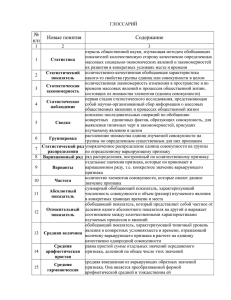
Средние величины
advertisement

Введение. Предмет и метод статистической науки История развития статистической науки Статистическая наука сложилась в результате теоретических обобщений накопленных человечеством опыта учетно-расчетных работ, обусловленных потребностями управления обществом. Термин «статистика» произошел от латинских слов stato (государство) status (положение вещей, политическое состояние). Статистика – это наука, изучающая количественную сторону массовых явлений и процессов в неразрывной связи с их качественной стороной, количественное выражение закономерностей общественного развития в конкретных условиях места и времени. Статистика – это отрасль практической деятельности по сбору, накоплению, обработке и анализ цифровых данных, характеризующих население, экономику, культуру, образование и другие явления общественной жизни и предназначенную для задач государственного регулирования и управления. Статистика – это собственно данные (цифровой материал), который обрабатывается определенными методами. Предмет и метод статистической науки Объектом исследования статистики как науки являются: общество; массовые социально-экономические явления; влияние природных и технических факторов на изменение количественных характеристик социально-экономических явлений; влияние жизнедеятельности общества на среду обитания. Предметом статистики выступают количественные характеристики и соотношения качественно определенных социально-экономических явлений, закономерности их связей и развития в конкретных условиях места и времени. Основой для разработки и применения статистической методологии (совокупности методов и приемов) является диалектический метод познания, когда общественные явления и процессы рассматриваются в развитии, взаимной связи и причинной обусловленности. Статистика опирается на диалектические категории: случайного и необходимого; единичного и массового; индивидуального и общего; причинность и закономерность. Многообразие статистических методов обусловлено сложностью объекта и сложностью и многоэтапностью трех стадий исследования экономических явлений: 1 стадия – сбор первичной информации – метод массового статистического наблюдения, обеспечивающий репрезентативность информации; 2 стадия – сводка, группировка, обработка первичной информации – метод статистических группировок математической статистики и теории вероятности; 3 стадия – обобщение и интерпретация статистической информации – метод обобщения и анализа на основе показателей абсолютных относительных и средних величин, вариаций динамики, индексов. На всех стадиях применяются графические, табличные и математические методы. Задачи статистики в современных условиях: 1) исследование происходящих в обществе преобразований социальных и экономических процессов на основе системы специальных показателей; 1 2) обобщение и прогнозирование тенденций развития народного хозяйства и его составляющих; 3) влияние имеющихся резервов эффективности общественного производства; 4) создание единого информационного пространства органов государственной власти; 5) организация статистики отраслей народного хозяйства и общества (прикладной статистики). Теория статистки – методологическая основа всех отраслевых (прикладных) статистик: экономической; социальной; труда; государственной; финансов. Организация и функции статистических служб В России в 1811 г. при департаменте полиции было образовано статистическое отделение, в 1857 г. – Центральный статистический комитет, губернские и земские Комитеты, с 25 июля 1918 г. – Центральное статистическое управление (ЦСУ). В настоящее время в соответствии со ст. 71 Конституции Российской Федерации – существует Государственный Комитет Российской Федерации по статистике (Госкомстат РФ). Органы Госкомстата составляют единую сеть государственной политики. Данные собираются по единым стандартам, а их представление является обязательным для хозяйствующих субъектов. «Российский статистический ежедневник», «Россия в цифрах». Функции Госкомстата РФ: 1) организация наблюдений по определенным формам; 2) обеспечение единого государственного реестра предприятий и организаций (ОГРПО); 3) обеспечение сбора, обработки и хранения информации и соблюдение государственной, коммерческой и личностной тайны; 4) сопоставление социально-экономических показателей во всем масштабе; 5) осуществление технических, информационных, научных и организационных задач статистических служб. Международные статистические службы: Статистическая комиссия ООН, ЮНЕСКО, ЕВРОСТАТ (страны общего рынка) – координирует деятельность статистических бюро, осуществляет консультации, обеспечивает сопоставимость показателей и распространение информации. Статистическое бюро Секретариата ООН, Всемирный банк, МВФ – исполнительный орган, собирают информацию от государств членов ООН, публикует эти данные в периодических изданиях: «Ежемесячный статистический бюллетень», «Демографический ежегодник», «Ежегодник по внешней торговле» и др. Международный статистический институт МСИ – ведет обобщение научных исследований в области теории методологии статистики. 2. Этапы статистического исследования Понятие о статистической информации Информация – (лат.) «осведомление, доведение сведений о чем-либо». Статистическая информация (статистические данные) – первичный материал о социальноэкономических явлениях, формирующийся в процессе статистических наблюдений, который затем подвергается систематизации, сводке, анализу и обобщению. В природе, технике, обществе, экономике нет явлений, в которых не присутствовали бы элементы случайности. Случайность (неопределенность) – когда исход не ясен в принципе – порождается одновременным влиянием множества изменяющихся факторов на изучаемый процесс. 2 Статистическое наблюдение Статистическое наблюдение – это такое наблюдение, которое обеспечивает получение объективной, сопоставимой, достоверной и полной информации о событии и обладает, как и вероятность, следующими свойствами: рассматривают события (данные) только тех испытаний (явлений), которые могут быть воспроизведены в сопоставимых условиях достаточно много раз; вероятность появления войн или гениальных произведений не определяется как статистическая закономерность; события (данные) должны обладать статистической устойчивостью, т.е. изменяться в пределах закономерностей больших чисел; число данных должно быть достаточно большим (массовым), чтобы вероятность Р(А) ~ приближенно равнялась частоте Р (А). Не всякий сбор данных является статистическим наблюдением. Статистическим можно назвать такое наблюдение, которое обеспечивает регистрацию устанавливаемых фактов. Объект статистического наблюдения – явление или процесс, обладающий свойствами однородности, воспроизводимости и устойчивости. Сводка и группировка статистических данных Получаемая в ходе статистического наблюдения информация характеризует единицы статистической совокупности с различных сторон и не позволяет сделать обобщающие выводы об объекте в целом (т.е. о всей статистической совокупности). Статистическая совокупность – это множество единиц явления, объединенных в соответствии с задачей исследования единой качественной основой (однородностью), но отличающиеся друг от друга признаками. Единицей статистической совокупности является элементы данного множества, которые характеризуются общими свойствами, т.е. признаками. Признаки бывают: атрибутивными, т.е. качественными; количественными (дискретными и непрерывными). Вариация признаков обуславливается случайным характером реальных явлений и процессов и зависит от изменения факторов, влияющих на объект статистического исследования. Статистическое наблюдение – это первый этап анализа. Статистическая сводка – это специальным образом организованная первичная обработка данных статистического наблюдения, включающая систематизацию, группировку данных, подсчет групповых, итоговых и относительных (средних показателей ). (Это второй этап обработки данных). Программа статистической сводки устанавливает следующие этапы: выбор группировочных признаков; определение порядка формирования групп; разработка системы статистических показателей для характеристик групп и объекта в целом; разработка макетов статистических таблиц или графиков. В сводке отдельные единицы статистической совокупности объединяются в группы при помощи метода группировок. С помощью метода группировок решаются задачи: выделение социально-экономических типов явлений; изучение структуры явления и структурных сдвигов, происходящих в нем; выявление связи и зависимости между явлениями. 3 Группировка – это процесс образования однородных групп на основе расчленения статистической совокупности на части или объединения изучаемых единиц в частные совокупности по существенным признакам. Различают следующие виды группировок: типологическая группировка, т.е. разделение качественно разнородной совокупности на классы или однородные группы; структурная группировка, в которой происходит разделение однородной совокупности на группы, характеризующие ее структуру по какому-либо варьируемому признаку; аналитическая группировка, выявляющая взаимосвязи между изучаемыми явлениями и их признаками (факторными и результативными); комбинированная группировка, образованная по двум или более признакам. В таблицах 2.1–2.3 приведены примеры различных группировок. Таблица 2.1 - Типологическая группировка № п/п 1 2 3 Число предприятий единиц в % к итогу 26326 93,6 420 1,5 1366 4,9 28112 100,0 Группы предприятий по форме собственности Федеральная собственность Муниципальная Частная Всего Таблица 2.2.- Структурная группировка № п/п 1 2 3 4 5 Группы населения по размеру среднедушевого дохода, руб. до 1000 руб. 1000–1800 1800–2600 2600–3400 3400–10000 Всего Численность населения всего, млн. чел. в % к итогу 2,4 2,0 24,8 18,0 34,2 25,0 29,4 21,5 45,7 33,5 136,5 100,0 Таблица 2.3 - Аналитическая группировка № п/п 1 2 3 4 5 Группы банков по сумме активов, млн.руб. до 20 20 – 30 30 – 40 40 – 50 50 и более Всего Количество банков 29 8 7 9 7 50 В среднем на 1 банк Численность Балансовая прибыль, занятых, чел. млрд. руб. 184 22,5 313 31,6 374 36,0 468 69,2 516 205,6 1855 360,0 Принципы построения статистических группировок 1. Выбор группировочного признака – признака, по которому производится разбиение совокупности на отдельные группы. В качестве признака необходимо использовать существенные обоснованные признаки. Группировочный признак – это основание (свойство объекта) для разделения объектов на группы. Признаки различаются: по форме выражения (атрибутивные и количественные); 4 по характеру колебания (альтернативные «да», «нет»; множественные); по роли во взаимосвязи явлений (результативные – могут меняться в зависимости от ситуации и целей анализа; факторные – воздействующие на другие признаки). 2. Определение количества групп. Если в основание группировки положен атрибутивный признак, то количество групп будет столько, сколько существует градаций (уровней) данного признака. Если основание группировки – количественный признак, то при определении количества групп в каждом конкретном случае следует исходить не только из степени колеблемости признака, но и из особенностей объекта и цели исследования. Если совокупность состоит из большого числа единиц и распределение единиц по группировочному признаку близко к нормальному, для определения количества групп (m) используют формулу Стерджесса: m = 1+3,322·lg N, где (2.1) N – численность единиц совокупности. Таблица 2.4 - Номограмма по формуле Стерджесса N 1524 2544 4589 90179 180359 360719 7201489 m 5 6 7 8 9 10 11 3. Определение интервала группировки. Интервал – это значение варьирующего признака, лежащее в определенных границах. Если вариация признака происходит в сравнительно узких границах и распределение носит равномерный характер, то строят группировку с равными интервалами: h где xmax xmin , m (2.2) h – величина интервала; xmax, xmin – максимальное и минимальное значения группировочного признака в совокупно- сти; m – число групп. Величина интервала округляется до ближайшего целого числа, или же кратного 10, 50, 100. Возможны и другие варианты определения интервала группировки. Интервалы могут быть двух видов: закрытыми, когда у интервала указаны обе границы; открытыми, когда у первого интервала указана верхняя граница, а у последнего – нижняя (например, в таблице 2.3, 1-я группа населения по размеру среднедушевого дохода – до 1000 руб.; последняя – 10000 и более). Возможно построение вторичных группировок. Основные задачи, вторичной группировки: приведение данных к сопоставимым результатам; укрупнение интервалов; долевая перегруппировка (образование новых групп с меньшими интервалами). Пример 2.1. Имеются первичные данные о количестве работников определенного возраста. Возраст, лет 20 24 29 30 32 39 42 50 51 54 55 58 59 60 Число сотрудников 3 2 1 1 3 1 8 6 1 3 2 3 4 1 5 Произведем группировку работников предприятия по возрасту. Для этого по формуле (2.1) рассчитаем число групп m = 1+3,322·lg 39 = 6,28 ≈ 6. Определим интервал группировки по формуле (2.2) h xmax xmin 60 20 6,67 . m 6 Округлим величину интервала до ближайшего целого h = 7. Тогда группировка будет следующей: Возраст, лет Число сотрудников Границы интервалов Число сотрудников в интервале 20 24 29 30 32 39 42 50 51 54 55 58 59 60 3 2 1 1 3 1 8 6 1 3 2 3 4 1 20 – 27 27 – 33 5 5 33–40 40–47 1 8 47 – 54 54 – 60 10 10 Граничное значение входит в тот интервал, где оно является верхней границей. Произведем вторичную группировку с укрупнением интервалов (h = 10): Возраст, лет Число сотрудников Границы интервалов Число сотрудников в интервале 20 24 29 30 32 39 42 50 51 54 55 58 59 60 3 2 1 1 3 1 8 6 1 3 2 3 4 1 20 – 30 30 – 40 40 – 50 50 – 60 7 4 14 14 6 Вариационные ряды При изучении совокупности интересующий нас признак у различных единиц совокупности принимает различные значения, т.е. он имеет некоторую вариацию. Вариацией признака называется наличие различий в численных значениях признаков у отдельных единиц совокупности. Чтобы выявить характер распределения единиц совокупности по варьирующим признакам, определить закономерности в этом распределении, строят ряды распределения единиц совокупностей по какому-либо варьирующему признаку. Ряды распределения, построенные по количественному признаку называются вариационными. При анализе вариационных рядов решают следующие задачи: 1) Определение меры вариации, т.