Министерство образования и науки Российской Федерации
ФГБОУ ВО
«Кубанский государственный технологический университет»
Кафедра информационных систем и программирования
Базы данных в MS SQL Server
Учебно-методическое пособие по дисциплинам «Базы данных» и
«Безопасность систем баз данных»
для студентов направлений 09.03.04 «Программная инженерия»,
10.03.01 «Информационная безопасность»,
10.05.03 «Информационная безопасность автоматизированных систем»
Краснодар
2016
Составители: канд. техн. наук, проф. М.П.Малыхина;
канд. техн. наук, доц. В. А.Частикова
УДК 681.31(031)
Базы данных в MS SQL Server: учебно-методическое пособие для
студентов направлений 09.03.04 «Программная инженерия», 10.03.01 «Информационная безопасность», 10.05.03 «Информационная безопасность
автоматизированных систем» / Сост.: М.П. Малыхина, В.А.Частикова; Кубан. гос. технол. ун-т. Каф. информационных систем и программирования.
– Краснодар: 2016. – 168 с.
Разработаны в соответствии с учебными планами КубГТУ, требованиями государственного образовательного стандарта высшего образования
и стандарта предприятия СТП 4.2.6. Составлены в соответствии с рабочими программами курсов «Базы данных» направления 09.03.04 Программная инженерия и «Безопасность систем баз данных» направлений 10.03.01
«Информационная безопасность», 10.05.03 «Информационная безопасность автоматизированных систем».
Ил. 58. Табл. 23. Библиогр.: 9 назв.
Печатается по решению методического совета ФГБОУ ВО
«Кубанский государственный технологический университет»
© КубГТУ, 2016
2
СОДЕРЖАНИЕ
ВВЕДЕНИЕ
7
ЧАСТЬ 1. УСТАНОВКА MS SQL SERVER. ПРОЕКТИРОВАНИЕ И
СОЗДАНИЕ РЕЛЯЦИОННОЙ БАЗЫ ДАННЫХ
8
Глава 1. ОБЩИЕ СВЕДЕНИЯ О SQL SERVER. УСТАНОВКА SQL
SERVER
9
1.1 Краткая историческая справка
9
1.2 Минимальные требования к установке Microsoft SQL Server 2012
11
1.3 Установка SQL Server
12
1.4 Конфигурирование SQL Server
16
Глава 2. ПРОЕКТИРОВАНИЕ БАЗЫ ДАННЫХ: КОНЦЕПТУАЛЬНОЕ И
ЛОГИЧЕСКОЕ ПРОЕКТИРОВАНИЕ
18
2.1 Планирование разработки базы данных
18
2.2 Определение требований к системе
19
2.3 Сбор и анализ требований пользователей
20
2.4 Проектирование базы данных
21
2.5 Концептуальное проектирование базы данных
21
2.6 Фундаментальные понятия
23
2.6.1 Атрибуты
25
2.6.2 Ключи. Связи между объектами
27
2.7 Логическое проектирование реляционной БД. Упрощение
концептуальной модели данных
33
2.7.1 Исключение связи типа «многие ко многим»
33
2.7.2 Исключение сложных и рекурсивных связей
34
2.7.3 Исключение связей с атрибутами
35
2.7.4 Исключение множественных атрибутов
35
2.7.5 Исключение избыточных связей
36
2.7.6 Специализация и генерализация
37
Глава 3. РАБОТА С SSMSE. ПОДКЛЮЧЕНИЕ К СЕРВЕРУ. СОЗДАНИЕ
БД И ТАБЛИЦ С ПОМОЩЬЮ ВИЗАРДОВ
44
3.1 Подключение к компоненту SQL Server Database Engine
44
3.2 Создание и удаление баз данных
45
3.3 Создание и удаление таблиц
46
3.4 Создание и удаление связей
47
Глава 4. СОЗДАНИЕ И РАБОТА С БД С ИСПОЛЬЗОВАНИЕМ T-SQL
50
4.1 Создание и удаление баз данных
50
4.2 Создание и удаление таблиц
52
4.3 Создание ограничений
53
4.3.1 Ограничение default
53
4.3.2 Ограничения not null и unique
54
3
4.3.3 Ограничение primary key
55
4.3.4 Ограничение foreign key
56
4.3.5 Ограничение check
56
4.4 Создание индексов
57
4.4.1 Понятие индексирования
57
4.4.2 Кластерные индексы
58
4.4.3 Некластерные индексы
59
4.4.4 Составные индексы
60
4.4.5 Создание индексов командой CREATE TABLE
60
4.4.6 Создание индексов командой CREATE INDEX
63
ЧАСТЬ 2. ПРОГРАММИРОВАНИЕ В MS SQL SERVER. РАЗРАБОТКА
КЛИЕНТСКОГО ПРИЛОЖЕНИЯ
65
Глава 5. ПРОГРАММИРОВАНИЕ В SQL SERVER
66
5.1 Добавление данных в таблицу
66
5.2 Выборка данных из таблицы
67
5.2.1 Простая форма оператора SELECT
67
5.2.2 Отбор столбцов
68
5.2.3 Изменение заголовков столбцов
69
5.2.4 Выражения в выборках
69
5.2.6 Ассоциативные условия отбора
74
5.2.7 Порядок вывода данных
75
5.2.8 Группировка данных с помощью функций агрегирования
76
5.2.9 Группировка данных
77
5.2.10 Опции CUBE и ROLLUP
80
5.2.11 Отбор данных для групп
80
5.3 Выборка данных из нескольких таблиц
80
5.3.1 Объединение с помощью предложения WHERE
81
5.3.2 Внутреннее объединение
82
5.3.3 Внешнее объединение
82
5.3.4 Объединение и опция JOIN
83
5.3.5 Подзапросы
83
5.3.6 Создание таблиц на основе выборки
84
5.3.7 Объединение выборок
85
5.4 Изменение данных в таблице
86
5.5 Удаление данных из таблицы
87
5.6 Представления
88
Глава 6. РАЗРАБОТКА КЛИЕНТСКОГО ПРИЛОЖЕНИЯ НА C# .NET
91
6.1 Создание проекта в MS VS 2016 C# .NET без использования LINQ
91
6.1.1 Класс InitSql
92
6.1.2 Класс DataStruct
93
6.1.3 Класс DataRW
94
6.1.4 Создание пользовательского интерфейса
95
4
6.1.5 Сведение всех модулей вместе
97
6.2 Создание проекта в MS VS 2016 C# .NET с использованием LINQ
99
Глава 7. ХРАНИМЫЕ ПРОЦЕДУРЫ И ТРИГГЕРЫ
107
7.1 Создание триггеров
107
7.2 Ограничения триггеров
111
7.3 Создание процедур
111
7.4 Назначение разрешений для хранимых процедур
114
7.5 Создание функций
114
7.5.1 Скалярные функции
115
7.5.2 Функции, возвращающие табличное значение
116
7.5.3 Детерминированные и недетерминированные функции
119
ЧАСТЬ 3. ПОДДЕРЖКА ФУНКЦИОНИРОВАНИЯ И ОБЕСПЕЧЕНИЕ
БЕЗОПАСНОСТИ БД
121
Глава 8. ТРАНЗАКЦИИ
122
8.1 Разработка
122
8.2 Атомарность (Atomicity)
124
8.3 Согласованность (Consistency)
126
8.4 Изолированность (Isolation)
127
8.4.1 Уровень изолированности транзакции READ
UNCOMMITTED
128
8.4.2 Уровень изолированности транзакции READ COMMITTED
128
8.5 Надежность (Durability)
129
Глава 9. ВОССТАНОВЛЕНИЕ БАЗЫ ДАННЫХ
132
9.1 Обзор моделей восстановления
132
9.2 Конфигурирование моделей восстановления
132
9.3 Резервное копирование
134
9.3.1 Выполнение полного резервного копирования
134
9.3.2 Выполнение разностного резервного копирования
136
9.3.3 Резервное копирование журнала транзакций
136
9.4 Восстановление базы данных
137
9.4.1 Восстановление полной резервной копии
137
9.4.2 Восстановление разностной резервной копии
138
9.4.3 Восстановление резервной копии журнала транзакций
138
9.5 Выполнение частичного восстановления
139
9.6 Восстановление поврежденных страниц
140
Глава 10. АДМИНИСТРИРОВАНИЕ
142
10.1 Управление доступом к SQL Server 2012
142
10.1.1 Проверка подлинности средствами Windows
142
10.1.2 Проверка подлинности средствами SQL Server
142
10.1.3 Выбор режима проверки подлинности
142
10.1.4 Смена режимов проверки подлинности
143
10.1.5 Управление разрешениями
143
5
10.1.6 Создание и управление учетными записями
144
10.1.7 Учетные записи SQL Server
145
10.1.8 Роли сервера
145
10.1.9 Доступ к базе данных
145
10.1.10 Роли базы данных
146
10.1.11 Управление разрешениями SQL Server
146
10.1.12 Предоставление разрешений уровня базы данных
146
10.1.13 Разрешения на выполнение операторов
147
10.1.14 Разрешения уровня объекта
147
10.2 Конфигурирование SQL Server. Изменение параметров конфигурации 147
Глава 11. ШИФРОВАНИЕ В SQL SERVER
153
11.1 Ключи шифрования
153
11.2 Шифрование на уровне ячеек
154
11.3 Демонстрация шифрования на уровне ячеек
155
11.4 Шифрование с использованием сертификата
158
11.5 Прозрачное шифрование данных (TDE)
159
11.6 Команды и функции
161
11.7 Представления каталога и динамические административные
представления
162
11.7 Использование прозрачного шифрования
162
11.8 Извлечение данных о шифровании
163
11.9 Ограничения
164
ЛИТЕРАТУРА
167
6
ВВЕДЕНИЕ
В настоящее время трудно представить какую-либо сферу деятельности человека, где бы ни стояла проблема создания и использования информационных систем. Сегодня такие системы стали насущной потребностью, и спрос на грамотных специалистов в этой области все более возрастает. А поскольку все здание информационных систем базируется на концепции баз данных, то естественно, что без более или менее детального
знакомства с основами дисциплины "Базы данных" в наше время невозможно быть не только квалифицированным программистом, но даже и
грамотным пользователем компьютеров. Поэтому можно смело сказать,
что навыки работы в этой области не только повышают интеллектуальный
потенциал пользователя, но являются в этом вопросе одним из основополагающих факторов.
Основное назначение книги — ознакомить читателя с основными
идеями и методами, которые используются в современных реляционных
системах управления базами данных. В книге описаны теоретические основы баз данных, методы проектирования баз данных, а также вопросы
управления базами данных: все то, что необходимо специалисту, работающему в области информационных систем.
В качестве платформы для ознакомления с перечисленным материалом используются технологии, реализованные в MS SQL Server.
Microsoft SQL Server – система управления реляционными базами
данных (СУБД), разработанная корпорацией Microsoft. Основной используемый язык запросов – Transact-SQL. Он является реализацией стандарта
ANSI/ISO языка SQL (структурированный язык запросов) с расширениями.
Microsoft SQL Server используется для создания и сопровождения
как небольших по размеру баз данных, так и крупных БД масштаба предприятия; успешно конкурирует с другими СУБД в этом сегменте рынка.
Авторы стремились представить необходимый теоретический и
практический материал в доходчивом изложении и в такой последовательности, которая позволит читателю самостоятельно спроектировать структуру базы данных, реализовать ее с помощью средств современных СУБД,
а также осуществлять поддержку функционирования созданной информационной системы.
Авторы выражают свою признательность и благодарность Е. Тихонову, Ю. Рябову, Е. Синченко за помощь в подготовке рукописи к изданию.
7
ЧАСТЬ 1. УСТАНОВКА MS SQL SERVER. ПРОЕКТИРОВАНИЕ И
СОЗДАНИЕ РЕЛЯЦИОННОЙ БАЗЫ ДАННЫХ
8
Глава 1. ОБЩИЕ СВЕДЕНИЯ О SQL SERVER. УСТАНОВКА
SQL SERVER
1.1 Краткая историческая справка
Исходный код MS SQL Server (до версии 7.0) основывался на коде
Sybase SQL Server, и это позволило Microsoft выйти на рынок баз данных
для предприятий, где конкурировали Oracle, IBM, и, позже, сама Sybase.
Microsoft, Sybase и Ashton-Tate первоначально объединились для создания
и выпуска на рынок первой версии программы, получившей название
SQL Server 1.0 для OS/2 (около 1989 года), которая фактически была эквивалентом Sybase SQL Server 3.0 для Unix, VMS и др.
Остановимся на некоторых значимых моментах дальнейшей эволюции данного широко используемого программного продукта.
Microsoft SQL Server 4.2 был выпущен в1992 году и входил в состав
операционной системы Microsoft OS/2 версии 1.3. Официальный релиз
Microsoft SQL Server версии 4.21 для ОС Windows NT состоялся одновременно с релизом самой Windows NT (версии 3.1). Microsoft SQL Server 6.0
был первой версией SQL Server, созданной исключительно для архитектуры NT и без участия в процессе разработки Sybase.
К тому времени, как вышла на рынок ОС Windows NT, Sybase и
Microsoft разошлись и следовали собственным моделям программного
продукта и маркетинговым схемам. Microsoft добивалась исключительных
прав на все версии SQL Server для Windows. Позже Sybase изменила
название своего продукта на Adaptive Server Enterprise во избежание путаницы с Microsoft SQL Server. До 1994 года Microsoft получила от Sybase
три уведомления об авторских правах как намёк на происхождение
Microsoft SQL Server.
После разделения компании сделали несколько самостоятельных релизов программ. SQL Server 7.0 был первым сервером баз данных с настоящим пользовательским графическим интерфейсом администрирования.
Для устранения претензий со стороны Sybase в нарушении авторских прав,
весь наследуемый код в седьмой версии был переписан.
Версия SQL Server 2008 – была представлена в 2008 году. Она доступна для скачивания и может бесплатно распространяться вместе с использующим её программным обеспечением. Следует отметить, что данная версия полюбилась как начинающим разработчикам, так и опытным
специалистам, работавшим раннее с прежними версиями данного продукта.
9
Данная книга посвящена уже версии Microsoft SQL Server 2012, в
которой значительно расширена функциональность и которая включает
несколько технологий управления данными и анализа данных.
Следует отметить, что пользователи очень часто ищут ответы на неясные для них вопросы по использованию программных продуктов, в том
числе и по работе в Microsoft SQL Server, в электронной документации, где
приведено описание задач, а также дана справочная документация.
В связи с этим необходимо подчеркнуть тот факт, что в документации по SQL Server 2012 имеется два существенных изменения:
появилось новое средство просмотра справки, в котором изменился
способ установки и просмотра документации;
проведена реструктуризация документации, которая позволила
устранить недостатки предыдущих версий электронной документации.
Электронная документация по SQL Server 2012 содержит подмножество основного содержимого, оптимизированное для тех пользователей,
которые ищут сведения о выполнении конкретной задачи.
В электронной документации по SQL Server 2012 используется средство просмотра справки, выпущенное в среде Microsoft Visual Studio 2010 с
пакетом обновления 1 (SP1).
Кроме того, документация SQL Server больше не помещается на
установочный носитель, поэтому ее необходимо либо просматривать в режиме в сети, либо загрузить как локальную разделов справки.
Технологии SQL Server
SQL Server включает несколько технологий управления данными и
анализа данных.
Прежде чем приступить к проектированию базы данных надо точно
себе уяснить, к какому типу будет относиться разрабатываемая система.
Различают:
системы типа Online Transaction Processing (OLTP, интерактивная обработка транзакций);
системы типа Online Analytical Processing (OLAP, интерактивная
аналитическая обработка).
Системы OLTP обеспечивают немедленное обновление данных. С
этой целью такие системы проектируют со своим собственным пользовательским интерфейсом, написанным на языке .NET, который вызывает БД
и немедленно осуществляет любые изменения, внесенные пользователем в
базовые данные. Системы OLTP хранят и обрабатывают, как правило,
нормализованные (приведенные не ниже чем к третьей нормальной форме
таблицы), что гарантирует скорость обработки за максимально короткое
время, надежность и целостность данных. Достигается это путем исключе10
ния избыточных и дублирующих значений. Системы OLTP выполняют
обычно множество обновлений, не повреждая данные.
В системах OLАP данные обновляются относительно редко. В таких
системах большая часть обработки – это анализ данных. Данные, как правило, хранятся в ненормализованном виде и их компактное хранение не
рассматривается. Поскольку в таких системах обновления очень редки
(только тогда, когда обнаруживаются некорректные данные или для анализа требуются дополнительные данные) выполнение транзакций не предусматривается.
Здесь следует читателя сразу предупредить, что в данной книге приводится материал для построения систем OLTP. Построение OLАP систем
осуществляется при создании и работе с хранилищами данных для их анализа и выходит за рамки этой работы.
Тем не менее, ниже приведены ссылки на компоненты, задачи и
справочную документацию по каждой из этих и других технологий.
Службы SQL Server Data Quality Services (DQS) являются решением для очистки данных на основе знаний. Службы DQS позволяют создать
базу знаний, а затем выполнить в ней исправление данных и удаление дубликатов с помощью как автоматизированных, так и интерактивных
средств. Можно использовать службы справочных данных на основе облачных вычислений, а также создавать решения по управлению данными,
где службы DQS будут интегрированы со службами SQL Server Integration
Services и Master Data Services.
Службы Analysis Services — это платформа аналитических данных
и набор средств для бизнес-аналитики на личном уровне, уровне рабочей
группы и организации.
Серверный и клиентский конструкторы поддерживают стандартные
решения OLAP, новые решения для создания табличных моделей, а также
самостоятельную аналитику и совместную работу с помощью PowerPivot,
Excel и среды SharePoint 5еп/ег. Службы Analysis Services также включают
интеллектуальный анализ данных, который позволяет выявлять закономерности и связи на основе больших объемов данных.
1.2 Минимальные требования к установке Microsoft SQL Server
2012
Поддерживаемые операционные системы:
Windows 7;
Windows Server 2008 R2;
Windows Server 2008 Service Pack 2;
Windows Vista Service Pack 2.
11
Для 32-разрядных систем: компьютер с процессором Intel или совместимым процессором с тактовой частотой 1 ГГц и выше (рекомендуется 2
ГГц и выше).
Для 64-разрядных: Процессор с тактовой частотой 1,4 ГГц и выше.
Минимум 512 МБ ОЗУ (рекомендуется 2 ГБ и выше).
Необходимо перечислить дополнительные требования.
На компьютере должен быть установлен .NET Framework 3.5 с пакетом обновления 1. Он доступен в комплекте с установочным пакетом
SQL Server 2012.
Кроме того, требуется установщик Windows Installer 4.5, который
можно установить с помощью мастера установки.
Также, на компьютере должен быть установлен Microsoft Visual
Studio 2010 с пакетом обновления 1. Это программное обеспечение недоступно в установочном комплекте SQL Server 2012, поэтому, в случае отсутствия, MS Visual Studio 2010 SP1 придётся установить самостоятельно
из отдельного источника.
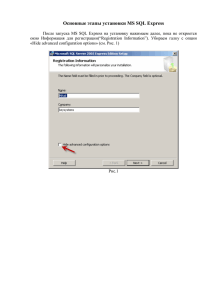
1.3 Установка SQL Server
1. Вставьте установочный носитель SQL Server и затем необходимо выполнить ряд действий:
– дважды щелкнуть файл setup.exe в корневом каталоге;
– в появившемся окне центра установки SQL Server 2012 выбрать
пункт «Установка»;
– в появившемся меню справа нажать «Новая установка изолированного экземпляра SQL Server или добавление компонентов к существующей установке».
2. Средство проверки конфигурации проконтролирует выполнение
правил поддержки установки. Чтобы продолжить, требуется нажать кнопку ОК. В этот момент будут созданы файлы журналов программы установки для данной установки.
3. На странице «Ключ продукта» нажмем переключатель, определяющий, производится ли установка бесплатного выпуска SQL Server или
имеется регистрационный номер продукта (PID) рабочей версии продукта.
4. На странице «Условия лицензии» установим флажок, подтверждая принятие условий соглашения. Чтобы продолжить, нажмем кнопку
Далее. Чтобы выйти из программы установки, нажмем кнопку Отмена.
5. На странице «Выбор компонентов» (рис. 1.1) предлагается выбрать компоненты для установки.
12
Рисунок 1.1 – Страница «Выбор компонентов»
6. На странице «Настройка экземпляра» (рис. 1.2) укажем способ
установки: как экземпляр по умолчанию или как именованный экземпляр.
Чтобы продолжить, нажмем кнопку Далее. Суффикс идентификатора
экземпляра – по умолчанию используется имя экземпляра. Он предназначен для идентификации каталогов установки и разделов реестра для данного экземпляра SQL Server. У экземпляра по умолчанию имя экземпляра и
суффикс идентификатора экземпляра будут равны «MSSQLSERVER».
Рисунок 1.2 – Страница «Настройка экземпляра»
13
7. На странице «Конфигурация сервера» (рис. 1.3) необходимо указать учетные записи входа для служб SQL Server. Набор служб, представленных для конфигурирования на этой странице, зависит от компонентов,
выбранных для установки. Можно назначить одну учетную запись входа
всем службам SQL Server или настроить учетные записи служб индивидуально. Можно также задать способ запуска служб: автоматически или
вручную.
Рисунок 1.3 – Страница «Конфигурация сервера»
8. На вкладке Конфигурация сервера — Параметры сортировки
можно задать параметры сортировки для компонента Database Engine и
служб Analysis Services, отличные от заданных по умолчанию.
На странице «Настройка компонента Database Engine Конфигурация сервера» (рис. 1.4) укажем следующие сведения.
Режим проверки подлинности – выберем для экземпляра SQL
Server один из режимов проверки подлинности: «Режим проверки подлинности Windows» или «Смешанный режим» (с собственным паролем).
Администраторы SQL Server – для экземпляра SQL Server должен
быть задан как минимум один системный администратор. Чтобы добавить
14
учетную запись, с которой выполняется программа установки SQL Server,
нажмем кнопку Добавить текущего пользователя.
9. На странице «Настройка служб Analysis Services» зададим пользователей или учетные записи, которые будут обладать разрешениями администратора для служб Analysis Services. Чтобы добавить учетную запись, с которой выполняется программа установки SQL Server, нажмем
кнопку Добавить текущего пользователя.
Рисунок 1.4 – Страница «Настройка компонента Database Engine»
10. На странице «Настройка служб Reporting Services» укажем тип
установки служб Reporting Services. Доступны следующие параметры.
конфигурация собственного режима по умолчанию.
конфигурация по умолчанию для режима интеграции с SharePoint.
установка служб Reporting Services без настройки.
11. Средство проверки конфигурации выполнится еще раз для оценки конфигурации компьютера с выбранными компонентами SQL Server.
12. На странице готовности к установке показано древовидное представление параметров установки, заданных в программе установки. Чтобы
продолжить, нажмем кнопку Установить.
13. В процессе установки на странице «Ход выполнения установки» отражается текущее состояние процесса установки, за которым можно
наблюдать.
15
14. Чтобы завершить процесс установки SQL Server, нажмем кнопку
Закрыть. После этого необходимо выполнить перезагрузку.
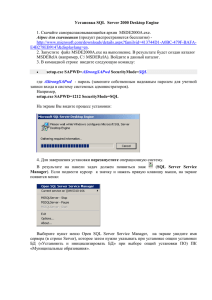
1.4 Конфигурирование SQL Server
Откроем Диспетчер конфигурации SQL Server и в разделе «Службы SQL Server» выберем справа | SQL Server (SQLEXPRESS) | Свойства. Во вкладке «Параметры запуска» настраиваются опции, с которыми будет производиться запуск соответствующей службы. Конфигурировать SQL Server можно (с помощью хранимой процедуры sp_configure) из
любой программы, позволяющей выполнять команды Transact-SQL на
сервере. В SQL Server 2012 для этого предусмотрен продукт SQL Server
Management Studio. Синтаксис хранимой процедуры для изменения конфигурации представлен в листинге 1.1.
Листинг 1.1– Команда изменения конфигурации
Sp_configure <параметр>, <значение>
Reconfigure [with override]
Выполнение команды reconfigure обязательно для того, чтобы новый параметр вступил в силу. Но для некоторых параметров необходим
ещё и перезапуск сервера. Выполнение sp_configure без параметров отображает значения всех параметров конфигурации, а если указать только
название параметра, то отображается его значение.
Таблица 1.1 – Параметры конфигурации SQL Server
Параметр
Описание
Максимальный размер полей типа text или image, которые могут быть
тиражированы при репликации данных. Параметр введен для совместиMax
text мости с различными ODBC-драйверами. Если все подписчики вашей БД
repl size
– серверы Microsoft SQL Server, то установите значение 2 147 483 647.
При значении 65 536 (по умолчанию) все данные большего размера при
тиражировании усекаются
Количество потоков используемых SQL Server для обработки запросов
пользователей. Для достижения максимальной производительности неMax worker
обязательно увеличивать это значение до максимального, так как SQL
threads
Server динамически переключает пользователей между потоками
Windows NT.
Количество дней, в течение которых архивная копия БД по умолчанию
media
считается действительной (при создании каждой копии можно указать
retention
индивидуальный срок действия)
nested triggers Разрешает вызов одного триггера из другого
Размер сетевого пакета. Устанавливаемое значение должно быть кратно
network
512. При увеличении количества передаваемых по сети данных следует
packet size
повысить это значение
Open objects Максимальное количество одновременно используемых объектов.
Remote
Разрешает (если 1) или запрещает (если 0) доступ к серверу с других
16
Параметр
Описание
access
серверов. Должно быть установлено в 1 при тиражировании данных
Параметр, устанавливающий режим выполнения распределенных транRemote
закций. По умолчанию этот параметр равен 0 – не использовать
proc trans
Distributed Transaction Coordinator. Использование DTC может быть задано явно оператором BEGIN DISTRIBUTED TRANSACTION
Remote query Время ожидания SQL Server перед возвратом результатов вызова внешtimeout
ней процедуры
Признак выделения памяти. Если этот параметр равен 1, то Windows NT
Set working
будет выделять необходимую SQL Server память при запуске SQL
set size
Server, иначе ( 0) память будет выделяться по мере необходимости
Show
Признак отображения параметров конфигурации. По умолчанию (0) SQL
advanced
Server отображает только стандартные параметры. При значении 1 устаoptions
навливается режим отображения всех параметров конфигурации
Максимальное количество одновременно возможных подключений. При
установке этого значения необходимо учитывать, что несколько соедиUser
нений всегда используются для служебных целей и внутренних процесconnections
сов SQL Server. Количество текущих пользовательских подключений
определяем, используя системную процедуру sp_who
Контрольные вопросы и упражнения
1) Перечислить минимальные требования SQL Server к компьютеру.
2) Какой язык программирования используется для SQL Server?
3) Для чего используется Диспетчер конфигурации SQL Service?
4) Какие существуют компоненты баз данных в SQL Server?
5) Что такое суффикс идентификатора пользователя?
6) Какие способы проверки подлинности допускает Database
Engine?
7) Какие параметры конфигурации Reporting Service доступны?
8) Назовите программу для изменения конфигурации SQL Server?
9) Приведите синтаксис хранимой процедуры для изменения конфигурации.
17
Глава
2.
ПРОЕКТИРОВАНИЕ
БАЗЫ
ДАННЫХ:
КОНЦЕПТУАЛЬНОЕ И ЛОГИЧЕСКОЕ ПРОЕКТИРОВАНИЕ
Как и любой программный продукт, база данных обладает собственным жизненным циклом (ЖЦБД), который включает (учитывая, что БД
разрабатывается для системы OLTP) в себя следующие основные этапы:
планирование разработки базы данных;
определение требований к системе;
сбор и анализ требований пользователей;
проектирование базы данных:
а) концептуальное проектирование базы данных;
б) логическое проектирование базы данных;
в) физическое проектирование базы данных;
г) разработка приложений:
д) проектирование транзакций;
е) проектирование пользовательского интерфейса;
реализация;
загрузка данных;
тестирование;
эксплуатация и сопровождение:
а) анализ функционирования и поддержка исходного варианта БД;
б) адаптация, модернизация и поддержка переработанных вариантов.
Обстоятельства разработки конкретной системы могут потребовать
расширения приведенного перечня необходимых для выполнения этапов.
В общем же случае этапу проектирования БД предшествует разрешение
вопросов первых трех этапов. Рассмотрим их основные положения.
2.1 Планирование разработки базы данных
Содержание данного этапа разработка стратегического плана, в
процессе которой осуществляется предварительное планирование конкретной системы управления базами данных. Общая информационная модель, созданная на этом шаге, должна быть вновь проанализирована и, если нужно, изменена на последующем этапе, этапе разработки проекта реализации.
Планирование разработки базы данных состоит в определении трех
основных компонентов: объема работ, ресурсов и стоимости проекта. Планирование разработки базы данных должно быть связано с общей стратегией построения информационной системы организации.
Важной частью разработки стратегического плана является проверка
осуществимости проекта, состоящая из нескольких частей.
18
Первая часть проверка технологической осуществимости. Она состоит в выяснении вопроса, существует ли оборудование и программное
обеспечение, удовлетворяющее информационным потребностям фирмы.
Вторая часть проверка операционной осуществимости выяснение наличия экспертов и персонала, необходимых для работы БД.
Третья часть проверка экономической целесообразности осуществления проекта. При исследовании этой проблемы весьма важно дать
оценку ряду факторов, в том числе и таким:
целесообразность совместного использования данных разными отделами;
величина риска, связанного с реализацией системы базы данных;
ожидаемая выгода от внедрения подлежащих созданию приложений;
время окупаемости внедренной БД;
влияние системы управления БД на реализацию долговременных
планов организации.
Планирование разработки баз данных также должно включать разработку стандартов, которые определяют, как будет осуществляться сбор
данных, каким будет их формат, какая потребуется документация, как будет выполняться проектирование и реализация приложений.
Для поддержки планирования разработки базы данных может быть
создана корпоративная модель данных, имеющая вид упрощенной ERдиаграммы.
Если результат проверки осуществимости проекта оказался положительным, можно перейти к определению требований к проекту.
2.2 Определение требований к системе
На данном этапе необходимо определить диапазон действия приложения базы данных, состав его пользователей и области применения.
Определение требований включает выбор целей БД, выяснение информационных потребностей различных отделов и руководителей фирмы
и требований к оборудованию и программному обеспечению. При этом
также требуется рассмотреть вопрос, следует ли создавать распределенную
базу данных или же централизованную, и какие в рассматриваемой ситуации понадобятся коммуникационные средства. Написать краткий комментарий, описывающий цели системы.
Прежде чем приступать к проектированию приложения базы данных,
важно установить границы исследуемой области и способы взаимодействия приложения с другими частями информационной системы организации. Эти границы должны охватывать не только текущих пользователей и
19
области применения разрабатываемой системы, но и будущих пользователей и возможные области применения.
2.3 Сбор и анализ требований пользователей
Этот этап является предварительным этапом концептуального проектирования базы данных. Проектирование базы данных основано на информации о той части организации, которая будет обслуживаться базой
данных.
Информационные потребности выясняются с помощью анкет, опросов менеджеров и работников фирмы, с помощью наблюдений за деятельностью предприятия, а также отчетов и форм, которыми фирма пользуется
в текущий момент.
На данном этапе необходимо создать для себя модель движения
важных материальных объектов и уяснить процесс документооборота. По
каждому документу необходимо установить периодичность использования, определить данные, необходимые для выполнения выделенных функций (анализируя существующую и планируемую документацию, выясняют, как получается каждый элемент данных, кем получается, где в дальнейшем используется, кем контролируется).
Самое пристальное внимание должно быть уделено дублированию
информации, возможности появления ложной информации и причинам,
которые ведут к их появлению. Также на этом этапе желательно представить общие параметры создаваемой базы.
В итоге собранная информация о каждой важной области применения приложения и пользовательской группе должна включать следующие
компоненты: исходную и генерируемую документацию, подробные сведения о выполняемых транзакциях, а также список требований с указанием
их приоритетов. На основании всей этой информации будут составлены
спецификации требований пользователей в виде набора документов, описывающих деятельность предприятия с разных точек зрения.
Формализация собранной на этом этапе информации может быть повышена с помощью методов составления спецификаций требований, к
числу которых относятся, например, технология структурного анализа и
проектирования, диаграммы потоков данных и графики «вход – процесс –
выход».
Поскольку системы с неадекватной или неполной функциональностью будут лишь раздражать пользователей, а чрезмерно увеличенный
набор функциональных возможностей вызовет существенное усложнение
системы, важность этого этапа в процессе разработки БД сложно переоценить.
20
2.4 Проектирование базы данных
Полный цикл разработки базы данных включает концептуальное, логическое и физическое ее проектирование.
Основными целями проектирования базы данных являются:
представление данных и связей между ними, необходимых для
всех основных областей применения данного приложения и любых существующих групп его пользователей;
создание модели данных, способной поддерживать выполнение
любых требуемых транзакций обработки данных;
разработка предварительного варианта проекта, структура которого позволяет удовлетворить требования, предъявляемые к производительности системы.
В создании БД как модели ПрО выделяют:
объектную (предметную) систему, представляющую фрагмент реального мира;
информационную систему, описывающую некоторую объектную
систему;
датологическую систему, представляющую информационную систему с помощью данных.
Оптимальная модель данных должна удовлетворять таким критериям как: структурная достоверность, простота, выразительность, отсутствие
избыточности, расширяемость, целостность, способность к совместному
использованию.
В данной лабораторной работе будут рассмотрены не все стадии
проектирования баз данных, а только концептуальное и логическое проектирование. Остальные этапы ЖЦБД будут освещены в последующих работах.
