Лекция 1 - Теоретические основы статистической науки
advertisement

ФЕДЕРАЛЬНОЕ АГЕНСТВО ПО ОБРАЗОВАНИЮ
РОССИЙСКОЙ ФЕДЕРАЦИИ
ГОСУДАРСТВЕННОЕ ОБРАЗОВАТЕЛЬНОЕ УЧРЕЖДЕНИЕ ВЫСШЕГО
ПРОФЕССИОНАЛЬНОГО ОБРАЗОВАНИЯ
Пензенский государственный университет
ФАКУЛЬТЕТ ЭКОНОМИКИ И УПРАВЛЕНИЯ
Кафедра бухгалтерского учета,
налогообложения и аудита
Общая теория статистики
Конспект лекций
Пенза Издательство ПГУ 2010
2
УДК 311(075.8)
Общая теория статистики: конспект лекций / сост.: Ф.К. Туктарова. Пенза: Издательство ПГУ, 2010. - 93 с.
Представлен конспект лекций по дисциплине «Общая теория статистики»,
подготовленный на кафедре «Бухгалтерский учет, налогообложение и аудит»
Пензенского государственного университета.
УДК 311(075.8)
ГОУ ВПО «Пензенский государственный университет», 2010
3
Содержание
Введение
1. Теоретические основы статистической науки
2. Статистическое измерение и наблюдение социально-экономических
явлений
3. Сводка и группировка статистических данных
4. Статистические показатели
5. Статистические ряды
6. Выборочное наблюдение
7. Индексы
8. Статистическое изучение взаимосвязей социально-экономических
явлений
4
5
11
22
28
47
59
71
81
4
Введение
Конспект лекций предназначен для использования в учебном процессе
студентами, обучающимися по специальностям 080102 «Мировая экономика»,
080105 «Финансы и кредит», 080116 «Математические методы в экономике»,
081111 «Маркетинг», 080507 «Менеджмент организации», 080107 «Налоги и
налогообложение» и разработано в соответствие с требованиями действующих
учебных планов.
Материалы учебного пособия позволяют студентам получить необходимые
знания по одной из важнейших дисциплин подготовки специалистов – статистике.
В учебном пособии рассмотрены основные методы статистического
исследования: статистическое наблюдение, сводка и группировка, исследование
рядов распределения, анализ рядов динамики, выборочный метод, корреляционнорегрессионный анализ, индексный метод анализа.
В пособии раскрываются:
• сущность статистики как науки, особенности статистической методологии,
основные понятия и категории статистики;
• методология исчисления абсолютных, относительных и средних показателей
и их использование в экономико-статистическом анализе;
• методы сбора статистической информации (формы, виды и способы
статистического наблюдения), программно-методологические и организационные
вопросы статистического наблюдения, сущность ошибок наблюдения и контроль
данных наблюдения;
• метод статистических группировок;
• статистические методы и показатели структуры изучаемого явления, такие
как построение и анализ вариационных рядов, уровня вариации признака,
• анализ рядов динамики, выявление и описание тренда, методы
статистического прогнозирования на основе экстраполяции тренда;
• статистическое изучение взаимосвязей социально-экономических явлений.
5
1. Теоретические основы статистической науки
1. Предмет, метод и задачи статистики
2. Понятия и категории, используемые в статистической науке
3. Организация статистики в Российской Федерации
4. Табличное и графическое отражение статистических данных
1. Предмет, метод и задачи статистики
Полная и достоверная статистическая информация является тем необходимым
основанием, на котором базируется процесс управления экономикой.
В настоящее время под статистикой понимается:
- совокупность итоговых сведений, количественно характеризующих
различные стороны общественной жизни: производство, распределение и обмен
товарами, политику, культуру и т.д.;
- практическая деятельность по сбору, обработке и анализу количественных
данных об общественной жизни и их публикация;
- научная дисциплина, отрасль знаний, изучающая количественную сторону
массовых явлений и процессов в неразрывной связи с их качественной стороной с
целью выявления закономерностей их развития.
Для получения статистической информации проводится статистическое
исследование.
Процесс статистического исследования включает три основные стадии:
1) сбор первичной статистической информации. На этой стадии
исследования решается задача получения информации от отдельных единиц
совокупности. Для этого используется метод статистического наблюдения.
2) сводка и группировка статистических данных. На этой стадии решается
задача
группировки статистической информации, подсчитываются итоги,
производится систематизация единиц совокупности по признакам и изучается
взаимосвязь между признаками
3) анализ и расчет обобщающих показателей. Рассчитываются средние
показатели и показатели распределения, анализируется структура совокупности,
исследуется динамика и взаимосвязи между изучаемыми явлениями и процессами.
Общим принципом, лежащим в основе исследования статистических
закономерностей, выступает Закон больших чисел, который в самой простой
формулировке гласит, что количественные закономерности массовых явлений
отчетливо проявляются лишь в достаточно большом их числе.
Используемые на всех стадиях исследования приемы и методы сбора,
обработки и анализа данных являются предметом изучения общей теории
статистики, которая является базовой отраслью статистической науки.
Основными подразделами статистики являются экономическая и социальная
6
статистики, которые в свою очередь подразделяются на отраслевые подразделы
(статистика населения, статистика сельского хозяйства и т.д.).
Статистика имеет огромное познавательное значение, которое заключается в
следующем:
- статистика дает численное и содержательное освещение изучаемых явлений
и процессов, служит надежным способом оценки действительности;
- статистика дает доказательную силу экономическим выводам позволяет
проверить выдвигаемые гипотезы, отдельные теоретические положения;
- статистика раскрывает взаимосвязи между явлениями, показывает их
конкретную форму и силу;
- статистика, как правило, первой обнаруживает новые явления, процессы и
закономерности, дает их количественную и качественную характеристику.
Основной задачей статистики на современном этапе является разработка
способов и методов получения, обработки и анализа статистических данных.
Второстепенными задачами являются:
1. Предоставление
заинтересованным
пользователям
информации,
необходимой для принятия решений
2. Внедрение наиболее эффективных форм организации статистического
наблюдения (таких как выборочные, с тем чтобы с наименьшими трудовыми и
материальными затратами получать оперативные и точные данные о происходящих
в ходе экономических реформ преобразованиях).
3. Внедрение новых статистических показателей
4. Организация мониторинга за общественно значимыми явлениями и
процессами.
и др.
2. Понятия и категории, используемые в статистической науке
В процессе изучения количественной стороны массовых общественных
явлений и процессов статистика использует ряд особых понятий, называемых
категориями. К ним относятся:
-признак;
-вариация;
-статистическая совокупность;
-показатель;
-система показателей.
Признаком в статистике принято называть свойство, характер, черты объекта,
которые могут быть наблюдаемы или измерены. Например, признаками при
исследовании промышленных предприятий могут выступать: размеры
производства, численность работников, величина основных средств.
Признаки могут быть количественные и качественные (это признаки,
отдельные значения которых отличаются друг от друга существенными
моментами, например, профессия человека может отличаться характером труда –
слесарь, токарь, плотник). Так же признаки могут быть варьирующие (принимают
различные значения у отдельных единиц объекта) и постоянные.
Вариацией называют колеблемость, многообразие, изменчивость величины
признака у отдельных единиц совокупности.
7
Статистическая совокупность – это множество объектов или явлений,
изучаемых статистикой, которые имеют один или несколько общих признаков, но
различающихся между собой по другим признакам.
Показатель – это количественная мера общественного явления, обладающая
качественной определенностью.
Система показателей – это совокупность статистических показателей. Вся
система показателей включает в себя объемные и качественные показатели.
Например, объемные – объем выпущенной или отгруженной продукции
организации. Качественные – средняя заработная плата одного работника,
себестоимость единицы продукции и т.п.
Кроме того, имеются показатели, которые исчисляются на макроуровне (ВВП,
ВПЭ и др.) и на уровне предприятий и организаций (прибыль предприятия,
списочная численность работников и др.)
3. Организация статистики в Российской Федерации
Задачей государственной статистики является обеспечение информационных
потребностей общества в достоверной, научно обоснованной, своевременной и
полной информации о социальном, экономическом, демографическом и
экологическом положении государства.
Централизованное руководство всей системой учета и статистики, работой
органов государственной статистики осуществляет Федеральная служба
государственной статистики ФСГС (Росстат). Сложившаяся в Российской
Федерации информационно-статистическая система имеет межведомственную
структуру. Наряду с Федеральной службой государственной статистики,
осуществляющей межотраслевую координацию и функциональное регулирование
статистической деятельности в России, более 50 федеральных органов
исполнительной власти формируют официальную статистическую информацию.
Направления развития государственной статистики в рамках повышения
эффективности государственного управления и регулирования определяются
Программами социально – экономического развития РФ утверждаемыми
распоряжениями Правительства РФ. Накопленный потенциал государственной
статистики требует продолжения преобразований, на осуществление которых и
направлена федеральная целевая программа "Развитие государственной статистики
России в 2007 - 2011 годах" (утв. распоряжением Правительства РФ от 5 августа
2006 г. N 1086-р)
В
рамках
модернизации
информационно-вычислительной
системы
Федеральной службы государственной статистики будут осуществлены
проектные работы по частичной реконструкции Главного межрегионального
центра обработки и распространения статистической информации Федеральной
службы государственной статистики и 58 территориальных органов Службы и
начаты строительно-монтажные работы по переоборудованию помещений для
установки серверного и телекоммуникационного оборудования с монтажом
инженерных систем, коммуникаций, охраны и жизнеобеспечения в указанном
центре и 34 территориальных органах Службы с целью создания современных
центров обработки статистических данных.
4. Табличное и графическое отражение статистических данных
8
Результаты группировки и сводки материалов оформляются в виде
статистических таблиц, которые придают данным наглядность.
Статистическая таблица – это комплекс взаимосвязанных показателей,
отражающих в определенной последовательности и связи статистическую
информацию о социально – экономических явлениях и процессах (состоит из
системы строк и столбцов).
Таблица - наиболее рациональная и удобная для восприятия форма
представления статистической информации об изучаемых явлениях при помощи
цифр, расположенных в определенной последовательности. Показатели в таблице
располагаются в более логичной и последовательной форме, занимают меньше
места по сравнению с текстовым изложением и познавательный эффект
достигается значительно быстрее.
Макетом таблицы называется таблица, состоящая из строк и граф, которые
еще не заполнены цифрами, разрабатывается на стадии подготовки исследования,
уточняется по ходу его проведения и является его основой.
Всякая статистическая таблица состоит из трех основных элементов:
заголовка, подлежащего и сказуемого.
Общее содержание и форма таблицы обозначаются в наименовании (в
заголовке). Заголовки граф таблицы должны содержать названия показателей и
единицы их измерения.
Подлежащее таблицы — это объект нашего изучения. Сказуемое — это
система показателей, которыми характеризуется объект изучения, т. е. подлежащее
таблицы. Обычно подлежащее располагается слева, в виде наименования
вертикальных граф.
В зависимости от характера подлежащего различают три вида таблиц:
1) простые;
2) групповые;
3) комбинационные.
Простые таблицы дают справочный материал, здесь дается перечень единиц.
Единицы упорядочивают по одному - двум признакам по убыванию или по
возрастанию. Сказуемое содержит данные о каждой единице совокупности.
Простые перечневые и динамические таблицы отражают сведения о ходе
выполнения планов работ организациями области, о получении продукции по
бригадам. Эти сведения имеют большое информационное значение для
специалистов.
Групповые таблицы отражают результаты типологических и аналитических
группировок по одному признаку. Статистическое подлежащее состоит из групп, а
сказуемое содержит ряд характеризующих эти группы показателей (таблица 1).
Таблица 1 - Зависимость относительного уровня издержек обращения
от размера товарооборота в городских магазинах
Группы магазинов
по размерам
Число магазинов в
Издержки обращения,
товарооборота
группе
% к товарообороту
за месяц, тыс. руб.
по группе
До 3
50
20, 1
9
От 3-6
От 6-12
От 12-18
Свыше 18
80
110
95
45
17, 4
15, 0
13, 2
10, 3
Таблица, в подлежащем которой представлена группировка единиц
наблюдения по двум и более признакам, называется комбинационной. При
составлении такой группировки сначала все единицы разбиваются на три группы
по одному какому-нибудь признаку, а затем внутри каждой выделенной группы на
подгруппы по другому признаку.
Пример комбинационной таблицы - таблица 2.
Таблица 2 - Группировка заводов по стоимости основных производственных
фондов и фактическому выпуску продукции
Группы
заводов по
стоимости
основных
производственных
фондов, тыс.
руб.
1,2 - 2,7
Итого
2,7-4,2
Подгруппы
заводов по
фактическому
выпуску
продукции, тыс.
руб.
Число
заводов
Основные
производств
енные
фонды, тыс.
руб.
Численность
работающих
1,3-3,0
3,0-5,0
Свыше 5,0
-
7
2
9
13,1
3,7
16,8
1656
607
2263
15,1
6,9
22,0
9124,3
11307,3
9725,5
1,3-3,0
3,0-5,0
Свыше 5,0
3
8
-
9,2
26,1
-
711
2704
-
6,6
31,4
-
8560,0
11612,4
-
11
35,3
3475
38,0
10935,2
1
6
4,7
29,3
341
2610
4,5
37,3
13196,5
14291.1
26
86,1
8689
95,2
11608,3
Итого
4,2-5,7
Всего
1,3-3,0
3,0-5,0
Свыше 5,0
Фактический
Средняя
выпуск про- выработка на 1
дукции, тыс. работающего,
руб.
руб.
При составлении таблицы или её макета надо соблюдать ряд правил:
1) четко формулировать наименование, которое должно точно отражать цель
составления таблицы;
2) ясно и кратко формулировать название строк и граф таблицы;
3) соблюдать последовательность расположения показателей сказуемого;
4) указывать единицы измерения;
5) нумеровать графы;
6) давать итоговые показатели.
Изучение статистических таблиц завершается их анализом. Анализ таблицы это получение выводов на основе представленных в таблице статистических
показателей. Величина отдельно показателя может быть оценена путем ее
сравнения с табличными данными, общеизвестными данными, имеющимися
нормативами, данными других таблиц. Сравнение заканчивается общим выводом,
характеризующим тенденцию представленных табличных данных.
Для наглядности статистические данные нередко представляют в виде
10
графиков, которые облегчают восприятие информации, позволяют изобразить
совокупность показателей во взаимосвязи, выявить тенденцию развития и
типичные соотношения показателей посредством геометрических фигур, знаков,
рисунков или схематических карт. Недостатком графиков является то, что в него
может быть включено ограниченное количество данных, в противном случае
теряется наглядность графиков. Заголовок графиков, в отличие от таблиц,
располагают под полем графика.
По способу построения графики делятся на:
- диаграммы;
- картограммы;
- картодиаграммы.
Диаграммы в свою очередь бывают линейные, плоскостные, радиальные,
точечные, объемные, фигурные, круговые и т.д. Линейные диаграммы
используются для предоставления количественных переменных: характеристики
вариационных значений, динамики, взаимосвязи между переменными. При
графическом изображении динамики по оси абсцисс (х) показывается время(годы,
кварталы, месяцы…), по оси ординат (у) – значения показателей. Наибольшее
распространение среди плоскостных диаграмм получили столбиковые диаграммы.
Картограмма используется для иллюстрации территориального распределения
статистического признака между отдельными районами для выявления
закономерностей этого распределения.
Картограммы бывают фоновые и точечные. На фоновых картограммах
изображение изучаемого явления и представленных данных фиксируется
различной раскраской территориальных единиц. Точечная картограмма
применяется для изображения абсолютных величин
Картодиаграмма - это сочетание диаграммы с географической картой. В
качестве знаков часто используются различные геометрические фигуры, особенно
круги.
Кроме перечисленных видов графиков на практике встречаются более
сложные изображения статистических данных (для управления города создаются
мониторинги в электронном виде).
11
2. Статистическое измерение и наблюдение социально –
экономических явлений
1. Информационная база статистического исследования, статистическое
наблюдение и его этапы
2. Задачи статистического наблюдения
3. Формы, виды и способы проведения статистического наблюдения
4. Ошибки статистического наблюдения
1. Информационная база статистического исследования, статистическое
наблюдение и его этапы
Для исследования социально-экономических явлений и процессов
необходимо, прежде всего, собрать первичные статистические данные
(информацию), под которыми понимается совокупность количественных
характеристик массовых явлений и процессов, полученных в результате
статистического наблюдения. Эти данные являются исходным материалом для
получения обобщающих показателей и выводов о тенденциях его развития. Не
всякие собранные факты об изучаемом явлении могут считаться статистической
информацией. Они должны отвечать определенным требованиям:
• Быть полной - это означает, что а) она должна охватывать либо все единицы
статистической совокупности, либо такую их часть, по которой можно делать
выводы о совокупности в целом; б) информация должна охватывать все
существенные стороны явления, его свойства, внутренние и внешние связи; в) она
должна собираться за максимально длительный срок
Это способствует
ослаблению воздействия случайных факторов и выявлению закономерностей
развития явления;
• быть достоверной, что означает соответствие данных о явлении, собранных
в процессе наблюдения фактическому состоянию явления;
• быть сопоставимой – для этого данные должны собираться в установленные
сроки, по единой программе, с использованием одинаковых методов и т. д., - иначе
невозможно обеспечить их дальнейшее сопоставление;
• своевременно предоставляться – особенно, если она используется для
осуществления управленческих функций.
Основными свойствами статистической информации являются ее массовость
и стабильность. Первое свойство связано с особенностями предмета статистики,
вторая - с неизменностью собранной информации, ее способностью устаревать и с
необходимостью получения новой информации для принятия верных
управленческих решений. Практический менеджмент нуждается в постоянно
пополняемых статистических данных, достоверная, полная, но запоздалая
информация оказывается практически ненужной.
Состав статистической информации определяется потребностями развития
12
общества. В условиях рыночной экономики ее потребителями являются как
государственные органы, так и различные негосударственные структуры. Так,
данные о состоянии экономики, численности и структуре населения, его
покупательной способности, об уровне инфляции и т п. нужны как
государственным органам, так и частным структурам для планирования и
организации своей деятельности.
Основными источниками статистической информации являются издания
органов государственной статистики. Высшим органом государственной
статистики является Государственный Комитет Статистики Российской
Федерации. Его ежегодное официальное издание – статистический сборник
«Российский статистический ежегодник» содержит наиболее полную информацию
о Российской Федерации - макроэкономические, демографические показатели,
показатели состояния различных отраслей национального хозяйства, данные о
развитии
здравоохранения,
о
доходах
и
потреблении
населения,
продолжительности жизни и т. д. Кроме этого, данные о социальноэкономическом положении страны в каком-либо году можно найти в кратком
статистическом сборнике Госкомстата РФ «Россия в цифрах».
Местные статистические органы издают региональные статистические
сборники.
Предоставление статистической информации является основной задачей
органов госстатистики, а сама статистическая информация – продукцией их
деятельности, имеющей, как и любая другая продукция, свою стоимость. Особенно
высокую стоимость имеет та информация, получение которой выходит за пределы
программы работы органов государственной статистики.
Основным источников получения первичной статистической информации
является статистическое наблюдение.
Статистическое наблюдение представляет собой планомерный, научно
организованный сбор данных или сведений о массовых явлениях и процессах,
который заключается в регистрации отобранных признаков у каждой единицы
совокупности.
Не всякий сбор сведений может называться статистическим наблюдением. О
статистическом наблюдении можно говорить лишь тогда, когда изучаются
статистические закономерности, проявляющиеся в массовых процессах, в большом
количестве единиц совокупности. Поэтому наблюдение считается статистическим,
если оно соответствует следующим условиям:
• является планомерным;
• является массовым;
• является систематическим.
Планомерность статистического наблюдения предполагает, что оно
готовится и проводится по заранее разработанному плану, являющего частью
общего плана проведения статистического исследования; в такой план включаются
вопросы методологии, организации, техники сбора информации, контроля ее
качества, его достоверности и оформления итоговых результатов.
Массовый характер статистического наблюдения означает, что оно
охватывает количество случаев проявления изучаемого явления, достаточное для
получения достоверных статистических данных, характеризующих совокупность в
целом.
13
Систематичность наблюдения определяется тем, что оно должно
проводиться либо непрерывно, либо систематически, либо регулярно, так как
только такой подход позволяет изучать тенденции и закономерности социальноэкономических явлений и процессов.
Примером статистического наблюдения являются опросы общественного
мнения, проводимые с целью изучения мнения граждан по вопросам,
представляющим для них интерес.
Процесс проведения статистического наблюдения состоит из нескольких
этапов:
• подготовка наблюдения;
• проведение массового сбора данных;
• подготовка данных наблюдения к обработке;
• разработка
предложений
по
совершенствованию
проведения
статистического наблюдения.
При проведении первого этапа – подготовке наблюдения необходимо в первую
очередь решить программно-методологические вопросы, важнейшими из которых
являются определение цели и задач наблюдения, его объекта, выбор единиц
наблюдения, состава признаков, подлежащих регистрации, формы, вида и способа
наблюдения, разработка документов для сбора информации, программы
наблюдения. На этом же этапе решаются и организационные вопросы, такие как:
подготовка работников, проводящих наблюдение, тиражирование документов для
проведения наблюдения и т. д.
Второй этап связан с непосредственным проведением наблюдения и включает
в себя такие работы как рассылка бланков, анкет, форм статистической отчетности,
переписных листов, их заполнение и дача в органы, проводящие наблюдение.
При выполнении третьего этапа – подготовке данных к наблюдению собранная
информация проверяется на полноту, подвергается арифметическому и
логическому контролю с целью выявления и исключения допущенных ошибок.
На последнем этапе проведения статистического наблюдения анализируются
причины, которые вызвали ошибки в заполнении статистических формуляров, и
разрабатываются предложения по совершенствованию проведения статистического
наблюдения.
2. Задачи статистического наблюдения
Статистическое наблюдение должно проводиться по заранее разработанному
плану, при разработке которого необходимо решить множество важных задач. Эти
задачи можно разделить на программно-методологические и организационные.
К программно-методологическим задачам статистического наблюдения
относятся:
• определение цели и задач наблюдения;
• выбор объектов и единиц наблюдения;
• разработка программы наблюдения;
• выбор формы, вида и способа проведения наблюдения.
