Язык SQL_v3 - Система управления электронными
advertisement

ЯЗЫК SQL
История языка SQL
Начало истории языка SQL (англ. Structured Query Language)
относится в середине 70-х годов прошлого века.
•1974 г., Д. Чемберлен и Р. Бойс, работавшие в компании IBM,
публикуют определения языка SEQUEL (англ. Structured
English Query Language ).
1976 г., Д. Чемберлен и Р. Бойс выпускают переработанную
версию языка SEQUEL/2, которая позже переименовывается
в SQL по юридическим соображениям.
•1979 г., компания Oracle выпускает коммерческую СУБД,
основанную на языке SQL.
•1987 г., публикуется стандарт SQL-87. В этом стандарте
были опущены ряд важнейших функций, а также
присутствовала избыточность языка.
История языка SQL
•1989 г., публикуется стандарт SQL-89. В этом стандарте
были добавлены функции поддержки целостности данных.
•1992 г., публикуется стандарт SQL-92. В этом стандарте
были добавлены ряд функций, уже реализованных в
коммерческих СУБД.
•1999 г., публикуется стандарт SQL-1999. В этом стандарте
были добавлены функции поддержки рекурсивных запросов,
триггеров, процедурные расширения.
•2003 г., SQL-2003, в нем введены расширения для работы с
XML-данными, оконные функции (применяемые для работы
с OLAP-базами данных), генераторы последовательностей и
основанные на них типы данных.
История языка SQL
•2006, SQL-2006, функциональность работы с XML-данными
значительно расширена. Появилась возможность совместно
использовать в запросах SQL и XQuery.
•2008, SQL-2008, улучшены возможности оконных функций,
устранены некоторые неоднозначности стандарта SQL-2003.
Язык SQL
SQL является информационно-логическим языком,
предназначенным для описания, изменения и
извлечения данных, хранимых в реляционных базах
данных.
SQL нельзя назвать языком программирования, но его
стандарт позволяет создавать для него процедурные
расширения, которые расширяют его функциональность
до полноценного языка программирования.
Структура языка SQL
Язык SQL представляет собой совокупность операторов
инструкций и вычисляемых функций.
Операторы делятся на 4 основные группы:
• операторы определения данных DDL (Data Definition
Language)
• операторы
манипуляции
данными
DML (Data
Manipulation Language)
• операторы определения доступа к данным DCL (Data
Control Language)
• операторы управления транзакциями TCL (Transaction
Control Language)
операторы определения данных DDL
• CREATE - создает объект БД (саму базу, таблицу,
представление, пользователя и т. д.)
• ALTER - изменяет объект
• DROP - удаляет объект
операторы манипуляции данными DML
• SELECT - считывает данные, удовлетворяющие
заданным условиям
• INSERT - добавляет новые данные
• UPDATE - изменяет существующие данные
• DELETE - удаляет данные
операторы определения доступа к
данным DCL
• GRANT - предоставляет пользователю (группе)
разрешения на определенные операции с объектом
• REVOKE - отзывает ранее выданные разрешения
• DENY - задает запрет, имеющий приоритет над
разрешением
операторы управления транзакциями
TCL
• COMMIT - применяет транзакцию.
• ROLLBACK - откатывает все изменения, сделанные в
контексте текущей транзакции.
• SAVEPOINT - делит транзакцию на более мелкие
участки.
Преимущества
• Независимость от конкретной СУБД
• Наличие стандартов
• Декларативность
Недостатки
Создатели реляционной модели данных Эдгар Кодд,
Кристофер Дейт и их сторонники указывают на то, что
SQL не является истинно реляционным языком. В
частности, они указывают на следующие проблемы
SQL:
• Повторяющиеся строки
• Неопределённые значения (nulls)
• Явное указание порядка колонок слева направо
• Колонки без имени и дублирующиеся имена колонок
• Отсутствие поддержки свойства «=»
• Использование указателей
• Высокая избыточность
Недостатки
• Сложность
• Отступления от стандартов
• Сложность работы с иерархическими структурами
Процедурные расширения
СУБД
InterBase/Firebird
Название
PSQL
Расшифровка
Procedural SQL
SQL Procedural Language
(расширяет SQL/PSM); также в DB2
хранимые процедуры могут
писаться на обычных языках
программирования: Си, Java и т. д.
IBM DB2
SQL PL
MS SQL Server/
Sybase ASE
Transact-SQL
MySQL
SQL/PSM
Oracle
PL/SQL
Procedural Language/SQL (основан
на языке Ada)
PL/pgSQL
Procedural Language/PostgreSQL
Structured Query Language (очень
похож на Oracle PL/SQL)
PostgreSQL
Transact-SQL
SQL/Persistent Stored Module
Типы данных
Язык SQL поддерживает следующие типы данных:
• Логические данные. Для логических данных используется тип
BOOLEAN. Значения логических данных TRUE или FALSE.
• Символьные данные. Для символьных данных в кодировке
ASCII постоянной длины используется тип CHAR(N). Для
символьных данных в кодировке ASCII переменной длины
используется тип VARCHAR(N) и VARCHAR2(N). Для
символьных данных в кодировке UNICODE используются типы
NCHAR(N), NVARCHAR(N) и NVARCHAR2(N) .
• Точные числа. Для точных чисел используются типы INT и
NUMERIC(P,S).
