Конспект часть 2
advertisement

Конспект лекций по дисциплине
«Обнаружение и распознавание сигналов»
Лекция 18. Цифровая обработка сигналов.
Введение.
1. Предисловие к цифровой обработке сигналов. Цифровые сигналы. Преобразование
сигнала в цифровую форму. Обработка цифровых сигналов. Z-преобразование. Природа
сигналов. Функциональные преобразования сигналов.
2. Ключевые операции цифровой обработки. Линейная свертка. Корреляция. Линейная
цифровая фильтрация. Дискретные преобразования. Модуляция сигналов.
3. Области применения цифровой обработки сигналов. Процессоры ЦОС. Запись,
воспроизведение, использование звука. Применение ЦОС в телекоммуникациях.
1. Основные положения.
Физические величины макромира, как основного объекта наших измерений и источника
информационных сигналов, как правило, имеют непрерывную природу и отображаются
непрерывными (аналоговыми) сигналами. Цифровая обработка сигналов (ЦОС или DSP - digital
signal processing) работает исключительно с дискретными величинами, причем с квантованием
как по координатам динамики своих изменений (по времени, в пространстве, и любым другим
изменяемым параметрам), так и по амплитудным значениям физических величин. Математика
дискретных преобразований зародилась в недрах аналоговой математики еще в 18 веке в рамках
теории рядов и их применения для интерполяции и аппроксимации функций, однако ускоренное
развитие она получила в 20 веке после появления первых вычислительных машин. В принципе, в
своих основных положениях математический аппарат дискретных преобразований подобен
преобразованиям аналоговых сигналов и систем. Однако дискретность данных требует учета
этого фактора, а его игнорирование может приводить к существенным ошибкам. Кроме того, ряд
методов дискретной математики не имеет аналогов в аналитической математике.
Стимулом быстрого развития дискретной математики является и то, что стоимость
цифровой обработки данных ниже аналоговой и продолжает падать, даже при очень сложных ее
видах, а производительность вычислительных операций непрерывно возрастает. Немаловажным
является также и то, что системы ЦОС отличаются высокой гибкостью. Их можно дополнять
новыми программами и перепрограммировать на выполнение различных функций без изменения
оборудования. В последние годы ЦОС оказывает постоянно возрастающее влияние на ключевые
отрасли современной промышленности: телекоммуникации, средства информации, цифровое
телевидение и пр. Следует ожидать, что в обозримом будущем интерес и к научным, и к
прикладным вопросам цифровой обработке сигналов будет нарастать во всех отраслях науки и
техники.
Цифровые сигналы формируются из аналоговых операцией дискретизации –
последовательными отсчетами (измерением) амплитудных значений сигнала через интервалы
времениΔ. В принципе известны методы ЦОС для неравномерной дискретизации данных, однако
области их применения достаточно специфичны и ограничены. Условия, при которых возможно
полное восстановление аналогового сигнала по его цифровому эквиваленту с сохранение всей
исходно содержавшейся в сигнале информации, выражаются теоремами Найквиста, Уиттекера,
1
Котельникова, Шеннона, сущность которых практически одинакова. Для дискретизации
аналогового сигнала с полным сохранением информации в его цифровом эквиваленте
максимальные частоты в аналоговом сигнале должны быть не менее чем вдвое меньше, чем
частота дискретизации, то есть fmax (1/2)fd. Если это условие нарушается, в цифровом сигнале
возникает эффект маскирования (подмены) действительных частот "кажущимися" более низкими
частотами. Наглядным примером этого эффекта может служить иллюзия, довольно частая в кино
– вращающееся колесо автомобиля вдруг начинает вращаться в противоположную сторону, если
между последовательными кадрами (аналог частоты дискретизации) колесо совершает более чем
пол-оборота. При этом в цифровом сигнале вместо фактической регистрируется "кажущаяся"
частота, а, следовательно, восстановление фактической частоты при восстановлении аналогового
сигнала становится невозможным.
Преобразование сигнала в цифровую форму производится аналого-цифровыми
преобразователями (АЦП). Как правило, они используют двоичную систему представления при
равномерной шкале с определенным числом разрядов. Увеличение числа разрядов повышает
точность измерений и расширяет динамический диапазон измеряемых сигналов. Потерянная изза недостатка разрядов АЦП информация невосстановима, и существуют лишь оценки
погрешности, например, через мощность шума, порожденного ошибкой в последнем разряде.
Для того чтобы оценить влияние помехи, вводится понятие “отношение сигнал-шум” отношение мощности сигнала к мощности шума (в децибелах).
Наиболее часто используются 8-, 10-, 12-, 16-, 20- и 24-х разрядные АЦП. Каждый
дополнительный разряд улучшает отношение сигнал-шум на 6 децибел. Однако увеличение
количества разрядов снижает скорость дискретизации и увеличивает стоимость аппаратуры.
Важным аспектом является также динамический диапазон, определяемый максимальным и
минимальным значением сигнала. Для обратного преобразования используется цифроаналоговый преобразователь (ЦАП), основные характеристики которого (разрядность, частота
дискретизации, число каналов и т.п.) аналогичны характеристикам АЦП.
Для компенсации ошибки, порожденной неточной дискретизацией, существуют
определенные методы. Например, усредняя по нескольким реализациям, можно добиться
выделения даже сигнала, меньшего в несколько десятков раз по амплитуде по сравнению с
ошибкой дискретизации. Иногда используется и искусственное привнесение помехи (при
обработке звука – слабый гауссовский шум для маскирования шума квантования и
воспринимающийся на слух приятнее “точного” сигнала).
Обработка цифровых сигналов выполняется либо специальными процессорами, либо на
универсальных ЭВМ и компьютерах по специальным программам. Наиболее просты для
рассмотрения линейные системы. Линейными называются системы, для которых имеет место
суперпозиция (отклик на сумму двух входных сигналов равен сумме откликов на эти сигналы по
отдельности) и однородность, или гомогенность (отклик на входной сигнал, усиленный в
определенное число раз, будет усилен в то же число раз). Линейность позволяет рассматривать
объекты исследования по частям, а однородность - в удобном масштабе. Для реальных объектов
свойства линейности могут выполняться приближенно и в определенном интервале входных
сигналов.
Если входной сигнал x(t-t0) порождает одинаковый выходной сигнал y(t-t0) при любом
сдвиге t0, то систему называют инвариантной во времени. Ее свойства можно исследовать в
любые произвольные моменты времени. Для описания линейной системы вводится специальный
2
входной сигнал - единичный импульс (импульсная функция). В силу свойства суперпозиции и
однородности любой входной сигнал можно представить в виде суммы таких импульсов,
подаваемых в разные моменты времени и умноженных на соответствующие коэффициенты.
Выходной сигнал системы в этом случае представляет собой сумму откликов на эти импульсы,
умноженных на указанные коэффициенты. Отклик на единичный импульс называют импульсной
характеристикой системы h(n), а отклик на произвольный входной сигнал s(k) можно выразить
сверткой g(k) = h(n)*s(k-n).
Если h(n)=0 при n<0, то систему называют каузальной (причинной). В такой системе
реакция на входной сигнал появляется только после поступления сигнала на ее вход.
Некаузальные системы реализовать физически невозможно. Если требуются физически
реализовать свертку сигналов с двусторонними операторами (при дифференцировании,
преобразовании Гильберта, и т.п.), то это выполняется с задержкой (сдвигом) входного сигнала
минимум на длину левосторонней части оператора свертки.
Преобразование Лапласа дискретного сигнала. Z – преобразование. В цифровых
системах сигналы представляют собой последовательности отсчетов, взятые, как правило, через
равные промежутки времени
. Рассмотрим дискретный сигнал
Графически процесс дискретизации сигнала показан на рисунке.
Рисунок 1: Графическое представление дискретного сигнала
Рассмотрим преобразование Лапласа от дискретного сигнала
, которое равно:
3
Z-преобразование. Для облегчения анализа цифровых сигналов вводят z-преобразование путем
отображения комплексной s-плоскости в комплексную z-плоскость вида:
Тогда преобразование Лапласа дискретного сигнала переходит в z – преобразование:
Поскольку
то все бесконечные периодические повторения нулей и полюсов дискретного фильтра в
плоскости s преобразуются в одну точку в плоскости z.
Системы обычно описывается линейными разностными уравнениями с постоянными
коэффициентами: y(k) = ∑ b(n) x(k-n) - ∑ a(m) y(k-m), n=0, 1, … , N, m=1, 2, … , M. Этим
уравнением устанавливается, что выходной сигнал y(k) системы в определенный момент ki
(например, в момент времени kiΔt) зависит от значений входного сигнала x(k) в данный (ki) и
предыдущие моменты (ki-n) и значений сигнала y(k) в предыдущие моменты (ki-m).
Z-преобразование этого уравнения, выраженное относительно передаточной функции
системы H(z) = Y(z)/X(z), представляет собой рациональную функцию от z в виде отношения
двух полиномов от z. Корни полинома в числителе называются нулями, а в знаменателе полюсами функции H(z). Значения нулей и полюсов позволяют определить некоторые свойства
линейной системы. Так, если все полюсы лежат вне единичной окружности |z|=1 на комплексной
z-плоскости (по модулю больше единицы), то система является устойчивой (не пойдет “вразнос”
ни при каких входных воздействиях). Нули функции Y(z) обращают в ноль H(z) и показывают,
какие колебания вовсе не будут восприниматься системой (“антирезонанс”). Полюса функции
X(z) обращают H(z) в бесконечность, такой сигнал на входе системы вызывает резонанс и
неограниченное возрастание сигнала на выходе. Систему называют минимально-фазовой, если
все полюсы и нули передаточной функции лежат вне единичной окружности. Попутно заметим,
что применение z-преобразования с отрицательными степенями z-1 меняет положение полюсов и
нулей относительно единичной окружности |z|=1 (область вне окружности перемещается внутрь
окружности, и наоборот).
Природа сигналов. По своей природе сигналы могут быть случайные или
детерминированные. К детерминированным относят сигналы, значения которых в любой момент
времени или в произвольной точке пространства (а равно и в зависимости от любых других
аргументов) являются априорно известными или могут быть достаточно точно определены
(вычислены) по известной или предполагаемой функции, даже если мы не знаем ее явного вида.
4
Случайные сигналы в принципе не имеют определенного закона изменения своих значений во
времени или в пространстве. Для каждого конкретного момента (отсчета) случайного сигнала
можно знать только вероятность того, что он примет какое-либо значение в какой-либо
определенной области возможных значений. Закон распределения (функция распределения –
вероятность того, что случайная величина примет значение меньшее аргумента функции, или
плотность распределения – производная функции распределения) далеко не всегда известен.
Одним из самых распространенных является нормальный закон (Гаусса), плотность
распределения которого имеет вид симметричного колокола. Для его описания достаточно двух
первых моментов. Его распространенность обусловлена тем, что сумма случайных величин по
мере увеличения их количества стремиться к нормальному закону. Определенное
распространение имеют и равномерный на заданном отрезке закон, и двойной
экспоненциальный, похожий по форме на нормальный, но с более длинными “хвостами”
(вероятность больших отклонений больше, чем для нормального), и другие, в том числе
несимметричные законы.
Наиболее простые характеристики законов распределения – среднее значение случайных
величин (математическое ожидание) и дисперсия (математическое ожидание квадрата
отклонения от среднего), характеризующая разброс значений случайных величин относительно
среднего значения. Параметры динамики случайных сигналов (процессов) во времени
характеризуются функциями автокорреляции (количественная оценка взаимосвязи значений
случайного сигнала на различных интервалах) или автоковариации (то же, при центрировании
случайных сигналов). Аналогичной мерой взаимосвязи двух случайных процессов и степени их
сходства по динамике развития является кросскорреляция или кроссковариация (взаимная
корреляция или ковариация). Максимальное значение взаимной корреляции достигается при
совпадении двух сигналов. При задержке одного из сигналов по отношению к другому
положение максимума корреляционной функции дает возможность оценить величину этой
задержки.
Функциональные преобразования сигналов. Одним из основных методов частотного
анализа и обработки сигналов является преобразование Фурье. Различают понятия
“преобразование Фурье” и “ряд Фурье”. Преобразование Фурье предполагает непрерывное
распределение частот, ряд Фурье задается на дискретном наборе частот. Сигналы также могут
быть заданы в наборе временных отсчетов или как непрерывная функция времени. Это дает
четыре варианта преобразований – преобразование Фурье с непрерывным или с дискретным
временем, и ряд Фурье с непрерывным временем или с дискретным временем. Наиболее
практична с точки зрения цифровой обработки сигналов дискретизация и во временной, и в
частотной области, но не следует забывать, что она является аппроксимацией непрерывного
преобразования. Непрерывное преобразование Фурье позволяет точно представлять любые
явления. Сигнал, представленный рядом Фурье, может быть только периодичен. Сигналы
произвольной формы могут быть представлены рядом Фурье только приближенно, т.к. при этом
предполагается периодическое повторение рассматриваемого интервала сигнала за пределами
его задания. На стыках периодов при этом могут возникать разрывы и изломы сигнала, и
возникать
ошибки обработки, вызванные явлением Гиббса, для минимизации которых
применяют определенные методы (весовые окна, продление интервалов задания сигналов, и т.п.).
При дискретизации и во временной, и в частотной области, вместо “дискретно-временной
ряд Фурье” обычно (что не слишком точно) говорят о дискретном преобразовании Фурье (ДПФ).
Применяется оно для вычисления спектров мощности, оценивания передаточных функций и
5
импульсных откликов, быстрого вычисления сверток при фильтрации, расчете корреляции,
расчете преобразований Гильберта, и т.п. Расчет ДПФ по приведенной формуле требует
вычисления n коэффициентов, каждый из которых зависит от k элементов исходного отрезка, так
что число операций не может быть меньше nk. Существует целое семейство алгоритмов,
известное, как “Быстрое Преобразование Фурье” - БПФ, сокращающее время работы до n log(k)
операций. “Быстрое” не следует трактовать, как “упрощенное” и “неточное”. При точной
арифметике результаты расчетов ДПФ и по алгоритмам БПФ совпадают.
Известное применение находят и варианты преобразования Фурье: косинусное для четных
и синусное для нечетных сигналов, а также преобразование Хартли, где базисными функциями
являются суммы синусов и косинусов, что позволяет повысить производительность вычислений
и избавиться от комплексной арифметики. Вместо косинусных и синусных функций
используются также меандровые функции Уолша, принимающие значения только +1 и -1. И,
наконец, в последнее время в задачах спектрально-временнного анализа нестационарных
сигналов, изучения нестационарностей и локальных особенностей сигналов "под микроскопом",
очистки от шумов и сжатия сигналов начинают получать в качестве базисов разложения
вейвлеты ("короткие волны"), локализованные как во временной, так и в частотной области.
КЛЮЧЕВЫЕ ОПЕРАЦИИ ЦИФРОВОЙ ОБРАБОТКИ.
Существуют многочисленные алгоритмы ЦОС как общего типа для сигналов в их
классической временной форме (телекоммуникации, связь, телевидение и пр.), так и
специализированные в самых различных отраслях науки и техники (геоинформатике, геологии и
геофизике, медицине, биологии, военном деле, и пр.). Однако все эти алгоритмы, как правило –
блочного типа, построены на сколь угодно сложных комбинациях достаточно небольшого набора
типовых цифровых операций, к основным из которых относятся свертка (деконволюция),
корреляция, фильтрация, функциональные преобразования, модуляция. Частично эти операции
уже рассматривались нами в "Теории сигналов и систем". Ниже приводятся только ключевые
позиции по этим операциям ("повторенье – мать ученья").
Линейная свертка – основная операция ЦОС, особенно в режиме реального времени. Для
двух конечных причинных последовательностей h(n) и y(k) длиной соответственно N и K свертка
определяется выражением:
s(k) = h(n) ③ y(k) h(n) * y(k) =
N
h(n) y(k-n),
(1.2.1)
n 0
где: ③ или * - символьные обозначения операции свертки. Как правило, в системах
обработки одна из последовательностей y(k) представляет собой обрабатываемые данные (сигнал
на входе системы), вторая h(n) – оператор (импульсный отклик) системы, а функция s(k) –
выходной сигнал системы. В компьютерных системах с памятью для входных данных оператор
h(n) может быть двусторонним от –N1 до +N2, например – симметричным h(-n) = h(n), с
соответствующим изменением пределов суммирования в (1.2.1), что позволяет получать
выходные данные без сдвига фазы частотных гармоник относительно входных данных. При
строго корректной свертке с обработкой всех отсчетов входных данных размер выходного
массива равен K+N1+N2-1 и должны задаваться начальные условия по отсчетам y(k) для
значений y(0-n) до n=N2 и конечные для y(K+n) до n=N1. Пример выполнения свертки приведен
на рис. 1.2.1.
6
Рис. 1.2.1. Примеры дискретной свертки.
Преобразование свертки однозначно определяет выходной сигнал для установленного
значения входного сигнала при известном импульсном отклике системы. Обратная задача
деконволюции - определение функции y(k) по функциям s(k) и h(n), имеет решение только при
определенных условиях. Это объясняется тем, что свертка может существенно изменить
частотный спектр сигнала s(k) и восстановление функции y(k) становится невозможным, если
определенные частоты ее спектра в сигнале s(k) полностью утрачены.
Корреляция существует в двух формах: автокорреляции и взаимной корреляции.
Взаимно-корреляционная функция (ВКФ, cross-correlation function - CCF), и ее частный
случай для центрированных сигналов функция взаимной ковариации (ФВК)– это показатель
степени сходства формы и свойств двух сигналов. Для двух последовательностей x(k) и y(k)
длиной К с нулевыми средними значениями оценка взаимной ковариации выполняется по
формулам:
K n
Kxy(n) = (1/(K-n+1))
k 0
x(k) y(k+n), n = 0, 1, 2, …
(1.2.2)
x(k-n) y(k), n = 0, -1, -2, …
(1.2.2')
K n
Kxy(n) = (1/(K-n+1))
k 0
Рис. 1.2.2. Функция взаимной ковариации двух детерминированных сигналов.
7
Пример определения сдвига между двумя детерминированными сигналами,
представленными радиоимпульсами, по максимуму ФВК приведен на рис. 1.2.1. В принципе, по
максимуму ФВК может определяться и сдвиг между локальными сигналами, достаточно
различными по форме.
Рис. 1.2.3. ФВК двух сигналов, один из которых сильно зашумлен.
На рис. 1.2.3 приведен аналогичный пример ФВК двух одинаковых по форме сигналов, на
один из которых наложен шумовой сигнал, мощность которого превышает мощность сигнала.
Вычисление ФВК в этом случае обычно выполняется по варианту 2 – с постоянным
нормировочным множителем. Это определяется тем, что по мере возрастания сдвига n и
уменьшения количества суммируемых членов в формуле (1.2.2) за счет шумовых сигналов
существенно нарастает ошибка оценки ФВК, которая к тому же увеличивается за счет
нелинейного увеличения значения нормировочного множителя, особенно при малом количестве
отсчетов. Сохранение множителя постоянным в какой-то мере компенсирует этот эффект.
Рис. 1.2.4. ФВК двух зашумленных радиоимпульсов.
На рис. 1.2.4 приведен пример вычисления функции взаимной ковариации двух одинаковых
сигналов, скрытых в шумах. ФВК позволяет не только определить величину сдвига между
сигналами, но и достаточно уверенно оценить период колебаний в исследуемых радиоимпульсах.
Относительный количественный показатель степени сходства двух сигналов x(k) и y(k) функция взаимных корреляционных коэффициентов
rxy(n).
Она вычисляется через
центрированные значения сигналов (для вычисления взаимной ковариации нецентрированных
сигналов достаточно центрировать только один из них), и нормируется на произведение
значений стандартов (средних квадратических вариаций) функций x(k) и y(k):
rxy(n) = Kxy(n)/σx σy).
K
σx2 = Kxx(0) = (1/(K+1))
k 0
(1.2.3)
K
(x(k))2, σy2 = Kyy(0) = (1/(K+1))
(y(k))2.
(1.2.4)
k 0
8
Интервал изменения значений корреляционных коэффициентов при сдвигах n может
изменяться от –1 (полная обратная корреляция) до 1 (полное сходство или стопроцентная
корреляция). При сдвигах n, на которых наблюдаются нулевые значения rxy(n), сигналы
некоррелированны. Коэффициент взаимной корреляции позволяет устанавливать наличие
определенной связи между сигналами вне зависимости от физических свойств сигналов и их
величины.
Автокорреляционная функция (АКФ, correlation function, CF)
количественной интегральной характеристикой формы сигнала, дает информацию о
сигнала и его динамике во времени. Она, по существу, является частным случаем
одного сигнала и представляет собой скалярное произведение сигнала и его
функциональной зависимости от переменной величины значения сдвига:
является
структуре
ВКФ для
копии в
K -n
Bx(n) = (1/(K-n+1))
x(k) x(k+n), n = 0, 1, 2, …
(1.2.5)
k 0
АКФ имеет максимальное значение при n=0 (умножение сигнала на самого себя), является
четной функцией Bxy(-n)=Bxy(n), и значения АКФ для отрицательных координат обычно не
вычисляются. АКФ центрированного сигнала Kx(n) представляет собой функцию
автоковариации (ФАК). ФАК, нормированная на свое значение Kx(0)= σx2 в n=0:
rx(n) = Kx (n)/Kx(0)
(1.2.6)
называется функцией автокорреляционных коэффициентов.
Рис. 1.2.5. Автокорреляционные функции.
В качестве примера на рис. 1.2.5 приведены два сигнала – прямоугольный импульс и
радиоимпульс одинаковой длительности Т, и соответствующие данным сигналам формы их
АКФ. Амплитуда колебаний радиоимпульса установлена равной T амплитуды прямоугольного
импульса, при этом энергии сигналов будут одинаковыми, что подтверждается равными
значениями максимумов АКФ. При конечной длительности импульсов длительности АКФ также
конечны, и равны удвоенным значениям длительности импульсов (при сдвиге копии конечного
импульса на интервал его длительности как влево, так и вправо, произведение импульса со своей
копией становится равным нулю). Частота колебаний АКФ радиоимпульса равна частоте
колебаний заполнения радиоимпульса (боковые минимумы и максимумы АКФ возникают
каждый раз при последовательных сдвигах копии радиоимпульса на половину периода
колебаний его заполнения).
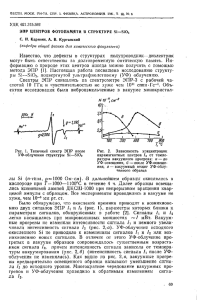
Лекция 19. Линейная цифровая фильтрация.
Линейная цифровая фильтрация является одной из операций ЦОС, имеющих
9
первостепенное значение, и определяется как
N
s(k) =
h(n) y(k-n),
(1.)
n 0
где: h(n), n=0, 1, 2, … , N –
коэффициенты фильтра, y(k) и s(k) –
вход и выход фильтра. Это по сути
свертка
сигнала
с
импульсной
характеристикой фильтра.
На рис. 1 показана блок-схема
фильтра, который в таком виде широко
известен, как трансверсальный (z –
Рис. 1. Трансверсальный цифровой фильтр.
задержка на один интервал дискретизации).
К основным операциям фильтрации информации относят операции сглаживания,
прогнозирования, дифференцирования, интегрирования и разделения сигналов, а также
выделение информационных (полезных) сигналов и подавление шумов (помех). Основными
методами цифровой фильтрации данных являются частотная селекция сигналов и оптимальная
(адаптивная) фильтрация.
Дискретные преобразования позволяют описывать сигналы с дискретным временем в
частотных координатах или переходить от описания во временной области к описанию в
частотной. Переход от временных (пространственных) координат к частотным необходим во
многих приложениях обработки данных.
Самым распространенным преобразованием является дискретное преобразование Фурье.
При K отсчетов функции:
K -1
S(n) =
s(k) exp(-j 2π kn/K).
(2.)
k 0
Напомним, что дискретизация функции по времени приводит к периодизации ее спектра, а
дискретизация спектра по частоте - к периодизации функции. Для дискретных преобразований
s(kΔt) S(nΔf), и функция, и ее спектр дискретны и периодичны, а числовые массивы их
представления соответствуют заданию на главных периодах Т = KΔt (от 0 до Т или от -Т/2 до
Т/2), и 2fN = NΔf (от -fN до fN), где K, N – количество отсчетов сигнала и его спектра
соответственно, при этом:
Δf = 1/T = 1/(KΔt), Δt = 1/2fN = 1/(NΔf), ΔtΔf = 1/N, N = 2TfN = K.
(3)
Соотношения (1.2.9) являются условиями информационной равноценности динамической и
частотной форм представления дискретных сигналов. Другими словами: для преобразований без
потерь информации число отсчетов функции и ее спектра должны быть одинаковыми.
В принципе, согласно общей теории информации, последнее заключение действительно и
для любых других видов линейных дискретных преобразований.
Модуляция сигналов. Системы регистрации, обработки, интерпретации, хранения и
использования информационных данных становятся все более распределенными, что требует
10
коммуникации данных по высокочастотным каналам связи. Как правило, информационные
сигналы являются низкочастотными и ограниченными по ширине спектра, в отличие от
широкополосных высокочастотных каналов связи, рассчитанных на передачу сигналов от
множества источников одновременно с частотным разделением каналов. Перенос спектра
сигналов из низкочастотной области в выделенную для их передачи область высоких частот
выполняется
операцией
модуляции.
При
модуляции
значения
информационного
(модулирующего) сигнала переносятся на определенный параметр высокочастотного (несущего)
сигнала.
Самые распространенные схемы модуляции для передачи цифровой информации по
широкополосным каналам – это амплитудная (amplitude shift keying – ASK), фазовая (phase shift
keying – PSK) и частотная (frequensy shift keying – FSK) манипуляции. При передаче данных по
цифровым сетям используется также импульсно-кодовая модуляция (pulse code modulation –
PCM).
ОБЛАСТИ ПРИМЕНЕНИЯ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ.
Нет смысла перечислять и давать оценку возможностей ЦОС в различных областях науки
и техники. С весьма малой вероятностью можно попытаться найти отрасль, где ЦОС еще не
получили широкого распространения. Поэтому коснемся только тех областей, где применение
ЦОС развивается наиболее быстрыми темпами.
Процессоры ЦОС. Обработка данных в реальном времени обычно выполняется на
специальных процессорах (чипах) ЦОС. Они, как правило, имеют:
Встроенные умножители или умножители-накопители, работающие параллельно.
Отдельные шины и области памяти для программ и данных.
Команды организации циклов.
Большие скорости обработки данных и тактовые частоты.
Использование конвейерных методов обработки данных.
Запись, воспроизведение, использование звука.
Цифровое микширование – регулирование и смешивание многоканальных аудиосигналов
от различных источников. Это выполняется аудиоэквалайзерами (наборами цифровых
полосовых фильтров с регулируемыми характеристиками), смесителями и устройствами
создания специальных эффектов (реверберация, динамическое выравнивание и пр.).
