5 1 309 2 432 3 346 4 432 5 369 6 329 5.Одна половина маркетологов кондитерской компании утверждает, что эти батончики одинаковы на вкус и едва отличаются друг от друга. Другая половина с ними не согласна. Кто прав? Данные ждут вашего анализа в таблице «Глава 17. Набор данных 4» (Chapter 17. Data Set 4). Шоколадные батончики Орешки без спешки Беконовый сюрприз Димплс Фрогги Шоколадное наслаждение Количество людей, которым они нравятся (на 100 чел.) 9 27 16 17 31 6.Вот результаты опроса, в котором изучалось предпочтение орехового или обычного драже «M&Ms» и уровень тренировок. Связаны ли эти переменные? Сделайте расчеты вручную или при помощи SPSS. Предпочтения «M&Ms» Обычные С орехами Уровень тренировок Сложные Средние Простые 160 400 175 150 500 250 Глава 17 Что делать с ненормальными 347 7.В наборе данных под названием «Глава 17. Набор данных 5» (Chapter 17. Data Set 5) вы найдете ячейки с двумя переменными: категория возраста (молодой, средний и пожилой) и силы после весовых тренировок (слабая, средняя, большая). Являются ли эти факторы не зависящими друг от друга? Возраст Молодой Средний Пожилой Слабая 12 20 9 Сила Средняя 18 22 10 Сильная 22 20 5 18 Еще несколько (важных) статистических процедур, о которых вам стоит знать Уровень сложности: (довольно легко – просто немного текста и продолжение того, о чем вы уже знаете) В ЭТОЙ ГЛАВЕ ВЫ УЗНАЕТЕ: о более продвинутых статистических процедурах и о том, когда и как их применять. Введение в главу 18 В «Статистике для тех, кто…» мы рассмотрели только небольшую часть всей области статистики. У нас нет места в этом учебнике, чтобы охватить все, т. к. всего очень много! Что еще важнее, когда вы только приступаете к изучению, важно начинать с простых и понятных вещей. Однако это не означает, что в научной статье, которую вы читаете, или на обсуждении на занятии вам не встретятся другие аналитические методики, о которых вам будет полезно знать. Так что вот девять таких методик для вашего дальнейшего образования с описаниями того, что они делают, и примерами исследований, в которых применялись эти методики для поиска ответа на вопрос. МНОГОМЕРНЫЙ ДИСПЕРСИОННЫЙ АНАЛИЗ 348 Вряд ли вас удивит, что существует множество различных вариаций дисперсионного анализа (ANOVA), каждая из которых разработана Глава 18 Еще несколько (важных) статистических процедур для определенной ситуации «сравниваем средние значения более чем у двух групп». Одна из них, многомерный дисперсионный анализ (MANOVA), применяется, когда имеется более чем одна зависимая переменная. Так что, вместо того чтобы рассматривать только один результат или зависимую переменную, этот анализ может работать с несколькими. Если зависимые, или результирующие, переменные связаны друг с другом, как обычно и бывает (см. технические подробности о множественных t-критериях в главе 13), то будет сложно четко определить влияние экспериментальной переменной на отдельный результат. И здесь MANOVA спешит на помощь. Например, Джонатан Плакер (Jonathan Plucker) из Университета Индианы проверил влияние пола, расы и класса обучения на то, каким образом одаренные подростки справляются с давлением в школе. В исследовании применялся многомерный дисперсионный анализ 2 (пол: мужской и женский) × 4 (раса: европейцы, афроаме­ риканцы, азиаты и латиноамериканцы) × 5 (классы: от 8 до 12). Многомерная часть анализа заключалась в использовании пяти вариантов шкалы стрессоустойчивости для подростков. При помощи многофакторной методики можно оценить влияние независимых переменных (пол, раса и класс) на каждую из пяти шкал, причем независимо друг от друга. Хотите узнать больше? Найдите в интернете или библиотеке статью… Plu­cker J. A. Gender, race, and grade differences in gifted adolescents’ coping strategies. Journal for the Education of the Gifted, 1998. Р. 423– 436. 349 Многомерный дисперсионный анализ ДИСПЕРСИОННЫЙ АНАЛИЗ ПОВТОРНЫХ ИЗМЕРЕНИЙ Вот еще один вид дисперсионного анализа. Дисперсионный анализ повторных измерений очень похож на любой другой дисперсионный анализ, в котором, как вы помните, средние значения двух или более групп проверяются на различия (см. главу 13, если вам нужно повторить тему). Для дисперсионного анализа повторных измерений участники тестируются по одному и тому же фактору несколько раз. Поэтому измерения и называются повторными, ведь вы повторяете процесс измерения одного и того же фактора в нескольких временных точках. Например, Бренда Лунди (Brenda Lundy), Тиффани Филд (Tiffany Field), Кэми МакБрайд (Cami McBride), Тори Филд (Tory Field) и Шей Ларги (Shay Largie) изучили взаимодействия с лучшими друзьями одного и того же и противоположного пола учащихся средних и старших классов. Одним из основных инструментов анализа служил дисперсионный анализ по трем факторам, таким как пол (мужской или Дисперсионный анализ повторных измерений 350 Часть V Больше статистики! Больше инструментов! Больше веселья! женский), дружба (со своим полом или противоположным) и класс обучения в школе (средний или старший). Измерения повторялись по классу обучения в школе, т. к. те же самые участники несколько раз проходили опрос в разных классах школы. Хотите узнать больше? Найдите в интернете или библиотеке статью… Lundy B., Field T., McBride C., Field T. & Largie S. Same-sex and opposite-sex best friend interactions among high school juniors and seniors. Adolescence, 1998. Р. 279–289. КОВАРИАЦИОННЫЙ АНАЛИЗ Ковариационный анализ А это наша последняя вариация дисперсионного анализа. Ковариационный анализ (ANCOVA) представляет особый интерес, потому что, по сути, он позволяет вам уравнивать исходные различия между группами. Скажем, что вы спонсируете программу по увеличению скорости бега и хотите сравнить, как быстро две группы атлетов пробегают стометровую дистанцию. Поскольку сила часто связана со скоростью, вы должны внести некоторые корректировки, чтобы не учитывать влияния силы на различия в результатах в конце программы. Вам, вероятно, хочется увидеть эффект от тренировок за вычетом силы. Тогда вы измерите силу участников перед началом программы, а затем воспользуетесь ковариационным анализом, чтобы скорректировать итоговую скорость на основании изначально замеренной силы. Микаэла Хайни (Michaela Hynie), Джон Лидон (John Lydon) и Али Тарадаш (Ali Taradash) из Университета Макгилла использовали ковариационный анализ в своем исследовании влияния доверительных отношений и ответственности на допустимость добрачного секса и использование контрацептивов. В рамках ANCOVA они использовали социальную допустимость сексуальной активности в качестве зависимой переменной (по которой они искали различия между группами), а рейтинги конкретных сценариев – как ковариат. Ковариационный анализ дал возможность скорректировать различия в социальной допустимости при использовании рейтингов, так что это различие было контролируемым. Хотите узнать больше? Найдите в интернете или библиотеке статью… Hy­nie M., Lydon J. & Taradash A. Commitment, intimacy, and women’s perceptions of premarital sex and contraceptive readiness. Psychology of Women Quarterly, 1997. Р. 447–464. Глава 18 Еще несколько (важных) статистических процедур 351 МНОЖЕСТВЕННАЯ РЕГРЕССИЯ В главе 16 вы узнали, как можно использовать значение одной переменной для предсказания значения другой. Этим анализом часто интересуются исследователи в области социальных и поведенческих наук. Например, довольно хорошо установлено, что родительские привычки чтения (например, наличие книг в доме) связаны с количеством и качеством чтения у их детей. Так что кажется довольно интересным взглянуть на такие переменные, как возраст родителей, уровень образования, связанную с книгами деятельность и совместное чтение с детьми, чтобы проверить, что вносит каждая из них в раннее языковое развитие и интерес к книгам. Паула Лии­ тинен (Paula Lyytinen), Марья-Леена Лааксо (Marja-Leena Laakso) и Анна-Майя Пойккеус (Anna-Maija Poikkeus) именно это и сделали, применив ступенчатый регрессионный анализ для изучения влияния переменных родительских характеристик на грамотность детей. Они обнаружили, что материнский уровень образования и связанная с книгами деятельность вносят значимый вклад в языковые навыки детей, тогда как возраст матерей и совместное чтение – нет. Хотите узнать больше? Найдите в интернете или библиотеке статью… Lyyti­nen P., Laakso M. L. & Poikkeus A. M. Parental contributions to child’s early language and interest in books. European Journal of Psychology of Education, 1998. Р. 297–308. Множественная регрессия МЕТААНАЛИЗ Если только вы не ушли на каникулы на весь семестр и не устроили себе полный отдых от чтения даже местных газет, то знаете, что сейчас время огромного потока данных. Специалисты по количест­ венному анализу в мире бизнеса перемалывают данные, чтобы получить малейшее конкурентное преимущество. И есть еще всесторонне подготовленные парни из статистики, такие как Нэйт Силвер (Nate Silver). Он при помощи собственных моделей вероятности очень точно предсказал результаты президентских выборов в США в 2012 г. Один из инструментов, которыми пользуются эти «щелкунчики данных», а также многие ученые в области социальных и поведенческих наук, – это метаанализ. Исследователи комбинируют данные из нескольких работ, чтобы изучить паттерны и тренды. Учитывая, сколько данных сегодня собрано, метаанализ является мощным инструментом, помогающим организовать разрозненную информацию и направлять стратегические решения. Например, эта методология приносит пользу, когда речь заходит об изучении гендерных различий. Существует множество исследова- 352 Часть V Больше статистики! Больше инструментов! Больше веселья! ний, показывающих так много различий (и отсутствие таковых), что методика вроде метаанализа, определенно, может помочь прояснить значение результатов всех этих работ. Если говорить о результативности на работе, то существует множество различных взглядов на гендерные различия. Филип Рот (Philip Roth), Кристен Первис (Kristen Purvis) и Филип Бобко (Philip Bobko) предположили, что во многих ситуациях, включая результаты работы, мужчин в целом оценивают выше, чем женщин. Для того чтобы прояснить природу различий, найденных в результативности труда у разных полов, эти исследователи провели метаанализ показателей результативности из полевых исследований. Они обнаружили, что, в то время как рейтинги результативности были выше у женщин, рейтинги потенциа­ла карьерного роста были выше у мужчин. Это очень интересная штука! И хороший пример того, как методика метаанализа дает точный обзор результатов множества различных исследований. Хотите узнать больше? Найдите в интернете или библиотеке статью… Roth P. L., Purvis K. L., & Bobko P. A meta-analysis of gender group differences for measures of job performance in field studies. Journal of Management, 2012. Р. 719–739. ДИСКРИМИНАНТНЫЙ АНАЛИЗ Поскольку принадлежность к той или иной группе часто является интересующей нас переменной, дискриминантный анализ оказывается очень полезной техникой, когда вы хотите увидеть, какой набор переменных отличает одних людей от других. Например, он может ответить на такие вопросы, как какой набор переменных отличает пациентов, получающих лечение А, от тех, кто получает лечение Б. Он дает нам представление о том, как различные оценки могут отличать одну группу от другой. Исследователи из Государственного университета Янгстауна изуча­ли студентов, записавшихся на университетский курс экономической статистики. В частности, их интересовало, чем отличаются друг от друга те, кто пользуется и не пользуется интернет-инструкциями в качестве дополнения к традиционным аудиторным лекциям и решению задач. Они использовали дискриминантный анализ, чтобы сравнить мнения пользователей и не-пользователей. Пользователи полагали, что дистанционное обучение через интернет является не только хорошим способом получения информации, но также и полезным инструментом для повышения академической успеваемости по предмету. Не-пользователи думали, что университет должен давать финансовую помощь на подключение к сети и что интернет-задания не должны быть обязательным требованием для выпуска. А теперь вы знаете, почему нужно быть поклонником интернет-обуче­ния! Глава 18 Еще несколько (важных) статистических процедур 353 Хотите узнать больше? Найдите в интернете или библиотеке статью… Usip E. E. & Bee R. H. Economics: A discriminant analysis of students’ perceptions of web-based learning. Social Science Computer Review, 1998. Р. 16–29. ФАКТОРНЫЙ АНАЛИЗ Факторный анализ – это методика, основанная на том, насколько тесно различные объекты связаны друг с другом и как они формируют кластеры или факторы. Каждый фактор представляет несколько переменных, и факторы оказываются более полезными для описания результатов некоторых исследований, чем отдельные переменные. При использовании данной методики цель состоит в том, чтобы описать связанные друг с другом вещи более общим термином, а именно фактором. Названия, которые вы даете факторам, не выбираются с бухты-барахты; они отражают содержание и идеи, лежащие в основе того, как могут быть связаны переменные. Например, Давид Вольф (David Wolfe) и его коллеги из Университета Западного Онтарио попытались понять, как влияет опыт плохого обращения, полученный детьми в возрасте до 12 лет, на дружеские и любовные отношения в подростковом периоде. Для этого исследователи собрали данные по многим переменным, а затем посмотрели на отношения между всеми ними. Те, которые, как казалось, содержали связанные данные (и принадлежали к группе, которая имела теоретический смысл), были объединены в факторы, такие, например, как фактор под названием «Насилие/Вина» в этом исследовании. Другой фактор, называющийся «Позитивная коммуникация», состоял из 10 компонентов, каждый из которых был связан со всеми другими. Хотите узнать больше? Найдите в интернете или библиотеке статью… Wol­fe D. A., Wekerle C., Reitzel-Jaffe D. & Lefebvre L. Factors associated with abusive relationships among maltreated and non-maltreated youth. Developmental Psychopathology, 1968. Р. 61–85. АНАЛИЗ ПУТИ Вот еще одна статистическая методика, которая изучает корреляцию, но позволяет исследователям предположить направление, или причинность, в связи между факторами. Анализ пути в целом изучает направление связи посредством первоначального постулирования некоего теоретического отношения между переменными и последующей проверки, поддерживается ли направление этой связи имеющимися данными. 354 Часть V Больше статистики! Больше инструментов! Больше веселья! Например, Анастасия Эфклидес (Anastasia Efklides), Мария Пападаки (Maria Papadaki), Георгия Папантониу (Georgia Papantoniou) и Грегорис Киоссеоглоу (Gregoris Kiosseoglou) проверили индивидуальные случаи трудностей, связанных с изучением математики. Для этого они провели несколько типов тестирования (таких, например, как проверка когнитивных способностей) и обнаружили, что ощущение сложности в основном формируется под влиянием когнитивных (связанных с решением проблем), а не аффективных (эмоциональных) факторов. Одно из самых интересных применений анализа пути заключается в использовании методики под названием «моделирование структурных уравнений» для представления результатов в виде графического изображения взаимосвязей между всеми рассматриваемыми факторами. Таким образом, вы можете в самом деле увидеть, что, с чем и в какой степени связано. Затем вы можете оценить, согласуются ли ваши данные с ранее предложенной мо­делью. Круто. Хотите узнать больше? Найдите в интернете или библиотеке статью… Efkli­des A., Papadaki M., Papantoniou G. & Kiosseoglou G. Individual differences in fee­lings of difficulty: The case of school mathematics. European Journal of Psychology of Education, 1998. Р. 207–226. МОДЕЛИРОВАНИЕ СТРУКТ УРНЫХ УРАВНЕНИЙ Моделирование структурных уравнений Моделирование структурных уравнений (structural equation mode­ ling – SEM) – это относительно новая методика, набирающая все большую популярность с момента ее разработки в 1960-х гг. Некоторые исследователи полагают, что это зонтичный термин для таких методик, как регрессионный и факторный анализы и анализ пути. Другие считают его подходом самостоятельным и полностью отдельным от других. Моделирование основано на отношениях между переменными (так же, как и три предыдущие описанные методики). Основное различие между SEM и другими продвинутыми методиками вроде факторного анализа состоит в том, что SEM является скорее утверждающим, чем исследующим. Другими словами, исследователь будет использовать моделирование структурных уравнений, чтобы подтвердить, что какая-то предложенная модель работает (т. е. что данные согласуются с этой моделью). Исследующие методики, напротив, нацелены на то, чтобы обнаружить определенные связи с меньшим (или вообще отсутствующим) предварительным моделированием. Например, Хизер Готэм (Heather Gotham), Кеннет Шер (Kenneth Sher) и Филлип Вуд (Phillip Wood) изучили связь между алкоголизмом у молодых людей, переменными, описывающими их более ранний опыт (такими как пол, семейная история алкоголизма, факторы Глава 18 Еще несколько (важных) статистических процедур стресса в детстве, рейтинг в старших классах школы, религиозность, невротизм, экстраверсия, психотизм), и задачами развития (завершением обучения в бакалавриате, полной занятостью, браком). При помощи методики моделирования структурных уравнений они обнаружили, что переменные, описывающие юношеский опыт, куда точнее предсказывали выполнение задач развития, чем диагноз юношеского алкоголизма. Хотите узнать больше? Найдите в интернете или библиотеке статью... Gotham H. J., Sher K. J. & Wood P. K. Alcohol involvement and developmental task completion during young adulthood. Journal of Studies on Alcohol, 2003. Р. 32–42. 355 Реальная статистика ВЫВОДЫ ПО ГЛАВЕ Несмотря на то что вы, вероятно, не будете в ближайшее время использовать эти более продвинутые процедуры, все равно есть причина узнать о них хоть что-то, потому что вы наверняка увидите упоминания о них в различных научных публикациях, а может, даже услышите о них на занятиях по другим предметам. Имея базовое понимание этих методик в сочетании с пониманием основ статистики (из всех глав данной книги вплоть до этой), вы можете быть уверены, что усвоили большую долю важной информации о начальной ста­ тистике (и даже немного из статистики среднего уровня). Выводы по главе 19 Интеллектуальный анализ данных Знакомство с тем, как выжать максимум из ваших БОЛЬШИХ данных В ЭТОЙ ГЛАВЕ ВЫ УЗНАЕТЕ: что такое интеллектуальный анализ данных; как интеллектуальный анализ данных может помочь извлечь смысл из очень больших наборов данных; как применить базовые методики интеллектуального анализа при помощи SPSS; как анализировать большие наборы данных с помощью свободных таб­лиц. Что такое интеллек­ туальный анализ данных? 356 К тому времени, когда вы будете читать это 6-е издание «Ста­ тистики для тех, кто…», количество данных, имеющихся в распоряжении ученых, политиков, спортивных обозревателей, профессионалов здравоохранения, бизнесменов и просто всех, кто имеет дело с данными, будет уже просто астрономическим, причем будет продолжать расти, расти и расти. Они не просто так называются БОЛЬШИМИ данными. Насколько они большие? В настоящее время информация измеряется эксабайтами, что равно 1 152 921 504 606 846 976 байтам (где каждый байт представляет собой 1 или 0), или примерно 1 квинтиллиону байт. И сейчас существует около 1000 экзабайт информации (и этот объем стремительно возрастает). Это действительно много. Почему данных так много, и что мы можем с ними делать? Технологические достижения способствуют большей взаимосвязанности между институтами, людьми и машинами (скоро вы увидите интернет вещей на собственном компьютере), и та же самая технология позволяет собирать каждый имеющийся отдельный кусочек данных, если может быть обеспечена их приватность и другие моменты (и суды все еще занимаются этими моментами). Подумайте об интернете всего. Глава 19 Интеллектуальный анализ данных Вы удивитесь, насколько «большие» эти данные, и сколько их вокруг нас, в том числе: zz записи о медицинском обслуживании; zz взаимодействия в соцсетях; zz подробный анализ спортивных событий; zz что вы купили онлайн, когда, сколько это стоило, какая следующая покупка может заинтересовать вас; zz ваша ежедневная физическая активность; zz картирование человеческого генома; zz анализ данных о погоде и ее прогнозы; zz маршруты движения транспорта; zz даже такая вроде бы безобидная информация о том, сколько батончиков «Твинки» продается каждый год (ладно, ладно… 500 млн). Бизнес – он обожает большие данные, потому что люди, желающие продавать продукты и услуги, полагают (в чем-то вполне обоснованно), что эту груду информации можно проанализировать, чтобы понять паттерны (в чем и состоит суть анализа больших данных) потребительского поведения на самом микроуровне. После этого результаты анализа данной информации можно будет использовать для предсказания, понимания и влияния на покупательские привычки потребителей. Задумывались когда-нибудь, откуда «Амазон» знает, что вы недавно искали, и затем предлагает альтернативные продукты? Из аналитики, вот откуда – а это просто другое название интеллектуального анализа данных. Все эти данные бесценны, но информации так много, что очень сложно вычленить из нее какой-то смысл. Тут нужен набор инструментов, которые могут искать паттерны, и здесь-то и появляется интеллектуальный анализ данных (и SPSS). Хорошо, значит, это большие данные. Есть вал работы для обладателей математических способностей, готовых изучать эти данные (этих ребят часто называют «квантами», как в фильме «Игра на понижение»). Но будьте начеку: большие данные вовсе не означают хорошие данные, а мы склонны думать, что чем больше, тем лучше (а это верно только на День благодарения). Итак, поскольку вы наверняка столк­нетесь с большими данными в том или ином виде, необходимо задавать себе о них те же вопросы, что и обо всех наборах данных, в том числе: откуда эти данные взялись, могут ли они помочь ответить на заданный вопрос, надежны и валидны ли они, кто их собрал и с какой целью­ или намерением и т. д. Мы подозреваем, что в ближайшие годы анализ больших данных принесет значительные находки во многих областях, но мы также думаем, что необходимо будет заняться возможными ловушками больших данных и их применения. 357 358 Часть V Больше статистики! Больше инструментов! Больше веселья! Эта глава посвящена простому вопросу: как найти смысл в очень больших наборах данных. Наша цель состоит в том, чтобы сделать эти наборы данных более управляемыми при помощи инструментов, позволяющих легко добывать нужную нам информацию. Для этого в главе дается общее описание применения SPSS для интеллектуального анализа данных (который состоит в поиске паттернов в больших наборах данных) и обсуждаются различные опции SPSS, которые помогут вам разобраться с большими наборами данных. Вы также получите краткий вводный курс по сводным и комбинационным таблицам, которые можно перестраивать одним щелчком мыши, так чтобы видеть информацию конкретным образом. Ни для кого не станет сюрпризом, что существует целая отрасль, посвященная интеллектуальному анализу данных. Эти компании, фирмы и т. д. стремятся работать в соответствии с межотраслевым стандартом интеллектуального анализа – CRoss-Industry Standard Processfor DataMining (CRISP-DM). Эти пошаговые инструкции помогают поддерживать согласованность во всех попытках интеллектуального анализа данных. А сейчас несколько больших оговорок для этой главы. Во-первых, SPSS предлагает продвинутый набор инструментов для интеллектуального анализа данных и текста под названием SPSS Modeler. Это дополнение к обычному пакету SPSS, и крайне маловероятно, что оно будет доступно в вашем учебном заведении (так же, как и в домашних пакетах). Так что, стремясь сделать эту главу как можно более доступной для многих пользователей этой (и других) книги, мы сфокусируемся на функциях SPSS, которые не связаны со средством моделирования. Во-вторых, эта глава дает представление о том, как работать с большими наборами данных при помощи SPSS. Все, что вы здесь прочитаете, можно применить и к малым наборам данных, но мы хотим показать вам, как эти инструменты помогают найти смысл в очень больших наборах. Меньшие наборы данных почти всегда можно проверить на наличие трендов или паттернов визуально. В-третьих, и позже мы скажем об этом больше, набор данных, с которым мы работаем в этой главе, был взят с веб-сайта, и он изменяется каждый месяц или около того с появлением новых данных. То, что вы видите на экране, может не совпадать с цифрами в этой главе. Однако, несмотря на то что содержание может немного различаться, формат и инструкции останутся теми же. Глава 19 Интеллектуальный анализ данных 359 НАШ ПОДОПЫТНЫЙ НАБОР ДАННЫХ – КТО НЕ ЛЮБИТ МЛАДЕНЦЕВ? В сущности, БОЛЬШИЕ данные – это очень большая коллекция случаев или переменных, а обычно и того, и другого. Концептуально большие данные представляют собой набор данных, огромный для того, чтобы «пробежаться по нему глазами» и понять, какие в нем могут быть тренды или какие важные, возможно, не столь очевидные, паттерны в нем присутствуют. Для целей демонстрации выбрали базу данных под названием «Baby Names: Beginning 2007» («Имена младенцев: начиная с 2007 г.») с сайта https://health.data.ny.gov/Health/Baby-Names-Beginning-2007/ jxy9-yhdk/. Это база данных штата Нью-Йорк, содержащая более 52 000 (достаточно большая?) имен детей. База показывает год рождения, имя ребенка, название округа или района Нью-Йорка, в котором проживала мать в соответствии с сертификатом о рождении ребенка, пол ребенка и количество (или частота) раз, с которым это имя встречается в наборе данных. Переменные таковы: zz Year_of_Birth (год рождения); zz First_Name (имя); zz County (округ рождения); zz Count (количество (сколько раз встречается это имя)); zz Gender (пол). Например, на рис. 19.1 вы можете видеть несколько первых запи­сей. Рис. 19.1 Несколько первых записей в базе данных имен младенцев База данных имен младенцев изменяется со временем, потому что в нее по мере поступления добавляется новая информация. Такое происходит со многими онлайновыми базами данных, особенно когда они финансируются правительственными агентствами. Так что, поскольку примеры в этой главе отображают данные, доступные в момент ее написания, полученные вами результаты могут отличаться по содержанию. Однако их формат будет таким же. Другими словами, могут быть различия в числах, которые вы видите, но не в их представлении. 360 Часть V Больше статистики! Больше инструментов! Больше веселья! Общественности доступны тысячи баз данных, похожих на базу данных имен младенцев, и есть множество мест, в которых вы можете их найти. Некоторые базы данных позволяют только делать поиск по ним, например Большая база данных комиксов (Grand Comics Database – http://comics.org), тогда как другие базы содержат данные, которые можно скачивать, обычно в разнообразных форматах. В данном случае база «Baby Names» была доступна для скачивания в виде .csv-файла с сайта data.gov, где вы можете найти более чем 100 000 наборов данных, в том числе в таких категориях, как здравоохранение, погода, изучение потребителей, научные исследования. SPSS может с легкостью читать и конвертировать .csv-файл в файл с расширением .sav. Бродить по базам данных на data.gov весело. Возможно, вы также захотите заглянуть на DataUSA (http://datausa.io), проект Массачусетского технологического института, который делает данные с data.gov прозрачными и простыми для понимания, а также предлагает очень классный визуальный интерфейс, чтобы помочь с их пониманием. Есть еще целая часть SPSS, которая называется SPSS Syntax. Там вы можете пользоваться командами (такими как COMPUTE (Вычислить) и SUM (Сумма)) для выполнения действий в SPSS с большим контролем и точностью, чем при использовании меню, как мы делали на протяжении всей этой книги. Использование команд из меню удобнее и быстрее, но дает меньше контроля. SPSS Syntax – это в каком-то смысле язык программирования SPSS. Мы не будем углубляться в SPSS Syntax в этой главе, но вы должны знать, что он существует и что вы всегда можете попробовать его. Просто откройте новое окно Syntax из Файл (File) ⇒ Новое меню (New menu) и примените разные функции к любому набору данных. Посмотрите, что получится! ПОДСЧЕТ РЕЗУЛЬТАТОВ В SPSS есть много «подсчитывающих» команд, которые очень полезны для агрегирования и понимания сущности данных в большом наборе данных. Вот только несколько из этих команд с примерами их использования. Подсчет по частотам Подсчет по частотам У вас есть этот большой набор данных по именам младенцев, и вы хотите подсчитать количество записей по годам. Вот как это можно сделать. Глава 19 Интеллектуальный анализ данных 1.