е. количественное измерение степени колеблемости признака. Это позволяет сравнивать различные совокупности между собой по степени рассеяния и отслеживать уровень вариации признака одной и той же совокупности в различные периоды. 2) Исследование закономерностей вариации в статистических совокупностях для изучения причин, вызывающих вариацию. Для описания статистических распределений обычно используются следующие виды характеристик (показателей): 1) средние величины; 2) характеристики вариации (рассеяния); 3) характеристики дифференциации и концентрации; 4) характеристики формы распределения. Графическое отображение вариационных рядов Вариационный ряд по своей конструкции имеет 2 характеристики: значения варьирующего признака – варианты xi, i = 1,2,…,m; число случаев вариантов: абсолютные – частоты ni (fi), относительные – частости wi (относительные доли частот в общей сумме частот). Тогда можно сказать, что вариационный ряд – это ранжированный (упорядоченный) в порядке возрастания или убывания ряд статистических частот (частостей). Вариационные ряды по способу построения бывают дискретные и интервальные. Дискретный вариационный ряд можно рассматривать как такое преобразование ранжированного ряда, при котором перечисляются отдельные значения признака и указывается их частота. Если число вариантов велико или признак имеет непрерывную вариацию, то строится интервальный вариационный ряд, в котором отдельные варианты объединяются в интервалы (группы). Принципы построения групп рассмотрены в разделе 2.4.Существуют следующие виды графического отображения вариационных рядов (рис. 3.1, 3.2): полигон для отображения дискретных рядов, когда фиксируются значения ( xi; ni, i = 1,2,…,m); гистограмма для отображения интервальных рядов (ki = х(i+1)– хi, ni(wi)); кумулята (кумулятивный ряд) – кривая накопленных частот. 7 Пример 3.1. Построить графическое отображение вариационного ряда. Дано распределение рабочих механического цеха по тарифному разряду: Тарифный разряд, хi Количество рабочих (частота), ni Частость, wi = ni/n 1 2 3 4 5 6 Сумма 2 0,04 3 0,06 6 0,12 25 0,5 9 0,18 5 0,1 50 1 Данный вариационный ряд является дискретным, его графическое отображение представлено: полигон (на рис. 3.1, а), кумулята (на рис. 3.2, а). ni wi ni wi 25 0,5 25 0,5 20 0,4 20 0,4 15 0,3 15 0,3 10 0,2 10 0,2 5 0,1 5 25 20 1 2 3 4 5 6 17 14 9 0,1 94 100 106 112 118 124 130 Тарифный разряд (xi) а) Дискретный вариационный ряд, (полигон) 15 Выработка в % (xi) б) Интервальный вариационный ряд, (гистограмма, полигон) Рис. 3.1. Графическое отображение вариационных рядов wiнак wiнак 1,0 1,0 0,8 0,8 0,6 0,6 0,4 0,4 0,2 0,2 1 2 3 4 5 6 94 100 106 112 118 124 130 Тарифный разряд (xi) а) Дискретный вариационный ряд, (кумулята) б) Интервальный вариационный ряд, (кумулята) Рис. 3.2. Графическое отображение к умулятивного ряда 8 Выработка в % (xi) Обобщающие статистические показатели Экономико-статистические показатели содержат количественную характеристику тех или иных свойств экономических явлений и представляют собой модель. С помощью показателей определяются результаты экономической деятельности и состояние общества. Система статистических показателей основана на содержательном единстве характеристик объекта исследования. Развитие систем статистических показателей происходит в соответствии с развитием отражаемой объективной реальности и в результате углубления процессов познания реальных систем. Под статистическим показателем понимается количественная характеристика изучаемого объекта или его свойства. На этапе статистической сводки от индивидуальных значений признаков совокупности путем суммирования переходят к показателям совокупности, которые называются обобщающими. Например, система статистических показателей продукции промышленного предприятия включает следующие показатели: товарная продукция; отгруженная продукция; реализованная продукция; чистая продукция; добавленная стоимость и др. Раньше учитывали товарную продукцию, а в новых условиях – чистую и добавленную стоимость. Система экономико-статистических показателей в управлении предприятиями призвана выполнять четыре функции: директивную (плановые показатели, нормативы, разряды, ставка); учетную (фактические результаты деятельности); стимулирующую (зарплата, средняя численность, развитие производства); познавательную (сведения о налогах, трудоустройстройстве, среднем возрасте и т.д.). В зависимости от методов расчета обобщающие статистические показатели могут быть: абсолютными; относительными; средними величинами. Абсолютные и относительные статистические показатели Абсолютными в статистике называются суммарные обобщающие показатели, характеризующие размеры, объемы, уровни, мощности, темпы и др. изменения величин. Абсолютные показатели являются именованными числами, т.е. измеримы. Существуют: натуральные, стоимостные и условно-натуральные (условное топливо, эталонные лошадиные силы) измерители. Они служат для описания фактического состояния объекта, установления плановых и прогнозных значений. Абсолютные показатели могут быть сравнимы в разные периоды времени (прошлый, настоящий, будущий). Абсолютные показатели позволяют точно характеризовать объект в данный момент времени, но должны уточняться в динамике (сопоставимые цены, инвестиции с учетом инфляции и т.д.). Относительные статистические величины – это показатели в виде коэффициентов, характеризующих долю отдельных частей, изучаемой совокупности во всем ее объеме. Относительные показатели при исследовании экономических явлений и процессов изучаются совместно с абсолютными показателями и обеспечивают сопоставимость сравниваемой и базовой величин. Относительный показатель динамики (ОПД) представляет собой отношение уровня исследуемого процесса или явления за данный период времени (по состоянию на данный момент времени) к уровню этого же процесса или явления в прошлом: 9 ОПД xi x0 или ОПД xi . xi 1 (4.1) Пример 4.1. Менеджер получал 400$, ему снизили заработную плату на 10%. Через год опять повысили на 10%. Сколько будет получать менеджер? 1-й год: было 400$; стало 400·0,9 = 360$; 2-й год: было 360$; стало 360·1,1 = 396$, т.е. на 4$ меньше, чем в самом начале. Относительный показатель структуры (ОПС) представляет собой отношение структурных частей изучаемого объекта и их целого: ОПС xi . x i (4.2) Выражается относительный показатель структуры в долях единицы или в процентах. Рассчитанные величины, соответственно называемые долями или удельными весами, показывают, какай долей обладает или какой удельный вес имеет та или иная часть в общем итоге. Относительный показатель координации (ОПК) представляет собой отношение одной части совокупности к другой части этой же совокупности: ОПК xi . xk (4.3) При этом в качестве базы сравнения выбирается та часть, которая имеет наибольший удельный вес или является приоритетной с экономической, социальной или какой-либо другой точки зрения. В результате получают величину, отражающую во сколько раз данная часть больше базисной или сколько процентов от нее составляет, или сколько единиц данной структурной части приходится на 1 единицу (иногда – на 100, 1000 и т.д. единиц) базисной структурной части. Относительный показатель сравнения (ОПСр) представляет собой отношение одноименных абсолютных показателей, характеризующих разные объекты (предприятия, фирмы, районы, области, страны и т.п.): x ОПСр i . (4.4) zi Относительный показатель интенсивности (ОПИ) характеризует степень распространения изучаемого процесса или явления и представляет собой отношение исследуемого показателя к размеру присущей ему среды: ОПИ где xA , YA (4.5) xA – показатель, характеризующий явление А; YA – показатель, характеризующий среду распространения явления А. Данный показатель получают сопоставлением уровней двух взаимосвязанных в своем развитии явлений. Поэтому, наиболее часто он представляет собой именованную величину, но может быть выражен и в процентах и т.п. Обычно ОПИ рассчитывается в тех случаях, когда абсолютная величина оказывается недостаточной для формулировки обоснованных выводов о масштабах явления, его размерах, насыщенности, плотности распространения. Так, например, для определения уровня обеспеченности населения легковыми автомобилями рассчитывается число автомашин, приходящихся на 100 семей, для определения плотности населения рассчитывается число людей, приходящихся на 1 км2. 10 Например, если число граждан, состоящих на учете в службе занятости, составляет 3064 тыс. человек, а число заявленных предприятиями вакансий – 309 тыс., то на каждых 100 незанятых приходилось 10 свободных мест ( 309 100 ). 3064 Разновидностью относительных показателей интенсивности являются относительные показатели уровня экономического развития, характеризующие производство продукции в расчете на душу населения и играющие важную роль в оценке развития экономики государства. Так как объемные показатели производства продукции по своей природе являются интервальными, а показатель численности населения – моментным, в расчетах используют среднюю за период численность населения. Относительные показатели плана и реализации плана используются для целей планирования и сравнения реально достигнутых результатов с ранее намеченными. пл x ОПП i 1 xi где (4.6) , ОПП – относительный показатель плана; xiпл 1 – уровень, планируемый на i+1 период; xi – уровень, достигнутый в i-м периоде. x ОПРП i 1 xiпл 1 где (4.7) , ОПРП – относительный показатель реализации плана; xi – уровень, достигнутый в (i+1)-м периоде. ОПП характеризует напряженность плана, т.е. во сколько раз намечаемый объем производства превысит достигнутый уровень или сколько процентов от этого уровня составит. ОПРП отражает фактический объем производства в процентах или коэффициентах по сравнению с плановым уровнем. Относительные величины выполнения плана и динамики связаны между собой следующими соотношениями: ОПД = ОПП · ОПРП xiпл x 1 xi 1 пл i 1 . xi xi 1 xi (4.8) Пример 4.2. Оборот торговой фирмы в базисном году составил 2 млрд.руб. Руководство фирмы считает реальным в следующем году довести оборот до 2,8 млрд. руб. Найти ОПП, ОПРП, ОПД, если фактический оборот фирмы за отчетный год составил 2,6 млрд. руб. 2,8 100% = 140,0%; 2,0 2,6 ОПРП = 100% = 92,9%. 2,8 ОПП = ОПД = 1,4·0,929 = 2,6 =1,3 или 130%. 2,0 11 1. Средние величины Средняя величина является обобщающей характеристикой совокупности однотипных явлений по изучаемому признаку. Средняя величина должна вычисляться с учетом экономического содержания определяемого показателя. Все виды средних делятся на: степенные (аналитические, порядковые) средние (арифметическая, гармоническая, геометрическая, квадратическая); структурные (позиционные) средние (мода и медиана) – применяются для изучения структуры рядов распределения. 1.1 Средние степенные величины Средняя степенная (при различной величине k) определяется: k xi f i X k fi k 1 (1.1). Таблица 1.1 - Виды средних степенных величин Наименование Формула средней Когда используется средней Средняя арифмеИспользуется, когда расчет xi x тическая простая осуществляется по несгруп(1.2) n (невзвешенная) пированным данным где xi – i-й вариант осредняемого признака ( i 1, n ); n – число вариант 1 Средняя арифметическая взвешенная xi f i x fi Используется, когда данные представлены в виде рядов распределения или группировок (1.3), где fi – частота повторяемости i-го варианта -1 Средняя гармоническая взвешенная x wi w (1.4), wi x i f i . где xi i -1 0 0 2 2 Средняя гармоническая невзвешенная Средняя геометрическая невзвешенная Средняя геометрическая взвешенная Средняя квадратическая невзвешенная Средняя квадратическая взвешенная x n 1 / xi xi x x1m1 x2m2 ... xkmk m ximi m x x Используется в случае, когда веса равны (1.5) x k x1 x2 x3 ... xk k xi2 Используется, когда известны индивидуальные значения признака и веса W за ряд временных интервалов (1.6) (1.7) Используется в анализе динамики для определения среднего темпа роста (1.8) n Используется при расчете показателей вариации xi2 f i fi (1.9) В статистическом анализе также применяются степенные средние 3-го и более высоких порядков. 12 Правило мажорантности средних: с ростом показателя степени значения средних возрастают. x гарм x геом x a x кв x куб (1.10) Средняя прогрессивная – средняя для “лучших” значений признака. Свойства средней арифметической 1. Средняя арифметическая постоянной величины равна самой величине. 2. Если все варианты xi увеличить (уменьшить) на одно и тоже число c, x a увеличится (уменьшится) на то же число. m xa c x a c ( xi c)ni i 1 n m xi ni i 1 n c. (1.11) 3. Если все варианты xi увеличить (уменьшить) в одно и то же число раз k, x a увеличится (уменьшится) в то же число раз. m kx a k x a 4. (kxi )ni i 1 n m xi ni k i 1 n . (1.12) Средняя арифметическая отклонений вариантов от средней арифметической равна 0. m xi x a ( xi x a )ni 0 . (1.13) i 1 По свойству 2 при c x a : x a c x a c x a x a 0 . 5. Средняя арифметическая алгебраической суммы признаков равна такой же сумме средней арифметической этих признаков. x y x y. (1.14) 6. Если ряд состоит из нескольких групп, общая средняя равна средней арифметической групповых средних, причем весами являются объемы группы. m xa где x i ni i 1 , N (1.15) xi – средняя арифметическая группы i; m N – общий объем ряда ( N ni ); i 1 ni – объем группы i ( ni m k j ). j 1 m x jkj xi j 1 ni . (1.16) 13 1.2 Средние структурные величины В условиях недостаточности средних используют структурные средние величины – моду и медиану. Медиана (Ме) – это вариант, который находится а середине вариационного ряда. Медиана делит ряд на две равные (по числу наблюдений) части. В ранжированных рядах не сгруппированных данных нахождение медианы сводится к отысканию порядкового номера и значения варианта у этого номера. Медиана в интервальных вариационных рядах рассчитывается по формуле: Me x0 hMe 1 ni S Me1 2 , nMe (1.17) где х0 – нижняя граница медианного интервала (накопленная частота которого превышает половину общей суммы частот); hMe – величина медианного интервала; S Me1 – накопленная частота интервала, предшествующего медианному; n Me – частота медианного интервала. Также в интервальных вариационных рядах медиана может быть найдена с помощью кумуляты как значение признака, для которого n xнак n 2 или 1 wxнак . 