Цель и задачи наблюдения. Каждое статистическое наблюдение проводится с
целью получения достоверных данных об исследуемых процессах и явлениях. Она
должна быть конкретной и четко сформулированной, исходить из общих задач,
поставленных перед статистическим исследованием явления. В соответствии с
14
принципами системного подхода задачи наблюдения должны соподчиняться
поставленной цели, исходить из нее. Цель и задачи предопределяют программу и
форму организации наблюдения. Если они поставлены неясно, неконкретно, то
будут собраны излишние сведения или, наоборот, получены неполные
статистические данные.
В зависимости от цели и решаемых задач определяются объект и единица
наблюдения.
Объект статистического наблюдения - это статистическая совокупность, в
которой проистекают исследуемые социально-экономические явления и процессы.
Установление объекта наблюдения означает определение точных границ и состава
совокупности. Например, при переписи населения необходимо установить, какое
население следует регистрировать - наличное, под которым понимается фактически
находящееся в момент переписи в данной местности, или постоянное, т. е.
живущее на данной территории постоянно.
В ряде случаев для отграничения объекта наблюдения используют понятие
ценза. Ценз есть пороговое значение признака, которое ограничивает объект
наблюдения. Например, при обследовании промышленности объектом могут быть
средние и крупные предприятия, к которым в соответствии с существующим
законодательством, относятся предприятия с числом работников более 100
человек.
Любой объект наблюдения состоит из единиц наблюдения.
Единица наблюдения – элемент статистической совокупности, являющийся
носителем признаков, подлежащих регистрации, то есть это то первичное звено, от
которого должны быть получены необходимые статистические сведения.
Например, при проведении демографических обследований это может быть
человек, но может быть и семья, при бюджетных обследованиях – домохозяйство
или семья.
В соответствии с поставленной целью, задачами, выбранным объектом
разрабатывается программа наблюдения.
Программа наблюдения – перечень признаков, подлежащих регистрации
(при непосредственном наблюдении), либо это перечень вопросов, по которым
собираются сведения (при опросах). Составление программы наблюдения является
сложной и ответственной задачей, поскольку от этого зависит качество собранной
информации. Состав и содержание программы наблюдения определяются задачами
исследования и особенностями изучаемого общественно-экономического явления.
Всякое явление обладает множеством признаков. Собирать информацию по всем –
нецелесообразно и невозможно. Поэтому необходимо отобрать наиболее важные,
отвечающие поставленным задачам и соответствующие цели наблюдения.
К программе наблюдения предъявляются следующие требования:
• в программу включаются только существенные признаки, непосредственно
характеризующие изучаемое явление, его тип, основные черты и свойства. Не
должны включаться второстепенные вопросы, не связанных с решением
представленных задач.
• в программу не включаются вопросы, на которые могут быть получены
заведомо неточные ответы, - то есть вопросы, способные вызвать подозрения, что
ответы на них могут быть использованы во вред опрашиваемым.
• в программу должны включаться вопросы контрольного характера для
15
проверки собираемой информации, например, это логически связанные вопросы
о возрасте, семейном положении, образовании, наличии детей и т.д.
• все вопросы программы должны быть ориентированы на определенную
форму ответа: либо цифровую, либо альтернативную, либо многовариантную.
При цифровой – ответ дается в количественной форме (о возрасте, стаже,
заработке и т.д.); при альтернативной – в форме «да» или «нет» (пол, семейное
положение и т.д.); при многовариантной – выбор одного или нескольких вариантов
из предлагаемого меню. Например, на вопрос о состоянии в браке возможны
следующие варианты ответов: - состоит в браке; - никогда не состоял; - вдовец; разведен.
• ответы в программах для облегчения обработки кодируются числовыми
кодами.
• при разработке программы необходимо не только определить состав
вопросов, но и их последовательность, так как логика расположения вопросов
способствует получению более достоверных данных.
Одновременно с программой разрабатывается инструментарий наблюдения в
виде статистических формуляров и инструкций по их заполнению.
Статистический формуляр – это документ единого образца, содержащий
программу и результаты наблюдения. Он может иметь разные названия: бланк
обследования, переписной лист, анкета, отчет и т. д.
Обязательными элементами статистического формуляра являются титульная и
адресная части. В титульной части указываются: наименование статистического
наблюдения и органа, его проводящего; номер формуляра, а также, кто и когда его
утвердил. В адресной – адрес отчетной единицы, ее подчиненность.
Кроме формуляра разрабатывается инструкция по порядку проведения
наблюдения, по заполнению формуляра. В зависимости от сложности программы
наблюдения это может быть документ в виде отдельной брошюры, либо подсказки
в ответах, либо разъяснения на обратной стороне бланка.
При подготовке статистического наблюдения помимо программнометодологических вопросов необходимо решить и организационные вопросы. К
ним относятся:
• определение органа (исполнителя) наблюдения. Наблюдение может
проводиться собственными силами или организациями, специализирующимися на
проведении наблюдений;
• определение времени наблюдения: даты начала, даты окончания наблюдения,
критической даты. Срок (период) наблюдения устанавливается исходя из объема
работы и численности персонала, занятого сбором данных. Критической датой
считается конкретный день года, час дня, по состоянию на который проводится
регистрация признаков по каждой единицы статистической совокупности.
• определение места (территории) проведения наблюдения. Выбор места
проведения наблюдения определяется его целью. Например, если определяется
стоимость потребительской корзины в г. Пензе, то местом проведения наблюдения
будет территория города.
Важнейшим организационно-методологическим вопросом, определяющим
эффективность статистического наблюдения (достоверность полученной
информации, затраты на проведение наблюдения и т.д.) является выбор формы,
вида и способа проведения наблюдения.
16
3. Формы, виды и способы проведения статистического наблюдения
Формы
В статистической практике используют три организационные формы
статистического наблюдения:
• отчетность (предприятий, организаций, учреждений и т. п.);
• специально организованное статистическое наблюдение;
• регистры.
Статистическая отчетность является основной формой статистического
наблюдения в Российской Федерации. Статистические сведения в виде
установленных законом отчетных документов в определенные сроки
представляются всеми предприятиями, организациями и учреждениями страны.
Статистическая отчетность является составной частью государственной
статистики, для нее характерно следующее:
• она утверждается органами Государственной статистики;
• имеет обязательный характер;
• имеет юридическую силу (подписывается должностными лицами);
• имеет документальную обоснованность (базируется на документах
первичного учета).
Постановлением Государственного Комитета по Статистике РФ от 16 сентября
1997 года с 1 января 1998 года предприятия и организации (юридические лица)
обязаны предоставлять следующие унифицированные формы федерального
государственного статистического наблюдения:
Форма № П-1 «Сведения о производстве и отгрузке товаров и услуг»;
Форма № П-2 «Сведения об инвестициях»;
Форма № П-3 «Сведения о финансовом состоянии организации»;
Форма № П-4 «Сведения о численности, заработной плате и движении
работников»;
Форма № П-5(м) «Основные сведения о деятельности организации» (введена
постановлением Росстата от 27.07.2004 № 34).
Состав представляемых форм является различным для разных организаций в
зависимости от специфики деятельности и количества работников. Предприятия с
численностью работников более 15 человек с января 2005 г. обязаны ежемесячно
представлять формы № П-1 с приложением 3 «Сведения об объемах платных услуг
населению по видам», П-3, П-4, а ежеквартально – форму № П-2. Малые
предприятия, штат которых не превышает 15 человек отчитываются ежемесячно по
форме № П-4 и ежеквартально – по форме № П-5.
Статистическая отчетность подается в территориальные управления
статистики. Региональные подразделения отраслевых ведомств, структуры,
регулирующие деятельность естественных монополий.
Специально организованные статистические наблюдения представляют
собой сбор сведений посредством переписей, единовременных учетов и
обследований. Эта форма наблюдения позволяет более углубленно изучать
изменения в составе населения, семейном бюджете, изучать рыночный спрос и т.д.
Такие наблюдения проводятся с целью получения данных, отсутствующих в
отчетности, или для проверки сведений, взятых из нее.
Специально организованное статистическое наблюдение требует специально
17
подготовленных людей, специально разработанной программы, является
трудоемким и дорогостоящим. Например, перепись населения проводится
одновременно по всей территории страны, охватывает всех живущих на
критический момент времени.
Регистром называется форма непрерывного статистического наблюдения
за долговременными процессами по совокупности показателей.
К наиболее известным относятся два вида регистров: регистры населения и
регистры предприятий.
Регистры населения представляет собой поименованный и регулярно
обновляемый перечень жителей страны. Наблюдение проводится по следующим
признакам: пол, дата и место рождения (постоянные данные), брачное состояние
(переменный признак).Информация в регистр заносится на каждого родившегося
или прибывшего из-за границы. В случае смерти или отъезда на постоянное место
жительства в другую страну данные из регистра убираются. Такие регистры
ведутся в государствах с небольшой численностью населения и по ограниченному
числу признаков, так как это требует больших затрат.
Регистр предприятий ведется по всем видам экономической деятельности. По
каждому предприятию в регистре находятся следующие сведения: время
регистрации предприятия; его название; адрес; организационно-правовая форма;
организационная структура и структура управления; виды экономической
деятельности; численность занятых; и т. д.
В настоящее время в Российской Федерации действует единый
государственный регистр предприятий и организаций (ЕГРПО), который содержит
данные по всем предприятиям, организациям, учреждениям, любой формы
собственности и любого вида деятельности, в том числе и общественным
организациям.
В информационном фонде регистра содержатся следующие данные:
- сведения об отраслевой принадлежности и территориальной, вид
экономической деятельности;
- вид собственности и организационная форма;
- справочные данные (адрес, фамилии руководителей, телефоны, факсы);
- экономические показатели (среднесписочная численность, средства,
направленные на потребление, остаточная стоимость ОПФ, уставный фонд и т.д.)
Регистр ведется в территориальном разрезе. Если предприятие закрывается, то
служба ведения регистра получает информацию об этом в течение 10 дней после
решения ликвидации комиссией.
Виды
По характеру регистрации фактов во времени выделяют несколько видов
наблюдений:
• текущее;
• периодическое;
• единовременное.
Текущее наблюдение состоит в том, что факты регистрируются непрерывно по
мере их поступления (регистрация рождений, смертей, учет отработанного времени
табельным путем, учет посещаемости и т.д.).
При периодическом наблюдении данные, отражающие изменение изучаемых
18
явлений собираются в ходе нескольких наблюдений. Такие наблюдения
проводятся по схожей программе через определенные промежутки времени, то есть
периодически (переписи населения, регистрация цен на определенные виды
товаров, учет успеваемости).
При единовременном наблюдении сведения об изучаемом явлении получают
один раз в момент наблюдения. Повторное наблюдение может и не проводиться,
как, например, инвентаризация незавершенного производственного строительства
в 1990г.
По полноте охвата исследуемой совокупности различают два вида
статистических наблюдений:
• сплошное наблюдение;
• несплошное наблюдение.
Задачей сплошного наблюдения является получение информации обо всех
единицах исследуемой совокупности. Оно применяется при проведении переписи
населения, инвентаризаций разного рода и т. д.
При несплошном наблюдении обследованию подлежит часть единиц
статистической совокупности. Несплошное наблюдение обладает существенными
преимуществами по сравнению со сплошным: требует меньших материальных и
трудовых затрат, позволяет применять более совершенные способы учета,
повышает оперативную значимость статистических данных, поскольку они могут
быть получены в более короткие сроки.
Несплошное наблюдение подразделяется на:
• выборочное;
• монографическое;
• обследование основного массива (метод основного массива).
Выборочное наблюдение основано на принципе случайного отбора части
единиц статистической совокупности, подлежащих исследованию. Случайный
отбор гарантирует независимость результатов наблюдения. При правильной
организации выборочное наблюдение дает достаточно точные результаты,
позволяющие оценить всю исследуемую совокупность. При этом значительно
сокращаются затраты на проведение наблюдения.
Выборочное наблюдение широко используется в промышленности – для
контроля качества продукции, в маркетинге – для изучения спроса населения на
различные товары и т. п.
Монографическое наблюдение (описание) заключается в подробном описании
отдельных единиц статистической совокупности. Наблюдение проводится по
широкой программе, используется для глубокого всестороннего изучения
особенностей наблюдаемых объектов. При этом не ставится цель получить
характеристику всей совокупности. Такие наблюдения позволяют уловить
пропорции и связи, которые ускользают из поля зрения при массовых
наблюдениях. Часто монографические наблюдения проводятся для составления
программы массового наблюдения.
Обследование основного массива характеризуется тем, что наблюдение
проводится за наиболее крупными единицами совокупности – основным массивом.
Например, наблюдение за финансовым положением в строительстве, транспорте,
промышленности ведется по данным предприятий с численностью работников не
менее 500 человек.
19
Способы:
По способам получения информации различают следующие типы
наблюдений:
• непосредственное;
• документальное наблюдение (учет);
• опрос.
При непосредственном наблюдении информацию собирают специально
подготовленные люди, в задачу которых входит получение сведений путем
личного учета единиц совокупности: подсчета, взвешивания, измерения и т. д.
значения признака. Это наиболее точный и надежный способ получения данных, но
и наиболее трудоемкий и дорогостоящий.
При документальном наблюдении (учете) в качестве источника информации
используются различного рода учетные документы. Этот способ наблюдения
используется предприятиями, организациями, учреждениями при составлении
отчетности на основе документов первичного учета и является достаточно
достоверным и надежным источником информации.
Опрос – способ наблюдения, при котором сведения получают со слов
респондента (опрашиваемого). Опрос используется для получения информации о
процессах и явлениях, неподдающихся непосредственному прямому наблюдению.
Он может быть организован по-разному. В практике статистики применяются
следующие основные способы опроса:
- экспедиционный (устный);
- саморегистрации;
- корреспондентский;
- анкетный
При устном (экспедиционном) опросе специально подготовленные
регистраторы на основе опроса обследуемого лица заполняют переписные листы
(фиксируют факты). При этом регистратор одновременно контролирует
достоверность полученных сведений. Устный опрос обеспечивает достаточно
точные результаты, но является весьма дорогостоящим способом получения
данных.
Способ саморегистрации состоит в том, что формуляры заполняются
самими опрашиваемыми лицами (респондентами), а регистраторы раздают
опросные бланки, инструктируют респондентов, собирают заполненные
формуляры, контролируя при этом правильность заполненных сведений.
Корреспондентский способ заключается в том, что формуляры заполняются
и отсылаются опрашиваемыми лицами в адрес организации, проводящей
исследование, без участия регистраторов на основе инструкций по их заполнению.
Этот вид опроса требует наименьших затрат, но не обеспечивает высокого
качества полученных данных, так как проверить точность сообщаемых сведений
не всегда возможно.
Анкетный способ предполагает сбор информации в виде анкет. Анкеты
распространяются разными способами, заполняются на добровольных началах,
как правило, анонимно. При этом количество анкет, полученных организацией,
проводящей обследование, всегда значительно меньше количества разосланных
анкет. Данный вид опроса дает приблизительные, ориентировочные данные и
используется обычно при изучении общественного мнения по различным вопросам.
20
4. Ошибки статистического наблюдения
Любое статистическое наблюдение, как бы тщательно оно не готовилось,
допускает наличие в собранной информации ошибок, которые необходимо
своевременно устранить.
Ошибками наблюдения называются расхождения между данными
наблюдения и фактическими значениями признаков исследуемого явления.
Ошибки наблюдения разнообразны по происхождению и своему содержанию.
В зависимости от причин возникновения различают следующие виды ошибок:
• методические ошибки;
• ошибки регистрации;
• ошибки репрезентативности (представительности).
Методические ошибки возникают в результате использования
несовершенных методик, неправильных теоретических концепций, лежащих в
основе исследования.
Ошибки регистрации возникают при получении данных об отдельных
единицах совокупности вследствие неправильного установления фактов в
процессе наблюдения или неправильной их записи. Они подразделяются на:
-объективные (непреднамеренные) причиной появления которых является
неправильное восприятие наблюдаемых фактов, неисправность измерительных
приборов и неправильная регистрация. Такие ошибки являются результатом
добросовестного заблуждения регистратора;
- субъективные (преднамеренные) ошибки, возникающие по причине
сознательного искажения фактов. К ним относятся всевозможные
преднамеренные ошибки и приписки, при которых опрашиваемый преднамеренно
сообщает неправильные сведения; регистратор преднамеренно воздействует на
респондента с целью получения нужного ответа; регистратор преднамеренно
искажает в формулярах результаты наблюдения.
Ошибки репрезентативности (представительности) характерны только
для несплошного наблюдения. Они возникают в результате того, что состав
отобранной для обследования части единиц совокупности (выборки) не
полностью отражает состав и свойства всей изучаемой совокупности,
несмотря на то, что регистрация сведений по каждой отобранной единице была
проведена точно.
По форме проявления (по влиянию на результат) ошибки делятся на:
• систематически;
• случайные.
Систематические ошибки возникают по какой-то определенной причине и
вызывают одностороннее искажение значений признака у наблюдаемых единиц
(увеличение или уменьшение). Они очень опасны, так как величина показателя,
рассчитанная в целом по всей совокупности будет включать накопленную ошибку.
Случайные ошибки являются результатом действия различных случайных
факторов. Они не имеют какой-либо направленности. В больших совокупностях в
результате действия закона больших чисел эти ошибки взаимно погашаются и не
оказывают существенного влияния на точность наблюдения. Оба вида ошибок в
любом исследовании выступают совместно и составляют совокупную ошибку
наблюдения Δ:
21
Δ=σ+ε;
где σ - систематическая ошибка наблюдения,
ε - случайная ошибка наблюдения.
Для выявления и исправления ошибок, данные наблюдения необходимо
тщательно контролировать.
Процедура контроля сводится к следующему:
• Проверка материалов наблюдения на полноту и правильность оформления.
Проверяется полнота охвата статистических единиц наблюдения, правильность
заполнения каждого формуляра.
• Арифметический (счетный) контроль. Этот вид контроля основан на
использовании количественных связей между показателями, которые могут быть
проверены арифметическими действиями. Такие связи обычно отражаются в
заголовках граф или строк формуляров. Например, графа x = графа y - графа z и
т.д. Арифметический контроль используется для проверки итоговых данных, с его
помощью устанавливается наличие ошибки.
• Логический контроль основан на использовании логической взаимосвязи
показателей, установлении логического соответствия между ними. Он не
выявляет ошибки наблюдения, а лишь ставит под сомнение правильность
полученных данных. Логический контроль заключается в проверке ответов на
вопросы программы наблюдения путем их логического осмысления или сравнения
полученных данных с другими источниками по данному вопросу. Классическим
примером логического контроля является соответствие данных при переписи
населения о возрасте, образовании и семейном положении.
Для проверки данных наблюдения обычно составляется схема контроля, в
которую включаются различные виды контроля.
При обнаружении ошибок нельзя самостоятельно их исправлять. Для этого
необходимо получить дополнительную информацию путем повторного
наблюдения. Данные наблюдения считаются принятыми, если они прошли
контроль, и в них внесены все необходимые исправления.
Проверкой
собранных
данных
заканчивается
начальная
стадия
статистического исследования.
После этого можно переходить ко второй стадии исследования обработке
данных наблюдения. Обработка заключается в классификации и систематизации
полученного статистического материала, осуществляемых через сводку и
группировку.
22
3. Сводка и группировка статистических данных
1. Понятие и виды статистических сводок
2. Понятие статистической группировки
3. Виды группировок
1. Понятие и виды статистических сводок
Статистические данные, собранные в процессе наблюдения не позволяют
получить обобщающие характеристики изучаемой совокупности, выявить
закономерности ее развития, так как в процессе наблюдения фиксируются
характеристики только отдельных единиц совокупности.
Для получения обобщающих характеристик собранную информацию
необходимо систематизировать, превратить ее в упорядоченную систему
статистических показателей. Систематизация полученной информации и
обобщение наблюдаемых факторов является содержанием второй стадии
статистического исследования, называемой сводкой и группировкой.
Статистическая сводка представляет собой комплекс последовательных
операций по обобщению конкретных единичных фактов, образующих
совокупность, для выявления типичных черт и закономерностей, присущих
изучаемому явлению.
Таким образом, целью сводки является получение итоговых данных путем
подсчета единичных сведений.
По глубине проработки материала различают простые и сложные сводки.
Простой сводкой называется операция по подсчету общих итогов по
совокупности единиц наблюдения, то есть определение размера исследуемого
явления.
Сложной сводкой называется комплекс операций, включающих группировку
единиц наблюдения, подсчет итогов по каждой группе и совокупности в целом, а
также представление результатов группировки в табличной форме.
По форме обработки материала сводки делятся на централизованные и
децентрализованные.
При централизованной сводке весь первичный материал поступает в одну
организацию, где и подвергается обработке по принятой программе, по единой
методике (например, в Государственном комитете по статистике РФ или
территориальных управлениях статистики).
При децентрализованной сводке разработка статистического материала
осуществляется
по
иерархической
системе
управления,
подвергаясь
соответствующей обработке на каждом уровне. Например, предприятия сдают
отчеты в районные отделы статистики, которые делают сводку по своему району, и
отправляют обобщенную информацию в региональные управления или комитеты,
которые свои сводки отправляют в Государственный комитет по статистике РФ,
где и определяются показатели в целом по народному хозяйству страны.
23
Статистическая сводка осуществляется по специальной программе, которая
должна составляться одновременно с разработкой плана и программы проведения
наблюдения.
Программа статистической сводки включает в себя:
• выбор группировочных признаков;
• определение порядка формирования групп;
• разработка системы статистических показателей для
характеристики выделенных групп и совокупности в целом;
• разработка макетов таблиц для представления результатов сводки.
План статистической сводки содержит указания о сроках и
последовательности выполнения отдельных этапов сводки, ее исполнителях, о
порядке представления ее результатов.
2. Понятие статистической группировки
Статистическая группировка, представляет собой процесс образования
однородных групп на основе расчленения (разделения) статистической
совокупности на части или объединение изучаемых статистических единиц в
частные совокупности по существенным для них признакам.
Группировка является методом исследования содержания изучаемого явления.
На ее основе рассчитываются обобщающие показатели по группам, выявляется
строение совокупности, взаимосвязи между изучаемыми признаками, а затем
проводится анализ полученных результатов.
Основными категориями метода группировок являются группировочный
признак (основание группировки) и интервал.
Группировочным признаком (основанием группировки) называется
признак, по которому происходит выделение однородных групп. В качестве
группировочного обычно выбирается один из существенных легко распознаваемых
признаков, носящих как атрибутивный, так и количественный характер.
Интервал – это совокупность варьирующих значений признака в группе, он
определяет количественные границы групп, а его ширина представляет собой
промежуток между максимальным и минимальным значениями признака в группе.
