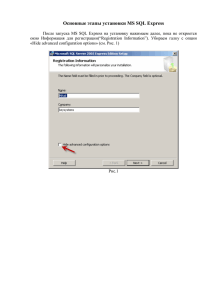
Уровни защиты SQL Server в режиме AlwaysOn
advertisement

Руководство по решениям Microsoft SQL Server в режиме AlwaysOn, предназначенным для обеспечения высокого уровня доступности и аварийного восстановления Автор: Лерой Таттл мл. (Майкрософт) Соавторы: Сефас Лин (Майкрософт), Джастин Эриксон (Майкрософт), Линдси Аллен (Майкрософт), Мин Хе (Майкрософт), Санджей Мишра (Майкрософт) Рецензенты: Алексей Халяко (Майкрософт), Аллан Хирт (SQLHA), Айад Шаммут (Caregroup), Бенджамин Райт-Джонс (Майкрософт), Чарльз Мэттьюс (Майкрософт), Дэвид П. Смит (ServiceU), Юрген Томас (Майкрософт), Кевин Фарли (Майкрософт), Шахьяр Г. Хашеми (Motricity), Вольфганг Кучера (Bwin Party) Опубликовано: январь 2012 г. Область применения: SQL Server 2012 Сводка. В этом техническом документе описываются способы сокращения запланированного и незапланированного времени простоя, увеличения доступности приложений и обеспечения защиты данных с помощью решений высокого уровня доступности и аварийного восстановления SQL Server 2012 в режиме AlwaysOn. Основная цель этого документа — определить общий контекст для рассмотрения соответствующих вопросов, обсуждаемых специалистами по коммерческим вопросам, сотрудниками, отвечающими за технические решения, специалистами по системной архитектуре, инженерами по инфраструктуре и администраторами баз данных. Содержимое представлено в двух основных частях. Основные понятия высокого уровня доступности и аварийного восстановления. Краткое описание факторов и трудностей планирования, администрирования и измерения бизнес-целей среды баз данных с высокой доступностью. После этого описания следует краткий обзор возможностей обеспечения высокого уровня доступности и аварийного восстановления, которые предоставляют решения SQL Server 2012 в режиме AlwaysOn и Windows Server. Уровни защиты SQL Server в режиме AlwaysOn. Более подробное описание обоснования, возможностей и зависимостей уровней защиты, предоставляемых решением SQL Server в режиме AlwaysOn. Описание доступности инфраструктуры, защиты на уровнях экземпляра SQL Server и базы данных, а также возможностей приложений уровня данных. Руководство по решениям высокого уровня доступности и аварийного восстановления Microsoft SQL Server в режиме AlwaysOn i Руководство по решениям высокого уровня доступности и аварийного восстановления Microsoft SQL Server в режиме AlwaysOn ii Авторские права Данный документ предоставляется согласно принципу «как есть». Сведения и мнения, содержащиеся в этом документе, включая URL-адреса, а также ссылки на другие веб-сайты, могут изменяться без предварительного уведомления. Вы принимаете на себя риск, связанный с использованием этого документа. Некоторые примеры, содержащиеся в этом документе, вымышлены и приводятся исключительно в демонстрационных целях. Любое сходство с реальными ситуациями случайно. Настоящий документ не предоставляет пользователям права интеллектуальной собственности на какие-либо продукты Майкрософт. Разрешается копирование и использование документа только для внутреннего использования с целью предоставления справочных сведений. © Корпорация Майкрософт (Microsoft Corporation), 2012. Все права защищены. Руководство по решениям высокого уровня доступности и аварийного восстановления Microsoft SQL Server в режиме AlwaysOn iii Содержание Основные понятия высокого уровня доступности и аварийного восстановления .......................... 1 Описание высокого уровня доступности .............................................................................................. 1 Запланированный и незапланированный простой ......................................................................... 1 Ухудшенная доступность .................................................................................................................... 2 Количественное выражение простоя .................................................................................................... 3 Цели восстановления.......................................................................................................................... 3 Обоснование рентабельности инвестиций и утраченных возможностей ..................................... 4 Отслеживание состояния доступности ............................................................................................. 4 Планирование аварийного восстановления..................................................................................... 4 Обзор. Высокий уровень доступности в Microsoft SQL Server 2012.................................................... 5 SQL Server в режиме AlwaysOn........................................................................................................... 6 Существенное сокращение времени планового простоя ............................................................... 6 Исключение бесполезного оборудования и улучшение рентабельности и производительности ........................................................................................................................ 7 Простое развертывание и управление.............................................................................................. 7 Сравнение возможностей RPO и RTO ................................................................................................ 7 Уровни защиты SQL Server в режиме AlwaysOn .............................................................................. 9 Доступность инфраструктуры............................................................................................................... 10 Операционная система Windows..................................................................................................... 10 Отказоустойчивая кластеризация Windows Server ........................................................................ 11 Мастер проверки кластера WSFC .................................................................................................... 13 Режимы кворума WSFC и конфигурация голосования .................................................................. 15 Аварийное восстановление WSFC через принудительный кворум ............................................. 18 Уровень защиты экземпляра SQL Server ............................................................................................. 20 Улучшения доступности — экземпляры SQL Server ....................................................................... 20 Экземпляры отказоустойчивого кластера в режиме AlwaysOn .................................................... 21 Доступность базы данных .................................................................................................................... 23 Группы доступности AlwaysOn ......................................................................................................... 24 Отработка отказа группы доступности ............................................................................................ 25 Прослушиватель группы доступности ............................................................................................. 27 Улучшения доступности — базы данных ........................................................................................ 29 Рекомендации по возможности подключения клиентов ................................................................. 30 Заключение.................................................................................................................................... 32 Руководство по решениям высокого уровня доступности и аварийного восстановления Microsoft SQL Server в режиме AlwaysOn iv Основные понятия высокого уровня доступности и аварийного восстановления Вы сможете выбрать лучшую технологию баз данных для решения высокого уровня доступности и аварийного восстановления, если всем заинтересованным лицам будет понятна взаимосвязанность бизнес-факторов, задач и целей планирования, администрирования и измерения, а также целей по времени и точке восстановления. Читатели, знакомые с этими основными понятиями, могут перейти к разделу Обзор. Высокий уровень доступности с использованием Microsoft SQL Server 2012 данного документа. Описание высокого уровня доступности Для данного приложения или службы высокий уровень доступности соизмеряется с ожиданиями пользователей и удобством их работы. Материальное выражение влияния простоев на бизнес может быть определено в виде потерь информации, повреждениях собственности, уменьшении производительности, утраченных возможностях, убытках по контрактам и утрате деловой репутации. Основной целью решения высокого уровня доступности является сведение к минимуму или смягчение последствий простоя. Хорошая стратегия оптимально балансирует бизнесы-процессы и соглашения об уровне обслуживания (SLA) с техническими возможностями и затратами на инфраструктуру. Платформа считается высокодоступной в соответствии с соглашением и ожиданиями клиентов и заинтересованных лиц. Доступность системы можно выразить следующим вычислением. 𝐴𝑐𝑡𝑢𝑎𝑙 𝑢𝑝𝑡𝑖𝑚𝑒 × 100% 𝐸𝑥𝑝𝑒𝑐𝑡𝑒𝑑 𝑢𝑝𝑡𝑖𝑚𝑒 Полученное значение часто выражается отраслью в количестве девяток, обеспечиваемых решением. Оно передает количество минут возможного времени работы в году или, наоборот, времени простоя. Количество девяток 2 3 4 5 Процент доступности Общее время простоев за год 99% 99,9% 99,99% 99,999% 3 дня, 15 часов 8 часов, 45 минут 52 минуты, 34 секунды 5 минут, 15 секунд Запланированный и незапланированный простой Простои системы могут быть как ожидаемыми и запланированными, так и происходить в результате спонтанного сбоя. Время простоя не считается отрицательным явлением, если оно контролируется и надлежащим образом управляется. Существует два основных вида ожидаемых простоев. Руководство по решениям высокого уровня доступности и аварийного восстановления Microsoft SQL Server в режиме AlwaysOn 1 Плановое обслуживание. Временное окно для проведения планового обслуживания, например обновления программного обеспечения, оборудования и паролей, повторного индексирования в режиме «вне сети», загрузки данных или тестирования процедур аварийного восстановления, предварительно объявляется и координируется. Хорошо продуманные и управляемые процедуры должны свести к минимуму время простоя и предотвратить потерю данных. Операции планового обслуживания можно рассматривать в качестве инвестиций, необходимых для предотвращения других, потенциально более серьезных незапланированных вариантов сбоев. Незапланированный простой. На уровне системы, инфраструктуры или процесса могут произойти как незапланированные, неконтролируемые, так и ожидаемые сбои, вероятность которых считалась достаточно низкой, а влияние расценивалось как приемлемое. Надежное решение высокого уровня доступности обнаруживает эти виды сбоев, автоматически восстанавливает систему и обеспечивает сохранение работоспособности. При заключении соглашения об уровне обслуживания для обеспечения высокого уровня доступности следует вычислить отдельные ключевые показатели эффективности (KPI) для операций планового обслуживания и незапланированных простоев. Такой подход позволяет сравнивать инвестиции в операции планового обслуживания с преимуществами предотвращения незапланированных простоев. Ухудшенная доступность Высокий уровень доступности не следует расценивать как предложение типа «все или ничего». В качестве альтернативы полному простою системы частичная ее доступность, ограниченная функциональность или сниженная производительность часто являются приемлемыми вариантами для пользователей. Ограниченная доступность имеет