2 (1.18) Главное свойство медианы заключается в том, что сумма абсолютных отклонений значений признака от медианы меньше, чем от любой другой величины: xi Me min . Модой (Мо) вариационного ряда называется вариант, которому соответствует наибольшая частота. Для вычисления моды в интервальном ряду сначала находится модальный интервал, имеющий наибольшую частоту (или наибольшую плотность распределения – отношение частоты интервала к его величине ni/hi – в интервальном ряду с неравными интервалами), а значение моды определяется линейной интерполяцией: Mo x0 hMo где ( f Mo f Mo f Mo1 , f Mo1 ) ( f Mo f Mo1 ) (1.19) хо – нижняя граница модального интервала; hMe – величина модального интервала; f M 0 , f Mo1 , f Mo1 – частота ni (в интервальном ряду с равными интервалами) или плотность распределения ni/hi (в интервальном ряду с неравными интервалами) модального, до и послемодального интервала. Мода так же, как и медиана обладает определенной устойчивостью к вариации признака. Если в совокупности первичных признаков нет повторяющихся значений, то для определения моды проводят группировку. Графически отобразить моду по гистограмме можно следующим образом: нужно взять столбец, имеющий наибольшую высоту, и из его левого верхнего угла провести отрезок в угол последующего столбца, а из правого угла – в верхний правый угол предыдущего столбца, абсцисса точки пересечения отрезков и будет соответствовать модальному значению признака в изучаемой совокупности. Медиану приближенно можно определить графически - по кумуляте. Для этого высоту наибольшей ординаты, которая соответствует общей численности совокупности, делят пополам. Через полученную точку проводят прямую, параллельную оси абсцисс, до пересечения ее с кумулятой. Абсцисса точки пересечения и есть медиана (рисунок 1.1) 14 28 ni 20 20 19 15 11 10 10 7 5 3 2 x 1 94 100 106 112 118 124 130 136 142 Mo =120,8 Выработка в % 0,69 0,5 0,41 0,25 94 100 106 112 118 124 130 136 142 Me = 119,9 Рис. 1.1 Графическое отображение интервального вариационного ряда В симметричных рядах имеет место следующее соотношение моды, медианы и средней x Me Mo (1.20). В случае, если x Me Mo (1.21), имеет место левосторонняя асимметрия ряда. В случае, если Mo Me x (1.22), имеет место правосторонняя асимметрия ряда. арифметической Мода и медиана, в отличие от степенных средних, являются конкретными характеристиками ряда. Медиана – характеризует центр, вычисляется проще и не чувствительна к концам интервала. Мода – наиболее вероятное значение в изучаемой совокупности (например, наиболее возможные результаты). 1 2 3 f 1 2 f х f х 1 – распределение с левосторонней асимметрией 2 – распределение с правосторонней асимметрией 3 – нормальное (симметричное) распределение 15 3 х 2. Анализ вариационных рядов 2.1. Показатели вариации Вариацией называется изменяемость, колеблемость величины признака. Вариация проявляется в отклонениях от средних и зависит от множества факторов, влияющих на социальноэкономическое явление. Вариация бывает случайной и систематической, существует в пространстве и во времени. Показатели вариации делятся на абсолютные и относительные (таблица 2.1). Таблица 2.1 - Показатели вариации Формула расчета показателя Показатель простой взвешенный R x max x min Размах (2.1) m n Абсолютные Среднее линейное отклонение d xi x d i 1 xi x f i i 1 (2.3) m (2.2) n * fi i 1 m n Дисперсия σ 2 ( xi x ) 2 2 i 1 ( xi x ) 2 f i i 1 n (2.5) m (2.4) fi i 1 m n относительные Среднее квадратическое отклонение ( xi x ) 2 i 1 ( xi x ) 2 f i i 1 (2.6) n m (2.7) fi i 1 Коэффициент вариации V σ 100 % x (2.8) Линейный коэффициент вариации Vd d 100 % x (2.9) Коэффициент осцилляции VR * – Здесь fi – частота ( R 100 % x (2.10) fi n i ). fi n Относительные показатели (коэффициент вариации, линейный коэффициент вариации, коэффициент осцилляции) строятся с учетом базы (в виде средней), выражаются в процентах и дают характеристику однородности совокупности. Совокупность считается однородной, если коэффициент вариации V 33% . (2.11) Для расчета дисперсии можно использовать модифицированную формулу: σ 2 х 2 ( x) 2 . (2.12) 16 Выведем эту формулу из формулы (2.5) 2 ( xi x ) 2 f i i fi x i2 f i i x i2 f i i fi 2x i fi 2 xi x f i i i fi i fi i xi f i x i i 2 fi i fi x 2 fi i fi i x 2 2( x) 2 ( x) 2 x 2 ( x) 2 i Для расчета дисперсии можно использовать способ отсчета от условного нуля, который позволяет упростить вычисления при больших значениях признака. Тогда дисперсия вычисляется по формуле: 2 x A i h fi 2 i h 2 ( x А) 2 , fi (2.13) i где h – величина интервала; А – условный нуль, в качестве которого можно использовать как середину серединного интервала, так и середину интервала с наибольшей частотой. 2.1.1. Свойства дисперсии 1. Дисперсия постоянной величины равна нулю. 2. Если у всех значений вариантов отнять какое-то постоянное число А, то средний квадрат отклонений (дисперсия) от этого не изменится (2xi A) (2xi ) . (2.14) Это значит, что дисперсию можно вычислить не по заданным значениям признака, а по их отклонениям от какого-то постоянного числа, например условного нуля (см. формулу 2.13). 3. Если все значения вариантов разделить на какое-то постоянное число А, то дисперсия уменьшится в А2 раз: 2xi A 2xi A2 . (2.15) 4. Если распределение признака близко к нормальному или симметричному, то по правилу мажорантности (т.к. среднее квадратическое отклонение – средняя геометрическая величина, а среднее линейное отклонение – средняя арифметическая) среднее квадратическое отклонение больше среднего линейного отклонения ( d ), причем 1,25d , d 0,8 . (2.16) Размах вариации, среднее линейное и среднее квадратичное отклонение – это именованные величины. Единицей измерения у них и у исходных значений признака совпадают. Дисперсия может быть задана в ед.2 признака или в % отклонений. 17 2.1.2 Вариация альтернативного признака Альтернативные признаки – два противоположных, взаимоисключающих друг друга качественных признака, которыми одни единицы совокупности обладают (значение варианта 1), а другие не обладают (значение варианта 0) (например, пол – мужской и женский, население – городское и сельское, продукция – годная и бракованная). Частостью (p) является доля единиц, обладающих данным признаком, в общей численности совокупности и (q = 1 – p) – доля единиц, не обладающих данным признаком, в общей численности совокупности. xi fi 1 p 0 q=1–p Средняя арифметическая альтернативного признака x 1 p 0 q p. pq (2.18) Дисперсия альтернативного признака (1 p) 2 p (0 p) 2 q q 2 p p 2 q pq , pq pq 2 (2.19) т.е. дисперсия альтернативного признака равна произведению доли единиц, обладающих данным признаком, и доли единиц, не обладающих этим признаком. Исходя из того, что p + q = 1: 2 p q 0,25 ; p q 0,5 . (2.20) 2.2. Виды дисперсий в совокупности, разделенной на части. Правило сложения дисперсий Если исходная совокупность является такой, что по значениям признака она делится на l групп, то общая дисперсия складывается из частных дисперсий. В таблице 2.2 представлен анализ такой совокупности. Таблица 2.2 - Определение исходной совокупности по группам Число единиц в j-й группе Значение признака х 1 … j … l Итого l х1 f11 … f1j … f1l … … … … … … f1 j j 1 m1 … l хi fi1 … fij … fil f ij mi … … … … … … … хk fk1 … fkj … fkl f kj mk j 1 l k Итого fi1 n1 i 1 k … fij n j i 1 18 k … fil nl i 1 j 1 l k j 1 i 1 N n j mi Здесь j – номер группы ( j 1;l ); хi – i-е значение признака ( i 1;k ); fij – частота i-го значения признака, число единиц в j-й группе; mi – сумма частот i-го значения признака в каждой группе; nj – сумма частот всех значений признака в j-й группе; N – сумма частот всех значений признака во всех группах (объем совокупности). Сначала вычисляем l частных средних ( x j ), т.е. среднее значение признака в каждой группе: k xj xi f ij i 1 . nj (2.22) ~ На основе частных средних определяем общую среднюю ( X ) по формулам l k ~ X xi mi i 1 ~ X или N x jn j j 1 . N (2.23) Общая дисперсия совокупности k 2 общ ~ ( xi X ) 2 mi i 1 . N (2.24) Общая дисперсия отражает вариацию признака за счет всех факторов, действующих в данной совокупности. Вариацию между группами за счет признака-фактора, положенного в основу группировки, отражает межгрупповая дисперсия, которая исчисляется как средний квадрат отклонений групповой средней от общей средней: l ~ (x j X )2 n j 2 j 1 . N (2.25) Межгрупповая дисперсия характеризует систематическую вариацию результативного признака, т.е. вариацию между группами за счет признака-фактора, положенного в основу группировки. Вариацию внутри каждой группы изучаемой совокупности отражает внутригрупповая дисперсия, которая исчисляется как средний квадрат отклонений значений признака х от частной средней x j : k 2j ( xi x j ) 2 i 1 k f ij или nj 2j xi2 f ij i 1 nj ( x j ) 2 . (2.26) Для всей совокупности внутригрупповую вариацию будет выражать средняя из внутригрупповых дисперсий, которая рассчитывается как средняя арифметическая из внутригрупповых дисперсий: l 2j n j 2 j 1 N . (2.27) 19 Внутригрупповая дисперсия отражает случайную вариацию, т.е. часть вариации обусловленную влиянием неучтенных факторов и не зависящую от признака-фактора, положенного в основу группировки. Между представленными видами дисперсий существует определенное соотношение, которое известно как правило сложения дисперсий: 2 общ 2 2 . (2.28) Таким образом, общая дисперсия складывается из двух слагаемых: первое – средняя из внутригрупповых дисперсий – измеряет вариацию внутри частей совокупности, второе – межгрупповая дисперсия – вариацию между средними этих частей. Правило сложения дисперсий позволяет выявить зависимость результатов от определяющих факторов с помощью соотношения межгрупповой и общей дисперсий. Это соотношение называется эмпирическим коэффициентом детерминации (η2) и показывает долю вариации результативного признака под влиянием факторного. 2 2 2 общ . (2.29) Эмпирическое корреляционное отношение (η) показывает тесноту связи между исследуемым явлением и группировочным признаком. 2 2 îáù . (2.30) η2 и η [0, 1]. (2.31) Если связь отсутствует, то = 0. В этом случае межгрупповая дисперсия равна нулю (δ2=0), т.е. все групповые средние равны между собой и межгрупповой вариации нет. Это означает, что группировочный признак не влияет на вариацию исследуемого признака х. Если связь функциональная, то = 1. В этом случае дисперсия групповых средних равна общей дисперсии ( σ общ ). Это означает, что группировочный признак полностью определяет характер изменения изучаемого признака. Чем больше значение корреляционного отношения приближается к единице, тем полнее (сильнее) корреляционная связь между признаками (таблица 2.3). 2 2 Таблица 2.3 - Качественная оценка связи между признаками (шкала Чэддока) Значение теор Характер связи Значение теор Характер связи η=0 Отсутствует 0,5 ≤ η < 0,7 Заметная 0 < η < 0,2 Очень слабая 0,7 ≤ η < 0,9 Сильная 0,2 ≤ η < 0,3 Слабая 0,9 ≤ η < 1 Весьма сильная 0,3 ≤ η < 0,5 Умеренная η=1 Функциональная 20 Пример 2.1. Определим групповые дисперсии, среднюю из групповых дисперсий, межгрупповую дисперсию, общую дисперсию по данным о производительности труда в двух бригадах: Количество рабочих, имеющих соответствующую производительность труда Изготовлено деталей за час, шт. (производительность труда) в бригаде 1 в бригаде 2 fi1 fi2 хi 10 12 14 16 18 20 1 3 3 2 1 0 0 0 1 3 2 4 Промежуточные расчеты занесем в таблицы: хi Бр. 1 Бр. 2 fi1 fi2 Промежуточные расчеты для определения средних величин mi хi·fi1 хi·fi2 хi·mi 10 1 0 1 10 0 10 12 3 0 3 36 0 36 14 16 18 20 Σ 3 2 1 0 n1=10 1 3 2 4 n2=10 4 5 3 4 N=20 42 32 18 0 Σхi·fi1=138 14 48 36 80 Σхi·fi2=178 56 80 54 80 Σхi· mi =316 Промежуточные расчеты для определения дисперсий хi ~ ~ (хi – x 1 ) (хi – x 2 ) (хi – X ) (хi – x 1 )2·fi1 (хi – x 2 )2·fi2 (хi – X )2·mi 10 12 14 16 -3,8 -1,8 0,2 2,2 -7,8 -5,8 -3,8 -1,8 -5,8 -3,8 -1,8 0,2 14,44 9,72 0,12 9,68 0,00 0,00 14,44 9,72 33,64 43,32 12,96 0,20 18 4,2 0,2 2,2 17,64 0,08 14,52 20 Σ 6,2 – 2,2 – 4,2 – 0,00 51,60 19,36 43,60 70,56 175,20 Средняя производительность труда для 1-й бригады: 6 x1 xi f i1 i 1 n1 138 = 13,8 шт./ч. 10 21 Средняя производительность труда для 2-й бригады: 6 x2 xi f i 2 i 1 n2 178 = 17,8 шт./ч. 10 Средняя производительность труда для 1-й и 2-й бригады: 2 6 ~ X xi mi i 1 N 316 20 x jn j j 1 N 13,8 10 17,8 10 = 15,8 шт./ч. 20 Дисперсия 1-й группы (бригады) 6 12 ( xi x 1 ) 2 i 1 Дисперсия 2-й группы (бригады) 6 f i1 n1 51,6 = 5,16 10 22 Средняя из групповых дисперсий ( xi x 2 ) 2 f i 2 i 1 n2 2 2j n j j 1 ~ (x j X )2 n j 2 = 4,76 N 43,6 = 4,36 10 Межгрупповая дисперсия 2 2 6 Общая дисперсия 2 îáù Проверка по правилу сложения дисперсий: j 1 N = 4,0 ~ ( xi X ) 2 mi i 1 N =8,76 2 общ 2 2 = 4,76 + 4,00 = 8,76 Эмпирический коэффициент детерминации: 2 2 2 общ 4,00 = 0,457 = 45,7%. 8,76 Отсюда можно сделать вывод, что общая вариация производительности труда на 45,7% обусловлена вариацией между группами. Эмпирическое корреляционное отношение 2 2 общ 4,00 = 0,6757. 8,76 Значение = 0,6757 показывает заметную связь по шкале Чэддока (см. таблицу 2.3) между исследуемым явлением (производительностью труда) и группировочным признаком (бригады). 22 3. Моменты распределения Показатели формы распределения 3.1. Моменты распределения Для подробного описания особенностей распределения используют дополнительные характеристики – моменты распределения. Момент распределения k-го порядка – средняя величина отклонений k-й степени от некоторой постоянной величины А: Mk ( õi A) k fi fi . (3.1) Практически используют моменты первых четырех порядков. Если А = x a , то моменты центральные; А = 0, то моменты начальные; А – произвольное число, то моменты условные. Начальные моменты mk õik f i fi (3.2) m0 = 1; m1 – средняя арифметическая ( x a ) Нормированные моменты Центральные моменты mk ( xi õ ) k fi fi (3.3) m0 = 1; m1 = 0 m2 – средний квадрат отклонений, дисперсия ( ) 2 k μ0=1; 3 mk (3.4) k μ1=0; m3 3 μ2=1; – показатель асимметрии 3.2. Показатели формы распределения Нормированный момент третьего порядка является показателем асимметрии распределения : As 3 m3 3 . (3.5) Степень существенности асимметрии характеризуется средней квадратической ошибкой, которая зависит от объема наблюдения: As Если Аs As 6( N 1) , ( N 1)( N 3) (3.6) 3 , то асимметрия существенна. При симметричном распределении варианты, равноудаленные от x , имеют одинаковую частоту, поэтому m3 = 0, а следовательно, и μ3=0. Если μ3 < 0, то в вариационном ряду преобладают (имеют большую частоту) варианты, которые меньше x , т.