При выполнении группировок используются следующие типы интервалов:
• равные – во всех выделенных группах ширина интервала является
одинаковой;
• неравные – в каждой группе ширина интервала различна; при этом ее
изменение может изменяться закономерно (например, равномерно возрастать), или
произвольно, то есть быть свободной;
• закрытые если известны верхняя и нижняя границы интервалов
(максимальное и минимальное значения признака в группах);
• открытые - если известна только одна граница интервала, верхняя или
нижняя.
Число групп должно быть достаточным для объективного представления
изучаемой совокупности. При большом числе групп различия между ними
становятся малозаметными, а в самих группах в виду их малой наполняемости
перестает действовать закон больших чисел и возможно проявления случайности.
При малом же их числе в одну группу могут попасть статистические единицы с
24
существенно различающимися значениями признака.
На количество выделяемых групп влияют следующие факторы:
• уровень колеблемости группировочного признака - чем значительнее
вариация признака, тем большее количество групп необходимо выделять при
прочих равных условиях;
• размер изучаемой статистической совокупности - чем больше размер
исследуемой совокупности, тем большее количество групп необходимо выделять.
Выделенные группы должны быть достаточно заполненными. Наличие пустых
групп или малое число статистических единиц в них свидетельствуют о
неправильном определении их числа.
Равные интервалы в совокупности можно сформировать по формуле:
Хmax – Хmin
I = –––––––––––––
число групп
Ориентировочно число групп можно определить использую эмпирическую
зависимость, называемую формулой Стерджесса:
m ≈ 1 + 3,322 × lg N ,
где m – количество групп;
N - численность единиц статистической совокупности.
В практических расчетах можно использовать следующие соотношения,
полученные на основании формулы Стерджесса:
Таблица 3 – Оптимальное количество групп в однородной совокупности
N
15-24
25-44
45-89
90-179
180-359
360 и более
m
5
6
7
8
9
10
Зависимость Стерджесса дает хорошие результаты, если совокупность состоит
из большого числа единиц, распределение близко к нормальному, и при этом
используются равные интервалы.
Существуют и другие (более сложные) способы определения оптимального
числа групп в совокупности.
При выполнении группировок необходимо исходить из следующего принципа:
различия между единицами, отнесенными к одной группе должны быть меньше,
чем между единицами, отнесенными к разным группам.
С помощью группировок в статистике решают следующие задачи:
• изучение состава статистических совокупностей;
• выделение отдельных типов явлений внутри совокупности;
• выявление причинно-следственных связей разных признаков внутри
совокупности;
• классификация единиц совокупности по множеству признаков.
Для решения указанных задач применяют разные виды статистических
группировок.
3. Виды группировок
В зависимости от степени сложности изучаемого явления и от поставленных
25
задач статистические группировки могут выполняться по одному или нескольким
группировочным признакам. Группировка называется простой (одномерной),
если однородные группы формируются по одному признаку одновременно.
Если однородные группы образуются по двум и более признакам, то
группировка называется сложной.
В классе одномерных группировок выделяют следующие типы:
• структурные – предназначены для выявления состава изучаемого явления;
• типологические – предназначены для выделения в статистической
совокупности различных социально-экономических типов явлений;
• аналитические (факторные) – используются для изучения связей и
зависимости между варьирующими признаками.
Структурные группировки имеют большое практическое значение для
изучения структуры однотипных явлений. Они позволяют описать составные части
совокупности или строения типов, а также проанализировать структурные сдвиги.
Например, группировка предприятий по проценту выполнения плана, по числу рабочих и т. д.
Значение такого рода группировок заключается в том, что с их помощью могут
быть выделены и изучены группы предприятий передовых, средних, отстающих;
выявлены неиспользованные резервы производства, например, в области
улучшения использования основных фондов, повышения производительности
труда, улучшения качества продукции и т.д.
Таблица 4 - Группировка рабочих по стажу работы
№ группы
Стаж работы, лет
Число рабочих в
группе
1
От 0 до 4
6
2
От 4 до 8
8
3
От 8 до 12
11
4
От 12 до 16
13
5
От 16 до 20
6
6
От 20 до 24
4
7
От 24 до 28
2
Итого
От 0 до 28
50
К типологическим группировкам относят все группировки, которые
характеризуют качественные особенности и различия между типами явлений.
Например, группировка предприятий строительства по формам собственности.
По технике выполнения типологическая группировка похожа на структурную
группировку, за исключением первых этапов – группировочный признак,
количество групп, их параметры определяются на основе качественного анализа. В
таких группировках очень часто применяются специализированные интервалы
Таблица 5 - Группировка населения поселка городского типа по возрастным
категориям
Возрастные категории Границы интервалов Численность Удельный
населения
(лет)
в группе (чел.) вес (%)
нижняя верхняя
26
Дошкольный возраст
До 7
192
14,3
Школьный
7
17
218
16,3
Рабочий
18
55 (60)
574
42,8
Пенсионный
56 (61) и более
357
26,6
Итого
1340
100
Аналитические (факторные) группировки позволяют оценить связи между
взаимодействующими признаками. Явления общественной жизни и их признаки
тесно связаны между собой и зависят один от другого.
Факторным называется признак, под воздействием которого изменяется
другой, зависящий от него признак, называемый результативным.
Взаимодействие проявляется в том, что с изменением значения факторного
признака систематически возрастает или убывает значение признака
результативного. Например, себестоимость продукции зависит от уровня
производительности труда: чем выше производительность труда, тем ниже, в
среднем, себестоимость продукции.
Таблица 6 – Исследование зависимости заработной платы рабочих участка
от стажа работы
Группы рабочих по стажу, лет
Число
Общая
Средняя
зарплата
Границы интервала
Середина рабочих в зарплата
№ группы нижняя
рабочих в рабочих в
интервала группе
верхняя
группе
группе
1
0
4
2
6
18 000
3 000
2
4
8
6
8
28 000
3 500
3
8
12
10
11
41 800
3 800
4
12
16
14
13
59 800
4 600
5
16
20
18
6
34 800
5 800
6
20
24
22
4
27 200
6 800
7
24
28
26
2
14 800
7 400
Итого
0
28
14
50
224 400
4 448
Объектом анализа в этой таблице является среднее значение результативного
признака – среднемесячная заработная плата рабочих в группах и середина
интервала – средний стаж работы. Если среднее значение результативного
признака, установленное по группам имеет некоторое различие, то связь между
признаками можно считать установленной. Если средний результат при переходе
от одной группе к другой практически не меняется, то связь между признаками
отсутствует.
В рассматриваемом примере изменение стажа работы приводит к изменению
заработной платы. Таким образом, с помощью аналитической группировки можно
установить наличие связи между признаками, но описать ее нельзя.
К сложным группировкам относятся группировки, выполняемые по двум и
более основаниям. Сложные группировки делятся на комбинационные и
многомерные.
Комбинационные группировки выполнятся по нескольким признакам
27
последовательно. Последовательность устанавливается исходя из логики
взаимосвязи показателей. Как правило, группировку начинают с атрибутивного
признака. При комбинационной группировке совокупность логически
последовательно разбивается на однородные части по отдельным признакам: на
группы - по одному признаку, затем внутри каждой группы по второму признаку на подгруппы и т.д.
Такие группировки предназначены для более глубокого анализа изучаемого
явления, позволяют выявить и сравнить различия и связи между исследуемыми
признаками, которые невозможно установить на основе изолированных
группировок по каждому из исследуемых признаков. Однако следует иметь в виду,
что при изучении влияния большого числа признаков применение
комбинационных группировок невозможно, так как это приводит к дроблению
информации, а значит, к затушевыванию проявлений закономерности. Даже при
наличии больших объемов информации приходится ограничиваться двумя –
четырьмя признаками.
Комбинационная группировка по двум признакам (X, Y) оформляется в виде
шахматной таблицы, в которой значения одного признака X откладываются по
строкам, а значения второго признака Y – по столбцам.
К многомерным относятся группировки, выполненные по нескольким
группировочным признакам одновременно.
Цель многомерных группировок – классификация данных на основе множества
признаков, то есть выделение групп статистических единиц, однородных по
нескольким признакам одновременно. В процессе такой группировки решаются,
например, задачи типизации – выделяются самостоятельные экономические или
социальные типы явлений. Так, приемами многомерной классификации можно всю
совокупность промышленных предприятий разбить на «мелкие», «средние» и
«крупные», используя следующие признаки: численность промышленнопроизводственного персонала, объем продукции, стоимость основных
производственных фондов, потребление материальных ресурсов и т.д.
Кроме группировок по количественным признакам, применяются
группировки, в основу которых положены атрибутивные признаки, т. е. такие
признаки, как пол, национальность, профессия, специальность рабочего, отрасль
производства и др. Такие признаки у различных единиц совокупности не имеют
количественного выражения. Группировки по этим признакам могут быть
сравнительно простыми, где число групп предопределено самим признаком
(группировка населения по полу), и довольно сложным (группировка рабочих по
профессиям, промышленных предприятий по отраслям производств, группировка
затрат производства — по видам затрат).
Сложные группировки по атрибутивным признакам часто называют в
статистике классификациями. Классификация — это устойчивая группировка по
атрибутивному признаку, которая обычно содержит очень подробную
номенклатуру групп и подгрупп, их перечень рассматривается как статистический
стандарт, утверждаемый обычно Федеральной службой государственной
статистики.
Так, в экономической статистике применяют классификацию видов
экономической деятельности, в обрабатывающих производствах - классификацию
28
продукции, отраслей производства, в сельскохозяйственной статистике —
классификацию посевных площадей и скота, в статистике торговли —
классификацию товаров, в статистике транспорта - классификацию грузов, в
статистике труда - классификацию профессий.
4. Статистические показатели
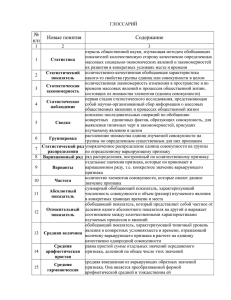
1. Понятие и виды статистических показателей
2. Абсолютные статистические показатели
3. Относительные показатели
4. Средние показатели
5. Показатели вариации
6. Сопоставимость показателей
1. Понятие и виды статистических показателей
Статистическое исследование независимо от его масштабов и целей всегда
завершается расчетом и анализом различных по виду и форме выражения
статистических показателей.
Статистические показатели являются одной из важнейших категорий
статистики, Они используются для описания исследуемых массовых явлений и
процессов, являются инструментом их познания.
Статистический
показатель
есть
количественно-качественная
обобщающая характеристика какого-либо свойства статистической
совокупности в условиях конкретного места и времени. Этим он отличается от
индивидуальных значений признака (вариант). Например, средняя заработная
плата работников предприятия – статистический показатель, а заработная плата
конкретного работника – это индивидуальное значение признака (варианта).
В отличие от индивидуального значения признака статистический показатель
может быть получен только расчетным путем. Это может быть простой подсчет
единиц совокупности, суммирование их значений признак, или более сложные
расчеты. В соответствии с определением статистический показатель имеет
определенную структуру, в нем различают качественную и количественную
стороны.
Качественная сторона статистического показателя определяется признаком,
который подлежит изучению и отражается в названии показателя, количественная
сторона - в численном значении показателя. Еще одной особенностью
статистических показателей является то, что они всегда привязаны к конкретным
обстоятельствам места и времени.
Таким образом, с помощью статистических показателей определяется что, где,
когда и каким образом следует измерять или оценивать.
Как правило, изучаемые статистикой процессы и явления достаточно сложны,
и их сущность не может быть отражена посредством одного отдельно взятого
показателя. В таких случаях используется система статистических показателей.
Система статистических показателей — это совокупность взаимосвязанных
показателей, имеющая одноуровневую или многоуровневую структуру и
нацеленная на решение конкретной статистической задачи. Так, например,
сущность промышленного предприятия заключается в производстве какой-либо
29
продукции на базе эффективного взаимодействия средств производства и
трудовых ресурсов. Следовательно, для полной экономической характеристики
функционирования предприятия необходимо использовать систему, включающую
прежде всего такие показатели, как прибыль, рентабельность, численность
промышленно-производственного
персонала,
производительность
труда,
фондовооруженность и др.
Следует иметь в виду, что любая система статистических показателей всегда
лишь схематично, с упрощениями, в зависимости от сложившихся представлений
отражает изучаемое явление. Поэтому важно постоянно совершенствовать такие
системы.
На практике для отражения разнообразных сторон социально-экономических
явлений и процессов используются разнообразные статистические показатели,
которые можно классифицировать следующим образом.
Таблица 7 - Классификация статистических показателей
Плановые показатели - отражают директивную функцию, ориентированы на
выполнение поставленных задач, учётные – показывают реальное состояние
изучаемого явления, а прогностические – его возможное состояние в будущем.
Индивидуальные – характеризуют отдельный объект или отдельную единицу
совокупности – предприятие, домохозяйство и др. Примером индивидуальных
статистических показателей может быть объем продаж торговой фирмы,
численность работающих предприятия и т.д.
Сводные (обобщающие) показатели исчисляются по всей совокупности в
целом, являются научными абстракциями и занимают особое место в познании
статистических закономерностей.
Абсолютные – исходная первичная форма выражения статистических
показателей.
Относительные – производные, вторичные показатели по отношению к
абсолютным, выражающие определённые соотношения между количественными
характеристиками статистических совокупностей.
Средние – наиболее распространённая форма статистических показателей,
характеризующая наиболее типичный уровень явления. Рассчитываются на
единицу статистической совокупности или на единицу признака.
2. Абсолютные статистические показатели
Абсолютные показатели характеризуют численность совокупности, либо
объём изучаемого явления в конкретных границах пространства и времени, т. е.
отражают уровень развития явления, его размер.
30
Абсолютный показатель можно получить одним из двух способов:
- путём подсчёта единиц совокупности, обладающих конкретным значением
признака; например, число транспортных предприятий в Санкт-Петербурге на
конкретную дату, численность промышленно-производственного персонала
предприятия и т.д.
- путём суммирования значения признака по всей статистической
совокупности; например, объём товарооборота предприятий торговли города в
2008 г.
Абсолютные показатели всегда являются именованными числами. В
зависимости от социально-экономической сущности исследуемых явлений они
выражаются в натуральных, стоимостных и трудовых единицах измерения.
Натуральные измерители используются в тех случаях, когда единицы
измерения соответствуют потребительским свойствам изучаемых явлений,
например: производство автомобилей измеряется в штуках, производство стали - в
тоннах, урожайность - в центнерах и т.д.
Натуральные единицы измерения могут быть составными (сложными).
Такие единицы применяются в тех случаях, когда для характеристики изучаемого
явления одной единицы измерения недостаточно, и используется произведение
двух единиц. Например, производство электроэнергии измеряется в киловаттчасах, грузооборот – в тонно-километрах и т. д.
В группу натуральных, включаются также условно-натуральные единицы
измерения. Они используются, когда какой-либо продукт имеет несколько
разновидностей, и общий объем можно получить только исходя из общего для всех
разновидностей
потребительского
свойства.
Например,
в
консервной
промышленности объёмы производства определяются в условных консервных
банках объёмом 353,4 см3., в топливной – в условном топливе с теплотой сгорания
7000 ккал/кг (29,3 мДж/кг).
Чтобы получить обобщённые итоги одна из разновидностей продукта
принимается в качестве единого измерителя, а другие приводятся к нему с
помощью соответствующих коэффициентов пересчёта. Например, если
месторождение даёт за год 100 тыс. тонн нефти с теплотой сгорания 45,0 МДж/кг,
то в условном топливе это будет эквивалентно 100.45,0/29,3=153,6 тыс. тонн
условного топлива.
Стоимостные измерители позволяют дать денежную оценку изучаемым
явлениям и процессам. Эти измерители используются при обобщении данных,
начиная с уровня предприятия и до уровня народного хозяйства, при оценке
неоднородных статистических совокупностей. В стоимостных единицах
измеряется объем выпущенной продукции предприятия, доходы населения и т. д.
Показатели, выраженные в стоимостных единицах, можно суммировать,
получать по ним итоговые данные, но при их использовании необходимо
учитывать изменение цен с течением времени. Для устранения указанного
недостатка стоимостных измерителей следует применять «неизменные» или
«сопоставимые» цены одного итого же периода.
Трудовые единицы измерения применяются для оценки общих затрат труда
и трудоемкости отдельных операции техпроцесса. К ним относятся: человеко-часы,
человеко-дни (оценка затрат рабочего времени), нормо-минуты (оценка
трудоёмкости).
31
Сами по себе абсолютные показатели не дают полного представления об
изучаемом явлении, не показывают его структуру, развитие во времени,
соотношение между частями явления, на их основе сложно проводить сравнения с
другими подобными явлениями. Перечисленные аналитические функции
выполняют относительные показатели.
3. Относительные показатели
Относительным статистическим показателем называется обобщающая
характеристика, выраженная в виде числовой меры соотношения двух
сопоставляемых абсолютных величин.
Такие показатели используются в различных целях: для выяснения структуры
изучаемого явления, для сравнения его уровня развития с уровнем развития
другого явления, для оценки происходящих в изучаемом явлении изменений и т. д.
Относительный статистический показатель получают путём деления одного
абсолютного показателя на другой. Схема расчета относительного показателя
выглядит следующим образом:
Таким образом, по способу получения относительные показатели всегда
являются величинами производными, их можно получить только расчетным путем.
Относительные показатели выражаются в разных формах - коэффициентов,
процентов, промилле, продецимилле. Если база сравнения принимается за единицу,
то относительный показатель выражается в форме коэффициента. Например, в
2003г в Санкт-Петербурге родилось 40,3тыс. детей, а в 2002г. – 37,2тыс.
Коэффициент роста числа родившихся составит 1,083 (40,3/37,2). Если база
сравнения принимается за 100 единиц, то относительный показатель выражается в
процентах. По предыдущим данным рост количества родившихся составит
108,3%. Если база сравнения принимается за 1000 единиц, то относительный
показатель выражается в промилле (десятая часть процента), если – за 10 000, то
относительный показатель выражается в продецимилле (сотая часть процента).
Промилле широко применяются в демографической статистике для характеристики
рождаемости, смертности населения и других демографических процессов.
Продецимилле используются для оценки обеспечения населения больничными
койками, местами в высших учебных заведениях и т.д.
Следует заметить, что безразмерным по форме относительным показателям
может быть приписана конкретная единица измерения. Например, показатели
естественного движения населения – коэффициент рождаемости, коэффициент
смертности, исчисляется в промилле, но показывает число родившихся или
умерших за год в расчёте на 1000 чел. Например, показатель рождаемости в СанктПетербурге в 2003г. составил 8,9 промилле, что означает 8,9 рождений на тысячу
населения.
По содержанию выражаемых количественных соотношений выделяют
32
шесть видов относительных показателей: динамики, плана и выполнения
плана, структуры, координации, интенсивности и уровня экономического развития,
сравнения.
Относительный показатель динамики характеризует изменение изучаемого
явления во времени и представляет собой соотношение показателей,
характеризующих явление в текущем периоде и предшествующем (базисном)
периоде.
Рассчитанный таким образом показатель называется коэффициентом роста
(снижения). Он показывает, во сколько раз показатель текущего периода больше
(меньше) показателя предшествующего (базисного) периода. Выраженный в %,
относительный показатель динамики называется темпом роста (снижения)
Например, если численность населения РФ по данным переписи населения
2002 г. составила 145181,9 тыс. чел., а поданным переписи 1989 г. – 147021,9 тыс.
чел., то коэффициент (темп) снижения численности населения составил:
К=145181,9/147021,9=0,987 или 98,7%.
Относительный показатель плана (прогноза) и выполнения плана
Относительный показатель плана (ОПП) и относительный показатель
выполнения плана (ОПВП) используют все субъекты финансово-хозяйственной
деятельности, осуществляющие текущее и стратегическое планирование. Они
рассчитываются следующим образом:
Относительный показатель выполнения плана характеризует напряженность
планового задания, а относительный показатель выполнения плана – степень его
выполнения.
Пример расчета ОПП и ОПВП: фактический оборот фирмы в 2003 г. составил
2 млрд. руб., анализ рынка показал, что за 2004 г. реально довести оборот до 2,6
млрд. руб., фактический же оборот в 2004 г. составил 2,5 млн. руб.
ОПП= 2,6 / 200 = 1,30
ОПВП = 2,5 / 2,6 = 0,96
Расчеты показывают, что плановое задание на 2004 г. в 1,3 раза превышает
фактический уровень 2003 г., но план 2004 г. выполнен только на 96%.
33
Если обозначить базисный уровень показателя - Уо, предусмотренный планом Упл и фактически достигнутый — У1, то относительная величина
У пл.
;
У0
У
выполнения плана – 1 ;
У пл.
планового задания –
У1
.
У0
У
У У
Отсюда взаимосвязь 1 1 пл. то есть ОПД = ОПП х ОПВП
У 0 У пл. У 0
динамики -
Относительные показатели структуры (ОПС) характеризуют доли
(удельные веса) составных частей совокупности в общем ее объеме. Они
показывают структуру совокупности, ее строение. Расчет относительных
показателей структуры заключается в исчислении удельных весов отдельных
частей во всей совокупности:
ОПС обычно выражаются в форме коэффициентов или процентах, сумма
коэффициентов должна составлять 1, а сумма процентов – 100, так как удельные
веса приведены к общему основанию.
Относительные показатели структуры используются при изучении состава
сложных явлений, распадающихся на части, например: при изучении состава
населения по различным признакам (возрасту, образованию, национальности и
др.).
Пример расчёта структуры розничного товарооборота приведен в таблице 8.
Таблица 8 - Структура розничного товарооборота города в 2008 г
Показатели
Сумма, млрд. руб.
В % к итогу
1. Организации розничной
42,4
51
торговли
2. Неторговые
20,8
25
организации
3. Физические лица на
19,9
24
рынках
Всего розничный
83,1
100
товарооборот
Совокупность относительных величин структуры показывает строение
совокупности.
Относительные показатели координации (ОПК) характеризуют
отношение частей данных статистической совокупности к одной из них, взятой
34
за базу сравнения и показывают, во сколько раз одна часть совокупности больше
другой, или сколько единиц одной части совокупности приходится на 1,10,100 и
т.д. единиц другой части. За базу сравнения выбирается часть, имеющая
наибольший удельный вес или являющаяся приоритетной в совокупности.
