Взаимодействие в распределенных сценариях
advertisement

msdevcon.ru
#msdevcon
MICROSOFT SQL SERVER В ОБЛАКЕ.
МИГРАЦИЯ И ВЗАИМОДЕЙСТВИЕ В
РАСПРЕДЕЛЕННЫХ СЦЕНАРИЯХ
Алексей Шуленин, Microsoft
Содержание
Распределенные сценарии предполагают, что часть данных находится
в Облаке, часть – традиционно on-premise
Обсуждение по схеме: когда, где, что и как?
Когда имеет смысл мигрировать данные в Azure
Где именно их там хранить в зависимости от задачи: SQL Azure, SQL Server на Azure
VM, HDInsight, Azure Table Storage, ...
Что именно переносить: базу целиком, отдельные таблицы, фрагменты таблиц, ...
Как? Как конкретно переносить и как с этим потом работать?
В данном докладе мы сконцентрируемся, в основном, на
технической стороне, т.е. последнем вопросе, а «что-где-когда»
обсудим в рамках вечерней дискуссии, например...
Когда?
Вспоминаем классические преимущества облачных
вычислений:
Эластичность ресурсов - возможность быстро нарастить вычислительную
мощь без необходимости наращивания затрат на оборудование и
программное обеспечение
Pay-for-play - оплата только за используемые ресурсы: время работы
приложения, объем данных и количество операций с данными
(транзакций), сетевой трафик
Абстрагируемость пользователя от управляемой извне инфраструктуры поддержка и масштабирование приложений не требует инвестиций в
аппаратное обеспечение, инфраструктурное администрирование,
привлечения временнЫх и людских ресурсов
Виртуализация делает вычислительные ресурсы автономными и взаимно
независимыми
Типовой пример
Отчетность за период
Disclaimer: имеется в виду общий случай, т.к. в жизни всегда возможны
нюансы
Требуется привлечение интенсивной вычислительной нагрузки (расчет
аналитики) на сравнительно короткий период (конец месяца)
Если держать свои вычислительные мощности, адекватные пику, большую часть времени они
будут простаивать
Грузим в Облако детальные транзакции – их много, но входящий трафик,
как правило, бесплатен
Возвращаем посчитанные агрегатные показатели. Исходящий трафик стоит
денег, но их не так много.
Либо смотрим их там же в Облаке через Azure Reporting
Или PowerView
Основные способы работы с данными в Облаке
•
PaaS
•
•
IaaS
•
•
Windows Azure SQL Database
(SQL Azure)
SQL Server на виртуальной
машине в Облаке
Чему отдать предпочтение? - Зависит от задачи
Взаимодействие в
распределенных сценариях
http://msdn.microsoft.com/ru-ru/library/windowsazure/ff394102.aspx
•
Backup / Restore
•
Replication
•
Extended Stored
Procedures
•
SQL Server
Agent/Jobs
•
Common Language
Runtime (CLR) and CLR
User-Defined Types
•
Database Mirroring
•
Service Broker
•
Table Partitioning
•
Typed XML and XML
indexing is not supported.
The XML data type is
supported by Windows
Azure SQL Database.
•
Integrated Full-Text
Search
•
Change Data Capture
•
Data Auditing
•
Data Compression
•
FILESTREAM Data
•
Performance Data
Collection (Data Collector) •
•
Policy-Based
Management
•
Resource Governor
•
SQL Server Replication
Extended Events
•
External Key
Management /
Extensible Key
Management
•
Transparent Data
Encryption
Подключиться к облачной базе не сложнее, чем к обычному
SQL Server
Соединение происходит по сетевой библиотеке ТСР, порт 1433
Необходимо учитывать, что в SQL Azure действует только
стандартная модель аутентификации
Все соединения с SQL Azure в обязательном порядке шифруются на
основе TLS (SSL), что соответствует добавлению в строку соединения
свойств Encrypt=True;TrustServerCertificate=true
Их можно не прописывать в явном виде - при установлении
соединения с сервером SQL Azure оно будет зашифровано по его
инициативе. Делается это по аналогии с шифрованием
пользовательских соединений в обычном SQL Server
Имя сервера = <имя сервера SQL Azure>.database.windows.net
В SQL Azure нет команды USE. Надо соединяться сразу с нужной
базой.
Также необходимо учитывать firewall rules в конфигурации
сервера SQL Azure. В противном случае
Предположим, на сервере SQL Azure хранится
таблица Customer, содержащая счета
клиентов, при этом клиент обезличен (только
ID)
Персонифицирующая его информация
находится на on-premise SQL Server в таблице
Person
Если бы все хранилось вместе в одной базе,
мы могли бы связать таблицы в одном
запросе и получить всю информацию вместе
select top 10 c.CustomerID, c.AccountNumber,
p.FirstName, p.LastName from Sales.Customer c
join Person.Person p on c.CustomerID =
p.BusinessEntityID order by c.CustomerID
Как это сделать в гетерогенном сценарии?
Разобьем упражнение на 2 этапа
Этап 1. Соединимся с БД SQL Azure из приложения, вытащим запросом из нее
данные
Ничем не отличается от работы с on-premise SQL Server с точностью до строки
соединения
using
using
using
using
using
System;
System.Data;
System.Data.SqlClient;
System.Diagnostics;
System.Resources;
namespace DevCon2013
{
class Program
{
static void Main(string[] args)
{
ResourceManager resMan = new ResourceManager("DevCon2013.Properties.Resources",
System.Reflection.Assembly.GetExecutingAssembly());
string sqlAzureConnString =
String.Format(@"Server=tcp:u1qgtaf85k.database.windows.net,1433;Database=AdventureWorks2012;User
ID=alexejs;Password={0};Trusted_Connection=False;Encrypt=True", resMan.GetString("Password"));
//Trusted_Connection=False - имеется в виду Trust_Server_Certificate=false
SqlConnection cnn = new SqlConnection(sqlAzureConnString); cnn.Open();
SqlCommand cmd = cnn.CreateCommand(); cmd.CommandText = "select top 100 CustomerID, AccountNumber from Sales.Customer
order by CustomerID";
DataTable tbl = new DataTable(); tbl.Load(cmd.ExecuteReader());
cnn.Close();
foreach (DataRow r in tbl.Rows)
{
for (int i = 0; i < tbl.Columns.Count; i++) Debug.Write(String.Format("{0}\t", r[i]));
Debug.WriteLine("");
}
}
}
}
Аналогично вытаскиваются данные из on-premise SQL Server:
string sqlOnPremiseConnString = @"Server=(local);Integrated Security=true;Database=AdventureWorks2012";
DataTable resultsOnPremise = ExecuteSQL(sqlOnPremiseConnString, "select BusinessEntityID, FirstName, LastName from
Person.Person where BusinessEntityID between 1 and 100");
string sqlAzureConnString = String.Format(@"Server=tcp:u1qgtaf85k.database.windows.net,1433;Database=AdventureWorks2012;User
ID=alexejs;Password={0};Trusted_Connection=False;Encrypt=True", resMan.GetString("Password"));
DataTable resultsFromAzure = ExecuteSQL(sqlAzureConnString, "select CustomerID, AccountNumber from Sales.Customer where
CustomerID between 1 and 100");
...