Синтезаторы речи представляют собой достаточно сложные устройства генерации
голосовых звуков. Микросхемы синтезаторов вместе с процессорами обычно содержат в ПЗУ
словари слов и фраз в форме кадров (25 мс речи) с внешним управлением интонацией, акцентом
и диалектом, что позволяет на высоком уровне имитировать человеческую речь.
Распознавание речи активно изучается и развивается, особенно для целей речевого ввода
информации в компьютеры. Как правило, в режиме обучения выполняется их настройка на речь
пользователя, в процессе которой система оцифровывает и создает в памяти эталоны слов. В
режиме распознавания речь также оцифровывается и сравнивается с эталонами в памяти.
Системы распознавания речи внедряются и в товары бытового назначения (набор телефонных
номеров, включение/выключение телевизора, и пр.).
11
Аудиосистемы воспроизведения компакт-дисков при плотности записи выше 106 бит на
мм2 обеспечивают очень высокую плотность хранения информации. Аналоговый звуковой
сигнал в стереоканалах дискретизируется с частотой 44.1 кГц и оцифровывается 16-битным
кодом. При записи на диск сигналы модулируются (EFM – преобразование 8-ми разрядного кода
в 14-ти разрядный для надежности), при считывании сигналы демодулируется, исправляются и
маскируются ошибки (по возможности) и выполняется цифро-аналоговое преобразование.
Применение ЦОС в телекоммуникациях.
Цифровая сотовая телефонная сеть – двусторонняя телефонная система с мобильными
телефонами через радиоканалы и связью через базовые радиостанции. Мировым стандартом
цифровой мобильной связи является система GSM. Частотный диапазон связи 890-960 МГц,
частотный интервал канала 200 кГц, скорость передачи информации 270 кбит/с. В мобильной
связи ЦОС используется для кодирования речи, выравнивания сигналов после многолучевого
распространения, измерения силы и качества сигналов, кодирования с исправлением ошибок,
модуляции и демодуляции.
Цифровое телевидение дает потребителям интерактивность, большой выбор, лучшее
качество изображения и звука, доступ в Интернет. ЦОС в цифровом телевидении играет
ключевую роль в обработке сигналов, кодировании, модуляции/демодуляции видео- и
аудиосигналов от точки захвата до момента появления на экране. ЦОС лежит в основе
алгоритмов кодирования MPEG, которые используются для сжатия сигналов перед их передачей
и при декодировании в приемниках.
ЦОС в биомедицине. Основное назначение – усиление сигналов, которые обычно не
отличаются хорошим качеством, и/или извлечение из них информации, представляющей
определенный интерес, на фоне существенного уровня шумов и многочисленных артефактов
(ложных изображений как от внешних, так и от внутренних источников). Так, например, при
снятии электрокардиограммы плода регистрируется электрическая активность сердца ребенка на
поверхности тела матери, где также существует определенная электрическая активность,
особенно во время родов. Применение ЦОС во многих областях медицины позволяет переходить
от чисто качественных показателей к объективным количественным оценкам, как например, в
анестезии к оценке глубины анестетического состояния пациента при операции по электрической
активности мозга. ЦАП и АЦП
Принцип работы ЦАП
12
Цифро-аналоговый преобразователь (ЦАП) — устройство для преобразования цифрового
(обычно двоичного) кода в аналоговый сигнал (ток, напряжение или заряд). Цифро-аналоговые
преобразователи являются интерфейсом между дискретным цифровым миром и аналоговыми
сигналами.
Звуковой ЦАП обычно получает на вход цифровой сигнал в импульсно-кодовой модуляции
(англ. PCM, pulse-code modulation). Задача преобразования различных сжатых форматов в PCM
выполняется соответствующими кодеками.
АЦП.
Когда необходимо разрешение 12, 14 или 16 разрядов и не требуется высокая скорость
преобразования, а определяющими факторами являются невысокая цена и низкое
энергопотребление, то обычно применяют АЦП последовательного приближения. Этот тип АЦП
чаще всего используется в разнообразных измерительных приборах и в системах сбора данных.
В настоящий момент АЦП последовательного приближения позволяют измерять напряжение с
точностью до 16 разрядов с частотой дискретизации от 100К (1х103) до 1М (1х106) отсчетов/сек.
Рис. 3 показывает упрощенную блок-схему АЦП последовательного приближения. В
основе АЦП данного типа лежит специальный регистр последовательного приближения. В
начале цикла преобразования все выходы этого регистра устанавливаются в логический 0, за
исключением первого (старшего) разряда. Это формирует на выходе внутреннего цифроаналогового преобразователя (ЦАП) сигнал, значение которого равно половине входного
диапазона АЦП. А выход компаратора переключается в состояние, определяющее разницу
между сигналом на выходе ЦАП и измеряемым входным напряжением.
Рис. 3. АЦП последовательного приближения
Например, для 8-разрядного АЦП последовательного приближения (рис. 4) выходы
регистра при этом устанавливаются в "10000000". Если входное напряжение меньше половины
входного диапазона АЦП, тогда выход компаратора примет значение логического 0. Это дает
регистру последовательного приближения команду переключить свои выходы в состояние
"01000000", что соответственно приведет к изменению выходного напряжения с ЦАП,
подаваемого на компаратор. Если при этом выход компаратора по-прежнему оставался бы в "0",
то выходы регистра переключились бы в состояние "00100000". Но на этом такте преобразования
выходное напряжение ЦАП меньше, чем входное напряжение (рис. 4), и компаратор
переключается в состояние логической 1. Это предписывает регистру последовательного
приближения сохранить "1" во втором разряде и подать "1" на третий разряд. Описанный
алгоритм работы затем вновь повторяется до последнего разряда. Таким образом, АЦП
13
последовательного приближения требуется один внутренний такт преобразования для каждого
разряда, или N тактов для N-разрядного преобразования.
Рис. 4. Преобразование в АЦП последовательных приближений
Тем не менее, работа АЦП последовательного приближения имеет особенность, связанную
с переходными процессами во внутреннем ЦАП. Теоретически, напряжение на выходе ЦАП для
каждого из N внутренних тактов преобразования должно устанавливаться за одинаковый
промежуток времени. Но на самом деле этот промежуток в первых тактах значительно больше,
чем в последних. Поэтому время преобразования 16-разрядного АЦП последовательного
приближения более, чем в два раза превышает время преобразования 8-разрядного АЦП данного
типа.
Лекция 20. Оконное преобразование Фурье
Оконное преобразование Фурье — это разновидность преобразования Фурье, определяемая
следующим образом:
где
—
некоторая оконная
функция.
преобразования оконная функция используется аналогично:
В
случае дискретного
Существует множество математических формул визуально улучшающих частотный спектр
на разрыве границ окна. Для этого применяются преобразования: прямоугольное (никакое),
треугольное, сужающийся косинус, фрагмент синусоиды, синус в кубе, синус в 4-й степени,
преобразование Парзена, Велша, Гаусса, Хеннинга, Хэмминга, Чебышёва, с пульсациями,
Розенфилда, Блэкмана-Харриса, горизонтальное и с плоской вершиной. Также существует
методика по взаимному перекрытию окон, при этом обычно можно выбрать сколько сэмплов из
предыдущего окна будет усреднено с текущим окном.
В большинстве задач цифровой обработки нет возможности исследовать сигнал на
бесконечном интервале. Нет возможности узнать, какой был сигнал до включения устройства и
14
какой он будет в будущем. Также ограничение интервала исследования может быть
обусловлено нестационарностью исследуемого сигнала. Ограничение интервала анализа
равносильно произведению исходного сигнала на оконную функцию. Таким образом,
результатом оконного преобразования Фурье является не спектр исходного сигнала, а спектр
произведения сигнала и оконной функции. Спектр, полученный при помощи оконного
преобразования Фурье, является оценкой спектра исходного сигнала и принципиально допускает
искажения. Искажения, вносимые применением окон, определяются размером окна и его
формой. Выделяют два основных свойства частотных характеристик окон: ширина главного
лепестка и максимальный уровень боковых лепестков. Применение окон, отличных от
прямоугольного, обусловлено желанием уменьшить влияние боковых лепестков за счет
увеличения ширины главного. При использовании оконного преобразования Фурье невозможно
одновременно обеспечить хорошее разрешение по времени и по частоте. Чем уже окно, тем
выше разрешение по времени и ниже разрешение по частоте.
Разрешение по осям является постоянным. Это нежелательно для ряда задач, в которых
данные по частотам распределены неравномерно. В таких задачах в качестве альтернативы
оконному преобразованию Фурье может использоваться вейвлет-преобразование, временное
разрешение которого увеличивается с частотой (частотное снижается).
Вейвлеты Добеши (англ. Daubechies Wavelet) — семейство ортогональных вейвлетов с
компактным носителем, вычисляемым итерационным путем. Названы в честь математика
из США, первой построившей данное семейство, Ингрид Добеши.
Построение вейвлетов Добеши
Для построения вейвлетов воспользуемся уравнением растяжения и вейвлет-уравнением
Компактность носителя функций
и
может быть достигнута, если будет выбрано конечное
число
таким образом, чтобы была достигнута ортогональность и гладкость вейвлета,
либо чтобы выполнялось условие моментов. Для области Фурье условие ортогональности и
гладкости выглядит следующим образом:
, где
— тригонометрический
полином,
при условии моментов
принимающий вид:
Если положить, что
моментов дает
Для поиска коэффициентов
,для
— полином по
, где
необходимо получить
, то условие нулевых
— полином по
, выделив форму полинома . Из
15
условия ортогональности и условия нулевых моментов следует, что
(1)
Разложив
до порядка
, получим явный вид полинома:
Путем спектрального разложения на множители можно извлечь корни
Искомые коэффициенты вейвлета
порядке.
из
будут являться коэффициентами при
:
в обратном
Также для построения вейвлетов данного типа используется каскадный алгоритм. Он
позволяет поточечно строить масштабирующую функцию φ по известным коэффициентам
.
На каждом шаге алгоритма функция φ уточняется по оси t в 2 раза. Далее при необходимости
применяется сглаживание φ. После этого, зная φ и
, находится функция самого вейвлета ψ.
Виды вейвлетов
Итак, вейвлет-преобразование - преобразование, похожее на преобразование Фурье (или
гораздо больше на оконное преобразование Фурье) с совершенно иной оценочной функцией.
Основное различие лежит в следующем: преобразование Фурье раскладывает сигнал на
составляющие в виде синусов и косинусов, т.е. функций, локализованных в Фурье-пространстве;
напротив, вейвлет-преобразование использует функции, локализованные как в реальном, так и в
в Фурье-пространстве. В общем, вейвлет-преобразование может быть выражено следующим
уравнением:
где * - символ комплексной сопряженности и функция ψ - некоторая функция. Функция
может быть выбрана произвольно, но она должна удовлетворять определённым правилам.
Как видно, вейвлет-преобразование на самом деле является бесконечным множеством
различных преобразований в зависимости от оценочной функции, использованной для его
расчёта.
Это
является
основной
причиной,
почему
термин «вейвлетпреобразование» используется в весьма различных ситуациях и применениях. Также существует
множество типов классификации вариантов вейвлет-преобразования. Здесь мы покажем только
деление. основанное на ортогональности вейвлетов. Можно использовать ортогональные
вейвлеты для разработки дискретного вейвлет-преобразования и неортогональные вейвлеты для
непрерывного. Эти два вида преобразования обладают следующими свойствами:
1.
Дискретное вейвлет-преобразование возвращает вектор данных той же длины, что
и входной. Обычно, даже в этом векторе многие данные почти равны нулю. Это соответствует
16
факту, что он раскладывается на набор вейвлетов (функций), которые ортогональны к их
параллельному переносу и масштабированию. Следовательно, мы раскладываем подобный
сигнал на то же самое или меньшее число коэффициентов вейвлет-спектра, что и количество
точек данных сигнала. Подобный вейвлет-спектр весьма хорош для обработки и сжатия
сигналов, например, поскольку мы не получаем здесь избыточной информации.
2.
Непрерывное вейвлет-преобразование, напротив, возвращает массив на одно
измерение больше входных данных. Для одномерных данных мы получаем изображение
плоскости время-частота. Можно легко проследить изменение частот сигнала в течение
длительности сигнала и сравнивать этот спектр со спектрами других сигналов. Поскольку здесь
используется неортогональный набор вейвлетов, данные высоко коррелированы и обладают
большой избыточностью. Это помогает видеть результат в более близком человеческому
восприятию виде.
Дополнительные подробности о вейвлет-преобразовании доступны на тысячах интернетресурсов о вейвлетах в сети. В библиотеке обработки данных Gwyddion реализованы оба этих
преобразования и использующие вейвлет-преобразование модули доступны в меню Обработка
данных → Интегральные преобразования.
Дискретное вейвлет-преобразование
Дискретное вейвлет-преобразование (DWT) - реализация вейвлет-преобразования с
использованием дискретного набора масштабов и переносов вейвлета, подчиняющихся
некоторым определённым правилам. Другими словами, это преобразование раскладывает сигнал
на взаимно ортогональный набор вейвлетов, что является основным отличием от непрерывного
вейвлет-преобразования (CWT), или его реализации для дискретных временных рядов, иногда
называемой непрерывным вейвлет-преобразованием дискретного времени (DT-CWT).
Вейвлет может быть сконструирован из функции масштаба, которая описывает свойства
его масштабируемости. Ограничение, что функция масштаба должна быть ортогональна к своим
дискретным преобразованиям, подразумевает некоторые математические ограничения на них,
которые везде упоминаются, т.е. уравнение гомотетии
где S - фактор масштаба (обычно выбирается, как 2). Более того, площадь под функцией
должна быть нормализована и функция масштабирования должна быть ортогональна к своим
численным переносам, т.е.
17
После введения некоторых дополнительных условий (поскольку вышеупомянутые
ограничения не приводят к единственному решению) мы можем получить результат всех этих
уравнений, т.е. конечный набор коэффициентов ak которые определяют функцию
масштабирования, а также вейвлет. Вейвлет получается из масштабирующей функции
как N где N - чётное целое. набор вейвлетов затем формирует ортонормированный базис,
который мы используем для разложения сигнала. Следует отметить, что обычно только
несколько коэффициентов ak будут ненулевыми, что упрощает расчёты.
На следующем рисунке показаны некоторые масштабирующие функции и вейвлеты.
Наиболее известным семейством ортонормированных вейвлетов явлется семейство Добеши. Её
вейвлеты обычно обозначаются числом ненулевых коэффициентов ak, таким образом, мы обычно
говорим о вейвлетах Добеши 4, Добеши 6, и т.п. Грубо говоря, с увеличением числа
коэффициентов вейвлета функции становятся более гладкими. См. сравнение вейвлетов Добеши
4 и 20 ниже. Другой из упомянутых вейвлетов - простейший вейвлет Хаара, который использует
прямоугольный импульс как масштабирующую функцию.
Функция масштабирования Хаара и вейвлет (слева) и их частотные составляющие (справа).
Функция масштабирования Добеши 4 и вейвлет (слева) и их частотные составляющие
(справа).
18
Функция масштабирования Добеши 20 и вейвлет (слева) и их частотные составляющие
(справа).
Существует несколько видов реализации алгоритма дискретного вейвлет-преобразования.
Самый старый и наиболее известный – алгоритм Малла (пирамидальный). В этом алгоритме два
фильтра – сглаживающий и несглаживающий составляются из коэффициентов вейвлета и эти
фильтры рекуррентно применяются для получения данных для всех доступных масштабов. Если
используется полный набор данных D = 2N и длина сигнала равна L, сначала рассчитываются
данные D/2 для масштаба L/2N - 1, затем данные (D/2)/2 для масштаба L/2N - 2, … пока в конце не
получится 2 элемента данных для масштаба L/2. результатом работы этого алгоритма будет
массив той же длины, что и входной, где данные обычно сортируются от наиболее крупных
масштабов к наиболее мелким.
В Gwyddion для расчёта дискретного вейвлет-преобразования используется пирамидальный
алгоритм. Дискретное вейвлет-преобразование в двумерном пространстве доступно в модуле
DWT.
Дискретное вейвлет-преобразование может использоваться для простого и быстрого
удаления шума с зашумлённого сигнала. Если мы возьмём только ограниченное число наиболее
высоких коэффициентов спектра дискретного вейвлет-преобразования, и проведём обратное
вейвлет-преобразование (с тем же базисом) мы можем получить сигнал более или менее
очищенный от шума. Есть несколько способов как выбрать коэффициенты, которые нужно
сохранить. В Gwyddion реализованы универсальный порог, адаптивный по масштабу порог и
адаптивный по масштабу и пространству порог. Для определения порога в этих методах мы
сперва определяем оценку дисперсии шума, заданную
где Yij соответствует всем коэффициентам наиболее высокого поддиапазона масштаба
разложения (где, как предполагается, должна присутствовать большая часть шума). Или же
дисперсия шума может быть получена независимым путём, например, как дисперсия сигнала
АСМ когда сканирование не идёт. Для наиболее высокого поддиапазона частот (универсальный
порог) или для каждого поддиапазона (для адаптивного по масштабу порога) или для окружения
19
каждого пикселя в поддиапазоне (для адаптивного по масштабу и пространству порога)
дисперсия рассчитывается как
Значение порога считается в конечном виде как
где
Когда порог для заданного масштаба известен, мы можем удалить все коэффициенты
меньше значения порога (жесткий порог) или мы можем уменьшит абсолютное значение этих
коэффициентов на значение порога (мягкий порог).
Непрерывное вейвлет-преобразование
Непрерывное вейвлет-преобразование (CWT) - реализация вейвлет-преобразования с
использованием произвольных масштабов и практически произвольных вейвлетов.
Используемые вейвлеты не ортогональны и данные, полученные в ходе этого преобразования
высоко коррелированы. Для дискретных временных последовательностей также можно
использовать это преобразование, с ограничением что наименьшие переносы вейвлета должны
быть равны дискретизации данных. Это иногда называется непрерывным вейвлетпреобразованием дискретного времени (DT-CWT) и это наиболее часто используемый метод
расчёта CWT в реальных применениях.
В принципе непрерывное вейвлет-преобразование работает используя напрямую
определение вейвлет-преобразования, т.е. мы рассчитываем свёртку сигнала с
масштабированным вейвлетом. Для каждого масштаба мы получаем этим способом набор той же
длины N, что и входной сигнал. Используя M произвольно выбранных масштабов мы получаем
поле N×M, которое напрямую представляет плоскость время-частота. Алгоритм, используемый
для этого расчёта может быть основан на прямой свёртке или на свёртке посредством умножения
в Фурье-пространстве (это иногда называется быстрым вейвлет-преобразованием).
Выбор вейвлета для использования в разложении на время-частоту является наиболее
важной вещью. Этим выбором мы можем влиять на разрешение результата по времени и по
частоте. Мы не можем изменить этим путём основные характеристики вейвлет-преобразования
(низкие частоты имеют хорошее разрешение по частотам и плохое по времени; высокие имеют
плохое разрешение по частотам и хорошее по времени), но мы можем несколько увеличить
общее разрешение по частотам или по времени. Это напрямую пропорционально ширине
используемого вейвлета в реальном и Фурье-пространстве. если мы используем вейвлет Морле,
20
например (реальная часть – затухающая функция косинуса), мы можем ожидать высокого
разрешения по частотам, поскольку такой вейвлет очень хорошо локализован по частоте.
Лекция 21. Преобразование случайных сигналов в КПС.
Лекция 21.1 Случайные величины и процессы
1.Вероятность случайного события есть численная мера степени объективной
возможности этого события и связана с опытом, практическим понятием частоты события, Тогда
вероятность
некоторого события
лежит в диапазоне
2. Случайные величины
Событие является качественной характеристикой опыта. Для количественной
характеристики опыта вводится понятие случайной величины, которая в результате опыта может
принять то или иное значение, причем неизвестно заранее, какое именно. Случайные величины и т.п., а возможные значения и т.п.
Функция распределения:
вероятность события
, т.е. вероятность того, что
случайная величина
примет значение, меньшее чем . Интегральный закон распределения
Рассмотрим основные свойства функции распределения.
1.
2.
.
при
имеем
3.
.
4.
.Функция
.
распределения
или
непрерывна
слева,т.е.
.
Плотность распределения вероятности: вероятность попадания случайной величины
на полуинтервал
длинной
равна приращению функции распределения:
называется плотностью распределения вероятностей (короче- плотностью вероятности).
основные свойства плотности распределения вероятностей:
1. В
силу
монотонного
неубывания
и
21
2. Вероятность
попадания
случайной
величины
на
интервал
.
3. Функция распределения -
Размерность плотности распределения вероятностей
величины .
обратна размерности случайной
2.1. Система случайных величин
Примером такой системы из двух случайных величин являются яркости двух источников
фона,
расположенных
в
разных
Двумерная функция распределения
двух неравенств
и
точках
пространства
.
, т.е. вероятность совместного выполнения
Свойства двумерной функции распределения выводятся как обобщение, рассмотренных
выше
свойств
одномерной
функции
распределения.
Плотность распределения вероятностей системы двух случайных величин представляет собой
вторую смешанную частную производную двумерной функции распределения
что
Свойства
двумерной
одномерного
1. Вероятность попадания
прямоугольника площадью
плотности
двумерной
:
вероятности
случайной
,так
аналогичны
величины
свойствам
распределения
.
внутрь элементарного
.
2. Вероятность попадания случайной точки
в произвольную область
:
22
3. Если закон распределения величины
величина
,то:
Для
4.
не зависит от того, какое значение приняла
независимых
непрерывных
случайных
величин:
2.2. Числовые характеристики случайных величин
Математическим ожиданием
называется:
и
его
называют
просто
Основные свойства математического ожидания.
средним
значением.
Математическое ожидание константы:
1.
2. Свойство линейности:
3. Для независимых величин:
4. Математическое ожидание центрированной случайной величины
равно
нулю:
Начальный момент
-го порядка:
При этом первые начальные моменты:
представляют
собой
математические
ожидания
величин
и
и
определяют
координаты
средней точки на плоскости, вокруг которой происходит рассеивание
точки со
случайными
Переход к центрированной случайной величине
координатами
.
равносилен переносу начала
23
координат в среднюю точку, координата которой равна математическому ожиданию.
Центральным моментом -го порядка является:
Второй центральный носит название дисперсии:
Основные свойства:
1.
Дисперсия константы:
2.
3.
4.
Дисперсия имеет размерность квадрата случайной величины. Она называется средним
квадратическим отклонением случайной величины
и равна корню квадратному из дисперсии:
2.3. Центральные моменты системы двух случайных величин
Центральным
называется:
моментом
порядка
двумерной
случайной
величины
На практике широко применяются вторые центральные моменты системы. Два из них
представляют
собой
дисперсии
случайных
величин
и
:
Смешанный центральный момент
24
носит специальное название корреляционного момента (иначе – «момента связи») случайных
величин
.
Безразмерная числовая нормированная характеристика
Коэффициент корреляции характеризует наличие некоторой вероятностной зависимости
между величинами.
2.4. Случайные функции
Наглядное представление о случайной функции можно получить из самых различных
областей физики и техники. Осциллограмма напряжения шумов на выходе ПИ, распределение
яркости фона в пространстве, изменение мощности или длины волны ОКГ в процессе генерации,
перемещение броуновской частицы - все это примеры случайных функций.
Основные определения. Случайная функция -это семейство случайных величин, зависящих от
параметра ,
пробегающего
некоторое
множество
значений .
В оптике часто аргумент случайной функции является пространственной переменной; такую
функцию
называют случайным
полем.
Примерами случайных полей (случайных функций нескольким переменных - пространственных
координат и времени) могут служить:
распределение
яркости
фона
;яркость
диффузного рассеивателя
высота
волн
равномерно
освещенного
;
на
поверхности
моря
Запись наблюдаемой величины, т.е. конкретный вид, принимаемый случайной
функцией
обозначается
называется реализацией(траекторией)
случайной
функции
н
. Каждая реализация - это обычная (неслучайная) функция, так что в
результате опыта случайная функция
превращается в обычную функцию
.
Случайная функция как расширение понятия системы случайных величин
Случайная величина
полностью задана, если известна ее плотность
распределения вероятностей
,где
вероятности
ординат
случайной
Соответствующие случайные величины
двумерной плотностью вероятности
для
которых
взяты
Случайная функция задана, если
за чертой обозначает, что речь идет о плотности
функции
в
момент
времени .
могут быть полностью охарактеризованы
,где и
указывают моменты времени,
ординаты
случайной
функции.
ее конечно-мерная, плотность распределения
25
вероятностей
известна для любого числа произвольно
выбранных
значений
из
области
изменения
аргумента .
Рассмотренный способ определения случайной функции не всегда удобен вследствие своей
громоздкости. Вместо самих многомерных законов распределения на практике ограничиваются
заданием соответствующих числовых параметров этих законов, подобно тому как в теории
случайных величин часто вместо закона распределения этих величин указывают
соответствующим образом выбранные параметры этих законов.
2.4.2. Моменты случайных функций. Корреляционная теория
Начальный момент первого порядка
является математическим ожиданием ординаты случайной функции в произвольный
момент времени.
Дисперсией случайной
функции
называется
неслучайная
функция
,
- среднее
квадратическое
отклонение случайной
функции.
Для описания внутренней структуры случайного процесса служит второй смешанный
центральный момент (корреляционный момент)
Эта характеристика называется корреляционной (иначе автокорреляционной) функцией и
выражает степень зависимости между ординатами случайной функции.
Нормированная корреляционная функция
Для определения рассмотренных моментов первого и второго порядков требуется знание
только одномерного и двумерного законов распределения
2.4.3. Стационарные случайные функции
Стационарность - независимость свойств случайной функции от начала
26
2.4.4. Стационарные процессы
Все вероятностные характеристики стационарного случайного процесса не должны
меняться
при
изменении
начала
отсчета
времени.
так
что
где
,
- любое число. Тогда для математического ожидания, дисперсии и корреляционной
функции стационарного процесса
получим
Нормальные, или гауссовские, случайные
вероятностей, например, в двумерном случае
процессы.
Плотность
распределения
Для стационарного случайного процесса свойства корреляционной функции приобретают
более простой вид вследствие того, что она является функцией одного аргумента
.
характеризует среднюю мощность переменной составляющей,
мощность постоянной составляющей, а
,т.е.
средняя мощность случайного процесса.
функция четная.
Время кореляции:
2.4.5. Однородные поля
В
общем
случае
случайная
функция
,
удовлетворяющая
условию
27
(где
- любое число), называется однородной по аргументу
.
Еще более частным видом случайной функции двух переменных является однородное
изотропное случайное поле, для которого корреляционная функция
расстояния
и
не
направления вектора:
зависит только от
зависит
от
2.4.6. Эргодическое свойство стационарной случайной функции
Чтобы определить основные характеристики стационарной случайной функции, нужно
располагать известным числом реализаций, т.е. иметь ансамбль систем. Однако обычно на
практике имеется одна установка и экспериментатор за данный промежуток времени
может получить лишь одну реализацию. Оказывается, что эргодичность случайной функции
позволяет получать все статистические характеристики из одной достаточно длинной
реализации.