следующие степени. Операции только для чтения и отложенные операции. Во время обслуживания или во время поэтапного аварийного восстановления получение данных возможно, но новые рабочие процессы и фоновая обработка могут быть временно остановлены или помещены в очередь. Задержка данных и быстрота реакции приложений. В условиях высокой рабочей нагрузки, невыполненных операций или частичного отказа платформы ограниченных ресурсов оборудования может быть недостаточно. Качество работы пользователей может пострадать, но при этом они все равно смогут продолжать работать, хоть и менее продуктивно. Частичные, временные или неизбежные сбои. Надежность логики приложения или стека оборудования, которые пытаются повторно выполнить операцию или автоматически исправляют ошибку при ее обнаружении. Для пользователей такие проблемы могут проявляться в виде задержки данных или низкой скорости ответа приложений. Частичный сквозной сбой. Плановые или незапланированные простои могут возникать в вертикальных уровнях стека решения (инфраструктура, платформа и приложение) или по горизонтали между различными функциональными компонентами. Пользователи могут выполнять часть операций успешно или с ухудшением производительности в зависимости от затронутых функций или компонентов. Руководство по решениям высокого уровня доступности и аварийного восстановления Microsoft SQL Server в режиме AlwaysOn 2 Приемлемость этих неоптимальных ситуаций следует рассматривать как один из вариантов снижения доступности, приводящего к полному простою, а также как промежуточные шаги поэтапного аварийного восстановления. Количественное выражение простоя При возникновении простоя, независимо от того, запланирован он или нет, основная цель компании — восстановить работоспособность системы в сети и свести к минимуму потерю данных. Каждая минута простоя приводит к прямым и косвенным затратам. При незапланированном простое необходимо найти баланс между временем и усилиями, необходимыми для определения причины сбоя, текущего состояния системы и шагов, необходимых для восстановления после сбоя. В предварительно определенный момент любого простоя необходимо предпринять следующие шаги: принять решение о прекращении анализа сбоя или выполнения задач обслуживания, восстановить работоспособность системы в сети и при необходимости восстановить ее отказоустойчивость. Цели восстановления Избыточность данных является ключевым компонентом решений высокого уровня доступности баз данных. Транзакционные операции, выполняемые на основном экземпляре SQL Server, синхронно или асинхронно применяются к одному или нескольким вторичным экземплярам. Если возникает сбой, то транзакции, которые были в процессе обработки, могут быть отменены или потеряны во вторичных экземплярах из-за задержки в распространении данных. Вы можете оценить влияние сбоя и задать цели восстановления в виде времени, необходимого для получения работоспособной системы, и величины задержки последней восстановленной транзакции. Целевое время восстановления (RTO). Это длительность простоя. Начальная цель — вернуть систему в рабочий режим в сети хотя бы с возможностью доступа только для чтения, чтобы можно было проанализировать причины и последствия сбоя. Однако основная задача заключается в восстановлении полной работоспособности системы, после чего можно будет выполнять новые транзакции. Целевая точка восстановления (RPO). Этот параметр часто называют мерой приемлемой потери данных. Это время паузы между последней зафиксированной транзакцией данных до появления сбоя и последними данными, восстановленными после сбоя. Фактическая потеря данных может быть различной в зависимости от рабочей нагрузки системы в момент возникновения сбоя, вида этого сбоя и типа используемого решения высокого уровня доступности. Значения RTO и RРO необходимо использовать в качестве целей, показывающих допустимое для компании время простоя и приемлемую потерю данных, а также как показатели мониторинга работоспособности системы. Руководство по решениям высокого уровня доступности и аварийного восстановления Microsoft SQL Server в режиме AlwaysOn 3 Обоснование рентабельности инвестиций и утраченных возможностей В случае простоя компания может понести потери, выраженные финансово или в виде утраты доверия со стороны клиентов. Эти затраты могут проявиться как непосредственно в момент сбоя, так и по прошествии какого-то времени. Помимо планирования затрат на устранение сбоя с заданным целевым временем и целевой точкой восстановления данных можно также вычислить инвестиции в бизнес-процессы и инфраструктуру, которые потребуются для достижения целевых показателей RTO и RPO или предотвращения сбоя. Такие вложения делаются по следующим пунктам. Предотвращение простоев. Затраты на восстановление после сбоев можно предотвратить лишь путем исключения самой возможности сбоев. Инвестиции включают в себя следующие составляющие: стоимость отказоустойчивого и избыточного оборудования или инфраструктуры, распределение рабочей нагрузки между отдельными точками и плановый простой для профилактического обслуживания. Автоматическое восстановление. Если возникает сбой системы, то значительно смягчить последствия простоя для клиентов можно с помощью прозрачного и автоматического восстановления. Использование ресурсов. Дополнительная или резервная инфраструктура может находиться в режиме ожидания до сбоя. Ее также можно использовать для обработки рабочих нагрузок только для чтения и улучшения общей производительности системы за счет распределения рабочей нагрузки по всему доступному оборудованию. Инвестиции в доступность и восстановление, необходимые для достижения целевых значений RTO и RPO, вкупе с плановыми расходами, связанными с простоем, можно представить как функцию времени. Во время фактического сбоя это позволяет принять решение на основе расходов в зависимости от прошедшего времени простоя. Отслеживание состояния доступности Если исходить из соображений эффективности работы, то во время фактического сбоя не следует пытаться учесть все соответствующие переменные и вычислить рентабельность инвестиций или утраченные возможности в реальном времени. Вместо этого необходимо отследить задержку данных в резервных экземплярах как предварительное значение для вычисления ожидаемой целевой точки восстановления. Во время сбоя также необходимо сократить время на поиски первопричины его возникновения. Вместо этого нужно уделить основное внимание проверке работоспособности среды восстановления, а впоследствии произвести всеобъемлющий анализ, изучив подробные системные журналы и дополнительные копии данных. Планирование аварийного восстановления Действия, направленные на обеспечение высокого уровня доступности, необходимы для предотвращения сбоя, а действия для аварийного восстановления выполняются для восстановление высокого уровня доступности после сбоя. Руководство по решениям высокого уровня доступности и аварийного восстановления Microsoft SQL Server в режиме AlwaysOn 4 Порядок процедур аварийного восстановления и специалистов, ответственных за этот участок работы, необходимо определить до возникновения самого сбоя. На основе активного мониторинга и предупреждений решение по запуску автоматической или ручной отработки отказа и план восстановления должны быть привязаны к предварительно заданным пороговым значениям RTO и RPO. В область надежного плана аварийного восстановления должны входить следующие компоненты. Степень детализации сбоя и восстановления. В зависимости от места и типа сбоя можно предпринять действия по исправлению на различных уровнях. Например, в центре обработки данных, в инфраструктуре, на платформе, в приложении или в рабочей нагрузке. Исходный материал для анализа. Базовые показатели и журнал мониторинга последних операций, системные предупреждения, журналы событий и диагностические запросы должны быть доступны соответствующим сторонам. Координация зависимостей. Каковы зависимости системы и организации в стеке приложения и между заинтересованными лицами? Дерево принятия решений. Предопределенный, повторяемый, проверенное дерево (алгоритм) принятия решений, включающее в себя ответственности разных ролей, расследование сбоя, критерии отработки отказа с точки зрения целевых значений RTO и RPO и предписанные действия для восстановления. Проверка. Что необходимо сделать после восстановления, чтобы убедиться, что система вернулась в обычный режим работы? Документация. Соберите все приведенные выше элементы в комплект достаточно подробной и ясной документации, чтобы сторонняя группа могла выполнить план восстановления с минимальной помощью. Этот тип документации часто называется книгой выполнения или руководством по внедрению. Тестирование восстановления. Регулярно на практике проверяйте план аварийного восстановления, чтобы установить базовые значения RTO, и учитывайте регулярную ротацию основного рабочего объекта и каждого из объектов, предназначенных для аварийного восстановления. Обзор. Высокий уровень доступности в Microsoft SQL Server 2012 Достижение необходимых целевых значений RTO и RPO целей позволяет обеспечить непрерывное время работы важнейших приложений и защиту важных данных от плановых и незапланированных простоев. SQL Server предоставляет набор компонентов и возможностей, которые помогут достичь этих целей без увеличения затрат и усложнения системы. Читатели, хорошо знакомые с новыми возможностями AlwaysOn, могут перейти к более подробному описанию в разделе Уровни защиты SQL Server в режиме AlwaysOn этого документа. Руководство по решениям высокого уровня доступности и аварийного восстановления Microsoft SQL Server в режиме AlwaysOn 5 SQL Server в режиме AlwaysOn AlwaysOn — это новое встроенное, гибкое и экономически эффективное решение обеспечения высокого уровня доступности и аварийного восстановления. Оно обеспечивает избыточность данных и оборудования в одном или нескольких центрах обработки данных и улучшает время отработки отказа, что повышает уровень доступности ваших важнейших приложений. AlwaysOn обеспечивает гибкость конфигурации и позволяет повторно использовать имеющееся оборудование. Для настройки доступности на уровне базы данных и экземпляра решения AlwaysOn может использовать два основных компонента SQL Server 2012. Группы доступности AlwaysOn (новая возможность SQL Server 2012) значительно улучшают возможности зеркального отображения базы данных и обеспечивают доступность базы данных приложения. Они также предотвращают потерю каких-либо данных за счет перемещения последних на основе журналов для защиты данных без использования общих дисков. Группы доступности предоставляют встроенный набор возможностей, в том числе переход на другой ресурс логической группы баз данных, выполняемый как автоматически, так и вручную, поддержка до четырех вторичных реплик, быстрая отработка отказа приложений и автоматическое восстановление страниц. Экземпляры отказоустойчивого кластера AlwaysOn расширяют возможности отказоустойчивой кластеризации SQL Server и поддерживают кластеризацию нескольких объектов в различных подсетях, что позволяет реализовать отработку отказа экземпляров SQL Server в нескольких центрах обработки данных. Более быстрая и прогнозируемая отработка отказа экземпляров — еще одно основное преимущество, которое ускоряет процесс восстановления приложений. Существенное сокращение времени планового простоя Главная причина простоя приложения в любой организации — плановая остановка в целях исправления операционной системы, обслуживания оборудования и т. д. Это может составлять почти 80 процентов от всех простоев в ИТ-среде. SQL Server 