static DataTable ExecuteSQL(string cnnStr, string query)
{
SqlConnection cnn = new SqlConnection(cnnStr); cnn.Open();
SqlCommand cmd = cnn.CreateCommand(); cmd.CommandText = query;
DataTable tbl = new DataTable(); tbl.Load(cmd.ExecuteReader());
cnn.Close(); return tbl;
}
static void DumpTable(DataTable tbl)
{
foreach (DataRow r in tbl.Rows)
{
for (int i = 0; i < tbl.Columns.Count; i++) Debug.Write(String.Format("{0}\t", r[i]));
Debug.WriteLine("");
}
}
Аналогично вытаскиваются данные из on-premise SQL Server
Этап 2. Остается сджойнить в коде приложения две полученные DataTables
Классическая задача ADO.NET. Известны два наиболее распространенных
способа ее решения: с помощью DataRelation и через Linq.
Рассмотрим оба
По смыслу задачи условием связи между таблицами выступает равенство (эквиджойн)
Для простоты не будем затрагивать случай композитного ключа, т.е. предполагаем, что
связь осуществляется простым приравниванием одной колонки в одной таблице одной
колонке в другой
DumpTable(JoinTablesADO(resultsFromAzure, resultsOnPremise, "CustomerID", "BusinessEntityID"));
...
static DataTable JoinTablesADO(DataTable parentTbl, DataTable childTbl, string parentColName, string
childColName)
{
DataSet ds = new DataSet(); ds.Tables.Add(parentTbl); ds.Tables.Add(childTbl);
DataRelation dr = new DataRelation("ля-ля", parentTbl.Columns[parentColName],
childTbl.Columns[childColName]);
ds.Relations.Add(dr);
DataTable joinedTbl =
foreach (DataColumn c
foreach (DataColumn c
//К сож., Clone() над
new DataTable();
in parentTbl.Columns) joinedTbl.Columns.Add(c.Caption, c.DataType);
in childTbl.Columns) joinedTbl.Columns.Add(c.Caption, c.DataType);
DataColumn не поддерживается :(
foreach (DataRow childRow in childTbl.Rows)
{
DataRow parentRow = childRow.GetParentRow("ля-ля");
DataRow currentRowForResult = joinedTbl.NewRow();
for (int i = 0; i < parentTbl.Columns.Count; i++) currentRowForResult[i] = parentRow[i];
for (int i = 0; i < childTbl.Columns.Count; i++) currentRowForResult[parentTbl.Columns.Count + i] =
childRow[i];
joinedTbl.Rows.Add(currentRowForResult);
}
return joinedTbl;
}
DumpTable(JoinTablesLinq(resultsFromAzure, resultsOnPremise, "CustomerID", "BusinessEntityID"));
...
static DataTable JoinTablesLinq(DataTable parentTbl, DataTable childTbl, string parentColName,
string childColName)
{
DataTable joinedTbl = parentTbl.Clone();
var childColumns = childTbl.Columns.OfType<DataColumn>().Select(c => new
DataColumn(c.ColumnName, c.DataType, c.Expression, c.ColumnMapping));
joinedTbl.Columns.AddRange(childColumns.ToArray());
var joinedTblRows = from parentRow in parentTbl.AsEnumerable()
join childRow in childTbl.AsEnumerable()
on parentRow.Field<int>(parentColName) equals
childRow.Field<int>(childColName)
select parentRow.ItemArray.Concat(childRow.ItemArray).ToArray();
foreach (object[] values in joinedTblRows) joinedTbl.Rows.Add(values);
return joinedTbl;
}
Будет выступать единой точкой входа
То есть для SQL Azure на нем нужно создать прилинкованный сервер
В качестве способа доступа можно использовать SQL Server Native Client
Либо ODBC, которое наше все
if exists (select 1 from sys.servers where
name = 'SQLAzure_NCli') exec sp_dropserver
@server = 'SQLAzure_NCli', @droplogins =
'droplogins'
go
exec sp_addlinkedserver
@server='SQLAzure_NCli',
@srvproduct='',
@provider='sqlncli',
@datasrc='u1qgtaf85k.database.windows.net',
@location='',
@provstr='',
@catalog='AdventureWorks2012'
go
exec sp_addlinkedsrvlogin
@rmtsrvname = 'SQLAzure_NCli',
@useself = 'false',
@rmtuser = 'alexejs',
@rmtpassword = 'Password'
go
select CustomerID, AccountNumber from
SQLAzure_NCli.AdventureWorks2012.Sales.Custom
er where CustomerID between 1 and 100
exec sp_serveroption 'SQLAzure_NCli',
'rpc out', true
exec ('CREATE TABLE TestTbl(fld1 int
not null CONSTRAINT PK_fld1 PRIMARY KEY
CLUSTERED (fld1) )') at SQLAzure_Ncli
exec ('INSERT INTO TestTbl VALUES (1),
(2), (3)') at SQLAzure_NCli
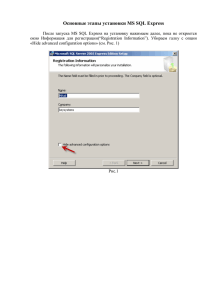
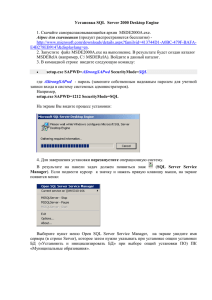
Запустить odbcad32.exe или Control Panel\System and
Security\Administrative Tools -> Data Sources (ODBC)
Автоматизировать процесс можно импортом в реестр (regedit.exe) примерно такого .REGфайла:
[HKEY_LOCAL_MACHINE\SOFTWARE\ODBC\ODBC.INI]
[HKEY_LOCAL_MACHINE\SOFTWARE\ODBC\ODBC.INI\SQLAzure]
"Driver"="C:\\Windows\\system32\\sqlncli10.dll"
"Server"="u1qgtaf85k.database.windows.net"
"LastUser"=“alexejs"
"Database"=“AdventureWorks2012"
[HKEY_LOCAL_MACHINE\SOFTWARE\ODBC\ODBC.INI\ODBC Data Sources]
“SQLAzure"="SQL Server Native Client 10.0“
*Соответствует выбору нижней строчки на первом скриншоте пред.слайда
if exists (select 1 from sys.servers where
name = 'SQLAzure_ODBC') exec sp_dropserver
@server = 'SQLAzure_ODBC', @droplogins =
'droplogins‘
go
exec sp_addlinkedserver @server =
'SQLAzure_ODBC', @srvproduct = 'Any',
@provider = 'MSDASQL', @datasrc = 'SQLAzure',
@catalog='AdventureWorks2012'
go
exec sp_addlinkedsrvlogin @rmtsrvname =
'SQLAzure_ODBC', @useself = 'false', @rmtuser
= 'alexejs', @rmtpassword = 'Password'