• Приблизительные числа. Для приблизительных чисел
используются типы FLOAT и REAL.
• Дата и время. Для даты используется тип DATE. Для времени
используется тип TIME. Для даты и времени используется тип
DATETIME.
ТИПЫ ДАННЫХ
Типы данных
• Логический
• Символьный
• Числовой
• Дата и время
• Бинарный
• Пользовательский
Логический тип данных
BIT (тип данных SQL2003: BOOLEAN)
Хранит значения 1 (True), 0 (False) или NULL,
которое обозначает «unknown».
Столбцы типа BIT нельзя индексировать.
Символьный тип данных
CHAR[n], CHARACTER[n]
(тип данных SQL2003: CHARACTER[n])
Хранит символьные данные фиксированной длины от 1 до
8000 символов. Все неиспользованное место по умолчанию
заполняется пробелами. (Автоматическое заполнение
пробелами можно отключить.) Тип занимает n байт.
VARCHAR[n], CHAR VARYING[n]
(тип данных SQL2003: CHARACTER VARYING[n])
Хранит символьные данные фиксированной длины размером
от 1 до 8000 символов. Занимаемое место равно реальному
размеру введенного значения в байтах, а не значению n.
Символьный тип данных
NCHAR(n), NATIONAL CHAR(n)
(тип данных SQL2003: NATIONAL СНАRACTER(n))
Хранит данные формата UNICODE фиксированной
длины до 4000 символов. Для хранения требуется n*2
байт.
NVARCHAR(n), NATIONAL CHAR VARYING(n)
(тип данных SQL2003: NATIONAL CHARACTER VARYING(n))
Хранит UNICODE-данные переменной длины до 4000
символов. Для хранения требуется (число символов * 2).
Символьный тип данных
TEXT (тип данных SQL2003: CLOB)
Хранит очень большие фрагменты текста длиной до 2 147 483
647 символов. Значениями типа ТЕХТ часто гораздо труднее
манипулировать, чем, скажем, значениями типа VARCHAR.
Например, нельзя создавать индекс по столбцу типа TEXT.
Для манипулирования значениями типа TEXT применяются
специальные функции такие, как DATALENGTH, PATINDEX,
SUBSTRING, TEXTPTR и ТЕХTVALID, а также команды
READTEXT,SET TEXTSIZE, UPDATETEXT и WRITETEXT.
NTEXT, NATIONAL TEXT (тип данных SQL2003: NCLOB)
Хранит фрагменты текста в формате UNICODE длиной до 1
073 741 823 символа.
Числовой тип данных
TINYINT
Хранит целые числа без знака в диапазоне от 0 до 255 и занимает 1
байт.
SMALLINT (тип данных SQL2003: SMALLINT)
Хранит целые числа со знаком или без знака в диапазоне от -32 768
до 32 767. Занимает 2 байта.
INT (тип данных SQL2003: INTEGER)
Хранит целые числа со знаком или без знака в диапазоне от -2 147
483 648 до 2 147 483 647. Занимает 4 байта.
BIGINT (тип данных SQL2003: BIGINT)
Хранит целые числа со знаком и без знака в диапазоне от -9 223 372
036 854 775 808 до 9 223 372 036 854 775 807. Занимает 8 байт.
Числовой тип данных
FLOAT[(n)] (тип данных SQL2003: FLOAT, FLOAT (n))
Хранит значения с плавающей точкой в диапазоне от1.79Е + 308 до 1.79Е + 308. Точность, определяемая
параметром и, может изменяться в пределах от 1 до 53.
Для хранения 7 цифр (n – от 1 до 24) требуется 4 байта.
Значения, превышающие 7 цифр, занимают 8 байт.
Дата и время
DATETIME (тип данных SQL2003: TIMESTAMP)
Хранит значение даты и времени в диапазоне
с 01-01-1753 00:00:00 до 31-12-9999 23:59:59.
Для хранения требуется 8 байт.
DATE (тип данных SQL2003: отсутствует)
Хранит значение даты и времени в диапазоне
с 01-01-1753 до 31-12-9999. Для хранения требуется 3 байт.
TIME (тип данных SQL2003: отсутствует)
Хранит значение времени в диапазоне
с 00:00:00 до 23:59:59. Для хранения требуется 3 байт.
Бинарный тип данных
BINARY[n] (тип данных SQL2003: BLOB)
Хранит двоичное значение фиксированной длины от 1 до
8000 байт. Значение типа BINARY занимает n + 4 байта.
IMAGE (тип данных SQL2003: BLOB)
Хранит двоичное значение переменной длины до 2 147
483 647 байт. Этот тип данных часто используется для
хранения графики, звука и файлов, таких, как документы
MS Word и электронные таблицы MS Excel.
ОПЕРАТОРЫ
операторы определения данных DDL
• CREATE - создает объект БД (саму базу, таблицу,
представление, пользователя и т. д.)
• ALTER - изменяет объект
• DROP - удаляет объект
Оператор CREATE
• CREATE DATABASE – создать базу данных
• CREATE TABLE – создать таблицу
• CREATE VIEW – создать представление
• CREATE INDEX – создать индекс
• CREATE TRIGGER – создать триггер
• CREATE PROCEDURE – создать процедуру
и т.д.