Нажмите Анализ (Analyze) ⇒ Описательные статистики (Descriptive Statistics) ⇒ Частоты (Frequencies), и вы увидите диалоговое окно, как на рис. 19.2. 2.Щелкните по Year (Год рождения) и переместите его в поле Переменные (Variables(s)). 3.Нажмите на ОК, и вы увидите количество имен младенцев в каждом году, как показано на рис. 19.3. Рис. 19.2 Диалоговое окно Частоты Рис. 19.3 Результаты простого анализа частот Если понадобится, вы можете выполнить эту же операцию по любой другой переменной, включая текстовые или строковые переменные, такие как FirstName (Имя), результаты для которого вы видите на рис. 19.4. Он показывает, например, что среди 52 000+ имен 361 362 Часть V Больше статистики! Больше инструментов! Больше веселья! (на самом деле 52 252) имя Abigail (Эбигейл) встречается 235 раз (что составляет 0,4 % от всех имен), а Aahil (Ахил) встречается всего однажды. Крайне маловероятно, что вы смогли бы определить частоту любого имени младенца, просто просматривая набор из 52 000+ имен, но применение программы вроде SPSS вытаскивает все частоты на поверхность. Рис. 19.4 Результаты применения подсчета частот для текстовых или строковых значений Еще один эффективный инструмент SPSS – это опция Таблицы сопряженности (Crosstabs) в меню Анализ (Analyze), которая позволяет создавать таблицы для более чем одной переменной. Таблицы сопряженности суммируют категориальные данные (такие как год или пол в базе данных имен младенцев, с которой мы работаем), чтобы создать таблицу с суммами по строкам и столбцам и подсчетом значений в ячейках. Например, если бы мы хотели знать, сколько мальчиков и девочек, родившихся в каждом году, содержит наш набор данных, мы бы выполнили следующие шаги. Глава 19 Интеллектуальный анализ данных 1.Нажмите Анализ (Analyze) ⇒ Описательные статистики (Descriptive Statistics) ⇒ Таблицы сопряженности (Crosstabs), и вы увидите диалоговое окно, как на рис. 19.5. 2. Переместите переменную Year (Год) в поле Строки (Row(s)). 3. Переместите переменную Sex (Пол) в поле Столбцы (Column(s)). 4. Нажмите ОК, и вы увидите результаты анализа, как на рис. 19.6. Рис. 19.5 Диалоговое окно Таблицы сопряженности Рис. 19.6 Результаты анализа таблиц сопряженности 363 364 Часть V Больше статистики! Больше инструментов! Больше веселья! Например, 3365 мужских имен были даны новорожденным в 2007 г., а 4121 женское имя – в 2014 г. Еще раз повторим, что использовать такие наблюдения разумно только тогда, когда вы можете взять и проанализировать все отдельные данные в большом наборе данных. Это легко можно сделать с инструментом вроде SPSS. СВОДНЫЕ ТАБЛИЦЫ И ТАБЛИЦЫ СОПРЯЖЕННОСТИ: НАХОДИМ СКРЫТЫЕ ПАТТЕРНЫ После того как вы организовали «сырые» данные, как было показано в этой главе, пора задуматься о том, как можно «раскопать» эту информацию дальше в поисках паттернов, которые могут помочь вам принять важные решения. Для этих целей весьма полезен такой инструмент, как сводные таблицы – особый тип таблиц, позволяющий легко визуализировать и манипулировать рядами и строками наряду с содержимым ячеек. Существует много разных способов создания, использования и изменения сводных таблиц в SPSS. Мы покажем вам примеры тех, которые, по нашему мнению, проще всего использовать и понимать. Создание сводной таблицы Создание сводной таблицы Когда сводные таблицы впервые появились в программах статистического анализа, их создание и использование были утомительными и занимали много времени. К счастью, в новых версиях SPSS сводная таблица находится лишь в нескольких кликах мышкой от вас. Управление таблицей состоит просто в перетаскивании заголовка строки или столбца либо содержимого ячеек на новое место. Всем сводным таблицам нужно что-то, вокруг чего «сводиться», так что в SPSS вам понадобится определенный вывод, на котором вы будете работать. Другими словами, вам сначала нужно создать таб­ лицу с результатами, чтобы затем сделать и использовать сводную таблицу. Обратите внимание, что все таблицы в SPSS можно сделать сводными – это лишь вопрос понимания, что вы хотите отобразить и каким образом. Давайте воспользуемся примером с именами младенцев и создадим сводную таблицу, чтобы показать количество женских и мужских имен, учтенных с 2007 по 2014 г. (это года рождения детей). Если вы хотите следовать за нашими действиями, вам понадобится вывести на экран таблицу сопряженности, которая показана на рис. 19.6. Глава 19 Интеллектуальный анализ данных Сводную таблицу можно создать практически для любых выводов SPSS, и их применение не ограничивается только таблицами сопряженности, выводами описательных статистик или частот. Какой бы вывод вы не сгенерировали, почти все их можно превратить в сводную таблицу. 1.Дважды щелкните по таблице с данными, из которых вы хотите сделать сводную таблицу. Когда вы это сделаете, увидите пунктирную линию снизу и справа от таблицы, как показано на рис. 19.7. 2.Щелкните правой клавишей мыши по выделенной таблице и выберите опцию Поля вращения (Pivoting Trays), как показано на рис. 19.8. Рис. 19.7 Выделение таблицы для создания сводной таблицы Рис. 19.8 Поля вращения 365 366 Часть V Больше статистики! Больше инструментов! Больше веселья! Это было просто и быстро. Как видите, SPSS создает сводную таб­ лицу, разместив Sex (Пол) в столбцы, а Year (Год) в строки. Теперь, перетаскивая и компонуя столбцы и колонки так, как нам кажется удобным, мы можем организовать данные любым нужным способом, учитывая доступную исходную информацию и поля, по которым были организованы исходные данные. Например, если вы хотите увидеть таблицу, которая показывает год рождения по каждому полу, перетащите поле под названием Year (Год) в область COLUMN под записью Sex (Пол). Вы можете увидеть результат на рис. 19.9. Та же самая информация, но представление. Рис. 19.9 Сводная таблица, показывающая годы рождения по полу Помните, что если вы хотите создать таблицу со строками или столбцами, охватывающими более одной переменной, просто нужно перетащить эти переменные в область строк или столбцов в соответствии с тем, что диктует вам заданный вопрос. Ваши возможности изменять представление переменных или полей в сводной таблице ограничены только тем, какие переменные или поля вы задали изначально в заголовках строк или столбцов при вводе исходных данных. Так что в целом будьте дотошны и обстоятельны, поскольку никогда нельзя знать наверняка, что потребуется изучать в таблице, пока не наступит время ее изучения. Изменение сводной таблицы Как только вы получили представление информации, как на рис. 19.9, изменение и переосмысление сводной таблицы – это просто пара пустяков для вас. На рис. 19.10 вы видите таблицу сопряженности «Пол по округам», созданную так же легко, как и другие таблицы сопряженности в этой главе. Только в этот раз мы выбрали опцию Создать диаграмму ⇒ Столбчатую (Display clustered bar charts). На рис. 19.11 вы можете видеть получившуюся диа­грамму. Глава 19 Интеллектуальный анализ данных Рис. 19.10 Таблица сопряженности Рис. 19.11 Столбиковая диаграмма, отображающая данные из таблицы сопряженности Вы также можете создать таблицу, а затем использовать выпадающие меню, чтобы получить доступ к нужной информации. 367 368 Часть V Больше статистики! Больше инструментов! Больше веселья! Например, мы создали сводную таблицу, которая показывает количество повторений (Count) по году рождения (Year), а затем переместили каждую из этих переменных под поле Статистика (Statistics), как вы видите на рис. 19.12. Теперь мы можем воспользоваться выпадающими меню, чтобы изучить любую комбинацию значений из этой таблицы. Например, если мы хотим знать, сколько имен повторилось ровно 9 раз в 2009 г., мы просто выберем эти значения из выпадающего меню. Это даст нам результат, как на рис. 19.13, где мы можем видеть, что в 2009 г. было 255 различных имен, имеющих общую частоту 9 раз. Рис. 19.12 Использование выпадающих меню для выбора различных значений в сводной таблице Хотите принарядить свои таблицы сопряженности? Просто щелк­ ните правой клавишей мыши, а затем нажмите на Шаблоны таблиц (TableLooks) и выберите сочетание цвета и оформления, которое вам нужно. Глава 19 Интеллектуальный анализ данных 369 Рис. 19.13 Демонстрация точных результатов из сводной таблицы ВЫВОДЫ ПО ГЛАВЕ Довольно сложно дать даже введение к интеллектуальному анализу данных в книге с вводным курсом статистики, но в этой главе мы хотели показать вам, как таблицы сопряженности и сводные таблицы SPSS могут помочь в поиске паттернов в больших данных. Надеемся, это вдохновит вас на изучение наборов данных вроде тех, что вы найдете в главе 21. ВРЕМЯ ПРАКТИКИ 1.На основании данных из файла «Глава 19. Набор данных 1» (Chapter 19. Data Set 1) создайте таблицу сопряженности и покажите категорию усердия (поле Industriousness, имеет значения от 1 до 10, где 10 – самый усердный) как функцию от профессионального уровня (поле Proficiency, имеет значения от 1 до 5, где 5 – самый высокий уровень). Сколько участников на самом деле очень усердны, но не очень, мягко говоря, профессиональны? 370 Проблема 2 Часть V Больше статистики! Больше инструментов! Больше веселья! 2.На основании данных из файла «Глава 19. Набор данных 2» (Chapter 19. Data Set 2) создайте таблицу сопряженности, которая показывает количество женщин-атлетов уровня 4 на 1000 студентов. В наборе данных переменная Gender (Пол) имеет значения 1 = муж, 2 = жен. И пришло время сводных таблиц! Теперь сделайте диаграмму для результатов и покажите что-то визуально интересное и информативное. (Обратитесь к главе 4 за подсказками о создании диаграмм, которые нравятся людям.) 20 Подборка программ для статистического анализа Уровень сложности: (пустяковый!) В ЭТОЙ ГЛАВЕ ВЫ УЗНАЕТЕ: все о других программных продуктах, которые помогут вам анализировать, визуализировать и лучше понимать данные. Н е нужно быть ботаником или кем-то вроде того, чтобы ценить и наслаждаться тем, что могут дать различные компьютерные программы для изучения и применения базовой статистики. Задача этой главы состоит в том, чтобы дать вам обзор некоторых наиболее часто используемых программ и их основных свойств, а также быстро взглянуть на их работу. Но, прежде чем мы перейдем к описаниям, примите небольшой совет. Вы можете найти большой список программ и ссылок на домашние страницы компаний, создавших их, по адресу http:// en.wikipedia.org/wiki/List_of_statistical_packages. В этой главе мы рассматриваем только несколько из тех, которые нам действительно нравятся, так что если вам нужна программа (платная или бесплатная), загляните на эту страничку и потратьте время на ее изучение. КАК ВЫБРАТЬ ИДЕАЛЬНУЮ ПРОГРАММУ Д ЛЯ СТАТИСТИКИ? Вот несколько проверенных опытом рекомендаций, чтобы вы точно получили от программы статистического анализа то, что требуется: 1)дорогая ли программа (вроде SPSS) или не очень (как Statistica), обязательно опробуйте ее, прежде чем покупать. Почти 371 372 Программное обеспечение для статистики Часть V Больше статистики! Больше инструментов! Больше веселья! все перечисленные статистические программы предлагают для скачивания демоверсию (обычно на своем веб-сайте), а в некоторых (невероятно редких) случаях вы даже можете попросить компанию прислать вам демоверсию на CD. Эти версии могут даже быть полнофункциональными, имеющими срок работы до 30 дней, что дает кучу времени для испытаний перед покупкой; 2)если говорить о цене, то покупка напрямую от производителя может оказаться самым дорогим вариантом, особенно если вы покупаете сразу, не поинтересовавшись скидками для студентов и преподавателей (которые иногда называются образовательными скидками). Скидку можно найти в школьном книжном магазине, а у компании дистанционных продаж предложение может быть даже лучше (и еще раз напоминаем, спросите о студенческих скидках). Вы можете найти бесплатные номера телефонов этих продавцов в любом популярном компьютерном журнале. Может оказаться также, что некоторые учебники по статистике идут в комплекте с ограниченной/ студенческой версией программного обеспечения, а в некоторых случаях оно может быть полнофункциональным и готовым к использованию. А что лучше всего, многие учебные заведения и другие институты покупают у производителя лицензию на программы, которая разрешает скачивать их дома и пользоваться ими в компьютерных классах (разве это не здорово?); 3)многие вендоры, производящие программы для статистического анализа, предлагают две опции. Первая – это коммерческая версия, а вторая – академическая. Обычно они одинаковы по содержанию (но могут иметь очень специфичные ограничения, например по количеству переменных, которые вы можете тестировать) и всегда различны, иногда очень существенно, по цене. Если вы нацеливаетесь на академическую версию, убедитесь, что она такая же, как и полнофункциональная коммерческая. Если нет, спросите себя, проживете ли вы с этими различиями. Почему академическая версия продается настолько дешевле? Компания надеется, что, будучи сейчас студентом, вы завершите обучение, найдете какую-нибудь денежную работу и купите полную версию, навсегда перейдя на нее. Кроме того, академические версии часто доступны только на условиях аренды, так что их полезность истекает через 6 месяцев или год… читайте мелкий шрифт. Такие компании, как Student Discounts (http://studentdiscounts.com) и OnTheHub (http://onthehub.com), предлагают, например, SPSS по очень разумной ставке аренды; 4)трудно точно сказать заранее, что вам понадобится, когда вы начнете работу, но некоторые пакеты предлагаются по модулям. Зачастую вам не нужно покупать все из них, чтобы по- Глава 20 Подборка программ для статистического анализа лучить нужные для выполнения работы инструменты. Прочитайте каталоги и сайт компании, позвоните им и задайте вопросы; 5)еще один вариант – условно бесплатное и бесплатно распространяемое программное обеспечение, и можно найти множество таких программ. Условно бесплатное распространение – это способ распространения программного обеспечения, когда вы платите за него только в том случае, если оно вам понравилось. Звучит так, словно система держится на честном слове, да? Ну, так и есть. Предлагаемые взносы почти всегда очень разумны. Условно бесплатные программы зачастую лучше многих коммерческих продуктов. Если вы за них заплатите, то поддержите умных авторов и дадите им возможность продолжать разработку новых, еще более хороших версий продукта. Бесплатно распространяемое программное обеспечение именно такое и есть: бесплатное; 6)не покупайте программ, у которых нет телефона технической поддержки или хотя бы какого-то канала связи по электронной почте или через онлайн-чат. Для проверки позвоните на номер техподдержки (еще до покупки!) и проверьте, сколько времени потребуется, чтобы кто-то ответил на звонок. Если ваш звонок стоит в очереди уже 20 мин, это может указывать на то, что компания не относится к техподдержке достаточно серьезно, чтобы быстро получать вопросы пользователей. Если вы написали им письмо и не получили на него ответа, а также если их онлайн-чат, похоже, никогда не работает, то лучше поищите другой продукт; 7)почти все большие пакеты статистического анализа делают одинаковые вещи – разница только в том, как именно они их делают. Например, SPSS, Minitab и JMP отлично анализируют данные и вполне приемлемы. Но именно мелкие детали могут повлиять на впечатление. Например, возможно, вы хотите импортировать данные из другого приложения. Одни программы позволяют это делать, а другие – нет. Если какая-то конкретная опция имеет для вас значение, обязательно проверьте перед покупкой, что у программы она имеется; 8)убедитесь, что ваше оборудование может работать с программой, которую вы хотите использовать. Например, большинство программ не имеет ограничений по количеству случаев и переменных для анализа (если только вы не пользуетесь пробной версией). Единственным ограничением выступает объем хранилища данных, что становится все меньшей проблемой, т. к. многие программы теперь связываются с облачными серверами и т. п. Если у вас «медленный» компьютер и меньше 1 Гб оперативной памяти, тогда, вероятно, вам придется сидеть и глядеть на песочные часы, пока ваш центральный про- 373 Дополнительно о выборе программы статистического анализа 374 Часть V Больше статистики! Больше инструментов! Больше веселья! цессор выполняет задачу. Убедитесь, что ваше оборудование может работать с программой, перед загрузкой демоверсии; 9)операционные системы постоянно изменяются, но программы не всегда успевают за ними. Например, некоторые пакеты работают только на ОС Windows, при этом иные не работают на последних версиях Windows. Если сомневаетесь, позвоните в техподдержку и убедитесь, что в вашей системе есть все необходимое для работы программы. Некоторые статистические программы работают и на Windows, и на Mac OS, а многие пакеты сейчас также совместимы с Linux; 10)наконец, некоторые компании предлагают только загрузку продукта через интернет, так что вы не получите именно диска с программой. В целом это нормально, но тех, кто очень любит ставить все точки над i, может сводить с ума мысль о невозможности иметь свой собственный CD с программой. Еще раз повторим: проверьте все заранее. ЧТО ЖЕ У НАС ЕСТЬ? В мире существует больше программ статистического анализа, чем вам когда-либо может понадобиться. Вот список из некоторых наиболее популярных программ с указанием их выдающихся парамет­ ров. Помните, что многие из них делают одно и то же. Если это возможно, как мы подчеркивали выше, попробуйте, прежде чем покупать. Изучайте, изучайте, изучайте! Список статистических пакетов (со ссылками на многие из них) из Википедии (http://en.wikipedia.org/wiki/List_of_statistical_packages) включает в себя более 50 программ с открытым кодом (открытых для изменения пользователями), три общедоступные программы, шесть бесплатных программ и проприетарные (что означает, что вы должны будете заплатить) программы в количестве большем, чем вам когда-либо понадобится. Это хорошее место для начала поисков доступных вариантов под конкретные или общие потребности. Сначала о бесплатном Ничего не предпринимайте, пока не просмотрите список бесплатных статистических программ на странице Википедии, которую мы уже упоминали, и на http://freestatistics.altervista.org/?p=stat. Здесь есть множество пакетов, которые можно скачать и использовать для выполнения многих процедур, о которых вы узнали в «Статистике для тех, кто…». У нас нет возможности рассмотреть все из них в этой книге, но потратьте немного времени на то, чтобы осмотреться и выбрать то, что соответствует вашим потребностям. Глава 20 Подборка программ для статистического анализа 375 OpenStat Моя любимая программа на все времена! OpenStat (http://openstat. en.softonic.com/), написанная д-ром Биллом Миллером (Bill Miller) из Государственного университета Айовы. Что в ней такого хорошего? Ну, во-первых, она полностью бесплатна – никаких «бесплатна в течение 124 дней» или чего-то такого. Она очень похожа на SPSS и в некотором смысле даже легче в использовании (см. рис. 20.1). Она также включает в себя множество опций (гораздо больше, чем любая коммерческая платная программа), в том числе массу непарамет­ рических критериев, инструментов измерения и даже инструментов для финансового анализа (например, как для вопроса «сколько я смогу сэкономить, если рано выплачу кредит на обучение?»). И наконец, для тех, кто любит повозиться и настроить все под себя, «Open» в названии «OpenStat» означает, что у программы открытый код. Она написана на С++, и если вы хоть немного знаете этот язык, то сможете изменять ее конфигурацию так, как вам нужно. Это отличная сделка со всех сторон. А на сайте вы можете узнать о новой программе, совместимой с операционными системами Linux и Mac OSX. Рис. 20.1 Окно ввода данных OpenStat PSPP – (почти) SPSS Если вы не можете избавиться от очарования SPSS, но у вас нет сотен долларов, которые можно потратить, посмотрите на PSPP (креа­ тивное название, а?) по адресу http://www.gnu.org/software/pspp/, которая является версией с открытым программным кодом для про- 376 Часть V Больше статистики! Больше инструментов! Больше веселья! граммы, очень близко повторяющей SPSS. Вы действительно можете делать в ней многое бесплатно, получив очень наглядное представление о том, как выглядит и как работает SPSS. Если вы любите возиться с настройками, открытый исходный код этой программы (и все это движение) дает вам полную свободу изменения кода и внесения предложений по улучшению программы. R А если вы готовы к масштабным вычислениям, то обратитесь к программе с открытым кодом под названием R (возможно, названной так в честь двух ее авторов, Роберта Джентльмена (Robert Gentleman) и Росса Айхаки (Ross Ihaka)). У R есть несколько коммерческих версий, к которым предлагается полная техническая поддержка, но существует также огромное сообщество пользователей R, способных прийти на помощь. R также является программой с открытым кодом (как PSPP) и имеет свой собственный журнал (The R Journal). Она работает на платформах Linux, Unix, Windows и Mac. К ней действительно нужно сначала привыкнуть. Однако, из-за того что она управляется через командную строку (это означает, что вы не щелкаете мышкой, но вводите команды вручную), она невероятно гибко подстраивается под то, что вы говорите ей сделать, а также каким образом. Найти все, что вы хотите знать о R, а также скачать ее можно по адресу http://www.r-project.org. Это очень мощная программа, ограниченная только пользовательским пониманием ее возможностей. Скриншот программы можно увидеть на рис. 20.2. Рис. 20.2 Снимок экрана программы R Глава 20 Подборка программ для статистического анализа 377 Час расплаты JMP JMP (доступная сейчас в виде версии 12 и как часть статистической системы анализа) рекламируется как программа для «статистических открытий». Она работает на платформах Mac, Windows и Linux и «связывает статистику с графикой для интерактивного изучения, понимания и визуализации данных». Одна из особенностей JMP – это вывод диаграммы для каждой статистики, так что вы всегда можете видеть результаты анализа и в текстовом, и в графическом виде. И все это происходит автоматически, без запроса со стороны пользователя. Хотите узнать больше? Зайдите на http://www.jmp.com. Стоимость: 1620 долл. за лицензию на одного пользователя и 2995 долл. за академическую лицензию на 3 года. JMP Student Edi­tion встречается во многих учебниках, но недоступна в качест­ ве самостоятельного продукта. Minitab Это одна из первых статистических программ, которая стала доступной для персональных компьютеров. Сейчас вышла уже версия 17 (она уже давненько существует!). Это означает, что программа за эти годы много менялась в ответ на потребности клиентов. Вот некоторые наиболее выдающиеся черты данной версии: zz Quality Trainer™ – онлайн-курс для обучения пользователя (который также можно приобрести отдельно); zz ReportPad™ – инструмент для создания отчетов; zz менеджер проектов, который организует анализ; zz Smart Dialog Boxes™ – диалоговые окна, запоминающие недавние настройки. На рис. 20.3 вы можете увидеть, как выглядит вывод Minitab для простого регрессионного анализа. Хотите узнать больше? Зайдите на http://www.minitab.com. Стоимость: 1495 долл. за полноценную лицензию на одного пользователя, но есть также разнообразные опции аренды с разной ценой за разные периоды, в том числе полугодовая лицензия за 30 долл. Этот продукт стоит выбирать, если вы готовы потратить деньги и вам нужен мощный набор инструментов. STATISTICA Компания «StatSoft» (принадлежащая «Делл») предлагает семейство продуктов STATISTICA (версия 13.1) для Windows (вплоть до последней Windows 10), но, простите, без версии для Mac. Некоторые из особо приятных функций этой мощной программы включают в себя подсказывающие диалоговые окна (вы нажимаете на ОК, и STATIS- 378 Часть V Больше статистики! Больше инструментов! Больше веселья! TICA говорит вам, что нужно ввести); кастомизацию интерфейса; легкую интеграцию с другими программами; STATISTICA Visual Basic, который дает доступ к более чем 10 000 функций и позволяет использовать эту среду разработки для создания специальных приложений; возможность использовать макросы для автоматизации задач. Приятный бонус на веб-сайте – электронный учебник по статистике, в котором можно найти информацию по многим различным темам. Рис. 20.3 Вывод Minitab для простого регрессионного анализа Регрессия Y = 20,81 – 163x + 321,6x**2 1,2 1,0 0,8 0,6 0,4 0,2 0,0 0,23 0,25 0,27 0,29 0,31 Хотите узнать больше? Зайдите на http://www.statsoft.com/. Стоимость: 795 долл. за базовую лицензию (и еще можно добавить много-много модулей), а также есть бесплатный базовый академический пакет (аренда на 12 месяцев). Это еще одна хорошая сделка. SPSS SPSS является одним из самых популярных первоклассных статис­ тических пакетов, и поэтому мы посвятили ему целое приложение в книге, которую вы держите в своих руках! Мы также разбираем на этих страницах упражнения с использованием компьютера. Программа имеет множество модулей, покрывающих все аспекты статистического анализа как базового, так продвинутого уровня, и почти для каждой платформы есть своя версия. Недавно этот пакет приобрела компания «IBM» (после кратковременного периода переименования его в PWAS; слава богу, что новые владельцы избавились от этого названия). Глава 20 Подборка программ для статистического анализа 379 Хотите узнать больше? Зайдите на сайт http://www.spss.com. Стоимость – высокая! 2610 долл. в год (!!!) за стандартную версию (но 1170 долл. в год за базовую версию), и много разных планов и периодов действия для академического рынка. STATISTIX для Windows Десятая версия STATISTIX предлагает управляемый через меню интерфейс, что особенно облегчает обучение пользованию ей, и она почти сравнима по мощности с другими упомянутыми здесь программами (но все это только для Windows, ребята). Компания предлагает бесплатную техническую поддержку и – вы готовы? – настоящую 450-страничную инструкцию по пользованию. И когда вы звоните в техподдержку, то разговариваете с настоящими программистами, которые знают, о чем они говорят (на мой вопрос ответили через 10 с!). На рис. 20.4 показан вывод STATISTIX для двухвыборочного t-критерия. Со всех сторон хорошая сделка. Хотите узнать больше? Зайдите на сайт http://www.statistix.com. Стоимость: 495 долл. за коммерческую и 395 долл. за академическую версию, и обе они только для Windows. Рис. 20.4 Вывод STATISTIX для двухвыборочного t-критерия 380 Часть V Больше статистики! Больше инструментов! Больше веселья! ВЫВОДЫ ПО ГЛАВЕ На этом заканчивается часть V и почти заканчивается «Статистика для тех, кто (думает, что) ненавидит статистику». Но читайте дальше! В следующей главе мы расскажем о 10 лучших во вселенной интернет-сайтах с информацией по статистике, после чего в главе 22 дадим 10 заповедей сбора данных. Желаем вам приятно провести время с ними обеими. ЧАСТЬ VI Десять вещей (умножить на два), которые вы хотите узнать и запомнить «А теперь переходим к главе 12 432…» 381 21 Десять (или более) лучших (и самых увлекательных) интернет-сайтов для статистики К онечно же, вы используете (и любите) интернет. Наверное, это первое место, куда вы идете, когда хотите найти что-то новое. Что ж, так же, как и в случае с рецептами, музыкальными приложениями и последними результатами бас­кетбольных матчей, в интернете есть тонны материалов по статистике для тех, кто только начинает (и не продолжает) изучать и применять ее. Если вы еще не пользуетесь интернетом для поддержки своей учебы и исследований, то упускаете уникальный ресурс. То, что можно найти в интернете, не восполнит дефицита занятий или мотивации (ничто не сможет это сделать), но вы, определенно, можете найти множество информации, которая обогатит ваш опыт обучения. И мы еще даже не упомянули, как это может быть весело! Итак, теперь, когда вы стали сертифицированным начинающим статистиком, представляем вам несколько интернет-сайтов, которые могут оказаться весьма полезны, если вы захотите узнать о статистике побольше. 