go
select * from openquery(SQLAzure_ODBC,
'select * from sys.tables')
Независимо от способа создания
прилинкованного сервера
дальнейшее очевидно
select c.CustomerID,
c.AccountNumber, p.FirstName,
p.LastName from
openquery(SQLAzure_NCli, 'select
CustomerID, AccountNumber from
Sales.Customer where CustomerID
between 1 and 100') c join
Person.Person p on c.CustomerID =
p.BusinessEntityID order by
c.CustomerID
предпочтительно использовать
OpenQuery, чем нотацию имени
из 4-х частей, чтобы не тащить из
Облака лишние записи
отфильтровывать их по
возможности прямо там
if exists (select 1 from sys.sequences where name = 'Seq1') drop sequence Seq1
create sequence dbo.Seq1 as int start with 1 increment by 1 maxvalue 1000
cycle
select * from sys.objects order by name offset 1 rows fetch next 1 rows only
begin try; select 1 / 0; end try
begin catch; if ERROR_NUMBER() = 8134 select 'Ошибка деления на ноль'; else
throw; end catch
if exists (select 1 from sys.indexes where object_id = object_id('dbo.Table1')
and name = 'ColumnStoreTest' and type_desc = 'NONCLUSTERED COLUMNSTORE') drop
index ColumnStoreTest on dbo.Table1
create columnstore index ColumnStoreTest on dbo.Table1(Column1, Column2)
select name, object_id, lag(name, 1) over (order by object_id), lead(name, 1)
over (order by object_id) from sys.objects order by object_id
select Column1, ID, SUM(ID) over (order by Column1 rows between unbounded
preceding and 1 preceding) from dbo.Table1
Шардинг
Разбиение БД на множество мелких и распределение их по нодам
облачного датацентра («физическим» SQL Serverам) с целью
параллельного использования физических ресурсов и сокращения
времени обработки запросов
Как и секционирование, федерирование осуществляется по ключу
Каждый член федерации содержит набор атомарных единиц
Напр., если ключ – OrderID, это какой-то диапазон его значений и
соответствующие им записи из Orders, OrderDetails и др. связанных
таблиц
Секционированные таким образом таблицы называются
федерированными
Справочные таблицы не секционируются, а копируются целиком по
членам федерации
Как в PDW – разбиваются здоровые таблицы фактов, измерения
копируются
Оплата
Члены федерации, включая корень, физически реализуются как
отдельные БД, так что каждый член федерации увеличивает число
баз, за которые придется платить согласно действующим тарифам
Особенности шардинга
Преимущества
Помогает преодолеть ограничение в 150 ГБ на базу
Удобен при обслуживании в базе многих организаций
(multi-tenant сценарий, чтобы не создавать БД под
каждого заказчика)
Кстати, кол-во БД тоже ограничено в 150. За
вычетом master – 149
Помогает избегать узких мест в потреблении ресурсов
и SQL Azure Throttling
Чтобы кривой запрос не поставил SQL Server в
раскоряку, в on-premise применяется регулятор
ресурсов
В SQL Azure с этим обстоит строже
Не забываем, что экземпляр SQL Server в
облачном датацентре - это колхоз, в котором в
данный момент пашут не только ваши базы, но
и много, кого еще. Просто вам их не видно, а им
вас.
Соответственно, при попытке себя порушить, он
не миндальничает, а сразу дает по рукам
Недостатки
Маршрутизирование в корневой базе федерации
сводится к тому, что она «знает», какому значению
ключа федерирования какая база соответствует
USE FEDERATION Customer_Federation(CustID =
15000) WITH RESET, FILTERING = OFF
В отличие от секционирования не поддерживает fanout запросы - приложение должно само
реализовывать логику объединения данных из
нескольких членов федерации
Как правило делается с помощью ADO.NETприложения, которое получает метаданные по
членам федерации и их диапазонам от корневой
базы, затем последовательно их обходит, выполняя
запросы к каждому и генерирует общий результат
- примерно, как Map/Reduce в Hadoop
Миграция
Перенос базы предполагает дополнительную головную боль о массе внешних моментов: логины;
серверные роли; триггеры уровня сервера, в т.ч. на логон; прилинкованные сервера; CLR-сборки;
объекты сервис-брокера; задания SQL Agent; репликация; коллация; ...
Например, на ровном месте не работает запрос
SELECT * FROM #foo AS a INNER JOIN dbo.foo AS b ON a.bar = b.bar
Msg 468, Level 16, State 9, Line 1
Cannot resolve the collation conflict between "SQL_Latin1_General_CP1_CI_AI" and "Сyrillic_General_CI_AS" in the equal to
operation.
Потому что база перенеслась в своей прежней коллации, а объекты tempdb по умолчанию создаются с коллацией
нового сервера
В 2012 появилось понятие самодостаточной (пока частично) БД
Частично, п.ч. SQL Server не препятствует созданию внешних сущностей, нарушающих достаточность базы; только
показывает их - DMV sys.dm_db_uncontained_entities
Внутри базы можно создавать логины:
EXEC sp_configure 'contained database authentication', 1;
RECONFIGURE WITH OVERRIDE;
ALTER DATABASE ContainedDB1 SET CONTAINMENT = PARTIAL;
USE ContainedDB; GO CREATE USER MyUser WITH PASSWORD = ‘Abra Cadabra';
Новая процедура sys.sp_migrate_user_to_contained
Миграция базы в Windows Azure SQL Database
Выписываем известные способы синхронизировать экземпляры
человеческого SQL Server.
