использование библиотеки mpi для организации параллельных
advertisement

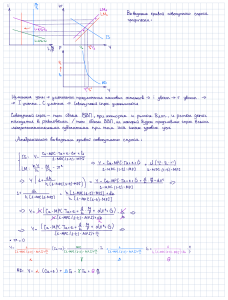
ИСПОЛЬЗОВАНИЕ БИБЛИОТЕКИ MPI ДЛЯ ОРГАНИЗАЦИИ ПАРАЛЛЕЛЬНЫХ ВЫЧИСЛЕНИЙ В КОНЕЧНО-ЭЛЕМЕНТНОМ АНАЛИЗЕ НЕСТАЦИОНАРНОЙ ТЕПЛОПРОВОДНОСТИ Н.Б.Живова (*), А.В.Забродин (**), Н.Н.Шабров (*) (*) Санкт-Петербургский государственный технический университет, Санкт-Петербург, (**) Институт прикладной математики РАН им. М.В.Келдыша, Москва Тел./факс: (812) 552-77-70, e-mail: nikesh@mail.ru Решение сложных задач теплопроводности, механики твердого деформируемого тела требует применения мощной вычислительной техники и связано с большими затратами машинного времени. Переход на качественно новый уровень производительности может быть достигнут при организации параллельного решения задачи на разных процессорах суперкомпьютера или в кластере рабочих станций. Для организации параллельных вычислений в таких системах специалистами Аргоннской Национальной Лаборатории (США) разработана библиотека MPI (Message Passing Interface). Программирование с использованием MPI требует разбиения исходной задачи на несколько относительно независимых подзадач (процессов). Каждая подзадача имеет свое пространство данных. В процессе работы параллельного приложения подзадачи обмениваются между собой результатами своей работы. Обмен данными происходит при вызове процедур библиотеки MPI. Код программы – один и тот же для всех процессов. В данной работе параллельные вычисления с использованием MPI производились в многопроцессорной вычислительной системе МВС-1000 в ИПМ РАН в режиме удаленного доступа. Система МВС-1000 состоит из четырех компонент: многопроцессорного вычислителя, управляющей ЭВМ, сервера и шлюза. Управляющая ЭВМ и сервер представляют собой рабочие станции Alpha. Шлюз – рабочая Intel-совместимая станция с ОС Linux. Задача пользователя выполняется на одном или нескольких процессорах вычислителя. Для пользователей Интернет рабочим местом является шлюз (в домашнем каталоге пользователя хранятся программы и исходные данные). Старт (завершение) задач инициируется пользователем на шлюзе, затем передается серверу. Сервер передает команды управляющей ЭВМ. Управляющая машина служит для запуска (завершения, управления) на вычислителе пользовательских задач. Из управляющей ЭВМ домашний каталог пользователя виден под тем же именем, что из сервера и из шлюза. Рассмотрим подробнее проблему организации параллельных вычислений при решении задач нестационарной теплопроводности. Нестационарное распределение температуры в твердом теле описывается уравнением в частных производных, граничными условиями трех видов и начальным распределением температуры. После применения метода конечных элементов к этому уравнению получаем систему обыкновенных дифференциальных уравнений с заданным начальным условием. Решая эту систему методом Рунге-Кутты, на каждом шаге численного интегрирования по времени имеем одну или несколько (в зависимости от конкретного вида метода Рунге-Кутты) систем линейных алгебраических уравнений с симметричной и положительно определенной матрицей. Матрица системы является разреженной в силу свойств метода конечных элементов. Для решения системы алгебраических уравнений используются как прямые методы решения (обычно метод Холецкого), так и итерационные методы (метод сопряженных градиентов и др.). Положительной особенностью итерационных методов является отсутствие локального заполнения, поэтому в памяти хранятся только ненулевые элементы матрицы. В данной работе распараллеливалось решение системы уравнений методами Холецкого и методом сопряженных градиентов. В случае использования метода Холецкого матрица системы хранится на жестком диске в профильном виде. Профиль нарезается на NSEG сегментов, число процессоров равно NP. Логический номер процессора обозначим IP, IP=1,..NP. Сегменты содержат целое количество строк. В каждом узле хранятся сегменты с номерами IP, IP+NP, IP+2NP,...NSEG-(NP-IP)+1. Алгоритм состоит из NP шагов. На i-м шаге пассивным для всех процессов является сегмент с номером i. Процессор, вычисляющий сегмент i, постепенно отправляет вычисленные элементы сегмента во все остальные процессы, которые используют полученные данные для вычислений в своем сегменте. В конце шага с номером i процессы синхронизируются вызовом специальной процедуры MPI. В случае использования метода сопряженных градиентов все ненулевые элементы матрицы системы уравнений хранятся на жестком диске в одномерном массиве длиной m, где m – число ненулевых элементов. Дополнительно используются два индексных массива длинами n и m (адреса диагональных элементов и номера столбцов всех элементов). Распараллеливается умножение матрицы на вектор и все операции с векторами.