2.5 Концептуальное проектирование базы данных
Первая фаза процесса проектирования базы данных заключается в
создании для анализируемой части предприятия концептуальной модели
данных. Построение ее осуществляется в определенном порядке: вначале
создаются подробные модели пользовательских представлений данных; затем они интегрируются в концептуальную модель данных. Концептуальное проектирование приводит к созданию концептуальной схемы базы
данных.
Существует два основных подхода к проектированию систем баз
данных: «нисходящий» и «восходящий».
При восходящем подходе, который применяется для проектирования
простых баз данных с относительно небольшим количеством атрибутов,
работа начинается с самого нижнего уровня – уровня определения атрибу21
тов, которые на основе анализа существующих между ними связей группируются в отношения. Полученные отношения в дальнейшем подвергаются процессу нормализации, который приводит к созданию нормализованных взаимосвязанных таблиц, основанных на функциональных зависимостях между атрибутами.
Проектирование сложных баз данных с большим количеством атрибутов, поскольку установить среди атрибутов все существующие функциональные зависимости довольно затруднительно, осуществляется использованием нисходящего подхода. Начинается этот подход с разработки моделей данных, которые содержат несколько высокоуровневых сущностей и
связей, затем работа продолжается в виде серии нисходящих уточнений
низкоуровневых сущностей, связей и относящихся к ним атрибутов.
Нисходящий подход демонстрируется в концепции модели «сущность-связь» (Entity-Relationship model – ER-модель) – самой популярной
технологии высокоуровневого моделирования данных, предложенной П.
Ченом.
Модели «сущность-связь» относится к семантическим моделям. Семантическое моделирование данных, связанное со смысловым содержанием данных, независимо от их представления в ЭВМ, изначально возникло с
целью повышения эффективности и точности проектирования баз данных.
Методы семантического моделирования оказались применимы ко многим
пользовательским проблемам и легко преобразуемы в сетевые, иерархические и реляционные модели.
Помимо «нисходящего» и «восходящего» подходов, для проектирования баз данных могут применяться другие подходы, являющиеся некоторыми комбинациями указанных.
В построении общей концептуальной модели данных выделяют ряд
этапов.
Выделение локальных представлений, соответствующих обычно
относительно независимым данным. Каждое такое представление проектируется как подзадача.
Формулирование объектов, описывающих локальную предметную
область проектируемой БД, и описание атрибутов, составляющих структуру каждого объекта.
Выделение ключевых атрибутов.
Спецификация связей между объектами. Удаление избыточных
связей.
Анализ и добавление не ключевых атрибутов.
Объединение локальных представлений.
Построение концептуальной модели данных осуществляется на естественном языке на основе анализа описания предметной области, сделанного конечным пользователем. В процессе разработки концептуальная мо22
дель данных постоянно подвергается тестированию и проверке на соответствие требованиям пользователей. Созданная концептуальная модель данных предприятия является источником информации для фазы логического
проектирования базы данных.
2.6 Фундаментальные понятия
Для нормального функционирования информационной системы
необходимо, чтобы концептуальная модель адекватно отображала реалии
той предметной области, для которой она разрабатывается. Фундаментальными же реалиями в концептуальном моделировании являются данные с
их свойствами и связи между ними. Причем такое моделирование помимо
указания о наличии определенных данных и связей нуждается и в указаниях относительно смыслового, семантического их содержания, независимого от представления в ЭВМ. Методологии, позволяющие эффективно
отображать существующую смысловую содержательность реальности в
конструкции модели, относятся к так называемым семантическим методологиям.
Рисунок 2.1 Обозначения элементов диаграммы
Главными элементами семантической модели данных являются типы
объектов, их атрибуты и типы связей. Типы объектов часто представляют в
виде существительных, а типы связей в виде глаголов.
Семантическая модель предметной области изображается в виде диаграммы с учетом принятых обозначений для ее элементов (рис. 2.1).
Объекты. Объекты обозначают вещи, которые пользователи считают важными в моделируемой части реальности. Объект это то, о чем
накапливается информация в информационной системе и что может быть
однозначно идентифицировано. Объекты могут быть атомарными или составными. Для составного объекта определяется его внутренняя структура.
Каждый объект в конкретный момент времени характеризуется своим со23
стоянием. Это состояние определяется с помощью ограниченного набора
средств и связей с другими объектами. Составляющая время позволяет моделировать динамические системы.
Объект тип (в дальнейшем просто объект) характеризуется независимым существованием и представляет множество объектов реального
мира с одинаковыми свойствами. Отдельные объекты, которые входят в
данный тип, называют экземплярами объекта. Различают реальные и концептуальные объекты. Примерами объектов могут быть люди, товары, дома, детали, книги и так далее. Это реальные объекты. Концептуальными
объектами будут навыки, организации, деловые операции, штатное расписание и многое другое.
Рисунок 2.2 Обозначение объекта на ER - диаграмме
Каждый объект имеет имя и изображается на диаграммах в виде
прямоугольника, а экземпляр объекта в виде точки в прямоугольнике данного объекта (рис. 2.2).
Объекты бывают лексическими и абстрактными. Экземпляры лексических объектов можно напечатать, а экземпляры абстрактных объектов
напечатать нельзя. Так, например, ИМЯ будет лексическим объектом, поскольку его экземплярами являются имена, то есть строки символов, которые можно напечатать. С другой стороны, ШКОЛЬНИК является абстрактным объектом, поскольку человека напечатать нельзя.
В концептуальной модели могут присутствовать объекты двух видов: сильные и слабые. Объект, существование которого не зависит от существования другого объекта, называется сильным.
Слабый объект, наоборот, это тот объект, который находится в зависимости от некоторого другого объекта, т.е. он не может существовать в
модели, если в ней не существует этот другой объект. Поскольку в концептуальной модели все взаимосвязано, то один и тот же объект по отношению к одному объекту может быть сильным, а по отношению к другому –
слабым.
24
2.6.1 Атрибуты
Атрибут – это поименованная характеристика объекта, с помощью
которой моделируется его свойство. Каждому объекту присущи свои атрибуты. Например, объект КНИГА должен иметь такие атрибуты: наименование, автор, издательство, год издания. У человека есть имя, дата рождения, рост, вес, пол, цвет волос, мать, отец и так далее.
Если для некоторого экземпляра объекта значение некоторого атрибута не определено, то этот атрибут для данного экземпляра объекта имеет
пустое значение. На диаграммах атрибуты объекта соединяются с ним линиями (рис.2.3).
Значения каждого атрибута выбираются из соответствующего множества значений, включающего все потенциальные значения, которые могут быть присвоены атрибуту. Это множество значений называется доменом. Так, например, допустим, что количество товара определяется в единицах и может варьироваться от нуля до 1000 единиц. Следовательно,
набор допустимых значений для данного атрибута можно определить как
набор целых чисел от 0 до 1000.
Объект и экземпляр объекта могут быть определены и так:
Объект: СТУДЕНТ (ФИО, Группа, Год_рождения)
Рисунок 2.3 Объект «ТОВАР» и его атрибуты
Экземпляр объекта (Петров П.И., 93-ОА-22, 1974)
Атрибуты делятся на простые и составные.
Простые атрибуты не могут быть разделены на более мелкие компоненты. Например, атрибут Количество объекта ТОВАР является простым атрибутом. Простой атрибут еще называют атомарным.
Если же атрибут можно разбить на более мелкие составляющие, то
такой атрибут называется составным. Хорошим примером составного атрибута является Дата рождения (Год, Месяц, Число). Каждый из его
компонентов можно использовать в отдельности. Но в тех ситуациях, где
не требуется по отдельности использовать составные части такого атрибу25
та, его можно рассматривать как простой атрибут и определять, допустим,
как строковый тип. Если атрибут является составным, то на диаграммах
его атрибуты-компоненты присоединяются к нему линиями (рис. 2.4).
Рисунок 2.4 Объект «ТОВАР» с составным атрибутом
Атрибуты в концептуальном плане нужно отделять от объектов, которые они описывают. Значения атрибутов могут часто меняться, в то время как описываемый ими объект остается тем же самым. Так, у экземпляра
объекта ТОВАР может измениться значение атрибута Количество, но сам
объект останется тем же.
Если атрибут каждого отдельного экземпляра объекта может иметь
только одно значение, то такой атрибут называется однозначным. Например, атрибуты Фамилия, Год рождения, Рост каждого экземпляра объекта СТУДЕНТ могут иметь только одно значение. Большинство атрибутов
относятся именно к этой разновидности.
Некоторые атрибуты могут иметь несколько значений для каждого
экземпляра объекта. Например, некоторая фирма может иметь несколько
телефонных номеров или несколько равнозначных представителей. Такой
атрибут является многозначным. Многозначный атрибут на диаграммах
обводится двойным контуром.
Атрибут может быть базовым, а может быть производным. Производным считается такой атрибут, значение которого определяется по значению другого атрибута или других атрибутов. Например, значения атрибута Возраст студента могут быть вычислены по значениям атрибута Дата рождения объекта СТУДЕНТ. Для того чтобы задать атрибут нужно
дать ему имя, описать его и задать множество допустимых значений, т. е.
специфицировать.
26
2.6.2 Ключи. Связи между объектами
Среди атрибутов особое положение занимают такие, с помощью которых можно идентифицировать экземпляр объекта. Такие атрибуты называются ключами. Атрибут или несколько атрибутов, значения которых
уникальным образом идентифицируют каждый экземпляр объекта, являются потенциальным ключом данного объекта. Потенциальных ключей
может быть несколько. Например, экземпляр объекта ФАКУЛЬТЕТ
(Код_факультета, Название_факультета, ФИО_ декана) может однозначно идентифицироваться любым из первых двух указанных атрибутов.
Третий атрибут не рекомендуется использовать в качестве идентификационного, поскольку нельзя гарантировать отсутствие полного совпадения
значений атрибута ФИО_декана для нескольких экземпляров данного
объекта.
Один из потенциальных ключей может быть выбран в качестве первичного ключа. Обычно в качестве первичного ключа выбирается тот, который имеет наименьшую длину. Остальные потенциальные ключи называются альтернативными. В рассмотренном выше примере атрибут
Код_факультета имеет меньшую длину, чем атрибут Название_факультета, поэтому его следует выбрать в качестве первичного
ключа. Тот факт, что атрибут служит первичным ключом, отмечается его
подчеркиванием.
Идентификацию некоторых объектов иногда приходится осуществлять при помощи составных ключей, которые включают несколько атрибутов.
Два объекта могут быть связаны между собой. Подобная связь осуществляется через связь экземпляров одного объекта с экземплярами другого объекта, образуя набор экземпляров связи между двумя объектами,
который называется типом связи.
Каждому типу связи присваивается имя, которое должно представлять его функцию. Рассмотрим объекты ПРЕПОДАВАТЕЛЬ и КУРС.
Между этими объектами можно определить связь ЧИТАЕТ, сопоставив
каждому преподавателю ту дисциплину, по которой он читает лекции, или
наоборот, каждой дисциплине преподавателя. Связь ЧИТАЕТ составлена
из множества пар, в каждой из которых преподаватель из объекта ПРЕПОДАВАТЕЛЬ, а дисциплина из объекта КУРС (рис. 2.5).
Полученная структура сама по себе является объектом, состоящим из
пар экземпляров, взятых из двух объектов, связанных между собой. Объект
ЧИТАЕТ, полученный путем связи между объектами ПРЕПОДАВАТЕЛЬ
и КУРС, называется составным объектом.
27
Рисунок 2.5 Экземпляры типа связи «ЧИТАЕТ»
Описанная ситуация на диаграммах имеет свое графическое изображение, где тип связи обозначаются в виде ромбика с указанным на нем
именем связи, который соединен линиями со связываемыми объектами
(рис. 2.6).
Рисунок 2.6 Диаграмма типа связи «ЧИТАЕТ»
В связи может участвовать не два, а большее количество объектов,
которые в данном случае являются участниками этой связи. Количество
участников некоторой связи называется степенью связи. До сих пор обсуждались связи между двумя объектами. Такие связи называются бинарными.
Помимо бинарных связей существуют и другие типы связей:
тернарные – между тремя объектами;
кватернарные – между четырьмя объектами;
N-арные – между N объектами.
В подавляющем числе случаев проектирования БД можно ограничиться рассмотрением бинарных связей.
Для характеристики свойств связи, также как и для объектов, можно
использовать атрибуты.
Связь, имеющая максимальную мощность в одном из направлений,
равную одному, называется функциональной в этом направлении. В последней рассмотренной ситуации связь между преподавателем и курсом
является функциональной в направлении от курса к преподавателю. Это
означает, что, зная курс, можно однозначно определить преподавателя, читающего его. Это отношение не является функциональным в обратном
28
направлении, поскольку преподаватель, как было оговорено раннее, может
читать несколько курсов.
Для того, чтобы указать количество возможных связей для каждого
экземпляра участвующего в связи объекта используют показатель кардинальности. Показатели кардинальности связей между объектами определяются, прежде всего, установленными на производстве правилами и относятся к так называемым бизнес-правилам.
Для бинарных связей показатель кардинальности может иметь следующие значения:
«один к одному» (1:1), «один ко многим» (1:N), «много ко многим»
(M:N).
Если максимальная мощность связи в обоих направлениях равна одному, мы называем ее связью «один к одному» (1:1).
Например, на факультете может быть один декан, и обратно, один и
тот же декан может руководить только одним факультетом, что может
быть обозначено и так:
ФАКУЛЬТЕТ < ——— > ДЕКАН.
Если максимальная мощность в одном направлении равна одному, а
в другом — многим, то связь называется «один ко многим» (1:N).
Например, в группе учатся много студентов, но каждый студент
учится только в одной группе:
ГРУППА < —— >> СТУДЕНТ.
На диаграмме могут быть использованы два способа обозначения
вида бинарной связи: символическая (со стороны объекта ГРУППА выход
связи может быть помечен символом «1», а со стороны объекта СТУДЕНТ – символом «N») и стрелками (в направлении, где максимальная
мощность равна многим, проставлена двойная стрелка, а со стороны, где
она равна единице – одинарная). Реально при построении диаграмм выбирают один из них.
И, наконец, если максимальная мощность в обоих направлениях равна многим, то связь называется «много ко многим» (M:N). Например, преподаватель работает в разных группах, и в одной и той же группе работают
различные преподаватели:
ПРЕПОДАВАТЕЛЬ << —— >> ГРУППА.
Связь между объектами осуществляется посредством атрибутов.
Например, рассмотрим два объекта:
Объект:
СТУДЕНТ
Атрибуты:
Номер зачетной книжки
ФИО студента
29
Объект:
ГРУППА
Атрибуты:
Код группы
Количество студентов
ФИО старосты
Сейчас эти два объекта не связаны между собой. Для их связи в число атрибутов объекта СТУДЕНТ необходимо добавить код группы, в которой он учится, и значение которого будет использовано для связи экземпляра одного объекта с экземпляром другого объекта.
Следует отметить, что атрибут объекта – частный случай связи одного объекта с другим объектом. При нормальном использовании атрибуты
имеют функциональные связи в направлении от объекта к атрибуту. Это
означает, что значение атрибута однозначно определено для каждого экземпляра объекта. Например, у каждого человека есть ровно одна дата
рождения и одна мать. Максимальная мощность связи со стороны атрибута
в такой ситуации всегда равна одному, поэтому в диаграммах ее можно
опустить. Если нет необходимости использовать атрибут как объект,
участвующий в других связях, то для его изображения на диаграммах применяют уже рассмотренную краткую запись.
Степень участия. В методологии проектирования баз данных весьма
важной характеристикой типов связей между объектами является степень
участия объекта в связи. Если каждый экземпляр некоторого объекта обязательно должен участвовать в связи, то степень участия этого объекта в
данной связи является полной. О таком объекте еще говорят, что его класс
принадлежности обязательный.
Если же для объекта допустимо неучастие его некоторых экземпляров в связи, то степень участия данного объекта в этой связи является частичной, а его класс принадлежности – необязательный.
Рассмотрим еще раз связь между объектами ПРЕПОДАВАТЕЛЬ и
КУРС. Известно, что в состав преподавателей кафедры входят специалисты разных категорий: ассистенты, старшие преподаватели, доценты, профессора. Ассистентам, как правило, не поручается чтение лекций, поэтому
степень участия объекта ПРЕПОДАВАТЕЛЬ в связи ЧИТАЕТ является частичной.
В то же время для качественной подготовки специалистов необходимо, чтобы все дисциплины, предусмотренные учебным планом, были
изучены. Предположим, что для всех дисциплин запланировано чтение
лекций. Если это так, то степень участия объекта КУРС в связи ЧИТАЕТ
является полной. Однако, если учебный план содержит изучение дисциплин, по которым чтение лекций не предусмотрено, то в этой ситуации
степень участия объекта КУРС в связи ЧИТАЕТ будет также частичной.
На диаграммах участники связи с полным участием соединяются со зна30
ком связи двойной линией, а участники связи с частичным участием —
одинарной линией.
Для пояснения процесса проектирования возьмем фрагмент упрощенной предметной области «УЧЕБНЫЙ ПРОЦЕСС». Предположим, что
для успешного решения возложенных на систему задач рассматриваемая
модель должна включать следующие объекты: факультет; кафедра; преподаватель; группа; студент (табл. 2.1).
Взаимодействие и взаимосвязь выделенных объектов базируются на
следующих выявленных в результате обследования ПрО концепциях:
факультет объединяет ряд кафедр; кафедра может иметь ряд
направлений подготовки;
каждый преподаватель занимает определенную должность;
студент учится в определенной группе; каждая группа включает
много студентов;
преподавание дисциплин каждого направления ведется в соответствии с учебным планом многими преподавателями, работающими с группами;
с каждой группой работают многие преподаватели; один и тот же
преподаватель может работать в нескольких группах.
Таблица 2.1 Объекты и их атрибуты
ОБЪЕКТ
ФАКУЛЬТЕТ
АТРИБУТ
Код_факультета
Наименование_факультета
Количество_ студентов
КАФЕДРА
Код_кафедры
Наименование_кафедры
ПРЕПОДАВАТЕЛЬ Табельный_номер
Фамилия
Имя
Отчество
Должность
НАПРАВЛЕНИЕ
Шифр_ направления
ПОДГОТОВКИ
Наименование_ направления
ГРУППА
Код_Группы
Староста
Количество_студентов
СТУДЕНТ
Номер_зачетной_книжки
Фамилия
Имя
Отчество
Адрес
ПЕРВИЧНЫЙ КЛЮЧ
Код_факультета
Код_кафедры
Табельный_номер
Шифр_ направления
Код_группы
Номер_зачетной_ книжки
Для выделенных объектов необходимо установить типы связей, соответствующие тем, что существуют в реальном мире. Для каждой связи
31
следует также определить показатель кардинальности и степень участия
сторон в связи. Все связи и их характеристики приведены в таблице 2.2.
Таблица 2.2 Типы связей и их характеристики
СВЯЗЬ
ОБЪЕКТЫ
ВХОДИТ
ФАКУЛЬТЕТ
КАФЕДРА
РАБОТАЕТ КАФЕДРА
ПРЕПОДАВАТЕЛЬ
ГОТОВИТ КАФЕДРА
НАПРАВЛЕНИЕ
ИМЕЕТ
НАПРАВЛЕНИЕ ГРУППА
ПОКАЗАТЕЛЬ
КАРДИНАЛЬНОСТИ
1:N
СТЕПЕНЬ
УЧАСТИЯ
Полная Полная
1:N
Полная Полная
1:N
Полная Полная
1:N
Полная Полная
N:M
1:N
Полная Полная
Полная Полная
УЧИТ
ПРЕПОДАВАТЕЛЬ ГРУППА
УЧИТСЯ_В ГРУППА СТУДЕНТ
ФАКУЛЬТЕТ
Код_Факультета
ВХОДИТ
Наименование_Ф
Таб_Номер
ГОТОВИТ
НАПРАВЛЕНИЕ
Наименование
Код_Группы
Наименование_К
КАФЕДРА
Код_Кафедры
Шифр_Направ.
Кол_Студентов
РАБОТАЕТ
Фамилия
ПРЕПОДАВАТЕЛЬ
ИМЕЕТ
УЧИТ
Имя
Должность
Отчество
ГРУППА
Кол_Студентов
Староста
УЧИТСЯ_В
Фамилия
Ном_Зач_Кн
Отчество
СТУДЕНТ
Адрес
Имя
Рисунок 2.4 EER–диаграмма фрагмента предметной области
«УЧЕБНЫЙ ПРОЦЕСС»
Приведенная в таблицах 2.1-2.2 информация должна быть использована при построении EER–диаграммы (рис. 2.4). Для всех объектов рас32
сматриваемой предметной области определена полная степень участия в
связи. Это значит, что каждый экземпляр объекта должен участвовать в
связи.
2.7 Логическое проектирование реляционной БД. Упрощение
концептуальной модели данных
Преобразование концептуальной модели данных в логическую модель, в результате которого будет определена схема реляционной модели
данных, может иметь два подхода.
Один из подходов состоит в том, что проектировщик работает с концептуальной моделью напрямую, не прибегая к ее предварительному преобразованию. В этом случае ему придется столкнуться с необходимостью
преобразования разнообразных структур данных, причем на пути преобразования некоторых из них он может встретить ряд трудностей.
Второй же подход состоит в том, что проектировщик, прежде чем
приступить к процессу перехода от концептуальной модели к логической
модели, стремится вначале данный переход максимально упростить, проведя предварительные преобразования концептуальной модели, преобразования некоторых ее, не подходящие для реляционных СУБД, структур
данных. К таким структурам данных относятся:
связи типа «многие ко многим»;
сложные связи;
рекурсивные связи;
связи с атрибутами;
множественные атрибуты;
избыточные связи.
Точка зрения второго подхода на процесс преобразования концептуальной модели такова: если в модели присутствуют перечисленные нежелательные структуры, то они должны быть исключены путем тождественной их замены на структуры данных, допустимые для логической модели.
2.7.1 Исключение связи типа «многие ко многим»
Преобразование связи типа «многие ко многим» осуществляется путем введения некоторого промежуточного объекта с заменой одной связи
двумя связями типа «один ко многим» с вновь созданным объектом.
При организации новых связей необходимо следить за тем, чтобы
максимальная мощность связи «один» была направлена к исходному объекту, а максимальная мощность связи «много» – к вновь созданному объекту.
В рассматриваемой локальной предметной области, допустима ситуация (рис. 2.8), когда один и тот же преподаватель может заниматься с не33
сколькими группами, и в одной и той же группе может работать несколько
преподавателей.
N
N
M
ПРЕПОДАВАТЕЛЬ
ГРУППА
УЧИТ
Рисунок 2.8 Диаграмма связи типа «многие ко многим»
Введем дополнительный объект «ЗАНЯТИЕ» и определим новые две
связи (рис. 2.9):
ПР_УЧИТ типа 1: N между объектами ПРЕПОДАВАТЕЛЬ и ЗАНЯТИЕ;
УЧИТСЯ типа 1: M между объектами ГРУППА и ЗАНЯТИЕ.
ПРЕПОДАВАТЕЛЬ
1
ПР_УЧИТ
ГРУППА
N
ЗАНЯТИЕ
M
УЧИТСЯ
Рисунок 2.9 Преобразованная диаграмма связи типа «многие ко
многим»
2.7.2 Исключение сложных и рекурсивных связей
Хотя с помощью бинарных связей могут быть описаны многие ситуации реального мира, тем не менее, неизбежно возникновение и таких ситуаций, в которых построение разумной модели организации не может
быть сведено к реализации только таких связей. Не так уж редко, например, возникает потребность моделирования трехсторонних связей.
Напомним, что такая связь, в которой количество участников превышает два, т. е. тернарные связи и связи более высокого порядка, называемые N-арными связями, считается сложной. Исключение такой связи из
концептуальной модели происходит по следующему сценарию:
в модель вводится новый объект;
сложная связь заменяется бинарными связями типа «один ко многим» исходных объектов с вновь созданным объектом, причем количество бинарных связей равно степени сложной связи.
Рекурсивные связи с точки зрения их реализации в реляционных схемах БД также относятся к нежелательным структурам. Рекурсивная связь
34
это особый вид связи, в которой одни и те же экземпляры объекта участвуют несколько раз в разных ролях. Например:
РАБОТАЕТ
ПРЕПОДАЕТ
ЗАВЕДУЮЩИЙ
СОТРУДНИК
Рисунок 2.10 Диаграмма рекурсивной связи
Если концептуальная модель содержит такие связи, то перед переходом к реляционной схеме БД они должны быть исключены из модели. Исключение осуществляется также как и в предыдущих случаях, путем ввода
в модель дополнительного объекта и определения его связей.
2.7.3 Исключение связей с атрибутами
Существование в модели связей с атрибутами также относится к тем
факторам, которые желательно не иметь в логической модели данных.
Исключение связи с атрибутами может протекать по уже знакомому
сценарию: добавление в модель нового объекта с определением его связей.
2.7.4 Исключение множественных атрибутов
Поскольку в качестве логической модели данных в данном разделе
рассматривается реляционная модель данных, то необходимо не упускать
из виду тот факт, что 1НФ для реляционного отношения требует, чтобы
все его атрибуты имели простые атомарные значения. Поэтому если какойлибо объект концептуальной модели имеет атрибут множественного типа,
то эта модель должна быть преобразована. Преобразование и в этом случае, также как и в предыдущих, осуществляется введением дополнительного объекта.
Допустим, что в концептуальной модели в качестве объекта присутствует ОТДЕЛ организации, который имеет атрибут Номер_телефона. В
том случае, если в некотором отделе установлен не один, а несколько контактных телефонов, то данный атрибут имеет множественный тип. Для его
исключения из модели введем дополнительный объект ТЕЛЕФОН и установим связь его с объектом ОТДЕЛ.
35
2.7.5 Исключение избыточных связей
Избыточность информации вообще в базах данных относится к нежелательным факторам, которые по возможности необходимо устранять.
Наличие в концептуальной модели избыточной связи, например, характеризуется тем, что одна и та же информация может быть получена не только
через нее, но и с помощью другой связи. Для выявления избыточных связей модель подвергается всестороннему исследованию по поводу того, какими путями может быть получена разнообразная требуемая информация.
Если в модели будет обнаружена избыточная связь, то она должна быть
исключена из нее, поскольку в информативном плане она является излишней, но ее присутствие усложняет модель.
В результате выполнения перечисленных выше действий по исключению из модели различных нежелательных структур данных будет получена упрощенная концептуальная модель предметной области (рис. 2.11),
которая в соответствии с определенной рассматриваемой ниже методикой
может легко быть преобразована в реляционную модель данных.
ФАКУЛЬТЕТ
Код факультета
Кол-во студент.
Кол-во препод.-лей
Название
КАФЕДРА
Код кафедры
Код преподавателя
Название
Имя
Код специальности
Отчество
НАПРАВЛЕНИЕ
ПРЕПОДАВАТЕЛЬ
Название
Фамилия
Номер группы
Научное звание
ГРУППА
ЗАНЯТИЕ
Кол-во студентов
Предмет
Имя студента
Аудитория
Отчество
Дата-время
СТУДЕНТ
Фамилия
Рисунок 2.11 Упрощенная концептуальная модель предметной области
36
При построении концептуальной модели большое внимание уделяется анализу атрибутов. В хорошо спроектированной БД должно соблюдаться правило: среди атрибутов объекта должна наблюдаться зависимость
описательного атрибута от ключевого, но не должна существовать зависимость между описательными атрибутами.
В заключение данной главы нельзя не затронуть еще один аспект
рассматриваемого вопроса. Этот аспект касается того факта, что для удовлетворения новых требований, выдвигаемых все более усложняющимися
приложениями, в семантическое моделирование были введены дополнительные концепции, расширяющие его возможности. Такая модель получила название расширенной ER-модели (EER-модели), которая включает
все концепции ER-модели плюс концепции специализации, генерализации
и категоризации. Все эти нововведения создают дополнительные возможности для моделирования неоднородных по своей структуре объектов. Дополнительные концепции базируются на таких понятиях как суперкласс и
подкласс, а также используют процесс наследования атрибутов.
2.7.6 Специализация и генерализация
Суперкласс – это объект, включающий разные подклассы, которые
необходимо представить в модели данных.
Подкласс – это объект, являющийся членом суперкласса, но выполняющий отдельную роль в нем.
Суперкласс может иметь несколько разных подклассов. Так, например, подклассы: АССИСТЕНТ, СТАРШИЙ ПРЕПОДАВАТЕЛЬ, ДОЦЕНТ,
ПРОФЕССОР являются членами суперкласса ПРЕПОДАВАТЕЛЬ. Это
означает, что каждый экземпляр подкласса является в то же время и экземпляром суперкласса. Связь между суперклассом и подклассом относится к
типу «один к одному».
Использование понятий суперкласса и подклассов позволяет при моделировании выделить для подкласса свои собственные атрибуты и атрибуты, наследуемые им от суперкласса. Так, например, подкласс ДОЦЕНТ
должен иметь те же атрибуты, что и все преподаватели – это наследуемые
им от суперкласса ПРЕПОДАВАТЕЛЬ атрибуты. Однако он имеет и свой
собственный атрибут, который не определяется для других категорий преподавателей – Номер_диплома_доцента. В отсутствие выделенных подклассов в этой ситуации пришлось бы для объекта ПРЕПОДАВАТЕЛЬ
ввести такой атрибут, который бы имел неопределенное значение для всех
преподавателей, не являющихся доцентами. Подкласс может иметь свои
собственные связи, которые не подходят для всех экземпляров суперкласса. Например, профессору разрешается руководить аспирантами.
37
На диаграмме рассмотренная ситуация выглядит так, как обозначено
на рис 2.12. Подклассы соединяются линиями с кружком, который в свою
очередь соединяется с суперклассом. На каждой линии, идущей от подкласса, располагается U-образный символ, который обозначает направление включения. Верхняя часть U «открывается» в сторону суперкласса.
Внутри кружка располагается буква «d», если подклассы не пересекаются,
и буква «о» – для пересекающихся подклассов. В последнем случае экземпляр суперкласса может быть сразу членом нескольких подклассов. Изображенная на диаграмме ситуация исключает пересечение подклассов, поэтому в кружок помещен символ «d».
Введение понятий суперклассов и подклассов, позволяя избежать
повторного описания атрибутов, экономит время проектировщика, повышает читабельность, сокращает объем неопределенных значений. Помимо
этого использование этих понятий увеличивает количество семантической
информации, содержащейся в модели, позволяет ее сделать более понятной.
ПРЕПОДАВАТЕЛЬ
D
ДОЦЕНТ
СТАРШИЙ ПРЕПОДАВАТЕЛЬ
ПРОФФЕССОР
АССИСТЕНТ
РУКОВОДИТ
АСПИРАНТ
Рисунок 2.12 – Диаграмма с использованием понятий суперклассподкласс
В EER-модели различают два имеющих противоположные направления процесса: специализация и генерализация.
Специализация представляет собой процесс увеличения различий
между отдельными экземплярами объекта за счет выделения их отличительных характеристик. Этот процесс представляет собой нисходящий
подход к определению множества суперклассов и связанных с ним под38
классов. При выявлении набора подклассов объекта выполняется также
выделение специфических для каждого подкласса атрибутов и их связей с
другими объектами. Специфические для подкласса атрибуты соединяются
с ним непосредственно.
Опираясь на различные характеристики объекта, для одного и того
же объекта можно выделить несколько независимых специализаций.
Например, тот же объект ПРЕПОДАВАТЕЛЬ можно специфицировать,
разбив его на два подкласса: ОСНОВНАЯ_РАБОТА и РАБОТА_ПО_СОВМЕСТИТЕЛЬСТВУ. К первому подклассу относятся те преподаватели, для которых эта работа является основной, ко второй — те,
которые ее совмещают с другой основной работой. Это пример специализации на пересекающиеся подклассы, поскольку один и тот же преподаватель может быть участником обоих подклассов. Такая ситуация, например,
возникает при наличии вакансий, то есть тогда, когда количество имеющихся в наличии преподавателей меньше требуемого. В этой ситуации некоторому преподавателю может поручиться выполнение дополнительной
нагрузки, а он сам будет оформлен еще и как совместитель.
Генерализация представляет собой восходящий подход, а именно:
процесс сведения различий между объектами к минимуму путем выделения их общих характеристик. Этот подход позволяет создать суперкласс на
основе различных исходных подклассов. Допустим, что в наличии имеются следующие объекты: АССИСТЕНТ, СТАРШИЙ ПРЕПОДАВАТЕЛЬ,
ДОЦЕНТ, ПРОФЕССОР. Применение метода генерализации к ним приведет к выявлению их общих свойств и связей. Общность их заключается в
том, что все они являются преподавателями, а значит можно определить
суперкласс ПРЕПОДАВАТЕЛЬ, который будет иметь все совместно используемые атрибуты.
На процедуру специализации, помимо ограничения пересечения,
может быть наложено еще одно ограничение, которое называется ограничением участия и может быть полным или частичным.
При специализации с полным участием каждый экземпляр суперкласса должен быть экземпляром этой специализации, то есть принадлежать
какому-либо выделенному подклассу. Для обозначения на диаграммах
полного участия между суперклассом и кружком проводят двойную линию.
Примером специализации с полным участием могут служить суперкласс ПРЕПОДАВАТЕЛЬ и его подклассы, где каждый преподаватель должен относиться к одной из указанных четырех категорий (рис. 2.12)
Специализация с частичным участием означает, что каждый экземпляр объекта не обязательно должен быть членом подкласса этой специализации. Для обозначения на диаграммах частичного участия между суперклассом и кружком проводят одинарную линию.
39
Подклассы наследуют не только атрибуты, но и все связи суперкласса (рис. 2.13).
В данном случае конкретный профессор Иванов Иван Иванович работает в Вузе, так как Иванов Иван Иванович из объекта ПРОФЕССОР
связан с Ивановым Иваном Ивановичем из объекта ПРЕПОДАВАТЕЛЬ,
который работает в Вузе (Рис. 2.13).