Случайная функции называется эргодической. если любая ее вероятностная характеристика,
полученная усреднением по множеству возможных реализаций с вероятностью сколь угодно
близкой к единице, равна среднему, полученному из одной реализации при достаточно большом
изменении аргумента. В случае эргодического стационарного процесса
математическое
ожидание, дисперсия и корреляционная функция могут быть вычислены по формулам:
Для эргодического однородного изотропного случайного поля имеем соответственно
28
Необходимым условием эргодичности случайных процессов является их стационарность
(однородность).
Случайные процессы, наблюдаемые в стационарно и устойчиво работающих системах,
обычно имеют конечное время корреляции .
Спектральная плотность стационарной случайной функции
Стационарные случайные функции вследствие неизменности их вероятностных
характеристик
во
времени
имеют
квазипериодический
характер.
Спектральной
плотностью случайного процесса называется прямое преобразование Фурье от корреляционной
функции
(теорема Хинчина-Винера):
∞
̃𝑥 (𝑣𝜏 ) = ∫ 𝐾𝑥 (𝜏) exp(−2𝜋𝑗𝑣𝑡 ) 𝑑𝑡
𝐾
−∞
Справедливо и обратное преобразование Фурье
Основные свойства спектральной плотности
1.
является действительной и четной функцией как фурье-образ действительной и
четной функции.
2.
является неотрицательной функцией частоты, так как имеет место следующее
неравенство:
.
29
Сушествование конечной дисперсии требует, чтобы
настолько быстро,
что^
Спектральная плотность
и корреляционная
свойствами, характерными для пары преобразований Фурье.
функция Kx(τ) обладают
всеми
Случайные функции часто реализуются в технике в виде напряжения или электрического
тока. При этом моменты второго порядка имеют энергетический смысл. Тогда
выражение
пропорционально энергии внутри диапазона частот
, так как энергия
электрического тока пропорциональна квадрату амплитуды соответствующей гармоники. В
случае однородного случайного поля двух переменных
функции
имеет
спектр корреляционной
вид:
Обратное преобразование Фурье дает спектральное разложение корреляционной функции
Таким образом, и для однородного случайного поля задание корреляционной функции
эквивалентно заданию спектральной плотности и, наоборот, спектральная плотность случайного
поля однозначно характеризует корреляционную функцию.
Белый шум
Рассмотрим стационарный случайный процесс
, функция корреляции которого имеет
вид
Из
следует, что любые две ординаты
и
в сколь угодно близкие моменты
времени некоррелированы. Про такой процесс говорят, что он дельта-коррелирован.
Спектральная плотность дельта-коррелированного процесса
Случайный процесс, спектральная плотность которого постоянна на всех частотах,
называется белым шумом. Так как дисперсия становится бесконечно большой
30
то в этом смысле понятно белого шума является математической абстракцией. Однако понятием
белого шума широко пользуются в технике, применяя его в тех случаях, когда энергетическая
ширина спектра случайного процесса много больше, чем полоса пропускания системы, на входе
которой он действует. Рассмотрим приближенную замену реального шума (процесса) на белый
шум
. Пусть на систему с постоянной времени τc воздействует реальный шум
функцией
спектром
корреляции
,которая характеризуется достаточно широким
и, следовательно, малым, но конечным временем корреляции
значение спектральной плотности
с
. За
"эквивалентного" белого шума берется значение
Примером шума, который в очень многих случаях можно считать дельта-коррелированным,
является тепловой шум ПИ, обусловленный тепловым движением микрозарядов.
Лекция 21.2 Преобразование случайных сигналов.
Постановка задачи для КПС, как линейной инвариантной системы
Рис. 1
Пусть на входе линейной инвариантной системы (рис. 1) задан сигнал в виде однородной
случайной функции
функцией
, которая характеризуется корреляционной
или спектральной плотностью
.
Сигнал на выходе линейной системы также будет случайным, т.е. будет описываться
случайной функцией
. Вычислим математическое ожидание
, корреляционную функцию
и спектральную плотность
корреляционной функции на выходе линейной системы.
1. Корреляционный метод расчёта
31
Если известен временной или пространственный импульсный отклик (функция рассеяния)
линейной системы
, то сигнал на входе связан с сигналом на выходе интегралом свёртки
Тогда для математического ожидания получим
Корреляционная функция на выходе линейной системы имеет вид
Меняя местами операции интегрирования и математического ожидания, с учётом
однородности (стационарности ) входного сигнала найдём
где
Так как
корреляционная
.
выражается через однородную
функция
, то она тоже однородна. Иначе говоря,
зависит
только
от
разности
аргументов
, так что
32
Таким образом, в силу однородности
выражение (4.3) имеет вид
В результате, если на вход линейной инвариантной системы поступает однородный
(стационарный) случайный сигнал, то на выходе системы сигнал оказывается однородным
(стационарным).
В частности, дисперсия сигнала на выходе системы
так что для её определения необходимо знать лишь корреляционную функцию на входе.
Соответствующие зависимости для стационарного случайного процесса
имеют вид
1.2. Частотный метод расчета
Найдем связь между спектральной плотностью стационарного случайного сигнала на входе и
выходе линейной инвариантной системы. Имеем:
33
Вводя новую переменную
, получим:
или
Если
-
действительная
функция
оптической системы), то
(например
функция
рассеяния
некогерентной
,так что
В частности, для дисперсии имеем
Для случайного однородного поля W(x,y) соответствующие зависимости имеют вид
Отношение сигнал/помеха (С/П) в КПС
34
Понятие отношения
широко используют при выделении сигнала из шумов, т.е. речь
идёт о возможности обнаружения или изменения сигнала. Полученные ранее зависимости,
описывающие многомерные преобразования детерминированных и случайных сигналов в КПС,
позволяют определить ОСП на выходе ЭТ. При этом под помехой на выходе понимают смесь
внутреннего шума с внешней (от фоновых излучений) помехой.
Рассмотрим методику определения сигнала и помехи на выходе ЭТ, структурная схема
которой приведена на рис. 2.
Рис. 2. ИС – источник сигнала, СП – слой пространства, ПФ – пространственный фильтр, СУ –
скакнирующее устройство, ДИ – детектор излучения, ЭТ – электронный тракт.
Под ОСП в зависимости от специфики задачи принято понимать:
1.
отношение квадрата амплитуды сигнала к дисперсии помехи;
2.
отношение квадрата пикового значения сигнала к дисперсии результирующей помехи;
3.
отношение амплитуды сигнала к среднеквадратическому значению помехи;
4.
отношение мощности сигнала к мощности случайной помехи;
5.
отношение энергии сигнала к энергии случайной помехи.
Указанные ОСП связаны со статистическими характеристиками обнаружения.
В предметной плоскости на ПФ расстоянии l от системы расположен излучающий объект Обт
с энергетической яркостью
, и во входной зрачок ПФ попадает поток излучения от
объекта и случайного фона. Далее суммарное поле освещённости преобразуется СУ и ДИ во
временной электрический сигнал, который затем обрабатывается в ЭТ. Считаем, что поле
излучения случайного фона является однородным и описывается пространственным спектром
или корреляционной функцией
, приведёнными к плоскости анализа.
Пусть ЧВС сигнала от излучающего объекта на выходе ЭТ описывается функцией
,а
спектр мощности фоновой помехи
. Кроме этого, на выходе ЭТ будет присутствовать
помеха, обусловленная шумами ДИ и ЭТ, спектр мощности которой описывается зависимостью
.
35
Обычно счтают, что помеха от внешнего фона и внутренние шумы некоррелированы между
собой, поэтому при расчёте их спектральные плотности можно складывать. Спектр мощности
результирующей помехи на выходе ЭТ при апериодическом сканировании определяется
формулой
Рассмотрим функциональную схему ЭПС обнаружения, изображенную на рис. 1.
Рис. 1.Функциональная схема обнаружения с предварительной фильтрацией сигнала: СПОсистема первичной обработки сигнала; ФЛ-бесшумный линейный ЧВФ; ПУ-пороговое
устройство.
Аддитивная смесь полезного сигнала и фоновой помехи, приходящая на вход системы
первичной обработки и (СПО), преобразуется этой системой в некоторую одномерную
реализацию
, являющуюся функцией времени и представляющую собой электрический
сигнал, снимаемый с ДИ. В силу линейности СПО реализация
(рис.1) состоит из суммы
полезного сигнала
и помехи
, которая учитывает как фоновую помеху, так и
собственный шум ПИ. Вид реализации также изображен на рис. 1, где штриховой кривой показан
полезный сигнал, пиковое значение которого соответствует времени . Поскольку момент
появления цели в плоскости неизвестен, то время
Реализация
является случайной величиной.
поступает на вход нешумящего линейного ЧВФ, имеющего ПФ
выходе которого формируется реализация
, на
. ПУ выдает решение по
методу однократного отсчета, непрерывно сравнивая мгновенное значение реализации
с
порогом, рассчитанным в соответствии с одним из критериев качества. Надо только установить
значения необходимых для расчета параметров полезного сигнала и помехи на входе ПУ с учетом
характеристик ЧВФ. Обозначив ЧВС полезного сигнала и энергетический ЧВС, помехи на входе
ЧВФ через
и
, а аналогичные ЧВС, корреляционную функцию и дисперсию
36
помехи
на
выходе
ЧВФ
–
через
,
Сигнал запаздывает по отношению к началу реализации на время
входе ЧВФ
,
и
.
. Поэтому ЧВС сигнала на
,
где
- ЧВС полезного сигнала для которого за начало отсчета времени принято
ЧВС на выходе получим
Для
Для полезного сигнала, корреляционной функции и дисперсии помехи на выходе ЧВФ имеем
Лекция 22. Частотно-временной спектр потока излучения на выходе сканирующего
устройства (СУ)
Если СУ непрерывно движется по закону
на выходе СУ будет функцией времени
и
, то поток излучения
.
(0)
В общем случае освещённость в изображении объекта также может изменяться во времени,
т.е.
. Однако в подавляющем большинстве практических случаев время
анализа изображения достаточно мало, поэтому изменением освещенности в течение времени
37
анализа можно пренебречь. В дальнейшем будем считать, что распределение освещённости в
изображении объекта от времени не зависит.
Зависимости
и
в (0) описывает закон анализа изображения.
Выражение (0) позволяет в общем виде найти поток излучения на выходе СУ при его
произвольном законе движения. Если СУ движется поступательно, то
, так что
.
При вращательном движении СУ
(1)
, тогда
,
(2)
Откуда, переходя к полярным координатам
.
Поток излучения на выходе СУ как функция смещения
и поворота
определяется зависимостью (3.4). Если СУ движется, то (3.4) принимает следующий вид:
Рассмотрим методику определения частотно-временного спектра (ЧВС) потока излучения
на выходе СУ для поступательного и вращательного движения.
Поступательное движение СУ
В случае поступательного движения СУ (
) центр СУ может двигаться по
прямолинейной, круговой, циклоидальной, эллиптической, спиральной и т.д. траектории.
1. Поступательное движение вдоль прямолинейной траектории
Если СУ движется с постоянной скоростью
. Подставляя
вдоль некоторой прямой линии, то
и
.
(3)
38
Частотно-временной спектр (ЧВС) потока излучения на выходе СУ имеет вид
.
(4)
-функции
),
(+)
получим
(*)
2. Линейное сканирование СУ вдоль оси Оx
При сканировании вдоль оси
со скоростью
(рис.3.8).
-функции
39
.
(5)
.
Таким образом, для определения ЧВС
вдоль оси
1)
при линейном сканировании изображения
необходимо знать:
ПЧС объекта;
2) Передаточная функция ПФ;
3)
ППФ СУ.
Кроме частотного метода определения ЧВС потока излучения на выходе СУ может
использоваться так называемый получастотный метод. Этот метод удобен тогда, когда известна
не передаточная функция оптической системы, а ее функция рассеяния.
Пусть СУ движется с постоянной скоростью
и
вдоль оси
поток
на
. В этом случае
выходе
СУ
равен
. Тогда ЧВС потока излучения имеет
вид
.
Переходя от переменной t к хм по формуле
, получим
(6)
Введя обозначения
40
(6) можно представить в виде
,
где
, так как
– действительная функция.
В случае пространственно-инвариантной оптической системы освещенность изображения
пропорциональна свертке распределения яркости предмета с нормированной некогерентной
функцией рассеяния:
.
ЧВС освещенности
Проведя замену переменной
(7)
с учетом (7) принимает вид
и вводя обозначения
найдем
.
(8)
льное выражение для временного спектра
монохроматического потока излучения на выходе СУ
41
Лекция 23. Обнаружение и распознавание сигналов.
Задачи обнаружения, распознавания и противодействия.
5.2. Вероятностные характеристики обнаружения
Априорные и апостериорные вероятности обнаружения
Задачей любой системы в режиме обнаружения является выдача решений о наличии или
отсутствии объекта поиска в поле анализа системы. Источником сигналов, используемых для
принятия решения, служит яркостное поле в пространстве предметов. В общем случае поле
имеет полихроматический спектр излучения и случайное поле
времени.
, зависящее от
За счёт сканирования (в сканирующих системах) или с помощью СУ (в следящих системах)
излучение элементов предметного пространства, находящихся в поле зрения (поле обзора)
системы, преобразуется в одномерную реализацию случайного процесса. Пусть s(t) – реализация
42
случайного сигнала
= = c(t) + Псл(t)= {s(t) = c(t) + П(t)}. Такая реализация s(t),
изображенная на рис. 5.1, представляет собой в простейшем случае некоторую сумму полезного
сигнала c(t) и реализации фоновой помехи П(t), так что
s(t) = c(t) + П(t).
(5.1)
В общем случае реализация s(t) представляет собой некоторую комбинацию полезного
сигнала с фоновой помехой (если объект поиска находится в пределах поля зрения Системах),
либо является результатом действия одной фоновой помехи (если объекта в поле зрения нет). В
обоих случаях она служит единственным «сырьем» для принятия требуемого решения и поэтому
представляет исключительный интерес.
В дальнейшем обозначим вероятность наличия полезного сигнала c(t) в реализации s(t)
через
, а вероятность его отсутствия
. Эти вероятности называют
апостериорными условными вероятностями наличия и отсутствия полезного сигнала в
реализации. Апостериорными вероятности называют потому, что их можно определить только
после опыта, т.е. после получения и анализа реализации s(t). Условными, вероятности называют
потому, что они соответствуют условию получения конкретной реализации s(t). Если вид
реализации изменится, то изменятся и значения
и
. С нахождения этих
43
апостериорных вероятностей обнаружения
обнаружения
и
начинается решение задачи
Формулы для определения вероятностей
и
можно найти, если
воспользоваться известным выражением для вероятности совместного появления двух событий А
иВ
,
(5.2)
где
и
– вероятности появления одного события А или В;
и
– условные вероятности появления события В или А при условии, что второе событие (А или В)
уже имело место. Если в нашем случае считать, что событие
реализации
, а событие
заключается в получении
в наличии полезного сигнала c(t), то
,
откуда
(5.2 )
.
Аналогично при
(если считать, что событие
сигнала c(t)) имеем
(5.3)
заключается в отсутствии
,
так что
(5.2
.
)
(5.4)
Величины
и
определяют полные априорные вероятности наличия и
отсутствия полезного сигнала, т.е. априорные вероятности наличия или отсутствия объекта в
поле зрения Системах, а величина
s.
– полную априорную вероятность получения реализации
В свою очередь
- апостериорная условная вероятность появления конкретной
реализации s при условии наличия и отсутствия сигнала и идентифицируют два значения
функции правдоподобия (см. рис. 5.1_1). Иначе говоря, они показывают насколько
правдоподобна реализация s.
Так как в задаче обнаружения оба события « » и « » являются противоположными (т.е.
несовместимыми и образующими полную группу событий), то справедливы следующие
равенства
,
.
(5.5)
Разделив (5.3) на (5.4) с учетом (5.5) получим
.
(5.6)
44
Величину
называют абсолютным, или обобщённым, отношением правдоподобия.
Она важна в теории обнаружения, которая базируется на теории статистических решений
обнаружения. Поскольку из (5.6) следует
,
(5.7)
то можно сделать вывод, что абсолютное отношение правдоподобия полностью определяет
вероятность наличия (а следовательно и отсутствия) сигнала в реализации s(t). И если бы,
например, анализ реализации показал, что
учетом (5.5)
>1, то на основании (5.7)
>0,5, так что с
.
(5.7´)
Таким образом, было бы установлено, что
, т.е. вероятность присутствия
полезного сигнала в реализации больше, чем вероятность его отсутствия, и тем более
обоснованным было бы принятие решения «Да» (объект поиска находится в поле зрения
Системах), чем альтернативное решение «Нет». К сожалению, та же формула (5.6) показывает,
что для определения
отношение
необходимо не только извлечь из анализа полученной реализации
,
т.е. найти вероятности
на практике не всегда возможно.
(5.8).
и
, но и знать априорные значения
и
, что
Апостериорные условные вероятности правильных и ошибочных решений
Эти вероятности
метода обнаружения с помощью рабочих характеристик.
оценивают качество конкретного
Решение о наличии сигнала может быть правильным или ошибочным. Это осуществляется
с помощью соответствующих вероятностей, приведённых в Таблице 1. Из неё следует, что
принятие любого решения всегда сопровождается ошибками. Иначе говоря, работа систем в
неопределенной ситуации (объект может находиться в поле зрения, а может и не находиться) при
воздействии случайных помех сопровождается ошибками, имеющими вероятностный характер и
в той или иной степени характеризующими качество работы системы в режиме обнаружения.
В режиме обнаружения в рамках определенного метода возможны ошибки двух типов.
Первая, называемая ложной тревогой, возникает тогда, когда при отсутствии объекта в поле
зрения прибор выдает решение «Да». Вторая – соответствует случаю, когда при наличии объекта
в поле зрения прибор выдает решение «Нет». Такая ошибка называется пропуском объекта
(сигнала).
45
Обозначим событие, заключающееся в выдаче Системах решения «Да», через
событие, заключающееся в выдаче решения «Нет», – через
ошибок первого и второго типов можно обозначить как
, а
. Тогда вероятности появления
и
. Вероятность
, т.е. вероятность принятия решения «Да» при условии отсутствия объекта
обнаружения в поле зрения, называют условной апостериорной вероятностью ложной тревоги.
Вероятность
, т.е. вероятность принятия решения «Нет» при условии
присутствия объекта в поле зрения, называют условной апостериорной вероятностью пропуска
объекта.
Учитывая, что принципиально возможны лишь два взаимоисключающих решения
, имеем
и
,
.
Откуда можно получить
,
(5.9)
.
(5.10)
Величину
, т.е. вероятность принятия решения «Да» при условии, что объект
находится в поле зрения системы, называют условной апостериорной вероятностью правильного
обнаружения. Величину
, т.е. вероятность принятия решения «Нет» при условии, что
объект в поле зрения отсутствует, называют условной апостериорной вероятности правильного
необнаружения.
Чем меньше значения
(т.е. чем большие значения
и
), которые
характеризуют работу системы обнаружения, тем выше ее качество. В математической
статистике величину
решения.
Используя
вероятностей
называют уровнем значимости, а величину
понятие
условных
и
вероятностей
– мощностью
и
априорных
, можно получить:
безусловные (абсолютные) вероятности правильных и ошибочных решений
1)
,
46
2)
,
3)
(5.10 )
,
4)
,
а также безусловную вероятность появления любой ошибки вне зависимости от её характера
.
(5.11)
Безусловные вероятности
характеризуют (в среднем) частоты
появления соответствующих правильных и ошибочных решений в длинной последовательности
принятия решений. Вероятность ошибки любого рода
определяет (в среднем) суммарную
частоту ошибочных решений, т.е. является более общей вероятностной характеристикой
системы обнаружения.
Существует еще одна более универсальная характеристика системы обнаружения – так
называемый средний риск
. Найти его можно следующим образом. При отсутствии
объекта в поле зрения Системах полезный сигнал с = 0. В результате возможны два решения
и
и соответственно два результата: ложная тревога (ЛТ) и правильное необнаружение
(необн), характеризующиеся условными вероятностями
и
.
Вполне закономерно считать, что за ошибку ложной тревоги придется «расплачиваться» и
учесть это положительным коэффициентом («платой» за ошибку)
. Положительные
последствия правильного необнаружения (т.е. некоторый «выигрыш») можно оценить
неположительным коэффициентом (неположительной «платой»)
уменьшается. Величину
,
, так как риск
(5.12)
в теории статистических решений называют условным средним риском, соответствующим
отсутствию объекта в поле зрения.
Рассуждая аналогичным образом, можно
соответствующий наличию объекта в поле зрения
,
где
получить
условный
средний
риск,
(5.13)
– положительный коэффициент, характеризующий «плату» за ошибку
пропуска объекта;
– неположительный коэффициент, характеризующий «выигрыш»,
полученный при правильном обнаружении.
Сумму условных рисков, взвешенных с априорными вероятностями
соответствующих событий, называют безусловным средним риском
и
появления
47
.
Подставляя в (5.14)
(5.14)
и
из (5.12) и (5.13) и учитывая (5.9) и (5.10), получим
. (5.15)
Очевидно, что из нескольких систем обнаружения лучше та, которая обеспечивает
наименьший средний риск
в
.
Нетрудно видеть, что при
(5.11), т.е. средний риск
в
этом
и
случае
равен
, формула (5.15) переходит
безусловной вероятности
появления ошибки любого рода.
Оценка системы обнаружения по среднему риску на практике сопряжена с определенными
трудностями, связанными с необходимостью априорного знания величины
или
и всех
коэффициентов
, хотя некоторые общие соотношения очевидны. Ложная тревога как
правило связана с лишними затратами времени, физической и нервной энергии, материальных
средств. Пропуск объекта при использовании системы обнаружения, например в условиях
боевых действий может повлечь за собой большие человеческие потери и значительный
материальный ущерб. Однако как эти общие соображения трансформировать в систему
оптимально взвешенных между собой коэффициентов? Эта задача может быть решена лишь
применительно к конкретным условиям работы системы с использованием: накопленного опыта,
здравого смысла, интуиции.
Лекции 24. Критерии, лежащие в основе принятия решения системой.
Для решения задачи обнаружения в системе на стадии ее проектирования должно быть
заложено определенное правило, следуя которому обеспечивается выдача решений
(«Да»)
или
(«Нет»). Этим правилом, называемым правилом выбора решения, должно
предписываться, в каком направлении следует проводить анализ полученной реализации и при
каком результате этого анализа должна выдать одно из двух альтернативных решений.
Очевидно, что чем лучше заложенное в систему правило, тем качественнее будут результаты
её работы. Это говорит о целесообразности при разработке правила и оценке его эффективности
базироваться на рассмотренных выше вероятностных характеристиках обнаружения. Иными
словами, использовать величины
выбора решения.
или средний риск
для построения правила
Критерий максимума апостериорной условной вероятности,
48
или критерий Котельникова
Кр 1°.
Рассмотрим правило выбора решения основанное на критерии максимума
апостериорной условной вероятности
двух решений
или
или
всегда следует выбирать такое, которому соответствует большая
апостериорная условная вероятность
или
полезного сигнала в реализации s(t), т.е. при
а при
в виде
. Суть метода состоит в том, что из
- решение
, наличия (c) или отсутствия (0)
следует принимать решение
,
. На основании формулы (5.6) это правило можно записать
,
,
или с учётом (5.8)
(5.16)
Таким образом, процедура принятия решения, предписываемая правилом, базирующемся
на критерии максимума апостериорной вероятности, состоит в извлечении из полученной
реализации отношения правдоподобия
и его сравнении с пороговым
данного критерия численно равно отношению априорных вероятностей
(для Кр 1° Котельникова)
При
принимается решение
(«Да»), при
, которое для
(5.16´)
– решение
(«Нет»).
Какой же практический результат позволяет получить правило, базирующееся на этом
критерии? Теория статистических решений дает такой ответ: система обнаружения, в которой
реализовано правило выбора решения по критерию максимума апостериорной вероятности,
позволяет минимизировать число ошибочных решений. Правило не устанавливает какого-либо
соотношения между числом ложных тревог и пропусков сигнала. Однако их сумма в достаточно
длинной последовательности решений, т.е. вероятность
ошибки любого рода, минимальна
по сравнению с системой, использующей правило, базирующееся на любом другом критерии.
Поэтому применять рассматриваемое правило следует в том случае, когда ложная тревога и
пропуск сигнала нежелательны в одинаковой степени и эффективность системы обнаружения
может быть оценена их общим числом на каком-то отрезке времени.
Критерий максимума апостериорной вероятности часто называют критерием Котельникова,
применившего его для решения задачи синтеза оптимальных приемных устройств, или
критерием идеального наблюдателя, беспристрастно фиксирующего ошибку любого рода.
49
Критерий минимального среднего риска (Критерий Байеса)
Кр 2°. Для выработки правила решения вместо вероятности
можно использовать и
другую, более универсальную характеристику - средний риск
. Если критерием
эффективности правила поставить условие минимизации среднего риска, то запись правила
имеет вид:
(5.17)
[
в Кр 2° Байеса]. Этот критерий называют критерием минимума среднего риска, или
критерием Байеса.
Процедура принятия решения, предписываемая полученным правилом (5.17), ничем не
отличается от предыдущей: нужно также определить отношение правдоподобия
и сравнить
его с пороговым значением
. Однако пороговое отношение правдоподобия здесь уже другое
и зависит не только от отношения априорных вероятностей, но и от значения коэффициентов
(«платы» за ошибку или выигрыш). При
и
значения
порогового отношения правдоподобия в правилах (5.17) и (5.16) одинаковы и равны
, что вполне объяснимо, так как в этом случае средний риск равен безусловной
вероятности
появления ошибки любого рода [см. (5.11) и (5.15)]. Следовательно, правило
выбора решения по критерию максимума апостериорной вероятности является частным случаем
правила выбора решения по критерию минимума среднего риска.
Критерий максимума правдоподобия
Кр 3°.
В тех случаях, когда значения априорных вероятностей
, P(s/o) и
коэффициентов потерь
с достаточной степенью достоверности не могут быть установлены,
необходимо применять правила выбора решения, базирующиеся на других вероятностных
критериях. Одним из таких критериев является критерий максимума правдоподобия.
Вытекающий из это критерия принцип принятия решения можно сформулировать следующим
образом: наиболее правдоподобно то событие В для которого значение функции правдоподобия
максимально. Как уже указывалось (см. п. 5.1), в задаче обнаружения функция
правдоподобия имеет два значения:
и P(s/o). Поэтому при
> P(s/o). следует
принимать решение
(«Да»), в противоположном случае – решение
правило выбора решения можно записать в виде
(«Нет»). С учетом (5.8)
.
(5.18)
[
в Кр 3° максимального правдоподобия]. Таким образом, и здесь процедура принятия
решения остается прежней. Изменяется лишь порог, который в данном случае равен единице.
