Критерий Шапиро-Уилка. - LMS
advertisement

ФЕДЕРАЛЬНОЕ ГОСУДАРСТВЕННОЕ АВТОНОМНОЕ
ОБРАЗОВАТЕЛЬНОЕ УЧРЕЖДЕНИЕ
ВЫСШЕГО ПРОФЕССИОНАЛЬНОГО ОБРАЗОВАНИЯ
«НАЦИОНАЛЬНЫЙ ИССЛЕДОВАТЕЛЬСКИЙ УНИВЕРСИТЕТ
«ВЫСШАЯ ШКОЛА ЭКОНОМИКИ»
Московский институт электроники и математики
Морозова Анастасия Алексеевна
СТАТИСТИЧЕСКИЙ АНАЛИЗ ДАННЫХ ЭРГОСПИРОМЕТРИИ ПАЦИЕНТОВ С
ХРОНИЧЕСКОЙ СЕРДЕЧНОЙ НЕДОСТАТОЧНОСТЬЮ НА STATISTICA
Выпускная квалификационная работа
студента образовательной программы бакалавриата
«Прикладная информатика»
по направлению 09.03.03 Прикладная информатика
Студент
А.А. Морозова
Рецензент
д. ф. м. н., проф.
Г. И. Ивченко
Научный руководитель
к. ф. м. н., проф.
Л. А. Манита
Консультант
к. ф. м. н., проф.
В. П. Боровиков
Москва 2015 г.
Оглавление
ВВЕДЕНИЕ ............................................................................................................................................................. 3
ГЛАВА 1. ПОСТАНОВКА ЗАДАЧИ. ОСНОВНЫЕ ПОНЯТИЯ ФАКТОРНОГО АНАЛИЗА. 8
§1. Постановка задачи ................................................................................................................................................................ 8
§2. Факторный анализ. ............................................................................................................................................................... 8
ГЛАВА 2. ВИЗУАЛЬНЫЙ И ОПИСАТЕЛЬНЫЙ АНАЛИЗ ДАННЫХ,
ИСПОЛЬЗУЮЩИХСЯ В ДИПЛОМНОЙ РАБОТЕ, И ИХ ОПИСАНИЕ.....................................13
§1. Структура данных .............................................................................................................................................................. 13
§2. Описание переменных .......................................................................................................................................................... 14
§3. Половозрастная характеристика ..................................................................................................................................... 17
§4. Визуальный анализ ............................................................................................................................................................... 18
§5. Описательный анализ.......................................................................................................................................................... 25
ГЛАВА 3.ПРИМЕНЕНИЕ ФАКТОРНОГО АНАЛИЗА ДЛЯ ВЫДЕЛЕНИЯ ГЛАВНЫХ
ФАКТОРОВ ..........................................................................................................................................................27
ЗАКЛЮЧЕНИЕ...................................................................................................................................................34
ГЛОССАРИЙ ..........................................................................................................................................................35
СПИСОК СОКРАЩЕНИЙ .............................................................................................................................36
СПИСОК ЛИТЕРАТУРЫ ...............................................................................................................................37
ПРИЛОЖЕНИЕ ..................................................................................................................................................39
2
Введение
В современном мире невозможно обойтись без всестороннего анализа данных,
это касается и медицины, для этого существует самостоятельный раздел медицинская статистика. Медицинская статистика – наука, которая позволяет
изучить
количественную
сторону
каких-либо
общественных
явлений
в
совокупности с их качественной стороной. Она позволяет методом обобщающих
характеристик исследовать закономерности различных явлений, встречающихся в
медицине, важнейших процессов, протекающих в организме человека и другие.
В медицине статистические методы чаще всего используются для:
изучения здоровья населения в целом и его основных групп,
которые проводятся путём сбора таблиц данных с различными
характеристиками;
выявления эпидемиальных факторов;
учёта смертности населения;
проверки
эффективности
и
оценки
качества
работы
учреждений здравоохранения;
определения статистической значимости результатов каких-
либо исследований.
Особенности работы с медицинскими данными
Поскольку мы имеем дело с медицинскими данными, то стоит упомянуть, что
такие данные имеют некоторые особенности, которые отличают их от данных,
полученных из других отраслей человеческой деятельности.
Во-первых,
в
таких
исследованиях
используется
лишь
ограниченное
количество данных. Эта проблема возникает из-за того, что исследователи не могут
принуждать пациентов участвовать в их экспериментах. Человеческий фактор
играет очень большую роль в медицинских исследованиях.
3
Во-вторых, мы имеем дело с большим разбросом, т.е. с вариабельностью
данных, что вытекает из первого пункта. Существуют заболевания, которым
подвержены различные возрастные группы пациентов, т.е. вы не можете отбирать
для
исследования
только
мужчин
от
30
до
35
лет
с
определёнными
антропометрическими данными и необходимыми клиническими параметрами. Вам
необходимо использовать при анализе тех пациентов, которые вам доступны.
В-третьих, в медицине очень распространены категориальные (качественные)
показатели, такие как: пол, тяжести заболевания, показатели наличия или отсутствия
какого-либо заболевания и т.д.
В-четвертых, медицинские данные очень часто являются неполными. Это
касается особенно длительных исследований, т.е. у вас может не быть постоянного
доступа к каким-либо параметрам, которые вы исследуете. Так как вы работаете с
реальными людьми, то каждый показатель, который был получен должен быть
обязательно учтён. Для этого были придуманы различные разделы анализа данных,
например, анализ выживаемости.
И, наконец, в-пятых, при проведении многоцентровых исследований вы
можете столкнуться с неоднородностью данных. Эта проблема возникает из-за
отсутствия определённых стандартов для введения характеристик пациентов в
таблицы данных.
Каждое исследование ( это касается математической статистики в целом) идёт
по определённому «сценарию», который состоит из следующих разделов:
1. Планирование исследования;
2. Сбор данных;
3. Импорт данных;
4. Чистка данных;
5. Описательный и визуальный анализ;
6. Группировка;
7. Вычисление статистик для групп;
8. Нахождение связей и зависимостей;
4
9. Построение прогноза;
10.Верификация моделей.