Вычеркиваем то, что не поддерживается SQL Azure
Оставшееся рассмотрим
Синхронизация на
уровне отдельных баз с
Синхронизация на
минимальным
уровне экземпляров
временем задержки
обеспечивается при
достигается при
помощи Windows Server помощи
Failover Clustering
зеркалирования
•
•
•
•
Вычеркиваем
•
Вычеркиваем
В принципе, резервное
копирование/восстано
вление можно тоже
рассматривать как
некоторую кондовую
синхронизацию базы забэкапили в одном
месте, подняли в
другом. Логично?
•
Вычеркиваем
•
Репликация?
•
Вычеркиваем –
агента нет, лог
ридера нет, ...
•
А снэпшоты?
•
А вот это
попробуйте
BCP
Берем таблицу Product, находящуюся в схеме Production базы данных
AdventureWorks2012 на локальном SQL Server (localhost), c которым устанавливаем
доверительное (-Т) соединение на основе Windows-аутентификации, и
экспортируем (out) ее в текстовый файл, используя символы Юникода (-w):
bcp AdventureWorks2012.Production.Product out
c:\Temp\AdventureWorks2012.Production.Product.dat -Slocalhost -T -w
Практикой хорошего тона является тут же сделать файл формата, описывающий результаты
экспорта, т.к. AdventureWorks2012.Production.Product.dat не включает сведения о схеме
При удалении таблицы восстановить ее структуру будет проблематично, если отсутствует файл форматирования
Следующая команда изготавливает форматный файл в виде XML
bcp AdventureWorks2012.Production.Product format nul -Slocalhost -T -w -x -f
c:\Temp\Product_fmt.xml
<?xml version="1.0"?>
<BCPFORMAT
xmlns="http://schemas.microsoft.com/sqlserver/2004/bulkload
/format" xmlns:xsi="http://www.w3.org/2001/XMLSchemainstance">
<RECORD>
<FIELD ID="1" xsi:type="NCharTerm" TERMINATOR="\t\0"
MAX_LENGTH="24"/>
<FIELD ID="2" xsi:type="NCharTerm" TERMINATOR="\t\0"
MAX_LENGTH="100" COLLATION="SQL_Latin1_General_CP1_CI_AS"/>
<FIELD ID="3" xsi:type="NCharTerm" TERMINATOR="\t\0"
MAX_LENGTH="50" COLLATION="SQL_Latin1_General_CP1_CI_AS"/>
<FIELD ID="4" xsi:type="NCharTerm" TERMINATOR="\t\0"
MAX_LENGTH="2"/>
<FIELD ID="5" xsi:type="NCharTerm" TERMINATOR="\t\0"
MAX_LENGTH="2"/>
<FIELD ID="6" xsi:type="NCharTerm" TERMINATOR="\t\0"
MAX_LENGTH="30"
...
<ROW>
<COLUMN SOURCE="1" NAME="ProductID" xsi:type="SQLINT"/>
<COLUMN SOURCE="2" NAME="Name" xsi:type="SQLNVARCHAR"/>
<COLUMN SOURCE="3" NAME="ProductNumber"
xsi:type="SQLNVARCHAR"/>
<COLUMN SOURCE="4" NAME="MakeFlag" xsi:type="SQLBIT"/>
<COLUMN SOURCE="5" NAME="FinishedGoodsFlag"
xsi:type="SQLBIT"/>
<COLUMN SOURCE="6" NAME="Color" xsi:type="SQLNVARCHAR"/>
<COLUMN SOURCE="7" NAME="SafetyStockLevel"
xsi:type="SQLSMALLINT"/>
<COLUMN SOURCE="8" NAME="ReorderPoint"
xsi:type="SQLSMALLINT"/>
<COLUMN SOURCE="9" NAME="StandardCost"
xsi:type="SQLMONEY"/>
...
</BCPFORMAT>
Предварительно в SQL Azure требуется создать таблицу идентичной структуры под заливку
Скрипт создания таблицы проще всего получить с помощью SSMS
•
Как одной отдельно взятой
•
Так и совокупности таблиц
В принципе, вместе со схемой таблицы можно заскриптовать и содержащиеся в ней данные,
если на экране визарда генерации скрипта нажать кнопку Advanced и сказать, чтобы
скриптовались данные или структура вместе с данными
Таблица скриптуется как традиционный оператор CREATE TABLE (в опциях можно предварить его DROP), данные - как
INSERT каждой строки таблицы.
Соединяемся с БД SQL Azure и выполняем скрипт
Необходимо учитывать особенности SQL
Azure: в нем нет команды USE, каждая
таблица обязана иметь кластерный индекс,
файл-группы не поддерживаются,
ROWGUIDCOL, WITH (PAD_INDEX = OFF ...),
тоже и т.д.
Что-то из этого можно пометить в опциях, напр.,
поставить Script USE DATABASE = false
Но, в целом, нужно быть готовым, что
автосгенерированный скрипт, скорее всего,
потребует ручной корректировки
После чего он успешно выполняется в базе SQL
Azure
Выполнять вставку данных таким образом
можно, но не нужно - вставлять каждую
запись таблицы по отдельности слишком
накладно для больших таблиц
При необходимости - изменить файл данных и форматный файл в соответствии с адаптированной к SQL
Azure структурой таблицы
Например, переносить не всю таблицу, а результаты запроса:
declare @qry varchar(8000) = 'select [ProductID], [Name], [ProductNumber], [MakeFlag],
[FinishedGoodsFlag], [Color], [SafetyStockLevel], [ReorderPoint], [StandardCost], [ListPrice],
[Size], [SizeUnitMeasureCode], [WeightUnitMeasureCode], [Weight], [DaysToManufacture],
[ProductLine], [Class], [Style], [ProductSubcategoryID], [ProductModelID], [SellStartDate],
[SellEndDate], [DiscontinuedDate], [ModifiedDate] from [Production].[Product]'
declare @cmd varchar(8000) = 'bcp "' + @qry + '" queryout
c:\Temp\AdventureWorks2012.Production.Product.dat -Slocalhost -T -dAdventureWorks2012 -w'
exec xp_cmdshell @cmd
Изменить подобным образом форматный файл не удастся, потому что его создание возможно только
когда bcp делается из таблицы, а не из запроса
Остается модифицировать вручную
Выполняем импорт:
bcp TestDB.dbo.Product in
c:\Temp\AdventureWorks2012.Production.Product.dat Sfxv4koqar4.database.windows.net -Ualexejs -PTiwanaku -f
c:\Temp\Product_fmt.xml
SSIS
Хотя функциональность SQL Azure имеет большую долю
пересечения с привычным SQL Server, знак равенства между ними
поставить нельзя, как мы только что убедились
Скорее всего, схемы источника и назначения не будут тождественны,
следовательно, потребуется кастомизация перекачки. Для этого
удобнее использовать SSIS
В SSDT заводим новый проект на основе шаблона Integration
Services Project
Обратите внимение, что несмотря на установленную VS2012 используется VS2010 Shell
Перетаскиваем слева из SSIS Toolbox задачу Data Flow Task на рабочую
поверхность пакета. Это шланг, один конец которого нужно подключить к
источнику данных, другой - к назначению.