50
Нетрудно заметить, что правило выбора решения (5.18) является частным случаем правила
(5.16), получаемого при
. Таким образом, реализация правила (5.18) также
позволяет минимизировать общее число ошибочных решений, если условия работы системы
обнаружения таковы, что априорные вероятности нахождения и отсутствия объекта в его поле
зрения одинаковы.
Не следует думать, что критерий 3º [правило (5.18)] лучше, чем критерий 1º [правило (5.16)].
Верно лишь то, что использование критерия 3º на практике представляется более реальным, так как в
этом случае не требуется знания априорных вероятностей
и
. Однако за отсутствие любых
сведений о состоянии исследуемого пространства событий всегда приходится «расплачиваться». Так
происходит и в данном случае. Не зная действительных значений
и
, вполне обоснованно (хотя
бы и в порядке гарантии) при проектировании взять такие их значения, которые соответствовали бы
наихудшим условиям ее работы в режиме обнаружения. Такими значениями как раз и являются
значения
. Поэтому минимум числа ошибочных решений
, полученный с
помощью правила (5.18), является наибольшим из всех других минимумов, которые могут быть
получены по правилу (5.16) при
(минимаксный критерий).
Критерий Неймана-Пирсона
Кр 4°. Рассмотрим ещё один критерий, используемый для построения правила выбора
решения - критерий Неймана-Пирсона. Правило, базирующееся на этом критерии, обеспечивает
получение максимальной условной вероятности правильного обнаружения
при заданной
условной вероятности ложной тревоги
. Говоря языком математической статистики, правило
выбора решения по критерию Неймана-Пирсона при заданном уровне значимости даёт
наибольшую мощность решения по сравнению со всеми другими правилами.
Запись правила аналогична (5.16) - (5.18), т.е. в ней также присутствуют неравенства вида
и
. Однако пороговое отношение правдоподобия
для нахождения
не требуется знать ни априорных вероятностей
определяют иначе. Так,
и
, ни коэффициентов
. Пороговое отношение полностью определяется значениями
и
(см. например (5.34)
с. 293), которые должна обеспечить система обнаружения. В этом состоит преимущество критерия
Неймана-Пирсона.
На практике целесообразно использовать критерий Неймана-Пирсона в несколько ином
виде, когда вместо условной вероятности ложной тревоги
1) среднее число
используют:
ложных тревог в единицу времени или средний временной интервал
между ложными тревогами, причём
;
(5.19)
51
2) вероятность
времени
возникновения ложной тревоги на заданном отрезке рабочего
системы обнаружения.
Правило выбора решения, использующее критерий Н
максимизировать
условную
значениях
или
,
вероятность
и
правильного
обнаружения
при
заданных
.
Вероятностные характеристики обнаружения в методе непрерывного сравнения
мгновенных значений реализации
с
Теперь можно перейти к определению вероятностных характеристик обнаружения
.
Условная вероятность ложной тревоги
Условная вероятность ложной тревоги, очевидно, равна вероятности того, что мгновенное
значение
реализации превысит порог
в отсутствии полезного сигнала, т.е.
Произведя замену переменной
, получим
.
Поскольку
где
, то
,
(5.26)
- функция Лапласа (интеграл вероятностей) вида
[В статистике]
Подставляя в (5.26)
(5.26¢)
из (5.25¢), найдем окончательно
,
(5.27)
52
где
,
(5.28)
равен отношению квадрата пикового значения сигнала к дисперсии помехи.
Условная вероятность пропуска объекта
Условная вероятность пропуска объекта равна вероятности того, что при наличии сигнала
величина
окажется меньше
После замены переменной
, так что
получим
,
а после подстановки
(5.29)
из (5.25¢) в (5.29) имеем
.
Поскольку
, то формула
обнаружения может быть записана в виде
для
условной
(5.30)
вероятности
.
правильного
(5.31)
Подставляя (5.27) и (5.30) в (5.11) и (5.15), можно получить зависимости, определяющие
вероятность ошибки любого рода и средний риск:
(5.32)
53
(5.33)
Напомним, что если в соответствии с критерием максимума апостериорной вероятности
положить в (5.32)
, то формула дает минимальное значение
. Точно так же,
приняв в (5.33) в соответствии с критерием Байеса
получим
,
.
Отношение сигнал/помеха. Рабочие характеристики системы
в режиме обнаружения
Выражения (5.27) – (5.33), определяющие вероятностные характеристики системы
обнаружения, получены применительно к случаю обнаружения методом однократного отсчета.
Однако, как показано в дальнейшем, они справедливы не только для этого метода, а имеют более
общий характер. Поэтому прежде чем перейти к другим методам обнаружения, проведем анализ
полученных выражений с позиций их практического использования в энергетическом расчете.
Начнем с формулы (5.28), которая определяет величину
, равную отношению квадрата
максимального значения полезного сигнала к дисперсии помехи. Эта величина, называемая
отношением сигнал/помеха (ОСП), играет важнейшую роль при решении задачи обнаружения. Причем
практическое использование этого понятия всегда требует конкретизации, т.е. указания конкретно ПЭ
структурной схемы системы, к которой относится величина
. Выражения (5.27) – (5.33), в
которых
относится ко входу ПУ, показывают, что полученное ОСП непосредственно влияет
на все основные вероятностные характеристики обнаружения.
Рабочие характеристики системы обнаружения
на основе Кр4º (Неймана-Пирсона)
Используя зависимости (5.27), (5.30) и (5.31), можно ответить на вопрос (п. 5.2) о
нахождении порогового отношения правдоподобия, соответствующего критерию НейманаПирсона. Поскольку этот критерий базируется на вероятностях
и
(или
), которые
для энергетического расчета должны быть заданы, то (5.27) и (5.31) или (5.27) и (5.30) следует
рассматривать как систему уравнений с двумя неизвестными
из уравнений (5.27) и (5.31) величину
и
. Исключая, например
, получим формулу для вычисления
:
,
(5.34)
54
где
– обратная функция Лапласа, т.е. аргумент функции Лапласа
при значении самой функции, равном .
Полученная формула подтверждает высказанное ранее положение о том, что пороговое
отношение правдоподобия
по критерию Неймана-Пирсона не зависит от априорных
вероятностей и коэффициентов потерь и определяется только значениями условных вероятностей
ложной тревоги и правильного обнаружения. Если из (5.27) и (5.31) исключить
получить
, то можно
.
(5.35)
Зависимости
при
, построенные на основе (5.35),
называют рабочими характеристиками системы обнаружения, работающей на основе критерия
Неймана–Пирсона.
Лекции 25, 26. Оценка измеряемых сигнальных параметров при аддитивных
помехах с нормальным распределением.
Измерение произвольного параметра
(Кр3º)
по критерию максимума правдоподобия
Конкретизируя постановку задачи, будем считать, что входная реализация
s(t )
представляет собой сумму нормально распределенной помехи, имеющей нулевое
математическое ожидание, с полезным сигналом c(t, ) , форма которого и все параметры,
кроме α, известны, так что
s(t ) c(t, ) Ï (t ) .
Предположим также, что оптимизация оценки осуществляется по критерию максимума
правдоподобия (Кр3º). В этом случае значение функции правдоподобия P(s / B )
максимально, т.е.
P(s / ) P(s / 0) или ()
P ( s / )
1 прг .
P(s / 0)
Критерий 3º – это частный случай критерия максимума апостериорной вероятности (Кр1º)
при Pc P0 0,5 . В результате Кр3º позволяет также минимизировать число ошибочных
решений, но этот минимум оказывается наибольшим из всех других минимумов, получаемых с
помощью Кр1º. Поэтому Кр3º называется также минимаксным критерием.
Последнее означает, что для решения задачи входная реализация должна быть обработана
так, чтобы получить отношение правдоподобия () как функцию измеряемого параметра α.
На основе анализа на экстремум функции () измерительная система должна определить
значение опт , при котором эта функция () достигает верхней грани.
55
При помехе с нормальным распределением отношение правдоподобия () также
является гауссовой функцией. Поэтому для упрощения измерительной системы целесообразно
вместо функции () использовать ln[()] . В самом деле, т.к. логарифм является
монотонной функцией своего аргумента, то экстремальное исследование функций () и
ln[()] приводит к одинаковому результату.
Расчет ln[()] при объеме выборки N в общем случае нестационарной помехи
выполняют на основании (5.57) , так что
t0
t0
0
0
ln[()] s(t )V (t, )dt 0,5 c(t, )V (t, ) dt J1() J 2 () , (5.82)
где V (t,) - решение линейного интегрального уравнения
t0
0 KrП (t, )V (, )d c(t, )
(5.83)
с ядром KrП (t , ) = M Π сл (t ) Π сл () в виде корреляционной функции помехи.
В соответствии с (5.82) функциональная схема измерительной системы представлена на
рис. 5.21.
56
Входная реализация
s(t )
(напряжение с выхода ПИ) обрабатывается в m каналах, в каждом
из которых последовательно производится:
1) умножение
s(t ) на функцию V (t, j )
2) интегрирование произведения
(j = 1, 2, …, m);
s(t )V (t, j ) ;
3) суммирование полученного результата J1( j ) с величиной
t0
J 2 ( j ) 0,5 c(t, j )V (t, j ) dt .
0
При этом m значений
ln[( j )] поступают в решающее устройство (РУ), где
сравниваются между собой. Чем ближе значение j в j-м канале к истинному значению
параметра сигнала в реализации
является значение
s(t ) , тем больше величина ln[( j )] . Поэтому выходом РУ
j того из каналов, в котором значение ln[( j )] максимально.
Соответствующая величина j и принимается за оптимальную оценку опт измеряемого
параметра по критерию максимального правдоподобия (Кр3º).
Сравнение функциональных схем измерительной системы (рис. 5.21) и корреляционной
системы обнаружения, работающей в условиях неизвестной фазы сигнала (рис. 5.12),
показывает, что они близки между собой.
В обоих случаях качество работы ОиЛзЭС улучшается с увеличением количества каналов.
Причем требуемое число каналов при заданном качестве, определяемом вероятностными
57
характеристиками обнаружения или точностью измерений, зависит от диапазона изменения
неизвестного параметра .
5.9.2. Система измерения амплитуды (пикового значения) сигнала
Задача построения измерительной ОиЛзЭС существенно упрощается, если необходимость в
сравнении значений ln[(i )] в РУ отпадает, т. е. в том случае, когда можно получить в явном
виде решение уравнения
{ln[()]} 0 опт
оц ,
называемого уравнением правдоподобия. При оценке произвольного параметра сигнала
имеется возможность получения лишь приближенного решения, да и то при условии, что
измерение производится при большом ОСП.
В то же время при измерении амплитуды (пикового значения) сигнала имеется
возможность получить точное решение. В этом случае, обозначая измеряемую амплитуду через
a , введем в рассмотрение нормированный сигнал сN (t ) , так что
с(t, ) с(t, a) aсN (t ) .
(5.84)
Вводя в рассмотрение по аналогии с (5.84) функцию V (t ) aVN (t ) , интегральное
уравнение (5.83) представим в виде
t0
0 KrП (t, )VN ()d cN (t ) ,
(5.83')
где VN (t ) - решение этого интегрального уравнения.
Тогда на основании (5.82) имеем
t0
ln[(a)] a s(t )VN (t )dt 0,5a
0
2
t0
0 cN (t )VN (t )dt ,
откуда получаем уравнение правдоподобия
{ln[(a)]} a a a
опт
t0
t0
0 s(t )VN (t )dt aопт 0 cN (t )VN (t )dt 0 .
Решение уравнения правдоподобия дает оценку амплитуды (пикового значения) сигнала по
критерию максимума правдоподобия (Кр3º)
опт
оц
a
t0
t0
t0
0 s(t )VN (t )dt 0 cN (t )VN (t )dt 0 s(t )VN (t )dt
Kмсшт .
(5.85)
58
Структурно-функциональная схема системы измерения амплитуды сигнала приведена на
рис. 5.22.
Устройство, состоящее из 1) генератора функции VN (t ) ; 2) перемножителя и 3)
t0
интегратора, которое формирует на входе РУ значение интеграла s(t )VN (t )dt , называется
0
оптимальным приёмником (ОП). ОП выдает отсчёт выходного напряжения в момент
t0 ,
т.е.
величину интеграла в числителе (5.85). Сигнал на выходе РУ определяет оценку опт
оц в
масштабе
Kмсшт
t0
0 cN (t )VN (t )dt ,
который зависит от априорно известных функций
cN (t )
и VN (t ) .
5.9.3. Статистические характеристики оптимальной оценки
амплитуды
a опт
оц
опт
( M[a опт
оц ] и D[a оц ] )
Очевидно, что оценка
опт
aоц
является случайной величиной
сл
aопт
. Поэтому для нахождения
её статистических характеристик необходимо знать закон распределения оценки. Как следует из
(5.85), оценка получается интегрированием реализации s(t ) с весом, зависящим от функции
VN (t ) , или в соответствии с (5.84) – от вида сигнала и корреляционной функции помехи.
Следовательно, оценка формируется в результате линейной обработки реализации и поэтому
сл
закон распределения оценки aопт
при нормальном распределении помехи П сл (t ) также будет
59
нормальным. Тогда для статистического описания оценки качества процесса измерения
амплитуды сигнала достаточно найти её математическое ожидание и дисперсию.
5.9.3.1. Математическое ожидание случайной оптимальной оценки
опт
a сл
опт a оц
измеряемой амплитуды а
Поскольку при аддитивной помехе
s сл(t) a cN (t) П сл (t) ,
(5.86)
то, подставляя (5.86) в (5.85), для математического ожидания оценки получим
t0
t0
сл
a c (t ) П (t ) VN (t )dt
N
0
сл
M[aопт
] M 0
t0
cN (t )VN (t )dt
0
a c
N
(t ) M П сл (t ) VN (t )dt
t0
.
0 cN (t )VN (t )dt
Так как по условию математическое ожидание M П сл (t ) помехи равно нулю, то
сл
M[aопт
] a , т.е. математическое ожидание оценки амплитуды сигнала по критерию максимума
правдоподобия равно истинному значению амплитуды. Такая оценка в математической
статистике называется несмещенной.
5.9.3.2. Дисперсия случайной оптимальной оценки
сл
опт
aопт
aоц
измеряемой амплитуды а
Найдем дисперсию оценки
60
2
t0
s сл (t )V (t )dt
N
2
2
сл
сл
сл
сл
M 0
aопт
D[aопт
] D aопт
aопт
a
a
t
0
cN (t )VN (t )dt
0
2
2
t0
t0
a c (t ) П сл (t ) V (t )dt
П сл (t )VN (t )dt
N
N
0
M 0
a
M
a
a
t0
t0
0 cN (t )VN (t )dt
0 cN (t )VN (t )dt
2
t0
t0
cN (t )VN (t )dt VN (t )VN () M П сл (t ) П сл () dtd
0
0
2
t0
t0
t0
VN (t ) VN ()KrП (t , )d dt cN (t )VN (t )dt .
0
0
0
Так как с учетом (5.84') и (5.85')
2
t0
0 VN ()KrП (t, )d cN (t ) ;
t0
2
c (t )VN (t )dt Kмсшт
,
0 N
то в итоге получим
сл
D[aопт
] 1 Kмсшт .
(5.87)
Дисперсия (5.87) оценки по критерию максимума правдоподобия является минимальной по
сравнению с дисперсиями других оценок амплитуды сигнала. В математической статистике
оценка с наименьшей дисперсией называется эффективной.
5.9.4. Аналогия между задачами обнаружения объекта и измерения параметров сигнала
В заключение еще раз остановимся на аналогии в решении задач обнаружения и измерения
параметров сигналов. С одной стороны, имеется большое сходство работы оптимального
приемника ОП (рис. 5.22) с нахождением корреляционного интеграла в корреляционном методе
обнаружения. С другой стороны, так как корреляционный метод и применение оптимальной
фильтрации при определенных условиях (см. п. 5.6) дают одинаковые результаты, то правомерна
постановка вопроса о реализации ОП в виде оптимального пассивного ЧВФ. Решение этой
задачи дано в п. 5.6, где показано, что первое слагаемое J1 () в выражении (5.82) для
отношения правдоподобия можно получить, пропуская входную реализацию через оптимальный
линейный ЧВФ с ПФ
Hопт (t ) кфл c *(t ) KrПвх (t ) exp i2tзадржt ,
где
кфл
(5.66)
имеет размерность сигнала. Второе слагаемое в (5.82) J 2 () равно половине
ОСП на выходе ЧВФ
61
t0
0
2
J 2 () 0,5 c(t, )V (t, ) dt 0,5опт () 0,5 c(t , ) KrП (t ) d t .(5.88)
Таким образом, функциональная схема измерительной ЭС может быть представлена в виде,
изображенном на рис. 5.23.
Реализация
s(t )
принимается m каналами, каждый из которых состоит из оптимального
ЧВФ с ПФ [см. (5.66)] и сумматора, в котором текущее значение сигнала на выходе ЧВФ
(t, i ) кфл s (t ) c *(t , i ) KrП (t ) exp i2 t tзадрж t d t
J1 (t , ) кфл sЧВФ
складывается с величиной 0,5опт ( j ) . Полученные в каждом канале функции
кфл ln[(t, j )] поступают в РУ, где сравниваются между собой. Выходом РУ является оценка
сл
опт измеряемого параметра по критерию максимума правдоподобия, равная значению j в
том из каналов, в котором величина
кфл ln[(t, j )] максимальна.
В том случае, когда измеряемый параметр не влияет на ОСП, измерительная ЭС
0,5опт ( j ) и её
суммирования с сигналом на выходе оптимального ЧВФ. Такие параметры иногда называют
неэнергетическими, в противоположность энергетическим параметрам, влияющим на ОСП.
упрощается, т.к. отпадает необходимость выработки величины
Для определения амплитуды (пикового значения) сигнала функциональная схема
измерительной ЭС, приведенная на рис. 5.24, содержит последовательно включенные
оптимальный ЧВФ и РУ с ПФ фильтра
62
Hопт (t ) кфл cN(t ) KrП (t ) exp i2tзадржt .
На выходе оптимального ЧВФ получаем
опт
sЧВФ
(t, i ) s (t ) cN(t ) KrП (t ) exp i2 t t задрж t d t ,
(5.89)
а РУ формирует отсчет этой функции в момент времени
tзадрж tкr
по отношению к
моменту прихода сигнала. В соответствии с (5.57) и (5.89) этот отсчет равен числителю (5.85),
т.е. величине pN опт .
Поскольку
cN (t ) c(t ) a
и VN (t ) V (t )
a , то дисперсия оценки амплитуды сигнала в
соответствии с (5.87) и (5.88) равна
D[aопт ] a 2 опт опт
N ,
1
где опт
- ОСП на выходе оптимального ЧВФ для сигнала с единичной амплитудой. Таким
N
образом, чем больше ОСП, тем меньше ошибка измерения амплитуды. Оптимальный ЧВФ,
максимизируя , позволяет минимизировать дисперсию, т. е. получать эффективную оценку.
Лекция 27.Статистические критерии принятия решения.
Классификация представляет собой отнесение исследуемого объекта, задаваемого в виде
совокупности наблюдений, к одному из взаимоисключающих классов. Это означает, что
существует однозначное отображение совокупности наблюдений, являющейся конечным
числовым множеством {X}, на множество классов
В зависимости от полноты сведений о статистических характеристиках классов
классификация получает наименование различение (при полной априорной информации о
классах сигналов) или распознавание (при неполной априорной информации). Задача распозна63
вания объектов в случае, когда количество классов K = 2, формулируется как задача
классического обнаружения.
В классической постановке задачи распознавания универсальное множество разбивается на
части - образы. Отображение объекта на воспринимающие органы распознающей системы
принято называть изображением, а множества таких изображений, объединенные какими-либо
общими свойствами, представляют собой образы.
Процесс, в результате которого система постепенно приобретает способность отвечать
нужными реакциями на определенные совокупности внешних воздействий, называется
обучением. Обучение является частью процесса классификации и имеет своей конечной целью
формирование эталонных описаний классов, форма которых определяется способом их
использования в решающих правилах.
Методика отнесения элемента к какому-либо образу называется решающим правилом. Для
построения решающих правил нужна обучающая выборка. Обучающая выборка - это множество
объектов, заданных значениями признаков, принадлежность которых к тому или иному классу
достоверно известна "учителю" и сообщается им "обучаемой" системе.
Качество решающих правил оценивается по контрольной выборке, куда входят объекты,
заданные значениями признаков, принадлежность которых тому или иному образу известна
только "учителю". Предъявляя объекты контрольной выборки обучаемой системе для
распознавания, "учитель" может оценить качество (достоверность) распознавания.
К обучающей и контрольной выборкам предъявляются определённые требования.
Например, важно, чтобы объекты контрольной выборки не входили в обучающую выборку
(иногда, правда, это требование нарушается, если общий объём выборок мал и увеличить его
либо невозможно, либо чрезвычайно сложно).
Кроме того, обучающая и контрольная выборки должны достаточно полно представлять
генеральную совокупность (гипотетическое множество всех возможных объектов каждого
образа).
Основные этапы статистического распознавания - это формирование признакового
пространства, получение эталонных описаний классов (если априорно эти сведения отсутствуют)
и построение правила принятия решения о наблюдаемом классе объектов.
Если в результате
предварительного анализа за наблюдаемой совокупностью выборочных значений возможно хотя
бы приближенно установить вид закона их распределения, то априорная неопределенность
относится только к параметрам этого закона; целью обучения в этом случае становится
получение оценок параметров распределения. Методы распознавания, применяемые в этом
случае, называются параметрическими. В наиболее общем случае отсутствуют априорные
сведения не только о параметрах, но и о самом виде закона распределения наблюдаемой
совокупности
выборочных
значений.
Такая
априорная
неопределенность
называется
64
непараметрической,
а
методы
распознавания,
применяемые
в
этих
условиях,
-
непараметрическими. Целью обучения в этом случае является получение оценок условных
плотностей вероятностей.
При непараметрическом оценивании плотности вероятности используются в основном
гистограммный метод, метод Парзена, метод разложения по базисным функциям, метод
полигонов Смирнова, метод локального оценивания по к ближайшим соседям, а также ряд
специальных методов нелинейного оценивания.
Формирование признакового пространства
Для распознавания объекты предъявляются в виде совокупности (выборки) наблюдений,
обычно записываемой в виде матрицы:
Каждый столбец xi =(,xpi)T, i = 1...n матрицы X представляет собой p-мерный вектор
наблюдаемых значений признаков X1, X2,...,Xn, являющихся безразмерными переменными.
Совокупность признаков должна в наибольшей степени отражать те свойства объектов,
которые важны для классификации. При этом от размерности p признакового пространства
зависит вычислительная сложность процедур обучения и принятия решения, достоверность
классификации, затраты на измерение характеристик объектов.
Первоначальный
набор
признаков формируется из
числа доступных
измерению
характеристик объекта Y1,.,Yg, отражающих наиболее существенные для классификации
свойства.
На следующем этапе формируется новый набор X1,.,Xp;p < g. Традиционные способы
формирования новых признаков в условиях полного априорного знания основаны на
максимизации некоторой функции J(Y 1 ,...,Yg), называемой критерием и обычно понимаемой
как некоторое расстояние между классами в признаковом пространстве с координатами
Yb...,Yg. В других случаях критерий J(Yb...,Yg) выражает диаметр или объем области,
занимаемый классом в признаковом пространстве, и новые признаки формируются путем
минимизации критерия.
65
Принятие решений
В теории статистических решений все виды решающих правил для K > 2 классов основаны
на формировании отношения правдоподобия L и его сравнения с определенным порогом с,
значение которого определяется выбранным критерием качества:
где
- условная n-мерная плотность вероятности выборочных значений
x1,., xn при условии их принадлежности к классу aj. В статистическом распознавании эти
плотности, в принципе, не известны, и в (1.1) подставляются их оценки, получаемые в процессе
обучения
. Таким образом, в решающем правиле с порогом с сравнивается
оценка отношения правдоподобия
Решающее правило при использовании байесовского критерия
при K = 2 имеет вид
(1.2)
- матрица потерь, элемент П k,n
количественно выражает потери от принятого решения в пользу класса ak, когда в
действительности выборка принадлежит классу al; P(a;-) - априорные вероятности классов.
Критерий (1.2) минимизирует средний риск
где Pkl - вероятность
принятия решения о принадлежности выборки классу ak, когда в действительности она
принадлежит al. Определим для K > 2 классов вероятности ошибочных решений следующим
образом.
Обозначим через ак вероятность отнесения выборки из п контрольных наблюдений к
любому из классов a1, a2,..., ак-1, ак+1,..., aK, отличному от класса ак, когда на самом деле выборка
относится именно к этому классу, а через вк - вероятность отнесения контрольной выборки к
классу ак, когда она ему не принадлежит.
Ошибка 1-го рода - это отнесение выборки не к тому классу, к которому она принадлежит
в действительности. Ошибка 2-го рода - это отнесение выборки к какому-либо определенному
классу, к которому она на самом деле не принадлежит.
При двух классах (K = 2) выполняются очевидные равенства а1 = р2 и а2 = и вероятности а1
и в1 совпадают с вероятностями ошибок 1-го и 2-го рода (рис. 1.1),
66
Рис. 1.1. Плотности вероятностей наблюдений классов а1 и а2 и порог принятия решения c
при этом порог с определяется таким образом, чтобы вероятность ошибочного решения P12
была не больше заданного значения а:
Использование критерия целесообразно, если одну из вероятностей ошибок можно
выделить как основную и сделать ее равной некоторому требуемому значению. Однако критерий
несимметричен относительно вероятностей ошибок P12 и P21, а при классификации важно
обеспечить минимальные или, по крайней мере, ограниченные заданными пределами обе
вероятности ошибочных решений.
Критерий максимального правдоподобия
не требует знания априорных вероятностей классов и функции потерь, позволяет оценивать
достоверность решений, обобщается на случай многих классов, прост в вычислениях. Поэтому
критерий (1.5) широко применяется в практических задачах распознавания образов.
Методы распознавания путем сравнения
67
Кластеризация
Разделяющие поверхности в пространстве
признаков
Методы, использующие искажение изображения для сравнения.
68
Пример искажения решётки исходного изображения
Эластичные деформации для сопоставления двух изображений целиком, рис. 4.
Эластичные деформации: исходное изображение (слева), пиксел отмеченный квадратом
сдвигается в позицию пиксела отмеченного окружностью, три результата с различными
праметрами деформации. Вышеприведённые методы сравнивают только суммарное искажение,
не пытаясь учесть его характер, и в этом заключается их недостаток. Характер искажения
изображения
несёт
важные
сведения
для
распознавания
изображения,
и
поэтому
нижеприводимые методы имеют лучшую точность распознавания.
Преобразование Карунена - Лоэва
Пример:
Для изображения типа «портрет», распределение количества информации вдоль компонент
имело следующий вид: 92.72%, 6.73%, 0.55%.