382 Несмотря на то что адреса сайтов стали стабильными как никогда, они все равно могут часто меняться. Работающий сегодня URL (uniform resource locator – унифицированный указатель ресурсов, который мы называем веб-адресом) может не открыться завтра. Если вы не попадаете туда, куда нужно, используйте поисковую систему «Гугл» или другие поисковики для поиска по названию веб-сайта (возможно, есть новый URL или другой вебадрес, который работает). Глава 21 Десять (или более) лучших (и самых увлекательных) интернет-сайтов 383 НЕ ДУМАЛИ ПОУ ЧИТЬ СТАТИСТИКУ В СТОКГОЛЬМЕ? Страница называется «The World Wide Web Virtual Library: Statistics» (Виртуальная библиотека всемирной сети: статистика), и это действительно виртуальная всемирная библиотека. На сайте, созданном хорошими людьми в Университете Флориды, http://www.stat.ufl. edu/vlib/statistics.html, собрана информация почти по всем аспектам статистики. В том числе там есть источники данных, объявления о работе, отделения, подразделения и школы статистики (описания образовательных программ по всему миру), исследовательские статистические группы, институты и ассоциации, статис­тические сервисы, статистические архивы и ресурсы, поставщики программного обеспечения по статистике и само программное обес­печение, статистические журналы, архивы рассылок и связанные со статистикой области. Здесь находятся тонны отличной информации. Загляните сюда между делом. КТО ЕСТЬ КТО И ЧТО СЛУ ЧИЛОСЬ? Страница, посвященная истории статистики, находится по адресу http://anselm.edu/homepage/jpitocch/biostats/biostatshist.html и содержит портреты и биографии знаменитых статистиков, а также хронологию важных вкладов в область статистики. Возбуждают ли ваше любопытство такие имена, как Бернулли, Гальтон, Фишер и Спирмен? Что насчет разработки первого критерия проверки двух средних в начале XX в.? Это может показаться немного скучным, пока у вас не появится возможность почитать о людях, которые создали эту область, и их идеях (в целом довольно классных идеях и довольно классных людях). И конечно же, Википедия (http://en.wikipedia.org/wiki/History_ of_statistics) отлично знакомит с историей статистики, так же как и eMathZone по адресу http://www.emathzone.com/tutorials/basicstatistics/history-of-statistics.html. ВСЕ ЗДЕСЬ Сайт SurfStat Australia (https://surfstat.anu.edu.au/surfstat-home/contents.html) является онлайн-частью базового курса статистики, преподаваемого в Университете Ньюкасла (в Австралии), но он давно перерос простые заметки, изначально написанные Аннеттой Добсон (Annette Dobson) в 1987 г. и обновляемые в течение нескольких лет Анной Янг (Anne Young), Бобом Джиббердом (Bob Gibberd) и др. Среди всего прочего SurfStat (а вы можете увидеть часть подробного содержания курса на рис. 21.1) содержит полный интерактивный 384 Часть VI Десять вещей (умножить на два), которые вы хотите узнать и запомнить статистический учебник. Кроме текста, в нем есть упражнения, список других статистических сайтов и коллекция апплетов на языке Ява (маленькие крутые программки, которые можно использовать для выполнения разных статистических процедур). Рис. 21.1 Часть содержания курса SurfStat HYPERSTAT Этот онлайн-курс из 18 уроков, находящийся на http://davidmlane. com/hyperstat, предлагает приятно оформленное и дружелюбное к пользователям изложение самых важных тем. Что нам действительно нравится на данном сайте, так это глоссарий, в котором гипертекстовые ссылки соединяют между собой разные концепции. Например, на рис. 21.2 вы можете видеть темы, связанные ссылками (живыми подчеркнутыми словами) с другими темами. Нажмите на любую из них, и вы уже там (или по меньшей мере на пути туда). Глава 21 Десять (или более) лучших (и самых увлекательных) интернет-сайтов 385 Рис. 21.2 Пример экрана Hyperstat ДАННЫЕ? ВАМ НУЖНЫ ДАННЫЕ? В интернете множество данных, готовых к скачиванию. Вот только несколько их источников. Что с ними делать? Скачать и использовать в качестве примеров в своих работах или в качестве примеров аналитики, которую вы можете делать. В качестве образца можете обратиться вот к этим ресурсам: zz наборы статистических данных на http://itl.nist.gov/div898/ strd/; zz данные Бюро переписи населения США (огромная коллекция и кладезь данных, любезно предоставленные American FactFinder) на https://factfinder.census.gov/faces/nav/jsf/pages/index.xhtml; zz библиотека данных «The Data and Story Library» с отличными аннотациями к данным по адресу https://dasl.datadescription. com; zz тонны экономических наборов данных от Growth Data Sets представлены на http://www.bris.ac.uk/Depts/Economics/ Growth/datasets.htm. Еще больше наборов данных можно найти на сайтах федерального правительства. Эти ресурсы поддерживаются на деньги налогоплательщиков, так почему бы не воспользоваться ими? Например, сайт Федерального комитета по статистической методологии США (https://nces.ed.gov/FCSM/index.asp), на котором более 70 правитель- Данные от правительства США 386 Часть VI Десять вещей (умножить на два), которые вы хотите узнать и запомнить ственных агентств США публикуют статистику, представляющую интерес для публики. У большинства штатов также есть доступные в сети данные. Мы взяли данные для демонстрации процедур в главе 17 с сайта Data. gov, а именно со страницы http://catalog.data.gov/dataset?q=baby+n ames&sort=score+desc%2C+name+asc. Мы щелкнули по опции CSV (которая позволяет открывать набор данных в Excel) и продолжили отсюда. БОЛЬШЕ И БОЛЬШЕ РЕСУРСОВ На сайте руководств к исследованиям Университета Мичигана (https://guides.lib.umich.edu) находятся сотни ссылок на ресурсы, в том числе на информацию о банковском секторе, издательствах, пожилых людях, и на ресурсы для тех, кто страдает аллергией, о содержании пыльцы в воздухе. Загляните туда, чтобы посмотреть, что можно найти, или задайте поиск именно по тому, что вам необходимо (в любом случае вы точно найдете что-нибудь интересное). И КОНЕЧНО, YOUTUBE… Да, в YouTube можно найти материалы по статистике от «Statz Rappers» (http://www.youtube.com/watch?v=JS9GmU5hr5w), группы талантливых юношей и девушек, которые, видимо, отлично проводят время на своем курсе по статистике. Это подходящее место для отдыха на пути к тому, что хранит интернет для интересующихся статистикой. Но есть также и более серьезная информация. Загляните, например, сюда: http://www.youtube.com/watch?v=HvDqbzu0i0Efrom KhanAcademy.org. Здесь тысячи видеоинструкций обо всем, начиная с алгебры, продолжая экономикой и инвестициями и заканчивая, конечно (вы уже догадались), статистикой! НАКОНЕЦ… На сайте http://animatedsoftware.com/statglos/statglos.htm#index вы найдете залежи определений статистических терминов, предоставленных д-ром Говардом С. Хоффманом (Howard S. Hoffman). Информативно и очень весело. 22 Десять заповедей сбора данных Т еперь, когда вы знаете, как анализировать данные, будет уместно прочитать что-нибудь о том, как их собирать. Процесс сбора данных может быть долгим и напряженным. Даже если вам требуется только раздать простой одностраничный опросник группе студентов, родителей, пациентов или избирателей, то сбор данных вполне может оказаться самой длинной частью вашего проекта. Но, как уже поняли многие исследователи, хороший сбор данных нельзя отделить от хороших результатов исследования. Представляем вам 10 заповедей, чтобы вы могли точно собрать данные в виде, пригодном для использования. В отличие от оригинальных 10 заповедей, эти не нужно вырезать в камне (потому что они, конечно, могут измениться), но если вы будете им следовать, то избежите множества сложностей. Заповедь 1. Как только вы начинаете думать о вопросе исследования, начинайте думать и о виде данных, которые вам придется собрать для ответа на него. Интервью? Опросник? Бумажный тест? Компьютерный тест? Почитайте подходящие научные журналы в своей области и найдите, как другие люди делали это раньше. Затем подумайте, не сделать ли вам так же. По меньшей мере один из уроков, который вы можете извлечь, – это не повторять чужих ошибок. Если что-то не сработало у других, вероятно, оно не сработает и у вас. Заповедь 2. Во время размышлений над видом данных задумайтесь о том, где вы будете доставать эти данные. Если вы ищете исторические данные в библиотеке или пользуетесь уже собранными данными, такими как данные от Бюро переписи населения, у вас не будет больших логистических проблем. Но что делать в том случае, если вы хотите изучить взаимодействие между новорожденными Сбор и анализ данных 387 388 Часть VI Десять вещей (умножить на два), которые вы хотите узнать и запомнить и их родителями или возраст, в котором люди старше 50 думают, что они уже старые? Для ответа на все эти вопросы нужны люди, и найти их может быть трудно. Начинайте уже сейчас. Заповедь 3. Убедитесь, что используемые вами формы сбора информации простые и понятные для использования. Попрактикуйтесь на пилотном наборе данных, чтобы проверить, что их можно легко перенести с оригинальных оценочных листов или форм сбора данных в цифровой формат. А затем попросите несколько коллег заполнить форму, чтобы убедиться, что она работает. Заповедь 4. Всегда делайте копию файла с данными и таблицами собранных данных и храните ее в отдельном от основного файла мес­те. Имейте в виду, что есть два типа людей: те, кто уже терял свои данные, и те, кто их потеряет. На самом деле сделайте два бэкапа электронных данных! В наши дни можно воспользоваться для этого онлайн-сервисами в дополнение к собственному физическому резервному диску. Заповедь 5. Не полагайтесь на других людей при сборе и передаче данных, если только вы лично не обучили их и не уверены, что они понимают процесс сбора данных так же хорошо, как вы. Иметь помощников здорово, и это помогает поддерживать боевой дух во время долгих сборов данных. Но если только эти помощники не обладают бесспорными компетенциями, то вы можете легко обесценить весь свой тяжелый труд и планы. Заповедь 6. Составьте детальное расписание того, где и когда вы будете собирать данные. Если вам нужно посетить три школы и протестировать в каждой по 50 детей в течение 10 мин, то это означает 25 ч тестирования. Это не значит, что вы можете просто выделить в своем расписании 25 ч на эту деятельность. Как насчет дороги от одной школы до другой? Что по поводу ребенка, который отошел в туалет, когда подошла его очередь, и вы должны подождать 10 мин, пока он не вернется в класс? Как насчет дня, когда вы приехали, а в школе особый гость Ковбой Боб… и т. д. и т. п. Будьте готовы ко всему, заложите в расписание от 25 до 50 % дополнительного времени на непредвиденные события. Заповедь 7. Как можно скорее начинайте окучивать возможные источники по вашему предмету. Поскольку у вас уже есть какие-то знания по своей дисциплине, вероятно, вы также знаете, какие люди работают с интересующей вас генеральной совокупностью, или то, кто может вам помочь получить доступ к этим выборкам. Если вы учитесь в университете, вероятно, сотни людей охотятся за той же выборкой, которая вам нужна. Вместо того чтобы конкурировать с ними, почему бы не взять более далекий (может быть, в получасе езды) школьный район, социальную группу, общественную организацию или больницу, где вы сможете отобрать выборку с меньшей конкуренцией? Глава 22 Десять заповедей сбора данных Заповедь 8. Попробуйте снова связаться с испытуемыми, которые пропустили тестирование или интервью. Перезвоните им и попробуйте переназначить встречу. Если у вас войдет в привычку пропускать возможных участников исследования, ваша выборка легко сократится до слишком малого размера. К тому же никогда нельзя знать наверняка: может быть, отсеявшиеся люди пропустили встречу по причинам, связанным с тем, что вы изучаете. Это может означать, что ваша итоговая выборка качественно отличается от выборки, с которой вы начали. Заповедь 9. Никогда не выбрасывайте исходные данные, такие как брошюрки с тестами, заметки с интервью и т. д. Возможно, другие исследователи захотят воспользоваться этими же данными, или, может быть, вам придется вернуться к оригинальным материалам, чтобы выудить из них дополнительную информацию. И заповедь 10. Следуйте предыдущим девяти заповедям. Без шуток! 389 Приложение A SPSS Statistics меньше, чем за 30 мин Э 390 то приложение научит вас навыкам работы с IBM SPSS, достаточным для выполнения упражнений в «Статистике для тех, кто…». Изучение SPSS не требует космических знаний: дайте себе время, работайте в удобном для себя темпе и попросите сокурсников или преподавателя о помощи, если нужно. Вы, вероятно, знакомы с другими приложениями Windows, тогда увидите, что функции SPSS работают точно так же. Мы предполагаем, что вы знаете, как перетаскивать, щелкать и дважды щелкать мышкой, умеете работать с Windows или Mac (версии SPSS для этих двух операционных систем очень похожи). Если это не так, то можете обратиться к одной из многих популярных компьютерных книг за помощью. SPSS работает на базе Microsoft Windows XP, Vista, 7, 8 и с самой последней, 10-й, версией операционной системы. Для Mac она работает на Mountain Lion 10.8 и более поздних версиях. Это приложение почти полностью посвящено версии Windows, потому что она более популярна, чем Mac, но если вы пользуетесь Mac, то вам не должно быть трудно следовать инструкциям и примерам. Это приложение является введением в работу с SPSS (версия 23) и показывает только некоторые вещи, которые может делать программа. Почти вся информация в этом приложении подходит и для более ранних версий SPSS: от 11 до 22. Во всех примерах этого приложения мы будем использовать набор данных, приведенный в приложении C, который называется «Набор данных. Пример» (Sample Data. Set.sav). Вы можете ввести эти данные в SPSS вручную, или загрузить их с веб-сайта издательства SAGE edge.sagepub.com/salkind6e, или написать автору на njs@ku.edu. Приложение A SPSS Statistics меньше, чем за 30 мин 391 ЗАПУСК SPSS Как и другие программы для Windows, пакет SPSS сгруппирован в папку и располагается в меню Пуск. Эта папка была создана при установке SPSS. Для запуска SPSS выполните следующие шаги: 1)нажмите на Пуск (Start), а затем наведите указатель мыши на Программы (Programs); 2)найдите и щелкните по значку SPSS. Когда вы это сделаете, то увидите приветственное окно SPSS, как на рис. А.1. Следует заметить, что разные компьютеры настроены по-разному, и ваша иконка SPSS может находиться на рабочем столе. В этом случае для запуска SPSS просто дважды щелкните по значку. Приветственное окно SPSS Как вы видите на рис. А.1, приветственное окно предлагает ряд опций, которые позволяют вам выбирать между вводным обучающим курсом, работой с редактором данных, работой с выводами и другими вариантами. Если вы не хотите видеть этот экран каждый раз при запуске SPSS, то отметьте опцию Не показывать это диалоговое окно в будущем (Don’t show this dialog in the future) в левом нижнем углу окна. Рис. А.1 Приветственное окно SPSS 392 Статистика для тех, кто (думает, что) ненавидит статистику Для целей нашего обучения вы сейчас щелкнете по Отмена (Cancel), а когда это сделаете, то увидите, что окно Представление данных (Data View) (также называемое Редактором данных (Data Editor)) стало активным (рис. А.2). Именно здесь вы вводите данные, с которыми хотите работать в SPSS, как только вы с ними определились. Если думаете, что Редактор данных похож по виду и функциям на электронную таблицу, то вы правы. По форме это, определенно, электронная таблица, потому что Редактор данных состоит из строк и столбцов – в точности как лист Excel. Можно вносить значения и затем производить над ними действия. По функциям Редактор данных также очень похож на электронную таблицу. Введенные значения можно изменять, сортировать, организовывать и т. д. Рис. А.2 Окно Представление данных (Data View) Хотя этого и не видно, когда SPSS открывается в первый раз, но есть еще одно открытое (хотя и неактивное) окно. Это Представление переменных (Variable View), где определяются переменные и задаются их параметры. Окно вывода Viewer показывает создаваемые вами статистические результаты и графики. Пример части окна вывода показан на рис. А.3. Набор данных создается при помощи Редактора данных (Data Editor), а после анализа или построения графиков вы изучаете результаты анализа в окне вывода. Приложение A SPSS Statistics меньше, чем за 30 мин 393 Рис. А.3 Часть окна вывода ПАНЕЛЬ ИНСТРУМЕНТОВ И СТРОКА СОСТОЯНИЯ SPSS Использование панели инструментов – набора иконок под строкой меню – может существенно помочь вашим действиям в SPSS. Если вы хотите узнать, что делает иконка с панели инструментов, просто наведите на нее указатель мыши. В этом случае вы увидите подсказку с указанием, что делает этот инструмент. Некоторые кнопки на панели инструментов затенены. Это означает, что они не активны. Строка состояния, расположенная внизу окна SPSS, является еще одним полезным инструментом. Здесь вы можете видеть однострочный отчет о том, какие действия сейчас выполняет SPSS. Сообщение «Процессор IBM SPSS Statistics готов» (IBM SPSS Statistics Processor is Ready) говорит о том, что SPSS готова к вашим указаниям или вводу данных. В качестве другого примера: «Выполняется Средние» (Running Means) говорит вам, что SPSS выполняет процедуру под названием «Средние». ИСПОЛЬЗОВАНИЕ СПРАВКИ SPSS Справка SPSS находится всего в нескольких щелчках мышкой и особенно полезна, когда в середине файла с данными вам требуется информация о какой-то функции SPSS. Справка SPSS настолько подробна, что может указать вам путь, даже если вы новичок в работе с программой. Справку SPSS можно вызвать через пункт меню Справка (Help), который вы видите на рис. А.4. 394 Статистика для тех, кто (думает, что) ненавидит статистику Рис. А.4 Разнообразные опции Справки В меню Справка (Help) даны 12 опций (что существенно больше, чем в более ранних версиях программы), и шесть из них напрямую предлагают помощь вам: zz Темы (Topics) – выдает вам список тем, по которым вы можете получить помощь; zz Учебник (Tutorial) – предлагает краткий курс по всем аспектам использования SPSS; zz Примеры анализа (Case Studies) – показывает реальные примеры из жизни по применению SPSS; zz Работа с R (Working with R) – предоставляет информацию о том, как работать со статистическим пакетом с открытым исходным кодом, который называется R; zz Инструктор по статистике (Statistics Coach) – проводит вас шаг за шагом по процедурам; zz Руководство по синтаксису (Command Syntax Reference) – помогает изучить и использовать язык программирования SPSS; zz SPSS Community – дает доступ к другим пользователям SPSS и информации; zz О программе… (About…) – показывает некоторую техническую информацию про SPSS, включая используемую вами версию; zz Алгоритмы (Algorithms) – фокусируется на вычислениях, используемых для получения результатов, которые вы видите в SPSS; zz Базовая страница продуктов IBM SPSS (IBM SPSS Products Home) – ведет вас на домашнюю страницу SPSS в интернете; Приложение A SPSS Statistics меньше, чем за 30 мин 395 zz Программируемость (Programmability) – предоставляет информацию о создании дополнений и других программных надстроек к SPSS; zz Диагностировать (Diagnose) – помогает определить, почему SPSS может работать не так, как нужно. КРАТКИЙ Т УР ПО SPSS А теперь садитесь удобнее и наслаждайтесь кратким обзором того, что может делать SPSS. Здесь не будет ничего сложного. Просто немного простых описаний данных, проверка значимости и график (или два). Мы хотим показать вам, как просто пользоваться SPSS. Открываем файл Вы можете внести собственные данные, чтобы создать новый файл данных SPSS, можете использовать существующий файл или даже импортировать в SPSS данные из таких приложений, как Microsoft Excel. Не важно, как вы это сделаете, но вам нужны данные, чтобы работать с ними. На рис. А.5 показаны данные из приложения С (под названием «Набор данных. Пример» (Sample Data. Set.sav)). Этот файл также доступен на сопутствующем книге веб-сайте, или его можно получить напрямую от автора. Рис. А.5 Открытый файл SPSS 396 Статистика для тех, кто (думает, что) ненавидит статистику Простая таблица и диаграмма Пора перейти к причине, по которой вы прежде всего используете SPSS, – к разнообразным доступным аналитическим инструментам. Для начала скажем, что мы хотим знать общее деление на мужчин и женщин. Ничего, кроме: просто посчитать, сколько мужчин и сколько женщин находится в нашей общей выборке. Мы также хотим создать простую столбиковую диаграмму распределения. На рис. А.6 вы видите вывод, который показывает именно ту информацию, что мы запросили, т. е. частоты по мужчинам и женщинам. Для вычисления этих значений мы воспользовались опцией Частоты (Frequencies) в пункте меню Описательные статистики (Descriptive Statistics), который находится в выпадающем главном меню Анализ (Analyze). После этого мы создали простую столбиковую диаграмму. Рис. А.6 Результаты простого описательного анализа Приложение A SPSS Statistics меньше, чем за 30 мин 397 Простой анализ Давайте проверим, различаются ли мужчины и женщины по среднему значению результатов по Тесту 1 (столбец Test 1). Это простой анализ, требующий применения t-критерия для независимых выборок. Процедура состоит в сравнении мужчин и женщин по среднему значению результатов Теста 1 по каждой группе. На рис. А.7 вы можете видеть сводку результатов проверки по t-критерию. Обратите внимание, что список в левой панели (просмотр структуры) окна выводов SPSS теперь включает в себя процедуры Частоты (Frequencies) и T-кри­терий (T-test). Для того чтобы увидеть любую часть вывода, нам нужно всего лишь щелкнуть по нужному элементу. Почти всегда, когда SPSS показывает выводы, вам придется прокручивать вниз, чтобы увидеть вывод целиком. Рис. А.7 Результаты t-критерия для независимых выборок СОЗДАНИЕ И РЕДАКТИРОВАНИЕ ФАЙЛА ДАННЫХ В качестве живого примера давайте создадим начало файла данных выборки, который вы видите в приложении С. Сначала нужно определить переменные в вашем наборе данных, а затем ввести данные. У вас должно быть открыто новое окно Редактора данных (нажмите Файл (File) ⇒ Создать (New) ⇒ Данные (Data)). Определение переменных SPSS не может работать, пока не определены переменные. Вы можете дать SPSS определить переменные за вас, или можете сделать определение самостоятельно, следовательно, лучше контролируя, как все будет выглядеть и работать. SPSS автоматически назовет первую переменную VAR00001. Если вы определяете переменную в строке 1, столбце 5, то SPSS назовет переменную VAR00005 и пронумерует остальные столбцы по порядку. 398 Статистика для тех, кто (думает, что) ненавидит статистику Настраиваемое определение переменных: использование представления переменных Для того чтобы самостоятельно определить переменную, сначала нужно перейти в окно Представление Переменные (Variable View), щелкнув по вкладке Представление Переменные (Variable View) внизу экрана SPSS. После чего вы увидите окно представления переменных, как показано на рис. А.8, и сможете определить любую переменную, какую захотите. Оказавшись в окне представления переменных, вы сможете определять переменные по следующим параметрам: zz Имя (Name) – позволяет вам задать переменной имя длиной до 8 символов; zz Тип (Type) – определяет тип переменной, такой как текстовая, числовая, строковая, экспоненциальная запись и т. д.; zz Ширина (Width) – задает количество символов в столбце, содержащем данную переменную; zz Знаков после запятой (Decimals) – определяет количество десятичных знаков, которые будут показаны в представлении данных; zz Метка (Label) – задает метку переменной длиной до 256 символов; zz Значения (Values) – определяет метки, соответствующие определенным числовым значениям (например, 1 для мужчин и 2 для женщин); zz Пропущенные (Missing) – указывает, как обращаться с пропущенными данными; zz Ширина столбца (Columns) – определяет количество символов, выделенное для переменной в окне представления данных; zz Выравнивание (Align) – определяет, как будут располагаться данные в ячейке (по левому краю, правому краю или по центру); zz Мера (Measure) – определяет шкалу измерения, которая лучше всего описывает переменную (номинальная, порядковая или интервальная); zz Роль (Role) – определяет роль, которую играет переменная в анализе (входная, целевая и т. д.). Если вы поместите курсор в первую ячейку в колонке Имя (Name), введете любое имя и нажмете на клавишу Ввод (Enter), то SPSS автоматически предоставит вам значения по умолчанию для всех характеристик переменной. Даже если вы не находитесь на экране Представление Данные (Data View) (нажмите на вкладку внизу окна), то SPSS автоматически назовет переменные VAR0001, VAR0002 и т. д. Приложение A SPSS Statistics меньше, чем за 30 мин 399 Рис. А.8 Окно Представление Переменные (Variable View) В окне Представление Переменные (Variable View) введите названия переменных, как вы видите на рис. А.9. Рис. А.9 Определение переменных в окне Представление Переменные (Variable View) Теперь, если хотите, можете переключиться на Представление Данные (Data View) (см. рис. А.10) и просто ввести все данные, которые вы видите на рис. А.5. Но сначала давайте взглянем на один из крутых прибамбасов SPSS. Рис. А.10 Окно Представление Данные (Data View) для ввода данных Определение значения меток данных Вы можете оставить все данные в виде числовых значений в Редакторе данных SPSS, а можете назначить метки для представления соответствующих числовых значений (что вы видели на рис. А.5). Почему вы можете захотеть изменить метку переменной? Вы, вероятно, уже знаете, что в целом целесообразнее работать с числами 400 Статистика для тех, кто (думает, что) ненавидит статистику (вроде 1 или 2), чем со строковыми или буквенно-цифровыми переменными (как «мужчина» или «женщина»). Частая ошибка состоит во вводе данных в виде текста (как «мужчина» или «женщина»), а не в виде числа, обозначающего переменную пола. Когда дело дойдет до анализа, окажется, что очень трудно работать с нечисловыми запи­сями (такими, например, как «мужчина»). Но, определенно, намного проще смотреть на файл данных и видеть вместо чисел слова. Просто подумайте о разнице между файлом данных, где разные уровни переменной записаны числами (вроде 1 или 2), и файлом, где указаны их настоящие значения (как «мужчина» или «женщина»). Параметр Значения (Values) на экране Представление Переменные (Variable View) позволяет вам вводить в ячейки значения, но вы будете видеть их метки. Если вы нажмете на скругленную кнопку в столбце Значения (Values) (см. рис. А.11), то увидите диалоговое окно Метки значений (Value Labels), которое показано на рис. А.12. Рис. А.11 Столбец Значения (Values) на экране Представление Переменные (Variable View) Рис. А.12 Диалоговое окно Метки значений (Value Labels) Приложение A SPSS Statistics меньше, чем за 30 мин 401 Изменение меток значений Для назначения или изменения метки переменной следуйте этим шагам. Здесь мы будем назначать метку «муж» для 1 и «жен» для 2: 1)для переменной Gender (Пол) щелкните по скругленному прямоугольнику (см. рис. А.11), чтобы открыть диалоговое окно Метки значений (Value Labels); 2)введите значение для переменной (в данном случае – 1 для мужчин); 3)введите метку значения для этого значения (в данном случае – «муж»); 4) нажмите Добавить (Add); 5)сделайте то же самое для женщин и значения 2. Когда вы завершите все задачи в диалоговом окне Метки значений (Va­ lue Labels) (см. рис. А.13), нажмите ОК, и новые метки будут применены к значениям. Рис. А.13 Диалоговое окно Метки значений (Value Labels) с завершенной работой Если в окне Представление Данные (Data View) вы выберете Вид (View) ⇒ Метки значений (Variable Labels), то увидите в редакторе данных метки. Обратите внимание, что значение записи на рис. А.14 на самом деле равно 2, хотя метка в ячейке показывает «Жен» (Female). 