е. ряд отрицательно ассиметричен (или с левосторонней скошенностью – более длинная ветвь влево). Положительная асимметрия (правосторонняя скошенность – более длинная ветвь вправо) характеризуется значением μ3 > 0 (рис. 2.1). В качестве показателя асимметрии применяется и коэффициент асимметрии Пирсона (As): Аs x Mo . σ (3.7) Если As= 0, (т.е. x Mo ), то распределение симметричное (нормальное). Если As < 0, то имеет место левосторонняя асимметрия. 23 Если As > 0,то имеет место правосторонняя асимметрия. Если |As| > 0,25, то асимметрия значительна; если |As| < 0,25 – незначительна. Ft As = 0 As < 0 As > 0 x Рис. 2.1 Асимметрия распределения Нормированный момент четвертого порядка характеризует крутизну (заостренность) графика распределения: 4 m4 4 . (3.8) Для нормального распределения μ4 = 3, поэтому для оценки крутизны исследуемого распределения в сравнении с нормальным из μ4 вычитается 3 и таким образом рассчитывается показатель эксцесса: Ex Если m4 4 3. (3.9) Ex = 0, то распределение симметрично; Ex > 0, то распределение островершинное; Ex < 0, то распределение плосковершинное (рис. 3.2). Ft Ex > 0 Ex = 0 Ex < 0 x Рис. 3.2. Эксцесс распределения 3.3. Теоретические кривые распределения Анализ вариационных рядов предполагает выявление закономерностей распределения, определение и построение (получение) некой теоретической (вероятностной) формы распределения. Характер распределения лучше всего проявляется при большом числе наблюдений и малых интервалах. В этом случае графическое отображение эмпирического вариационного ряда принимает вид плавной кривой, именуемой кривой распределения. Кривая распределения может рассматриваться как некая теоретическая (вероятностная) форма распределения, свойственная определенной совокупности в конкретных условиях. Таким образом, анализируя частоты в эмпирическом распределении, можно описать его с помощью математической модели – закона распределения, установить по исходным данным парамет- 24 ры теоретической кривой и проверить правильность выдвинутой гипотезы и типе распределения данного ряда. При исследовании закономерностей распределения очень важно выдвинуть верную гипотезу о типе кривой распределения, так как, если кривая описана математически (с помощью уравнения) верно, она более точно отражает закономерности данного распределения и может быть использована в различных практических расчетах и прогнозах. Кроме того, в этом случае можно сформулировать рекомендации для принятия практических решений. Теоретическое распределение случайной величины – это математическое выражение функциональной зависимости значений случайной величины x и вероятности ее попадания в соответствующий интервал. Для построения функции теоретического распределения необходимо знать x и и обосновать вид кривой из сведений об экономическом явлении или процессе. Рассмотрим только нормальное распределение, поскольку именно оно наиболее широко применяется при построении статистических моделей. Распределение непрерывной случайной величины x называют нормальным, если соответствующая ей плотность распределения выражается формулой f ( x) ( x, x, 2 ) 1 e 2 ( x x ) 2 22 , (3.10) t 1 2 (t ) e , 2 или где 2 x – значение изучаемого признака; x – средняя арифметическая ряда; 2 – дисперсия значений изучаемого признака; – среднее квадратическое отклонение изучаемого признака; π = 3,1415926; е = 2,7182; t xx – нормированное отклонение. Кривая нормального распределения (рис. 3.3) симметрична относительно вертикальной прямой x x , поэтому среднюю арифметическую ряда называют центром распределения. Случайные величины, распределенные по нормальному закону, различаются значениями параметров x и , поэтому важно выяснить, как эти параметры влияют на вид кривой нормального распределения. Если x не меняется, а изменяется только , то: 1) чем меньше , тем более вытянута кривая (рис. 3.3, а), а так как площадь, ограниченная осью x и данной кривой, равна 1, то вытягивание вверх компенсируется сжатием около центра распределения x и более быстрым приближением кривой к оси абсцисс; 2) чем больше , тем более плоской и растянутой вдоль оси абсцисс становится кривая. Если остается неизменной, а x изменяется, то кривые нормального распределения имеют одинаковую форму, но отличаются друг от друга положением максимальной ординаты (рис 3.3, б). Особенности кривой нормального распределения. 1) Кривая x Mo Me . симметрична и имеет максимум в точке, соответствующей значению 2) Кривая асимптотически приближается к оси абсцисс, продолжаясь в обе стороны до бесконечности. Чем больше отдельные значения x отклоняются от x , тем реже они встречаются. 25 3) Кривая имеет две точки перегиба на расстоянии от x . 4) Площадь между ординатами, проведенными на расстоянии x (заштрихованная область на рис 3.3, б), составляет 0,683. Это означает, что 68,3% всех исследуемых единиц (частот) отклоняется от средней арифметической не более, чем на , т.е. находится в пределах x . В промежутке x 2 находится 95,4%, а в промежутке x 3 соответственно, 99,7% всех единиц исследуемой совокупности. 5) Коэффициенты асимметрии и эксцесса равны нулю. f(x) а) 1 x = const 1 < 2 < 3 2 3 x x Mo Me б) f(x) = const x1 – x1 < x 2 < x3 x2 x3 x Рис. 3.3 Кривые нормального распределения 4. Выборочное наблюдение в статистике Наиболее широко распространенным видом несплошного наблюдения является выборочное наблюдение, при котором обследуются не все единицы изучаемой совокупности, а лишь определенным образом отобранная их часть. Вся подлежащая изучению совокупность объектов (наблюдений) называется генеральной совокупностью. Выборочной совокупностью или выборкой называется часть генеральной совокупности, отобранная для изучения свойств обеспечивающая репрезентативность. Отбор из генеральной совокупности проводится таким образом, чтобы на основе выборки можно было получить достаточно точное представление об основных параметрах совокупности в целом. При этом речь идет как о точечной оценке, в качестве которой принимается соответствующее значение средней, доли и т.д., полученное в результате выборки, так и об интервальной оценке, т.е. о тех пределах, в которых с определенной вероятностью может находиться значение искомого параметра в генеральной совокупности. Главное требование, которому должна отвечать выборочная совокупность, — это требование ее репрезентативности, т.е. представительности. 26 В статистике результаты сплошного наблюдения иногда оцениваются как выборочные характеристики. Такая трактовка полученных данных имеет место в тех случаях, когда число обследованных единиц невелико и нет твердой уверенности в том, что изучаемые характеристики не могут принимать иных значений, кроме выявленных в результате наблюдения. При проведении экспериментов число значений может быть бесконечно большим, поэтому, формулируя выводы на основе ограниченного их числа, необходимо рассматривать полученные данные как выборочные характеристики. Распространяя результаты выборочного обследования на генеральную совокупность, следует иметь в виду, что между характеристиками генеральной и выборочной совокупности возможно расхождение, обусловленное тем, что обследуется не, вся совокупность, а лишь ее часть. Ошибкой статистического наблюдения считается величина отклонения между расчетным и фактическим значениями признаков изучаемых объектов. Выборочный метод обеспечивает значительную экономию материальных и финансовых ресурсов при проведении статистического наблюдения, что позволяет расширить программу обследования и повысить его оперативность. Второе преимущество – высокая достоверность получаемых данных, так как при относительно небольшом объеме выборки можно организовать эффективный контроль за качеством собираемой информации. Таким образом, снижается вероятность появления ошибок регистрации и необнаружения их на стадии проверки первичной информации. И наконец, в ряде случаев, когда сплошное наблюдение связано с уничтожением или порчей обследуемых единиц (например, при проверке качества поступающих в продажу продуктов питания), возможно только выборочное обследование. Точность оценок, полученных на основе выборочного метода, зависит не от доли обследованных единиц, а от их числа. Основные этапы выборочного наблюдения; 1) определение цели, задач и составление программы наблюдения; 2) формирование выборки; 3) сбор данных на основе разработанной программы; 4) анализ полученных результатов и расчет основных характеристик выборочной совокупности; 5) расчет ошибки выборки и распространение ее результатов на генеральную совокупность. Различают виды выборки: 1) случайная (собственно-случайная); 2) механическая (например, каждый 10, 20 и т.д.); 3) типическая (стратифицированная), когда генеральная совокупность разбита на группы и в каждой группе обследуются по нескольку объектов)); 4) серийная (гнездовая), когда случайным образом отбираются целые серии. Наиболее простой способ формирования выборочной совокупности – собственно случайный отбор. Теоретические основы выборочного метода, первоначально разработанные применительно к собственно случайному отбору, используют и для определения ошибок выборки при других способах наблюдения. Собственно случайный отбор может быть повторным и бесповторным. При повторном отборе каждая единица, отобранная в случайном порядке из генеральной совокупности, после проведения наблюдения возвращается в эту совокупность и может быть вновь подвергнута обследованию. На практике такой способ отбора встречается редко. Гораздо более распространен собственно случайный бесповторный отбор, при котором обследованные единицы в генеральную совокупность не возвращаются и не могут быть обследованы повторно. При повторном отборе вероятность попадания в выборку для каждой единицы генеральной совокупности остается неизменной. При бесповторном отборе она меняется, но для всех единиц, оставшихся в генеральной совокупности после отбора из нее нескольких единиц, вероятность попадания в выборку одинакова. 4.1. Закон больших чисел и предельные теоремы Под законом больших чисел в широком смысле понимается общий принцип, согласно которому, по формулировке академика Колмогорова, совокупное действие большого числа случайных факторов приводит к результату, почти не зависящему от случая. Или иначе: При большом числе случайных величин их средней результат перестает быть случайным и может быть предсказан с большой степенью определенности. 27 Под законом больших чисел в узком смысле понимается ряд математических теорем, в каждой из которых для тех или иных условий устанавливается факт приближения средних характеристик большого числа испытаний к некоторым определенным постоянным. Неравенство Чебышева: для любой случайной величины, имеющей математическое ожидание M(X) и дисперсию D(X) справедливо: P x H x или D( x) , 2 P ( x M ( x ) ) 1 (4.1) D( x) , (4.2) 2 Если формула (6.1) устанавливает верхнюю границу рассматриваемого события, то (4.2) – нижнюю границу вероятности события, состоящего в том, что отклонения значения случайной величины от математического ожидания не превысит (не будет менее) величины D( x) 2 , где 2 – доста- точно малая величина. В приложении к выборочному методу неравенство Чебышева может быть сформулировано так: при неограниченном увеличении числа наблюдений ( n ) в генеральной совокупности с ограниченной дисперсией с вероятностью близкой к единице можно ожидать, что отклонение выборочной средней ( X ~ ~ ) от генеральной средней X будет сколь угодно мало: P(( Х Х ) ) 1 при n . Эту вероятность в теореме А.М. Ляпунова (1901г.) используют для определения ошибки наблюдений. ~ P( Х Х t x ) F (t ) , где (4.3) F (t ) - нормированная формула Лапласса. – средняя квадратическая или стандартная ошибка выборки. t2 t2 1 t 2 2 t 2 F (t ) * e dt e dt . 2 t 2 0 (4.4) Пусть надо измерить некоторою величину, истинное значение которой равно a. Пусть результат каждого измерения – случайная величина Xi (i=1,2,…,n). Если при измерениях отсутствует систематические погрешности, то M(Xi)=a при любом i. Тогда средняя арифметическая результатов и измерений сходится по вероятности к истинному значению a. n Xi i 1 n a; (4.5) Дисперсия средней случайной величины Xi равна n Xi D i 1 n 2 n 1 D X 1 n 2 ; i 2 n2 n i 1 n Среднее квадратическое отклонение ошибок выборки 28 (4.6) 2 x , n n (4.7) ~ x ~x x ~ x ~x . (4.8). Зная выборочную среднюю X и предельную ошибку выборки x можно определить гра- ~ ницы, в которых размещена генеральная средняя X . Величина средней квадратической ошибки простой случайной повторной выборки может быть определена по формуле: x 2 , (4.9) n т.е. чем больше вариация признака в генеральной совокупности, тем больше ошибка выборки. Величину t x называют предельной ошибкой для определения значения вероятности. Если ~ X с вероятностью 0,9545, то надо полуx x 2 x ) Ft 2 0,9545 (функция чить значение выборочной средней из соотношения P( ~ требуется оценить среднюю генеральной совокупности Лапласа). Для выборки объема n 30 предельная ошибка x t x может быть определена из соот- 2 . n ношения x t t 1,00 1,96 2,00 2,58 3,00 F(t) 0,683 0,9500 0,9545 0,9901 0,9973 x 3 x – это предел возможной ошибки (правило «трех сигм»). Формула предельной ошибки выборки используется не только для оценки пределов, в которых находится изучаемый признак в генеральной совокупности, но и для определения необходимого объема выборки при заданной ее ошибке. Третий тип задач, которые могут быть решены с использованием предельной ошибки выборки, – это определение вероятности, с которой можно гарантировать, что ошибка выборки не выйдет за заданные пределы. Величина дисперсии генеральной совокупности ген принципиально не известна и можно говорить лишь о ее оценке по результатам одной выборки. xi x 2 n 2 При i 1 n 1 –для простой случайной выборки. n 30 , поправка г в * n становится 3,5% (30/(30-1)), поэтому ею можно n 1 пренебречь. 