Для источника и назначения нужно создать соединения. Кликаем правой кнопкой на среднюю панель,
которая называется Connection Managers (на ней написано Right-click here to add a new connection manager
to the SSIS package). Говорим, что это будет New ADO.NET Connection. В открывшемся окне Configure
ADO.NET Connection Manager кликаем на кнопку New, чтобы создать новое соединение.
Открывается привычное окно, где нужно выбрать провайдера, имя сервера, БД и т.д. Источником данных,
как и в примере с BCP, будет выступать таблица Production.Product в БД AdventureWorks2012,
расположенной на локальном SQL Server, экземпляре по умолчанию:
Аналогично создаем соединение к SQL Azure - для назначения
Переходим в Data Flow Task, кликнув по ней два раза или кликнув на закладку Data Flow вверху рабочей
поверхности дизайнера пакета, и перетаскиваем в нее из левого тулбокса ADO.NET Source и ADO.NET
Destination.
Дважды кликаем по ADO.NET Source и в открывшемся окне редактора задаем созданное соединение
localhost.AdventureWorks2012, в качестве Data access mode - что это будет таблица, а не SQL-запрос и в
Name of the table or the view выбираем из комбобокса таблицу Production.Product.
Зацепляем торчащую из прямоугольника с надписью ADO.NET Source синюю стрелку и тащим ее в
прямоугольник ADO.NET Destination, чтобы она в него уперлась. Дважды кликаем по прямоугольнику
ADO.NET Destination. Устанавливаем для него соединение аналогично, только в качестве Connection
Manager здесь будет использоваться, понятно, соединение назначения – SQL Azure. В панели слева
редактора ADO.NET Destination Editor выбираем пункт Mappings и при необходимости корректируем, какие
поля источника переносятся в какие поля таблицы-назначения.
Запускаем (F5) пакет на выполнение
DACPAC
Если база данных достаточно проста, вместо раздельного переноса
объектов схемы, организации заливки данных из таблицы в таблицу,
было бы эффективней иметь механизм, позволяющий перенести разом
всю базу, с данными или без. Такой механизм дебютировал в SQL Server
2008R2 под названием Data-tier applications. Он позволяет упаковывать
структуры всех поддерживаемых им объектов базы в самодостаточный
архивный файл DACPAC - Data-tier application component package сродни msi или манифесту.
DAC ориентирован на перенос в SQL Azure небольших по объему и
несложных по логике баз.
Data-tier application - это способ представить базу в виде приложения.
DACPAC можно затем импортировать в датабазный проект Visual Studio
(с использованием предоставляемых ею преимуществ командной
разработки, контроля версий, рефакторинга, IntelliSense и др.) или
развернуть на другом SQL Server или сервере SQL Azure, получив копию
исходной базы.
Приложения DACPAC интегрируются с Utility Control Point и позволяют
устанавливать в себя политики Policy-based Management Framework, но
эти возможности мы сегодня не затронем.
В SSMS в контекстном меню БД можно видеть относящиеся к DAC
пункты, которые позволят мигрировать ее в SQL Azure.
Выбираем первый пункт секции - Extract Data-tier
application. Визард подключается к базе данных,
считывает ее объекты и их свойства и создает в
памяти модель БД.
Подобно тому, как определенные объекты
проверяются в процессе сборки сборки, так и
здесь происходит проверка на согласованность
(если какое-нибудь представление ссылается на
несуществующую таблицу, произойдет ошибка, как
и в случае Т-SQL) и самодостаточность (все ссылки
и зависимости не выходят за пределы текущей
базы).
Не дозволенные в SQL Azure или не
поддерживаемые в in-memory модели DAC
объекты блокируются. После валидации
построенная в памяти модели DACPAC
записывается на диск.
Файл представляет собой архив, который можно
распаковать и посмотреть, что внутри.
Основным содержанием являются файлы
model.sql и model.xml. Первый есть обычный
DDL-скрипт создания объектов, проживающих в
БД
Второй - его XMLное представление в формате,
понимаемом DAC Framework (DAC Fx).
1-я версия была выпущена с SQL Server 2008R2.
В промежутке между ним и SQL Server 2012 (примерно с СТР3) вышла DAC
Fx 2.0. Была добавлена поддержка геопространственных типов, упаковкa в
архив не только схемы, но и самих данных (import/export) и др. Наиболее
заметным новшеством стал in-place upgrade. Ранее применялся подход
side-by-side. Чтобы доставить изменения на SQL Server, создавалась новая
база с временным именем, в которой генерировались объекты из DACPAC,
переливались данные из старой базы, старая база дропалась, новая
переименовывалась в старую. Это требовало в два раза больше места на
сервере и делало бесполезным T-Log. С помощью компоненты ScriptDom
теперь генерируются скрипты, которые с учетом версии SQL Server
стараются по максимуму обойтись командой ALTER для обновления схемы.
C SQL Server 2012 RTM поставляется версия DAC Fx 3.0. Физически это
Microsoft.SqlServer.Dac.dll (пространства имен Microsoft.SqlServer.Dac и
Microsoft.SqlServer.Dac.Extensions).
Отдельно можно скачать в составе Microsoft® SQL Server® 2012 Feature
Pack (см. MICROSOFT SQL SERVER 2012 MANAGABILITY FEATURE PACK
COMPONENTS, Microsoft® SQL Server® 2012 Data-Tier Application
Framework).
•
Описание формата можно найти
здесь –
http://msdn.microsoft.com/enus/library/ff719373(v=sql.105).aspx
•
[MS-DACPAC]: Data-Tier Application
Schema File Format Structure
Specification.