2012 помогает значительно сократить время простоя, уменьшая требования к обновлению и позволяя выполнить больше операций по обслуживанию без выхода из режима «в сети». Windows Server Core. SQL Server 2012 поддерживает развертывания на основе Windows Server Core — это является минимальным упрощенным вариантом развертывания Windows Server 2008 и Windows Server 2008 R2. Эта конфигурация операционной системы может сократить время простоя, снизив требования к обновлениям операционной системы на 60 %. Операции в сети. Расширенная поддержка таких операций в сети, как повторное индексирование больших двоичных объектов и добавление столбцов со значениями по умолчанию, помогает сократить время простоя при обслуживании базы данных. Последовательное обновление и исправление. Функции AlwaysOn позволяют выполнять последовательные обновления и исправления экземпляров, что помогает значительно сократить время простоя приложений. Руководство по решениям высокого уровня доступности и аварийного восстановления Microsoft SQL Server в режиме AlwaysOn 6 SQL Server на Hyper-V. Экземпляры SQL Server, размещенные в среде Hyper-V, получают дополнительные преимущества динамической миграции, с помощью которой вы можете переносить виртуальные машины между узлами с нулевым временем простоя. Администраторы могут выполнять операции обслуживания на узле, не влияя на приложения. Исключение бесполезного оборудования и улучшение рентабельности и производительности Обычные решения для обеспечения высокого уровня доступности подразумевают развертывание дорогих, избыточных, пассивных серверов. Группы доступности AlwaysOn позволяют использовать реплики базы данных-получателя на серверах, которые в противном случае были бы пассивными или бесполезными, для обработки рабочих нагрузок только для чтения, например запросов операций отчетов служб SQL Server Reporting Services или операций резервного копирования. Возможность одновременно использовать первичные и вторичные реплики баз данныхполучателей улучшает производительность всех рабочих нагрузок за счет улучшенной балансировки ресурсов всего имеющегося серверного оборудования. Простое развертывание и управление Такие функции, как мастер настройки, поддержка интерфейса командной строки Windows PowerShell, панели мониторинга, динамические административные представления, управление на основе политик и интеграция System Center, упрощают развертывание групп доступности и управление ими. Сравнение возможностей RPO и RTO Бизнес-цели для целевой точки восстановления (RPO) и целевого времени восстановления (RTO) должны быть основными факторами при выборе технологии SQL Server для решения высокого уровня доступности и аварийного восстановления. В этой таблице приведен сравнительный перечень результатов, полученных с помощью этих решений. Руководство по решениям высокого уровня доступности и аварийного восстановления Microsoft SQL Server в режиме AlwaysOn 7 Возможная потеря данных (RPO) Возможное время восстановления (RTO) Автоматическая отработка отказа Доступные для чтения вторичные реплики(1) Группа доступности AlwaysOn — синхронная фиксация Нуль Секунды Да(4) 0-2 Группа доступности AlwaysOn — асинхронная фиксация Секунды Минуты Нет 0-4 Недоступно(5) Да Недоступно Нуль Секунды — минуты Секунды Да Недоступно Зеркальное отображение базы данных(2) — высокая производительность (асинхронно) Секунды(6) Минуты(6) Нет Недоступно Доставка журналов Минуты(6) Минуты — часы(6) Нет Часы(6) Часы — дни(6) Нет Не во время восстановления Не во время восстановления Решение высокого уровня доступности и аварийного восстановления SQL Server Экземпляр отказоустойчивого кластера в режиме AlwaysOn Зеркальное отображение базы данных(2) — высокий уровень безопасности (синхронизации + следящий сервер) Резервное копирование, копирование, восстановление(3) (1) Группа доступности AlwaysOn может содержать не более 4 вторичных реплик независимо от их типа. (2) В будущей версии Microsoft SQL Server этот компонент будет удален. Вместо него используйте группы доступности AlwaysOn. (3) Операции восстановления, копирования, в том числе и резервного, подходят для аварийного восстановления, но не для обеспечения высокого уровня доступности. (4) Автоматический переход на другой ресурс отказоустойчивого кластера или с кластера в группу доступности не поддерживается. (5) Сам по себе экземпляр отказоустойчивого кластера не обеспечивает защиту данных. Потеря данных зависит от реализации системы хранения. (6) В значительной степени зависит от рабочей нагрузки, объема данных и процедур отработки отказа. Руководство по решениям высокого уровня доступности и аварийного восстановления Microsoft SQL Server в режиме AlwaysOn 8 Уровни защиты SQL Server в режиме AlwaysOn Решения SQL Server в режиме AlwaysOn позволяют обеспечить отказоустойчивость и аварийное восстановление на нескольких физических и логических уровнях компонентов инфраструктуры и приложений. Исторически сложилось так, что обычно используется разделение обязанностей между различными аудиториями и ролями, при котором каждая аудитория или роль отвечает только за некоторые уровни решения. Этот раздел документа организован так, чтобы читатель смог ознакомиться с более подробным описанием каждого из этих уровней и получить рекомендации, следуя которым он в дальнейшем сможет принимать правильные решения по конструкции и реализации. Для создания успешного решения SQL Server в режиме AlwaysOn требуется понимание и взаимодействие на всех этих уровнях. Уровень инфраструктуры. Для обеспечения отказоустойчивости на уровне сервера и взаимодействия между сетевыми узлами используются возможности отказоустойчивой кластеризации Windows Server (WSFC) для мониторинга работоспособности и координации отработки отказа. Уровень экземпляра SQL Server. Экземпляр отказоустойчивого кластера (FCI) SQL Server в режиме AlwaysOn — это экземпляр SQL Server, установленный на нескольких узлах, который может переключаться между узлами в кластере WSFC. Узлы, в которых размещаются FCI, связаны с надежным симметричным общим хранилищем (SAN или SMB). Уровень базы данных. Группа доступности — это набор пользовательских баз данных, для которых отработка отказа выполняется одновременно. Группа доступности состоит из первичной реплики и от одной до четырех вторичных реплик. Каждая реплика размещается на экземпляре SQL Server (это может быть простой экземпляр или экземпляр отказоустойчивого кластера) в отдельном узле кластера WSFC. Возможность подключения клиентов. Клиентские приложения баз данных могут подключаться либо непосредственно к сетевому имени экземпляра SQL Server, либо к имени виртуальной сети (VNN), привязанному к прослушивателю группы доступности. Имя виртуальной сети абстрагирует кластер WSFC и топологию группы доступности, логически перенаправляя запросы на соединение соответствующему экземпляру SQL Server и реплике базы данных. Логическая топология решения AlwaysOn изображена на следующей диаграмме. Руководство по решениям высокого уровня доступности и аварийного восстановления Microsoft SQL Server в режиме AlwaysOn 9 Доступность инфраструктуры И группы доступности AlwaysOn, и экземпляры отказоустойчивых кластеров в режиме AlwaysOn используют в качестве технологии платформы операционную систему Windows Server и WSFC. Как никогда прежде успешные администраторы баз данных Microsoft SQL Server будут полагаться на четкое понимание этих технологий. Операционная система Windows SQL Server использует платформу Windows для предоставления базовой инфраструктуры и служб для работы в сети, хранения данных, обеспечения безопасности, обновления и мониторинга. Различные выпуски SQL Server 2012 прогрессивно основываются на возрастающих возможностях и ресурсах аналогичных выпусков операционной системы Windows Server 2008 R2, включая операционные системы Windows Server 2008 R2 Standard, Windows Server 2008 R2 Enterprise и Windows Server 2008 R2 Datacenter. Дополнительные сведения см. в статье Требования к оборудованию и программному обеспечению для установки SQL Server 2012 (http://msdn.microsoft.com/ru-ru/library/ ms143506(SQL.110).aspx). Установка Windows Server Core SQL Server 2012 поддерживает установку Server Core в Windows Server 2008 или более поздних версий в качестве основного компонента высокой доступности. Установка Server Core позволяет сформировать минимальную среду для запуска определенных ролей сервера с ограниченной функциональностью и довольно ограниченной поддержкой графического интерфейса пользователя. По умолчанию включаются только необходимые службы и среда командной строки. Руководство по решениям высокого уровня доступности и аварийного восстановления Microsoft SQL Server в режиме AlwaysOn 10 Этот режим работы уменьшает количество возможных направлений для атак и сокращает издержки операционной системы, а также может значительно снизить требования к текущему обслуживанию и обновлению. Ключевым аспектом развертывания SQL Server 2012 в Windows Server Core является то, что все операции развертывания, настройки, администрирования и обслуживания SQL Server и операционной системы должны выполняться с использованием среды скриптов, например Windows PowerShell, или с помощью средств командной строки или удаленных инструментов. Оптимизация SQL Server для частного облака Ценность вариантов обеспечения высокого уровня доступности и аварийного восстановления сильно возрастает в среде частного облака. Выполните развертывание SQL Server в частном облаке, чтобы ресурсы компьютера, сети и хранилища использовались эффективно. Это позволит уменьшить объем используемых физических ресурсов, а также сократить капитальные и эксплуатационные расходы. Это позволяет консолидировать развертывания, эффективно масштабировать ресурсы и развертывать ресурсы по запросу, не жертвуя при этом управлением. Помимо поддержки отказоустойчивой кластеризации Windows Server (WSFC) для узла и гостевой системы Hyper-V, SQL Server также поддерживает динамическую миграцию, т. е. возможность перемещения виртуальных машин между узлами без какого-либо ощутимого простоя. Динамическая миграция также работает совместно с кластеризацией гостевой системы. Дополнительные сведения см. в статье Вычисление в частных облаках — оптимизация SQL Server для частного облака (http://www.microsoft.com/SqlServerPrivateCloud). Отказоустойчивая кластеризация Windows Server Отказоустойчивая кластеризация Windows Server (WSFC) предоставляет компоненты инфраструктуры, поддерживающие варианты обеспечения высокого уровня доступности и аварийного восстановления для таких размещенных серверных приложений, как Microsoft SQL Server. При отказе узла или службы кластера WSFC все службы или ресурсы, которые размещались на этом узле, могут автоматически или вручную переноситься на другой доступный узел в рамках процесса, называемого отработкой отказа. В решениях AlwaysOn эта процедура применяется и к экземплярам отказоустойчивого кластера, и к группам доступности. Узлы в кластере WSFC за счет совместной работы обеспечивают следующие типы возможностей. Распределенные метаданные и уведомления. Метаданные служб и размещенных приложений WSFC хранятся на каждом узле кластера. Среди этих метаданных не только параметры размещенных приложений, но также конфигурация и состояние WSFC. Изменения в метаданных или в состоянии одного узла автоматически распространяются на другие узлы кластера. Управление ресурсами. Отдельные узлы в кластере могут предоставлять физические ресурсы, например подключаемое напрямую хранилище (DAS), сетевые интерфейсы и доступ к общему дисковому хранилищу. Размещенные приложения, такие как