Статистическая обработка данных представляет собой сложный многоэтапный
процесс, от уровня научной организации которого зависят такие параметры, как:
качество накапливаемых статистических данных;
результаты обработки данных;
результаты анализа данных.
Существует большое количество программных пакетов, позволяющих
провести грамотную статистическую проверку, мы остановим свой выбор на
программе
STATISTICA
и
проведём
статистический
анализ
данных
эргоспирометрии пациентов с хронической сердечной недостаточностью.
Выбор программного пакета STATISTICA не был случайным, так как
существует большое количество литературы и статей, в которых говориться о том,
что STATISTICA- это наилучший выбор для данной цели.
В
[1]
приводиться
обзор
программных
пакетов,
использующихся в медицине. Они выделяют STATISTICA, прежде
всего, как многофункциональный программный пакет, простой в
освоении, имеющий подробные методические разработки, как к
программе STATISTICA [2], так и руководства по использованию
данного программного обеспечения в медицине [3]. Авторы отмечают,
что STATISTICA подойдёт для начинающих и для профессионалов,
благодаря
русскоязычной
документации
и
большому
перечню
профессиональных возможностей.
В [4] излагается подробная классификация модели и
методов исследований в медицинской статистике, обосновываются
преимущества выполнения исследований в программных пакетах Biostat
и STATISTICA.
5
[2]
представляет собой наиболее полное руководство
пользователя на русском языке к программе STATISTICA. Здесь есть
большое количество доступных для понимая примеров работы в
программе.
[3] посвящена наиболее современным методам статистического анализа
медицинских
данных
в
STATISTICA.
Изложены
требования,
предъявляемые к представлению результатов анализа и в [6] содержится
большое количество примеров.
В [5] анализируются исследования в области медицинской
статистики. Автор утверждает, что выбор программного обеспечения и
методов исследования зависит от предпочтений самого исследователя,
отмечая две наиболее популярные в этой среде программы Excel и
STATISTICA.
В [6] приведены убедительные аргументы в пользу
STATISTICA, такие как: сведение к минимуму случайных ошибок в
расчётах,
экономия
времени,
возможность
выбора
наиболее
подходящего метода анализа и графического представления на каждом
этапе исследования.
В дипломной работе программный пакет
STATISTICA используется для
обработки и анализа данных, полученных в результате обследования пациентов с
хронической сердечной недостаточностью. Основная задача – определить, какие из
показателей, полученных в результате использования кардиопульмонального теста
(эргоспирометрии), являются зависимыми, выделить факторы, которые определяют
эту зависимость, а тем самым, сократить число переменных, которые несут
основную информацию о состоянии пациента. Основной метод решения задач
такого типа – факторный анализ.
Факторный анализ развивался в результате применения статистических
методов в психологии, а затем его применение пришло в социологию и медицину. В
6
основе моделей, используемых в нем, положено следующее соображение:
исследуемые параметры являются косвенными характеристиками объекта, имеются
скрытые параметры (факторы), которые определяют значения наблюдаемых
параметров. Причём количество этих факторов существенно меньше, чем
количество исходных параметров. Возникает задача: как по имеющимся данным
выделить величину, которая объяснит наблюдения. Факторный анализ позволяет
свести большое количество данных к более простой структуре с наименьшими
потерями информации.
Факторный анализ в медицине становиться все более популярным, в силу
развития компьютерной диагностики. Этот метод анализа данных находит своё
применение в самых различных областях медицины [7 , 8]. Подробной изложение
этого метода можно найти в [9].
Дипломная работа состоит из введения, трех глав, списка сокращений,
глоссария и заключения.
В Главе 1 приводится описание основной модели и понятий факторного
анализа.
В Главе 2 приводится исходные данные, которые подлежат анализу. Описаны
все показатели, которые получаются в результате применения эргоспирометрии.
Таких показателей больше 22. В дипломной работе используются только 6: рост,
вес, систолическое артериальное давление, диастолическое артериальное давление,
частота сердечных сокращений, частота дыхательных движений. Для этих
показателей проводится визуальный и описательный анализы, проверка на
нормальное распределение.
В Главе 3 формулируется гипотеза, что имеются скрытые факторы, которые
определяют выделенные 6 показателей. Ставится задача выявить скрытые факторы.
Для этого используется метод главных компонент. Используем пакет STATISTICA,
модуль «Факторный анализ», выделяем 2 фактора, которые несут основную
информацию.
7
Глава 1. Постановка задачи. Основные понятия факторного
анализа.
§1. Постановка задачи
Эргоспирометрия – метод диагностирования, который разрешает проблему
выявления таких
сердечных расстройств, как сердечная недостаточность,
ишемическая болезнь сердца, стенокардия и тому подобное. С помощью метода
можно оценить влияние физических нагрузок на обследуемого. Также этот метод
позволяет определить индивидуально для каждого пациента самый подходящий
уровень физических упражнений.
Хроническая сердечная недостаточность (ХСН) является одной из важнейших
проблем современной кардиологии, поскольку её развитие
значительным
ухудшением
качества
жизни,
частыми
сопряжено со
госпитализациями
и
сокращением продолжительности жизни.
При описании пациентов фиксируется 22 измерения. Среди данных
переменных мы хотим выделить такие показатели или комбинации показателей,
которые бы наиболее полно и компактно описывали пациентов. Для дипломной
работы было выбрано 6 показателей: частота дыхания, частота сердечных
сокращений, давление нижние и верхнее, рост и вес. Предполагается, что такое
количество избыточно.
§2. Факторный анализ.