Преобразование цветного изображения в полутоновое (слева-направо): исходное (цветное),
преобразование Карунена-Лоэва, два других преобразования
Преобразование Карунена-Лоэва (КЛ) представляет собой разложение сигнала
по
базису ортогональных функций, каждая из которых является собственной функцией
интегрального "характеристического" уравнения с симметричным непрерывным ядром:
Основная идея заключается именно в существовании и использовании некого ядра,
связанного со свойствами сигнала
. При заданном виде ядра приведенное интегральное
69
уравнение определяет ортогональный базис разложения по его собственным функциям, что
упрощает разложение и минимизирует квадрат ошибки.
Чаще всего
трактуется в виде корреляционной функции
в
общем случае непериодического и нестационарного случайного процесса с нулевым
математическим ожиданием
и существующим вторым моментом
распознавания случайных образов ядро определяется как
. В задачах
т.е. – в виде корреляционной функции между классами сигналов, с некоторой
вероятностью
принадлежащих одному из
искомых образов.
В дискретном случае оно диагонализирует матрицу некоторой заданной квадратичной
формы , т.е. приводит её к виду
, где
искомая диагональная матрица, а матрица собственных векторов искомого преобразования
. Метод во многом носит
геометрический характер, но в большинстве источников он описывается с точки зрения теории
вероятности. В таком описании матрица
является дискретным представлением
корреляционной функции
в общем случае непериодического случайного процесса
наблюдения сигнальных векторов
.
Мы рассматриваем КЛ-преобразование применительно к растровым изображениям. Такое
изображение всегда содержит избыточные данные, как следствие содержательного и шумового
взаимовлияния его соседних элементов. В связи с этим рассматриваются:
ковариационная матрица
координатной плоскости изображения
, которая описывает аппроксимацию отсчетов в
многомерной гауссовой функцией распределения,
соответствующая ей корреляционная матрица
.
Для выравнивания интервалов, соответствующих верхним и нижним частотам применяется
логарифмирование. Это даёт наглядное представление о спектре, но снижает точность
распознавания, поскольку при этом увеличивается вклад в представление изображения,
вносимый высокочастотными составляющими. А они характеризуют мелкие несущественные
детали, а не общие черты изображений, и при этом сильно изменчивы.
Преобразование Фурье: исходное изображение, прологарифмированная амплитуда, фаза
Пример дискретного косинусного преобразования. Исходный размер изображения 100х100
(10000 пикселей), реконструкция по первым 496 коэффициентам. Коэффициент сжатия 95%.
70
Дискретное косинусное преобразование: исходное изображение, реконструированное
изображение, участок спектра для реконструкции, ошибка реконструкции (деконволюции)
Блочное косинусное преобразование используется в современных методах сжатия
изображений (JPEG например).
Вейвлетное преобразование
Оперирует изображением целиком за счёт своих фрактальных свойств.
Различные степени вейвлетного сжатия (использовались вейвлеты Добеши): a)
оригинальное изображение, b) 45% коэффициентов отброшено, c) 95%, d) 98%, e) 99%, f) 99.9%
71
Рис. 10. Сравнение JPEG-сжатия 10:1 (слева) и вейвлетного сжатия 100:1 (справа)
Кроме сжатия изображений вэйвлетные преобразования используются так же для
извлечения ключевых характеристик изображений и поиска одинаковых участков на разных
изображениях.
Реконструирование
изображения
f (r , ) Ckl cos(l ) S kl sin( m )Rkl (r ).
k
по
моментам
Цернике
m0
Пример реконструкции по моментам Цернике и Лежандра:
Реконструкция по моментам Зернике (верхний ряд) и по моментам Лежандра (два нижних
ряда), под изображениями указано число используемых для реконструкции моментов. Внизу
справа – исходное изображение.
Структура методов распознавания изображений
72
Линейный дискриминантный анализ (линейный дискриминант, Linear Discriminant
Analysis, LDA), который описывается ниже, выбирают проекцию пространства изображений на
пространство признаков таким образом, чтобы минимизировать внутриклассовое и
максимизировать межклассовое расстояние в пространстве признаков, рис 18. В этих методах
предполагается что классы линейно разделимы.
Пример проекций в пространство характеристик для двух классов с помощью главных
компонент (PCA) и линейного дисриминанта Фишера (FLD).
73
В простейшем случае для поиска на новом изображении точки с аналогичными
a a
j
характеристиками в функции подобия фазу не учитывают:
S a ( J , J )
j
j
a a
2
j
j
2
.
j
j
Функция подобия является достаточно гладкой, для того чтобы получить быструю и надёжную
сходимость при поиске с применением простейших методов, таких как диффузия или
градиентный спуск.
Непрерывное преобразование Карунена-Лоэва
Пусть
- случайный процесс, описывается ансамблем реализаций
Требуется найти базис
, в котором
некоррелированы.
Представление
в таком базисе является результатом применения непрерывного
преобразования Карунена-Лоэва. Итак, требуется:
Одно из решений достигается в случае предположения, что
.
Таким образом
Коэффициенты разложения вычисляются следующим образом:
Итак, преобразование Карунена-Лоэва представляет собой разложение сигнала
по
базису ортогональных функций, каждая из которых является собственной функцией
интегрального "характеристического" уравнения с симметричным непрерывным ядром:
При заданном виде ядра приведенное интегральное уравнение определяет ортогональный
базис разложения по его собственным функциям, что упрощает разложение и минимизирует
квадрат ошибки.
Чаще всего
трактуется в виде корреляционной функции
в
общем случае непериодического и нестационарного случайного процесса с нулевым
математическим ожиданием
и существующим вторым моментом
распознавания случайных образов ядро определяется как
. В задачах
74
т.е. – в виде корреляционной функции между классами сигналов, с некоторой
вероятностью
принадлежащих одному из
искомых образов.
Манхеттенская мера
В метрике городских кварталов длины красной, жёлтой и синей линий равны между собой
(12). В геометрии Евклида зелёная линия имеет длину 12/√2 ≈ 8.49 и представляет собой
единственный кратчайший путь.
Расстояние городских кварталов — метрика, введённая Германом Минковским.
Согласно этой метрике, расстояние между двумя точками равно сумме модулей разностей их
координат.
У этой метрики много имён. Расстояние городских кварталов также известно
как манхэттенское расстояние, метрика прямоугольного города, метрика L1 или норма
(см. пространство Lp), метрика
городского
квартала, метрика
такси, метрика
Манхэттена, прямоугольная метрика, метрика прямого угла; на
гриды и 4-метрикой].
её называют метрикой
Название «манхэттенское расстояние» связано с уличной планировкой Манхэттена.
Окружности в дискретной и непрерывной геометрии городских кварталов
75
Расстояние
городских
кварталов
между
двумя
векторами
в nмерном вещественном векторном пространстве с заданной системой координат — сумма длин
проекций отрезкамежду точками на оси координат. Более формально,
где
и
— векторы.
Например,
на плоскости расстояние
городских
кварталов
между
и
равно
Свойства
Манхэттенское расстояние зависит от вращения системы координат, но не зависит
от отражения относительно оси координат или переноса. В геометрии, основанной на
манхэттенском расстоянии, выполняются все аксиомы Гильберта, кроме аксиомы о
конгруэнтных треугольниках.
Шар в этой метрике имеет форму октаэдра, вершины которого лежат на осях координат.
Манхэттенское расстояние между двумя полями шахматной доски равно минимальному
количеству ходов, которое необходимо визирю, чтобы перейти из одного поля в другое.
Расстояния в шахматах
Расстояние между полями шахматной доски для визиря (или ладьи, если расстояние
считать в клетках) равно манхэттенскому расстоянию; король и ферзь пользуются расстоянием
Чебышёва, а слон — манхэттенским расстоянием на доске, повёрнутой на 45°.
Пятнашки
Сумма манхэттенских расстояний между костяшками и позициями, в которых они
находятся в решённой головоломке «Пятнашки», используется в качестве эвристической
функции для поиска оптимального решения.
Клеточные автоматы
Множество клеток на двумерном квадратном паркете, манхэттенское расстояние до
которых от данной клетки не превышает r, назвается окрестностью фон Неймана диапазона
(радиуса) r.
Метрика Махаланобиса.
Формально,
вектора
значением
образом[2]:
расстояние
Махаланобиса
до
множества
и матрицей
ковариации
от
многомерного
со
определяется
средним
следующим
76
Расстояние Махаланобиса также можно определить как меру несходства между
двумя случайными
ковариации :
векторами
и
из
одного распределения
вероятностей с матрицей
Если матрица ковариации является единичной матрицей, то расстояние Махаланобиса
становится равным расстоянию Евклида. Если матрица ковариации диагональная (но
необязательно единичная), то получившаяся мера расстояния носит название нормализованное
расстояние Евклида:
Здесь
— среднеквадратичное отклонение
от
в выборке.
Лекция 28. Введение в стеганографию
Историческая справка. Принятая терминология.
Скрыть сообщение можно разными способами, например, зашифровать. Правда, в этом
случае противник знает, что вы передаете некоторое секретное сообщение, но не может его
прочитать (криптография). Во многих случаях достаточно и самого факта передачи для
получения сведений о каком-то событии, особенно если рассматривать и сопоставлять все факты
вместе - на этом основана разведка по материалам из открытых источников. Другой способ
состоит в том, чтобы скрыть не только сообщение, но и сам факт его передачи. Такой способ
скрытия данных и сообщений называется стеганографией.
Исторически стеганография предшествовала появлению криптографии. Этимология слова
«стеганография» уходит в далекое прошлое. В переводе с греческого «стеганография» означает
«тайнопись». Стеганография, так же как когда-то и криптография, превращается постепенно из
технического искусства в отдельную область научных исследований и постепенно приобретает
статус самостоятельной прикладной науки, изучающей способы и методы сокрытия секретных
сообщений.
В 1996 году, на первом открытом симпозиуме в Кембридже, официально посвященном
проблематике сокрытия данных, были подведены итоги терминологическим дискуссиям.
Обсуждением руководил сподвижник стеганографии в Массачусетском институте технологии
Росс Андерсон (Ross Anderson), известный своими научными результатами и в криптографии.
Результат обсуждения был зафиксирован Биргитом Пфитцманом. С этого момента
опубликованный в трудах симпозиума набор терминов можно считать устоявшимся, по крайней
мере, в западной литературе.
Русская стеганографическая терминология на данный момент не имеет подобного
кембриджскому документу. Учитывая, что после появления большого количества разнородных
77
открытых материалов по криптографии в криптографическую терминологию было внесено
много путаницы, и она еще долго будет испытывать трудности из-за неточного определения
многих терминов, к вопросу о стеганографической терминологии следует подходить
чрезвычайно деликатно.
Как видно, терминология и математические модели стеганографии во многом сходны с
понятиями и моделями, знакомыми нам из криптографии, однако они имеют иную смысловую
окраску. В стеганографических системах сегодня часто используются методы
криптографического преобразования данных, поэтому важно верно определять смысл соответствующих терминов исходя из контекста.
Одним из таких «скользких» терминов является понятие секретной компоненты
стеганографической системы — ключа, который является параметром как стеганографических,
так и криптографических систем.
Однако в разных системах термин «ключ» имеет различный смысл. Поэтому в случае,
когда в стеганографической системе присутствуют еще и криптографические преобразования,
важно различать используемые ключи по их предназначению и способу использования.
Стеганография изучает способы сокрытия данных и сообщений. Поэтому она является
одним из направлений достаточно широкой области исследований, в которой изучаются способы
сокрытия данных (information hiding).
Строго говоря, стеганография изучает способы, с помощью которых производится
сокрытие самого факта передачи информации. Чтобы более точно понять очертить данное
направление, попробуем описать разные подходы к сокрытию информации.
Проще всего возможные способы сокрытия информации рассмотреть на примере
абстрактной модели канала скрытой передачи сообщений. Пусть имеется некоторый канал связи
для передачи скрываемых данных, включающий отправителя, получателя и использующий
конкретный способ передачи. Способ передачи должен быть выбран с учетом имеющейся
ситуации, оговорен заранее и фиксирован. Отправитель и получатель также должны
договориться о едином способе представления информации в виде сообщений, так как в
противном случае получатель не сможет понять ни одного полученного сообщения. Информация
скрывается от третьего лица, которого будем называть противником. В зависимости от
конкретного приложения противником может быть также не один человек, а группа лиц.
Противник может ставить перед собой различные цели, в том числе:
• обнаружение факта передачи скрытых данных и сообщений,
• ознакомление со скрываемыми данными,
• уничтожение скрытых данных,
• подделка (искажение) передаваемых сообщений,
• навязывание ложных данных.
В зависимости от ситуации и возможностей противника возможны различные постановки
задач и методы их решения.
Перечислим некоторые возможные подходы к сокрытию
передаваемой информации, упорядочив их по степени возрастания возможностей противника.
1) Попытаться скрыть сам факт передачи и, в частности,
78
• скрыть канал связи,
• скрыть отправителя,
• скрыть получателя,
• скрыть способ передачи,
• скрыть способ представления информации в виде сообщений.
2) Попытаться в открытом канале связи создать трудности для перехвата передаваемых
сообщений, например, путем использования современных трудно доступных для противника
технологий (микроточки, сверхскоростной способ передачи, использование скачков частоты,
скремблирование и т.д.)
3) Попытаться в открытом канале связи, доступном для перехвата, спрятать скрытые
данные в передаваемых открытых сообщениях так, чтобы они не могли быть обнаружены без
специальных средств, например, химических, оптических и т.п.
4) Попытаться в открытом канале связи, доступном для перехвата, спрятать скрытое
сообщение в протоколе, т.е. в порядке выбора и последовательности передачи открытых
сообщений.
5) В открытом канале связи, доступном для перехвата и обнаружения наличия скрытых
сообщений, попытаться затруднить возможность противника по обнаружению скрытых данных в
передаваемых сообщениях, в частности, путем использования особенностей человеческого
восприятия.
6) В открытом канале связи, доступном для перехвата и обнаружения противником наличия
скрытых сообщений, попытаться затруднить возможность противника по ознакомлению с
содержанием скрытых данных в передаваемых сообщениях, например, путем использования:
• кодов,
• шифрования сообщений.
7) В открытом канале связи, доступном для перехвата, обнаружения наличия и
ознакомления с содержанием крытой информации, попытаться затруднить возможность
противника по пониманию смысла передаваемых сообщениях путем использования таких
методов, как:
• дезинформация,
• многозначное толкование.
Данный перечень, как и всякая классификация, далеко не исчерпывает всех возможных
подходов к сокрытию данных. Он как бы фиксирует уровни, на которых решается задача
обеспечения надежности сокрытия.
1.2 Основные понятия и определения стеганографии
Попробуем отделить круг вопросов, который решает стеганография, от области применения
других методов. Как было сказано выше, стеганографическая техника является одним из
разделов общего направления по сокрытию данных. Но помимо стеганографии существуют и
другие направления, изучающие методы сокрытия. Это — криптография, всевозможные
сигнальные системы и условные знаки, маскировка и введение в заблуждение, наконец,
различные толкования одних и тех же фраз и др.
79
В отличие от криптографии, которая также изучает методы сокрытия данных для хранения
или передачи, причем данные преобразуются в форму сообщения, которое специально не
скрывается, и допускается возможность его анализа противником, цель классической
стеганографии состоит в том, чтобы скрыть секретные данные в других открытых наборах или
потоках данных таким способом, который не позволяет обнаружить, что в них имеется какая-то
скрытая составная часть, и тем самым выделить эти сообщения среди остальных. Поэтому можно
было бы сказать, что стеганография — это искусство и наука о способах передачи (хранения)
сообщений, скрывающих факт существования скрытого канала связи (скрываемых данных).
Вместе с тем, такое определение было бы не совсем полным.
Дело в том, что к кругу задач, решаемых стеганографическими методами, помимо
собственно скрытой передачи сообщений (secret communication) непосредственно примыкают
направления, связанное со вставкой в передаваемые данные специальных скрытых меток — цифровых водяных знаков (digital copyright watermarking) и цифровых отпечатков пальцев (digital
fingerprinting & traitor tracing). Так как данные метки служат для установления и защиты
авторских прав, а также для контроля за нелегальным распространением, то их наличие в исходной информации, как правило, не составляет секрета, и факт их присутствия не скрывается.
Более того, средства для проверки данной вложенной информации легко доступны и, как
правило, встроены в приемные устройства. Вместе с тем, сам способ вставки информации
должен быть неизвестен, чтобы ее нельзя было извлечь либо обнаружить ее месторасположение.
Главным же требованием к этому способу внедрения скрытой информации является стойкость к
ее удалению и изменению, даже при выполнении определенных преобразований над исходной
информацией.
Существуют также технологии внесения в исходные сообщения специальных вставок
(feature tagging, captioning).
Так, в изображения могут вставляться заголовки, аннотации,
временные метки и другие описательные элементы, например имена изображенных людей на
фото или названия мест на карте. Такие вставки могут нести и служебные сведения. Например,
вставленные в изображения ключевые слова можно использовать для проведения быстрого
поиска в базе данных изображений. Спрятанные во фрагменты видеоизображений временные
метки могут быть полезными для синхронизации со звуком. Понятно, что сам факт наличия
скрытых данных в данном случае также общеизвестен.
Стеганографию следует отличать и от сигнальных систем. С древних времен применяется
метод сокрытия данных, основанный на построении некоторой сигнальной системы с
использованием «условных знаков», т.е. не привлекающих внимание знаков и сообщений, смысл
которых оговорен заранее и держится в секрете. С их помощью одна из сторон может передавать
другой короткие сообщения о ходе событий или интересующих объектах, а также
информировать другую сторону о том, какой способ поведения необходимо выбрать в данный
момент.
Подобные «условные знаки», стоящие в передаваемом тексте, могут применяться для
указания того, в каком смысле следует понимать этот текст и как к нему следует относиться.
В разное время стеганография использовала различные технологии. Каждый новый способ
передачи информации порождал и новые подходы к созданию скрытых каналов.
Классическая документальная стеганография использует целый ряд методов сокрытия
информации в передаваемых и хранимых документах. Это невидимые чернила, микроточки,
80
акростих, трафареты и т.д. Это направление потеряло актуальность и в настоящих материалах не
рассматривается.
С появлением радиосвязи было разработано много методов сокрытия сообщений в
различных аналоговых потоках: широкополосные шумоподобные сигналы (spread spectrum),
включение сигналов в радиосообщения и музыку, передача с использованием прыгающих частот
и т.д. Это направление можно назвать радиоэлектронной стеганографией. Вопросы скрытой
передачи сообщений по радиоканалам, а также оптико-электронным и акустоэлектронном
каналах детально рассматриваются в конспекте дисциплины «Обнаружение и распознавание
сигналов» [https://gir.bmstu.ru].
В последнее время с развитием цифровых систем передачи данных появилось много
исследований в области цифровой стеганографии. Под цифровой стеганографией понимается
сокрытие информации в потоках оцифрованных (т.е. преобразованных в дискретную форму) сигналов, имеющих непрерывную аналоговую природу.
Компьютерная стеганография изучает способы сокрытия в компьютерных данных,
представляющих собой различные файлы, программы, пакеты протоколов и т.п. С учетом общей
компьютеризации всех областей человеческой деятельности в настоящее время очень трудно
провести различие между цифровой и компьютерной стеганографией. Подобно тому, как в
системах связи аналоговые сигналы (аудио, видео) преобразуются в форму дискретных
последовательностей или потоков, которые разбиваются на пакеты и передаются по сети,
компьютерные данные, соответствующие изображениям, звуковым или видеофрагментам,
представляются в виде файлов или передаются в виде пакетов по компьютерной сети.
На самом деле с компьютерами связано множество различных направлений сокрытия
информации, которые не стоит относить к стеганографии. Например, существует много
способов, позволяющих обеспечить анонимность работы с маскировкой адресов и имен по
открытым сетям и защитить (точнее замаскировать) трафик от анализа (anonymity & traffic
analysis). Данное направление включает вопросы организации анонимных ремейлеров,
позволяющих скрывать обратные адреса, создания цифровых псевдонимов, принятия мер по
маскировке получателя путем отправки широковещательных сообщений. Возможно также
использование изменяемых форм запросов, поддельных сообщений, изменение активности
передач или скрытие пауз.
Кроме того, в литературе изучаются методы создания скрытых каналов (covert channals)
для организации съема информации с компьютерных систем. Например, «Оранжевая книга»,
посвященная критериям оценки безопасности компьютерных систем (Trusted Computer System
Evaluation Criteria, TCSEC), определяет два типа скрытых каналов, позволяющих осуществлять
съем информации с компьютерных систем: по памяти и по времени [9]. Можно использовать
также программные способы управления режимами монитора, которые, будучи встроенными в
лицензионные программные продукты, позволяют, например, снимать серийные номера
используемого ПО с помощью простых приемников и тем самым контролировать правомерность
их использования.
Традиционно из вышеперечисленных направлений сокрытия информации к стеганографии
относят передачу (хранение) информации с использованием стеганографического контейнера.
Это такие способы сокрытия информации в другом сообщении (data hiding), когда сначала
выбирается сообщение-контейнер (coverf, host data, message, container), потом в нем каким-либо
81
образом прячется скрываемая информация, которая затем с помощью сообщения-контейнера
передается или хранится в нем.
Определение 1. Стеганография — это искусство и наука о способах передачи (хранения)
скрытых сообшений, при которых скрытый канал организуется на базе и внутри открытого
канала с использованием особенностей восприятия информации, причем для этой цели могут
использоваться такие приемы, как:
• полное сокрытие факта существования скрытого канала связи,
• создание трудностей для обнаружения, извлечения или модификации передаваемых
скрытых сообщений внутри открытых сообщений-контейнеров,
• маскировки скрытой информации в протоколе.
В настоящее время наблюдается большой интерес именно к компьютерной стеганографии.
Появляется множество открыто распространяемых и коммерческих программных продуктов,
использующих стеганографическую технику.
Это объясняется многими причинами.
Вопервых, использование криптографических средств приводит к появлению сообщений, которые
по своим статистическим свойствам близки к случайным равновероятным последовательностям
и поэтому легко обнаруживаются в канале связи. Наличие таких сообщений всегда служит
настораживающим признаком. Во-вторых, распространение криптографических продуктов
регулируется законодательно и имеет множество ограничений при экспорте. В то же время для
использования и распространения стеганографических средств законодательных ограничений ни
в одной стране пока не имеется. В-третьих, методы цифровой и компьютерной стеганографии
стали мощным средством решения задач по созданию различных систем контроля над
соблюдением авторских прав на рынке цифровой фото-, аудио-, видеопродукции и при распространении программных продуктов (водяные знаки, подписи, защита от подделки, вставка
заголовков в оцифрованные аналоговые сигналы и т.д.). Последний факт является серьезным
стимулом для финансирования исследований в этой области со стороны крупных
производителей.
Основными стеганографическими понятиями являются сообщение и контейнер. Термин
«контейнер» употребляется в отечественной литературе большинством авторов, поскольку
является дословным переводом устоявшегося английского термина «container', обозначающего
несекретную информацию, которую используют для сокрытия сообщений. По сути же,
контейнер в стеганографической системе является ни чем иным как носителем сокрытой
информации, поэтому вполне возможно использование и такого термина. В некоторых
источниках термин контейнер также заменяют названием «стего», который также является
производным от английского сокращения «stego» (полное название «stegano»).
Определение 2. Контейнером (носителем) b (где b В — множеству всех контейнеров)
называют несекретные данные, которые используют для сокрытия сообщений.
В компьютерной стеганографии в качестве контейнеров могут быть использованы
различные оцифрованные данные: растровые графические изображения, цифровой звук,
цифровое видео, всевозможные носители цифровой информации, а также текстовые и другие
электронные документы.
82
Определение 3. Сообщением m будем называть секретную информацию, наличие которой
в контейнере необходимо скрыть. Всевозможные сообщения объединяются в пространство
сообщений М (естественно, что ему также принадлежит и наше m).
Определение 4. Ключом K называют секретную информацию, известную только
законному пользователю, которая определяет конкретный вид алгоритма сокрытия.
Через К обозначается множество всех допустимых секретных ключей. Заметим, что в
работах по стеганографии ключ понимается как в широком, так и в узком смысле. В широком
смысле стеганографический ключ — это сам неизвестный противнику способ сокрытия
информации. В узком смысле по аналогии с криптографией под стеганографическим ключом
понимается секретный параметр применяемого стеганографического алгоритма, без знания
которого извлечение скрытой информации должно быть невозможным. Поэтому будем
различать бесключевые стеганографические системы, в которых применяется одно и то же неизвестное противнику стеганографическое преобразование, и системы, в которых
стеганографический ключ присутствует. При этом необходимо отличать стеганографический
ключ от криптографического, который также может присутствовать в системе и использоваться
для предварительного криптографического закрытия внедряемой информации.
В общем случае в качестве сообщений, контейнеров и ключей могут быть использованы
объекты произвольной природы. В компьютерной стеганографии в качестве сообщений,
контейнеров и секретных ключей используют, как правило, двоичные последовательности, т.е.
M Z 2n для некоторого фиксированного целого п, B Z 2q и К = Z 2p , при этом q n .
Определение 5. Пустой контейнер (или, еще говорят, немодифицированный контейнер) —
это некоторый контейнер b, не содержащий сообщения.
Определение 6. Заполненный контейнер (или соответственно модифицированный
контейнер) — это контейнер b, содержащий сообщение т, в дальнейшем обозначаемый как bm , k
(или bm для случая бесключевой системы).
Определение 7. Стеганографическим алгоритмом принято называть два преобразования:
прямое стеганографическое преобразование F: М х В х К B и обратное стеганографическое
преобразование F 1 : В х К М, сопоставляющие соответственно тройке (сообщение, пустой
контейнер, ключ) контейнер-результат и паре (заполненный контейнер, ключ) — исходное
сообщение, причем
F(m,b,k)=bm,k;
F 1 ( b m . k , k ) = m ,
где m М; b, bm,k В; к К.
Определение 8. Под стеганографической системой будем понимать систему S = (F, F 1
,M,B,K), представляющую собой совокупность сообщений, секретных ключей, контейнеров и
связывающих их преобразований.
Отметим, что помимо приведенного определения стеганографической системы существует
еще одно, в котором определена более ранняя (классическая) схема [8], являющаяся частным
случаем данной схемы. Ее отличительной особенностью является отсутствие зависимости от
секретного ключа, т.е.
83
F(m,b) = bm ;
F 1 (bm) = m,
где m М; b,bm В.
Определение 9. Под внедрением (сокрытием) сообщения с помощью системы S в
контейнер b понимают применение прямого стеганографического преобразования F к
конкретным т, b, и к.
Определение 10. Извлечение сообщения есть не что иное, как применение обратного
стеганографического преобразования с теми же значениями аргументов.
Определение 11. По аналогии с криптографией сторону, пытающуюся раскрыть
стеганографическую систему передачи информации и определить наличие сообщения, называют
стеганоаналитиком, или, по аналогии с английскими источниками, стегоаналитиком (что с
точки зрения этимологии является менее предпочтительным, поскольку слово «стего» есть не
что иное, как сленговое сокращение от полного названия «стегано»).