SQL Server, регистрируют себя как ресурсы кластера и могут настраивать запуск и зависимости от исправности других ресурсов. Руководство по решениям высокого уровня доступности и аварийного восстановления Microsoft SQL Server в режиме AlwaysOn 11 Мониторинг исправности. Определение исправности основного узла и исправности между узлами осуществляется за счет сочетания сетевых соединений по типу тактовых импульсов и мониторинга ресурсов. Общее состояние работоспособности кластера определяется голосами кворума узлов в кластере. Координация отработки отказа. Все ресурсы настроены для размещения на основном узле, и каждый из них может быть автоматически или вручную перенесен на один или несколько второстепенных узлов. Политика отработки отказа в зависимости от исправности управляет автоматическим переносом владения ресурсами между узлами. Узлы и размещенные приложения получают уведомления об отработке отказа, что позволяет им выполнить соответствующие действия. Дополнительные сведения см. в статье Windows Server | Отказоустойчивая кластеризация и балансировка узлов (http://www.microsoft.com/windowsserver2008/en/us/failover-clusteringmain.aspx). Примечание. Очень важно, чтобы администраторы баз данных в полной мере понимали внутренние процессы кластеров WSFC и управления кворумом. Мониторинг исправности, управление и действия для восстановления AlwaysOn тесно связаны с конфигурацией WSFC. Конфигурации хранилища WSFC В отказоустойчивой кластеризации Windows Server (WSFC) каждый узел кластера используется для управления подключенными устройствами хранения, дисковыми томами и файловой системой. WSFC предполагает, что подсистема хранения крайне надежна, поэтому, если устройство хранения, подключенное к узлу, недоступно, узел кластера считается неисправным. Для операций, основанных на записи, дисковый том логически подключается к одному узлу кластера с помощью постоянного резервирования SCSI-3. В зависимости от возможностей и конфигурации подсистемы хранилища при сбое узла логическое владение дисковым томом можно передать другому узлу кластера. Решения SQL Server в режиме AlwaysOn могут использовать только определенные сочетания конфигураций хранилища WSFC, в том числе: Хранилище с прямым подключением и удаленное хранилище. Устройства хранения либо подключены к серверу напрямую, либо представлены удаленным устройством по сети или с помощью адаптера шины (HBA). К технологиям удаленного хранилища относятся решения на основе сети хранения данных (SAN), такие как iSCSI и Fibre Channel, а также решения на основе общих файловых ресурсов SMB. Симметричное и асимметричное хранилище. Устройства хранения считаются симметричными, если на каждом узле кластера используется абсолютно одинаковая конфигурация логических дисковых томов. Физическая реализация и емкость дисковых томов могут различаться. Руководство по решениям высокого уровня доступности и аварийного восстановления Microsoft SQL Server в режиме AlwaysOn 12 Выделенное и общее хранилище. Выделенное хранилище зарезервировано для использования и назначается одному узлу в кластере. Общее хранилище доступно нескольким узлам кластера. Управление и владение общими устройствами хранения можно передавать от одного узла другому с помощью протоколов SCSI-3. WSFC поддерживает параллельное размещение общих томов кластера на нескольких узлах для обеспечения общего доступа к файлам. Однако SQL Server не поддерживает параллельный доступ к общему тому на нескольких узлах. Примечание. Для экземпляров отказоустойчивого кластера SQL Server симметричное общее хранилище должно быть доступно для всех возможных владельцев узлов экземпляра. Однако сейчас с появлением групп доступности AlwaysOn стало возможным развертывать различные экземпляры SQL Server (которые не являются экземплярами отказоустойчивого кластера) в кластере WSFC, каждый с собственным уникальным, выделенным, локальным или удаленным хранилищем. Обнаружение исправности ресурсов WSFC и отработка отказа Все ресурсы на узле кластера WSFC могут сообщать о своем состоянии и исправности периодически или по запросу. На сбой ресурса кластера могут указывать различные обстоятельства, в том числе: неисправность системы электропитания, ошибки дисков, памяти или связи, неправильная настройка или неотвечающие службы. Ресурсы кластера WSFC, например сети, хранилища и службы, можно делать взаимозависимыми. Совокупная исправность ресурса определяется путем последовательного суммирования его исправности с исправностью каждой из зависимостей ресурсов. Для групп доступности AlwaysOn группа доступности и прослушиватель группы доступности регистрируются как ресурсы кластера WSFC. Для экземпляров отказоустойчивого кластера в режиме AlwaysOn служба SQL Server и служба агента SQL Server регистрируются как ресурсы кластера WSFC, и они становятся зависимыми от ресурса имени виртуальной сети экземпляра. Если в ресурсе кластера WSFC возникло несколько ошибок или сбоев в течение определенного периода времени, то настроенная политика отработки отказа приводит к тому, что служба кластеров выполняет одно из следующих действий: перезапуск ресурса на текущем узле; перевод ресурса в режим «вне сети»; запуск автоматической отработки отказа и зависимостей на другом узле. Примечание. Определение исправности ресурсов кластера WSFC не влияет напрямую на работоспособность отдельного узла или общую работоспособность кластера. Мастер проверки кластера WSFC Мастер проверки кластера — это компонент, интегрированный в отказоустойчивую кластеризацию в Windows Server 2008 и Windows Server 2008 R2. Это основное средство для администратора баз данных, которое позволяет получить чистую, исправную и стабильную среду WSFC перед развертыванием решения SQL Server в режиме AlwaysOn. Руководство по решениям высокого уровня доступности и аварийного восстановления Microsoft SQL Server в режиме AlwaysOn 13 С помощью мастера проверки кластера можно проводить ряд тестов в коллекции серверов, которые будут использоваться либо в самом кластере, либо в качестве узлов кластера. Этот процесс проверяет базовое оборудование и программное обеспечение напрямую и по отдельности для точной оценки того, насколько хорошо кластер WSFC будет поддерживаться в данной конфигурации. Процесс проверки состоит из ряда тестов и сбора данных на каждом узле в следующих категориях. Инвентаризация. Сведения о версиях BIOS, уровнях среды, адаптерах шины, ОЗУ, версиях операционных систем, устройствах, службах, драйверах и т. д. Сеть. Сведения о порядке привязки сетевых адаптеров, обмене данными по сети, конфигурации IP-адресов и конфигурации брандмауэра. Проверка взаимодействия узлов на всех сетевых адаптерах. Хранилище. Сведения на дисках, емкость дисков, задержка доступа, файловые системы и т. д. Проверка команд SCSI, функций отработки отказа дисков и симметричной или асимметричной конфигурации хранилища. Конфигурация системы. Проверка конфигурации Active Directory, подписей драйверов, параметров дампа памяти, необходимых компонентов и служб операционной системы, совместимой архитектуры процессора и уровней пакетов обновления и обновлений программного обеспечения Windows. Эти проверочные тесты позволяют собрать сведения, необходимые для точной настройки кластера, отслеживания конфигурации и определения потенциальных проблем конфигурации кластера еще до того, как они приведут к простою. Отчет с результатами тестов можно сохранить как HTML-документ для последующего просмотра. Необходимо выполнить эти тесты до и после внесения каких-либо изменений в конфигурацию WSFC, перед установкой SQL Server и в процессе любой операции аварийного восстановления. Отчет о проверке кластера является одним из условий, предъявляемых службой поддержки Майкрософт (CSS) для предоставления поддержки данной конфигурации кластера WSFC. Дополнительные сведения см. в разделе Пошаговое руководство по отказоустойчивому кластеру. Проверка оборудования для отказоустойчивого кластера (http://technet.microsoft.com/ruru/library/cc732035(WS.10).aspx). Примечание. Если конфигурация кластера предусматривает асимметричное хранилище, как в случае с решениями аппаратной геокластеризации или с группами доступности AlwaysOn, то может потребоваться несколько исправлений, чтобы избежать ошибок во время проверки. Дополнительные сведения см. в статье Необходимые компоненты, ограничения и рекомендации для групп доступности AlwaysOn (http://msdn.microsoft.com/ruru/library/ff878487(SQL.110).aspx#SystemReqsForAOAG). Руководство по решениям высокого уровня доступности и аварийного восстановления Microsoft SQL Server в режиме AlwaysOn 14 Режимы кворума WSFC и конфигурация голосования В WSFC для мониторинга общей исправности кластера и обеспечения максимальной отказоустойчивости на уровне узлов используется подход, основанный на кворуме. Для проектирования, эксплуатации и устранения неполадок решений высокого уровня доступности AlwaysOn и решений аварийного восстановления требуется отличное знание режимов кворума WSFC и конфигурации голосования узлов. Определение исправности кластера по кворуму Все узлы в кластере WSFC участвуют в периодической передаче тактового импульса, сообщающего состояние исправности узла другим узлам. Неотвечающие узлы считаются неисправными. Набор узлов кворума — это большинство узлов с правом голоса и следящих объектов в кластере WSFC. Общая исправность и состояние кластера WSFC определяются периодическим голосованием с кворумом. Наличие кворума означает, что кластер исправен и может обеспечивать отказоустойчивость на уровне узла. Отсутствие кворума указывает на то, что кластер неисправен. Необходимо поддерживать общую исправность кластера WSFC, чтобы обеспечить доступность и работоспособность вторичных узлов, на которые в случае сбоя смогут переключаться основные узлы. Если голосование с кворумом завершается неудачей, в качестве меры предосторожности весь кластер WSFC переводится в режим «вне сети». При этом также останавливаются все экземпляры SQL Server, зарегистрированные в кластере. Примечание. Если кластер WSFC переводится в режим «вне сети» из-за отсутствия кворума, перевести его обратно в оперативный режим «в сети» можно будет только вручную. Дополнительные сведения см. в разделе Аварийное восстановление WSFC с помощью принудительного кворума далее в этом документе. Режимы кворума Режим кворума настраивается на уровне кластера WSFC. Он определяет метод проведения голосования с кворумом. Диспетчер отказоустойчивого кластера рекомендует использовать определенный режим кворума, исходя из количества узлов в кластере. Для определения кворума голосов можно использовать следующие режимы кворума. Большинство узлов. Кластер признается исправным, если больше половины узлов подтверждают свою работоспособность. Большинство узлов и общих папок. Аналогичен режиму кворума большинства узлов, за исключением того, что удаленная общая папка также настраивается в качестве следящего объекта с правом голоса, и возможности подключения от любого узла к этой папке также считаются голосами, подтверждающими исправность кластера. Кластер признается исправным, если больше половины возможных голосов подтверждают свою работоспособность. Рекомендуется, чтобы следящая общая папка не размещалась ни на одном узле в кластере и была видима для всех узлов в кластере. Руководство по решениям высокого уровня доступности и аварийного восстановления Microsoft SQL Server в режиме AlwaysOn 15 Большинство узлов и дисков. Аналогичен режиму кворума большинства узлов, за исключением того, что общий дисковый кластерный ресурс также признается следящим объектом с правом голоса, а все возможности