ТАБЕЛ НОМЕР
ИМЯ
ПРЕПОДАВАТЕЛЬ
РАБОТАЕТ
АДРЕС
ПРОФЕССОР
ВУЗ
НОМ_ДИПЛОМА
Рисунок 2.13 Наследование подклассом связей суперкласса
Категоризация
Иерархия объектов разрабатываемой модели может быть достаточно
сложной. Так, например, можно представить такую ситуацию, при которой
один подкласс может быть связан с несколькими суперклассами, которые в
свою очередь являются подклассами одного общего для них суперкласса.
В этом случае данный подкласс называется совместно используемым подклассом так, что каждый экземпляр подкласса должен одновременно являться экземпляром каждого связанного с ним суперкласса (рис.2.14).
Подкласс будет являться категорией, если он связан сразу с несколькими суперклассами разных типов (рис 2.15). Подкласс категории
обладает выборочным наследованием, что означает наследование каждым
экземпляром категории атрибутов только одного суперкласса. Категория
может быть также двух типов: с полным участием и частичным участием.
40
СУПЕРКЛАСС
СУПЕРКЛАСС 2
СУПЕРКЛАСС 1
СОВМЕСТНО ИСПОЛЬЗУЕМЫЙ
ПОДКЛАСС
Рисунок 2.14 Диаграмма с совместно используемым подклассом
Наиболее жестким является ограничение, связанное с полным участием, поскольку оно предполагает, что каждый экземпляр всех суперклассов должен быть представлен в данной категории. При частичном же участии присутствие в категории всех экземпляров всех суперклассов необязательно. При полном участии от подкласса-категории идет двойная линия
к кружку категоризации, при частичном участии – одинарная.
Суперкласс 1
Суперкласс 2
U
Подкласс-категория
Рисунок 2.15 Диаграмма с категоризацией
Отметим еще раз тот факт, что в результате грамотно проведенных
концептуального и логического проектирований разработчик получит
нормализованную модель БД, находящуюся не менее чем в третьей нормальной форме.
41
Контрольные вопросы и упражнения
1.
Объясните своими словами смысл терминов:
база данных;
предметная область;
информационная система;
жизненный цикл базы данных.
2.
Охарактеризуйте жизненный цикл базы данных. Какие основные этапы он включает?
3.
Назовите основные цели процесса проектирования базы данных и дайте характеристику его фазам.
4.
Опишите процесс концептуального проектирования БД.
5.
Что такое модель "сущность-связь"?
6.
Дайте определения объекта и атрибута в концептуальной модели.
7.
Для чего используются ключи?
8.
Какие бывают типы связей в концептуальной модели?
9.
Объясните своими словами смысл терминов:
бинарная связь;
один-ко-многим;
мощность;
показатель кардинальности;
степень участия;
ключ;
рекурсивная связь;
составной объект.
10. Объясните, какой информацией можно воспользоваться для
определения следующих конструкций концептуальной модели данных:
объектов;
атрибутов;
связей.
11. Опишите процесс логического проектирования БД.
12. Как преобразуется связь типа "M:N" при переходе к РМД?
13. Приведите пример концептуальной модели некоторой предметной области.
42
14. Объясните понятия специализации, генерализации, категоризации.
15. Создайте концептуальную модель данных некоторого университета, которая бы позволяла получить следующую информацию:
количество преподавателей, работающих на факультете;
список преподавателей факультета;
дисциплины, изучаемые студентами определенной специальности в шестом семестре;
фамилии преподавателей, ведущих высшую математику на факультете.
43
Глава 3. РАБОТА С SSMSE. ПОДКЛЮЧЕНИЕ К СЕРВЕРУ.
СОЗДАНИЕ БД И ТАБЛИЦ С ПОМОЩЬЮ ВИЗАРДОВ
SQL Server Management Studio (SSMS) – графическое средство
управления и настройки компонентов MS SQL Server.
3.1 Подключение к компоненту SQL Server Database Engine
При открытии SSMS на экране появится окно (рис. 3.1).
Рисунок 3.1 – Соединение с сервером
В открытом в режиме диалога окне «Соединение с сервером» необходимо указать:
тип сервера – в нашем случае это Компонент Database Engine;
так же, с помощью SSMS можно подключиться к таким компонентам SQL
Server 2012 как «Службы Analysis Services», «Службы Reporting Services», «SQL Server Compact Edition», а так же «Службы Integration
Services»;
имя сервера – именем сервера может быть сетевое имя машины с
установленным SQL Server 2012, наименование экземпляра SQL Server
2012, а так же IP – адрес;
тип проверки подлинности – выбирается в зависимости от
настройки экземпляра SQL Server 2012, доступны 2 типа проверки подлинности:
• проверка подлинности Windows,
• проверка подлинности SQL Server.
После заполнения всех полей и нажатия кнопки Соединить появляется окно обозревателя объектов. В левой части окна, в панели «Обозрева44
тель объектов» отображается дерево объектов SQL Server Database
Engine.
3.2 Создание и удаление баз данных
Для создания баз данных, таблиц и связей между таблицами понадобится ветка «Базы данных».
При раскрытии ветки «Базы данных» появится структура, изображенная на рис. 3.2.
Рисунок 3.2 – Обозреватель объектов – ветка «База данных»
Для создания базы данных необходима следующая последовательность действий:
щелкнуть правой кнопкой мыши по узлу «Базы данных», а затем
выбрать «Создать базу данных …», после чего откроется окно «Создание
базы данных»;
в поле «Имя базы данных» необходимо внести желаемое название создаваемой базы данных, например uch_proc. В таблице «Файлы базы
данных» появятся название 2-х файлов: «uch_proc» – *.mdf-файл и
«uch_proc_log» – *.ldf-файл, при желании название и путь к файлам можно
изменить;
установить начальный размер файла (по умолчанию 3 Мб для
файла данных и 1 Мб для журнала);
нажать кнопку ОК, теперь в списке пользовательских баз данных
появилась база данных uch_proc (рис. 3.3).
Для удаления базы данных необходимо нажатием правой кнопки
мыши на названии базы данных вызвать контекстное меню и выбрать
пункт Удалить, затем нажать ОК.
45
Рисунок 3.3 – Визард «Создание базы данных»
3.3 Создание и удаление таблиц
Для создания таблицы в базе данных откройте дерево объектов для
БД, в которой необходимо создать таблицу, затем откройте контекстное
меню для объекта «Таблицы» и выберите пункт «Создать таблицу …» откроется вкладка создания таблицы.
В середине экрана появится таблица, хранящая список полей (в данном случае это 3 поля kod типа nchar(10), naimenovanie типа nchar(10) и
kol_studentov типа int).
Завершив заполнение строк, можно вызвать контекстное меню первого поля и выбрать «Задать первичный ключ». Для сохранения изменений нажимаем на значок дискеты в левой верхней части окна, что вызовет
появление диалогового окна с предложением дать имя сохраняемой таблице. В данном случае это будет «FAKULTET». Таблица создана, и она появилась в дереве объекта «Таблицы» для указанной базы данных (рис.
3.4).
Для создания всех таблиц, соответствующих логической модели, полученной в главе 2, требуется повторить эти действия для каждой таблицы.
Необходимо помнить, что после сохранения таблицы, изменить названия
полей, типы данных или первичные ключи, можно только полностью удалив таблицу и создав заново.
Для удаления таблицы из БД необходимо нажатем правой кнопки
мыши на названии таблицы вызвать контекстное меню и выбрать пункт
«Удалить», затем нажать кнопку ОК.
46
Рисунок 3.4 Обозреватель объектов – ветка Таблицы
3.4 Создание и удаление связей
Самый простой способ создания связей между таблицами в базе данных – использование диаграммы базы данных и графического отображения таблиц и связей между ними.
Для создания диаграммы базы данных необходимо вызвать контекстное меню для объекта «Диаграммы баз данных» в списке объектов
определенной БД и выбрать пункт меню «Создать диаграмму базы данных». Далее появится окно со списком имеющихся пользовательских таблиц в базе данных, необходимо выбрать и добавить те из них, связи между
которыми требуется создать.
Таблицы на шаблоне диаграммы представлены в виде блоков, с указанием первичных ключей (рис. 3.5).
Для создания связи, например, «один ко многим» между таблицами
FAKULTET и KAFEDRA требуется выполнить несколько шагов:
нажав и удерживая левой кнопкой мыши символ ключа таблицы
со стороны «один», нужно протянуть его к внешнему ключевому полю в
таблице со стороны «ко многим» и отпустить;
после этого на экране должно появиться окно подтверждения создания связи с указанием таблицы первичного и внешнего ключей;
нажать кнопку ОК.
После выполнения вышеописанных шагов на экране должна появиться линия, символизирующая связь между двумя таблицами (рис. 3.6).
Обратите внимание на то, как реализована связь «многие ко многим»
в реляционной модели и в чем заключается отличие этой реализации от
концептуальной.
47
Рисунок 3.5 – Диаграмма базы данных без связей
Для удаления связи из базы данных необходимо нажатием правой
кнопки мыши на изображении связи вызвать контекстное меню и выбрать
пунт «Удалить», а затем нажать ОК.
Рисунок 3.6 – Диаграмма базы данных со связями
48
Контрольные вопросы и упражнения
1) Что такое SQL Server Management Studio, для чего используется?
2) Опишите процесс создания базы данных с помощью SSMS.
3) Опишите процесс создания таблиц с помощью SSMS.
4) Опишите процесс создания связей с помощью SSMS.
5) Используя созданную в главе 2 логическую модель БД и графическое средство управления и настройки компонентов MS SQL Server SQL –
Server Management Studio (SSMS), создайте реляционную БД, выполнив
следующие шаги:
подключение к компоненту SQL Server Database Engine;
создание базы данных;
создание таблиц базы данных;
создание связей базы данных;
построение диаграммы базы данных со связями.
49
Глава 4. СОЗДАНИЕ И РАБОТА С БД С ИСПОЛЬЗОВАНИЕМ
T-SQL
Язык запросов, используемый в Microsoft SQL Server, является
расширением языка, определенного стандартами SQL (Structured Query
Language), которые опубликованы Американским национальным институтом стандартов (ANSI). Он называется Transact-SQL, в дальнейшем TSQL.
Администраторы и разработчики баз данных должны овладеть этим
языком, чтобы создавать сами базы данных, а также читать и записывать
информацию в базы данных SQL Server. Использование Transact-SQL
это единственный способ работы с данными в SQL Server.
Информация, хранящаяся в БД, не была бы полезной, если бы пользователи не могли извлекать ее в нужном формате. Одно из основных
назначений языка T-SQL – позволить разработчикам БД создавать запросы, возвращающие данные. Эта глава посвящена знакомству с различными
методами создания запросов данных с помощью T-SQL.
Следует отметить, что T-SQL, как и стандартный вариант языка
SQL, включает несколько групп операторов, каждая из которых имеет свое
назначение.
Прежде всего, среди этих групп необходимо выделить операторы,
предназначенные для создания реляционных баз данных (операторы определения данных).
В последующих разделах данной главы рассмотрим указанные конструкции языка, правила их определения и примеры использования в конкретных ситуациях.
4.1 Создание и удаление баз данных
Шаблоном базы является БД model, поэтому любая вновь созданная
БД уже имеет некоторое количество системных таблиц. Нужно учесть, что
команду создания CREATE DATABASE может выполнять только системный администратор, а значит, для создания БД необходимо обладать
правами администратора. Функции администратора заключаются в выделении места и выдаче другим пользователям прав на использование объектов БД (лист. 4.1).
Листинг 4.1 – Синтаксис команды CREATE DATABASE
CREATE DATABASE <Имя базы данных>
[ON
{ [PRIMARY] (NAME = <Название файла данных>,
FILENAME = '<Полный путь к файлу данных>'
[, SIZE = <Размер файла данных>]
[, MAXSIZE = <Максимальный размер файла данных>]
[, FILEGROWTH = <Увеличение файла данных>] )
} [,...n]
]
[LOG ON
50
{ ( NAME = logical_file_name,
FILENAME = 'os_file_name'
[, SIZE = size] )
} [,...n]
]
Здесь FILENAME – полный путь и имя файла для размещения БД,
должен указывать на локальный диск компьютера, на котором установлен
SQL Server.
SIZE – начальный размер каждого файла.
MAXSIZE – максимальный размер файла в Мб, если не указан, размер не ограничивается.
FILEGROWTH – единица увеличения файла, указывается в Мб (по
умолчанию) или в процентах (т.е. к числу добавляется %), значение 0 запрещает увеличение файла.
Пример создания базы данных «Учебный процесс» приведен в листинге 4.2.
Листинг 4.2 – Пример создания базы данных «Учебный процесс»
CREATE DATABASE uch_pr
ON PRIMARY
(
NAME = N'uch_pr_primary',
FILENAME = N'D:\databases\uch_pr_primary.mdf',
SIZE = 10240KB,
MAXSIZE = 20480KB,
FILEGROWTH = 2048KB
)
LOG ON
(
NAME = N'uch_pr_primary_log',
FILENAME = N'D:\databases\uch_pr_primary_log.ldf',
SIZE = 20480KB,
MAXSIZE = 204800KB,
FILEGROWTH = 2048KB
)
Для удаления БД применяется команда DROP DATABASE. В примере (лист. 4.3) удаляются база данных uch_pr и все её файлы.
Листинг 4.3 – Пример удаления базы данных «Учебный процесс»
USE master
GO
DROP DATABASE uch_pr
GO
После удаления базы данных следует обновить резервную копию базы данных master, чтобы в ней не содержалась информация о только что
удалённой БД. База данных не может быть удалена в том случае, если к
51
ней имеют доступ пользователи. Перед удалением БД необходимо всех
пользователей от неё отключить.
4.2 Создание и удаление таблиц
Программно
таблицы
CREATE TABLE (лист. 4.4).
создаются
с
помощью
команды
Листинг 4.4 – Синтаксис команды CREATE TABLE
CREATE TABLE <Имя БД>. <Имя владельца>. <Имя таблицы>
(
<Имя поля> <Свойства поля> <Ограничения>,
)
<Имя БД> - имя базы данных, в которой будет находиться таблица.
Можно не указывать данный аргумент, если находитесь в БД, в которой
создается таблица,
<Имя владельца> – владелец создаваемой таблицы,
<Имя таблицы> – название таблицы, которое должно удовлетворять правилам именования объектов SQL Server и быть уникальным в БД.
Для создания таблицы у пользователя должны быть права на выполнение этой операции. Если у него есть права на создание таблицы в какойлибо БД, то можно, находясь в ней, создавать таблицы в другой БД, полностью указывая к ней путь в аргументе <Имя БД>.
В том случае, если не указывается имя пользователя, необходимо
ставить вторую точку после имени базы данных, <Имя поля> – имя
столбца, которое должно удовлетворять правилам SQL Server и быть уникальным в таблице.
Далее указывается тип поля и его длина (если это требуется). Если
необходимо, чтобы поля заполнялись последовательным набором чисел
независимо от действий пользователя, используется опция IDENTITY,
первый параметр которой указывает начало отсчета, а второй – значение
приращения. С помощью опции IDENTITY может быть задан только один
столбец в таблице. Свойство IDENTITY можно применить только к полям
типа tinyint, smallint, int, decimal(p,0), numeric(p,0).
Ключевые слова NULL и NOT NULL служат для установки возможности принимать значения типа NULL или, напротив, запрета ввода таких
значений.
В синтаксисе команды показано, что они необязательны, потому что
данная опция устанавливается глобально для всех вновь создаваемых
столбцов, но для облегчения в дальнейшем работы с БД рекомендуется явно указывать эти ключевые слова (лист. 4.5).
52
Листинг 4.5 – Пример создания таблицы «Факультет»
CREATE TABLE uch_pr.dbo.FAKULTET
(
kod int NOT NULL,
naimenovanie nchar(100) NOT NULL,
kol_studentov int NOT NULL
)
Команда DROP TABLE применяется для удаления таблиц. Ниже
показаны команды, которые удаляют таблицу FAKULTET (лист. 4.6).
Листинг 4.6 – Пример удаления таблицы «Факультет»
USE master
GO
DROP TABLE uch_pr.dbo.FAKULTET
GO
4.3 Создание ограничений
Умолчания, ограничения и правила – это необязательные атрибуты,
которые можно определять по столбцам и таблицам БД. Умолчания – это
значения, которые заносятся в определённый столбец, когда не указано явно никакого значения.
Ограничения (constraints) используются как способ идентификации
допустимых значений для столбца (чтобы отклонять недопустимые значения), а также как средство обеспечения целостности данных в таблицах БД
и между связанными таблицами.
Создавать и модифицировать умолчания и ограничения можно с помощью как T-SQL, так и с Server Enterprise Manager.
4.3.1 Ограничение default
Это ограничение используется для установки значений по умолчанию (лист. 4.7).
Листинг 4.7 – Синтаксис ограничения DEFAULT
[CONSTRAINT <Имя ограничения>]
DEFAULT {<Выражение> | <Функция> | NULL}
[FOR <Имя колонки>]
К примеру, если большинство преподавателей – доценты, тогда имеет смысл использовать ограничение, которое приведено в листинге 4.8.
Листинг 4.8 – Пример создания ограничения DEFAULT
USE uch_pr
GO
CREATE TABLE PREPODAVATEL
(
TAB_NOMER nchar(20) PRIMARY KEY CLUSTERED,
FAMILIYA nchar(100),
IMYA nchar(50),
53
OTCHESTVO nchar(100),
DOLJNOST char(20) CONSTRAINT DK_DOLJNOST DEFAULT 'доцент',
)
GO
Ограничения автоматически обеспечивают целостность данных, задавая правила, определяющие значения данных, допустимые для какоголибо столбца, чтобы в нем не оказались неверные значения. Например, с
помощью ограничения можно ограничить значения атрибута целого типа
диапазоном от 1 до 100. В результате любые значения вне этого диапазона
нельзя будет ввести в данный столбец.
Ограничения только по одному столбцу называется ограничением
столбца. Ограничение, накладываемое на несколько столбцов, называется
табличным ограничением; в этом случае комбинация значений для атрибутов, указанных в данном ограничении, должна отвечать требованиям этого
ограничения.
Имеется пять типов ограничений: NOT NULL, UNIQUE, PRIMARY
KEY, FOREIGN KEY и CHECK.
4.3.2 Ограничения not null и unique
Ограничение NOT NULL задаётся в описании столбца, чтобы воспрепятствовать вставке в него null-значений. Следует использовать NOT
NULL вместо NULL там, где это возможно, поскольку операции с nullзначениями, такие, как сравнения, сопряжены с большей дополнительной
нагрузкой при обработке.
Ограничение UNIQUE не допускает дублированные значения, обеспечивая уникальность значений в одном или ряде столбцов. Для поддержки уникальности SQL Server создаёт по умолчанию некластеризованный
индекс по указанным столбцам.
Ограничение UNIQUE можно использовать для любого столбца, который не является частью ограничения PRIMARY KEY, которое также
обеспечивает уникальность значений. UNIQUE можно использовать для
столбцов, в которых разрешены null-значения, в то время как PRIMARY
KEY для таких столбцов использовать нельзя.
Чтобы создать ограничение UNIQUE по таблице с помощью T-SQL,
используется оператор CREATE TABLE или ALTER TABLE.
Оператор, создающий таблицу SPECIALNOST с ограничением
UNIQUE по столбцу NAZVANIE (название специальности) в виде кластеризованного индекса, приведен в листинге 4.9.
Листинг 4.9 – Пример создания ограничения UNIQUE
USE uch_pr
GO
CREATE TABLE SPECIALNOST
(
K_KOD int NOT NULL,
SHIFT char(30) NOT NULL,
54
NAIMENOVANIE nchar(100) NOT NULL UNIQUE CLUSTERED,
)
GO
Чтобы добавить ограничение UNIQUE к существующей таблице,
используйте ALTER TABLE.
4.3.3 Ограничение primary key
Это ограничение используется, чтобы задать простой или составной
первичный ключ таблицы, уникальным образом идентифицирующий строку таблицы. Поскольку первичный ключ идентифицирует строку, соответствующий столбец никогда не содержит значения NULL. В этом состоит
отличие ограничения PRIMARY KEY от ограничения UNIQUE, которое
допускает null-значения. И, подобно ограничению UNIQUE, ограничение
PRIMARY KEY не допускает дублированных значений.
По столбцам первичного ключа автоматически создаётся уникальный индекс.
Некоему ограничению можно присвоить имя, добавив ключевое слово CONSTRAINT. PK_F_name – имя ограничения (лист. 4.10).
Листинг 4.10 – Создание ограничения PRIMARY KEY
USE uch_pr
GO
CREATE TABLE FAKULTET
(
kod int NOT NULL CONSTRAINT PK_FAKULTET PRIMARY KEY,
naimenovanie nchar(100) NOT NULL,
kol_studentov int NOT NULL
)
GO
Рассматриваемое ограничение можно также добавить к таблице, не
имеющей ограничения PRIMARY KEY. Для этого необходимо использовать оператор ALTER TABLE.
Следующий оператор добавляет ограничение PRIMARY KEY к таблице SPECIALNOST:
USE uch_pr
GO
ALTER TABLE SPECIALNOST
ADD CONSTRAINT PK_SPECIALNOST PRIMARY KEY (K_KOD)
GO
Аналогично можно удалить ограничение:
USE uch_pr
GO
ALTER TABLE SPECIALNOST
DROP CONSTRAINT PK_SPECIALNOST
GO
55
4.3.4 Ограничение foreign key
Это ограничение определяет внешний ключ, задающий связь между
двумя таблицами. При этом внешний ключ одной таблицы (дочерней) ссылается на потенциальный ключ в другой (родительской) таблице.
При вставке строки в дочернюю таблицу с этим типом ограничения,
заносимые значения в столбцы внешнего ключа, сравниваются со значениями в потенциальном ключе родительской таблицы. Вставка новой строки
будет выполнена только тогда, когда значения внешнего ключа, которые
нужно внести в таблицу, имеются в потенциальном ключе родительской
таблицы. При этом для ограничения FOREIGN KEY является допустимым для заносимых данных наличие NULL-значения.
Кроме того, ограничения этого типа проверяются, если необходимо
удалить какую-либо строку из ссылочной таблицы. Будет невозможным
удалить строку из ссылочной таблицы, если строка какой-либо таблицы с
внешним ключом (таблицы, содержащей ограничение FOREIGN KEY)
содержит ссылку на значение в колонке внешнего ключа (лист. 4.11).
Листинг 4.11 – Пример создания ограничения FOREIGN KEY
USE uch_pr
GO
CREATE TABLE KAFEDRA
(
kod int NOT NULL CONSTRAINT PK_KAFEDRA PRIMARY KEY,
naimenovanie nchar(100) NOT NULL,
F_kod int NOT NULL,
CONSTRAINT FK_KAFEDRA_FAKULTET FOREIGN KEY (F_kod) REFERENCES
FAKULTET(kod)
)
GO
4.3.5 Ограничение check
Ограничение CHECK используется, чтобы ограничить множество
допустимых для столбца значений.
Значения, которые используются при вставке в столбец или его обновлении, проверяются на истинность (значение TRUE) выполнения указанного ограничения. Ограничение диапазона возможных значений, допустимых для столбца Num_year (количества проработанных лет) базы данных Teacher показано в листинге 4.12.
Листинг 4.12 – Пример создания ограничения CHECK
USE uch_pr
GO
CREATE TABLE PREPODAVATEL
(
TAB_NOMER nchar(20) PRIMARY KEY CLUSTERED,
FAMILIYA nchar(100),
IMYA nchar(50),
56
OTCHESTVO nchar(100),
DOLJNOST char(20),
Num_year smallint NOT NULL,
CONSTRAINT CK_year CHECK(Num_year>=1 AND Num_year<=100)
)
GO
4.4 Создание индексов
4.4.1 Понятие индексирования
Индексы – одно из самых мощных средств, доступных разработчику
БД. Они очень важны для обеспечения требуемого порядка вывода данных, поддержания связей между таблицами и ускорения выборки данных.
Индекс позволяет системе SQL Server находить данные, используя меньшее число операций ввода-вывода, чем при поиске данных путём доступа
только к таблице базы данных.
В SQL Server можно создать 2 типа индексов кластерные (clustered)
и некластерные (non-clustered). В зависимости от типа индекса он хранится либо вместе с данными, либо отдельно от них.
В индексах кластерного типа порядок строк в индексе совпадает с
физическим порядком. В связи с тем, что кластерный индекс непосредственно содержит данные, таблица может иметь только один такой индекс.
Он обеспечивает наиболее быстрый доступ к данным. Стоит хорошо подумать перед тем, как выбрать столбец для создания кластерного индекса.
Как правило, в качестве такого поля может выступать:
первичный ключ;
столбец, который наиболее часто используется для поиска;
столбец, часто используемый в опциях ORDER BY или GROUP
BY команды SELECT.
Некластерные индексы физически не связаны с данными. Для одной таблицы их может быть несколько. Некластерные индексы занимают
больше места, чем кластерные. Индексы некластерного типа обеспечивают
лучшую производительность при добавлении или изменении данных.
Схема, представленная на рис. 4.1, называется балансирующим деревом, или В-деревом. Индексы SQL Server состоят из индексных страниц.
Они обладают теми же физическими характеристиками, что и страницы
данных.
Индексные страницы состоят из 32-байтного указателя и индексных
строк размером до 2016 байт.
57
Рисунок 4.1 – Схема организации индексов
Индексные строки (записи) содержат указатели на индексные страницы (это узлы дерева), страницы данных или на записи с данными в зависимости от типа индекса.
Страницы индекса, расположенные на одной высоте, называются
уровнем. Индексные страницы одного уровня соединены друг с другом.
Самый нижний уровень называется нулевым. Самый верхний уровень
называется корневым. Он содержит только одну страницу. Число промежуточных уровней зависит от длины индексного ключа, числа включаемых в индекс полей, типа индекса и объема таблицы.
4.4.2 Кластерные индексы
Индексные страницы кластерных индексов состоят из индексных записей, которые содержат указатели на другие страницы индекса (узлы дерева) или (на самом нижнем уровне) на страницы данных (листы дерева).
Таким образом, страницы данных физически упорядочены по ключевому
значению, связанному с кластерным индексом.
Каждый кластерный индекс описан в таблице sysindexes (значение
поля indid для него равно 1). Это описание указывает на первую страницу
данных в цепи таблиц посредством логического номера страницы и на
корневую страницу кластерного индекса посредством ее логического номера.
При создании кластерного индекса данные в таблице физически сортируются в соответствии с ключом кластерного индекса. Поэтому SQL
Server позволяет создать только один кластерный индекс. Кластерный индекс напоминает файловую структуру: так же, как каждая папка содержит
файлы или подпапки, страница индекса ссылается либо на другие страницы индекса, либо на страницы данных.
Такая структура кластерного индекса позволяет очень быстро выполнять запросы, основанные на выборе значений по индексному ключу в
каком-то диапазоне, так как требуемые страницы с данными будут физически располагаться в соответствующей последовательности.
При поиске данных с использованием кластерного индекса SQL
Server выполняет следующие действия:
58
1) в таблице sysindexes определяется адрес индексной страницы
верхнего уровня;
2) искомое значение сравнивается с ключевым значением, содержащимся в индексной странице верхнего уровня;
3) ищется страница, для которой ключевое значение меньше или
равно искомому;
4) по соответствующему указателю выполняется переход на страницу следующего, более низкого уровня;
5) шаги 3 и 4 повторяются до тех пор, пока не будут достигнуты
страницы с данными;
6) на странице с данными ищется строка, содержащая искомое значение.
Индексы требуют места на диске (1,21*размер таблицы). Дополнительное пространство необходимо для хранения первоначальной последовательности до тех пор, пока индекс не будет построен и не будет отведено
пространство для кластерного индекса.
Пространство, требуемое для создания индекса, отводится в той базе
данных, в которой расположена таблица.
Использование ключевого слова SORTED_DATA значительно
уменьшает размеры дискового пространства для кластерного индекса.
Кластерный индекс следует создавать до других индексов и его использование выгодно при поиске значений в широком диапазоне.
Первичный ключ является наиболее удачным кандидатом в кластерные индексы, но следует проверить его настройку и оптимизацию.
Если не указывать ключевое слово CLUSTERED, то по умолчанию
создается некластерный индекс.
4.4.3 Некластерные индексы
Некластерный индекс имеет структуру, не зависящую от порядка
сортировки данных в таблице. Страницы такого индекса состоят из индексных записей, которые содержат указатели на другие индексные страницы или записи данных (на самом низком уровне). Следствие этого страницы данных не упорядочиваются по ключу.
Каждый некластерный индекс представлен в таблице sysindexes как
запись со значением поля indid, большим 1 (но меньшим 250). Это описание указывает на первую страницу индекса посредством логического номера страницы и корневую страницу некластерного индекса посредством
ее логического номера.
При поиске данных с использованием некластерного индекса SQL
Server выполняет следующие шаги:
1) в таблице sysindexes определяется адрес индексной страницы
верхнего уровня;
2) на этой странице ищется первое ключевое значение, которое
меньше или равно искомому;
59
3) по найденному указателю выполняется переход на страницу следующего, более низкого уровня;
4) шаги 2 и 3 повторяются до тех пор, пока не будут достигнуты
страницы с данными;
5) на странице с данными ищется строка, содержащая искомое значение; после того как соответствующее значение найдено, по указателю
страницы с данными считывается требуемая запись.
Создавая некластерный индекс, необходимо учитывать, что:
физическое упорядочение записей отличается от упорядочения индекса;
указатели добавляют лишний уровень между индексом и данными;
можно иметь до 249 некластерных индексов, каждый из которых
обеспечивает доступ к данным в различном порядке сортировки.
Сначала создайте кластерные индексы, а затем – некластерные.
4.4.4 Составные индексы
Помимо простых индексов, построенных по одному полю, используют сложные индексы, построенные по нескольким полям. Сложные индексы полезны, например, когда часто приходится искать информацию по
данным из нескольких полей. В сложный индекс можно объединить до 16
столбцов, а максимальный размер такого индексного выражения – 256
байт.
При использовании составных индексов нужно учитывать:
составной индекс имеет многостолбцовый ключ сортировки;
такой индекс используется, если первый столбец ключа указан в
опции WHERE;
поисковые таблицы или любые поля, к которым требуется частый
доступ, являются кандидатами на составной индекс;
нежелательны индексы, имеющие большой размер (>8 байт) и те, в
которых только второй или третий столбец используются в опции WHERE;
при создании составного индекса очень важен порядок полей;
индекс по столбцам {столбец1, столбец2} не то же самое, что индекс по столбцам {стобец2, столбец1}.
Cоздание индекса следует начинать с наиболее уникального столбца.
4.4.5 Создание индексов командой CREATE TABLE
С помощью параметра CONSTRAINT (ограничение) команды
CREATE TABLE разработчик может создать первичные, уникальные, не
допускающие дублирования значения ключа в разных строках таблицы и
60
внешние индексы, с помощью которых создаются постоянные связи между
таблицами (эти индексы можно называть ссылками). Рассмотрим примеры
ограничений для создания индексов. Обратите внимание на синтаксис
ограничений для первичного и внешнего ключа (лист. 4.13).
Листинг 4.13 – Синтаксис создания первичного ключа
[CONSTRAINT <Имя ограничения>]
PRIMARY KEY [CLUSTERED | NONCLUSTERED]
(<Имя столбца> [,<Имя столбца 2> […, < имя столбца 16>]])
[ON <Имя сегмента>]
Ограничение для внешнего ключа (ссылки):
[CONSTRAINT <Имя ограничения >]
[FOREIGN KEY (<Имя столбца> [, <Имя столбца 2> […, <Имя столбца 16>]])
REFERENCES [<Имя владельца>.] < Имя таблицы> [( <Имя колонки>
[, <Имя колонки 2> [… <Имя колонки 16 >]])]
Примеры ограничений – создание первичного индекса для таблицы
STUDENT и внешнего ключа к таблице KAFEDRA (лист. 4.14).
Листинг 4.14 – Пример создания первичного ключа
USE uch_pr
GO
CREATE TABLE STUDENT
(
FAMILIYA char(20),
IMYA char(10),
OTCHESTVO char(20),
zach_kn char(20)PRIMARY KEY CLUSTERED,
K_name int REFERENCES KAFEDRA(kod),
)
GO
В вышеприведенном примере создается таблица STUDENT, которая
будет состоять из пяти полей, иметь первичный ключ по полю zach_kn и
внешний ключ по полю K_name.
В этом примере мы не давали имена ограничениям, поскольку и первичный, и внешний ключи состоят из одного поля. Тем не менее, можно
переписать команду CREATE TABLE так, как показано в листинге 4.15.
Листинг 4.15 – Альтернативный вариант создания первичного ключа
USE uch_pr
GO
CREATE TABLE STUDENT
(
FAMILIYA char(20),
IMYA char(10),
OTCHESTVO char(20),
zach_kn char(20)
CONSTRAINT PK_zach_kn PRIMARY KEY CLUSTERED (Zach_kn),
K_name int
CONSTRAINT FK_K_name
61
FOREIGN KEY (K_name)
REFERENCES KAFEDRA (kod)
)
GO
В том случае, если для создания ограничения используется комбинация из нескольких полей, нет другой альтернативы, кроме использования
комбинации из ключевого слова CONSTRAINT, названия ограничения,
его типа и перечисления полей, которые входят в ограничение. Чем позже
на этапе разработки придется использовать ограничения из комбинации
полей, тем более продуманной можно считать свою БД.