Оператор ALTER
• ALTER DATABASE – изменить базу данных
• ALTER TABLE – изменить таблицу
• ALTER VIEW – изменить представление
• ALTER INDEX – изменить индекс
• ALTER TRIGGER – изменить триггер
• ALTER PROCEDURE – изменить процедуру
и т.д.
Оператор DROP
• DROP DATABASE – удалить базу данных
• DROP TABLE – удалить таблицу
• DROP VIEW – удалить представление
• DROP INDEX – удалить индекс
• DROP TRIGGER – удалить триггер
• DROP PROCEDURE – удалить процедуру
и т.д.
Оператор CREATE TABLE
Создать таблицу.
CREATE TABLE [имя таблицы]
([имя поля1] [тип] [ограничение] [ключ],
[имя поля2] [тип] [ограничение] [ключ], …..
CONSTRAINT [имя ограничения] …)
SELECT [поле1], [поле2]… INTO [новая таблица]
FROM [таблица]
CREATE TABLE [новая таблица]
AS
SELECT [поле1], [поле2]…. FROM [таблица]
Оператор CREATE TABLE
Оператор ALTER TABLE
Изменить структуру таблицу.
ALTER TABLE [имя таблицы]
ADD [новое поле1] [тип], [новое поле2] [тип],…
ALTER TABLE [имя таблицы]
DROP COLUMN [поле1], [поле2],…
ALTER TABLE [имя таблицы]
ALTER COLUMN [поле1] [новый тип],…
ALTER TABLE [имя таблицы]
MODIFY [поле1] [новый тип],…
Оператор ALTER TABLE
Оператор DROP TABLE
Удаление таблицы
DROP TABLE [имя таблицы]
Оператор DROP TABLE нельзя использовать для
удаления таблицы, на которую ссылается ограничение
FOREIGN KEY. Сначала следует удалить ссылающееся
ограничение FOREIGN KEY или ссылающуюся таблицу.
операторы манипуляции данными DML
• SELECT - считывает данные, удовлетворяющие
заданным условиям
• INSERT - добавляет новые данные
• UPDATE - изменяет существующие данные
• DELETE - удаляет данные
Оператор INSERT
Вставка (добавление) данных
INSERT INTO [таблица] (поле1, поле2, …)
VALUES (значение1, заначение2, …)
INSERT INTO [таблица]
VALUES (значение1, заначение2, …)
INSERT INTO [таблица] (поле1, поле2, …)
SELECT значение1, значение2, … FROM [таблица]
Оператор SELECT
Выборка данных
SELECT *
FROM Таблица1
SELECT Столбец1, Столбец2, ….СтолбецN
FROM Таблица1
SELECT Столбец1 AS Псевдоним1, Столбец2, … СтолбецN
FROM Таблица1
SELECT ТабПсевдоним1.Столбец1 AS Псевдоним1…
FROM Таблица1 AS ТабПсевдоним1
Оператор SELECT
Выборка записей из таблицы без повторения
SELECT DISTINCT Столбец1, Столбец2, ….СтолбецN
FROM Таблица1
Выборка записей с выполнением вычисления значения
SELECT Столбец1*Столбец2 AS Псевдоним1
FROM Таблица1
Выборка записей, удовлетворяющих некоторому условию
SELECT Столбец1, Cтолбец2
FROM Таблица1
WHERE Столбец1>100
Оператор SELECT
Существует пять основных типов условий:
1.
2.
3.
4.
5.
сравнение - сравниваются результаты вычисления одного
выражения с результатами вычисления другого выражения;
диапазон - проверяется, попадает ли результат вычисления
выражения в заданный диапазон значений;
множество - проверяется, принадлежит ли результат
вычисления выражения заданному множеству значений;
шаблон - проверяется, отвечает ли строковое выражение
заданному шаблону;
NULL - проверяется, содержит ли данное поле пустое
значение.
Оператор SELECT
Выборка записей, удовлетворяющих некоторому условию
SELECT Столбец1, Cтолбец2
FROM Таблица1
WHERE Столбец1>100 AND Столбец2=0
При записи условий на сравнения используются операторы
отношения =, <>, >, <, >=, <= и логические операции AND, OR и
NOT. Порядок вычисления выражения может быть изменен с
помощью круглых скобок.