подключения от любого узла к этому общему диску считаются голосами, подтверждающими работоспособность. Кластер признается исправным, если больше половины возможных голосов подтверждают свою работоспособность. Только диск. Общий дисковый кластерный ресурс признается следящим, а возможность подключения от любого узла к этому общему диску считается голосом, подтверждающим исправность кластера. Дополнительные сведения см. в разделе Пошаговое руководство по отказоустойчивому кластеру. Настройка кворума в кластере (http://technet.microsoft.com/ru-ru/library/cc770620(WS.10).aspx). Примечание. Если все узлы в кластере не настроены для использования одного общего дискасвидетеля кворума, следует использовать режим кворума «Большинство узлов» при нечетном числе узлов с правом голоса или режим кворума «Большинство узлов и общих папок» при четном числе узлов с правом голоса. Узлы с правом и без права голоса По умолчанию каждый узел в кластере WSFC включается в качестве члена кворума кластера. Каждый узел, файловый ресурс-свидетель и диск-свидетель имеют один голос, который учитывается при определении общей исправности кластера. На данный момент в этом документе были четко определены узлы кластера WSFC, принимающие участие в голосовании по исправности кластера, которые называются узлами с правом голоса. В некоторых случаях требуется сделать так, чтобы у некоторых узлов не было права голоса. Каждый узел в кластере WSFC постоянно пытается установить кворум. Ни один отдельный узел в кластере не может окончательно определить, является ли кластер в целом исправным. В любой момент времени с точки зрения любого узла может казаться, что некоторые другие узлы не работают, находятся в процессе отработки отказа или не отвечают из-за сбоя сетевого подключения. Главная задача голосования с кворумом — определить, является ли видимое состояние каждого узла в кластере WSFC фактическим состоянием этих узлов. Для всех режимов кворума, кроме «Только диск», эффективность голосования кворума зависит от надежности соединений между всеми узлами с правом голоса в кластере. Необходимо доверять кворуму, если все узлы находятся в одной физической подсети. Однако если в голосовании кворума кажется, что узел из другой подсети не отвечает, но на самом деле они находятся в сети и в рабочем состоянии, то, скорее всего, это происходит из-за сбоя соединения между подсетями. В зависимости от топологии кластера, режима кворума и конфигурации политики отработки отказа сбой сетевого соединения может приводить к созданию более одного набора (или подмножества) узлов с правом голоса. Если подмножества узлов с правом голоса могут установить свой собственный кворум, это называется сценарием с дроблением. В этом случае узлы в отдельных кворумах могут вести себя по-разному и находиться в конфликте друг с другом. Руководство по решениям высокого уровня доступности и аварийного восстановления Microsoft SQL Server в режиме AlwaysOn 16 Примечание. Сценарий с дроблением возможен только в случаях, когда системный администратор вручную организует принудительную работу кворума или в очень редких случаях принудительной отработки отказа вручную, когда набор узлов кворума явно разделяется. Дополнительные сведения см. в разделе Аварийное восстановление WSFC с помощью принудительного кворума далее в этом документе. Чтобы упростить настройку кворума и увеличить время безотказной работы, можно задать параметр NodeWeight (значение 0 или 1) каждого узла, который указывает, учитывается ли голос этого узла при определении кворума. Рекомендуемые настройки для голосования с кворумом Для определения рекомендуемой конфигурации голосования с кворумом для кластера используйте следующие рекомендации в указанном порядке. 1. По умолчанию голосов нет. Предположите, что каждый узел не должен голосовать без явного обоснования. 2. Включите все основные узлы. Каждый узел, в котором размещается первичная реплика группы доступности AlwaysOn или который является предпочитаемым владельцем экземпляра отказоустойчивого кластера в режиме AlwaysOn, должен иметь голос. 3. Включайте возможных владельцев автоматического перехода на другой ресурс. Каждый узел, на котором в результате автоматического перехода на другой ресурс может размещаться первичная реплика или экземпляр отказоустойчивого кластера, должен иметь голос. 4. Исключайте узлы вторичного сайта. В общем случае не давайте голоса узлам, которые находятся на вторичном сайте аварийного восстановления. Не следует допускать, чтобы узлы на вторичном сайте принимали участие в решении о переводе кластера в режим «вне сети», когда на первичном сайте нет никаких проблем. 5. Нечетное число голосов. Если необходимо, добавьте в кластер следящую общую папку, следящий узел (с экземпляром SQL Server или без него) или следящий диск и измените режим кворума, чтобы избежать возможного разделения голосов пополам при голосовании с кворумом. 6. Перераспределяйте назначение голосов после отработки отказа. Не следует допускать отработкy отказа с переходом на конфигурацию кластера, если она не поддерживает работоспособность кворума. Дополнительные сведения об изменении голосования узлов см. в статье Настройка параметров NodeWeight кворума кластера (http://msdn.microsoft.com/ru-ru/library/hh270281(SQL.110).aspx). Нельзя настроить голос общей папки-свидетеля. Вместо этого нужно выбрать другой режим кворума, чтобы включить или исключить голос этого ресурса. Примечание. SQL Server предлагает несколько системных динамических административных представлений, которые могут помочь в управлении параметрами конфигурации кластера WSFC и голосовании с кворумом узлов. Дополнительные сведения см. в статье Отслеживание групп доступности (http://(msdn.microsoft.com/ru-ru/library/ff878305(SQL.110).aspx). Руководство по решениям высокого уровня доступности и аварийного восстановления Microsoft SQL Server в режиме AlwaysOn 17 Аварийное восстановление WSFC через принудительный кворум Обычно сбой кворума бывает вызван системной аварией или постоянным сбоем связи, затрагивающим несколько узлов в кластере WSFC. Помните, что сбой кворума приведет к переходу в автономный режим всех служб, поддерживающих работу в кластере, экземпляров SQL Server и групп доступности в кластере WSFC вне сети, поскольку настроенный таким образом кластер не сможет гарантировать отказоустойчивость на уровне узлов. Сбой кворума означает, что исправные голосующие узлы в кластере WSFC больше не удовлетворяют модели кворума. Некоторые узлы, возможно, полностью вышли из строя, на других могла просто отключиться служба WSFC, а в остальном они работают исправно, за исключением потери возможности взаимодействовать с кворумом. Для перевода отказоустойчивого кластера Windows Server обратно в режим «в сети» необходимо устранить основную причину сбоя кворума как минимум на одном узле в существующей конфигурации. В случае аварии, возможно, потребуется перенастроить или указать другое оборудование для использования. Также может потребоваться перенастроить остальные узлы в кластере WSFC в соответствии с работоспособной топологией кластера. Можно использовать процедуру принудительного кворума на узле кластера WSFC, чтобы переопределить управляющие параметры безопасности, которые привели к переходу кластера в режим «вне сети». Она предписывает кластеру приостановить проверки голосования кворума и позволяет привести ресурсы кластера WSFC и SQL Server обратно в режим «в сети» на любом из узлов кластера. Этот тип процесса аварийного восстановления должен включать следующие этапы. 1) Определите область сбоя. Определите, какие группы доступности или экземпляры SQL Server не отвечают, какие узлы кластера работают в режиме «в сети» и доступны для использования после аварии, изучите журналы событий Windows и системные журналы SQL Server. Там, где это практически возможно, следует сохранить аналитические данные и системные журналы для последующего анализа. 2) Запустите кластер WSFC с помощью принудительного кворума на одном узле. На узле, который в остальном является исправным, вручную запустите работу кластера в сети с помощью процедуры принудительного кворума кластера. Чтобы свести к минимуму потенциальную потерю данных, выберите последний узел, на котором размещалась первичная реплика группы доступности. Дополнительные сведения см. в статье Принудительный запуск кластера WSFC без кворума (http://msdn.microsoft.com/ru-ru/library/hh270275(v=SQL.110).aspx). Примечание. Если вы используете принудительное задание кворума, проверки кворума блокируются в пределах всего кластера до тех пор, пока кластер WSFC не получит большинство голосов и автоматически не перейдет в обычный режим работы кворума. 3) Запустите службу WSFC обычным образом на каждом узле, исправном во всех остальных отношениях, по одному за раз. Не нужно указывать параметр принудительного кворума при запуске службы кластеров на других узлах. Руководство по решениям высокого уровня доступности и аварийного восстановления Microsoft SQL Server в режиме AlwaysOn 18 Поскольку служба WSFC на каждом узле возвращается в состояние «в сети», она взаимодействует с другими исправными узлами, чтобы синхронизировать новое состояние конфигурации кластера. Помните, что эти действия необходимо выполнять на одном узле за раз, чтобы предотвратить создание условий для соперничества в кластере при разрешении последнего известного состояния кластера. Примечание. Убедитесь, что каждый запущенный узел может взаимодействовать с новыми исправными узлами в сети, в противном случае вы можете создать несколько наборов узлов кворума, а это будет сценарий с дроблением. Если на шаге 1 получены точные результаты, этого не должно произойти. 4) Примените новый режим кворума и конфигурацию голосования узлов. Если вы успешно перезагрузили все узлы в кластере с помощью принудительного кворума и устранили главную причину сбоя кворума, вам не требуется вносить изменения в исходный режим и конфигурацию голосования с кворумом узлов. В противном случае следует оценить восстановленный узел кластера и топологию доступности реплики, после чего внести требуемые изменения режима кворума и голосования для каждого узла. Переведите службу кластера WSFC на узлах, которые не были восстановлены, в режим «вне сети» или задайте в качестве числа их голосов значение «нуль». Примечание. В этот момент может показаться, что узлы и экземпляры SQL Server в кластере восстановлены в режим нормального функционирования. Однако на самом деле кворум может так и оставаться неисправным. Убедитесь, что кворум восстановлен, с помощью диспетчера отказоустойчивости кластеров на панели мониторинга AlwaysOn в среде SQL Server Management Studio или с помощью соответствующих динамических административных представлений. 5) При необходимости восстановите реплики баз данных групп доступности. Некоторые базы данных могут сами восстановиться и вернуться в режим «в сети» в процессе обычного запуска SQL Server. Для восстановления других баз данных могут потребоваться дополнительные действия, выполняемые вручную. Можно сократить потенциальные потери данных и время восстановления для реплик групп восстановления путем их перевода в режим «в сети» в следующем порядке, если возможно: первичная реплика, синхронные вторичные реплики, асинхронные вторичные реплики. 