402 Статистика для тех, кто (думает, что) ненавидит статистику Рис. А.14 Вывод на экран меток значений Как открыть файл данных После сохранения файла вам нужно будет открыть или прочитать его, когда вы захотите снова им воспользоваться. Шаги очень простые: 1)нажмите Файл (File) ⇒ Открыть (Open). Вы увидите диалоговое окно Открыть данные (Open Data File); 2) найдите файл, который вы хотите открыть, и выделите его; 3) нажмите ОК. ПЕЧАТЬ ИЗ SPSS Здесь представлена информация о последнем действии, которое вы делаете после создания файла данных. Создав нужный файл данных или завершив любой вид анализа и нарисовав диаграмму, вероятно, вы захотите распечатать копию результатов, чтобы бережно хранить ее или приложить к отчету либо статье. Когда документ будет напечатан и вы захотите завершить работу, придет время для выхода из SPSS. Печать является почти таким же важным процессом, как редактирование или сохранение файлов данных. Если вы не можете распечатать результат, вам нечего вынести с рабочей сессии. Вы можете экспортировать данные из файла SPSS в другое приложение, но создание бумажной копии напрямую из SPSS зачастую оказывается и быстрее, и важнее. Печать файла данных SPSS Распечатать целый файл данных или его часть довольно легко: 1)убедитесь, что файл, который вы хотите напечатать, находится в активном окне; 2)нажмите Файл (File) ⇒ Печать (Print). Когда вы это сделаете, увидите диалоговое окно печати; 3)нажмите ОК, и то, что находится в активном окне, будет распечатано. Приложение A SPSS Statistics меньше, чем за 30 мин 403 Как видите, вы можете выбрать распечатку всего документа или определенной его части (которую вы должны были уже выделить в окне редактора данных). Также вы можете увеличить количество копий с 1 до 99 (максимальное количество копий, которое можно напечатать). Вы также можете настроить диалоговое окно печати так, чтобы создавался файл .pdf. Печать выделения в файле данных SPSS Печать выделения в файле данных SPSS требует выполнения точно таких же шагов, что перечислены выше для печати целого файла, за исключением того, что вы выделяете то, что нужно распечатать, в редакторе данных, и отмечаете опцию Выделенный фрагмент (Selection) в диалоговом окне печати. Последовательность действий такая: 1)убедитесь, что вы выделили данные, которые хотите напечатать; 2) нажмите на Файл (File) ⇒ Печать (Print); 3)отметьте опцию Выделенный фрагмент (Selection) в диалоговом окне печати; 4) нажмите ОК, и то, что было выделено, будет распечатано. СОЗДАНИЕ ДИАГРАММЫ В SPSS Лучше один раз увидеть, и SPSS предлагает вам те самые инструменты, которые оживят результаты вашего анализа. Мы пройдемся по шагам создания нескольких разных типов диаграмм и покажем примеры разных графиков. Затем мы покажем вам, как изменить диаграмму, в том числе и то, как добавить к ней заголовок и подписи осей, изменить масштаб и поработать с узорами, шрифтами и т. п. По какой-то причине SPSS использует слова «графики» и «диаграммы» как взаимозаменяемые. Создание простой диаграммы У всех диаграмм есть одна общая черта: они все основаны на данных. Хотя вы можете импортировать данные для того, чтобы создать диаграмму, в этом примере мы будем использовать данные из приложения C, чтобы создать столбиковую диаграмму (как та, что вы видели на рис. А.6) количества мужчин и женщин в каждой группе. Создание столбиковой диаграммы Шаги для создания любой диаграммы в целом одинаковы. Сначала вы вводите данные, которые хотите использовать в диаграмме, выбираете нужный вам тип диаграммы из меню Графика (Graphs), 404 Статистика для тех, кто (думает, что) ненавидит статистику определяете, как должна выглядеть диаграмма, а затем нажимаете на ОК. Вот действия, которые мы выполнили, чтобы создать диаграмму, которую вы видите на рис. А.6: 1)введите данные, которые вы хотите использовать для создания диа­граммы; 2)нажмите на Графика (Graphs) ⇒ Устаревшие диалоговые окна (Legacy Dialogs) ⇒ Столбцы (Bar). Когда вы это сделаете, увидите диалоговое окно Столбцы (Bar), как на рис. А.15: Рис. А.15 Диалоговое окно Столбцы (Bar) 3) щелкните по Простая (Simple); 4)отметьте Итоги по группам наблюдений (Summaries for groups of cases); 5)нажмите на Задать (Define). После этого вы увидите диалоговое окно Простые столбцы: итожащие функции по группам наблюдений (Define Simple Bar: Summaries for Groups of Cases); 6) отметьте N наблюдений (Cum n of cases); 7)щелкните по переменной Gender (Пол). Затем перетащите ее в поле Категориальная ось (Category Axis); 8) нажмите ОК, и вы увидите результаты, как на рис. А.16. Приложение A SPSS Statistics меньше, чем за 30 мин 405 Рис. А.16 Простая столбиковая диаграмма Это только начало создания диаграммы. Для добавления любых изменений нужно будет использовать инструменты редактора диаграмм. Сохранение диаграммы Диаграмма является только частью окна выводов. Это часть выводов, создаваемых, когда вы проводите какой-либо анализ. Диаграмма не является отдельной самостоятельной сущностью, и ее нельзя сохранить в качестве таковой. Для того чтобы сохранить диаграмму, вам нужно сохранить содержимое всего окна просмотра. Следуйте перечисленным ниже пунктам, чтобы сделать это: 1) нажмите на Файл (File) ⇒ Сохранить (Save); 2) задайте имя для окна просмотра; 3)нажмите ОК. Вывод сохранен под названием, которое вы задали, и с расширением .spo. УЛУЧШЕНИЕ ДИАГРАММ SPSS После того как создадите диаграмму по инструкциям, приведенным в предыдущем параграфе, вы сможете редактировать ее, чтобы отобра­зить в точности то, что хотите сказать. Можно менять цве- 406 Статистика для тех, кто (думает, что) ненавидит статистику та, формы, шкалы, шрифты и многое другое. Мы будем работать со столбиковой диаграммой, которая была вам показана на рис. А.16. Редактирование диаграммы Для начала редактирования диаграммы нужно дважды щелкнуть по ней, а затем развернуть окно на весь экран. Вы увидите всю диаграмму в окне Редактор диаграмм (Chart Editor), как показано на рис. А.17. Рис. А.17 Окно Редактор диаграмм (Chart Editor) Работа с заголовками и подзаголовками Наша первая задача – ввести заголовок и подзаголовок диаграммы, которую вы видите на рис. А.16: 1)щелкните по иконке Вставить заголовок (Insert a Title) на панели инструментов. Когда вы это сделаете, то, как видно на рис. А.18, сможете редактировать элемент Заголовок (Title) прямо на экране и вводить туда все, что хотите; Приложение A SPSS Statistics меньше, чем за 30 мин 407 2)для добавления подзаголовка (или фактически такого коли­ чества заголовков, которое вам требуется) просто продолжайте нажимать на иконку Вставить заголовок (Insert a Title). Рис. А.18 Добавление заголовка Работа со шрифтами После создания заголовка или заголовков вы можете поработать со шрифтами, двойным щелчком мыши выделив текст, который хотите изменить. Вы увидите диалоговое окно Свойства (Properties), как на рис. А.19. Щелкните по вкладке Стиль текста (Text Style) и можете производить любые изменения, какие вам нравятся. Работа с осями Оси x и y можно калибровать как для независимой (обычно отражаемой на оси x), так и для зависимой (обычно отражаемой по оси y) переменной. SPSS называет ось y Шкалы (Scale), а ось x – Категории (Category). Каждую ось можно изменить множеством способов. Для изменения любой оси дважды щелкните по ней. 408 Статистика для тех, кто (думает, что) ненавидит статистику Рис. А.19 Работа со шрифтами Как изменить ось шкалы (y) Для изменения оси y выполните следующие шаги: 1)вы все еще в редакторе диаграмм? Надеемся, что да. Дважды щелкните по оси (не по ее названию); 2)щелкните по вкладке Шкалы (Scale) в диалоговом окне Свойства (Properties). После этого вы увидите диалоговое окно Шкалы (Scale), как показано на рис. А.20; 3)выберите нужные вам опции в диалоговом окне Шкалы (Scale). Как изменить ось категорий (x) Работа с осью x не сложнее, чем с осью y. Вот как изменяется ось x: 1)дважды щелкните мышью по оси x. Откроется диалоговое окно Категории (Category Axis). Оно очень похоже на диалоговое окно Шкалы (Scale), которое вы видите на рис. А.20; 2)выберите нужные вам опции в диалоговом окне Категории (Category Axis). Приложение A SPSS Statistics меньше, чем за 30 мин 409 Рис. А.20 Диалоговое окно Шкалы (Scale) Когда закончите, закройте редактор диаграмм, дважды щелкнув по значку окна или выбрав Файл (File) ⇒ Закрыть (Close). ОПИСАНИЕ ДАННЫХ Теперь у вас некоторое представление о том, как создаются файлы данных в SPSS. Давайте перейдем к примерам простого анализа. Частоты и сопряженные таблицы Частоты просто подсчитывают количество случаев возникновения определенного значения. Сопряженные таблицы позволяют подсчитать количество случаев возникновения определенного значения с разбивкой по одной или более категориям, например по полу и возрасту. И частоты, и сопряженные таблицы часто показываются в отчетах по исследованиям в первую очередь, поскольку они дают читателю представление о том, на что похожи данные. Для вычис- 410 Статистика для тех, кто (думает, что) ненавидит статистику ления частот следуйте этим пунктам. Вы должны находиться в окне редактора данных: 1)нажмите Анализ (Analyze) ⇒ Описательные статистики (Descriptive Statistics) ⇒ Частоты (Frequencies). По завершении вы увидите диалоговое окно, как показано на рис. А.21; Рис. А.21 Диалоговое окно Частоты (Frequencies) 2)дважды щелкните мышью по переменным, для которых вы хотите посчитать частоты. В нашем случае это Test 1 и Test 2; 3)щелкните по кнопке Статистики (Statistics). Вы увидите диалоговое окно Частоты: статистики (Frequencies: Statistics), как показано на рис. А.22; 4)в разделе Разброс (Dispersion) отметьте Стандартное отклонение (Std. deviation); 5)в разделе Положение центра распределения (Central Tendency) отметьте Среднее значение (Mean); 6) нажмите на Продолжить (Continue). 7) нажмите ОК. Вывод состоит из списка частот для каждого значения по переменным Test 1 и Test 2, плюс итоговые статистики (среднее значение и стандартное отклонение) для каждой из них, как вы видите на рис. А.23. Приложение A SPSS Statistics меньше, чем за 30 мин 411 Рис. А.22 Диалоговое окно Частоты: статистики (Frequencies: Statistics) Рис. А.23 Итоговые статистики для переменных Test 1 и Test 2 Применение t-критерия для независимых выборок t-критерий для независимых выборок используется для анализа данных в различных видах исследований, в том числе экспериментальных, квази-экспериментальных и полевых исследованиях, таких же, как в нашем следующем примере, в котором мы проверяем гипотезу, что существуют различия в чтении между мужчинами и женщинами. 412 Статистика для тех, кто (думает, что) ненавидит статистику Как рассчитать t-критерий для независимых выборок Для расчета t-критерия для независимых выборок следуйте перечисленным ниже шагам: 1)нажмите Анализ (Analyze) ⇒ Сравнение средних (Compare Means) ⇒ Т-критерий для независимых выборок (Independent-Samples T Test). После этого вы увидите диалоговое окно Т-критерий для независимых выборок (Independent-Samples T Test), как на рис. А.24. В левой области диалогового окна вы видите список всех переменных, которые можно использовать в анализе. Сейчас вам нужно определить проверяемые и группируемые переменные; 2)щелкните по переменной Test 1 (Тест 1) и перетащите ее в область Проверяемые переменные (Test Variable(s)); 3)щелкните по переменной Gender (Пол) и перетащите ее в область Группировать по (Grouping Variable); Рис. А.24 Диалоговое окно Т-критерий для независимых выборок (Independent-Samples T Test) 4) нажмите на Задать группы (Define Groups); 5) в поле Группа 1 (Group 1) введите 1; 6) в поле Группа 2 (Group 2) введите 2; 7) нажмите на Продолжить (Continue); 8) нажмите ОК. Вывод содержит средние значения и стандартные отклонения для каждой переменной, а также результаты проверки t-критерия, как показано на рис. А.25. Приложение A SPSS Statistics меньше, чем за 30 мин 413 Рис. А.25 Результаты простого анализа t-критерия ВЫХОД ИЗ SPSS Для выхода из SPSS щелкните по Файл (File) ⇒ Выход (Exit). SPSS позаботится о том, чтобы вы сохранили все не сохраненные ранее или отредактированные окна, а затем закроется. Мы только что дали вам кратчайшие вводные инструкции к SPSS. Конечно, все эти навыки ничего не значат, если вы не знаете ценности или смысла данных, которые первоначально ввели в программу. Так что не восхищайтесь своими или чужими навыками пользования такими программами, как SPSS. Восхищайтесь, когда эти люди могут рассказать, что означает этот вывод и как он отображает ответ на поставленный вами вопрос. И особенно восхищайтесь, если вы сами можете это сделать! Приложение B Таблицы ТАБЛИЦА B.1. ПЛОЩАДИ ПОД КРИВОЙ НОРМАЛЬНОГО РАСПРЕДЕЛЕНИЯ Как использовать эту таблицу: 1)рассчитайте z-показатель на основании исходных данных и среднего значения выборки; 2)посмотрите в таблице на значение справа от z-показателя, чтобы определить процентную долю площади под кривой нормального распределения между средним значением и рассчитанным z-показателем. Площадь между средним значением и z-показа­телем z-показатель Площадь между средним значением и z-показа­телем z-показатель Площадь между средним значением и z-показа­телем z-показатель Площадь между средним значением и z-показа­телем z-показатель Площадь между средним значением и z-показа­телем z-показатель Площадь между средним значением и z-показа­телем z-показатель Площадь между средним значением и z-показа­телем z-показатель Площадь между средним значением и z-показа­телем Площадь под кривой нормального распределения z-показатель Таблица B.1 0,00 0,00 0,01 0,40 0,51 19,50 1,01 34,38 1,51 43,45 2,01 47,78 2,51 49,40 3,01 49,87 3,51 49,98 0,02 0,80 0,52 19,85 1,02 34,61 1,52 43,57 2,02 47,83 2,52 49,41 3,02 49,87 3,52 49,98 0,03 1,20 0,53 20,19 1,03 34,85 1,53 43,70 2,03 47,88 2,53 49,43 3,03 49,88 3,53 49,98 0,04 1,60 0,54 20,54 1,04 35,08 1,54 43,82 2,04 47,93 2,54 49,45 3,04 49,88 3,54 49,98 0,05 1,99 0,55 20,88 1,05 35,31 1,55 43,94 2,05 47,98 2,55 49,46 3,05 49,89 3,55 49,98 0,06 2,39 0,56 21,23 1,06 35,54 1,56 44,06 2,06 48,03 2,56 49,48 3,06 49,89 3,56 49,98 0,07 2,79 0,57 21,57 1,07 35,77 1,57 44,18 2,07 48,08 2,57 49,49 3,07 49,89 3,57 49,98 0,08 3,19 0,58 21,90 1,08 35,99 1,58 44,29 2,08 48,12 2,58 49,51 3,08 49,90 3,58 49,98 0,10 3,98 0,60 22,57 1,09 36,21 1,59 44,41 2,09 48,17 2,59 49,52 3,09 49,90 3,59 49,98 414 Продолжение ⇒ Площадь между средним значением и z-показа­телем z-показатель Площадь между средним значением и z-показа­телем z-показатель Площадь между средним значением и z-показа­телем z-показатель Площадь между средним значением и z-показа­телем z-показатель Площадь между средним значением и z-показа­телем z-показатель Площадь между средним значением и z-показа­телем z-показатель Площадь между средним значением и z-показа­телем 415 z-показатель Таблицы Площадь между средним значением и z-показа­телем z-показатель Приложение B 0,11 4,38 0,61 22,91 1,10 36,43 1,60 44,52 2,10 48,21 2,60 49,53 3,10 49,90 3,60 49,98 0,12 4,78 0,62 23,24 1,11 36,65 1,61 44,63 2,11 48,26 2,61 49,55 3,11 49,91 3,61 49,98 0,13 5,17 0,63 23,57 1,12 36,86 1,62 44,74 2,12 48,30 2,62 49,56 3,12 49,91 3,62 49,98 0,14 5,57 0,64 23,89 1,13 37,08 1,63 44,84 2,13 48,34 2,63 49,57 3,13 49,91 3,63 49,98 0,15 5,96 0,65 24,22 1,14 37,29 1,64 44,95 2,14 48,38 2,64 49,59 3,14 49,92 3,64 49,98 0,16 6,36 0,66 24,54 1,15 37,49 1,65 45,05 2,15 48,42 2,65 49,60 3,15 49,92 3,65 49,98 0,17 6,73 0,67 24,86 1,16 37,70 1,66 45,15 2,16 48,46 2,66 49,61 3,16 49,92 3,66 49,98 0,18 7,14 0,68 25,17 1,17 37,90 1,67 45,25 2,17 48,50 2,67 49,62 3,17 49,92 3,67 49,98 0,19 7,53 0,69 25,49 1,18 38,10 1,68 45,35 2,18 48,54 2,68 49,63 3,18 49,93 3,68 49,98 0,20 7,93 0,70 25,80 1,19 38,30 1,69 45,45 2,19 48,57 2,69 49,64 3,19 49,93 3,69 49,98 0,21 8,32 0,71 26,11 1,20 38,49 1,70 45,54 2,20 48,61 2,70 49,65 3,20 49,93 3,70 49,99 0,22 8,71 0,72 26,42 1,21 38,69 1,71 45,64 2,21 48,64 2,71 49,66 3,21 49,93 3,71 49,99 0,23 9,10 0,73 26,73 1,23 39,07 1,73 45,82 2,23 48,71 2,73 49,68 3,23 49,94 3,73 49,99 0,24 9,48 0,74 27,04 1,24 39,25 1,74 45,91 2,24 48,75 2,74 49,69 3,24 49,94 3,74 49,99 0,25 9,97 0,75 27,34 1,25 39,44 1,75 45,99 2,25 48,78 2,75 49,70 3,25 49,94 3,75 49,99 0,26 10,26 0,76 27,64 1,26 39,62 1,76 46,00 2,26 48,81 2,76 49,71 3,26 49,94 3,76 49,99 0,27 10,64 0,77 27,94 1,27 39,80 1,77 46,16 2,27 48,84 2,77 49,72 3,27 49,94 3,77 49,99 0,28 11,03 0,78 28,23 1,28 39,97 1,78 46,25 2,28 48,87 2,78 49,73 3,28 49,94 3,78 49,99 0,29 11,41 0,79 28,52 1,29 40,13 1,79 46,33 2,29 48,90 2,79 49,74 3,29 49,94 3,79 49,99 0,30 11,79 0,80 28,81 1,30 40,32 1,80 46,41 2,30 48,93 2,80 49,74 3,30 49,95 3,80 49,99 0,31 12,17 0,81 29,10 1,31 40,49 1,81 46,49 2,31 48,96 2,81 49,75 3,31 49,95 3,81 49,99 0,32 12,55 0,82 29,39 1,32 40,66 1,82 46,56 2,32 48,98 2,82 49,76 3,32 49,95 3,82 49,99 0,33 12,93 0,83 29,67 1,33 40,82 1,83 46,64 2,33 49,01 2,83 49,77 3,33 49,95 3,83 49,99 0,34 13,31 0,84 29,95 1,34 40,99 1,84 46,71 2,34 49,04 2,84 49,77 3,34 49,95 3,84 49,99 0,35 13,68 0,85 30,23 1,35 41,15 1,85 46,78 2,35 49,06 2,85 49,78 3,35 49,96 3,85 49,99 0,36 14,06 0,86 30,51 1,36 41,31 1,86 46,86 2,36 49,09 2,86 49,79 3,36 49,96 3,86 49,99 0,37 14,43 0,87 30,78 1,37 41,47 1,87 46,93 2,37 49,11 2,87 49,79 3,37 49,96 3,87 49,99 0,38 14,80 0,88 31,06 1,38 41,62 1,88 46,99 2,38 49,13 2,88 49,80 3,38 49,96 3,88 49,99 0,39 15,17 0,89 31,33 1,39 41,77 1,89 47,06 2,39 49,16 2,89 49,81 3,39 49,96 3,89 49,99 0,40 15,54 0,90 31,59 1,40 41,92 1,90 47,13 2,40 49,18 2,90 49,81 3,40 49,97 3,90 49,99 0,41 15,91 0,91 31,86 1,41 42,07 1,91 47,19 2,41 49,20 2,91 49,82 3,41 49,97 3,91 49,99 0,42 16,28 0,92 32,12 1,42 42,22 1,92 47,26 2,42 49,22 2,92 49,82 3,42 49,97 3,92 49,99 0,43 16,64 0,93 32,38 1,43 42,36 1,93 47,32 2,43 49,25 2,93 49,83 3,43 49,97 3,93 49,99 0,44 17,00 0,94 32,64 1,44 42,51 1,94 47,38 2,44 49,27 2,94 49,84 3,44 49,97 3,94 49,99 0,45 17,36 0,95 32,89 1,45 42,65 1,95 47,44 2,45 49,29 2,95 49,84 3,45 49,98 3,95 49,99 0,46 17,72 0,96 33,15 1,46 42,79 1,96 47,50 2,46 49,31 2,96 49,85 3,46 49,98 3,96 49,99 0,47 18,08 0,97 33,40 1,47 42,92 1,97 47,56 2,47 49,32 2,97 49,85 3,47 49,98 3,97 49,99 0,48 18,44 0,98 33,65 1,48 43,06 1,98 47,61 2,48 49,34 2,98 49,86 3,48 49,98 3,98 49,99 0,49 18,79 0,99 33,89 1,49 43,19 1,99 47,67 2,49 49,36 2,99 49,86 3,49 49,98 3,99 49,99 416 Статистика для тех, кто (думает, что) ненавидит статистику ТАБЛИЦА B.2. ЗНАЧЕНИЯ T, НЕОБХОДИМЫЕ Д ЛЯ ОТК ЛОНЕНИЯ НУЛЕВОЙ ГИПОТЕЗЫ Как использовать эту таблицу: 1) рассчитайте значение t-критерия; 2)сравните наблюдаемое значение t с критическим значением, указанным в этой таблице. Проверьте, что вы правильно рассчитали количество степеней свободы и выбрали подходящий уровень значимости; 3)если наблюдаемое значение больше, чем критическое или таб­ личное, тогда нулевая гипотеза (о том, что средние значения равны) не является самым привлекательным объяснением любых наблюдаемых различий; 4)если наблюдаемое значение меньше, чем критическое или табличное, тогда нулевая гипотеза является самым предпочтительным объяснением для любых наблюдаемых различий. Таблица B.2 Степени свободы 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 Значения t, необходимые для отклонения нулевой гипотезы Односторонний критерий 0,10 0,05 0,01 3,078 6,314 31,821 1,886 2,92 6,965 1,638 2,353 4,541 1,533 2,132 3,747 1,476 2,015 3,365 1,44 1,943 3,143 1,415 1,895 2,998 1,397 1,86 2,897 1,383 1,833 2,822 1,372 1,813 2,764 1,364 1,796 2,718 1,356 1,783 2,681 1,35 1,771 2,651 1,345 1,762 2,625 1,341 1,753 2,603 1,337 1,746 2,584 1,334 1,74 2,567 1,331 1,734 2,553 1,328 1,729 2,54 1,326 1,725 2,528 1,323 1,721 2,518 1,321 1,717 2,509 1,32 1,714 2,5 Степени свободы 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 Двусторонний критерий 0,10 0,05 0,01 6,314 12,706 63,657 2,92 4,303 9,925 2,353 3,182 5,841 2,132 2,776 4,604 2,015 2,571 4,032 1,943 2,447 3,708 1,895 2,365 3,5 1,86 2,306 3,356 1,833 2,262 3,25 1,813 2,228 3,17 1,796 2,201 3,106 1,783 2,179 3,055 1,771 2,161 3,013 1,762 2,145 2,977 1,753 2,132 2,947 1,746 2,12 2,921 1,74 2,11 2,898 1,734 2,101 2,879 1,729 2,093 2,861 1,725 2,086 2,846 1,721 2,08 2,832 1,717 2,074 2,819 1,714 2,069 2,808 Продолжение ⇒ Приложение B Степени свободы 24 25 26 27 28 29 30 35 40 45 50 55 60 65 70 75 80 85 90 95 100 ∞ Таблицы Односторонний критерий 0,10 0,05 0,01 1,318 1,711 2,492 1,317 1,708 2,485 1,315 1,706 2,479 1,314 1,704 2,473 1,313 1,701 2,467 1,312 1,699 2,462 1,311 1,698 2,458 1,306 1,69 2,438 1,303 1,684 2,424 1,301 1,68 2,412 1,299 1,676 2,404 1,297 1,673 2,396 1,296 1,671 2,39 1,295 1,669 2,385 1,294 1,667 2,381 1,293 1,666 2,377 1,292 1,664 2,374 1,292 1,663 2,371 1,291 1,662 2,369 1,291 1,661 2,366 1,29 1,66 2,364 1,282 1,645 2,327 417 Степени свободы 24 25 26 27 28 29 30 35 40 45 50 55 60 65 70 75 80 85 90 95 100 ∞ Двусторонний критерий 0,10 0,05 0,01 1,711 2,064 2,797 1,708 2,06 2,788 1,706 2,056 2,779 1,704 2,052 2,771 1,701 2,049 2,764 1,699 2,045 2,757 1,698 2,043 2,75 1,69 2,03 2,724 1,684 2,021 2,705 1,68 2,014 2,69 1,676 2,009 2,678 1,673 2,004 2,668 1,671 2,001 2,661 1,669 1,997 2,654 1,667 1,995 2,648 1,666 1,992 2,643 1,664 1,99 2,639 1,663 1,989 2,635 1,662 1,987 2,632 1,661 1,986 2,629 1,66 1,984 2,626 1,645 1,96 2,576 ТАБЛИЦА B.3. КРИТИЧЕСКИЕ ЗНАЧЕНИЯ Д ЛЯ ДИСПЕРСИОННОГО АНАЛИЗА, ИЛИ F - КРИТЕРИЯ Как использовать эту таблицу: 1) рассчитайте значение F; 2)определите количество степеней свободы для числителя (k – 1) и количество степеней свободы для знаменателя (n – k); 3)определите критическое значение, найдя по горизонтали количество степеней свободы для числителя, а по вертикали – количество степеней свободы для знаменателя. Критическое значение находится на пересечении этих столбца и строки; 4)если наблюдаемое значение больше, чем критическое или таб­ личное, тогда нулевая гипотеза (о том, что средние значения равны) не является самым привлекательным объяснением любых наблюдаемых различий; 5)если наблюдаемое значение меньше, чем критическое или таб­личное, тогда нулевая гипотеза является самым предпоч­ тительным объяснением для любых наблюдаемых различий. 418 Статистика для тех, кто (думает, что) ненавидит статистику Таблица B.3 Критические значения для дисперсионного анализа, или F-критерия Ст. св. для Ошибка знаменателя I рода 1 2 3 4 5 6 7 8 9 10 11 12 13 14 0,01 0,05 0,10 0,01 0,05 0,10 0,01 0,05 0,10 0,01 0,05 0,10 0,01 0,05 0,10 0,01 0,05 0,10 0,01 0,05 0,10 0,01 0,05 0,10 0,01 0,05 0,10 0,01 0,05 0,10 0,01 0,05 0,10 0,01 0,05 0,10 0,01 0,05 0,10 0,01 0,05 0,10 1 4052,00 162,00 39,90 98,50 18,51 8,53 34,12 10,13 5,54 21,20 7,71 4,55 16,26 6,61 4,06 13,75 5,99 3,78 12,25 5,59 3,59 11,26 5,32 3,46 10,56 5,12 3,36 10,05 4,97 3,29 9,65 4,85 3,23 9,33 4,75 3,18 9,07 4,67 3,14 8,86 4,60 3,10 2 4999,00 200,00 49,50 99,00 19,00 9,00 30,82 9,55 5,46 18,00 6,95 4,33 13,27 5,79 3,78 10,93 5,14 3,46 9,55 4,74 3,26 8,65 4,46 3,11 8,02 4,26 3,01 7,56 4,10 2,93 7,21 3,98 2,86 6,93 3,89 2,81 6,70 3,81 2,76 6,52 3,74 2,73 Ст. св. для числителя 3 4 5403,00 5625,00 216,00 225,00 53,60 55,80 99,17 99,25 19,17 19,25 9,16 9,24 29,46 28,71 9,28 9,12 5,39 5,34 16,70 15,98 6,59 6,39 4,19 4,11 12,06 11,39 5,41 5,19 3,62 3,52 9,78 9,15 4,76 4,53 3,29 3,18 8,45 7,85 4,35 4,12 3,08 2,96 7,59 7,01 4,07 3,84 2,92 2,81 6,99 6,42 3,86 3,63 2,81 2,69 6,55 6,00 3,71 3,48 2,73 2,61 6,22 5,67 3,59 3,36 2,66 2,54 5,95 5,41 3,49 3,26 2,61 2,48 5,74 5,21 3,41 3,18 2,56 2,43 5,56 5,04 3,34 3,11 2,52 2,40 5 6 5764,00 5859,00 230,00 234,00 57,20 58,20 99,30 99,33 19,30 19,33 9,29 9,33 28,24 27,91 9,01 8,94 5,31 5,28 15,52 15,21 6,26 6,16 4,05 4,01 10,97 10,67 5,05 4,95 3,45 3,41 8,75 8,47 4,39 4,28 3,11 3,06 7,46 7,19 3,97 3,87 2,88 2,83 6,63 6,37 3,69 3,58 2,73 2,67 6,06 5,80 3,48 3,37 2,61 2,55 5,64 5,39 3,33 3,22 2,52 2,46 5,32 5,07 3,20 3,10 2,45 2,39 5,07 4,82 3,11 3,00 2,40 2,33 4,86 4,62 3,03 2,92 2,35 2,28 4,70 4,46 2,96 2,85 2,31 2,24 Продолжение ⇒ Приложение B Таблицы Ст. св. для Ошибка знаменателя I рода 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 0,01 0,05 0,10 0,01 0,05 0,10 0,01 0,05 0,10 0,01 0,05 0,10 0,01 0,05 0,10 0,01 0,05 0,10 0,01 0,05 0,10 0,01 0,05 0,10 0,01 0,05 0,10 0,01 0,05 0,10 0,01 0,05 0,10 0,01 0,05 0,10 0,01 0,05 0,10 0,01 0,05 0,10 0,01 0,05 1 8,68 4,54 3,07 8,53 4,49 3,05 8,40 4,45 3,03 8,29 4,41 3,01 8,19 4,38 2,99 8,10 4,35 2,98 8,02 4,33 2,96 7,95 4,30 2,95 7,88 4,28 2,94 7,82 4,26 2,93 7,77 4,24 2,92 7,72 4,23 2,91 7,68 4,21 2,90 7,64 4,20 2,89 7,60 4,18 419 2 6,36 3,68 2,70 6,23 3,63 2,67 6,11 3,59 2,65 6,01 3,56 2,62 5,93 3,52 2,61 5,85 3,49 2,59 5,78 3,47 2,58 5,72 3,44 2,56 5,66 3,42 2,55 5,61 3,40 2,54 5,57 3,39 2,53 5,53 3,37 2,52 5,49 3,36 2,51 5,45 3,34 2,50 5,42 3,33 Ст. св. для числителя 3 4 5,42 4,89 3,29 3,06 2,49 2,36 5,29 4,77 3,24 3,01 2,46 2,33 5,19 4,67 3,20 2,97 2,44 2,31 5,09 4,58 3,16 2,93 2,42 2,29 5,01 4,50 3,13 2,90 2,40 2,27 4,94 4,43 3,10 2,87 2,38 2,25 4,88 4,37 3,07 2,84 2,37 2,23 4,82 4,31 3,05 2,82 2,35 2,22 4,77 4,26 3,03 2,80 2,34 2,21 4,72 4,22 3,01 2,78 2,33 2,20 4,68 4,18 2,99 2,76 2,32 2,19 4,64 4,14 2,98 2,74 2,31 2,18 4,60 4,11 2,96 2,73 2,30 2,17 4,57 4,08 2,95 2,72 2,29 2,16 4,54 4,05 2,94 2,70 5 4,56 2,90 2,27 4,44 2,85 2,24 4,34 2,81 2,22 4,25 2,77 2,20 4,17 2,74 2,18 4,10 2,71 2,16 4,04 2,69 2,14 3,99 2,66 2,13 3,94 2,64 2,12 3,90 2,62 2,10 3,86 2,60 2,09 3,82 2,59 2,08 3,79 2,57 2,07 3,75 2,56 2,07 3,73 2,55 6 4,32 2,79 2,21 4,20 2,74 2,18 4,10 2,70 2,15 4,02 2,66 2,13 3,94 2,63 2,11 3,87 2,60 2,09 3,81 2,57 2,08 3,76 2,55 2,06 3,71 2,53 2,05 3,67 2,51 2,04 3,63 2,49 2,03 3,59 2,48 2,01 3,56 2,46 2,01 3,53 2,45 2,00 3,50 2,43 Продолжение ⇒ 420 Статистика для тех, кто (думает, что) ненавидит статистику Ст. св. для Ошибка знаменателя I рода 30 35 40 45 50 55 60 65 70 75 80 85 90 95 100 0,10 0,01 0,05 0,10 0,01 0,05 0,10 0,01 0,05 0,10 0,01 0,05 0,10 0,01 0,05 0,10 0,01 0,05 0,10 0,01 0,05 0,10 0,01 0,05 0,10 0,01 0,05 0,10 0,01 0,05 0,10 0,01 0,05 0,10 0,01 0,05 0,10 0,01 0,05 0,10 0,01 0,05 0,10 0,01 1 2,89 7,56 4,17 2,88 7,42 4,12 2,86 7,32 4,09 2,84 7,23 4,06 2,82 7,17 4,04 2,81 7,12 4,02 2,80 7,08 4,00 2,79 7,04 3,99 2,79 7,01 3,98 2,78 6,99 3,97 2,77 6,96 3,96 2,77 6,94 3,95 2,77 6,93 3,95 2,76 6,91 3,94 2,76 6,90 2 2,50 5,39 3,32 2,49 5,27 3,27 2,46 5,18 3,23 2,44 5,11 3,21 2,43 5,06 3,18 2,41 5,01 3,17 2,40 4,98 3,15 2,39 4,95 3,14 2,39 4,92 3,13 2,38 4,90 3,12 2,38 4,88 3,11 2,37 4,86 3,10 2,37 4,85 3,10 2,36 4,84 3,09 2,36 4,82 Ст. св. для числителя 3 4 2,28 2,15 4,51 4,02 2,92 2,69 2,28 2,14 4,40 3,91 2,88 2,64 2,25 2,14 4,31 3,91 2,84 2,64 2,23 2,11 4,25 3,83 2,81 2,61 2,21 2,09 4,20 3,77 2,79 2,58 2,20 2,08 4,16 3,72 2,77 2,56 2,19 2,06 4,13 3,68 2,76 2,54 2,18 2,05 4,10 3,65 2,75 2,53 2,17 2,04 4,08 3,62 2,74 2,51 2,16 2,03 4,06 3,60 2,73 2,50 2,16 2,03 4,04 3,56 2,72 2,49 2,15 2,02 4,02 3,55 2,71 2,48 2,15 2,01 4,02 3,54 2,71 2,47 2,15 2,01 4,00 3,52 2,70 2,47 2,14 2,01 3,98 3,51 5 2,06 3,70 2,53 2,05 3,59 2,49 2,02 3,51 2,45 2,00 3,46 2,42 1,98 3,41 2,40 1,97 3,37 2,38 1,96 3,34 2,37 1,95 3,31 2,36 1,94 3,29 2,35 1,93 3,27 2,34 1,93 3,26 2,33 1,92 3,24 2,32 1,92 3,23 2,32 1,91 3,22 2,31 1,91 3,21 6 1,99 3,47 2,42 1,98 3,37 2,37 1,95 3,29 2,34 1,93 3,23 2,31 1,91 3,19 2,29 1,90 3,15 2,27 1,89 3,12 2,26 1,88 3,09 2,24 1,87 3,07 2,23 1,86 3,05 2,22 1,86 3,04 2,22 1,85 3,02 2,21 1,85 3,01 2,20 1,84 3,00 2,20 1,84 2,99 Продолжение ⇒ Приложение B Таблицы Ст. св. для Ошибка знаменателя I рода ∞ 0,05 0,10 0,01 0,05 0,10 1 3,94 2,76 6,64 3,84 2,71 421 2 3,09 2,36 4,61 3,00 2,30 Ст. св. для числителя 3 4 2,70 2,46 2,14 2,00 3,78 3,32 2,61 2,37 2,08 1,95 5 2,31 1,91 3,02 2,22 1,85 6 2,19 1,83 2,80 2,10 1,78 ТАБЛИЦА B.4. ЗНАЧЕНИЯ КОЭФФИЦИЕНТА КОРРЕЛЯЦИИ, НЕОБХОДИМЫЕ Д ЛЯ ОТК ЛОНЕНИЯ НУЛЕВОЙ ГИПОТЕЗЫ Как использовать эту таблицу: 1) рассчитайте значение коэффициента корреляции; 2)сравните значение коэффициента корреляции с критическим значением, указанным в таблице; 3)если наблюдаемое значение больше, чем критическое или таб­ личное, тогда нулевая гипотеза (о том, что коэффициент корреляции равен нулю) не является самым привлекательным объяснением любых наблюдаемых различий; 4)если наблюдаемое значение меньше, чем критическое или таб­ личное, тогда нулевая гипотеза является самым предпочтительным объяснением для любых наблюдаемых различий. Таблица B.4 Степени свободы 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Значения коэффициента корреляции, необходимые для отклонения нулевой гипотезы Односторонний критерий 0,05 0,01 0,9877 0,9995 0,9000 0,9800 0,8054 0,9343 0,7293 0,8822 0,6694 0,8320 0,6215 0,7887 0,5822 0,7498 0,5494 0,7155 0,5214 0,6851 0,4973 0,6581 0,4762 0,6339 0,4575 0,6120 0,4409 0,5923 0,4259 0,5742 0,4120 0,5577 Степени свободы 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Двусторонний критерий 0,05 0,01 0,9969 0,9999 0,9500 0,9900 0,8783 0,9587 0,8114 0,9172 0,7545 0,8745 0,7067 0,8343 0,6664 0,7977 0,6319 0,7646 0,6021 0,7348 0,5760 0,7079 0,5529 0,6835 0,5324 0,6614 0,5139 0,6411 0,4973 0,6226 0,4821 0,6055 Продолжение ⇒ 422 Статистика для