Основной объект преобразований в факторном анализе – это матрица
корреляций, которая состоит из коэффициентов корреляции Пирсона (в некоторых
случаях – дисперсионно-ковариационная матрица), вычисленная классическим
путём обработки массива данных X. Под сжатием информации в факторном анализе
подразумевается сокращение размерности корреляционной матрицы, а не самих
данных, тем более что воссоздать начальные данные по корреляционной матрице
невозможно.
8
Поскольку коэффициенты, из которых состоит корреляционная матрица,
могут быть вычислены разными способами, существуют последующие технологии
факторного анализа:
1. R – техника, когда коэффициенты корреляции вычисляют между
переменными и исходную матрицу Х сжимают по столбцам, т.е.
количество признаков уменьшится с m до р;
2. Q – техника, когда изучают корреляция между объектами и их
количество уменьшают с n до р;
3. Р
–
техника,
подразумевающая
факторный
анализ
итогов
экспериментальных изысканий, которые выполнены на одном и том же
объекте в разные отрезки времени.
Модель факторного анализа - это представление исходных переменных как
линейной композиции факторов 𝐹 (Рисунок 1):
Рисунок 1
вычисленных так, чтобы представить 𝑋 с наименьшей погрешностью:
𝑝
𝑋𝑗 = ∑𝑘=1 𝑎𝑗𝑘 𝐹𝑘 + 𝑈𝑗 (1)
В модели (1) скрытые переменные 𝐹𝑘 (𝑘 = 1,2, ⋯ , 𝑝) получили название общих
факторов,
а
факторов. Значения
переменные
𝑈𝑗 ( 𝑗 = 1,2, ⋯ , 𝑚) – специфических
𝑎𝑗𝑘 называются факторными
нагрузками
(коэффициент
корреляции фактора со всеми показателями, использованными в исследовании).
Если мы предположим, что все признаки 𝑋𝑗 приведены к стандартной форме,
то есть имеют нулевые математические ожидания и единичную дисперсию.
9
(𝜎𝑖 = 1, 𝑚(𝑋𝑗 ) = 0),
факторы
𝐹1 , 𝐹2 , ⋯ , 𝐹𝑝 независимы между собой и
независимы от специфических факторов 𝑈𝑗 , то факторные нагрузки 𝑎𝑗𝑘 совпадут с
коэффициентами корреляции между общими факторами и переменными 𝑋𝑗 .
§2.1. Элементы дисперсии.
Дисперсию
признака 𝑋𝑗 можно
представить
в
виде
суммы
квадратов
факторных нагрузок 𝐻𝑖2 , и дисперсию специфического фактора (специфичность)
как 𝑆𝑢2𝑖 :
𝑆𝑥2𝑖 = 𝐻𝑖2 + 𝑆𝑢2𝑖 ,
где 𝐻𝑖2 = ∑𝑘 𝑎𝑖𝑘 2 .
Определим два важных понятия:
𝐻𝑖2 - общность параметра 𝑋𝑖 , вклад общих факторов в дисперсию 𝑋𝑖 ;
𝑆𝑢2𝑖 – специфичность, вклад специфического фактора в дисперсию 𝑋𝑖 .
2
Таким образом, 𝑎𝑖𝑘
– доля дисперсии параметра 𝑋𝑗 , приходящаяся на фактор
𝐹𝑘 .
Необходимо так выделить факторы 𝐹1 , 𝐹2 , ⋯ , 𝐹𝑝 , чтобы общность их
принимала значение, близкое к 1 (напомним, что 𝑆𝑥2𝑖 =1).
Описанная модель носит название классической факторной модели или метод
главных факторов. Так же широко применяется метод главных компонент (далее
МГК).
§2.2. Метод главных компонент.
Основное отличие метода от классической факторной модели состоит в том,
что используется следующая линейная модель:
10
𝑝
𝑋𝑗 = ∑ 𝑎𝑗𝑘 𝐹𝑘
𝑘=1
МГК более прост в расчётах и интерпретации результатов. В дипломной
работе будет использоваться именно он.
Отыскание компонент сводится к следующему алгоритму:
1. На первом этапе необходимо привести исходные данные к стандартной
форме. Определим переменные:
𝑧𝑖𝑗 =
̅̅̅𝑗
𝑥𝑖𝑗 −𝑥
𝑆𝑗
,
1
где 𝑥̅𝑗 = ∑𝑛𝑖=1 𝑥𝑖𝑗 среднее значение для наблюдаемого параметра j,
𝑛
1
𝑆𝑗 2 = ∑𝑛𝑖=1 𝑥𝑖𝑗 – выборочная дисперсия. 𝑧𝑖𝑗
𝑛
значением параметра
называют нормированным
j для объекта i. Таким образом, математическое
ожидание 𝑧𝑗 равно 0, а дисперсия 𝑧𝑗 равна 1.
2. В МГК основная задача --- выделение факторов, которые вносят в общность
наибольшую дисперсию. Основные вычисления связаны с корреляционной
матрицей. На 1-ом этапе ищем коэффициенты при первом факторе 𝐹1 , так
чтобы суммарный вклад в общность был максимальным:
𝑛
2
→ 𝑚𝑎𝑥,
∑ 𝑎𝑖1
𝑖=1
при этом должны выполняться условия:
𝑟𝑗𝑘 = ∑𝑚
𝑙=1 𝑎𝑗𝑙 𝑎𝑘𝑙 .
Решение этой задачи приводит к проблеме определения собственных чисел и
собственных векторов корреляционной матрицы R. Число l называется собственным
значением матрицы R с собственным вектором 𝑣(𝑣 ≠ 0), если 𝑅𝑣 = 𝑙𝑣.
11
3. Из последовательности собственных значений 𝑙𝑘 выбирается p наибольших.
Величина 𝑙 𝑘 - часть суммарной дисперсии исходных данных по данной
компоненте 𝐹𝑘 . Необходимо знать, что первые несколько членов разложения
вносят основной вклад в интерпретацию величин в исходных данных.