6) Исправьте или замените неисправные компоненты и выполните проверку кластера еще раз. Теперь, выполнив восстановление после первоначальной аварии и сбоя кворума, исправьте или замените отказавшие узлы и соответствующим образом измените связанные конфигурации узлов WSFC и AlwaysOn. Для этого могут потребоваться такие действия, как удаление реплик групп доступности, удаление узлов из кластера либо сведение и переустановка программного обеспечения на узле. Примечание. Необходимо восстановить или удалить все неисправные реплики доступности. SQL Server 2012 не будет усекать журнал транзакций за последней известной точкой самой последней реплики доступности. Если отказавшая реплика не будет исправлена или удалена из группы доступности, журналы транзакций будут расти с риском превышения пределов объема журналов в других репликах. Руководство по решениям высокого уровня доступности и аварийного восстановления Microsoft SQL Server в режиме AlwaysOn 19 7) При необходимости повторите шаг 4. Цель заключается в восстановлении соответствующего уровня отказоустойчивости и высокого уровня доступности для исправной работы. 8) Анализ RPO/RTO. Следует проанализировать системные журналы SQL Server, отметки времени баз данных, журналы событий Windows, чтобы выявить главную причину аварии и задокументировать фактические значения точки восстановления и времени восстановления. Уровень защиты экземпляра SQL Server Следующий уровень защиты в решениях AlwaysOn — это сама платформа данных. Это возможности и компоненты, предоставляемые Microsoft SQL Server 2012, а также интеграция с компонентами инфраструктуры Windows Server. Улучшения доступности — экземпляры SQL Server Это новые возможности SQL Server 2012 на уровне экземпляра, которые улучшают доступность как для экземпляров отказоустойчивого кластера в режиме AlwaysOn, так и для автономных экземпляров, на которых размещаются группы доступности AlwaysOn. Эти улучшения представляют собой усовершенствования вариантов администрирования и устранения неполадок отработки отказа. Гибкая политика отработки отказа. Для передачи серьезной ошибки, влияющей на экземпляр SQL Server, в выходных данных новой системной хранимой процедуры, используемой для надежного обнаружения сбоев, sp_server_diagnostics, применяется свойство FailureConditionLevel. Политика отработки отказа WSFC управляет тем, как это значение влияет на экземпляр SQL Server — от относительного допуска ошибок до чувствительности к любой ошибке внутреннего компонента SQL Server. Отработка отказа может быть активирована (в соответствии с настройками) ошибками любого уровня из следующего диапазона: сбой сервера, сервер не отвечает, критическая ошибка, умеренная ошибка или любая соответствующая ошибка. Свойство FailureConditionLevel может использоваться для политик отработки отказа экземпляров отказоустойчивого кластера и групп доступности. До SQL Server 2012 степени детализации условий ошибок для управления отработкой отказа не существовало; любой сбой на уровне службы приводил к отработке отказа. Дополнительные сведения см. в статье Политика отработки отказа для экземпляров отказоустойчивого кластера (http://msdn.microsoft.com/ru-ru/library/ff878664(SQL.110).aspx). Улучшенный инструментарий и ведение журнала. Существует несколько связанных с AlwaysOn представлений конфигурации системы, динамических административных представлений, счетчиков производительности и расширенный сеанс работоспособности событий, который записывает сведения, необходимые для устранения неполадок, настройки и отслеживания развертывания AlwaysOn. Многие из них доступны с помощью новых политик аспектов управления политиками SQL Server. Дополнительные сведения см. в статье Динамические административные представления и функции, связанные с группами доступности AlwaysOn (http://msdn.microsoft.com/ruru/library/ff877943(SQL.110).aspx) и sys.dm_os_cluster_nodes (http://msdn.microsoft.com/ruru/library/ms187341(SQL.110).aspx). Руководство по решениям высокого уровня доступности и аварийного восстановления Microsoft SQL Server в режиме AlwaysOn 20 Поддержка общих файловых ресурсов SMB. Можно разместить файлы базы данных в удаленном файловом ресурсе Windows Server 2008 или более поздней версии для автономных экземпляров и экземпляров отказоустойчивого кластера, устраняя потребность в отдельной букве диска для каждого экземпляра отказоустойчивого кластера. Это хороший вариант для консолидации хранилища или размещения файлового хранилища базы данных на физическом сервере для гостевой операционной системы виртуальной машины. С правильной конфигурацией производительность операций ввода-вывода может практически приблизиться к производительности хранилища с прямым подключением. Дополнительные сведения см. в статье База данных SQL в общих папках ― пришло время пересмотреть сценарий (http://blogs.msdn.com/b/sqlserverstorageengine/archive/2011/10/18/sql-databases-on-fileshares-it-s-time-to-reconsider-the-scenario.aspx). Примечание. В кластере WSFC нельзя добавить зависимость общего файлового ресурса SMB в группу ресурсов SQL Server. Для обеспечения доступности общего ресурса необходимо принять отдельные меры. Если общий ресурс становится недоступным, SQL Server вызывает исключение ввода-вывода и переходит в режим «вне сети». Взаимодействие WSFC с DNS. Имя виртуальной сети (VNN) для экземпляра отказоустойчивого кластера или прослушивателя группы доступности регистрируется в DNS только при создании имени виртуальной сети или при внесении изменений в конфигурацию. Все виртуальные IPадреса, независимо от режима («в сети» или «вне сети»), регистрируются в DNS с тем же именем виртуальной сети. Вызовы клиента для разрешения имени виртуальной сети в DNS возвращают все зарегистрированные IP-адреса с различной последовательностью циклического перебора. Экземпляры отказоустойчивого кластера в режиме AlwaysOn Главная задача экземпляра отказоустойчивого кластера SQL Server в режиме AlwaysOn — улучшить доступность экземпляра SQL Server, размещенного на локальном сервере и оборудовании хранилища в одном центре обработки данных. Экземпляр отказоустойчивого кластера — это один логический экземпляр SQL Server, установленный на нескольких узлах отказоустойчивой кластеризации Windows Server (WSFC), который в каждый отдельный момент времени активен только на одном узле. Клиентские приложения подключаются к имени виртуальной сети и виртуальному IP-адресу, которые принадлежат активному узлу кластера. Каждый установленный узел имеет идентичную конфигурацию и набор двоичных файлов SQL Server. Служба кластеров WSFC также реплицирует соответствующие изменения из записей активного экземпляра в реестре Windows на каждый установленный узел. Каждый узел, на котором установлен экземпляр отказоустойчивого кластера, отмечается как возможный владелец экземпляра и его ресурсов в предпочитаемой последовательности отработки отказа. Файлы базы данных хранятся на томах общего симметричного хранилища и регистрируются как ресурс в кластере WSFC. Они принадлежат узлу, на котором в данный момент размещается экземпляр отказоустойчивого кластера. Руководство по решениям высокого уровня доступности и аварийного восстановления Microsoft SQL Server в режиме AlwaysOn 21 Дополнительные сведения см. в статье Экземпляры отказоустойчивого кластера в режиме AlwaysOn (http://msdn.microsoft.com/ru-ru/library/ms189134(SQL.110).aspx). Процесс отработки отказа экземпляра отказоустойчивого кластера Если происходит сбой зависимого ресурса кластера, экземпляр отказоустойчивого кластера в режиме AlwaysOn взаимодействует со службой кластеров WSFC для отработки отказа с использованием следующего режима высокого уровня. 1) Инициируется перезагрузка. Периодическая проверка WSFC или конфигурации политики отработки отказа SQL Server указывает на сбой. По умолчанию перед инициацией отработки отказа с переходом на другой узел осуществляется попытка перезапуска службы. Превышение времени ожидания при попытке перезапуска указывает на сбой ресурса. 2) Указывает отработку отказа. Проверка политики отработки отказа указывает на необходимость отработки отказа узла. 3) Служба SQL Server останавливается. Если в настоящий момент служба SQL Server запущена, предпринимается попытка правильного завершение ее работы. 4) Выполняется передача ресурса кластера WSFC. Владение группой кластерных ресурсов SQL Server и зависимых ресурсов сети и общего хранилища передается следующему предпочитаемому владельцу узла отказоустойчивого кластера. 5) SQL Server запускается на новом узле. Экземпляр SQL Server проходит обычные процедуры запуска. Если он не возвращается в режим «в сети» в течение времени ожидания, служба кластеров отмечает ресурс на новом узле как неисправный. 6) Пользовательские базы данных восстанавливаются на новом узле. Все пользовательские базы данных переводятся в режим восстановления, применяются операции повтора журнала транзакций, и выполняется откат незафиксированных транзакций. Улучшения экземпляра отказоустойчивого кластера Предыдущие версии SQL Server предлагали параметр установки отказоустойчивого кластера. Однако в SQL Server 2012 представлено несколько усовершенствований, которые увеличивают степень доступности и удобства обслуживания. Кластеризация с несколькими подсетями. SQL Server 2012 поддерживает узлы кластера WSFC, находящиеся в нескольких подсетях. Любой экземпляр SQL Server, который находится на узле кластера WSFC, может быть запущен, если доступен какой-либо сетевой интерфейс. Это называется зависимостью кластерного ресурса OR. Для запуска или отработки отказа предыдущим версиям службы SQL Server требовалось, чтобы все сетевые интерфейсы были работоспособными, а также чтобы все они присутствовали в одной подсети или виртуальной локальной сети. Примечание. Репликация на уровне хранилища между узлами кластера не включается явно при кластеризации в нескольких подсетях. Решение отказоустойчивого кластера с несколькими подсетями должно использовать стороннее решение на основе SAN для репликации данных и координированной отработки отказа между узлами кластера. Руководство по решениям высокого уровня доступности и аварийного восстановления Microsoft SQL Server в режиме AlwaysOn 22 Дополнительные сведения см. в статье SQL Server 2012 в режиме AlwaysOn. Многосайтовый экземпляр отказоустойчивого кластера (http://sqlcat.com/sqlcat/b/whitepapers/archive/2011/12/22/sql-server-2012-alwayson_3a00_multisite-failover-cluster-instance.aspx). Надежное обнаружение сбоев. Служба кластеров WSFC поддерживает выделенное административное соединение с каждым экземпляром отказоустойчивого кластера SQL Server 2012 на узле. По этому соединению специальный периодический вызов специальной системной хранимой процедуры sp_server_diagnostics возвращает большой массив данных диагностики исправности системы. До SQL Server 2012 основной механизм определения исправности для экземпляра отказоустойчивого кластера был реализован как простой односторонний процесс опроса. В рамках этого процесса служба кластеров WSFC периодически создавала новое клиентское соединение SQL с экземпляром, запрашивала имя сервера, а затем отключалась. Ошибка подключения или превышение времени ожидания запроса, независимо от причины, вызывали отработку отказа с небольшим объемом доступных сведений диагностики. Дополнительные сведения см. в статье sql_server_diagnostics (http://msdn.microsoft.com/ruru/library/ff878233(SQL.110).aspx). Теперь поддержка вариантов хранилища экземпляров отказоустойчивого кластера расширена. Улучшенная поддержка точек подключения. Программа установки SQL Server теперь распознает параметры точек подключения диска кластера. Во время установки указанные диски кластера и все диски, подключенные к нему, автоматически добавляются в зависимость ресурсов SQL Server. tempdb в локальном хранилище. Экземпляры отказоустойчивого кластера теперь поддерживают размещение tempdb в локальном хранилище, которое не является