тех, кто (думает, что) ненавидит статистику Степени свободы 16 17 18 19 20 25 30 35 40 45 50 60 70 80 90 100 Односторонний критерий 0,05 0,01 0,4000 0,5425 0,3887 0,5285 0,3783 0,5155 0,3687 0,5034 0,3598 0,4921 0,3233 0,4451 0,2960 0,4093 0,2746 0,3810 0,2573 0,3578 0,2428 0,3384 0,2306 0,3218 0,2108 0,2948 0,1954 0,2737 0,1829 0,2565 0,1726 0,2422 0,1638 0,2301 Степени свободы 16 17 18 19 20 25 30 35 40 45 50 60 70 80 90 100 Двусторонний критерий 0,05 0,01 0,4683 0,5897 0,4555 0,5751 0,4438 0,5614 0,4329 0,5487 0,4227 0,5368 0,3809 0,4869 0,3494 0,4487 0,3246 0,4182 0,3044 0,3932 0,2875 0,3721 0,2732 0,3541 0,2500 0,3248 0,2319 0,3017 0,2172 0,2830 0,2050 0,2673 0,1946 0,2540 ТАБЛИЦА B.5. КРИТИЧЕСКИЕ ЗНАЧЕНИЯ ХИ - КВАДРАТ Как использовать эту таблицу: 1) рассчитайте значение χ2; 2)определите количество степеней свободы для рядов (R – 1) и количество степеней свободы для столбцов (C – 1). Если у вас одномерная таблица, тогда вы работаете только со столбцами; 3)найдите критическое значение, найдя количество степеней свободы в столбце «Ст. св.». Затем идите по горизонтали до столбца с соответст­вующим уровнем значимости; 4)если наблюдаемое значение больше, чем критическое или табличное, тогда нулевая гипотеза (о том, что частоты равны друг другу) не является самым привлекательным объяснением любых наблюдаемых различий; 5)если наблюдаемое значение меньше, чем критическое или таб­личное, тогда нулевая гипотеза является самым предпоч­ тительным объяснением для любых наблюдаемых различий. Приложение B Таблица B.5 423 Критические значения хи-квадрат Степени свободы 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 Таблицы 0,10 2,71 4,00 6,25 7,78 9,24 10,64 12,02 13,36 14,68 16,99 17,28 18,65 19,81 21,06 22,31 23,54 24,77 25,99 27,20 28,41 29,62 30,81 32,01 33,20 34,38 35,56 36,74 37,92 39,09 40,26 Уровень значимости 0,05 3,84 5,99 7,82 9,49 11,07 12,59 14,07 15,51 16,92 18,31 19,68 21,03 22,36 23,68 25,00 26,30 27,60 28,87 30,14 31,41 32,67 33,92 35,17 36,42 37,65 38,88 40,11 41,34 42,56 43,77 0,01 6,64 9,21 11,34 13,28 15,09 16,81 18,48 20,09 21,67 23,21 24,72 26,22 27,69 29,14 30,58 32,00 33,41 34,80 36,19 37,57 38,93 40,29 41,64 42,98 44,81 45,64 46,96 48,28 49,59 50,89 Приложение C Наборы данных Н а эти файлы данных мы ссылаемся на протяжении всей «Статистики для тех, кто (думает, что) ненавидит статистику». Они приведены здесь, чтобы их можно было ввести вручную. Также вы можете скачать их в одном из двух мест: zz с веб-страницы, поддерживаемой издательством SAGE, edge. sagepub.com/salkind6e; zz с веб-сайта автора https://www.onlinefilefolder.com. Имя пользователя: ancillaries, пароль: files. Обратите внимание, что в таблицах введены числовые значения (такие как 1 и 2), в то время как метки (например, мужчины или женщины) этих значений – нет. Например, в табл. «Глава 11. Набор данных 2» (Chapter 11. Data Set 2) пол представлен как 1 (муж) или 2 (жен). Если вы используете SPSS, то можете обратиться к опции меток значений, чтобы назначить этим числам метки1. Глава 2. Набор данных 1 Предубеждения 87 99 87 87 67 1 424 Предубеждения 87 77 89 99 96 Предубеждения 76 55 64 81 94 Предубеждения 81 82 99 93 94 Заголовки таблиц в приложении С переведены на русский язык, тогда как при скачивании файлов по приведенным выше ссылкам вы увидите англоязычные заголовки. В примерах с использованием файлов данных в тексте учебника приводятся названия переменных и на английском, и (в скобках) на русском языке. – Прим. перев. Приложение C Наборы данных 425 Глава 2. Набор данных 2 Набор 1 3 7 5 4 5 6 7 8 6 5 Набор 2 34 54 17 26 34 25 14 24 25 23 Набор 3 154 167 132 145 154 145 113 156 154 123 Глава 2. Набор данных 3 Количество коек 234 214 165 436 432 Заболеваемость 1,7 2,4 3,1 5,6 4,9 Количество коек 342 276 187 512 553 Заболеваемость 5,3 5,6 1,2 3,3 4,1 Глава 2. Набор данных 4 Группы: 1 = мало опыта; 2 = средний объем опыта; 3 = большой опыт. Группа 1 1 2 2 1 1 2 2 3 3 Отношение 4 5 6 6 5 7 6 5 8 9 Группа 2 2 1 1 2 2 3 2 1 1 Отношение 8 1 6 5 4 3 4 6 7 8 Глава 3. Набор данных 1 Время реакции 0,4 0,7 0,4 0,9 0,8 0,7 Время реакции 0,3 1,9 1,2 2,8 0,8 0,9 Время реакции 1,1 1,3 0,2 0,6 0,8 0,7 Время реакции 0,5 2,6 0,5 2,1 2,3 0,2 Время реакции 0,5 0,7 1,1 0,9 0,6 0,2 426 Статистика для тех, кто (думает, что) ненавидит статистику Глава 3. Набор данных 2 Оценка_математика 78 67 89 97 67 56 67 77 75 68 78 98 92 82 78 Оценка_чтение 24 35 54 56 78 87 65 69 98 78 85 69 93 100 98 Оценка_математика 72 98 88 74 58 98 97 86 89 69 79 87 89 99 87 Глава 3. Набор данных 3 Рост 53 46 54 44 56 76 87 65 45 44 Вес 156 131 123 142 156 171 143 135 138 114 Рост 57 68 65 66 54 66 51 58 49 48 Глава 3. Набор данных 4 Точность 12 15 11 5 3 8 19 16 23 19 Вес 154 166 153 140 143 156 173 143 161 131 Оценка_чтение 77 89 76 56 78 99 83 69 89 73 60 96 59 89 87 Приложение C Наборы данных 427 Глава 4. Набор данных 1 Понимание текста 12 15 11 16 21 25 21 8 6 2 Понимание текста 22 26 27 36 34 33 38 42 44 47 Понимание текста 54 55 51 56 53 57 49 45 45 47 Понимание текста 43 31 12 14 15 16 22 29 29 54 Понимание текста 56 57 59 54 56 43 44 41 42 7 Глава 4. Набор данных 2 Понедельник 12 9 6 4 9 10 13 22 1 5 7 10 4 15 3 Вторник 17 11 8 0 7 5 12 16 3 8 0 4 5 12 6 Среда 10 10 9 5 8 4 7 18 6 4 3 1 8 10 4 Четверг 15 4 5 4 5 4 3 15 4 6 8 8 6 9 7 Пятница 20 0 10 9 11 15 10 20 2 7 2 12 9 11 10 Глава 4. Набор данных 3 Вишневый Яблочный Шоколадный Вишневый Шоколадный Шоколадный Яблочный Шоколадный Яблочный Шоколадный Шоколадный Шоколадный Шоколадный Яблочный Шоколадный 428 Статистика для тех, кто (думает, что) ненавидит статистику Глава 5. Набор данных 1 Доход (долл.) 36 577 54 365 33 542 65 654 45 765 24 354 43 233 44 321 23 216 43 454 Образование 11 12 10 12 11 7 12 13 9 12 Доход (долл.) 64 543 43 433 34 644 33 213 55 654 76 545 21 324 17 645 23 432 44 543 Образование 12 14 12 10 15 14 11 12 11 15 Глава 5. Набор данных 2 Количество верных ответов 17 13 12 15 16 Отношение 94 73 59 80 93 Количество верных ответов 14 16 16 18 19 Глава 5. Набор данных 3 Скорость 21,6 23,4 26,5 25,5 20,8 Сила 135 213 243 167 120 Скорость 19,5 20,9 18,7 29,8 29,7 Глава 5. Набор данных 4 Достижения 0,07 0,03 0,05 0,07 0,02 0,01 0,05 0,04 0,04 Бюджет 0,11 0,14 0,13 0,26 0,08 0,03 0,06 0,12 0,11 Сила 134 209 176 156 177 Отношение 85 66 79 77 91 Приложение C Наборы данных 429 Глава 5. Набор данных 5 Упражнения 25 30 20 60 45 90 60 0 15 10 Средний балл 3,6 4,0 3,8 3,0 3,7 3,9 3,5 2,8 3,0 2,5 Глава 5. Набор данных 6 Возраст 25 16 8 23 31 19 15 31 21 26 Уровень лечения 1 2 2 3 4 4 4 5 1 1 Оценка лечения 78 66 78 89 87 90 98 76 56 72 Возраст 24 25 36 45 16 23 31 53 11 33 Уровень лечения 5 5 4 4 4 1 2 2 3 2 Оценка лечения 84 87 69 87 88 92 97 69 79 69 Глава 6. Набор данных 1 Осень 21 38 15 34 5 32 24 3 17 32 33 15 21 8 Весна 7 13 35 45 19 47 34 1 12 41 3 20 39 46 Осень 3 16 34 50 14 14 3 4 42 28 40 40 12 5 Весна 30 26 43 20 22 25 50 17 32 46 10 48 11 23 430 Статистика для тех, кто (думает, что) ненавидит статистику Глава 6. Набор данных 2 ID 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 Вариант 1 Вариант 2 89 78 98 75 83 70 78 97 70 91 86 82 83 97 73 88 86 81 83 80 83 95 94 75 90 96 81 87 82 93 98 82 99 84 83 78 72 77 86 94 80 85 80 86 93 92 100 98 84 98 89 99 87 83 82 95 95 90 99 92 82 78 94 89 97 100 71 81 91 96 83 85 95 75 72 88 98 74 89 88 83 80 100 81 ID 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 Вариант 1 Вариант 2 73 93 91 87 81 78 97 84 97 85 91 79 71 99 82 97 95 97 70 76 70 88 96 96 70 77 71 70 87 89 97 71 81 75 89 75 71 73 71 82 75 81 72 97 88 78 86 77 70 92 79 88 96 81 82 88 97 74 93 72 70 82 76 84 74 88 81 81 88 86 70 90 91 73 96 94 81 99 95 86 72 100 93 90 Продолжение ⇒ Приложение C ID Наборы данных Вариант 1 Вариант 2 43 44 45 46 47 48 49 50 72 97 71 74 79 91 81 87 100 82 81 93 82 70 90 85 431 ID Вариант 1 Вариант 2 93 94 95 96 97 98 99 100 76 91 100 76 78 74 80 93 78 90 78 92 87 88 92 96 Глава 11. Набор данных 1 Группа: 1 = экспериментальная (было воздействие); 2 = контрольная (не было воздействия). Группа 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 Память 7 3 3 2 3 8 8 5 8 5 5 4 6 10 10 5 1 1 4 3 Группа 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 Память 5 7 1 9 2 5 2 12 15 4 5 4 4 5 5 7 8 8 9 8 Группа 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 Память 3 2 5 4 4 6 7 7 5 6 4 3 2 7 6 2 8 9 7 6 Глава 11. Набор данных 2 Пол 1 2 2 2 1 Поднимали руку 9 3 5 1 8 Пол 1 2 1 2 1 Поднимали руку 8 7 9 9 8 Продолжение ⇒ 432 Статистика для тех, кто (думает, что) ненавидит статистику Пол Поднимали руку Пол Поднимали руку 1 2 2 1 1 2 1 2 1 2 4 2 6 9 3 4 8 3 10 6 2 2 2 2 1 1 1 1 2 2 7 3 7 6 10 7 6 12 8 8 Глава 11. Набор данных 3 Группа: 1 = городские жители; 2 = сельские жители. Группа 1 2 2 2 1 1 1 2 2 1 2 1 2 1 2 Отношение 6,50 7,90 4,30 6,80 9,90 6,80 4,80 6,50 3,30 4,00 13,17 5,26 9,25 8,00 1,25 Группа 1 1 2 1 2 2 1 1 1 1 2 1 2 1 2 Отношение 4,23 6,95 6,74 5,96 5,25 2,36 9,25 6,36 8,99 5,58 4,25 6,60 1,00 5,00 3,50 Глава 11. Набор данных 4 Группа: 1 = первая группа четвероклассников; 2 = вторая группа четвероклассников. Группа 1 1 1 1 Результаты 11 11 10 7 Группа 2 2 2 2 Результаты 14 7 8 10 Продолжение ⇒ Приложение C Наборы данных 433 Группа Результаты Группа Результаты 1 1 1 1 1 1 1 1 1 1 1 2 6 12 5 7 11 9 7 3 4 10 2 2 2 2 2 2 2 2 2 2 2 15 9 19 9 17 18 19 8 7 9 14 Глава 11. Набор данных 5 Группа: 1 = проверяемая группа 1; 2 = проверяемая группа 2. Данные для расчета t-критерия для различий между двумя группами по проверяемой переменной. Группа 1 1 1 1 1 Результаты 5 5 5 7 8 Группа 2 2 2 2 2 Результаты 6 4 8 6 7 Глава 11. Набор данных 6 Данные для расчета t-критерия для различий между двумя группами (группой 1 и группой 2) по проверяемой переменной. Группа 1 1 1 1 1 1 1 1 1 1 Результаты 5 5 5 7 8 5 5 5 7 8 Группа 2 2 2 2 2 2 2 2 2 2 Результаты 6 4 8 6 7 6 4 8 6 7 434 Статистика для тех, кто (думает, что) ненавидит статистику Глава 12. Набор данных 1 До программы 3 5 4 6 5 5 4 5 3 После программы 7 8 6 7 8 9 6 6 7 До программы 6 7 8 7 6 7 8 8 9 После программы 8 8 7 9 10 9 9 8 8 До программы 9 8 7 7 6 7 8 После программы 4 4 5 6 9 8 12 Глава 12. Набор данных 2 Количество тонн используемой бумаги до и после внедрения программы переработки ресурсов. До 20 6 12 34 55 43 54 24 33 21 34 33 54 После 23 8 11 35 57 76 54 26 35 26 29 31 56 До 23 33 44 65 43 53 22 34 32 44 17 28 После 22 35 41 56 34 51 21 31 33 38 15 27 Глава 12. Набор данных 3 Уровень удовлетворенности семей социальными центрами до и после вмешательства социальных служб. До 1,30 2,50 2,30 8,10 После 6,50 8,70 9,80 10,20 До 9,00 7,60 4,50 1,10 После 8,40 6,40 7,20 5,80 Продолжение ⇒ Приложение C Наборы данных 5,00 7,00 7,50 5,20 4,40 7,60 1,30 7,90 6,50 8,70 7,90 8,70 9,10 6,50 435 5,60 6,20 7,00 6,90 5,60 5,20 9,00 6,90 5,90 7,60 7,80 7,30 4,60 8,40 Глава 12. Набор данных 4 Смены работников и их ощущение стресса. Первая смена 4 6 9 3 6 7 5 9 5 4 Вторая смена 8 5 6 4 7 7 6 8 8 9 Первая смена 3 6 6 9 6 5 4 4 3 3 Вторая смена 7 6 7 6 4 4 4 8 9 0 Глава 12. Набор данных 5 Плотность костной ткани у взрослых, участвовавших в занятиях тяжелой атлетикой. Осень 2 7 6 5 8 7 8 9 8 9 4 6 5 Весна 7 6 9 8 7 6 7 8 9 9 9 7 8 Осень 2 5 4 3 6 7 6 5 4 3 5 4 Весна 7 6 4 6 7 7 6 9 0 9 8 7 436 Статистика для тех, кто (думает, что) ненавидит статистику Глава 13. Набор данных 1 Группа: 1 = 5 ч дошкольных занятий в неделю; 2 = 10 ч дошкольных занятий в неделю; 3 = 20 ч дошкольных занятий в неделю. Группа 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 Развитие речи 87 86 76 56 78 98 77 66 75 67 87 85 99 85 79 Группа 2 2 2 2 2 3 3 3 3 3 3 3 3 3 3 Развитие речи 81 82 78 85 91 89 91 96 87 89 90 89 96 96 93 Глава 13. Набор данных 2 Тренировки: 1 = меньше 15 ч; 2 = 15–25 ч; 3 = 25 ч и более. Тренировки 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 Время 59 55 62 50 65 61 66 51 54 59 64,4 55,8 58,7 54,7 52,7 67,8 61,6 58,7 Тренировки 2 2 2 2 2 3 3 3 3 3 3 3 3 3 3 3 3 3 Время 54,6 51,5 54,7 61,4 56,9 68 65,9 54,7 53,6 58,7 58,7 65,7 66,5 56,7 55,4 51,5 54,8 57,2 Приложение C Наборы данных 437 Глава 13. Набор данных 3 Смена С 4:00 до полуночи С 4:00 до полуночи С 4:00 до полуночи С 4:00 до полуночи С 4:00 до полуночи С 4:00 до полуночи С 4:00 до полуночи С 4:00 до полуночи С 4:00 до полуночи С 4:00 до полуночи С полуночи до 8:00 С полуночи до 8:00 С полуночи до 8:00 С полуночи до 8:00 С полуночи до 8:00 С полуночи до 8:00 С полуночи до 8:00 С полуночи до 8:00 Стресс 7 7 6 9 8 7 6 7 8 9 5 6 3 5 4 6 5 4 Смена С полуночи до 8:00 С полуночи до 8:00 С полуночи до 8:00 С полуночи до 8:00 С полуночи до 8:00 С 8:00 до 16:00 С 8:00 до 16:00 С 8:00 до 16:00 С 8:00 до 16:00 С 8:00 до 16:00 С 8:00 до 16:00 С 8:00 до 16:00 С 8:00 до 16:00 С 8:00 до 16:00 С 8:00 до 16:00 С 8:00 до 16:00 С 8:00 до 16:00 С 8:00 до 16:00 Стресс 5 5 6 7 6 1 3 4 3 1 1 2 6 5 4 3 4 5 Глава 13. Набор данных 4 Предпочтения потребителей по толщине лапши. Толщина Толстая Толстая Толстая Толстая Толстая Толстая Толстая Толстая Толстая Толстая Толстая Толстая Толстая Толстая Толстая Толстая Толстая Толстая Толстая Толстая Приятность 1 3 2 3 4 4 5 4 3 4 3 2 2 3 3 4 5 4 3 2 Толщина Средняя Средняя Средняя Средняя Средняя Средняя Средняя Средняя Средняя Средняя Средняя Средняя Средняя Средняя Средняя Средняя Средняя Средняя Средняя Средняя Приятность 3 4 3 2 3 4 4 4 3 3 3 4 5 4 3 4 3 3 2 3 Толщина Тонкая Тонкая Тонкая Тонкая Тонкая Тонкая Тонкая Тонкая Тонкая Тонкая Тонкая Тонкая Тонкая Тонкая Тонкая Тонкая Тонкая Тонкая Тонкая Тонкая Приятность 1 3 2 1 1 1 2 2 3 2 1 1 2 2 3 3 2 1 2 1 438 Статистика для тех, кто (думает, что) ненавидит статистику Глава 14. Набор данных 1 Программа: 1 = сложная, 2 = простая. Пол: 1 = мужской, 2 = женский. Программа 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 Пол 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 Потеря веса 76 78 76 76 76 74 74 76 76 55 88 76 76 76 56 76 76 98 88 78 Программа 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 Пол 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 Потеря веса 65 90 65 90 65 90 90 79 70 90 65 67 67 87 78 56 54 56 54 56 Глава 14. Набор данных 2 Уровень боли: 1 – низкий, 2 – высокий. Уровень боли 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 Лекарство Результат Лекарство № 1 Лекарство № 1 Лекарство № 1 Лекарство № 1 Лекарство № 1 Лекарство № 1 Лекарство № 1 Лекарство № 1 Лекарство № 1 Лекарство № 1 Лекарство № 1 Лекарство № 1 Лекарство № 1 Лекарство № 1 Лекарство № 1 Лекарство № 1 6 6 7 7 7 6 5 6 7 8 7 6 5 6 7 8 Уровень боли 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 Лекарство Результат Лекарство № 2 Лекарство № 2 Лекарство № 2 Лекарство № 2 Лекарство № 2 Лекарство № 2 Лекарство № 2 Лекарство № 2 Лекарство № 2 Лекарство № 2 Лекарство № 2 Лекарство № 2 Лекарство № 2 Лекарство № 2 Лекарство № 2 Лекарство № 2 6 5 4 5 4 3 3 3 4 5 5 5 6 6 7 6 Уровень боли 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 Лекарство Результат Плацебо Плацебо Плацебо Плацебо Плацебо Плацебо Плацебо Плацебо Плацебо Плацебо Плацебо Плацебо Плацебо Плацебо Плацебо Плацебо 2 1 3 4 5 4 3 3 3 4 5 3 1 2 4 3 Продолжение ⇒ Приложение C Уровень боли 2 2 2 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 Наборы данных Лекарство Результат Лекарство № 1 Лекарство № 1 Лекарство № 1 Лекарство № 1 Лекарство № 1 Лекарство № 1 Лекарство № 1 Лекарство № 1 Лекарство № 1 Лекарство № 1 Лекарство № 1 Лекарство № 1 Лекарство № 1 Лекарство № 1 Лекарство № 1 Лекарство № 1 Лекарство № 1 Лекарство № 1 Лекарство № 1 Лекарство № 1 Лекарство № 1 Лекарство № 1 Лекарство № 1 Лекарство № 1 9 8 7 7 7 8 8 9 8 7 6 6 6 7 7 6 7 8 8 8 9 0 9 8 Уровень боли 2 2 2 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 439 Лекарство Результат Лекарство № 2 Лекарство № 2 Лекарство № 2 Лекарство № 2 Лекарство № 2 Лекарство № 2 Лекарство № 2 Лекарство № 2 Лекарство № 2 Лекарство № 2 Лекарство № 2 Лекарство № 2 Лекарство № 2 Лекарство № 2 Лекарство № 2 Лекарство № 2 Лекарство № 2 Лекарство № 2 Лекарство № 2 Лекарство № 2 Лекарство № 2 Лекарство № 2 Лекарство № 2 Лекарство № 2 5 7 6 8 7 5 4 3 4 5 4 4 3 3 4 5 6 7 7 6 5 4 4 5 Уровень боли 2 2 2 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 Лекарство Результат Плацебо Плацебо Плацебо Плацебо Плацебо Плацебо Плацебо Плацебо Плацебо Плацебо Плацебо Плацебо Плацебо Плацебо Плацебо Плацебо Плацебо Плацебо Плацебо Плацебо Плацебо Плацебо Плацебо Плацебо 5 4 2 3 4 5 6 5 4 4 6 5 4 2 1 3 2 2 3 4 3 2 2 1 Глава 14. Набор данных 3 Пол: 1 = мужской, 2 = женский. Пол 1 1 2 1 1 1 1 1 2 2 2 2 2 2 1 Потребление кофеина 5 6 7 7 5 6 8 8 9 8 9 7 4 3 0 Стресс 1 3 3 2 3 1 2 2 1 1 1 2 1 1 1 Продолжение ⇒ 440 Статистика для тех, кто (думает, что) ненавидит статистику Пол 2 1 2 1 1 1 2 1 1 1 2 1 1 1 1 Потребление кофеина 4 5 6 2 4 5 5 4 3 7 8 9 11 2 3 Стресс 2 1 2 2 3 3 3 2 2 3 2 2 1 2 1 Глава 14. Набор данных 4 Пол Муж. Муж. Муж. Муж. Муж. Муж. Муж. Муж. Муж. Муж. Муж. Муж. Муж. Муж. Муж. Муж. Муж. Муж. Муж. Жен. Жен. Жен. Жен. Жен. Жен. Тренировки На силу На скорость На силу На скорость На силу На скорость На скорость На силу На силу На скорость На скорость На скорость На скорость На скорость На силу На скорость На силу На скорость На силу На скорость На силу На силу На силу На скорость На силу Навык 10 5 9 3 9 2 5 0 0 4 3 2 2 3 10 4 3 3 0 9 3 2 3 9 1 Продолжение ⇒ Приложение C Наборы данных Пол Жен. Жен. Жен. Жен. Жен. Тренировки На силу На скорость На скорость На скорость На скорость 441 Навык 1 9 8 7 9 Глава 15. Набор данных 1 Качество брака: 1 = низкое, 2 = среднее, 3 = высокое. Кач-во брака 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 Кач-во отношений с детьми 58,7 55,3 61,8 49,5 64,5 61,0 65,7 51,4 53,6 59,0 64,4 55,8 58,7 54,7 52,7 67,8 61,6 58,7 Кач-во брака 2 2 2 2 2 3 3 3 3 3 3 3 3 3 3 3 3 3 Кач-во отношений с детьми 54,6 51,5 54,7 61,4 56,9 68,0 65,9 54,7 53,6 58,7 58,7 65,7 66,5 56,7 55,4 51,5 54,8 57,2 Глава 15. Набор данных 2 Мотивация 1 6 2 7 5 4 3 1 8 6 5 6 5 5 6 Средний балл 3,4 3,4 2,5 3,1 2,8 2,6 2,1 1,6 3,1 2,6 3,2 3,1 3,2 2,7 2,8 Мотивация 6 7 7 2 9 8 8 7 6 9 7 8 7 8 9 Средний балл 2,6 2,5 2,8 1,8 3,7 3,1 2,5 2,4 2,1 4,0 3,9 3,1 3,3 3,0 2,0 442 Статистика для тех, кто (думает, что) ненавидит статистику Глава 15. Набор данных 3 Уровень образования: 1 = низкий, 2 = средний, 3 = высокий. Доход (долл.) 45 675 34 214 67 765 67 654 56 543 67 865 78 656 45 786 87 598 88 656 Уровень образования 1,0 2,0 3,0 3,0 2,0 1,0 3,0 2,0 3,0 3,0 Доход (долл.) 74 776 89 689 96 768 97 356 38 564 67 375 78 854 78 854 42 757 78 854 Уровень образования 3,0 3,0 2,0 3,0 2,0 3 3 3 1 3 Глава 15. Набор данных 4 Часы 0 5 8 6 5 3 4 8 6 2 Оценка 80,0 93,0 97,0 100,0 75,0 83,0 98,0 100,0 90,0 78,0 Глава 15. Набор данных 5 Возраст 15 22 56 7 25 57 12 45 76 14 34 56 9 44 56 Размер обуви Маленький Средний Большой Маленький Средний Большой Маленький Средний Большой Маленький Средний Большой Маленький Средний Большой Интеллект 110 109 98 105 110 125 110 98 97 107 125 106 110 123 109 Образование 7,0 12,0 15,0 4,0 15,0 8 11 15 12 10 12,0 12,0 5,0 12,0 18,0 Приложение C Наборы данных 443 Глава 16. Набор данных 1 Тренировки 12 3 22 12 11 31 27 31 8 16 14 26 36 26 15 Травмы 8 7 2 5 4 1 5 1 2 2 7 2 2 2 6 Тренировки 11 16 14 15 16 22 24 26 31 12 24 33 21 12 36 Травмы 5 7 8 3 7 3 8 8 2 2 3 3 5 7 3 Глава 16. Набор данных 2 Время 14,5 13,4 12,7 16,4 21.0 13,9 17,3 12,5 16,7 22,7 Прав. отв. 5 7 6 2 4 3 12 5 4 3 Глава 16. Набор данных 3 Кол-во проданных домов 8 6 12 3 17 4 13 16 4 Лет в бизнесе 10 7 15 3 18 6 5 16 3 Образование 11 12 11 12 11 12 11 12 11 Продолжение ⇒ 444 Статистика для тех, кто (думает, что) ненавидит статистику Кол-во проданных домов 8 6 3 14 15 4 6 4 11 12 15 Лет в бизнесе 7 6 6 13 15 6 3 6 12 14 21 Образование 12 11 12 11 12 11 12 11 12 11 12 Глава 17. Набор данных 1 Ваучеры 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 Ваучеры 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 Ваучеры 2 2 2 2 3 3 3 3 3 3 3 3 3 3 3 3 3 3 Ваучеры 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 Ваучеры 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 Глава 17. Набор данных 2 Пол: 1 = мужской, 2 = женский. Голосование: 1 = да, 2 = нет. Пол 1 1 1 1 1 1 1 Голосование 1 1 1 1 1 1 1 Пол 2 2 2 2 2 2 2 Голосование 1 1 1 1 1 1 1 Пол 1 1 1 1 1 1 1 Голосование 2 2 2 2 2 2 2 Продолжение ⇒ Приложение C Пол 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 Наборы данных Голосование 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 Пол 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 1 1 1 1 1 1 1 1 1 1 1 445 Голосование 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 Пол 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 Голосование 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 Глава 17. Набор данных 3 Пол: 1 = мужской, 2 = женский. Пол 1 1 1 1 1 1 1 1 Пол 1 1 1 1 1 1 1 1 Пол 1 1 1 1 1 2 2 2 Пол 2 2 2 2 2 2 2 2 Пол 2 2 2 2 2 2 2 2 Продолжение ⇒ 446 Статистика для тех, кто (думает, что) ненавидит статистику Пол 1 1 1 1 1 1 1 1 1 1 1 1 Пол 1 1 1 1 1 1 1 1 1 1 1 1 Пол 2 2 2 2 2 2 2 2 2 2 2 2 Пол 2 2 2 2 2 2 2 2 2 2 2 2 Пол 2 2 2 2 2 2 2 2 2 2 2 2 Глава 17. Набор данных 4 Предпочтение Орешки без спешки Орешки без спешки Орешки без спешки Орешки без спешки Орешки без спешки Орешки без спешки Орешки без спешки Орешки без спешки Орешки без спешки Беконовый сюрприз Предпочтение Беконовый сюрприз Беконовый сюрприз Беконовый сюрприз Беконовый сюрприз Беконовый сюрприз Беконовый сюрприз Беконовый сюрприз Беконовый сюрприз Беконовый сюрприз Беконовый сюрприз Предпочтение Димплс Димплс Димплс Димплс Димплс Димплс Димплс Димплс Димплс Димплс Беконовый сюрприз Беконовый сюрприз Димплс Беконовый сюрприз Беконовый сюрприз Димплс Беконовый сюрприз Беконовый сюрприз Фрогги Беконовый сюрприз Беконовый сюрприз Фрогги Беконовый сюрприз Беконовый сюрприз Фрогги Беконовый сюрприз Беконовый сюрприз Фрогги Беконовый сюрприз Димплс Фрогги Беконовый сюрприз Димплс Фрогги Беконовый сюрприз Димплс Фрогги Беконовый сюрприз Димплс Фрогги Предпочтение Фрогги Фрогги Фрогги Фрогги Фрогги Фрогги Фрогги Фрогги Фрогги Шоколадное наслаждение Шоколадное наслаждение Шоколадное наслаждение Шоколадное наслаждение Шоколадное наслаждение Шоколадное наслаждение Шоколадное наслаждение Шоколадное наслаждение Шоколадное наслаждение Шоколадное наслаждение Шоколадное наслаждение Предпочтение Шоколадное наслаждение Шоколадное наслаждение Шоколадное наслаждение Шоколадное наслаждение Шоколадное наслаждение Шоколадное наслаждение Шоколадное наслаждение Шоколадное наслаждение Шоколадное наслаждение Шоколадное наслаждение Шоколадное наслаждение Шоколадное наслаждение Шоколадное наслаждение Шоколадное наслаждение Шоколадное наслаждение Шоколадное наслаждение Шоколадное наслаждение Шоколадное наслаждение Шоколадное наслаждение Шоколадное наслаждение Приложение C Наборы данных 447 Глава 17. Набор данных 5 Сила Большая Большая Большая Большая Большая Большая Большая Большая Большая Большая Большая Большая Большая Большая Большая Большая Большая Большая Большая Большая Большая Большая Большая Большая Большая Большая Большая Большая Большая Большая Большая Большая Большая Большая Большая Большая Большая Большая Большая Большая Большая Большая Большая Возраст Молодой Молодой Молодой Молодой Молодой Молодой Молодой Молодой Молодой Молодой Молодой Молодой Молодой Молодой Молодой Молодой Молодой Молодой Молодой Молодой Молодой Молодой Средний Средний Средний Средний Средний Средний Средний Средний Средний Средний Средний Средний Средний Средний Средний Средний Средний Средний Средний Средний Пожилой Сила Большая Средняя Средняя Средняя Средняя Средняя Средняя Средняя Средняя Средняя Средняя Средняя Средняя Средняя Средняя Средняя Средняя Средняя Средняя Средняя Средняя Средняя Средняя Средняя Средняя Средняя Средняя Средняя Средняя Средняя Средняя Средняя Средняя Средняя Средняя Средняя Средняя Средняя Средняя Средняя Средняя Средняя Средняя Возраст Пожилой Молодой Молодой Молодой Молодой Молодой Молодой Молодой Молодой Молодой Молодой Молодой Молодой Молодой Молодой Молодой Молодой Молодой Молодой Средний Средний Средний Средний Средний Средний Средний Средний Средний Средний Средний Средний Средний Средний Средний Средний Средний Средний Средний Средний Средний Средний Пожилой Пожилой Сила Средняя Средняя Средняя Средняя Средняя Слабая Слабая Слабая Слабая Слабая Слабая Слабая Слабая Слабая Слабая Слабая Слабая Слабая Слабая Слабая Слабая Слабая Слабая Слабая Слабая Слабая Слабая Слабая Слабая Слабая Слабая Слабая Слабая Слабая Слабая Слабая Слабая Слабая Слабая Слабая Слабая Слабая Слабая Возраст Пожилой Пожилой Пожилой Пожилой Пожилой Молодой Молодой Молодой Молодой Молодой Молодой Молодой Молодой Молодой Молодой Молодой Молодой Средний Средний Средний Средний Средний Средний Средний Средний Средний Средний Средний Средний Средний Средний Средний Средний Средний Средний Средний Средний Пожилой Пожилой Пожилой Пожилой Пожилой Пожилой Продолжение ⇒ 448 Статистика для тех, кто (думает, что) ненавидит статистику Сила Большая Большая Большая Возраст Пожилой Пожилой Пожилой Сила Средняя Средняя Средняя Возраст Пожилой Пожилой Пожилой Сила Слабая Слабая Слабая Возраст Пожилой Пожилой Пожилой Глава 19. Набор данных 1 и Глава 19. Набор данных 2 Это довольно большие наборы данных, поэтому лучше скачать их с сайта edge.sagepub.com/salkind6e. Набор данных. Пример Пол: 1 = мужской, 2 = женский. Группа: 1 = контрольная, 2 = экспериментальная. ID 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 Пол 1 2 2 2 1 1 2 2 2 1 2 2 1 2 2 2 1 2 1 2 1 1 2 1 1 Группа 1 2 1 1 2 1 1 2 2 2 1 1 1 1 1 2 1 1 1 1 1 2 2 1 1 Тест 1 98 87 89 88 76 68 78 98 93 76 75 65 76 78 89 81 78 83 88 90 93 89 86 77 89 Тест 2 32 33 54 44 64 54 44 32 64 37 43 56 78 99 87 56 78 56 67 88 81 93 87 80 99 Приложение D Ответы на задания ГЛАВА 1 Все эти вопросы даны для размышления, у них нет обязательного правильного ответа. Цель состоит в том, чтобы вы начали думать о статистике как об области науки и полезном инструменте. ГЛАВА 2 1. Вручную (легкое задание!) Среднее значение = 87,55 Медиана = 88 Мода = 94 2. Среднее значение Медиана Мода Набор 1 5,6 5,5 5 Набор 2 27,6 25 25,34 Набор 3 144,3 149,5 154 3. Вот вывод SPSS: N Среднее Статистика Количество коек Валидные 10 Пропущенные 0 335,1 Заболеваемость 10 0 3,72 4. Вот как может выглядеть ваш параграф. Как обычно, «Куриные малышки» (мода) лидировали по продажам. Общая сумма продаж составила 303 долл., со средним значением 2,55 долл. для каждого блюда. 449 450 Статистика для тех, кто (думает, что) ненавидит статистику 5.В значениях данных нет каких-то особенностей, т. е. нет слишком больших или слишком маленьких значений, и они не выглядят странно (а это все причины использовать медиану), поэтому мы просто возьмем среднее значение. Вы можете видеть средние значения для трех магазинов в последней колонке. Похоже, это те числа, которые вы хотели бы получить от нового магазина, чтобы он в среднем был равен всем магазинам под вашим управлением. Показатель Продажи (тыс. долл.) Количество проданных штук Количество посетителей Магазин 1 323 3454 4534 Магазин 2 234 5645 6765 Магазин 3 308 4565 6654 Средн. знач. 288,83 4554,67 5984,33 6.Похоже, побеждает цыпленок в пиве, а фруктовая кружка идет последней. Мы рассчитали среднее значение, поскольку это рейтинг значений по интервальной шкале (во всяком случае, по своему назначению). Вот данные: Еда Начос с добавками Фруктовая кружка Острые крылышки Гигантская пицца с доп. начинкой Цыпленок в пиве Фанаты Севера 4 2 4 3 5 Фанаты Востока 4 1 3 4 5 Фанаты Юга 5 2 3 4 5 Фанаты Запада 4 1 3 5 4 Средний рейтинг 4,25 1,5 3,25 4 4,75 7.Медиана используется, когда имеются выбивающиеся значения, которые диспропорционально сместят среднее значение. Одна из ситуаций, когда медиана предпочтительнее среднего, – это отчет по доходам. Поскольку доходы сильно различаются, вам нужна мера центральной тенденции, нечувствительная к выбивающимся значениям. В качестве еще одного примера скажем, что вы изучаете скорость, с которой группа подростков бежит стометровку, когда 1 или 2 человека в группе бегают исключительно быстро. 8.Вы будете использовать медиану, т. к. она нечувствительна к выбивающимся значениям. 9.