29 Выборочное наблюдение Наименование показателя Вид выборки повторная Случайная выборка Средняя (стандартная) ошибка Средняя ошибка доли признака Х t 2 2 n 2 Типическая выборка Средняя ошибка Объем выборки Серийная выборка Средняя ошибка Объем выборки n p(1 p) n Х Объем выборки 2 2i n n t 2 2i Х 2 2 s t 2 2 s 2 бесповторная 2 n 1 n N Х Х p(1 p) n 1 n N t 2 2 N n 2 N t 2 2 2i n 1 n N n t 2 2i N 2 N t 2 2i Х 2 s 1 s S t 2 2 S s 2 S t 2 2 Величина ошибки зависит от колеблемости признака в генеральной совокупности и от объема выборки. Т.е. чем больше вариация тем больше ошибка, чем больше выборка, тем меньше ошибка. Величину t Х~ называют предельной ошибкой выборки. Следовательно, предельная ошибка выборки Х~ t Х~ , т.е. предельная ошибка равна t-кратному числу средних ошибок выборки. t – коэффициент доверия n – объем выборки; N – объем генеральной совокупности; s - число отобранных серий; S – общее число серий; i - средняя из групповых дисперсий; - межгрупповая дисперсия. 30 4.2. Ошибка выборки для альтернативного признака Теорема Бернулли утверждает, что при достаточно большом объеме выборки вероятность P расхождения между долей признака в выборочной совокупности р и долей в генеральной совокупности Pг будет стремиться к 1. P Pг р t P 1` , (4.10) Для альтернативного признака среднее квадратическое отклонение равно pq , где q 1 p . Тогда средняя ошибки выборки для альтернативного признака равна p pq , n (4.11) p t p , (4.12) Доля в генеральной совокупности Pг неизвестна и может быть только оценена при выборочном наблюдении P Pг; p PP 1 , n (4.13) При простой случайной выборке средняя квадратическая ошибки определяется по формулам: Средняя квадратическая Повторная выборка Бесповторная выборка ошибка При определении среднего размера признака При определении доли признака 2 , (4.14) x n P1 P p ,(4.15) n 2 n x * (1 ) , n N p (4.16) P1 P n * 1 . (4.17) n N 4.3 Определение необходимой численности выборки Численность стандартной x и предельной x ошибки выборки связано с увеличением объема выборки n. При проектировании выборочного наблюдения заранее задается величина допустимой ошибки x и доверительная вероятность для определения предельной ошибки x . Если P=0,954, то 2 x (2σ) Если P=0,997, то 3 x (3σ) 2 t x t x t , n n n t 2 2x 2x (4.18) . (6.19) Для определения дисперсии признака в генеральной совокупности используются приближенные методы. 31 1. Можно провести несколько пробных обследований и по ним выбирать наибольшее значение x n 2 дисперсии j i 1 i x проб 2 , где достаточно пробных наблюдений. nпроб 1 2. Можно использовать данные прошлых или аналогичных обследований. 3. Можно использовать размах вариации R X max X min , если распределение нормальное, то R 6 , т.е. x 1 R. 6 Объем выборки N Повторный отбор При определении среднего размера признака n t 2 x2 2x , Бесповторный отбор n (4.20) 2x N t 22 , (4.22) t 2 p(1 p) N . (4.23) n 2 p N t 2 p(1 p) t 2 p(1 p) , (4.21) n 2p При определении доли признака t 22x N 4.4 Формы организации выборочного наблюдения Типическая (стратифицированная) выборка: общий список разбивается на отдельные списки (однородной группы). Общий объем выборки n разбивается пропорционально между списками: 1-й вариант ni n где Ni , (4.24) N n – объем выборки N – объем генеральной совокупности ni – число наблюдений из i-ой типической группы Ni – объем i-ой типической группы в генеральной совокупности. 2-й вариант – равномерный (из каждой группы поровну) ni n , k (4.25) где k – число групп. 3-й вариант – оптимальный (для групп с большей вариацией признака объем наблюдений увеличивается) ni n Ni i k . (4.26) Ni i i 1 Серийная (гнездовая) выборка – в случайном порядке отбираются серии сплошного контроля. Тогда X в сериях определяется без случайной ошибки. При равновеликих сериях стандартная ошибка выборки определяется s x где ; x0 s 2 xi i 1 s xi x0 s ; 2 s – число серий; δ – межгрупповая дисперсия. При бесповторном отборе 32 2 i 1 s , (4.27) 2 s x 1 , s S где (4.28) S – общее число серий в генеральной совокупности. Механическая выборка – при ранжировании генеральной совокупности устанавливается шаг отбора в зависимости от предполагаемого % отбора. Если совокупность не ранжирована, то это случайный отбор, т.е. по известным формулам. 2 n x 1 , n N (4.29) Механический отбор удобен, прост и широко применяется, так при 2%-й выборке отбирается каждая 500-я единица (1:0,02), при 5%-й – каждая 20-я. Пример Исходя требований ГОСТа необходимо установить оптимальный размер выборки из партии изделий 2000 штук, чтобы с вероятностью 0,997 предельная ошибка не превысила 3% от веса 500 гр. Изделия (батона). Решение. x 500(3) 15 гр для средней количественного признака ÷ 100 Nt 2 x2 2000 * 3 2 * 15,4 2 nx 2 9,41 10 шт. x N t 2 x2 2000 * 15 2 3 2 * 15,4 2 5. Статистические методы изучения взаимосвязи социально-экономических явлений Корреляционная связь (частный случай стохастической) – связь, проявляющаяся при достаточно большом числе наблюдений в виде определенной зависимости между средним значением результативного признака и признаками-факторами. Задача корреляционного анализа – измерение тесноты связи между варьируемыми признаками и оценка факторов, оказывающих наибольшее влияние. Задача регрессионного анализа – выбор типа модели (формы связи), устанавливающих степени влияния независимых переменных. Связь признаков проявляется в их согласованной вариации, при этом одни признаки выступают как факторные, а другие – как результативные. Причинно-следственная связь факторных и результативных признаков характеризуется по степени: тесноты; направлению; аналитическому выражению. 5.1 Регрессионный анализ Для оценки параметров уравнений регрессии наиболее часто используется метод наименьших квадратов (МНК), суть которого заключается в следующем требовании: искомые теоретические значения результативного признака y х должны быть такими, при которых бы обеспечивалась минимальная сумма квадратов их отклонений от эмпирических (фактических) значений, т.е. S ( y y x ) 2 min . (5.1) При изучении связей показателей применяются различного вида уравнения прямолинейной и криволинейной связи. Так, при анализе прямолинейной зависимости применяется уравнение: у а0 а1 x (5.2) 33 Это наиболее часто используемая форма связи между коррелируемыми признаками, при парной корреляции она выражается уравнением (6.2), где а0 – среднее значение в точке x=0, поэтому экономической интерпретации коэффициента нет; а1 – коэффициент регрессии, показывает, на сколько изменяется в среднем значение результативного признака при увеличении факторного на единицу собственного измерения. При криволинейной зависимости применяется ряд математических функций: y a0 а1 lg x полулогарифмическая (5.3) y a0 а1 y a xа показательная степенная x (5.4) (5.5) 1 y а0 а1 x а2 x 2 1 y а0 а1 x параболическая гиперболическая (5.6) (5.7) Система нормальных уравнений МНК для линейной парной регрессии имеет следующий вид: na0 a1 x y; a0 x a1 x 2 xy. (5.8) Отсюда можно выразить коэффициенты регрессии: a1 xy x y x (x) a0 y a1 x . 2 2 ; (5.9) При численности объектов анализа до 30 единиц возникает необходимость проверить, насколько вычисленные параметры типичны для отображаемого комплекса условий, не являются ли полученные значения параметров результатом действия случайных причин. Значимость коэффициентов регрессии применительно к совокупности n<30 определяется с помощью t-критерия Стьюдента. При этом вычисляются фактические значения t-критерия: для параметра а0: t a a0 n2 , оcт (5.10) для параметра а1: t a a1 n2 х. оcт (5.11) 0 1 В формулах (6.10) и (6.11): оcт ( уi у хi ) 2 n – среднее квадратическое отклонение результативного признака у i от выровненных значений у х . (5.12) i x x x – среднее квадратическое отклонение факторного признака xi от общей n 2 i средней x . (5.13) Полученные по формулам (5.10) и (5.11) фактические значения t a и t a сравниваются с кри0 1 тическим t k , который получают по таблице Стьюдента с учетом принятого уровня значимости и числа степеней свободы ν (ν=n-k-1, где n – число наблюдений, k – число факторов, включенных в уравнение регрессии). Рассчитанные параметры а0 и а1 уравнения регрессии признаются типичными, если t фактическое больше t критического. На практике часто приходится исследовать зависимость результативного признака от нескольких факторных признаков. Аналитическая форма связи результативного признака от ряда фак- 34 торных признаков выражается и называется многофакторным (множественным) уравнением регрессии. Линейное уравнение множественной регрессии y1, 2,...k a0 a1 x1 a2 x2 ... ak xk . (5.14) Система нормальных линейных уравнений МНК для оценки коэффициентов двухфакторной регрессии y x x a0 a1 x1 a2 x2 имеет вид: 1 2 na0 a1 x1 a2 x2 y; 2 a0 x1 a1 x1 a2 x1 x2 x1 y; 2 a0 x2 a1 x1 x2 a2 x2 x2 y. (5.15) 5.2 Корреляционный анализ Различают: парную корреляцию – это зависимость между результативным и факторным признаком; частную корреляцию – это зависимость между результативным и одним факторным признаком при фиксированном значении других факторных признаков; множественную – многофакторное влияние в статической модели y x f ( x1 x2 ...xk ) . Теснота связи при линейной зависимости измеряется с помощью линейного коэффициента корреляции, который рассчитывается по одной из формул: r а1 r x y (5.16) xy x y . x y (5.17) Оценка линейного коэффициента корреляции Значение r r=0 0<r<1 -1 > r > 0 Характер связи Отсутствует Прямая Обратная r=1 Функциональная Интерпретация связи Изменение x не влияет на изменения y С увеличением x увеличивается y С увеличением x уменьшается y и наоборот Каждому значению факторного признака строго соответствует одно значение результативного Значимость линейного коэффициента корреляции проверяется на основе t-критерия Стьюдента. Для этого определяется фактическое значение критерия tрасч : t расч |r| r r n2 1 r 2 , (5.18) Вычисленное по формуле (6.18) значение tрасч сравнивается с критическим t k , который полу- чают по таблице Стьюдента с учетом принятого уровня значимости и числа степеней свободы ν. Коэффициент корреляции считается статистически значимым, если tрасч превышает t k : tрасч > t k . Универсальным показателем тесноты связи является теоретическое корреляционное отношение: 35 ф2 теор где 2y 2 2y ост 2y 1 2 ост , 2y (5.19) у2 – общая дисперсия эмпирических значений y, характеризует вариацию результативного признака за счет всех факторов, включая х; ф2 – факторная дисперсия теоретических значений результативного признака, отражает влияние фактора х на вариацию у; 2 – остаточная дисперсия эмпирических значений результативного признака, отражает ост влияние на вариацию у всех остальных факторов кроме х. По правилу сложения дисперсий: 2 у2 ф2 ост , т.е. ( y 2 2 2 ( у y ) ( y у y ) x i x ) i . n n n i i (5.19) Оценка связи на основе теоретического корреляционного отношения (шкала Чеддока) Значение теор Значение теор Характер связи Характер связи η=0 0 < η < 0,2 0,2 ≤ η < 0,3 0,3 ≤ η < 0,5 Отсутствует Очень слабая Слабая Умеренная 0,5 ≤ η < 0,7 0,7 ≤ η < 0,9 0,9 ≤ η < 1 η=1 Заметная Сильная Весьма сильная Функциональная Для линейной зависимости теоретическое корреляционное отношение тождественно линейному коэффициенту корреляции, т.е. η = |r|. Множественный коэффициент корреляции в случае зависимости результативного признака от двух факторов вычисляется по формуле: R y / x1x2 где 2 2 ryx r 2ryx1 ryx2 rx1x2 yx 1 2 1 rx21x2 , (5.20) ryx1 , ryx2 , rx1x2 – парные коэффициенты корреляции между признаками. Множественный коэффициент корреляции изменяется в пределах от 0 до 1 и по определению положителен: 0 R 1 . Условие включения факторных признаков в регрессионную модель – наличие тесной связи между результативным и факторными признаками и как можно менее существенная связь между факторными признаками. Значимость коэффициента множественной детерминации, а соответственно и адекватность всей модели и правильность выбора формы связи можно проверить с помощью критерия Фишера: Fрасч где R2 n k 1 , k 1 R2 (5.21) R2 – коэффициент множественной детерминации (R2 R y / x1x2 ); k – число факторных признаков, включенных в уравнение регрессии. 2 Связь считается существенной, если Fрасч > Fтабл – табличного значения F-критерия для заданного уровня значимости α и числе степеней свободы ν1 = k, ν2 = n – k – 1. 36 Частные коэффициенты корреляции характеризуют степень тесноты связи результативного признака и фактора, при элиминировании его взаимосвязи с остальными факторами, включенными в анализ. Расчет частных коэффициентов корреляции в случае двухфакторной регрессии (в первом случае исключено влияние факторного признака х2, во втором – х1): ryx1 / x2 ryx1 ryx2 rx1x2 2 (1 ryx ) (1 rx21x2 ) 2 ryx2 / x1 ; ryx2 rx1 y rx1x2 2 (1 ryx ) (1 rx21x2 ) 2 , (5.22) где r – парные коэффициенты корреляции между указанными в индексе переменными. Для оценки сравнительной силы влияния факторов, по каждому фактору рассчитывают частные коэффициенты эластичности: Эxi ai где xi , y (5.23) x i – среднее значение соответствующего факторного признака; y – среднее значение результативного признака; a i – коэффициент регрессии при i-м факторном признаке. Данный коэффициент показывает, на сколько процентов следует ожидать изменения результативного показателя при изменении фактора на 1% и неизменном значении других факторов. Частный коэффициент детерминации показывает, на сколько процентов вариация результативного признака объясняется вариацией i-го признака, входящего в множественное уравнение регрессии, рассчитывается по формуле: d xi ryxi xi , где (5.24) ryxi – парный коэффициент корреляции между результативным и i-м факторным признаком; xi – соответствующий стандартизованный коэффициент уравнения множественной регрес- сии: xi ai xi y . (5.25) Пример По данным о стоимости основных производственных фондов (СОПФ) и объеме валовой продукции (ВП) определить линейное уравнение связи. Номер предприятия 1 2 3 4 5 6 7 8 9 10 Сумма Среднее СОПФ ( xi ), млн. руб. 1 2 3 4 5 6 7 8 9 10 55 5,5 ВП (y), млн. руб. 20 25 31 31 40 56 52 60 60 70 445 44,5 xi уi xi 20 50 93 124 200 336 364 480 540 700 2907 290,7 1 4 9 16 25 36 49 64 81 100 385 38,5 уi 2 2 400 625 961 961 1600 3136 2704 3600 3600 4900 22487 2248,7 37 у хi 19,4 25 30,6 36,2 41,8 47,4 53 58,6 64,2 69,8 445 44,5 у у 2 i хi 0,36 0 0,16 27,04 3,24 73,96 1 1,96 17,64 0,04 125,4 x x 2 i 20,25 12,25 6,25 2,25 0,25 0,25 2,25 6,25 12,25 20,25 82,5 10 a0 55a1 445; 55a0 385 a1 2907 . 290,7 5,5 44,5 a1 5,6 ; 38,5 (5,5) 2 a0 44,5 5,6 5,5 13,7 . Уравнение регрессии имеет вид: у х 13,8 5,6 x . Следовательно, с увеличением стоимости основных фондов на 1 млн.