Так, приняв за базу в предыдущем примере товарооборот организаций
розничной торговли, можно рассчитать ОПК для неторговых организаций:
ОПК = 25/51 = 0,49; что означает следующее - на каждый рубль товарооборота
розничной торговли приходится 49 копеек товарооборота неторговых организаций.
Относительные показатели координации играют важную роль в
экономическом анализе, так как с их помощью существующие в совокупности
соотношения представляются более отчетливо и наглядно.
Относительные показатели интенсивности и уровня экономического
развития (ОПИ) характеризуют степень распространения или уровень развития
изучаемых явлений или процессов в определённой среде и образуются как
результат сравнения разноименных, но определенным образом связанных между
собой величин. Указанные показатели рассчитываются следующим образом:
ОПИ исчисляются в расчете на 100, 1000, 1000 и т.д. единиц изучаемой
совокупности и используются в тех случаях, когда невозможно по значению
абсолютного показателя определить масштаб распространения явления. Так, при
изучении демографических процессов рассчитываются показатели рождаемости,
смертности, естественного прироста (убыли) населения как отношение числа
родившихся (умерших) или величины естественного прироста за год к
среднегодовой численности населения данной территории на 1000 или 10 000
человек.
Например, по состоянию на 1.01.04г. в Санкт-Петербурге родилось 40,3тыс.
новорожденных, в Ленинградской области - 13,4тыс. Сопоставление абсолютных
показателей не позволяет оценить уровень рождаемости, определить, где этот
уровень выше. Это можно сделать через ОПИ – коэффициенты рождаемости в
Санкт-Петербурге и Ленинградской области. Население Санкт-Петербурга в 2003г.
составило – 4631 тыс. чел., в Ленинградской области - 1662 тыс. чел.
Сравнивая полученные значения показателей рождаемости, можно сделать
следующий вывод: рождаемость в Санкт-Петербурге выше, чем в Ленинградской
области.
В эту же группу включаются относительные показатели уровня
экономического развития, характеризующие эффективность использования
35
ресурсов и эффективность производства. Это показатели выработки
продукции, затрат на единицу продукции, эффективности использования
производственных фондов и т.д., поскольку их получают сопоставлением
разноименных величин, относящихся к одному и тому же явлению и одинаковому
периоду времени.
Относительные
показатели
сравнения
(ОПСр)
характеризуют
сравнительные размеры одноименных абсолютных показателей, относящихся к
различным объектам или территориям, но за одинаковый период времени. Их
получают как частные от деления одноименных абсолютных показателей,
характеризующих разные объекты, относящихся к одному и тому же периоду или
моменту времени.
С помощью таких показателей сравнения можно сопоставлять
производительность труда в разных странах и определять, где и во сколько раз она
выше; сравнивать цены на различные товары, экономические показатели разных
предприятий и т. д.
Например, можно сравнить среднюю заработную плату в промышленности
Санкт-Петербурга в 2003г. и в образовании, принимая заработную плату в
промышленности за базу сравнения. Средняя заработная плата в промышленности
составила 7871руб., в образовании – 5403руб. ОПСр = 5403/7871= 0,686;
следовательно, средняя заработная плата в образовании составляет 68,6% от
заработной платы в промышленности.
Относительные показатели имеют важное значение в практической
деятельности, но их нельзя рассматривать в отрыве от абсолютных показателей,
через которые они рассчитываются, в противном случае можно прийти к
неправильным выводам. Таким образом, только совместное использование
абсолютных и относительных показателей позволяет провести качественный
анализ различных явлений социально-экономической жизни.
4. Средние показатели
Средние показатели являются наиболее распространённой формой
статистических
показателей,
используемых
в
социально-экономических
исследованиях.
Средним
называется
обобщающий
показатель
статистической
совокупности, характеризующий наиболее типичный уровень явления.
Особенности средних показателей заключаются в том, что они, во-первых,
отражают то общее, что присуще всем единицам совокупности; во-вторых, в них
взаимопогашаются те отклонения значений признака, которые возникают под
воздействием случайных факторов. Это означает, что средний показатель отражает
типичный уровень признака, формирующийся под воздействием основных
доминирующих неслучайных факторов. Применение средних величин позволяет
охарактеризовать определенный признак совокупности одним числом, несмотря на
то, что у разных единиц совокупности значения признака отличны друг от друга.
36
Средние величины, характеризующие совокупность в целом называются
общими, а средние, отражающие особенности группы или подгруппы –
групповыми.
В социально-экономическом анализе используются два класса средних
величин:
- степенные средние;
- структурные средние.
К степенным средним относятся несколько видов средних, построенных
по одному общему принципу:
- степенная средняя простая
хk
х
k
n
- степенная средняя взвешенная
х f
f
k
хk
где х – индивидуальные значения признака
f – частота повторений индивидуальных значений признака
n – общее число значений признака
k – показатель степени.
Показатель степени k может принимать любые значения, но на практике
обычно используются несколько его значений:
при k = 1 получают среднюю арифметическую;
k = -1 – среднюю гармоническую;
k = 0 – среднюю геометрическую;
k = 2 – среднюю квадратическую.
1) Средняя арифметическая
Простая исчисляется путем деления суммы значений признака на число
значений по следующей формуле:
х
х1 х2 х3 ... хn х
,
n
n
где х - средняя арифметическая;
х1, х2, х3,…хn – индивидуальные значения признака;
n - число значений признака.
Взвешенная используется если данные предварительно сгруппированы
х
хf
f
где х - значение признака;
f - частота повторения (вес) соответствующего значения признака.
37
Если данные сгруппированы и представлены в виде интервального ряда, то
принцип расчета средней остается прежним, но предварительно вычисляется
среднее значение признака для каждого интервала (среднее значение интервала —
х), представляющее полусумму нижнего и верхнего значений интервала. Если есть
интервалы с открытыми границами, то для первой группы (с открытым
интервалом) величина интервала принимается равной её величине в последующей
группе, а для последней группы с открытым интервалом величина интервала
берется равной величине интервала предыдущей труппы.
2) Средняя гармоническая
Используется в тех случаях, когда статистическая информация не содержит
частот по отдельным значениям признака, а представлена произведением значения
признака на частоту.
Простая
х
n
1
х
Взвешенная
х
f
f
х
VVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVV
Пример использования средней гармонической простой: Три предприятия
производят микроволновые печи. Себестоимость их производства на 1-ом
предприятии составила 4000руб., на 2-ом - 3000руб., на 3-ем – 5000руб.
Необходимо определить среднюю себестоимость производства микроволновой
печи при условии, что на каждом предприятии общие затраты на ее изготовление
составляют 600тыс. руб.
Применять среднюю арифметическую в данном случае нельзя, так как
предприятия выпускают разное количество микроволновых печей: первое – 150шт.
(600000/4000); второе – 200шт. (600000/3000); третье – 120шт. (600000/5000).
Если в данном примере принять, что на предприятиях было произведено
разное количество печей при разных общих затратах, то для определения средней
себестоимости следует использовать формулу средней гармонической взвешенной.
Пусть на первом предприятии общие затраты на производство микроволновых
печей составили 600тыс. руб., на втором – 660 тыс. руб., на третьем – 500 тыс. руб.;
произведено было соответственно 150, 220 и 100 единиц продукции. Средняя
себестоимость одной микроволновой печи составила:
38
ΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛ
3) Средняя геометрическая
Применяется в тех случаях, когда общий объем усредняемого признака
является мультипликативной величиной, т.е. определяется не суммированием,
а умножением индивидуальных значений признака.
х к х1 х 2 х3 ... х к к Пхi - невзвешенная;
х m х1m1 х2m2 х3m3 ...хкmк m Пхimi - взвешенная.
В социально-экономических исследованиях средняя геометрическая
применяется в анализе рядов динамики при определении среднего коэффициента
роста, когда задана последовательность относительных величин динамики.
VVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVV
Пример.
В результате инфляции за первый год цена товара возросла в 2 раза по
сравнению к предыдущему году, а за второй ещё в 1,5 раза по сравнению к
предыдущему. Необходимо определить средний коэффициент роста цены.
За два года цена возросла в 3 раза (2·1,5). Если использовать среднюю
арифметическую, то средний коэффициент роста составит 1,75; за два года цена
при таком среднем коэффициенте роста должна составить 1,75·1,75=3,0625 раза,
что выше реального на 0,625 или на 6,25%. В действительности средний
коэффициент роста следует определить по формуле средней геометрической:
х
геом
2 15 1,73
Средняя геометрическая используется также для определения равноудаленной
величины от максимального и минимального значения признака. Например,
страховая фирма заключает договоры страхования имущества граждан. В
зависимости от вида имущества, его состояния, категории фирмы, конкретного
рискового случая и т. д. страховая сумма может изменяться от 3 тыс. руб. до 1 млн.
руб. Средняя сумма по страховке составит:
х
геом
3 1000 54,772 тыс. руб.
ΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛ
4) Средняя квадратическая
Используется в тех случаях, когда при замене индивидуальных значений
признака на среднюю величину необходимо сохранить неизменной сумму
квадратов исходных величин.
Главная сфера её использования – измерение степени колеблемости
39
индивидуальных значений признака относительно средней арифметической
(среднее квадратическое отклонение). Кроме этого, средняя квадратическая
применяется в тех случаях, когда необходимо вычислить средний величину
признака, выраженного в квадратных или кубических единицах измерения (при
вычислении средней величины квадратных участков, средних диаметров труб,
стволов и т. д.).
Простая
x
х
n
Взвешенная
x f .
х
f
2
2
.
Все степенные средние различаются между собой значениями показателя
степени. При этом, чем выше показатель степени, тем больше количественное
значение среднего показателя: гарм х ≤ геом х ≤ арифм х ≤ кв х .
Это свойство степенных средних называется свойством мажорантности
средних.
Таким образом, выбор вида среднего показателя оказывает существенное
влияние на его численную величину. Выбор вида средней определяется в каждом
отдельном случае путем анализа исследуемой совокупности, изучения содержания
явления. Степенная средняя выбрана правильно, если на всех этапах
вычислений не меняется её логическая формула, т.е. реально сохраняется
социально-экономическое содержание усредняемого признака.
Особый вид средних показателей – структурные средние. Они используются
при изучении внутреннего строения рядов распределения значений признака.
Структурные или непараметрические средние – мода и медиана.
Мода — величина признака (варианта), наиболее часто повторяющаяся в
изучаемой совокупности.
Для несгруппированной совокупности данных модой будет значение признака
(варианты) с наибольшей частотой.
Для интервальных радов с равными интервалами мода определяется по
формуле:
Мо хМо iМо
f Мо f Мо1
,
f Мо f Мо1 f Мо f Мо1
где хМо - начальное значение интервала, содержащего моду;
iМо – величина модального интервала;
fМо – частота модального интервала;
fМо-1 – частота интервала, предшествующего модальному;
fМо+1– частота интервала, следующего за модальным.
VVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVV
40
Пример расчета моды в интервальном ряду.
Таблица 9 - Группы предприятий по числу работающих, чел.
Группы предприятий по
числу работающих, чел.
Число
предприятий
Группы предприятий
по числу работающих, чел.
Число
предприятий
100-200
200-300
300-400
400-500
1
3
7
30
500-600
600-700
700-800
19
15
5
80
итого
В этом примере наибольшее число предприятий (30) имеет численность
работающих от 400 до 500 чел. Следовательно, этот интервал является модальным
интервалом ряда распределения.
хМо = 400; iМо = 100; fМо = 30; fМо-1 = 7; fМо+1 = 19.
Подставив эти значения в формулу, получим:
Мо 400 100
30 7
468 чел.
30 7 30 19
ΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛ
Медианой в статистике называется значение признака (варианта),
приходящееся на середину упорядоченной совокупности (упорядоченный ряд – это
расположение единиц совокупности в возрастающем или убывающем порядке).
Медиана делит упорядоченный ряд на две равные по числу единиц части, так,
что у половины единиц значение признака меньше медианы, а у другой половины
больше ее.
Для несгруппированных данных с нечетным числом членов медианой будет
значение признака (варианта), находящегося в середине упорядоченного ряда
Если упорядоченный несгруппированный ряд состоит из четного числа
членов, медианой будет среднее арифметическое из значений показателя (вариант),
расположенных в середине ряда.
Для определения медианы в сгруппированной неинтервальной совокупности
надо подсчитать сумму накопленных частот ряда. Наращивание итога
продолжается до получения накопленной суммы частот, превышающей половину.
Значение признака (варианта), соответствующая этой частоте и будет медианой.
Если сумма накопленных частот равна точно половине суммы частот, то
медиана определяется как средняя арифметическая этого значения признака и
последующего.
VVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVV
Пример
Таблица 10 - Расчет медианы в сгруппированной неинетрвальной
совокупности (вариант 1)
Месячная заработная плата
100
120
150
170
200
Число рабочих
2
6
16
12
4
Сумма накопленных частот
2
8 (2 + 6)
24 (8 + 16)
-
41
Итого
40
В нашем примере сумма частот составила 40, ее половина - 20. Накопленная
сумма частот ряда получилась равной 24. Варианта, соответствующая этой сумме,
т. е. 150 руб., и есть медиана ряда.
Таблица 11 - Расчёт медианы в сгруппированной неинетрвальной
совокупности (вариант 2)
Месячная заработная плата
Число рабочих
100
120
150
170
200
2
6
12
16
4
Итого
40
Сумма накопленных частот
2
8 (2 + 6)
20 (8 + 12)
-
Медиана будет равна Ме = 150+170 / 2 = 160 руб.
ΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛ
Медиана в интервальном вариационном ряду определяется по формуле
Ме хМе iМе
0,5 f S Ме1
,
f Ме
где хМе – начальное значение интервала, содержащего медиану;
iМе – величина медианного интервала;
Σf – сумма частот ряда;
SМе-1 – сумма накопленных частот, предшествующая медианному интервалу;
fМе – частота медианного интервала.
VVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVV
Пример
Таблица 12 - Группировка предприятий по числу рабочих, чел.
Группировка предприятий
числу рабочих, чел.
100-200
200-300
300-400
400-500
500-600
600-700
700-800
Итого
Число предприятий
1
3
7
30
19
15
5
80
Сумма
накопления
частот
1
4(1 +3)
11 (4 + 7)
41 (11 + 30)
-
Определим медианный интервал. Он соответствует интервалу 400—500, так
как сумма накопленных частот (41) превышает половину суммы всех значений
(80).
42
Значит хМе = 400; iМе = 100; Σf = 80; SМе-1 = 11; fМе = 30.
Ме 400 100
0,5 80 11
400 96,66 496,66.
30
Отсюда
ΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛ
5. Показатели вариации
Средние
величины
не являются безукоризненной
характеристикой
изучаемых совокупностей. За ними скрывается колеблемость, вариация
индивидуальных значений признаков вокруг средней.
Вариацией признаков называется различие численных значений у отдельных
единиц совокупности.
В одних случаях отдельные значения признака могут незначительно
отличаться друг от друга и от средней; в других, наоборот, - эти различия
значительны.
Для характеристики размера вариации используются специальные показатели
колеблемости:
1. размах вариации (R);
2. среднее линейное отклонение (d);
3. средний квадрат отклонения (дисперсия 2 );
4. среднее квадратическое отклонение( );
5. коэффициент вариации (V).
2
Показатели d, , , как и средние величины, могут быть простыми и
взвешенными, чем меньше d и , тем однороднее совокупность
1) Размах вариации (R) - величина разности между максимальным и
минимальным значениями признака (R= хmax xmin ).
Этот показатель представляет собой разность между максимальным и
минимальным значениями признаков и характеризует разброс элементов
совокупности. Размах улавливает только крайние значения признака в
совокупности, не учитывает повторяемость его промежуточных значений, а также
не отражает отклонений всех вариантов значений признака. Размах часто
используется в практической деятельности, например, различие между max и min
пенсией, заработной платой в различных отраслях и т.д.
2) Среднее линейное отклонение (d) - средняя арифметическая абсолютных
отклонений индивидуальных значении признака от среднего значения.
Формула среднего линейного отклонения
Простая
d
xx
n
Взвешенная d
;
xx f
f
Среднее линейное отклонение показывает, насколько в среднем отличаются
индивидуальные значения признака от среднего их значения. В практических
расчетах среднее линейное отклонение используется для оценки ритмичности
43
производства, равномерности поставок и др.
3) Средний квадрат отклонений - дисперсия ( ) представляет собой
средний квадрат отклонений индивидуальных значений признаков от их средней
величины.
Дисперсия является общепринятой мерой вариации. В зависимости от
исходных данных дисперсия также определяется по формуле простой и
взвешенной
2
Простая
2
хх
;
n
2
2
хх f
Взвешенная
f
2
При использовании взвешенной средней для расчета дисперсии в
интервальных рядах распределения в качестве вариантов значений признака
используются серединные значения (середины интервалов), не являющиеся
средним значением в группе. В результате получают приближенное значение
дисперсии.
Дисперсия как базовый показатель вариации обладает рядом вычислительных
свойств, позволяющих упростить её расчет.
К ним относятся:
• дисперсия постоянной величины равна 0;
• дисперсия не меняется, если все варианты увеличить или уменьшить на одно
и то же число А;
• если все варианты умножить (разделить) на число А, то дисперсия
увеличится (уменьшится) в A в квадрате раз.
Размерность дисперсии соответствует квадрату размерности исследуемого
признака, поэтому данный показатель не имеет общепринятой экономической
интерпретации.
Для сохранения экономического смысла рассчитывается ещё один показатель
вариации – среднее квадратическое отклонение.
4) Среднее квадратическое отклонение ( , - сигма) равно квадратному
корню из среднего квадрата отклонений индивидуальных значений признака от
средней арифметической. Его формула
Для первичного ряда
Для ряда распределения
( х х ) 2
n
( х х ) 2 f
f
Среднее квадратическое отклонение является именованной величиной, имеет
размерность усредняемого признака, экономически хорошо интерпретируется.
44
Используется для оценки надежности средней: чем меньше cреднее
квадратическое отклонение σ, тем надежнее cреднее значение признака x , тем
лучше средняя представляет исследуемую совокупность.
Для распределений, близких к нормальным между средним квадратическим
отклонением и средним линейным отклонением существует следующая
зависимость:
σ ≈ 1,25 ⋅ d.
Среднее квадратическое отклонение также, как и среднее линейное,
показывает, насколько в среднем отличаются индивидуальные значения признака
от среднего значения. По величине среднее квадратическое отклонение превышает
среднее линейное. В статистике для измерения вариации используют среднее
квадратическое отклонение.
Размах вариации, среднее линейное отклонение и среднее квадратическое
отклонение выражаются в именованных числах, в которых выражены значения
признака. Они характеризуют абсолютную меру вариации.
Их нельзя использовать для сравнения степени вариации по одному и тому же
признаку в двух группах с разным уровнем средних, а также для сравнения
вариаций двух различных признаков в одной группе.
В этих случаях используется коэффициент вариации.
5) Коэффициент вариации
V
х
100%
Он показывает, на сколько процентов в среднем индивидуальные значения
отличаются от средней арифметической. В известной степени коэффициент
является критерием надежности средней, если он велик (превышает 40%), то это
свидетельствует о сильной колеблемости в величине признака у отдельных единиц
группы, а следовательно, средняя недостаточно надежна.
Коэффициент вариации используется для характеристики однородности
исследуемой
совокупности.
Статистическая
совокупность
считается
количественно однородной, если коэффициент вариации не превышает 33% .
Коэффициент вариации - это величина относительная, что удобно для
сравнения вариаций в любых совокупностях.
VVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVV
Пример
По данным о заработной плате рабочих цеха определим среднее
квадратическое отклонение и коэффициент вариации. Среднее квадратическое
отклонение выражается в тех же единицах измерения, что и признак (метры,
тонны, рубли, проценты).
Таблица 13 - Заработная плата рабочих цеха
Заработная плата, руб
200-400
400-600
600-800
Число рабочих, чел
6
9
5
Вычислению среднего квадратического отклонения предшествует расчет
дисперсии.
45
Таблица 14 - Расчет дисперсии
Заработ
Число
ная плата, руб рабочих (f)
(х)
300
6
500
9
700
5
итого
20
хf
x- х
(x- х ) 2
(x- х ) 2 f
1800
4500
3500
9800
-190
-10
+210
-
36100
100
44100
-
216600
900
220500
438000
Определим:
среднюю арифметическую взвешенную - х
дисперсию - 2
хf 9800
490 руб.;
f
20
х х f 438000
21900 руб.;
f
20
2
среднеквадратическое отклонение - 2 21900 148 руб.
Заработная плата колеблется вокруг среднего значения на 148 руб.
Коэффициент вариации V
х
* 100%
148
* 100 30.2%
490
ΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛ
6. Сопоставимость показателей
Главнейшим требованием статистики является требование обеспечения
сопоставимости показателей, так как без сопоставимости нет сравнения, а значит,
нет объективных выводов об изучаемом социально-экономическом явлении или
процессе.
В статистике выработана определённые правила, обеспечивающие
сопоставимость показателей:
• показатели должны обладать общим содержанием: еще древние говорили,
что абсурдно сравнивать “что длиннее - дерево или ночь” или “чего больше – ума
или зерна”.
• статистические показатели должны выражаться в одинаковых единицах
измерения: расстояние – в километрах, вес – в килограммах, и т.д. Если
используются стоимостные измерители, то для обеспечения сопоставимости
должны применяться сопоставимые цены – цены базисного, либо отчётного
периода.
Например: если сравниваются стоимостные объёмы продаж 1995 и 2004 г., то
для обеспечения корректности сравнения необходимо физические (натуральные)
объёмы продаж выразить либо в ценах 1995г, либо в ценах 2004г. Кроме этого,
сопоставимость разных по содержанию главного компонента разновидностей
продукта может быть обеспечена применением условно-натуральных измерителей.
• сравниваемые показатели должны рассчитываться по единой методике.
Например, нельзя непосредственно сравнивать показатели безработицы в
России и в США, так как они рассчитываются по разным методикам.
• сравниваемые статистические показатели должны быть однородными
по времени и территории – они должны определяться за одинаковые периоды
времени, на одни и те же даты, по одной территории.
В соответствии с перечисленными правилами для обеспечения сопоставимости
46
статистических
показателей
на
практике
используются
следующие
статистические приёмы:
- для обеспечения общего содержания
– разделение разнородных совокупностей на однородные части, т.е.
группировку;
- для приведения к одинаковым единицам измерения
- использование единой системы мер и весов, условно-натуральных
измерителей, сопоставимых цен или индексов при сравнении стоимостных
показателей;
- пересчёт несопоставимых показателей по единой методике;
- приведение показателей к одинаковым периодам и моментам времени;
- приведение показателей к единой территории или кругу охватываемых
единиц.