Лучшей мерой центральной тенденции является медиана, и она лучше всего представляет весь набор значений. Почему? Потому что на нее практически не влияет (довольно) выбивающаяся точка данных 199 000 долл. Как вы можете видеть в таб­лице ниже, среднее значение попадает под ее влияние (она становится выше, чем 83 000 долл., когда в расчет добавлено самое высокое значение). Приложение D Ответы на задания До исключения максимального значения После исключения максимального значения 451 Среднее Медиана Среднее Медиана 83 111 77 153 75 318 76 564 10.Средние значения таковы: группа 1 = 5,88, группа 2 = 5,00, группа 3 = 7,00. 11.Это должен быть простой вопрос. Всегда, когда значения выражаются как категории, единственным имеющим смысл показателем среднего является мода. Итак, кому пирога? На первой неделе побеждает яблочный, и на неделе 2 яблочный опять лидирует. На неделе 3 это «Дуглас Каунти», на неделе 5 месяц заканчивается при множестве продаж «Шоколадного шелка». ГЛАВА 3 1.Диапазон является самой удобной мерой изменчивости, потому что для его расчета нужно только вычесть одно число (минимальное значение) из другого (максимального значения). Он неточен, потому что не принимает во внимание значения, которые находятся между минимальным и максимальным значениями в распределении. Используйте диапазон, когда вам нужна очень грубая (не особо точная) оценка изменчивости в распределении. 2. Максимальное значение 12,1 92 42 7,5 27 Минимальное значение 3 51 42 6 26 Включающий диапазон 10,1 42 1 2,5 2 Исключающий диапазон 9,1 41 0 1,5 24 3.В большинстве своем студенты первого курса уже перестали расти, и огромная вариабельность, наблюдаемая в раннем детстве и отрочестве, уже выровнялась. Однако личностные характеристики и их индивидуальные различия довольно постоянные и выражаются одинаково в любом возрасте. 4.По мере того как студенты получают все более одинаковые оценки, их результаты приближаются к среднему значению, а отклонение от среднего становится меньше. Следовательно, и стандартное отклонение уменьшается. Количество – это сила. Чем больше набор данных, тем больше в него включено. То есть он включает в себя скорее больше, чем меньше, одинаковых друг с другом значений (следовательно, изменчивость уменьшается). 452 Статистика для тех, кто (думает, что) ненавидит статистику 5.Исключающий диапазон равен 39. Несмещенное стандартное отклонение выборки равно 13,10. Смещенная оценка равна 12,42. Различие возникает из-за деления на размер выборки 9 (для несмещенной оценки) по сравнению с делением на размер выборки 10 (для смещенной оценки). Несмещенная оценка дисперсии – 171,66, а смещенная – 154,49. 6.Несмещенная оценка всегда больше, чем смещенная, потому что несмещенная оценка на самом деле намеренно завышает значение показателя, чтобы быть более осторожной. И знаменатель (n − 1) для несмещенной статистики всегда меньше, чем для смещенной (для которой знаменатель равен n), что дает в результате большее значение. 7. Тест 1 Среднее Медиана Мода Диапазон Станд. отклонение Дисперсия 49 49 49 5 1,41 2 Тест 2 Среднее Медиана Мода Диапазон Станд. отклонение Дисперсия 50,1 49,5 49 9 2,69 7,21 Тест 3 Среднее Медиана Мода Диапазон Станд. отклонение Дисперсия 49,3 48 45 10 3,94 15,57 У теста 2 самый высокий средний результат, а у теста 1 самая маленькая изменчивость. Кроме того, существует множество мод, и SPSS рассчитывает и показывает самые маленькие значения. 8. Стандартное отклонение – 12,39, дисперсия – 153,53. 9.Стандартное отклонение – это квадратный корень из дисперсии (которая равна 36). Это означает, что стандартное отклонение равно 6. Нет возможности узнать, чему равен диапазон, зная только стандартное отклонение или дисперсию. Нельзя даже сказать, большой он или маленький, потому что вы не знаете, что измерялось и по какой шкале (крошечные жучки или выработка паровых двигателей). 10. а) диапазон = 6, стандартное отклонение = 2,58, дисперсия = 6,67; б) диапазон = 0,6, стандартное отклонение = 0,25, дисперсия = 0,06; в) диапазон = 3,5, стандартное отклонение = 1,58, дисперсия = 2,49; г) диапазон = 123, стандартное отклонение = 55,7, дисперсия = 2326,5. 11. Вот таблица с результатами. Выглядит знакомо? Должна бы – именно так выглядит вывод SPSS. Приложение D Ответы на задания 453 Статистика N Валидные Пропущенные Станд. отклонение Дисперсия Диапазон Рост 20 0 11,44 130,78 43 Вес 20 0 15,66 245,00 59 12.Ладно, вот как вы можете это проверить. Рассчитайте стандартное отклонение для любого набора из 10 или около того чисел вручную по формуле стандартного отклонения с (n – 1) в знаменателе (несмещенную оценку). Затем сравните ее для вывода SPSS для тех же чисел. Как видите, они одинаковы. Это указывает, что SPSS рассчитывает несмещенную оценку. Если вы поняли это, то знаете, что делаете, – переходите в первые ряды. Еще один способ – это написать ребятам из SPSS и спросить их. Кроме шуток, посмот­рите, что будет. 13.Несмещенная оценка стандартного отклонения – 6,49, а смещенная оценка – 6,15. Несмещенная оценка дисперсии – 42,1, а смещенная оценка дисперсии – 37,89. Смещенные оценки (всегда) меньше, потому что они используют большее значение n и являются более консервативными оценками. 14.Стандартное отклонение 0,94 означает, что в среднем каждый результат теста в наборе величин находится на расстоянии в 0,94 правильного слова от среднего результата. ГЛАВА 4 1. a) Вот распределение частот. Интервал класса 55–59 50–54 45–49 40–44 35–39 30–34 25–29 20–24 15–19 10–14 5–9 0–4 Частота 7 5 5 7 2 3 5 4 4 4 3 1 454 Статистика для тех, кто (думает, что) ненавидит статистику На рис. D.1 показано, на что будет похожа гистограмма (созданная с по­мощью SPSS). Рис. D.1 Гистограмма для данных из файла «Глава 4. Набор данных 1» (Chapter 4. Data Set 1) Вы можете заметить, что ось x в созданной вами гистограмме отличается от того, что представлено здесь. Мы дважды щелкнули по ней и, зайдя в Редактор диаграмм (Chart Editor), изменили количество делений, диапазон и начальную точку для этой оси. Ничего особо не изменилось – просто так она выглядит немного симпатичнее; б) Мы остановились на интервале класса 5, потому что он позволяет нам иметь близкое к 10 количество интервалов; это удовлетворяет критериям выбора интервала класса, которые мы обсуждали в данной главе; в) распределение является отрицательно скошенным, т. к. среднее значение меньше медианы. 2.На рис. D.2 вы можете видеть, на что может быть похожа гис­ тограмма, но помните, что ее вид зависит от вашего выбора параметров осей x и y. Приложение D Ответы на задания Рис. D.2 Простая гистограмма 3.Ваша столбиковая диаграмма может выглядеть по-разному в зависимости от длины ваших осей x и y и других переменных. Сначала вам нужно посчитать сумму для каждого дня (используйте опцию Анализ (Analyze) ⇒ Описательные статистики (Descriptive Statistics) ⇒ Частоты (Frequencies)). Затем используйте эти данные для создания столбиковой диаграммы, как показано на рис. D.3. 455 456 Статистика для тех, кто (думает, что) ненавидит статистику Рис. D.3 Простая столбиковая диаграмма 4.Мы использовали SPSS, чтобы создать простую «пирожковую» диаграмму, а затем изменили заливку каждой секции, как показано на рис. D.4. Какой пирог предпочитаете вы? 5. а) круговую, потому что вас интересуют доли; б) линейную, потому что вы смотрите на тренд (во времени); в) столбиковую, потому что вы смотрите на количество дискретных категорий; г) круговую, потому что вы смотрите на категории, заданные как пропорции; д) столбиковую, потому что вы смотрите на количество дискретных категорий. Приложение D Ответы на задания 457 Рис. D.4 Простая круговая диаграмма Пирог Вишневый Яблочный Шоколадный 6.Вы приведете собственные примеры, но вот несколько наших. Напишите свои собственные примеры: а) количество слов, которые знает ребенок, как функция от возраста с 12 до 36 месяцев; б) количество пожилых граждан, являющихся членами Американской ассоциации пенсионеров, как функция от пола и этнической принадлежности; в) графическое отображение парных показателей, таких как рост и вес, для каждого человека. Мы не особо обсуждали этот тип диаграмм, но загляните в меню Графика (Graph) в SPSS, и вы все поймете. 7. Самостоятельно! 8.Мы нарисовали в графическом редакторе SPSS рис. D.5, и он такой же уродливый, как и неинформативный. Мощная атака графического мусора. 9.Лучше один раз увидеть (график или диаграмму). Другими словами, на этот вопрос есть много возможных ответов, но в целом задача графика или диаграммы состоит в как можно 458 Статистика для тех, кто (думает, что) ненавидит статистику более простом визуальном представлении информации при одновременной ясной и четкой передаче основного ее смысла. Рис. D.5 Очень, очень уродливая диаграмма Средние часы Мощная атака графического мусора Редбад Оак Хилл ьд МакДонал Либерти й Центральн ы ие ожен л Распо Школа ГЛАВА 5 1. 2. а) r = 0,596; б) из ответа 1а вы уже знаете, что корреляция является прямой. Но вы можете предсказать, что она будет такой (еще не зная знака коэффициента корреляции), по диаграмме рассеяния, показанной на рис. D.6 (мы использовали SPSS, но вы должны нарисовать ее вручную), потому что точки данных группируются от нижнего левого угла графика к верхнему правому углу, что предполагает положительный наклон. а) r = 0,609; б) в соответствии с табл. 5.4 общая степень корреляции с таким значением является сильной. Коэффициент детерми- Приложение D Ответы на задания нации равен 0,6092, так что 0,371, или 37,1 %, дисперсии объясняется связью. Субъективная оценка (сильная корреляция) и объективная (37,1 % дисперсии объясняется связью­) не противоречат друг другу. Диаграмма рассеяния для данных из файла «Глава 5. Набор данных 2» (Chapter 5. Data Set 2) Количество верных ответов Рис. D.6 Отношение 3.Обратите внимание, что у 0,71 и 0,47 не указан знак, и в таких случаях мы всегда предполагаем, что значения положительны. +0,36 –0,45 +0,47 –0,62 +0,71 4.Корреляция равна 0,64. Это означает, что увеличение бюджета и повышение достижений в классе положительно связаны друг с другом (и обратите внимание, что мы должны еще проверить значимость этой связи). В плане описания чуть больше 40 % дисперсии являются общими у двух переменных. 5.Корреляция между количеством минут упражнений в день и средним баллом равна 0,39. Это показывает, что при увеличении занятий возрастает и средний балл. Конечно, при уменьшении занятий снижается средний балл. Хотите быть красавчиком и получать хорошие оценки? Занимайтесь, учитесь, читайте больше (и часто принимайте душ). Имейте в виду, что средний балл не имеет никакого отношения к тому, 459 460 Статистика для тех, кто (думает, что) ненавидит статистику как вы выглядите в спортзале. Это может быть случайностью, и мы здесь говорим только про ассоциативную связь. 6.Корреляция равна –0,22 и так мала, потому что и количество часов учебы, и средние баллы имеют очень малую изменчивость. Когда изменчивость так мала, наборам данных нечем поделиться, у них мало общего, а отсюда и низкая корреляция. 7. а) 0,09; б) очень сильная; в) 1,00 – 0,81, или 0,19 (19 %). 8. Вот матрица… Возраст получения травмы Уровень лечения Оценка годового лечения Возраст получения травмы 1 0,0557 –0,154 Уровень лечения Оценка годового лечения 1 0,389 1 9.Для изучения связи между полом (мужским или женским) и политической принадлежностью вам нужно использовать фи-коэффициент, потому что обе переменные являются номинальными. Для изучения связи между конфигурацией семьи и средним баллом в старших классах вы выберете бисериальную корреляцию, потому что одна переменная – номинальная (конфигурация семьи), а другая – интервальная (средний балл). 10.То, что две вещи связаны, не означает, что одна из них вызывает другую. Многие бегуны, обладающие средней силой, могут бегать быстро, и есть множество очень сильных людей, которые бегают медленно. Сила может помочь людям бежать быстрее, но техника гораздо важнее (и, кстати говоря, гораздо больше влияет на дисперсию). 11.Вы должны дать собственные объяснения, но вот несколько примеров: а) спорим, вы ждали этого – потребление мороженого и количество преступлений; б) количество денег, потраченных на политическую рекламу, и количество голосующих людей; в) внедрение программ воздержания в средней школе и количество сексуально активных подростков; г) доход и удовлетворенность работой; д) уровень образования и потребление наркотиков. 12.Отличный вопрос. Корреляции отображают, сколько общего есть у двух переменных, но то общее, что у них есть, не имеет никакого отношения к тому, что заставляет одну или другую Приложение D Ответы на задания 461 переменную возрастать или убывать. Вы видели, как это работает, на примере потребления мороженого и уровня преступности (когда оба связаны с температурой на улице, но не друг с другом). То же самое можно сказать об отношении между школьными успехами и уровнем образования родителей, где переплетается множество переменных, таких как размер класса, структура семьи и семейный доход. Так что важно то, что является общим, а не то, что кажется удобно связанным. 13.Частичные корреляции применяются, когда вы хотите изучить корреляцию между двумя переменными, исключив влияние третьей. ГЛАВА 6 1. Сделайте это самостоятельно. 2.Ретестовая надежность должна быть установлена тогда, когда вас интересует согласованность оценивания в течение времени (например, как в исследованиях результатов до и после тес­тирования или в лонгитюдных исследованиях). Надежность параллельных форм важно проверять для того, чтобы убедиться, что разные формы одного и того же теста похожи друг на друга. 3.Ретестовая надежность устанавливается путем вычисления простого коэффициента корреляции между двумя случаями тестирования. В данном случае корреляция между осенними и весенними результатами равна 0,139, и вероятность, что такая корреляция возникнет случайно, равна 0,483. Корреляция, равная 0,139, даже близко не равна тому, что нам требуется (по меньшей мере, 0,85), чтобы заключить, что тест надежен по времени. 4.В общем, надежный, но недостоверный тест выполняет то, что он делает, раз за разом, но не выполняет то, для чего он предназначался. И – упс! Тест не может быть достоверным, если он не является надежным, потому что если он не делает чегото последовательно, тогда он, определенно, не может делать какую-то конкретную вещь успешно. 5.Коэффициент надежности для параллельных форм одного и того же теста равен –0,09. Вы отлично справились с расчетом этого коэффициента, но что касается надежности теста? Не особо велика. 6.Это просто. Тест должен уметь делать то, что он делает, раз за разом (надежность) до того, как можно заключить, что он делает то, для чего предназначался (достоверность). Если тест 462 Статистика для тех, кто (думает, что) ненавидит статистику непоследователен (или ненадежен), тогда он никак не может быть достоверным. Например, несмотря на то что тест, состоящий из вопросов вроде «15 × 3 = ?», определенно, надежен, в том случае, если 15 таких вопросов называются «Орфографический тест», он не может быть достоверным. 7.Вам нужно использовать одновременно и надежный, и достоверный тест, потому что если вы получите нулевой результат, то никогда не будете уверены в причине произошедшего: это оттого, что ваш инструмент не измерил то, что предполагалось, или же гипотеза действительно оказалась неверна. 8.Содержательная достоверность рассматривает тест на предмет того, действительно ли он, «судя по внешним признакам», отображает оцениваемую понятийную область. Например, содержит ли школьная контрольная по Американской революции вопросы, которые относятся к предмету «История Америки»? Предсказательная достоверность проверяет, насколько хорошо тест предсказывает конкретный результат. Например, насколько хорошо тест на пространственные навыки предсказывает успешность в качестве инженера-механика? Конструктивная достоверность присутствует, когда тестирующий инструмент оценивает лежащий в основе конструкт. Например, насколько хорошо инструмент наблюдения оценивает одно измерение биполярного расстройства у подростков? 9.Это трудный вопрос. Давайте предположим (что вам понадобится), что у вас есть сильная теоретическая база по «нестандартному мышлению», которая может сформировать основу для вопросов теста. Вы найдете независимую группу экспертов по нестандартному мышлению, попросите их пройти тест, а затем попросите тестирующих наблюдать и подсчитывать реакцию на созданные вами вопросы. В теории, если ваш конструкт верен и если тест работает, те люди, которые раньше были обозначены как продвинутые нестандартные мыслители, покажут другие результаты, чем те, кто не был независимо оценен как нестандартный мыслитель. К этому можно подойти разными способами, и тот, который мы вам показали, только один из них. ГЛАВА 7 1. Самостоятельно! 2. Опять самостоятельно! Приложение D Ответы на задания 3. а)Нулевая гипотеза: дети с неустойчивым вниманием по шкале «Наблюдаемая устойчивость внимания» демонстрируют такое же количество неусидчивого поведения, как и дети с устойчивым вниманием. Направленная: дети с неустойчивым вниманием по шкале «Наблюдаемая устойчивость внимания» демонстрируют большее количество неусидчивого поведения, чем дети с устойчивым вниманием. Ненаправленная: дети с неустойчивым вниманием по шкале «Наблюдаемая устойчивость внимания» демонстрируют другое количество неусидчивого поведения, чем дети с устойчивым вниманием. б)Нулевая гипотеза: нет никакой связи между качеством брака и отношениями супругов со своими братьями и сест­ рами. Направленная: существует положительная связь между качеством брака и отношениями супругов со своими братьями и сестрами. Ненаправленная: существует связь между качеством брака и отношениями супругов со своими братьями и сестрами. в)Нулевая гипотеза: фармакологическое лечение в сочетании с традиционной психотерапией оказывает такой же эффект при лечении нервной анорексии, как и традиционная психотерапия в отдельности. Направленная: фармакологическое лечение в сочетании с традиционной психотерапией оказывается более эффективным при лечении нервной анорексии, чем традиционная психотерапия в отдельности. Ненаправленная: фармакологическое лечение в сочетании с традиционной психотерапией оказывает отличающееся воздействие на лечение нервной анорексии, чем традиционная психотерапия в отдельности. 4. Самостоятельно! 5.Наиболее существенная проблема состоит в том, что проверка альтернативной гипотезы, возможно, окажется неубедительной. Независимо от результата плохой язык ведет к ошибочным заключениям. К тому же может оказаться, что исследование невозможно повторить, а его результаты – обобщить, что в целом дает сомнительную попытку. 6.Нулевая (что буквально означает «отсутствующая») гипотеза представляет отсутствие любых наблюдаемых различий между группами результатов. Она является начальной точкой любого исследования и отличается от альтернативной гипоте- 463 464 Статистика для тех, кто (думает, что) ненавидит статистику зы по множеству параметров (прежде всего тем, что является утверждением о равенстве, тогда как альтернативная гипотеза является утверждением о неравенстве). 7.Если вы только начинаете исследовать вопрос (который затем превратится в гипотезу) и у вас мало знаний о результате (почему вы и задаете свой вопрос и проводите эксперимент), тогда нулевая гипотеза является отличной начальной точкой. Это утверждение о равенстве, которое, в сущности, говорит: «При отсутствии любой другой информации об отношениях, которые мы изучаем, я должна начать с самого начала, где я знаю очень мало». Нулевая гипотеза является идеальной, непредубеж­денной и объективной начальной точкой, потому что это место, в котором предполагается равенство всего, пока не будет доказано обратное. 8.Как вы уже знаете, нулевая гипотеза утверждает, что между переменными нет связи. Почему? Просто это лучшее начало при отсутствии любой другой информации. Например, если вы изучаете роль ранних событий в развитии языковых навыков, тогда лучше всего предположить, что они не играют никакой роли, если только вы не докажете обратное. Именно поэтому мы готовимся проверять нулевые гипотезы, а не доказывать их. Мы хотим быть как можно более непредубежденными. ГЛАВА 8 1.У кривой нормального распределения среднее значение, медиана и мода равны друг другу; кривая симметрична относительно среднего; его хвосты приближаются к горизонтальной оси. Примерами могут быть рост и вес, так же как интеллектуальные способности и навыки решения задач. 2.Исходные данные, среднее значение и стандартное отклонение. 3.Потому что все они используют одну и ту же величину измерения (стандартное отклонение), и мы можем сравнивать значения в единицах стандартного отклонения. 4.z-оценка – это стандартный показатель (сравнимый с другими показателями такого же типа), потому что она основана на степени изменчивости в соответствующем распределении величин. z-оценка всегда является мерой расстояния между средним значением и какой-то точкой на оси x (независимо от того, как различаются средние значения и стандартные отклонения в разных распределениях). Поскольку используются одни и те же единицы измерения (количество стандартных от- Приложение D Ответы на задания 465 клонений), z-оценки можно сравнивать друг с другом. Вот это настоящее волшебство – сравнимость. 5.z-оценка для исходного значения 55 в распределении со средним значением 50 и стандартным отклонением 2,5 равна 2. Так что изменчивость в этом наборе данных в 2 раза меньше, а соответствующая z-оценка в 2 раза больше (она изменилась от 1 до 2). Это указывает, что по мере уменьшения вариабельности при неизменности всех остальных параметров то же самое исходное значение становится более экстремальным. Чем больше различаются значения (и чем выше изменчивость), тем менее экстремальным будет то же самое значение. 6. Исходные данные 68,0 58,16 82,0 92,09 69,0 69,14 85,0 91,10 72,0 z-оценка –0,61 –1,6 0,79 1,8 –0,51 –0,5 1,09 1,7 –0,21 7. 18 19 15 20 25 31 17 35 27 22 34 29 40 33 21 8. –1,01 –0,88 –1,41 –0,75 –0,10 0,69 –1,14 1,21 0,17 –0,49 1,08 0,43 1,87 0,95 –0,62 а) вероятность попадания значения в промежуток между исходным значением 70 и исходным значением 80 равна 0,5646. z-оценка для исходного значения 70 равна –0,78, а z-оценка для исходного значения 80 равна 0,78. Площадь 466 Статистика для тех, кто (думает, что) ненавидит статистику между средним значением и z-оценкой 0,78 составляет 28,23 %. Площадь между двумя z-оценками равна 28,23 × на 2, или 56,46 %; б) вероятность попадания значения в область выше исходного значения 80 равна 0,2177. z-оценка для исходного значения 80 равна 0,78. Площадь между средним значением и z-оценкой 0,78 составляет 28,23 %. Площадь ниже z-оценки 0,78 равна 0,50 + 0,2823, или 0,7823. Разность между 1 (всей площадью под кривой) и 0,7823 составляет 0,2177, или 21,77 %; в) вероятность попадания значения в промежуток между 81 и 83 равна 0,068. z-оценка для исходного значения 81 равна 0,94, а для исходного значения 83 – 1,25. Площадь между средним значением и z-оценкой 0,94 составляет 32,64 %. Площадь между средним значением и z-оценкой 1,25 составляет 39,44 %. Разница между ними – это 0,3944 – 0,3264 = 0,068, или 6,8 %; г) вероятность попадания значения в область ниже исходного значения 63 равна 0,03. z-оценка для исходного значения 63 равна –1,88. Площадь между средним значением и z-оценкой –1,88 составляет 46,99 %. Площадь области ниже z-оценки 1,88 равна 1 – (0,50 + 0,4699) = 0,03, или 3 %. 9.Немного магии поможет нам найти исходное значение при помощи тех же формул вычисления z-оценки, которые вы видели в этой главе. Вот преобразованная формула: _ X = (s × z) + X. А дальше все, что нам нужно знать, – это z-оценка для 90 % (или 40 % в таблице B.1), которая равна 1,29. Так что, подставив значения в формулу, получаем: X = 78 + (5,5 × 1,29) = 85,095. Джейк будет свободен, если получит такой результат, а вместе с ним и сертификат. 10.Это не имеет смысла, потому что нельзя сравнивать сырые значения друг с другом, когда они принадлежат разным распределениям. Исходное значение 80 для теста по математике со средним значением по классу 40 просто несравнимо с результатом в 80 баллов по тесту о приемах написания эссе, где все ответили на один вопрос правильно. Распределения, как и люди, не всегда сравнимы друг с другом. Не все (и не всех) можно сравнивать с чем-то еще. 11.Вот таблица с заполненными неизвестными значениями (выделены жирным). Приложение D Ответы на задания Математика Среднее значение по классу Стандартное отклонение по классу Чтение Среднее значение по классу Стандартное отклонение по классу 467 81 2 87 10 Исходные баллы Ноа Талья Ноа Талья Математика 85 87 z-оценки Математика 2 3 Чтение 88 81 Среднее 86,5 84 Чтение 0,1 –0,6 Среднее 1,05 1,2 У Ноа более высокое среднее значение по исходным баллам (86,5 против 84 у Тальи), но у Тальи более высокая средняя z-оценка (1,2 против 1,05 у Ноа). Помните, что мы спрашивали, кто из них учится лучше, а это требует применения стандартного показателя (мы использовали z-оценку). Но почему Талья учится лучше, чем Ноа? Потому что в тестах с минимальной вариабельностью (у математики стандартное отклонение равно 2) Талья действительно выделяется с z-оценкой 3. Это выводит ее вперед. 12.То, что хвосты никогда не прикасаются к оси x, указывает присутствие постоянной вероятности (хотя и очень, очень маленькой), что могут появиться экстремальные значения (стоящие далеко-далеко в любом направлении по оси x). Если бы хвосты касались оси x, это означало бы, что есть ограничения на то, насколько невероятным может быть результат. Другими словами, независимо от результата всегда есть вероятность, что он произойдет. ГЛАВА 9 1.Понятие значимости необычайно важно для изучения и применения статистики вывода, потому что значимость (выраженная в виде уровня значимости) задает критерий для определения уверенности, что наблюдаемый нами результат правдив. Далее он определяет, в какой мере эти результаты можно обобщить на всю генеральную совокупность, из которой была отобрана выборка. 2.Статистическая значимость – это идея о том, что определенные результаты появились не из-за случайности, но благодаря факторам, выявленным и проверенным исследователем. Этим 468 Статистика для тех, кто (думает, что) ненавидит статистику результатам можно назначить величину, которая представляет уровень вероятности того, что они получились случайно или под воздействием какого-то другого фактора или набора факторов. Статистическая значимость этих результатов и есть величина данной вероятности. 3.Критическое значение представляет собой минимальное значение, при котором нулевая гипотеза перестает быть допустимым объяснением любых наблюдаемых различий. Это точка отсечения: наблюдаемые значения, превышающие ее, указывают на отсутствие равенства и присутствие различий (а сущность различий зависит от поставленного вопроса). Помните, что эту точку отсечения задает сам исследователь (даже если 0,01 и 0,05 традиционно используются чаще всего). 4. 5. а) отклонить нулевую гипотезу. Поскольку уровень значимости меньше 5 %, существует связь между тем, какую музыку выбирает человек, и его или ее криминальными наклонностями; б) не можем отклонить нулевую гипотезу. Вероятность выше 0,05, что означает отсутствие связи между количеством потребляемого кофе и средним баллом; в) нет никакой связи с таким высоким уровнем вероятности. а) уровень значимости относится только к отдельной независимой проверке нулевой гипотезы, а не к множественным проверкам; б) нельзя задавать уровень ошибки, равный нулю, потому что нельзя гарантировать, что мы никогда не отклоним нулевую гипотезу, когда она верна. Всегда есть вероятность, что мы так сделаем; в) принимаемый вами уровень риска, что вы отклоните нулевую гипотезу, когда она верна, не имеет никакого отношения к осмысленности результатов вашего исследования. Вы можете получить значимый результат, который не имеет смысла, или у вас может быть относительно высокая ошибка первого рода (0,10) и очень осмысленная находка. 6.На уровне 0,01 оставлено меньше места для ошибок, потому что проверка будет более тщательной. Другими словами, сложнее найти результат, который достаточно удален от того, что вы могли бы получить по случайности (нулевой гипотезы), когда связанная с ним вероятность меньше (например, 0,01), чем когда она больше (например, 0,05). 7.Вот отличная мысль, которая довольно сильно возбуждает людей. Мы не можем отклонить нулевую гипотезу, потому что Приложение D Ответы на задания 469 мы никогда не проверяем ее напрямую. Помните, что нулевая гипотеза отражает характеристики генеральной совокупности, а все дело в том, что мы не можем напрямую проверять генеральные совокупности, а только выборки. Если мы не можем ее проверить, как мы можем ее отклонить? 