руб. объем валовой продукции увеличивается в среднем на 5,6 млн. руб. Проверим значимость полученных коэффициентов регрессии. Рассчитаем ост и x : 125,4 3,54 10 82,5 x 2,87 10 ост 10 2 10,9 3,54 10 2 t a1 5,6 2,87 12,8 . 3,54 t a0 13,7 для параметра а0: для параметра а1: По таблице Стьюдента с учетом уровня значимости 1=8 получаем t k =2,306. =5% и числа степеней свободы ν =10-1- Фактические значения t a и t a превышают табличное критическое значение t k . Это позволя0 1 ет признать вычисленные коэффициенты корреляции типичными. Пример По данным предыдущего примера оценить тесноту связи между признаками, оценить значимость найденного коэффициента корреляции. r а1 x 2,87 xy x y 290,7 5,5 44,5 5,6 0,98 , или r 0,98 . y 16,4 x y 2,87 16,4 Значение коэффициента корреляции свидетельствует о сильной прямой связи между рассматриваемыми признаками. t расч r n2 1 r 2 0,98 10 2 1 0,98 2 13,9 Значение tрасч превышает найденное по таблице значение t k =2.306, что позволяет сделать вывод о значимости рассчитанного коэффициента корреляции. 38 Пример Имеются некоторые данные о среднегодовой стоимости ОПФ (СОПФ), уровне затрат на реализацию продукции (ЗРП) и стоимости реализованной продукции (РП). Считая зависимость между этими показателями линейной, определить уравнение связи; вычислить множественный и частные коэффициенты корреляции, оценить значимость модели. СОПФ (х1), млн.руб. 3 3 5 6 7 6 8 9 9 10 = 66 х1 =6,6 ЗРП (х2), РП (y), x 22 x12 в % к РП млн.руб. 4 20 9 16 3 25 9 9 3 20 25 9 5 30 36 25 10 32 49 100 12 25 36 144 12 29 64 144 11 37 81 121 15 36 81 225 15 40 100 225 = 90 = 294 = 490 = 1018 х 2 =9,0 у =29,4 – х1 х2 х1 y х2 y yˆ x1x2 12 9 15 30 70 72 96 99 135 150 = 688 60 75 100 180 224 150 232 333 324 400 = 2078 80 75 60 150 320 300 348 407 540 600 = 2880 20,36 20,05 24,21 26,91 30,54 29,08 33,24 35,01 36,25 38,33 = 294 х1 х 2 =68,8 х1 у =207,8 х2 у =288,0 – – Решение. Составим систему нормальных уравнений МНК: 10a0 66a1 90a2 294; 66a0 490 a1 688 a 2 2078; 90a 688 a 1018 a 2880; 0 1 2 Выразим из 1-го уравнения системы a0 = 29,4 – 6,6·a1 – 9·a2. Подставив во 2-е уравнение это выражение, получим: а1 137,6 94а2 . 54,4 Далее подставляем в 3-е уравнение вместо a0 и a1 полученные выражения и решаем его относительно a2 с точностью не менее 3-х знаков после запятой. Итак: a0 = 12,508; a1 = 2,672; a2 = – 0,082; у x1x2 = 12,508 + 2,672·х1 – 0,082·х2. rx1 y = x1 y x1 y 207,8 6,6 29,4 = 0,884; x1 y 2,46 6,96 rx2 y = x2 y x2 y 288,0 9,0 29,4 = 0,777; x2 y 4,81 6,96 rx1x2 = R y / x1x2 x1 x2 x1 x2 68,8 6,6 9,0 = 0,893; x1 x 2 2,46 4,81 ryx2 1 ryx2 2 2ryx1 ryx2 rx1x2 1 rx21x2 0,884 2 0,777 2 2 0,884 0,777 0,893 1 0,893 2 =0,893. Проверим значимость r (α = 0,01 и ν = 7): x1 t расч 0,884 10 2 1 1 0,884 2 x2 t расч 0,777 = 5,00; 39 10 2 1 1 0,777 2 = 3,27. x1 =5,00 > tтабл=3,50 – коэффициент корреляции x1 значим; t расч x2 =3,27 < tтабл=3,50 – коэффициент корреляции x2 не значим. t расч Произведенные расчеты подтверждают условие включения факторных признаков в регрессионную модель – между результативным и факторными признаками существует тесная связь ( rx y = 1 0,884; rx y = 0,777), однако между факторными признаками достаточно существенная связь ( rx x = 2 1 2 0,893). Включение в модель фактора x2 незначительно увеличивает коэффициент корреляции ( rx y = 1 0,884; R y / x x =0,893), поэтому включение в модель фактора x2 нецелесообразно. 1 2 Вычислим стандартизованные коэффициенты уравнения множественной регрессии: x1 2,672 5,44 0,94 43,64 x 2 0,082 20,8 0,06 43,64 Отсюда вычислим частные коэффициенты детерминации: d x1 0,884 0,94 0,83 d x 2 0,777 (0,06) 0,05 т.е. вариация результативного признака объясняется главным образом вариацией фактора x1. Вычислим частные коэффициенты эластичности: Эx1 2,672 6,6 0,6 29,4 Эx 2 0,082 9 0,03 29,4 Проверим адекватность модели на основе критерия Фишера: Fрасч 0,893 2 7 13,7 1 0,893 2 2 Найдем значение табличного значения F-критерия для уровня значимости α=0,05 и числе степеней свободы ν1 = 2, ν2 = 10 –2 – 1 : Fтабл=4,74. Превышение значения Fрасч над значением Fтабл позволяет считать коэффициент множественной детерминации значимым, а соответственно и модель – адекватной, а выбор формы связи - правильным. 6. Ряды динамики 6.1 Анализ динамических рядов Динамический ряд представляет собой хронологическую последовательность числовых значений статистических показателей. Виды рядов динамики (РД): 1) моментные (моментальные) РД; 2) интервальные РД; 3) РД с нарастающими итогами; 4) производные РД. Моментные ряды динамики отображают состояние изучаемых явлений на определенные даты (моменты) времени. Особенностью моментного ряда динамики является то, что в его уровни могут входить одни и те же единицы изучаемой совокупности. Пример моментного ряда динамики: Дата Число работников, чел. 1.01.2001 192 1.04.2001 190 1.07.2001 195 1.10.2001 198 1.01.2002 200 Интервальные ряды динамики отображают итоги развития (функционирования) изучаемых явлений за отдельные периоды (интервалы) времени. Каждый уровень интервального ряда складывается из данных за более короткие интервалы. Пример интервального ряда динамики: 40 Год 1997 1998 1999 2000 2001 Объем розничного товаро885,7 932,6 980,1 1028,7 1088,4 оборота, тыс. руб. Статистическое отображение развития изучаемого явления во времени может быть представлено рядами динамики с нарастающими итогами. Их применение обусловлено потребностями в результатах развития изучаемых показателей не только за данный отчетный период, но и с учетом предшествующих периодов. При составлении таких рядов производится последовательное суммирование смежных уровней. Этим достигается суммарное обобщение результата развития изучаемого показателя с начала отчетного периода (месяца, квартала, года и т.д.). Производные ряды – ряды, уровни которых представляют собой не непосредственно наблюдаемые значения, а производные величины: средние или относительные. Основные направления изучения закономерностей развития социально-экономических явлений с помощью рядов динамики: характеристика уровней развития изучаемых явлений во времени; измерение динамики изучаемых явлений посредством системы статистических показателей; выявление и количественная оценка основной тенденции развития (тренда); изучение периодических колебаний; экстраполяция и прогнозирование. Таблица 8.1 Уровни (показатели) ряда динамики Показатель Базисные Цепные Средние Формула Абсолютный прирост Δ y б i = yi – у0 Темп роста Tр бi yi y0 (6.2) Темп прироста Tп бi y б i Tр бi 1 y0 (6.3) Абсолютный прирост Δ y цi = yi – yi-1 Темп роста Tр цi Темп прироста Tп цi Темп наращивания Тнi Абсолютное значение 1% прироста А1% Абсолютный прирост y Темп роста Тр Темп прироста Tп Тр 1 n (6.1) (6.4) yi yi 1 (6.5) yц i Tр цi 1 (6.6) Тр бi Тр бi 1 (6.7) yi 1 yцi y0 yцi 0,01 yi 1 (6.8) y n y0 y áï . = n 1 n 1 (6.9) Тп цi Трцi 41 n n Тр б n yn y0 (6.10) (6.11) Средний уровень ряда динамики характеризует типическую величину абсолютных уровней. Средний уровень интервального ряда определяется по формуле средней арифметической простой: y yi n y 0 y1 ... y n , n (6.12) где n – число уровней. В моментном ряду динамики с равностоящими датами средний уровень определяется по формуле средней хронологической простой: 1 1 y0 y1 y2 ... yn 2 . y 2 n 1 (6.13) В моментном ряду динамики с неравноотстоящими датами средний уровень определяется по формуле средней хронологической взвешенной: y где ti yi ti t1 y1 t 2 y 2 ... t n y n , t1 t 2 ... t n (6.14) уi – уровни ряда динамики, сохранившиеся без изменения в течение промежутка времени ti. Между базисными и цепными темпами роста имеется взаимосвязь: произведение последовательных цепных темпов роста равно базисному темпу роста, а частное от деления последующего базисного темпа роста на предыдущий равно соответствующему цепному темпу роста. Трбn Трцi ; Тр цi Тр бi Тр бi 1 . (6.15) 6.2 Методы анализа тенденций рядов динамики Одной из важнейших задач статистики является определение в рядах динамики общей тенденции развития явления. На развитие явления во времени оказывают влияние факторы, различные по характеру и силе воздействия. Одни из них оказывают практически постоянное воздействие и формируют в рядах динамики определенную тенденцию развития. Воздействие же других факторов может быть кратковременным или носить случайный характер. Основная тенденция (тренд) – изменение, определяющее общее направление развития, это систематическая составляющая долговременного действия. Задача – выявить общую тенденцию в изменении уровней ряда, освобожденную от действия различных случайных факторов. Методы выявления тренда: 1) Метод укрупнения интервалов основан на укрупнении периодов времени, к которым относятся уровни ряда динамики (одновременно уменьшается количество интервалов). Средняя, исчисленная по укрупненным интервалам, позволяет выявить направление и характер (ускорение или замедление роста) основной тенденции развития, в то время как слишком малые интервалы между наблюдениями приводят к появлению ненужных деталей в динамике процесса, засоряющих общую тенденцию. Месяц Объем выпуска, млн.руб. Месяц Объем выпуска, млн.руб. Январь 5,1 Июль 5,6 Февраль 5,4 Август 5,9 Март 5,2 Сентябрь 6,1 Апрель 5,3 Октябрь 6,0 Май 5,6 Ноябрь 5,9 Июнь 5,8 Декабрь 6,2 42 Различные направления изменений уровней ряда по отдельным месяцам затрудняют выводы об основной тенденции производства. Если соответствующие месячные уровни объединить в квартальные и вычислить среднемесячный выпуск продукции по кварталам, т.е. укрупнить интервалы, то решение задачи упрощается. Квартал 1 2 3 4 Объем производства, млн.руб. в квартал в среднем в месяц 15,7 5,23 16,7 5,57 17,6 5,87 18,1 6,03 После укрупнения интервалов основная тенденция роста производства стала очевидной: 5,23<5,57<5,87<6,03 млн.руб. 2) Метод скользящей средней заключается в том, что исчисляется средней уровень из определенного числа (обычно нечетного) первых по счету уровней ряда, затем – из такого же числа уровней, но начиная со второго по счету, далее – начиная с третьего и т.д. Таким образом, средняя как бы “скользит” по ряду динамики, передвигаясь на один срок. Недостатком сглаживания ряда является укорачивание сглаженного ряда по сравнению с фактическим, а, следовательно, потеря информации. Скользящая средняя Год Урожайность, ц/га трехлетняя пятилетняя 1991 15,4 – – 1992 14,0 15,7 = 15,4+14,0+ +17,6)/3 – 1993 1994 1995 1996 1997 1998 1999 2000 17,6 15,4 10,9 17,5 15,0 18,5 14,2 14,9 15,7 = 14,0+17,6+ +15,4)/3 14,6 14,6 14,5 17,0 15,9 15,9 – 14,7 15,1 15,3 15,5 15,2 16,0 – – Итого 153,4 Сглаженный ряд урожайности по трехлетиям короче фактического на один член ряда в начале и в конце, по пятилетиям – на два члена в начале и в конце ряда. Он меньше, чем фактический, подвержен колебаниям из-за случайных причин, и четче выражает основную тенденцию роста урожайности за изучаемый период, связанную с действием долговременно существующих причин и условий развития. Укрупнение интервалов и метод скользящей средней дают возможность определить лишь общую тенденцию развития явления, более или менее освобожденную от случайных или волнообразных колебаний. Получить обобщенную статистическую модель тренда посредством этих методов нельзя. 43 19 18 17 16 15 14 13 12 11 10 1991 1993 1995 эмпирические уровни 1997 1999 сглаженные по трехлетиям сглаженные по пятилетиям Рис. 8.2. Эмпирические и сглаженные уровни ряда динамики 3) Аналитическое выравнивание ряда динамики используется для того, чтобы дать количественную модель, выражающую основную тенденцию изменения уровней ряда динамики во времени. Общая тенденция развития рассчитывается как функция времени: ŷt = f(t), (6.16) где ŷt – уровни динамического ряда, вычисленные по соответствующему аналитическому уравнению на момент времени t. Определение теоретических (расчетных) уровней ŷt производится на основе так называемой адекватной математической модели, которая наилучшим образом отображает (аппроксимирует) основную тенденцию ряда динамики. Простейшими моделями, выражающими тенденцию развития, являются (где a0, a1 – параметры уравнения; t – время): Линейная функция (прямая) ŷt = a0 + a1·t. (6.17) Показательная функция yˆ t a0 a1t . (6.18) Степенная функция (парабола) ŷt = a0 + a1·t + a2·t2. (6.19) Расчет параметров функции обычно производится методом наименьших квадратов. Выравнивание ряда динамики заключается в замене фактических уровней yi плавно изменяющимися уровнями ŷt, наилучшим образом аппроксимирующими статистические данные. Выравнивание по прямой используется в тех случаях, когда абсолютные приросты практически постоянны, т.е. когда уровни изменяются в арифметической прогрессии. Выравнивание по показательной функции используется в тех случаях, когда ряд отражает развитие в геометрической прогрессии, т.е. когда цепные коэффициенты роста практически постоянны. Выравнивание ряда динамики по прямой ŷt = a0 + a1·t. Параметры a0, a1 согласно МНК находятся решением следующей системы нормальных уравнений: na0 a1 t y; 2 a0 t a1 t t y, где y – фактические (эмпирические) уровни ряда; 44 (6.20) t – время (порядковый номер периода или момента времени). t = 0, так что система нормальных уравнений (8.20) принимает вид: na0 y; 2 a1 t t y. (6.21) Отсюда можно выразить коэффициенты регрессии: а0 a1 y; (6.22) n t y . t 2 (8.23) Если расчеты выполнены правильно, то y = ŷt. Пример Для выравнивания ряда из примера 8.3 используем линейную трендовую модель – уравнение прямой ŷt = a0 + a1·t. n = 10. Расчет уравнения регрессии выполним в табличной форме. Таким образом, y =153,4; y·t = 6,8; t2 = 330. Вычислим параметры a0, a1 по формулам (8.22, 8.23): а0 y 153,4 = 15,34; n a1 10 t y 6,8 t 2 330 = 0,021. yi – ŷt 7 0,25 -1,19 2,37 0,12 -4,42 2,14 -0,40 3,05 -1,29 -0,63 0 (yi– ŷt)2 8 0,0625 1,4161 5,6169 0,0144 19,5364 4,5796 0,0160 9,3025 1,6641 0,3969 42,6050 Расчет уравнения регрессии Год 1 1991 1992 1993 1994 1995 1996 1997 1998 1999 2000 Итого y 2 15,4 14,0 17,6 15,4 10,9 17,5 15,0 18,5 14,2 14,9 153,4 t 3 -9 -7 -5 -3 -1 1 3 5 7 9 0 t2 4 81 49 25 9 1 1 9 25 49 81 330 y·t 5 -138,6 -98,0 -88,0 -46,2 -10,9 17,5 45,0 92,5 99,4 134,1 6,8 ŷt 6 15,15 15,19 15,23 15,28 15,32 15,36 15,40 15,45 15,49 15,53 153,4 Уравнение прямой будет иметь вид: ŷt = 15,34+0,021·t. Подставляя в данное уравнение последовательно значения, находим выравненные уровни ŷt (гр. 6 табл. 7.3). Проверим расчеты: y = ŷt = 153,4. Следовательно, значения уровней выравненного ряда найдены верно. 