- Замена несравнимых абсолютных показателей относительными или
средними показателями: показателями структуры, координации и т.д.
Все статистические показатели исчисляются на основе первичных данных,
собранных и определённым образом обработанных в процессе статистического
исследования.
47
5. Статистические ряды
1. Понятие и виды статистических рядов
2. Показатели рядов распределения
3. Показатели рядов динамики
4. Анализ и выравнивание рядов динамики
1. Понятие и виды статистических рядов
Результаты статистических сводок и группировок могут быть представлены в
виде статистических рядов – упорядоченных совокупностей значений
показателей (статистического признака). По своему содержанию статистические
ряды подразделяются на ряды динамики и ряды распределения.
Ряд
распределения,
представляет
собой
систематизированную
последовательность статистических единиц, сгруппированных по конкретному
признаку. Он характеризует состав изучаемого явления, позволяет судить об
однородности совокупности, закономерности распределения статистических
единиц. Обычно ряд распределения представляет собой результат структурной
группировки. Ряд распределения считается построенным, если известно, каким
образом меняются в совокупности значения признака и как часто встречаются
отдельные значения признака.
Для различных статистических признаков строятся ряды распределения
разного типа:
• атрибутивные – строятся по описательным признакам в порядке возрастания
или убывания наблюденных значений признака; примером атрибутивных рядов
могут служить распределения населения по национальности, по профессиям, по
полу; распределение предприятий по формам собственности;
• вариационные - строятся по количественным признакам, например,
распределение рабочих по уровню квалификации, по заработной плате,
распределение студентов по успеваемости.
Вариационные ряды делятся на дискретные и интервальные. В дискретных
рядах признак принимает только целые значения, например, размер семьи,
тарифный разряд. Интервальные ряды основаны на непрерывных признаках,
принимающих любые, в том числе и дробные значения. В зависимости от того,
какая структурная группировка лежит в основе интервального ряда, различают
равноинтервальные и неравноинтервальные ряды. В равноинтервальных рядах
ширина интервала является величиной постоянной, в неравноинтервальных – она
различна для разных групп.
Для отображения процессов развития, движения социально-экономических
48
явлений во времени строятся ряды динамики (хронологические, временные,
динамические
ряды),
представляющие
собой
последовательность
упорядоченных во времени значений статистического показателя.
Любой ряд динамики состоит из двух элементов:
1. показатель времени ti - это моменты или периоды времени, к которым
относятся числовые значения показателей;
2. уровень ряда yi , под которым понимается значение статистического
показателя, относящееся к определенному моменту или периоду времени.
Каждый ряд динамики может быть представлен в табличной форме - в виде
пар значений t и y; и в графической форме - в виде линейной диаграммы.
С помощью рядов динамики в статистике решают следующие задачи:
• Получение характеристик интенсивности изменения явления во времени и
характеристик отдельных уровней;
• Выявление и количественная оценка основной долговременной тенденции
развития явления;
• Изучение периодических и сезонных колебаний явления;
• Экстраполяция и прогнозирование.
При обработке статистических данных используются ряды динамики,
различающиеся по следующим признакам: по времени, форме представления
уровней, числу показателей, по расстоянию между датами или интервалами.
По времени различают моментные и интервальные ряды динамики.
В моментных рядах уровни выражают состояние явления на критический
момент времени. Особенностью моментного динамического ряда является то, что
сумма членов ряда не имеет реального смысла.
Например, численность населения, численность работающих и т.д. В таких
рядах каждый последующий уровень полностью или частично содержит значение
предыдущего уровня, поэтому суммировать уровни нельзя, так как это приводит к
повторному счету.
В интервальных – уровни отражают состояние явления за определенный
период времени – сутки, месяц, год и т.д. Это ряды показателей объема
производства, объема продаж по месяцам года, количества отработанных человекодней и т.д. Уровни интервального ряда можно суммировать.
По форме представления уровней различают ряды абсолютных,
относительных и средних величин.
По числу показателей выделяют изолированные и комплексные ряды
динамики (многомерные). Изолированный ряд строится по отдельному показателю,
комплексный – по системе взаимосвязанных показателей.
По расстоянию между датами или интервалами ряды динамики делятся на
ряды с равноотстоящими и неравноотстоящими уровнями. В рядах с
равноотстоящими уровнями расстояние между датами или периодами одинаково,
в рядах с равноотстоящими уровнями – оно различно.
Следует помнить о требовании сопоставимости уровней рядов динамики. Они
должны относиться к одинаковой территории, включать одинаковый круг
объектов, выражаться одинаковыми единицами измерения, рассчитываться до
единой методологии.
2. Показатели рядов распределения
49
Основными элементами рядов распределения являются:
1) значение признака (варианта):
2) частота (n) - число единиц совокупности, обладающих данным значением
признака. Частота показывает, сколько раз данное значение признака встречается в
совокупности; сумма всех частот всегда равна объему статистической
совокупности.
Она является исходной характеристикой любого ряда распределения. На ее
основе можно рассчитать и другие характеристики:
Частость (q) – удельный вес (доля) единиц совокупности, имеющих
определенное значение признака, т. е. это частота, выраженная в виде
относительной величины (доли единицы или процента).
Накопленная частота (N) – число единиц совокупности, у которых значение
признака не превышает данного, т. е. это частота нарастающим итогом:
Накопленная частость (Q) – удельный вес (доля) единиц, у которых значение
признака не превосходит данное, т. е. это частость нарастающим итогом:
Плотность распределения – универсальная частотная характеристика,
позволяющая перейти от эмпирического к теоретическому распределению. Для
рядов с неравными интервалами только эта характеристика дает правильное
представление
о
характере
распределения.
Плотность
распределения
рассчитывается в 2-х вариантах:
- как абсолютная плотность распределения
n
a
- как относительная плотность распределения
q
a
Плотность распределения обеспечивает сопоставимость различных рядов
распределения. Разные ряды распределения характеризуются разным набором
частотных характеристик.
VVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVV
Пример
Расчет частотных характеристик рассмотрим на следующем примере: имеется
распределение рабочих участка по стажу работы. 50 человек, стаж измеряется
числом полностью отработанных лет. На основании структурной группировки,
выполненной ранее, построим равноинтервальный вариационный ряд, m = 7, ai = 4
года. Для такого ряда рассчитываются все частотные характеристики, результаты
расчета приведены в таблице 15.
Таблица 15 – Расчет характеристик распределения рабочих участка
по стажу работы
№
Стаж работы
Часто Часто Накопле Накопле Плотность
п/п
та,
сть,
нная
нная
распределения, φ
50
Интервал шири чел.
q
частота, частость абсолю относител
N
,Q
тная
ьная
нача кон на, a n
ло
ец
1
0
4
4
6
0,12
6
0,12
1,5
0,03
2
4
8
4
8
0,16
14
0,28
2
0,04
3
8
12
4
11
0,22
25
0,5
2,75
0,055
4
12
16
4
13
0,26
38
0,76
3,25
0,065
5
16
20
4
6
0,12
44
0,88
1,5
0,03
6
20
24
4
4
0,08
48
0,96
1
0,02
7
24
28
4
2
0,04
50
1
0,5
0,01
Ито 0
28
28
50
1
1,78
0,036
го
ΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛ
Графики являются наглядной формой отображения рядов распределения. Для
изображения рядов применяются линейные графики и плоскостные диаграммы,
построенные в прямоугольной системе координат.
Для графического представления атрибутивных рядов распределения
используются различные диаграммы: столбиковые, линейные, круговые, фигурные,
секторные и т. д.
Для дискретных вариационных рядов графиком является полигон
распределения.
Для анализа рядов распределения широко используются средние показатели и
показатели вариации.
Для характеристики положения центра ряда распределения можно
использовать 3 показателя: среднее значение признака, мода, медиана.
При выборе вида и формы конкретного показателя центра распределения
необходимо исходить из следующих рекомендаций:
• для устойчивых социально-экономических процессов в качестве показателя
центра используют среднюю арифметическую. Такие процессы характеризуются
симметричными распределениями, в которых x = Me = Mo;
• для неустойчивых процессов положение центра распределения
характеризуется с помощью Mo или Me. Для асимметричных процессов
предпочтительной характеристикой центра распределения является медиана,
поскольку занимает положение между средней арифметической и модой.
Медиану используют как наиболее надежный показатель типичного значения
неоднородной совокупности, так как она нечувствительна к крайним значениям
признака, которые могут значительно отличаться от основного массива его
значений. Кроме этого, медиана находит практическое применение вследствие
особого математического свойства:
Σ |x − Me| → min
Кроме того, используются и другие структурные характеристики – квантили.
Квантили предназначены для более глубокого изучения структуры ряда
распределения (в литературе встречается другое название - градиенты).
51
Квантиль – это значение признака, занимающее определенное место в
упорядоченной по данному признаку совокупности. Различают следующие виды
квантилей:
• квартили – значения признака, делящие упорядоченную совокупность на 4
равные части;
• децили – значения признака, делящие совокупность на 10 равных частей;
• перцентели - значения признака, делящие совокупность на 100 равных
частей.
Если данные сгруппированы, то значение квартиля определяется по
накопленным частотам: номер группы, которая содержит i-ый квантиль.
Определяется как номер первой группы от начала ряда, в котором сумма
накопленных частот равна или превышает i ·N, где I – индекс квантиля.
Если ряд интервальный, то значение квантиля определяется по формуле:
Первый квартиль
Третий квартиль
1
f S Q1
Q1 хQ i 4
fQ
3
f S Q1
Q3 хQ i 4
fQ
Где х – начальное значение интервала содержащего данный квартиль
i – ширина интервала
f Q - частота интервала, содержащего данный квартиль
S – накопленная частота интервала, предшествующего интервалу,
содержащему данный квартиль
3. Показатели рядов динамики
Для обобщающих характеристик рядов динамики применяется средний
уровень, а для изучения интенсивности развития явлений абсолютный прирост,
темп роста, темп прироста, абсолютное значение одного процента прироста.
При расчете показателей динамики сравниваемый уровень называется
текущим, а уровень, с которым производятся сравнения - базисным.
Эти показатели могут рассчитываться в цепной и базисной системе расчета.
Базисная система расчета предполагает сравнение каждого последующего уровня с
уровнем, принятым за базу. При цепной системе расчета каждый последующий
уровень сравнивается с предыдущим.
Таблица 16 - Базисная и цепная системы расчетов показателей динамики
Система расчёта
Показатель
цепная
базисная
52
Абсолютный
прирост
∆у = уi –уi-1
∆у = уi –у0
Темп роста
Тр = уi / уi-1
Тр = уi / у0
Темп прироста
Тпр = Тр-1
Тпр = Тр-1
Абсолютное
значение
1% прироста
А = ∆у / Тпр(%) =
0,01· уi-1
уi – текущий (сравниваемый) уровень;
уi-1 – предыдущий уровень;
у0 – базисный уровень.
Для
обобщающей характеристики динамики рассчитывают средние
показатели.
Средний уровень моментного ряда с равноотстоящими уровнями определяется
по средней хронологической простой:
1
1
у1 у 2 у3 ... у n
2 .
у 2
n 1
Средний уровень моментного ряда с неравноотстоящими
определяется по средней хронологической взвешенной:
уi yi1 * t1 .
у
2 t i
уровнями
Средний уровень интервального ряда с равноотстоящими интервалами по
средней
арифметической
простой,
неравноинтервального
по
средней
арифметической взвешенной.
Средний абсолютный прирост - у
у n у0 у (цепн.)
.
n 1
n 1
Средний темп роста (простая средняя геометрическая)
Т n1 Т р1 Т р 2 Т р 3 ... Т рm n1
уn
.
у0
Средний темп прироста - Тпр = Тр – 1 или
Тпр = Тр · 100% - 100%,
Для изучения колеблемости (устойчивости) динамических рядов также
пользуются показателями вариации.
4. Анализ и выравнивание рядов динамики
Уровни любого ряда динамики формируются под совместным влиянием
факторов, различных как по характеру, так и силе воздействия. В первую очередь
необходимо выделить факторы эволюционного характера, оказывающие
постоянное воздействие и определяющие общее направление развития явления,
53
его долговременную эволюцию. Такие изменения динамического ряда называют
основной тенденцией развития или трендом.
Вторую группу факторов составляют факторы осциллятивного характера,
оказывающие периодическое воздействие.
Они вызывают циклические и сезонные колебания уровней динамического
ряда.
Циклические (или периодические) долговременные колебания – это
регулярные колебания, вызываемые постоянно действующими причинами,
например, циклы экономической конъюнктуры. Схематично циклические
колебания можно представить в виде синусоиды
Сезонные колебания – колебания, периодически повторяющиеся в некоторое
определенное время каждого года, в определенные дни каждого месяца или в
определенные часы суток. Они могут вызываться природно-климатическими
условиями, действием экономических, культурных и иных факторов.
Последней группой факторов, влияющих на ряд динамики являются факторы,
вызывающие нерегулярные колебания уровней. Эти факторы подразделяются
в свою очередь на:
• вызывающие спорадические изменения уровней (война, экологические
катастрофы, эпидемии и т.д.),
• случайные, слабо воздействующие, второстепенные факторы
вызывающие случайные разнонаправленные изменения уровней.
Первая задача, которая возникает при анализе рядов динамики, заключается в
выявлении и описании основной тенденции развития изучаемого явления (тренда).
Трендом называется плавное и устойчивое изменение уровней явления во
времени, свободное от случайных колебаний.
Изучение тренда включает в себя два этапа:
1. Проверка ряда на наличие тренда
2. Выравнивание ряда динамики и непосредственное выделение тренда.
В настоящее время для проверки наличия тренда известно около десятка
критериев, различающихся как по мощности, так и по сложности математического
аппарата. Наиболее часто используются метод, основанный на проверке разности
средних двух разных частей одного и того же ряда (используется t-критерий
Стьюдента) и второй метод Фостера-Стюарта.
Для непосредственного выявления тренда используют следующие методы:
• метод укрупнения интервалов;
• метод скользящей средней;
• метод аналитического выравнивания.
Все перечисленные методы относятся к группе методов сглаживания,
предполагающих наличие в исходном ряду динамики только одной компоненты –
тренда.
Метод укрупнения интервалов является одним из наиболее простых методов
непосредственного выявления основной тенденции. При использовании этого
метода ряд динамики, состоящий из мелких интервалов, заменяется рядом,
состоящим из более крупных интервалов.
Так как на каждый уровень исходного ряда влияют факторы, вызывающие их
54
разнонаправленное изменение, то это мешает видеть основную тенденцию. При
укрупнении интервалов влияние факторов нивелируется, и основная тенденция
проявляется более отчетливо. Расчет среднего значения уровня по укрупненному
интервалу осуществляется по формуле простой средней арифметической.
Недостатком этого способа является то, что сокращается число уровней ряда,
а это не позволяет учитывать изменения внутри укрупненного интервала. К его
преимуществам можно отнести сохранение природы явления.
Метод скользящей средней предполагает замену исходного ряда
теоретическим, уровни которого рассчитываются по формуле скользящей
средней. Скользящая средняя относится к подвижным динамическим средним,
вычисляемым по ряду при последовательном перемещении на один интервал. При
этом, как и в предыдущем методе, происходит укрупнение интервалов. Число
уровней, по которым укрупняется интервал, называется диапазоном укрупнения,
интервалом или периодом сглаживания α. Средняя может применятся простая и
взвешенная.
В основу расчета берут любое число периодов, всё зависит от характера
динамики и длительности ряда
У1
у1 у 2 у3
;
3
У2
у 2 у3 у 4
;
3
У3
у3 у 4 у5
и т. д.
3
Эти методы дают возможность определить общую тенденцию развития
явления, освобожденную от случайных и волнообразных колебаний, но не
позволяют получить количественного описания тренда исследуемого ряда. Для
получения обобщенной статистической модели тренда применяют метод
аналитического выравнивания.
Целью аналитического выравнивания является определение аналитической
или графической зависимости. Выравнивание ведется по разным уравнениям:
прямой, параболе, показательной кривой, гиперболе и др. (их называют полиномы).
Функция выбирается таким образом, чтобы она давала содержательное
объяснение изучаемого процесса.
Подбор функции обычно осуществляется методом наименьших квадратов
(МНК), в соответствии с которым наилучшим образом тренд описывает временная
функция, обеспечивающая минимальную величину суммы квадратов отклонений
эмпирических уровней ряда от соответствующих уровней теоретического ряда:
y
~
yi
min
2
i
где yi - фактические уровни;
~
y i - выровненные по функции уровни ряда (т.н. теоретические).
Уравнение прямой используют в тех случаях, когда стабильны абсолютные
приросты. Оно имеет следующий вид:
~
~
У t a bt
где У t — теоретическое значение выровненного ряда;
a,b - параметры уравнения.
Параметры уравнения находятся методом наименьших квадратов,
соответствии с которым получают систему нормальных уравнений:
n a b t y
2
a t b t yt
в
55
Для решения системы можно использовать любой известный метод, но
предварительно необходимо решить проблему замены показателей времени, что
позволит значительно упростить расчет параметров.
Хронологические показатели заменяются числовыми аналогами таким
образом, чтобы сумма новых показателей времени по ряду была равна нулю.
При нечетном числе уровней за начало отсчета t=0 принимают центральный
интервал. Например,
2000 г. 2001 г. 2002 г. 2003 г. 2004 г. 2005 г. 2006 г.
-3
-2
-1
0
+1
+2
+3
При четном числе уровней значения условных уровней будут выглядеть
следующим образом:
2000 г. 2001 г. 2002 г. 2003 г. 2004 г. 2005 г.
-3
-2
-1
+1
+2
+3
Применение условных показателей позволяет упростить систему уравнений до
вида:
n a y
2
b t yt
Таким образом, параметры нашего уравнения будут равны:
а
b
y
n
yt
t
2
Параметр a в линейной трендовой модели обычно интерпретации не имеет, но
иногда его рассматривают как обобщенный начальный уровень ряда.
Параметр b в трендовом уравнении называется коэффициентом регрессии.
Он определяет направление развития явления: при b>0 –уровни ряда динамики
равномерно возрастают, при b<0 – равномерно снижаются. Коэффициент
регрессии показывает, насколько в среднем изменится уровень ряда при изменении
времени на единицу. Это означает, что параметр b можно рассматривать как
средний абсолютный прирост с учетом тенденции к равномерному росту (росту в
арифметической прогрессии).
Уравнение параболы используется тогда, когда абсолютные приросты не
стабильны, а изменяются (возрастая или снижаясь) примерно на одну и ту же
величину. Оно имеет следующий вид:
~
У t a bt ct 2 ,
Параметры уравнения полученные методом наименьших квадратов имеют вид:
t y t yt
a
n t ( t )
4
2
4
2 2
2
yt
b
t
2
c
n yt 2 t 2 y
n t 4 ( t 2 ) 2
56
~
t
У
Показательная функция: t ab ,
Применяется для описания динамических рядов со стабильными цепными
темпами роста. Такие динамические ряды отражают развитие в геометрической
прогрессии.
Для исследования близости трендового уравнения фактическому ряду
применяется критерий Фишера.
Исследования динамики социально-экономических явлений, выявление и
характеристика основной
тенденции развития дают основание для
прогнозирования, определения будущих размеров уровня экономического
явления.
Применение прогнозирования предполагает, что закономерность развития,
действующая в прошлом (внутри ряда динамики), сохранится и в прогнозируемом
будущем, т. е. прогноз основан на экстраполяции. Экстраполяция, проводимая в
будущее, называется перспективой.
Следует иметь в виду, что экстраполяция в рядах динамики носит
приближенный характер. Точность прогноза зависит от сроков прогнозирования:
чем они короче, тем надежнее результат экстраполяции, так как за короткий период
времени не успевают значительно измениться условия развития явления и характер
его динамики. Обычно рекомендуется, чтобы срок прогноза не превышал 1/3
длительности базы расчета тренда.
В зависимости от того, какие принципы и какие исходные данные положены в
основу прогноза, можно выделить следующие элементарные методы
экстраполяции: среднего абсолютного прироста, среднего темпа роста и
экстраполяции на основе выравнивания рядов по какой-либо аналитической
формуле.
Прогнозирование по среднему абсолютному приросту может быть выполнено
в том случае, если есть уверенность считать общую тенденцию линейной, т. е.
метод основан
на
предположении равномерном изменении уровня (под
равномерностью понимается стабильность абсолютных приростов).
Для нахождения интересующего нас аналитического выражения тенденции на
любую дату t необходимо определить средний абсолютный прирост и
последовательно прибавить его к последнему уровню ряда столько раз, на сколько
периодов экстраполируется ряд, т. е. экстраполяцию можно сделать по следующей
формуле:
~
У n1 У n У ,
где
У n - фактическое значение в последней n-ой точке ряда;
~
У n1 _ прогнозная оценка значения уровня в точке п + 1;
у - значение среднего прироста, рассчитанное для временного ряда у1, у2, …,
уп.
Прогнозирование по среднему темпу роста можно осуществлять в случае,
когда есть основание считать, что общая тенденция ряда характеризуется
показательной кривой. Для нахождения тенденции в этом случае необходимо
57
определить средний
коэффициент
роста,
возведенный
соответствующую периоду экстраполяции, т. е. по формуле
в
степень,
~
У n1 У n Т р ,
где Уn+1 — прогнозная оценка значения уровня в точке n + 1;
Уn - фактическое значение в последней n-ой точке ряда;
Тр
— средний темп роста, рассчитанный для ряда у1, у2, ..., уn (не в %-м
выражении).
Прогнозирование на основе аналитического выравнивания является
наиболее распространенным методом прогнозирования. Для получения прогноза
используется аналитическое выражение тренда. Чтобы получить прогноз,
достаточно в подобранной модели продолжить значение условного показателя
времени.
VVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVV
Пример
На основании данных таблицы необходимо
выявить характер и тип динамики;
определить существующую тенденцию изменения, используя для этого
аналитический прием,
осуществить прогноз.
Таблица 17 - Выплавка металла
Месяц
1 2 3 4 5 6 7 8 9 10 11 12
Выплавка
металла, 36 42 44 54 43 55 41 43 39 37 40 42
т
Произведем сглаживание ряда динамики методом трехчленной скользящей
средней. Взяв данные за каждые три месяца, исчислим трехчленные скользящие
суммы, со сдвигом на месяц:
у1
36 42 44 122
40,7;
3
3
у2
42 44 54
46,7.