4. Матрица факторных нагрузок 𝐴 каждой исходной переменной 𝑗 на всякий
отобранный фактор 𝑘, которая соответствует коэффициентам линейных
преобразований 𝑎𝑗𝑘 ,, вычисляется по формуле
𝑎𝑗𝑘 = 𝑣𝑖𝑘 ∙ ( 𝜆 )0.5 , 𝑗 = 1, 2 , … , 𝑚; 𝑘 = 1, 2 , … , 𝑝 .
5. Уменьшенная
матрица
факторов F,
соответствующая
изначальной
таблице X наблюдений, в которой число столбцов снижено с m до p,
рассчитывается по формуле:
𝑓𝑖𝑘 = ∑𝑚
𝑗=1 𝑎𝑗𝑘 𝑧𝑖𝑗 .
Главная проблема анализа состоит в решении вопроса, какое количество
главных
компонент
нужно
сформировать
для
наилучшего
изображения
рассматриваемых исходных факторов.
Задачу о том, сколько же стоит выделить значимых факторов, можно решить с
помощью использования графика «каменистой осыпи». Он заключается в том,
чтобы найти на графике собственных значений точку, где уменьшение собственных
значений замедляется наиболее сильно. Правая часть графика представляет собой
незначительные остатки - "каменистую осыпь". Осыпь - это термин из геологии,
который означает каменные осколки, лежащие у подножия скалы. Нам нужно
оставить не больше факторов, чем расположено слева от осыпи.
Для пояснения того, что же собой представляют сами факторы необходимо
присвоить всякому из них какой-либо определённый содержательный смысл,
который связан с предметной областью. Чтобы раскрыть, какая линейная
комбинация скрыта в факторах, следует выполнить анализ корреляций факторных
нагрузок с исходными переменными.
12
Глава 2. Визуальный и описательный анализ данных,
использующихся в дипломной работе, и их описание.
§1. Структура данных
Исходные данные представляют собой Таблицу 1, в которой:
каждая строка соответствует одному пациенту;
каждый столбец соответствует одному определённому
показателю.
Нас интересуют переменные с седьмой по двенадцатую. Приведём небольшой
кусок исходной таблицы данных( Таблица 1).
Таблица 1
13
§2. Описание переменных
Для того чтобы работать с данными их необходимо описать, чтобы понимать
их логическую взаимосвязь
Возраст – возрастной показатель пациента (непрерывная переменная),
продолжительность периода от момента рождения пациента до определённого
момента времени;
ИБС – ишемическая болезнь сердца (категориальная переменная); 1 – наличие
заболевания,
0
–
отсутствие
заболевания:
патологическое
состояние,
характеризующееся абсолютным или условным нарушением кровоснабжения
миокарда (мышцы сердца) из-за поражения коронарных артерий;
Q зубец – патологический зубец Q (категориальная переменная); 1 – наличие,
0 – отсутствие: он отражает продолжительность проведения импульса возбуждения
по предсердиям, атриовентрикулярному узлу, пучку Гиса до желудочков;
ДКМП – Дилатационная кардиомиопатия (категориальная переменная); 1 –
наличие заболевания, 0 – отсутствие заболевания: заболевание миокарда, связано с
развитием дилатации (растяжения) полостей сердца, с последующим появлением
систолической дисфункции, при этом рост толщины стенок не наблюдается;
Инфекционный миокардит – категориальная переменная; 1 – он есть, 0 – его
нет: поражение мышцы сердца- миокарда. Чаще миокардит носит воспалительный
характер;
Атеросклероз артерий н.к. – атеросклероз артерий нижних конечностей
(категориальная переменная); 1 – наличие заболевания, 0 – отсутствие заболевания:
хроническая болезнь артерий ног, которое в начале течения заболевания может
отражаться только в малозаметной хромоте, небольшим чувством онемения или
иногда похолодания в стопе. Однако если своевременно не начать лечение и при
дальнейшем развитии заболевания вполне возможно развитие гангрены ноги, что в
своей очереди приведёт к ее потере;
ЧДД – частота дыхательных движений (непрерывная переменная): число
циклов дыхания (полный вдох и полный выдох) в единицу времени. Анализ
проводится так , что фиксируются движения грудной клетки пациента. Для того
14
чтобы исследование было эффективным сначала измеряют пульс, а потом
количество дыхательных движений за минуту, затем так же определяют какой тип
дыхания: грудной, брюшной или смешанный, глубину и ритм дыхания.
ЧСС
–
частота
сердечных
сокращений
(непрерывная
переменная):
ритмическое расширение артерии, производимое увеличенным объёмом крови,
выбрасываемой в сосуд посредством сокращения сердца;
Систолическое АД – систолическое артериальное давление (непрерывная
переменная): верхний показатель давления, который показывает артериальное
давление во время, когда сердце сокращается и вытесняет кровь в артерии, оно
зависит от того насколько сильно сокращаются мышцы сердца, сопротивление,
которое удерживают стенки кровеносных сосудов, и числа сжатий в единицу
времени;
Диастолическое АД – диастолическое артериальное давление (непрерывная
переменная): нижний показатель давления, который выражает давление в артериях в
момент расслабления мышцы сердца. Это наименьшее давление в артериях, оно
отображает сопротивление сосудистой периферии. По мере продвижения крови по
сосудистому руслу величина изменения кровяного давления снижается, однако на
венозное и капиллярное давление почти не влияют фазы сердечного цикла;
Рост – ростовой показатель пациента (непрерывная переменная): расстояние
от верхушечной точки головы до плоскости стоп.
Вес – весовой показатель пациента (непрерывная переменная): общая масса
тела человека;
ИМТ – индекс массы тела пациента (BMI), измеряется в кг/м2 (непрерывная
переменная): величина, позволяющая оценить степень соответствия массы человека
и его роста и тем самым косвенно оценить, является ли масса слишком маленькой ,
нормальной
или
избыточной.