8.Значимость – это статистический термин, который просто задает область, в которой вероятность, связанная с нулевой гипотезой, оказывается для нас слишком маленькой, чтобы мы могли прийти к какому-то другому выводу, кроме «альтернативная гипотеза представляет наиболее привлекательное объяснение». Осмысленность имеет дело с применимостью результатов и с тем, имеют ли результаты значение или смысл в широком контексте задаваемого вопроса. 9.Вы можете придумать что-то самостоятельно, но что насчет вот таких примеров: а) были обнаружены статистически значимые различия между двумя группами читателей, когда группа, прошедшая интенсивное обучение техникам понимания текста, превзошла группу, не получившую никакого обучения (но такую же долю внимания), по результатам теста на понимание; б) изучив огромную выборку (причина, по которой результаты были значимыми), исследователь обнаружил очень сильную положительную корреляцию между размером обуви и ежедневно потребляемым количеством калорий. Глупо, но правда… 10.Случайность отображается в степени риска (в ошибке первого рода) отклонить верную нулевую гипотезу, который мы готовы принять на себя. Она всегда, в первую очередь и раньше всего, является правдоподобным объяснением для любых различий, которые мы можем наблюдать, и самым привлекательным объяснением при отсутствии любой другой информации. 11. а) заштрихованная область представляет значения, которые являются достаточно крайними, чтобы ни одно из них не относилось к результатам, поддерживающим нулевую гипотезу; б) большее количество значений отражает более высокую вероятность ошибки первого рода. ГЛАВА 10 1.Одновыборочный Z-критерий применяется, когда вы хотите сравнить среднее значение выборки с параметром генераль- 470 Статистика для тех, кто (думает, что) ненавидит статистику ной совокупности. На самом деле думайте о нем как о критерии проверки, принадлежит ли одно число (т. е. среднее значение) к огромному набору чисел. 2.(БОЛЬШАЯ) Z аналогична маленькой z по одной простой причине – это стандартный показатель. У z-оценки в знаменателе стоит стандартное отклонение выборки, тогда как у значения Z-критерия в знаменателе стоит стандартная ошибка среднего (или мера изменчивости всех средних значений в генеральной совокупности). Другими словами, они оба основаны на стандартном показателе, что позволяет нам использовать таблицу для кривой нормального распределения (в приложении B), чтобы понять, насколько далеко найденные значения находятся от тех, что могли бы получиться только благодаря случайности. 3. а) потеря веса в группе Боба из людей, сидящих исключительно на шоколадной диете, не является репрезентативной для потери веса в большой генеральной совокупности мужчин среднего возраста, сидящих исключительно на шоколадной диете; б) заболеваемость гриппом на 1000 граждан в прошлом сезоне гриппа вовсе не сравнима с заболеваемостью за прошедшие 50 сезонов; в) расходы Блэра в этом месяце не отличаются от его среднемесячных расходов за прошедшие 20 лет. 4.Результат расчета Z-критерия равен –1,48. Это даже не приближается к необходимой крайней величине (нам нужно значение ±1,96) для вывода о том, что среднее количество случаев (15) сколь-либо отличается от среднего по штату (которое равно 16). 5.Результат расчета Z-критерия равен 0,31, что недостаточно велико для того, чтобы сказать, что группа работников в выбранных специализированных магазинах (пересчитывающая по 500 продуктов) работает лучше (или отличается), чем группа всех работников данной сети. 6.Чего здесь не хватает, так это уровня значимости, на котором проверяется гипотеза. Если уровень равен 0,01, тогда критическое значение z для отклонения нулевой гипотезы и заключения, что выборка отличается от генеральной совокупности, равно 1,96. Если уровень проверки гипотезы – 0,05, тогда критическое значение z – 1,65. Это представляет самый интересный вопрос, связанный с компромиссом между совершением ошибки первого рода (1 % или 5 % вероятности отклонения верной нулевой гипотезы) и утверждением статистической значимости. Вы должны уметь аргументировать свой ответ о том, какой уровень значимости вы выбрали. Приложение D Ответы на задания 471 7.Если вы подставите данные в формулу 10.1, то получите Z-критерий, равный 12,22, что находится далеко за пределами значений (на удаленном конце кривой). Но помните, что чем ниже счет в гольфе, тем лучше, так что группа Миллмана совсем не похожа на участников-профи. Очень жаль, Миллман. 8.Посмотрите на вывод SPSS, показанный на рис. D.7. Как вы видите, значение 31 456 находится вполне в пределах (t = –1.681, p = 0,121) общего диапазона значений ежемесячных продаж в прошлом году. Нет, разницы нет. Рис. D.7 Результаты одновыборочного t-критерия ГЛАВА 11 1.Среднее значение для мальчиков равно 7,93, а для девочек – 5,31. Наблюдаемое значение t равно 3,006, а критическое значение при уровне значимости 0,05 для одностороннего критерия (мальчики чаще поднимают руку, помните?) равно 1,701. Наш вывод? Мальчики поднимают руку значительно чаще! 2.А вот это очень интересно. У нас те же самые данные, конечно, но другая гипотеза. Здесь гипотеза состоит в том, что количество поднятий рук отличается (а не просто больше или меньше), что требует использования двустороннего критерия. Итак, при помощи таблицы B.2 мы видим, что на уровне значимости 0,01 для двустороннего критерия критическое значение равно 2,764. Наблюдаемое значение 3,006 (результат такой же, как в предыдущем вопросе) действительно превосходит то, что мы могли бы ожидать по простой случайности, и, учитывая данную гипотезу, различия существуют. Так что, сравнивая две гипотезы, мы видим, что односторонний критерий (как в вопросе 1) для одних и тех же данных не должен быть таким экстремальным, как двусторонний, для подтверждения 472 Статистика для тех, кто (думает, что) ненавидит статистику того же самого вывода (о том, что поддержана альтернативная гипотеза). 3. 4. a) t(18) = 1,58 b) t(46) = 0,88 c) t(32) = 2,43 а) tкрит (18) = 2,101. Поскольку наблюдаемое значение t превосходит критическое значение, мы отклоняем нулевую гипотезу; б) tкрит (46) = 2,009 (при использовании значения для 50 степеней свободы). Поскольку наблюдаемое значение t не превосходит критического значения, мы не смогли отвергнуть нулевую гипотезу; в) tкрит (32) = 2,03 (при использовании значения для 35 степеней свободы). Поскольку наблюдаемое значение t превосходит критическое значение, мы отклоняем нулевую гипотезу. 5.Во-первых, вот вывод результатов проверки t-критерия для независимых выборок, рассчитанных при помощи SPSS. Группа Тревожность N Вне дома На дому 20 20 Статистика группы Среднеквадратичное Среднее отклонение 5,50 1,732 4,15 2,207 Среднеквадратичная ошибка среднего 0,387 0,494 Нижняя Верхняя 0,339 Среднеквадратичная ошибка разности Не предполагаются равные дисперсии 0,938 Средняя разность Предполагаются равные дисперсии Знач. (двусторонняя) Тревожность Критерий для независимых выборок Критерий равенства t-критерий для равенства средних дисперсий Ливиня 95%-ный доверительный интервал для разности F Значимость т ст. св. 2,152 38 0,038 1,350 0,627 0,0800 2,620 2,152 35,968 0,038 1,350 0,627 0,0777 2,622 А вот результирующий параграф… Наблюдается значимое различие между средним результатом группы, которая получала консультации на дому, и сред- Приложение D Ответы на задания ним результатом группы, которая получала консультации вне дома. Среднее значение для группы «На дому» равно 4,15, а среднее значение для группы «Вне дома» равно 5,5. Вероятность, связанная с этим различием, равна 0,038. Это означает, что есть меньше 4 % вероятности, что наблюдаемые различия объясняются случайностью. Гораздо более вероятно, что программа консультаций вне дома была более эффективна. 6.Вы можете видеть вывод SPSS на рис. D.8, где не наблюдается никакого значимого различия (p = 0,253) между городскими и сельскими жителями по их отношению к контролю над оружием. 7.Это, определенно, хороший вопрос для размышлений, поскольку у него много различных правильных ответов. Если все, что вас заботит, – это уровень ошибки первого рода, тогда мы полагаем, что выводы д-ра Л. внушают больше доверия, потому что эти результаты предполагают меньшую вероятность совершить ошибку первого рода. Однако оба результата значимы даже при том условии, что значимость одного из них находится на границе. Следовательно, если ваша личная система оценки такого рода результатов говорит: «Я полагаю, что значимость есть значимость, именно она важна», тогда можно считать оба результата одинаково достоверными и надежными. Однако имейте в виду, что осмысленность результатов также имеет существенное значение (и вы должны получить дополнительные баллы, если вынесете это на обсуждение). Нам кажется, что независимо от уровня ошибки первого рода результаты обоих исследований имеют высокое значение, потому что программа, вероятно, приведет к большей безопасности для детей. Рис. D.8 Вывод SPSS для t-критерия для независимых средних 473 474 Статистика для тех, кто (думает, что) ненавидит статистику 8. Вот данные и ответы: Эксперимент 1 2 3 Размер эффекта 2,6 1,3 0,65 Как вы видите, когда стандартное отклонение удваивается, размер эффекта становится в 2 раза меньше. Почему? Если вы помните, размер эффекта дает еще одно указание на то, насколько осмысленны различия между группами. Если изменчивость очень мала, то между индивидуумами мало различий, а любые расхождения средних становятся интересными (и вероятно, более существенными). В первом эксперименте при стандартном отклонении 2 размер эффекта равен 2,6. Но когда изменчивость повышается до 8 (третий эксперимент), интересно, что размер эффекта сокращается до 0,65. Сложно говорить об осмысленности различий между группами, когда наблюдается все меньше и меньше сходства между участниками этих групп. 9.И каков ответ? Как вы видите, средний результат группы 2 (12,20) выше, чем средний результат группы 1 (7,67), и на осно­ вании вывода, представленного на рис. D.9, это различие значимо на уровне 0,004. Наш вывод заключается в том, что вторая группа четвероклассников пишет грамотнее. 10.Для данных из файла «Глава 11. Набор данных 5» (Chapter 11. Data Set 5) значение t равно –0,218. Для данных из файла «Глава 11. Набор данных 5» (Chapter 11. Data Set 5) значение t равно –0,327. И в обоих случаях средние значения равны 6,00 (для группы 1) и 6,2 (для группы 2). К тому же изменчивость большего набора данных слегка меньше. Причина, по которой у второго набора данных получается большее (или более крайнее) значение t, заключается в большем в 2 раза размере выборки (20 против 10). t-критерий учитывает это, что приводит к большему значению t (и идет по направлению к «значимости»), потому что большая выборка сильнее приближается к размеру генеральной совокупности. Можно прийти к выводу, что с таким же средним значением и меньшей изменчивостью значение t будет более экстремальным и связанным с размером выборки. Приложение D Рис. D.9 Ответы на задания 475 t-критерий для среднего значения результатов орфографического теста у двух групп четвероклассников 11.Ответить на этот вопрос на самом деле легче, чем вы могли подумать. Различия между двумя группами в некоторой (если не в полной) степени не зависят от размера эффекта. В данном примере статистически значимое различие, вероятно, объясняется очень большим размером выборки, однако эффект не очень различим. Этот результат абсолютно возможен и правдоподобен и добавляет новое измерение к пониманию двойной важности значимости размера эффекта. ГЛАВА 12 1.t-критерий для независимых средних проверяет две различные группы участников, и каждая группа оценивается один раз. t-критерий для зависимых средних проверяет одну группу участников, и каждый участник оценивается дважды. 2. а) независимых; б) независимых; в) зависимых; г) независимых; д) зависимых. 3.Среднее значение до программы переработки было равно 34,44, а среднее значение после запуска равно 34,84. Переработка возросла, но значимы ли различия в 25 районах? Наблюдаемое значение t равно 0,262. При 24 степенях свободы различия не значимы на уровне 0,01 (это уровень проверки альтернативной гипотезы). Вывод: программа переработки не привела к увеличению объема переработки. 476 Статистика для тех, кто (думает, что) ненавидит статистику 4.Вот выводы SPSS для t-критерия для зависимых или парных выборок. Среднеквадратичная ошибка среднего 2,02390 1,65827 Критерий парных выборок Парные разности Среднекв. Среднее отклонение Пара 1 До – –4,10000 После 10,59245 95%-ный Среднекв. т ст. св. доверительный ошибка интервал для разности среднего Нижняя Верхняя 2,36854 -9,05742 ,85742 –1,731 19 Значимость (двусторонняя) Статистика парных выборок Среднеквадратичное Среднее N отклонение Пара 1 До 32,8500 20 9,05117 После 36,9500 20 7,41602 ,100 Наше заключение? Среднее значение до воздействия было ниже (что показывает меньшую толерантность), чем после воздействия. Однако различия между двумя средними отнюдь не значимы, так что направление этого различия не не важно. 5.Наблюдается повышение уровня удовлетворенности с 5,480 до 7,595, в результате чего значение t = –3,893. Различиям соответствует уровень вероятности 0,001. Очень вероятно, что вмешательство социальных служб сработало. 6.Средний показатель предпочтения Нибблз равен 5,1, а средний показатель предпочтения Рибблз равен 6,5. При 19 степенях свободы t-критерий для зависимых средних равен –1,965, а критическое значение для отклонения нулевой гипотезы – 2,093. Поскольку наблюдаемое значение t –1,965 не превосходит критического значения, консультанты по маркетингу пришли к выводу, что оба вида крекеров нравятся примерно одинаково. 7.Нет. Средние значения не так уж и различаются (5,35 для первой смены и 6,15 для второй), а значение t = –1,303 (так что стресс немного меньше) вовсе не значимо. Не столь важно, в какую смену работает человек: уровень стресса будет одинаковым. 8.Определенно. Показатели увеличились с 5,52 до 7,04, и различия между двумя наборами данных значимы на уровне 0,005. В качестве бонуса: размер эффекта равен 0,75, что довольно много. Приложение D Ответы на задания 477 ГЛАВА 13 1.Несмотря на то что обе методики изучают различия между средними, уместно использовать дисперсионный анализ при сравнении более двух средних. Его можно применять для прос­той проверки средних, но он предполагает, что группы не зависят друг от друга. 2.Однонаправленный ANOVA изучает различия только между разными уровнями одной переменной, тогда как факторный дисперсионный анализ смотрит на различия между двумя или более уровнями по более чем одной переменной. 3. Вид анализа Простой дисперсионный анализ Двухфакторный дисперсионный анализ Трехфакторный дисперсионный анализ Группирующая(ие) переменная(ые) Четыре уровня (градации) часов тренировки: 2, 4, 6 и 8 ч Три возрастные группы: 20, 25 и 30 лет Шесть уровней типов работ Два уровня тренировки и пола (дизайн 2×2) Три уровня возраста (5, 10 и 15 лет) и количество братьев/сестер Тип образовательной программы (Тип 1 или Тип 2), средний балл (выше или ниже 3,0) и участие в мероприятиях (да или нет) Зависимая переменная Точность печати Сила Результативность работы Точность печати Социальные навыки Результаты тестирования в колледже 4.Средние значения для трех групп равны 58,06, 57,96 и 59,03 с, а вероятность того, что это значение F (F(2,33) = 0,160) получится благодаря случайности, равна 0,853. Это существенно выше того, что мы ждали от тренировок. Каковы наши выводы? Количество часов тренировок не влияет на то, как быстро вы плаваете! 5.Значение F равно 28,773, что значимо на уровне 0,000 (!), а это говорит о том, что уровень стресса у трех групп различается. Как вы видите, меньше всего стресса у группы, работающей с 8.00 до 16.00. 6.Для решения этой задачи требуется апостериорный анализ (мы использовали процедуру Бонферрони). Как вы видите на выводе SPSS на рис. D.10, у тонкой лапши самый низкий средний показатель (1,80 – вы ведь уже это знаете, да?) со значимыми различиями между парными комбинациями всех трех типов лапши. 7.Помните, что критерий Фишера для дисперсионного анализа является универсальным устойчивым критерием для проверки различий между средними, при этом не уточняет, где именно находится данное различие. Так что если общая величина F не значима, то не имеет смысла сравнивать отдельные 478 Статистика для тех, кто (думает, что) ненавидит статистику группы при помощи апостериорной процедуры, потому что отсутствуют различия, которые можно изучать. Рис. D.10 Вывод для одностороннего дисперсионного анализа с апостериорными сравнениями ГЛАВА 14 1.Легкий вопрос. Многофакторный дисперсионный анализ применяется только при наличии более чем одного фактора или независимой переменной! На самом деле к этому ответу не так-то просто прийти (но если вы к нему пришли, то действительно поняли материал) при формулировке гипотезы о взаимодействии. 2.Вот один из множества возможных примеров. Здесь есть три уровня одного лечения (или фактора) и два уровня тяжести заболевания. Приложение D Ответы на задания Лекарство № 1 479 Лечение Лекарство № 2 Лекарство № 3 Тяжесть заболевания Тяжелая Легкая 3. И таблица дисперсионного анализа будет выглядеть вот так: Критерии межгрупповых эффектов Зависимая переменная: Pain_Score Сумма квадратов ст. Средний Источник F Значимость типа III св. квадрат Свободный член Гипотеза 3070,408 1 3070,408 23,303 0,040 Ошибка 263,517 2 131,758a Severity Гипотеза 0,075 1 0,075 0,048 0,848 Ошибка 3,150 2 1,575b Treatment Гипотеза 263,517 2 131,758 83,656 0,012 Ошибка 3,150 2 1,575b Severity * Treatment Гипотеза 3,150 2 1,575 0,774 0,463 Ошибка 231,850 114 2,034c a. MS (Treatment) b. MS (Severity * Treatment) c. MS (ошибка) Что до нашей интерпретации, что в этом наборе данных отсутствует главный эффект для выраженности боли, есть эффект для лечения и нет взаимодействия между двумя основными факторами. 4. а) нет. Значение критерия F для дисперсионного анализа не значимо (F = 0,004, p = 0,996); б) нет. Значение критерия F для дисперсионного анализа не значимо (F = 0,899, p = 0,352); в) значимые взаимодействия отсутствуют. 5.Конечно, когда вы проведете анализ в SPSS, то увидите, что главный эффект для пола отсутствует, но присутствует для тренировок, а также есть значимое взаимодействие. Но затем, когда вы нарисуете средние значения на графике и создадите картинку этого взаимодействия (как показано на рис. D.11), то увидите, что уровень навыков у мужчин выше при условии силовых тренировок, а у женщин – при условии тренировок на скорость. При оценке взаимодействия очень важно внимательно изучать эти рисунки. 480 Рис. D.11 Статистика для тех, кто (думает, что) ненавидит статистику Эффект взаимодействия между полом и условиями тренировок Уровень навыков Пол и метод тренировок Скорость Сила Мужчины Пол Женщины ГЛАВА 15 1. а) при 18 степенях свободы (df = n − 2) и уровне значимости 0,01 критическое значение для отклонения нулевой гипотезы составляет 0,516. Наблюдается значимая корреляция между скоростью и силой, и эта корреляция отвечает за 32,15 % дисперсии; б) при 78 степенях свободы и уровне значимости 0,05 критическое значение для отклонения нулевой гипотезы составляет 0,183 для одностороннего критерия. Наблюдается значимая корреляция между количеством правильных ответов и временем. Был выбран односторонний критерий, потому что альтернативная гипотеза утверждала наличие обратной или отрицательной связи. Примерно 20 % дисперсии объясняется этой корреляцией; в) при 48 степенях свободы и уровне значимости 0,05 критическое значение для отклонения нулевой гипотезы составляет 0,273 для двустороннего критерия. Наблюдается значимая корреляция между количеством друзей у ребенка и средним баллом, и эта корреляция отвечает за 13,69 % дисперсии. Приложение D Ответы на задания 481 2. Корреляции Мотивация Средний балл Корреляция Пирсона 1 0,434* Знач. (двусторонняя) 0,017 N 30 30 1 Средний балл Корреляция Пирсона 0,434* Знач. (двусторонняя) 0,017 N 30 30 * Корреляция значима на уровне 0,05 (двусторонняя). Мотивация a) и б). При помощи SPSS мы рассчитали коэффициент корреляции 0,434, что является значимым на уровне 0,017 для двустороннего критерия; в) верно. Чем более вы мотивированы, тем больше будете учиться. Чем больше вы учитесь, тем больше вы мотивированы. Но (и это большое «но») увеличение объема занятий не является причиной более высокой мотивации, так же как и более высокая мотивация не является причиной большего объема занятий. 3. Корреляции Доход Корреляция Пирсона Доход Уровень образования 1 0,629* Знач. (двусторонняя) N 20 Уровень образования Корреляция Пирсона 0,629* Знач. (двусторонняя) 0,003 N 20 * Корреляция значима на уровне 0,05 (двусторонняя). 0,003 20 1 20 а) корреляция между доходом и образованием равна 0,629, как вы видите на выводе SPSS; б) корреляция значима на уровне 0,003; в) единственный довод, который вы можете привести, – это тот, что две переменные имеют что-то общее (чем больше у них общего, тем выше корреляция), при этом ни одна из них не является причиной другой. 4. а) r(8) = 0,69; б) tкрит(8) = 0,6319. Наблюдаемая корреляция 0,69 превосходит критическое значение для 8 степеней свободы. Следовательно, наблюдаемый коэффициент корреляции статистически значим на уровне 0,05; 2 = 0,47); в) общая дисперсия равна 47 % (r часы.оценка 482 Статистика для тех, кто (думает, что) ненавидит статистику г) наблюдается сильная положительная связь между объемом занятий в часах и оценкой, полученной на контрольной, и эта связь статистически значима. Чем больше часов человек учился, тем выше его или ее оценка, а чем меньше часов человек учился, тем меньше оценка за контрольную! 5.Корреляция значима на уровне 0,01, а утверждение неверно, потому что связь между двумя переменными не означает, что одна из них является причиной для другой. Эти две переменные связаны, и тому может быть множество других причин, но независимо от объема потребляемого кофе мы не можем сказать, что это приведет к изменению уровня стресса из-за причинно-следственной связи. 6. а) корреляция равна 0,671; б) при 8 степенях свободы и уровне значимости 0,05 критическое значение для отклонения нулевой гипотезы о том, что корреляция равна нулю, составляет 0,5494 (см. табл. B.4). Наблюдаемое значение 0,671 больше, чем критическое значение (или то, что вы могли бы ожидать от чистой случайности), и мы приходим к выводу, что корреляция значима и две переменные связаны; в) если вы помните, лучший способ интерпретации любого коэффициента корреляции Пирсона – это возведение его в квадрат, что дает нам коэффициент детерминации 0,58. Это означает, что 58 % дисперсии в возрасте связано с дисперсией в количестве известных слов. Это не огромная величина, но для переменных в области человеческого поведения значение довольно существенное. 7.Примером может быть количество часов, которое вы потратили на занятия, и оценка за первую контрольную по статис­тике. Эти переменные не имеют причинно-следственной связи. Например, у вас будут одногруппники, которые часами зубрили, но плохо написали контрольную, потому что совсем не поняли материал, и будут одногруппники с очень хорошими результатами без какой-либо дополнительной подготовки, потому что у них уже были такие же темы в рамках какого-то другого предмета. Просто представьте, что мы заставим кого-то сидеть за столом и учиться по 10 ч в течение четырех дней перед экзаменом. Гарантирует ли это, что он или она получит хорошую оценку? Конечно, нет. Только то, что переменные связаны, не означает, что одна из них является следствием из другой. 8.На самом деле вам нужно самостоятельно решить, каким образом вы интерпретируете эти корреляции, и определить, какие из значимых корреляций имеют смысл. Например, раз- Приложение D Ответы на задания 483 мер обуви и возраст, конечно, имеют значимую корреляцию (r = 0,938), потому что по мере старения человека размер его или ее стопы увеличивается. Но имеет ли смысл эта связь? Мы думаем, что нет. С другой стороны, например, уровень интеллекта не связан ни с одной из трех переменных. И это вполне ожидаемо, учитывая, что IQ-тест стандартизирован по возрас­ ту, при этом для всех возрастов среднее значение равно 100. Другими словами, в терминах этого теста вы не становитесь с возрастом умнее, несмотря на то что детям говорят родители. ГЛАВА 16 1.Основное различие состоит в том, что линейная регрессия применяется для выяснения того, предсказывает ли одна переменную другую. Дисперсионный анализ изучает различия между средними значениями групп, но не обладает предсказательной силой. 2. а) уравнение регрессии: Y ′ = −0,214 × (прав. отв.) + 17,202; б) Y ′ = −0,214 × 8 + 17,202 = 15,49. в) Время (Y ) 14,5 13,4 12,7 16,4 21.0 13,9 17,3 12,5 16,7 22,7 3. Прав. отв. (X) 5 7 6 2 4 3 12 5 4 3 Y' 16,13 15,70 15,92 16,77 16,35 16,56 14,63 16,13 16,35 16,56 Y – Y' –1,6 –2,3 –3,2 –0,4 4,7 –2,7 2,7 –3,6 0,4 6,1 а) дополнительная независимая переменная не должна быть связана ни с одной другой независимой переменной. Только когда они не зависят друг от друга, могут привнести уникальную информацию для предсказания значения зависимой переменной; б) например, это могут быть условия проживания (в одиночестве или с группой людей) и доступность медицинского обслуживания (высокая, средняя, низкая); в) наличие Альцгеймера = (уровень образования) × b1 + (общее состояние здоровья) × b2 + (условия проживания) × b3 + (доступность мед. обслуживания) + a. 484 Статистика для тех, кто (думает, что) ненавидит статистику 4.На этот вопрос дайте ответ самостоятельно. Выберите статьи по вашей специализации или по действительно интересующему вас вопросу. 5. 6. 7. а) можно рассчитать корреляцию между двумя переменными, которая равна 0,204. По информации, полученной из главы 5, это довольно низкая корреляция. Можно прийти к заключению, что количество побед не очень хорошо предсказывает победу в Суперкубке; б) многие переменные являются категориальными (пол, раса, социальный класс и политическая партия), и их не просто измерить (например, по шкале от 1 до 100). Использование категориальных переменных дает нам больше гибкости; в) дополнительными переменными могли бы быть, например, количество игроков национального уровня, соотношение побед и проигрышей у тренеров и посещаемость домашних игр. а) потребление кофе; б) группа по уровню стресса; в) коэффициент корреляции, рассчитанный в главе 15, равен 0,373. Его нужно возвести в квадрат, чтобы получить значение R2 = 0,139. Очень ловко! а) лучше всего предсказывает переменная «количество лет опыта», но поскольку ни одна их них не является значимой (0,102), то можно сказать, что все три одинаково хороши (или плохи)! б) вот уравнение регрессии: Y ′ = 0,959(X1) – 5,786(X2) – 1,839(X3) + 96,377. Если мы подставим значения X1, X2 и X3, то получим сле­ дующий результат: Y ′ = 0,959 × 12 – 5,786 × 2 – 1,839 × 5 + 96,377. И предсказанный результат для шефа равен 64,062. Нестандартизованные коэффициенты (Константа) Опыт_лет Образование Позиции B 96,377 0,959 –5,786 –1,839 Стандартная ошибка 10,068 0,551 3,935 1,412 Стандартизованные коэффициенты Бета 0,671 –0,352 –0,489 т Значимость 9,573 1,741 –1,470 –1,303 0,000 0,102 0,162 0,212 Приложение D Ответы на задания 485 Обратите также внимание, что количество лет опыта и уровень образования были значимыми предсказывающими переменными. 8.Причина, по которой уровень образования имеет такую плохую предсказательную способность, состоит в его низкой изменчивости, что означает очень маленькую корреляцию между ним и количеством проданных домов (–0,074, никакого влияния), а вследствие этого маленькую корреляцию с любой другой переменной. Следовательно, у уровня образования нет предсказательной ценности. Какая переменная предсказывает лучше всего? Количество лет в бизнесе, причем со значимостью, далеко превосходящей уровень 0,001. После проведения множественного регрессионного анализа вы обнаружили, что уровень образования ничего не добавляет к нашему пониманию, почему эти риелторы (так же, как и другие, если мы хотим сделать такой вывод) продают разное количество домов. 9.Чтобы максимизировать ценность предсказывающих переменных, нужно учитывать, что они все должны быть связаны с зависимой, или результирующей, переменной, но не должны иметь корреляции с другими независимыми переменными (если это вообще возможно). ГЛАВА 17 1.