Полученный файл без проблем развертывается на сервере SQL Azure
Обратите внимание, что некоторые таблицы в БД Northwind
были кучами, и в таком же виде они переехали в Облако
SQL Azure не запрещает создание таблиц без кластерного ключа
Он даже позволяет из них читать (кстати, видно, что таблицы
пусты, т.е. перенеслись только метаданные), однако при попытке
вставить запись мы получим ошибку
Подробнее о DACPAC мы поговорим в докладе F10 “Разработка
БД с использованием VS2012”
BACPAC
Вместо того, чтобы сначала переносить схему, а
затем заливать в нее данные, миграцию базы
можно выполнить в один прием. Как уже
говорилось, в DAC 2.0 появилась возможность
экспорта/импорта (Export/Import), которая в
отличие от извлечения/развертывания
(Extract/Deploy) позволяет перетаскивать
между SQL Serverами (включая SQL Azure) не
только схему базы, но и содержащиеся в ней
данные.
Экспорт ведет себя интеллектуальней, чем
экстракт. Он проверяет экспортируемые
объекты на соответствие ограничениям SQL
Azure. С другой стороны, эти проверки нельзя
отключить, если база переносится не в
Облако, а между двумя инстансами обычного
SQL Server.
На закладке Advanced (1-й экран пред.слайда) галки отмечают те таблицы,
для которых будут перенесены данные, но структуры таблиц она будет
переносить (и проверять) тупо все.
Полученный файл по умолчанию имеет
расширение bacpac (в отличие dacpac в
результате операции извлечения схемы)
Глубинный смысл буквы b, по-видимому,
призван символизировать bulk copy
Школьники, впервые наткнувшиеся на этот
функционал, радостно пишут в блоге, что
открыли возможность бэкапа SQL Azure
Свидетельствует о непонимании работы
BACKUP/RESTORE в транзакционной БД
Это просто мгновенный снимок состояния схемы +
данных
Как и dacpac, bacpac-файл представляет собой архив, только в
контекстное меню для этого расширения в оболочку не
регистрируется пункт Unpack. Его просто можно открыть
архиватором.
Помимо структуры базы в файле model.xml, в архиве bacpac
хранятся данные - см. папку Data. Она состоит из подпапок по
одной на каждую из таблиц. Каждая папка имеет табличные
данные в формате JSON (JavaScript Object Notation) и файлы с
расширением .bin, соответствующие бинарным ячейкам.
Напр., таблица Employees имеет поле Photo типа image и 9 записей - 9 binфайлов.
Для импорта bacpac на другой сервер следует пойти в SSMS -> Object
Explorer -> Databases, вызвать контекстное меню, только выбрать не Deploy
Data-tier Application, как в прошлый раз, а Import Data-tier Application.
В отличие от dacpac, который переносит только метаданные, а таблицы после
деплоймента остаются пустые, операция экспорта/импорта Data-tier application
переносит как схемы объектов БД, так и сами данные
Примечания:
Dacpac можно открыть в SSDT, поработать с базой, а потом применить сделанные изменения на сервере, сказав базе
upgrade. Bacpac так делать не умеет - BACPAC Import operations are limited to new or empty databases. Апгрейд-визард
не воспринимает bacpac
В контекстном меню базы в SSMS значится еще одна возможность - Deploy Database to SQL Azure. Она использует
только что рассмотренный bacpac. Вызывается экспорт и сразу за ним незамедлительный импорт.
Azure Data Sync
Настроить репликацию между облачной базой данных и базой на onpremise (безоблачном) SQL Server нельзя, потому что SQL Azure ее не
поддерживает
Как вариант, можно написать приложение с использованием Microsoft Sync
Framework, которое будет отслеживать изменения на одном конце и
применять их на другом и наоборот
Такое приложение под названием SQL Azure Data Sync было написано в
виде Web-сервиса и размещено во всех облачных датацентрах. Оно умеет
реплицировать данные между облачными БД на серверах SQL Azure, между
SQL Azure и обычным SQL Server или через SQL Azure между обычными SQL
Serverами
Репликация происходит по схеме hub-spokes, т.е. изменения, произошедшие
на одном луче звезды, поступают в центр, который распространяет их во все
остальные концы, входящие в ту же группу синхронизации, что и тот, где
случились изменения. В роли ступицы, т.е. дистрибутора, выступает БД SQL
Azure.
Примечание: SQL Reporting и Azure Data Sync упорно не входили в новый
интерфейс Windows Azure Management Portal
Отчетность в конце концов вошла (в Data Services, там же, где и SQL Azure Database)
Будем надеяться, что и службы синхронизации там появятся, а пока – доступ через
старый портал (https://windows.azure.com/switch.aspx?v=2))
Создание группы синхронизации
Предлагается указать подписку (здесь имеется в виду не
подписка в смысле репликации, а подписка на Azure), под
которую будет заготовлен сервер синхронизации. В одной
облачной подписке можно создавать не более одного
сервера синхронизации.
Под группой синхронизации понимается, условно говоря,
подписка (на этот раз в смысле репликации), т.е. группа баз
на издателе и подписчике
Мы рассмотрим двунаправленную репликацию, т.е.
подписчик может быть, в свою очередь, издателем
Задаем название группы синхронизации. Еще сразу горит
кусок экрана с конфигурацией, хотя по-хорошему заполнять
его предстоит на 4-м шаге. Можно заполнить сейчас - без
разницы. Под конфигурацией понимается период
проведения сеансов связи на предмет синхронизации, а
также reconciliation - за кем остается правда, если оба
поменяли одну и ту же запись в одной и той же таблице.
На втором шаге задается база данных на
необлачном SQL Server, который будет участвовать
в синхронизации.
Каждая база данных в текущей версии SQL Azure Data
Sync может входить не более, чем в 5 групп
синхронизации.
В пределах одной группы синхронизации можно
создать не более 30 спиц (облачных и необлачных
баз данных, обменивающихся между собою
информацией), из них необлачных не более 5.