45 Полученное уравнение показывает, что, несмотря на значительные колебания в отдельные годы, наблюдается тенденция увеличения урожайности: с 1991 по 2000 г. урожайность зерновых культур в среднем возрастала на 0,021 ц/га в год. Тенденция роста урожайности зерновых культур в изучаемом периоде отчетливо проявляется в результате построения выравненной прямой. 6.3 Сезонные колебания Уровни ряда динамики формируются под влиянием различных взаимодействующих факторов, одни из которых определяют тенденцию развития, а другие –колеблемость (вариацию) Колебания уровней ряда носят различный характер. Наряду с трендом выделяют циклические (долгопериодические), сезонные (обнаруживаемые в рядах, где данные приведены за кварталы или месяцы) и случайные колебания. y ŷt – линия тренда y – средний уровень уi – фактические уровни t Колебания фактических уровней yi относительно среднего уровня y и линии тренда ŷ t Периодические колебания являются результатом влияния природно-климатических условий, общих экономических факторов, а также многочисленных и разнообразных факторов, которые часто являются регулируемыми. В широком понимании к сезонным относят все явления, которые обнаруживают в своем развитии четко выраженную закономерность периодических изменений, т.е. более или менее устойчиво повторяющиеся колебания уровней. Динамический ряд в этом случае называют сезонным рядом динамики. Метод изучения и измерения сезонности заключается в построении специальных показателей, которые называются индексами сезонности. Индексами сезонности являются процентные отношения фактических внутригрупповых уровней к теоретическим уровням, выступающим в качестве базы сравнения. Порядок определения индекс сезонности: 1) Для каждого месяца рассчитывается средняя величина уровня 2) Затем вычисляется среднемесячный уровень для всего ряда 3) Определяется показатель сезонной волны – индекс сезонности Is: Is где yi y 100 % , (6.24) y i – средний уровень для каждого месяца; y – среднемесячный уровень для всего ряда. 46 Когда уровень проявляет тенденцию к росту или к снижению, то отклонения от постоянного среднего уровня могут исказить сезонные колебания. Пример Месяц Объем пассажирских авиаперевозок 1997 1 94,0 2 98,0 3 107,6 4 112,8 5 121,2 6 112,0 7 110,0 8 102,5 9 97,0 10 94,0 11 96,4 12 92,5 Итого 1237,9 В среднем 103,2 1998 89,3 93,1 102,2 107,1 115,2 106,4 104,5 97,4 92,2 89,3 91,6 87,9 1176,0 98,0 1999 92,6 96,6 106,2 111,4 119,8 110,6 108,6 101,1 95,6 92,6 95,0 91,1 1221,1 101,8 Средний 92,0 95,9 105,3 110,4 118,7 109,7 107,7 100,3 94,9 92,0 94,3 90,5 1211,7 101,0 Is, % 91,1 95,0 104,2 109,3 117,6 108,6 106,6 99,3 94,0 91,1 93,4 89,6 1199,7 100,0 Средний индекс сезонности для 12 месяцев должен быть равен 100%, тогда сумма индексов должна составлять 1200%. У нас – 1199,7% (погрешность – следствие округлений). Значит, расчеты верны. Выводы: 1) объем пассажирских авиаперевозок характеризуется ярко выраженной сезонностью; 2) объем пассажирских авиаперевозок по отдельным месяцам года значительно отклоняется от среднемесячного; 3) наибольший объем характерен для мая, наименьший – для декабря. Для наглядного изображения сезонной волны индексы сезонности изображают в виде графика. 120% 110% 100% 90% 80% 1 2 3 4 5 6 7 8 9 10 11 Ì åñÿöû Индекс сезонности авиаперевозок пассажиров 47 12 6.4. Статистические методы прогнозирования экономических показателей Прогнозирование – процесс определения возможных в будущем значений экономических показателей на основании уже известных. Различают прогнозы по периоду упреждения: оперативные (до 1 мес.); краткосрочные (до 1 года); среднесрочные (1 – 5 лет); долгосрочные (более 5 лет). Различают методы прогнозирования: Экстраполяция тенденций: - упрощенные приемы, основанные на средних показателях динамики (средние темпы роста, прироста); - аналитические методы (метод наименьших квадратов, тренды, т.е. математические функции); - адаптивные методы, учитывающие степень устаревания данных (методы скользящих и экспоненциальных средних, методы авторегрессии). Методы статистического моделирования: - статические (методы парной и множественной регрессии); - динамические (анализ динамических рядов): - методы агрегатного моделирования (разложение ряда на тенденции, сезонность, случайные составляющие); - методы регрессии по взаимосвязанным рядам динамики (включаются в модель не только факторы, но и лаговые переменные); - методы регрессии по пространственно-временной информации (для каждого ряда строится регрессионная модель по совокупности объектов). 6.4.1. Прогнозирование на основе экстраполяции тренда Тренд – основная тенденция развития. Методы выявления тренда называются методами выравнивания временного ряда (метод наименьших квадратов, скользящей средней, конечных разностей). При наличии тенденции в ряду динамики модель уровня динамического ряда: yt y ( yˆ t y ) ( yt yˆ t ) , где (6.25) y – средний уровень динамического ряда; ŷ t – теоретический (расчетный, трендовый) уровень; ( yˆ t y ) – эффект тенденции; ( yt yˆ t ) – случайная составляющая (остаточные колебания) ε. ( yt yˆ t ) , тем выше адекватность (практическая значиЧем меньше остаточные колебания мость) модели. Следовательно, результаты прогноза зависят от типа кривой тренда ŷ(t). 1. Линейный тренд ŷt = a0 + a1·t означает, что уровни динамики ряда изменяются с одинаковой скоростью. a0 – начальный уровень тренда (t = 0); a1·– средний абсолютный прирост в единицу времени. В линейном тренде уровни динамики ряда изменяются в арифметической прогрессии, а темпы роста уровня – падающие. 2. Параболический тренд ŷt = a0 + a1·t + a2·t2 применяется, если ряд характеризуется относительным абсолютным ускорением, т.е. постоянными являются вторые разности (производные) – приросты абсолютных приростов. a0 – начальный уровень тренда (t = 0); 48 a1·– средний абсолютный прирост за период; a2·– половина абсолютного ускорения динамического ряда. Парабола означает смену тенденций (рост сменяется падением или наоборот). Это, как правило, связано с новым этапом в развитии явления по времени. Применяется для краткосрочного прогноза. 3. Парабола кубическая характеризует три этапа развития: рост, падение и опять рост. Число наблюдений должно быть около 6–7 временных единиц на один шаг прогноза. Следовательно, чтобы применить полином третьей степени надо иметь ряд за 20 лет, и корректно это только в стабильной экономике. a a t 4. Показательная кривая yˆ t a0 a1 , yˆ t e 0 1 применяется при стабильном темпе роста динамического ряда. Рост по экспоненте означает геометрическую прогрессию уровней ряда. Это возможно в экономике в сравнительно небольшой период времени, когда ограничены ресурсы, меняются условия рынка. t a0 – начальный уровень тренда (t = 0); a1·– средний абсолютный прирост за период; 4. Логистическая кривая yˆ t 1 c abt (кривая Перла-Рида) (кривые Гомперца), имеющая асимптоту, применяется, когда существует ограничение на рост показателя (уровней динамического ряда). Если изучается динамика детской смертность, то нижняя асимптота – уровень жизни, верхняя – демографический состав населения. 8.4.2. Выбор наилучшего тренда при прогнозировании При выборе уравнения тренда можно руководствоваться средней ошибкой аппроксимации А 1 n yt yˆ t 100 , %. n t 0 yt (6.26) А 5÷7% – хорошая аппроксимация. Доверительные интервалы прогноза определяются по дисперсии уточненного тренда n dy где ( yt yˆ t ) 2 t 0 n m 1 , %. (6.27) yt – фактические уровни ряда; ŷ t – расчетные (трендовые) значения; n – длина ряда; m – число параметров в уравнении тренда (без свободного члена). Доверительный интервал с учетом табличного значения критерия Стьюдента tl ,k , равен d y yˆ t tl ,k d y . (6.28) Если распространить этот интервал на следующий отрезок времени, то надо ввести поправочный коэффициент q, зависящий от длины ряда и периода l упреждения 49 (tl t ) 2 1 , q 1 2 n ( t t ) l где (6.29) n – длина ряда; tl – порядковый номер прогнозируемого периода (tl = n + l); t – порядковый номер середины ряда. Тогда ошибка прогноза d p d y q yˆ t t l ,k d y q . y pt yˆ t . (6.30) (6.31) 7. Экономические индексы Индексом в статистике называется относительный показатель, характеризующий изменение величины какого-либо явления по сравнению с эталоном. Таблица – Классификация индексов Классификационный признак Вид индексов Количественные (объемные) индексы (физического объема, товарооборота национального дохода) Индивидуальные (изменение одного показателя однотоварного) Качественные индексы (интенсивности) (курса валют, цен, себестоимости, производительности труда) общие (групповые или субидексы (по отраслям)) 3. Метод расчета Агрегатные Средние 4. База сравнения Динамические Территориальные (например, индекс цен на товары в РФ и ФРГ) 5. Вид весов С постоянными весами С переменными весами 6. Состав явления Постоянного состава Переменного состава Структурных сдвигов 7. Период исчисления Годовые Квартальные Помесячные и т.д. 1. Содержание изучаемых объектов 2. Степень охвата элементов совокупности Таблица – Обозначения индексируемых величин Обозначение Индексируемая величина q количество (объем) какого-либо товара в натуральном выражении p цена единицы товара pq товарооборот (стоимость продукции) z (c) y П Обозначение Индексируемая величина t затраты времени на производство единицы продукции, трудоемкость W выработка продукции в единицу времени или на одного работника (производительность труда) T=tq общие затраты времени на производство продукции или численность работников себестоимость единицы продукции урожайность отдельных сельскохозяйственных культур посевная площадь под отдельными культурами 50 7.1 Общие индексы количественных показателей Индекс физического объема продукции показывает относительное изменение стоимости продукции из-за изменения объема производства. где Индивидуальный индекс: iq q1 , q0 Агрегатный индекс: Iq q1 p0 , q0 p0 (7.1) (7.2) q1 и q0 – объем выпуска продаж в базисном и отчетном периодах соответственно; p0 – цена в базисном периоде. Индекс товарооборота (или стоимости продукции), показывает во сколько раз изменилась стоимость продукции. Агрегатный индекс товарооборота I pq p1q1 . p0 q 0 (7.4) На сколько изменилась стоимость продукции показывает разница между числителем и знаменателем индекса: pq p1q1 q0 p0 . (7.3) При построении индекса физического объема продукции в качестве соизмерителей (весов) принимаются сопоставимые, неизменные, фиксированные цены, отличающиеся от текущих (действующих) цен (это в условиях инфляции могут быть цены предшествующего периода) или себестоимость продукции z0. В этом случае индекс характеризует изменение издержек производства. Iq q1 z 0 . q0 z 0 (7.5) Аналогично строятся индексы товарооборота и потребления. Значение общего индекса Ipq зависит от изменения двух индексируемых величин объема продукции (q0, q1) и цен (p1,p0). В зависимости от вида исходных данных можно исчислить средние взвешенные (арифметические) индексы физического объема. Если неизвестно q1, но дано значение q0 и iq q1 , а также стоимость продукции базисq0 ного периода p0, то средний арифметический индекс физического объема равен: Iq iq q 0 p 0 . q p 0 0 (7.6) Средний гармонический индекс физического объема используется для аналитических оценок в случае, когда неизвестно q0, но дано значение q1 и базисного периода p0: 51 iq q1 , а также стоимость продукции q0 Iq q1 p0 q p 1i 0 q . (7.7) Индекс физического объема в прошлом вычисляется в сопоставимых, фиксированных ценах и отражает динамику выпуска продукции. В торговле чаще вычисляется в фактических ценах, отражая одновременное изменение цен и объема. Пример Предприятие выпускает 3 вида неоднородной продукции. Данные об их производстве и ценах на них за два периода приведены в таблице (графы 1–5). Определить индивидуальные и агрегатные индексы физического объема. Выработано тыс. единиц Товар Стоимость продукции в базисных ценах, тыс.руб. базисный отчетный базисный отчетный базисный отчетный период период период период период период q0 А Б В Σ Цена за единицу товара, руб. q1 80 50 40 — p0 60 30 35 — p1 13 18 6 — q0p0 16 20 8 — q1p0 1040 900 240 2180 780 540 210 1530 Индивидуальный индекс физического объема iq q1 q0 0,750 0,600 0,875 — Агрегатный индекс физического объема: Iq q1 p0 q0 p0 1530 = 0,702 (70,2%). 2180 Вычитая из числителя знаменатель q1 p0 q0 p0 = 1530 – 2180 = –650, определяем, что в абсолютном выражении за счет уменьшения выпуска стоимость продукции в отчетном периоде уменьшилась на 650 тыс.руб. 8.2 Общие индексы качественных показателей Индексы цен показывают, как изменилась стоимость продукции за счет изменения цен. Агрегатный индекс цен Пааше: Ip где p1q1 , p0 q1 (7.8) p1q1 – фактическая стоимость продаж (товарооборот) в отчетном периоде; p0q1 – условная стоимость товаров, реализованных в отчетном периоде по базисным ценам. Агрегатный индекс цен Ласпейреса: Ip p1q0 , p0 q0 (7.9) где p0q0 – фактическая стоимость продаж (товарооборот) в базисном периоде; p1q0 – условная стоимость товаров, реализованных в базисном периоде по отчетным ценам. Индекс цен Пааше показывает изменение цен отчетного периода по сравнению с базисным (на сколько товары стали дороже (дешевле)). Если бы товары были реализованы в отчетном периоде по базисным ценам, то фактическая экономия составила 52 Ppq p1q1 p0 q1 . (7.10) Индекс цен Ласпейреса показывает условную экономию, т.е. на сколько изменились цены в отчетном периоде по сравнению с базисным, но по той продукции, которая была реализована в базисном периоде. Этот индекс применяется при прогнозировании объема товарооборота в связи с предлагаемым изменением цен. В условиях стабильности применяют индекс Пааше, при инфляции – индекс Ласпейреса. Основываясь на рассмотренных двух вариантах построения индексов, Фишер предложил рассчитывать среднюю геометрическую индексов цен Пааше и Ласпейреса: Ip p1q0 p1q1 . p0 q0 p0 q1 (7.11) Этот индекс носит название “идеальный” индекс цен Фишера. Индекс цен Фишера “обратим” во времени (т.