Неотъемлем
для
того,
необходимость лечения пациента;
Расчёт данного показатель осуществлялся по формуле:
BMI
15
weight (kg )
.
height (m)2
чтобы
определить
BSA – площадь поверхности тела пациента, измеряется в м2 (непрерывная
переменная): рассчитанная поверхность тела пациента. Для многих клинических
целей ППТ является наилучшим показателем метаболизма человека, чем масса тела,
так как она в меньшей степени зависит от излишнего количества жировой ткани;
Расчет данного показатель осуществлялся по формуле Дюбуа:
𝐵𝑆𝐴(𝑚2 ) = 0,007184 ∗ 𝑤𝑒𝑖𝑔ℎ𝑡(𝑘𝑔)0,425 ∗ ℎ𝑒𝑖𝑔ℎ𝑡(𝑐𝑚)0,725
Кашель – категориальная переменная; 1 – наличие, 0 – отсутствие:
форсированный выдох через рот, вызванный сокращениями мышц дыхательных
путей из-за раздражения рецепторов;
Одышка – категориальная переменная; 1 – наличие, 0 – отсутствие:
нарушение частоты и глубины дыхания, сопровождающееся чувством нехватки
воздуха;
Гемоглобин
(непрерывная
обладающих
–
уровень
переменная):
гемоглобина
сложный
кровообращением,
у пациента, измеряется
железосодержащий
который
конвертируемо
белок
образует
в
г/л
животных,
связь
с
кислородом, тем самым позволяя его переносить по организму;
Лимфоциты – уровень лимфоцитов у пациента, измеряется в % (непрерывная
переменная): главные клетки иммунной системы, обеспечивают выработку антител,
клеточный иммунитет, а также регулируют деятельность клеток других типов;
Мочевая_кислота – уровень мочевой кислоты в крови пациента, измеряется в
мкмоль/л (непрерывная переменная): она выводит избыток азота из организма
человека, она производится в печени и в виде соли натрия содержится в плазме
крови;
Общий_холестерин – уровень общего холестерина у пациента, измеряется в
ммоль/л (непрерывная переменная): похожее на жир вещество, необходимое
организму для нормального функционирования клеток, метаболизма, создания
многих гормонов;
Натрий – уровень натрия у пациента, измеряется в ммоль/л (непрерывная
переменная): основной компонент межклеточного пространства, он регулирует
объем внеклеточной жидкости, осмотическое давление;
16
Креатинин – уровень креатинина у пациента, измеряется в мкмоль/л
(непрерывная
переменная):
конечный
продукт
креатин-фосфатной
реакции,
формируется в мышцах и затем поступает в кровь, участвует в энергетическом
трансфере в мышечной и других тканях.
§3. Половозрастная характеристика
Для того чтобы понять, что из себя представляет наша выборка, необходимо
составить половозрастную характеристику.
Лучше всего для такой цели подходят такие методы, как:
круговая диаграмма;
категоризованная гистограмма.
Начнем с построения круговой диаграммы для переменной «Пол».
Рисунок 2
Из круговой диаграммы (Рисунок 2) видно, что большую часть пациентов
составляют женщины, их 75%, мужчин в 3 раза меньше, их 25% соответственно.
Построим
категоризованную
гистограмму,
распределение пациентов относительно пола.
17
отображающую
возрастное
Рисунок 3
На данной гистограмме (Рисунок 3) мы видим, что подавляющее большинство
женщин имеют возраст от 50 до 70 лет, женщины в возрасте от 20 до 30 лет в
исследовании не участвовали. Большая часть мужчин имеет возраст от 60 до 80 лет.
Средний возраст женщин, участвующих в исследовании равен 60,5 лет, а
средний возраст мужчин равен 61,04 год.
§4. Визуальный анализ
Прежде
чем
работать
с
переменными
необходимо
грамотно
их
визуализировать и определить их близость к нормальному распределению, так как
именно от распределения переменных зависит дальнейший анализ.
Существует три способа поверки распределения на нормальность:
экспертная проверка;
визуальная проверка;
статистическая проверка.
В нашем случае, мы использовали совместно визуальную и статистическую
проверки для определения распределения переменных.
Построим гистограммы для исследуемых переменных, добавив на график
линию подгонки, отображающую нормальное распределение.
18
Начнем с проверки переменной «ЧДД».
Рисунок 4
Если посмотреть на полученную гистограмму (Рисунок 4) и сравнить ее с
линией подгонки, то визуально можно определить, что распределение переменной
«ЧДД» отлично от нормального. Для определения нормальности выборки
используется Критерий Шапиро-Уилка.
Для большей точности посмотрим на p – уровень для критерия Шапиро –
Уилка, он равен 0,0000, что меньше, чем заданный уровень значимости 0,05,
следовательно, мы отклоняем нулевую гипотезу в пользу альтернативной и также
получаем, что распределение переменной «ЧДД» отлично от нормального.
Рассмотрим переменную «ЧСС».
19
Рисунок 5
Сравним полученную гистограмму (Рисунок 5) с линией подгонки, визуально
можно предположить, что распределение данной переменной не сильно отклоняется
от нормального распределения.
Теперь посмотрим на полученный p – уровень для критерия Шапиро – Уилка,
он равен 0,00424, что меньше, чем заданный уровень значимости 0,05,
следовательно, мы отклоняем нулевую гипотезу в пользу альтернативной и
получаем, что распределение переменной «ЧСС» отлично от нормального.
Таким образом, мы увидели, что не всегда стоит полагаться лишь на
визуальную проверку, так как бывают случаи, что графически распределение
похоже на нормальное, а по критерию – нет. А поскольку статистическая проверка
более достоверная, то, в конечном итоге, мы принимаем те результаты, которые даст
нам она.
Рассмотрим переменную «Систолическое АД».
20
Рисунок 6
Посмотрим на гистограмму (Рисунок 6) и линию подгонки, они близки, то
есть визуально можно предположить, что распределение данной переменной не
сильно отклоняется от нормального распределения.
