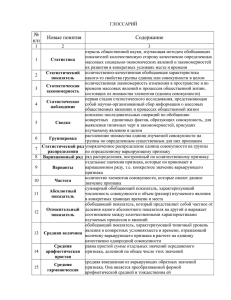
теория статистики - Камышинский технологический институт
advertisement

СТАТИСТИКА (ЧАСТЬ I. ОБЩАЯ ТЕОРИЯ СТАТИСТИКИ) ФЕДЕРАЛЬНОЕ АГЕНТСТВО ПО ОБРАЗОВАНИЮ ГОСУДАРСТВЕННОЕ ОБРАЗОВАТЕЛЬНОЕ УЧРЕЖДЕНИЕ ВЫСШЕГО ПРОФЕССИОНАЛЬНОГО ОБРАЗОВАНИЯ «ВОЛГОГРАДСКИЙ ГОСУДАРСТВЕННЫЙ ТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ» КАМЫШИНСКИЙ ТЕХНОЛОГИЧЕСКИЙ ИНСТИТУТ (ФИЛИАЛ) ГОУ ВПО «ВОЛГОГРАДСКИЙ ГОСУДАРСТВЕННЫЙ ТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ» Г. Н. Андреев, М. А. Иванова, Л. Л. Савелло, Ж. А. Чеснокова, А. Г. Андреев СТАТИСТИКА (ЧАСТЬ I. ОБЩАЯ ТЕОРИЯ СТАТИСТИКИ) Краткий курс лекций Волгоград 2010 1 ББК 60.6 С 78 Рецензенты: Военный инженерно-технический генеральный директор ЗАО «Петралюм» В. М. Набатов университет; СТАТИСТИКА (ЧАСТЬ I. ОБЩАЯ ТЕОРИЯ СТАТИСТИКИ): краткий курс лекций / Г. Н Андреев [и др.]. ВолгГТУ, Волгоград, 2010. – 160 с. ISBN 978-5-9948-0392-9 Содержит краткий курс лекций по общей теории статистики. Помогает студентам и преподавателям уяснить методологию статистического исследования. Дает возможность преподавателю, используя этот курс, добавлять материал в любую из тем из других имеющихся у него источников, в зависимости от времени, отведенного на это в учебном плане. Предназначено для студентов ВПО. Ил. 49. Табл. 66. Библиогр.: 8 назв. Печатается по решению редакционно-издательского совета Волгоградского государственного технического университета Учебное издание Генри Николаевич Андреев, Мира Анатольевна Иванова, Лариса Леонидовна Савелло Жанна Александровна Чеснокова, Андрей Генриевич Андреев СТАТИСТИКА (ЧАСТЬ I. ОБЩАЯ ТЕОРИЯ СТАТИСТИКИ) Краткий курс лекций Редактор Л. В. Попова Компьютерная верстка Н. М. Сарафановой Темплан 2010 г., поз. № 44К. Подписано в печать 05. 04. 2010 г. Формат 60×84 1/16. Бумага листовая. Печать офсетная. Усл. печ. л. 10,0. Усл. авт. л. 9,81. Тираж 100 экз. Заказ № Волгоградский государственный технический университет 400131, г. Волгоград, пр. Ленина, 28, корп. 1. Отпечатано в КТИ 403874, г. Камышин, ул. Ленина, 5, каб. 4.5 ISBN 978-5-9948-0392-9 2 Волгоградский государственный технический университет, 2010 СОДЕРЖАНИЕ ПРЕДИСЛОВИЕ………………………………………………………. ЛЕКЦИЯ 1. СТАТИСТИЧЕСКАЯ МЕТОДОЛОГИЯ; СТАТИСТИЧЕСКОЕ НАБЛЮДЕНИЕ......................................................................................... 1. Статистика как наука................................................................. 2. Статистическое наблюдение.................................................... 3. Источники статистической информации или способы наблюдений в статистике....................................................................... 4. Государственные статистические органы............................... ЛЕКЦИЯ 2. СВОДКА МАТЕРИАЛОВ СТАТИСТИЧЕСКОГО НАБЛЮДЕНИЯ 1. Общие понятия о статистической сводке................................ 2. Статистические показатели....................................................... 3. Статистические группировки.................................................... 4. Статистические таблицы и графики......................................... ЛЕКЦИЯ 3. АБСОЛЮТНЫЕ И ОТНОСИТЕЛЬНЫЕ ВЕЛИЧИНЫ.................. 1. Вводная часть............................................................................. 2. Абсолютные статистические величины.................................. 3. Относительные статистические величины.............................. 4. Относительные величины динамики....................................... 5. Общие принципы построения относительных статистических величин........................................................................................ ЛЕКЦИЯ 4. РЯДЫ РАСПРЕДЕЛЕНИЯ........................................................ 1. Основные виды рядов распределения...................................... 2. Определение числа групп в вариационном ряду; графические изображения вариационного ряда............................................. 3. Ряды динамики.......................................................................... ЛЕКЦИЯ 5. СРЕДНИЕ ВЕЛИЧИНЫ........................................................... 1. Средняя величина как выражение закономерности............... 2. Средние арифметические и средняя гармоническая.............. 3. Средние в рядах динамики........................................................ 4. Другие виды средних................................................................. 5. Заключение по теме................................................................... ЛЕКЦИЯ 6. ПОКАЗАТЕЛИ РАЗМЕРА И ХАРАКТЕРА ВАРИАЦИИ.............. 1. Показатели вариации................................................................ 2. Внутригрупповая и межгрупповая дисперсии; правило сложения дисперсий........................................................................... 3. Анализ характера распределения в вариационных рядах...... 3 5 6 6 8 10 10 14 14 14 17 25 29 29 29 30 32 33 35 35 36 41 45 45 46 53 56 58 61 61 64 66 ЛЕКЦИЯ 7. ВЫБОРОЧНОЕ НАБЛЮДЕНИЕ............................................... 1. Понятие о выборочном наблюдении и его задачах................ 2. Репрезентативность выборки и методы её достижения........... 3. Ошибки выборки; численность выборки................................... 4. Моментные наблюдения и малая выборка................................. ЛЕКЦИЯ 8: АНАЛИЗ ТЕНДЕНЦИЙ РАЗВИТИЯ............................. 1. Приемы выявления общей тенденции развития..................... 2. Выравнивание (сглаживание) рядов динамики...................... 3. Измерение колебаний в динамическом ряду........................... ЛЕКЦИЯ 9. СТАТИСТИЧЕСКИЕ ПРИЕМЫ ИЗУЧЕНИЯ ВЗАИМОСВЯЗЕЙ.... 1. Виды взаимосвязей, изучаемых в статистике......................... 2. Корреляционные связи и корреляционный анализ................ 3. Балансовые приемы анализа взаимосвязей............................ ЛЕКЦИЯ 10. ИНДЕКСЫ........................................................................... 1. Индексы индивидуальные и сводные...................................... 2. Средние индексы........................................................................ 3. Индексный метод анализа факторов динамики (система взаимосвязанных индексов)............................................................... СПИСОК ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ............................................ ТЕСТЫ................................................................................................... ОТВЕТЫ НА ТЕСТЫ................................................................................ ЗАДАЧИ................................................................................................ 4 71 71 73 77 83 85 85 88 92 98 98 99 113 116 116 121 121 126 127 139 142 ПРЕДИСЛОВИЕ Настоящее пособие предназначено для студентов и преподавателей экономических специальностей. Теоретический материал, изложенный в пособии, позволит более глубоко изучить методологию статистических наблюдений и исследований, познакомиться с приемами расчета основных статистических показателей и научиться их использовать при анализе социально-экономических явлений, возникающих в российском обществе. Задачи, разработанные авторами пособия, позволят будущим экономистам уяснить навыки работы со статистической информацией, на практике освоить технику исчисления абсолютных и относительных средних величин, представлять результаты статистических исследований и расчетов в виде таблиц, графиков и диаграмм. Доступность, практическая значимость и разнообразие представленного материала делают пособие интересным и полезным при изучении общего курса статистики и других экономических дисциплин. Авторы благодарны старшему преподавателю кафедры «Экономика и бухгалтерский учет» Машенцевой Галине Александровне за разработку комплекса тестов для компьютерного тестирования, а также за компьютерный набр приложений к данному учебному пособию. Образец постановки вопроса и ответа на тест в ЭВМ: ВОПРОСЫ ОТВЕТЫ 1.Из перечисленных показателей уровня жизни выделите те, которые относятся к синтетическим стоимостным: ◄ объём потребления мясных продуктов да ◄ ВНП да ◄ совокупные доходы населения ◄ % населения с доходом выше 100000 руб. на душу в месяц 5 «Статистика знает всё … Как много жизни, полной пыла, страстей и мысли, глядит на нас со статистических таблиц! … От статистики не скроешься никуда…» Илья Ильф, Евгений Петров «12 стульев», гл. XV. ЛЕКЦИЯ 1. СТАТИСТИЧЕСКАЯ МЕТОДОЛОГИЯ; СТАТИСТИЧЕСКОЕ НАБЛЮДЕНИЕ 1. Статистика как наука. 2. Статистическое наблюдение. 3. Источники статистической информации или способы наблюдений в статистике. 4. Государственные статистические органы. 1. Статистика как наука 1.1. Общие положения Status (лат.) – состояние, положение вещей; Statista (итал.) – знаток государства. Под статистикой учёные последовательно понимали следующие аспекты: ● государствоведение; ● политическая арифметика (polis – государство). Главным недостатком этих аспектов являлось сведение объектов и предметов статистических исследований к их количественной стороне в отрыве от качественного содержания последних. Например, констатируя рост грамотности населения (количественная сторона), статистики ещё не чувствовали становления через него науки как самостоятельной производительной силы. Современное понимание статистики как науки: статистика изучает количественную сторону массовых общественных явлений в неразрывной связи с их качественной стороной, исследует количественное выражение закономерностей общественного развития в конкретных условиях места и времени. Сам же термин «статистика» в настоящее время имеет несколько вариантов использования: 1) отрасль знаний; 6 2) отрасль практической деятельности (собирание, обработка, анализ и публикация данных о массовых явлениях и процессах общественной жизни); 3) цифровые сведения, характеризующие какое-либо общественное явление или совокупность таких явлений; 4) в математической статистике – решающее правило, по которому на основе результатов наблюдений принимается задача проверки гипотез (например, по величине индекса корреляции проверяется корректность выбора уравнения регрессии). 1.2. Статистическая методология 1.2.1. Объекты и предмет общей теории статистики Пример 1.1: На нескольких однотипных заводах взяты данные по уровню энерговооруженности труда в кВт-часах на одного работника и годовой товарной выработке. Эти данные являются количественной стороной статистического наблюдения. Затем была выведена формула: y = a0 + 0,75x, (1.1) где у – годовая товарная выработка одного рабочего; х – энерговооруженность. Формула «говорит»: от энерговооруженности в значительной степени зависит производительность труда (изменение энерговооруженности на один порядок приводит к изменению производительности труда на 0,75 порядка). Таким образом, формула (1) характеризует качественную сторону данного явления. Объектами социально-экономической статистики являются общественные явления во всём их разнообразии. Эти явления – объекты изучаются на предмет выявления качественных (причинно-следственных, факторно-результативных) отношений между составляющими этих явлений через их количественные признаки и показатели. 1.2.2. Основные методы статистического исследования Статистическая наука опирается на следующие законы и категории диалектики: ● закон перехода количества в качество; ● категория «сущность и явление»; ● категория «часть и целое». 7 Основным законом, определяющим объективность выводов из какого-либо статистического наблюдения, является центральный закон теории вероятностей – закон больших чисел. Основными конкретными методами статистического исследования являются следующие: 1) метод массового наблюдения (переход количества в качество; закон больших чисел); 2) метод группировок статистического наблюдения (часть и целое); 3) метод обобщающих показателей (сущность и явление). 1.2.3. Требования к статистическому исследованию: ● конкретность; ● примат качественного анализа, т. е. исследование должно проводиться для выяснения сущности явления с учётом места и времени его развития; ● выделение однородных статистических совокупностей (развёрнутые понятия см. ниже); ● применение системы показателей, позволяющих дать всестороннюю характеристику изучаемых явлений и процессов, т. е. закономерностей их развития во времени и пространстве. 1.2.4. Ценз объекта наблюдения Начнём с расшифровки некоторых первичных понятий-категорий. Признак в статистике – одна из отличительных черт, свойств, качеств, присущих всем единицам исследуемой совокупности. Единица статистического наблюдения – первичный элемент объекта наблюдения, являющийся носителем регистрируемых признаков. Объект статистического наблюдения – статистическая совокупность, которую образуют единицы статистического наблюдения. Совокупность статистическая – множество явлений, предметов, объединённых общими признаками. Ценз объекта статистического наблюдения – ряд признаков, наличие которых служит основанием для отнесения той или иной единицы к объекту наблюдения. Пример 1.2: Признаки: Ценз объекта: Единицы наблюдения: уровни реальных • бизнесмен доход каждого из доходов интеллигенции, • посредник наблюдаемых рабочих, бизнесменов, • реальные доходы бизнесменовв том числе посредников посредников 2. Статистическое наблюдение 8 2.1. Сущность и виды статистических наблюдений. 2.1.1. Сущность статистического наблюдения. Статистическое наблюдение – это планомерный научно-организованный сбор данных о явлениях и процессах общественной жизни путём регистрации по заранее разработанной программе их существенных признаков. Составляется план статистического наблюдения (рис. 1.1). ПЛАН СТАТИСТИЧЕСКОГО НАБЛЮДЕНИЯ Концепция (основной замысел) наблюдения: ● цели и задачи; ● определение объекта (объектов) наблюдения; ● программа наблюдения Организационный план наблюдения: ● место, время, сроки; ● круг лиц и организаций, отвечающих и привлекаемых к наблюдению; ● подбор, изучение, инструктаж кадров; ● размножение и рассылка формуляров Рис. 1.1 Программа наблюдения – это развёрнутый ценз объекта наблюдения, воплощённый в формализованный документ, называемый формуляром наблюдения. Требования к программе: ▪ в неё включаются только варьирующие признаки; ▪ включаются только те вопросы, которые будут использованы при обобщении материалов наблюдения; ▪ формулировка вопросов должна исключать двойственность их понимания и толкования. Формуляр наблюдения (статистический формуляр) – бланк в виде опросного листа или анкеты или иной формы отчётности, содержащей вопросы (пункты) программы наблюдения и место для ответов для них. Мы уже останавливались на понятии «статистическая совокупность», необходимо рассмотреть это понятие глубже. 2.1.2. Виды статистических наблюдений по охвату генеральной совокупности и характеру регистрации фактов (рис. 1.2). ВИДЫ СТАТИСТИЧЕСКИХ НАБЛЮДЕНИЙ 9 По охвату генеральной совокупности: ● сплошное наблюдение или ● несплошное наблюдение По характеру регистрации фактов: ● непрерывное наблюдение или ● прерывное наблюдение Рис. 1.2 3. Источники статистической информации или наблюдений в статистике 3.1. Рассмотрим рис. 1.3: ИСТОЧНИКИ СТАТИСТИЧЕСКОЙ ИНФОРМАЦИИ Статистическая отчётность способы Специально организованные статистические наблюдения Рис. 1.3 3.2. Статистическая отчётность: обязательные отчёты предприятий и организаций перед государственными органами статистики. Эти отчёты содержат регламентированные вопросы, на которые организация (предприятие) должна обязательно ответить; ● учётно-отчётная документация предприятий и организаций. 3.3. Специально организованные статистические наблюдения: ● непосредственные наблюдения, при которых необходимые сведения получаются путём непосредственного пересчёта, измерения, взвешивания и т. п. единиц объекта наблюдения; ● устный опрос – производится регистраторами или счётчиками согласно разработанным статистическим формулярам. Частным случаем устного опроса является интервью; ● письменные опросы в виде анкет и тестов. Статистическое наблюдение является первым этапом статистического исследования, задачей которого является сбор первоначального статистического материала, который необходимо свести в систему – этот процесс мы начнём изучать в следующей теме. ● 4. Государственные статистические органы 4.1. Структура органов государственной Российской Федерации представлена на рис. 1.4: 10 статистики 11 СИСТЕМА ОРГАНОВ ГОСУДАРСТВЕННОЙ СТАТИСТИКИ Федеральный уровень Государственный комитет Российской Федерации по статистике (Госкомстат России): Центральный аппарат-руководство, управления и отделы Главный межрегиональный центр обработки и распространения статистической информации (ГМЦ Госкомстата России) Научно-исследовательский институт проблем социальноэкономической статистики (НИИ статистики Госкомстата России) 11 Информационно-издательский центр «Статистика России» (АНО ИИЦ «Статистика России») Межотраслевой институт повышения квалификации руководящих работников и специалистов в области учета и статистики (МИПК учета и статистики Госкомстата России) Межведомственный центр социально-экономических измерений РАН и Госкомстата России Научно-исследовательский и проектно-технологический институт статистической информации (НИПИ статинформ Госкомстата) Управление по эксплуатации зданий Учебные заведения (10 колледжей, 12 техникумов, 34 учебных центра) Территориальный уровень Комитеты государственной статистики в субъектах Российской Федерации Районные органы государственной статистики Районные (городские) отделы статистики Межрайонные отделы статистики Специалисты в районах (городах) области (края) без образования отдельного структурного подразделения Рис. 1.4 Структура централизованной системы органов государственной статистики Российской Федерации 10 4.2. Основные задачи и функции Государственного Комитета РФ по статистике представлены на рис. 1.5: Основные задачи Госкомстата 12 представление официальной статистической информации Президенту Российской Федерации, Правительству Российской Федерации Федеральному Собранию Российской Федерации, Федеральным органам исполнительной власти, общественности, а также международным организациям; разработка научно обоснованной статистической методологии соответствующей потребностям общества на современном этапе, а также международным стандартам; координация статистической деятельности федеральных органов исполнительной власти и органов исполнительной власти субъектов Российской Федерации, обеспечение условий для использования указанными органами официальных статистических стандартов при проведении ими отраслевых (ведомственных) статистических наблюдений; Рис. 1.5 11 разработка экономикостатистической информации, ее анализ, составление национальных счетов, необходимых балансовых расчетов; гарантирование полноты и научной обоснованности всей официальной статистической информации; предоставление всем пользователям равного доступа к открытой статистической информации путем распространения официальных докладов о социально-экономическом положении Российской Федерации, субъектов Российской Федерации, отраслей и секторов экономики, публикации статистических сборников и других статистических материалов; Вопросы и задания для самоконтроля 1. Как вы понимаете термин «статистика как наука»? 2. Что является объектами и предметом изучения статистики? 3. Какие методы анализа использует статистика? 4. Назовите основные требования, предъявляемые к статистическим исследованиям. 5. Каковы особенности статистического метода наблюдения? 6. Назовите основные виды статистических наблюдений. 7. Как выглядит структура органов государственной статистики? 8. Назовите основные задачи и функции государственной статистики РФ. 13 ЛЕКЦИЯ 2. СВОДКА МАТЕРИАЛОВ СТАТИСТИЧЕСКОГО НАБЛЮДЕНИЯ «Свести… – соединить в какоелибо новое целое … свести данные в таблицу…» Ожегов. 1. Общие понятия о статистической сводке. 2. Статистические показатели. 3. Статистические группировки. 4. Статистические таблицы и графики. 1. Общие понятия о статистической сводке 1.1. Сводка – это процесс систематизации материала статистического наблюдения. Типичные действия при статистической сводке: ● разбор первичного статистического материала; ● группировка данных статистического наблюдения по определённым признакам с одновременной разработкой системы показателей для выделяемых групп и подгрупп; ● изложение результатов исследования при помощи таблиц, графиков и статистических рядов. 1.2. Составной частью разбора статистического материала является его предварительный контроль, который включает в себя следующие позиции: ● проверка наличия сведений обо всех обследуемых единицах; ● выяснение присутствия пропусков в ответах на вопросы программы; ● проверка степени достоверности сообщенных сведений с помощью счетного контроля и контроля логического. Контроль счетный заключается в проверке правильности арифметических итогов и сумм, которые должны находиться в балансе в формулярах, например ∑ пассивов = ∑ активов (по стоимости). Контроль логический – это сопоставление ответов на взаимосвязанные вопросы формуляра с целью выявления ложных и несовместимых ответов, пример несовместимых ответов на вопросы о семейном положении и возрасте: «женат, трое детей; возраст 10 лет» 2. Статистические показатели 2.1. Соотношение признаков и показателей В теме 1 нами дано следующее определение: признак – это одна из отличительных черт, свойств, качеств, присущих единицам исследуемой совокупности. Показатель – количественно-качественная характеристика социально-экономического явления. 14 Таким образом, признак – это только одна из отличительных черт единицы совокупности, в частности она может быть или количественной или качественной, а показатель обязательно содержит две стороны: количественную и качественную. Относительные отличия в применении показателя и признака: ● признак – свойство, присущее единицам исследуемой совокупности, а показатель, кроме того, может характеризовать совокупность в целом (свойство совокупности); ● многие свойства, называемые показателями, можно применять только к совокупности в целом, но они бессмысленны по отношению к её отдельным единицам, например средняя величина. 2.2. Неотъемлемые (атрибутивные) принадлежности показателя Attributum (лат.) – приданное – существенный признак, постоянное свойство чего-либо (кого-либо) – неотъемлемая часть предмета. Пример 2.1: Таблица 2.1. Атрибуты показателя 1. Качественная сторона: объект, свойства, категория 2. Количественная сторона: число или единицы времени 3. Границы, в т. ч. территориальные, объекта 4. Интервал или момент времени Пример 2.1 Ввод в действие жилых домов 41880,2 тыс. м2 Российская Федерация В течение 1993 года Таким образом, показатель включает в себя ряд признаков, четыре которых являются атрибутами (табл. 2.1). 2.3. Основная классификация признаков и показателей (табл. 2.2) Таблица 2.2 Группы классификации признаков и показателей По характеру их выражения По способу измерения По отношению По характеру к вариации характеризуемому объекту А Б В Г 1. Описательные 1. Первичные или 1. Прямые 1. (атрибутивные) учитываемые 2. Косвенные Альтернативные 2. (абсолютные) 3. Обратные 2. Дискретные Количественные 2. Вторичные или 3. Непрерывные расчётные или производные (относительные) П р и з н а к и Для показателя П о к а з а т е л и и то и другое 15 По отношению ко времени Д 1. Моментные 2. Интервальные Объяснения по группам (А, Б, В, Г, Д) и пунктам (1, 2, 3): А.1 – эти признаки выражаются в основном словесно, например: национальность, род, вид. А.2 – эти признаки выражаются числами: возраст человека, величина площади пашни и т. д. Б.1 – признаки, замеренные непосредственно в процессе статистического наблюдения по каждой единице совокупности, это абсолютные величины. Б.2 – это выводные признаки, рассчитанные на основании первичных признаков, – относительные величины, полученные через соотношение первичных признаков, например, если мы разделим объём продукции в стоимостном измерении на каком-либо предприятии на численность его работников, то получим признак – товарная выработка. В.1 – это свойства, присущие непосредственно характеризуемым единицам (объектам). В.2 – свойства, которые выводятся не непосредственно, а через прямые, например, по уровню дохода гражданина можно вывести такой признак, как качество его жизни, а по среднему возрасту человека вывести уровень благосостояния нации. В.3 – получаются путём деления единицы на величину прямого 1 признака (показателя) (Фондоёмкость = ). фондоотдач а Группа Г: вариация – колеблиемость, изменение величины признака в статистической совокупности, т. е. принятие единицами совокупности или их группами разных значений признака. Alternati (лат.) – чередоваться – каждая из исключающих друг друга возможностей. Г.1 – это признаки, отвечающие на вопрос: есть или нет какое-либо из свойств у единицы (объекта), например, студенты, желающие или не желающие получить стипендию. Г.2 – количественные признаки, принимающие только конечные значения. Г.3 – их ещё называют – непрерывно варьирующие. Они в определённых границах могут принимать любые значения, в т. ч. дробные (количество знаков после запятой может быть бесконечным). Д.1 – они характеризуют объект в какой-либо фиксированный момент времени (поголовье скота на конец года…). Д.2 – они характеризуют результаты процессов динамики за какойлибо интервал (период) времени (количество родившихся за год; месячный товарооборот). Статистика использует все показатели, выработанные для характеристики социально-экономических явлений, как микро -, так и 16 макроэкономические. Но у неё есть, выработанные ею самой, показатели, например, показатели вариации, связи признаков, структуры и распределения, темпов изменения в динамике. 3. Статистические группировки 3.1. Понятие о группировке Пример 2.2: При исследовании потребностей населения в витамине «С» по возрастам статистики – медики не будут приводить соответствующие цифры по каждому возрасту от одного года до 100 лет, а сделают это по группам, например: до 1 года, от одного года до 5-ти лет, от 5-ти до 10-ти лет, …, от 60-ти до 100 лет. Группировка – это процесс образования из единиц совокупности групп однородных в каком-либо существенном отношении или имеющих одинаковые или близкие значения признака группировочного. 3.2. Процесс группировки: 1) устанавливается признак (показатель), по которому единицы исследуемой совокупности распределяют по группам, например, рейтинг студентов в совокупности студентов всех курсов или рентабельность продукции предприятий малого бизнеса; 2) определяется число групп и их обозначение (границы), например, три группы (0 – 40 баллов; 40 – 60 баллов; 60 – 100 баллов) или три группы рентабельности продукции (предприятия с высокой, средней и низкой рентабельностью); 3) каждая единица совокупности относится к соответствующей группе в зависимости от значений в ней группировочного признака; 4) производится подсчёт единиц в каждой группе (частота признака). В зависимости от целей исследования, а значит, и установленных показателей (признаков) принимается тот или иной вид группировки. 