общим, например на локальном твердотельном накопителе, что позволяет значительно снизить нагрузку ввода-вывода на общее хранилище SAN. До SQL Server 2012 для экземпляра отказоустойчивого кластера было необходимо, чтобы база данных tempdb размещалась на томе симметричного общего хранилища, отработка отказа которого выполнялась с другими системными базами данных. Примечание. Расположение базы данных tempdb хранится в базе данных master, которая во время отработки отказа перемещается между узлами. Оно должно быть представлено допустимым симметричным путем к файлу (диск, папки и разрешения) на всех возможных владельцах узла, иначе служба SQL Server на некоторых узлах не запустится. Доступность базы данных Возможности обеспечения высокого уровня доступности, предоставляемые инфраструктурой и компонентами уровня экземпляра SQL Server, взаимодействуют друг с другом для неявной защиты размещенных баз данных. Решение AlwaysOn предоставляет дополнительный набор вариантов для явной защиты баз данных и приложений уровня данных. Руководство по решениям высокого уровня доступности и аварийного восстановления Microsoft SQL Server в режиме AlwaysOn 23 Группы доступности AlwaysOn Группа доступности — это набор пользовательских баз данных, которые совместно выполняют отработку отказа с одного экземпляра SQL Server на другой внутри одного кластера WSFC. Клиентские приложения могут подключиться к базам данных группы доступности с помощью имени виртуальной сети кластера WSFC, которое также называется прослушивателем группы доступности и которое абстрагирует базовые экземпляры SQL Server. Группы доступности AlwaysOn используют отказоустойчивую кластеризацию WSFC для мониторинга исправности, координации отработки отказа и возможности подключения к серверу. Необходимо включить поддержку AlwaysOn на экземпляре SQL Server, который находится на узле кластера WSFC. Однако этот экземпляр не обязательно должен быть экземпляром отказоустойчивого кластера, и он не требует использования симметричного общего хранилища. Дополнительные сведения см. в статье Обзор групп доступности AlwaysOn (http://msdn.microsoft.com/ru-ru/library/ff877884(SQL.110).aspx). Реплики доступности и роли В каждом экземпляре SQL Server в группе доступности размещается реплика доступности, содержащая копию пользовательских баз данных в группе доступности. В экземпляре SQL Server может размещаться только одна реплика доступности из данной группы доступности, при этом несколько групп доступности могут находиться на одном экземпляре. У экземпляра SQL Server должны быть выделенные (не общие) тома хранилища. Одна из реплик доступности выступает в роли первичной реплики. Она обозначается как мастеркопия баз данных группы доступности и включается для операций чтения и записи. Группа доступности может содержать от одной до четырех дополнительных реплик доступности, используемых только для чтения, каждая из которых выполняет роль вторичной реплики. Синхронизация реплики доступности Содержимое каждой базы данных в группе доступности синхронизируется от первичной реплики на каждую вторичную реплику с помощью механизма перемещения данных SQL Server на основе журнала. Поэтому для всех баз данных в группе доступности должна быть задана модель полного восстановления. Вторичные реплики инициализируются с полным резервным копированием и восстановлением баз данных и журналов транзакций первичной реплики. По мере фиксации новых транзакций в первичной реплике соответствующая часть журнала транзакций кэшируется, помещается в очередь, а затем передается по сети конечной точке зеркального отображения базы данных для каждого из узлов вторичных реплик. Таким образом, новые записи в журнале транзакций первичной реплики добавляются в каждый из журналов транзакций вторичной реплики. Каждая вторичная реплика периодически сообщает регистрационный номер транзакции в журнале (LSN) первичной реплике, чтобы указать отметку для той части журнала транзакций, которая была записана на удаленный диск. Руководство по решениям высокого уровня доступности и аварийного восстановления Microsoft SQL Server в режиме AlwaysOn 24 Примечание. Каждая реплика доступности имеет собственный набор независимых потоков повтора журнала транзакций, которые не являются частью процесса синхронизации реплик доступности. В процессе повтора журнала на вторичных репликах может возникнуть задержка данных. Кроме первичной или вторичной роли каждая реплика доступности также обладает режимом доступности, который управляет координацией записи журналов транзакций на диск во время выполнения инструкции COMMIT TRAN. Режим синхронной фиксации. Первичная реплика фиксирует транзакцию только после того, как все вторичные реплики с синхронной фиксацией подтверждают, что они зафиксировали соответствующие записи журнала после номера LSN этой транзакции на диск. Группа доступности может содержать до двух вторичных реплик с синхронной фиксацией. Режим синхронной фиксации приводит к задержке транзакций в базах данных первичной реплики, но он гарантирует отсутствие потери данных во вторичных репликах для зафиксированных транзакций. Режим асинхронной фиксации. Первичная реплика фиксирует транзакции после записи локального журнала транзакций на диск, но не дожидается подтверждения того, что вторичная реплика с асинхронной фиксацией записала свой журнал транзакций на диск. Группа доступности может содержать до четырех вторичных реплик с асинхронной фиксацией, но не более четырех вторичных реплик любого типа. Режим асинхронной фиксации минимизирует задержку транзакций в базах данных первичной реплики, но позволяет отставать журналам транзакций вторичных реплик, что создает риск возможной потери данных. Дополнительные сведения см. в статье Режимы доступности (http://msdn.microsoft.com/ruru/library/ff877931(SQL.110).aspx). Общая исправность потока данных между двумя репликами доступности отображается состоянием синхронизации каждой реплики. Вероятность потери данных высока, если при отработке отказа вторичная реплика имеет состояние синхронизации, отличное от «Синхронизировано» или «Выполняется синхронизация». У потока синхронизации каждой вторичной реплики есть свойство времени ожидания сеанса. Если происходит сбой вторичной реплики, работающей в режиме доступности синхронной фиксации, с истечением времени ожидания сеанса, она временно отмечается как асинхронная. Это необходимо, чтобы сбой вторичной реплики не влиял на запись транзакций первичной реплики на диск журнала. После восстановления работоспособности вторичной реплики и ее синхронизации с первичной репликой она автоматически возвращается к работе в обычном режиме синхронной фиксации. Отработка отказа группы доступности Группа доступности и соответствующее имя виртуальной сети регистрируются как ресурсы в кластере WSFC. Группа доступности отрабатывает отказ на уровне реплики доступности в зависимости от исправности и политики отработки отказа первичной реплики. Руководство по решениям высокого уровня доступности и аварийного восстановления Microsoft SQL Server в режиме AlwaysOn 25 Для указания уровня серьезности допуска для ошибки, влияющей на группу доступности, в политике отработки отказа группы доступности используется свойство FailureConditionLevel совместно с системной хранимой процедурой sp_server_diagnostics. Этот же механизм используется для политик отработки отказа экземпляров отказоустойчивого кластера. При отработке отказа вместо переноса владения общих физических ресурсов на другой узел WSFC используется для перенастройки вторичной реплики на другом экземпляре SQL Server в первичную реплику. Затем ресурс виртуального сетевого имени группы доступности переводится на этот экземпляр. Все клиентские соединения с репликами доступности сбрасываются. В зависимости от текущего состояния работоспособности, синхронизации и режима доступности у каждой реплики есть состояние готовности к отработке отказа, которое показывает вероятность потери данных. Эти сведения об исправности реплики отображаются на панели мониторинга AlwaysOn или в системном представлении sys.dm_hadr_availability_replica_states. Для каждой реплики доступности также настроен режим отработки отказа, который управляет поведением при отработке отказа. Автоматическая отработка отказа (без потери данных). Обеспечивает самое быстрое время отработки отказа для любой конфигурации AlwaysOn, поскольку журнал транзакций вторичной реплики уже записан на диск и синхронизирован. Открытые транзакции на первичной реплике откатываются, а роль первичной реплики переносится на вторичную реплику без вмешательства пользователя. Первичная и вторичная реплики должны быть настроены для использования режима автоматической отработки отказа, обе они должны находиться в режиме доступности синхронной фиксации. Состояние синхронизации между репликами должно быть задано как «Синхронизировано». Кроме того, в кластере WSFC должен быть исправный кворум. Автоматическая отработка отказа не поддерживается, если первичная или вторичная реплика находятся на экземпляре отказоустойчивого кластера. Это запрещено во избежание состояния гонки, которое может возникнуть между отработками отказа группы доступности и экземпляра отказоустойчивого кластера. Отработка отказа вручную. Это позволяет администратору оценить состояние первичной реплики и принять решение о намеренной отработке отказа на вторичную реплику. В зависимости от режима доступности и состояния синхронизации доступны следующие варианты. o Запланированная отработка отказа вручную (без потери данных). Вы можете выполнять этот тип отработки отказа, только если и первичная и вторичная реплики исправны и находятся в состоянии «Синхронизировано». Функционально это эквивалентно автоматической отработке отказа. o Принудительная отработка отказа вручную (с вероятностью потери данных). Это единственная форма отработки отказа, которая возможна, если целевая вторичная реплика находится в режиме доступности с асинхронной фиксацией или не синхронизирована с первичной репликой. Руководство по решениям высокого уровня доступности и аварийного восстановления Microsoft SQL Server в режиме AlwaysOn 26 Внимание! Этот вариант отработки отказа следует использовать только в случае аварийного восстановления. Если первичная реплика исправна и доступна, необходимо изменить режим доступности используемых реплик на синхронную фиксацию, а затем выполнить запланированную отработку отказа вручную. Дополнительные сведения см. в статье Выполнение принудительного перехода на другой ресурс вручную для группы доступности (http://msdn.microsoft.com/ruru/library/ff877957(SQL.110).aspx). Необходимо выполнить отработку отказа вручную, если выполняется любое из следующих условий для первичной или вторичной реплики, на которую требуется перейти. Установлен ручной режим отработки отказа. Установлен режим доступности асинхронной фиксации. Реплика размещена на экземпляре отказоустойчивого кластера. Дополнительные сведения см. в статье Режимы отработки отказа (группы доступности AlwaysOn) (http://msdn.microsoft.com/ru-ru/library/hh213151(SQL.110).aspx). Примечание. Если после отработки отказа новая первичная реплика не настроена для работы в режиме синхронной фиксации, то вторичные реплики будут иметь состояние синхронизации «Приостановлено». Никакие данные не будут передаваться на вторичные реплики, пока для первичной реплики установлен режим синхронной фиксации. Прослушиватель группы доступности Прослушиватель группы доступности — это имя виртуальной сети (VNN) WSFC, которую клиенты могут использовать для доступа к базе данных в группе доступности. Кластерный ресурс VNN