Говорим, что это будет новый SQL Server, т.е. в
конфигурируемой группе синхронизации он еще
не отмечен, и мы предполагаем, что
синхронизация будет идти в обоих направлениях:
как от SQL Server в Облако, так и обратно
На on premise SQL Server необходимо установить
специального агента синхронизации с Облаком, либо
воспользоваться уже установленным, но т.к. до этого агент
не ставился, то устанавливаем
Будет предложено его поставить из традиционных Microsoft
Downloads
• Во время установки
спрашивается учетная запись,
под которой будет работать
сервис агента синхронизации
Она должна иметь права на
выход в Интернет и Log On as
a Service
•
Локальный админ не проходит,
доменный - ОК
В ходе сетапа устанавливаются конфигурационный клиент
Microsoft SQL Azure Data Sync Preview (C:\Program Files
(x86)\Microsoft SQL Azure Data
Sync\bin\SqlAzureDataSyncAgent.exe) и сервис агента
синхронизации Microsoft SQL Azure Data Sync (C:\Program
Files (x86)\Microsoft SQL Azure Data
Sync\bin\LocalAgentHost.exe), стартуемый под введенной
учетной записью
Необходимо зарегистрировать агента на сервере
синхронизации при помощи ключа, генерируемого в
процессе установки
Генерируем ключ
Запускаем клиента
Регистрируем
В конфигурации агента должна быть прописана строка соединения с
обычным SQL Server, базу которого мы начали определять для участия в
группе синхронизации
В случае выбора Windows-аутентификации учетная запись сервиса
агента синхронизации Microsoft SQL Azure Data Sync должна иметь
доступ к БД настольного SQL Server, которую предполагается
синхронизовать в Облако
Служба синхронизации обеспечивает шифрование всех
конфиденциальных хранящихся в ней данных, в том числе:
учетные данные пользователя базы данных SQL Azure
учетные данные пользователя базы данных SQL Server
файл конфигурации клиентского агента Data Sync
учетные данные самой службы Data Sync для system storage в Windows Azure
Покидаем клиентское приложение и возвращаемся к продолжению
облачной настройки Data Sync. Кнопка Get Database List наполняет
комбобокс списком баз, зарегистрированных на агенте по имени Смит
(мы дали ему такое имя). Из этого списка выбираем нужное соединение
На следующем этапе задаем облачную
БД, которая будет выступать в роли
дистрибутора
Прописываем строку соединения с ней
в мастере синхронизации
Далее спрашивается частота
синхронизаций и правило разрешения
конфликтов. Мы их задали еще в
начале.
Далее предстоит создать статьи репликации. Здесь это называется Sync
Dataset
У нас имеются две базы данных: Northwind1 на локальном SQL Server и пустая
Northwind1_Azure в облачном. Для начала мы хотим наполнить Northwind1_Azure,
т.е. Northwind1 выступает в качестве источника. Говорим это мастеру
синхронизации в верхнем комбобоксе.
По нажатию кнопки Get Latest Schema слева отображается список таблиц;
при навигации от таблицы к таблице - справа список полей текущей
таблицы.
В одной группе синхронизации может участвовать не более 100 таблиц,
каждая из которых может иметь не более 1000 полей.
Для того или иного поля можно отметить чекбокс Filter. Тогда внизу
нарисуется заготовка под условие where по этому полю. Операторы
ограничиваются >, <, = и их комбинациями. Например, like еще не
домыслили.
Кнопка ОК сейчас недоступна, потому что у фильтра пустое поле Value. Мы не будем
использовать горизонтальное нарезание таблиц (как и вертикальное). Убираем галку
фильтра и жмем ставшую доступной ОК.
Остается нажать кнопку Deploy, чтобы загрузить на сервер Data Sync
конфигурацию группы синхронизации
Экран светлеет, Status: Provisioning в зеленой строке сменяется на Synchronizing и
наконец Good:
На портале Windows Azure в секции Data Sync
имеется просмотр журналов синхронизации пункт меню Log Viewer, либо слева выбрать
соответствующий пункт из участников
синхронизации и справа кликнуть View Log.
Три нижние строчки в журнале - это перенос
в Облако 3-х выбранных таблиц, но пока я
это писал, прошло 5 заданных минут
интервала синхронизации, проснулся агент
Смит, проверил, есть ли ля него работа, и
снова заснул
Все 3 заказанные таблицы появились в
облачной базе и наполнились данными
Проверяем, что в обратную сторону синхронизация тоже работает.
Поменяем в Облаке какие-нибудь данные
И не позже, чем через 5 мин. эти изменения отразятся в настольной базе
Northwind1.
Пока что можно обратить внимание, что структуры таблиц Northwind1
переехали в Облако вместе с ограничениями, поэтому delete from
Categories where CategoryID = 6 не получится по причине The DELETE
statement conflicted with the REFERENCE constraint
"FK_Products_Categories".
Не переносятся ограничения типа CHECK, триггеры, представления и
хранимые процедуры
Если впоследствии схема какой-либо из участвующих в синхронизации
таблиц, поменяется и эти изменения захочется тоже синхронизировать,
единственный способ - пересоздать группу синхронизации
Categ
oryID
1
update_scop
e_local_id
NULL
scope_update
_peer_timesta
mp
4002
local_updat
e_peer_time
stamp
925
scope_creat
e_peer_time
stamp
4002
local_create
_peer_times
tamp
9
sync_row_i
s_tombsto
ne
0
2
1
4003
8
4002
8
0
Образовались служебные таблицы схемы DataSync в обеих базах. Вот, как
выглядит таблица DataSync.Categories_dss_tracking после внесения
изменений
3
1
4004
7
4002
7
0
4
1
4005
6
4002
6
0
5
1
4006
5
4002
5
0
А к самим таблицам добавились триггеры. Напр., :
Categories_dss_delete_trigger, Categories_dss_insert_trigger,
Categories_dss_update_trigger
6
1
4007
4
4002
4
0
7
1
4008
3
4002
3
0
8
1
4009
2
4002
2
0
Это Sync Framework для версий, ранее 2008-го, потому что Change
Tracking в SQL Azure не поддерживается
9
926
0
NULL
NULL
926
NULL
last_change_d
atetime
09-05-12
09:33:58
09-05-12
09:15:15
09-05-12
09:15:15
09-05-12
09:15:15
09-05-12
09:15:15
09-05-12
09:15:15
09-05-12
09:15:15
09-05-12
09:15:15
09-05-12
09:33:58
Тем временем можно уже смотреть, что получилось в
настольной БД Northwind1
Сделанные изменения доставились в таблицу
dbo.Categories (записи №№1, 9). Удручает, правда, то,
что вместо кириллицы нарисовались знаки вопроса.
Это потому, что в редакторе SSMS они не были юникодовскими
Достаточно сохранить файл запроса, как UTF-8
Помимо озвученных в контексте ограничений на колво издателей/подписчиков в группе синхронизации,
количество таблиц, колонок и т.д., существенным
ограничением выступает отсутствие API
Т.е. заскриптовать проделанное на вышеприведенных картинках в
настоящий момент нельзя.
При необходимости программного доступа пока рекомендуется
использовать Sync Framework - по сути, написать свой собственный
Azure Data Sync.