3.3. Виды группировок 3.3.1. Типологическая группировка Typos (греч.)… – обобщенный образ. Типологическая группировка предполагает выделение однородных групп по важнейшим социально-экономическим качествам, например, предприятий – по формам собственности, населения – по социальным группам, продукции – по экономическому значению. Пример 2.3: В городе N на момент M1 имелось 100 промышленных предприятий, их типологическая группировка по признаку «форма собственности» была такой: ● муниципальная – 20 предприятий; ● федеральная – 30 предприятий; 17 частная – 50 предприятий. В тот же момент типологическая группировка по уровню рентабельности продукции предприятий в частном секторе: ● высокая рентабельность – 10 предприятий; ● средняя рентабельность – 25 предприятий; ● низкая рентабельность – 15 предприятий. 3.3.2. Структурная группировка Structura (лат.) – строение, устройство. Структуризация – выделение элементов (подсистем) и определённых соотношений между ними в системе. Структурная группировка – группировка, выявляющая строение однородной в качественном отношении совокупности статистической по определённому признаку. Продолжение примера 2.3: Структуры на моменты M1 и M2 промышленных предприятий по признаку «форма собственности» (рис. 2.1). ● M1 M2 Ап Частная 50% Федеральная 30% Федеральная 30% Частная 55% Муниципа- Муниципальная 15% льная 20% Рис. 2.1 Примечание 2.1: Однородность совокупности в данном случае заключается в признаке «промышленные предприятия в городе N». Подобные структуры мы могли бы выявить и по уровню рентабельности продукции промышленных предприятий в частном секторе экономики; тогда однородность совокупности в этом варианте состоит в том, что в неё включены только промышленные предприятия частного сектора экономики. Сопоставление данных структурных группировок во времени даёт представление о «структурных сдвигах», что проиллюстрировано на рис.2.1. 3.3.3. Аналитическая группировка 18 До сих пор мы рассматривали группировки в однородных совокупностях по величинам, уровням, атрибутам одного из признаков (показателей). Однако в однородных совокупностях весьма часто значение одного признака (показателя) находится в зависимости от другого признака (показателя). Пример 2.4 (рис. 2.2): Производительность Энерговооруженность труда труда у = х ↓ ↓ результат y = f(x) фактор Рис. 2.2 Признак факторный (признак-фактор) – признак, оказывающий влияние на другой, связанный с ним результативный признак и обуславливающий изменение (вариацию) последнего. Признак результативный (признак-результат) – признак зависимый, т. е. изменяющий свое значение (вариацию) под влиянием изменения (вариации) другого, связанного с ним и действующего на него признака факторного. Вариация признака-фактора порождает вариацию признака-результата. Группировка аналитическая – группировка в однородной совокупности, с помощью которой выявляются взаимосвязи (отношения) между явлениями через связь их определённых признаков. Вариант определения: группировка аналитическая – группировка для выявления степени связи между признаками-факторами и признакомрезультатом. Группы образуют обычно по значениям признака-фактора, а затем для каждой группы выявляется величина признака результата. Пример 2.5 (табл. 2.3): Таблица 2.3 Группы магазинов по размеру товарооборота за квартал, ден. ед. До 2 2–4 4 – 16 16 – 32 ………… Признак-фактор (х) Средние издержки к товарообороту, % 19,2 13,9 8,5 5,9 ………… Признак-результат (у) y = f (x) Примечание 2.2: Как же узнать наличие в совокупности взаимосвязанных признаков (показателей)? 19 Конечно, в основном мы пользуемся данными прошлых исследований. Но принципиальный подход состоит в принципе стохастичности: stochastistiros (греч.) – умение угадывать. По этому поводу математик Д. Попп высказался так: «Законченная математика… выглядит как чисто доказательная. Но математика в процессе создания напоминает любые другие человеческие знания, находящиеся в процессе создания. Вы должны догадаться о математической теореме, прежде чем вы её докажете, вы должны догадаться об идее доказательства, прежде чем вы его проведёте в деталях». Результат творческой работы математика… доказательство; но доказательство открывается с помощью правдоподобного рассуждения, с помощью догадки». 3.3.4. Группировка территориальная – это распределение сводных статистических данных по экономико-географическому или административно-территориальному признаку. 3.3.5. Группировка комбинированная – группировка, в которой расчленение совокупности статистической на группы производится по двум или более признакам, взятым в сочетании (комбинации). Пример 2.6 (рис. 2.3): Типы предприятий по собственности: • федеральные; • муниципальные; • частные. Структура каждого типа по товарообороту • до 40 млн. руб.; • более 40 млн. руб. Распределение этих предприятий по районам Волгоградской области: • Камышинский район; • Дубовский район; • Михайловский район; • ………………………. Анализ: зависимость издержек обращения в зависимости от величины товарооборота в разрезе территорий и форм собственности Рис. 2.3 3.4. Интервальная группировка (образование групп и интервалов Группировка называется простой (монететической) при использовании в её процессе одного признака и сложной (комбинированной, полититической) при использовании нескольких признаков. Процесс группировки является альтернативным: как малое, так и большое количество групп для конкретной совокупности может нарушить проявление закона больших чисел. Закон больших чисел в социально-экономической статистике – общий принцип, в силу которого количественно-качественные закономерности, присущие массовым общественным явлениям, отчётливо проявляются лишь в достаточно большом числе наблюдений. При многомерной (полититической) группировке количество групп 20 может быть слишком большим, а поэтому в каждой группе будет слишком мало единиц наблюдения. К = L × m, (2.1) где К – число групп всего (для двухмерной группировки); m – число групп по признаку m; L – число групп по признаку ℓ/. Проявление закона больших чисел рассмотрим на примере 2.7. Пример 2.7 (табл. 2.4): Таблица 2.4 Добавка в пищу препарата А, дозы Привес поросят за ед. времени, кг 1 2 3 4 5 6 7 8 9 10 11 12 2 2,5 1,5 2 7 5 6 6 6 2 2 6 Группировка доз и средний привес поросят, дозы кг Дозы Привес Дозы Привес (средние) средний (средние) средний 2,5 (1 – 4) 2 6,5 (5 – 8) 6 10 (9 – 12) Группировка 1 4 3,5 (1 – 6) 3,3 (1 – 6) 9,5 (7 – 12) 4,6 (7 – 12) Группировка 2 Группировка 3 Данные таблицы приведены в виде графиков: Первая группировка привес привес 8 6 4 2 0 1 2 3 4 5 6 7 8 9 Рис. 2.4 Проанализируем представленные графики. 21 10 11 12 дозы При первой группировке (рис. 2.4) признак-результат подвержен колебаниям, не выявляющим четко влияние признака-фактора: внутри каждой из групп не действует закон больших чисел. При второй группировке (рис. 2.5) поведение признака-результата подчиняется определённому закону: средние величины результатов по группам показывают некую зависимость их от фактора (в своё время мы это проверим). Вторая группировка привес привес 7 6 5 4 3 2 1 0 2,5 6,5 10 дозы Рис. 2.5 Третья группировка привес привес 5 4 3 2 1 0 3,5 9,5 дозы Рис. 2.6 При третьей группировке (рис. 2.6) – всего 2 группы. Мало групп – не улавливается закономерность колеблиемости (вариации) между группами. В каждой из групп должно быть оптимальное количество наблюдаемых единиц, как с позиции проявления закона больших чисел внутри каждой группы, так и с позиции проявления этого закона между группами. Это не значит, что в каждой группе количество единиц наблюдения должно быть одинаковым: интервалы групп могут быть равными и неравными. Равные интервалы применяют обычно при 22 относительно узких пределах вариации и при распределении единиц совокупности по выбранному признаку близкому к равномерному. Пример 2.8: В 1980 году заработная плата рабочих на предприятиях в промышленности колебалась от 60-ти до 160-ти руб. в месяц. По этому признаку можно образовать пять групп, тогда групповой 160 60 интервал будет равен: 20 рублей; образуются следующие 5 группы: 60 – 80; 80 – 100; 100 – 120; 120 – 140; 140 – 160 (руб.). В данном случае приведён пример интервалов, когда верхние границы каждого из них могут быть включены в нижние границы следующего интервала, во избежание такого повтора к верхним границам применяются выражения «включая» и «исключая», например: «60 – 80 (включая)» означает, что следующий интервал начнётся с цифры обязательно большей 80-ти. Деление совокупности на равномерные интервалы может привести к их неоправданно большому количеству. Очень часто влияние признакафактора на признак-результат не является равномерным, а убывающим или возрастающим по определённой закономерности. Пример 2.9: Увеличение численности квалифицированных рабочих на 50 человек на предприятии с прежней численностью в 200 человек может значительно увеличить темп прироста объёма товарной продукции этого предприятия, а такое же увеличение числа рабочих на предприятии с их числом 3000 человек вряд ли заметно повлияет на этот показатель. Промышленные предприятия по численности рабочих обычно группируются так: до 200, 201 – 1000, 1001 – 3000, 3001 – 10000, 10001 и более. В данном случае применены так называемые закрытые интервалы и открытые интервалы: закрытые интервалы имеют и нижнюю и верхнюю границы; открытые интервалы не имеют или нижней границы (до 200) или верхней границы (10001 и более). Иногда первичная группировка не удовлетворяет исследователя, но получить дополнительные данные ему не представляется возможным, поэтому он прибегает (если это возможно) ко вторичной группировке. 3.5. Вторичная группировка Метод вторичной группировки – приём, используемый в статистическом исследовании для образования новых групп на основании ранее произведённой (первичной) группировки. 3.5.1. Вторичная группировка методом изменения интервалов 23 Необходимость в этой группировке возникает тогда, когда первичная группировка содержит больше или меньше групп, чем это необходимо для характеристики типичных отношений. Пример 2.10: Представим пример 2.5 в графическом варианте (без соблюдения масштабов) (рис. 2.7): интервалы 2 средние издержки, % 19,2 4 16 13,9 32 8,5 Рис. 2.7 5,9 Исследователю понадобилось выделить интервал «3 – 8». Так как фактических данных по этому интервалу у него нет, ему приходится принимать гипотезу равномерного уменьшения издержек в каждом из интервалов. Тогда в интервале «2 – 4» значение 13,9 соответствует величине оборота «3», а в интервале «4 – 16» соответственно «8,5» и «10» (рис. 2.8). интервалы средние издержки, % 2 3 4 10 13,9 16 32 8,5 Рис. 2.8 Для интервала «3 – 10» серединное (принимаемое по гипотезе) 13,9 8,5 значение издержек равно 11,2 ( ); этому значению соответствует 2 «отметка» по товарообороту «6,5» ( 3 10 ). 2 На каждую единицу уменьшения товарооборота в интервале «3 – 10» приходится 1,06 единиц увеличения издержек ( 13,9 8,5 ). 10 3 До отметки «8» они наберут 2,12 единиц издержек [(10 – 8) × 1.06]. То есть на отметке «8» значение издержек будет равно: 8,5 + 2,12 = 10,62. Среднее значение издержек в интервале «3 – 8» будет равно: 13,9 10,62 12,16 (%). 2 В любом случае при выделении новых интервалов по вышеназванной гипотезе следует исходить из серединных значений уже существующих интервалов как по признаку-фактору, так и по признакурезультату. 3.5.2. Долевая группировка 24 Группировка по абсолютным значениям признака часто не даёт качественной картины явления. Её может дать группировка в относительных величинах. Пример 2.11: Первичная группировка торговых точек (штук) по преобладающему ассортименту товаров на бульваре и улице, примыкающих к университету «У»: ● напитки безалкогольные ................. 11 ● выпечка ............................................. 2 ● кондитерские изделия ...................... 2 ● цветы ................................................. 2 ● табачные изделия ............................. 1 ● мороженое ........................................ 3 ● пиво ................................................... 4 Итого: ................................................... 25 Вторичная группировка по признаку необходимости товаров в этих ларьках обыкновенному студенту (табл. 2.5): Таблица 2.5 Степень необходимости товара Нужны часто Периодически нужны Не нужны Итого: Количество ларьков 13 8 4 25 % Доли 52 32 16 100 0,52 0,32 0,16 1,00 4. Статистические таблицы и графики 4.1. Общие правила построения таблиц статистических (ТС) 4.1.1. Общая форма статистической таблицы (табл. 2.6): Таблица 2.6 Наименование таблицы (общий заголовок) Наименование подлежащего А Подлежащие (боковые заголовки) Наименование сказуемого Заголовки сказуемого (верхние заголовки) 1 2 n • • графоклетка • • • • • • графы (столбцы, колонки) Пример 2.12 (табл.2.7): нумерация граф строки итоговая строка итоговая графа Таблица 2.7 25 Распределение городов РФ по численности постоянного населения Число жителей, тыс. чел. А 4,9 и менее • 20 – 49,9 • 1 млн. и более Итого: число 29 • 348 • 8 999 Число городов по годам 2001 2002 % число 2,9 24 • • 34,8 372 • • 0,8 12 100 1064 % 2,2 • 34,9 • 1,1 100 Итак, подлежащим статистической таблицы являются единицы совокупности или их группы – это атрибутивные, неотъемлемо принадлежащие свойства единиц наблюдения. Сказуемым статистической таблицы являются цифровые данные (количественные признаки, характеризующие подлежащее). Таким образом, статистическая таблица представляет собой статистическое предложение. Примечание 2.3: Довольно часто некоторые свойства (признаки), характеризующие подлежащее, выносятся в ту часть таблицы, которая предназначена для верхних заголовков, например, в табл. 2.7 примера 2.12 это признаки «1995 год» и «2002 год». Такое построение таблиц производится в целях их компактности. Общие правила построения статистических таблиц: ● первое правило: не следует загружать ТС излишними подробностями, затрудняющими анализ явления; ● второе правило: необходимо избегать образования графо-клеток, не имеющих смысла; если же они появились, следует в них поставить крест «х»; ● третье правило: заголовки ТС должны быть краткими и понятными; ● четвёртое правило: если все приводимые в ТС данные имеют одну единицу измерения, то она указывается в общем заголовке; если же разные – то в заголовках строк или граф, обычно через запятую. ● пятое правило: при наличии в ТС данных, отличающихся какимилибо особенностями (предварительными, относящимися к части территории и т. п.), их необходимо указывать в примечаниях или сносках; ● шестое правило: нулевые значения признака принято обозначать знаком тире «–», отсутствие данных – тремя точками «…» или буквами «н. с.» (нет сведений). По строению подлежащего ТС может быть таблицей простой, групповой и комбинационной, а по сказуемому – с простой и сложной разработкой. 26 4.1.2. Классификация таблиц по строению подлежащего: а) простые таблицы по строению подлежащего – в подлежащем отсутствуют группировки, например, перечень всех городов с указанием числа жителей в каждом из них – такие перечни, видимо, предшествовали разработке таблицы, изображённой в примере 2.12; б) групповые таблицы по строению подлежащего – подлежащее разделено на группы по тому или иному признаку (пример 2.12); в) комбинационные таблицы по строению подлежащего – подлежащие сгруппированы по нескольким признакам (полититическая группировка). Пример 2.13 (табл. 2.8): Таблица 2.8 Распределение жителей города N по занятости, человек Вид занятости Всего На предприятиях и в организациях Учащиеся Пенсионеры (неработающие) Бомжи • • В том числе по полу мужскому женскому • • 4.1.3. Классификация таблиц по степени разработки сказуемого: таблицы с простой разработкой сказуемого – графы, выделенные по каждому признаку, располагаются независимо друг от друга; ● таблицы со сложной разработкой сказуемого – каждая графа имеет подграфы, детализирующие признак, при этом каждая подграфа имеет свой итог. Пример 2.14 (табл. 2.9): Таблица 2.9 ● Населённые пункты А Б • Итого: Трудоспособные мужчины женщины • • Нетрудоспособные мужчины женщины • • 4.2. Статистические графики В статистике графиком называют наглядное изображение статистических величин при помощи геометрических линий и фигур (диаграмм) или географических картосхем (картограмм). 4.2.1. Основные элементы графика 1. Графический образ (основа графика) – это геометрические знаки (совокупность точек, линии, фигуры), с помощью которых изображаются 27 статистические величины. В зависимости от применяемых геометрических знаков графики разделяются на точечные, линейные, столбиковые, полосовые, квадратные, круговые и т. д. 2. Поле графика – это то место, где расположены геометрические фигуры. Обычное соотношение сторон поля от 1 : 1,33 до 1 : 1,5. 3. Пространственные ориентиры, дающие геометрическим знакам на поле количественную определённость. В статистических графиках применяются прямолинейные масштабные шкалы, криволинейные (например, круговые секторные диаграммы). Чаще всего применяются равномерные масштабные шкалы, но иногда (в случаях очень разнящихся интервалов совокупности) используются логарифмические шкалы. Пример 2.15 (рис. 2.9): Числа 1 10 Логарифмы 0 1 100 1000 2 3 10000 4 100000 5 1000000 6 10000000 7 Рис. 2.9 Примечание 2.4: масштаб по строке «числа» не соблюдён из-за невозможности этого. 5. Экспликация графика – это словесное пояснение его содержания, а именно: название графика, подписи вдоль или в конце масштабных шкал, пояснение к отдельным частям графика. 4.2.2. Виды статистических графиков С точки зрения решаемых задач статистические графики можно разделить на: 1) графики сравнения статистических показателей; 2) графики динамики; 3) графики структуры и структурных сдвигов; 4) графики контроля выполнения плана; 5) графики вариационных рядов; 6) графики зависимости варьирующих признаков. В процессе дальнейшего изложения материала дисциплины мы приведём наглядно ряд видов. На этом заканчиваем лекцию 2, но не заканчиваем изучение процесса статистической сводки, мы его продолжим в лекции 4 (статистические ряды). Но перед этой темой следует детально разобраться в том, что мы понимаем под абсолютными и относительными величинами, так как это необходимо для понимания всего последующего материала. Вопросы и задания для самоконтроля 1. Дайте понятие о статистической сводке. 28 2. Чем отличается термин «признак» от термина «показатель»? 3. Что означает «неотъемлемые принадлежности показателя»? 4. Назовите основные группы классификации признаков показателей. 5. Что такое статистическая группировка? Приведите примеры. 6. Назовите виды группировок. 7. Что представляет собой интервальная группировка? 8. Каковы общие правила построения статистических таблиц? Приведите примеры. 9. Что такое статистические графики? и ЛЕКЦИЯ 3. АБСОЛЮТНЫЕ И ОТНОСИТЕЛЬНЫЕ ВЕЛИЧИНЫ 1. Вводная часть. 2. Абсолютные статистические величины. 3. Относительные статистические величины. 4. Относительные величины динамики. 5. Общие принципы построения относительных статистических величин. 1. Вводная часть В лекции 2 мы дали классификацию признаков и показателей, в том числе, по способу их измерения: ● абсолютные табл. 2.2 , графа Б ● относительные В этой теме остановимся подробнее на этих категориях, будем опираться в дальнейшем на пример 3.1. Пример 3.1: Таблица 3.1 Данные по заработной плате на предприятии N за февраль-месяц 2002 г. Группы работников Количество, человек А 1 Выплаченная заработная плата, руб. 2 Рабочие 200 400000 0,93 30000 0,046 0,024 Служащие 10 Руководители 3 30000 Итого: 213 460000 Доля в общей численности и доля в зарплате 3 0,87 Средняя зарплата, руб. 4 2000 0,065 3000 0,065 10000 1 1 2170 Примечание: данные по графе 4 итоговые значения получены путём деления итога по графе 2 на итог по графе 1. 29 2. Абсолютные статистические величины Абсолютная величина в статистике – форма количественного выражения статистических показателей, непосредственно характеризующая абсолютные размеры явлений, их признаков в единицах мер протяжённости, площади, массы, в единицах счёта времени, в денежных единицах или в виде числа элементов (единиц) статистической совокупности и т. д. Абсолютные величины классифицируются (рис. 3.1). В примере 3.1 (табл.3.1) в графах 1 и 2 все величины абсолютные. Прежде чем была произведена группировка, в примере 3.1 были взяты данные (признаки) по каждому работнику предприятия N – индивидуальные величины. Классификация абсолютных величин индивидуальные групповые общие Получаются или непосредственно в процессе наблюдения или расчётным путём (например, данные по строке «Итого») Рис. 3.1 Групповые признаки даны абсолютными величинами в графах 1 и 2 по группам: рабочие, служащие, руководители. Величины по строке «Итого» являются общими, т. е. характеризуют всю совокупность работников по их численности и заработной плате. 3. Относительные статистические величины 3.1. Относительные величины отображают относительные размеры социально-экономических явлений, их качественные стороны. В примере 3.1 – это признаки по графам 3 и 4. Относительная величина получается как частное от деления одной величины на другую. 3.2. Виды относительных величин 3.2.1. Относительная величина выполнения плана – соотношение величины показателя за какое-либо время (или к какому-либо моменту времени) и величины этого же показателя, установленной по плану на это же время. Обычно выражается в процентах. 3.2.2. Относительные величины структуры – это набор соотношений величин частей какого-либо целого и величины этого целого. 30 В примере 3.1 величины по графе 3 выражают структуру производственного персонала предприятия N и структуру распределение его зарплаты. 3.2.3. Относительная величина интенсивности (ОВИ) Intensio (лат) – напряжение. ОВИ – показатель степени развития какого-либо явления; он получается путём сравнения численности разных совокупностей, находящихся в определённых связях друг с другом. К показателям интенсивности можно отнести: плотность населения, производительность труда (товарная выработка), урожайность (например, центнеры зерна на гектар посевной площади) и т. д. Пример 3.2: а) Число родившихся за 1990 год, детей Степень интенсивности рождаемости (детей на 1000 чел.) например, 10 на 1000, записывается часто так: 10 0/00*) Среднее количество населения в 1990 году, тыс. чел. б) Число родившихся за 2000 год, детей Среднее количество населения в 2000 году, тыс. чел. *) 0 /00 промилле, тысячная часть числа 3.2.4. Относительная величина сравнения – соотношение величин одноимённых показателей относящихся к разным объектам, например: сравнение путём деления себестоимости однотипных деталей, производимых на двух разных предприятиях. 3.2.5. Относительная величина приближения к «идеалу» За «идеалы» могут быть приняты нормы расхода чего-либо, плановые показатели, оптимальные показатели и т. д. Пример 3.3: Норма расхода кирпича на 1 метр кубический стены установлена в размере 400 штук, фактический средний расход на строительном участке составил 402 штуки. Фактический расход к расходу по норме составил 101 %, расстояние до «идеала» равно 1 %. 31 3.2 6. Относительная величина взаимосвязи между разными признаками объекта. Пример 3 4: Статистическое наблюдение показало, что увеличение подачи газа в котельную на 1 % приводит к увеличению температуры в квартирах в среднем на 0,7 %. y = a0 + 0,7x, (3.1), результат фактор где 0,7 – относительная величина взаимосвязи между разными признаками объекта или относительная величина, выражающая соотношение вариаций признаков. В примере 3.4 изменение вариаций признака x на один порядок изменяет вариацию признака у на 0,7 порядка. Относительной величиной взаимосвязи является известный вам коэффициент эластичности. 3.2.7. Относительные величины экономического развития выравниваются обычно через соотношения величин важнейших экономических показателей и численности населения (так называемые показатели на душу населения). 3.2.8. Относительная величина координации – соотношение размеров частей целого между собой – показывает, сколько единиц одной части целого приходится на 1, 100, 1000 и т. д. единиц другой его части, например, сколько приходится женщин на 1000 мужчин среди населения в каком-то регионе. 3.2.9. Относительная частота (рассмотрим в теме, посвящённой вариационным рядам). 3.2.10. Относительные величины динамики (это следующий вопрос данной темы). 4. Относительные величины динамики 4.1. Введение Относительная величина динамики представляет собой соотношение какого-либо признака за данное время и величины его же за какое-либо аналогичное предшествующее время. Пример 3.5 (табл. 3.2): 1. Исходные данные: Таблица 3.2 Численность населения в городе N, тыс. чел. Года Всего в т. ч. пенсионеров 2000 100 20 2001 102 21 32 2002 105 21 2003 110 23 2. Динамика численности населения «от года к году» (табл. 3.3): Таблица 3.3 а) выросла в б) составила к предыдущему году в) увеличилась по сравнению прошлым годом на 2000–2001 1,02 раза 102 % Года 2001–2002 1,03 раза 103 % 2002–2003 1,05 раза 105 % 2% 3% 5% с 3. Динамика численности населения по сравнению с базисным моментом (2000 годом): Продолжение табл. 3.3 г) выросла в д) составила к базисному году е) увеличилась по сравнению базисным годом на 2000–2001 1,02 раза 102 % Года 2000–2002 1,05 раза 105 % 2000–2003 1,1 раза 110 % 2% 5% 10 % с 4.2. Относительные величины динамики цепные (ОВДЦ) Так называются величины, рассчитанные в примере 3.5 по пунктам а, б, в – мы их рассматривали «по цепочке от года к году». ОВДЦ показывают, как изменяется величина признака между отдельными моментами (периодами) времени. 4.3. Относительные величины динамики базисные (ОВДБ) Так называют величины, рассчитанные в примере 3.5 по пунктам г, д, е. Они показывают, как постепенно изменилась величина признака по отношению к его же величине в базисном периоде (моменте). Более подробно о показателях динамики мы будем говорить в следующей теме. 5. Общие принципы построения относительных статистических величин 5.1. Общие принципы построения относительных статистических величин Первый принцип: объективность в части связей соотносимых показателей, например, нельзя сравнивать качество жизни населения двух разных регионов только путём соотношения средних доходов на душу, надо делать поправку на соотношение цен. Второй принцип: при построении относительного статистического показателя сравниваемые исходные показатели могут отличаться только по одному атрибутивному признаку. Пример 3.6 (табл. 3.4): 33 Таблица 3.4 Исходные данные для атрибутивной группировки по скоту: Основной признак 1 а) количество свиней б) количество овец Признак типический Признак временный 2 а) в совхозах и колхозах 3 б) в фермерск их хозяйства х а) в 1999 г. б) в 2002 г. Признак по характеру показателя 4 а) б) по фактиче прогно ски зу Распишем соотношение атрибутивных признаков так: 1a , 2a , 3a, 4б ; 2) 1a , 2a , 3б, 4а . 