SELECT Столбец1, Cтолбец2
FROM Таблица1
WHERE (Столбец1>100 OR Столбец1<50) AND Столбец2=0
Оператор SELECT
Выборка записей, удовлетворяющих некоторому условию
SELECT Столбец1, Cтолбец2
FROM Таблица1
WHERE Столбец1>=100 AND Столбец1=<200
SELECT Столбец1, Cтолбец2
FROM Таблица1
WHERE Столбец1 BETWEEN 100 AND 200
SELECT Столбец1, Cтолбец2
FROM Таблица1
WHERE Столбец1 NOT BETWEEN 100 AND 200
Оператор SELECT
Выборка записей, удовлетворяющих некоторому множеству
значений
SELECT Столбец1, Cтолбец2
FROM Таблица1
WHERE Столбец1 IN (1,200,30)
SELECT Столбец1, Cтолбец2
FROM Таблица1
WHERE Столбец2 IN (‘Yes’, ’No’, ’Cancel’)
SELECT Столбец1, Cтолбец2
FROM Таблица1
WHERE (Столбец1+ Cтолбец2) NOT IN (1,200,30)
Оператор SELECT
Выборка записей, удовлетворяющих строковому шаблону
SELECT Столбец1, Cтолбец2
FROM Таблица1
WHERE Столбец1 LIKE ‘%при%’
SELECT Столбец1, Cтолбец2
FROM Таблица1
WHERE Столбец1 LIKE ‘при%’ OR Столбец2 NOT LIKE ‘%при’
SELECT Столбец1, Cтолбец2
FROM Таблица1
WHERE Столбец1 LIKE ‘Ханты_Мансийск’
Оператор SELECT
Выборка записей, удовлетворяющих пустому значению
SELECT Столбец1, Cтолбец2
FROM Таблица1
WHERE Столбец1 IS NULL
SELECT Столбец1, Cтолбец2
FROM Таблица1
WHERE Столбец1 IS NOT NULL
Оператор SELECT
Сортировка данных
SELECT Столбец1, Cтолбец2
FROM Таблица1
ORDER BY Столбец1 ASC, Столбец2 DESC
SELECT Столбец1, Cтолбец2
FROM Таблица1
WHERE Столбец1>100
ORDER BY Столбец1, Столбец2 DESC
Оператор SELECT
Ограничение количества выбираемых записей
SELECT TOP(5) Столбец1, Cтолбец2
FROM Таблица1
ORDER BY Столбец1 ASC, Столбец2 DESC
SELECT TOP(10) PERCENT Столбец1, Cтолбец2
FROM Таблица1
Оператор SELECT
Агрегирующие функции
• COUNT() – возвращает количество записей
• MAX() – возвращает максимальное значение по столбцу
• MIN() – возвращает минимальное значение по столбцу
• AVG() – возвращает среднее значение по столбцу
• SUM() – возвращает сумму по столбцу
Оператор SELECT
Агрегирующие функции COUNT
SELECT COUNT(*) AS Кол
FROM Таблица1
SELECT COUNT( DISTINCT Столбец1, Столбец2) AS Ц1
FROM Таблица1
SELECT COUNT(*) AS Кнт1
FROM Таблица1
WHERE Столбец2>4
Оператор SELECT
Агрегирующие функции MIN, MAX, AVG
SELECT MIN(Столбец4) AS МинСт4
FROM Таблица1
SELECT MAX(Столбец2) AS МинСт2
FROM Таблица1
SELECT AVG(Столбец4) AS AvgСт4
FROM Таблица1
WHERE Столбец2 BETWEEN 10 AND 20
Оператор SELECT
Агрегирующие функции SUM
SELECT SUM(Столбец1)
FROM Таблица1
SELECT SUM(Столбец4)
FROM Таблица1
WHERE Столбец2 LIKE ‘А%’
Оператор SELECT
Группировка данных
SELECT Столбец2, SUM(Столбец1) AS СумСт1
FROM Таблица1
GROUP BY Столбец2
SELECT Столбец2, SUM(Столбец1) AS СумСт1
FROM Таблица1
GROUP BY Столбец2
HAVING SUM(Столбец1)>100
Оператор SELECT
Соединение таблиц
SELECT Столбец1, Столбец2, …
FROM
Table1
{INNER | {LEFT | RIGHT | FULL} OUTER | CROSS } JOIN
Table2
ON <Условие соединения>
Оператор SELECT
Соединение таблиц
SELECT Столбец1, Столбец2, …
FROM
Table1 CROSS JOIN Table2
SELECT Столбец1, Столбец2, …
FROM
Table1 JOIN Table2 ON <Условие соединения>
SELECT Столбец1, Столбец2, …
FROM
Table1 INNER JOIN Table2 ON <Условие соединения>
Оператор SELECT
Соединение таблиц
SELECT Столбец1, Столбец2, …
FROM
Table1 LEFT OUTER JOIN Table2
ON <Условие соединения>
SELECT Столбец1, Столбец2, …
FROM
Table1 RIGHT OUTER JOIN Table2
ON <Условие соединения>
SELECT Столбец1, Столбец2, …
FROM
Table1 FULL OUTER JOIN Table2
ON <Условие соединения>
Оператор SELECT
Соединение таблиц
SELECT Столбец1, Столбец2, …
FROM Table1, Table2
SELECT Столбец1, Столбец2, …
FROM Table1, Table2
WHERE <Условие соединения>
Оператор SELECT
Соединение таблиц
Люди, проживающие в
городах (таблица Person)
Города (таблица City)
Name
CityId
Id
Name
Дмитрий
1
1
Омск
Василий
2
2
Ханты-Мансийск
Сергей
1
3
Сургут
Петр
4
SELECT * FROM Persons AS P, City AS C
P.Name
P.CityId
C.Id
C.Name
Дмитрий
1
1
Омск
Василий
2
1
Омск
Сергей
1
1
Омск
Петр
4
1
Омск
Дмитрий
1
2
Ханты-Мансийск
Василий
2
2
Ханты-Мансийск
Сергей
1
2
Ханты-Мансийск
Петр
4
2
Ханты-Мансийск
Дмитрий
1
3
Сургут
Василий
2
3
Сургут
Сергей
1
3
Сургут
Петр
4
3
Сургут
SELECT *
FROM Persons AS P
INNER JOIN City AS C
ON P.CityId=C.Id
P.Name
P.CityId
C.Id
C.Name
Дмитрий
1
1
Омск
Василий
2
2
Ханты-Мансийск
Сергей
1
1