Соответственно, попытку определить наличие сообщения и его смысл называют атакой на
стеганографическую систему. Задача стеганоаналитика состоит в раскрытии стеганографической
системы и определении тайно переданного сообщения. В отличие от криптографии, под
раскрытием (взломом) стеганографической системы принято понимать нахождение такой ее
конструктивной либо иной уязвимости, которая позволяет определить факт сокрытия
информации в контейнере, и возможность доказать данное утверждение третьей стороне с высокой степенью достоверности. Учитывая это, аналогично криптографическим атакам, атаки на
стеганографические системы можно разделить на классы:
• атаки со знанием только модифицированного контейнера — аналог криптографической
атаки со знанием шифртекста. Стеганоаналитик в этом случае обладает только
модифицированным контейнером, по которому он пытается определить наличие сокрытого сообщения. Данный вид стеганографических атак — базовый из всех, по которым оцениваются
стеганосистемы;
• атаки со знанием немодифицированного контейнера возможны в случае, когда
стеганоаналитик также обладает способностью узнавать, какой именно немодифицированный
контейнер был использован для сокрытия сообщения. Данная атака определяет возможность
определения факта сокрытия сообщений в дальнейшем, в зависимости от наличия однажды
перехваченного контейнера и раскрытого сообщения;
• об атаках с выбором сообщения говорят, когда стеганоаналитик имеет возможность
указывать, какие именно сообщения будут сокрыты, но при этом не имеет возможности указать
контейнер, который будет для этого использоваться. Стойкость к данной атаке характеризует
стойкость системы к перехвату и отслеживанию сообщений, посланных с использованием
одного и того же контейнера. Данный вид атак иногда также позволяет определить тип
примененной стеганографической системы;
• атаки с выбором контейнера, аналогично предыдущим, позволяют определить стойкость
стеганосистемы к раскрытию в случае повторного использования одного и того же сообщения с
различными контейнерами;
84
• атаки по подмене и имитации не призваны определить факт наличия сообщения или
извлечь его, их применяют для модификации скрытой информации, либо имитации такой
передачи;
• атаки по противодействию передаче информации используют для уничтожения
сокрытой информации и снижения пропускной способности каналов скрытой передачи данных.
При проведении анализа стеганографической системы следует по аналогии с
криптографией учитывать необходимость применения правила Керкгоффа, которое заключается
в том, что стойкость секретной системы должна определяться только секретностью ключа.
Сам процесс стеганоанализа контейнера можно разделить на два различных по сути
действия:
• определение наличия сообщения в контейнере;
• извлечение содержания сокрытого сообщения.
Стеганоаналитик, перед которым стоит задача первого или второго типа, является, по сути,
пассивным нарушителем, поскольку он не модифицирует доступные ему для анализа данные. С
другой стороны, стеганоаналитик, который может вносить изменения в передаваемые по каналу
данные, носит название активный нарушитель (активный противник). Атаки по подмене,
имитации и противодействию характерны только для активного нарушителя, в то время как
остальные виды атак присущи только пассивным нарушителям.
Устоявшимся является использование термина активный стеганоанализ для описания
действий активного нарушителя,
что несколько противоречит смысловому содержанию
понятия стеганоанализа. В дальнейшем, для того чтобы не вносить путаницу, использование термина «активный стеганоанализ» будет максимально сокращено. При этом смысл термина будет
оговариваться отдельно в каждом случае.
Для удобства введем еще несколько понятий, связанных с эффективностью стеганосистем.
Пусть В — контейнер, а М — скрываемое сообщение, и соответственно B — объем
контейнера, а M — размер сообщения.
Определение 12. Пространством сокрытия (ПС) будем называть те участки контейнера
(биты, поля и т.д.), в которых стеганосистема может сокрыть информацию.
Определение 13. Используемое пространство сокрытия (ИПС) представляет собой
совокупность областей пространства сокрытия, в которых действительно произошло сокрытие в
процессе работы стеганосистемы. Обозначив для удобства файл, содержащий контейнер через
File, получим цепочку соотношений, которой связаны эти величины:
M ИПС ПС B File .
Обычно файл File помимо контейнера содержит некоторые дополнительные данные.
Вследствие того, что в большинстве случаев размер этих данных существенно меньше объема
контейнера, мы можем пренебречь разницей и считать, что B File .
85
Определение 14. Коэффициент сокрытия определяется соотношением КС = |M|/|B| и
пригоден для предварительного определения объема контейнера В, который должен быть
обработан для передачи сообщения размером M .
Определение 15. По аналогии с коэффициентом сокрытия, коэффициент использования
контейнера (КЭ или коэффициент эффективности) — это отношение размера наибольшего
сообщения, которое возможно скрыть в контейнере, к объему контейнера:
КЭ ( B )
M max ( B )
B
Можно также определить информационную емкость контейнера как
И ( B)
ПС
B
Очевидно, что значения коэффициентов КЭ и И зависят не только от выбранного
контейнера, но также и от используемого стегано-графического метода.
Для систем скрытого обмена информацией, безусловно, желательно использовать
контейнеры с возможно большей информационной емкостью.
Однако применение таких
контейнеров чревато их высокой уязвимостью к обнаружению наличия скрытой информации.
Поэтому, как правило, предпочтение отдается большей защищенности, чем высокой скорости
передачи.
Для систем цифровых водяных знаков, наоборот, информационная емкость не играет
никакой важной роли, поскольку объем скрываемой информации, как правило, намного меньше
объема контейнера. С другой стороны, для обеспечения невозможности удаления водяного знака
его следует разнести по всему пространству сокрытия, чтобы он содержался в каждом фрагменте
файла-контейнера.
Заметим, что данные оценки являются очень грубыми и не учитывают таких свойств
информации, содержащейся в контейнере, как избыточность, наличие разнородных участков,
применяемый алгоритм сжатия и т.д. Вместе с тем, даже при таком общем подходе проявляется
основное отличие стеганографических систем от криптографических, а именно, зависимость всех
свойств системы от конкретного контейнера.
1.3 Общая схема стеганографической системы
Рассмотрим общую схему стеганографической системы, используемой для передачи
данных при наличии как пассивного, так и активного противника. Согласно данной схеме, на
передающей стороне сообщение скрывается в контейнере при помощи прямого
стеганографического преобразования. Затем полученный модифицированный контейнер по
открытым каналам связи отправляется принимающей стороне, где после его получения при
помощи обратного стеганографического преобразования извлекается исходное сообщение (рис.
1.).
86
Прямое стеганографическое преобразование
Генератор данных контейнера
Сообщение
Ключ
Контейнер
Контейнер-носитель
Пассивный противник
Активный противник
Канал передачи данных
Ключ
Контейнер-носитель
Сообщение
Генератор данных контейнера
Обратное стеганографическое преобразование
Рис. 1. Обобщенная структура стеганографической системы.
Как было сказано выше, задача пассивного противника состоит в определении факта
наличия в контейнере сокрытых данных, при этом делается допущение о том, что он может
перехватывать все посланные контейнеры и анализировать их как по отдельности, так и в
совокупности. В случае если пассивному противнику удалось верно определить факт наличия
скрытого сообщения в контейнере, он может пытаться извлечь его с целью ознакомления с его
содержанием. Однако, как правило, перед сокрытием сообщение шифруется, и поэтому, даже
если противнику удастся извлечь сообщение, то для ознакомления с его содержимым будет
необходимо его дешифровать. Если же пассивный противник не сможет определить факт
наличия сообщения, то попытки извлечь сообщение ни к чему не приведут в силу того, что эта
задача будет иметь огромное множество решений, выбрать верное из которых практически
невозможно.
Активный противник может вносить изменения в передаваемый по каналам связи
контейнер, при этом предполагается, что ни на принимающей, ни на передающей стороне не
знают, какой контейнер был изменен во время передачи, а какой нет. На этот вопрос должно
верно отвечать обратное стеганографическое преобразование. Самая простая задача активного
противника — это уничтожение сокрытой информации без определения факта наличия
сообщения. Если же перед активным противником стоит задача изменения сокрытого
сообщения, то перед ее выполнением он должен проанализировать контейнер, чтобы
удостовериться, что в контейнере действительно содержится сообщение, которое он должен
изменить.
Очевидно, что стеганографическая система, предназначенная для передачи данных, в
первую очередь должна быть стойкой к попыткам определить факт ее использования. Но если
при этом она не будет стойкой к попыткам уничтожить скрытое с ее помощью сообщение, т.е. к
попыткам понизить пропускную способность канала скрытой передачи (а в идеале — не
допустить никакой скрытой передачи, даже той, наличие которой неизвестно), то эффективность
ее практического использования при наличии активного противника может достигнуть нуля.
Поэтому стойкость к таким атакам пассивного и активного противника — это и есть основное
требование, которое предъявляется к стеганографической системе.
87
Впервые схема стеганографической системы для передачи данных с наличием только
пассивного противника была подробно описана в работе Густава Симмонса в 1983 году.
Представим себе, что Алиса и Боб находятся в тюрьме и хотят разработать план побега. Все их
послания друг другу просматриваются противником (в данном случае это надзиратель Ева,
которая желает разрушить их план и переведет их в тюрьму более строгого режима, как только
поймет, что в их посланиях содержится скрытая от нее информация). Задача, стоящая перед
Алисой и Бобом, состоит в том, чтобы разработать такой способ обмена информацией, при
использовании которого Ева ничего не смогла заподозрить.
Лекции 29, 30. Основы защиты КПС стеганографическими методами. Структура
цифровой стеганографической системы.
В настоящем разделе для краткости принято обозначать стеганографическое сообщение,
как цифровой водяной знак (ЦВЗ). Рассмортрим структуру цифровой стеганографической
системы.
Структурная схема типичной цифровой стегосистемы
Стегосистема, представленная на рисунке, выполняет задачу встраивания и выделения
цифровых водяных знаков (ЦВЗ) из изображения-контейнера. Предварительный кодер устройство, предназначенное для преобразования скрываемого водяного знака к виду, удобному
для встраивания в контейнер. Устройство встраивания ЦВЗ предназначено для осуществления
встраивания (вложения) скрытого ЦВЗ в изображение-контейнер. В стегосистеме происходит
объединение двух типов информации так, чтобы они могли быть различимы двумя
принципиально разными детекторами. В качестве одного из детекторов выступает система
выделения ЦВЗ, в качестве другого – человек. Предварительная обработка часто выполняется с
использованием ключа для повышения секретности встраивания. Далее ЦВЗ «вкладывается» в
контейнер, например, путем модификации младших значащих бит коэффициентов. Этот процесс
возможен благодаря особенностям системы восприятия человека. Хорошо известно, что
88
изображения обладают большой психовизуальной избыточностью. Глаз человека подобен
низкочастотному фильтру, пропускающему мелкие детали. Особенно незаметны искажения в
высокочастотной
области
изображений. В стегодетекторе (Детектор ЦВЗ) происходит
обнаружение ЦВЗ в (возможно измененном) защищенном ЦВЗ изображении. Это изменение
может быть обусловлено влиянием ошибок в канале связи, операций обработки сигнала,
преднамеренных атак нарушителей.
Различают стегодетекторы, предназначенные для обнаружения факта наличия ЦВЗ и
устройства, предназначенные для выделения этого ЦВЗ (стегодекодеры, Декодер ЦВЗ). В первом
случае возможны детекторы с жесткими (да/нет) или мягкими решениями. Решение о наличии
или отсутствии ЦВЗ выносится либо на основании расстояния по Хэммингу, либо на основании
взаимной корреляции между имеющимся сигналом и оригиналом (при отсутствии которого,
используются статистические методы).
В зависимости от того, какая информация требуется детектору для обнаружения ЦВЗ,
стегосистемы ЦВЗ делятся на три класса:
открытые;
полузакрытые;
закрытые системы.
Существуют 2 типа закрытых систем: в первом типе, детектору требуется и исходный
контейнер и исходный ЦВЗ, а на выходе система выдает решение о наличии или отсутствии ЦВЗ
(такие стегосистемы имеют наибольшую устойчивость по отношению к внешним воздействиям);
во втором типе детектору нужен только исходный контейнер, а на выходе система выдает
восстановленный ЦВЗ. В полузакрытых системах детектору требуется исходный ЦВЗ, на выходе
выдается решение о наличии или отсутствии ЦВЗ. Наибольшее применение имеют открытые
стегосистемы ЦВЗ, так как они аналогичны системам скрытой передачи данных, и в них
детектору не нужны ни исходный контейнер, ни исходный ЦВЗ, а на выходе система выдает
восстановленный из контейнера ЦВЗ.
Встраивание сообщения в контейнер может производиться при помощи ключа, одного или
нескольких. Ключ - псевдослучайная последовательность (ПСП) бит, порождаемая генератором,
удовлетворяющим определенным требованиям (криптографически безопасный генератор).
Числа, порождаемые генератором ПСП, могут определять позиции модифицируемых отсчетов
(пикселей на изображении). Скрываемая информация внедряется в соответствии с ключом в те
отсчеты, искажение которых не приводит к существенным искажениям контейнера. Эти биты
образуют стегопуть. Под существенным искажением можно понимать искажение, приводящее
как к неприемлемости для человека-адресата заполненного контейнера, так и к возможности
выявления факта наличия скрытого сообщения после стегоанализа.
Встраиваемые ЦВЗ могут быть трех типов:
робастные;
89
хрупкие;
полухрупкие.
Под робастностью понимается устойчивость ЦВЗ к различного рода воздействиям на
стегоконтейнер. Робастные ЦВЗ могут быть 3-х типов. Это ЦВЗ, которые могут быть
обнаружены всеми желающими, хотя бы одной стороной, либо это могут быть ЦВЗ которые
трудно модифицировать или извлечь контента (контейнера) (ЦВЗ для аутентификации).
Хрупкие ЦВЗ разрушаются при незначительной модификации заполненного контейнера и
применяются для аутентификации сигналов (изображений). Отличие от средств электронной
цифровой подписи заключается в том, что хрупкие ЦВЗ все же допускают некоторую
модификацию контента. Это важно для защиты мультимедийной информации, так как законный
пользователь может, например, пожелать сжать изображение. Другое отличие заключается в
том, что хрупкие ЦВЗ должны не только отразить факт модификации контейнера, но также вид
и местоположение этого изменения.
Полухрупкие ЦВЗ устойчивы по отношению к одним воздействиям и неустойчивы по
отношению к другим. Вообще говоря, все ЦВЗ могут быть отнесены к этому типу. Однако
полухрупкие ЦВЗ специально проектируются так, чтобы быть неустойчивыми по отношению к
определенного рода операциям. Например, они могут позволять выполнять сжатие изображения,
но запрещать вырезку из него или вставку в него фрагмента.
Классификация систем цифровой стеганографии
90
3.2 Алгоритмы встраивания данных в изображения
Все современные алгоритм встраивания информации в контейнеры должны обеспечивать
робастность встраиваемых ЦВЗ. В частности, изображения-контейнеры со встроенными ЦВЗ
должны предусматривать возможность сжатия контейнера любым из методов. Поэтому
стегоалгоритмы учитывают свойства системы человеческого зрения аналогично алгоритмам
сжатия изображений, и используют те же преобразования, что и в современных алгоритмах
сжатия (дискретное косинусное преобразование в JPEG, вейвлет-преобразование в JPEG2000).
Следовательно, вложение информации может производится либо в исходное изображение, либо
одновременно с осуществлением сжатия изображения-контейнера, либо в уже сжатое алгоритмом
изображение.
Под сжатием понимается уменьшение числа бит, требующихся для цифрового
представления изображений. В основе сжатия лежат два фундаментальных явления: уменьшение
статистической и психовизуальной избыточности. Статистическая избыточность может быть
пространственной, или корреляцией между соседними пикселями, либо спектральной, или
корреляцией между соседними частотными полосами. В алгоритмах сжатия осуществляют
обнуление не пикселов изображения, а спектральных коэффициентов. Преимущество такого
подхода заключается в том, что близкие к нулю спектральные коэффициенты имеют тенденцию
располагаться в заранее предсказуемых областях, что приводит к появлению длинных серий
нулей и повышению эффективности кодирования. Большие по величине коэффициенты
(«значимые») подвергают более или менее точному квантованию и также сжимают кодером длин
серий. Последним этапом алгоритма сжатия является применение энтропийного кодера
(Хаффмана или арифметического).
Для оценки качества восстановленного изображения
среднеквадратического искажения, определяемую как
СКО
1
N
используют
либо
меру
N
( x xˆ )
i 1
i
i
2
,
где N - число пикселей в изображении,
xi , xˆi - значение пикселей исходного и
восстановленного изображений.
Либо применяется
определяемое как
ПОСШ 10 log 2
модификация
N 2552
N
( xi xˆi )2
этой
меры
-
пиковое
отношение
сигнал/шум,
,
i 1
где 255 - максимальное значение яркости полутонового изображения (т.е. 8 бит/пиксель).
Восстановленное изображение считается приемлемым, если
ПОСШ 28 30 дБ (в среднем).
Часто используется принцип встраивания данных, когда сигнал контейнера представлен
последовательностью из n бит. Скрытие информации начинается с определения бит контейнера,
91
которые можно изменять без внесения заметных искажений – стегопути. Далее среди этих бит
обычно в соответствии с ключом выбираются биты, заменяемые битами ЦВЗ.
По способу встраивания информации стегоалгоритмы можно разделить на линейные
(аддитивные), нелинейные и другие. Алгоритмы аддитивного внедрения информации
заключаются в линейной модификации исходного изображения, а ее извлечение в декодере
производится корреляционными методами. При этом ЦВЗ обычно складывается с изображениемконтейнером, либо «вплавляется» (fusion) в него. В нелинейных методах встраивания
информации используется скалярное либо векторное квантование. Среди других методов
определенный интерес представляют методы, использующие идеи фрактального кодирования
изображений.
3.2.1 Алгоритмы встраивания данных в пространственной области
Преимуществом алгоритмов встраивания данных в пространственной области является то,
что ЦВЗ внедряется в области исходного изображения и нет необходимости выполнять
вычислительно громоздкие линейные преобразования изображений. ЦВЗ внедряется за счет
манипуляций яркостью или цветовыми составляющими l ( x, y ) {1,..., L} (r ( x, y ), g ( x, y ), b( x, y )) .
Большинство алгоритмов встраивания ЦВЗ в пространственную область изображений
основаны на использовании широкополосных сигналов (ШПС). Основной идеей применения
ШПС в стеганографии является то, что данные внедряются в шумовой сигнал малой мощности.
Так как сигнал малой мощности, то для защиты ЦВЗ применяют помехоустойчивые коды.
3.2.1.1. Алгоритм Катера (Kutter)
Алгоритм Катера предполагает что изображение имеет RGB кодировку. Встраивание
выполняется в канал синего цвета, так как к синему цвету система человеческого зрения
наименее чувствительна.
Si - встраиваемый бит, I {R, G, B} - контейнер, p ( x, y ) - псевдослучайная позиция, в
которой выполняется вложение. Секретный бит встраивается в канал синего цвета путем
модификации яркости
l ( p) 0.299r ( p) 0.587 g ( p) 0.114b( p ) ,
b( p ) ql ( p ), если si 0.
b '( p)
,
b( p ) ql ( p ), если si 1.
где q - константа, определяющая энергию встраиваемого сигнала. Ее величина зависит от
предназначения схемы. Чем больше q, тем выше робастность вложения, но тем сильнее его
заметность. Извлечение бита получателем осуществляется без наличия у него исходного
изображения, то есть вслепую. Для этого выполняется предсказание значения исходного,
немодифицированного пиксела на основании значений его соседей.
92
Также существует и модификация этого алгоритма, в котором для получения оценки
пикселя используют значения нескольких пикселов, расположенных в том же столбце и той же
строке. В этом случае оценка b ''( p) имеет вид:
b ''( p)
c
c
1
2
b
''(
p
)
b
''(
x
i
,
y
)
b ''( x, y k ) ,
4c
i c
k c
где c - число пикселов сверху (снизу, слева, справа) от оцениваемого пиксела (c=3). Так как
в процессе встраивания ЦВЗ каждый бит был повторен cr раз, то мы получим cr оценок одного
бита ЦВЗ. Секретный бит находится после усреднения разности оценки пиксела и его реального
значения
1 cr ˆ
bi ( p) bi ( p) .
cr i 1
Знак этой разности определяет значение встроенного бита.
Данный алгоритм не гарантирует всегда верного определения значения секретного бита, так
как функция извлечения бита не является обратной функции встраивания. Алгоритм является
робастным ко многим из известных атак: низкочастотной фильтрации изображения, его сжатию в
соответствии с алгоритмом JPEG, обрезанию краев.
3.2.1.2. Алгоритм Брундокса (Bruyndonckx)
ЦВЗ представляет собой строку бит. Для повышения помехоустойчивости применяется код
Боуза-Чоудхури-Хоквингема (БЧХ). Внедрение осуществляется за счет модификации яркости
блока 8х8 пикселов. Процесс встраивания осуществляется в три этапа:
1)
Классификация пикселов внутри блока на две группы с примерно однородными
яркостями.
2)
Разбиение каждой группы на категории, определяемые данной сеткой.
3)
Модификация средних значений яркости каждой категории в каждой группе.
При классификации выделяются два типа блоков: блоки с шумовым контрастом и блоки с
резко выраженными перепадами яркости. В блоках второго типа зоны с отличающейся яркостью
не обязательно должны располагаться вплотную друг к другу, не обязательно должны содержать
равное количество пикселов. Более того, некоторые пиксели вообще могут не принадлежать ни
одной зоне. В блоках первого типа классификация особенно затруднена.
Для выполнения классификации значения яркости сортируются по возрастанию. Далее
находится точка, в которой наклон касательной к получившейся кривой максимален. Эта точка
является границей, разделяющей две зоны в том случае, если наклон больше некоторого порога.
В противном случае пиксели делятся между зонами поровну.
Для сортировки пикселов по категориям на блоки накладываются маски, разные для
каждой зоны и каждого блока. Назначение масок состоит в обеспечении секретности внедрения.
93
Множество пикселов оказалось разделенным на пять подмножеств: две зоны, две
категории, и пиксели, не принадлежащие какой-либо зоне (для блоков первого типа).
l1 A , l2 A , l1B , l2 B - Среднее значение яркости для пикселей двух зон и категорий. l1 A l2 A , l1B l2 B
Встраивание бита ЦВЗ s (модификация) и равенство значений яркостей в каждой зоне
обеспечивается:
1,
s
0,
l '1 A l '1B
n l' n l'
l '2 A l '2 B n1 Al '1 A n1B l '1B
l1 и 2 A 2 A 2 B 2 B l2 .
,
n1 A n1B
n2 A n2 B
l '1 A l '1B
l '2 A l '2 B
Алгоритм извлечения ЦВЗ является обратным алгоритму внедрения.
вычисляются средние значения яркостей и находятся разности
При этом
0, если l ''1 A l ''1B 0 и l ''2 A l ''2 B 0
s ''
.
1, если l ''1 A l ''1B 0 и l ''2 A l ''2 B 0
3.2.1.3. Алгоритм Ленгелаара (Langelaar)
Данный алгоритм также работает с блоками 8х8. Вначале создается псевдослучайная маска
нулей и единиц такого же размера pat ( x, y ) {0,1} . Далее каждый блок B делится на два
субблока B0 и B1, в зависимости от значения маски. Для каждого субблока вычисляется среднее
значение яркости, l0 и l1. Далее выбирается некоторый порог , и бит ЦВЗ встраивается
следующим образом:
1, l0 l1 ,
S
.
0, l0 l1 .
Если это условие не выполняется, необходимо изменять значения яркости пикселов
субблока B1. Для извлечения бита ЦВЗ вычисляются средние значения яркости субблоков – l’0 и
1, l l 0,
l’1. Разница между ними позволяет определить искомый бит: S 0 1
.
0,
l
l
0.
0
1
3.2.1.4. Алгоритм Питаса (Pitas)
В данном алгоритме ЦВЗ представляет собой двумерный массив бит размером с
изображение, причем число единиц в нем равно числу нулей. Существует несколько версий
алгоритма, предложенного Питасом. Вначале предлагалось встраивать бит ЦВЗ в каждый
пиксель изображения, но позже благоразумно было решено использовать для этой цели блоки
размером 2х2 или 3х3 пикселя, что делает алгоритм более робастным к сжатию или фильтрации.
ЦВЗ складывается с изображением:
l '( x, y ) l ( x, y) s( x, y) .
В случае использования для внедрения блоков детектор ЦВЗ вычисляет среднее значение
яркости этого блока. Отсюда появляется возможность неравномерного внедрения ЦВЗ в пиксели,
то есть величина const . Таким образом можно получить ЦВЗ, оптимизированный по
94
критерию робастности к процедуре сжатия алгоритмом JPEG. Для этого в блоке 8х8 элементов
заранее вычисляют «емкость» каждого пикселя (с учетом ДКП и матрицы квантования JPEG).
Затем ЦВЗ внедряют в соответствии с вычисленной емкостью. Эта оптимизация производится
раз и навсегда, и найденная маска применяется для любого изображения.
3.2.1.5. Алгоритм Роджена (Rongen)
В этом алгоритме, также, как и в алгоритме Питаса, ЦВЗ представляет собой двумерную
матрицу единиц и нулей с примерно равным их количеством. Пикселы, в которые можно
внедрять единицы (то есть робастные к искажениям), определяются на основе некоторой
характеристической функции (характеристические пиксели). Эта функция вычисляется локально,
на основе анализа соседних пикселов. Характеристические пиксели составляют примерно 1/100
от общего числа, так что не все единицы ЦВЗ встраиваются именно в эти позиции. Для
повышения количества характеристических пикселов в случае необходимости предлагается
осуществлять небольшое предыскажение изображения. Детектор находит значения
характеристических пикселов и сравнивает с имеющимся у него ЦВЗ. Если в изображении ЦВЗ
не содержится, то в характеристических пикселях количество единиц и нулей будет примерно
поровну
3.2.1.6. Алгоритм PatchWork
В основе алгоритма Patchwork лежит статистический подход. Вначале псевдослучайным
образом на основе ключа выбираются два пикселя изображения. Затем значение яркости одного
из них увеличивается на некоторое значение (от 1 до 5), значение яркости другого – уменьшается
на то же значение. Далее этот процесс повторяется большое число раз (~10000) и находится
сумма значений всех разностей. По значению этой суммы судят о наличии или отсутствии ЦВЗ в
изображении.
Значения выбираемых на каждом шаге пикселей - ai и bi, величина приращения – δ. Сумма
разностей значений пикселов
n
n
i 1
i 1
Sn [(ai ) (bi )] 2 n (ai bi )
n
Матожидание величины
(a b )
i 1
i
i
(суммы разности значений пикселов в незаполненном
контейнере) близко к нулю при достаточно большом n. Матожидание величины Sn будет больше
2δ. Sn имеет гауссовское распределение. В стегодетекторе в соответствии с ключом проверяется
значение и в том случае, если она значительно отличается от нуля, выносится решение о наличии
ЦВЗ. Для повышения робастности алгоритма вместо отдельных пикселов можно использовать
блоки, или patches (отсюда и название алгоритма). Использование блоков различного размера
может рассматриваться как формирование спектра вносимого ЦВЗ шума (шейпинг), аналогично
тому, как это применяется в современных модемах.