1) 1б , 2a , 3a, 4б 1а , 2б , 3б, 4a Запишите эти соотношению словами и убедитесь в их осмысленности. Пример по бессмысленному сравнению показателей: 1a , 2a , 3a, 4б ; 3) 1б , 2a , 3a, 4a Третий принцип: необходимо знать возможные границы существования относительного показателя, например, относительный показатель теряет смысл, когда при его расчёте знаменатель близок к нулю. 5.2. Понятие о системе статистических показателей Под системой статистических показателей подразумевается совокупность связанных между собой показателей, отражающих разносторонние свойства объекта (совокупности, явления, процесса). Эта система, как правило, включает в себя абсолютные и относительные показатели. Пример 3.7: Объект: агропромышленный комплекс (АПК) в Федеральном округе N в 200_ году (табл. 3.5). Таблица 3.5 А. Абсолютные показатели 1. Основные производственные фонды 300,1 млн. руб. 2. Средняя численность занятых 15,6 тыс. чел. 3. Объём продукции в текущих ценах 559,3 млн. руб. Б. Относительные показатели 4. Фондовооружённость работника 19,24 тыс. руб. 1 раб. ( показатель1 ) показатель2 1,864 руб. прод. 5. Фондоотдача ( показатель3 ) показатель1 1 руб. ОФ 34 6. Производительность труда (товарная выработка на 1-го работника) ( показатель3 ) показатель 2 35,85 тыс. руб. Теперь мы можем возвратиться к продолжению изучения процесса сводки статистической. Вопросы и задания для самоконтроля 1. Дайте определение абсолютных статистических величин. 2. Приведите примеры классификации абсолютных величин. 3. Что такое относительные величины? Приведите примеры. 4. Каковы особенности основных видов относительных величин? 5. С помощью примера проиллюстрируйте показатели относительной величины динамики. 6. Каковы принципы построения относительных статистических величин? ЛЕКЦИЯ 4. РЯДЫ РАСПРЕДЕЛЕНИЯ 1. Основные виды рядов распределения. 2. Определение числа групп в вариационном ряду; графические изображения вариационного ряда. 3. Ряды динамики. Рядом распределения в статистике называется упорядоченное распределение единиц совокупности на группы по какому-либо варьирующему группировочному признаку. 1. Основные виды рядов распределения 1.1. Введения и рассуждения Variato (лат.) – изменение; варьировать – изменяться, колебаться в определённых пределах. Из лекции 1 «Статистическая методология; статистическое наблюдение»: в программу наблюдения должны включаться только те признаки, которые варьируют. В лекции 2 (вопрос 3 «Статистические группировки») мы узнали, что искусство образования групп зависит от умения правильно уловить характер вариации того или иного признака в исследуемой статистической совокупности. 35 То есть статистика изучает то, что варьирует. Поэтому названия видов распределения, которые будут даны в следующем параграфе, носят принятый условно характер. 1.2. Атрибутивные ряды распределения Обратимся к примеру 2.12 (лекция 2). В таблице этого примера по графе «А» произведено распределение городов РФ по числу жителей, это атрибутивный ряд распределения. Атрибутивные ряды распределения раскрывают (показывают) состав совокупности по тем или иным существенным, неотъемлемым признакам. 1.3. Вариационные ряды распределения В вышеназванном примере по каждой группе городов приведены количественные данные о том, сколько их в каждой группе, например, данные по графе «1». В данном случае графы «А» и «1» в комплексе представляют собой вариационный ряд распределения. Для того, чтобы дать определение вариационного ряда, рассмотрим некоторые понятия ему присущие. Варианты – ими называют отдельные значения (обозначения) группировочного признака. Частоты – числа, которые показывают, как часто встречаются те или иные варианты в ряду распределения группировочного признака. Частоты, выраженные в относительных величинах называют частотностями, например, графа «2» в упомянутом примере. Частоты часто называют весами. Таким образом, в вариационном ряду содержится два элемента: совокупность вариант и совокупность частот. Вариационным рядом распределения называется ряд, в котором по каждой варианте группировочного признака приведена её частота или частотность. Вариационные ряды бывают как дискретными, так и интервальными. Как особый вид рядов распределения следует выделить для изучения ряды динамики, этому будет посвящён 3 вопрос данной лекции. 2. Определение числа групп в вариационном ряду; графические изображения вариационного ряда 2.1. Определение числа групп в вариационном ряду Опираясь на пример 2.7 и комментарии к нему (лекция 2) и пользуясь категориями, данными п. 1.2.2, изобразим альтернативность процесса группировки схематично (рис. 4.1): Число групп в совокупности статистической последовательности Слишком большое Слишком малое 36 в каждой из групп недостаток вариант недостаток средних групповых вариант внутри групп между группами не работает закон больших чисел Рис. 4.1 Мы ещё вернёмся в последующем к этой схеме, а пока рекомендуем для определения числа групп (n) в вариационном ряду формулу американского статистика Стержесса: n = 1 + 3,321 lgN, (4.1) где N – численность совокупности. Пример 4.1: Исходные данные: ● число зерновых с/х предприятий в области – 143; ● наименьшее значение урожайности – 10,7 ц га ; наибольшее значение урожайности равно 53,1 ц/га. Требуется построить вариационный ряд распределения с/х предприятий по урожайности зерновых культур. Решение: 1. n = 1 + 3,321 lg143 = 8,19, т. е. можно сгруппировать 8 или 9 групп, примем 9. Величина интервала (i) рассчитывается так: ● i= xmax xmin , n (4.2) где x max x min – соответственно максимальная и минимальная варианты. 53,1 - 10,7 i= 4,7 (ц/га); округляем i до 5 ц/га. 9 2. В результате группировки материалов статистического наблюдения получилась следующая табл. 4.1. Таблица 4.1 Распределение хозяйств по урожайности зерновых культур Группы хозяйств по урожайности, ц/га xi 10 – 15 Число хозяйств Середина интервала Сбор зерна, ц fi 6 x′i 12,5 x′i × fi 75 37 Накопленная частота прямая 6 обратная 143 15 – 20 20 – 25 25 – 30 30 – 35 35 – 40 40 – 45 45 – 50 50 – 55 Итого: 9 20 41 26 21 14 5 1 143 17,5 22,2 27,5 32,5 37,5 42,5 47,5 52,5 157,5 450,0 1127,5 845,0 787,5 595,0 237,5 52,5 4327,5 15 35 76 102 123 137 142 143 137 128 108 67 41 20 6 1 Примечание 4.1: округлённое целое значение признака зачислено в тот интервал, в котором оно появилось в первый раз. Совокупность граф xi и fi представляет собой необходимый по заданию вариационный ряд распределения; данные остальных граф нам потребуются в дальнейшем. 2.2. Графические изображения вариационного ряда распределения 2.2.1. Гистограмма и полигон распределения Гистограмма происходит от сочетания греческих слов: столб и написание, т. е. это столбчатая диаграмма, один из способов графического изображения интервального распределения вариант с указанием их частот. Основания столбцов изображают интервалы значений варьирующего признака (интервалы вариант), обычно откладываются по оси абсцисс. Высоты столбцов соответствуют частотам интервалов вариант (обычно по оси ординат). Изобразим решение примера 4.1 в виде гистограммы (обводка сплошной линией; на пунктирные линии пока не обращаем внимания): 38 Рис. 4.2 Произведём следующие действия на рис. 4.2: ● изобразим условные крайние интервалы с нулевыми частотами «5 – 10» и «55 – 60»; ● середины верхних сторон столбцов, включая середины условных интервалов, соединим прямыми линиями. Полученная таким образом диаграмма называется полигоном распределения (обводка ломаной пунктирной линией). Полигон (от греч) – многоугольник. Мы построили полигон распределения для интервального ряда; на нём отображается распределение серединных значений вариант по интервалам. Вообразим, что эти серединные значения представляют собой дискретный вариационный ряд (7,5; 12,5; 17,5; … 57,5), тогда этот полигон будет представлять распределение вариант в дискретном вариационном ряду. Не трудно доказать, что площади гистограммы и полигона, отображающих один и тот же вариационный интервальный ряд, равны. В 39 примере 4.1 (табл. 4.1) эти площади равны объёму группировочного признака, в нашем случае сбору зерна, равному 4327,5 ц. Заметим, что табл. 4.1 и соответствующая ей гистограмма и полигон показывают большие частоты вариант, близких к среднему интервалу и меньшие частоты вариант крайних значений. 2.2.2. Абсолютная плотность распределения (АПР) АПР представляет собой величину частоты, приходящейся на единицу размера интервала каждой отдельной группы ряда. f К= i , (4.3) i где К – АПР; fi – частота интервала; i – размер интервала. Например, для интервала «10 – 15» (табл. 4.1): 6 К = = 1,2. 5 Если вариационный ряд дан в неравных интервалах, то для правильного представления характера распределения необходимо произвести расчёт абсолютной плотности распределения; при построении гистограммы по оси ординат следует наносить показатели плотности распределения, а не частот. Необходимость этой процедуры покажем на примере 4.2 Пример 4.2: Построим гистограмму для условного ряда распределения с равными интервалами и равными частотами (обведена сплошными линиями), а затем два крайних интервала объединим в один и построим тоже гистограмму (пунктир) (рис. 4.3). f 8 4 0 2 4 6 х Рис. 4.3 Характеры вариации по этим двум гистограммам совершенно разные, в первом случае соотношения 4/4 = 1, во втором – 8/4 = 2. Построим гистограмму с заменой частот на АПР (рис. 4.4): К0-2 = 4/2 = 2; К2-6 = 8/4 = 2. Масштабы уменьшились, но их соотношения остались прежними, что для сравнения самое главное. K 40 2 0 2 6 х Рис. 4.4 2.2.3. Кумулята и огива распределения (вариант по частотам) Cumulantis (лат.) – собирающий, накапливающий. Продолжение примера 4.1: На основании табл. 4.1 построим нижеследующую табл. 4.2. Таблица 4.2 Кумулятивное распределение вариант по частотам Получают не больше, чем ц / га 12,5 17,5 22,5 27,5 32,5 37,5 42,5 47,5 52,5 Количество хозяйств 6 15 35 76 102 123 137 142 143 урожайность, ц/га Кумулята (кривая сумм частот) 160 150 140 130 120 110 100 90 80 70 60 50 40 30 20 10 0 12,5 17,5 22,5 27,5 32,5 37,5 42,5 47,5 52,5 количество хозяйств Рис. 4.5 По аналогии с табл. 4.2 мы можем построить и кривую распределения ряда по огиве, в этом случае принимается правило «получают не меньше, чем ц / га». 41 Если кумулята – возрастающая кривая (рис. 4.5), то огива – убывающая. 3. Ряды динамики 3.1. Элементы ряда динамики и виды рядов динамики Рядом динамики в статистике называется вариационный ряд, характеризующий изменение общественного явления (объекта наблюдения) во времени. Каждый ряд динамики состоит из двух элементов: 1) ряд уровней, которые характеризуют величину явления, его размер; 2) ряд периодов либо моментов времени, к которым относятся уровни ряда. Пример 4.3: Таблица 4.3 Парк и поставка комплектов оборудования типа «n» в регион «N» Парк на конец года Поставка в течение года Гост поставок цепной (%) 1999 2000 Годы 2001 2002 2003 2004 1985 2171 2460 2612 2821 3132 269 334 377 438 425 482 124 113 116 97 113 Виды показателей Моментные абсолютные Периодические абсолютные Периодические относительные В табл. 4.3 три ряда динамики: I (1999 – 2004) и (парк на конец года); II (1999 – 2004) и (поставка в течение года); III (1999 – 2004) и (рост поставок цепной). Ряды динамики классифицируются (рис. 4.6). Классификация рядов динамики Моментные Периодические В абсолютных или в относительных показателях Рис. 4.6 3.2. Наиболее распространенные показатели динамики и их взаимосвязь Основной функцией рядов динамики является анализ закономерностей развития того или иного явления (процесса) во времени; на основании анализа выявляются тенденции (тренд) этого развития. Для анализа применяется ряд показателей. Основной принцип формирования показателей динамики заключается в сравнении между собой уровней ряда динамики. 42 Сравниваемый уровень называют текущим, уровень, с которым производится сравнение – базисным. Примечание 4.2: Следует отличать понятие «базисный» для наименования периода (момента) и для наименования уровня. Базисным периодом (моментом) называется тот период (момент) в ряду динамики, с показателями которого сравнивают уровни показателей всех остальных периодов (моментов) в этом ряду динамики. Базисным уровнем можно называть любой уровень в ряду динамики, с которым производится сравнение другого какого-либо уровня в этом же ряду. Наиболее распространёнными показателями динамики являются следующие: ● прирост абсолютный; ● темп роста; ● темп прироста; ● коэффициент опережения; ● абсолютное значение одного процента. Обратимся к примеру 3.5 и прокомментируем смысл приводимых ниже показателей динамики и формулы их расчёта. 3.2.1. Прирост абсолютный 1. Прирост показателя абсолютный цепной показывает, на сколько единиц изменился его текущий уровень по сравнению с уровнем в предшествующем периоде (моменте). Он рассчитывается по формуле: Пцi = уi – уi-1, (4.4) где Пцi – абсолютный прирост цепной; уi – текущий уровень показателя; уi-1 – уровень показателя в предшествующем периоде. В примере 3.5 Пц(2002) = 3 тыс. чел. 2. Прирост показателя абсолютный базисный показывает, на сколько единиц увеличился или уменьшился его текущий уровень по сравнению с уровнем в базисном периоде (моменте), т. е. один из периодов (моментов) принимается за базисный. Он рассчитывается по формуле: Пбi = уi – у1 или Пбi = уi – у0, (4.5) где Пбi – абсолютный прирост базисный; у1 или у0 – величины показателя в базисном периоде (моменте). В примере 3.5 принят за базисный 2000-й год: Пб(2002) = 5 тыс. чел. 3.2.2. Темпы роста 1. Темп роста показателя цепной показывает, во сколько раз его текущий уровень больше или меньше уровня предшествующего периода (момента). Он рассчитывается по формуле: 43 ● ● в относительных величинах: Трцi = yi y i 1 Трцi = yi 100 % , yi 1 , (4.6) в процентах: (4.7) где Трцi – темп роста. В примере 3.5 это показатели по строкам «а» и «б». 2. Темп роста показателя базисный показывает во сколько раз его уровень больше или меньше уровня в базисном периоде (моменте) или сколько процентов составил текущий уровень к уровню базисного периода (момента). Он рассчитывается по формулам: ● в относительных величинах: y y Трбi = i или i , (4.8) y1 y0 ● в процентах: y y Трбi = i 100 % или i 100 % , (4.9) y0 y1 где Трбi – темп роста базисный. В примере 3.5 это показатели по строкам «г» и «д». 3.2.3. Темп прироста, выраженный в процентах, показывает, на сколько процентов увеличился или уменьшился текущий уровень показателя по сравнению с его сравниваемым уровнем. Темп прироста цепной Тпрцi рассчитывается по формуле: Тпрцi = Трцi(%) – 100%, (4.10) Темп прироста базисный Тпрбi рассчитывается по формуле: Тпрбi = Трбi(%) – 100%, (4.11) В примере это показатели по строкам «в» и «е». 3.2.4. Коэффициент опережения В примере 3.5 приведён ряд динамики по пенсионерам. Темп роста базисный 2003 г. составил по ним 115 % (23 : 20 × 100); темп прироста соответственно равен 15 %. Темп прироста всего населения базисный составил соответственно 10 %, т. е. темп прироста пенсионеров за период с 2000 г. по 2003 г. (включительно) в 1,5 раза больше, чем темп прироста всего населения в этом городе. Коэффициент опережения показывает, во сколько раз быстрее растёт уровень соответствующего показателя одного ряда динамики по сравнению с уровнем подобного показателя другого ряда. 44 3.2.5. Абсолютное значение одного процента прироста Пример 4.4: Таблица 4.4 Рост производства товара «А» в РФ Годы Производство млн. т Темп прироста за 5 лет (%) Тпрцi Абсолютный прирост, млн. т Пцi А 1995 2000 2005 1 71 148 243 2 108 64 3 77 95 Абсолютное значение одного процента прироста, млн. т Аi = Пцi : Тпрцi 4 0,71 1,48 По данным табл. 4.4 видно: несмотря на то, что во втором пятилетнем периоде темп прироста производства по сравнению с темпом прироста в первом пятилетнем периоде значительно снизился, однако один процент прироста во втором периоде в два раза «весомее» нежели в первом. До сих пор мы рассматривали статистическое исследование с его количественной стороны, со следующей темы мы будем всё больше рассматривать его качественную сторону. Вопросы и задания для самоконтроля 1. 2. 3. 4. Дайте определение и назовите основные виды рядов распределения. Как определяется абсолютная плотность распределения? Что представляют собой ряды динамики? Назовите основные показатели динамики и как они определяются? 45 ЛЕКЦИЯ 5. СРЕДНИЕ ВЕЛИЧИНЫ 1. Средняя величина как выражение закономерности. 2. Средние арифметические и средняя гармоническая. 3. Средние в рядах динамики. 4. Другие виды средних. 5. Заключение по теме. Средней величиной в статистике называется обобщающая характеристика наблюдаемой статистической совокупности по какомулибо варьирующему признаку; она показывает уровень признака, отнесённый к абстрактной единице совокупности. 1. Средняя величина как выражение закономерности 1.1. Однородность и вариация массовых явлений Пример 5.1: 1. Издержки производства одного и того же товара на разных предприятиях могут отличаться, но рынок усредняет их в абстрактные издержки, которые в основном и формируют рыночную цену товара. 2. Не в каждой семье взрослые дети выше своих родителей; но сравнение средних ростов поколений проявляет такую общую закономерность как акселерация. 3. Рассмотрим и проанализируем ряд совокупностей величин. Генеральная совокупность: 10; 12; 20; 8; 3; 11; 9; 7; 6; 5. ∑ = 91. 91 Средняя величина = 9,1 ; обозначим её так: xгс . 10 Отклонения индивидуальных величин ( xi ) от xгс (∆ xi = xi - xчс ): 0,9; 2,9; 10,9; -1,1; -6,1; 1,9; -0,1; -2,1; -3,1; -4,1. ∑∆ xi = 0. Выборочная совокупность из генеральной совокупности пяти случайных величин: 20; 3; 6; 5; 7. Средняя величина по выборочной совокупности xвыб = 8,2. Просчитаем отклонения индивидуальных величин, представленных в выборочной совокупности от xгс (∆ x j = x j - xгс ), где j обозначает j-ую величину в выборочной совокупности: 10,9; -6,1; -3,1; -4,1; -2,1. ∑∆ x j = 4,5. Среднее отклонение: x в ыб 4,5 0,9 . Отсюда формула: 5 xвыб = xгс + ∆ xвыб = 9,1 – 0,9 = 8,2. 46 (5.1) Великий русский математик Пафнутий Львович Чебышев дал следующий вариант закона больших чисел: «Чем больше объём однородной совокупности, тем полнее взаимное погашение случайных (по отношению к совокупности в целом, её законам) элементов признака х, тем полнее и надёжнее с большей вероятностью среднее значение признака измеряет действие общей для совокупности закономерности». Однако, вариация (∆ xi ) является неотъемлемым свойством массовых явлений, без неё немыслимо развитие природы и общества, отсутствовали бы их эволюция. 1.2. Основные правила применения средних в статистике ♦ Требования качественной однородности совокупности, для которой выводится средняя величина. Если средняя величина обобщает качественно однородные (подчинённые одному закону развития по концепции исследования) значения признака, то она является типичной характеристикой признака данной совокупности. Однако статистика использует и средние величины, обобщающие явно не однородные значения признака, например, величина ВВП на душу населения в стране обобщает совершенно разные по производству и потреблению «души». Но этот показатель характеризует систему – государство в сравнении его с другими системами – государствами. Нетипичные средние, характеризующие какой-либо объект как систему, называются системными средними. ♦ Требование массового обобщения фактов или опора на закон больших чисел. ♦ Использование наряду со средней, характеризующей совокупность в целом, групповых средних. На примере 4.1 мы видим, что многие хозяйства имеют резервы роста урожайности. ♦ Дополнение средних показателей рядами распределения, ибо в этом случае не утрачиваются индивидуальные значения признака, что важно для выявления тенденций развития явления. 2. Средние арифметические и средняя гармоническая 2.1. Средняя арифметическая простая Пример 5.2 (табл. 5.1): Таблица 5.1 Данные по заработной плате в звене рабочих за период времени (t): Рабочие Алексеев Михайлов Васин Завьялов 1 1 1 1 Заработная плата, ден. ед. (хi) 5 6 6 4 47 Красивый Итого рабочих Численность совокупности (nсов) 1 5 4 Итого зар. платы 25 Общий объём признака в совокупности (Vсов) Средняя заработная плата абстрактного рабочего рассчитывается по формуле: x Vсов , nсов (5.2) 25 ден. ед. 5ден. ед. / рабочий 5 рабочих Заметим, что средняя величина распределила общий объём признака между единицами совокупности поровну: n n x xi , (5.3) 1 где n – численность совокупности; xi – величина признака i-ой единицы совокупности. Практическая формула расчёта простой средней: n x x 1 n i . (5.4) 2.2. Средняя арифметическая взвешенная Пример 5.3: Исходные данные примера 5.2 сгруппируем следующим образом (табл. 5.2): Таблица 5.2 Заработная плата, ден. ед. xj 5 6 4 Итого: Численность (частота) по группам fj 1 2 2 5 Численность совокупности Объёмы признака по группам, ден. ед. xj × fj 5 12 8 25 Общий объём признака в совокупности 25 5ден. ед. / рабочий. 5 Таким образом, мы нашли среднюю заработную плату, как и в первом случае, делением общего объёма признака в совокупности на её численность. Общий объём признака получен так: ∑xj × fj = ∑wj, (5.5) где wj – объём признака в группе j. Численность совокупности рассчитана по следующей формуле: x 48 ∑fj = n. (5.6) Примечание 5.1: слово «частота» заменено на слово «вес»: 5 ден. ед. «взвешено» один раз; 6 ден. ед. «взвешено» 2 раза … Формулы для определения средней взвешенной: x fj (5.7) x j f или x w f j j (5.8) . j Модернизированная формула: x f j xj f j . (5.9) 2.3. Средняя в интервальном ряду Обратимся к примеру 4.1. В случае интервального ряда серединное значение каждого интервала (xj) принимается за среднее значение признака в этом интервале, то есть принимается гипотеза о равномерном распределении единиц совокупности по интервалам значения признака, то есть в каждом интервале: (5.10) x j f j xj f i x x f f j j (5.11) j Средняя в интервальном ряду определяется по тому же принципу, что и средняя взвешенность, но вместо индивидуальных величин признаков в каждом интервале берутся их серединные значения. В том случае, когда в интервальном ряду имеются открытые интервалы, их следует искусственно и искусно закрыть. Пусть в примере 4.1 добавился интервал «55 и более». По опыту известно, что в данной области максимальный урожай достигал иногда 62 ц / га ; добавим искусственный интервал «55 – 62», серединное значение которого x55 62 58,5ц / га . 2.4. Средняя вторичных относительных величин Пример 5.4: Дана следующая статистика по промышленным предприятиям района «Р» (табл. 5.3): Таблица 5.3 Номера предприятий Общий объём продукции, ден. ед. 1 2 138 650 49 Доля товаров оборонного значения в объёме продукции по каждому предприятию 0,75 0,38 3 4 Итого: 1040 219 2047 0,12 0,64 Требуется найти среднюю долю товаров оборонного значения в совокупности продукции района. Обратимся к формуле 5.2. Для её применения необходимо решить следующие задачи: ● что считать за объем признака в совокупности и какова его величина; ● что приять за численность совокупности или по-другому за частоты признака по группам и каковы их значения. Решение: 1. Так как итог по графе «3» не является содержательной величиной, то следует исчислить реальный объём оборонной продукции. По строке «1» он равен w1 = 0,75 × 138 = 103,5 ден. ед. Логично считать по этой строке величиной признака х1 = 0,75, а его частотой f1 = 138, то есть признак «0,75» 138 раз встречается в общей численности совокупности 2047. Последовательно всем строкам wj = xi × fi :103,5; 247; 124; 140,2. ∑xi × fi = 614,7 ден ед. – это объём оборонной промышленности. 2. x xi fi 614,7 0,302 (30,2%) (5.12) f 2047 i Таким образом, за величины признака по группам приняты их относительные величины, а за частоты – абсолютные значения тех величин, от которых исчислена их доля (процент). Основным правилом при нахождении средних относительных величин является обязательное представление общего объёма признака в его абсолютном выражении. 2.5. Важнейшие свойства средней арифметической ■ Свойство 1: произведение средней на сумму частот всегда равно сумме произведений вариант на частоты: x f i xi f i (5.13) ■ Свойство 2: если от каждой варианты отнять какое-либо произвольное число А, то средняя уменьшится на то же число: ( xi A) f i xп A , fi (5.14) где индекс «п» обозначает прежнее значение. ■ Свойство 3: если к каждой варианте прибавить какое-либо произвольное число А, то средняя увеличится на это же число: ( xi A) f i xп A , fi 50 (5.15) или xп ( xi A) f i A, fi (5.16) ■ Свойство 4: если каждую варианту разделить на какое-либо произвольное число А, то средняя арифметическая уменьшится во столько же раз: x ( ) fi x A п . A fi (5.17) ■ Свойство 5: если каждую варианту умножить на какое-либо произвольное число А, то средняя арифметическая увеличится во столько же раз: ( xi A) f i xп A . fi (5.18) ■ Свойство 6: если все частоты (веса) умножить или разделить на произвольное число А, то средняя арифметическая от этого не изменится: f xi ( i ) A x , п fi A (5.19) или xi ( f i A) xп . fi A (5.20) Перед формулированием следующих свойств рассмотрим пример: Пример 5.5: Произведены следующие расчёты (табл. 5.4): Таблица 5.4 Показатели Рабочие A Алексеев Васильев Бочкарёв Ерофеев Итого: Выработано продукции, шт. х Отклонения от средней арифметической d = хi - x Квадраты отклонений Квадраты отклонения d2 Отклонение от произвольного числа А = 4 x-A 1 5 6 7 2 20 2 0 1 2 -3 0 3 0 1 4 9 14 4 1 2 3 -2 4 5 1 4 9 4 18 (x - A)2 ■ Свойство 7: сумма отклонений вариант от средней арифметической всегда равняется нулю – это значит в средней взаимно 51 погашаются отрицательные и положительные отклонения вариант от средней: (5.21) ( xi x ) 0 , (пример 5.5, гр. 2). ■ Свойство 8: сумма квадратов отклонений индивидуальных значений признака от средней арифметической всегда меньше, чем сумма квадратов отклонений этих индивидуальных значений от любого произвольного числа А (сравнение итогов по гр.гр. 3 и 5): 2 2 (5.22) ( xi x ) ( xi A) 2.6. Средняя гармоническая Пример 5.6: Данные по закупкам материала М предприятием П (табл. 5.5): Таблица 5.5 Номер партий материала М 1 1-ая 2-ая 3-яя Итого: Стоимость партий, ден. ед. (wj) 2 500 2000 4500 7000 (∑wj) Цена за 1 кг, ден. ед. (xi) 3 5 10 15 Требуется определить среднюю цену 1 кг закупленного материала. Варианты решения: 1 вариант 5 500 10 2000 15 4500 12,8 ден. ед. 7000 На кажущуюся логичность этот вариант не верен, так как в знаменателе формулы (5.8) должна быть частота (численность) совокупности, а фактически был поставлен её общий объём, который был на предприятии так: 5 руб. × f1 (кг) + 10 руб. × f2 (кг) + 15 руб. × f3 (кг) = 7000 руб. = ∑wj. А числитель в расчёте сильно завышен, потому что по группам вместо групповых частот подставлены групповые объёмы признака. 2 вариант Определяем групповые численности (частоты) и общую численность совокупности: wj 500 2000 4500 = 600 (кг). fi xi 5 10 15 Средняя цена 1 кг товара равна 7000 ден. ед. =11,67ден. ед./кг. 600 кг Это верный вариант решения. 