На одну таблицу можно иметь не более одного первичного ключа
(состоящего из одного или нескольких полей), тем не менее, используя
ограничение UNIQUE, можно определить уникальные поля и в дальнейшем переустановить первичный ключ для таблицы с помощью команды
ALTER TABLE. Ограничение UNIQUE будет следить за уникальностью
данных и комбинации составляющих его столбцов (лист. 4.16).
Листинг 4.16 – Синтаксис создания уникального индекса
[CONSTRAINT <Имя ограничения>]
UNIQUE [CLUSTERED | NONCLUSTERED]
(<Имя колонки> [, <Имя колонки 2> […, <Имя колонки 16>]])
[ ON <Имя сегмента >]
Чуть усложним команду, рассмотренную в предыдущем примере
(лист. 4.17).
Листинг 4.17 – Пример создания уникального индекса
USE uch_pr
GO
CREATE TABLE STUDENT
(
FAMILIYA char(20),
IMYA char(10),
OTCHESTVO char(20),
zach_kn char(20)
CONSTRAINT PK_zach_kn PRIMARY KEY CLUSTERED (Zach_kn),
K_name int
CONSTRAINT FK_K_name
FOREIGN KEY (K_name)
REFERENCES KAFEDRA (kod)
CONSTRAINT UK_FAMILIYA UNIQUE (FAMILIYA)
)
GO
После ввода ограничения UNIQUE больше нельзя добавить одинаковые значения в столбец FAMILIYA.
62
4.4.6 Создание индексов командой CREATE INDEX
Команда CREATE INDEX имеет синтаксис, показанный в лист.
4.18.
Листинг 4.18 – Синтаксис создания индекса
CREATE [UNIQUE] [CLUSTERED | NONCLUSTERED] INDEX <Имя индекса>
ON [[<Имя БД>.] < Имя владельца>.] <Имя таблицы>
(<Имя столбца> [,<Имя столбца >]…)
[WITH
[FILLFACTOR = <Значение>]
[[,] IGNORE_DUP_KEY]
[[,] {SORTED DATA | SORTED_DATA_REORG}]
[[,] {IGNORE_DUP_ROW | ALLOW_DUP_ROW}]]
[ON <Имя сегмента>]
Ключевое слово UNIQUE указывает, что будет создан уникальный
индекс, в котором никогда не повторятся значения в двух разных записях
по всем полям, которые входят в индекс. Если при операциях вставки (команда INSERT) и модификации (команда UPDATE) будет осуществлена
попытка дублирования, система это обнаружит и сгенерирует сообщение
об ошибке.
Создать ключ по полю, которое имеет повторяющиеся значения, невозможно, даже если это значение NULL. В листинге 4.19 приводится
пример создания некластерного уникального индекса для таблицы
GROUPS по полю G_name.
Листинг 4.19 – Пример создания индекса
USE uch_pr
GO
CREATE UNIQUE NONCLUSTERED
INDEX UK_G_name
ON GROUPS (G_name)
GO
N.B. перед созданием индекса не забудьте создать таблицу GROUPS:
USE uch_pr
GO
CREATE TABLE GROUPS
(
G_name char(20),
F_kod int
FOREIGN KEY (F_kod)
REFERENCES KAFEDRA (kod)
)
GO
Перед тем, как создавать уникальный индекс по столбцу, который
уже содержит записи, имеет смысл проверить наличие повторяющихся
значений. Это можно сделать с помощью SQL-выражения (лист. 4.20).
63
Листинг 4.20 – Проверка на уникальность значений
SELECT <инд_столбец>, COUNT (<инд_столбец>)
FROM <имя_таблицы>
GROUP BY <инд_столбец>
HAVING COUNT (<инд_столбец>) >1
где: <инд_столбец> – имя столбца, который подлежит индексированию; <имя_таблицы> – имя таблицы, в которой этот столбец находится.
Уникальный индекс очень удобен для обеспечения целостности, так
как каждая запись идентифицируется однозначно. Нельзя создавать уникальный индекс по столбцу, который обязательно будет иметь повторяющиеся значения, (например, имя автора книг) или величину NULL.
Контрольные вопросы и упражнения
1) Для чего используется язык T-SQL?
2) Объясните назначение БД model.
3) Опишите процесс создания БД с использованием T-SQL.
4) С помощью какого оператора и при каких условиях производится
удаление БД?
5) Опишите процесс создания таблиц с использованием T-SQL.
6) С помощью какого оператора производится удаление таблицы из
БД? Приведите пример последовательности команд.
7) Приведите пример использования умолчания.
8) Опишите виды ограничений и процесс их создания в T-SQL.
9) Для чего используется индексирование? Какие бывают индексы?
10) Опишите процесс создания индексов с использованием T- SQL.
11) Для разработанной во второй главе логической модели БД создайте базу данных в MS SQL Server с использованием конструкций T-SQL.
64
ЧАСТЬ 2. ПРОГРАММИРОВАНИЕ В MS SQL SERVER. РАЗРАБОТКА КЛИЕНТСКОГО ПРИЛОЖЕНИЯ
65
Глава 5. ПРОГРАММИРОВАНИЕ В SQL SERVER
Данная глава посвящена различным методам создания запросов данных с помощью Transact-SQL, в том числе с дополнительными возможностями, упрощающими извлечение информации из баз данных. Но прежде
чем извлекать данные из таблиц, необходимо освоить варианты заполнения таблиц информацией.
5.1 Добавление данных в таблицу
Для того чтобы добавить новые записи в уже существующую таблицу БД, в Transact-SQL используется команда INSERT (лист. 5.1), которая
состоит из двух главных предложений – INSERT и VALUES.
Предложение INSERT служит для того, чтобы указать таблицу, в которую будут добавляться записи. Помимо этого, если не требуется добавлять значения во все столбцы новой записи, можно перечислить имена
столбцов, в которые предполагается добавление информации.
Предложение VALUES указывает данные, которые требуется добавить. VALUES – это обязательное ключевое слово, используемое для создания списка значений для каждого столбца, перечисленного в списке
столбцов или таблицы (если список столбцов отсутствует).
Листинг 5.1 Синтаксис команды INSERT
INSERT [INTO]
{<Имя столбца> | < Имя представления>
[(<Список колонок>)]
{DEFAULT VALUES | <Список значений> | <Выражение выборки>
Некоторые типы данных требуют использования связанного с ними
формата – например, символьные данные и даты необходимо вводить в кавычках (лист. 5.2).
Листинг 5.2 Ввод в таблицу Teacher информации о преподавателе
INSERT INTO Teacher
VALUES (‘Сергей’,’Петрович’,’Иванов’,’доцент’,’ИСП’)
В данном примере мы не использовали список колонок. Тот же пример можно переписать по-другому:
INSERT INTO Teacher
(T_name)
VALUES (‘Сергей’)
Предложение DEFAULT VALUES (лист. 5.3-5.4) добавляет запись,
которая будет содержать значения по умолчанию для каждого столбца.
При этом записи в столбце со свойством IDENTITY будет присвоено следующее подходящее значение. Для тех столбцов, которым присваиваются
значения по умолчанию, естественно, будут присвоены эти значения. Если
66
значения по умолчанию столбцам не присвоены, но записи не могут принимать значение NULL, будет возвращена ошибка, и команда INSERT не
выполнится.
Листинг 5.3 – Пример команды INSERT
INSERT INTO body DEFAULT VALUES
Слово DEFAULT встречается в синтаксисе команды INSERT INTO
еще в списке значений, когда при необходимости можно заменить им подставляемое значение. В этом случае для столбца типа timestamp, также как
и в случае с предложением DEFAULT VALUES, будет подставлено следующее значение, а вот поле со свойством IDENTITY вообще не позволяет заполнять данные с помощью ключевого слова DEFAULT. Столбцы со
свойством IDENTITY не следует перечислять в списке столбцов или в
списке значений. Значения для столбцов с подобным свойством не следует
использовать и в предложении INSERT.
Листинг 5.4 Пример использования
INSERT INTO body
(name_body)
VALUES (DEFAULT)
В команде INSERT может использоваться предложение SELECT,
которое позволяет добавлять записи из существующих таблиц (лист. 5.5).
Можно добавлять записи из той же таблицы.
Листинг 5.5 Синтаксис
INSERT <Имя таблицы>
SELECT <Список столбцов>
FROM <Список таблиц>
WHERE <Условие поиска>
В том случае, если вы используете SELECT, наборы столбцов таблицы, в которую добавляются данные, и результаты выборки должны совпадать по числу столбцов, порядку их следования, типам данных и длине.
Типы данных должны быть либо полностью совместимы, либо такими,
чтобы SQL Server смог их конвертировать. Если какое-либо имя столбца
пропущено, то вы должны быть уверены, что столбец имеет значение по
умолчанию, подставляемое значение или может принимать NULL. Команда INSERT SELECT, как правило, добавляет больше чем одну запись, в то
время как команда INSERT – только одну.
5.2 Выборка данных из таблицы
5.2.1 Простая форма оператора SELECT
Основа для любого запроса это таблицы, содержащие данные, необходимые для его выполнения. Следовательно, при написании запроса,
прежде всего, нужно выбрать таблицы, которые будут в нем использовать67
ся. Разработчик баз данных должен позаботиться о том, чтобы для выполнения запроса было задействовано как можно меньше таблиц. Включение
дополнительных таблиц может ухудшить производительность: для того
чтобы вернуть запрошенные данные, серверу приходится выполнять
больше работы, чем это необходимо.
Оператор SELECT состоит из трех обязательных фраз:
SELECT, FROM и WHERE.
Синтаксис оператора представлен в листинге 5.6.
Листинг 5.6 Краткий синтаксис оператора SELECT
SELECT список столбцов
FROM список таблиц
WHERE условия поиска
Первый элемент оператора SELECT определяет столбцы, значения
которых требуется получить. Директива FROM определяет таблицы, из
которых извлекаются столбцы, а WHERE – условие, задающее ограничение на отображение данных (лист. 5.7).
Листинг 5.7 Полный синтаксис оператора SELECT
SELECT [ALL|DISTINCT] [TOP n [PERCENT] [WITH TIES]]
список _ столбцов
[INTO имя _ новой _ таблицы]
[FROM
таблицы _ источники]
[WHERE условия поиска]
[GROUP BY [ALL] выражение _ группирования [,…n]
[WITH { CUBE | ROLLUP } ] ]
[HAVING условия _ поиска ]
[ORDER BY { имя _ столбца [ASC | DESC ]} [,...n] ]
[COMPUTE { { AVG | COUNT | MAX | MIN | SUM } (выражение) }
[,…n] [ BY выражение [,...n] ]
[ FOR BROUSE ] [OPTION (параметр _ запроса [,…n] ) ]
5.2.2 Отбор столбцов
Запрос SELECT * FROM имя_таблицы составляет основу любого
запроса. Оператор SELECT со звездочкой (*), введенный вместо параметра список_столбцов, возвращает все столбцы таблицы.
Чтобы перечислить только часть столбцов, нужно перечислить их
имена, разделив их запятыми. После последнего имени столбца запятая не
ставится (лист. 5.8).
Листинг 5.8 – Синтаксис запроса SELECT с отбором столбцов
SELECT <Имя столбца> {,<Имя столбца>…}
FROM <Имя _ таблицы>
68
5.2.3 Изменение заголовков столбцов
По умолчанию заголовками столбцов в итоговой выборке являются
их имена, которые присвоены им при создании таблицы. Можно изменить
заголовки столбцов, включив их в список выборки, используя два варианта
синтаксиса.
Первый – указать заголовки столбцов в списке выборки перед их
именами (лист. 5.9).
Листинг 5.9 Синтаксис изменения заголовков столбцов
SELECT <3аголовок столбца> = <Имя столбца> {,<Имя столбца>}
FROM <Имя таблицы>
Второй – указать заголовок столбца после его имени через пробел:
SELECT <Имя столбца> <3аголовок столбца> {,<Имя столбца>]
FROM <Имя таблицы>
Пример:
SELECT S_lastname Фамилия, S_name Имя, S_patronymic Отчество
FROM Student
Результат выборки:
Фамилия Имя
Отчество
----------- --------- ------------Андреев Андрей Александрович
Краснов Николай Дмитриевич
Петров
Петр
Петрович
Валентинов Николай Александрович
(4 row(s) affected)
5.2.4 Выражения в выборках
Ко всем числовым полям типа int, smallint, tinyint, float, real,
money и smallmoney можно применять арифметические операторы.
При работе с арифметическими операторами необходимо учитывать,
что:
они могут выполнять вычисления с числовыми столбцами или
числовыми константами;
остаток после деления целых чисел не может вычисляться для
столбцов с типом данных money, smallmoney, float или real.
Правила очередности выполнения арифметических операторов в
сложных выражениях осуществляется в соответствии с их приоритетом.
Приведем пример использования арифметических операторов (лист.
5.10), который выводит фамилию студента и соответствующую ему стипендию – без вычетов на взносы и с 20% вычетом.
Листинг 5.10 Синтаксис изменения заголовков столбцов
SELECT Фамилия = S_lastname, Стипендия = Money_size,
69
Стипендия c вычетом = Money_size – Money_size*0.2
FROM Student
GO
Результат выборки
Фамилия Стипендия Стипендия с вычетом
----------- --------- ------------------Андреев
7000
5600
Краснов
3000
2400
Петров
1000
800
Валентинов 1500
1200
(4 row(s) affected)
Не стоит спешить создавать собственную функцию – сначала надо
рассмотреть список встроенных математических функций Microsoft SQL
Server, который приводится в таблице 5.1. Возможно, там отыщется требуемая функция.
Таблица 5.1 Числовые функции MS SQL Server
Функция
ABS
ACOS, ASIN,
ATAN, ATN2
COS, SIN,
COT, TAN
Типы аргументов
Число
CEILING
Число
DEGRESS
EXP
Число
Число с плавающей запятой
FLOOR
Число
LOG
LOG10
PI
POWER
RADIANS
Число с плавающей запятой
Число с плавающей запятой
Заданное число
Число, Y(число)
Число
RAND
Аргумент необязателен
ROUND
Число, количество цифр
SIGN
Число
SQRT
Число с плавающей запятой
Число с плавающей запятой
Число с плавающей запятой
(в радианах)
70
Результат
Абсолютное значение
Обратные косинус, синус и тангенс.
Возвращают угол в радианах
Косинус, синус, котангенс или тангенс угла
Наименьшее целое число, которое
больше или равно указанному аргументу
Преобразование из радиан в градусы
Экспонента от аргумента
Наибольшее целое, которое меньше
или равно указанному аргументу
Натуральный логарифм аргумента
Десятичный логарифм аргумента
Константа 3.141592653589793
Возвращает аргумент в степени Y
Преобразует из градусов в радианы
Возвращает случайное число с плавающей запятой в диапазоне от 0 до
1. Можно использовать с параметром
Число округляет до указанного количества цифр после запятой
Возвращает знак числа (положительно, отрицательно или ноль)
Квадратный корень от числа
В качестве примера приведем выборку, которая округляет значение
вычета из стипендии с точностью до одного знака после запятой (лист.
5.11).
Листинг 5.11 – Пример выборки с округлением значений
SELECT Стипендия = Money_size,
Стипендия = ROUND (Money_size* 0. 22,2)
FROM Student
Большинство строковых функций могут быть использованы только с
типами данных char и varchar (или с типами данных, которые легко конвертируются в char и varchar). При использовании строковых констант в
качестве аргументов строковых функций требуется заключать их в кавычки (лист. 5.12).
Листинг 5.12 Синтаксис строковых функций:
SELECT <Имя функции (параметры)>
В таблице 5.2 приводится список строковых функций с требуемыми
аргументами и возвращаемые ими значения.
Таблица 5.2 Строковые функции MS SQL Server
Функция
+
ASCII
CHAR
CHARINDEX
DIFFERENCE
LOWER
LTRIM
PATINDEX
REPLICATE
REVERSE
RIGHT
RTRIM
SOUNDEX
SPACE
STR
Типы аргументов
Строка плюс строка
Строка
Результат
Объединяет две строки (столбцы)
ASCII-код самого левого символа
Символьный эквивалент ASCII-кода переЦелое число
данного в качестве аргумента
Возвращает начальную позицию шаблона
Шаблон, строка
внутри строки (второго параметра)
Выясняет степень схожести строк, возвраСтрока 1, Строка 2
щая значение от 0 до 4. Число 4 означает
полное совпадение
Строка
Переводит выражение в нижний регистр
Возвращает выражение без начальных
Строка
пробелов
Возвращает позицию первого вхождения
Шаблон, строка
шаблона в строку (О, если шаблон не
найден)
Строка, целое число
Повторяет строку указанное число раз
Возвращает строку «задом наперед»
Строка
Часть строки, начиная с указанной позиСтрока, целое число
ции
Строка
Строка без пробелов сначала и в конце
Возвращает код из четырех цифр, указыСтрока, строка
вающий схожесть двух строк
Возвращает строку с указанным числом
Целое число
пробелов. Если число отрицательное, возвращается нулевая строка
Число с плавающей за- Возвращает символьное представление
пятой, длина (целое числа. Параметр «длина» указывает об71
Функция
STUFF
SUBSTRING
UPPER
Типы аргументов
Результат
число), количество де- щую длину получаемого выражения,
сятичных знаков (целое включая десятичный разделитель, знак,
число)
цифры и пробелы. Аргумент «количество
десятичных знаков» указывает количество
знаков после запятой
Строка 1, начальная Удаляет число знаков, равное параметру
позиция (целое число), «длина» из строки 1, начиная с начальной
длина (целое число), позиции. Затем заменяет удаленные знаки
строка 2
строкой 2
Строка, начальная по- Возвращает часть (указанной длины) строзиция (целое число), ки от начальной позиции
длина (целое число)
Переводит символы из нижнего регистра в
Строка
верхний
Особого отношения к себе требуют столбцы типа datetime. Для манипуляций с данным типом используются специальные функции (таблица
5.3).
Таблица 5.3 Функции для работы с датами Microsoft SQL Server
Функция
DATEADD
DATEDIFF
Типы аргументов
Часть даты, число, дата
Часть даты, дата 1, дата 2
DATENAME
Часть даты, дата
DATEPART
Часть даты, дата
Результат
Добавляет число частей даты к дате
Число частей даты между двумя датами
Возвращает ASCI (-значение части даты
для выбранной даты (например, May)
Возвращает числовое значение (например, 5) части даты для выбранной даты
Возвращает текущее время и дату во
внутреннем формате SQL Server
GETDATE
При использовании технологии «клиент-сервер» количество передаваемых по сети данных очень сильно влияет на производительность. Идеальный способ обработки данных – использование хранимых процедур,
когда приложение обменивается с сервером только параметрами и результатами. Но это не всегда возможно, а часто и не нужно потому, что просмотр пользователем информации тоже имеет значение.
Основная забота программиста – построение предложения WHERE.
Оно может включать в себя операторы, перечисленные в таблице 5.4.
При построении условий поиска необходимо помнить, что оптимизатор запросов не может работать с отрицанием, например NOT BETWEEN.
Поэтому хорошим стилем является стремление избегать операторов отрицания.
72
Таблица 5.4 Операторы, используемые в предложении WHERE
Тип операторов
Сравнение
Интервал
Список
Сравнение строк
Проверка значения
Логические
Отрицание
Операторы
(=, >, <, >=, <=, <>, !=, !<, !>)
BETWEEN, NOT BETWEEN
IN, NOT IN
LIKE, NOT LIKE
IS NULL, IS NOT NULL
AND, OR
NOT
При использовании операторов сравнения необходимо придерживаться двух простых правил:
выражения могут содержать константы, имена столбцов, функции,
вложенные запросы и арифметические операторы;
использовать одинарные кавычки с данными типа char, varchar,
text, datetime и smalldatetime; хотя двойные кавычки не запрещены, одинарные кавычки предпочтительней для совместимости со стандартом
ANSI.
Часто требуется просмотреть данные в их отношении друг к другу.
Microsoft SQL Server предоставляет для этой цели операторы сравнения.
В большинстве диалектов операторы сравнения ограничиваются набором,
представленным в таблице 5.5.
Таблица 5.5 Операторы сравнения
Оператор
=
>
<
>=
<=
!=
<>
Значение
Равно
Больше чем
Меньше чем
Не меньше
Не больше
Не равно
Не равно
Обычно операторы сравнения используются для работы с числами.
Но в SQL можно их использовать и с типами char и varchar: тогда знак
“<” значит раньше по алфавиту, а “>” – позже.
Кроме того, операторы сравнения можно использовать для дат. Как
уже отмечалось, при работе с этими типами данных главное – не забыть
поставить вокруг выражений одинарные кавычки.
Обычно в предложении WHERE приходится использовать несколько условий поиска, которые объединяются логическими операторами
AND, OR, NOT (их еще называют булевыми операторами). Смысл этих
операторов такой же, как и во всех языках программирования: AND – это
логическое И, a OR – ИЛИ.
В качестве примера рассмотрим запрос, в котором производится поиск преподавателей, следующих за фамилией «Иванов» и до фамилии
«Сидоров» (лист. 5.13).
73
Листинг 5.13 – Пример запроса «Поиск преподавателей»
SELECT Фамилии преподавателей = T_lastname
FROM Teacher
WHERE T_lastname >= ‘Иванов’ AND T_lastname <= ‘Сидоров’
Этот же запрос можно сформировать по-другому, используя оператор BETWEEN:
SELECT Фамилии преподавателей = T_lastname
FROM Teacher
WHERE T_lastname BETWEEN ‘Иванов’ AND ‘Сидоров’
Результат выборки:
Фамилии преподавателей
------------------Иванов
Гаечкин
Сапрыкин
Братчиков
Семенов
Ястребов
Хвостенко
(7 row(s) affected)
5.2.6 Ассоциативные условия отбора
При выборке символьных данных иногда возникают трудноразрешимые вопросы, связанные с тем, что мы не всегда можем точно вспомнить какую-либо информацию. В этом случае на помощь приходит оператор LIKE (лист. 5.14).
Листинг 5.14 Синтаксис оператора LIKE
WHERE <Имя столбца> [NOT] LIKE < 'Шаблон' > [ESCAPE <Символ>]
Шаблон должен быть заключен в кавычки и включать знаки подстановки. Опция ESCAPE используется в том редком случае, когда поисковое
значение включает в себя один из знаков подстановки и необходимо рассматривать его буквально. ANSI SQL обеспечивает два знака подстановки
для LIKE: процент «%» и подчеркивание «_».
Знак «%» заменяет собой строку из нуля и более символов, а знак
«_» – только один символ.
В некоторых SQL-диалектах, в том числе и Transact-SQL, поддерживаются ещё два вида подстановки – скобки «[]», показывающие, что
символ должен лежать в указанном списке, и «[^]», показывающие, что
символ не должен принадлежать диапазону.
74
Например, необходимо отобрать фамилии, которые начинаются на
буквы «С» или «Я», но в то же время вторая буква не должна быть «а», то
достаточно сформировать запрос, представленный в листинге 5.15.
Листинг 5.15 – Пример запроса с оператором LIKE
SELECT T_lastname
FROM Teacher
WHERE T_lastname LIKE ‘[СЯ] [^а]%’
Результат выборки:
T_lastname
------------------Семенов
Ястребов
(2 row(s) affected)
5.2.7 Порядок вывода данных
Для вывода данных, отсортированных по какому-либо столбцу, используется ключевое слово ORDER BY. Результат выборки можно отсортировать одновременно по 16 столбцам. В Transact-SQL в предложение
ORDER BY можно включать столбцы или выражения, отсутствующие в
списке выборки. Сортировать можно по именам столбцов, по заголовкам
столбцов, по выражению или по номеру, указывающему позицию столбца
в списке выборки. При сортировке по номеру столбца необходимо указывать тот номер, который реально присутствует в списке выборки. То есть
если в списке выборки два столбца, а необходимо отсортировать по третьему, то произойдет ошибка. При использовании в запросе ключевого слова
COMPUTE BY обязательно необходимо проводить сортировку с помощью предложения ORDER BY.
Нужно помнить, что значение NULL при сортировке выводится
раньше всех других. Столбцы типа text и image использовать в предложении ORDER BY нельзя. Подзапросы и представления не могут включать
предложения ORDER BY, COMPUTE BY или ключевое слово INTO.
Самое главное, для чего предназначено предложение ORDER BY, –
сделать результаты выборки более удобными для восприятия. Порядок
сортировки зависит от используемого набора символов и кодовой страницы.
Рассмотрим один из приведенных выше запросов. Следующий запрос выводит имена, фамилии, имена и отчества студентов, но уже в отсортированном виде, причем сортировка проводится сразу по 3 колонкам,
представлен в листинге 5.16.
Листинг 5.16 – Пример запроса с сортировкой
SELECT 'Студент:'+space(1), S_lastname Фамилия, S_name Имя,
S_patronymic Отчество
75
FROM Student
ORDER BY S_lastname, S_name, S_patronymic
Результаты выборки:
Фамилия Имя
Отчество
--------- ----------- --------- ------------Студент: Ткаченко Татьяна Александровна
Студент: Белышев Виталий Леонидович
Студент: Попов
Ярослав Петрович
Студент: Шевченко Дмитрий Николаевич
Студент: Строчинская Оксана Александровна
(5 row(s) affected)
По умолчанию сортировка производится по возрастанию. Если нужна сортировка в обратном порядке, можно воспользоваться опцией DESC
предложения ORDER BY. Например, если в предыдущем запросе в предложении ORDER BY будет добавлена опция DESC, то выборка будет отсортирована в обратном алфавитному порядке (лист. 5.17).
Листинг 5.17 – Пример запроса с сортировкой в обратном порядке
SELECT 'Студент:'+space(1), S_lastname Фамилия, S_name Имя,
S_patronymic Отчество
FROM Student
ORDER BY S_lastname, S_name, S_patronymic DESC
5.2.8 Группировка данных с помощью функций агрегирования
Функциями агрегирования называются функции, которые используются для получения суммарных значений. Они применяются ко: всем
записям в таблице; только тем записям, которые выбираются в предложении WHERE; группам записей, созданным с помощью предложения
GROUP BY (см. ниже). Неважно, как создаются наборы записей, – в любом случае будет получено одно значение для каждого набора.
Функции агрегирования всегда требуют аргумента. Аргумент является выражением и заключается в скобки (лист. 5.18).
Листинг 5.18 – Синтаксис функций агрегирования
<Функция агрегирования> ([DISTINCT] <Выражение>)
Выражением, как правило, является столбец, но это может быть константа, функция, комбинация имён столбцов, констант, функций, объединенных арифметическими операторами. В таблице 5.6 перечислены все
функции агрегирования, доступные в SQL Server.
Опцию DISTINCT можно использовать со всеми функциями, кроме
COUNT(*). Однако нет смысла использовать её с такими функциями, как
МАХ или MIN. Схожесть COUNT и COUNT(*) может привести к неожиданным казусам. Однако следует помнить, что COUNT принимает в рас76
чет все не-NULL значения аргумента, в то время как COUNT(*) подсчитывает все записи.
Таблица 5.6 Функции агрегирования SQL Server
Функция
AVG
COUNT
COUNT_BIG
GROUPING
MAX
MIN
STDEV
STDEVP
SUM
VAR
VARP
Результат
Возвращает среднее арифметическое для значений выражения; nullзначения игнорируются
Возвращает количество элементов в выражении (равное количеству
строк)
То же самое, что и COUNT, но результат имеет тип данных Bigint, а
не Int
Возвращает специальную дополнительную колонку; применяется,
только когда предложение GROUP BY содержит операцию CUBE
или ROLLUP.
Возвращает наибольшее значение из значений выражения
Возвращает наименьшее значение из значений выражения
Возвращает статистическое стандартное отклонение для всех величин выражения. Эта функция предполагает, что выражения, используемые в расчёте, являются образцом всей совокупности данных
Возвращает статистическое стандартное отклонение для всех величин выражения. Эта функция предполагает, что выражения, используемые в расчёте, являются всей совокупностью данных
Возвращает сумму всех значений в выражении (либо по всем записям, либо только по уникальным)
Возвращает статистическое отклонение для всех значений выражения. Эта функция предполагает, что выражения, используемые в
расчёте, являются образцом всей совокупности данных
Возвращает статистическое отклонение для всех значений выражения. Эта функция предполагает, что выражения, используемые в
расчёте, являются всей совокупностью данных
Функции SUM и AVG могут использоваться только с числовыми
выражениями. Остальные функции можно применять с выражениями любого типа.
Использование опции DISTINCT позволяет не учитывать дублирующие друг друга значения из выборки перед применением функций SUM,
AVG, COUNT.
Использовать функции агрегирования в предложении WHERE нельзя. Тем не менее, можно задействовать предложение WHERE для выбора
необходимых записей.
SELECT AVG (Summa)
FROM Account
WHERE Date_write >= 1/1/96' AND Date_write < 4/1/97'
5.2.9 Группировка данных
При подготовке сложных выборок, которые включают несколько
столбцов, не обойтись без группировки данных. Для группировки данных
в команде SELECT используется опция GROUP BY (лист. 5.20).
77
Листинг 5.20 – Синтаксис запроса с оператором GROUP BY
GROUP BY [ALL] <Условие группировки l> {,<Условие группировки
2>]. ..
[, <Условие группировки 3>] [WITH {CUBE | ROLLUP}]
При группировке данных обычно подсчитываются какие-либо результирующие для данной группы значения. Поэтому группировка данных
обычно сопровождается использованием функций агрегирования.
В некоторых диалектах SQL каждый элемент в списке GROUP BY
должен обязательно присутствовать в списке выборки – другими словами,
группировать можно только по тому, что выбрали. В Transact-SQL такого
строгого ограничения нет. В то же время в Transact-SQL группировать
можно только по именам столбцов и по выражениям. Можно группировать
данные внутри групп. Каждый элемент группы надо отделять друг от друга
запятой и располагать их по порядку от большей группы к меньшей.
Например, вопрос, встречается ли в списке групп студентов, название специальности соответствующее этой группе несколько раз, решается с помощью следующего запроса, представленного в листинге 5.21.
Листинг 5.21 – Пример запроса с оператором GROUP BY
SELECT P_name, COUNT(P_name)
FROM Groups
GROUP BY P_name
Результат выборки:
P_name
------------ ---программисты 3
механики 2
схемотехники 1
(3 row(s) affected)
Иногда требуется расширить функциональность запросов и придать
им черты генераторов отчетов. Для этого используется предложение
COMPUTE. Решим следующую задачу: необходимо получить список
названий специальностей и количество групп, обучающихся по этим специальностям (лист. 5.22).
Листинг 5.22 – Пример запроса с оператором COMPUTE
SELECT P_name, G_number
FROM Groups
ORDER BY P_name, G_number
COMPUTE COUNT(G_number) BY P_name
Результат выборки:
P_name G_number
----------- --------78
механики 03-M-61
механики 03-M-62
count
=========
2
P_name
G_number
------------ --------программисты 03-ПО-21
программисты 03-ПО-22
программисты 03-ПО-23
count
=========
3
P_name
G_number
------------ --------схемотехники 03-KT-11
count
=========
1
(8 row(s) affected)
Как видно, результат выборки теперь отличается от реляционного, и
его нельзя использовать для дальнейших выборок. Но в тех случаях, когда
необходимы выборки, напоминающие отчет, можно воспользоваться предложением COMPUTE. Предложение COMPUTE, так же как и GROUP
BY, не может работать с заголовками столбцов. Если использовать
COMPUTE без опции BY, то получаем не промежуточный итог для группы, а общий итог для всей таблицы. При этом надо помнить, что использование COMPUTE с опцией BY обязательно требует предложения ORDER
BY. При этом есть существенные ограничения на столбцы, перечисляемые
в ORDER BY. Если ORDER BY содержит несколько столбцов, и необходимо все их использовать в COMPUTE BY, то надо перечислять их именно в том порядке, как они расположены в ORDER BY. Если требуется задействовать не все столбцы из списка сортировки, то нельзя, например,
пропустив первый, указать второй и третий и т. д. GROUP BY без функций агрегирования ведет себя как DISTINCT. Он разделяет таблицу на
группы (по значению) и возвращает одну запись для каждой группы (с
одинаковым значением группировки).
При использовании GROUP BY с предложением WHERE необходимо помнить о последовательности выполнения операций. Вначале предложение WHERE фильтрует данные, а затем, из оставшихся записей,
GROUP BY создает наборы. Те записи, которые не будут отобраны
WHERE, не попадут ни в одну группу.
При использовании GROUP BY никакой сортировки не происходит.
Для того чтобы отсортировать полученные данные в нужном порядке, ис79
пользуйте ORDER BY. Однако здесь есть одно существенное «но». Предложение GROUP BY должно обязательно находиться перед предложением
ORDER BY.
5.2.10 Опции CUBE и ROLLUP
Опция CUBE используется для получения при группировке данных
дополнительных строк в результате. Столбцы, включенные в опцию
GROUP BY, образуют перекрестную таблицу, что позволяет получить дополнительные группы. Если для этих столбцов используются функции агрегирования (обычно суммирование), то мы получаем дополнительные
рассчитываемые значения. Число дополнительных групп определяется
числом столбцов, включенных в опцию GROUP BY.
Опция CUBE может использоваться со всеми функциями агрегирования, включая AVG, SUM, МАХ, MIN и COUNT.
Опция ROLLUP используется для однонаправленного перебора всех
столбцов, используемых для агрегирования данных. Опция CUBE перебирает все варианты сочетаний столбцов. Например, при перечислении трех
столбцов в опции GROUP BY получим 3*3 – 1 = 8 групп. При использовании опции ROLLUP в результате будут только четыре группы, так как перебраны они будут только в одном направлении без образования полного
сочетания.
Опция CUBE часто используется при подготовке данных для отчетов, графиков или диаграмм.
Не используйте совместно с опциями CUBE или ROLLUP предложение GROUP BY ALL.