Такое случается, когда ожидаемое и наблюдаемое значения идентичны. Например, когда вы ожидали, что придет неравное количество студентов с первого и со второго курсов, и так оно в самом деле и было! 2. Вот таблица для расчета значения хи-квадрат: Категория О (наблюдаемая частота) Республиканцы 800 Демократы 700 Независимые 900 Е (ожидаемая частота) 800 800 800 D (разница) (О – Е )2 0 0 100 10000 100 10000 При двух степенях свободы и уровне значимости 0,05 критическое значение, необходимое для отклонения нулевой гипотезы, равно 5,99. Наблюдаемое значение 25,00 позволяет нам отклонить нулевую гипотезу и заключить, что наблюдается значимое различие в количестве проголосовавших людей в зависимости от партии. (О – Е )2/Е 0,00 12,50 12,50 486 Статистика для тех, кто (думает, что) ненавидит статистику 3. Вот таблица для расчета значения хи-квадрат: Категория Мальчики Девочки О (наблюдаемая частота) 45 55 Е (ожидаемая частота) D (разница) (О – Е )2 50 5 25 50 5 25 (О – Е )2/Е 0,50 0,50 При одной степени свободы и уровне значимости 0,01 критическое значение, необходимое для отклонения нулевой гипотезы, равно 6,64. Наблюдаемое значение 1,00 означает, что нулевую гипотезу нельзя отклонить, нет различия в количестве мальчиков и девочек, играющих в футбол. 4.Сначала немного забавных фактов. Общее количество записавшихся учеников из всех шести классов равно 2217 чел., ожидаемая частота для каждой ячейки равна 2217/6 = 369,50. Наблюдаемое значение хи-квадрат равно 36,98. При пяти степенях свободы и уровне значимости 0,05 критическое значение, необходимое для отклонения нулевой гипотезы, равно 11,07. Поскольку наблюдаемое значение 36,98 превосходит критическое, мы приходим к заключению, что количество заявок не соответствует ожидаемому. Действительно, в каждый класс записалось статистически значимое разное количество учеников. 5.Ладно, ребята, вот наше решение. Значение хи-квадрат 15,8 значимо на уровне 0,003, что, определенно, говорит о наличии предпочтений у поедателей шоколадных батончиков. 6.Значение критерия независимости хи-квадрат равно 8,1, и при двух степенях свободы его более чем достаточно (на самом деле p = 0,0174), чтобы прийти к выводу о невозможности принять нулевую гипотезу о независимости. Действительно, предпочтение обычных или ореховых драже зависит от уровня тренировок. 7.Как вы видите в своем выводе SPSS, значение критерия хиквадрат 3,991 с четырьмя степенями свободы (2 × 2) значимо на уровне 0,41. Это недостаточно значимо и недостаточно велико, чтобы мы могли заключить, что две переменные зависят или связаны друг с другом. ГЛАВА 19 1.Вы можете видеть на рис. D.12, что количество самых усердных (уровень 10) и наименее профессиональных (уровень 1) людей равно 15. Приложение D Рис. D.12 Ответы на задания Таблица сопряженности усердности и профессионализма для 500 участников 2.На рис. D.13 показана диаграмма, которую вы легко можете создать. Рис. D.13 Столбиковая диаграмма распределения уровней атлетов по полу для 1000 участников 487 Приложение E Математика: самые основы Е сли вы это читаете, значит, знаете, что вам не помешает немного подтянуть базовые математические навыки. Многим людям это не помешает, особенно тем, кто возвращается к учебе после перерыва. Нет ничего зазорного в том, чтобы чуть-чуть углубиться в это, прежде чем продолжать работу со «Статистикой для тех, кто…». Вы уже обладаете большинством навыков для того, чтобы следовать за примерами в этой книге и выполнять практические задания в конце глав. Например, вы умеете складывать, вычитать, умножать и делить. Вы также, вероятно, знаете, как при помощи калькулятора вычислить квадратный корень из числа. Путаница начинается, когда мы переходим к уравнениям и различным операциям, которые заключены в круглые () или квадратные [] скобки. Вот им мы и посвятим немного времени, показав вам примеры для лучшего понимания того, как разбираться со сложными, на первый взгляд, вычислениями. Будьте уверены, при разложении на отдельные составляющие посчитать их – пара пустяков. БОЛЬШИЕ ПРАВИЛА: ПРИВЕТСТВУЕМ СВД У ПМ 488 Звучит как шпионская шифровка, да? Нет. Это просто первые буквы слов, которые указывают на порядок операций вычисления математических выражений или уравнений. 1.С – скобки: круглые или квадратные, оба вида могут присутствовать в выражении или уравнении; 2.В – возведение в степень: как, например, возведение 4 во вторую степень, или 42; 3. Д – деление: как 6 : 3; 4. У – умножение: как 6 × 3; Приложение E Математика: самые основы 5. П – плюс: как 2 + 3; 6. М – минус: как 5 – 1. Операции выполняются в перечисленном порядке. Например, первое, что вы делаете, – это работаете внутри скобок, затем возводите числа в степень (например, в квадрат), делите, потом умножаете и т. д. Если ничего не нужно возводить в квадрат, пропускаете шаг 2. Если ничего не нужно складывать, пропускаете шаг 5. Если в выражении есть и квадратные, и круглые скобки, сначала займитесь квадратными, а затем круглыми. Например, посмотрите на простое выражение: (3 + 2) × 2 = ? Помня порядок действий, мы знаем, что 1)первое, что мы делаем, – это вычисления в скобках. Так что 3 + 2 = 5; 2)затем на следующем шаге мы умножаем 5 на 2 и получаем 10, что есть наш ответ. Вот еще один пример… (4 : 2 × 5) + 7 = ? И вот что мы делаем: 1)сначала делим 4 на 2, получая 2, затем эту 2 мы умножаем на 5, получая 10; 2) затем к 10 прибавляем 7 и получаем итоговую сумму 17. Давайте добавим немного роскоши и применим возведение в квадрат. (102 × 3) : 150 = ? Вот что мы делаем: 1) смотрим внутрь скобок (как всегда, это первый шаг); 2)возводим 10 в квадрат, получаем 100, затем умножаем его на 3, что дает 300; 3) делим 300 на 150, получаем 2. Давайте добавим еще один уровень сложности (иногда мы имеем дело не с одним набором скобок). Вам нужно только запомнить, что начинать надо с самых внутренних скобок, следуя порядку выполнения действий. Приступим: [(15 × 2) − (5 + 7)] : 6 = ? 1) 2) 3) 4) 15 умножить на 2 равно 30; 5 плюс 7 равно 12; 30 – 12 равно 18; 18 разделить на 6 равно 3. 489 490 Статистика для тех, кто (думает, что) ненавидит статистику МАЛЕНЬКИЕ ПРАВИЛА И еще чуть-чуть. В книге встречаются и положительные, и отрицательные значения, и вам нужно знать, как они ведут себя в различных комбинациях. При умножении отрицательных и положительных чисел верно следующее: 1)отрицательное число, умноженное на положительное (или положительное число, умноженное на отрицательное), всегда дает отрицательное число. Например: −3 × 2 = −6 или 4 × −5 = −20. 2)отрицательное число, умноженное на другое отрицательное число, дает положительное число. Например: −4 × −3 = 12 или −2,5 × −3 = 7,5. А если поделить отрицательное число на положительное, то получится отрицательное число. Например: −10/2 = −5 или 25/−5 = 5. Наконец, если поделить отрицательное число на отрицательное, то получится положительное число. Например: −10/−5 = 2. Повторение – мать учения, так что вот 10 примеров и ответы к ним. Если у вас не получается верный ответ, проверьте порядок вычислений, приведенный выше, или попросите кого-нибудь из группы посмотреть, где вы ошиблись. Начинаем… 1. 75 + 10. 2. 104 − 50. 3. 50 − 104. 4. 42 × −2. 5. −50 × −60. 6. 25 : 5 – 6 : 3. 7. 6392 − (−700). 8. (510 − 500)/−10. Приложение E Математика: самые основы 491 9. [(402 − 207) − (802 − 400)] : 35 × 24. 10. ([(502 − 300) − 25] − [(242 − 100) − 50]) : 20 × 30. Ответы 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 85. 54. −54. −84. 3000. 3. 7092. −1. −5,48. 0,141. Хотите еще больше практики и объяснений? Загляните на эти сайты: http://www.webmath.com/index.html http://www.math.com/homeworkhelp/BasicMath.html Нет ничего хуже, чем начинать изучать предмет и при этом так волноваться, что не понимать в нем ничего. Тысячи студентов, которые были подготовлены хуже, чем вы, преуспели в статистике, и у вас тоже получится. Перечитайте советы в главе 1 о том, как пользоваться материалами в этой книге. Удачи! Приложение F Бонус: рецепт брауни К акого лешего делает рецепт брауни в учебнике по начальному курсу статистики? Хороший вопрос. Нет, серьезно. Вы, вероятно, усердно изучали этот материал (не важно, для каких целей). За все приложенные усилия вы заслуживаете награды. Вот она. Этот рецепт основан на нескольких разных рецептах и доработан напильником. Все это сделал ваш автор, и он рад поделиться им с вами. Раскрываю секрет. Сразу с противня, еще горячими, эти брауни потрясающе идут с мороженым. Постояв немного, они становятся очень приятными для жевания. К тому же хороши они и в охлажденном виде сразу из холодильника. Если вы их заморозите, имейте в виду, что на размораживание их во рту уйдет больше калорий, чем содержится в самих брауни. Ешьте столько замороженных брауни, сколько хотите. Ингредиенты: zz 115 г (8 ст. л.) сливочного масла; zz 100 г горького шоколада (или больше); zz ½ ст. л. соли; zz 2 яйца; zz 125 г муки; zz 400 г сахара; zz 1 ст. л. ванили; zz 2 ст. л. майонеза; zz 170 г шоколадных капель (или больше); zz 100 г целых грецких орехов (не обязательно). 492 Способ приготовления 1. Предварительно разогрейте духовку до 160 °С. 2. Растопите горький шоколад и масло в сотейнике. 3. Смешайте в отдельной миске муку и соль. 4. Добавьте сахар, ваниль, орехи, майонез и яйца к растопленной шоколадно-масляной массе и хорошо перемешайте. Приложение F Бонус: рецепт брауни 493 5. Добавьте всю смесь из п. 4 к муке и хорошо перемешайте. 6. Добавьте шоколадные капли. 7. Вылейте в форму для запекания 20×20 см. 8. Выпекайте 35–40 мин или до тех пор, пока спичка или лучинка не будут выходить из теста сухими. Примечания zz Я знаю про заморочки с майонезом. Если вам кажется, что это чересчур, просто не кладите его. Однако эти брауни получаются вкусными не просто так, поэтому отказывайтесь от этого ингредиента на собственный страх и риск. zz Берите хороший шоколад – чем выше содержание жира, тем лучше. Можно использовать до 170 г несладкого шоколада и даже еще больше шоколадных капель. Глоссарий Y ′, или Y с апострофом Рассчитанное значение Y в уравнении регрессии. случаев в высокой области распределения, и это называется распределением с отрицательной асимметрией. z-оценка Асимптота Сырое значение данных, приведенное к среднему значению и стандартному отклонению распределения, к которому принадлежит это значение. Для кривой нормального распределения это горизонтальная ось, к которой стремятся ее хвосты, но никогда ее не пересекают. Альтернативная гипотеза Утверждение о неравенстве между двумя переменными (см. Нулевая гипотеза). Апостериорный После совершившегося факта, относится к проверкам, выполняемым для определения истинного источника различий между тремя или более группами. Взаимная надежность оценивающих Вид надежности, который определяет, согласны ли наблюдатели друг с другом. Выборка Подмножество генеральной совокупности (см. Генеральная совокупность). Выбросы Мера центральной тенденции, рассчитанная путем сложения всех значений и деления на их количество (см. Среднее значение). Такие величины в распределении, значения которых заметно выбиваются из большинства величин. Является значение выбросом или нет, обычно определяется волей исследователя. Асимметрия, или скошенность Генеральная совокупность Арифметическое среднее Качество распределения, которое отвечает за неравномерность частот некоторый значений. Более длинный, по сравнению с левым, правый хвост соответствует меньшему количеству случаев в высокой области распределения, это называется распределением с положительной асимметрией. Более короткий, по сравнению с левым, правый хвост соответствует большему количеству Все возможные интересующие нас предметы или случаи (см. Выборка). Гипотеза Условное утверждение о предполагаемой связи между переменными, которое используется для отражения общей постановки проблемы или вопроса, побуждающего сформулировать вопрос исследования. Глоссарий Гистограмма Графическое представление распределения частот, в котором используются столбики разной высоты для отображения количест­ ва значений, попадающих в каждый интервал класса. 495 Доверительный интервал Наилучшая приближенная оценка диапазона генеральной совокупности при данном значении выборки. Главный эффект Достоверность Насколько хорошо тест измеряет то, что он должен. Ситуация в дисперсионном анализе, когда фактор или независимая переменная оказывает существенное влияние на результирующую переменную. Зависимая переменная Ррезультирующая, или предсказываемая, переменная в уравнении регрессии. Данные Значение критерия См. Наблюдаемое значение критерия. Ззапись о наблюдении или событии, например результат теста, оценка по математике или время отклика. Двусторонний критерий Ненаправленный критерий, отображающий ненаправленную гипотезу. Диаграмма, или график рассеяния График из парных точек данных, отложенных по осям x и y, используемый для визуального представления корреляции. Диапазон Положительная разница между самым большим и самым маленьким значениями в распределении. Это грубая мера изменчивости. Исключающий диапазон – это самое большое значение минус самое маленькое значение. Включающий диапазон – это самое большое значение минус самое маленькое значение плюс 1. Дисперсионный анализ Проверка различий между двумя или более средними значениями. В простом дисперсионном анализе (или ANOVA) используется только одна независимая переменная, тогда как в факторном дисперсионном анализе – более чем одна. Однонаправленный дисперсионный анализ изучает различия между средними более чем двух групп. Дисперсия Квадрат стандартного отклонения и еще одна мера размаха или рассеяния в распределении. Изменчивость Насколько величины отличаются друг от друга, или, другими словами, величина рассеяния или разброса в наборе данных. Интеллектуальный анализ данных Изучение больших наборов данных для выявления паттернов в них. Интервал класса Фиксированный диапазон значений, используемый при создании распределения частот. Интервальный уровень измерения Уровень измерения, при котором значения переменной размещаются по равноудаленным категориям, как, например, когда точки равномерно расставлены по шкале. Инференциальная статистика Методики, используемые для вывода характеристик генеральной совокупности на основании данных по выборке из этой совокупности. Истинная оценка Оценка, которая, при условии что мы могли бы ее увидеть, отражает реальные параметры измеряемой способности или поведения. Колоколообразная кривая Распределение величин, симметричное относительно среднего значения, медианы и моды и имеющее асимптотические хвосты. Часто называется кривой нормального распределения. 496 Статистика для тех, кто (думает, что) ненавидит статистику Конструктивная достоверность Критическое значение Тип достоверности, который проверяет, насколько хорошо тест отображает лежащее в его основе понятие, например интеллект или агрессию. Значение, получаемое при применении статистического критерия, которое необходимо для отклонения (или непринятия) нулевой гипотезы. Коэффициент алиенации Крутовершинность Объем дисперсии одной переменной, который не объясняется дисперсией другой переменной. Свойство кривой нормального распределения, которая имеет более острую вершину по сравнению с обычным нормальным распределением. Коэффициент детерминации Объем дисперсии одной переменной, который объясняется дисперсией другой переменной. Коэффициент корреляции Числовой индекс, выражающий отношения между переменными (в частности, как изменяется значение одной переменной, когда меняется значение другой). Коэффициент неопределенности См. Коэффициент алиенации. Кривая нормального распределения См. Колоколообразная кривая. Критериальная достоверность Тип достоверности, который проверяет, насколько тест отображает соответствие какому-то критерию, существующему или в настоящем (текущая достоверность), или в будущем (предсказательная) времени. Критерий независимости Ккритерий хи-квадрат для двух или более уровней, который проверяет, является ли распределение частот переменной, не зависящей от других переменных. Критерий согласия Одноуровневый критерий хи-квадрат, который проверяет, отличается ли распределение частот от того, что можно было бы ожидать от случайного распределения. Критерий текущей достоверности Насколько результат теста соответствует критерию, существующему в настоящем времени. Кумулятивное распределение частот Распределение частот, которое показывает частоты по интервалам классов наряду с накопленными частотами для каждого интервала. Куртозис Качество распределения, которое определяет, насколько оно плоское или островершинное. Линейная корреляция Корреляция, которая визуально лучше всего отображается в виде прямой линии. Линейный коэффициент корреляции Пирсона См. Коэффициент корреляции. Линия лучшего соответствия Линия регрессии, которая лучше всего соответствует наблюдаемым значениям и минимизирует ошибку предсказания. Линия тренда См. Прямая регрессии. Матрица корреляции Таблица, показывающая коэффициенты корреляции между более чем двумя переменными. Медиана Срединная точка в наборе значений, такая, что 50 % всех случаев в распределении оказывается ниже медианы, а 50 % – выше нее. Меры центральной тенденции Среднее значение, медиана и мода. Глоссарий 497 Многофакторный дисперсионный анализ Ненаправленная альтернативная гипотеза Дисперсионный анализ с более чем одним фактором или независимой переменной. Альтернативная гипотеза, которая утверждает различие между группами, но не указывает его направления (см. Направленная альтернативная гипотеза). Множественная регрессия Статистическая методика, когда используется несколько переменных для предсказания одной. Мода Наиболее часто встречающееся значение в распределении. Наблюдаемая оценка Оценка, которая была записана или наблюдаема (см. Истинная оценка). Наблюдаемое значение критерия Рассчитанное критерия. значение статистического Набор данных Набор из точек данных. Надежность Согласованность теста. Надежность внутренней согласованности Вид надежности, который определяет, отражают ли элементы теста только одно измерение, компонент или интересующую область. Надежность параллельных форм Вид надежности, который проверяет согласованность разных форм (вариантов) одного и того же теста. Направленная альтернативная гипотеза Альтернативная гипотеза, утверждающая существование различий между группами в определенном направлении (см. Ненаправленная альтернативная гипотеза). Независимая переменная Изменяемая экспериментатором переменная воздействия, или предсказывающая переменная в уравнении регрессии. Непараметрическая статистика Статистика, не имеющая распределения, которая не требует выполнения тех же предположений, что и параметрическая статистика. Несмещенная оценка Консервативная оценка параметра генеральной совокупности. Номинальный уровень измерения Наиболее грубый уровень измерения, при котором значение переменной может находиться в одной (и только одной) категории. Нулевая гипотеза Утверждение о равенстве между наборами переменных (см. Альтернативная гипотеза). Обратная корреляция Отрицательная корреляция, при которой значения переменной изменяются в противоположных направлениях. Огива Визуальное представление кумулятивного распределения частот. Одновыборочный Z-критерий Используется для сравнения среднего значения выборки со средним значением генеральной совокупности. Однонаправленный дисперсионный анализ См. Дисперсионный анализ. Односторонний критерий Направленный критерий, соответствующий направленной гипотезе. Описательная статистика Величины, которые организуют и описывают характеристики набора данных. 498 Статистика для тех, кто (думает, что) ненавидит статистику Отрицательная корреляция Порядковый уровень измерения См. Обратная корреляция. Уровень измерения, при котором значение переменной помещается в категорию, и этой категории присваивается ранг (порядок) по отношению к другим категориям. Оценка ошибки Часть результатов теста, которая является случайной и вносит вклад в ненадежность теста. Ошибка второго рода Вероятность принять нулевую гипотезу, когда она ложна. Ошибка выборки Разница между значениями выборки и генеральной совокупности. Ошибка первого рода Вероятность отклонить нулевую гипотезу, когда она верна. Ошибка предсказания Разница между наблюдаемым (Y) и прогнозируемым (Y ′) значениями. Параметрическая статистика Статистика, используемая для вывода предположений о генеральной совокупности на основании выборки, которая предполагает, что дисперсии каждой группы похожи и что выборка достаточно велика, чтобы представлять генеральную совокупность (см. Непараметрическая статистика). Плосковершинность Свойство кривой нормального распределения, которая имеет более плоскую вершину относительно нормального распределения. Полигон частот Графическое представление распределения частот, в котором используется непрерывная линия для отображения количества значений, попадающих в каждый интервал класса. Положительная корреляция См. Прямая корреляция. Популяция См. Генеральная совокупность. Предсказательная достоверность Насколько результат теста согласуется с критерием, который проявится в будущем. Пропорциональный уровень измерения Уровень измерения, в котором присутствует абсолютный ноль. Простой дисперсионный анализ См. Дисперсионный анализ. Процентильная точка Процентная доля случаев со значениями, меньшими или равными определенной величине в распределении или наборе величин. Прямая корреляция Положительная корреляция, когда значения обеих переменных изменяются в одном направлении. Прямая регрессии Прямая, построенная по значениям из уравнения регрессии. Также известна как линия тренда. Размер эффекта Мера величины различий между двумя группами, обычно вычисляется как d Коэна. Распределение частот Метод отображения того, как часто встречаются величины в определенных группах, называемых интервалами класса. Ретестовая надежность Тип надежности, проверяющий согласованность результатов теста в течение времени. Сводная таблица Инструмент в статистическом программном обеспечении, например в SPSS или Excel, который позволяет пользователю легко управлять строками, столбцами и частотами, входящими в таблицы сопряженности. Глоссарий Содержательная достоверность Тип достоверности, который проверяет, насколько хорошо тест отображает понятийную область. Срединная точка Центральная точка в интервале класса. Среднее Наиболее репрезентативная величина из набора величин. Среднее значение Тип среднего, вычисляемый путем сложения величин и деления суммы на их количество. Среднее отклонение Среднее отклонение всех величин от среднего значения распределения. Считается как сумма абсолютных значений отклонения величин от среднего, поделенная на количество величин. Стандартная ошибка оценки Мера точности предсказания, которая показывает изменчивость по линии регрессии (см. Ошибка предсказания). 499 приближается к размеру выборки количест­ ва индивидуальных ячеек в экспериментальной таблице. Таблица сопряженности Таблица, которая показывает частоты по двум или более переменным. Уровни одной переменной становятся заголовками столбцов, а уровни другой переменной становятся заголовками строк. Точка данных Наблюдение. Уравнение регрессии Уравнение, которое определяет точки и прямую, ближе всего находящуюся к наблю­дае­ мым значениям. Уровень значимости Установленный исследователем риск отклонить нулевую гипотезу, когда она верна. Факторный план План исследования более чем одной воздействующей переменной. Частичная корреляция Средняя величина изменчивости набора значений, или среднее отклонение величин от среднего значения. Числовой индекс, отображающий отношение между двумя переменными при исключении влияния третьей переменной (которая называется опосредующей, или искажающей). Стандартный показатель Шкалы измерения Стандартное отклонение См. z-оценка. Статистика Набор методов и инструментов для описания, организации и объяснения информации или данных. Статистика вывода См. Инференциальная статистика. Статистическая значимость См. Уровень значимости. Степени свободы Величина, рассчитываемая по-разному для разных статистических критериев, которая Различные способы категоризации результатов измерения. Шкала может быть номинальной, порядковой, интервальной и пропорциональной. Эксабайт 1 152 921 504 606 846 976 байтов данных, множество и множество данных. Пока вы это читали, количество данных в мире возросло. Вау! Эффект взаимодействия Результат, в котором влияние одного фактора дифференцируется в зависимости от другого фактора. Предметный указатель ANOVA. См. Дисперсионный анализ Data mining. См. Интеллектуальный анализ данных Анализ пути, 353 Асимметрия, 194 Выборка, 45, 164 Выброс, 64 Генеральная совокупность, 45, 164 Гипотеза, 163 альтернативная, 167 направленная, 168 ненаправленная, 168 нулевая, 165 проверка, 217 Гистограмма, 96 Данные, набор, 44 Детерминации коэффициент. См. Коэффициент детерминации Диаграмма круговая, 104 линейный график, 103 линейчатая, 103 рассеяния, 118 столбиковая, 102 Диапазон, 79 Дискриминантный анализ, 352 Дисперсионный анализ, 265 ковариационный, 350 многомерный, 349 многофакторный, 268, 283 повторных измерений, 349 простой, 266 Дисперсия, 85 Достоверность, 153 конструктивная, 155 критериальная, 154 предсказательная, 154 текущая, 154 содержательная, 153 Значение критерия критическое, 218 наблюдаемое, 218 Значения крайние, 63 Значимость статистическая, 208 уровень, 207 Изменчивость, 78 Интеллектуальный анализ данных, 358 Интервал доверительный, 220 класса, 94 Интервал класса, центр, 96 Колоколообразная кривая. См. Кривая нормального распределения Корреляция коэффициент, 113 формула расчета, 116 коэффициент Пирсона. См. Корреляция, коэффициент линейная, 121 матрица, 122 обратная, 114 отрицательная. См. Корреляция обратная положительная. См. Корреляция прямая прямая, 114 Предметный указатель частичная, 131 Коэффициент алиенации, 125 детерминации, 124 корреляции, 113 формула расчета, 116 Кривая нормального распределения, 178 Меры центральной тенденции, 57 медиана, 61 мода, 64 среднее значение арифметическое, 58 взвешенная средняя, 60 Метаанализ, 351 Моделирование структурными уравнениями, 354 Надежность, 142 внутренней согласованности, 146 Альфа Кронбаха, 147 параллельных форм, 145 ретестовая, 144 Отклонение среднее, 82 стандартное, 80 Оценка истинная, 143 наблюдаемая, 143 несмещенная, 83 смещенная, 83 Ошибка второго рода, 210 первого рода, 210 предсказания, 311 репрезентативности, 164 Переменная зависимая, 142, 313 независимая, 142, 313 Показатели стандартные, 184 z-оценка, 185 Полигон частот, 98 огива, 101 Популяция. См. Генеральная совокупность Размер эффекта, 231 d Коэна, 231 для многофакторного ANOVA, 292 501 онлайн-калькулятор, 244 Распределение бимодальное, 65 крутовершинное, 196 мультимодальное, 65 нормальное, 180 плосковершинное, 196 тримодальное, 66 частот, 94 кумулятивное, 100 Регрессия, 308 множественная, 321 прямая, 310 уравнение, 310 Среднее определение. См. Меры центральной тенденции Среднее значение, определение, 57 Статистика, 46 вывода. См. Инференциальная инференциальная, 45, 214 описательная, 44 определение, 44 Статистический критерий F-критерий Фишера, 269 t-критерий, 238 для зависимых средних, 252 Z-критерий, 225 двусторонний, 170 односторонний, 170 Степени свободы, 241 Точка данных, 66 Факторный анализ, 353 Хи-квадрат критерий независимости, 332 формула, 337 критерий согласия, 332 формула, 333 Шкала измерения, 66, 68 интервальная, 67 номинальная, 67 порядковая, 67 пропорциональная, 67 Эксцесс, 196 Эффект воздействия, 287 главный, 284 Книги издательства «ДМК Пресс» можно заказать в торгово-издательском холдинге «Планета Альянс» наложенным платежом, выслав открытку или письмо по почтовому адресу: 115487, г. Москва, 2-й Нагатинский пр-д, д. 6А. При оформлении заказа следует указать адрес (полностью), по которому должны быть высланы книги; фамилию, имя и отчество получателя. Желательно также указать свой телефон и электронный адрес. Эти книги вы можете заказать и в интернет-магазине: www.a-planeta.ru. Оптовые закупки: тел. (499) 782-38-89. Электронный адрес: books@alians-kniga.ru. Нил Дж. Салкинд Статистика для тех, кто (думает, что) ненавидит статистику Главный редактор Мовчан Д. А. dmkpress@gmail.com Перевод Корректор Верстка Дизайн обложки Ермолина М. В. Синяева Г. И. Чаннова А. А. Мовчан А. Г. Формат 70×100 1/16. Гарнитура «PT Serif». Печать офсетная. Усл. печ. л. 40,14. Тираж 200 экз. Веб-сайт издательства: www.dmkpress.com