52 Формула расчёта средней величины признака, когда численность совокупности явно не выражена, а приведены только объёмы признака по группам и его общий объём по всей совокупности. w j (5.23) x wj . xi Этот вид средней называется средней гармонической. harmonia (греч.) – соразмерность. 2.7. Средняя степенная Есть общая форма представления различных средних величин: xc r r xi n , (5.24) где x c – средняя степенная; r – показатель степени; n – число наблюдений (численность совокупности). При разных значениях r формула (5.24) приводит к следующим вариантам средних: а) при r = 1 получается формула простой средней арифметической: xап xc ; n (5.25) б) при r = -1 – формула средней гармонической простой: n xг , x1 (5.26) i т. е. средняя гармоническая простая получается из обратных значений признака; в) при r = 2 формула средней квадратичной: xкв x n 2 ; (5.27) г) при r = 0 (r → 0) получается формула простой средней геометрической: x геом n x1 x2 ... xn 1 xn . (5.28) Примечание 5.2: формула (5.27) получается путём преобразования формулы (5.24) по правилу Лопиталя. Если вариация усредняемого признака небольшая, то использование любой из этих формул приводит к мало отличающимся друг от друга результатам. Пример 5.7: Обратимся к примеру 5.2. Пусть заработная плата у всех рабочих одинаковая, равна 5 руб. 53 xan = 5 руб. 5 x г 1 1 1 1 1 = 5 (руб.); 5 5 5 5 5 x кв 25 5 = 5 (руб.); 5 x геом 5 5 5 5 5 5 = 5 (руб.). При «ощутимой» вариации ранжирование средних, получается, по возрастанию r (правило мажорантности): (5.29) xкв хап х геом х г . По данным примера 5.2: xкв 5,1; хап 5; х геом 4,9; х г 4,85. Применение той или иной формулы средней степенной зависит от содержания усредняемого признака. Из степенных средних в статистике наиболее часто используется средняя арифметическая, реже – средняя гармоническая; средняя геометрическая применяется только при исчислении средних темпов динамики, а средняя квадратическая – только при исчислении показателей вариации. 3. Средние в рядах динамики 3.1. Пример 5.8: Таблица 5.6 Данные по саду: Годы и периоды 1990 1991 100 110 Количество деревьев, шт. На конец года Посажено с конца i-го по конец (i + 1) года 20 25 1992 130 1993 100 10 1994 120 30 В табл. 5.6 два ряда динамики: моментный и периодический. 3.2. Средняя в рядах динамики с равными промежутками времени ♦ Средняя для периодического ряда ( y П ): m уП y y 1 j , (5.30) t где уj – уровень ряда за j-ый интервал; t – продолжительность всего изучаемого периода в единицах времени, принятых для измерения интервалов (год, месяц и т. д.). 85 В пример 5.7: =21,25 (саженцев). 4 ♦ Средняя для моментного ряда с равными интервалами времени. 54 Для моментного ряда подсчёт средней как простой арифметической даёт не точный результат, так как в этом случае не учитываются изменения величины признака внутри периодов (между моментами). Используется следующая формула: n 1 yj ум j 1 n 1 , (5.31) где n – количество моментов; j – период между моментами; y j – среднее значение признака внутри периода j (между моментами i и i+1): y yi 1 уj i . (5.32) 2 В примере 5.7: у 100 110 105 ; у 2 = 120; у 3 = 115; у 4 = 110; 1 2 105 120 115 110 ум 112 ,5. 4 Раскроем числитель формулы (5.31): y yn 1 yn 1 y n y y1 y2 y2 y3 y ... n 2 1 y2 ... yn 1 n 2 2 2 2 2 2 Преобразованная формула (5.31): y y y 2 ... yn 1 2n . (5.33) y n 1 3.3. Средняя для моментного ряда с неравными интервалами времени ♦ Способ учёта неравности интервалов. 1 2 Пример 5.9: Предположим, что в примере 5.7 отсутствуют данные за 1991 год. Средние моментного ряда по интервалам ( y j ) и продолжительности интервалов y1(1990 1992 ) 115 2 года y2 (1992 1993 ) 115 1 год y3(1993 1994) 110 1 год 115 2 115 1 110 1 Средняя 113,8 4 Результат отличается от ранее рассчитанного (112,5), но так и должно было случиться, так как в моментных рядах точность средней уменьшается с увеличением величины интервалов между соседними датами. 55 Формула подсчёта абсолютной средней в моментном ряду динамики: ум где yj yj tj , t j (5.34) – средний уровень показателя между «i-1» и «i-м» моментными наблюдениями; tj – промежуток времени в принятых его единицах измерения между «i-1» и «i-м» моментами. ♦ Расчёт средней для моментного ряда с неравными интервалами, способом выделения интервалов, в течение которых их уровень изменялся несущественно. Пример 5.10: Данные по числу работников в цехе А предприятия N (табл. 5.7). Таблица 5.7 Календарные периоды, в течение которых количество работников не изменялось, дни, сентябрь 1 – 10 11 – 25 26 – 30 Итого: Продолжительность в днях, ti 10 15 5 30 Списочное количество работников, yi 25 22 28 Количество человекодней, yi × ti 250 330 140 720 Среднесписочное количество работников: 720 чел. - дн. 24 чел. 30 чел. yi t i , (5.35) ti где yi – уровень моментного ряда, сохраняющийся в течение промежутка ti. Средние рядов динамики часто называются средними хронологическими. Средняя хронологическая моментного ряда в принципе исчисляется, как средневзвешенная арифметическая величина (формула (5.7) и (5.8)); индивидуальные значения признака (xi) представляют индивидуальные уровни ряда (yi), а частоты (fi) представляют промежутки времени в принятом их измерении. у 3.4. Средние темпы роста и прироста Пример 5.11 (табл. 5.8): Возьмём данные примера 5.7 и рассчитаем рост и прирост уровней динамики. Таблица 5.8 Показатели Годы 56 Абсолютный прирост цепной (Пцi) Абсолютный прирост на конец всего периода Цепные темпы роста 1990 - 1991 10 - 1992 20 - 1993 -30 - 1994 20 20 1,0 1,10 1,18 0,77 1,20 Расчёт среднего абсолютного прироста количества деревьев: ● Вариант I: 10 20 30 20 5 деревьевгод . ● Вариант II: 120 100 55 деревьев год . 4 4 П П цi S (5.36) y y1 , (5.37) П n n 1 где П – средний абсолютный прирост показателя (признака); Пцi – цепной абсолютный прирост за i-й интервал; S – число интервалов; yn – последний уровень изучаемого ряда; у1 – первый уровень изучаемого ряда; n – количество уровней. Для вывода формулы расчёта следующего показателя произведём следующие выкладки и рассуждения: или y2 y3 y y y (5.38) n 1 n n , y1 y2 yn 2 yn 1 y1 то есть произведение цепных темпов роста ряда равняется темпу роста за весь рассматриваемый период, или произведение цепных темпов роста равно базисному темпу роста. Базисный темп роста является итоговой величиной этого признака. Если итоговая величина признака образуется как произведение отдельных его вариант, то более точной средней является геометрическая. y Обозначим i 1 через Tpj. yi Так как количество вариант темпов роста равно n-1, то: y (5.39) Tp n 1 Tp1 Tp 2 Tp ( n 1) n 1 n . y1 По примеру 5.10: T p 4 1,10 1,18 0,77 1,20 1,05 (105%) 1,2 1,05 (105%) . 1 Средний темп прироста определяется так: или T p 4 57 Tпp (%) Tp 100 105% 100% 5% (в год) . (5.40) 4. Другие виды средних Средние арифметические и гармонические являются обобщающими характеристиками совокупности по тому или иному варьирующему признаку. Вспомогательными описательными характеристиками распределения варьирующего признака являются медиана и мода. 4.1. Mediana (лат.) – средняя (а лучше, серединная) Медианой распределения называется такое значение признака, которое делит число единиц ранжированного ряда пополам таким образом, что в одной половине оказываются величины меньше величины медианы, а в другой – превышающие величину медианы. ♦ Расчёт медианы в ранжированном дискретном ряду. Пример 5.12: Имеются данные результатов измерения семи деталей одного предназначения (в сантиметрах): 0,6; 0,41; 0,79; 0,73; 1,24; 0,85; 1,46. Требуется найти медиану. Решение: а) результаты измерения представим в виде ранжированного ряда: х1; х2; х3; х4; х 5; х6; х7 0,41; 0,6; 0,73; 0,79; 0,85; 1,24; 1,46 б) определяется номер медианы: № Me n 1 . 2 (5.41) В нашем случае № Ме = 4; в) определяется величина признака, соответствующая медиане по её номеру. В нашем случае Ме = 0,79. Продолжение примера 5.12: Пусть варианты х7 нет, тогда № Ме = 3,5; значит она находится между 3-им и 4-ым признаками: Me 0,73 0,79 0,76 (см) . 2 ♦ Расчёт медианы для интервального вариационного ряда. Пример 5.13 (табл. 5.9): Таблица 5.9 Распределение 100 рабочих по длительности производственного стажа Длительность производственного стажа в годах х 0–2 Число рабочих Кумулятивные частоты f 4 ∑f = s 4 58 2–4 4–6 6–8 8 – 10 10 – 12 Итого: 23 20 35 11 7 100 27 47 82 93 100 Требуется найти медиану по длительности рабочего стажа. Решение: 1) № Me n 1 100 1 50,5. 2 2 Из ряда накопленных частот видно, что Ме располагается в интервале «6 – 8» (47 < 50,5 < 82). 2) Медиана определяется по следующей формуле: Mc xe ie f 2 S (e 1) , (5.42) fe где хе – начальное значение медианного интервала; ie – величина медианного интервала; S(e-1) – сумма накопленных частот в интервалах, предшествующих медианному; fе – частота медианного интервала. 100 47 Ме = 6 + 2 × 2 6,17 6,2 (года). 35 4.2. Мода Moda (фр.) – господство. Модой распределения называется такая величина изучаемого признака, которая в данной совокупности встречается наиболее часто. В вариационном ряду это будет варианта, имеющая наибольшую частоту. Пример 5.14: 100 рабочих на предприятии N распределяются следующим образом (табл. 5.10): Таблица 5.10 Тарифный разряд 1 2 3 4 5 6 Итого: Число рабочих 1 3 12 50 18 16 100 Модой данного ряда распределения является Мо = 4 (разряд). В интервальном вариационной ряду мода определяется приближенно по следующей формуле: Mo xo io f o f 1 , ( f o f 1 ) ( f o f 1 ) 59 (5.43) где i o – величина модального интервала (интервал, которому соответствует наибольшая частота); x o – нижняя граница модального интервала; f o – модальная (наибольшая) частота; f 1 – частота группы, предшествовавшей модальному интервалу; f 1 – частота группы, следующей за модальным интервалом. По исходным данным примера 5.12: Mo 6 2 35 20 = 6,77 (года). (35 20 ) (35 11) 5. Заключение по теме Мы убедились в том, что средняя величина является обобщающей характеристикой определённой закономерности, присущей исследуемой статистической совокупности по заданному признаку. Но мы должны понимать и тот факт, что средняя величина может скрыть от исследователя сам характер процесса протекания этой закономерности. Пример 5.15 (табл. 5.11): Средняя и распределение вариант с указанием частот (выработка в штуках на 1 человека в день): Таблица 5.11 Случай 1 х f x×f x- 2 3 4 5 6 7 8 Итого: 2 15 120 300 180 35 8 660 -3 -2 -1 0 +1 +2 +3 1 5 30 60 30 5 1 132 x xx ×f 3 10 30 0 30 10 3 86 Случай 2 x f 2 3 4 5 6 7 8 30 20 10 50 10 20 30 170 x×f x- 60 60 40 250 60 140 240 850 -3 -2 -1 0 +1 +2 +3 x xx 90 40 10 0 10 40 90 280 x1 = 5 x2 = 5 Графическое изображение отклонений вариант от средней (рис. 5.1) 60 ×f 70 f 60 50 40 30 2 случай 20 10 1 случай 0 -3 -2 -1 0 1 2 3 x- x Рис. 5.1 Средние величины в обоих случаях одинаковы ( x1 x2 660 5; 132 850 5 ), но отклонения от средней имеют различный характер: 170 ■ в первом случае 120 единиц совокупности (60 + 30 + 30) из 132-х отклоняется от средней не более, чем на 1, т. е. 91 % членов ряда; ■ во втором случае отклонение не более 1 от средней имеют 70 единиц совокупности (50 + 10 + 10) из 170 единиц, т. е. только 41 % членов ряда. Понятно, что в первом случае средняя характеристика более типична, нежели во втором. Эта разница в типичности характеристики могла произойти: ● или из-за меньшей однородности 2-ой совокупности; ● или от воздействия на вариацию 2-ой совокупности более разнообразных факторов. Поэтому средние характеристики следует дополнять показателями вариации признака. О них мы будем говорить в лекции 6. Примечание 5.3: данные в табл. 5.11 по графам «х f» и «│х- x │f» будут нужны для дальнейшего развития примера в следующей теме. Вопросы и задания для самоконтроля 61 1. Какова роль средней величины в обобщении данных статистического наблюдения? 2. Назовите основные правила применения средних величин в статистике. 3. В чем заключаются особенности вычисления средних арифметических простой и взвешенной? 4. Какие свойства средней арифметической вы знаете? 5. Каковы особенности средней гармонической? 6. Как исчисляются средние величины в рядах динамики? 7. В чем заключаются особенности расчета медианы на основе дискретных и интегральных рядов динамики? 8. Что такое мода и как ее исчислять? 62 ЛЕКЦИЯ 6. ПОКАЗАТЕЛИ РАЗМЕРА И ХАРАКТЕРА ВАРИАЦИИ 1. Показатели вариации. 2. Внутригрупповая и межгрупповая дисперсии; правило сложения дисперсий. 3. Анализ характера распределения в вариационных рядах. 1. Показатели вариации 1.1. Размах вариации и средний модуль отклонения Наиболее простым, но и менее надежным показателем является размах вариации (R): R = xmax – xmin, (6.1) где xmax – xmin – наибольшее и наименьшее значения варьирующего признака. В примере 5.13 размахи вариации для обоих случаев одинаковы (6). Этот показатель улавливает только крайние отклонения, но не дает обобщающую характеристику распределения отклонений вариант от средней в совокупности. Более точным, но редко употребляемым, показателем является средний модуль отклонений ( d ): xi x f i . (6.2) d fi Часто этот показатель называется отклонением средним линейным. 280 В примере 5.13 d 1 86 0,65 (шт); d 2 1,6 (шт); d 2 2,4 раза . 170 d 132 1 Но математические свойства модулей не позволяют поставить их в соответствие с каким-либо из законов (формул) вероятности. Чаще всего в статистике, как меры вариации, используют средний квадрат отклонения (дисперсию), среднее квадратическое отклонение и коэффициент вариации. 1.2. Дисперсия, среднее квадратическое отклонение и коэффициент вариации ♦ Дисперсия и среднее квадратическое отклонение. Disperus (лат) – рассеянный, рассыпанный. Дисперсия генеральная – математическое ожидание (или средняя) квадрата отклонения величины (х) от её математического ожидания (или среднего значения x ). На дисперсии практически основаны все методы статистического исследования. Дисперсия (σ2) или средний квадрат отклонения рассчитывается так: 2 2 ( xi x ) f i fi 63 (6.3) Для негруппированного вариационного ряда: 1 n 1 n (6.4) 2 ( xi x ) 2 xi2 ( x ) 2 . n i 1 n i 1 Корень квадратный из дисперсии является средним квадратическим отклонением (σ): 2 ( xi x ) f i . fi (6.5) Для негруппированного вариационного ряда: ( x x) n 2 (6.6) или x2 x 2 . (6.7) Продолжение примера 5.14 (табл. 6.1): Таблица 6.1 Случай первый ( f ) (x - x )2 (x - x )2 × f 1 5 30 60 (x - x )2 × f 5 1 9 4 1 0 1 4 9 9 20 30 0 30 20 9 10 20 30 ∑ (x Случай второй ( f ) (x - x )2 30 30 20 x )2 × f = 118 10 50 9 4 1 0 1 4 9 270 80 10 0 10 80 270 ∑ (x - x )2 × f = 720 118 σ2 (1 случай) = 0,89; 132 720 σ2 (2 случай) = 4,2; 170 σ (1 случай) = 0,89 0,94 (шт); σ (2 случай) = 4,2 2,65 (шт). Показатели дисперсии говорят о том, что она во втором случае больше, нежели в первом; но она имеет другую размерность, отличную от размерности признака. Среднее квадратическое отклонение имеет ту же размерность, что и размерность признака: (2 сл.) 2,05 2,18 (раза). (1 сл.) 0,94 64 График квадратов отклонений вариант от средней (рис. 6.1) (к примеру 5.13). 70 f 60 50 40 2 случай 0 30 20 10 1 случай 0 0 1 2 3 4 5 6 7 8 9 (x x)2 Рис. 6.1 ♦ Коэффициент вариации. Пример 6.1 (табл. 6.2): Таблица 6.2 Цена (ден. ед.) Товар А Товар Б x 32 x 114 σ=4 σ=6 Что варьирует больше ? Средние квадратические отклонения разных явлений сравнивать нельзя. Для сравнения вариаций разных явлений используется коэффициент (процент) вариации ( ): x 100% . (6.8) По примеру: 4 100 6 100 (вес) 12,5% ; (рост) 5,3% 32 114 Варьирует больше цена товара А. Процентное отношение среднеквадратического отклонения к среднеарифметической называется коэффициентом вариации 65 Пример 6.2 (табл. 6.3): Таблица 6.3 Урожайность кукурузы, центнеры Районы I II x 40 x 30 σ = 10 σ=9 То есть явление (урожайность) одно и тоже, но разные исходные данные для среднеквадратических отклонений (уровни x ). В этом случае для сравнения вариаций тоже используют коэффициент вариации: υ1 = 25 %; υ2 = 30 %; Следующий пример служит переходом ко второму вопросу. Пример 6.3: Данные лабораторных исследований урожайности (участки по 1 м 2, урожай грамм/см2) (табл. 6.4). Таблица 6.4 Участки Все из них: неудобренные удобренные Количество, шт. f 125 Средний урожай 140,20 σ2 338,40 Среднеквадратическое отклонение σ 18,4 55 70 126,64 150,86 200,00 190,00 14,1 13,8 x Дисперсия Рассуждения: 1) общая дисперсия (338,4) больше каждой из дисперсий в группах (200; 190), это значит, что удобренность повлияла на величину общей дисперсии, что естественно, так как урожайность по группам значительно отличается (126, 64; 150, 86); значит, кроме вариации внутри группы присутствует вариация между группами; 2. Внутригрупповая и межгрупповая дисперсии; правило сложения дисперсий 2.1. Внутригрупповая и межгрупповая дисперсии Продолжение рассуждений по примеру 6.3: 2) если бы все участки остались не удобренными, то дисперсия была бы между 200 и 190, эта дисперсия вызвана всеми прочими факторами, за исключением удобренности; Общая мера влияния этих других факторов определяется как средняя взвешенная из внутригрупповых дисперсий. i2 2 i f i 200 55 190 70 194 ,4 , 125 fi (6.9) где i – номера групп. 3) общая дисперсия равна 338,2, значит её «недостающую» часть (338,4 – 194,4 = 144) обусловил группировочный признак (удобренность). 66 Эту дисперсию, вызванную группировочным признаком, называют межгрупповой дисперсией ( 2 ). Её можно рассчитывать и следующим образом: Продолжение примера 6.3 (табл. 6.5): Примем за варианты средние по группам и рассчитаем среднюю из этих средних ( x ): 126,64 55 150,86 70 x 140,2 . 125 Исчислим средний квадрат отклонений (дисперсию) между этими средними ( 2 ): Таблица 6.5 f 2 x (x-x) (x-x) ( x - x )2 × f 126,64 150,86 Итого: 55 70 125 2 -13,56 10,66 183,9 113,6 10114,5 7952,0 18066,5 2 ( x x ) f 18066 ,5 144 125 f (6.10) Вывод по примеру 6.3: ● 43 % общей дисперсии вызваны группировочным признаком – удобренностью 144 100 43% ; 338,4 57 % общей дисперсии обусловлены прочими факторами 194,4 100 57% . 338 , 4 Таким образом, дисперсия, вызванная группировочным признаком (признаком-фактором) рассчитывается как средний квадрат отклонений групповых средних из этих средних. 2.2. Правило сложения дисперсий Выкладки по примеру 6.3 позволяют сформулировать следующее правило: общая дисперсия является суммой внутригрупповой дисперсии и дисперсии групповых средних (рис. 6.2). ● x1 Средняя внутригрупповых дисперсий или внутригрупповая дисперсия Дисперсия внутригрупповых средних x + x2 Общая дисперсия Рис. 6.2 i2 2 . 67 2 (6.11) 2.3. Коэффициент детерминации и эмпирическое корреляционное отношение Отношение дисперсии групповых средних (дисперсии, вызванной группировочным признаком) к общей дисперсии называется коэффициентом детерминации ( 2 ). Determinantis (лат.) – определяющий. 2 2 . 2 (6.12) В примере 6.3 2 = 0,43. Корень квадратный из коэффициента детерминации называется эмпирическим корреляционным отношением ( ). Эмпирическое корреляционное отношение показывает тесноту связи между признакомфактором и признаком-результатом. В привязке к примеру 6.3: 2 0,43 0,66 , 2 при 1 – идеальное корреляционное отношение, т. е. между признаком-фактором и признаком-результатом функциональная зависимость; при 0 – никакой связи между признаками нет. Как мы уже отмечали, дисперсия в статистике является одной из основных мер вариации признака, но для исследования вариации следует дать оценку тому, как вариация признака распределяется в изучаемом вариационном ряду с учётом частот. 2 3. Анализ характера распределения в вариационных рядах 3.1. Нормальное распределение В учебной дисциплине «Математическая статистика» вы изучили такую категорию, как «кривая нормального распределения». Главные свойства этой кривой переносятся и на любую идеальнооднородную генеральную совокупность. Из этих свойств нам в дальнейшем будут необходимы перечисляемые ниже. 1-ое свойство. Средняя, медиана и мода по величине совпадают рис. 6.3). 2-е свойство. Распределение вариант имеет следующие закономерности: ● в пределах от « x + σ» до « x – σ» находится 68,3 % вариант совокупности (рис. 6.4); ● в пределах « x ± 2σ» – 95,4 % вариант совокупности (рис.6.4); 68 ● в пределах « x ± 3σ» – 99,7 % вариант совокупности. f х x , Ме, Мо Рис. 6.3 Это свойство называют «правилом трёх сигм». f х 2σ σ σ x 2σ 68,3 % хi 95,4 % хi 99,7 % х Рис. 6.4 Пример 6.4: Обратимся к примеру 5.1 (3). Ранжируем представленный в примере ряд, изобразим его графически и рассчитаем медиану (рис. 6.5) № хi 1 2 3 х 0 ………………………………….20 Мегс xгс ; 4 5 6 7 3,0 № Мегс = 10 1 5,5 ; 2 Рис. 6.5 69 8 10 9 5,0 6,0 7,0 8,0 9,0 10, 11 12 егс = 8 9 8,5 . 2 Таким образом, наша генеральная совокупность не является идеально однородной. Рассчитаем среднее квадратическое отклонение, для этого используем данные этого же примера по строке «Δхi = …»: 0,92 2,92 10,92 1,12 6,12 1,92 0,12 2,12 3,12 4,12 гс2 20,149; 10 гс 20,149 4,88 4,9. Выделим ранжированную выборочную совокупность по данным этого же примера и необходимые для сравнения её характеристик параметры генеральной совокупности. При этом xгс обозначим через , а xвыб через x . х 0 3,0 5,0 6,0 7,0 x = 8,2 = 9,1 σгс = 4,9 …………………………..20 σгс = 4,9 2σгс 2σгс 3σгс 3σгс Рис. 6.6 Выводы по рис. 6.6: 1) x находится в области « – σгс»; 2) 3 варианты выборочной совокупности (5, 6, 7), т. е. 60 % находятся в области« – σгс»; 3) 4 варианты (3, 5, 6, 7), т. е. 80 % – в области« – 2σгс»; 4) все варианты не превышают по величине « ± 3σгс». Все рассуждения и примеры, рассмотренные в этом вопросе, нам будут необходимы при изучении теории ошибок выборочного наблюдения (тема 7). 3.2. Выравнивание фактического распределения по кривой нормального распределения При углубленных статистических исследованиях необходимо проверять, насколько совокупность, которую приняли за генеральную «подчиняется» законам нормального распределения. Для этого параметры кривой фактического распределения сравнивают с параметрами кривой теоретического распределения. Для этого фактические частоты (частотности) пересчитывают по следующей формуле: ni f m f (t ) , (6.13) 70 где f(t) = xx , называемая нормированным отклонением. Пример 6.5 (табл. 6.6): Таблица 6.6 Распределение урожая культуры «К» по участкам и расчётам параметров для выравнивания этого ряда по кривой нормального распределения Вес урожая, г/м2 1 90 – 100 100 – 110 110 – 120 120 – 130 130 – 140 140 – 150 150 – 160 160 – 170 170 – 180 Итого: x f 2 95 105 115 125 135 145 155 165 175 3 2 5 13 17 18 31 22 12 5 125 x x 4 45,2 35,2 25,2 15,2 5,2 4,8 14,8 24,8 34,8 t 5 2,47 1,92 1,38 0,83 0,28 0,26 0,81 1,35 1,90 f (t ) f m f (t ) 6 0,0189 0,0632 0,1539 0,2827 0,3836 0,857 0,2874 0,1604 0,0656 n i 7 1 4 11 19 26 27 20 11 5 124 Объяснение к табл. 6.6: x = 140,2 г/м2; x m = 139 г/м2; f fm f fm 8 2 7 20 37 55 86 108 120 125 9 1 5 16 35 61 88 108 119 124 10 1 2 4 2 6 2 0 1 1 σ = 18,3 г/м2; n i 125 10 = 68,306 = const. 18,3 По данным таблицы построим кривые фактического распределения частот (рис. 6.7). 35 теоретического f 30 25 20 15 10 5 0 95 105 115 125 135 145 155 165 Кривая фактического распределения Кривая теоретического распределения 71 175 x' и Рис. 6.7 На графиках (см. рис.6.7) видна большая близость фактических частот распределения вариант к теоретическим. Но эту близость надо оценить количественно. 3.3. Критерий согласия Критерий согласия – это статистический показатель, по которому можно судить, на сколько фактическое распределение согласуется с нормальным (теоретическим). Таких показателей имеется несколько видов. Выберем критерий согласия А. Н. Колмогорова (критерий лямбда): Д , (6.14) n где Д – максимальная разность (по абсолютной величине) между кумулятивными фактическими и теоретическими частотами исследуемого ряда. В таблице примера 6.5 Д = 6. 6 0,55 . 125 По специальной таблице, называемой «таблица функции P ( ) n » находим, что при λ = 0,55 P ( ) n = 0,9229, что означает, что с вероятностью 0,9229 можно утверждать, что отклонение фактических частот от теоретических является случайным. Вопросы и задания для самоконтроля 1. Что такое размах вариации и в чем его особенности как показателя вариации? 2. Назовите основные показатели вариации. 3. Как определяется дисперсия, среднее квадратическое отклонение и что такое коэффициент вариации? 4. Что представляет собой правило сложения дисперсии? 5. Что показывает эмпирическое корреляционное отношение, формула его расчета? 6. В чем особенности анализа характера распределения в вариационных рядах? 7. Как определяется критерий согласия лямбда? 72 ЛЕКЦИЯ 7. ВЫБОРОЧНОЕ НАБЛЮДЕНИЕ Статистика далеко не всегда имеет дело с данными сплошного наблюдения, наоборот, ей чаще приходится иметь дело с несплошной выборкой. 1. Понятие о выборочном наблюдении и его задачах. 2. Репрезентативность выборки и методы её достижения. 3. Ошибки выборки, численность выборки. 4. Моментные наблюдения и малая выборка. 1. Понятие о выборочном наблюдении и его задачах 1.1. Выборочное наблюдение и его задачи (рис. 7.1) Виды статистических наблюдений по охвату генеральной совокупности сплошные не сплошные метод основного массива Выборочные наблюдения Рис. 7.1 Метод основного массива заключается в том, что обследованию подвергаются наиболее крупные, существенные единицы наблюдения. Сущность выборочного наблюдения: обследованию подлежит определённое число единиц, отобранных из генеральной совокупности в порядке случайного (но не бессистемного) отбора с целью вывода обобщающих характеристик генеральной совокупности. Согласно теории вероятностей выборочная совокупность будет N правильно отражать свойства всей ○ ● ● совокупности, если выбор ○ №е производится случайно, то есть так, что любая из возможных ○ выборочных совокупностей n ○ заданной численности n из всей ○ ● совокупности численностью N ○ ○ ○ имеет возможность быть выбранной (рис.7.2). ○ ○ 73 Рис.7.2 Две главные и взаимосвязанные проблемы выборочного наблюдения: ■ расчет объёма выборочной совокупности при заданной точности исследования (точности характеристик генеральной совокупности); ■ определение, так называемой, ошибки выборки (возможной величины расхождения с той или иной из характеристик генеральной совокупности) при данной её численности. Основные этапы выборочного наблюдения: 1) формулировка цели наблюдения; 2) ограничение генеральной совокупности и подготовка основы отбора; 3) установление системы отбора единиц для наблюдения; 4) определение числа единиц, подлежащих отбору; 5) проведение наблюдения; 6) расчёт выборочных характеристик и их ошибок; 7) распространение выборочных данных (характеристик с поправками на ошибки) на генеральную совокупность. На рис. 7.3 приведена укрупнённая последовательность выборочного наблюдения ▪ цели наблюдения; ▪ ограничение генеральной совокупности; ▪ система отбора; ▪ численность отбора Генеральная совокупность (N) Выборочная совокупность (n) Распространение выводных характеристик Выборочные Рис.7.3 характеристики и их ошибки (выводные характеристики) Рис. 7.3 Итак, задача выборочного наблюдения заключается в том, чтобы получить правильное представление о характеристиках (показателях) всей генеральной совокупности. 