5.2.11 Отбор данных для групп
Для отбора в группы только некоторых данных в команде SELECT
используется предложение HAVING. Если охарактеризовать его самыми
общими словами, то его можно назвать «WHERE для групп». Так же как
WHERE фильтрует записи, HAVING фильтрует группы. Таким образом,
вместе с опцией GROUP BY чаще используют опцию HAVING. Есть существенное отличие между HAVING и WHERE: можно включать функции агрегирования в предложение HAVING, но не в предложение
WHERE (лист. 5.23).
Листинг 5.23 – Пример запроса с оператором HAVING
SELECT G_namber, COUNT (*)
FROM Groups
GROUP BY G_namber
HAVING COUNT (*) > 1
5.3 Выборка данных из нескольких таблиц
80
5.3.1 Объединение с помощью предложения WHERE
Объединять таблицы можно с помощью предложения WHERE.
Пример объединения, в котором выводится фамилия студента вместе с
названием специальности, на которой он обучается, представлен в листинге 5.24.
Листинг 5.24 – Пример выборки из нескольких таблиц
SELECT Student.S_lastname, Groups.P_name
FROM Groups, Student
WHERE Student.G_number = Groups.G_number
Результат выборки:
S_lastname P_name
----------- ------Ткаченко Программисты
Белышев Механики
Попов Программисты
Шевченко Схемотехники
(5 row(s) affected)
Как видно из примера, для того чтобы связать две таблицы, мы использовали два столбца, по одному из каждой таблицы. Их можно назвать
связующими столбцами. Связующие столбцы должны иметь значения, которые могут легко сравниваться друг с другом, то есть иметь один и тот же
(или похожий) тип данных. В предыдущем примере у связующих столбцов
совпадает все, вплоть до названий. Общий синтаксис объединения представлен в листинге 5.25.
Листинг 5.25 – Синтаксис объединения
SELECT < Список столбцов>
FROM <Имя таблицы 1>, <Имя таблицы 2> [, <Имя таблицы
3>].....
WHERE [<Имя таблицы 1>.]<Имя столбца> <Оператор объединения> [<Имя таблицы 2>.]<Имя столбца>
Предложение FROM должно включать, по крайней мере, две таблицы, а столбцы, указанные в предложении WHERE, должны быть совместимы. Когда столбцы объединения имеют одинаковые имена, необходимо
указать перед ними названия таблиц с точкой, для того чтобы их можно
было различить.
Обычно при связывании двух или более таблиц используют оператор
«=», но можно задействовать и другие операторы. В таблице 5.7 приводятся операторы, которые можно использовать для связи таблиц.
81
Таблица 5.7 Операторы связывания таблиц
Символ
=
>
<
>=
<=
!=, <>
!>
!<
=*
*=
Значение
Равно
Больше чем
Меньше чем
Не меньше
Не больше
Не равно
Не больше чем
Не меньше чем
Внешнее правое соединение
Внешнее левое соединение
5.3.2 Внутреннее объединение
В некоторых случаях необходимо объединить те или иные записи
таблицы с другими записями той же таблицы. Такое объединение проще
представить как объединение двух копий таблиц. По сути, запрос такого
рода ничем не отличается от других многотабличных запросов, за исключением того, что таблицы абсолютно идентичны. Для того чтобы различать поля в копиях (на самом деле никаких копий не создается, но так понятнее), можно воспользоваться временными именами, которые присваивают в предложении FROM. Их чаще называют псевдонимами, но иногда
они имеют название «переменная диапазона» или «переменная корреляции». В предложении FROM имя таблицы от псевдонима отделяется пробелом.
5.3.3 Внешнее объединение
Если обратиться к таблице 5.7, то рядом с тривиальными операторами там присутствуют два оператора со звездочками (=* и *=). С их помощью создаются внешние объединения. Внешние объединения позволяют
ограничить выборку из одной таблицы, но выбрать все записи из другой
таблицы, как бы отключив для нее условия связи. Приведем пример, когда
такое объединение может быть полезно. Представим, что в таблице Student
хранятся данные обо всех имеющихся студентах, а в таблице Student_c
хранятся данные о студентах, обучающихся на коммерческой основе. В результате будут отобраны из таблицы Student все студенты, занимающиеся
на коммерческой основе (лист. 5.26).
Листинг 5.26 – Пример с внешним объединением
SELECT S_lastname, P_name
FROM Student, Student_c
WHERE Student.S_Lastname =* Student_c.Lastname
Результаты выборки:
S_lastname P_name
----------- ------82
Ткаченко Программисты
Попов
Механики
(3 row(s) affected)
Внешние объединения могут быть созданы только для двух таблиц.
При этом нельзя использовать функцию ISNULL в качестве критерия поиска для внутренней таблицы (таблицы, для которой работают ограничения). Оператор «*= » включает все записи из первой (левой) таблицы, невзирая на ограничения. В свою очередь, оператор «=*» аналогично работает с записями из второй (правой) таблицы.
5.3.4 Объединение и опция JOIN
В SQL Server для объединения таблиц можно использовать опцию
JOIN. Этот способ имеет ряд неоспоримых преимуществ.
Сравните два варианта написания запроса, которые приведут к совершенно одинаковому результату (лист. 5.27-5.28).
Листинг 5.27 Использование опции WHERE
SELECT S_lastname, G_number
FROM Gtudent M, Student_c A
WHERE A.S_lastname = M.Lastname
GROUP BY S_lastname
Листинг 5.28 Использование синтаксиса ANSI-92 (опции JOIN)
SELECT S_lastname, G_number
FROM Student M JOIN Student_c A ON A.S_lastname = M.lastname
GROUP BY S_lastname
ANSI-92 позволяет объединять в одном запросе до 16 таблиц. Соответственно, если вы решились объединить данные из максимально возможного количества таблиц, вам придется указать 15 условий объединения, то есть 15 предложений JOIN.
5.3.5 Подзапросы
Запросы на выборку могут быть вложены внутрь других запросов.
Вложенные запросы обычно называются подзапросами. Так как вложенные запросы могут выбирать данные из других таблиц, то запросы, использующие подзапросы, могут зачастую дать те же результаты, что и использование многотабличных запросов.
Когда выражение выборки вложено внутрь другой команды
SELECT, то внутренний запрос выполняется первым. Если подзапрос возвращает одно значение, то его можно использовать везде, где требуется
сравнить одно значение с другим. Если подзапрос возвращает много значений, то его можно использовать только в предложении WHERE.
83
Оператор EXISTS оценивает выборку на фактор существования:
есть ли указанные записи или нет. Оператору EXISTS не должно предшествовать имя столбца, константы или другого выражения. Список выборки
подзапроса, который обрабатывается с помощью EXISTS, всегда состоит
из звездочки, то есть включает в себя все поля. Предложение WHERE
проверяет факт существования выбранных записей. Таким образом, подзапрос не должен выводить записей, он должен просто вернуть значение
TRUE или FALSE (лист. 5.29).
Листинг 5.29 Подзапрос c применением EXISTS
SELECT Student_c.Lastname Фамилия, Money_size Стипендия
FROM Student_c
WHERE EXISTS
(SELECT S_lastname
FROM Student
WHERE Money_size > 1000)
Результат выборки:
Фамилия Стипендия
----------- --------Ткаченко 7000
Попов 3000
Шевченко 1500
(4 row(s) affected)
5.3.6 Создание таблиц на основе выборки
Команда SELECT с оператором INTO позволяет определить таблицу и добавить в неё данные без использования команды CREATE TABLE.
Команда SELECT INTO создает новую таблицу (лист. 5.30-5.31), опираясь на результаты запроса. В случае если таблица с таким именем уже существует, команда заканчивается неудачно и генерируется системное сообщение. Новая таблица создается со столбцами, которые указаны в списке выборки.
Листинг 5.30 Синтаксис запроса для создания таблиц
SELECT <Список столбцов>
INTO <Имя новой таблицы>
FROM <Список таблиц>
WHERE <Условие поиска>
При использовании данной команды необходимо учесть следующие
факторы:
новая таблица создастся в результате выполнения команды
SELECT INTO только в том случае, если включена опция базы данных
select into/bulkcopy;
84
даже если эта опция не установлена, можно копировать данные
во временную таблицу; временные таблицы обозначаются с помощью знака номера (#) в качестве первого символа имени таблицы или двух подобных знаков, если создается глобальная временная таблица;
если требуется добавить записи в уже существующую таблицу,
то используется команда INSERT;
если не используются заголовки столбцов в списке выборки, то
столбцы в новой таблице также не будут иметь названий; обращаться к
столбцам, не имеющим названий, можно только с помощью запросов
SELECT * FROM <Имя та6лицы>;
добавляемые записи не заносятся в журнал транзакций;
новые названия столбцов не должны содержать пробелов;
у пользователя должно быть разрешение на создание таблиц в текущей базе данных;
нельзя создать таблицу на основе запроса, использующего
COMPUTE, или внутри пользовательской транзакции.
Листинг 5.31 Создание таблицы на основании данных из двух таблиц
SELECT ИМЯ = S_firstname, ФАМИЛИЯ = S_lastname,
СПЕЦИАЛЬНОСТЬ = P_name
INTO #SPbReport
FROM Student, Student_c
WHERE Student.S_lastname = Student_c.Lastname
5.3.7 Объединение выборок
Оператор UNION позволяет объединить в одну выборку результаты
нескольких выборок (увеличивая количество записей). При работе с оператором UNION необходимо помнить, что он удаляет дублирующие значения. Если вам необходимы все записи, используйте оператор ALL сразу за
оператором UNION. Все списки выборки должны совпадать по количеству, а соответствующие элементы выборок (столбцы, константы, выражения) по типу и по номеру в списке. Имена столбцов в любом случае определяются в первой команде SELECT. В том случае, если во второй выборке не хватает столбцов, подставляйте вместо них константы (лист. 5.32).
Листинг 5.32 – Пример запроса с UNION
SELECT S_firstname, S_lastname
FROM Student
UNION ALL
SELECT Firstname, Lastname
FROM Student_c
85
5.4 Изменение данных в таблице
Для модификации данных в SQL Server используется команда
UPDATE (лист. 5.33).
Листинг 5.33 Синтаксис оператора UPDATE
UPDATE {<Имя таблицы> | <Имя представления>}
SET [{<Имя таблицы> | <Имя представления>}]
{<Список столбцов>
| <Список переменных>
| <Список переменных или столбцов>}
[, {<Список столбцов 2>
| <Список переменных 2>
| <Список переменных или столбцов 2>}
…
[, { <Список столбцов N>
| <Список переменных N>
| <Список переменных или столбцов N>}]]
[WHERE <Опция>]
SET указывает столбцы, которые будут изменяться, и значения, которые им присваиваются. С помощью предложения WHERE отбираются
записи, которые будут обновляться. Команда UPDATE не может вставить
в колонку данные «чужого» типа либо значения, которые нарушают правила ввода для столбца. В случае неудачи хотя бы с одним столбцом изменения произведены не будут.
Допустим, в таблице Teacher задано количество проработанных преподавателем лет и требуется увеличить его на 1 (лист. 5.34).
Листинг 5.34 – Пример использования запроса с UPDATE
UPDATE Teacher
SET Num_year = Num_year +1
Если требуется уменьшить стаж работы преподавателей, звание
которых «профессор», то:
UPDATE Teacher
SET Num_year = Num_year -2
WHERE Zvanie = ’профессор’
Значения столбцов в таблице могут изменяться на основании данных, которые хранятся в других таблицах. Для этого служит предложение
FROM, которое является расширением стандарта SQL. Для каждой записи
в таблице, которая должна быть обновлена, производится проверка на критерий, указанный в предложении WHERE (лист. 5.35).
Листинг 5.35 Синтаксис команды UPDATE с предложением FROM
UPDATE {<Имя таблицы> | <Имя представления>}
86
SET [{<Имя таблицы> | <Имя представления>}]
{<Список столбцов>
| <Список переменных>
| <Список переменных или столбцов>}
[, {<Список столбцов 2>
| <Список переменных 2>
| <Список переменных или столбцов 2>}
…
[, { <Список столбцов N>
| <Список переменных N>
| <Список переменных или столбцов N>}]]
[FROM {<Имя таблицы> | <Имя представления>}
[, {<Имя таблицы> | <Имя представления>}]…]
[…, {<Имя таблицы 16> | <Имя представления 16>}]]
[WHERE <Опция>]
Ниже приводится пример запроса с предложением FROM в команде
UPDATE по выбору из таблицы Student имен, фамилий и отчеств студентов группы 03-КТ-22. Для этого требуется создать новую таблицу
St_03КТ22 (лист. 5.36).
Листинг 5.36 – Пример команды UPDATE с предложением FROM
CREATE TABLE St_03КТ22
-- создается таблица
(Name char, Patronymic char, Lastname char, Group char)
INSERT St_03КТ22
-- заполняется данными
SELECT Student.S_Name, Student.S_Patronymic, Student.S_Lastname
FROM Student
-- идёт обновление информации
UPDATE St_03КТ22
SET Group = (SELECT G_name
FROM Student
WHERE Student.G_name = ‘03-КТ-22’)
5.5 Удаление данных из таблицы
Для того чтобы удалить одну или несколько записей, в T-SQL используется команда DELETE (лист. 5.37).
Листинг 5.37 Синтаксис оператора DELETE
DELETE [FROM] {<Имя таблицы> | <Имя представления>}
[WHERE <Условия>]
Если не указать в предложении WHERE условие отбора, будут удалены все записи таблицы! Если, например, необходимо удалить из таблицы записи преподавателей кафедры ИСП (лист. 5.38).
Листинг 5.38 – Пример удаления записей
DELETE Teacher
87
WHERE K_name = ‘ИСП’
Кроме этого, существует расширение команды DELETE с помощью
предложения FROM:
DELETE [FROM] {<Имя таблицы> | <Имя представления>}
[FROM {<Имя таблицы> | <Имя представления>}
[, {<Имя таблицы n> | <Имя представления n>}]…]
[…, {<Имя таблицы 16> | <Имя представления 16>}]]
[WHERE <Условия>]
Не подумайте, что мы ошиблись, написав одно и то же перед FROM
и после него. В первом случае подразумевается, что сравнивается какое-то
поле с набором данных, независимых от исходной таблицы. Во втором
случае непосредственно связываются столбцы исходной таблицы со
столбцами других таблиц.
5.6 Представления
Представление — это обычный запрос SELECT, имеющий имя и
хранящийся в Microsoft SQL Server. Представления, подобно виртуальным таблицам, имеют ряд преимуществ.
С помощью представлений разработчики могут обеспечить стандартный способ выполнения запросов: нужно лишь один раз написать
наиболее частые запросы как представления, а затем включать эти представления в код приложения. Таким образом, во всех приложениях будет
одна и та же версия запроса.
Представления также выполняют функции механизма безопасности:
пользователям можно предоставить доступ только к подмножеству данных
в таблицах, лежащих в основе представления.
Представления позволяют отобразить данные в базе данных в более
логичном, удобном для пользователей виде. Кроме того, использование
индексированных представлений существенно повышает производительность, особенно некоторых типов сложных запросов.
Большинство представлений разрешает только чтение базовых данных, но также можно создавать обновляемые представления, которые поддерживают модификации данных.
Для создания представлений на основании одной или нескольких
таблиц служит инструкция Transact-SQL CREATE VIEW (лист. 5.39).
Листинг 5.39 Синтаксис создания представления
CREATE VIEW [ имя_схемы . ] имя_представления [ (столбец [ ,
. . п ] ) ] [ WITH <атрибут_представления> [ ,...п ] ] AS конструкция
_ select [ ; ] [ WITH CHECK OPTION ]
<view_attribute> : . =
{
[
ENCRYPTION ]
[
SCHEMABINDING ]
88
[
VIEW_METADATA ]
}
Сначала нужно указать имя представления. Его имя, как и имена
других объектов, должно соответствовать правилам для идентификаторов.
Первое предложение команды, WITH, позволяет задать для представления три различных параметра: ENCRYPTION, SCHEMABINDING
и VIEW_METADATA. С помощью параметра ENCRYPTION можно задать шифрование определения представления при его сохранении в базе
данных.
Определение зашифрованного представления не видно никому, в том
числе членам фиксированной серверной роли sysadmin. Поэтому при
шифровании представления нужно обязательно убедиться в том, что у вас
есть копия исходного кода, так как дешифровать определение невозможно.
Установка параметра SCHEMABINDING запрещает удаление таблиц, представлений или функций, на которые ссылается представление,
прежде чем оно будет удалено.
Контрольные вопросы и упражнения
1)
Понятие выборки. Где и для каких целей применяется выбор-
ка?
2)
Из каких основных фраз состоит команда, осуществляющая
выборку? Перечислить и указать их функциональное назначение.
3)
Как просмотреть результаты выборки?
4)
Как определить заголовок столбца при выборке?
5)
Перечислить четыре основных вида функций SQL Server.
6)
Перечислить операторы, которые могут применяться в предложении WHERE, определить их функциональную значимость.
7)
Понятие ассоциативных условий, перечислить операторы,
применяемые для построения ассоциативных условий отбора.
8)
Какое предложение применяется для сортировки данных выборки, условия его применения?
9)
Перечислить функции агрегирования, описать их назначение.
10) Роль предложения COMPUTE BY, синтаксис, особенности его
использования.
11) Какая опция используется для однонаправленного перебора
всех столбцов, используемых для агрегирования данных, описать синтаксис применения данной опции?
12) Роль предложения HAVING. Что необходимо учитывать при
его использовании?
13) Предназначение оператора UNION, синтаксис его применения.
14) Какую функцию нужно использовать для поиска точного совпадения слов / фраз или префиксов слов/фраз?
15) Можно ли использовать инструкцию SELECT INTO для вставки данных в уже существующую таблицу?
89
16) В какой блок следует поместить код, который может привести
к ошибкам?
17) Какие элементы нельзя использовать в инструкции SELECT в
представлении?
18) Провести выборку по условию из одной таблицы, осуществить
выборку из нескольких таблиц с сортировкой по условию.
19) Создать представления к таблицам.
90
Глава 6. РАЗРАБОТКА КЛИЕНТСКОГО ПРИЛОЖЕНИЯ НА
C# .NET
Для работы с СУБД MS SQL Server 2012 в MS Visual Studio .NET
включена библиотека классов System.Data.SqlClient. Эта библиотека
предназначена для доступа к базам данных MS SQL Server. Есть и альтернативный способ подключения к базам данным MS SQL Server 2012 с использованием LINQ технологии. Данный подход выполняет самостоятельно генерацию кода запросов таким образом, что таблицы из базы данных в
MS Visual Studio .NET являются классами. Таким образом, работа с базой
данных сводится к принципу работы с ООП. Рассмотрим оба подхода.
6.1 Создание проекта в MS VS 2016 C# .NET без использования
LINQ
Для создания нового проекта необходимо, после успешного запуска
MS VS 2016 C# .NET, выбрать элемент меню Файл >> Создать >> Проект…, после этого откроется окно Создание проекта (рис. 6.1).
Рисунок 6.1 Окно создания проекта
Далее необходимо выбрать «Приложение Windows Forms» и задать
имя проекту в поле «Имя». После этого нажать на кнопку «ОК». В результате будет создан новый проект win-forms.
91
В обозревателе решений, представленном на рисунке 6.2, добавим
новый класс. Для этого щелкнем правой кнопкой мыши по проекту (в данном случае на рисунке 6.2 это «TestBD»). Выберем → добавить → класс.
Назовите класс «InitSql».
Рисунок 6.2 Обозреватель решений
Если все было сделано верно, то студия откроет только что созданный файл для редактирования, как показано на рисунке 6.3.
Рисунок 6.3 Сгенерированный класс InitSql
6.1.1 Класс InitSql
Данный сгенерированный класс будет отвечать за инициализацию
подключения к базе данных. В нем будет храниться строка подключения.
Для работы с базой данных MS SQL Server требуется подключить
библиотеку: System.Data.SqlClient. Добавим директиву в соответствующий блок.
Настроим подключение. Для этого создадим метод:
92
public SqlConnection Connect(string server, bool local, Tuple<string,string> user)
Переменные, которые передаются в функцию, нужны для формирования строки подключения. Переменная server хранит в себе названия сервера базы данных. Логическая переменная local определяет то, как будет
производиться авторизация: с помощью подлинности windows или парой
имя и пароль. В случае, если авторизация производится вторым способом,
то в кортеже user хранятся логин и пароль. В строке подключения после
«Catalog=» можно поставить название своей базы данных.
Листинг 6.1 Метод подключения
public SqlConnection Connect(string server, bool local, Tuple<string,string> user)
{
string connection;
if (local)
{
connection = "Persist Security Info=False;Integrated Security=True;Initial
Catalog=Students;Server="+server;
}
else
{
connection
=
"Persist
Security
Info=False;User
ID="+user.Item1+";Password="+user.Item2+";Initial Catalog=Students;Server="+server;
}
SqlConnection sqlc = sqlc = new SqlConnection(connection);
sqlc.Open();
return sqlc;
}
Метод подключения приведен в листинге 6.1. Если не произошло исключение, метод возвращает созданное соединение. На этом работа с классом IniSql закончена.
6.1.2 Класс DataStruct
Для хранения на локальном компьютере данных таблицы, загруженной для редактирования базы данных, создадим аналогично процедуре в
пункте 6.1 класс DataStruct.
Листинг 6.2 Полный листинг класса DataStruct
public class DataStruct
{
public string nameTable;
public Dictionary<string, List<string>> rows = new Dictionary<string,
List<string>>();
public DataStruct(string nameTable)
{
this.nameTable = nameTable;
}
}
В листинге 6.2 приведен класс DataStruct, в нём содержатся имя
таблицы и словарь пары имени столбца и списка их значений.
93
6.1.3 Класс DataRW
Создадим следующий класс DataRW. Данный класс будет служить
для записи и чтения данных из базы данных.
Создадим метод чтения, назовем его Read. Метод чтения приведен в
листинге 6.3.
Листинг 6.3 Метод чтения из базы данных
public DataStruct Read(DataStruct data, SqlConnection connection)
{
try {
SqlCommand command = new SqlCommand("SELECT * FROM " +
ta.nameTable);
command.Connection = connection;
SqlDataReader sdr = command.ExecuteReader();
data.rows.Clear();
while (sdr.Read())
{
for (int i = 0; i < sdr.FieldCount; i++)
{
string nameColumn = sdr.GetName(i);
if (!data.rows.ContainsKey(nameColumn))
{
data.rows.Add(nameColumn, new List<string>());
}
da-
data.rows[nameColumn].Add(sdr[i].ToString());
}
}
sdr.Close();
return data;
}
catch(Exception ex)
{
System.Windows.Forms.MessageBox.Show(ex.Message);
return null;
}
}
Для того, чтобы провести какое-либо действие с базой данных либо с
данными, хранящимися в ней, нужно написать запрос на языке T-SQL.
Для этого служит класс SqlCommand, в его конструктор передается запрос
на языке T-SQL.
В листинге 6.3 метод принимает 2 значения, структуру data, в которую будет сохранена информация, и объект, который отвечает за связь локального приложения и сервера базы данных. Из первого входного значения извлекается имя таблицы (см. пункт 6.3) и подставляется в запрос.
Объекту, хранящему запрос, также передается объект, обеспечивающий соединение с базой данных. Запрос select должен вернуть таблицу,
поэтому для её сохранения используется объект SqlDataReader. После вызова метода ExecuteReader() в него будут считаны все данные, которые
вернет запрос. Остается только их занести в структуру DataStruct.
Метод sdr.Read() читает следующую порцию данных и возвращает
истину, если данные еще не закончились. В теле цикла while находится
двойной цикл, внешний цикл перебирает строки, внутренний перебирает
94
ключи от словаря, которые являются именами столбцов. После манипуляции с чтением из базы данных SqlDataReader обязательно нужно закрыть
иначе следующие чтение будет неуспешным.
Метод записи приведен в листинге 6.4. Данный метод выполняет обратную задачу. Он записывает данные в базу данных. Для этого сначала
посылается запрос на очищение таблицы (TRUNCATE), чтобы избежать
дублирования данных. Целая переменная d содержит в себе количество
строк. Далее идет двойной знакомый цикл, который перебирает строки и
ключи. В теле внутреннего цикла собирается запрос INSERT INTO, который выполняется после завершения работы внутреннего цикла (лист. 6.4).
Листинг 6.4 Метод записи в базу данных
public void Write(DataStruct data, SqlConnection connection)
{
try {
SqlCommand command = new SqlCommand("TRUNCATE TABLE " + data.nameTable);
command.Connection = connection;
command.ExecuteNonQuery();
int
d
=
(data.rows.Keys.Count
==
0)
?
0
:
data.rows[data.rows.Keys.ToArray<string>()[0]].Count;
for (int i = 0; i < d; i++)
{
command.CommandText = "INSERT INTO " + data.nameTable + "
VALUES ('";
foreach (string key in data.rows.Keys)
{
command.CommandText += data.rows[key][i] + "','";
}
command.CommandText=
command.CommandText.Remove(command.CommandText.Length - 2, 2);
command.CommandText += ")";
command.ExecuteNonQuery();
}
}catch(Exception ex)
{
System.Windows.Forms.MessageBox.Show(ex.Message);
}
}
6.1.4 Создание пользовательского интерфейса
Для создания пользовательского интерфейса нужно открыть конструктор форм на Form1.cs и сконструировать интерфейс пользователя такой же, как на рисунке 6.4.
На данной форме добавлен SplitContainer, для удобства установлено
свойство dock в fill у данного элемента. Это позволит масштабировать
форму и настраивать интерфейс для удобства работы.
Большую часть экрана занимает элемент DataGridView. На нем будут выводиться данные из базы данных. Меньшую часть экрана занимают
элементы управления. Сверху находится кнопка «Сохранить в БД». Она
нужна для синхронизации локальных изменений в базе данных. По центру
95
этого отдела контейнера расположит listbox. В нём будут перечислены все
таблицы из подключаемой базы данных.
Рисунок 6.4 Пользовательский интерфейс
Снизу расположены элементы, предназначенные для подключения к
серверу. При установке флажка «Проверка подлинности» для входа заполнение полей «Логин» и «Пароль» не требуется. В поле «Сервер»
нужно вводить имя сервера, на котором хранится база данных. После корректного ввода данных нажатие кнопки «Подключиться» установит соединение с базой данных. На рисунке 6.5 изображен пример работы с таблицей.
Рисунок 6.5 Работа с таблицей Преподаватель
96
6.1.5 Сведение всех модулей вместе
Откройте код формы, это можно сделать, если выделить форму и
нажать клавишу F7, либо правой кнопкой мыши вызвать контекстное меню и выбрать соответствующую кнопку.
Прежде всего, нужно инициализировать переменные (лист 6.5).
Листинг 6.5 Инициализация переменных
InitSql initConnection = new InitSql();
Dictionary<string, DataStruct> tablesDictionary = new Dictionary<string,
DataStruct>();
SqlConnection sql;
DataRead dr = new DataRead();
После этого реализуем подключение к базе данных по нажатию на
соответствующую кнопку. Создадим обработчик событий и поместим
внутри него следующий код из листинга 6.6.
Листинг 6.6 Обработчик события нажатия кнопки
try
{
sql = initConnection.Connect(server.Text,checkBox1.Checked,new
Tuple<string, string>(login.Text,pass.Text));
SqlCommand com = new SqlCommand("SELECT * FROM sys.objects WHERE
type in (N'U')");
com.Connection = sql;
SqlDataReader sdr = com.ExecuteReader();
while (sdr.Read())
{
if (sdr[0].ToString() != "sysdiagrams")
{
tables.Items.Add(sdr[0].ToString());
if (!tablesDictionary.ContainsKey(sdr[0].ToString()))
{
tablesDictionary.Add(sdr[0].ToString(), new DataStruct(sdr[0].ToString()));
}
}
}
checkBox1.Enabled = false;
login.Enabled = false;
pass.Enabled = false;
server.Enabled = false;
Connect.Enabled = false;
sdr.Close();
}
catch (Exception ex)
{
MessageBox.Show(ex.Message);
}
Данный обработчик вызывает у объекта initConnection функцию
Connection, в которую передаются параметры для формирования строки
подключения. Далее выполняется запрос на сервер:
SELECT * FROM sys.objects WHERE type in (N'U'),
он вернет список всех таблиц, находящихся в этой базе данных. С помощью условия требуется отфильтровать системную таблицу. В теле цикла
while происходит первичная инициализация всех DataStructure объектов и
заносится туда имя таблицы, также добавляются имена таблиц в listbox.
97
Далее требуется реализовать реакцию программы на выбор пользователя. Для этого создадим обработчик (двойным кликом), который будет
читать информацию из базы данных (лист. 6.7).
Листинг 6.7 Чтение таблицы из базы данных
DataStruct
table
=
dr.Read(tablesDictionary[tables.SelectedItem.ToString()],
sql);
int
d
=
(table.rows.Keys.Count
==
0)
?
ble.rows[table.rows.Keys.ToArray<string>()[0]].Count;
grid.Rows.Clear();
grid.Columns.Clear();
foreach (string key in table.rows.Keys)
{
grid.Columns.Add(key,key);
}
if (d != 0)
grid.Rows.Add(d);
for (int i = 0; i < d; i++)
{
int j = 0;
foreach (string key in table.rows.Keys)
{
grid.Rows[i].Cells[j].Value = table.rows[key][i];
j++;
}
}
0
:
ta-
Данный метод просто копирует информацию в DataGridView.
Листинг 6.8 Сохранение новой информации
private void SaveRecords_Click(object sender, EventArgs e)
{
foreach (string key in tablesDictionary[tables.SelectedItem.ToString()].rows.Keys)
{tablesDictionary[tables.SelectedItem.ToString()].rows[key].Clear();
}
for (int i = 0; i < grid.Rows.Count; i++)
{
for (int j = 0; j <grid.Rows[i].Cells.Count; j++)
{
if (grid.Rows[i].Cells[j].Value != null)
tablesDictionary[tables.SelectedItem.ToString()].rows[grid.Columns[j].HeaderText].Add(grid.Rows[i].
Cells[j].Value.ToString());
}
}
dr.Write(tablesDictionary[tables.SelectedItem.ToString()], sql);
}
Метод записи (лист 6.8) обнуляет информацию выбранной таблице в
DataStruct и копирует информацию в неё из dataGridView, после этого
новая таблица передается в метод записи информации в базу данных.
Создадим два обработчика события на закрытие формы и на изменение галочки и вставим туда строки из листинга 6.9.
Листинг 6.9 Блокировка ненужных элементов
private void checkBox1_CheckedChanged(object sender, EventArgs e)
{
login.Enabled = !checkBox1.Checked;
pass.Enabled = !checkBox1.Checked;
}
98
private void MainMenu_FormClosed(object sender, FormClosedEventArgs e)
{
if (sql != null) sql.Close();
}
Обработчик событий для галочки будет выключать поля для логина
и пароля тогда, когда они уже не нужны.
Обработчик события формы будет корректно закрывать подключение к базе данных при завершении приложения.
6.2 Создание проекта в MS VS 2016 C# .NET с использованием
LINQ
Создадим новый Windows Forms проект точно так же, как это было
сделано в пункте 6.1.
Откроем вкладку «Источник данных» и выберем «Добавить новый
источник данных», как показано на рисунке 6.6.
Рисунок 6.6 Источник данных
Откроется мастер настройки источника данных (рис. 6.7).
99
Рисунок 6.7 Мастер настройки источника данных
Выберем тип источника «База данных». В следующем окне выберем
«Набор данных». Откроется окно, изображенное на рисунке 6.8.
Рисунок 6.8 Подключение к базе данных
100
Нажмем на кнопку «Создать подключение...». Откроется окно,
изображенное на рисунке 6.9.
Возле выпадающего списка «Имя сервера» нажмем кнопку обновить. В выпадающем списке выберем нужный сервер. После этого группа
«Подключение к базе данных» станет доступной. Выберем базу данных,
к которой требуется подключиться. После этого нажмем на «Проверить
подключение», если подключение успешно, нажмем ОК, если нет, то
необходимо проверить службу «MSSQLSERVER».
Возможно использовать аутентификацию SQL Server, для этого
должна быть заведена отдельная учетная запись. При выборе этой опции
требуется ввести пару логин и пароль.
Рисунок 6.9 Настройка строки подключения
101
Для этого вернемся в «Мастер настройки источников данных»,
выберем Далее. На вопрос сохранить ли подключение ответим положительно. Далее нужно выбрать все таблицы, как на рисунке 6.10.
Рисунок 6.10 Выбор таблиц
После этого нажмем Готово и новый источник данных будет добавлен. Следующим шагом является добавление компонента LINQ. В обозревателе решений добавим новый компонент. Введем в поиске LINQ и выберем компонент «LINQ to SQL». Выберем имя, как показано на рисунке
6.11.
102
Рисунок 6.11 Добавление нового элемента в проект
После этих действий откроется конструктор, перетащим в него из
обозревателя серверов все таблицы (рис. 6.12).
Рисунок 6.12 Конструктор Object Relational Designer
После этого будет построена диаграмма модели базы данных (рис.
6.13).
103
Рисунок 6.13 Диаграмма модели базы данных
Возьмем форму из пункта 6.1.4 и упростим её (рис. 6.14), так как
строку подключения уже сформировал мастер настройки.
Рисунок 6.14 Упрощенный дизайн пользовательского интерфейса
104
Теперь задействуем кнопки. Добавим два обработчика событий для
обеих кнопок. Вставим в них код из листинга 6.10.