Обратим внимание на полученный p – уровень для критерия Шапиро – Уилка,
он равен 0,00608, что меньше, чем заданный уровень значимости 0,05,
следовательно, мы отклоняем нулевую гипотезу в пользу альтернативной и
получаем, что распределение переменной «Систолическое АД» отлично от
нормального.
Рассмотрим переменную «Диастолическое АД».
21
Рисунок 7
Сравним полученную гистограмму (Рисунок 7) с линией подгонки, визуально
можно определить, что распределение данной переменной отлично от нормального
распределения.
Теперь посмотрим на полученный p – уровень для критерия Шапиро – Уилка,
он равен 0,0000, что меньше, чем заданный уровень значимости 0,05, следовательно,
мы отклоняем нулевую гипотезу в пользу альтернативной и получаем, что
распределение переменной «Диастолическое АД» отлично от нормального.
Рассмотрим переменную «Рост».
22
Рисунок 8
Посмотрим на гистограмму (Рисунок 8) и линию подгонки, они близки, то
есть визуально можно предположить, что распределение данной переменной не
сильно отклоняется от нормального распределения.
Обратим внимание на полученный p – уровень для критерия Шапиро – Уилка,
он равен 0,17297, что больше, чем заданный уровень значимости 0,05,
следовательно, мы не отклоняем нулевую гипотезу и получаем, что распределение
переменной «Рост» близко к нормальному.
Рассмотрим переменную «Вес».
23
Рисунок 9
Сравним полученную гистограмму (Рисунок 9) с линией подгонки, визуально
можно определить, что распределение данной переменной близко к нормальному
распределению.
Обратим внимание на полученный p – уровень для критерия Шапиро – Уилка,
он равен 0,58120, что больше, чем заданный уровень значимости 0,05,
следовательно, мы не отклоняем нулевую гипотезу и получаем, что распределение
переменной «Вес» близко к нормальному.
На основе полученных результатов составим сводную таблицу, в которой
будет отражено то, какое распределение имеют исходные переменные.
24
Таблица 2
#
Название переменной
№
1
p–
уровень
Распределение переменной
ЧДД
0,00000
Отличное от нормального
ЧСС
0,00424
Отличное от нормального
Систолическое_АД
0,00608
Отличное от нормального
Диастолическое_АД
0,00000
Отличное от нормального
Рост
0,17297
Близко к нормальному
Вес
0,58120
Близко к нормальному
1
2
2
3
3
4
4
5
5
6
6
§5. Описательный анализ
После того как мы визуально представили исходные переменные, необходимо
их представить в численном эквиваленте.
Для этого составим таблицу описательных (дескриптивных) статистик.
25
Таблица 3
Из данной Таблицы 3 видно, что для переменной «Рост»:
Минимальный рост пациентов составляет 142 сантиметра;
Среднее значение для данной переменной равно – 171,8
сантиметров;
Максимальный рост пациентов составляет – 194 сантиметра;
Стандартное отклонение для переменной «Рост» равно 8,80178
сантиметра;
Нижняя квартиль для переменной «Рост» равна 165 сантиметров,
это значит, что 25% все пациентов ниже, чем 165 сантиметров;
Медиана равна 172 сантиметра, т.е. 50% всех пациентов выше, чем
172 сантиметра, и 50% ниже, чем 172 сантиметра;
Верхняя квартиль для переменной «Рост» равна 178 сантиметров,
это значит, что 25% все пациентов выше, чем 178 сантиметров;
Квартильный размах равен 37 сантиметров, это разность между
верхней и нижней квартилями.
Описание всех остальных переменных выглядит аналогичным образом.
26
Глава 3.Применение Факторного анализа для выделения
главных факторов
Для достижения целей приступим к работе в программном пакете
STATISTICA.
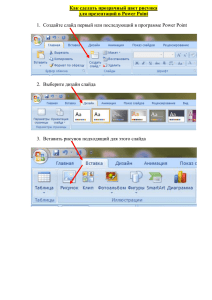
Шаг 1. В меню «Анализ» выбираем модуль «Многомерный разведочный
анализ» - «Факторный анализ»:
Рисунок 10. Выбор анализа
Шаг 2. В открывшемся диалоговом окне (Рисунок 10) нажимаем на кнопку
Переменные и выбираем переменные 7 – 12.
Замечание
В качестве файла данных для анализа можно подавать корреляционную
матрицу переменных. В нашем случае мы используем сами переменные, поэтому
оставляем в поле «Файл данных» режим «Исходные данные» (Рисунок 11).
27
Рисунок 11. Задание переменных для анализа
Шаг 3. Мы перешли в окно «Задайте метод выделения факторов» (Рисунок
12).
Рисунок 12
Во вкладке Быстрый можно задать:
28
Максимальное число факторов – наибольшее число новых факторов.
Поскольку мы хотим существенно сократить число переменных, то позволим
методу выявить не более 2 наиболее информативных фактора.
Минимальное собственное значение – каждому фактору соответствует число
(собственное значение). Каждой исходной переменной соответствует 1. Более
информативному фактору соответствует более большое число. Нас не интересуют
факторы с собственным числом меньшим 1, поскольку они будут менее
информативными, чем исходные.
Шаг 4. Во вкладке Дополнительно можно выбрать метод выделения новых
факторов (Рисунок 13).
Рисунок 13. Выбор метода
Для выявления значимых факторов в данном случае наиболее целесообразно
использовать Метод главных компонент (для этого нужно отметить в диалоговом
окне Главные компоненты). Это основной общепринятый способ уменьшить
количество переменных, потеряв наименьшее количество информации. Выбираем
этот метод.
29
Шаг 5. Во вкладке Описательные (Рисунок 14) нажимаем на Просмотреть
корреляции/средние/стандартные отклонения. Затем строим таблицу корреляций.
Рисунок 14. Описательные статистики
Таблица 4. Корреляционная матрица переменных
Как
видно
из
корреляционной
таблицы
(Таблица
4),
переменные
Систолическое АД и Диастолическое АД сильно коррелируют между собой. Также
довольно сильно коррелируют переменные Рост и Вес. Это говорит об
избыточности этих переменных.