е. если рассчитывать индекс базисного периода к отчетному, он будет равен обратной величине первоначального индекса), но лишен экономического содержания. При синтезировании общего индекса цен вместо фактического количества товаров (в отчетный и базисный периоды) в качестве соизмерителей индексируемых величин р1 и р0 могут применяться средние величины реализации товаров. При таком способе расчета формула сводного индекса цен (называемого индексом цен Лоу) выглядит следующим образом: Ip p1 q . p0 q (7.12) Индекс цен Лоу применяется в расчетах при закупках или реализации товаров в течение продолжительных периодов времени (пятилетках, десятилетиях и т.п.), поскольку он дает возможность анализа цен с учетом происходящих внутри отдельных субпериодов изменений в ассортиментном составе товаров. Пример По имеющимся данным о ценах и реализации неоднородных товаров за два периода необходимо определить индексы цен: 1) индивидуальные; 2) агрегатные, в т.ч. а) индекс Пааше; б) индекс Ласпейреса; в) “идеальный” индекс Фишера; г) индекс Лоу. Базисный период Отчетный период Единица Цена за единицу Продано Цена за единицу Продано Товар измерения продукции, руб. единиц продукции, руб. единиц p0 q0 p1 q1 А т 20 7500 25 9500 Б м 30 2000 30 2500 В шт. 15 1000 10 1500 Сведем расчет индивидуальных индексов цен и промежуточные расчеты для определения агрегатных индексов цен в таблицу: Индивиду- Стоимость товаров Стоимость товаров Стоимость товаров для средальный базисного периода, руб. отчетного периода, руб. него за период выпуска, руб. индекс цен Товар в базисных в отчетных в базисных в отчетных базисного отчетного периоp1 периода да ценах ценах ценах ценах ip p0 q p1 q p0q0 p1q0 p0q1 p1q1 p0 А Б В Сумма 1,250 1,000 0,667 — 150000 60000 15000 225000 187500 60000 10000 257500 190000 75000 22500 287500 53 237500 75000 15000 327500 170000 67500 18750 256250 212500 67500 12500 292500 а) Индекс цен Пааше I pP p1q1 p0 q1 327500 = 1,1391 (113,91%). 287500 Абсолютный прирост товарооборота за счет фактора изменения цен в текущем периоде по сравнению с базисным периодом составил p1q1 p 0 q1 = 327500 – 287500 = 40000 руб., т.е. если бы уровень цен остался на уровне базисного периода, экономия потребителя составила бы 40000 руб. б) Индекс цен Ласпейреса I Lp p1q0 p0 q0 257500 = 1,1444 (114,44%). 225000 Абсолютный прирост товарооборота за счет фактора изменения цен в текущем периоде по сравнению с базисным периодом составил p1q 0 p 0 q 0 = 257500 – 225000 = 32500 руб. в) “Идеальный” индекс цен Фишера I Fp 1,1391 1,1444 =1,1418 (114,18%). г) Индекс цен Лоу I lp p1 q 292500 = 1,1415 (114,15%). p0 q 256250 Товарооборот Сводный индекс товарооборота: I pq pq p q 1 1 0 0 I pP I qL pq p q p q p q 1 1 0 1 0 0 0 1 . (7.13) Построение моделей взаимосвязанных индексов возможно лишь для сопоставимого круга элементов, т.е. при неизменном ассортименте отдельных товаров в отчетном и базисном периодах. Абсолютное изменение товарооборота в отчетном периоде по сравнению с базисным одновременно за счет изменения физического объема продаж и изменения цен характеризует разница между числителем и знаменателем индекса, рассчитываемое по формуле (7.3): pq p1q1 q0 p0 . Измерить изолированное влияние каждого из этих факторов можно через разность числителя и знаменателя соответствующих аналитических индексов. Разность числителя и знаменателя индекса физического объема (по формуле Ласпейреса) pqq p0 q1 p0 q0 (7.14) показывает изменение товарооборота за счет роста (сокращения) физического объема продаж. Разность числителя и знаменателя индекса физического объема (по формуле Пааше) pq p p1q1 p0 q1 (7.15) 54 показывает изменение товарооборота в результате роста (снижения) цен. Абсолютное изменение за счет отдельных факторов в сумме дают общее абсолютное изменение результативного признака: pq pqq pq ð . (7.16) Участие каждого фактора в формировании общего изменения товарооборота в относительном изменении определяется по следующим формулам: прирост (уменьшение) товарооборота за счет изменения физического объема продаж %pqq q1 p0 q0 p0 q0 p0 Iq 1; (7.17) прирост (уменьшение) товарооборота за счет изменения цен %pq p q1 p1 q1 p0 q0 p0 I pq I q . (7.18) Совокупное влияние факторов в относительном выражении отражается моделью %pqq %pq p q1 p1 q0 p0 q0 p0 I pq 1. (7.19) При проведении статистического анализа можно определить долю каждого фактора в формировании общего изменения результата: доля прироста (уменьшения) товарооборота за счет изменения физического объема продаж dpqq pqq pq Iq 1 I pq 1 ; (7.20) доля прироста (уменьшения) товарооборота за счет изменения цен dpq p При этом pq p pq I pq I q I pq 1 . (7.21) dpqq dpq p 1 (или 100%). (7.22) Оценка доли отдельных факторов в формировании результата проводится лишь в случае однонаправленного изменения признаков-факторов. 7.3 Индексы переменного и фиксированного состава. Индекс структурных сдвигов При изучении качественных показателей часто приходится рассматривать изменение во времени (или пространстве) средней величины индексируемого показателя для определенной совокупности. Будучи сводной характеристикой качественного показателя, средняя величина складывается как под влиянием значений показателя у индивидуальных элементов (единиц), из которых состоит объект, так и под влиянием соотношения их весов (“структуры” объекта). Если любой качественный индексируемый показатель обозначить через x, а его веса – через f, то динамику среднего показателя можно отразить как за счет изменения обоих факторов (x и f), так и за счет каждого фактора отдельно. В результате получим три различных индекса: индекс переменного состава, индекс фиксированного состава, индекс структурных сдвигов. Индекс переменного состава отражает динамику среднего показателя (для однородной совокупности) за счет изменения индексируемой величины x у отдельных элементов (частей целого) и за счет изменения весов f, по которым взвешиваются отдельные значения x. Любой индекс пере- 55 менного состава – это отношение двух средних величин для однородной совокупности (за два периода или по двум территориям): I ïñ x1 x0 x1 f1 : x0 f 0 . f1 f 0 (7.23) Индекс фиксированного состава отражает динамику среднего показателя лишь за счет изменения индексируемой величины x, при фиксировании весов на уровне, как правило отчетного периода f1: I ôñ x1 f1 : x0 f1 . f1 f1 (7.24) Другими словами индекс фиксированного состава исключает влияние изменения структуры (состава) совокупности на динамику средних величин, т.е. он характеризует динамику средних величин, рассчитанных для двух периодов при одной и той же фиксированной структуре. Аналогично можно показать динамику среднего показателя лишь за счет изменения весов f при фиксировании индексируемой величины на уровне базисного периода x0. Такой индекс условно назван индексом структурных сдвигов: I ññ x 0 f1 : x 0 f 0 . f1 f 0 Если от абсолютных весов перейти к относительным ( d средних величин примут вид: Индекс переменного состава: I ïñ x1d1 . x0 d 0 (7.25) f f и Σd =1), формулы индексов (7.26) Индекс фиксированного состава: I ôñ x1d1 . x 0 d1 (7.27) Индекс структурных сдвигов: I ññ x 0 d1 . x0 d 0 (7.28) Индекс переменного состава есть произведение индекса фиксированного состава на индекс структурных сдвигов: I ïñ I ôñ I ññ . (7.29) Пример По имеющимся данным о выпуске и себестоимости одноименного товара на двух предприятиях требуется определить изменение себестоимости единицы продукции на каждом предприятии, а также в целом по всем предприятиям с помощью индексов: а) переменного состава; б) фиксированного состава; в) структурных сдвигов. 56 Базисный период Отчетный период Предприятие Произведено Произведено СебестоиСебестоимость продукции продукции мость единиед. продукции, в долях к цы продукции, руб. в тыс. шт. в тыс. шт. в долях к итогу руб. итогу q0 d0 z0 q1 d1 z1 1 120 0,5 480 160 0,4 400 2 120 0,5 400 240 0,6 440 Итого 240 1,0 – 400 1,0 – Индивидуальные индексы для 1-го и 2-го предприятия соответственно: i z1 400 = 0,8333 (83,33%); 480 iz 2 440 = 1,1000 (110,00%). 400 Для дальнейших расчетов понадобятся дополнительные расчеты: Предприятие Базисный период q0 d0 z0 Отчетный период q1 d1 z1 Расчетные графы z0 d0 z1 d1 z0 d1 1 120 0,5 480 160 0,4 400 240 160 192 2 Итого 120 240 0,5 1 400 – 240 400 0,6 1 440 – 200 440 264 424 240 432 Средние себестоимости: в базисном периоде z0 z 0 q0 z d 240 200 440 0 0 q0 в отчетном периоде z1 z1q1 z d 160 264 424 1 1 q1 Индекс переменного состава: I ïñ z1q1 : z 0 q0 q1 q0 z1d1 z0 d 0 руб.; руб. z 1 440 0,9636 z 0 424 (96,36%). Индекс фиксированного состава: I ôñ z1q1 : z 0 q1 z1d1 q1 q1 z 0 d1 Индекс структурных сдвигов: I ññ z 0 q1 : z 0 q0 q1 q0 I ññ I ïñ I z 0 d1 z0 d 0 424 0,9815 432 (98,15%). 432 0,9818 440 (98,18%). 96,36 0,9818 98,18 98,15 ôñ Проверка %. Себестоимость по двум предприятиям в среднем снизилась на 3,64% Iпc – 100% = 96,36 – 100 = –3,64%. В том числе: - за счет изменения структуры выпуска продукции: Icc – 100% = 98,18 – 100 = –1,82%; - за счет снижения себестоимости на каждом предприятии Iпc – Icc = 96,36 – 98,18 = –1,82%. 57 ПРИЛОЖЕНИЕ Значение критерия Пирсона χ2 Уровень значимости α df(v) Уровень значимости α df(v) 0,10 0,05 0,01 0,10 0,05 0,01 1 2,71 3,84 6,63 21 29,62 32,67 38,93 2 4,61 5,99 9,21 22 30,81 33,92 40,29 3 6,25 7,81 11,34 23 32,01 35,17 41,64 4 7,78 9,49 13,28 24 33,20 36,42 42,98 5 9,24 11,07 15,09 25 34,38 37,65 44,31 6 10,64 12,59 16,81 26 35,56 38,89 45,64 7 12,02 14,07 18,48 27 36,74 40,11 46,96 8 13,36 15,51 20,09 28 37,92 41,34 48,28 9 14,68 16,92 21,67 29 39,09 42,56 49,59 10 15,99 18,31 23,21 30 40,26 43,77 50,89 11 17,28 19,68 24,73 40 51,81 55,76 63,69 12 18,55 21,03 26,22 50 63,17 67,50 76,15 13 19,81 22,36 27,69 60 74,40 79,08 88,38 14 21,06 23,68 29,14 70 85,53 90,53 100,43 15 22,31 25,00 30,58 80 96,58 101,88 112,33 16 23,54 26,30 32,00 90 107,57 113,15 124,12 17 24,77 27,59 33,41 100 118,50 124,34 135,81 18 25,99 28,87 34,81 19 27,20 30,14 36,19 20 28,41 31,41 37,57 58 ПРИЛОЖЕНИЕ Значение t-критерия Стьюдента Уровень значимости α df(v) Уровень значимости α df(v) 0,10 0,05 0,01 0,10 0,05 0,01 1 6,3137 12,7062 63,656 18 1,7341 2,1009 2,8784 2 2,9200 4,3027 9,9250 19 1,7291 2,0930 2,8609 3 2,3534 3,1824 5,8408 20 1,7247 2,0860 2,8453 4 2,1318 2,7765 4,6041 21 1,7207 2,0796 2,8314 5 2,0150 2,5706 4,0321 22 1,7171 2,0739 2,8188 6 1,9432 2,4469 3,7074 23 1,7139 2,0687 2,8073 7 1,8946 2,3646 3,4995 24 1,7109 2,0639 2,7970 8 1,8595 2,3060 3,3554 25 1,7081 2,0595 2,7874 9 1,8331 2,2622 3,2498 26 1,7056 2,0555 2,7787 10 1,8125 2,2281 3,1693 27 1,7033 2,0518 2,7707 11 1,7959 2,2010 3,1058 28 1,7011 2,0484 2,7633 12 1,7823 2,1788 3,0545 29 1,6991 2,0452 2,7564 13 1,7709 2,1604 3,0123 30 1,6973 2,0423 2,7500 14 1,7613 2,1448 2,9768 40 1,6839 2,0211 2,7045 15 1,7531 2,1315 2,9467 60 1,6706 2,0003 2,6603 16 1,7459 2,1199 2,9208 120 1,6576 1,9799 2,6174 17 1,7396 2,1098 2,8982 ∞ 1,6449 1,9600 2,5758 59 ПРИЛОЖЕНИЕ Значение F-критерия Фишера при уровне значимости 0,05 df1 (v1) df2 (v2) 1 df2 (v2) 1 2 3 4 5 6 7 8 9 10 11 12 14 16 20 30 ∞ 161 199 216 225 230 234 237 239 241 242 243 244 245 246 248 250 254 1 2 18,51 19,00 19,16 19,25 19,30 19,33 19,35 19,37 19,38 19,40 19,40 19,41 19,42 19,43 19,45 19,46 19,50 2 3 10,13 9,55 9,28 9,12 9,01 8,94 8,89 8,85 8,81 8,79 8,76 8,74 8,71 8,69 8,66 8,62 8,53 3 4 7,71 6,94 6,59 6,39 6,26 6,16 6,09 6,04 6,00 5,96 5,94 5,91 5,87 5,84 5,80 5,75 5,63 4 5 6,61 5,79 5,41 5,19 5,05 4,95 4,88 4,82 4,77 4,74 4,70 4,68 4,64 4,60 4,56 4,50 4,36 5 6 5,99 5,14 4,76 4,53 4,39 4,28 4,21 4,15 4,10 4,06 4,03 4,00 3,96 3,92 3,87 3,81 3,67 6 7 5,59 4,74 4,35 4,12 3,97 3,87 3,79 3,73 3,68 3,64 3,60 3,57 3,53 3,49 3,44 3,38 3,23 7 8 5,32 4,46 4,07 3,84 3,69 3,58 3,50 3,44 3,39 3,35 3,31 3,28 3,24 3,20 3,15 3,08 2,93 8 9 5,12 4,26 3,86 3,63 3,48 3,37 3,29 3,23 3,18 3,14 3,10 3,07 3,03 2,99 2,94 2,86 2,71 9 10 4,96 4,10 3,71 3,48 3,33 3,22 3,14 3,07 3,02 2,98 2,94 2,91 2,86 2,83 2,77 2,70 2,54 10 11 4,84 3,98 3,59 3,36 3,20 3,09 3,01 2,95 2,90 2,85 2,82 2,79 2,74 2,70 2,65 2,57 2,40 11 12 4,75 3,89 3,49 3,26 3,11 3,00 2,91 2,85 2,80 2,75 2,72 2,69 2,64 2,60 2,54 2,47 2,30 12 13 4,67 3,81 3,41 3,18 3,03 2,92 2,83 2,77 2,71 2,67 2,63 2,60 2,55 2,51 2,46 2,38 2,21 13 14 4,60 3,74 3,34 3,11 2,96 2,85 2,76 2,70 2,65 2,60 2,57 2,53 2,48 2,44 2,39 2,31 2,13 14 15 4,54 3,68 3,29 3,06 2,90 2,79 2,71 2,64 2,59 2,54 2,51 2,48 2,42 2,38 2,33 2,25 2,07 15 16 4,49 3,63 3,24 3,01 2,85 2,74 2,66 2,59 2,54 2,49 2,46 2,42 2,37 2,33 2,28 2,19 2,01 16 Примечание: df1 (v1) – число степеней свободы для большей дисперсии; df2 (v2) – число степеней свободы для меньшей дисперсии. 60 Окончание приложения df1 (v1) df2 (v2) df2 (v2) 1 2 3 4 5 6 7 8 9 10 11 12 14 16 20 30 ∞ 17 4,45 3,59 3,20 2,96 2,81 2,70 2,61 2,55 2,49 2,45 2,41 2,38 2,33 2,29 2,23 2,15 1,96 17 18 4,41 3,55 3,16 2,93 2,77 2,66 2,58 2,51 2,46 2,41 2,37 2,34 2,29 2,25 2,19 2,11 1,92 18 19 4,38 3,52 3,13 2,90 2,74 2,63 2,54 2,48 2,42 2,38 2,34 2,31 2,26 2,21 2,16 2,07 1,88 19 20 4,35 3,49 3,10 2,87 2,71 2,60 2,51 2,45 2,39 2,35 2,31 2,28 2,22 2,18 2,12 2,04 1,84 20 21 4,32 3,47 3,07 2,84 2,68 2,57 2,49 2,42 2,37 2,32 2,28 2,25 2,20 2,16 2,10 2,01 1,81 21 22 4,30 3,44 3,05 2,82 2,66 2,55 2,46 2,40 2,34 2,30 2,26 2,23 2,17 2,13 2,07 1,98 1,78 22 23 4,28 3,42 3,03 2,80 2,64 2,53 2,44 2,37 2,32 2,27 2,24 2,20 2,15 2,11 2,05 1,96 1,76 23 24 4,26 3,40 3,01 2,78 2,62 2,51 2,42 2,36 2,30 2,25 2,22 2,18 2,13 2,09 2,03 1,94 1,73 24 25 4,24 3,39 2,99 2,76 2,60 2,49 2,40 2,34 2,28 2,24 2,20 2,16 2,11 2,07 2,01 1,92 1,71 25 26 4,23 3,37 2,98 2,74 2,59 2,47 2,39 2,32 2,27 2,22 2,18 2,15 2,09 2,05 1,99 1,90 1,69 26 27 4,21 3,35 2,96 2,73 2,57 2,46 2,37 2,31 2,25 2,20 2,17 2,13 2,08 2,04 1,97 1,88 1,67 27 28 4,20 3,34 2,95 2,71 2,56 2,45 2,36 2,29 2,24 2,19 2,15 2,12 2,06 2,02 1,96 1,87 1,65 28 29 4,18 3,33 2,93 2,70 2,55 2,43 2,35 2,28 2,22 2,18 2,14 2,10 2,05 2,01 1,94 1,85 1,64 29 30 4,17 3,32 2,92 2,69 2,53 2,42 2,33 2,27 2,21 2,16 2,13 2,09 2,04 1,99 1,93 1,84 1,62 30 40 4,08 3,23 2,84 2,61 2,45 2,34 2,25 2,18 2,12 2,08 2,04 2,00 1,95 1,90 1,84 1,74 1,51 40 50 4,03 3,18 2,79 2,56 2,40 2,29 2,20 2,13 2,07 2,03 1,99 1,95 1,89 1,85 1,78 1,69 1,44 50 60 4,00 3,15 2,76 2,53 2,37 2,25 2,17 2,10 2,04 1,99 1,95 1,92 1,86 1,82 1,75 1,65 1,39 60 100 3,94 3,09 2,70 2,46 2,31 2,19 2,10 2,03 1,97 1,93 1,89 1,85 1,79 1,75 1,68 1,57 1,28 100 ∞ 3,84 2,99 2,60 2,37 2,21 2,09 2,01 1,94 1,88 1,83 1,79 1,75 1,69 1,64 1,57 1,46 1,00 ∞ 61 62