Листинг 6.10 Обработчики события кнопок в приложении с LINQ
using
using
using
using
using
using
using
using
using
System;
System.Collections.Generic;
System.ComponentModel;
System.Data;
System.Drawing;
System.Linq;
System.Text;
System.Threading.Tasks;
System.Windows.Forms;
namespace TestBd2
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
}
StbdDataContext stddcontext;
private void button2_Click(object sender, EventArgs e)
{
stddcontext = new StbdDataContext();
button2.Enabled = false;
tables.Items.AddRange(new object[] {
"Пр_Гр",
"Студент",
"Группа",
"Преподаватель",
"Специальность",
"Факультет",
"Кафедра",
"КодГр_НомЗач",
"КК_КФ",
"КК_КС",
"КП_КК"
});
}
private void button1_Click(object sender, EventArgs e)
{
stddcontext.SubmitChanges();
}
private void tables_SelectedIndexChanged(object sender, EventArgs e)
{
dataGridView1.DataSource
=
stddcontext.GetType().GetProperty(tables.SelectedItem.ToString()).GetValue(stddcontext);
}
}
}
Объект «StbdDataContext» есть тот компонент, который мы добавили ранее. Создаим его экземпляр «stddcontext». Все взаимодействия,
включая
запросы,
ведутся
через
него.
Функция
«stddcontext.SubmitChanges» сохраняет внесенные изменения из dataGridView в
базу данных.
105
Через «GetType().GetProperty(N).GetValues(C)», где N – имя таблицы, C – компонент, получают экземпляр источника, который подставляется в dataGridView для отображения и коррекции данных.
Контрольные вопросы и упражнения
1) Как осуществляется подключение к СУБД?
2) Опишите работу клиентского приложения.
3) Опишите процесс создания клиентского приложения.
4) Опишите процесс подключение через LINQ.
5) Для созданной базы данных разработайте клиентское приложение.
106
Глава 7. ХРАНИМЫЕ ПРОЦЕДУРЫ И ТРИГГЕРЫ
SQL Server поддерживает три типа программируемых объектов:
функции, хранимые процедуры и триггеры. Вместо исполнения отдельных
инструкций и команд эти объекты позволяют создавать богатую программную логику, содержащую циклы, управление исполнением программы, принятие решений и ветвление. Помимо встроенного набора функций
SQL Server, существует возможность создавать пользовательские функции (user-defined functions), содержащие многократно используемый код.
Хранимые процедуры, представляющие собой именованный код, используют в качестве интерфейса для доступа приложений к базам данных. Они
позволяют управлять доступом к данным, просты в обслуживании и не
требуют жесткого задания кода SQL в приложениях. Триггеры служат для
автоматического исполнения кода в ответ на определенные события базы
данных.
7.1 Создание триггеров
Триггер (trigger) – это специализированная программа TransactSQL или среды CLR, которая автоматически выполняется при возникновении события в базе данных. SQL Server позволяет создавать три типа
триггеров: DML-триггеры, которые выполняются при возникновении событий языка обработки данных (DML), DDL-триггеры, срабатывающие
при выполнении инструкций языка определения данных (DDL) и триггеры
входа, срабатывающие в ответ на событие LOGON, возникающее при
установке пользовательских сеансов.
DML-триггеры выполняются при изменении данных в указанной
таблице или представлении посредством инструкций INSERT, UPDATE
или DELETE.
DDL-триггеры выполняются при возникновении на сервере таких
DDL-событий, как создание, изменение или удаление объекта (CREATE,
ALTER, DROP), используются для администрирования базы данных,
например, для аудита и управления доступом к объектам.
Создание триггеров происходит с использованием
TRIGGER.
Синтаксис создания DML-триггера имеет вид:
CREATE
Trigger on an INSERT, UPDATE, or DELETE statement to a table or
view
CREATE TRIGGER [ schema_name . ]trigger_name
ON { table | view }
[ WITH <dml_trigger_option> [ ,...n ] ]
{ FOR | AFTER | INSTEAD OF }
{ [ INSERT ] [ , ] [ UPDATE ] [ , ] [ DELETE ] }
[ WITH APPEND ]
[ NOT FOR REPLICATION ]
107
AS { sql_statement [ ; ] [ ,...n ] | EXTERNAL NAME <method specifier [
;]>}
<dml_trigger_option> ::=
[ ENCRYPTION ]
[ EXECUTE AS Clause ]
<method_specifier> ::=
assembly_name.class_name.method_name
Синтаксис создания DDL-триггера:
Trigger on a CREATE, ALTER, DROP, GRANT, DENY, REVOKE, or
UPDATE STATISTICS statement
CREATE TRIGGER trigger_name
ON { ALL SERVER | DATABASE }
[ WITH <ddl_trigger_option> [ ,...n ] ]
{ FOR | AFTER } { event_type | event_group } [ ,...n ]
AS { sql_statement [ ; ] [ ,...n ] | EXTERNAL NAME < method specifier
> [;]}
<ddl_trigger_option> :цу:=
[ ENCRYPTION ]
[ EXECUTE AS Clause ]
<method_specifier> ::=
assembly_name.class_name.method_name
Синтаксис создание триггера входа:
Trigger on a LOGON event (Logon Trigger)
CREATE TRIGGER trigger_name
ON ALL SERVER
[ WITH <logon_trigger_option> [ ,...n ] ]
{ FOR| AFTER } LOGON
AS { sql_statement [ ; ] [ ,...n ] | EXTERNAL NAME < method specifier
> [;]}
<logon_trigger_option> ::=
[ ENCRYPTION ]
[ EXECUTE AS Clause ]
<method_specifier> ::=
assembly_name.class_name.method_name
Таблица 7.1 Аргументы триггеров
Аргумент
schema_name
trigger_name
table | view
Описание
Имя схемы, которой принадлежит триггер DML.
Имя триггера. Аргумент trigger_name должен соответствовать правилам для идентификаторов — за исключением того,
что trigger_name не может начинаться с символов # или ##.
Таблица или представление, в которых выполняется триггер DML,
иногда указывается как таблица триггера или представление триггера.
108
Аргумент
DATABASE
ALL SERVER
WITH
ENCRYPTION
EXECUTE AS
FOR | AFTER
INSTEAD OF
event_type
event_group
WITH APPEND
NOT FOR
REPLICATION
sql_statement
<
method_specifier
>
Описание
Применяет область действия триггера DDL к текущей базе данных.
Если этот аргумент определен, триггер срабатывает всякий раз при
возникновении
в
базе
данных
события
типа event_type или event_group.
Применяет область действия триггера DDL или триггера входа к
текущему серверу. Если этот аргумент определен, триггер срабатывает всякий раз при возникновении в любом месте на текущем
сервере события типа event_type или event_group.
Затемняет текст инструкции CREATE TRIGGER. Использование
аргумента WITH ENCRYPTION не позволяет публиковать триггер
как часть репликации SQL Server. Параметр WITH ENCRYPTION
не может быть указан для триггеров CLR.
Указывает контекст безопасности, в котором выполняется триггер.
Позволяет управлять учетной записью пользователя, используемой
экземпляром SQL Server для проверки разрешений на любые объекты базы данных, ссылаемые триггером.
Тип AFTER указывает, что триггер DML срабатывает только после
успешного выполнения всех операций в инструкции SQL, запускаемой триггером. Все каскадные действия и проверки ограничений,
на которые имеется ссылка, должны быть успешно завершены,
прежде чем триггер сработает.
Указывает, что триггер DML срабатывает вместо инструкции SQL,
используемой триггером, переопределяя таким образом действия
выполняемой инструкции триггера. Аргумент INSTEAD OF не может быть указан для триггеров DDL или триггеров входа.
Имя события языка Transact-SQL, которое после выполнения вызывает срабатывание триггера DDL.
Имя стандартной группы событий языка Transact-SQL. Триггер
DDL срабатывает после возникновения любого события языка
Transact-SQL, принадлежащего к группе event_group.
Указывает, что требуется добавить триггер существующего типа.
Указывает, что триггер не может быть выполнен, если агент репликации изменяет таблицу, используемую триггером.
Условия и действия триггера. Условия триггера указывают дополнительные критерии, определяющие, какие события — DML, DDL
или событие входа — вызывают срабатывание триггера.
Указывает метод сборки для связывания с CLR-триггером. Метод
не должен иметь аргументов и возвращать значение типа void. Аргументclass_name должен быть допустимым идентификатором
SQL Server, а в сборке должен существовать класс с таким именем,
видимый во всей сборке. Если класс имеет имя, содержащее точки
(.) для разделения частей пространства имен, имя класса должно
быть заключено в квадратные скобки ([ ]) или двойные кавычки ("
"). Класс не может быть вложенным.
Приведем ряд примеров кода создания разнообразных триггеров.
Листинг 7.1 – Пример создания DML-триггера
USE uch_pr;
GO
IF OBJECT_ID ('FAKULTET','TR') IS NOT NULL
109
DROP TRIGGER FAKULTET.rem;
GO
CREATE TRIGGER rem
ON FAKULTET
AFTER INSERT, UPDATE, DELETE
AS
EXEC msdb.dbo.sp_send_dbmail
@profile_name = 'УЧЕБНАЯ БД',
@recipients = 'user@mail.com',
@body = 'Произошли изменения в таблице FAKULTET',
@subject = 'ВНИМАНИЕ';
GO
Описанный в листинге 7.1 DML-триггер отправляет сообщение указанному пользователю по электронной почте.
Листинг 7.2 – Пример создания DDL-триггера
USE uch_pr
GO
CREATE TRIGGER CANTDROP
ON DATABASE
FOR DROP_TABLE, ALTER_TABLE
AS
PRINT 'Вы не можете удалять или изменять базу данных'
Описанный в листинге 7.2 DDL-триггер запрещает удалять или изменять таблицы в базе данных.
Листинг 7.3 – Пример создания триггера входа
USE master;
GO
CREATE LOGIN test WITH PASSWORD = 'test',
CHECK_EXPIRATION = OFF;
GO
GRANT VIEW SERVER STATE TO test;
GO
CREATE TRIGGER con_limit_trigger
ON ALL SERVER WITH EXECUTE AS 'test'
FOR LOGON
AS
BEGIN
IF ORIGINAL_LOGIN()= 'test' AND
(SELECT COUNT(*) FROM sys.dm_exec_sessions
WHERE is_user_process = 1 AND
original_login_name = 'test') > 3
ROLLBACK;
110
END;
Описанный в листинге 7.3 триггер запрещает пользователю test более 3 одновременных подключений к базе данных.
7.2 Ограничения триггеров
Инструкция CREATE TRIGGER должна быть первой инструкцией
в пакете и может применяться только к одной таблице.
Триггер создается только в текущей базе данных, но может, тем не
менее, содержать ссылки на объекты за пределами текущей базы данных.
Если для уточнения триггера указано имя схемы, имя таблицы необходимо уточнить таким же образом.
Одно и то же действие триггера может быть определено более чем
для одного действия пользователя (например, INSERT и UPDATE) в одной и той же инструкции CREATE TRIGGER.
Триггеры INSTEAD OF DELETE/UPDATE нельзя определить для
таблицы, у которой есть внешний ключ, определенный для каскадного выполнения операции DELETE/UPDATE.
Внутри триггера может быть использована любая инструкция SET.
Выбранный параметр SET остается в силе во время выполнения триггера,
после чего настройки возвращаются в предыдущее состояние.
7.3 Создание процедур
Хранимые процедуры (stored procedures) – это наиболее часто используемые в базах данных программные структуры. Процедура представляет собой просто имя, связанное с программным кодом SQL, который
хранится и исполняется на сервере. Хранимые процедуры, возвращающие
скалярные значения или результирующие наборы, являются основным интерфейсом, который должен использоваться приложениями для обращения
к любым данным в базах данных. Хранимые процедуры позволяют не
только управлять доступом к базе данных, но также изолировать код базы
данных для упрощения обслуживания, что исключает необходимость искать инструкции SQL в коде приложения для внесения каких-либо изменений.
Хранимые процедуры могут содержать практически любые конструкции или команды, исполнение которых поддерживается в SQL
Server. Процедуры можно использовать для изменения данных, возврата
скалярных значений или целых результирующих наборов.
Хранимые процедуры также выполняют очень важную функцию защиты базы данных. Пользователям можно предоставить разрешение на
исполнение хранимых процедур, обращающихся к данным, при этом, не
разрешая им прямой доступ к данным. Что еще важнее, хранимые процедуры скрывают от пользователя структуру базы данных и разрешают ему
выполнение только тех операций, которые запрограммированы в хранимой
процедуре.
111
Общий синтаксис Transact-SQL для создания хранимой процедуры
имеет вид:
CREATE { PROC | PROCEDURE } [schema_name.] procedure_name [ ;
number ]
[ { @parameter [ type_schema_name. ] data_type }
[ VARYING ] [ = default ] [ OUT | OUTPUT ]
] [ ,...n ]
[ WITH <procedure_option> [ ,...n ] ]
[ FOR REPLICATION ]
AS { <sql_statement> [;][ ...n ] | <method_specifier> }
[;]
<procedure_option> ::=
[ ENCRYPTION ]
[ RECOMPILE ]
[ EXECUTE_AS_Clause ]
<sql_statement> ::=
{ [ BEGIN ] statements [ END ] }
<method_specifier> ::=
EXTERNAL NAME assembly_name.class_name.method_name
Таблица 7.2 – Аргументы хранимых процедур
Аргумент
schema_name
procedure_name
; number
@ parameter
VARYING
default
OUTPUT
Описание
Имя схемы, которой принадлежит процедура.
Имя новой хранимой процедуры. Имена процедур должны соответствовать требованиям, предъявляемым к идентификаторам, и должны быть уникальными в схеме.
Необязательное целое число, используемое для группировки процедур с одним и тем же именем.
Параметр процедуры. В инструкции CREATE PROCEDURE можно
объявить один или более параметров. При выполнении процедуры
значение каждого из объявленных параметров должно быть указано
пользователем, если для параметра не определено значение по умолчанию или значение не задано равным другому параметру. Хранимая
процедура может иметь не более 2100 параметров.
Указывает результирующий набор, поддерживаемый в качестве выходного параметра. Этот аргумент динамически формируется хранимой процедурой, и его содержимое может различаться. Применяется только к аргументам типа cursor.
Значение
по
умолчанию
для
аргумента.
Если
значение default определено, процедуру можно выполнить без указания
значения соответствующего аргумента. Значение по умолчанию
должно быть константой или может равняться NULL. Если в процедуре используется аргумент с ключевым словом LIKE, он может
включать символы-шаблоны %, _, [] и [^].
Показывает, что аргумент процедуры является выходным. Значение
этого аргумента можно получить при помощи инструкции
EXECUTE. Используйте выходные аргументы для возврата значений
112
Аргумент
RECOMPILE
ENCRYPTION
EXECUTE AS
FOR
REPLICATION
<sql_statement>
EXTERNAL
NAME assembl
y_name.class_n
ame.method_na
me
Описание
коду,
вызвавшему
процедуру.
Аргументы
типов text, ntext и image не могут быть выходными, если процедура не
является процедурой CLR. Выходным аргументом с ключевым словом OUTPUT может быть заполнитель курсора, если процедура не
является процедурой CLR.
Показывает, что компонент Database Engine не кэширует план выполнения процедуры и что процедура компилируется во время выполнения. Этот аргумент нельзя использовать, если указан аргумент
FOR REPLICATION. Задать аргумент RECOMPILE для хранимой
процедуры CLR нельзя.
Показывает, что SQL Server выполнит затемнение исходного текста
инструкции CREATE PROCEDURE. Результат затемнения не виден
непосредственно ни в одном представлении каталога SQL Server
2008.
Определяет контекст безопасности, в котором должна быть выполнена хранимая процедура.
Указывает, что хранимые процедуры, созданные для репликации, не
могут выполняться на подписчике. Хранимая процедура, созданная с
аргументом FOR REPLICATION, используется как процедурафильтр и выполняется только во время репликации. Если указан аргумент FOR REPLICATION, параметры не могут быть объявлены.
Указать аргумент FOR REPLICATION для хранимой процедуры CLR
нельзя. Аргумент RECOMPILE не учитывается для процедур, созданных с аргументом FOR REPLICATION.
Одна или несколько инструкций языка Transact-SQL, которые будут
включены в состав процедуры.
Метод сборки .NET Framework, на который должна ссылаться хранимая процедура CLR. Аргумент class_name должен быть допустимым идентификатором SQL Server и соответствовать существующему в сборке классу. Если имя класса включает названия пространств
имен, отделенные точками (.), оно должно быть ограничено при помощи квадратных скобок ([ ]) или двойных кавычек (" "). Указанный
метод класса должен быть статическим.
Листинг 7.4 – Пример создания простой процедуры
USE uch_pr
GO
CREATE PROCEDURE StudentsCount
AS
DECLARE @cnt INTEGER
SELECT @cnt = COUNT(*)
FROM STUDENT
WHERE NOT G_kod IS NULL;
RETURN @cnt;
GO
Описанная в листинге 7.4 процедура не принимает никаких
аргументов, посредством оператора DECLARE объявлена локальная переменная @cnt (имена всех локальных переменных в SQL Server начина113
ются с символа @). Эта переменная затем используется в операторе
SELECT, так что он содержит значение, возвращаемое функцией
COUNT(). Наконец, оператор RETURN используется для возвращения результатов подсчета в вызывающее приложение – RETURN @cnt.
7.4 Назначение разрешений для хранимых процедур
Для любых объектов и операций в SQL Server необходимо явно задавать разрешения пользователей на их применение и выполнение. Чтобы
разрешить пользователям исполнять хранимую процедуру, используется
следующий общий синтаксис:
GRANT EXECUTE ON <хранимая_процедура> ТО <участник>
Каждому пользователю, имеющему разрешение на исполнение хранимой процедуры, автоматически делегируются разрешения на объекты и
команды, на которые есть ссылки в теле процедуры, на основе набора разрешений создателя этой хранимой процедуры.
Делегирование разрешений в хранимых процедурах является мощным механизмом безопасности SQL Server. Если все способы доступа к
данным – вставка, удаление, обновление или запрос – реализованы через
хранимые процедуры, пользователи не имеют прямого доступа ни к каким
таблицам базы данных. Только выполняя хранимые процедуры, они могут
осуществлять необходимые действия по управлению базой данных. И хотя
пользователи будут иметь разрешения, делегированные через хранимые
процедуры, эти разрешения будут ограничены кодом процедуры, которая
может производить следующие действия:
разрешать выполнение определенных операций только пользователям из списка, который хранится в другой таблице и ведется пользователем с административными правами;
проверять входные параметры для предотвращения атак на систему безопасности, таких как инъекция SQL (SQL injection).
7.5 Создание функций
SQL Server содержит набор встроенных функций, которые можно
многократно вставлять в приложения для обеспечения нужной функциональности. Например, функция GETDATEQ возвращает текущие системные дату и время в стандартном внутреннем формате SQL Server для значений datetime. Несмотря на то, что SQL Server предоставляет широкий
выбор встроенных функций, можно создавать свои собственные функции,
содержащие часто используемый код. Это позволяет один раз создать код
и многократно использовать его в приложениях.
Обычно пользовательские функции, инкапсулирующие сложные
фрагменты кода, создают таким образом, чтобы их реализация была незаметной для приложений.
114
7.5.1 Скалярные функции
Скалярные функции принимают 0 или несколько входных параметров и возвращают одно скалярное значение. Для создания функции используют инструкцию Transact-SQL CREATE FUNCTION. Эта инструкция имеет следующий синтаксис:
CREATE FUNCTION [ имя_схемы.
] имя_функции ( [ {
@имя_параметра [ AS ][ имя_схемы.
] тип_данных_параметра [ =
значение_параметра_по_умолчанию ]
} [
,...п ] ] ) RETURNS
тип_возвращаемых_данных
[ WITH <function_option> [ ,...n ] ]
[ AS ]
BEGIN
тело_функции RETURN скалярное_выражение END [
;
]
<function_option>::=
{
[ ENCRYPTION ]
| [ SCHEMABINDING ]
| [ EXECUTE_AS_Clause ] }
Каждая функция должна иметь уникальное имя, соответствующее
правилам для идентификаторов объектов.
Хотя для функций не обязательно определять входные параметры,
пользовательские функции редко без них обходятся. Поэтому обычно
нужно указать один или несколько входных параметров, а также тип данных для каждого из них.
Предложение RETURNS в этой инструкции указывает тип данных
для возвращаемого функцией скалярного значения. В этом предложении
можно указать несколько параметров. Параметр ENCRYPTION означает,
что SQL Server шифрует определение функции при его сохранении. Параметр SCHEMABINDING запрещает удаление любых объектов, от которых зависит функция. Параметр EXECUTE AS определяет контекст безопасности функции.
Тело функции находится внутри блока BEGIN...END, который должен содержать предложение RETURN, служащее для вывода вычисляемого функцией значения.
Понятно, что наиболее интересная работа выполняется в теле функции. Несмотря на то, что в функции можно выполнить фактически любой
код, существуют некоторые ограничения.
Наиболее существенным ограничением является то, что с помощью
функции нельзя изменить состояние любого объекта в базе данных или саму базу данных. Поэтому нельзя вставлять, обновлять и удалять данные в
таблицах, а также нельзя создавать, изменять и удалять объекты в базе
данных. Однако можно создать одну или несколько табличных переменных и применить к ним инструкции INSERT, UPDATE и DELETE.
115
Табличная переменная (table variable) – это особый тип переменных,
который используется для временного хранения набора строк, возвращаемых как результат возвращающей табличное значение функции. Скалярные функции возвращают одно значение, поэтому обычно они используются в списке столбцов инструкции SELECT, а также в предложении
WHERE.
В следующем примере (лист. 7.5) показано, как определить скалярную функцию, возвращающую количество указанного товара на складе:
Листинг 7.5 – Пример создания функции
CREATE FUNCTION [dbo].[ufnGetStock](@ProductID [int])
RETURNS [int]
AS
-- Возвращает количество указанного товара на складе. Эта
функция используется
-- только внутренне.
BEGIN
DECLARE @ret int;
SELECT @ret = SUM(p.[Quantity])
FROM [Production].[Productlnventory] p
WHERE p.[ProductID] - @ProductID
AND p.[LocationID] = '6';
-- Поиск только по товарам, -хранящимся на складе.
IF (@ret IS NULL)
SET @ret = 0 RETURN @ret END;
Эту функцию затем можно использовать в запросах, например:
SELECT *,
dbo.ufnGetStock(Production.Product.ProductID) FROM
Production.Product
7.5.2 Функции, возвращающие табличное значение
Возвращающие табличное значение функции (table-valued functions)
подчиняются тем же правилам, что и скалярные функции, но возвращают
результат в виде таблицы. Поэтому они в основном используются в предложении FROM инструкции SELECT, и их можно соединять с другими
таблицами и представлениями.
Общий синтаксис возвращающей табличное значение функции имеет вид:
CREATE FUNCTION [ имя_схемы. ] имя_функции
( [ { @имя_параметра [ AS ]
[ имя_схемы.
тип_данных_параметра
[ = значение_параметра_по_умолчанию ] }
116
]
RETURNS
@возвращаемая_переменная
TABLE
<
определение_табличного_типа_данных > [ WITH <function_option> [ ,...n
] ] [ AS ]
BEGIN
тело_функции
RETURN END [ ; ]
В следующем коде (лист. 7.6) возвращающая табличное значение
функция по ID контакта возвращает его контактную информацию (ID
контакта, имя, фамилия, должность и тип контакта) в табличной форме:
Листинг 7.6 – Пример создания возвращающей табличное значение
функции:
CREATE FUNCTION [dbo].[ufnGetContactInformation](@ContactID
int) RETURNS @retContactInformation TABLE
(
-- Возвращаемые функцией столбцы:
[ContactID] int PRIMARY KEY NOT NULL,
[FirstName] [nvarchar](50) NULL,
[LastName] [nvarchar](50) NULL,
[JobTitle] [nvarchar](50) NULL,
[ContactType] [nvarchar](50) NULL ) AS
-- Возвращает имя, фамилию, должность и тип контакта
-- для указанного контакта.
BEGIN
DECLARE
@FirstName [nvarchar](50),
@LastName [nvarchar](50),
@JobTitle [nvarchar](50),
@ContactType [nvarchar](50);
-- Получение общей контактной информации.
SELECT
@ContactID = ContactID,
@FirstName = FirstName,
@LastName = LastName
FROM [Person].[Contact] WHERE [ContactID] = @ContactID;
SET @JobTitle = CASE
-- Проверка, является ли контакт
сотрудником компании.
WHEN EXISTS(SELECT * FROM [HumanResources].[Employee] e
WHERE e.[ContactID] = @ContactID) THEN (SELECT [Title]
FROM [HumanResources].[Employee] WHERE [ContactID] =
@ContactID)
-- Проверка, является ли контакт поставщиком.
WHEN EXISTS
( SELECT * FROM [Purchasing].[VendorContact] vc
117
INNER JOIN [Person].[ContactType] ct ON vc.[ContactTypeID]
ct.[ContactTypelD]
WHERE vc.[ContactID] = @ContactID)
THEN (SELECT ct.[Name]
FROM [Purchasing].[VendorContact] vc
INNER JOIN [Person].[ContactType] ct ON vc.[ContactTypelD]
ct.[ContactTypelD]
WHERE vc.[ContactID] - @ContactID)
-- Проверка, является ли контакт работником склада.
WHEN EXISTS
(SELECT * FROM [Sales].[StoreContact] sc
INNER JOIN [Person].[ContactType] ct ON sc.[ContactTypelD]
ct.[ContactTypelD]
WHERE sc.[ContactID] = @ContactID)
THEN (SELECT ct.[Name]
FROM [Sales].[StoreContact] sc
INNER JOIN [Person].[ContactType] ct ON sc.[ContactTypelD]
ct.[ContactTypelD] WHERE [ContactID] = @ContactID)
ELSE NULL END,
SET @ContactType = CASE
-- Проверка, является ли контакт сотрудником компании.
WHEN EXISTS(SELECT * FROM [HumanResources].[Employee] e
WHERE e.[ContactID] = @ContactID) THEN "Employee"
-- Проверка, является ли контакт поставщиком.
WHEN EXISTS
(SELECT * FROM [Purchasing].[VendorContact] vc
INNER JOIN [Person].[ContactType] ct ON vc.[ContactTypelD]
ct.[ContactTypelD]
WHERE vc.[ContactID] = @ContactID)
THEN "Vendor Contact'
-- Проверка, является ли контакт сотрудником склада.
WHEN EXISTS
(SELECT * FROM [Sales].[StoreContact] sc
INNER JOIN [Person].[ContactType] ct ON sc.[ContactTypelD]
ct.[ContactTypelD]
WHERE sc.[ContactID] = @ContactID)
THEN "Store Contact'
-- Проверка, является ли контакт заказчиком.
WHEN EXISTS
(SELECT * FROM [Sales].[Individual] i WHERE i.[ContactID]
@ContactID)
THEN 'Consumer'
END;
-- Возврат результатов в вызывающее приложение.
IF @ContactID IS NOT NULL
118
=
=
=
=
=
=
=
BEGIN
INSERT @retContactInformation
SELECT @ContactID, @FirstName, @LastName,
@ContactType;
END;
RETURN;
END;
SELECT * FROM dbo.ufnGetContactlnformation(l);
@JobTitle,
7.5.3 Детерминированные и недетерминированные функции
Работая с функцией, важно знать, детерминированная она или недетерминированная. Детерминированные функции (deterministic functions)
при каждом вызове для одних и тех же входных параметров возвращают
одно и то же значение.
Примером детерминированной функции является встроенная функция SQL Server COS, возвращающая косинус заданного угла. В отличие
от детерминированной недетерминированная функция (nondeterministic
function) может возвращать разный результат при каждом вызове. Примером недетерминированной функции является встроенная функция SQL
Server GETDATE(), которая возвращает текущие системные время и дату.
SQL Server также считает недетерминированной функцию, которая вызывает недетерминированную функцию или расширенную хранимую процедуру.
От детерминированности или недетерминированности функции зависит, можно ли проиндексировать возвращаемые ею результаты и можно
ли определить кластеризованный индекс на представлении, которое ссылается на эту функцию.
Если функция недетерминированная, ее результаты нельзя индексировать ни с помощью индексов вычисляемых столбцов, вызывающих эту
функцию, ни с помощью индексированных представлений, которые на нее
ссылаются.
Контрольные вопросы и упражнения
1)
Определение триггера, процесс его выполнения.
2)
Назвать три возможных триггера, описать роль каждого из них.
3)
Описать отличия DML и DDL триггеров.
4)
Описать синтаксис набора команд создания триггеров.
5)
Что необходимо учитывать при использовании триггеров?
6)
Роль хранимых процедур. Определение.
7)
Что следует принимать во внимание при использовании хранимых процедур?
8)
Перечислить виды хранимых процедур.
119
9)
Описать синтаксис набора команд создания хранимых проце-
дур.
10) Какое наибольшее число параметров может быть реализовано в
хранимой процедуре?
11) Может ли быть хранимая процедура без параметров?
12) В чем отличие триггера от хранимой процедуры?
13) Создать DML-триггеры: вставки, модификации или удаления.
14) Создать DDL – триггер.
15) Написать функции обоих типов.
16) Написать хранимые процедуры:
поиска компонента в столбце по вводимой маске;
проверки на существование компонента.
120
ЧАСТЬ 3. ПОДДЕРЖКА ФУНКЦИОНИРОВАНИЯ И ОБЕСПЕЧЕНИЕ БЕЗОПАСНОСТИ БД
121
Глава 8. ТРАНЗАКЦИИ
Транзакции обеспечивают механизм для группирования нескольких изменений базы данных в одну логическую операцию. После
внесения изменений в базу данных они могут быть совместно зафиксированы или отменены. Microsoft SQL Server поддерживает транзакции.
Транзакция – это метод, посредством которого разработчики могут
определить единицу обработки информации, оставляющую после ее завершения базу данных в непротиворечивом состоянии.
Транзакции обеспечивают соблюдение свойств ACID (атомарность,
целостность, изоляция и надежность) таким образом, который создает правильную фиксацию данных в базе.
ACID – это тест, который проходит сформированная единица обработки. Он описывает требования к транзакционной системе (например,
к СУБД), обеспечивающие наиболее надёжную и предсказуемую её работу. Требования ACID были в основном сформулированы в конце 70-х годов Джимом Греем.
8.1
Разработка
При разработке приложений для работы с SQL Server 2012 следует
учитывать следующие различия между SQL Server 2012 и Microsoft SQL
Server 2008 R2.
SQL Server 2012 не поддерживает вложение транзакций, однако
поддерживает параллельные транзакции в ADO.NET.
Если в транзакции SQL Server 2012 открыт курсор, он существует в
пределах этой транзакции. Если транзакция прерывается, курсор перестает
существовать. Чтобы продолжить использование курсора после отмены
транзакции, необходимо создать его вне транзакции. В контексте OLE DB
для SQL Server 2012 это сделает набор записей недействительным и потребует его закрытия. Если транзакция будет зафиксирована, курсор будет
по-прежнему существовать, и сохранит полную функциональность.
SQL Server 2012 не поддерживает распределенные транзакции.
SQL Server 2012 не поддерживает точки сохранения. Точки сохранения позволяют приложению откатывать часть транзакции в случае обнаружения незначительной ошибки. Тем не менее, приложения должны полностью фиксировать и откатывать транзакцию по ее завершении.
BEGIN отмечает начальную точку явной локальной транзакции. Инструкция BEGIN TRANSACTION увеличивает значение функции
@@TRANCOUNT на 1.
COMMIT отмечает успешное завершение явной или неявной транзакции. Если значение @@TRANCOUNT равно 1, то инструкция
COMMIT TRANSACTION выполняет все изменения, сделанные с начала
транзакции постоянной частью базы данных, освобождает ресурсы, удерживаемые
транзакцией,
и
уменьшает
значение
параметра
122
@@TRANCOUNT до 0. Если значение переменной @@TRANCOUNT
больше 1, инструкция COMMIT TRANSACTION уменьшает значение
@@TRANCOUNT только на 1 и оставляет транзакцию активной.
ROLLBACK откатывает явные или неявные транзакции до начала
или до точки сохранения транзакции. ROLLBACK TRANSACTION можно использовать для отмены всех изменений данных, произведенных с
начала транзакции или до точки сохранения. Она также освобождает ресурсы, используемые транзакцией.
В транзакцию может быть включена любая манипуляция данными,
например, обновление, вставка или удаление. Она может обслуживать одну строку, несколько строк, несколько различных команд. В транзакцию
может входить несколько инструкций DELETE, UPDATE, INSERT или
их комбинация.
При работе с транзакциями необходимо помнить, что во время ее
выполнения будет блокироваться доступ других пользователей к определенным данным, которые инструкции данной транзакции должны обновить.
Две отдельные одновременно выполняемые манипуляции с данными
различных транзакций могут привести к взаимной блокировке. Происходит это потому, что каждая транзакция должна дождаться завершения выполнения другой транзакции, прежде чем сможет выполнить свое обновление. Особенно часто такая ситуация возникает, когда порядок обновления таблиц различен у одновременно, допустим, двух выполняемых транзакций.
В многопользовательской среде рекомендуется поддерживать как
можно более короткие транзакции и ставить блокировку не более, чем на
несколько секунд, ибо с каждой секундой возрастает опасность возникновения проблемы. Желательно, чтобы это было несколько строк кода с завершением транзакции или ее отката.
Необходимо помнить, что никогда не надо завершать сеанс с открытой транзакцией, с инструкцией BEGIN TRAN, но без инструкций
COMMIT TRAN или ROLLBACK TRAN.
Создадим базу данных и временную таблицу, добавим в нее несколько записей:
CREATE DATABASE TRANSACTION1;
GO
CREATE TABLE TRANSACTION1.DBO.TABLE1
(
ID INT IDENTITY
,NAME NVARCHAR(100)
,MONY INT DEFAULT(0)
,COMMENT NVARCHAR(100)
,CONSTRAINT CK_MONY_ZERO
CHECK (MONY>=0)
123
);
GO
INSERT TRANSACTION1.DBO.TABLE1(NAME,MONY)
VALUES
(N'Банк',100)
,(N'Потребитель',20);
SELECT
NAME AS "Владелец"
,MONY AS "Сумма"
FROM TRANSACTION1.DBO.TABLE1 ORDER BY NAME;
Рисунок 8.1 – Заполненная таблица
Рассмотрим суть каждого свойства ACID.