Алгоритм Patchwork является достаточно стойким к операциям сжатия изображения, его
усечения, изменения контрастности. Основным недостатком алгоритма является его
неустойчивость к аффинным преобразованиям, то есть поворотам, сдвигу, масштабированию.
Другой недостаток заключается в малой пропускной способности. Так, в базовой версии
алгоритма для передачи 1 бита скрытого сообщения требуется 20000 пикселов.
95
3.2.1.7. Алгоритм Бендера (Bender)
Алгоритм Бендера основан на копировании блоков из случайно выбранной текстурной
области в другую, имеющую сходные статистические характеристики. Это приводит к появлению
в изображении полностью одинаковых блоков. Эти блоки могут быть обнаружены следующим
образом:
1)
Анализ функции автокорреляции стегоизображения и нахождение ее пиков.
2)
Сдвиг изображения в соответствии с этими пиками и вычитание изображения из
его сдвинутой копии.
Разница в местоположениях копированных блоков должна быть близка к нулю.
3)
Выбирается некоторый порог и значения, меньшие этого порога по абсолютной величине,
считаются искомыми блоками.
Так как копии блоков идентичны, то они изменяются одинаково при преобразованиях всего
изображения. Если сделать размер блоков достаточно большим, то алгоритм будет устойчивым
по отношению к большинству из негеометрических искажений. Алгоритм является робастным к
фильтрации, сжатию, поворотам изображения. Основным недостатком алгоритма является
исключительная сложность нахождения областей, блоки из которых могут быть заменены без
заметного ухудшения качества изображения. Кроме того, в данном алгоритме в качестве
контейнера могут использоваться только достаточно текстурные изображения.
3.2.2. Алгоритмы встраивания данных в области преобразования
Реальные изображения вовсе не являются случайным процессом с равномерно
распределенными значениями величин. Хорошо известно, и это используется в алгоритмах
сжатия, что большая часть энергии изображений сосредоточена в низкочастотной части спектра.
Отсюда
и
потребность
в
осуществлении
декомпозиции
изображения
на
субполосы.
Cтегосообщение добавляется к субполосам изображения. Низкочастотные субполосы содержат
подавляющую часть энергии изображения и, следовательно, носят шумовой характер.
Высокочастотные субполосы наиболее подвержены воздействию со стороны различных
алгоритмов обработки, будь то сжатие или НЧ фильтрация. Таким образом, для вложения
сообщения наиболее подходящими кандидатами являются среднечастотные субполосы спектра
изображения. Типичное распределение шума изображения и обработки по спектру частоты
показано на рис.8.
96
Рис.8. Зависимость шума изображения и шума обработки от частоты
Шум обработки появляется в результате квантования коэффициентов трансформанты. Его
можно рассматривать как уменьшение корреляции между коэффициентами трансформанты
исходного изображения и квантованными коэффициентами. Например, при высоких степенях
сжатия может возникнуть ситуация, когда будут отброшены целые субполосы. То есть дисперсия
шума в этих субполосах, вообще говоря, бесконечна. Налицо уменьшение корреляции между
коэффициентами субполосы до квантования и после. Для получения приемлемых результатов
необходимо усреднить значение шума обработки по многим изображениям.
Преобразования можно упорядочить по достигаемым выигрышам от кодирования:
единичное, Адамара, Хаара, ДКП, Вейвлет, Карунена-Лоэва (ПКЛ). Под выигрышем от
кодирования понимается степень перераспределения дисперсий коэффициентов преобразования.
Наибольший выигрыш дает преобразование Карунена-Лоэва (ПКЛ), наименьший –
разложение по базису единичного импульса (то есть отсутствие преобразования).
Преобразования, имеющие высокие значения выигрыша от кодирования, такие как ДКП,
вейвлет-преобразование, характеризуются резко неравномерным распределением дисперсий
коэффициентов субполос. Высокочастотные субполосы не подходят для вложения из-за
большого шума обработки, а низкочастотные – из-за высокого шума изображения. Поэтому
приходится ограничиваться среднечастотными полосами, в которых шум изображения примерно
равен шуму обработки. Так как таких полос немного, то пропускная способность стегоканала
невелика. В случае применения преобразования с более низким выигрышем от кодирования,
например, Адамара или Фурье, имеется больше блоков, в которых шум изображения примерно
равен шуму обработки. Следовательно, и пропускная способность выше. Следовательно, для
повышения пропускной способности стеганографического канала лучше применять
преобразования с меньшими выигрышами от кодирования, плохо подходящие для сжатия
сигналов.
Эффективность применения вейвлет-преобразования и ДКП для сжатия изображений
объясняется тем, что они хорошо моделируют процесс обработки изображения в СЧЗ, отделяют
«значимые» детали от «незначимых». Значит, их более целесообразно применять в случае
активного нарушителя, так как модификация значимых коэффициентов может привести к
неприемлемому искажению изображения. При применении преобразования с низкими
97
значениями выигрыша от кодирования существует опасность нарушения вложения, так как
коэффициенты преобразования менее чувствительны к модификациям.
Блок 8x8 пикселей с расположением коэффициентов ДКП
3.2.2.1. Встраивание данных в коэффициенты дискретного косинусного преобразования
При использовании данного метода, контейнер разбивается на блоки размером 8х8
пикселов. ДКП применяется к каждому блоку, в результате чего получаются матрицы
коэффициентов ДКП, также размером 8х8. Коэффициенты обозначаются через cb ( j, k ) , где b –
номер блока, ( j , k ) - позиция коэффициента внутри блока. Если блок сканируется в
зигзагообразном порядке (как это имеет место в JPEG), то коэффициенты обозначаются через cb , j
. Коэффициент в левом верхнем углу cb (0, 0) обычно называется DC-коэффициентом. Он
содержит информацию о яркости всего блока. Остальные коэффициенты называются АСкоэффициентами. Иногда выполняется ДКП всего изображения, а не отдельных блоков. Далее
рассмотрим некоторые из алгоритмов внедрения ЦВЗ в области ДКП.
3.2.2.2 Алгоритм Коча (Koch)
В данном алгоритме в блок размером 8х8 осуществляется встраивание 1 бита ЦВЗ. Описано
две реализации алгоритма: псевдослучайно могут выбираться два или три коэффициента ДКП.
Рассмотрим вариацию алгоритма с двумя выбираемыми коэффициентами.
Встраивание информации осуществляется следующим образом: для передачи бита 0
добиваются того, чтобы разность абсолютных значений коэффициентов была бы больше
некоторой положительной величины, а для передачи бита 1 эта разность делается меньше
некоторой отрицательной величины:
cb ( ji , j , ki ,1 ) cb ( ji ,2 , ki ,2 ) , если si 0,
cb ( ji , j , ki ,1 ) cb ( ji ,2 , ki ,2 ) , если si 1.
98
3.2.2.3 Алгоритм Бенхама (Benham)
Этот алгоритм является улучшенной версией предыдущего. Улучшения проведены по двум
направлениям: для встраивания используются не все блоки, а лишь «пригодные» для этого,
внутри блока для встраивания выбираются не два, а три коэффициента, что уменьшает
искажения. Пригодными для встраивания информации считаются блоки изображения, не
являющиеся слишком гладкими, а также не содержащие малого числа контуров. Для первого
типа блоков характерно равенство нулю высокочастотных коэффициентов, для второго типа –
очень большие значения нескольких низкочастотных коэффициентов. Эти особенности и
являются критерием отсечения непригодных блоков.
При встраивании бита ЦВЗ псевдослучайно выбираются три коэффициента ДКП блока.
Если нужно вложить 1, коэффициенты изменяются так (если требуется), чтобы третий
коэффициент стал меньше каждого из первых двух; если нужно встроить 0 он делается больше
других. В том случае, если такая модификация приведет к слишком большой деградации
изображения, коэффициенты не изменяют, и этот блок просто не используется. Изменение трех
коэффициентов вместо двух, а тем более отказ от изменений в случае неприемлемых искажений
уменьшает вносимые ЦВЗ погрешности. Декодер всегда сможет определить блоки, в которые
ЦВЗ не встроен, повторив анализ, выполненный в кодере.
3.2.2.4Алгоритм Подилчука (Podilchuk)
При обнаружении ЦВЗ этот алгоритм требует наличия у детектора исходного изображения.
Встраиваемые данные моделируются вещественным случайным процессом с нормальным
распределением, единичной дисперсией и нулевым средним. Для каждого коэффициента ДКП
определяется значение порога, изменение сверх которого может привести к деградации
изображения. Этот порог зависит от позиции коэффициента в матрице (то есть частотного
диапазона, за который он отвечает). Кроме того, порог обуславливается и свойствами самого
изображения: контрастностью и яркостью блока.
Встраивание осуществляется следующим образом: если абсолютное значение
коэффициента меньше порога, то он не изменяется. В противном случае к нему прибавляется
произведение значения порога и значения ЦВЗ. При обнаружении ЦВЗ вначале коэффициенты
исходного изображения вычитаются из соответствующих коэффициентов модифицированного
изображения. Затем вычисляется коэффициент корреляции, и устанавливается факт наличия
ЦВЗ.
3.2.2.5 Алгоритм Хсю (Hsu)
В данном алгоритме декодеру ЦВЗ также требуется исходное изображение. Однако,
декодер определяет не факт наличия ЦВЗ, а выделяет встроенные данные. В качестве ЦВЗ
выступает черно-белое изображение размером вдвое меньше контейнера. Перед встраиванием
это изображение подвергается случайным перестановкам. ЦВЗ встраивается в среднечастотные
коэффициенты ДКП (четвертая часть от общего количества). Эти коэффициенты расположены
вдоль второй диагонали матрицы ДКП.
Для внедрения бита ЦВЗ si в коэффициент cb ( j, k ) , находится знак разности коэффициента
текущего
блока
и
соответствующего ему коэффициента из предыдущего блока
d1 (i) sign(cb ( j, k ) cb1 ( j, k )) . Если надо встроить 1, коэффициент cb ( j , k ) меняют так, чтобы
знак разности стал положительным, если 0 – то чтобы знак стал отрицательным.
99
Имеется и ряд улучшений основного алгоритма. Во-первых, вместо значений
коэффициентов можно использовать их абсолютные значения. Во-вторых, вместо коэффициента
из предыдущего блока можно использовать DC-коэффициент текущего блока. Также берется в
учет процесс квантования коэффициентов:
c ( j, k )
c (0, 0)
d 2 (i ) sign b
Q( j, k ) b
Q(0, 0) .
Q( j, k )
Q(0, 0)
Еще одним усовершенствованием этого алгоритма является
котором блоки ЦВЗ упорядочиваются по убыванию в них числа
изображения-контейнера также упорядочиваются по убыванию
выполняется соответствующее вложение данных. Данный алгоритм
отношению к JPEG-компрессии.
порядок сортировки, при
единиц. Блоки исходного
дисперсий. После этого
не является робастным по
3.2.2.6 Алгоритм Кокса (Cox)
Этот алгоритм является робастным ко многим операциям обработки сигнала. Обнаружение
встроенного ЦВЗ в нем выполняется с использованием исходного изображения. Внедряемые
данные представляют собой последовательность вещественных чисел с нулевым средним и
единичной дисперсией. Для вложения информации используются несколько АС-коэффициентов
ДКП всего изображения с наибольшей энергией. Автором предложено три способа встраивания
ЦВЗ в соответствии со следующими выражениями:
c 'i ci si ; c 'i ci (1 si ); c 'i ci e si .
Первый вариант может использоваться в случае, когда энергия ЦВЗ сравнима с энергией
модифицируемого коэффициента. В противном случае либо ЦВЗ будет неробастным, либо
искажения слишком большими. Поэтому так встраивать информацию можно лишь при
незначительном диапазоне изменения значений энергии коэффициентов.
При обнаружении ЦВЗ выполняются обратные операции: вычисляются ДКП исходного и
модифицированного
изображений,
находятся
разности
между
соответствующими
коэффициентами наибольшей величины.
3.2.2.7 Алгоритм Барни (Barni)
Этот алгоритм является улучшением алгоритма Кокса, и в нем также выполняется ДКП
всего изображения. В нем детектору уже не требуется исходного изображения, то есть схема
слепая. Для встраивания ЦВЗ используются не наибольшие АС-коэффициенты, а средние по
величине. В качестве ЦВЗ выступает произвольная строка бит.
Выбранные коэффициенты модифицируются следующим образом: c 'i ci si ci . Далее
выполняется обратное ДКП, и производится дополнительный шаг обработки: исходное и
модифицированное изображения складываются с весовыми коэффициентами:
l ''( x, y ) ( x, y )l '( x, y ) (1 )l ( x, y) .
Здесь
1
для
текстурированных
областей
(в
которых
человеческий
глаз
малочувствителен к добавленному шуму) и 0 в однородных областях. Значение β находится
не для каждого пикселя в отдельности, а для неперекрывающихся блоков фиксированного
100
размера. Например, в качестве целесообразно использовать нормализованную дисперсию
блоков. В детекторе ЦВЗ вычисляется корреляция между модифицированным изображением и
n
ЦВЗ,
c s
i 1
'' ''
i i
.
Лекция 33. Методы компьютерной стеганографии (КС).
Результаты сопоставительного анализа методов КС приведены в таблице 1
Таблица 1.
Методы КС
Краткая
характеристика методов
Недостатки
Преимущества
1. Методы использования специальных свойств компьютерных форматов данных
1.1. Методы
использования
зарезервированных для
расширения полей
компьютерных форматов
данных
Поля расширения
имеются во многих
мультимедийных
форматах, они
заполняются нулевой
информацией и не
учитываются
программой
Низкая
степень скрытности,
передача небольших
объемов
Простота
информации
использования
1.2. Методы
специального
форматирования
текстовых файлов:
1.2.1. Методы
использования
известного смещения
слов, предложений,
абзацев
1.2.2. Методы
выбора определенных
позиций букв (нулевой
шифр)
Методы основаны
на изменении
положения строк и
расстановки слов в
предложении, что
обеспечивается
вставкой
дополнительных
пробелов между
словами
Акростих частный случай этого
метода (например,
начальные буквы
каждой строки
образуют сообщение)
1.Слабая
производительность
метода,передача
небольших объемов
информации
2. Низкая
степень скрытности
Простота
использования.
Имеется
опубликованное
программное
обеспечение
реализации
данного метода
101
1.2.3. Методы
использования
специальных свойств
полей форматов, не
отображаемых на экране
Методы основаны
на использовании
специальных
"невидимых", скрытых
полей для организации
сносок и ссылок
(например,
использование черного
шрифта на черном
фоне)
1.3. Методы
скрытия в
неиспользуемых местах
гибких дисков
Информация
записывается в обычно
неиспользуемых местах
ГМД (например, в
нулевой дорожке)
1. Слабая
производительность
метода, передача
небольших объемов
информации
2. Низкая
степень скрытности
1.4. Методы
использования имитирующих
функций (mimic-function)
1.5. Методы удаления
идентифицирующего файл
заголовка
Метод основан на
генерации текстов и
является обобщением
акростиха. Для тайного
сообщения
генерируется
осмысленный текст,
скрывающий само
сообщение
1. Слабая
производительность
метода, передача
небольших объемов
информации
Простота
использования.
Имеется
опубликованное
программное
обеспечение
реализации
данного метода
Результирующий
текст не является
подозрительным
для систем
мониторинга сети
2. Низкая
степень скрытности
Скрываемое
Проблема
сообщение шифруется и скрытия решается
у результата удаляется только частично.
идентифицирующий
Необходимо заранее
заголовок,оставляя
передать часть
только шифрованные
информации
данные.
получателю
Получатель заранее
знает о передаче
сообщения и имеет
недостающий заголовок
Простота
реализации.
Многие средства
(White Noise
Storm, S-Tools),
обеспечивают
реализацию этого
метода с PGP
шифроалгоритмом
2. Методы использования избыточности аудио и визуальной информации
2.1. Методы
использования избыточности
Младшие разряды
За счет
цифровых отсчетов
введения
Возможность
скрытой передачи
102
цифровых фотографии,
цифрового звука и цифрового
видео
содержат очень мало
полезной информации.
Их заполнение
дополнительной
информацией
практически не влияет
на качество восприятия,
что и дает возможность
скрытия
конфиденциальной
информации
дополнительной
информации
искажаются
статистические
характеристики
цифровых потоков.
Для снижения
компрометирующих
признаков требуется
коррекция
статистических
характеристик
большого объема
информации.
Возможность
защиты
авторского права,
скрытого
изображения
товарной марки,
регистрационных
номеров и т.п
Как видно из таблицы 1, первое направление основано на использовании специальных
свойств компьютерных форматов представления данных, а не на избыточности самих данных.
Специальные свойства форматов выбираются с учетом защиты скрываемого сообщения от
непосредственного прослушивания, просмотра или прочтения. На основании анализа материалов
можно сделать вывод, что основным направлением компьютерной стеганографии является
использование избыточности аудио и визуальной информации.
Как показывает
предварительный анализ, применение стеганографических методов для решения задач,
поставленных в ТЗ, принципиально возможно. Однако все проанализированные методы
обладают следующими недостатками:
- Множество возможных реализаций в КС счетно и конечно, что позволяет реализовать
атаки простым перебором методов, хотя это требует значительных вычислительных затрат.
- Не все реализации отвечают требованию возможности аппаратной реализации.
2.2 Новые разработки в области компьютерной стеганографии
StegFS - стеганографическая файловая система, способная преодолевать указанные
выше недостатки, предлагая владельцам данных возможность отрицания существования этих
данных. StegFS надежно скрывает файлы, выбранные пользователем, в файловой системе таким
образом, что, без соответствующих ключей, взломщик не сможет угадать их существование,
даже если он хорошо знаком с файловой системой и имеет к ней полный доступ.
Контроль доступа пользователей и шифрование – стандартные механизмы защиты данных
в текущих продуктах, таких, как Encrypting File System (EFS). Эти механизмы позволяют
администратору ограничить доступ пользователей к тем или иным фалам и папкам. Однако,
контроль доступа и шифрование могут не помочь в случаях, когда речь идет об очень ценных
данных. Само присутствие зашифрованного файла или папки является свидетельством того, что
на компьютере присутствуют ценные данные.
Чтобы защитить данные в таких ситуациях, необходимо разработать файловую систему,
которая предоставляет доступ к данным только при правильно введенном пароле. Без этого
взломщик не сможет получить даже данных о том, существуют ли данные.
Таким образом, пользователи, находящиеся под давлением, смогут отрицать само
существование информации. Он может раскрыть наименее ценную информацию (например,
103
адресную книгу, переписку), но сохранить самую ценную, например, финансовую информацию.
Неавторизованные пользователи и даже администраторы не смогут получить доступ к такой
информации.
В последние годы было несколько решений для стеганографической файловой системы. В
этих решениях было множество ограничений и недостатков, связанных с огромным увеличением
операций ввода/вывода, малоэффективным использованием свободного пространства и даже
вероятностью потерять данные. Такие ограничения не позволили этим решениям выйти на
массовый рынок.
Новая система StegFS позволяет пользователю выборочно скрыть файлы и папки таким
образом, что взломщик даже не догадается об их существовании. Чтобы гарантировать свою
практичность, StegFS разработана с учетом трех требований:
1)
она не должна терять или повреждать данные
2)
она должна позволять владельцам информации отрицать ее существование
3)
должна минимизировать вычислительные затраты и затраты на пространство
StegFS исключает скрытые папки и файлы из центральной директории файловой системы.
Вместо этого, метаданные скрытой информации хранятся в заголовке непосредственно самого
объекта. Весь объект, включая заголовок и данные, зашифрован, чтобы сделать его неотличимым
от неиспользуемых блоков для наблюдателя. Только авторизованный пользователь с корректным
ключом может получить местоположение заголовка и доступ к самой информации через
заголовок.
StegFS была реализована в операционной системе Linux, и многочисленные эксперименты
подтвердили, что StegFS на самом деле качественно увеличивает такие показатели, как
производительность и использование дискового пространства, по сравнению с существующими
схемами.
2.2.2 Архитектура файловой системы StegFS.
Рисунок 3 дает краткий обзор файловой системы StegFS. Дисковое пространство
разбивается на блоки стандартного размера и битовый массив отслеживает, свободен ли каждый
блок или был зарезервирован – нулевой бит указывает на то, что соответствующий блок
свободен; бит = 1 – на используемый блок. Доступ ко всем простым файлам осуществляется
через центральную директорию, которая смоделирована через inode таблицу в Unix. Скрытые
файлы не зарегистрированы в центральной директории, хотя блоки, занимаемые ими, отделены в
битовом массиве, чтобы защитить пространство от перераспределения.
После того, как файловая система создана, произвольно сгенерированные шаблоны
записываются во все блоки таким образом, что оно не отличаются от свободных блоков. Кроме
того, некоторые произвольно выбранные блоки отброшены, при помощи включения
соответствующих им бит в битовый массив. Эти блоки необходимы для того, чтобы
предотвратить любую попытку найти скрытые данные при просмотре блоков, которые помечены
в битовом массиве, но не входят в центральную директорию. Чем выше число отброшенных
блоков, тем труднее достичь цели при таком исследовании « в лоб». Однако, это необходимо
согласовать с необходимостью правильно использовать дисковое пространство. На практике,
число отброшенных блоков может определяться администратором или произвольно
устанавливаться StegFS.
104
Центральная
директория
Битовый массив
1001101101101100
0110110111110111
1010110110110110
0110110110111101
ПФ1
0111011101110111
ПФ2
ПФ3
1101111101110111
ПФ1
ЛCФ1
CФ1
ЛCФ1
ОБ
CФ1
ЛCФ1
ОБ
ПФ2
ОБ
CФ2
ОБ
CФ1
CФ2
ПФ3
Условные обозначения:
--ПФ: простой файл
--СФ: скрытый файл
--ЛСФ: ложный скрытый файл
--ОБ: оставленные блоки
Рис. 2. Обзор стеганографической файловой системы StegFS
StegFS дополнительно поддерживает один или более ложные скрытые файлы, которые она
периодически обновляет. Это необходимо для того, чтобы удержать взломщика от
предположения, что блоки, размещенные в битовом массиве и не принадлежащие ни одному
простому файлу, должны содержать скрытые данные. Число таких файлов также может
выставляться вручную или автоматически.
Заголовок
Подпись
Список свободных
блоков
Свободный блок
Таблица индексов
Блок данных
Рис. 3. Структура скрытого файла
В примере на рисунке 2 в файловой системе находится два скрытых пользовательских
файла, один ложный скрытый файл и 3 простых файла, каждый из которых состоит из одного
или более дисковых блоков. Кроме того, в системе также присутствуют отброшенные блоки.
Структура скрытого файла показана на рисунке 3. Доступ к каждому скрытому файлу
осуществляется через его собственный заголовок, который состоит из 3-х структур данных:
1)
Ссылка на inode таблицу, которая адресует все блоки данных в файле
105
2)
Подпись, которая уникальным образом идентифицирует файл
3)
Присоединенный список указателей на свободные блоки, занимаемые
файлом
Все компоненты файла, включая заголовок и данные, зашифрованы при помощи ключа,
чтобы сделать их неотличимыми от отброшенных блоков и ложных файлов.
Поскольку скрытые файлы не записываются в центральную директорию, StegFS должна
иметь возможность найти заголовок файла, используя только имя файла и ключ. Во время
создания файла StegFS использует хэш-значение, вычисленное из имени файла и ключа для
генератора случайных номеров блоков. Затем, каждый успешно сгенерированный блок она
просматривает в битовом массиве до тех пор, пока не найдет свободный блок, чтобы сохранить в
него заголовок. После того, как заголовок сохранен, последующие блоки могут быть назначены
произвольно, согласуясь с битовым массивом, и затем присоединены к inode таблице файла.
Чтобы избежать перезаписи файла из-за того, что различные пользователи используют одно и то
же имя файла и пароль, физическое имя файла получается при помощи сложения
идентификатора пользователя с полным путем к файлу.
Чтобы восстановить скрытый файл, StegFS снова вводит хэш-значение, полученное из
имени файла и ключа, просматривает в битовом массиве первый блок, помеченный в качестве
используемого и соответствующего файловой подписи. Первые номера блоков, выданные
генератором, могут не содержать правильного заголовка, т.к. во время создания файла они были
не доступны. Таким образом, подпись, полученная из имени и ключа, наиболее важна при
получении местоположения необходимого заголовка. Чтобы избежать неправильные
соответствия, файловая подпись должна быть длинной строкой. Хэш-функция генерируется
таким образом, что взломщик не сможет получить ее из имени файла и ключа.
Другой особенностью скрытого файла является то, что он может держаться за свободные
блоки. Целью этого является удержание злоумышленника, который начинает просмотр файловой
системы сразу после того, как она была создана и который, следовательно, имеет возможность
убрать отброшенные блоки из рассмотрения, от отслеживания местонахождения ложных
скрытых файлов. Такой нарушитель, возможно, сможет выделить часть блоков, выделенных для
хранения скрытого файла. Поддерживая внутренний пул свободных блоков в скрытом файле,
StegFS препятствует взломщику в отделении ценных данных от свободных блоков. Когда
создается скрытый файл, StegFS напрямую выделяет для данного файла несколько блоков. Эти
блоки, отслеженные через связанный список указателей в заголовке файла, выбираются
произвольно из свободного пространства в файловой системе. Таким образом, увеличивается
трудность определения принадлежности блоков к данному файлу и порядка между ними. В
процессе расширения файла, блоки в произвольном порядке берутся из присоединенного списка
для хранения данных или inodes, до тех пор, пока число свободных блоков не превысит
некоторую границу. Наоборот, когда файл уменьшается, свободные блоки добавляются в пул до
тех пор, пока их число не превысит некоторое пороговое значение и тогда эти блоки
возвращаются в файловую систему.
2.2.3 Поддержка директорий
Хотя StegFS имеет несколько инструментов, сохраняющих файлы, скрытые пользователем,
наиболее эффективной она оказывается в мультипользовательской системе. Происходит это
потому, что когда много блоков, выделено для скрытых файлов, взломщик может оценить
106
размеры ценной информации в этих файлах, но точно оценить, сколько информации
принадлежит тому или иному пользователю не представляется возможным. Таким образом,
пользователь, действующий под давлением, имеет дополнительные возможности отрицания
того, что существует какая-либо ценная информация, принадлежащая ему.
Естественным требованием к мультипользовательской системе является необходимость
совместного использования скрытых файлов. Т.к. пользователь может захотеть совместно
использовать лишь выбранные им файлы, StegFS защищает каждый скрытый файл произвольно
сгенерированным ключом доступа к файлу (FAK), а не ключом пользователя, так, что
пользователи могут обмениваться именами файлов и ключами.