3
Таблица 18 - Выявление тенденции изменения объемов выплавки металла
Месяц
Выплавка
металла, т
1
2
3
36
42
44
4
5
6
54
43
55
Средняя
сумма по
трехмесячным
периодам
122
152
месячная
средняя по
трехмесячным
периодам
Средняя скользящая
период
скольжения
сумма
средняя
40,6
1-3
2-4
122
140
40,7
46,7
50,6
3-5
4-6
5-7
141
152
139
47,0
50,6
46,3
58
7
8
9
10
11
12
41
43
39
37
40
42
123
41,0
119
39,6
6-8
7-9
8-10
9-11
10-12
139
123
119
116
119
46,3
41,0
39,6
38,6
39,6
-
-
-
По результатам выравнивания можно сделать вывод о росте выплавки металла
в первом полугодии и затем о его снижении во втором.
Произведем сглаживание динамического ряда методом аналитического
выравнивания по уравнению прямой:
~
У t a bt
Способ наименьших квадратов дает систему двух нормальных уравнений для
нахождения параметров а и b.
Выполнив необходимые расчеты, получим:
a
у 516
43,0;
n
12
b
tу 59
0,32.
t 2 184
В результате получаем суммирующее уравнение основной тенденции
выплавки металла за 12 месяцев года
~
У t 43 0,32t.
Подставляя в уравнение принятые условные обозначения t, вычислим
выровненные уровни ряда динамики:
~
январь - У 1 = 43 - 0,32*7 = 40,76;
~
февраль - У 2 = 43 - 0,32*8 = 40,44 и т. д.
ΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛ
59
6. Выборочное наблюдение
1. Понятие и задачи выборочного наблюдения
2. Ошибки выборки
3. Определение необходимой численности выборки
4. Распространение выборочных результатов
5. Малая выборка
1. Понятие и задачи выборочного наблюдения
Выборочным называется такое статистическое исследование, при котором
обобщающие показатели и характеристики изучаемой совокупности
устанавливаются по некоторой ее части, сформированной на основе
положений случайного отбора.
В основе выборочного исследования лежит несплошное наблюдение, при
котором обследуются не все единицы совокупности, а лишь определенная их часть.
Выборочное исследование широко применяется на практике, поскольку
обладает существенными преимуществами по сравнению с другими методами
получения статистических данных. К ним относятся:
• Достаточно высокая точность результатов обследования благодаря
использованию более квалифицированных кадров, что приводит к сокращению
ошибок регистрации;
• Экономия времени и средств в результате сокращения объема работы,
большая оперативность в получении данных о результатах обследования;
• Возможность исследования очень больших статистических совокупностей;
• Выборочный метод является единственно возможным, если сбор
информации связан с разрушением или потерей по истечении времени единиц
наблюдения, например, при контроле качества продукции;
• Возможность исследования недоступных в полном объеме совокупностей.
При выборочном исследовании изучается сравнительно небольшая часть
статистической совокупности (5-10%, реже 20-25% объема ее единиц).
Переход статистики РФ на международные стандарты системы национального счетоводства требует
более широкого применения выборки для получения и анализа показателей Системы национальных счетов (СНС) не
60
только в промышленности, но и в других сферах экономики. К выборочному наблюдению статистика прибегает
по различным причинам. На современном этапе появилось множество субъектов хозяйственной деятельности,
которые характерны для рыночной экономики. Речь идет об акционерных обществах, малых и совместных
предприятиях и т. д. Сплошное обследование этих статистических совокупностей, состоящих из десятков и сотен
тысяч единиц, потребовало бы огромных материальных, финансовых и иных затрат. Использование же
выборочного обследования позволяет значительно экономить силы и средства, что имеет немаловажное значение.
Наряду с экономией ресурсов одной из причин превращения выборочного наблюдения в важнейший источник
статической информации является возможность значительно ускорить получение необходимых данных. Ведь при
обследовании, скажем, 10% единиц совокупности будет затрачено гораздо меньше времени, а результаты могут
быть представлены быстрее и будут более актуальными. Фактор времени важен для статистического исследования особенно в условиях изменяющейся социально-экономической ситуации.
При проведении выборочного наблюдения вся совокупность единиц
называется генеральной совокупностью, а та часть совокупности единиц, которая
подвергается выборочному обследованию — выборочной совокупностью.
Задача выборочного наблюдения — получить правильное представление о
показателях всей генеральной совокупности на основе изучения выборочной
совокупности. При выборочном наблюдении имеют дело с двумя категориями
обобщающих показателей: с относительными и средними величинами.
В таблице представлены основные характеристики параметров генеральной и
выборочной совокупности в общепринятой системе обозначений
Таблица 19 - Основные характеристики параметров генеральной и выборочной
совокупностей
Характеристика
Генеральная
совокупность
Выборочная
совокупность
Объем совокупности (общая
численность единиц)
Численность единиц, обладающих
определенным значением признака
Доля единиц, обладающих
определенным значением признака
Среднее значение признака
N
n
M
m
p = M/N
w = m/n
Дисперсия количественного
признака
Дисперсия доли
х
х
N
хх
2
N
p2 pq
~
х
2
х
n
2
х ~
х
n
2
w2 w(1 w)
Выборочная дисперсия немного меньше генеральной, при этом между ними
соблюдается следующее примерное соотношение (доказано математической
статистикой):
2 ген 2 выб (
n
)
n 1
61
Большое влияние на результаты выборочного наблюдения оказывает выбор
способа формирования выборочной совокупности.
Способ отбора определяет конкретный механизм или процедуру выборки
единиц из генеральной совокупности. В практике выборочных обследований
наибольшее распространение получили следующие виды выборки:
• собственно-случайная;
• механическая;
• типическая;
• серийная;
• комбинированная.
Собственно-случайная выборка заключается в отборе единиц из генеральной
совокупности наугад или наудачу без каких-либо элементов системности.
Технически собственно-случайный отбор проводят методом жеребьёвки или по
таблице случайных чисел.
Механическая выборка применяется в случаях, когда генеральная
совокупность каким-либо образом упорядочена, т. е. имеется определённая
последовательность в расположении единиц (табельные номера работников,
списки избирателей, телефонные номера респондентов, номера домов и квартир и
т. п.). Для определения средней ошибки механической выборки используется
формула средней ошибки при собственно-случайном бесповторном отборе.
Типический отбор используется в тех случаях, когда все единицы
генеральной совокупности можно разбить на несколько типических групп. При
обследовании населения такими группами могут быть, например районы,
социальные, возрастные или образовательные группы, при обследовании
предприятий — отрасль или подотрасль, форма собственности и т. п. Типический
отбор предполагает выборку единиц из каждой типической группы собственнослучайным или механическим способом.
Серийный отбор удобен в тех случаях, когда единицы совокупности
объединены в небольшие группы или серии. В качестве таких серий могут
рассматриваться упаковки с определенным количеством продукции, партии товара,
студенческие группы, бригады и другие объединения. Сущность серийной выборки
заключается в собственно-случайном или механическом отборе серий, внутри
которых производится сплошное обследование единиц. Число серий генеральной
совокупности – R, число серий выборочной совокупности – r.
По способу проведения отбор может быть повторным и бесповторным. При
повторном отборе каждая единица совокупности после исследования её признака
возвращается обратно в генеральную совокупность и может быть выбрана ещё раз.
При бесповторном отборе каждая единица совокупности может быть отобрана
один раз, так как после изучения её признака она не возвращается в генеральную
совокупность. Бесповторный отбор дает более точные результаты по сравнению с
повторным, так как при одном и том же объёме выборки наблюдения охватывает
больше единиц генеральной совокупности. Поэтому он находит более широкое
применение в статистической практике. И только в тех случаях, когда
бесповторный отбор провести нельзя, используется повторная выборка (при
обследовании потребительского спроса, пассажирооборота и т. п.).
62
Рассмотренные способы формирования выборки могут применяться в «чистом
виде», а могут комбинироваться в различных сочетаниях и последовательности.
Использование нескольких методов формирования выборки в одном выборочном
исследовании называется комбинированной выборкой (отбором).
2. Ошибки выборки
Выборочным обследованиям свойственны ошибки выборки – то есть
расхождения между значениями
показателей, полученный по выборке и
соответствующими параметрами генеральной совокупности.
По своей природе ошибки выборки могут быть тенденциозными и
случайными.
Основной организационный принцип выборочного наблюдения состоит в том,
чтобы не допускать тенденциозного подбора совокупности, т. е. необходимо
строгое соблюдение принципа отбора. Отбор конкретных единиц должен быть
произведен не по усмотрению того лица, которое проводит обследование, а в
случайном порядке. В этом заключается принцип случайного отбора. Случайный
отбор при правильной организации гарантирует от тенденциозных ошибок
выборки.
Ошибка выборки определяется, прежде всего, численностью выборки. Чем
больше численность выборки при прочих равных условиях, тем меньше величина
ошибки выборки. Охватывая выборочным обследованием все больше и больше
единиц генеральной совокупности, мы тем самым более точно характеризуем всю
генеральную совокупность. Если же численность выборки довести до численности
генеральной совокупности, то выборочное обследование становится сплошным и
вопрос об ошибке выборки отпадает.
Ошибка выборки также определяется степенью варьирования изучаемого
признака, а степень варьирования характеризуется в статистике средним квадратом
отклонений — дисперсией.
При одинаковой численности выборочных совокупностей ошибка выборки
будет меньше в той совокупности, в которой изучаемый признак варьирует
(колеблется) в меньшей степени, т. е. совокупность более однородна.
Зависимость величины ошибки выборки от ее абсолютной численности и. от
степени варьирования признака находит выражение в формулах средней ошибки
выборки. Средняя ошибка выборки - это расхождение между генеральными и
выборочными характеристиками.
Средняя ошибка выборки (собственно-случайный повторный отбор)
определяется по формуле:
2
n
где — средняя ошибка выборочной средней;
— дисперсия выборочной совокупности;
п — численность выборки.
63
Предельная ошибка выборки:
Δ = t*μ
где t – коэффициент кратности (доверия), определяемый в зависимости от
уровня вероятности.
Значения данного коэффициента определяются на основе специально
составленных математических таблиц.
Наиболее часто применяются следующие значения:
Таблица 20 – Значения коэффициента доверия при разных уровнях
вероятности
t
1,0
1,5
1,96
2,0
2,58
3,0
вероятность
0,683
0,866
0,950
0,954
0,990
0,997
Предельная ошибка выборки отвечает на вопрос о точности выборки с
определенной долей вероятности. Так, при t = 1 вероятность отклонения
выборочных характеристик от генеральной на величину средней ошибки
составляет 0,683. Следовательно, в среднем из каждой 1000 выборок 683 дадут
обобщающие характеристики, которые будут отличаться от генеральных не более
чем на величину средней ошибки.
Расчет средней и предельной ошибок выборки позволяет определить пределы,
в которых будут находиться характеристики генеральной совокупности:
х х х
w p w
VVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVV
Пример.
При проверке импортируемого груза на таможне методом случайной
повторной выборки было отобрано 200 изделий. В результате был установлен
средний вес изделия 30 г. при среднем квадратичном отклонении 4 г. С
вероятностью 0,997 определите пределы, в которых находится средний вес изделия
в генеральной совокупности.
Прежде всего, необходимо рассчитать предельную ошибку выборки. Так как
при вероятности 0,997 - t= 3, она равна
х t
х
n
3
4
0.84
200
Определим пределы генеральной средней
30 - 0,84 ≤ х ≤ 30 + 0,84.
С вероятностью 0,997 можно утверждать, что средний вес изделия в
генеральной совокупности находится в пределах 29,16 ≤ х ≤ 30,84.
ΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛ
Применительно к бесповторной случайной выборке формула средней ошибки
выборки будет иметь вид:
2
n
1
n
N
64
n
Так как всегда п меньше N, то дополнительный множитель 1 всегда
N
будет меньше единицы. Отсюда следует, что величина ошибки выборки при
бесповторном отборе всегда будет меньше, чем при повторном отборе. В то же
время при сравнительно небольшом проценте выборки этот множитель близок к
единице, например, при 5%-й выборке он равен 0,95. Поэтому часто в практике
пользуются для определения ошибки выборки формулой без добавления
n
множителя 1 , хотя выборку организуют как бесповторную. Тем самым
N
несколько увеличивается размер ошибки выборки. К этому нужно добавить, что
ошибка выборки зависит главным образом от абсолютной численности выборки и
в меньшей степени от её относительной доли.
Для увеличения точности расчетов, вместо множителя 1
n
следует брать
N
N n
множитель
. Но при большой численности генеральной совокупности
N 1
различие между этими выражениями практического значения не имеет.
Таблица 21 - Формулы расчета средней ошибки выборки при различных
способах отбора
Вид выборки
Отбор
повторный
средней
доли
Собственнослучайная
средней
2
n
w(1 w)
n
Серийная (с
равновеликими
сериями)
2
w2
2
r
r
Типическая
(пропорционально
объему групп) и
механическая
в г2
w(1 w)
n
2
n
бесповторный
доли
n
1
n
N
r
1
r R
2
n
1
n
N
w(1 w)
n
1
n
N
w2
r
1
r
R
w(1 w)
n
1
n
N
VVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVV
Пример.
Предположим, что производится 225 наблюдений в первом случае из
генеральной совокупности в 4500 единиц и во втором - из генеральной
совокупности в 225000 единиц. Пусть дисперсии в обоих случаях равны 25. Тогда в
первом случае при 5%-м отборе ошибка выборки составит
25
225
1
0,11 0,95 0.323
225 4500
65
225
100 она будет равна
Во втором случае при 0,1%-м отборе
225000
25
225
1
0,11 0,999 0.331
225 225000
Хотя во втором случае процент выборки уменьшился в 50 раз, ошибка
выборки увеличилась незначительно, так как численность выборки не изменилась.
Предположим теперь, что численность выборки увеличили до 625
наблюдений, при генеральной совокупности в 225000 единиц. В этом случае
ошибка выборки будет равна
25
625
1
0,04 0,99 0.199.
225 225000
Таким образом, увеличив численность выборки в 2,8 раза при одной и той же
численности генеральной совокупности в 225000 единиц, мы снизили размеры
ошибки более чем в 1,6 раза. Ошибка выборки в этом случае будет также в 1,6 раза
меньше, чем в первом случае, когда было отображено 225 единиц из 4500, хотя там
применялся 5%-й отбор, а здесь всего лишь около 0,3%-й.
ΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛ
VVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVV
Пример.
В городе проживает 250 тыс. семей. Для определения среднего числа детей в
семье была организована 2%-я случайная бесповторная выборка семей. По её
результатам было получено следующее распределение семей по числу детей
Таблица 22 - Распределение семей по числу детей
Число детей в семье
0
1
2
3
Количество семей
1000 2000 1200 400
4
200
5
200
С вероятностью 0,954 определите пределы, в которых будет находиться среднее
число детей в генеральной совокупности.
Вначале на основе имеющегося распределения семей определим выборочные
среднюю и дисперсию.
Таблица 23 - Расчетные данные для определения выборочной средней
и дисперсии
Число Количество
xi , fi
детей в семей, f i
хi – х̃
(хi – х̃)2 (хi – х̃)2 fi
семье, хi
0
10000
0
-1,5
2,25
2250
1
2000
2000
-0,5
0,25
500
2
1200
2400
0,5
0,25
300
3
400
1200
1,5
2,25
900
4
200
800
2,5
6,25
1250
5
200
1200
3,5
12,25
2450
Итого
5000
7400
7650
66
х̃ = 7400/5000 = 1,5 (чел.);
х2
7650
1,53.
5000
Вычислим предельную ошибку выборки с учётом того, что при р=0,954, t = 2.
~х t
~x
n
1.53
5000
1 2
1
0.035
n N
5000 250000
2
Следовательно, пределы генеральной средней: х ~х х 1,5 0,035.
Таким образом, с вероятностью 0,954 можно утверждать, что среднее число
детей в семьях города практически не отличается от 1,5, т. е. в среднем на каждые
две семьи приходится три ребёнка.
ΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛ
VVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVV
Пример.
В городе А 500 тыс. жителей. По материалам учета городского населения было
обследовано 50 тыс. жителей методом случайного бесповторного отбора. В
результате обследования установлено, что в городе 15% жителей старше 60 лет. С
вероятностью 0,683 определите пределы, в которых находится доля жителей в
городе в возрасте старше 60 лет. Генеральная доля равна
р ± w.
Выборочная доля равна w = 15%.
С вероятностью 0,683 определим ошибку выборки для доли:
w t
w (1 w)
n
0,15 0,85
1 1
0,9 0,048, или5%
n
50
N
Определим верхнюю границу генеральной доли pв = 0,15 + 0,045 - 0,20, или
20%.
Определим нижнюю границу генеральной доли pн = 0,15 - 0,05 = 0,1, или 10%.
С вероятностью 0,683 можно утверждать, что доля жителей в возрасте старше
60 лет в городе А находится в пределах 10 % < р < 20%.
ΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛ
3. Определение необходимой численности выборки
Прежде чем приступить к проведению выборочного наблюдения, надо
установить необходимую численность выборки, т.е. объем выборки, необходимый
для того, чтобы обеспечить результаты выборочного наблюдения с заранее
установленной точностью.
Необходимая численность выборки (n) определяется на основе формул
предельной выборки.
Предельная ошибка выборки и её вероятность при этом являются заданными.
При бесповторном случайном отборе (механическом бесповторном)
необходимая численность выборки определяется по формуле
n
t 2 2 N
.
N 2 t 2 2
При повторном случайном отборе (механическом повторном) численность
выборки определяется по формуле
67
n
t
.
2
2
2
Аналогично определяется объем выборки и при определении доли, только
вместо дисперсии используется выражение w(1-w)
Определение ошибки выборочной средней типической выборки.
При типической (районированной) выборке генеральная совокупность
разбивается на однородные типические группы по какому-либо признаку или
районы. Из каждой типической группы или района в случайном порядке
отбираются единицы выборочной совокупности. Отбор единиц из типов может
производиться тремя методами: пропорционально численности единиц типических
групп,
непропорционально
численности
единиц
типических
групп,
пропорционально колеблемости в группах.
Рассмотрим типическую выборку с пропорциональным отбором единиц из
типических групп. Объём выборки из типической группы при отборе,
пропорциональном численности единиц типических групп, определяется по
формуле
n ni
Ni
,
N
где ni - объём выборки из типической группы;
n - общий объём;
Ni - объём типической группы;
N - объём генеральной совокупности.
Определение необходимой численности выборки для расчета выборочной доли
при районированной и типической выборке.
Если отбор внутри типических групп производится методом случайного или
механического отбора, то численность выборочной совокупности определяется по
формуле:
n
t 2 w (1 w) N
,
2 N t 2 w (1 w)
где w (1 w) - средняя из групповых дисперсий.
VVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVV
Пример.
При определении средней продолжительности поездки на работу планируется
провести выборочное обследование населения города методом случайного
бесповторного отбора. Численность работающего населения города составляет
170,4 тыс. чел. Каков должен быть необходимый объём выборочной совокупности,
чтобы с вероятностью 0,954 ошибка выборки не превышала 5 мин. при
среднеквадратическом отклонении 25 мин.?
n
t 2 2 N
. t = 2, так как вероятность 0,954; σ = 25; N = 170400; ∆ = 5;
N 2 t 2 2
68
n
2 25 170400
2500 170400
4260000
99,9 100чел.
2
2
2500 170400 25
42625
2 25 170400 5
2
2
2
ΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛ
4. Распространение выборочных результатов
Распространение выборочных оценок на генеральную совокупность состоит в
определении характеристик генеральной совокупности на основе характеристик
выборочной. Применяются два способа распространения выборочных данных:
1) способ прямого пересчета;
2) способ поправочных коэффициентов.
При первом способе средние величины и доли, полученные в результате
исследования выборочной совокупности, переносятся на генеральную. Если
известна численность единиц этой совокупности, то можно найти общий объём
признака. Например, если средняя выборочная урожайность зерновых равна 20
ц/га, а предельная ошибка выборки ±1,5 ц/га, при известной посевной площади в
20000 га можно установить ожидаемые пределы валового сбора зерновых: от
18,5*20000 = 37 тыс. т до 21,5 * 20000 = 43 тыс. т с вероятностью, принятой при
расчете предельной ошибки.
Второй способ используется для уточнения данных сплошного наблюдения.
Сущность этого метода заключается в том, что на основании сопоставления
данных сплошного и данных выборочного наблюдения устанавливают процент
расхождений (процент недоучета), который служит коэффициентом поправки. Так,
если выборочное наблюдение показало, что недоучет величины исследуемого
явления составил 0,5%, то эту последнюю величину (поправочный коэффициент)
распространяют на результат, полученный при сплошном наблюдении, путём увеличения его на 0,5%.
VVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVV
Пример.
При проведении учета коммерческих палаток в городе было зарегистрировано
следующее их количество в районах: А — 2000; Б — 1500; В — 750. С целью
проверки данных сплошного учета проведены контрольные обходы части
обследованных районов. Их результаты содержатся в таблице.
Таблица 24 - Количество коммерческих палаток в районах города
до и после контрольных обходов
Район
Зарегистрировано при
сплошном учете
Установлено при
контрольном обходе
Коэффициент
недоучета
А
Б
400
300
420
310
1,050
1,033
В
150
160
1,067
Рассчитанный по каждому району коэффициент недоучета является основой
уточнения имеющихся данных.
В нашем примере количество коммерческих палаток (по данным сплошного
учета) следует умножить на рассчитанный для каждого района коэффициент
69
недоучета. В итоге получим результаты, представленные в таблице.
Таблица 25 - Уточненные данные учета коммерческих палаток в районах
города
Количество коммерческих палаток в районах
Данные сплошного наблюдения
Численность с поправкой на недоучет
А
Б
В
2000
2100
1500
1550
750
800
ΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛ
5. Малая выборка
В практике статистического исследования в условиях рыночной экономики всё
чаще приходится сталкиваться с небольшими по объёму так называемыми малыми
выборками. Под малой выборкой понимается такое выборочное наблюдение, численность единиц которого не превышает 30. В настоящее время малая выборка
используется более широко, чем раньше и, прежде всего, за счет статистическою
изучения деятельности малых и средних предприятий, коммерческих банков,
фермерских хозяйств и т. д. Их количество в определённых случаях, особенно при
региональных исследованиях, а также величина характеризующих их показателей
(например, численность занятых) часто незначительны. Поэтому, хотя общий
принцип выборочного обследования (с увеличением объёма выборки повышается
точность выборочных данных) остаётся в силе, иногда приходится ограничиваться
малым числом наблюдений. Наряду со статистическим изучением рыночных
структур эта необходимость возникает при выборочной проверке качества
продукции, в научно-исследовательской работе и в ряде других случаев.