Нажимаем ОК.
Шаг 6. Появится диалоговое окно Результаты факторного анализа (Рисунок
15).
30
Рисунок 15. Результаты
В шапке данного диалогового окна указана основная информация о методе
анализа.
Шаг 7. Нажимаем на «Собственные значения» и получаем таблицу, в которой
указаны собственные значения новых главных факторов и доли дисперсии, которые
они объясняют.
Таблица 5. Собственные значения
Согласно Таблице 5, два выделенных фактора объясняют чуть более 65%
общей дисперсии данных. Возникает вопрос, вдруг при добавлении третьего
фактора доля объясненной дисперсии увеличится? Проверим это с помощью
графика каменистой осыпи.
31
Шаг 8. На вкладке Объясненная дисперсия, нажмите на кнопку График
каменистой осыпи. На этом графике (Рисунок 16) показаны в порядке убывания
собственные
значения,
полученные
методом
главных
компонент.
Метод
заключается в том, чтобы найти на графике точку, после которого наклон графика
уменьшается. Число собственных значений, соответствующее этой точке и будет
оптимальным количеством факторов. На данном графике эта точка может
соответствовать либо двум факторам, либо трем. Поскольку третьему фактору
соответствует собственное значение, меньшее 1, то заключаем, что два фактора –
оптимальное число для нашей задачи.
Рисунок 16. График каменистой осыпи
Рисунок 10.
Шаг 9. Теперь во вкладке «Быстрый» построим таблицу «Факторных
нагрузок» (Таблица 6). Нагрузка – это корреляция между исходной переменной и
фактором. Чем больше нагрузка, тем больше фактор связан с исходной переменной.
В таблице факторных нагрузок выделены сильные корреляции – те, что больше 0,7.
32
Таблица 6. Факторные нагрузки
Помимо выделения факторов, представляет интерес интерпретация факторов.
Согласно таблице нагрузок фактор 1 отвечает за давление, а фактор 2 – за
показатели роста и веса.
Шаг 10. Перейдем во вкладку Значения и построим таблицу Коэффициентов
факторов.
Таблица 7. Коэффициенты факторов
В Таблице 7 находятся коэффициенты выделенных факторов. Учитывая
нагрузки, заключаем, что Фактор 1 является комбинацией Систолического АД и
Диастолического АД с коэффициентами 0,40 и 0,36, а Фактор 2 является
комбинацией Роста и Веса с коэффициентами 0,49 и 0,55.
33
Заключение
В работе была рассмотрена проблема редукции данных эргоспирометрии
пациентов с ХСН, на основе факторного анализа. Для решения данной задачи был
использован программный пакет STATISTICA.
Проведенный анализ показал, что некоторые из исходных 6 переменных
сильно коррелируют (Систолическое АД – Диастолическое АД и Рост – Вес).
Вместо исходных переменных можно использовать всего два фактора, которые
будут объяснять 65% общей дисперсии. Первый из данных факторов объясняет
37,6% дисперсии и является линейной комбинацией Систолического АД и
Диастолического АД. Второй фактор объясняет 27,5% дисперсии и является
линейной комбинацией Роста и Веса.
34
Глоссарий
Коэффициент корреляции
Пирсона
– коэффициент, характеризующий
существование линейной зависимости между двумя величинами.
Критерий Шапиро-Уилка – это критерий, используется для проверки гипотезы
𝐻0 : «распределение случайной величины X близко к нормальному» и является
одним из наиболее эффективных критериев проверки нормальности выборки.
Метод
главных
компонент
–
линейная
комбинация
переменных, которая обладает свойством ортогональности.
наблюдаемых
Расчёт главных
компонент сводится к вычислению собственных векторов и собственных значений
ковариационной матрицы исходных данных, при этом первая воспроизводит
большую часть общей дисперсии, вторая - следующую по величине долю и т.д.
Общие факторы – факторы, объясняющие часть дисперсии переменных.
Специфические факторы – факторы, объясняющие часть дисперсии,
обусловленную случайными ошибками или переменными, неучтёнными в модели.
Уровень значимости – вероятность принятия ложноположительного решения,
то есть вероятность отклонения 𝐻0 , когда на самом деле она является верной.
Факторная нагрузка – термин, который обозначает коэффициенты матрицы
факторного отражения или структуры. Чем выше факторная нагрузка, тем больше
данный фактор подходит для этой выборки.
Факторный анализ – метод, который применяется для исследования связей
между значениями переменных. Подразумевается, что исходные переменные
зависят от меньшего числа еще неизвестных переменных и случайной ошибки.
Эргоспирометрия - тест, который состоит из постоянной регистрации ЭКГ,
непрерывном
мониторинге
лёгочной
вентиляции,
потребления
кислорода,
выделения углекислого газа во время выполнения дозированной физической
нагрузки.
35
Список сокращений
BMI – body mass index.
BSA – body surface area.
АД – артериальное давление.
МГК - метод главных компонент.
ППТ – площадь поверхности тела.
ХСН - хроническая сердечная недостаточность.
ЧДД – частота дыхательных движений.
ЧСС – частота сердечных сокращений.
ЭКГ - электрокардиограмма.
36
Список литературы
1.
В.А. Герасевич, А.Р. Аветисов «Современное программное
обеспечение
для
статистической
обработки
биомедицинских
исследований»//Белорусский медицинский журнал №1, 2005.
2.
В. П. Боровиков. STATISTICA. Искусство анализа данных на
компьютере: для профессионалов (2-е издание), СПб.: Питер, 2003. – 688 с.:
ил.
3.
О.
Реброва,
Статистический
анализ
медицинских
данных.
Применение пакета прикладных программ STATISTICA, МедиаСфера:
Москва, 2002
4.