Рисунок 3 показывает структуру директорий, которую применяет StegFS, чтобы помочь
пользователям отслеживать их скрытые файлы. StegFS позволяет пользователю иметь несколько
пользовательских ключей доступа (UAK). Для каждого UAK StegFS поддерживает директорию
из пар значений (имени файла и FAK) для всех скрытых файлов, к которым можно иметь доступ
при помощи этого UAK.
Пользова
тельский
ключ
доступа 1
Файл1: Имя, FAK
Файл2: Имя, FAK
Ключ
доступа к
файлу
(FAK)
Пользова
тельский
ключ
доступа 2
Зашифрован
ный скрытый
файл
Файл1: Имя, FAK
Файл2: Имя, FAK
Рис. 4. Структура директорий в StegFS
107
Отправитель
Получатель
Ввод UAK-отправителя
Дешифрация (имя
файла, FAK)
Получение сообщения
Выбор файла для
общего доступа
Ввод открытого ключа
получателя
Восстановлени (имя
файла, FAK)
выбранного файла
Дешифрация сообщения
(имя файла, FAK)
Ввод открытого ключа
получателя
Ввод UAK-получатея
Шифрация (имя файла,
FAK) с открытым
ключом
Шифрация (имя файла, FAK)
при помощи UAK-получателя
Отправления
сообщения получателю
Добавление зашифрованной
пары в UAK-директорию
Рис. 5. Совместное использование файлов в StegFS
Вся директория зашифрована при помощи UAK и хранится в виде скрытого файла в
файловой системе. UAKи могут управляться независимо, например, храниться на независимых
картах для большей защищенности. Чтобы сделать файловую систему более дружественной к
пользователю, UAKи, принадлежащие пользователю могут быть организованы в виде иерархии
линейного доступа таким образом, что когда пользователь подписывается на данный уровень
доступа, все скрытые файлы, связанные с данным UAKом на этом уровне или ниже становятся
видимыми. Таким образом, под давлением пользователь может выборочно раскрыть только
подмножество своих UAKов. Не зная, как много UAKов у пользователя, взломщик не сможет
предположить, что пользователь удерживает часть UAKов.
Чтобы обмениваться скрытыми файлами между пользователями, владелец должен передать
пару (имя файла, FAK) получателю. Т.к. ни владелец, ни StegFS не имеют UAK получателя,
обмен файлов не может быть автоматическим. Вместо этого, информация о файле шифруется с
открытым ключом получателя, и результирующее сообщение посылается получателю, например,
по электронной почте. Используя утилиту StegFS, получатель дешифрует сообщение при
помощи своего закрытого ключа и ассоциирует скрытый файл со своим собственным UAKом, в
это время информация в файле добавляется в директорию UAK и сообщение уничтожается.
Практика передачи информации в файле – относительно слабое место в StegFS, т.к.
зашифрованное сообщение может предупредить взломщика о существовании скрытого файла.
Однако, т.к. у каждого скрытого файла имеется FAK, обнаруженное сообщение не подставляет
другие скрытые файлы в StegFS. Механизм обмена файлами показан на рисунке 4.
Наконец, когда владелец скрытого файла решает отменить права общего пользования
файлом, StegFS сначала делает новую копию с новым FAK и возможно с другим именем файла,
108
затем удаляет исходный файл, чтобы отменить старый FAK. Просроченный FAK будет удален из
директорий других пользователей после следующей загрузки.
Лекция 32. Стегоанализ
Стегоанализ — раздел стеганографии, посвященный выявлению факта передачи
скрытой информации в анализируемом сообщении. В некоторых случаях под стегоанализом
понимают также извлечение скрытой информации из содержащего её сообщения и (если это
необходимо) дальнейшую её дешифровку.
5.1 Общая методика стегоанализа
В качестве первого шага стегоаналитик представляет исследуемое сообщение в
виде контейнера, соответствующего известному ему методу стеганографии данного типа
сообщений. Для определения контейнера требуется понимание метода занесения скрытой
информации и знание места в сообщении, куда могло быть помещено стего. Таким образом, на
первом этапе стегоаналитик:
выбирает метод стеганографии, с помощью которого могла быть занесена скрытая
информация в исследуемое сообщение,
структурирует
сообщение
в
виде
соответствующего
контейнера
и
получает
представление о возможных способах добавления стего в сообщение выбранным методом.
Место в контейнере (или его объём), куда может быть занесено стего данным методом
стеганографии, как правило называют полезной ёмкостью контейнера.
Вторым шагом служит выявление возможных атак исследуемого сообщения — то есть
видоизменений контейнера (которым является данное сообщение в рамках выбранного метода
стеганографии) с целью проведения стегоанализа. Как правило, атаки проводятся путём внесения
произвольной скрытой информации в контейнер с помощью выбранного для анализа метода
стеганографии.
Третьим, и заключительным, шагом является непосредственно стегоанализ: контейнер
подвергается атакам, и на основе исследования полученных «атакованных» сообщений, а также
исходного сообщения, делается вывод о наличии или отсутствии стего в исследуемом
сообщении. Совокупность производимых атак и методов исследования полученных сообщений
представляет собой метод стегоанализа. Атака(и), с помощью которой(ых) удалось выявить
наличие скрытой информации, называют успешной атакой.
Как правило, стегоанализ даёт вероятностные результаты (то есть возможность наличия
стего в сообщении), и реже — точный ответ. В последнем случае, как правило, удаётся
восстановить исходное стего.
5.2 Пример стегоанализа с использованием гистограмм
В случае стеганографического встраивания т.е. замены НЗБ на случайную
последовательность, количество пикселей в парах выравняется. Гистограмма станет ступеньками
(по два соседних значения яркости). На рисунке синим цветом обозначена гистограмма
изображения без встраивания, а красным - гистограмма того же изображения после встраивания
109
заархивированных данных вместо последнего слоя. Сравнение двух гистограмм и дает
возможность стегоанализа последовательно скрываемых бит.
Стегоанализ - это противодействие стеганографии, как криптоанализ - это противодействие
криптографии. Основная
цель
стеганографии
- скрыть
факт
передачи
данных.
Следовательно, основная цель стегоанализа - обнаружить факт сокрытия передачи данных.
Рассмотрим метод обнаружения последовательного встраивания в LSB на примере изображения
формата BMP. Бытует мнение, что Указатели в LSB изображений являются случайными. На
самом деле это не так. Хотя человеческий глаз и не заметит изменений изображения при
изменении последнего бита, статистические параметры изображения будут изменены. Перед
сокрытием данные обычно архивируются (для уменьшения объема) или шифруются (для
обеспечения дополнительной стойкости сообщения при попадании в чужие руки). Это делает
биты данных очень близкими к случайным.Последовательное встраивание такой информации
заменит LSB изображения случайными битами. Это можно обнаружить. Для примера возьмем
одну цветовую компоненту полноцветного изображения BMP и на ней покажем процесс
отыскания встраивания. Яркость цветовой компоненты может принимать значения от 0 до 255. В
двоичной системе исчисления - от 0000 до1111. Рассмотрим пары:
0000 0000<->0000 0001;
0000 0010<->0000 0011;
...
1111 1100<->1111 1101;
1111 1110<->1111 1111.
Данные числа различаются между собою только в LSB. Таких пар для цветовой
компоненты BMP изображения: 256/2=128
В
случае
стеганографического
встраивания
т.е.
замены LSB на
случайную
последовательность, количество пикселей в парах выравняется. Гистограмма станет ступеньками
(по два соседних значения яркости рис. 10)
Рис.10. Гистограмма контейнера со встроенным сообщением.
На рисунке 10 синим цветом обозначена гистограмма изображения без встраивания, а
красным - гистограмма того же изображения после встраивания заархивированных данных
вместо последнего слоя. Сравнение двух гистограмм и дает возможность стегоанализа
последовательно скрываемых бит.
110
5.3 Необнаружимость скрываемых данных
Быстродействие и пропускная способность являются общепринятыми критериями оценки
каналов передачи сообщений и не учитывают специфики методов сокрытия данных, хотя и легко
поддаются измерению. Методики измерения необнаружимости не являются общепринятыми. В
данной работе предлагается универсальная и объективная методика, основанная на синтезе
оптимального алгоритма обнаружения.
Задачей сокрытия данных, по определению, является создание методов, аппаратуры и
программного обеспечения, совокупность которых обеспечивала бы минимальную вероятность
обнаружения скрытых данных. Данную вероятность можно оценить с помощью прогноза
теоретически возможных действий противника при анализе перехваченного сообщения.
Вероятные действия противника рассматривались, исходя из следующих постулатов:
• любые скрытые данные могут быть обнаружены и идентифицированы;
• задача обнаружения формируется относительно контейнера, вызывающего подозрение о
присутствии скрытых данных;
• контейнер, в отношении которого решается задача обнаружения, представляет собой
реализацию случайного процесса Y, поскольку случай возникновения подозрения непредсказуем;
• вероятность присутствия скрытых данных в реализации Y равна
скрытые данные;
, где
-
• вероятность отсутствия скрытых данных в реализации Y равна
.
Перечисленные вероятности являются условными и апостериорными. Они соответствуют
условию возникновения скрытых данных в анализируемом сообщении.
По теореме о вероятности совместного появления (произведения) двух событий А и В
Таким образом,
Следовательно искомая апостериорная вероятность наличия скрытых данных в реализации
Y:
Аналогично апостериорная вероятность отсутствия скрытых данных:
По формуле полной вероятности имеем:
, где
111
и
определяют априорные вероятности наличия и отсутствия скрытых данных в
анализируемого сообщении.
В задаче обнаружения скрытых данных оба из перечисленных выше случаев содержат
полную группу событий, поэтому
При такой постановке задачи можно воспользоваться основными выводами теории
обнаружения.
Поэтому, далее вводим в рассмотрение критерий абсолютного отношения правдоподобия
На основании изложенного можно записать
Таким образом, можно считать, что
определяет вероятность наличия скрытых данных в
анализируемом сообщении. Если в результате анализа подозрительного сообщения было
установлено, что
, то это означало бы, что
, и, следовательно
.
Отсюда следует, что
, то есть вероятность наличия скрытых данных в
подозрительном сообщении выше вероятности их отсутствия.
Однако, для определения
необходимо не только определить величину
отношение правдоподобия, но узнать заранее значения
и
.
-
Таким образом, можно считать, что решения задачи обнаружения всегда сопровождаются
ошибками. Программно-аппаратные средства, которыми располагает противник, могут также
вырабатывать ошибочные посылки, связанные с естественным несовершенством названных
средств, т. е. наличием методических ошибок, носящих случайный характер.
По аналогии с определениями,
рассматриваются следующие понятия:
выработанными
в
теории
обнаружения,
далее
• ошибка «ложной тревоги»;
• ошибка необнаружения скрытых данных в подозрительном сообщении.
Будем обозначать далее событие принятия решения об обнаружении скрытых данных в
подозрительном сообщении как «ДА», а событие, связанное с необнаружением скрытых данных
- как «НЕТ». Вводим далее следующие обозначения:
Р(ДА/0) - P(лт) - вероятность ложной тревоги
Р(НЕТ/ ) - Р(но) - вероятность необнаружения.
112
События, связанные с принятием решения о наличии, либо отсутствии скрытых данных в
подозрительном сообщении образуют полную группу, так что
Р(НЕТ/ ) + Р(ДА/ ) = 1,
Р(НЕТ/0) + Р(ДА/0) = 1.
Тогда вероятность обнаружения Р(обн) определяется зависимостью
Р(обн) = Р(ДА/ ) = 1 - Р(НЕТ/ )= 1 - Р(но),
Р(пно) = Р(НЕТ/0) = 1 - Р(ДА/0)= 1 - Р(лт).
Величина Р(обн) - вероятность заключения противника о наличии в подозрительном
сообщении скрытых данных при условии, что скрытые данные действительно присутствуют.
Величина Р(пно) - вероятность заключения противника об отсутствии скрытых данных в
подозрительном сообщении, при условии, что их действительно там нет - вероятность
правильного необнаружения.
Таким образом, можно считать, что чем больше значение Р(но) (или чем меньше Р(обн))
при заданном значении P(лт), тем выше качество системы сокрытия данных.
С учетом вышеперечисленного можно записать выражения для безусловных вероятностей:
Вышеперечисленные вероятности в среднем могут быть вычислены опытным путем через
частоты принятия противником правильных и ошибочных решений в процессе анализа
множества подозрительных контейнеров, содержащих (либо нет) сокрытые одним и тем же
методом данные.
Таким образом, оценка необнаружимости основывается в первую очередь
экспериментальных результатах обнаружения скрытых данных методами обнаружения.
на
5.4 Постановка задачи обнаружения скрытого сообщения
Подавляющее большинство методов обнаружения сокрытых данных основаны на
анализе характеристик вероятностного распределения элементов контейнера. Это позволяет
прогнозировать действия противника при решении задачи обнаружения скрытых данных. Ниже
рассматривается математическая модель основных наиболее вероятных действий противника,
основанная на положениях теории обнаружения.
Принятие противником решения о наличии скрытых данных на исследуемом носителе
производится не по одному значению какой-то величины, характеризующей содержимое
носителя, а по всему объему носителя, т.е. по выборке, состоящей из N значений реализации, что
позволяет более полно использовать априорную информацию и получить тем больший
положительный эффект, чем значительней объем выборки N.
113
Таким образом, задача противника
интерпретироваться, как задача оптимизации:
по
где
набор пустых контейнеров,
обнаружения,
разработке
метода
обнаружения
функция сокрытия данных,
Запишем функцию обнаружения через оценку
может
- функция
:
- пороговая оценка.
Так как в качестве контейнеров используются реальные избыточные источники сигнала,
содержимое контейнера можно разделить на сигнал и «шум», где под шумом понимается шум
дискретизации, квантовый шум и т.п. искажения, вносимые в «идеальный» сигнал. В случае
использования энергонезависимых носителей как контейнеров, под шумом будем понимать
неиспользуемые блоки файловой системы.
Представим контейнер I как
где
- контейнер без шумов,
- присутствующий в контейнере шум.
Тогда
где
- веса соответствующих оценок.
Очевидно, что с ростом ресурсов противника, в частности, числа доступных пустых
контейнеров , оценка
улучшается:
114
Кроме того внедрение сокрытых данных в сигнал-контейнер может привести к «видимым»
стороннему наблюдателю искажениям. Соответственно, исходя из результатов проведенного
анализа и модели скрытого канала передачи данных, практически применимые алгоритмы
сокрытия данных размещают скрываемые данные в шуме контейнера:
Таким образом, оптимальный метод обнаружения скрытых данных строится, основываясь
на следующем алгоритме обнаружения:
1)выделяютстся параметры шума
из предоставленного для анализа контейнера
помощью выбранного метода выделения шума N,
с
2)принимается решение «ДА» или «НЕТ» в зависимости от оценки наличия скрытых
данных в выделенном шуме
Следовательно, задача разработки метода обнаружения может быть представлена как поиск
оптимальной функции оценки
и оптимальной функции выделения шума :
Задача построения оценки шума
является задачей классификации.
Согласно ее
трактовки в рассматриваем случае требуется построить алгоритм, относящий объект шума,
полученный из представленного для анализа контейнера к одному из двух классов - классу
шумов, содержащих скрытые данные или классу шумов, не содержащих скрытые данные.
Объект шума в данном случае может быть представлен как вектор, состоящий из отдельных
характеристик шума. Для построения алгоритма используется учебная выборка, состоящая из
набора пустых и заполненных контейнеров.
Принято считать оптимальным методом решения данной задачи метод опорных векторов.
Метод опорных векторов основан на поиске гиперплоскости в p-мерном пространстве,
разделяющую два класса p-мерных векторов, так, что расстояние между гиперплоскостью и
ближайшими точками классов максимально.
Гиперплоскость определяется геометрическим местом точек x, таким что
- нормаль гиперплоскости,
- смещение гиперплоскости от начала координат.
В случае линейной разделимости классов
и
выбираются таким образом чтобы
максимизировать расстояние между максимально возможно удаленными разделяющими классы
гиперплоскостями
и
115
,равное
. Таким образом, требуется решить задачу минимизации
при условии
где
для параметров
- класс, к которому принадлежит вектор
Решением задачи является линейная комбинация векторов учебной выборки
Векторы
, для которых
, называются опорными. Для них верно
Следовательно
В случае линейной неразделимости классов в методе опорных векторов вводится величина
ошибки , соответствующая ошибке классификации вектора :
Задача оптимизации таким образом ставится как
при условии
Для нелинейной классификации вместо скалярного произведения векторов используется
нелинейная функция ядра. В соответствие со сложившейся практикой оптимальной функцией
представляется радиально-базисная функция
Таким образом, оценка параметров шума задается следующими параметрами:
• набором используемых характеристик шума
• параметром штрафной функции
• параметром радиально-базисной функции
Приложение 2. Расчет сканирующей системы в режиме обнаружения. (Подготовка к
выполнению домашнего задания).
116
Как было показано ранее, для расчета сканирующих ОЭС, РЭС и АЭС вполне приемлем
один и тот же способ. Поэтому далее не делается различий между СУ.
Техническое задание. Рассчитать диаметр
входного зрачка сканирующей системы,
обеспечивающей максимальную дальность действия
км при условной вероятности
правильного обнаружения
и условной вероятности ложной тревоги
.
Излучающая поверхность объекта обнаружения – плоская диффузная круглой формы,
температура поверхности
К, площадь
м2, коэффициент излучения
. Положение объекта в пространстве характеризуется горизонтальным направлением
нормали к поверхности излучения. Обнаружение должно осуществляться круглосуточно на
высотах
км при температуре воздуха на уровне моря
влажности
%, метеорологической дальности видимости
К, относительной
км и положении линии
визирования относительно нормали к излучающей поверхности в диапазоне углов
.
Фон представляет собой облачную структуру с пространственным спектром вида (4.52).
Дисперсия яркости фона
Вт∙м-2.
Вт2∙м-4∙ср-2, угловой радиус корреляции фона
Объектив сканирующей ОЭС (рис. 6.1) имеет следующие параметры: фокусное расстояние
зеркального сферического объектива
мм, диаметр плоского зеркала
диаметр защитной плоскопараллельной пластины из фтористого лития
,
, ее толщина
. НКФР ОИзС аппроксимируется (см. пример 2.12) двумерной гауссоидой при
.
В качестве ПИ используется охлаждаемый до 195 К фоторезистор из сернистого свинца с
входным окном-фильтром из германия, просветленного сернистым цинком. Толщина фильтра
мм,
а
размер
чувствительной
чувствительность, измеренная по АЧТ (500 К),
площадки
ПИ
мм2,
В∙Вт-1, постоянная времени
паспортная
с.
117
Энергетический ЧВС мощности шума ПИ
изображен на рис. 2,
а спектральная характеристика ПИ
для чувствительной площадки
мм2
– на рис. 6.5.
118
Просмотр углового поля осуществляется за счет строчно-кадрового сканирования с
перекрытием строк, равным 1/3 ширины строки. Угловая скорость поворота оптической оси в
направлении строки
рад/с.
Расчет проводят в предположении, что ЭС реализована в виде оптимального ЧВФ.
Поскольку по ТЗ заданы величины
и
, то в проектируемой ОЭС предполагается
использовать правило решения на основе критерия Неймана-Пирсона. По (5.35) находим
требуемое ОСП на выходе ПУ
.
Вычисляя значения аргументов функции Лапласа при значениях функции, равных 0,95 и
0,1, найдем,
и
, так что
.
Используя (6.4), рассчитаем ЧВС сигнала на выходе ПИ. Для этого следует определить:
1. Синус апертурного угла объектива в пространстве предметов. Так как
.
, то
(6.15´)
Таким образом, необходимо знать
, который отыскивается в энергетическом расчете.
Поэтому расчет ведется методом последовательных приближений и для его выполнения
задаются ожидаемым значением диаметра. Положим
мм, тогда из (6.15´) получим
.
2. Коэффициент
, характеризующий уменьшение пропускания объектива из-за
экранирования части входного зрачка плоским зеркалом. Он равен отношению площади рабочей
части зрачка, имеющей кольцевую форму, к площади круга диаметром
:
.
3. Радиус
кружка рассеяния объектива. Точное значение
определяется только после
изготовления объектива. На стадии проектирования можно дать либо расчетную оценку его
возможного значения, проведя габаритный и аберрационный расчет объектива, либо оценить
предельный размер кружка, исходя из опыта создания аналогичных объективов. Известно [10],
что для сферических зеркальных объективов минимальный угловой радиус
пропорционален кубу относительного отверстия:
рассеяния
.
Полагая, что объектив будет изготовлен достаточно качественно, найдем
119
мм.
4. Линейную скорость сканирования, приведенную к плоскости анализа:
мм/с.
5. Коэффициент
. Для сканирующих ОЭС основной составляющей потока на ПИ в
режиме обнаружения является постоянная составляющая фонового излучения. Поэтому в
практике проектирования таких ОЭС энергетическую характеристику ПИ часто называют
фоновой характеристикой и получают в виде зависимости чувствительности
от
редуцированной облученности
чувствительной площадки ПИ. Для фотосопротивления PbS
(195 К) такая характеристика в относительных единицах показана на рис. 6.3. Рассчитаем
постоянную составляющую фонового излучения на ПИ.
Общая формула, определяющая связь яркости фона
чувствительной площадки ПИ, может быть записана в виде
с облученностью
.
Редуцированная облученность ПИ
.
Постоянная
составляющая
математическое ожидание
Поэтому
яркости
фона
представляет
собой
яркости фона, которое измеряется в редуцированных единицах.
.
Для нахождения
эффективной
(6.16’)
воспользуемся рис. 6.4, откуда
120
,
причем
и
,
поэтому
.
При
приближенно
.
(6.17)
Из (6.16´) с учетом (6.30) найдем
Вт∙м-2.
При такой облученности ПИ чувствительность (рис. 6.3) составляет 80% от максимального
значения. Следовательно,
.
6. Произведение
, которое для диффузного излучателя находят из (6.10) при
предварительном вычислении входящих в нее интегралов. На рис. 6.5 показаны графики
функций, входящих в подынтегральные выражения. Графики рассчитаны на основании ТЗ с
использованием методик, описанных в [10, 25]. Интегралы в числителе и знаменателе (6.10)
равны соответственно площадям
и
заштрихованных областей
масштабов построения графиков. Приближенное интегрирование дает
и
с учетом
121
;
.
Подставляя все найденные выражения, а также данные ТЗ в (6.10) и учитывая, что
наихудшие условия обнаружения соответствуют
, получим
В∙ср-1.
7. Значение
, которое используется при расчете как полезного сигнала, так и ОСП.
Необходимость проведения такого расчета связана с тем, что функция
,
определяющая в (6.18) изменение спектральной плотности сигнала в зависимости от
смещения центра изображения объекта с оси строки сканирования, имеет вид, изображенный на
рис. 6.
Максимум функции соответствует нулевому значению аргумента, с ростом абсолютного
значения которого функция симметрично и монотонно убывает. Поэтому необходимо найти
расчетное значение
, которое соответствовало бы наихудшему в отношении
обнаружения положению объекта в поле зрения сканирующей ОЭС и позволило бы найти
расчетное значение
. Покажем, что значение
зависит от одного из важнейших
параметров сканирующей ОЭС – степени взаимного перекрытия строк.
На рис. 6.7 показаны три смежных строки 1, 2 и 3, имеющие ширину и перекрытие
для определения расчетного смещения изображения объекта с центра строки сканирования.
,
122
Рис. Сканирование с перекрытием строк.
Предположим, что центр изображения «точечного» излучателя (центр кружка рассеяния)
находится на оси
строки 2 в точке А. Тогда для строки 2 смещение
, для строки
1 –
, для строки 3 –
. Следовательно, наибольший сигнал
(максимально возможный при заданной ширине строки и заданном распределении облученности
в изображении «точечного» излучателя) получим при «просмотре» строки 2. Сигналы при
просмотре строк 1 и 3 меньше и, в силу осевой симметрии НКФР, равны между собой.
Таким образом. При положении центра изображения в точке А наиболее благоприятные
условия соответствуют просмотру строки 2. Но поскольку номер строки, при просмотре которой
произойдет обнаружение, никакой роли не играет, то расчет в этом случае следовало бы
проводить при смещении
, соответствующем второй строке, т. е. полагая
.
Однако изображение может находиться не в точке А, а, например, в точке В. В этом случае
сигнал строки 2 несколько уменьшится, а сигнал строки 1 увеличится. Дальнейшее смещение
изображения вверх от точки В к точке С приведет к непрерывному уменьшению сигнала строки 2
и увеличению сигнала строки 1. При перемещении центра изображения в точку С, находящуюся
на одинаковом расстоянии от осей
и
строк 1 и 2, сигналы этих строк сравняются.
Именно в этом случае условия обнаружения наименее благоприятны, так как решение будет
приниматься по наименьшему сигналу как по строке 1, так и по строке 2. При дальнейшем
смещении вверх сигнал строки 1 превышает сигнал строки 2 и при положении центра
изображения в точке D сигнал строки 1 достигает максимального значения. Аналогичные
рассуждения, но уже в отношении сигналов строк 2 и 3, можно провести при смещении центра
изображения вниз последовательно в точки B’, C’ и D’.
Таким образом, наименьший сигнал, снимаемый при просмотре любой из двух смежных
строк, соответствует положению центра изображения в точке, равноудаленной от середины
строк (точнее от линии, равноудаленной от середин строк)*. Следовательно, абсолютное
значение расчетного смещения
.
(6.18)
123
На основании изложенного, а также данных ТЗ (b = 3 мм,
следует принять
мм) для расчета
мм, откуда
.
Подставляя в (6.4) найденные в пп. 1-7 значения всех величин, получим
(6.19)
Рассчитываем энергетический ЧВС помехи на выходе ПИ, предварительно найдя значение
интеграла в (6.15). Подстановка исходных данных и приближенное интегрирование дают
.
На основании (6.15) и (6.16) имеем
.
(6.20)
Функцию
находим с помощью графика, изображенного на рис. 6.2. Для этого
каждую ординату графика нужно умножить на девять, т. е. перейти к чувствительной площадке
размером 3×3 мм2, и разделить на два, т. е. перейти от одностороннего ЧВС шума в диапазоне
частот
к двустороннему ЧВС в диапазоне
.
Используя формулы (5.64), (6.19) и (6.20), находим ОСП на выходе ЭС, реализуемой в виде
оптимального ЧВФ:
.
Нетрудно заметить, что функция
(6.20), является четной функцией, поэтому
, как результат деления квадрата модуля (6.19) на
.
124
Функция
показана на рис. 6.8.
Интегрирование дает
.
Так как требуемое значение ОСП равно 8,6, а реализуемое 8,5, то расчет можно считать
законченным. Заданные по ТЗ вероятностные характеристики обнаружения практически
обеспечиваются при диаметре входного зрачка объектива, равном 80 мм.
Это положение несправедливо для узких полос шириной
в начале и конце кадра. Для
этих зон наихудшие условия соответствуют положению центра изображения на краю строки и
*
расчетное смещение равно
отсутствии перекрытия
, т. е. значению
, определяемому формулой (6.18) при
.
125