Омск
SELECT *
FROM Persons AS P
LEFT OUTER JOIN City AS C
ON P.CityId=C.Id
P.Name
P.CityId
C.Id
C.Name
Дмитрий
1
1
Омск
Василий
2
2
Ханты-Мансийск
Сергей
1
1
Омск
Петр
4
NULL
NULL
SELECT *
FROM Persons AS P
RIGHT OUTER JOIN City AS C
ON P.CityId=C.Id
P.Name
P.CityId
C.Id
C.Name
Дмитрий
1
1
Омск
Василий
2
2
Ханты-Мансийск
Сергей
1
1
Омск
NULL
NULL
3
Сургут
SELECT *
FROM Persons AS P
FULL OUTER JOIN City AS C
ON P.CityId=C.Id
P.Name
P.CityId
C.Id
C.Name
Дмитрий
1
1
Омск
Василий
2
2
Ханты-Мансийск
Сергей
1
1
Омск
Петр
4
NULL
NULL
NULL
NULL
3
Сургут
Оператор SELECT
Объединение
Запрос1
UNION | UNION ALL | INTERSECT | MINUS
Запрос2
Оператор SELECT
Sales2005
Sales2006
person
amount
person
amount
Иван
1000
Иван
2000
Алексей
2000
Алексей
2000
Сергей
5000
Петр
35000
SELECT * FROM Sales2005
UNION
Select * FROM Sales2006
person
amount
Иван
1000
Алексей
2000
Сергей
5000
Иван
2000
Петр
35000
SELECT * FROM Sales2005
UNION ALL
Select * FROM Sales2006
person
amount
Иван
1000
Алексей
2000
Сергей
5000
Иван
2000
Петр
35000
Алексей
2000
SELECT * FROM Sales2005
INTERSECT
Select * FROM Sales2006
person
amount
Алексей
2000
SELECT * FROM Sales2005
MINUS
Select * FROM Sales2006
person
amount
Иван
1000
Сергей
5000
SELECT * FROM Sales2006
MINUS
Select * FROM Sales2005
person
amount
Иван
2000
Петр
35000
Подзапросы
Подзапросом называется запрос SELECT, определенный
внутри другого запроса SELECT.
Скалярный подзапрос.
SELECT *
FROM Таблица1 AS T
WHERE
T.Поле1=(Select SUM(A.Поле2) FROM Таблица2 AS A)
Скалярный подзапрос должен возвращать единственное
значение.
Подзапросы
Предикаты с подзапросами являются необратимыми.
Запрос является неверным.
SELECT *
FROM Таблица1 AS T
WHERE
(Select SUM(A.Поле2) FROM Таблица2 AS A)= T.Поле1
Подзапросы
Обработка подзапросов возвращающих множество строк.
SELECT *
FROM Таблица1 AS T
WHERE
T.Поле1 IN (Select A.Поле2 FROM Таблица2 AS A)
Подзапросы
Обработка подзапросов возвращающих множество строк.
SELECT *
FROM Таблица1 AS T
WHERE
(T.Поле1,T.Поле2….) IN (Select A.Поле2, A.Поле3….
FROM Таблица2 AS A)
Подзапросы
Соотнесенные подзапросы.
SELECT *
FROM Таблица1 AS T
WHERE
T.Поле1 IN (Select A.Поле2
FROM Таблица2 AS A
WHERE A.Поле3>T.Поле4)
Подзапросы
Оператор EXISTS
SELECT *
FROM Таблица1 AS T
WHERE
EXISTS (Select *
FROM Таблица2 AS A
WHERE A.Поле3>10)
Подзапросы
Оператор EXISTS
SELECT *
FROM Таблица1 AS T
WHERE
EXISTS (Select *
FROM Таблица2 AS A
WHERE A.Поле3>T.Поле4)
Подзапросы
Оператор EXISTS
SELECT *
FROM Таблица1 AS T
WHERE
NOT EXISTS (Select *
FROM Таблица2 AS A
WHERE A.Поле3>T.Поле4)
Подзапросы
Подзапросы (пример)
Оператор EXISTS
SELECT S.Название
FROM Специальности S
WHERE
NOT EXIST
(
SELECT D.Название
FROM Дисциплины D INNER JOIN Экзамены E
ON (D.[Код дисциплины]=E.[Код дисциплины])
WHERE (E.[Код специальности]=S. [Код специальности])
AND (D.Название=‘Русский язык’)
)
Подзапросы
Оператор ANY
SELECT *
FROM Таблица1 AS T
WHERE
T.Поле1=ANY (Select A.Поле2
FROM Таблица2 AS A
WHERE A.Поле3>T.Поле4)
Подзапросы
Оператор ALL
SELECT *
FROM Таблица1 AS T
WHERE
T.Поле1=ALL (Select A.Поле2
FROM Таблица2 AS A
WHERE A.Поле3>T.Поле4)
Подзапросы
Оператор ALL
SELECT *
FROM Таблица1 AS T
WHERE
T.Поле1<>ALL (Select A.Поле2
FROM Таблица2 AS A)
Подзапросы (пример)
SELECT S.Название
FROM Специальности S
WHERE
S.Название<>ALL
(
SELECT S1.Название
FROM Специальности S1
INNER JOIN Экзамены E
ON (S1.[Код специальности]=E.[Код специальности])
INNER JOIN Дисциплины D
ON (D.[Код дисциплины]=E.[Код дисциплины])
WHERE (D.Название=‘Русский язык’)
)
Подзапросы
Использование подзапросов в выводе
SELECT T.Поле1,
(
SELECT SUM(А.Поле2)
FROM Таблица2 AS A
WHERE A.Поле3=T.Поле2
) AS Поле_Сум
FROM Таблица1 AS T
SELECT T.Поле1,
(
SELECT COUNT(*)
FROM Таблица2 AS A
) AS Поле_кнт
FROM Таблица1 AS T
Подзапросы (примеры)
Использование подзапросов в выводе
SELECT A.Фамилия,
(
SELECT COUNT(*) FROM Заявления Z
WHERE Z.[Код абитуриента]=A.[Код абитуриента]
) [Количество заявлений]
FROM Абитуриенты A
SELECT A.Фамилия, COUNT(*) [Количество заявлений]
FROM Абитуриенты A INNER JOIN Заявления Z
ON (Z.[Код абитуриента]=A.[Код абитуриента]
GROUP BY A.Фамилия
Изменение данных
UPDATE Таблица1
SET Поле1=ЗНАЧЕНИЕ1,
Поле2=ЗНАЧЕНИЕ2,….