При оценке результатов малой выборки величина генеральной дисперсии в
расчетах не используется. Для определения возможных пределов ошибки
пользуются так называемым критерием Стьюдента, определяемым по формуле
t
где м.в.
n 1
~
xx
м.в.
,
- мера случайных колебаний выборочной средней в малой
выборке.
Приведем выдержку из таблицы распределения Стьюдента.
Таблица 26 - Распределение вероятности в малых выборках в зависимости
от коэффициента доверия t и объема выборки n*
t
n
0.5
1,0
1,5
2,0
2.5
3,0
4
5
6
7
8
9
10
15
20
∞
348
608
770
860
933
942
356
626
792
884
946
960
362
636
806
908
955
970
366
644
S16
908
959
970
368
650
832
914
963
980
370
654
828
920
966
938
372
656
832
924
968
984
376
666
846
936
936
975
992
378
670
850
940
978
992
383
683
865
954
988
997
При n = ∞ в таблице даны вероятности нормального распределения. Для определения вероятности соответствующие табличные значения следует разделить
70
на 1000.
Как видно из таблицы, при увеличении n это распределение стремится к
нормальному и при п = 20 уже мало от него отличается. Покажем, как пользоваться
таблицей распределения Стьюдента.
VVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVV
Пример.
Предположим, что выборочное обследование 10 рабочих малого предприятия
показало, что на выполнение одной из производственных операций рабочие
затрачивали времени (мин.): 3,4; 4,7; 1,8; 3,9; 4,2; 3,9; 4,2; 3,9; 3,7; 3,2; 2,2; 3,9.
Найдём выборочные средние затраты
3,4 4,7 1,8 ... 2,2 3,9
~
х
3,49 мин.
10
Выборочная дисперсия
(3,4 3,49) 2 (4,7 3,49) 2 ... (3,9 3,49) 2
0,713.
10
2
х
Отсюда средняя ошибка малой выборки равна
м .в .
0,713
0,28 мин.
10 1
По таблице находим, что для коэффициента доверия t = 2 и объема малой
выборки п — 10 вероятность равна 0,924. Таким образом, с вероятностью 0,924
можно утверждать, что расхождение между выборкой и генеральной средней
лежит в пределах от —2 μ до +2μ , т. е. разность х̃ - х не превысит по абсолютной
величине 0,56 (2 *· 0,28). Следовательно, средние затраты времени во всей
совокупности будут находиться в пределах от 2,93 до 4,05 мин. Вероятность того,
что это предположение в действительности неверно и ошибка по случайным
причинам будет по абсолютной величине больше, чем 0,56, равна 1 - 0,924 = 0,076.
ΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛ
71
7. Индексы
1.
2.
3.
4.
Понятие индексов
Виды и формы построения индексов
Индексы цен
Индексные системы и факторный анализ
1. Понятие индексов
Индексы используются в качестве обобщающих характеристик изучаемых
явлений. В переводе с латинского “index” означает указатель, показатель.
Под индексом в статистике понимается относительный показатель, который
характеризует соотношение уровней социально-экономического явления во
времени по сравнению с планом или в пространстве.
От обычных относительных показателей индексы отличаются тем, что
характеризуют изменение не только простых, но и сложных явлений. Сложные
явления состоят из непосредственно несоизмеримых элементов, а простые – только
из однородных элементов. Индексы, как правило, не ограничиваются простым
показом соотношения, а выявляют роль и значение отдельных условий и
составных частей данного сложного явления. Индекс применяется также для
изучения роли факторов, оказывающих влияние на изменение данного явления.
Показатель, для которого рассчитывается индекс, называется индексируемой
величиной. Так, в индексе себестоимости индексируемой величиной является
себестоимость, в индексе физического объема – объем выпуска в натуральном
выражении.
При расчете индексов особое внимание следует уделять базе сравнения. В
индексах, характеризующих изменение явления в динамике, различают два
периода: базисный и текущий (отчетный).
Базисный — это начальный период, т. е. период, с которым производится
сравнение. Текущий (отчетный) — это период, уровень которого сравнивается.
С помощью индексов решаются следующие задачи:
1. Оценка изменений сложных явлений и отдельных их частей (например, на
сколько в текущем периоде изменился объем продаж по сравнению с
предыдущим).
2. Определение влияния отдельных факторов на общую динамику сложного
явления (например, влияние изменения цен на объем продаж), для чего
используется индексный анализ.
Индекс является результатом сравнения двух одноименных величин,
72
числитель индексного отношения - показатели текущего периода и знаменатель
— база сравнения - показатели базисного периода или плана.
Показатели:
q – количество продукции одного вида в натуральном выражении,
p – цена единицы продукции,
z – себестоимость единицы продукции,
w – выработка продукции на 1-ого работника или в единицу времени,
t – трудоемкость единицы продукции.
2. Виды и формы построения индексов
Многообразие задач и исходного материала для расчетов вызывают
необходимость применения разного типа индексов. Для их систематизации
применяется сложная классификация.
73
Классификационные
признаки
Степень охвата
Индивидуальные
Сводные
База сравнения
Динамические
Территориальные
Вид соизмерителя
С постоянными весами
С переменными весами
Форма построения
Агрегатные
Средние
Характер объекта
исследования
Количественные показатели
Качественные показатели
Физический объем продукции
Объект
исследования
Производительность труда
Цена и др.
Состав явления
Переменного состава
Постоянного (фиксированного)
состава
Период исчисления
Годовой
Квартальный
Месячный
Недельный
Рисунок 1 - Классификации индексов
По характеру индексируемых величин индексы разделяются на индексы
объемных показателей и индексы качественных показателей. К индексам
объемных показателей относятся индекс физического объема продукции, индекс
объема выпущенной продукции и т. д. К индексам качественных показателей
относятся индексы цен, себестоимости, производительности труда и т. д.
74
По базе сравнения все индексы делятся на динамические и территориальные.
Первая группа индексов отражает изменение явления во времени, а вторая
применяется для межрегиональных сравнений.
Индексы могут быть индивидуальными и сводными (общими).
Индивидуальный индекс – простейшая форма индекса.
Индивидуальными индексами называются относительные показатели,
характеризующие соотношение отдельных величин экономических явлений: цены
одного товара, себестоимости одного изделия, количества какого-либо одного
реализованного продукта и т. п., обозначаются буквой i.
Индивидуальный индекс как относительное число получается в результате
сравнения двух абсолютных уровней изучаемого явления.
Для исчисления индивидуальных индексов применяются следующие формулы.
i
х1
х0
В качестве х может быть любой экономический показатель (количество
продукции, цена, себестоимость и др.).
Индивидуальный индекс цен:
ip
p1
p0
где p1 — цена за единицу количества продукта в текущем или отчетном
периоде;
ро — цена за единицу количества продукта в базисном периоде.
Например, цена за 1 кг картофеля в августе была 10 рублей, а в сентябре 8
рублей. Определить изменение цен в сентябре по сравнению с августом.
Отсюда индивидуальный индекс цен i составит
ip
p1 8
0,8 или 80 %
p 0 10
Это означает, что цена на картофель в сентябре по сравнению с августом
снизилась на 20%.
Для того чтобы показать изменение количества продаваемого продукта или
выпуска продукции, употребляется индивидуальный индекс количества, или
физического объема (iq):
iq
q1
q0
где q1 — количество реализованного товара в текущем или отчетном периоде;
qо — количество реализованного товара в базисном периоде.
Продолжим пример и предположим, что в августе было продано 3800 кг
картофеля, а в сентябре – 5200 кг.
Индивидуальный индекс физического объема:
iq
q1 5200
1,37 или 137 %
q 0 3800
Для того, чтобы определить насколько больше картофеля было продано в
денежной оценке, можно рассчитать индивидуальный индекс товарооборота:
75
q p
8 * 5200
iq 1 1
1.09 или 109 %
q 0 p 0 10 * 3800
То есть в сентябре стоимостной объем продажи картофеля по сравнению с
августом вырос на 9%.
К индивидуальным индексам относятся показатели, публикуемые в
сообщениях Росстата о численности населения, основных показателях денежного
обращения, производства продукции и т.д. Таким образом, они характеризуют,
например, рост производство отдельных видов продукции, демографические
изменения и др.
Сводными
индексами
называются
относительные
показатели,
характеризующие соотношения между такими совокупностями величин
экономических явлений, которые непосредственно в своей натуральной форме
несоизмеримы.
Если индексы охватывают не все элементы сложного явления, а только их
часть, то такие индексы называют групповыми, или субъиндексами, например,
индексы физического объема продукции по отдельным отраслям промышленности,
индексы цен по группам продовольственных и непродовольственных товаров.
Групповые индексы отражают закономерности в развитии отдельных частей
изучаемых явлений. В таких индексах проявляется связь с методом группировок.
Групповые индексы можно рассматривать как подвид сводных.
Сводные индексы по форме построения подразделяются на агрегатные
(взвешенные) и средние.
Сводные (общие) индексы состоят из двух показателей — индексируемой
величины (х) и веса, или коэффициента соизмерения ( f ).
Индексируемым показателем называют тот, измерение которого определяется.
Весом или соизмерителем называют показатель, служащий для измерения
(взвешивания).
Основным способом исчисления сводных (общих) индексов является агрегатный способ. Агрегатный индекс представляет собой отношение сумм
произведений индексируемых величин на соизмеритель.
Методика конструкции общих индексов (агрегатной формы):
а) количественных показателей
Jf
б) качественных показателей J x
f
f
1`
x0
0
x0
;
f1` x1
fx
1 0
Таблица 27 - Индивидуальные и сводные (общие) индексы
Название индекса
Индивидуальный индекс
Общий индекс
Индекс цен
i
p1
p0
J
pq
p q
1
1
0
1
76
Индекс физического
объема
i
Индекс себестоимости
i
Индекс производительности труда (трудовой)
i
q1
q0
J
z1
z0
J
t0
t1
J
p q
p q
0
1
0
0
z q
z q
1
1
0
1
t q
t q
0
1
1 1
Агрегатный индекс может быть преобразован в средний путем подстановки в
числителе или знаменателе вместо индексируемой величины индексируемого отношения (выражения, полученного из индивидуального индекса).
Как правило, индексируется величина отчетного периода, стоящая в числителе
агрегатного индекса, она заменяется произведением индивидуального индекса на
индексируемую величину базисного периода.
Индекс физического объема продукции (товарооборота) равен i
q1
, откуда
q0
q1 i q0
следовательно, I q 0 1 0 0 .
p0 q0 p0 q0
p q
i p q
В качестве весов здесь выступают фактические стоимости продукции
базисного периода. Это обстоятельство определяет преимущество и практическую
значимость среднего арифметического индекса физического объема продукции по
сравнению с агрегатным, так как его можно применить в том случае, когда в
исходной информации нет раздельных значений р и q.
При расчете среднего изменения количества используют формулу
среднеарифметического индекса, а когда учет количества не производится –
используется формула гармонического индекса.
Таблица 28 - Сравнительная характеристика агрегатного и среднего индексов
Агрегатный индекс
Средний индекс
Индекс физического объема
Средний арифметический индекс
физического объема
q1 p 0
J
q
`
0
p0
J
iq p
q p
0`
0
0
0
ля
изу
q1 p1
q1 p1
J
J
чен
q1 p1
q1 p0
i
ия
ди
намики средних показателей по однородной совокупности используются индексы
переменного состава.
Индексы переменного состава наряду с изменением индексируемого
Индекс цен
`
Средний гармонический индекс цен
`
Д
77
показателя отражают влияние изменения состава (структуры) той совокупности,
для которой рассчитаны средние.
Для разных качественных показателей (в однородной совокупности) индексы
переменного состава имеют следующий вид:
J цен
p1
p0
p q :p q
q q
J себестоимости
и т.д.
1 1
0
1
0
0
z1
z0
z q : z q
q q
1 1
0
1
0
0
Чтобы исключить влияние изменения структуры совокупности можно
рассчитать среднее по одной и той же структуре, индекс рассчитанный таким
способом называется индексом постоянного (фиксированного) состава.
Например,
J себестоимости
z q : z q
q q
1 1
0 1
1
1
z q
z q
1 1
0 1
Индекс постоянного (фиксированного) состава показывает изменение среднего
уровня при одной и той же фиксированной структуре. Он усредняет изменение
индексируемого показателя без учета изменения структуры.
Если разделить индекс переменного состава на индекс постоянного состава,
можно получить индекс структурных сдвигов (структуры), который показывает
влияние изменения структуры на динамику среднего уровня.
J стр.сдв игов J перем.состав а : J пост.состав а .
J себестоимости
z q : z q
q q
0 1
1
0
0
0
z q : q
z q q
0 1
1
0
0
0
В анализе динамики явлений возникает необходимость определять индексы не
за два, а за несколько последовательных периодов, поэтому при расчете получается
несколько индексов. В таких случаях индексы рассчитывают двумя способами:
цепным и базисным.
Базисные индексы – это индексы с постоянной базой сравнения, когда каждый
последующий период сравнивается с первоначальным (базисным). Цепные индексы
– это индексы и переменной базой сравнения, когда каждый последующий период
сравнивается с предыдущим.
Графически это можно представить следующим образом:
78
Рисунок 2 – Схема образования цепных и базисных индексов
Между цепными и базисными индексами существует взаимосвязь:
1) частное от деления последующего базисного индекса на предшествующий
равно цепному индексу
2) произведение ряда цепных индексов равно соответствующему базисному.
3. Индексы цен
Агрегатный индекс цен характеризует изменение результирующего
показателя (общей стоимости товаров и услуг) за счет изменения цен в текущем
периоде по сравнению с базисным. При его построении важно устранить влияние
изменения количества товара, т.е. физического объема.
Для этого в качестве соизмерителя (веса) индексируемой величины – цены
используется неизменный физический объем либо отчетного, либо базисного
периода. Таким образом, агрегатный индекс цен можно рассчитать по формуле
Пааше и по формуле Ласпейреса.
I p Ласпейреса
I p Пааше
pq
p q
pq
p q
1
0
0
0
1 1
0 1
Индексы позволяют определить относительное изменение цен, но оно не
будет одинаковым, так как имеет различное экономическое содержание.
Индекс Пааше показывает, во сколько раз изменился уровень цен на
продукцию текущего периода, а разность между числителем и знаменателем - на
сколько изменилась стоимость продукции в текущем периоде за счет изменения
цен.
Индекс Ласпейреса показывает, во сколько раз подорожала бы или
подешевела бы продукция базисного периода из-за изменения цен на нее в
отчетном периоде.
Применение того или иного индекса зависит от цели исследования.
Если целью анализа является определение экономического эффекта
(прибыль или убыток) от изменения цен в отчетном периоде по сравнению с
базисными, то используется индекс Пааше.
Индексы цен, рассчитанные по формуле Пааше, как правило, охватывают
более широкий круг товаров и услуг. В качестве весов используется не структура
потребительских расходов, а структура товарооборота, или добавленной
79
стоимости, или произведенной продукции в текущем периоде, потому они могут
быть определены лишь по истечении отчетного периода. Индекс Пааше
используется при измерении динамики цен компонентов ВВП, закупочных цен в
сельском хозяйстве, сметных цен в строительстве, экспортных цен.
Если целью анализа является прогнозирование объема продаж в связи с
возможным изменением цен в предстоящем периоде, то используется индекс
Ласпейреса, так как он позволяет определить стоимость продаж одного и того же
физического объема базисного периода по новым ценам.
Индексы цен, рассчитанные по формуле Ласпейреса, особенно широко
применяются при расчете индексов потребительских цен (ИПЦ), индексов цен
производителей на промышленную продукцию по данным о ценах на товарыпредставители. Однако данный индекс не включает инвестиционные товары, но
при этом учитываются цены на импортную продукцию.
Индекс Ласпейреса, как правило, больше, чем индекс Пааше. Эта
систематическая зависимость двух индексов известна как эффект Гершенкрота.
Достаточно часто в экономическом анализе используется ещё один вид общего
индекса цен - индекс Лоу (общий индекс на средних весах).
В его формуле в качестве соизмерителя используется средний физический
объем продаж q, рассчитанный как простая средняя арифметическая.
I p Лоу
p q
p q
1
0
Индекс Лоу используется в расчетах, связанных с закупкой или реализацией
товаров в течение длительного периода (по долгосрочным контрактам). Он
показывает, во сколько раз в среднем изменился бы объем продаж за счет
изменения цен.
Достоинством индекса Лоу является то, что при его использовании
устраняются недостатки индекса Пааше и Ласпейреса.
Кроме перечисленных индексов можно использовать «идеальный индекс»
Фишера.
Идеальный индекс Фишера рассчитывается как средняя геометрическая из
индексов цен Ласпейреса и Пааше:
Идеальный индекс Фишера используется при исчислении индексов цен на
длительный период времени для сглаживания тенденции в структуре и составе
объема продукции, в которых происходят значительные изменения. Его
недостаткам является то, что он не имеет конкретной экономической
интерпретации.
4. Индексные системы и факторный анализ
В индексных системах отражается взаимосвязь экономических
показателей: если экономические показатели связаны между собой определенным
образом, то таким же образом связаны между собой и характеризующие их
индексы, т.е. если z = x y , то Iz = Ix Iy .
Индексные системы дают возможность использовать индексный метод для
изучения взаимосвязи показателей и проведения факторного анализа с целью
определения влияния каждого фактора на результативный показатель.
80
Построение индексной системы рассмотрим на примере индекса стоимости,
индекса цен и индекса физического объема:
Индексы физического объема и цен являются факторными по отношению к
индексу стоимости продукции.
Индекс стоимости рассчитывается по формуле:
I pq
q
q
1
p1
0
p0
Индекс цен рассчитаем по формуле Пааше:
Ip
pq
p q
1 1
0
1
Индекс физического объема
Iq
p q
p q
0 1
0 0
Перемножение индекса цен и индекса физического объема дает следующий
результат:
pq хp q
p q p q
1 1
0 1
0 1
0
0
p q
p q
1 1
0
0
Таким образом: Ipq = Ip Iq
Аналогична взаимосвязь других результативных признаков с факторными.
Например, индекс объема продукции с индексом численности работающих и
индексом производительности труда (выработки) связан таким же образом, как
объем производства Q связан с выработкой одного работающего w и численностью
работающих r.
Индексные системы используются для определения влияния отдельных
факторов на формирование уровня результативного показателя, позволяют по 2-м
известным значениям индексов определить значение неизвестного.
Рассмотренные индексные системы относятся к двухфакторным, но
результативный признак можно разложить и на большее число факторов и
соответственно получить многофакторные индексные системы, которые могут
разложить изменение результативного показателя на элементы, вызванные
влиянием отдельных факторов.
Индексные системы позволяют разложить и абсолютное изменение
результативного показателя на составляющие, вызванные влиянием разных
факторов, т.е. разложить абсолютное изменение по факторам. Это можно сделать,
если
результативный
показатель
представляет
собой
произведение
количественного фактора на качественный.
Абсолютное изменение результативного показателя определяется как разница
между числителем и знаменателем формулы расчета индекса.
Например, абсолютное изменение стоимости: pq p1q1 p0 q0
Абсолютное изменение результативного показателя за счет изменения цен
составит: pq p p1q1 p0 q1
81
Абсолютное изменение результативного показателя за счет изменения
физического объема составит: pqq p0 q1 p0 q0 .
8. Статистическое изучение взаимосвязей
социально-экономических явлений
82
1. Понятие и виды связей в статистике
2. Корреляционный и регрессионный анализ
3. Непараметрические методы оценки связи
1. Понятие и виды связей в статистике
Одной из важнейших задач статистики является изучение объективно
существующих связей между явлениями. При исследовании таких связей
выясняются причинно-следственные отношения между явлениями, а это, в свою
очередь, позволяет выявить факторы, оказывающие основное влияние на вариацию
изучаемых явлений и процессов.
Причинно-следственные отношения представляют собой такую связь явлений,
при которой изменение одного из них – причины, ведёт к изменению другого –
следствия. Причинно-следственная форма связи определяет все другие формы,
носит всеобщий и многообразный характер.
Для описания причинно-следственной связи между явлениями и процессами
используется деление статистических признаков, отражающих отдельные стороны
взаимосвязанных явлений, на факторные и результативные. Факторными
считаются признаки, обуславливающие изменение других, связанных с ними
признаков, являющихся причинами и условиями таких изменений.
Результативными являются признаки, изменяющимися под воздействием
факторных.
Формы проявления существующих взаимосвязей весьма разнообразны. В
качестве самых общих их видов выделяют функциональную (жестко
детерминированную) и статистическую (стохастически детерминированную)
связи.
Функциональной называют такую связь, при которой определённому
значению факторного признака соответствует одно и только одно значение
результативного. Такая связь возможна при условии, что на поведение одного
признака (результативного) влияет только второй признак (факторный) и никакие
другие. Такие связи являются абстракциями, в реальной жизни они встречаются
редко, но находят широкое применение в точных науках и в первую очередь, в
математике (например, зависимость площади круга от радиуса). Однако
представление связей как функциональных широко используется не столько в
аналитических целях, сколько при прогнозировании.
Функциональная связь проявляется во всех случаях наблюдения и для каждой
конкретной единицы изучаемой совокупности.
В массовых явлениях проявляются статистические связи, при которых строго
определённому значению факторного признака ставится в соответствие множество
значений результативного. Такие связи имеют место, если на результативный
признак действуют несколько факторных, а для описания связи используется один
или несколько определяющих (учтённых) факторов.
Примером статистической связи может служить зависимость себестоимости
единицы продукции от уровня производительности труда: чем выше
производительность труда, тем ниже себестоимость. Но на себестоимость единицы
продукции помимо производительности труда влияют и другие факторы:
стоимость
сырья,
материалов,
топлива,
общепроизводственные
и
83
общехозяйственные расходы и т.д. Поэтому нельзя утверждать, что изменение
производительности труда на 5% (повышение) приведет к аналогичному снижению
себестоимости. Может наблюдаться и обратная картина, если на себестоимость
будут влиять в большей степени другие факторы, - например, резко возрастут цены
на сырье и материалы.