Филипенко Н.Г., Поветкин С.В. Методические основы проведения
клинических исследований и статистической обработки полученных
данных// Методические рекомендации для аспирантов и соискателей
медицинских вузов: Курский Государственный Медицинский Университет:
КУРСК-2010.
5.
Глушакова А. И. Применение статистических программ и методов
в медико-биологических научных исследованиях// Казанский медицинский
журнал том 90 №4, 2009, 550-555.
6.
Е.
А.
биологических
Петрова.
Возможности
экспериментов
в
анализа
программе
данных
медико-
STATISTICA//
Международный государственный экологический университет имени А.Д.
Сахарова, 2011
7.
А.П. Кулаичев. Методы и средства комплексного анализа данных. Изд. 4-е,
перераб. и доп. - М.: ИНФРА-М, 2006, с 315-350
8.
А.Г. Кочетов, О.В. Лянг, В.П. Масенко, И.В.Жиров, С.Н.Наконечников,
С.Н.Терещенко. Метод статистической обработки медицинских данных//
Российский кардиологический научно-производственный комплекс,2012,
42 с.
37
9.
Иберла К. Факторный анализ. Пер. с нем. В. М. Ивановой. М.: Статистика,
1980 - 398 стр.
10.
Г. И. Ивченко, Ю. И. Медведев. Введение в математическую статистику. –
ЛКИ, 2010. – 546-563 с.
11.
В.Ю. Павлова Основные вопросы статистического анализа в медицинских
исследованиях//
Клиническая
онкогематология.
Фундаментальные
исследования и клиническая практик.2009.№4.том 2
12.
Г. И. Ивченко, Ю. И. Медведев. Математическая статистика. – М.: Высшая
школа, 1984. – 248 с.
13.
Вероятность и математическая статистика: Энциклопедия / Под ред. Ю. В.
Прохорова. – М.: Большая Российская энциклопедия, 2003. – 912 с.
14.
Гланц С. Медико-биологическая статистика.—«Практика»
15.
Наглядная медицинская статистика, Петри А., Сэбин К., 2009
16.
В.Ф. Жерносек, И.В. Василевский, А.П. Рубан, О.В. Попова, В.Д. Юшко,
В.А. Русакович, Л.К. Данилович, С.А. Кострица, М.Л. Воскресова, Т.П.
Заяц, И.Н. Гирко. Медицинские новости. Юпоком ИнфоМед. 2009.
http://www.mednovosti.by/journal.aspx?article=4415
17.
О. О. Калмин, О. В. Калмин. Математическое моделирование показателей
структуры щитовидной железы при тиреоидной патологии.// Саратовский
научно-медицинский журнал выпуск № 1 / том 10 / 2014. с. 38-44
38
Приложение
Критерий Шапиро-Уилка.
В качестве статистического критерия мы используем критерий Шапиро –
Уилка. Данный критерий используется для определения нормальности выборки. Мы
можем увидеть пример его использования в [14].
Как и любой другой статистический критерий, критерий Шапиро – Уилка
имеет нулевую и альтернативную гипотезы, которые записываются следующим
образом:
𝐻0 : анализируемый признак (случайная величина) имеет распределение
близкое к нормальному распределению;
𝐻1 : распределение анализируемого признака (случайной величины) отлично
от нормального распределению.
Данный критерий является наиболее мощным критерием для проверки
распределения признака на нормальность, именно поэтому мы его и будем
использовать.
Критерии, проверяющие нормальность выборки, считаются частными
случаями критериев согласия. Если признак распределен нормально, то для
последующего анализа можно применять параметрические критерии, например, T –
критерий Стьюдента или критерий Фишера, которые являются более мощными по
сравнению с их непараметрическими альтернативами.
Критерий Шапиро-Уилка базируется на оптимальной линейной несмещённой
оценке дисперсии к её обыкновенной оценке методом максимального
правдоподобия. Статистика критерия выглядит так:
𝑊=
1
𝑠2
[∑𝑛𝑖=1 𝑎𝑛−𝑖+1 (𝑥𝑛−𝑖+1 − 𝑥𝑖 )]2,
1
где 𝑠 2 = ∑𝑛𝑖=1( 𝑥𝑖 − 𝑥̅ )2 , 𝑥̅ = ∑𝑛𝑖=1 𝑥𝑖 .
𝑛
39
Числитель - квадрат оценки среднеквадратического отклонения Ллойда.
Коэффициенты 𝑎𝑛−𝑖+1 можно найти в таблицах (см. Таблицу 8).
Таблица 8. Для небольших значений n и i (для критерия Шапира-Уилка).
Критические значения статистики 𝑊(𝛼) также ищется таблично.
Если 𝑊 < 𝑊(𝛼), то 𝐻0 (о нормальности распределения) отвергается при
уровне значимости 𝛼.
Критерий Шапиро-Уилка является очень сильным критерием для проверки
нормальности.
Решение «табличной проблемы».
Было выведено полезное приближение, позволяющее применить критерий
Шапиро-Уилка без помощи таблиц. Для 𝛼=0,05 предлагается статистика:
40
0,6695 𝑠 2
𝑊1 = (1 − 0,6518 ) ,
𝑛
𝐵
2
𝑛
0,899
2
(𝑛−2,4)0,4162
где 𝐵 = {∑𝑚
𝑗=1 𝑎𝑗 (𝑥𝑛−𝑗 − 𝑥𝑗 )} ; 𝑚 = [ ] ; 𝑎0 =
− 0,02 .
Если 𝑊1 < 1, то 𝐻0 отклоняется.
Если заданный уровень значимости 𝛼 = 0,05, то:
если полученный 𝑝 – уровень больше, чем заданный уровень
значимости, то нулевая гипотеза не отвергается, и мы можем сказать,
что распределение анализируемого признака близко к нормальному;
если полученный 𝑝 – уровень меньше, чем заданный уровень значимости, то
нулевая гипотеза отвергается в пользу альтернативной, и мы можем сказать, что
распределение анализируемого признака отлично от нормального.
41