WHERE (УСЛОВИЕ)
Изменение данных (примеры)
UPDATE Абитуриенты
SET Статус=‘Зачислен’
WHERE Пол=‘Мужской’
UPDATE Специальности
SET Вакансий=Вакансий+10
UPDATE Специальности
SET Вакансий=Вакансий*2
WHERE Название=‘Строительство’
Удаление данных
DELETE FROM Таблица1
WHERE (УСЛОВИЕ)
Быстрая очистка таблицы
TRUNCATE TABLE Таблица1
Удаление данных (примеры)
DELETE FROM Абитуриенты
WHERE Имя=‘Иван’
DELETE FROM Заявления
WHERE [Код абитуриента] IN
(SELECT [Код абитуриента]
FROM Абитуриенты
WHERE Пол=‘Мужской’)
DELETE FROM Заявления
WHERE Приоритет=4
ПРЕДСТАВЛЕНИЯ
VIEW
Представления, или (VIEW), представляют собой
временные, производные (виртуальные) таблицы и
являются объектами базы данных, информация в которых
не хранится постоянно, как в базовых таблицах, а
формируется динамически при обращении к ним.
Обычные таблицы относятся к базовым, т.е. содержащим
данные и постоянно находящимся на устройстве
хранения информации.
VIEW
Содержимое представлений выбирается из других
таблиц с помощью выполнения запроса, причем при
изменении значений в таблицах данные в представлении
автоматически меняются.
Представление - это фактически тот же запрос, который
выполняется всякий раз при участии в какой-либо
команде.
У пользователя создается впечатление, что он работает с
настоящей, реально существующей таблицей.
VIEW
Представление - это предопределенный запрос,
хранящийся в базе данных, который выглядит подобно
обычной таблице и не требует для своего хранения
дисковой памяти.
Для хранения представления используется только
оперативная память.
В отличие от других объектов базы данных
представление не занимает дисковой памяти за
исключением памяти, необходимой для хранения
определения самого представления.
VIEW
Создания и изменения представлений в стандарте языка
и реализации в MS SQL Server совпадают и
представлены следующей командой:
{CREATE| ALTER} VIEW имя_представления
[(имя_столбца [,...n])]
[WITH ENCRYPTION]
AS SELECT_оператор
[WITH CHECK OPTION]
DROP VIEW имя_представления
VIEW
По умолчанию имена столбцов в представлении
соответствуют именам столбцов в исходных таблицах.
Явное указание имени столбца требуется для
вычисляемых столбцов или при объединении нескольких
таблиц, имеющих столбцы с одинаковыми именами.
Имена столбцов перечисляются через запятую, в
соответствии с порядком их следования в
представлении.
VIEW
• Параметр WITH ENCRYPTION предписывает серверу
шифровать SQL-код запроса, что гарантирует
невозможность его несанкционированного просмотра и
использования. Если при определении представления
необходимо скрыть имена исходных таблиц и столбцов,
а также алгоритм объединения данных, необходимо
применить этот аргумент.
• Параметр WITH CHECK OPTION предписывает серверу
исполнять проверку изменений, производимых через
представление, на соответствие критериям,
определенным в операторе SELECT. Это означает, что
не допускается выполнение изменений, которые
приведут к исчезновению строки из представления.
VIEW
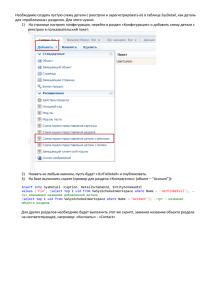
Пример Показать в представлении клиентов из Москвы.
Создание представления:
CREATE VIEW view1
AS
SELECT КодКлиента, Фамилия, ГородКлиента
FROM Клиент
WHERE ГородКлиента='Москва'
Выборка данных из представления:
SELECT * FROM view1
Обращение к представлению осуществляется с помощью оператора
SELECT как к обычной таблице.