1.2. Ситуации, при которых используется выборочное наблюдение: 1) в том случае, когда статистическое исследование связано с порчей единиц совокупности; 2) в том случае, когда сплошное наблюдение требует больших затрат тех или иных видов ресурсов; 74 3) когда есть основание предполагать, что большое количество единиц наблюдения, а значит, и количество наблюдателей приводит к таким тенденциозным ошибкам, которые исказят характеристики исследуемой генеральной совокупности. Выборочную совокупность принято называть выборкой. Выборка должна отражать (представлять) генеральную совокупность через соответствующие характеристики (показатели, признаки). 2. Репрезентативность выборки и методы её достижения Representant (фр.) – представлять; репрезентативность – представительность. 2.1. Описательная и выводная статистика Любая генеральная совокупность имеет свои характеристики (показатели, параметры). Но, как уже говорилось, мы часто не можем их рассчитать непосредственно через наблюдение всех членов, а выводим через наблюдение за выборкой. Набор характеристик совокупности, по которой полностью имеются исходные данные (например, выборка), называется описательной статистикой, а те характеристики, которые получаются методами статистического вывода из данных описательной статистики для генеральной совокупности называются выводной статистикой. Примечание 7.1: представление о статистических данных, как о выборочных, часто распространяется и на данные сплошных наблюдений. Такое представление имеет смысл в следующих случаях: а) когда генеральная совокупность имеет малое число единиц; б) при трактовке данных какого-либо-эксперимента, который гипотетически надо было бы для точности повторять бесконечное количество раз. Кончено, между параметрами выборки и параметрами генеральной совокупности (если бы они были рассчитаны напрямую) будут расхождения. Расхождение между значениями того или иного показателя (признака) совокупности выборочной и генеральной совокупности носит название ошибки выборки (ошибки репрезентативности) (рис. 7.4). Ошибки выборки Систематические (тенденциозные) Случайные Рис. 7.4 Случайная ошибка возникает в силу того, что выборочная совокупность недостаточно точно воспроизводит (репрезентует) 75 генеральную совокупность, но на неё (ошибку) можно по существующим правилам вывода сделать поправку. Систематическая ошибка выборки (представительности) возникает вследствие нарушения системы отбора, главным образом, принципа беспристрастности, непреднамеренности. Систематическая ошибка может привести к полной непригодности результаты наблюдения. 2.2. Отбор единиц генеральной совокупности для выборочного наблюдения Этот процесс должен носить характер беспристрастности и случайности (но не бессистемности). Процессы отбора классифицируются по видам (обеспечение принципа случайности) и способам (техника отбора по охвату генеральной совокупности) (рис. 7.5). Отбор По видам (обеспечение принципа случайности) по способам (техника отбора по охвату ГС) Рис. 7.5. Классификация процессов отбора. 2.3. Виды отбора 1. Собственно случайный отбор. 2. Случайный отбор единиц из генеральной совокупности по определённой схеме. ♦ Собственно-случайный отбор. Рассчитывается численность выборки, составляется «список» единиц генеральной совокупности с присвоением каждой единице цифрового кода, затем по принципу лототрона или с помощью таблиц случайных чисел отбираются единицы генеральной совокупности до достижения рассчитанной численности выборки. ♦ Отбор единиц по определённой схеме (направленная выборка). 1. Механический отбор. Рассчитывается численность выборки, составляется «список» всех единиц генеральной совокупности, определяется интервал выборки (i): N . (7.1) i n Затем отбор начинается с любой единицы генеральной совокупности с переходом к следующей по номеру единице через интервал; должен быть обеспечен полный круг отбора, т. е. если отбор начался с j-й единицы, то закончен должен быть «j – i»-й. 76 Иногда объём выборки назначают в относительных величинах, например: 5%-я, 10%-я и т. п. выборка; тогда интервал выборки рассчитывается так: 1 i (%) , (7.2) 100 где ρ – заданный процент выборки. 2. Типический отбор с механической выборкой. В этом случае схема должна отражать основные свойства и пропорции ГС. Такой отбор производится тогда, когда простой механический отбор может привести к образованию неоднородной по исследуемому показателю выборке. Пример 7.1: Исследуется динамика доходов граждан города Камышина. Выборке подлежат 1000 человек. Простая механическая выборка может привести к тому, что в выборке будет превалировать по численности одна–две социальные группы (например, посредники, чиновники). Следует изучить структуру 130-тысячного населения города (процентное соотношение социальных групп) и так организовать процесс отбора, чтобы выборка повторяла эту структуру. В социальных же группах генеральной совокупности производится или собственно случайный или простой механический отбор. Примечание 7.2: такой отбор, который повторяет структуру генеральной совокупности через определение количества единиц, отбираемых для выборки из каждой группы генеральной совокупности, часто называют квотной выборкой, а также – стратифицированной. 2.4. Способы отбора ♦ Повторный и бесповторный отборы. Если в процессе отбора раз отобранная единица совокупности не исключается из неё, и, следовательно, может быть вновь (повторно) отобранной, то такой отбор называется повторным или возвратным, в противном случае – бесповторным. Статистические исследования в социально-экономических системах производятся, как правило, бесповторным способом, но теория ошибок выборки основана на представлениях о повторной выборке (с последующими поправками на бесповторность). ♦ Отбор индивидуальный и отбор групповой (серийный, гнездовой). При индивидуальном отборе за каждую итерацию (шаг) отбирается только одна единица генеральной совокупности, следовательно, отбор повторяется столько раз, сколько нужно отобрать единиц. 77 При групповом (серийном) отборе отбираются не отдельные единицы, а целые их группы (серии), например, отбор какого-либо товара группами по 10 единиц или деталей сериями 100 единиц (рис. 7.6). При комбинированном отборе вначале по принципу случайности отбираются группы, а из них по этому же принципу – единицы совокупности. Серийный отбор Непосредственно серийный отбор Комбинированный отбор Обследование каждой единицы серии Обследование части единиц каждой серии Рис. 7.6. Способы серийного отбора ♦ Отбор одноступенчатый и отбор многоступенчатый. При одноступенчатом отборе единицы отбираются непосредственно из генеральной совокупности для совокупности выборочной. При многоступенчатом отборе сначала отбираются укрупненные единицы генеральной совокупности, а из каждой из них менее укрупненные и т. д. до такой ступени, при которой обеспечивается заданная единица измерения членов совокупности. Пример 7.2: Отбор домохозяйств при изучении потребления продуктов питания населения крупного города можно произвести по ступенчатой схеме (рис. 7.7). Ступени I ст. Отбор микрорайонов •• • ••• Ед. измерения: микрорайон II ст. Отбор жилых домов • • • • жилой дом III ст. Отбор домохозяйств домохозяйство Рис. 7.7 Примечание 7.3: на каждой ступени соблюдается принцип случайности, а при большой сосредоточенности тех или иных социальных групп по микрорайонам – и принцип типичности. 78 Следует заметить, что при многоступенчатом отборе каждая ступень имеет свою единицу отбора. ♦ Многофазовая выборка. При этом виде выборки единицы совокупности последовательно группируются по детализации ценза объекта наблюдения. Пример 7.3: Земскими статистиками в Пензенской губернии была проведена перепись крестьянских хозяйств по следующей схеме: ● все хозяйства: по трём признакам; ● каждое третье хозяйство: плюс ещё два дополнительных признака; ● каждое девятое хозяйство: плюс ещё два дополнительных признака; ● каждое двадцатое хозяйство: перечень по карточке, содержащей количество признаков, подробно описывающих параметры крестьянского хозяйства. Примечание 7.4. (историческая справка):Земство (земские учреждения) – выборные органы местного самоуправления; ведали просвещением, здравоохранением, строительством дорог; ресурсы земства формировались за счёт земских повинностей (натуральных и денежных). Земская статистика: статистическая работа земств по исследованию сельского хозяйства; с 1870 года по 1913 год ею собран материал (описи) 4,5 млн. крестьянских хозяйств. 3. Ошибки выборки; численность выборки 3.1. Обозначения параметров (показателей, характеристик) (табл. 7.1) Таблица 7.1 Средняя величина Относительная величина Дисперсия Среднеквадратическое отклонение Коэффициент корреляции Численность (объём) Генеральная совокупность µ (мю) π (пи) σ2 (сигма) σ Выборочная совокупность x (икс) ρ (пе) S2 (эс) S р (эр) N (эн) r (эр) n (эн) 3.2. Виды ошибок репрезентативности выборочной совокупности 1. Ошибка репрезентативности выборочной средней: (7.3) Ex x . 2. Ошибка репрезентативности выборочной относительной величины: (7.4) E . 3. Ошибка репрезентативности дисперсии: 79 E s 2 s 2 2 . (7.5) 4. Ошибка репрезентативности коэффициента корреляции: Er r . (7.6) 3.3. Гипотетическая средняя квадратическая ошибка репрезентативности выборочной средней Гипотеза: если бы была определена средняя генеральная совокупности, то можно было бы сделать серию повторных выборок, определить в каждой из них среднее значение изучаемого признака, а затем определить среднеквадратическое отклонение (среднеквадратическую ошибку) выборки: 2 ( x е ) f е , fе Sx (7.7) где е – номер очередной выборки; fе – частота этой выборки, т. е. сколько раз она «вынималась» из генеральной совокупности; xe – средняя в выборке за номером «е». Но поскольку мы предполагаем, что генеральная средняя арифметическая нам не известна и предполагается бесповторная выборка, использовать формулу (7) в практических целях нельзя. 3.4. Практический расчёт среднеквадратической ошибки выборочной средней ♦ Общие посылки. 1. За исходную посылку принимается схема повторной выборки; но в последующем должна быть сделана поправка на бесповторность. 2. При соблюдении принципа случайного отбора величину ошибки выборки определяют следующие факторы: ● численность выборки: чем больше численность выборки, тем меньше величина ошибки выборки; ● степень варьирования признака: например, если признак совсем не варьирует, то его дисперсия будет равна нулю и, значит, никакой ошибки средней не будет. Отсюда квадрат средней ошибки выборки ( S x2 ) можно теоретически рассчитать по следующей формуле: 2 , n (7.8) 2 . (7.9) S x2 где σ2 – дисперсия генеральной совокупности. Среднеквадратическая ошибка выборочной средней (теоретическая): Sx n 80 ♦ Практические формулы для расчёта средней ошибки выборочной средней. Вернемся к формуле (7.9), она предполагает две посылки: Первая – предполагается известной дисперсия генеральной совокупности (σ2). Вторая – предполагается повторная выборка. По поводу первой ссылки: нам ничего другого не остаётся, как предположить, что S2 (дисперсия выборки) близка к σ2 (дисперсия ГС). По поводу второй посылки: при бесповторной выборке численность единиц генеральной совокупности сокращается на 1 после каждой интеграции в процессе выборки, поэтому в подкоренное выражение формулы (9) добавляется множитель 1 n . N Итак, формула (7.9) преобразуется так: Sx 2 x 1 n , n N S (7.10) где S x – сокращённо называется средней ошибкой выборки. Для признаков, выраженных в относительных величинах (например, в долях). S (1 ) n 1 . n N (7.11) Однако полной уверенности в том, что при поправке выборочной средней на полученную ошибку выборки нет, ибо слишком много было предпосылок. ♦ Предельная ошибка выборочной средней. Если наша ГС подчиняется закону нормального распределения, то мы можем констатировать следующее: выборочная средняя обязательно попадёт в зону «µ ± 3σ», вполне вероятно в зону «µ ± 2σ» и может быть в «µ ± σ», то есть: с вероятностью 68,3 % x = «µ ± σ»; с вероятностью 95,4 % x = «µ ± 2σ»; с вероятностью 99,7 % x = «µ ± 3σ»; в общем виде x = «µ ± tσ». t x . (7.12) Это отношение называется нормированным отклонением ошибки выборки (кратности ошибки выборки, коэффициент доверия). 81 Расчёт средней ошибки выборки по формулам (7.10) и (7.11) может быть принят при вероятности 0,6827, а общая формула принимаемой в расчёт ошибки выборки будет такой: (7.13) x t Sx , где x называется предельной ошибкой выборки; отношение (коэффициент) t иногда называется коэффициентом кратности ошибки выборки, нормированным отношением ошибки выборки или коэффициентом доверия. Для признаков, выраженных в долях: (7.14) t S , Связь между значениями t и вероятностью определяется по таблице, построенной на основании уравнения Лапласа – Гаусса (табл. 7.2). Таблица 7.2 Выдержка из таблицы значений интеграла вероятностей Вероятность 0,6827 0,7287 • 0,9545 • 0,9973 t 1,0 1,1 • 2,0 • 3,0 Уточнения к формулам (7.10) и (7.11): ● при механическом отборе по нейтральному группировочному признаку S2 принимается общая дисперсия; при типическом отборе с механической выборкой за S2 принимается средняя внутригрупповых дисперсий; ● в некоторых источниках в подкоренное выражение формулы (7.9) вместо множителя 1 n предлагается вводить множитель N N n. N 1 Пример 7.4: 1. Средняя продолжительность горения лампочки по выборочным данным составила 300 часов, ошибка выборки ( S x ) рассчитана как 10 часов. тогда среднюю продолжительность горения любой лампочки из партии можно отсчитать как (300 ± 10) часов с вероятностью 0,6827, а с вероятностью 0,9545 как (300 ± 20) часов. 2. Выборочному обследованию подвергли качество произведённого кирпича. Взято 1600 проб из партии в 20000 штук, в 32 случаях кирпич забраковали. Требуется определить с вероятностью 0,954 (t = 2) в каких пределах заключается доля брака во всей продукции. Используем формулы (7.11) и (7.14): 82 t 2 (1 ) n 1 ; n N 32 0,02; 1600 0,02 0,98 1600 = 0,0035 или 0,35 %. 1 1600 20000 3.5. Объём (численность) выборки Численность выборки рассчитывается на стадии проектирования выборочного наблюдения. За основу принимаются формулы расчёта ошибки повторной выборки. Sxп 2 , n xп t (7.15) 2 , n (7.16) где индекс «п» обозначает «повтор». Из последней формулы: nп t 2 2 . 2 xп (7.17) Для бесповторной выборки формула (7.17) преобразуется: n nп nп ( N 1) N . (7.18) В формуле (7.17) проблемной является составляющая σ 2 , т. е. дисперсия генеральной совокупности, поэтому она принимается по данным аналогичных исследований в предшествующих периодах или пробных выборочных наблюдений по схеме повторной выборки; xп задаётся проектировщиками. Пример 7.5: По данным многочисленных наблюдений на скальных земляных работах на одной из крупных строек средняя выработка определена в 4,95 м3 на одного рабочего, а средний квадрат отклонения оказался равным 2,25 (среднеквадратическое отклонение 1,5 м 3). На стройке намерены внедрить новый инструмент для землекопов. Для эксперимента нужно определить количество рабочих (своеобразную выборку), чтобы затем подсчитать новую выработку, при этом размер ошибки по выработке не должен превышать Δ = 0,2 м3 с вероятностью 0,954 (t = 2): t 2 2 4 2,25 (рабочих) по формуле (7.17). nп 2 xn (0,2)2 225 Выборку предстоит осуществить из 2000 рабочих: 83 n nn 225 202 (рабочих) по формуле (7.18). nn ( N 1) 225 1999 2000 N 3.6. Оценка предпринимательского риска Пример 7.6: На заводе безалкогольных напитков изготавливается напиток «Шикарный» с разливом в бутылки. По опыту известно, что через 1400 часов хранения может случиться потеря некоторых качеств напитка. Отобрали партию в 100 бутылок (объём выборки рассчитан с учётом её бесповторности) и со дня разлива, начиная с 1400 часов до 1430 часов хранения, отбирали для проб по три-четыре бутылки. Средняя продолжительность живучести оказалось 1420 часов, со среднеквадратическим отклонением 61,03 часа. Пользуемся формулой (7.10) без поправок на бесповторность выборки, т. к. она учтена при определении численности выборки: Sx S2 n 61 .03 100 6,1 часа. Предприниматель считает, что предельная ошибка выборки может быть доведена до 10. Используем формулу (13): 10 t 6,1 = 1,64; ему соответствует доверительная вероятность dв = 0,899. Вероятность того, что предельная ошибка в проведённых испытаниях составила более десяти часов и равна: 1 dв 0,899 1 1 0,5 0,05, т. е. 5 %. 2 2 Предприниматель с риском в 5 % разрешает подчинённым хранить напиток 1410 часов (1420 – 10). 3.7. Алгоритмы применения формул ошибки выборки и её численности 1) x t среднеквадратичная ошибка среднеквадратичная ошибка при назначенной численности выборки: Sx при рассчитанной численности выборки: 2 x 1 n ; n N S Sx 84 S2 n ; S (1 ) n 1 ; n N S (1 ) n ; 2) численность выборки: n nп nп ( N 1) N nп t2 n 2 xп 2 2 xп п2 ▪ по аналогии ▪ задаётся при ▪ эмпирические данные проектировании 4. Моментные наблюдения и малая выборка 4.1. Моментные наблюдения Моментное наблюдение заключается в том, что на определённые моменты времени фиксируется наличие (отсутствие) отдельных элементов изучаемого процесса. Пример 7.7: В цехе должно работать 20 отлаженных станков. За восьмичасовую смену каждые полчаса проводились моментные регистрации состояния станков. Всего было сделано 320 отметок (20 × 16). В 288 случаях сделана отметка о работе, а в 32-х – о простое станков, т. е. доля работающих станков составила 0,9. Воспользуемся формулой: t (1 ) (повторная выборка). n Пусть t = 0,954, тогда 2 0,9 0,1 0,033 . 320 Следовательно, с вероятностью 0,954 можно констатировать, что доля работающих станков за смену составила 0,9 ± 0,033, т е. от 86,7 % до 93,3 %. 4.2. Малая выборка Под малой выборкой понимается такое выборочное наблюдение, численность единиц которого не превышает двадцати; используется распределение Стьюдента; для этого распределения разработаны таблицы с учетом численности выборки (табл. 7.3). 85 Таблица 7.3 Выдержка из таблицы распределения Стьюдента n 5 • • • • • • • • • 18 20 0,668 • 0,938 • 0,992 0,670 • 0,940 • 0,992 t 1 • 2 • 3 0,626 • 0,884 • 0,960 Ошибка малой выборки: S x ( м.в. ) S (2м.в. ) , (7.19) где индекс (м. в.) – малая выборка. ( x x ) 2 , S(2м.в. ) n x ( м.в.) t Sx ( м.в.) . (7.20) n (7.21) Вопросы и задания для самоконтроля 1. В чем сущность выборочного наблюдения и его основная задача? 2. Что такое репрезентативность выборки и каковы методы ее достижения? 3. Какие виды и способы отбора единиц совокупности вы знаете? 4. Что характеризует средняя ошибка выборки? 5. В чем заключаются моментные наблюдения? 6. Как определяется малая выборка? 86 Лекция 8: АНАЛИЗ ТЕНДЕНЦИЙ РАЗВИТИЯ 1. Приемы выявления общей тенденции развития. 2. Выравнивание (сглаживание) рядов динамики. 3. Измерение колебаний в динамическом ряду. 1. Приемы выявления общей тенденции развития 1.1. Укрупнение периодов в рядах динамики Пример 8.1 Дана статистика потребления продукта «П» по годам (табл. 8.1): Таблица 8.1 < > 103 135 n+3 120 n+4 n+5 n+6 n+7 125 131 140 107 n+8 n+9 > 125 n+2 > < > < < < > < > млн.т. n+1 < < n > Годы 152 121 По этой статистике трудно уловить общую тенденцию в потреблении продукта «П». Укрупним периоды и подсчитаем по ним среднегодовые уровни потребления продукта «П» (табл. 8.2): Таблица 8.2 Периоды n-(n+4) Среднегодовые уровни потребления млн.т. 121,6 (n+5)-(n+9) 130,2 Тенденция роста потребления проглядывается. 87 Предупреждение: однако, укрупнение может привести к потере характера динамики внутри анализируемого периода; по нашему примеру (табл. 8.3): Таблица 8.3 Периоды n - (n + 2) (n + 3) - (n + 5) (n + 6) - (n + 9) Среднегодовые уровни 121 125,3 130 Среднегодовой уровень прироста потребления продукта П в период с n по “n + 5”составил 4 млн.т., а в период с “n + 6” по “n + 9”– 4,7 млн.т.; то есть произошло ускорение темпа прироста. 1.2. Смыкание рядов динамики Пример 8.2 Требуется проанализировать изменение темпов роста реализации продукции «П» в районе «N» за период с 2002 года по 2007 год включительно. Но в 2004 году границы района увеличились. Данные по реализации продукции по годам, млн. рублей: 2002: 19,7; 2003: 20,0; 2004: 21,2 в старых границах; 23,3 в новых границах; 2005: 23,6; 2006: 24,5; 2007: 26,1. Фактически перед нами два ряда динамики: 2002–2004 г. (включительно в старых границах), 2004–2007 г. (включительно в новых границах). Но для анализа темпов роста их надо корректно объединить, сомкнуть. Существует, по крайней мере, два способа смыкания. 1. Смыкание через коэффициент соотношения переходного периода (Кп.п.): К n.n. У1.n.n. , У 0.n.n. (8.1) где У1.п.п – «новый» уровень показателя переходного периода; Уо.п.п. – «старый» уровень показателя переходного периода. В нашем примере Кп.п. = 23,3/21,2 = 1,1; все уровни ряда до переходного периода умножаются на этот коэффициент (уровень переходного периода назначается в новом его значении); 88 2. Смыкание рядов через приведение к одной базе. За базисный берется год перехода, рассчитываются базисные относительные показатели по всем моментам (периодам); например, базисные темпы роста по формуле: Уi (8.2) Тр.б.i * 100, Уб где Тр.б.i – базисный темп роста в i-том периоде; Yi – уровень признака в i-том периоде; Уб – уровень признака в базисном периоде, но при этом для периодов, предшествующих переходному Уб. берется «старый», а для последующих – «новый», например: – для 2003 года Тр.б.(03) = 20/21,2*100 % = 93,3 %; – для 2005 года Тр.б.(05) = 23,6/23,3*100 % = 100,2 %. Продолжение примера 8.2 Сомкнутые ряды реализации продукции «П» по району «N» (табл. 8.4): Таблица 8.4 Показатели Годы 2002 2003 2004 2005 2006 2007 Реализация, млн. руб. 21,7 22 23,3 23,6 24,5 26,1 Составило к 2004 году, % 92,9 93,3 100 100,2 103 104 1.3. Сравнение динамик непосредственно не сравниваемых явлений (приведение рядов динамики к общему основанию) Пример 8.3 Статистика по РФ: темпы роста различной продукции в % (табл. 8.5). Таблица 8.5 Годы, периоды А 1990 1996 2000 2002 Поголовье скота 1 100 105 106 108 Выплавка стали 2 100 120 130 140 Тракторный парк 3 100 150 160 200 Необходимо сравнить темпы роста этой непосредственно не сравнимой продукции. Используем такой показатель: средний базисный темп прироста Т пр.б . Т пр.б. Тр.б.(n)(%) 100% , t (8.3) где Тр.б. = (Тр.б.(n)% – темп роста базисный n-го (последнего) уровня ряда; t – продолжительность ряда в принятых единицах. Продолжение примера 8.3 (табл. 8.6) Таблица 8.6 89 А 1 Среднегодовой базисный темп прироста (%) 2 3 (108 - 100)/12 = 0,66 % (140 - 100)/12 = 3,3 % (200 - 100)/12 = 8,3 % ВЫВОДЫ: Прирост тракторов по сравнению с другими видами продукции шёл быстрее: – чем стали в 1,9 раза (8,3/3,3): – чем поголовья скота в 9,5 раз (8,3/0,66). Использован показатель – коэффициент опережения среднегодового прироста (Копр): Т пр ( ) , (8.4) Копр Т пр () где Т пр (>), Т пр (<) – соответственно больший и меньший среднегодовой уровень сравниваемых темпов прироста. Здесь использован метод приведения рядов динамики к общему основанию: если производить сравнительный анализ рядов динамики разных явлений, то сравнивать можно только относительные показатели, для этого обычно используют базисные темпы динамики (приведение к единой базе сравнения). Может быть использован коэффициент опережения темпа роста базисного (Кор): Тр ( ) . (8.5) Кор Тр () К примеру 8.3: – тракторный парк: Тр = 200 %; – поголовье скота: Тр = 108 %. Кор = 200/108 = 1,8 (раз). Коэффициент опережения можно использовать и при сравнительном анализе динамики. 2. Выравнивание (сглаживание) рядов динамики 2.1. Выравнивание методом скользящей средней Пример 8.4 По фактическим уровням тенденция развития явления в приведенном ряде не ясна, а по скользящим средним она проявилась (рис. 8.1). Выпуск продукции П в регионе N, млн. руб. Месяцы янв февр март апр 90 май июнь июль август Скользящие средние по трем месяцам 2,3 1,9 2,2 2,5 2,4 2,7 2,8 2,4 2,1 2,2 2,37 2,53 2,63 2,63 Рис. 8.1. Укрупнение периодов (интервалов) в примере произведено способом скольжения, т. е. постепенным исключением из принятого интервала укрупнения первого уровня и включения последующего (рис. 8.2). 2,8 2,7 2,6 2,5 2,4 Помесячные данные 2,3 Средняя скользящая 2,2 2,1 2,0 I II III IV V VI VII VIII месяцы Рис. 8.2 Формулы подсчёта скользящих средних: 1. При укрупнении по трем скользящим периодам: 91 У1 = У 1 У 2 У 3 ; 3 У 2 У 3 У 4 (в У2 = ; 3 У3 = числителе: минус У1, плюс У4) (8.6) У 3 У 4 У 5 (в числителе: минус У2, плюс У5) ; 3 и т. д. 2. При укрупнении по пяти скользящим периодам: У1 У 2 У 3 У 4 У 5 ; 5 У 2 У3 У 4 У5 Y6 У2 = 5 У1 = (8.7) и т. д. При построении графика полученный средний уровень относят к моменту (периоду), находящемуся в середине укрупненного скользящего периода (интервала). 2.2. Аналитическое выравнивание (сглаживание) 2.2.1. При аналитическом выравнивании ряда динамики фактические уровни динамики заменяются рядом плавно изменяющихся уровней, которые вычисляются на основе формулы определенной кривой, выбранной в предположении, что она отражает общее направление (тенденцию) изменения во времени изучаемого явления. 2.2.2. Процесс аналитического выравнивания: 1) выявляется характер динамики явления на протяжении анализирующего этапа, например, прогрессивное, регрессивное, зациклено-прогрессирующее и другие возможные характеры. Некоторые способы этого явления рассмотрены в первом вопросе данной темы и в первом подвопросе данного вопроса; 2) на основе выявленного характера динамики выбирается предполагаемое его математическое выражение: линейная зависимость; параболическая зависимость; показательная кривая; гипербола; и т. п.; 3) рассчитываются параметры аналитического уравнения кривой по фактическим значениям (уровням) анализируемого ряда; 4) рассчитываются показатели корректности произведенного выравнивания (этот пункт рассмотрим в следующей теме). Пример 8.5 92 Возьмем данные примера 8.4 и дополним их по ноябрь включительно. Линия скользящей средней дает возможность использования гипотезы выравнивания по прямой линии. Мы сознательно взяли данные только за 11 месяцев, т. к. это упростит дальнейшие расчеты; отсчет влево и вправо будем делать с шестого месяца (июня) (табл. 8.7). Таблица 8.7 Условные значения дат Эмпирические уровни ряда t -5 -4 -3 -2 -1 0 t 1 2 3 4 5 У 2.3 1.9 2.2 2.5 2.4 2.7 У 2.8 2.4 2.6 2.9 3.0 n = 11 ΣУ = 27.7 У*t -11.5 -7.6 -6.6 -5.0 -2.4 0.0 2.8 4.8 7.8 11.6 15 ΣУ*t = 6.9 Уравнение прямой: уt a + bt, (8.8) где параметры вычисляются решением следующей системы уравнений: У= n *a ; (8 . 9 ) ΣУ *t =b *Σ t В свою очередь при нечетном количестве уровней: Σt2 = (n 1)n(n 1) 10 *11 *12 110 . 