По направлению статистические (стохастические) связи делятся на прямые и
обратные. При прямой связи результативный признак растёт с увеличением
факторного, при обратной - рост факторного признака приводит к снижению
значений результативного признака. Например, чем больше стаж работы, тем выше
производительность труда – прямая связь, а чем выше производительность труда,
тем ниже себестоимость единицы продукции – обратная связь.
Частным случаем статистической (стохастической) является корреляционная
связь, при которой изменение среднего значения результативного признака
обусловлено изменением факторных признаков.
По форме (аналитическому выражению) связи делятся на линейные
(прямолинейные) и нелинейные (криволинейные) связи.
Линейные связи выражаются уравнением прямой, а нелинейные – уравнением
параболы, гиперболы, степенной и т. п.
По количеству взаимодействующих факторов связи делятся на парную
(однофакторную) и множественную (многофакторную) связи.
При парной связи на результативный признак действует один факторный, при
множественной – несколько факторных признаков.
2. Корреляционный и регрессионный анализ
Основным методом изучения статистической взаимосвязи является
статистическое моделирование связи на основе корреляционного и регрессионного
анализа.
Задачей корреляционного анализа является количественное определение
тесноты связи между двумя признаками при парной связи или между
результативным и несколькими факторными при множественной связи. Теснота
связи показывает меру влияния факторного признака на общую вариацию
результативного признака.
Регрессионный анализ заключается в определении аналитического
выражения связи в виде уравнения регрессии. Регрессией называется зависимость
среднего значения случайной величины результативного признака от величины
факторного, а уравнением регрессии – уравнение, описывающее корреляционную
зависимость между результативным признаком и одним или нескольким
факторными.
В экономическом анализе для изучения связи между двумя признаками
(парная регрессия) используются такие формулы:
~
~
а) линейная Yx a0 a1 x ;
б) степенная Yx axb ;
~
~
в) показательная Yx ab x ;
b
x
г) гипербола Yx a ;
~
д) парабола 2-го порядка Yx a0 a1 x a2 x 2 .
В основе отыскания параметров корреляционных уравнений лежит метод
наименьших квадратов.
84
Линейная парная регрессия имеет вид:
~
Yx a0 a1 x,
~
где Yx — результативный признак;
x — факторный;
a0 — начало отсчета, начальный уровень ряда;
a1 — коэффициент пропорциональности или коэффициент регрессии,
который показывает как изменится «у» при изменении «х» на единицу.
При линейной связи множественное линейное уравнение имеет вид:
~
YX ... X a0 a1 x1 a2 x2 ... an xn ,
1
n
~
где Yтеор расчетное значение регрессии, которое представляет собой оценку
ожидаемого
значения у при фиксированных значениях переменных
x1 , x2 ,..., xn , a1 , a2 ,..., an , коэффициенты регрессии, каждый из которых показывает, на
сколько единиц изменится у с изменением соответствующего признака х на
единицу при условии, что остальные признаки останутся на прежнем уровне.
Оценка параметров множественной регрессии вручную затруднительна, что приводит к
потерям точности и может лишь удовлетворить любопытство. Получение же оценок
параметров на ЭВМ в настоящее время не представляет большой проблемы. Гораздо важнее
выяснить, насколько линейная форма связи соответствует реально существующей
зависимости между у, с одной стороны, и множеством x— с другой.
Наиболее полно в статистике разработана методология парной корреляции,
рассматривающей влияние вариации одного факторного признака на результатный.
Исследование парной корреляции осуществляется на основе корреляционного
анализа, который предполагает последовательное решение ряда задач:
1) Выявление связи;
2) Описание выявленной связи;
3) Измерение тесноты связи;
4) Формулировка выводов о характере существующей связи.
Задача множественного корреляционно-регрессионного анализа в общем виде
формулируется следующим образом: «Пусть некоторая статистическая совокупность,
состоящая из n единиц наблюдения обладает определённым набором признаков, один из
которых играет роль результативного y, а остальные – факторных (x1, x2, ..., xn). На основе
наблюдаемых значений всех признаков требуется выявить и описать связь между ними в виде
множественной корреляционной модели».
Решение
задач
множественной
корреляции
требует
выполнения
дополнительных этапов исследования:
• предварительный отбор факторов, включаемых в модель;
• уточнение модели на основе анализа корреляционной матрицы;
• оценка надёжности множественной корреляционной модели;
• интерпретация модели.
Этапы решения задач парной корреляции.
1. Задача выявления связи между факторным и результативным признаками
может быть решена при помощи следующих приёмов:
- визуализации связи (построение и визуальный анализ корреляционного
поля);
85
- использования результатов аналитической группировки и др.
Корреляционное поле представляет собой точечный график в системе
координат {x,y}. Каждая точка соответствует единице совокупности. Положение
точек на графике определяется величиной двух признаков – факторного и
результативного.
y
x
Рисунок 3 - Корреляционное поле при наличии связи между признаками
Рисунок 4 - Корреляционное поле при отсутствии связи между признаками
При втором способе – использовании результатов аналитической группировки
связь считается установленной, если группировка показывает изменение среднего
значения результативного признака в группах при изменении факторного признака
(основания группировки).
2. Описание выявленной связи при проведении корреляционного анализа
проводится в двух формах – табличной и графической.
При табличном описании связи статистические единицы группируются по
значению факторного признака (располагаются в порядке его возрастания или
убывания).
86
Графическое описание связи заключается в построении линии эмпирической
регрессии – ломаной линии, соединяющей на корреляционном поле точки,
абсциссами которых являются значения факторного признака (индивидуальные
значения или групповые значения), а ординатами – средние значения
результативного признака.
Эмпирическая
линия
регрессии
отражает
основную
тенденцию
рассматриваемой зависимости. Если по своему виду она приближается к прямой
линии, то можно предположить наличие прямолинейной связи между признаками.
3. Оценка тесноты связи предполагает определение меры соответствия
вариации результативного признака от одного (для парных зависимостей) или
нескольких (множественных) факторов. Через тесноту связи определяется, в какой
степени влияют на результат учтённые и неучтённые факторы.
При проведении корреляционного анализа теснота связи измеряется с
помощью интегральных показателей, построенных на правиле сложения
дисперсии.
Линейный коэффициент корреляции характеризует тесноту и направление
связи между двумя коррелируемыми признаками в случае наличия между ними
линейной зависимости.
Формулы расчета данного коэффициента:
r
xy x y
;
x y
r
n xy x y
n x x n y
2
2
2
y
2
.
Данный коэффициент оценки связи изменяется в пределах от - 1 до + 1. Если
r > 0, то корреляция прямая, если r < 0, то обратная, а если r = 0, то связь
отсутствует.
В зависимости от того, насколько коэффициент стремится к единице,
различают следующие виды характеров связи
Таблица 29 - Количественные критерии оценки тесноты связи
Величина коэффициента корреляции
Характер связи
До 0,3
Практически отсутствует
0,3 - 0,5
Слабая
0,5 – 0,7
Умеренная
0,7 - 1,0
Сильная
Коэффициент корреляции является мерой тесноты связи только для линейной
формы связи, для нелинейной – используется индекс корреляции R.
Y 2
R
2
Для измерения тесноты связи при множественной корреляционной
зависимости, т. е. при исследовании трех и более признаков одновременно,
вычисляется также множественный коэффициент корреляции.
87
Множественный коэффициент корреляции для двух факторных признаков
вычисляется по формуле
r 2 r 2 2r r
r
yx1
yx2
yx1 yx2 х1 x 2
R
,
2
y/x x
1
r
1 2
x1 x 2
где ryx — парные коэффициенты корреляции между признаками.
Множественный коэффициент корреляции изменяется в пределах от 0 до 1 и
по определению положителен.
Чем ближе R к 1, тем более сильная связь между у и множеством х. Эта же
оценка R используется и как мера точности аппроксимации фактических данных
выровненным. Если R незначительно по величине (как правило, R < 0,3), то можно
утверждать, что либо не все важнейшие факторы взаимосвязи учтены, либо выбрана неподходящая форма уравнения. В этом случае следует пересмотреть список
переменных модели, а возможно, и сам ее вид.
i
Если индекс корреляции возвести в квадрат, то получим коэффициент
коэффициент детерминации (D или R2). Он показывает, какая часть вариации
зависимого признака объясняется включенными в модель факторами.
В случае наличия линейной и нелинейной зависимостей между двумя
признаками для измерения тесноты связи применяют так, называемое
корреляционное отношение.
Эмпирическое корреляционное отношение рассчитывается по данным
группировки, когда 2 характеризует отклонения групповых средних
результативного показателя от общей средней
2
2
2
2
2
1 2
2
где корреляционное отношение;
2 общая дисперсия;
2
средняя из частных (групповых) дисперсий;
2 межгрупповая дисперсия (дисперсия групповых средних).
Все эти дисперсии есть дисперсии результативного признака.
Корреляционное отношение изменяется в пределах от 0 до 1 0 1.
4. Выводы по результатам корреляционного анализа включают в себя
констатацию факта наличия связи, определение её направления, предварительную
оценку формы связи по линии эмпирической регрессии и классификацию связи по
степени её тесноты.
Часто для характеристики влияния изменения х на у используют так
называемый коэффициент эластичности (Э), который показывает, на сколько
процентов изменится у при изменении х на один процент. Например, для линейного
уравнения коэффициент эластичности фактора х выглядит как:
88
ax
a1 x
Э 1
.
y
a 0 a1 x
Для парной степенной функции ~y a0 x a1 коэффициент эластичности х равен ах.
Коэффициенты эластичности — это относительные величины. Их
использование
расширяет
возможности
сопоставления,
экономической
интерпретации результатов в дополнение к абсолютным величинам —
коэффициентам регрессии.
Получив оценки корреляции и регрессии, необходимо проверить их на
соответствие истинным параметрам взаимосвязи. Существующие программы для
ЭВМ включают, как правило, несколько наиболее распространенных критериев.
Для оценки значимости коэффициента парной корреляции рассчитывают
стандартную ошибку коэффициента корреляции
1 r 2
xy
.
r
n
2
xy
В первом приближении нужно, чтобы rxy rxy . Значимость rxy проверяется его
сопоставлением с rxy . При этом получают:
t
n2
r
,
расч
xy 1 r 2
xy
где t расч — так называемое расчетное значение t – критерия.
Если t расч больше теоретического (табличного) значения критерия Стьюдента
(t расч ) для заданного уровня вероятности и ( n 2) степеней свободы, то можно
утверждать, что rxy значимо.
Подобным же образом на основе соответствующих формул рассчитывают
стандартные ошибки параметров уравнения регрессии, а затем и t—критерии для
каждого параметра. Важно опять-таки проверить, чтобы соблюдалось условие
t расч t табл . В противном случае доверять полученной оценке параметра нет
оснований.
Вывод о правильности выбора вида взаимосвязи и характеристику значимости
всего уравнения регрессии получают с помощью F—критерия, вычисляя его
расчетное значение:
F
расч
R 2 (n m)
,
(1 R 2 )( m 1)
где n — число наблюдений;
m — число параметров уравнения регрессии.
Fрасч также должно быть больше Fтеор при 1 (m 1) и 2 (n m) степенях
свободы.
В противном случае следует пересмотреть форму уравнения, перечень
переменных и т. д.
89
3. Непараметрические методы оценки связи
Методы корреляционного и регрессионного анализа не универсальны: их
можно применять, если все изучаемые признаки являются количественными. При
использовании этих методов нельзя обойтись без вычисления основных
параметров распределения (средних величин, дисперсий), поэтому они получили
название параметрических методов.
Между тем в статистической практике приходится сталкиваться с задачами
измерения связи между качественными признаками, к которым параметрические
методы анализа в их обычном виде неприменимы. Статистической наукой
разработаны методы, с помощью которых можно измерить связь между явлениями,
не используя при этом количественные значения признака, а значит, и параметры
распределения. Такие методы получили название непараметрических.
При наличии соотношения между вариацией качественных признаков говорят
об их ассоциации, взаимосвязанности. Для оценки связи в этом случае используют
ряд показателей.
1) Коэффициент корреляции знаков (коэффициент Фехнера).
Коэффициент основан на сопоставлении знаков отклонений от средней и
подсчете числа случаев совпадения и несовпадения знаков. Коэффициент
корреляции знаков определяется по формуле
i
a b
ab
где a – число пар с одинаковыми знаками отклонений х и у от х и у
b – число пар с разными знаками отклонений х и у от х и у
Коэффициент корреляции знаков колеблется в пределах от -1 до +1. Чем ближе
коэффициент к 1, тем теснее связь. Если a>b, то i>0, так как число согласованных
знаков больше, чем несогласованных, связь прямая. При a<b, i<0, потому что
число несогласованных знаков больше, чем согласованных, связь обратная. Если
a=b, i=0, связи нет.
VVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVV
Пример.
Вычислим коэффициент корреляции знаков по десяти промышленным
организациям.
ООО«Стройдеталь»
ООО «Лига»
ОАО «Дом»
ОАО «Класс»
ОАО «Индустрия»
ООО «Элит»
ООО «Стиль»
6,0
8,0
9,0
10,0
10,0
11,0
12,0
Выпуск
продукции (у),
млн.руб.
Наименование
организации
Стоимость
основных
производственн
ых фондов (х),
млн.руб.
Таблица 30 – Стоимость основных фондов и выпуск продукции
по 10 предприятиям
2,4
4,0
3,6
4,0
4,5
4,6
5,6
Знак отклонения от средней
арифметической
х- х
у- у
+
+
+
90
ОАО «Бест»
ООО «Золотой век»
ООО «Барс»
Итого
Средняя
13,0
14,0
15,0
108,0
10,8
6,5
7,0
5,0
47,2
4,72
+
+
+
Х
Х
+
+
+
Х
Х
a b 9 1 8
0,8
Таким образом, а=9, b=1, i= a b 9 1 10
Это значит, что связь между
стоимостью основных фондов и выпуском продукции прямая и высокая.
ΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛ
Как видно, данный коэффициент исчисляется очень просто и в этом его
преимущество. Однако он неточен, так как учитывает только знаки отклонений, а
не числовые значения отклонений.
2) Коэффициенты ассоциации и контингенции.
Для определения тесноты связи двух качественных признаков, каждый из
которых состоит только из двух групп, применяются коэффициенты ассоциации и
контингенции. Коэффициенты вычисляются по формулам:
ассоциации:
Ka
ad bc
;
ad bc
ad bc
K
.
k
(
a
b
)(
b
d
)(
a
c
)(
c
d
)
контингенции:
Коэффициент контингенции всегда меньше коэффициента ассоциации. Связь
считается подтвержденной, если Ka ≥ 0,5 или Kк ≥ 0,3.
VVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVV
Пример.
Исследовалась социально-демографическая характеристика случайных
потребителей наркотиков и зависимость от их семейного положения в одном из
регионов РФ, тыс. чел.
Таблица 31 - Зависимость потребителей наркотиков от их семейного
положения
Потребление
замужем (женат)
Потреблял
Не потреблял
итого
Всего
Семейное положение
10,0
2,5
а
с
не замужем (не женат)
14,5
4,5
12,5 (а+ с)
b
d
24,5 (а+ b)
7,0 (с+d)
19 (b+ d)
31,5
Рассчитаем коэффициенты ассоциации и контингенции. Сформулируем
выводы, вытекающие из анализа полученных коэффициентов:
Ka
ad bc 10 4,5 14,5 2,5
0,108 ;
ad bc 10 4,5 14,5 2,5
91
ad bc
10 4,5 14,5 2,5
K
0,043.
k
(a b)(b d )( a c)(c d )
(10 14,5)(14,5 4,5)(10 2,5)( 2,5 4,5)
Так как Ka < 0,5 и Kk < 0,3, то потребление наркотиков случайными
потребителями не зависит от их семейного положения.
ΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛ3)
Когда каждый из качественных признаков состоит более чем из двух групп, то
для определения тесноты связи возможно применение коэффициента взаимной
сопряженности Пирсона-Чупрова.
Коэффициенты Пирсона и Чупрова вычисляется по следующим формулам:
Kn
2
;
12
Kч
2
( K 1 1) ( K 2 1)
,
где показатель взаимной сопряженности, который определяется как
сумма отношений квадратов частот каждой клетки таблицы к произведению
итоговых частот, соответствующего столбца и строки.
где K1 число значений (групп) первого признака;
K 2 число значений (групп) второго признака.
2
2
Вычитая из этой суммы 1, получим величину :
2
2
nxy
nx n y
1,
Можно преобразовать:
1
2
2
n xy
ny
nx
,
Чем ближе величина K n и Kч к 1, тем теснее связь.
VVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVV
Пример.
С помощью коэффициента взаимной сопряженности исследуем связь между
себестоимостью продукции и накладными расходами на реализацию
Таблица 32 - Зависимость между себестоимостью продукции
и накладными расходами на реализацию
Себестоимость
Накладные расходы
Итого
низкая
средняя
высокая
Низкие
Средние
Высокие
19
7
4
12
18
10
9
15
26
40
40
40
Итого
30
40
50
120
92
19 2 12 2 9 2 7 2 182 152 4 2 10 2 26 2
2
30
40
50
30
40
50
30
40
50 0,431 0,356 0,414 1,183 ;
1
40
40
40
1 2 1,183 ; 2 0,183 ; K n
Kч
0,183
0,155 0,39 ;
1,183
0,183
0,21. Связь средняя
22
ΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛ
В социально-экономических исследованиях нередко встречаются ситуации,
когда признак не выражается количественно, однако единицы совокупности можно
упорядочить. Такое упорядочение единиц совокупности по значению признака
называется ранжированием. Примерами могут быть ранжирование студентов
(учеников) по способностям, любой совокупности людей по уровню образования,
профессии, по способности к творчеству и т. д.
При ранжировании каждой единице совокупности присваивается ранг, т. е.
порядковый номер. При совпадении значения признака у различных единиц им
присваивается объединенный средний порядковый номер. Например, если у 5-й и
6-й единиц совокупности значения признаков одинаковы, обе получат ранг, равный
(5 + 6) / 2 = 5,5.
Измерение связи между ранжированными признаками производится с
помощью ранговых коэффициентов корреляции Спирмена (р) и Кендэлла (Т).
Эти методы применимы не только для качественных, но и для количественных
показателей, особенно при малом объеме совокупности, так как непараметрические
методы ранговой корреляции не связаны, ни с какими ограничениями
относительно характера распределения признака.
Сущность метода Спирмена состоит в следующем:
1) располагают варианты факторного признака по возрастанию — ранжируют
единицы по значению признака х;
2) для каждой единицы совокупности указывают ранг с точки зрения
результативного признака у.
Если связь между признаками прямая, то с увеличением ранга признака х ранг
признака у также будет возрастать; при тесной связи ранги признаков х и у в
основном совпадут. При обратной связи возрастанию рангов признака х будет, как
правило, соответствовать убывание рангов признака у. В случае отсутствия связи
последовательность рангов признака у не будет обнаруживать никакого порядка
возрастания или убывания.
Теснота связи между признаками оценивается ранговым коэффициентом
корреляции Спирмена:
1
6 d i2
n (n 2 1)
,
где d - разность рангов признаков х и у;
n - число наблюдаемых единиц (число пар рангов).
93
Коэффициент принимает значения от -1 до +1. В случае отсутствия связи ρ =
0. При прямой связи коэффициент ρ — положительная правильная дробь, при
обратной — отрицательная.
VVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVV
Пример.
Рассмотрим зависимость между успеваемостью учащихся средней школы по
физико-математическим и гуманитарным наукам.
Таблица 33 - Ранги успеваемости по наукам
Ранги успеваемости по наукам
учащиеся
А
Б
В
Г
Д
Е
Ж
З
И
К
Итого
Физико-математическим (Rx )
1
2
3
4
5
6
7
8
9
10
Гуманитарным ( Ry )
3
10
8
4
7
5
9
1
6
2
55
55
Коэффициент Спирмена
1
d=Rx - Ry
d2
-2
-8
-5
0
-2
+1
-2
+7
+3
+8
4
64
25
0
4
1
4
49
9
64
0
224
6 224
0,358.
10(10 2 1)
Таким образом, между способностями учеников к физико-математическим и
гуманитарным наукам имеется обратная связь, хотя и не очень сильная.
ΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛΛ
При ранжировании качественных признаков с целью изучения их взаимосвязи
используется коэффициент корреляции Кэндалла.
2S
n n 1
n - число наблюдений
S - сумма разностей между числом последовательностей и числом инверсий по
второму признаку.
S=P+Q
P - сумма значений рангов, следующих за данными и превышающих его
величину
Q - сумма значений рангов, следующих за данными и меньших его величины
(учитывается со знаком «-»).
Как правило, коэффициент Кэндалла меньше коэффициента Спирмена. При
достаточно большом объеме совокупности соблюдается следующая зависимость:
2
3
Связь между признаками можно считать статистически значимой, если
значения этих коэффициентов больше 0,5.
94
Для определения тесноты связи между произвольным числом
ранжированных признаков применяется множественный коэффициент ранговой
корреляции (коэффициент конкордации) W, который вычисляется по формуле
W
12S
,
m ( n 3 n)
2
где m количество факторов:
n число наблюдений:
S отклонение суммы квадратов рангов от средней квадратов рангов.
Коэффициент принимает значения от -1 до +1.
VVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVV
Пример.
Рассчитаем по коэффициент конкордации для выяснения связи между такими
показателями как размер уставного капитала, числом акций и численностью
персонала 10 предприятий.
Таблица 34 - Расчет коэффициента конкордации
Номер
предприятия
1
2
3
4
5
6
7
8
9
10
∑
Уставный
капитал,
(млн. руб.)
Число
выставленных
акций У
2954
1605
4102
2350
2625
1795
2813
1751
1700
2264
856
930
1563
682
616
495
815
858
467
661
Число
занятых на предприятиях
119
125
132
141
150
165
178
181
201
204
S 2863
W
Rx
Ry
Rz
9
1
10
6
7
4
8
3
2
5
7
9
10
5
3
2
6
8
1
4
1
2
3
4
5
6
7
8
9
10
Сумма
строк
17
12
23
15
15
12
21
19
12
19
165
Квадраты сумм
284
144
529
225
225
144
441
361
144
361
2863
(165) 2
2863 2722,5 140,5 ;
10
12S
12 140,5
0,19 ,
3
m (n n) 9(1000 10)
2
что свидетельствует о слабой связи между рассматриваемыми признаками.
Ранговые коэффициенты Спирмена, Кендалла и конкордации имеют то
преимущество, что с их помощью можно измерять и оценивать связи как между
количественными, так и между атрибутивными признаками, которые поддаются
ранжированию.