VIEW
Представление можно использовать в команде так же, как и
любую другую таблицу.
К представлению можно строить запрос, модифицировать его
(если оно отвечает определенным требованиям), соединять с
другими таблицами. Содержание представления не
фиксировано и обновляется каждый раз, когда на него
ссылаются в команде.
Представления значительно расширяют возможности
управления данными. В частности, это прекрасный способ
разрешить доступ к информации в таблице, скрыв часть
данных.
VIEW
В примере представление ограничивает доступ пользователя к
данным таблицы Клиент, позволяя видеть только часть значений.
Если выполнить команду:
INSERT INTO view1 VALUES (12,'Петров', 'Самара')
Это допустимая команда в представлении, и строка будет добавлена
с помощью представления view1 в таблицу Клиент. Однако,
добавленная информация исчезнет из представления, поскольку
название города отлично от Москвы.
Это может стать проблемой, т.к. данные уже находятся в таблице, но
пользователь их не видит и не в состоянии выполнить их удаление
или модификацию.
Для исключения подобных моментов служит WITH CHECK OPTION в
определении представления.
VIEW
ALTER VIEW view1
SELECT КодКлиента, Фамилия, ГородКлиента
FROM Клиент
WHERE ГородКлиента='Москва'
WITH CHECK OPTION
Для такого представления вставка значений будет проверятся
системой.
Таким образом, представление может изменяться командами
модификации DML, но фактически модификация воздействует
не на само представление, а на базовую таблицу.
VIEW
Не все представления в SQL могут быть модифицированы.
Модифицируемое представление определяется следующими критериями:
• основывается только на одной базовой таблице;
• содержит первичный ключ этой таблицы;
• не содержит DISTINCT в своем определении;
• не использует GROUP BY или HAVING в своем определении;
• по возможности не применяет в своем определении подзапросы;
• не использует константы или выражения значений среди выбранных полей
вывода;
• в просмотр должен быть включен каждый столбец таблицы, имеющий атрибут
NOT NULL
• оператор SELECT просмотра не использует агрегирующие (итоговые) функции,
соединения таблиц, хранимые процедуры и функции, определенные
пользователем;
• основывается на одиночном запросе, поэтому объединение UNION не
разрешено.
Если представление удовлетворяет этим условиям, к нему могут применяться
операторы INSERT, UPDATE, DELETE.
VIEW
Не модифицируемое представление с данными из разных таблиц.
CREATE VIEW view2
AS
SELECT Клиент.Фамилия, Клиент.Фирма, Сделка.Количество
FROM Клиент
INNER JOIN Сделка ON Клиент.КодКлиента=Сделка.КодКлиента
Не модифицируемое представление с группировкой и итоговыми
функциями.
CREATE VIEW view3(Тип, Общ_остаток) AS
SELECT Тип, Sum(Остаток)
FROM Товар
GROUP BY Тип
VIEW
Обычно в представлениях используются имена,
полученные непосредственно из имен полей основной
таблицы. Однако иногда необходимо дать столбцам
новые имена, например, в случае итоговых функций или
вычисляемых столбцов.
CREATE VIEW view4(Код, Название, Тип, Цена, Налог)
AS
SELECT КодТовара, Название, Тип, Цена, Цена*0.05
FROM Товар
VIEW
В представлении предложение ORDER BY используется
только для определения строк, возвращаемых предложением
TOP.
CREATE VIEW TopView AS
SELECT TOP 50 PERCENT * FROM Person.Contact
ORDER BY LastName
При запросах к собственно представлению SQL Server не
гарантирует, что результаты будут упорядочены, если это не
было явно указано пользователем.
SELECT * FROM TopView
ORDER BY LastName
VIEW
Преимущества использования представлений
• Cкрыть реальную структуру БД от пользователей
• Независимость от данных
• Актуальность
• Повышение защищенности данных
• Упрощенная структура запросов
• Выборка только нужной части данных
• Настройка индивидуального образа базы данных
• Обеспечение целостности данных
VIEW
Недостатки использования представлений
• Ограниченные возможности обновления
• Структурные ограничения
• Снижение производительности
ПОНЯТИЕ ТРАНЗАКЦИИ
Понятие транзакции
Транзакция - это последовательность операторов
манипулирования данными, выполняющаяся как единое
целое (все или ничего) и переводящая базу данных из
одного целостного состояния в другое целостное
состояние.
Свойства транзакции (ACID)
1.
атомарность (англ. Atomicity) - в транзакции выполняются
или все входящие в нее операции, или ни одна.
2.
согласованность (англ. Consistency) - после завершении
транзакции все данные должны находится в согласованном
состоянии.
3.
изоляция (англ. Isolation) - незафиксированные
модификации, выполняемые транзакцией, должны быть
недоступны другим транзакциями, выполняющимся
параллельно.
4.
устойчивость (англ. Durability) - по завершении транзакции
ее результат должен сохраниться в системе в любом
случае.
Управление транзакциями
SET TRANSACTION ISOLATION LEVEL – задает уровень
изоляции транзакции
BEGIN TRANSACTION – начать транзакцию
COMMIT – зафиксировать транзакцию
ROLLBACK – отменить транзакцию
Команды управления транзакциями относятся к языку
TCL (Transaction Control Language)
Проблемы согласованности данных
Потерянные обновления
Проблема может быть решена запретом транзакции A
считывать значение остатка до завершения транзакции B.