8.2
Атомарность (Atomicity)
Атомарность гарантирует, что никакая транзакция не будет зафиксирована в системе частично. Будут либо выполнены все её подоперации,
либо не выполнено ни одной. Поскольку на практике невозможно одновременно и атомарно выполнить всю последовательность операций внутри
транзакции, вводится понятие «отката» (ROLLBACK): если транзакцию
не удаётся полностью завершить, результаты всех её до сих пор произведённых действий будут отменены и система вернётся в исходное состояние.
SET NOCOUNT ON;
--Состояние до начала транзакции
SELECT
'До транзакции' AS "Состояние"
,NAME AS "Владелец"
,MONY AS "Сумма"
,@@SPID AS "Процесс"
,@@TRANCOUNT AS "Количество транзакций"
FROM TRANSACTION1.DBO.TABLE1 ORDER BY NAME;
124
Рисунок 8.2 – Информация о состоянии и номер процесса транзакции
Определяем количество транзакций для сеанса подключения:
--Начало транзакции
BEGIN TRANSACTION;
SELECT
@@TRANCOUNT AS "Количество транзакций";
UPDATE TRANSACTION1.DBO.TABLE1
SET MONY -= 50
WHERE NAME=N'Банк';
SELECT
'До транзакции' AS "Состояние"
,NAME AS "Владелец"
,MONY AS "Сумма"
,@@SPID AS "Процесс"
,@@TRANCOUNT AS "Количество транзакций"
FROM TRANSACTION1.DBO.TABLE1 ORDER BY NAME;
Для того чтобы прервать процесс транзакции и тем самым проверить
ее на атомарность, в новом запросе компонента используем:
KILL (номер процесса);
UPDATE TRANSACTION1.DBO.TABLE1
SET MONY += 50
WHERE NAME=N'Потребитель';
SELECT
'До транзакции' AS "Состояние"
,NAME AS "Владелец"
,MONY AS "Сумма"
,@@SPID AS "Процесс"
,@@TRANCOUNT AS "Количество транзакций"
FROM TRANSACTION1.DBO.TABLE1 ORDER BY NAME;
При возможной ошибке всё вернётся к первоначальному состоянию.
125
8.3 Согласованность (Consistency)
Транзакция, достигающая своего нормального завершения (EOT –
end of transaction, завершение транзакции), а, следовательно, фиксирующая свои результаты, сохраняет согласованность базы данных. Другими
словами, каждая успешная транзакция по определению фиксирует только
допустимые результаты. Это условие является необходимым для поддержки четвертого свойства.
Согласованность является более широким понятием. Например, в
банковской системе может существовать требование равенства суммы,
списываемой с одного счёта, сумме, зачисляемой на другой. Это бизнесправило и оно не может быть гарантировано только проверками целостности, его должны соблюсти программисты при написании кода транзакций.
Если какая-либо транзакция произведёт списание, но не произведёт зачисление, то система останется в некорректном состоянии и свойство согласованности будет нарушено.
Наконец, ещё одно замечание касается того, что в ходе выполнения
транзакции согласованность не требуется. В нашем примере, списание и
зачисление будут, скорее всего, двумя разными подоперациями и между их
выполнением внутри транзакции будет видно несогласованное состояние
системы. Однако не нужно забывать, что при выполнении требования изоляции, никаким другим транзакциям эта несогласованность не будет видна. А атомарность гарантирует, что транзакция либо будет полностью завершена, либо ни одна из операций транзакции не будет выполнена. Тем
самым эта промежуточная несогласованность является скрытой.
Любая инструкция языка SQL будет выполняться в рамках транзакции. Такая транзакция называется транзакцией с автоматическим подтверждением (AUTOCOMMIT TRANSACTION). Подтверждение транзакции
произойдет только в том случае, если все изменения выполнены без ошибок.
SET NOCOUNT ON;
--Состояние до начала транзакции
SELECT
NAME AS “Владелец”
,MONY AS “Сумма”
FROM TRANSACTION1.DBO.TABLE1 ORDER BY NAME;
--Начало транзакции
UPDATE TRANSACTION1.DBO.TABLE1
SET MONY =
CASE NAME
WHEN N’Банк’ THEN MONY-120
WHEN N’Потребитель’ THEN MONY+120
END
WHERE NAME IN (N’Банк’, N’Потребитель’);
126
Рисунок 8.3 – Ошибка при неправильности данных
--Состояние транзакции
SELECT
NAME AS "Владелец"
,MONY AS "Сумма"
FROM TRANSACTION1.DBO.TABLE1 ORDER BY NAME;
8.4 Изолированность (Isolation)
Во время выполнения транзакции параллельные транзакции не
должны оказывать влияние на её результат. Это свойство не соблюдается
на уровне изолированности Repeatable Read и ниже.
Посмотрим, как работают изолирующие механизмы в SQL Server
(блокирующий подход).
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
SET NOCOUNT ON;
--Состояние до начала транзакции
SELECT
NAME AS "Владелец"
,MONY AS "Сумма"
FROM TRANSACTION1.DBO.TABLE1 ORDER BY NAME;
BEGIN TRANSACTION;
SELECT
@@TRANCOUNT AS "Количество транзакций";
UPDATE TRANSACTION1.DBO.TABLE1
SET MONY -= 70
WHERE NAME=N'Банк';
Просмотрим состояние в середине выполнения транзакции:
SELECT
NAME AS "Владелец"
,MONY AS "Сумма"
FROM TRANSACTION1.DBO.TABLE1 ORDER BY NAME;
Что произойдет, если данные попытается посмотреть транзакция,
находящаяся в параллельном сеансе подключения? Рассмотрим ситуацию
подробнее.
127
8.4.1 Уровень изолированности транзакции READ UNCOMMITTED
Тем самым заявляем, что хотим видеть любые изменения:
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
SET NOCOUNT ON;
--Читаем неподтвержденные данные
SELECT
NAME AS "Владелец"
,MONY AS "Сумма"
FROM TRANSACTION1.DBO.TABLE1 ORDER BY NAME;
Рисунок 8.4 – Просматриваем сеанс в параллельном подключении
READ UNCOMMITTED
Видим еще несогласованные данные.
8.4.2 Уровень изолированности транзакции READ COMMITTED
Такой уровень изолированности транзакции указывает на то, что
должны быть показаны только подтвержденные изменения.
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
--Читаем только подтвержденные данные
SELECT
NAME AS "Владелец"
,MONY AS "Сумма"
FROM TRANSACTION1.DBO.TABLE1 ORDER BY NAME;
Рисунок 8.5 – Попытка просмотра незавершенного сеанса в
READ COMMITTED
128
За это приходится платить временем ожидания, то есть до тех пока
не будет завершена транзакция, либо подтверждением COMMIT, либо откатом ROLLBАCK.
UPDATE TRANSACTION1.DBO.TABLE1
SET MONY += 70
WHERE NAME=N'Потребитель';
COMMIT TRANSACTION;
После подтвержденных изменений блокировка снимается, доступ к
данным предоставляется, и транзакция видит совершенно правильные соответствующие логике данные.
Рисунок 8.6 – Просмотр завершенного сеанса в READ COMMITTED
8.5
Надежность (Durability)
Независимо от проблем на нижних уровнях (к примеру, обесточивание системы или сбои в оборудовании) изменения, сделанные успешно завершённой транзакцией, должны остаться сохранёнными после возвращения системы в работу. Другими словами, если пользователь получил подтверждение от системы, что транзакция выполнена, он может быть уверен,
что сделанные им изменения не будут отменены из-за какого-либо сбоя.
SET NOCOUNT ON;
--Состояние до начала транзакции
SELECT
'До транзакции' AS "Состояние"
,NAME AS "Владелец"
,MONY AS "Сумма"
FROM TRANSACTION1.DBO.TABLE1 ORDER BY NAME;
--Начало транзакции
BEGIN TRANSACTION;
UPDATE TRANSACTION1.DBO.TABLE1
SET MONY -= 55
WHERE NAME=N'Банк';
UPDATE TRANSACTION1.DBO.TABLE1
SET MONY += 55
WHERE NAME=N'Потребитель';
129
COMMIT TRANSACTION;
--Транзакция подтверждена
Остановим весь экземпляр SQL Server, никакие данные SQL Server
при выключении экземпляра сохраняться не будут. И сразу же произойдет
мгновенное отключение всех сеансов подключения к этому экземпляру.
Для того чтобы запустить SQL Server, необходимо открыть в Средствах настройки, Диспетчер конфигурации SQL Server.
Рисунок 8.7 – Меню ПУСК
И запустить SQL Server.
Рисунок 8.8 – Диспетчер конфигурации SQL Server
--Остановка SQL Server
130
SHUTDOWN WITH NOWAIT;
--Состояние после выполнения транзакции
SELECT
'После транзакции' AS "Состояние"
,NAME AS "Владелец"
,MONY AS "Сумма"
FROM TRANSACTION1.DBO.TABLE1 ORDER BY NAME;
Рисунок 9 – Результат транзакции
Транзакция, которая была подтверждена, успешно сохранилась на
SQL Server, и остановка SQL Server мгновенно после подтверждения
транзакции не помешала сохранению изменений.
Контрольные вопросы и упражнения
1)
В чем различие SQL Server 2012 с предыдущими версиями?
2) Что такое транзакция?
3)
Для чего необходимы транзакции?
4)
Что означает атомарность транзакции?
5)
Что означает изолированность транзакции?
6)
Что означает надежность транзакции?
7)
Что означает согласованность транзакции?
8)
Какие недостатки и достоинства транзакций?
9)
Что может произойти при неправильном выполнении процедур?
10)
Внутри каких блоков находятся команды транзакции?
11)
К каким командам относится термин «транзакция»?
12)
Для чего применяется блокировка данных?
13)
Какие типы блокировки реализует SQL Server?
14)
Как задаётся уровень изоляции транзакции?
15)
Как ведётся и для чего используется журнал транзакций?
16)
Как и когда можно прервать выполнение транзакции?
17) Определить транзакцию, содержащую несколько команд модификации данных. Выполнить созданную транзакцию.
131
Глава 9. ВОССТАНОВЛЕНИЕ БАЗЫ ДАННЫХ
Модель восстановления (recovery model) – это параметр конфигурации базы данных, который управляет регистрацией транзакций, созданием
резервных копий журнала транзакций и параметрами восстановления базы
данных.
9.1 Обзор моделей восстановления
В SQL Server 2012 поддерживаются три модели восстановления базы данных: модель полного восстановления, простую модель восстановления и модель с неполным протоколированием. Эти модели определяют,
как SQL Server работает с журналом транзакций, регистрирует транзакции
и выполняет усечение журнала. Усечение журнала транзакций – это процесс удаления зафиксированных транзакций и освобождения места для регистрации новых. Вот краткое описание каждой модели восстановления.
Модель полного восстановления рекомендуется использовать при
необходимости восстановления всех данных до точки сбоя или на момент
времени, предшествовавший сбою. Модель полного восстановления означает, что ядро базы данных регистрирует в журнале транзакций все операции и никогда не выполняет усечение журнала.
Простая модель восстановления используется, если допускается потеря всех обновлений, некоторых данных в журнале, выполненных с момента предыдущего резервного копирования до момента сбоя. Простая
модель восстановления регистрирует минимум данных о большинстве
транзакций и выполняет усечение журнала транзакций после каждой контрольной точки. Эта модель восстановления не поддерживает резервное
копирование и восстановление журнала транзакций. Более того, она не
позволяет восстанавливать отдельные страницы данных.
Модель восстановления с неполным протоколированием предназначена исключительно как дополнение к модели полного восстановления.
Рекомендуется применять ее только в периоды проведения крупномасштабных массовых операций, во время которых нет необходимости восстановления базы данных на определенный момент времени.
Модель с неполным протоколированием означает, что ядро базы
данных ведет минимальную регистрацию массовых операций, таких как
SELECT INTO. Если в резервной копии журнала содержатся какие-либо
массовые операции, базу данных можно восстановить до состояния, соответствующего концу резервной копии журнала транзакций, а не до определенного момента времени.
9.2 Конфигурирование моделей восстановления
Модель восстановления базы данных можно посмотреть на странице
Свойства базы данных (Database Properties).
132
Сконфигурировать модель восстановления базы данных можно либо
на странице (рис. 9.1) Свойства базы данных (Database Properties) в
SSMS, либо с помощью инструкции ALTER DATABASE.
Рисунок 9.1 – Изменение модели восстановления
Чтобы изменить модель восстановления, необходимо выполнить
следующие действия:
в обозревателе объектов раскрыть узел Базы данных
(Databases);
щелкнуть правой кнопкой нужную базу данных и выбрать
Свойства (Properties);
выбрать вкладку Параметры (Options);
выбрать модель восстановления в списке Модель восстановления (Recovery model), как показано на рисунке 9.1.
Модель восстановления можно также сконфигурировать с помощью
инструкции ALTER DATABASE со следующим синтаксисом:
ALTER DATABASE <имя_базы_данных>
SET RECOVERY FULL | SIMPLE | BULK_LОGGED
Для баз данных рекомендуется использовать модель полного восстановления, потому что она обладает наибольшими возможностями восстановления. Если периодически используются массовые операции для импорта данных, можно временно менять модель восстановления базы дан133
ных на модель с неполным протоколированием, чтобы повысить производительность массовых операций. Затем, после завершения импорта, вернуться к модели полного восстановления.
9.3 Резервное копирование
Очень важно, чтобы у администратора базы данных была хотя бы
одна копия базы данных на случай сбоя. Для этого чаще всего используется резервное копирование. Резервное копирование базы данных – это самая обычная операция, что, однако, не умаляет ее важности для стратегии
восстановления (restore strategy), определяющей порядок восстановления
базы данных с учетом допустимого времени простоя и максимальной потери данных. Без стратегии восстановления резервное копирование фактически не имеет смысла. Ниже описаны гибкие возможности Microsoft SQL
Server по резервному копированию базы данных и объясняется, как использовать резервные копии для восстановления данных на определенный
момент времени. С помощью резервного копирования/восстановления, отсоединения/присоединения и мастера копирования баз данных осуществляется перемещение базы данных.
9.3.1 Выполнение полного резервного копирования
Полное резервное копирование базы данных позволяет сохранить текущее состояние всех данных, хранящихся в базе.
Механизм резервного копирования выполняет резервное копирование за минимальное время и с использованием минимума ресурсов.
При запуске резервного копирования не требует сохранения точного
порядка страниц, SQL Server может открыть несколько потоков и записывать данные настолько быстро, насколько это позволяет сделать носитель
информации. Скорость резервного копирования ограничена только скоростью записи данных на устройство.
Механизм резервного копирования выполняет эту задачу, извлекая
все экстенты базы данных, выделенные для объектов. Затем полную резервную копию можно использовать для восстановления всей базы данных. Этот метод резервного копирования возможен всегда, независимо от
выбранной для базы данных модели восстановления.
Для хранения объекта в SQL Server выделяется экстент.
Механизм резервного копирования извлекает все страницы, выделенные для объекта, и, поскольку за один раз для объекта выделяется один
экстент, механизм резервного копирования фактически сохраняет все экстенты, выделенные для объектов, независимо от того, записал SQL Server
данные во все страницы этого экстента или нет.
Поскольку резервное копирование не является мгновенным и иногда
выполняется в то время, когда пользователи подключены к базе данных и
создают запросы, возможна логическая противоречивость базы данных.
Например, если страница данных была записана на резервный носитель, а
134
затем изменена другим запросом, восстановление этой резервной копии
приведет базу данных в противоречивое состояние.
Однако SQL Server не позволяет этому случиться, потому что в ходе
полного резервного копирования выполняется следующая последовательность действий:
SQL Server блокирует базу данных и все транзакции;
в журнал транзакций добавляется маркер;
снимается блокировка базы данных;
выполняется резервное копирование всех страниц базы данных;
устанавливается блокировка базы данных и всех транзакций;
в журнал транзакций добавляется маркер;
отключается блокировка базы данных;
извлекаются все транзакции между двумя маркерами в журнале транзакций и добавляются в резервную копию.
Этот процесс гарантирует, что база данных полностью согласована
на момент завершения резервного копирования.
Рисунок 9.2 – Процесс создания резервной копии
Листинг 9.1 – Команда для выполнения резервного копирования
BACKUP DATABASE <имя_базы_данных> TO DISK = '<папка>\<имя_файла.Bak>' WITH INIT
GO
В предложении ТО инструкции BACKUP DATABASE (лист. 9.1)
указывается устройство резервного копирования, на котором будет сохра135
нена резервная копия. Это может быть имя созданного логического
устройства резервного копирования или полный путь к диску (DISK) или
ленте (ТАРЕ).
В предложении WITH можно указать больше десятка параметров –
все они необязательные. Параметр INIT указывает SQL Server перезаписать на устройстве резервного копирования все имеющиеся резервные
наборы данных до начала операции резервного копирования.
9.3.2 Выполнение разностного резервного копирования
Разностное резервное копирование сохраняет все экстенты, которые
были изменены с момента последнего полного резервного копирования.
Разностное резервное копирование позволяет уменьшить число резервных
копии журнала транзакций. Разностное резервное копирование используется совместно с полной копией. При отсутствии полной копии разностную копию создать невозможно. Как и в случае полного резервного копирования, разностное резервное копирование можно выполнять независимо
от выбранной для базы данных модели восстановления.
При разностном резервном копировании всегда сохраняется каждый
экстент, измененный с момента последнего полного резервного копирования.
Инструкция для выполнения разностного резервного копирования:
BACKUP DATABASE <имя_базы_данных>
ка>\<имя файла>' WITH DIFFERENTIAL
TO DISK = '<пап-
Эта инструкция почти не отличается от инструкции для полного резервного копирования базы данных за исключением параметра
DIFFERENTIAL, который обозначает, что копируются только части, измененные с момента последнего полного резервного копирования базы
данных.
Для определения экстентов, которые должны войти в разностную резервную копию, SQL Server использует карту размещения экстентов. Карта размещения экстентов - это всего лишь еще одна страница данных в базе данных, каждый бит которой представляет один экстент.
Когда SQL Server изменяет экстент, он изменяет и соответствующий
ему бит с 0 на 1. При создании полной резервной копии SQL Server сбрасывает все биты до 0. Таким образом, чтобы определить экстенты, которые
нужно сохранить, SQL Server должен обратиться только к этой странице,
которая покрывает тысячи страниц данных.
9.3.3 Резервное копирование журнала транзакций
Резервные копии журнала транзакций можно создавать только для
баз данных, в которых установлена модель полного восстановления или
модель восстановления с неполным протоколированием и в которых не
выполнялись минимально протоколируемые транзакции.
136
Журнал транзакций это основной компонент системы управления базами данных (СУБД). Все изменения в базе данных записываются в журнал транзакций.
Резервное копирование журнала транзакций сохраняет активный
журнал. Оно начинается с номера транзакции в журнале (номер LSN), на
котором завершилось предыдущее резервное копирование журнала транзакций. Затем SQL Server сохраняет все последующие транзакции до тех
пор, пока не обнаружится открытая транзакция. Обнаружив открытую
транзакцию, SQL Server завершает резервное копирование журнала транзакций. Все сохраненные номера LSN затем могут быть удалены из журнала транзакций, что позволяет системе повторно использовать его пространство.
Команда для резервного копирование журнала транзакций имеет вид:
BACKUP LOG <имя_базы_данных> TO DISK =
файла>' WITH INIT
'<папка>\<имя
9.4 Восстановление базы данных
В этом разделе рассматриваются возможности восстановления всей
базы данных или ее части в SQL Server 2012 после сбоя.
9.4.1 Восстановление полной резервной копии
Полная резервная копия содержит всю информацию базы данных.
Чтобы реконструировать базу данных, операция восстановления должна по
порядку поместить файлы обратно в базу данных.
Восстановление полной резервной копии перезаписывает базу данных с тем же именем, если она уже существует на экземпляре, или создает
для базы данных файлы и файловые группы перед тем, как восстанавливать страницы. Для перемещения базы данных на другой сервер с другой
или измененной структурой папок, можно воспользоваться параметром
WITH MOVE.
Пример синтаксиса для полного восстановления базы данных:
RESTORE DATABASE <имя_базы_данных> FROM DISK = ‘<папка>\<имя файла>'
WITH NORECOVERY
GO
Эта команда использует содержимое файла сохраненной базы данных для восстановления.
Есть еще два важных предложения в любой команде восстановления
– WITH RECOVERY и WITH NORECOVERY.
Когда в операции восстановления использован параметр WITH
RECOVERY, база данных приводится в рабочее состояние, но дальнейшие операции восстановления невозможны.
137
Когда в операции восстановления используется параметр WITH
NORECOVERY, база данных или файловая группа остаются в состоянии
RESTORING. В этом состоянии можно восстанавливать дополнительные
резервные копии, что позволяет применить все изменения, внесенные после создания полной резервной копии.
9.4.2 Восстановление разностной резервной копии
Чтобы восстановить разностную резервную копию, нужно сначала
восстановить полную копию, но не восстанавливать базу данных. Затем к
базе данных применяется наиболее поздняя разностная копия.
Процесс восстановления разностной резервной копии файловой
группы очень похож на восстановление разностной копии. Для этого сначала нужно выполнить полное восстановление файловой группы, но при
этом не восстанавливать файловую группу (лист. 9.2).
Листинг 9.2 – Пример последовательности операций, при которой
сначала создается полная резервная копия, а затем разностная резервная
копия
RESTORE DATABASE <имя_базы_данных>
‘<папка>\<имя файла>' WITH NORECOVERY;
FROM
DISK
=
RESTORE LOG <имя_базы_данных> FROM DISK = ‘<папка>\<имя
файла>' WITH RECOVERY, STOPAT = 'Apr 15, 2020 12:00 AM';
Первая команда восстанавливает полную резервную копию, оставляя
базу данных невосстановленной. Вторая команда применяет разностную
резервную копию и затем восстанавливает базу данных.
9.4.3 Восстановление резервной копии журнала транзакций
Резервная копия журнала транзакций содержит последовательность
транзакций, на определенный момент времени соответствующих LSN.
С помощью параметра STOPAT можно задать восстановление базы
данных до определенного номера LSN конкретной транзакции или момента времени.
При наличии всех полных резервных копий и всех последовательных
копий журнала транзакций всегда можно восстановить базу данных на любой момент времени, начав с любой полной резервной копии и затем применив все последовательные резервные копии журнала транзакций.
Приведем пример двух различных последовательностей восстановления (лист. 9.3-9.4).
Листинг 9.3 – Последовательность восстановления с помощью резервной копии журнала транзакций
138
RESTORE LOG <имя_базы_данных> FROM DISK = ‘<папка>\<имя
файла>'
Листинг 9.4 – Последовательность восстановления с помощью полной резервной копии и нескольких резервных копий журнала транзакций.
– Полная резервная копия.
RESTORE DATABASE <имя_базы_данных>
FROM DISK = ‘<папка>\<имя файла>'
FILEGROUP - 'FGV
– Резервная копия журнала транзакций.
RESTORE LOG <имя_базы_данных> FROM DISK = ‘<папка>\<имя
файла>' WITH NORECOVERY
RESTORE LOG <имя_базы_данных> FROM DISK - ‘<папка>\<имя
файла>' WITH RECOVERY
При любом восстановлении базы данных нужно выполнить инструкцию BACKUP LOG (лист. 9.5).
Листинг 9.5 – Резервноу копирование заключительного фрагмента
журнала
BACKUP LOG <имя_базы_данных>
TO DISK = ‘<папка>\<имя файла>';
GO
9.5 Выполнение частичного восстановления
Новая возможность в SQL Server 2012 позволяет восстанавливать
базу данных частично, в то время как оставшаяся ее часть доступна для запросов.
Частичное восстановление выполняется благодаря тому, что каждая
файловая группа, за исключением первичной, имеет состояние, независимое от базы данных. Частичное восстановление всегда производится с
применением резервных копий файловых групп.
В зависимости от конструкции базы данных восстановление файловой группы может отразиться на нескольких таблицах, на одной таблице
или, в случае секционирования, на фрагменте таблицы.
После того как файловые группы восстановлены в базу данных,
можно применить разностные резервные копии и/или резервные копии
журнала транзакций, чтобы привести базу данных в соответствие со всеми
остальными файловыми группами.
Невозможно восстановить только часть базы данных на определенный момент времени, поскольку необходимо выполнить откат вперед всех
файловых групп к текущему номеру LSN, чтобы разрешить запись в отдельную файловую группу.
139
9.6 Восстановление поврежденных страниц
Восстановление страниц предназначено для исправления отдельных
поврежденных страниц. Восстановление нескольких отдельных страниц
может потребовать меньше времени, чем восстановление файла, и уменьшить объем данных, которые будут недоступны во время операции восстановления. В SQL Server 2012 есть другой способ решения этой проблемы.
Для
этого
нужно
воспользоваться
параметром
PAGE_VERIFY_CHECKSUM (лист. 9.6). После включения этой проверки в базе данных все испорченные страницы регистрируются в журнале и
изолируются.
Листинг 9.6 – Команда включения проверки страниц
ALTER
CHECKSUM
DATABASE
<имя_базы_данных>
SET
PAGE_VERIFY
Этот параметр по умолчанию отключен, поскольку он приводит к
небольшим издержкам при чтении и записи любой страницы базы данных.
Для исправления ошибки можно восстановить отдельную страницу из резервной копии (лист. 9.7).
Листинг 9.7 – Пример восстановления поврежденной страницы
RESTORE DATABASE <имя_базы_данных>
PAGE = 'file : page [ ,...n ]' [ ,...n ]
FROM <устройство_резервного_копирования> [ ,...n ]
WITH NORECOVERY
Контрольные вопросы и упражнения
Назовите три модели восстановления базы данных.
Дайте характеристику модели полного восстановления.
Дайте характеристику простой модели восстановления.
Дайте характеристику модели восстановления с неполным
протоколированием.
5) Что такое резервное копирование? Виды резервного копирования.
6) Что такое журнал транзакций?
7) Опишите процесс восстановления базы данных.
8) Особенности восстановления разностной резервной копии.
9) Какой параметр используется для восстановления поврежденных страниц?
10) Измените конфигурацию модели восстановления с помощью
запроса.
11) Выполните резервное копирование базы данных.
12) После внесения изменений в базу данных выполните разностное резервное копирование.
1)
2)
3)
4)
140
13) Выполните резервное копирование журнала транзакций.
14) Выполните восстановление резервной базы данных и журнала
транзакций.
141
Глава 10. АДМИНИСТРИРОВАНИЕ
10.1 Управление доступом к SQL Server 2012
Чтобы пользователь мог работать с БД или выполнять задания на
уровне сервера, SQL Server 2012 должен проверить его подлинность. В
SQL Server 2012 существует два режима проверки подлинности:
проверка средствами Windows;
проверка средствами SQL Server.
Для того чтобы пользователь имел возможность выполнять какиелибо действия, администратором SQL Server 2012 должна быть создана
учетная запись для этого пользователя с необходимыми разрешениями.
Чтобы разрешить пользователями доступ к SQL Server 2012, администратор должен определить права существующих учетных записей или
создать новые.
10.1.1 Проверка подлинности средствами Windows
После прохождения проверки подлинности пользователя в домене,
ОС предложит SQL Server 2012 доверять результатам такой проверки и
предоставить доступ на основании указанных логина и пароля. Для подтверждения личности пользователя передается билет Kerberos или маркер
доступа. SQL Server проверяет аутентичность билета Kerberos или маркера доступа и сравнивает полученные данные со списком пользователей и
групп, которым разрешен доступ. После этого SQL Server либо предоставляет, либо отказывает в доступе.
10.1.2 Проверка подлинности средствами SQL Server
Пользователь может предложить проверить его подлинность средствами SQL Server 2012 на основе указанных логина и пароля. SQL
Server, получая от пользователя связку логин-пароль, сравнивает их со
списком зарегистрированных пользователей. Информация о пользователях
SQL Server 2012 хранится в таблице sysxlogins. По окончании проверки
подлинности пользователя SQL Server либо предоставляет доступ, либо
отказывает в нем.
10.1.3 Выбор режима проверки подлинности
При установке SQL Server 2012 выбирается требуемый режим проверки подлинности:
Проверка подлинности Windows – пользователь может подключиться к SQL Server 2012, только используя учетную запись Windows.
Смешанный режим – пользователь может подключиться к SQL
Server 2012 как с использованием учетной записи Windows, так и с использованием учетной записи в SQL Server 2012.
142
10.1.4 Смена режимов проверки подлинности
Для смены режимов используйте MS SQL Server Management
Studio. В дереве консоли выберите Properties в выпадающем меню для
необходимого экземпляра сервера.
Рисунок 10.1 – Диалоговое окно Server Properties
На вкладке Security (рис. 10.1) нужно установить переключатель в
одно из необходимых положений. Для того чтобы изменения вступили в
силу необходимо перезапустить SQL Server 2012 и перезагрузить Windows.
10.1.5 Управление разрешениями
В SQL Server 2012 есть несколько предопределенных ролей уровня
сервера (таблица 10.1), обладающих правами администратора. Нельзя
удалить роли сервера или изменить их права.
Чтобы предоставить эти права пользователю, требуется добавить его
учетную запись в состав роли сервера.
143
Таблица 10.1 – Роли сервера и их описание
Роль
Sysadmin
Serveradmin
Setupadmin
db_owner
db_accessadmin
db_securityadmin
db_ddladmin
db_backupoperator
db_datareader
db_datawriter
db_denydatareader
db_denydatawriter
Описание
Выполняет любую задачу в любой БД SQL Server 2012.
Может конфигурировать SQL Server 2012 с использованием
системной хранимой процедуры sp_configure и останавливать
службу SQL Server 2012
Может устанавливать и изменять параметры конфигурации
удаленных и связанных серверов, а так же параметров репликации.
Может выполнять любые задачи в БД SQL Server 2012.
Имеет те же права, что владельцы БД.
Может добавлять в БД и удалять из нее пользователей
Windows или SQL Server (с помощью системной хранимой
процедуры sp_grantdbaccess)
Может управлять разрешениями, ролями, записями участников ролей и создателей объектов в БД
Может добавлять, изменять и удалять объекты
Может выполнять команды DBCC, инициировать процесс
фиксации транзакций, создавать резервные копии
Может считывать данные из пользовательских таблиц и
представлений в БД
Может изменять или удалять данные из пользовательских
таблиц и представлений в БД
Не может считывать данные из пользовательских таблиц
представлений. Эта роль может использоваться с ролью
db_ddladmin, чтобы предоставить администратору право создавать объекты, принадлежащие роли DBO, и при этом запретить чтение важных или секретных данных, содержащихся
в этих объектах
Не может изменять или удалять данные из пользовательских
таблиц в БД
10.1.6 Создание и управление учетными записями
Для создания учетной записи пользователя SQL Server 2012 воспользуйтесь мастером Create Login Wizard из SQL Server Management
Studio.
После запуска Create Login Wizard необходимо определить режим
проверки подлинности для создаваемой учетной записи.
Если была выбрана проверка подлинности Windows, то можно привязать идентификатор учетной записи к существующему пользователю или
группе Windows. Так же можно предоставить или запретить доступ к серверу этому пользователю или группе.
Если была выбрана проверка подлинности SQL Server, то необходимо создать учетную запись SQL Server 2012. Задайте имя и пароль нового пользователя SQL Server 2012. Чтобы запретить доступ, нужно удалить учетную запись из списка Logins в SQL Server Management Studio
или из таблицы sysxlogins БД master.
144
10.1.7 Учетные записи SQL Server
В таблице 10.2 перечислены системные хранимые процедуры, которые используются для предоставления или запрещения доступа и для изменения прав доступа учетной записи, связанной с регистрационной записью SQL Server 2012.
Таблица 10.2 – Системные хранимые процедуры для управления доступом
Системная хранимая процедура
sp_addlogin 'учетная_запись',
['пароль', 'база_данных' ,
'язык', 'sid', 'опция_шифрования']
sp_droplogin 'учетная__запись'
sp_password 'старый_пароль',
'новый_пароль' Учетная_запись’
sp_defaultdb 'учетная_запись',
'база_данных'
sp_defaultlanguage
'учетная_запись', 'язык'
Описание
Создает новую учетную запись SQL Server.
Удаляет учетную запись SQL Server
Добавляет или изменяет пароль учетной записи
Изменяет БД, установленную по умолчанию для
данной учетной записи
Изменяет язык, установленный по умолчанию для
данной учетной записи
Листинг 10.1 – Пример создания новой учетной записи userlogin c
паролем userpass и БД по умолчанию uch_proc:
sp_addlogin 'userlogin' , 'userpass' , 'uch_proc'
10.1.8 Роли сервера
Существуют две системные хранимые процедуры, которые используются для добавления и удаления участника роли сервера:
sp_addserverrolemember ‘учетная_запись’, ‘роль’ - добавление
sp_dropsrvrolemember ‘учетная_запись’, ‘роль’ - удаление
10.1.9 Доступ к базе данных
Существуют две системные хранимые процедуры, которые используются для добавления или удаления учетной записи или пользователя или
группы Windows как зарегистрированного пользователя к текущей БД:
sp_grantdbaccess ‘учетная_запись’, ‘имя в БД’ - добавление
sp_revokedbaccess ‘имя’ - удаление
Только участники роли сервера sysadmin и постоянных ролей БД
db_accessadmin и db_owner могут использовать эти хранимые процедуры.
145
Листинг 10.2 – Пример предоставления учетной записи userlogin доступа к текущей БД с использованием имени пользователя userlogin БД
uch_proc.