12 12 Расчет параметров прямой: a у 27.7 2.52 ; n 11 у * t 6.9 0.062 ; b t 110 2 уt 2.52 0.062 * t . Значения У t = 2,210; 2,272; 2,342; 2,396; 2,458; 2,520; 2,582; 2,644; 2,706; 2,763; 2,831. Продолжение примера 8.5 93 уровни 4 По аналитическому расчету 3 По эмпирическим данным 2 1 I II III IV V VI VII VIII IX X XI XII месяцы Рис. 8.3 Мы выпрямили (сгладили) эмпирические данные (рис. 8.3). Однако следует заметить, что наше предположение о линейной зависимости между признаком-фактором и признаком-результатом пока только предположительно. О том, как проверить корректность данного предположения, изложено в следующей – девятой теме данного курса лекций. 3. Измерение колебаний в динамическом ряду 3.1. В рядах динамики встречается такое явление как колебания уровня какого-либо показателя из года в год в одни и те же периоды. Например потребление кваса в летние месяцы повышается, а ближе к зиме понижается. Внутригодичные колебания, имеющие периодический характер, носят название сезонных колебаний. Измерение сезонных колебаний производится путем исчисления индексов сезонности (У сез): Уфакт (8.10) Усез * 100% ; У ср.мес или Уфакт Усез *100% , Уt (8.11) У ср. мес. – среднемесячный фактический уровень явлений; У t – аналитически выравненный уровень явлений ( У t = a + b•t). где – 94 Пример 8.6 Даны фактические и выравненные уровни динамики на примере количества отработанных крестьянами тыс. человеко-дней (табл. 8.8). Таблица 8.8 Месяцы 2000 год I 2001 год Уфакт. Уt Уфакт. Уt 8 11,04 10,6 13,87 II 8,2 11,27 10,0 14,10 III 10,2 11,51 11,6 14,34 IV 12,0 11,74 12,8 14,58 V 14,8 11,98 15,8 14,81 VI 16,8 12,22 19,0 15,05 VII 17,2 12,45 19,4 15,28 VIII 16,4 12,69 19,8 15,52 IX 15,2 12,92 19,0 15,76 X 11,6 13,16 17,4 15,99 XI 10,4 13,4 14,6 16,23 13,63 10 16,46 XII 9,2 Итого 150 180 Среднемес. кол-во 12,5 15 Расчет индексов сезонности затрат труда крестьянами (%). Таблица 8.9 Месяцы I Метод средней арифметической 2000 год 2001 год В среднем за 20002001 10,6 * 100 8 * 100 68 71 12,5 64 15 Метод выравнивания по прямой 2000 год 2001год В среднем за 20002001 8 * 100 76 74 11,04 72 II III 66 82 67 77 66 80 73 89 71 81 72 85 IV V VI VII VIII IX X XI XII 96 118 134 138 131 122 93 83 74 85 105 127 129 132 127 116 97 67 90 112 130 134 132 124 104 90 70 102 123 138 138 129 118 88 78 67 88 107 126 127 128 120 109 90 61 95 115 132 132 128 119 98 84 64 95 График сезонных колебаний затрат труда (по методу выравнивания по прямой) 160 140 120 Сезонная волна % 100 80 60 40 20 0 1 2 3 4 5 6 7 8 9 10 11 12 месяцы Рис. 8.4. Методы средней арифметической и выравнивание по прямой пригодны только в тех случаях, когда в ряду динамики нет отчетливо выраженной тенденции к росту или снижению уровня. Если же уровень явления имеет тенденцию к росту или снижению, то отклонения от координат среднего уровня могут дать искаженную картину сезонных колебаний. Поэтому в этих случаях нужно измерять колебания не около постоянного уровня, а около таких уровней, в которых выражена эта общая тенденция к росту или снижению; такими уровнями могут служить звенья двенадцатимесячной скользящей средней или уровни, полученные путем аналитического выравнивания. 3.2. Вычисление индексов сезонности в рядах с тенденцией развития Пример 8.7 (табл. 8.10). Таблица 8.10 Продажа шерстяных тканей в торговой сети г. Москвы, тыс. руб. Месяц Год Январь Февраль Март Апрель 2001 2002 2003 10,3 10,2 10,8 7,3 8,0 8,5 9,5 6,3 6,8 7,8 8,6 5,4 96 Май Июнь Июль Август Сентябрь Октябрь Ноябрь Декабрь Итого: 5,4 8,6 7,7 9,0 8,5 8,3 7,7 7,9 101,7 4,4 5,0 7,2 7,0 8,0 7,4 6,8 8,5 86,6 4,1 3,6 5,7 6,4 6,6 6,4 6,1 6,8 74,3 По итогам видно, что явление имеет тенденцию к снижению своих уровней, поэтому нужно выровнять ряд фактических данных по прямой: Уt = ao + a1 *t. Расчет параметров по прямой производится по следующей системе нормальных уравнений : n*ao+ a1Σt = Σу; ao Σt + a1 Σt2 = Σу*t. (8.12) где n – число членов ряда. Для упрощения расчетов принимают прием искусственного обозначения месяцев, чтобы Σt получилась равной 0, тогда a0 a1 у; (8.13) n у *t t 2 У нас фактически 36 членов ряда (12 мес*3 года = 36 мес) (рис. 8.5). Обозначение членов ряда – месяцев (t) (см. стр. 93) Таблица 8.11 Расчет составляющих системы (8.13) у 10,3 10,2 * 4,4 5,0 7,2 7,6 * 6,1 6,8 262,9 t -17. 5 -16.5 * -1.5 -0.5 0.5 1.5 * 16.5 17.5 Итого: a0 262,9 7,295; 36 t2 306,25 272,25 * 2,25 0,25 0,25 7,0 * 272,25 306,25 3885,0 a1 Пример расчета выравненного уровня: 97 364.9 0.09393. 3885.0 У*t -180,25 -168,30 * -6,6 -2,5 3,6 2,25 * 100,65 119,0 -364,9 у-17.5 = 7.295 + (-0.09393)(-17.5) = 8.94; уsij уsi *100% . (8.14) m где уsi – средний индекс сезонности в месяце i; уsij – индекс сезонности в месяце i в году j; m – количество лет в изучаемом периоде. Таблица 8.12 Расчет индексов сезонности Месяцы Выравненные данные (Уt) Фактические данные в % к выравненным Уsij 2001 2002 2004 2001 2002 2003 1 8,94 7,82 6,69 115,2 102,3 101,7 Средний индекс сезонности Уsi 106,4 2 8,85 7,73 6,60 115,3 110,0 118,2 114,5 3 8,79 7,63 6,50 123,3 124,5 132,1 126,6 4 8,67 7,54 6,41 81,1 83,6 84,3 83,0 5 8,57 7,45 6,32 63,0 59,0 64,9 62,3 6 8,48 7,35 6,22 101,4 68,0 58,0 75,8 7 8,38 7,26 6,13 91,9 99,2 93,0 94,7 8 9,29 7,16 6,04 108,6 97,8 106,0 104,1 9 8,20 7,07 5,94 103,7 113,1 111,1 109,3 10 8,10 6,97 5,85 102,5 106,0 109,4 105,2 11 8,01 6,88 5,75 96,1 100,0 106,1 100,7 12 7,91 6,79 5,65 100,0 125,2 120,2 115,1 98 2001 2002 2003 1 2 3 4 5 6 7 8 9 10 11 12 1 2 3 4 5 6 7 8 9 10 11 12 1 2 3 4 12 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36 96 -17,5;……………………..;- 2,5,-1,5 ,-0,5, 0,5;1,5, 2,5………. Рис. 8.5 99 17,5 Индекс сезонности 130 125 120 115 110 105 100 1 2 3 4 5 6 7 8 9 10 11 12 месяцы 95 90 85 80 75 70 65 60 Рис. 8.6. Сезонная волна продажи шерстяных тканей Вопросы и задания для самоконтроля 1. Какие приемы выявления общей тенденции развития вы знаете? Приведите примеры. 2. Какие методы используют при выравнивании рядов динамики? 3. С помощью примера покажите процесс аналитического выравнивания. 4. С помощью каких показателей измеряют колебания в динамическом ряду? 100 ЛЕКЦИЯ 9. СТАТИСТИЧЕСКИЕ ПРИЕМЫ ИЗУЧЕНИЯ ВЗАИМОСВЯЗЕЙ 1. Виды взаимосвязей, изучаемых в статистике. 2. Крреляционные связи и корреляционный анализ. 3. Балансовые приемы анализа взаимосвязей. Понятие «связь» – одно из важнейших научных понятий: с выявления устойчивых, необходимых связей начинается человеческое познание, а в основании науки лежит анализ связи причины и следствия (признакифакторы признак-результат); это универсальная связь явлений действительности, наличие которой делает возможными установления законов науки. 1. Виды взаимосвязей, изучаемых в статистике 1.1. Виды взаимосвязей по их характеру Факторные; в этом случае признаки изучаемой совокупности подразделяются на признаки-факторы и признак-результат и между ними определяется (выводится) вид и форма связи. Компонентные; в этом случае показатель (признак) сложного явления, сам по себе являющийся сложным (сводным), раскладывается по составляющим его компонентам и между ним и компонентами, и в свою очередь, между компонентами выявляется связь (например, система взаимосвязанных индексов, множественная корреляция). Балансовые; по характеру они являются компонентными, но из-за широкого применения выделены в отдельную группу ( активов по стоимости = пассивов по стоимости). 1.2. Виды взаимосвязей по способу выражения Аддитивные: additivus (лат) – прибавляю; y f ( x i ) . Мультипликативные: multiplico (лат) – умножаю, увеличиваю. y f ( П xi ) . (9.1) (9.2) 1.3. Виды взаимосвязей по их полноте 1. Детерминированные (полные) или функциональные (например, S ПR 2 ). 2. Стохастически детерминированные или статистические; stochastistikos (греч) – умение угадывать; Эти связи проявляются только при значительном числе испытаний (наблюдений); это т. н. вероятностные связи. Частным случаем стохастически детерминированных связей являют101 ся корреляционные связи. 2. Корреляционные связи и корреляционный анализ 2.1. Понятие корреляционной зависимости; особенности корреляционных связей Пример 9.1. Пусть y – прирост урожая зерна, x – количество удобрений. Удобрения внесли по 2 единицы (x = 2) на три одинаковых по площади участка земли; с трех разных участков получили: 5, 6, 10 единиц прироста урожая (у1 = 5; у2 = 6; у3 = 10). Значит между уровнем урожая и степенью удобренности связь есть. Средний рост урожайности при внесении 2-х единиц удобрения ( y 2 ): y x = 5 6 10 7 , где в данном случае x = 2; 3 y x называется условной средней; “x” соответствует уровню x (в нашем примере 2); Корреляционной зависимостью называют функциональную зависимость условной средней y x от x: (9.3) y x = f(x) Понятие “корреляция” введено в употребление английским биологом и статистиком Франсом Гальтоном; он ввел ее как альтернативу детерминированным (полным) связям. Особенности корреляционных связей. 1. Корреляционные связи характеризуются тем, что вариация того или иного признака происходит под влиянием комплекса факторов, значимость (сила) влияния которых на анализируемый признак может быть различной. Пример 9.2 (рис. 9.1). П р о и з в о д и т е л ь н о с т ь т р у д а Энерговооруженность Организация труда Снабжение ресурсами …… Рис. 9.1 2. Корреляционные связи обнаруживаются в массе однородных явлений, т. е. их проявление подвержено закону больших чисел. 3. Корреляционные связи не полные, и даже при массовом материале они могут только приближаться к функциональным с той или иной степенью точности. 2.2. Задачи и этапы корреляционного анализа 102 1. Обнаружение корреляционной зависимости в фактическом статистическом материале (построение поля корреляции, построение параллельных рядов; оценка эмпирической силы связи). 2. Установление формы связи между признаками-факторами и признаком-результатом (выравнивание, сглаживание рядов). 3. Измерение тесноты (силы) выведенной корреляционной связи, т. е. степени ее приближения к функциональной. 2.3. Выявление эмпирических корреляционных зависимостей 2.3.1. Построение поля корреляции Пример 9.3. Уровни энерговооруженности (x) и производительности труда (y) по 25-ти заводам (тыс. квт. час; тыс. шт. изделий на одного работающего в год). Таблица 9.1 № п/п 1 2 3 4 5 6 7 8 9 10 11 12 13 x 6,0 6,1 6,8 7,2 7,4 7,9 8,2 8,5 8,6 9,1 9,4 9,9 10,5 № п/п 14 15 16 17 18 19 20 21 22 23 24 25 y 2,0 3,0 6,0 4,0 2,0 3,0 4,0 5,0 6,0 8,0 5,0 7,0 7,0 Рис 9.2. 103 x 11,2 11,3 11,5 11,7 12,1 12,3 12,6 12,7 12,9 13 13,2 13,3 y 8,0 6,0 9,0 9,0 8,0 7,0 8,0 9,0 6,0 10,0 9,0 10,0 2.3.2. Построение параллельных рядов В параллельных рядах ряд признака-фактора ранжируется, затем сравнивается вариация рядов признака-фактора и признака-результата; визуально прослеживается тенденция поведения признака-результата в зависимости от роста (убывания) значения признака-фактора. Табл. 9.1. уже построена по признаку параллельных рядов. И табл. 9.1., и рис. 9.2. дают право предполагать о наличии связи между фактором (x) и результатом (y). Значительно отчетливее эта связь может проявиться после рациональной группировки. 2.3.3. Метод группировок как прием выявления корреляционных зависимостей В ряду признака-фактора производится интервальная группировка, а по признаку-результату рассчитываются средние величины признакафактора в каждом из интервалов ( y гр ). Пример 9.4 (развитие примера 9.3). При выборе варианта группировки будем пользоваться указанием русского статистика начала XX века А. А. Чупрова: «чем больше групп мы в состоянии нарезать, не наталкиваясь ни на одно исключение, тем прочнее вывод, что найденная связь или подмеченное отсутствие связи не случайны и свидетельствуют о действительных взаимоотношениях между признаками». Сравнение вариантов представленных параллельных рядов показывает в первом и втором случаях ясную тенденцию нарастания y в зависимости от роста x; в то же время в третьем варианте из правила (роста y по мере роста x) есть исключение во второй группе. В темах 2 и 4 мы показали, что как слишком большое, так и слишком малое количество членов в группе ведет к потере из поля зрения части свойств анализируемого явления. Теоретически оптимальную группировку можно получить так, как показано на рис. 9.3. Пользуясь указаниями Чупрова в табл. 9.2. выбираем 2-ой вариант группировки. Все рассмотренные виды анализа наличия корреляционных связей можно назвать визуальными; для исследователя надо определить количественные значения связи. 104 Таблица 9.2 Первый вариант группировки Второй вариант группировки x n гр y y гр 6,0-7,99 6 20 8,0-9,99 6 35 10,0-11,99 5 39 12 и выше 8 67 Итого и средние 25 161 Третий вариант группировки x n гр y y гр 3,3 6-7,49 5 17 5,8 7,5-8,99 4 18 7,8 9,0-10,49 3 20 8,4 10,5-11,99 5 39 12,0-13,49 8 67 6,44 Итого и средние 25 161 x n гр y y гр 3,4 6,0-7,24 4 15 3,75 4,5 7,25-8,49 3 9 3 6,7 8,5-9,74 4 24 6 7,8 9,75-10,99 2 14 7 8,4 11,0-12,24 5 40 8 7 59 8,4 6,44 12,25-13,49 Итого и средние 25 161 6,44 102 Любая произвольная группировка ранжированного признака-фактора. Проверка наличия исключений группировочных значений признака-результата Ис к люч е н ия Да Укрупнение интервалов ряда признака-фактора до первого исключения (исключений в значениях признака-результата), возврат к предшествующей группировке. ес ть? Нет Разукрупнение ряда признака-фактора до получения первых исключений в значениях признака-результата; возврат к предшествующей группировке. 105 Рис. 9.3. 106 2.3.4. Определение эмпирической силы связи (коэффициент детерминации, эмпирическое корреляционное отношение). В лекции 6 мы изучили эти категории: 2 ; 2 2 где , 2 – 2 , соответственно эмпирический коэффициент детерминации и эмпирическое корреляционное отношение; 2 , 2 – соответственно общая и межгрупповая дисперсии. В свою очередь: а) общая дисперсия: 2 у у ; п но мы будем пользоваться упрощенной формулой: σ y2 2 (9.4) y2 y . n Примечание 9.1: эта формула выводится из общей формулы дисперсии путем преобразований на основании следующего свойства дисперсии: дисперсия от средней всегда меньше дисперсий, исчисленных от других величин, т. е. она имеет свойства минимальности. Путем рассуждений можно прийти к следующему правилу: средний квадрат отклонений равен среднему квадрату значений признака минус квадрат среднего значения признака: 2 у 2 2 х2 х ; (9.5) б) межгрупповая дисперсия 2 2 угр у nгр nгр . (9.6) Пример 9.5 (развитие примеров 9.3 и 9.4) Дополнение к табл. 9.1: y2: 4; 9; 36; 16; 4; 9; 16; 25; 36; 64; 25; 49; 49; 64; 36; 81; 81; 64; 49; 64; 81; 36; 100; 81; 100. y 2 1179; 1179 2 (9.7) 6.44 5.69. 25 Расчет дисперсии групповых средних уровней производительности (на основании табл. 9.2 второй вариант группировки) (табл. 9.3). y2 107 Таблица 9.3 у у гр - у гр -3,04 -1,94 0,26 1,36 1,96 ИТОГО: у 2 у гр 9,242 3,764 0,068 1,850 3,842 у 2 nгр 46,21 15,06 0,20 9,25 30,74 101,45 101,45 4.06 4,06; 2 0.713(71.3%) ; 5.69 25 0.713 0.844 . То есть связь между энерговооруженностью и производительностью труда нами доказана в количественном выражении. 2 2.4. Нахождение теоретической формы связи Характер связи может быть прямым и обратным, а по форме связи могут быть линейными и криволинейными. 2.4.1. Выравнивание по прямой Уравнение линейной связи: yx = a0 + a1x. (9.8) Система нормальных уравнений для нахождения параметров уравнения (9.8): а0 n а1 а0 n а1 х х у (9.9) у Пример 9.6 (развитие предыдущих примеров) Характер поля корреляции (рис. 9.2) и параллельные ряды (табл. 9.2) приводят к предположению о возможности использования формулы 9.8 Таблица 9.4 Таблица расчетов составляющих системы уравнений 9.8, 9.9. № п/п 1 2 * 16 * 25 ∑ x 6,0 6,1 * 11,5 * 13,3 253,7 y 2 3 * 6 * 10 161 25а0 + 253,7а1 = 161; 253,7а0 + 2713,25а0 = 1753,1; 108 x2 36 37,21 * 132,25 * 176,89 2713,25 у·x 12,0 18,3 * 69 * 133,0 1753,1 а1 = 0,875; а0 = -2,25; ух = 0,875х – 2,25. Теоретическое управление связи между энерговооруженностью рабочих и производительностью их труда: уx = 0,857x - 2,25. (9.10) Параметры при x (в нашем случае 0,857) называются коэффициентами регрессии, regressio (лат.) – обратное движение, зависимость среднего значения какой-либо величины от некоторой другой величины или нескольких величин. Коэффициент регрессии в уравнении (9.10) «говорит»: изменение x на 1 пункт дает среднее изменение у на 0,857 пункта. Конкретно по примеру: прирост энерговооруженности труда на 1 тыс. кВт. ч. в году на одного работающего дает прирост производства одним рабочим 857-ми штук изделий в год (в среднем). Уравнение, приводящее корреляционную зависимость к функциональной, называется уравнением регрессии. Подставим значения х в это уравнение и получим теоретические значения у( у х ), попутно произведем вычисления, которые нам будут необходимы в дальнейшем: Таблица 9.5 у ух ух № п/п 1 2 * 16 * 25 2,9 3,0 * 7,6 * 9,2 161 Итого -0,9 0 * 1,4 * 0,8 -12,3 +12,3 ( у ух ) 2 0,81 0 * 1,96 * 0,64 39,52 Построим и сравним графики: у, у х и у . Анализ соотношения графиков, изображенных на рис. 9.4: 1. Сопоставление 2. Линия ух у с у демонстрирует общую дисперсию . 2 изображает теоретические значения у при абстрагировании от влияний факторов, кроме х; это переменная средняя значений у. 109 3. То, что переменная средняя отличается от средней постоянной, говорит о влиянии фактора х; дисперсия переменной средней по отношению к постоянной средней ( 2 ух ). Поле корреляции y 12 ух 10 8 6 у 6,44 4 2 0 0 5 10 15 x Рис. 9.4 4. у х не совпадает с линией у, говорит о том, То, что линия что связь между у и х не полная; колебания у по отношению ух являются вариацией, обусловленной другими нежели х факторами; количественно эту вариацию можно исчислить как дисперсию, измеряющую отклонения у от колебания у вокруг ух 2 у у х ; может выразиться так: ух . Этот анализ приводит к размышлению о том, что надо доказать правомерность выбранной формы регрессии. 2.4.2. Теоретическое корреляционное отношение (индекс корреляции) Необходимо измерить силу влияния х на ух . Общая дисперсия у (мера отклонений у от у ) нами определена как 5,69 (формула 9.7). Если от общей дисперсии мы вычтем дисперсию, вызванную 2 прочими факторами ( у у х ), то по правилу сложения дисперсий получается дисперсия, измеряющая отклонения у от ух обусловленные 2 110 фактором х ( ух ), (но это только в том случае, если уравнение регрессии выбрано верно), то есть: 2 2у Дисперсию ний у от ух: 2 у у х 2 к ух 2 у 2 у у х . (9.11) можно определить как средний квадрат отклоне- Отношение = х 2 = у ух п у у х 2у 2 . (9.12) покажет долю вариации, вызванную группировочным признаком х ( ух ) 2 2 ух 2 ух 2 2 у 2 у ух у 2 . (9.13) у ух Корень квадратный из называется теоретическим корреляционным отношением или индексом корреляции R. 2 R= 2 ух . (9.14) Корреляционное отношение – это числовой показатель силы связи между двумя варьирующими величинами; оно бывает эмпирическим и теоретическим: эмпирическое корреляционное отношение – это истинное корреляционное отношение; теоретическое корреляционное отношение – это «сила связи» между фактором и теоретически полученным результатом по гипотетически подобранному уравнению регрессии. Корреляционное отношение 0,0 0,3 связи нет или она очень слабая 0,7 связь есть Рис. 9.5 Пример 9.7 (развитие предыдущих примеров) 2 у = 5,69; 111 1,0 связь высокая, вплоть до функциональной пользуемся данными табл. 9.5: 2 у у х 39,52 1,58 , 25 2 = 5,69 1,58 0,722 , ух 5,69 т. е. 72,2 % дисперсии (вариации) вызвано признаком х. R = 0,722 = 0,85, Т. е. наш выбор уравнения регрессии (формулы 9.8, 9.10) правомерен. Примечание 9.2: теоретическое корреляционное отношение можно исчислять и по формуле: R= где 2 ух 2 2 ух , (9.15) у 2 ух у ; п 2 у у у п 2 . 2.4.3. Линейный коэффициент корреляции Этот коэффициент (r) является частным случаем индекса корреляции, применение которого ограничено только линейной формой связи; он показывает не только тесноту, но и направление связи (от -1 до +1). Линейный коэффициент корреляции построен на сопоставлении стандартных отклонений варьирующих признаков (среднеквадратическое отклонение или стандартная ошибка) от их среднего значения, он имеет следующую исходную формулу: х х у у : п, r = х у (9.16) дальнейшее преобразование этой формулы приводят её к такому виду: r= х у п 2 х у 2 у 2 2 х п п ху (9.17) Все данные для расчета этого коэффициента в сквозном примере есть; рассчитайте его и сравните с R. 2.4.4. Понятие о множественной корреляции Множественная корреляция заключается в анализе влияния на результативный признак (у) более одного признака-фактора (x, z, v, w и т. д.). При линейной зависимости уравнение связи выглядит так: 112 (9.18) у x , z , v , w a0 a1 x a2 z a3v a4 w В зависимости от количества аргументов используется соответствующая система нормальных уравнений, например при их наличии в количестве двух (x,z): а0 + а1∑х + а2∑z = ∑у а0∑х + а1∑х2 + а2∑хz = ∑ух . (9.19) а0∑z + а1∑хz + а2∑z2 = ∑уz Показателем тесноты связи в случае её линейного характера служит совокупный (общий) коэффициент корреляции, который при двух аргументах рассчитывается по следующей формуле: rxzy r 2 xy r 2 zy 2rxy rzy rxz 1 r 2 xz (9.20) , где rxy, rzy, rxz – линейные коэффициенты парной корреляции между соответствующими признаками. Так же как индекс корреляции, совокупный коэффициент корреляции изменяется от 0 до 1. При изучении зависимости результативного признака от факторов трех и более не следует вручную выводить параметры уравнения и совокупный коэффициент корреляции; следует пользоваться готовыми программами для их расчета на ЭВМ. Обобщим изученный выше материал в виде алгоритма – схемы (рис. 9.6). Мы все время имели дело с линейными зависимостями, однако, эти зависимости могут носить и криволинейный вид. 2.5. Криволинейные зависимости Последовательность количественно-качественного анализа будет такой же, как она представлена на рис. 9.6, однако в блоке 5 можно ошибиться, поэтому в алгоритме предусмотрен возврат к этому блоку в случае неподтверждения гипотезы о типе связи. 2.5.1. Выравнивание по гиперболе yx = а0 + а1* 1 ; (9.21) x а0*n + а1 Σ 1 = Σy ; x (9.22) y а0 Σ 1 + а1 1 x Σ x2 =Σ x Фрагмент таблицы для расчета параметров (табл. 9.6) Таблица 9.6 № п/п x y 1/x 1/x2 y/x yx . . . . . . . 113 Σ Σ Σ Σ Σ Уx рассчитываются после конкретизации по параметрам уравнения 9.21. Последовательность количественно – качественного анализа корреляционной связи 114 1 2 Построение параллельных рядов признакафактора и признака-результата 3 Группировка (интервальная) по признакуфактору (оптимальная) Факторный анализ Построение корреляционного поля 5 Выдвижение гипотезы о характере и типе связи; построение уравнения регрессии 6 Проверка гипотезы по выбору уравнения регрессии на её достоверность через теоретическое корреляционное отношение (индекс корреляции). Постановка вопроса: величина индекса корреляции достаточна? Ответ на последний вопрос Конец ДА Параметрическое исследование 4 Определение тесноты связи между признакомфактором и признаком-результатом через коэффициент детерминации и эмпирическое корреляционное отношение НЕТ Рис. 9.6 Использование ф-лы 9.21 будет необходимо при исследовании издержек производства и обращения при изменении масштабов производства (масштабов обращения). 115 2.5.2. Выравнивание по полулогарифмической прямой yx = а0 + а1logx ; (9.23) а0*n + а1Σ logx = Σy; (9.24) a0 Σ logx + a1 Σ(logx)2 = Σy logx Использование ф-лы 9.23 может быть необходимым в тех случаях, когда темп роста одного технико-экономического показателя (у) постепенно замедляется при равномерном росте другого, факторного по отношению к нему показателя (x). Фрагмент таблицы для расчета параметров (табл. 9.7) Таблица 9.7 № п/п x y logx (logx)2 y*logx yx . . . Σ . Σ . Σ . Σ . Σ 2.5.3. Выравнивание по параболе второго порядка yx = а0 + а1x + a2x2; (9.25) а0*n + а1Σx + a2Σx2 = Σy; а0Σx + а1Σx2 + а2Σx3 = Σyx; (9.26) а0Σx2 + а1Σx3 + а2 Σx4 = Σyx2 Упрощенный вариант расчетов параметров системы нормальных уравнений: а0*n + а2Σ (x- x ) = Σy; (9.26’) а1Σ (x- x )2 = Σ у(x- x ); а0Σ (x- x )2 + а2Σ (x- x )4 = Σ у(x- x )2 Таблица 9.8 x . Σ y . Σ x- x . - (x- x )2 . Σ у(x- x ) . Σ у (x- x )2 . Σ (x- x )4 . Σ yx . Σ Использование ф-лы 9.25 может принести положительный результат при такой зависимости между признаками, когда при постоянном росте одного из них второй тоже растет до определенного экстремума, а затем его значения начинают убывать. 2.6. Статистическое исследование зависимости между качественными признаками, вариация каждого из которых носит альтернативный характер Исследователь может поставить целью наблюдения только проверку наличия связи между двумя явлениями. При наблюдении регистрируются только частоты одновременного появления альтернативных признаков. Пример 9.8. Наблюдением установлена следующая статистика: Таблица 9.9 116 Данные по обучению рабочих (чел.) Обученность Прошедшие техническое обучение Не прошедшие техническое обучение Всего Выполнившие и перевыполнившие норму 112 Выполнение норм Не выполнившие норму Всего 19 131 15 52 67 127 71 198 В этом примере два признака (обученность, выполнение норм), альтернативно варьирующих («прошедших или не прошедших обучение» и «выполнившие или не выполнившие норму»); таким образом, одновременно фигурируют четыре частоты (число единиц одновременного появления) альтернативных признаков. Таблица 9.9. относится к групповой «таблице четырех полей». Формализованное представление таблицы четырех полей (табл. 9.10) Таблица 9.10 I Σ II 1 1 1 а c b d a+b c+d a+c b+d - 1 Σ Объяснение: I, II – варьирующие признаки; 1 – утвердительное высказывание признака; 1 – отрицательное высказывание признака. Силу связи между альтернативно варьирующими признаками можно определить через коэффициент ассоциации (К А). Associate (лат.) – соединение; КА= ad bc , (9.27) ad bc -1 ≤ КА ≤1, связь является подтвержденной при | КА| ≥ 0,5. Более точную оценку степени тесноты связи дает коэффициент контингенции (Кк). Contingengens – достающийся на долю. ad bc (9.28) Кк = (a b)(b d )( a c)(c d ) -1 ≤ Кк ≤ 1, и связь является подтвержденной при | Кк| ≥ 0,3. В примере по табл. 9.8: КА = + 0,91; Кк = + 0,62. 3. Балансовые приемы анализа взаимосвязей 3.1. Общие понятия о балансовом методе взаимосвязей 117 balance (франц.) – весы: – равновесие, уравновешивание; – количественное выражение отношений между сторонами какойлибо деятельности, которые должны уравновешивать друг друга. Пример 9.9. Σ активов = Σ пассивов; или в стоимостном Σ активов = капитал + Σ обязательств; выражении или Σ обязательств = Σ активов – капитал. Балансовый метод (в узком понятии): метод статистического изучения процесса воспроизводства, заключающийся в сопоставлении систем показателей, отражающих состояние взаимосвязанных элементов общественного воспроизводства. 