Проблемы согласованности данных
Грязное чтение
Проблема может быть решена запретом транзакции A
считывать значение остатка до завершения транзакции B.
Проблемы согласованности данных
• Неповторяемое чтение - возникает, когда первая
транзакция несколько раз обращается к одним и тем же
данным, однако данные меняются вследствие того, что
между обращениями вторая транзакция обновляет
данные и фиксирует.
Проблема может быть решена запретом второй
транзакции изменять выбираемые данные.
• Чтение фантомов - появляется в том случае, когда
записи выбранные в первой транзакции, добавляются
или удаляются второй транзакцией.
Проблема может быть решена запретом второй
транзакции изменять выбранный диапазон данных.
Уровни изоляции
1. READ UNCOMMITTED (неподтвержденное чтение) -
транзакция с этим уровнем изоляции может читать
записи, которые были изменены, но еще не
зафиксированы другой транзакцией.
2. READ COMMITTED (подтвержденное чтение) транзакция с этим уровнем изоляции может читать
только те записи, которые были изменены и уже
зафиксированы другой транзакцией.
Уровни изоляции
3. REPEATABLE READ (повторяемое чтение) -
транзакция с этим уровнем изоляции может читать
только те записи, которые были изменены и уже
зафиксированы другой транзакцией, и никакая другая
транзакция не может изменить записи, которые были
прочитаны в рамках этой транзакции.
4. SERIALIZABLE (упорядочение) - транзакция с этим
уровнем изоляции может читать только те записи,
которые были изменены и уже зафиксированы другой
транзакцией; никакая другая транзакция не может
изменить записи, которые были прочитаны в рамках
этой транзакции и никакая другая транзакция не может
добавить или удалить записи из диапазона записей,
прочитанного в рамках этой транзакции.
Уровни изоляции
Уровни
изоляции
Потерянные
обновления
Грязное
чтение
Неповторяемое
чтение
Чтение
фантомов
READ
UNCOMMITTED
Нет
Да
Да
Да
READ
COMMITTED
Нет
Нет
Да
Да
REPEATABLE
READ
Нет
Нет
Нет
Да
SERIALIZABLE
Нет
Нет
Нет
Нет
Блокировки данных
Блокировка - это объект, с помощью которого
показывается зависимость транзакции от каких-либо
данных.
Система управления блокировками запрещает другим
транзакциям выполнять над данными операции,
негативно влияющие на зависимость транзакции,
владеющей блокировкой, от этих данных. Блокировка
создает временное ограничение на выполнение
некоторых операций обработки тех данных, от которых
зависит транзакция. Блокировка может быть выполнена
для элементов самого различного размера - начиная с
базы данных в целом и заканчивая отдельным полем
конкретной записи.
Типы блокировок
• разделяемая (shared, S) - накладывается при
выполнении операций чтения данных. Блокирующая
транзакция, а также никакая другая транзакция не
сможет изменить или удалить данные, если на них
установлена разделяемая блокировка. Разделяемая
блокировка обычно освобождается после завершения
чтения данных, но если только уровень изоляции
транзакции установлен в REPEATABLE READ или выше,
то разделяемая блокировка сохраняется до завершения
транзакции. Поскольку разделяемые блокировки не
могут служить причиной конфликта,
допускается устанавливать разделяемые блокировки
для чтения одного и того же элемента одновременно со
стороны сразу нескольких транзакций.
Типы блокировок
• монопольная (exclusive, X) - накладывается при
выполении операций изменения данных. Блокирующая
транзакция может при этом выполнять любые операции
с блокированными данными, но никакая другая
транзакция не сможет ни изменить, ни даже прочитать
данные, если на них установления монопольная
блокировка. Исключение: прочитать данные с
установленной монопольной блокировкой возможно,
если только уровень изоляции транзакции установлен в
READ UNCOMMITTED. Монопольная блокировка
освобождается после завершения транзакции.
Монопольная блокировка может быть установлена для
одного и того же элемента только одной транзакцией.
Протокол двухфазной блокировки
• Важную роль в обеспечении корректной параллельной
обработки транзакций играет «протокол двухфазной
блокировки» (Two Phase Locking – 2PL).
• Суть 2PL в том, что нельзя снять однажды наложенную
блокировку до тех пор, пока не наложены все
блокировки, необходимые транзакции. Таким образом,
работа с блокировками в транзакции делится на две
фазы: фаза наложения блокировок и фаза снятия. В
практических реализациях, как правило, применяется
строгий протокол двухфазной блокировки – Strict 2PL.
Его особенность в том, что фаза снятия блокировок
наступает после фиксации транзакции.
Взаимоблокировка
Взаимоблокировка представляет собой тупиковую
ситуацию, которая может возникнуть, когда две (или
более) транзакции находятся во взаимном ожидании
освобождения блокировок, удерживаемых друг другом.
Для примера рассмотрим две транзакции T1 и T2.
Транзакция T1 осуществляет перевод средств со счета А
на счет Б, вначале уменьшая сумму на счете А, а затем
увеличивая сумму на счете Б. Транзакция T2
осуществляет перевод средств со счета Б на счет А,
вначале уменьшая сумму на счете Б, а затем увеличивая
сумму на счете А.