USE uch_proc
EXEC sp_grantdbaccess 'userlogin'
10.1.10 Роли базы данных
В таблице 10.3 перечислены системные хранимые процедуры, которые используются для изменения владельца БД, добавления или удаления
записи пользователя, создания или удаления роли БД, определенной пользователем.
Таблица 10.3 – Системные хранимые процедуры, которые используются для изменения владельца БД
Системная хранимая процедура
sp_changedbowner ' учетная_запись',
remap_alias_flag sp_addrolemember
'роль', 'регистрационная_записъ'
sp_droprolemember 'роль',
'регистрационная_запись'
sp_addrole 'роль', 'владелец’
sp_droprole 'роль'
Описание
Изменяет владельца пользовательской БД. Добавляет регистрационную запись к роли БД текущей базы.
Удаляет регистрационную запись из роли БД
текущей базы.
Создает новую роль, определенную пользователем, в текущей БД.
Удаляет роль, определенную пользователем, из
текущей БД.
Листинг 10.3 – Пример добавления к роли db_securityadmin БД
uch_proc записи пользователя userlogin2
Use uch_proc
EXEC sp_addrolemember 'db_securityadmin' , 'userlogin2'
10.1.11 Управление разрешениями SQL Server
После предоставления доступа к SQL Server 2012 и его БД пользователям и группам Windows, а так же, при необходимости, пользователям
SQK Server 2012, необходимо назначить им соответствующие разрешения.
10.1.12 Предоставление разрешений уровня базы данных
Пользователю БД необходимы разрешения на работу с данными, выполнение хранимых процедур, создание объектов БД и выполнение административных задач.
Пользователи получают разрешения доступа к БД следующими способами:
членство в серверной роли sysadmin,
право собственности на БД,
146
право собственности на объект БД,
членство в фиксированной роли БД,
отдельные разрешения доступа,
наследование разрешений роли public,
наследование разрешений пользователя guest.
10.1.13 Разрешения на выполнение операторов
Разрешения на выполнение операторов (statement permissions) – это
разрешения на выполнение отдельных операторов T-SQL, используемых
для создания БД и их объектов, например таблиц, представлений и хранимых процедур.
10.1.14 Разрешения уровня объекта
Разрешения доступа к объектам – это разрешения на выполнение
определенных операций с таблицами, представлениями, функциями и хранимыми процедурами.
Предоставление, блокировка или отзыв разрешений доступа для
каждого из операторов может выполняться членами роли сервера sysadmin
и фиксированных ролей БД db_owner и db_securityadmin.
10.2 Конфигурирование SQL Server. Изменение параметров конфигурации
Отображает или изменяет глобальные параметры конфигурации текущего сервера процедура sp_configure.
Общий синтаксис процедуры изменения параметров конфигурации
сервера sp_configure:
sp_configure [ [ @configname = ] 'option_name'
[ , [ @configvalue = ] 'value' ] ]
[@configname=] 'option_name' – имя параметра конфигурации;
[@configvalue =] 'value' – новое значение параметра конфигурации.
Соединения
Для изменения параметров пользовательского соединения с помощью SQL Server Management Studio щелкните правой кнопкой мыши на
имени сервера параметры соединений, который требуется изменить, затем
«Properties», далее перейдите в раздел «Connections» (рис. 10.2).
В таблице 10.4 описаны параметры пользовательского соединения,
при этом используются названия, определяемые процедурой sp_configure.
147
Таблица 10.4 – Параметры соединения
Название
параметра
User connections
User options
Remote access
Remote proc trans
Remote query
timeout
Описание
Определяет
число
пользователей,
которые
могут
одновременно подключиться к SQL Server.
Определяет параметры обработки запросов для всех
пользовательских
соединений,
устанавливаемые
по
умолчанию.
Разрешает или запрещает удаленный доступ с помощью
удаленных хранимых процедур.
Требует использования MS DTC при распределенных
транзакциях, чтобы обезопасить процесс выполнения
процедур на нескольких серверах.
Определяет время ожидания удаленного запроса SQL Server.
Рисунок 10.2 – Изменение параметров настройки клиентского соединения
148
Листинг 10.5 – Изменение системного параметра User connections в
БД uch_pro
USE uch_pro;
GO
EXEC sp_configure 'show advanced option', '1';
EXEC sp_configure 'User connections' , '3';
RECONFIGURE WITH OVERRIDE;
Параметр show advanced option следует использовать для отображения дополнительных параметров системной хранимой процедуры
sp_configure. Для получения возможности изменения дополнительных параметров конфигурации необходимо установить значение show advanced
option = 1.
База данных
Чтобы изменить параметры настройки БД с помошью SQL Server
Management Studio, в дереве консоли надо щелкнуть правой кнопкой имя
нужного экземпляра, выбрать Properties и в открывшемся диалоговом
окне SQL Server Properties перейти в раздел Options.
В таблице 10.5 описаны параметры настройки БД, используемые
системной хранимой процедурой sp_configure.
Таблица 10.5 – Параметры настройки БД
Название параметра
Fill factor
Media retention
Recoveru interval
Описание
Определяет процент заполнения страницы индекса при
создании нового индекса на основе существующих данных.
Определяет срок хранения каждой резервной копии.
Задает
время
завершения
операции
автоматического
восстановления (в минутах), тем самым определяя частоту
запуска процесса контрольной точки.
Память
Чтобы изменить параметры конфигурации памяти с помощью SQL
Server Management Studio, в дереве консоли щелкните правой кнопкой
имя экземпляра, выберите Properties и в раскрывшемся диалоговом окне
SQL Server Properties (Configure) перейдите в раздел Memory.
В таблице 10.6 описаны параметры конфигурации памяти, используемые системной хранимой процедурой sp_configure.
149
Таблица 10.6 – Параметры конфигурации памяти
Название параметра
Описание
Определяет максимальный размер памяти, которую SQL Server
Max server memory
может использовать для буферного пула.
Определяет минимальный размер памяти, используемый SQL
Min server memory
Server для буферного пула.
Устанавливает дополнительный объем физической памяти для
Set working set size
SQL Server. Используется с параметрами настройки
минимальной и максимальной памяти сервера.
Определяет минимальный объем памяти (в килобайтах),
Min memory per query предоставляемой
каждому
запросу.
По
умолчанию
определяется динамически.
Процессор
Чтобы изменить параметры конфигурации процессора с помощью
SQL Server Management Studio, в дереве консоли щелкните правой кнопкой нужный экземпляр сервера, выберите Properties и в открывшемся диалоговом окне Properties перейдите в раздел Processors.
В таблице 10.7 перечислены параметры настройки процессора, используемые системной хранимой процедурой sp_configure.
Таблица 10.7 – Параметры настройки процессора
Название
параметра
Affinity mask
Cost threshold for
parallelism
Lightweight pooling
Priority boost
Max degree of
parallelism
Max worker threads
Описание
Исключает процессор в многопроцессорной системе из
обработки потоков SQL Server.
Определяет короткие и длинные планы выполнения запросов. С
помощью этого параметра SQL Server определяет, когда ему
следует переходить к параллельному выполнению запросов.
Влияет на образование волокон в потоках (режим
планирования волокон) или на планирование потоков при
выполнении заданий.
Определяет приоритет планирования для процессора в SQL
Server.
Устанавливает число процессоров, параллельно выполняющих
план.
Определяет число рабочих потоков, доступных процессам SQL
Server.
Сервер
Чтобы изменить параметры настройки сервера с помощью SQL
Server Management Studio, в дереве консоли щелкните правой кнопкой
имя нужного экземпляра SQL Server, выберите Properties и в открывшемся диалоговом окне Properties перейдите в раздел Advanced.
В таблице 10.8 перечислены параметры настройки сервера, используемые системной хранимой процедурой sp_configure.
150
С помощью SQL Server Management Studio также можно установить язык, который будет использоваться по умолчанию для серверных сообщений.
Таблица 10.8 – Параметры настройки сервера
Название параметра
Allow updates
Nested triggers
Query governor
cost limit
Two digit year cutoff
Описание
Определяет, можно ли напрямую обновлять системные
таблицы. Если это запрещено, пользователь не может
непосредственно изменять таблицы, даже если данное право
было ему предоставлено с помощью оператора GRANT.
Контролирует
использование
каскадных
триггеров.
Максимально допустимый уровень вложенности — 32.
Определяет время обработки запроса (в секундах).
Определяет две предыдущие цифры при использовании только
двух последних в записи года, По умолчанию равно 2049, это
означает, что 49 интерпретируется как 2049 год, а 50 — как
1950 год.
Контрольные вопросы и упражнения
1) Какие режимы проверки подлинности доступны в SQL Server
2012?
2) Расскажите о режиме проверки подлинности средствами
Windows.
3) Расскажите о режиме проверки подлинности средствами SQL
Server.
4) Какие разрешения уровня сервера доступны в SQL Server 2012?
5) Как происходит управления учетными записями в SQL Server
2012?
6) С использованием каких системных хранимых процедур происходит управление учетными записями в SQL Server 2012?
7) Роли сервера – расскажите о них.
8) Каким образом происходит настройка разрешений на доступ к
базе данных?
9) Какие системные хранимые процедуры используются для
настройки ролей БД?
10) Расскажите про управление разрешениями на выполнение операторов.
11) Расскажите про управление разрешениями уровня объекта.
12) Расскажите про изменение параметров конфигурации: Соединения.
13) Расскажите про изменение параметров конфигурации: База данных.
14) Расскажите про изменение параметров конфигурации: Память.
15) Расскажите про изменение параметров конфигурации: Процессор.
151
16) Расскажите про изменение параметров конфигурации: Сервер.
17) Смените режим проверки подлинности в SQL Server 2012.
18) Создайте новую учетную запись в SQL Server 2012.
19) Используя системную хранимую процедуру sp_configure, измените параметры конфигурации: соединения.
20) Используя системную хранимую процедуру sp_configure, измените параметры конфигурации: база данных.
21) Используя системную хранимую процедуру sp_configure, измените параметры конфигурации: память.
22) Используя системную хранимую процедуру sp_configure, измените параметры конфигурации: процессор.
23) Используя системную хранимую процедуру sp_configure, измените параметры конфигурации: сервер.
152
Глава 11. ШИФРОВАНИЕ В SQL SERVER
Современные информационные системы хранят очень большие объемы информации, значительная часть которой является конфиденциальнокорпоративной, нежелательной для несанкционированного ознакомления,
и нуждающаяся в защите. Тем более, еще более строгая защита требуется
персональной информации, например, сведениям о клиентах.
Для таких ситуаций в последние версии SQL Server включено несколько расширений Transact-SQL и встроенных функций, направленных
на обеспечение более легкой защиты информации в БД. Это, прежде всего,
аспекты, связанные с шифрованием данных.
Рассмотрим некоторые из указанных возможностей.
11.1 Ключи шифрования
Модель шифрования SQL Server в основном предоставляет функции
управления ключами шифрования, соответствующие стандарту ANSI
X9.17. В этом стандарте определены несколько уровней ключей шифрования, использующихся для шифрования других ключей, которые в свою
очередь применяются для шифрования собственно данных. В таблице перечислены уровни ключей шифрования SQL Server и ANSI X9.17.
Таблица 11.1 – Уровни ключей шифрования SQL Server и
ANSI X9.17
Уровень SQL Server
SMK
Уровень ANSI X9.17
Главный ключ
DMK
Ключ шифрования ключей
Симметричные ключи, ас- Ключ данных
симетричные колючи и
сертификаты
Описание
SMK - ключ верхнего
уровня, используемый для
шифрования DMK, SMK
шифруется с применением
Windows DPAPI.
DMK - симметричный
ключ, используемый, для
шифрования симметричного ключа, асимметричного ключа и сертификата.
Для каждой базы данных
может быть только один
DMK
Симметричные ключи, ассиметричные ключи и сертификаты
используется
для шифрования данных
Главный ключ службы Service master key(SMK) – ключ верхнего
уровня и предок всех ключей в SQL Server. SMK – асимметричный ключ,
шифруемый с использованием Windows Data Protection API (DPAPI).
SMK автоматически создается, когда шифруется какой-нибудь объект, и
153
привязан к учетной записи службы SQL Server. SMK используется для
шифрования главного ключа базы данных Database master key (DMK).
Второй уровень иерархии ключей шифрования DMK. С его помощью шифруются симметричные ключи, асимметричные ключи и сертификаты. Каждая база данных располагает лишь одним DMK.
Следующий уровень содержит симметричные ключи, асимметричные ключи и сертификаты. Симметричные ключи основное средство
шифрования в базе данных. Microsoft рекомендует шифровать данные
только с помощью симметричных ключей. Кроме того, в SQL Server есть
сертификаты уровня сервера и ключи шифрования базы данных для прозрачного шифрования данных. На рисунке 11.1 показана иерархия ключей
шифрования для SQL Server.
Рисунок 11.1 Иерархия ключей шифрования в SQL Server
11.2 Шифрование на уровне ячеек
Шифровать данные в базах данных можно несколькими способами.
Вот один из следующих методов:
Пароль. Это наименее надежный способ, так как для шифрования и расшифровки данных используется одна и та же парольная фраза.
Если хранимые процедуры и функции не зашифрованы, то доступ к парольной фразе возможен через метаданные.
Сертификат. Этот способ обеспечивает надежную защиту и
высокое быстродействие. Сертификат можно связать с пользователем;
подписать его необходимо с помощью DMK.
Симметричный ключ. Достаточно надежен, удовлетворяет
большинству требований к безопасности данных и обеспечивает достаточное быстродействие. Для шифрования и расшифровки данных используется один ключ.
Асимметричный ключ. Обеспечивает надежную защиту, так
как применяются различные ключи для шифрования и расшифровки
данных. Однако это негативно влияет на быстродействие. Специалисты
154
Microsoft не рекомендуют использовать его для шифрования крупных
значений. Асимметричный ключ может быть подписан с использованием DMK или создан с помощью пароля.
SQL Server располагает встроенными функциями для шифрования и
расшифровки на уровне ячеек. Функции шифрования:
*ENCRYPTBYKEY, использует симметричный ключ для
шифрования данных;
*ENCRYPTBYCERT, использует открытый ключ сертификата для шифрования данных;
*ENCRYPTBYPASSPHRASE, использует парольную фразу
для шифрования данных;
*ENCRYPTBYASYMKEY, использует асимметричный ключ
для шифрования данных.
Функции расшифровки:
DECRYPTBYKEY, использует симметричный ключ для
расшифровки данных;
DECRYPTBYCERT, использует открытый ключ сертификата для расшифровки данных;
DECRYPTBYPASSPHRASE, использует парольную фразу
для расшифровки данных;
DECRYPTBYASYMKEY, использует асимметричный ключ
для расшифровки данных;
DECRYPTBYKEYAUTOASYMKEY, использует асимметричный
ключ, который автоматически расшифровывает сертификат.
SQL Server располагает двумя системными представлениями, с помощью которых можно получить метаданные для всех симметричных и
асимметричных ключей, существующих в экземпляре SQL Server. Как
видно из названий, sys.symmetric_keys возвращает метаданные для симметричных, а sys.asymmetric_keys для асимметричных ключей. Еще одно полезное представление sys.openkeys. В этом представлении каталога
содержится информация о ключах шифрования, открытых в текущем сеансе.
11.3 Демонстрация шифрования на уровне ячеек
В первую очередь создадим базу данных EncryptedDB:
USE [master]
GO
CREATE DATABASE [EncryptedDB]
GO
155
Создадим таблицу CreditCardInformation в базе данных EncryptedDB:
USE [EncryptedDB]
GO
CREATE TABLE [dbo].[CreditCardInformation]
([PersonID] [int] PRIMARY KEY,
[CreditCardNumber] [varbinary](max))
GO
Эта таблица будет содержать ложную информацию о кредитных картах. Номера кредитных карт будут сохранены в столбце двоичных переменных, потому что они будут шифроваться.
Затем используем следующий программный код для создания главного ключа DMK базы данных EncryptedDB, шифруемого с помощью парольной фразы $tr0nGPa$$w0rd:
USE [EncryptedDB]
GO
CREATE MASTER KEY
'$tr0nGPa$$w0rd'
ENCRYPTION
BY
PASSWORD
=
GO
Созданный ключ можно увидеть, выполнив:
select * from sys.key_encryptions
Удалить ключ можно инструкцией:
drop master key
Данные шифруются с использованием симметричного ключа, который будет зашифрован с помощью асимметричного ключа. Для этого
необходимо создать асимметричный ключ, зашифровать его парольной
фразой $tr0nGPa$$w0rd, создать симметричный ключ и зашифровать
симметричный ключ с помощью только что созданного асимметричного
ключа.
USE [EncryptedDB]
GO
CREATE ASYMMETRIC KEY MyAsymmetricKey
WITH ALGORITHM = RSA_2048
ENCRYPTION BY PASSWORD = 'StrongPa$$w0rd!'
GO
CREATE SYMMETRIC KEY MySymmetricKey
WITH ALGORITHM = AES_256
ENCRYPTION BY ASYMMETRIC KEY MyAsymmetricKey
GO
Теперь можно приступить к шифрованию данных. Для этого необходимо сначала открыть симметричный ключ, только что созданный с помо156
щью команды OPEN SYMMETRIC KEY, за которой следует имя симметричного ключа. Затем укажите, что нужно расшифровать его с использованием заданного асимметричного ключа. Программный код выглядит следующим образом:
USE [EncryptedDB]
GO
OPEN SYMMETRIC KEY MySymmetricKey
DECRYPTION BY ASYMMETRIC KEY MyAsymmetricKey
WITH PASSWORD = 'StrongPa$$w0rd!'
GO
После выполнения этого кода направьте запрос в представление
sys.openkeys, чтобы убедиться, что ключ открыт:
USE [EncryptedDB]
GO
SELECT * FROM [sys].[openkeys]
Будут получены результаты, аналогичные показанным на рисунке
11.2.
Рисунок 11.2 Использование представления sys.openkeys для проверки открытия ключа
Введем несколько
CreditCardInformation:
номеров
кредитных
карт
в
таблицу
DECLARE @SymmetricKeyGUID AS [uniqueidentifier]
SET @SymmetricKeyGUID =
KEY_GUID('MySymmetricKey')
IF (@SymmetricKeyGUID IS NOT NULL)
BEGIN
INSERT INTO [dbo].[CreditCardInformation] VALUES
(04,
ENCRYPTBYKEY(@SymmetricKeyGUID,N'234987329470wkfdsdfhkjlh'))
INSERT INTO [dbo].[CreditCardInformation] VALUES
(05, ENCRYPTBYKEY(@SymmetricKeyGUID,N'dftyuiop'))
INSERT INTO [dbo].[CreditCardInformation] VALUES
(06, ENCRYPTBYKEY(@SymmetricKeyGUID,N'ghjk'))
END
Направим запрос к таблице CreditCardInformation:
SELECT * FROM [dbo].[CreditCardInformation]
157
Как показано на рисунке 11.3, все данные в столбце CreditCardNumber представлены в двоичном формате.
Рисунок 11.3 Исследование зашифрованных данных
С помощью функции DECRYPTBYKEY можно просмотреть зашифрованные данные:
USE [EncryptedDB]
GO
SELECT [PersonID],
CONVERT([nvarchar](32), DECRYPTBYKEY(CreditCardNumber))
AS [CreditCardNumber]
FROM [dbo].[CreditCardInformation]
GO
Результаты показаны на рисунке 11.4.
Рисунок 11.4 Использование функции DECRYPTBYKEY для просмотра зашифрованных данных
11.4 Шифрование с использованием сертификата
В случае шифрования с использованием сертификата данные шифруются посредством асимметричного ключа, но на этот раз симметричный
ключ шифруется сертификатом. Сначала создается сертификат с помощью
инструкции CREATE CERTIFICATE.
CREATE CERTIFICATE [CertToEncryptSymmetricKey]
WITH SUBJECT = 'Самозаверяющий сертификат для
шифрования симметричного ключа.'
Проверка наличия созданного сертификата:
select * from sys.certificates
where name='CertToEncryptSymmetricKey'
Затем создается симметричный ключ, шифруемый сертификатом.
CREATE
edWithCert]
SYMMETRIC
KEY
158
[SymmetricKeyEncrypt-
WITH ALGORITHM = AES_256
ENCRYPTION BY CERTIFICATE
ricKey]
[CertToEncryptSymmet-
Открываем симметричный ключ.
OPEN
SYMMETRIC
KEY
edWithCert]
DECRYPTION BY CERTIFICATE
ricKey]
[SymmetricKeyEncrypt[CertToEncryptSymmet-
Наконец, открыв симметричный ключ, код вставляет три строки в
таблицу CreditCardInformation.
DECLARE @SymmetricKeyGUID AS [uniqueidentifier]
SET @SymmetricKeyGUID =
KEY_GUID('SymmetricKeyEncryptedWithCert')
IF (@SymmetricKeyGUID IS NOT NULL)
BEGIN
INSERT INTO [dbo].[CreditCardInformation]
VALUES (01, ENCRYPTBYKEY(@SymmetricKeyGUID,
N'9876-1234-8765-4321'))
INSERT INTO [dbo].[CreditCardInformation]
VALUES (02, ENCRYPTBYKEY(@SymmetricKeyGUID,
N'9876-8765-8765-1234'))
INSERT INTO [dbo].[CreditCardInformation]
VALUES (03, ENCRYPTBYKEY(@SymmetricKeyGUID,
N'9876-1234-1111-2222'))
END
У шифрования на уровне ячеек есть свои достоинства и недостатки.
Среди достоинств – более детальный уровень шифрования, что позволяет
зашифровать единственную ячейку внутри таблицы. Кроме того, данные
не расшифровываются, пока не придет время их использовать, то есть данные из загруженной в память страницы зашифрованы. Можно назначить
ключ пользователям и защитить его паролем, чтобы предотвратить автоматическую расшифровку.
Среди недостатков шифрования на уровне ячеек – необходимость
изменения схемы, так как все зашифрованные данные должны быть сохранены с использованием типа данных varbinary. Кроме того, снижается
общая производительность базы данных из-за дополнительной обработки
при шифровании и расшифровке данных. Требует времени и просмотр
таблицы, поскольку индексы для таблицы зашифрованы и не могут быть
использованы.
11.5 Прозрачное шифрование данных (TDE)
Чтобы защитить базу данных, можно принять ряд мер предосторожности, например, спроектировать систему безопасности, проводить шиф159
рование конфиденциальных ресурсов и поместить серверы базы данных
под защиту брандмауэра. Однако в случае с похищением физического носителя (например, диска или ленты) злоумышленник может просто восстановить или подключить базу данных и получить доступ к данным. Одним
из решений может стать шифрование конфиденциальных данных в базе
данных и защита ключей, используемых при шифровании, с помощью сертификата. Это не позволит ни одному человеку, не обладающему ключами,
использовать данные, однако такой тип защиты следует планировать заранее.
Функция прозрачного шифрования данных (TDE) выполняет в реальном времени шифрование и дешифрование файлов данных и журналов
в операциях ввода-вывода. При шифровании используется ключ шифрования базы данных (DEK), который хранится в загрузочной записи базы
данных для доступности при восстановлении. Ключ шифрования базы
данных является симметричным ключом, защищенным сертификатом, который хранится в базе данных master на сервере, или асимметричным
ключом, защищенным модулем расширенного управления ключами.
Функция прозрачного шифрования данных защищает «неактивные» данные, то есть файлы данных и журналов. Она дает возможность обеспечивать соответствие требованиям многих законов, постановлений и рекомендаций, действующих в разных отраслях. Это позволяет разработчикам программного обеспечения шифровать данные с помощью алгоритмов шифрования AES и 3DES, не меняя существующие приложения.
На следующем рисунке показана архитектура прозрачного шифрования данных.
160
Рисунок 11.5 – Архитектура прозрачного шифрования
11.6 Команды и функции
Чтобы в следующих инструкциях, расположенных в таблице 11.2,
можно было использовать сертификаты TDE, они должны быть зашифрованы главным ключом базы данных. Если они зашифрованы только паролем, то они будут отклонены инструкциями как шифраторы.
Таблица 11.2 – Команды и функции
Команда или функция
CREATE DATABASE ENCRYPTION KEY
(Transact-SQL)
ALTER DATABASE ENCRYPTION KEY
(Transact-SQL)
DROP DATABASE ENCRYPTION KEY
(Transact-SQL)
Параметры ALTER DATABASE SET
(Transact-SQL)
Назначение
Создает ключ, используемый для шифрования базы данных.
Изменяет ключ, используемый для шифрования базы данных.
Удаляет ключ, использовавшийся для
шифрования базы данных.
Объясняет параметр ALTER DATABASE,
который используется для включения TDE.
161
11.7 Представления каталога и динамические административные представления
В следующей таблице показаны представления каталогов и динамические административные представления TDE.
Таблица 11.3 Представления
Представление каталога или динамическое административное представление
sys.databases (Transact-SQL)
Назначение
sys.certificates (Transact-SQL)
sys.dm_database_encryption_keys (TransactSQL)
Представление каталога со сведениями о
базе данных.
Представление каталога с сертификатами
из базы данных.
Динамическое административное представление со сведениями о ключах шифрования, используемых в базе данных, и
состоянии шифрования базы данных.
11.7 Использование прозрачного шифрования
Прежде чем использовать прозрачное шифрование рекомендуется
сделать резервную копию базы данных. В следующем примере производится резервное копирование всей базы данных на диск и создание нового
набора носителей с помощью параметра FORMAT.
USE Название_БД;
GO
BACKUP DATABASE Название_БД
TO DISK = 'Z:\SQLServerBackups\Название_БД.Bak'
WITH FORMAT,
MEDIANAME = 'Z_SQLServerBackups',
NAME = 'Full Backup of Название_БД';
GO
Чтобы использовать прозрачное шифрование данных, следует выполнить ряд шагов.
1. Создать главный ключ.
2. Создать или получить сертификат, защищенный главным ключом.
3. Создать ключ шифрования базы данных и защитить его с помощью
сертификата.
4. Задать ведение шифрования базы данных.
Чтобы разрешить прозрачное шифрование данных, необходимо создать DMK и сертификат сервера в базе данных master. Для этого выполним следующий программный код:
USE master
GO
— Создание DMK.
162
CREATE MASTER KEY ENCRYPTION BY
PASSWORD = '$tr0ngPa$$w0rd1'
GO
— Создание сертификата сервера.
CREATE CERTIFICATE Название_Сертификата
WITH SUBJECT = 'Certificate to encrypt Название_БД';
GO
Важно немедленно сделать резервную копию сертификата и ключа
DMK, связанного с сертификатом. Если сертификат становится недоступным или нужно восстановить или присоединить базу данных к другому
серверу, то потребуются резервные копии, как сертификата, так и DMK. В
противном случае открыть базу данных не удастся.
Последний шаг – создать ключ шифрования базы данных и включить
шифрование для базы данных, которую нужно защитить. В следующем
примере включается прозрачное шифрование в базе данных EncryptedDB:
USE master
GO
CREATE DATABASE ENCRYPTION KEY
WITH ALGORITHM = AES_256
ENCRYPTION BY SERVER CERTIFICATE [Название_Сертификата]
GO
ALTER DATABASE [Название_БД]
SET ENCRYPTION ON;
GO
Включить прозрачное шифрование в базе данных можно также с использованием SQL Server Management Studio (SSMS). Для этого выполним следующие шаги.
В Object Explorer щелкнем на имени базы данных правой кнопкой
мыши.
Выберем Properties, а затем Options.
Измениим значение параметра Encryption Enabled на True.
11.8 Извлечение данных о шифровании
Чтобы узнать состояние шифрования всех баз данных на сервере,
выполним запрос:
USE master
GO
SELECT db.[name]
, db.[is_encrypted]
, dm.[encryption_state]
, dm.[percent_complete]
, dm.[key_algorithm]
, dm.[key_length]
163
FROM [sys].[databases] db
LEFT OUTER JOIN [sys].[dm_database_encryption_keys] dm
ON db.[database_id] = dm.[database_id];
GO
В этом запросе используется представление динамического управления с именем sys.dm_database_encryption_keys, чтобы выяснить состояние шифрования каждой базы данных. Как показано на рисунке 11.6, результат содержит информацию о ключе шифрования базы данных для
каждой базы данных.
Рисунок 11.6 – Результат шифрования
11.9 Ограничения
При первом шифровании базы данных, изменении ключа или дешифровании базы данных не допускаются следующие операции:
удаление файла из файловой группы в базе данных;
удаление базы данных;
перевод базы данных в режим «вне сети»;
отсоединение базы данных;
перевод базы данных или файловой группы в состояние READ
ONLY.
При выполнении инструкций CREATE DATABASE ENCRYPTION
KEY, ALTER DATABASE ENCRYPTION KEY, DROP DATABASE
ENCRYPTION KEY или ALTER DATABASE...SET ENCRYPTION не
допускаются следующие операции:
удаление файла из файловой группы в базе данных;
удаление базы данных;
перевод базы данных в режим «вне сети»;
отсоединение базы данных;
перевод базы данных или файловой группы в состояние READ
ONLY;
использование команды ALTER DATABASE;
164
запуск резервного копирования базы данных или файла базы данных;
запуск восстановления базы данных или файла базы данных;
создание моментального снимка.
Следующие операции или условия запрещают выполнение инструкций CREATE DATABASE ENCRYPTION KEY, ALTER DATABASE
ENCRYPTION KEY, DROP DATABASE ENCRYPTION KEY или
ALTER DATABASE...SET ENCRYPTION:
база данных предназначена только для чтения, или в ней есть файловые группы, доступные только для чтения;
выполняется команда ALTER DATABASE;
выполняется какая-либо операция резервного копирования;
база данных находится в состоянии восстановления или в состоянии
«вне сети»;
идет создание моментального снимка;
выполняется задача обслуживания базы данных.
При создании файлов базы данных быстрая инициализация файлов
недоступна при включенном TDE.
Чтобы зашифровать ключ шифрования базы данных с помощью
асимметричного ключа, используемый асимметричный ключ должен находиться в поставщике расширенного управления ключами.
Контрольные вопросы и упражнения
1) Опишите уровни ключей шифрования SQL Server.
2) Для чего нужен главный ключ?
3) Какие бывают уровни ANSI X9.17?
4) Каковы особенности симметричного ключа?
5) Каковы особенности ассиметричного ключа?
6) Преимущества шифрования на уровне ячеек.
7) Недостатки шифрования на уровне ячеек.
8) Какие типы данных подходят для шифрования на уровне ячеек?
9) Что такое TDE.
10) Перечислите элементы прозрачной архитектуры БД.
11) Объясните значение используемых команд и функций.
12) Объясните значения представлений.
13) Перечислите этапы прозрачного шифрования.
14) Перечислите ограничения для различных действий при прозрачном шифровании.
15) Для созданной базы данных сделайте резервное копирование.
16) Зашифруйте базу данных
17) Убедитесь в правильности ваших действий.
165
18) Разработайте базу данных, содержащую шифрованные таблицы с
помощью симметричного ключа.
19) В созданной базе данных добавить таблицу, зашифрованную с
помощью сертификата.
166
ЛИТЕРАТУРА
1. Малыхина М.П. Базы данных: основы, проектирование, использо-
вание : учеб. пособие для вузов по напр. "Информатика и вычислит. техника". - 2-е изд. - СПб. : БХВ-Петербург, 2007. - 517 с.
2. Безопасность систем баз данных [Электронный ресурс]: учеб. пособие /С. Н. Смирнов. – Гелиос АРВ,-2007.-21,1 Мб. - Режим доступа:
http://it-ebooks.ru/publ/it_secutity/security_system_of_databases/15-1-0-75.
3. Советов Б.Я. Базы данных: Теория и практика: учеб. для бакалавров по напр. " Информатика и вычисл. техника" и "Информационные системы". - 2-е изд. - М. : Юрайт, 2012. - 463 с.
4. Базы данных [Электронный ресурс]: учебник /Шустова Л.И., Тараканов О.В. - М.: ИД ФОРУМ: НИЦ Инфра-М, 2016. - 304 с. - Режим доступа:http://znanium.com/bookread2.php?book=491069.
5. Дунаев В.В. Базы данных. Язык SQL для студента [Электронный
ресурс]:. - 2-е изд., доп. и перераб. - СПб.: БХВ-Петербург, 2007. Режим
доступа: http://znanium.com/bookread2.php? book=350372.
6. Базы данных [Электронный ресурс]: учеб. пособие / О.Л. Голицына, Н.В. Максимов, И.И. Попов. - 2-e изд., испр. и доп. - М.: Форум: ИНФРА-М,
2009.
400
режим
доступа:
http://znanium.com/bookread2.php?book=182482
7. Ицик Бен-Ган. Microsoft SQL Server 2012. Высокопроизводительный код T-SQL. Оконные функции – СПб: БХВ-Петербург, 2013 – 256 c.
8. Уильям Р.C. Станек. Microsoft SQL Server 2012. Справочник администратора – СПб: БХВ-Петербург, 2013 – 576 c.
9. Александр Бондарь. Microsoft SQL Server 2012– СПб: БХВПетербург, 2013 – 608 c.
167
Базы данных в MS SQL Server
Учебно-методическое пособие по дисциплинам «Базы данных» и
«Безопасность систем баз данных»
Составители: проф. М.П.Малыхина;
доц. В.А. Частикова
Технический редактор
Подписано в печать
Формат 60х84/16
Бумага офсетная
Офсетная печать
Печ. л.
Изд. № _______
Усл. печ. л.
Тираж _______экз
Уч. – изд. л.
Издание кафедры
Кубанский государственный технологический университет
350072, г. Краснодар, ул. Московская, 2, корп.А
Типография ГОУВПО «КубГТУ»: 350058, г. Краснодар, ул. Старокубанская, 88/4
168