3.2. Некоторые виды балансов 3.2.1. Баланс материальных ресурсов На предприятии составляется по формуле: Начальный остаток + поступление = Ресурсы (9.29) = расход + остаток конечный Расходование ресурсов 3.2.2. Баланс движения товаров. Пример 9.10. С помощью этого примера проведем небольшой анализ статистических взаимосвязей. Баланс движения товаров за I квартал (ден. ед.) (табл. 9.11) Таблица 9.11 товар ы А а б в итого остаток на 1.01 1 5 8 2 15 поступ ило в I кв. итого в приходе (гр.1+ гр.2) продажи опто м 2 12 15 8 35 3 17 23 10 50 4 3 2 5 в розн ицу 5 8 18 5 31 итого (гр.4 + гр.5) 6 11 18 7 36 Возьмем за основу формулу этой таблицы: 118 остат ок на 1.04 итого в расходе (гр.6+ гр.7) 7 6 5 3 14 8 17 23 10 50 остаток на поступление продажи начало + за период = за период периода 1. В целом по движению товаров: остаток на поступление продажи начало + 35 = 36 15 поступление продажи остаток 35 = на конец 36 14 Разница между поступлением товаров и их продажами -1 + + - остаток на конец периода (9.30) остаток на конец 14 остаток на начало 15 (9.31) (9.32) Разница между остатком на конец периода и его начало -1 Интенсивность оборота товаров не увеличилась по сравнению с прошлым периодом, т. к. объем продаж выше его поступления произошел только за счет накопления на начало периода. 2. По товару «а» поступление продажи остаток остаток (9.33) 12 11 на конец на начало = 6 5 1 2 Интенсивность оборота товара «а», по крайней мере, не ниже, нежели в прошлом периоде, т. к. объем продаж увеличен не за счет накопления остатков в прошлом. 3. По этой балансовой таблице можно проанализировать характер движения товаров «б» и «в», а также по розничным и оптовым продажам. 4. Предположим, что в любой из строк таблицы пропущен один из показателей; вы понимаете, что его легко вычислить. Анализировать при желании можно и дальше. Балансовый вид связей, воплощенный в форму (формулу или таблицу) позволяет не только анализировать, но и выявлять и устранять неточности (ошибки) в величине отдельных показателей (увязать показатели). Пример 9.11. Предположим, что в табл. 9.10 по товару «а» получилась балансовая неувязка (неравенство): 119 остаток на начало 5 + поступление 12 < продажи 11 + остаток на конец 7 Остаток на конец квартала был выведен документально и вызывал некоторые сомнения в четкости постановки документального учета остатков. Инвентаризация (пересчет) остатков дал итог: 6 ден. ед. 3.2.3. Баланс оборота рабочей силы Этот баланс связывает в единую систему показатели: численности работников на начало периода, пополнения их за период по источникам, выбытия по видам и численности на конец периода. 3.2.4. Баланс денежных доходов и расходов населения показывает денежные доходы населения по источникам их образования и их расходование на различные нужды. На основе анализа этого баланса за изучаемый период и сопоставления с подобными балансами прошлых периодов прослеживается динамика платежеспособности населения, различных видов доходов, спроса на товары по их видам. 3.2.5. Баланс бухгалтерский – подробно изучали в дисциплине «Бухгалтерский учет». 3.2.6. Баланс народного хозяйства выявляет соотношения и пропорции в производстве отдельных продуктов, распределение их на производственное и непроизводственное потребление, выявляет валовой внутренний и валовой национальный продукты, распределение ВВП на потребление и накопление, пропорции между производством средств производства и производством предметов потребления, между промышленностью и сельским хозяйством и многие другие связи и пропорции. В общем, мы выявили два балансовых приема анализа взаимосвязей: составление балансовых уравнений; составление балансовых таблиц. Вопросы и задания для самоконтроля 1. 2. 3. 4. 5. 6. Какие виды взаимосвязей статистики вы знаете? Дайте понятие корреляционной зависимости. Какие особенности корреляционных связей выделяют? Как определяются эмпирические силы связи? Что такое корреляционное отношение? Дайте понятие балансового метода взаимосвязей и его видов. 120 ЛЕКЦИЯ 10. ИНДЕКСЫ 1. Индексы индивидуальные и сводные. 2. Средние индексы. 3. Индексный метод анализа факторов динамики (система взаимосвязанных индексов). Index (лат.) – показатель… – статистический относительный показатель, характеризующий соотношение во времени (динамический индекс) или в пространстве (территориальный индекс) социально-экономических явлений. Фактически мы уже имели дело с индексами при изучении средних показателей динамики и при анализе тенденций развития, например: темп роста, темп прироста и т. д. 1. Индексы индивидуальные и сводные 1.1. Общие понятия об индексах (рис. 10. 1) Рис. 10.1 Индекс индивидуальный ( i ) относительная величина, характеризующая изменение во времени отдельных элементов (отдельных явлений) сложного социально-экономического явления: i x1 x0 (10.1) где х1 уровень признака (показателя) в анализируемом периоде; х0 уровень признака (показателя) в базисном периоде. Индекс сводный (Jсв) относительная величина, характеризующая изменение во времени сложного явления, т. е. состоящего, в свою очередь, из отдельных явлений, непосредственно несоизмеримых: J св y св1 , y св 0 121 (10.2) где y св1 , y св 0 уровни сложного явления, разноименные признаки (показатели) которого сведены к одной мере (единице измерения). Основной формой индекса сводного является агрегатный индекс aggregates (лат.) – присоединенный. Он характеризует относительные изменения индексируемого показателя в периоде текущем по сравнению с периодом базисным. Индексируемый показатель – это показатель, изменение которого определяется. Например, увеличение (уменьшение) интегральной цены, интегральной себестоимости, интегрального физического объема продукции. Общие формулы исчисления агрегатных индексов: а) агрегатный индекс с учетом изменения весов в базисном и отчетном периодах (Jxf): J = x j 1 f j 1 ., (10.3) xf x j0 f j0 б) агрегатный индекс с весами периода базисного (Jx): J = x j1 f j 0 , x x j0 f j0 (10.4) в) агрегатный индекс с весами периода текущего (Jf): Jx = x j1 f j1 x j 0 f j1 , (10.5) где в формулах (10.3), (10.4), (10.5): xj величина индексируемого показателя в группе j в единицах измерения принятых в этой группе; “0”, “1” обозначения соответственно базисного и отчетного периодов; fj или вес единицы xj (например, цена килограмма картофеля) или количество взвешиваний xj (например, количество килограммов картофеля, проданных по определенной цене). Правило выбора формул (10.4) или (10.5). Если за fj ые принимаются веса единиц xj , то применяется формула 10.4; если за fjые принимается количество взвешиваний xj, то применяется формула 10.5. 1.2. Агрегатный индекс товарооборота Пример 10.1. Фирма торгует разноимёнными и разноизмеримыми товарами, указанными в табл. 10.1. 122 Таблица 10.1 Товары Базисный период Объем продаж q0 Отчетный период Цена ден.ед. p0 Объем продаж q1 Цена ден.ед. p1 Индивидуальные индексы Объем Цены продаж iq ip А 1 2 3 4 5 6 Молоко, тыс. л 5000 300 6000 276 1,2 0,92 Мясо, цент, 25000 200 32000 190 1,28 0,95 Картофель, т. 10000 120 11000 102 1,1 0,85 Требуется проанализировать: а) динамику физического товарооборота по каждому товару; б) динамику интегрального товарооборота. По пункту “а)” пользуемся формулой (10.1.) – расчет представлен в графе “ig”. Анализ динамики интегрального товарооборота требует сведения объемов разноименных товаров к общей мере. Пользуемся формулой (10.3): за xj принимаем объём продаж (gg); за fg – цену, т. е. вес каждой единицы xj в денежном выражении; обозначим Jxf через Jт.о. (индекс товарооборота). Jq J т.о q1 p1 ; q0 p0 (10.6) 6000 * 276 32000 * 190 25000 * 200 11000 * 102 5000 * 300 25000 * 200 10000 * 120 8858000 1,149 (114,9 %). 7700000 товарооборот возрос на 14,9 %. Изменение величины товарооборота, как мы видим по данным табл. 10.1, произошло из-за изменения объема продаж по каждому из видов товаров, а также изменения цен на них. Поэтому продолжим анализ. 1.3. Индекс интегрального физического (натурального) товарооборота Рассуждаем так: Если бы цены по каждому товару j оставались на уровне базисного периода «0», то есть Р1 = Р0, то разница (∑q1*p0 – ∑q0*p0) представляет собой прирост интегрального физического товарооборота; значит индекс 123 интегрального физического товарооборота (Jq) можно подсчитать по формуле Σq1 p0 Jq = Σq0 p0 . (10.7) В принципе мы пользовались формулой 10.5; за j принималось количество взвешиваний цены рj (количество взвешиваний единицы). Продолжение примера 10.1 ∑q1 p0 = 9520000 (ден.ед); ∑q0 p0 = 7700000 (ден.ед); Jq = 9520000 =1,236. 7700000 Вопрос: почему Jт.о получился меньше Jq? Ответ: видимо за счет изменения цен. 1.4. Индекс цен Рассмотрим произведение ∑рj1qj1; это произведение представляет собой товарооборот за отчетный период. Заменим все П j1 на Пj0, произведение ∑рj0qj1 представляет собой товарооборот отчетного периода в ценах базисного периода. Разница (∑рj1qj1–∑рj0qj1) является той величиной изменения товарооборота, которая вызвана изменением цен. Интегральный индекс цен можно подсчитать по формуле: Jр = p1 q1 p0 q1 . (10.8) Продолжение примера 10.1 Дополнительно требуется проанализировать: в) динамику цены по каждому товару; г) динамику цен в их совокупности (Jр). По пункту «в» пользуемся формулой 10.1 – расчет представлен в графе ip. ∑р1q1 = 8858000, ∑р0q1 = 9520000, Jр = 8858000 = 0,93. 9520000 1.5. Основные агрегатные индексы 1.5.1. Агрегатный индекс физического объёма продукции характеризует динамику производства продукции в неизменных ценах (Jп): 124 Σq1 p0 Jп= Σq0 p0 , (10.9) где q1, q0 – соответственно объёмы продукции по их видам в физических (натуральных) выражениях; p0 – цена продукции i в базисном периоде. Числитель индекса представляет собой валовую продукцию отчетного периода в ценах базисного периода. Знаменатель – фактическая валовая продукция базисного периода. 1.5.2. Агрегатный индекс физического товарооборота – рассмотрен выше. 1.5.3. Агрегатный индекс цен – рассмотрен выше 1.5.4. Агрегатный индекс себестоимости – среднее изменение себестоимости продукции отчетного периода по одноименной с базисным периодом, номенклатуре продукции. n Jz z i 1 n z i 1 i1 qi1 (10.10) , i0 qi1 где Zi0; Zi1 соответственно себестоимости продукции единицы i-го вида продукции в отчетном и базисном периодах; qj1 объем i-го вида продукции в исследуемом периоде в натуральном выражении. Числитель индекса затраты на производство продукции одноименной номенклатуры (издержки производства) в отчетном периоде. Знаменатель издержки производства по той же номенклатуре и в тех же физических объемах этой же продукции, если бы себестоимость каждого из видов продукции осталась на уровне базисного периода. 1.5.5. Агрегатный индекс производительности труда измеряется рядом способов; мы используем способ сопоставления затрат труда на единицу продукции(J t): n Jt t i 1 n i0 t i 1 qi1 , i1 (10.11) qi1 где tj1, tj0 соответственно затраты труда на единицу i-го вида продукции в отчетном и базисном периодах; qj1 объем i-го вида продукции в отчетном (анализируемом) периоде. 125 Числитель индекса затраты труда (например, в человеко-днях) на определенный объем продукции в отчетном периоде. Знаменатель затраты труда, которые были бы, если бы затраты труда на единицу каждого из видов продукции той же номенклатуры остались на уровне базисного периода. То есть рассуждаем по формуле: чем меньше затрат труда на фиксированный объем продукции, тем выше его производительность. 2. Средние индексы Средние индексы (арифметические и гармонические) – это разновидности индекса сводного. Вычисляются как средневзвешенные из индивидуальных индексов. 2.1. Средний арифметический индекс n Iq i iq i 1 qi 0 pi 0 q i 1 (10.12) . n pi 0 i0 Обратимся к ф-ле (10.4): Используем ф-лу (10.1) Таким образом эта ф-ла является прообразом ф-ы средней взвешенной, только за веса берутся объемы индексируемого показателя по группам. Индекс средней арифметической применяется в тех случаях, когда использование индексируемой величины текущего периода затруднено по каким–либо причинам. 2.2. Средний гармонический индекс n Ip p i 1 n i i1 qi1 . 1 i 1 ip (10.13) pi1 qi1 Продолжаем рассуждения предыдущего параграфа. Индекс средний гармонический применяется в тех случаях, когда прямое использование индексируемой величины базисного периода затруднено. 3. Индексный метод анализа факторов динамики (система взаимосвязных индексов) 3.1. Взаимосвязанные индексы Пример 10.2 Возьмем данные табл. 10.1 по молоку; yф1 = 6000 276 =1656000 руб.; yф0 = 5000 300 = 1500000 руб.; 126 где yф1 , yф0 – фактические товарообороты в анализируемом и базисном периодах. Индивидуальный индекс товарооборота по молоку: iy = 1656000 = 1,105 , 1500000 этот индекс можно вывести и так: iy = iq ip = 1,2 0,92 = 1,105. Заменим обозначение «у» на «qp», следовательно, iqp = iq ip. (10.14) Пример 10.3 (по данным примера 10.1). или по-другому (по примеру 10.1): Jq,p = Jq Jp = 1,236 0,93 = 1,149. (10.15) Если показатель сложного явления определяется в виде мультипликации составляющих явлений, то его индекс можно представить в виде мультипликации индексов этих явлений. Формулу 10.15 можно представить еще и так: q p q p 1 1 0 0 q p q p 1 0 0 0 pq p q 1 1 . (10.16) 0 1 3.2. Изучение структурных сдвигов с помощью индексов 3.2.1. Статистический парадокс Пример 10.4 Посевные площади, валовые сборы и урожайность зерновых культур (табл. 10.2). Индексы урожайности отдельных культур меньше индекса урожайности по всем зерновым? Это так называемый «статистический парадокс», он характеризуется тем, что изменение общей средней выходит за пределы изменения средних групповых. Это получилось потому, что изменилась структура посевных площадей. В данном случае она изменилась в пользу более высокоурожайной культуры (риса). Таблица 10.2 127 Прошлый год Текущий год Индекс урожайност и, % Текущий год Урожайность, ц./га. Прошлый год Валовые сборы, тыс. ц. Текущий год Зерновые культуры Прошлый год Посевные площади, тыс.га. Пшеница 8 7 160 154 20 22 110,0 Рис 4 8 128 296 32 37 115,6 Итого и среднее 12 15 288 450 24 30 125,0 Отношение площадей: Прошлый год: 1/0,5 В числителе пшеница, в знаменателе рис. Структура изменилась в пользу риса, а он – более урожайная культура. Текущий год: 1/1,14 3.2.2. Учет влияния динамики структуры на динамику среднего показателя Алгоритм этого анализа по примеру 10.4. 1. Определение влияния динамики непосредственного увеличения урожайности каждой из культур на динамику средней урожайности. (10.17) Jу = Σy1* Ï 1 , Σy * Ï 0 0 где Jy – индекс уровня непосредственной урожайности; у1, у0 – урожайность культур в текущем и базисном периоде; П1, П0 – площади посевов в текущем и базисном периодах. 2. Определение влияния структуры посева на динамику урожайности. (10.18) Jс = ΣÏ 1* y0 , ΣÏ 1,0* y0 где П1,0 – гипотетическая площадь под культурой в текущем году при сохранении структурного соотношения прошлого года. 3. Расчет индекса средней урожайности. J y = Jу * Jс. (10.19) Это выражение можно расписать и так: y1 J y = = 30 = 1, 25 . 24 y0 Продолжение примера 10.4. 1) Σy1 * П1 = 22*7 + 37*8 = 450 (ц); 128 (10.20) Σy0 * П 1 = 20*7 + 32*8 = 396 (ц); J y = 450 = 1,136 (113,6 %); 396 450 – 396 = 54 ц – прирост сбора за счет непосредственно урожайности; 2) гипотетические площади под культуры в текущем году при сохранении структурных соотношений базисного года (табл. 10.3). Таблица 10.3 15 га Пшеница 10 га (П1,0) (y0= 20 ц/га) ΣП 1,0 * y0 Рис 5 га (П1,0) (y1= 32,1 ц/га) = 10*20 + 32*5 = 360 ц/га; J c 396 1,1; (110 %); 360 396 – 360 = 36 ц – прирост сборов за счет структурного сдвига. 3) J y = Jу * Jс =1,136 * 1,1 = 1,25 (125 %); y1 J y= = 30 = 1, 25 . 24 y0 Итоги к примеру 10.4: 1. Увеличение сбора зерна за счет увеличения площади посевов 3га*24ц = 72 ц. 2. Увеличение от непосредственно урожайности и структурного сдвига (54+36) = 90 ц. 3. Итого 162 ц. Пример 10.5. Количество рабочих, объем продукции и выработка на одного рабочего (табл. 10.4). Таблица 10.4 3-го Количество, чел n0 n1 8 4 4-го 4 8 128 296 32 37 115,6 Итого и средние 12 12 288 384 24 32 133,3 Рабочие по разрядам Произведено продукции, ден. ед. g0 g1 160 88 Выработка, ден. ед. t0 t1 20 22 Индексы выработки, % 110 Проанализируем влияние компонентов на индекс средней выработки (Jt = 133,3): 1) индекс непосредственно производительности труда (J t): Σt1*n1 22*4 +37 *8 Jt = (10.21) = = 1,142 ; Σt 0*n1 20 *4 +32 *8 129 2) индекс изменения структурного состава рабочих: Σn1*t 0 4*20 +8*32 Jс = = = 1,162 ; Σn 0*t 0 8*20 + 4*32 3) индекс средней выработки: Jt = t1 = t0 Σt1 * n1 Σt 0 * n1 * Σn1 * t 0 Σn1, 0 * t 0 (10.22) = 1,142 * 1,162 = 1,33 . (10.23) 3.3. Общая формула системы индексов для анализа динамики средней За основу возьмем формулу индекса любой средней величины: J x = x1 , (10.24) x0 где X1, X0 – средние значения показателя в отчетном и базисном периодах. X1 = X0 = Σx1*w1 Σw1 Σx0 * w0 , (10.25) Σw0 где w1, w0 – частоты или частотности (веса). После несложных преобразований в общем виде система индексов для анализа рядов динамики средней (x) выглядит так: I II Σx1* w1 Jx = x1 x0 = Σw1 Σx0* w0 = Σw0 Σx1* w1 Σw1 Σx0* w1 Σw1 III * Σx0* w1 , Σw1 Σx0* w0 Σw0 (10.26) где I – называется индексом переменного состава; II – называется индексом постоянного состава; III – называется индексом структурных сдвигов. J y = Jx * Jс . (10.27) Пример 10.6. По данным примера 10.4. Таблица 10.5 Зерновые культуры пшеница Урожайность x0 20 x1 22 Посевные площади w0 8 130 w1 7 x1*w1 x0*w1 x0*w0 154 140 160 рис 32 37 4 8 296 256 128 Итого: 12 15 450 396 288 Σx 1*w 1 = Σw 1 Σx 0*w 0 = Σw 0 450 = 30 (ц/га); 15 288 30 1,25; 24 24 (ц/га); 12 Σx 0*w 1 396 26, 4 (ц/га); = Σw 1 15 30 1,136 ; 26, 4 26, 4 1,1 . 24 Вопросы и задания для самоконтроля 1. Дайте общее понятие об индексах. 2. Как исчисляется агрегатный индекс товарооборота? 3. Как определяется индекс цен? Дайте расшифровку. 4. Как исчисляются агрегатные и средние индексы? 5. Что такое взаимосвязанные индексы? 6. Какова взаимосвязь между индексами переменного, постоянного составов и структуры? СПИСОК ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ 1. Гусаров, В. М. Статистика: учеб. пособие для вузов / В. М. Гусаров. – М. : ЮНИТИ ДАНА, 2003. – 352 С. 131 2. Елисеева, И. И. Общая теория статистики: учебник для вузов / И. И. Елисеева. – М. : Финансы и статистика, 2004. – 565 с. 3. Ефимова, М. Р. Общая теория статистики: учебник для вузов / М. Р. Ефимова. – М. : Инфра-М. 2004. – 416 с. 4. Общая теория статистики: учебник для вузов / Под ред. А. А. Спирина, О. Э. Башиной, – М. : Финансы и статистика, 2003. – 439 с. 5. Практикум по статистике / Под ред. В. М. Симчеры. – М. : Финанстатинформ, 2005. – 321 с. 6. Ряузов, Н. Н. Общая теория статистики: учебник для вузов / Н. Н. Ряузов. – М. : Финансы и статистика, 1984. – 368 с. 7. Статистический словарь. – М. : Финанстатинформ, 1996. – 621 с. 8. Теория статистики: учебник для вузов / Под ред. Р. А. Шмойловой, – М. : Финансы и статистика, 2004. – 654 с. ТЕСТЫ Тесты к лекции 1 Статистическая методология, статистическое наблюдение Т. 1.1. Что означает слово «статистика»: а) отрасль знаний; б) медленно развивающееся общественное явление; в) практическая деятельность по собиранию и обработке данных об явлениях и объектах общественной жизни; г) совокупность цифровых сведений, характеризующих конкретное общественное явление; д) группу второстепенных объектов или лиц? Т 1.2. Даны следующие количественные показатели деятельности предприятия за исследуемый период: – объём прибыли; – стоимость основных фондов; – себестоимость продукции. Какие качественные (количественно-качественные) показатели можно по ним вывести: а) рентабельность производства; б) себестоимость единицы продукции; в) рентабельность продукции; г) среднюю зарплату работника; д) производительность труда (товарную выработку) работника? Т. 1.3. Основными методами статистического исследования являются: а) построение таблиц и графиков; б) математические расчёты; в) массовое наблюдение; 132 г) группировки статистического материала; д) экономико-математические методы; е) выведение обобщающих показателей? Т. 1.4. По какому из перечисленных признаков, при исследовании эффективности их деятельности, предприятия разных форм собственности однородны: а) по структуре; б) уровню рентабельности; в) средней заработной плате? Т. 1.5. Для ценза объекта наблюдения «Средний доход предпринимателей в малом бизнесе» выберите единицу наблюдения: а) стоимостный объём производства товара у каждого из них; б) выручка каждого из них за минусом налогов и платежей; в) стоимость покупок для личного потребления? Т 1.6. Программа наблюдения это: а) перечень действий наблюдателя; б) ценз объекта, воплощённый в формулярах наблюдения; в) замысел исследователя? Тесты к лекции 2 Сводка материалов статистического наблюдения. Статистические таблицы и графики Т. 2.1. Сводка (статистическая) это: а) отчётный документ о проведённом наблюдении; б) формуляр наблюдения; в) процесс систематизации статистического наблюдения? Т. 2.2. Какие действия включаются в статистическую сводку: а) разработка программы наблюдения; б) группировка данных статистического наблюдения; в) составление статистических рядов, таблиц, графиков; г) рассылка формуляров; д) отчёт о результатах наблюдения? Т. 2.3. Какие из перечисленных характеристик можно, безусловно, отнести к показателям: а) средний возраст жителей в стране А в 199…г.; б) себестоимость продукции А; в) валовой объём продукции предприятия А в 199…г. в городе N ; г) заработная плата гражданки N? Т.2.4. К какому относится по классификации признак «рентабельность»: 133 а) вторичному; б) первичному; в) альтернативному? Т.2.5. Какая из группировок позволяет выявить в количественном выражении связь между признаком-фактором и признаком-результатом: а) типологическая; б) аналитическая; в) структурная? Т.2.6. Если влияние признака-фактора на признак-результат носит возрастающую (убывающую) закономерность, то какие интервалы распределения признака-фактора желательно выбрать: а) равномерные; б) неравномерные; в) всё равно какие? Т. 2.7. Подлежащее статистической таблицы это: а) количественные признаки; б) атрибутивные свойства объектов; в) итоговые данные в таблице? Т.2.8. Сказуемое статистической таблицы это: а) количественные признаки; б) атрибутивные свойства объектов; в) общий заголовок таблицы. Т.2.9. Дана следующая таблица Распределение населения в районе R по трудоспособности Населённые пункты А Б • Итого Трудоспособные Мужчины Женщины • Нетрудоспособные Мужчины Женщины • • • Из предлагаемых сочетаний слов составьте предложение, характеризующее эту таблицу по строению подлежащего и степени сложности сказуемого. Это таблица: а) со сложной разработкой сказуемого; б) простая по строению подлежащего; в) сложная по строению подлежащего; г) с простой разработкой сказуемого. Тесты к лекции 3 Абсолютные и относительные величины 134 Т. 3.1. Выделите среди предлагаемого перечня величин все абсолютные: а) доля продукции А в общем объёме продукции; б) валовой объём продукции; в) численность населения в городе N; г) процентное соотношение безработных в общей численности трудоспособных; д) количество детей, приходящихся на 100 жителей? Т.3.2. Относительные величины интенсивности это: а) набор соотношений величин частей какого-либо целого и величины этого целого; б) соотношение величины конкретных показателей, установленных по плану и фактического их уровня за определённый период; в) соотношение размеров двух качественно различных явлений с целью изучения степени развития одного из них? Т.3.3. Какие из знаков, аргументов, параметров, приведенных ниже, представляют собой относительную величину взаимосвязи в уравнении «y = a * x1 + bx2»: а) «=»; б) «a»; в) «b»; г) «+»; д) «x1»; е) «x2»? Т. 3.4. Если относительный показатель выведен через соотношение соответствующих уровней абсолютных показателей в соседствующих моментах времени, находящихся в середине моментного ряда, то это скорее всего показатель динамики: а) цепной; б) базисный; в) периодический? Т.3.5. Если относительный показатель выведен через соотношение соответствующих абсолютных показателей, один из которых находится в начале, а второй – в конце периодического ряда, то это – скорее всего, показатель динамики: а) цепной; б) базисный; в) моментный? Т.3.6. По какому количеству атрибутивных признаков могут отличаться сравниваемые исходные показатели при построении относительного статистического показателя: а) одному; 135 б) двум; в) трём; г) в зависимости от количества признаков в исходных показателях? Тесты к лекции 4 Ряды распределения Т.4.1. Отметьте основные виды рядов распределения в статистике: а) бесконечная сумма вида n ; n 1 б) атрибутивные; в) вариационные; г) динамики; д) классификации признаков? Т.4.2. К какому из видов относится ряд распределения «Жители города N в работоспособном возрасте, в пенсионном возрасте, дети»: а) динамики; б) вариационному; в) атрибутивному? Т.4.3. К какому из видов относится ряд распределения «Заработная плата 6 ден ед. у 5 рабочих; 8 ден. ед. у 10 рабочих и т. д.»: а) динамики; б) вариационному; в) атрибутивному? Т.4.4. К какому из видов относится ряд распределения «Средняя зарплата 5 ден ед. в N-ом году; 6 ден ед. в (N+1)-ом году и т. д.: а) динамики; б) вариационному; в) атрибутивному? Т.4.5. Дан следующий рисунок: частоты Интервалы, варианты 136 Какие виды графического изображения вариационного ряда на нём представлены: а) кумулята; б) гистограмма; в) полигон распределения; г) огива? Т.4.6. Дан следующий ряд динамики: Периоды Уровни показателя n 1 n+1 2 n+2 3 n+3 6 Рассчитайте цепные темпы роста и базисный темп роста в (n + 3) периоде, приняв за базисный n-ый период. Ответ для цепных в виде последовательности цифр, базисный – цифра в овале. Т.4.7. Дан следующий ряд динамики: Периоды Уровни показателя n 1 n+1 2 n+2 3 n+3 6 Рассчитайте цепные темпы прироста (в %) и базисный темп прироста (в %) в (n + 3) периоде, приняв за базисный n-ый период. Ответ для цепных в виде последовательности цифр, базисный – цифра в овале. Т.4.8. Дано: Уровни показателей (объём производства, ден. ед.) Годы n (базисный) n+1 n+2 Продукция А 5 7 15 Продукция Б 6 8 12 Объёмы какой из продукции и во сколько раз быстрее возросли за весь рассчитываемый период («n» – «n + 2»)? Тесты к лекции 5 Средние величины Т. 5.1. Средняя величина – это уровень единицы совокупности: а) конкретной; б) абстрактной; 137 в) превалирующей? Т.5.2. К какому типу средней относится показатель «средняя заработная плата по стране»: а) типичная характеристика признака данной совокупности; б) выборочная средняя; в) системная средняя. Т.5.3. П. Л. Чебышев вывел: для однородной совокупности: тем точнее средняя, чем объём совокупности: а) больше; б) меньше; в) средний? Т.5.4. Дано: а) общий объём признака в совокупности; б) единица измерения объёма признака; в) численность (объём) совокупности. Напишите формулу расчёта средней в форме « г ) ». д) Т.5.5. Что понимается под термином «частота» при расчёте средней: а) величины вариант по группам совокупности; б) объём признака по группам совокупности; в) численность единиц по группам совокупности? Т.5.6. Средняя гармоническая применяется тогда, когда: а) вместо численностей групп совокупностей представляют их объёмы; б) недостаточен объём совокупностей; в) данные по группам даны в долях? Т.5.7. Какой знак надо поставить между произведениями « * f i » и « i * f i »: а) б) в) г) д) «>»; «<»; «≥»; «≤»; «=». Т.5.8. Если от каждой варианты отнять произвольное число А, то новая средняя: а) останется такой же; б) уменьшится на число А; в) увеличится на число А? 138 Т. 5.9. Если каждую варианту разделить на какое-либо произвольное число А, то новая средняя арифметическая: а) уменьшится в А раз; б) останется такой же; в) увеличится в А раз? Т. 5.10. Если все частоты (веса) разделить на какое-либо число А, то новая средняя арифметическая: а) останется такой же; б) уменьшится в А раз; в) увеличится в А раз? Т. 5.11. Сумма отклонений вариант от средней арифметической равна: а) случайной положительной величине А; б) нулю; в) случайной отрицательной величине А? Т. 5.12. Дано: 1. Сумма квадратов отклонений индивидуальных значений признака от средней арифметической. 