принадлежит экземпляру SQL Server, на котором хранится первичная реплика. Имя виртуальной сети регистрируется в DNS только при создании прослушивателя группы доступности или изменении конфигурации. Все виртуальные IP-адреса, определенные в прослушивателе группы доступности, зарегистрированы в DNS с одним именем виртуальной сети. Для использования прослушивателя группы доступности в запросе клиентского соединения должно быть указано имя виртуальной сети в качестве сервера и имя базы данных, которая находится в группе доступности. По умолчанию это должно привести к соединению с экземпляром SQL Server, на котором размещена первичная реплика. Во время выполнения операции клиент использует свой локальный сопоставитель DNS, чтобы получить список IP-адресов и TCP-портов, соответствующих имени виртуальной сети. Затем клиент пытается подключиться к каждому из IP-адресов, пока подключение не будет успешным или не будет превышено время ожидания соединения. Клиент попытается установить эти соединения параллельно, если для параметра MultiSubnetFailover задано значение TRUE, что значительно ускоряет переключение клиентов на резервный ресурс. Руководство по решениям высокого уровня доступности и аварийного восстановления Microsoft SQL Server в режиме AlwaysOn 27 В случае отработки отказа клиентские соединения на сервере сбрасываются, владение прослушивателем группы доступности переходит к роли первичной реплики на новый экземпляр SQL Server, а конечная точка VNN привязывается к виртуальным IP-адресам и TCP-портам нового экземпляра. Дополнительные сведения см. в статье Возможность подключения клиентов и отработка отказа приложений (http://msdn.microsoft.com/ru-ru/library/hh213417(SQL.110).aspx). Фильтрация целей приложений При подключении через прослушиватель группы доступности приложение может указать, требуется ли ему чтение и запись данных, или же оно будет выполнять операции только для чтения. Если этот параметр не указан, то намерение приложения по умолчанию — чтение и запись. Для первичной и вторичной роли каждой реплики доступности также можно задать свойство доступа к подключению, которое будет использоваться в качестве фильтра на уровне подключения для цели приложения клиента. По умолчанию недопустимое сочетание цели приложения и доступа к соединению приводит к отказу в соединении. SQL Server должен фильтровать запросы клиентских соединений, используя следующие правила. Если реплика доступности используется в первичной роли и доступ к соединению равен: Разрешить любое намерение приложения. Не фильтровать никакие клиентские соединения по намерению приложения. Разрешить только явное намерение чтения и записи. Если клиент указывает намерение только для чтения, отказать в соединении. Если реплика доступности используется во вторичной роли и доступ к соединению равен: Соединения не разрешены. Отклонить все соединения; реплика используется только для аварийного восстановления. Разрешить любое намерение приложения. Не фильтровать никакие клиентские соединения по намерению приложения. Намерение только для чтения. Если клиент не указывает намерение только для чтения, отказать в соединении. Дополнительные сведения см. в статье Настройка доступа для соединения в реплике доступности (http://msdn.microsoft.com/ru-ru/library/hh213002(SQL.110).aspx). Маршрутизация приложений с намерением только для чтения Самое ценное из того, что предлагают группы доступности AlwaysOn, — это возможность использовать инфраструктуру оборудования, находящегося в режиме ожидания, не только для аварийного восстановления. Можно разрешить в одной или нескольких вторичных репликах доступ только для чтения, что позволит снять значительную рабочую нагрузку с первичных реплик. Руководство по решениям высокого уровня доступности и аварийного восстановления Microsoft SQL Server в режиме AlwaysOn 28 К рабочим нагрузкам, которые можно сразу же перенести на вторичные реплики только для чтения, относятся: отчеты, резервные копии баз данных, проверки согласованности базы данных, анализ фрагментации индекса, извлечение конвейера данных, операционная поддержка и нерегламентированные запросы. Для каждой реплики доступности можно при необходимости настроить последовательный список маршрутизации только для чтения конечных точек экземпляра SQL Server, который будет применяться, когда реплика используется в первичной роли. Если этот список имеется в наличии, то его можно использовать для перенаправления на подключение тех клиентских запросов, в которых указано намерение приложения только для чтения, к первой доступной вторичной реплике в списке, соответствующей фильтрам намерения приложения, указанным выше. Примечание. Перенаправление маршрутизации только для чтения выполняется прослушивателем группы доступности, который привязан к первичной реплике. Если первичная реплика находится в режиме «вне сети», функция перенаправления клиентов работать не будет. Дополнительные сведения см. в статье Настройка маршрутизации только для чтения для группы доступности (SQL Server) (http://msdn.microsoft.com/ru-ru/library/hh653924(SQL.110).aspx). Улучшения доступности — базы данных В SQL Server 2012 представлено несколько усовершенствований, относящихся к настройке баз данных и их возможностям. Следующие улучшения сокращают время восстановления. Прогнозируемое время восстановления. Целевое время восстановления можно задать для каждой базы данных в целях управления планированием выполнения фоновой команды CHECKPOINT. Эта косвенная контрольная точка возникает периодически на основании приблизительного времени, необходимого для восстановления журнала транзакций при перезапуске или отработке отказа. Это приводит к сглаживанию операций ввода-вывода с примерно равными пропорциями для каждой контрольной точки и улучшению предсказуемости целевого времени восстановления (RTO). До SQL Server 2012 фоновые команды CHECKPOINT выполнялись с фиксированным интервалом независимо от объема или нагрузки транзакции, что могло привести к непредсказуемому времени восстановления. Дополнительные сведения см. в статье Контрольные точки базы данных (http://msdn.microsoft.com/ru-ru/library/ms189573(SQL.110).aspx). Эти улучшения устраняют риски общих сценариев, вызывающих запланированные простои. Операции с индексами в сети для столбцов больших двоичных объектов. Индексы, содержащие столбцы с типами данных varbinary(max), varchar(max), nvarchar(max) или типами данных XML, теперь можно перестроить или реорганизовать в режиме «в сети». Руководство по решениям высокого уровня доступности и аварийного восстановления Microsoft SQL Server в режиме AlwaysOn 29 Изменение схемы в режиме «в сети» для новых столбцов, не содержащих значение NULL. При добавлении нового столбца, не содержащего значение NULL, со значением по умолчанию в таблицу базы данных SQL Server 2012 для обновления системных метаданных требуется только заблокировать схему. При выполнении инструкции ALTER TABLE заполнять все строки не требуется. SQL Server физически сохраняет значение столбца по умолчанию, только если строка фактически изменяется или повторно индексируется. Если не существует фактического значения столбца, запросы возвращают значение по умолчанию из метаданных. Вот пример более обширной поддержки вариантов хранения. Автоматическое восстановление страниц. Определенные типы ошибок подсистемы хранения могут повредить страницу данных, делая ее нечитаемой. Группы доступности AlwaysOn могут обнаруживать и автоматически исправлять ошибки этих типов, асинхронно запрашивая и применяя новую копию затронутых страниц данных из другой реплики доступности. Аналогичная функциональность существовала и до зеркального отображения баз данных SQL Server 2012, но теперь она поддерживает несколько реплик. Дополнительные сведения см. в статье Автоматическое восстановление страниц (http://msdn.microsoft.com/ru-ru/library/bb677167(SQL.110).aspx). Рекомендации по возможности подключения клиентов Следуйте данным рекомендациям, чтобы позволить клиентским приложениям использовать все преимущества технологий Microsoft SQL Server 2012 в режиме AlwaysOn. Клиентская библиотека с поддержкой AlwaysOn. Используйте клиентскую библиотеку, которая поддерживает протокол потока табличных данных (TDS) версии 7.4 или более поздней версии. Он должен предоставить необходимую клиентскую функциональность для AlwaysOn. К примерам клиентских библиотек относится поставщик данных для SQL Server в .NET Framework 4.02 и собственный клиент SQL 11.0. Свойство поставщика подключения: MultiSubnetFailover = True. Используйте это ключевое слово в строках подключения, чтобы позволить клиентским библиотекам параллельно подключаться ко всем IP-адресам, зарегистрированным для прослушивателя группы доступности или экземпляра отказоустойчивого кластера с IP-адресом в нескольких подсетях. Свойство поставщика подключения: ApplicationIntent = ReadOnly. Там, где это необходимо, перенесите нагрузку только для чтения с первичной реплики на вторичные реплики. Время ожидания соединения старых клиентов. Старые клиентские библиотеки баз данных не используют параллельные попытки соединения, поэтому при наличии нескольких IP-адресов они пытаются подключиться к каждому из них последовательно, пока не будет превышено время ожидания по протоколу TCP или пока не будет установлено успешное соединение. Руководство по решениям высокого уровня доступности и аварийного восстановления Microsoft SQL Server в режиме AlwaysOn 30 Необходимо настроить время ожидания соединения для старых клиентов так, чтобы учитывать возможные последовательные периоды ожидания и повторные попытки при наличии нескольких IP-адресов, которое как минимум равно 15 секундам + 21 секунда для всех вторичных реплик. Руководство по решениям высокого уровня доступности и аварийного восстановления Microsoft SQL Server в режиме AlwaysOn 31 Заключение Этот технический документ содержит базовые сведения о том, как можно сократить время плановых и незапланированных простоев, увеличить доступность приложений и обеспечить защиту данных с помощью решений высокого уровня доступности и аварийного восстановления SQL Server 2012 в режиме AlwaysOn. Многие из бизнес-факторов и задач планирования, администрирования и измерения среды баз данных с высоким уровнем доступности можно выразить количественно в виде целевой точки восстановления (RPO) и целевого времени восстановления (RTO). SQL Server 2012 в режиме AlwaysOn предоставляет возможности на уровне инфраструктуры, платформы данных и базы данных, которые могут помочь вашей организации реализовать основные сценарии высокого уровня доступности и аварийного восстановления, обоснованные целевыми значениями RTO и RPO. Дополнительные сведения см. на следующих страницах: http://www.microsoft.com/sqlserver/. Веб-сайт SQL Server http://technet.microsoft.com/ru-ru/sqlserver/. Технический центр SQL Server http://msdn.microsoft.com/ru-ru/sqlserver/. SQL Server DevCenter Помогла ли вам эта статья? Пожалуйста, оставьте свой отзыв. Оцените материал по шкале от 1 (плохо) до 5 (отлично) и укажите причины выставления своей оценки. Например: Вы высоко оценили этот документ из-за наличия подходящих примеров, четких снимков экрана, ясного изложения или по какой-либо другой причине? Вы низко оценили степень полезности этого документа из-за неудачных примеров, нечетких снимков экрана и путаного изложения? Ваш отзыв поможет нам повысить качество выпускаемых нами технических документов. Отправить отзыв. ◊ Версия 1.1, 21 февраля 2012 г. Руководство по решениям высокого уровня доступности и аварийного восстановления Microsoft SQL Server в режиме AlwaysOn 32