Миграция в случае IaaS
Справедливо все вышесказанное плюс, поскольку в этом случае мы имеем обычный SQL Server, установленный на
облачной виртуалке, допустимы традиционные способы переноса базы, такие, как backup/restore, detach/attach
Осталось понять, как лучше доставить отчужденный файл с базой (.bak, .mdf, .bacpac, …) на облачную виртуалку с SQL
Server
Файлы небольших размеров можно, не мудрствуя лукаво, переносить обычным Copy/Paste на удаленный рабочий стол
виртуальной машины SQL Server
Разновидность этого способа - сделать на виртуалке папку общего доступа и скопировать туда, используя продвинутые средства
копирования с возможностью распараллеливания, коррекции и возобновления в случае сбоев, а также передать файл по FTP
Можно использовать Azure BLOB Storage и обмениваться через него при помощи сырого REST API (HTTP
Request/Response), как описано здесь
Можно сделать этот способ более человеческим, если использовать обертку, которую предлагает Azure SDK, как описано здесь
Проблема в том, что Azure Storage не является NTFS-видимым, поэтому восстановиться непосредственно с него нельзя
Он используется как промежуточное звено, с него бэкап приходится переносить на виртуальный диск виртуалки (а vhd хранится
там же в виде блоба), что приводит к задвоению расхода Azure Storage (и доп.затратам)
Гораздо лучше создать еще один vhd локально (Disk Management), положить туда бэкап, загрузить vhd в Облако при
помощи утилиты csupload, которая берется все из того же Azure SDK
Он начинает видеться в Azure Management Portal -> Virtual Machines -> Disks как еще один диск
Переключаемся на Virtual Machine Instances и подсоединяем его к нужной виртуалке, выбрав в нижней строке меню Attach
Восстанавливаем базу, детачим диск и убиваем, чтобы не занимал лишнее место
Cumulative Update 2 к SP1 еще более упростил этот процесс
Стало возможным создавать резервные копии базы непосредственно в Azure Storage с помощью штатных команд TSQL и, соответственно, восстанавливаться с них
Вся не относящаяся к функциональности SQL Server служебная работа по передаче резервной копии в Облако
встроена внутрь T-SQLных команд
Требуется только иметь учетную запись хранения (Windows Azure Storage Account), которая будет использоваться для
промежуточного хранения резервной копии
Создавать storage account имеет смысл в том же датацентре, где находится облачная виртуалка, чтобы не тратить
лишние деньги на трафик между ЦОДами
Внутри эккаунта мы создадим контейнер container1 в целях безопасности как private
что означает, что для доступа к его содержимому потребуется указывать Access Key (первичный или вторичный),
посмотреть которые можно в свойствах Storage Account
Еще понадобится установленный на локальном SQL Server 2012 CU2 к SP1
На данный момент его нужно устанавливать отдельно
По ссылке открывается форма, в форме отмечаем, какой именно файл нужен
Для наших целей достаточно поставить SQLServer2012_SP1_CU2_2790947_11_0_3339_x64, чтобы select @@version была не ниже
Microsoft SQL Server 2012 (SP1) - 11.0.3339.0 (X64), Jan 14 2013 19:02:10, Build 9200
Буквально сразу приходит письмо от hotfix@microsoft.com, содержащее ссылки, откуда брать
Чтобы локальный SQL Server смог доступиться
до облачного сториджа, на нем предварительно
нужно создать удостоверение (credential), в
котором будут указаны название учетной записи
сториджа и один из его ключей доступа
(первичный или вторичный, без разницы)
if exists (select 1 from sys.credentials
where name = 'SqlToAzureStorage' and
credential_identity = 'tststorage') drop
credential SqlToAzureStorage
CREATE CREDENTIAL SqlToAzureStorage
WITH IDENTITY= 'tststorage' --storage
account
, SECRET =
'oY1AUn6/5/IWz8dfQJzidOVY8HRUKOz1k5MsSnV86
xV46fEtQCAigC3Fd8Lgkn2fv6SotsRpZm6w2tRaQVA
ovw=='
Собственно, все. Создаем резевную копию
любимой базы AdventureWorks в облачный
сторидж.
BACKUP DATABASE AdventureWorks2012
TO URL =
'https://tststorage.blob.core.windows.net/
container1/AdventureWorks2012.bak'
WITH CREDENTIAL = 'SqlToAzureStorage',
INIT, STATS = 10
Строка URL формируется по принципу <имя учетной
записи Azure Storage>. blob.core.windows.net/<название
контейнера>/<как будет называться файл бэкапа,
созданный в этом контейнере>'. Ее можно посмотреть в
Windows Azure Management Portal в свойствах
контейнера:
Если теперь зайти в контейнер container1, мы
увидим, что там создался бэкап
AdventureWorks2012.bak
Примечания:
Максимальный размер резервной копии не должен
превышать 1 ТБ, что связано с ограничениями Azure
Blob Storage.
Поддерживается создание не только полной резервной
копии базы, но и резервных копий журнала
транзакций, файловых групп, дифференциальное
резервное копирование, а также сжатие бэкапов.
Если файл с таким именем уже существует в
контейнере, произойдет ошибка. Чтобы его переписать,
используйте опцию FORMAT.
Из интерфейса SSMS создание резервной копии базы в
Azure Blob Storage пока не поддерживается.
Итак, мы рассмотрели основные способы
переноса данных
BCP
SSIS
DACPAC
BACPAC
Azure Data Sync
Backup/Restore (в случае IaaS)
Внимание - конкурс!
Вопрос: Назовите редакции SQL
Server, которые могут быть
лицензированы в рамках
инфраструктурных сервисов
Windows Azure
Ответы пишите в сообществе:
facebook.com/groups/azurerus/
21:00
«Сосновый бор»
Круглый стол Windows Azure
«Облака: второе дыхание для ваших
решений»
Приглашенные эксперты:
Иван Бодягин. Заместитель директора по исследованиям и разработкам. Abbyy
Денис Смирнов. Директор отдела цифровых изданий. Sanoma Independent Media
Вопросы?
© 2013 Microsoft Corporation. All rights reserved. Microsoft, Windows, Windows Vista and other product names are or may be registered trademarks and/or trademarks in the U.S. and/or other countries.
The information herein is for informational purposes only and represents the current view of Microsoft Corporation as of the date of this presentation. Because Microsoft must respond to changing market conditions, it should not be interpreted to be a commitment on the part of
Microsoft, and Microsoft cannot guarantee the accuracy of any information provided after the date of this presentation. MICROSOFT MAKES NO WARRANTIES, EXPRESS, IMPLIED OR STATUTORY, AS TO THE INFORMATION IN THIS PRESENTATION.