2. Сумма квадратов этих же индивидуальных значений признака от произвольного числа А. Какой знак надо поставить между показателем 1) и показателем 2): а) «=»; б) «>»; в) «<». Т. 5.13. Определите среднюю для следующего моментного ряда: 1990 год 2 ед 1991 г. данных нет 1992 г. 2 ед 1993 г. 4 ед 1994 г. 6 ед Т. 5.14. Значение признака, которое делит число единиц ранжированного ряда пополам таким образом, что в одной половине оказываются все величины меньшие этого признака, называется: а) модой; б) средней величиной; в) медианой? Т. 5.15. Значение признака, которое в данной совокупности встречается наиболее часто называется: а) модой; б) средней величиной; в) медианой. Тесты к лекции 6 139 Показатели размера и характера вариаций Т. 6.1. Дисперсия это: а) среднеквадратическое отклонение от средней величины; б) средний квадрат отклонения от средней величины; в) средний квадрат отклонения от произвольной величины А; г) среднеквадратическое отклонение от произвольной величины А? Т. 6.2. Среднеквадратическое отклонение имеет ту же размерность, что и соответствующий ей признак: а) «Да»; б) «Нет»? Т. 6.3. Коэффициенты вариации используются: а) всегда для сравнения вариации явления; б) для сравнения вариаций разных явлений; в) при сравнении вариации одного и того же признака в разных рядах распределения с неодинаковыми средними значениями этого признака. Т. 6.4. Межгрупповая дисперсия – это вариация: а) вызванная группировочным признаком-фактором; б) вызванная прочими негруппировочными признаками; в) общая? Т. 6.5. Коэффициент детерминации показывает: а) общую вариацию признака-результата; б) долю вариации, вызванную группировочным признаком-фактором в общей вариации признака-результата; в) вариацию признака, вызванную прочими факторами? Т.6.6. Может ли быть эмпирическое корреляционное отношение больше единицы: а) «Да»; б) «Нет»? Т. 6.7. Что означает правило «Общая дисперсия является суммой внутригрупповой дисперсии и дисперсии групповых средних»: а) общая вариация признака-результата складывается из вариации признака-фактора и вариации прочих факторов; б) общая дисперсии является суммой вариации всего двух факторов? Т. 6.8. В пределах точек перегиба кривой нормального распределения находится вариант признака: а) 50 %; б) 100 %; в) 68 %? 140 Тесты к лекции 7 Выборочное наблюдение Т.7.1. Главная задача выборочного наблюдения: а) вывести характеристики отобранной для наблюдения группы; б) получить правильное представление о характеристиках генеральной совокупности; в) рассчитать среднюю величину? Т.7.2. Какие ошибки выборки можно «поправить» по правилам выводной статистики: а) случайные; б) никакие; в) систематические? Т.7.3. При каких видах отбора единиц в выборку необходимо соблюдать принцип случайности: а) при собственно случайном отборе; б) при всех видах отбора; в) при отборе из генеральной совокупности по определённой схеме? Т.7.4. Каким способом производятся выборки при статистических исследованиях в социально-экономических системах: а) повторным; б) повторным и бесповторным; в) бесповторным. Т.7.5. Что в формуле средней ошибки выборки x составляющая 2 2 n 1 n N означает : а) дисперсию (средний квадрат отклонения); б) среднеквадратическое отклонение; в) относительную величину дисперсии? Т.7.6. Чем отличается предельная ошибка выборки от средней ошибки выборки: а) это одно и то же; б) введением в расчёт нормированного отклонения ошибки выборки; в) правильного ответа нет? Тесты к лекции 8 Анализ тенденций развития Т.8.1. При сравнении динамики разных явлений используются: 141 а) относительные показатели; б) абсолютные показатели; в) и относительные и абсолютные показатели? Т.8.2. Если границы распространения какого-либо явления изменились в процессе изучения его динамики, то вначале следует применить метод: а) скользящей средней; б) смыкание рядов динамики; в) укрупнение ряда динамики? Т.8.3. Можно ли укрупнением периодов рядов динамики выявлять общую тенденцию развития явления: а) «Да»; б) «Нет»? Т.8.4. Скользящая средняя используется для: а) для упрощения расчёта среднего уровня явления; б) аналитического выравнивания эмпирического графика; в) выявления тенденции развития явления? Т.8.5. Аналитическое выравнивание эмпирического графика конечным итого предполагает: а) подбор (выбор) формулы той или иной кривой (прямой); б) построение скользящей средней; в) укрупнение рядов динамики? Тесты к лекции 9 Статистические приёмы изучения взаимосвязей Т. 9.1 Какие связи больше детерминированы: а) стохастические; б) функциональные? Т. 9.2 Степень тесноты связи между признаком-фактором и признакомрезультатом определяется с помощью: а) среднего квадрата отклонений; б) эмпирического корреляционного отношения; в) среднеквадратического отклонения? Т. 9.3 Степень тесноты связи между признаком-фактором и признакомрезультатом можно определить по: а) коэффициенту детерминации; б) среднеквадратическому отклонению; в) среднему квадрату отклонений? Т. 9.4 Соответствие уравнения регрессии фактическому характеру связи между признаком-фактором и признаком-результатом проверяется по: 142 а) коэффициенту детерминации; б) индексу корреляции; в) среднему квадрату отклонений? Т. 9.5 Интервальная группировка в параллельных рядах осуществляется: а) по признаку–фактору; б) по признаку-результату; в) по обоим факторам? Тесты к лекции 10 Индексы Т.10.1. Показатель, характеризующий соотношение во времени или пространстве уровней социально-экономического явления может быть назван: а) относительным; б) абсолютным; в) индексом? Т.10.2. Изменение отдельных (частных) явлений во времени могут характеризовать индексы: а) индивидуальные; б) средние арифметические; в) сводные? Т.10.3. Изменение сложных явлений во времени могут характеризовать индексы: а) индивидуальные; б) агрегатные; в) средние арифметические; г) средние гармонические? Т.10.4. Что является в формуле числителя ( xi * f i ) весами (частотами) при исчислении агрегатного индекса цен: а) физические объёмы купленных товаров; б) уровни цен; в) стоимость всех купленных товаров? Т.10.5. Что в формуле числителя ( xi * f i ) является вариантами при исчислении агрегатного индекса цен: а) физические объёмы купленных товаров; б) уровни цен; в) стоимость всех купленных товаров? 143 Т.10.6. Что в формуле числителя ( xi * f i ) является весами (частотами) при исчислении агрегатного индекса физического товарооборота: а) физические объёмы купленных товаров; б) уровни цен; в) стоимость всех купленных товаров? Т.10.7. Что является вариантами при исчислении агрегатного индекса физического товарооборота: а) физические объёмы купленных товаров; б) уровни цен; в) стоимость всех купленных товаров? Т.10.8. Если в формуле агрегатного индекса варианты даны в физическом выражении, то частоты следует брать из периода: а) базисного; б) анализируемого; в) всё равно какого? Т.10.9. Если в формуле агрегатного индекса варианты даны в стоимостном выражении, то частоты следует брать из периода: а) базисного; б) анализируемого; в) всё равно какого. Т.10.10. Если структура изучаемого явления изменилась в пользу увеличения объёма более интенсивного из двух однородных показателей, то средняя величина из этих показателей: а) увеличится; б) уменьшится; в) останется той же. Примечание: Суммарный объём показателей неизменен. Ответы на тесты: К лекции 1 1.1 ответ а), в), г); 1.2 ответ а), в); 1.3 ответ в), г), е); 1.4 ответ б); 1.5 ответ б); 1.6 ответ б). К лекции 2 144 2.1 2.2 2.3 2.4 2.5 2.6 2.7 2.8 2.9 ответ в); ответ б), в); ответ а), в); ответ а); ответ б); ответ б); ответ б); ответ а); ответ а), в). К лекции 3 3.1 ответ б), в); 3.2 ответ в); 3.3 ответ б), в); 3.4 ответ а); 3.5 ответ б); 3.6 ответ а). К лекции 4 4.1 ответ б), в), г); 4.2 ответ в); 4.3 ответ б); 4.4 ответ а); 4.5 ответ б), в); 4.6 ответ 2; 1,5; 2 6 или 200 %; 150 %; 200 %; 600 % ; 4.7 ответ 100 %; 50 %; 100 %; 500 % ; 4.8 ответ базисный темп роста А: 15 3 ; темп роста Б: 12 2 , 3 1,5 . 5 Ответ: А; 1,5. К лекции 5 5.1 ответ б); 5.2 ответ в) ; 5.3 ответ а); 5.4 ответ a ; в 5.5 ответ в); 5.6 ответ а); 5.7 ответ д); 5.8 ответ б). 5.9 ответ а); 5.10 ответ а); 145 6 2 5.11 ответ б); 5.12 ответ в); 5.13 ответ: 1990 - 92: 2 2 2.;.2.;.4 2 6 1992-93: 3.;. 1.;. 3 2 4 1993-94: 6 5.;. 1.;. 5 2 5.14 ответ в); 5.15 ответ а). К лекции 6 6.1 ответ б); 6.2 ответ да; 6.3 ответ б), в); 6.4 ответ а); 6.5 ответ б); 6.6 ответ нет; 6.7 ответ а); 6.8 ответ 68 %. К лекции 7 7.1 ответ б); 7.2 ответ а); 7.3 ответ б); 7.4 ответ в); 7.5 ответ а); 7.6 ответ б). К лекции 8 8.1 ответ а); 8.2 ответ б); 8.3 ответ да; 8.4 ответ в); 8.5 ответ а). К лекции 9 9.1 ответ б); 9.2 ответ б) ; 9.3 ответ а) ; 9.4 ответ б) ; 9.5 ответ а). 146 12 3 4 К лекции 10 10.1 ответ а), в); 10.2 ответ а); 10.3 ответ б); 10.4 ответ а); 10.5 ответ б); 10.6 ответ б); 10.7 ответ а); 10.8 ответ а); 10.9 ответ б); 10.10 ответ а). 147 Задачи Задача 1.1 Составьте логически оправданные варианты цензов объекта-наблюдения по следующим данным: Предприятия: малого бизнеса, средние и крупные, торговли, пищевой промышленности, строительных материалов. Варианты предметов наблюдения: рентабельность, производительность труда, средняя зарплата. Задача 2.1 Произведите три варианта типологических группировок среди следующих предприятий: 1) «Восток», ИЧП, продукты питания, рентабельность средняя; 2) «Восход», АО, промышленные товары, рентабельность высокая; 3) «Лада», ИЧП, рентабельность высокая, сантехника; 4) Хлебокомбинат, муниципальное, рентабельность средняя…ещё ряд предприятий с аналогичными признаками. Задача 2.2 Представьте структуру производимых ЗАО «Восток» товаров Товары Металлоконструкция, т Деревянные конструкции, м3 Прочие изделия, ден. ед. Кол-во 10000 5000 5000 Цена, ден ед. 2 3 Задача 2.3 Произведите аналитические группировки, сделайте выводы: № наблюдений 1 2 3 4 5 Признаки I 5 8 3 15 10 Факторы II 25 18 31 5 10 Результат III 6 4 10 5 3 15 10 20 4 6 Задача 2.4 Произведите вторичную группировку способом изменения интервалов. Группы предприятий по потенциальному объёму валовой продукции, (ден. ед.) Группы предприятий по потенциальному объёму, ВП 100 – 300 301 – 600 601 – 1000 Разделите средний интервал на два. 148 Число (шт) 50 20 5 % ВП в общем объёме (факт) 10 20 70 Задача 2.5 Произведите вторичную долевую группировку предприятий по объёму товарной продукции (ден. ед.) Группы предприятий по объёму тов., прод. 100 – 300 301 – 600 601 – 1000 Число 50 20 5 Задача 4.1 Из представленных в нижеприведенной таблице данных выведите относительные показатели для сравнения магазинов: Магазины в микрорайоне № По специализации Количество Товарооборот, ден. ед. Промтоварные Продуктовые Смешанные 3 4 2 300 500 100 Поступления от налогов, ден. ед. 90 150 40 Количество посещений в день 90 400 100 Задача 4.2 Дан следующий набор атрибутивных признаков по городу N: – число родившихся за год; – среднее число работающих в течение года; – среднее количество населения в течение года; – объем всей товарной продукции, произведенной в течение года; – площадь города (в гектарах). Перечислите три осмысленные относительные величины интенсивности, выводимые из данного набора признаков. Задача 4.3 Перечислите сочетания четырёх пар величин, которые можно сравнивать: а) себестоимость ед. продукции А на предприятии А в базисном периоде; б) себестоимость ед. продукции Б на предприятии А в базисном периоде; в) себестоимость ед. продукции А на предприятии Б в базисном периоде; г) себестоимость ед. продукции Б в отчетном периоде на предприятии Б; д) себестоимость ед. продукции Б в отчетном периоде на предприятии А; е) себестоимость ед. продукции А в отчетном периоде на предприятии А; ж) себестоимость ед. продукции А на предприятии Б в отчетном периоде. 149 Задача 4.4 Рассчитайте первичные относительные показатели динамики (исключая средние и коэффициенты опережения) по следующим данным: Равные периоды в порядке возрастания Уровень показателя исследуемого (абсолютные величины) I II III IV 102 100 105 110 За базисный считать первый период. Задача 4.5 «Постройте» четыре осмысленные относительные показателя из следующего набора атрибутивных признаков: Количество стариков; количество детей; в городе А; в городе Б; 2000 год; 2001 год; фактическая; прогнозируемое. Задача 4.6 По предприятию N даны следующие абсолютные показатели: 1. Стоимость основных произв. фондов – 300 тыс. руб. 2. Годовой объём валовой продукции – 600 тыс. руб. 3. Среднегодовая численность работников – 150 чел. 4. Годовая прибыль – 60 тыс. руб. Определите относительные показатели, выводимые из приведённых абсолютных показателей. Задача 5.1 Построить годные для анализа вариационный ряд и ряды динамики по следующим данным: Фондовооружённость и производительность труда на предприятии N Фондовооруж, тыс.р./ чел. 20 15 10 17 Произв. труда, тыс. р./ чел. 9 8 5 8 Годы 1995 1992 1991 1993 Задача 5.2 Численность совокупности 1000; наименьшее значение анализируемого показателя 50, наибольшее 120. Построить интервальный вариационный ряд распределения. Примечание: расчёт параметров в таблице достаточно сделать для трёх первых интервалов; иинтервал округлить так, чтобы частное 1000/i было целым числом. 150 Задача 5.3 Построить гистограмму и полигон распределения: Группы предприятий по уровню иссл. показателей Число предприятий 100 – 120 120 – 140 140 – 160 160 - 180 15 20 12 6 Задача 5.4 Построить гистограмму распределения: Группы предприятий иссл. показателей Число предприятий 80 – 120 120 – 140 140 – 160 160 - 180 22 20 12 6 Задача 5.5 Построить кумуляту и огиву распределения: Срединные значения интервалов Число единиц в интервале 90 5 110 10 130 20 150 12 170 6 Задача 5.6 Построить ряды динамики: моментный абсолютный; периодический абсолютный; периодический относительный цепной: Площади лесопосадок (га) в районе N: – на конец 1960 года – 400 га; – посажено: в 2001 – 200 га; в 2002 – 100 га; в 2003 – 150 га; в 2004 – 250 га. Примечание: порчи лесопосадок нет. Задача 5.7 Определить темпы прироста базисные и цепные: Равные периоды в порядке возрастания Уровень показателя исследуемого (абсолютные величины) I II III IV 102 100 105 110 Задача 5.8 Определить коэффициент опережения темпа роста базисного показателя «2» по сравнению с темпом роста показателя «1» Равные периоды в порядке возрастания Уровни исследуемого показателя 1 (абс. величины) Уровни исследуемого показателя 2 (абс. велич.) I 102 20 II 100 24 III 105 25 IV 110 26 За базисный принимается период «I», за исследуемый период «IV». 151 Примечание: в некоторых задачах дана избыточная информация. Задача 6.1 Дана следующая статистика по предприятию N за месяц: Число работников по подразделениям фирмы 5 1 6 8 3 5 10 20 7 4 Премия на всё подразделение, ден. ед. 500 150 1200 800 300 750 2000 3000 700 800 Требуется: 1. Рассчитать средние премии по подразделениям. 2. Используя (обязательно) данные первого расчёта, определить рациональным путём среднюю премию по фирме. Задача 6.2 Дана следующая статистика по населённому пункту «П»: Группы семей по среднедушевому доходу, ден. ед. до 200 200 – 400 400 – 600 600 – 1000 1000 - 3000 3000 и более Число семей 250 500 250 100 50 5 Определить среднедушевой доход по посёлку «П». Если Вам не хватает исходных данных, обратитесь к преподавателю. Задача 6.3 Дана следующая статистика по городским рынкам г. N: № рынков 1 2 3 Общий объём товарооборота, ден. ед. 100 400 200 Доля товарооботора фруктов (%) 50 20 80 Найти среднюю долю товарооборота фруктов в сети городских рынков в г. N. Задача 6.4 Дана следующая статистика по стоимости проезда пассажира из пункта К до пункта А, Б, В. Пункты Стоимость проезда, ден. ед. А Б 100 120 152 Стоимость (цена) проезда, ден. ед. 0,5 0,6 одного километра В 140 0,7 Определить среднюю стоимость (цену) одного километра проезда по сети транспортных сообщений (с точностью до одной сотой ден. ед.). Задача 6.5 Дана следующая статистика по количеству населения до 16 лет на 1000 жителей в государстве Y. Количество На конец года Увеличение указанного возраста за период Годы и периоды 1998 1999 400 500 110 2000 550 60 Определить: среднюю величину для периодического ряда и среднюю величину для моментного ряда. Примечание: для моментного ряда расчёт сделать с минимальным количеством промежуточных вычислений. Задача 6.6 Дана следующая статистика: Периоды (годы) 1990 – 1992 1992 – 1995 1995 - 1996 Среднегодовое производство товара «Т», единиц. 1000 1100 1000 Определить среднегодовое производство товара «Т» за весь представленный период. Задача 6.7 Определить средние цепные темпы роста и прироста показателей «П». Конец года Абсолютная величина показателя 1998 г. 400 1999 г. 350 2000 г. 500 Примечание: решение довести до формул с цифровой подстановкой составляющих. Задача 7.1 Найти среднюю внутригрупповую дисперсию в статистической совокупности, сгруппированной в две группы по показателю «П»: Группы Количество единиц 1-я 2-я 50 50 Среднее значение показателя 100 120 Средний квадрат отклонений 200 150 Среднее квалратическое отклонение 14,2 12,3 Примечание: в некоторых задачах исходные данные приводятся с излишком. Задача 7.2 153 Найти межгрупповую дисперсию в статистической совокупности, сгруппированной в две группы по показателю «П»: Группы Количество единиц 1-я 2-я 50 50 Среднее значение показателя 100 120 Средний квадрат отклонений 200 150 Среднее квалратическое отклонение 14,2 12,3 Примечание: в некоторых задачах исходные данные приводятся с излишком. Задача 8.1 При изучении доходов с «дачных» участков было их обследовано 100. Средний сезонный доход составил 1500 рублей. Дисперсия составила 4000. Общее количество дачных участков в обследуемом районе 1000. Определить интервал среднего дохода с дачного участка. Примечание: при недостатке исходных данных обратитесь к преподавателю. Задача 8.2 На крупной стройке для эксперимента из 2000 рабочих каменщиков требуется отобрать группу. Результатом эксперимента должны стать изменения в производительности труда (натуральной выработке). Задано и известно: средний квадрат отклонений на кирпичной кладке по опыту составляет 1 м3; размер ошибки по выработке не должен превышать 0,1 м3; коэффициент доверия = 2. Задача 9.1 Даны темпы роста покупок товаров А, Б и В в % к базисному (i - му) году: Покупки товаров А Б В 100 105 106 108 100 120 130 140 100 150 160 200 Годы i i+8 i + 10 i + 12 К покупкам какого из видов товаров за весь представленный период в большей степени стремились покупатели? Доказательство приводите в обобщённом числовом показателе. Задача 9.2 Дана статистика квартирных краж по n-му отделению ГОВД за ряд лет. В 1998 году район обслуживания этим отделением уменьшился: 154 Годы 1997 1998 в старых границах 1998 в новых границах 1999 Количество краж 12 10 8 11 Подготовить этот материал для статистического анализа (достаточно одним из известных методов). Задача 9.3 Дана статистика потребления продукта С по годам в ден. ед.: Годы 1996 1997 1998 1999 Потребление ден. ед. 10 11 8 7 Постройте на графике две точки скользящей средней. Задача 9.4 Дано следующее уравнение аналитически выравненной прямой: y t = 2,52 + 0,08 ti; за ti признаны 1996, 1997, 1998, 1999, 2000 годы Определите y t за 2000 год; отсчёт влево и вправо (в убывание и возрастание дат) при выводе формулы был сделан с 1998 года. Задача 10.1 Данные по продукции малого предприятия: Виды продукции Показатели Объёмы: 1999 г. 2000 г. Себестоимость единицы (ден. ед.): 1999 г. 2000 г. А м3 Б шт. В тонны 100 120 1000 1000 200 300 2 1,5 3 2,5 4 4 Проанализировать данные по себестоимости продукции в целом по предприятию. Задача 10.2 Данные по продукции малого предприятия: Виды продукции Показатели Объёмы: 1999 г. 2000 г. А м3 Б шт. В тонны 100 120 1000 1000 200 300 155 Себестоимость единицы (ден. ед.): 1999 г. 2000 г. 2 1,5 3 2,5 4 4 Проанализировать изменения в физическом объёме продукции в целом по предпритию; веса – по себестоимости. Задача 11.1 Дано: 1. Эмпирическая «кривая»: x y 1 2 3 2 5 4 7 2 9 6 2. Аналитически выровненная прямая: yx = 1 + 0,5 x 3. y = 3,2 Проанализировать словесно соотношения построенными по приведённым данным. между графиками, Задача 11.2 Произведите оптимальную интервальную группировку в следующей совокупности: x y 3,0 5 3,5 7 4,0 8 0,5 0,5 1,0 2,5 1,5 2,0 3,0 5,0 Задача 11.3 Дана следующая статистика: x y 1 2 2 3 3 4 Исследователь предлагает следующую формулу регрессии: yx = 2 + 0,7x. Насколько оправдан выбор? Докажите. Решение задач Задача 1.1 1. Предприятие; малый бизнес; рентабельность. 2. Предприятие; торговля; средняя зарплата. 3. Предприятие; крупное; производительность труда и т. п. Задача 2.1 1. По форме собственности: – ИЧП: «Восток», «Лада»; – АО: «Восход»; – Муниципальная: Хлебокомбинат. 2. По рентабельности: – высокая: «Восход», «Лада»; 156 2,5 6 – средняя: Хлебокомбинат; «Восток». 3. По продукции: – продукты питания: «Восток», Хлебокомбинат; – промышленные товары: «Восход», «Лада». Задача 2.2 – Металлоконструкции – 50 %; – Деревянные изделия – 37,5 %; – Прочие изделия – 12,5 %. (или в долях.) Задача 2.3 По фактору I: 3 5 20 15 обратная зависимость. По фактору II: 5 10 4 6 прямая зависимость. По фактору III: 3 4 6 10 есть исключения в зависимости. 8 10 10 6 15 4 18 10 25 15 31 20 5 4 6 15 10 20 Задача 2.4 Делим интервал 301 – 600; 600 – 300 = 300; 20 0,067 ; интервал 301 – 450 содержит: 300 150 • 0,067 = 10 предприятий и производит 10 % ВП; тоже по интервалу 450 – 600. Задача 2.5 50 + 20 + 5 = 75; 100 – 300 = 67 % 301 – 600 = 26 % 601 – 100 = 7 % Задача 4.1 Промтоварные Продуктовые Смешанные Товарооборот, ден. ед. 100 125 50 В среднем на один магазин Поступления от Количество налогов, ден. ед. посещений в день 30 30 37,5 100 20 50 Задача 4.2 Например: – число родившихся на тысячу жителей; 157 – количество жителей на гектар; – объём продукции на одного работника; – площадь на одного жителя. Задача 4.3 Например: – а) и в); – б) и д); – в) и ж); – е) и Ж); – …………… Задача 4.4 Показатель: II к I III к II – вырос (уменьшился) по отношению к предшествующему периоду в 1,02 1,05 – составил к предшествующему периоду % 98 105 – увеличился по отношению с предшествующим периодом на (%) -2 – вырос (уменьшился) по сравнению с базисным периодом 1,02 ) – оставил к базисному периоду % 98 – величился по отношению к базисному периоду -2 IV к III 1,048 104,8 5 4,8 в 1,03 1,08 103 108 на (%) 3 8 Задача 4.5 Сравниваются показатели, отличающиеся друг от друга только по одному признаку. Например: Б 2000 факт А 2000 факт, • • • • • • • • • Задача 4.6 158 Фондоёмкость: 300 0,5 руб ; 600 руб Фондоотдача: 600 2,0 руб ; руб 300 Фондовооружённость: 300 150 тыс. руб 2 ; чел. Рентабельность производства: 60 0,2 руб . 300 руб . Товарная выработка 600 150 4 руб . . руб Задача 5.1 Вариационный ряд 10 5 1991 10 15 8 1992 15 17 8 1993 17 20 9 1995 20 Ряды динамики 1991 5 1992 8 1993 8 1995 9 Задача 5.2 k = 1+3,32*3 = 11 I = (120 - 50)/11 = 6,4; округляем до 6-ти; 1000/6 = 170 групп; Интервалы 0–6 6 – 12 12 – 18 • • • Число хозяйств 6 6 6 • • • 159 Задача 5.3 20 15 12 0 90 100 120 140 160 180 120 140 160 Задача 5.4 1 К= f i 0,5 0 80 22 20 12 6 0,55; 1,0; 0,6; 0,3 40 20 20 20 160 180 Задача 5.5 f X’ прямая 5 15 35 47 53 90 110 130 150 170 обратная 53 48 38 18 6 50 37 25 12 0 90 110 130 Задача 5.6 1) Моментный абсолютный ряд: Конец года: 2001 2002 2003 400 600 700 Посажено в период: 200 100 150 250 Рост посадок 50 150 цепной % 161 150 2004 850 167 170 2005 110 Задача 5.7 Темпы прироста базисные (%) Темпы прироста цепные (%) -2; 3; 8 -2; 5; 4,8 Задача 5.8 Темп роста базисный (%) 110 по показателю 1 1,08 102 Темп роста базисный по показателю 2 26 1,3; 20 1,3 1,2 (в один и две десятых раза) 1,08 Задача 6.1 Средние премии по подразделениям: 100; 150; 200; 100; 150; 200; 150; 100; 200 Средневзвешенная премия: 100 • 4 150 • 3 200 • 3 145( руб.) 10 Задача 6.2 Первый интервал закрываем: 100 – 200 Последний интервал закрываем: 3000 – 4000 X’ f f 100 150 300 500 300 2000 3500 Итого: 250 500 250 100 50 5 2,5 5,0 2,5 1,0 0,5 0,05 11,55 X’ 375 1500 1250 800 1000 175 5100 5100 441,6 (руб.) 11,55 Задача 6.3 Итого: X % X •% 100 100 400 200 700 50 20 80 50 80 160 290 290 • 100(%) 41,4(%) 700 162 f 100 Задача 6.4 Стоимость проезда Цена одного километра 100 120 140 Итого: 360 0,5 0,6 0,7 стоимость.проезда цена.одного.километра 200 200 200 600 360 0,6. 600 Задача 6.5 Средняя для периодического ряда: 110 60 85( жителей). 2 1 1 400 500 550 2 2 487,5. Средняя для моментного ряда: 3 1 Задача 6.6 1000 • 2 1100 • 3 1000 • 1 1050(ед.). 6 Задача 6.7 350 0,88; 500 1,43 400 350 Т р 0,88 • 1,43 Т пр 0,88 • 1,43 1 Задача 7.1 G i2 = G • f f 2 i i i 200 • 50 150 • 50 175. 100 Задача 7.2 y 100 • 50 120 • 50 110; 100 b2 (100 110) 2 • 50 (120 110) 2 • 50 10000 100. 100 100 Задача 8.1 x 2 n (1 n 4000 100 ) (1 ) 400 • 0,99 6 ; N 100,0 1000 пусть t = 2 x 2 • 6 12 ( руб.) Средний доход равен (150 12) руб. 163 Задача 8.2 4 • 12 400; 0,12 400 333(чел.). 400 (1999) 2000 Задача 9.1 Темпы прироста базисные: среднегодовые: 108 100 140 100 200 100 0,67(%); 3,3; 6,3. 12 12 12 Темп прироста покупок товара В выше, чем: товара А в 6,3 9,5 раза; 0,67 6 товара Б в ,3 1,9 раза. 3,3 Задача 9.2 Используем способ смыкания: Годы кол-во краж 1997 1998 – в старых границах – в новых границах 1999 Коэффициент смыкания 12 10 8 11 8 0,8 . 10 Задача 9.3 точка «1997»: 10 11 8 9,67 3 точка «1998»: 11 8 7 = 8,67 3 9,67 8,67 0 97 98 164 кол-во краж в новых границах 9,6 8 8 11 Задача 9.4 Годы Условные ординаты y 2000 2,52 0,08 • 2 2,68 1996 -2 1997 -1 1998 0 1999 1 2000 2 Задача 10.1 I Z Z 1 • q1 0 • q1 1,5 • 120 2,5 • 1000 4 • 300 ; 2 •120 3 •1000 4 • 300 Задача 10.2 In q • q • 1 0 0 0 120 • 2 1000 • 3 300 • 4 . 100 • 2 1000 • 3 200 • 4 Задача 11.1 Несовпадение переменной средней со средней = влияние признакафактора; отклонение эмпирической кривой от переменной средней = влияние прочих факторов. 10 6 4 2 1 0 1 3 6 8 10 Задача 11.2 x yгр 0,5 0,5 x yгр x yгр 0,5 – 1,0 (вкл.) 1,5 1,0 2,5 1,5 2,0 2,0 5,0 0,5 – 2,0 (вкл.) 2,5 2,5 6,0 3,0 5,0 3,5 7,0 4,0 8,0 2,0 (искл.) – 4,0 6,5 1,0(искл.) – 2,0(вкл.) 3,5 165 2,5(искл.)-3,0(вкл.) 3,0(искл.)– 4,0(вкл.) 5,5 7,5 Задача 11.3 y 23 4 3 3 (2 3) 2 (3 3) 2 (4 3) 2 0,67; 3 yx: 2 + 0,7 = 2,7; 2 + 1,4 = 3,4; 2 + 2,1 = 4,1. G y2 (2,7 3) 2 (3,4 3) 2 (4,1 3) 2 0,49 3 Индекс корреляции (теоретическое корреляционное отношение): 0,49 0,73 0,86 (высокое, выбор оправдан). G yx2 0,67 166