Возможности использования локального контекста в вероятностных тематических моделях Анна Потапенко
advertisement

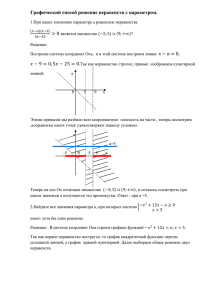
Возможности использования локального контекста в вероятностных тематических моделях Анна Потапенко Научный руководитель: д.ф-м.н. Воронцов К.В. 26 ноября 2015 Задача предсказания контекста по слову Архитектура нейронной сети word2vec Mikolov et al. – Distributed Representations of Words and Phrases and their Compositionality, 2013. Word2vec (Skip-gram model) Вероятность предсказать слово «O» по слову «I»: exp(hwI , wO0 i) p(O|I ) = PV 0 v =1 exp(hwI , wv i) Функция потерь аддитивна по элементам выборки: E =− N X n=1 log p(On |In ) → min 0 W ,W Эффективные способы подсчета softmax: I Hierarchical softmax I Negative sampling Чем полезны обученные векторы (word embeddings): I плотные векторы небольшой размерности I близость векторов соответсвует близости слов: Вероятностная тематическая модель Дано: D — корпус документов; W — множество слов (словарь); ndw — сколько раз термин w ∈ W встретился в документе d ∈ D Найти: I ϕwt = p(w |t) — распределение слов в темах t ∈ T ; I θtd = p(t|d) — распределение тем в документах d ∈ D. Вероятностная модель порождения документа: P P p(w |d) = p(w |t) p(t|d) = ϕwt θtd t∈T t∈T Задача максимизации правдоподобия: X XX ndw log ϕwt θtd → max, d∈D w ∈d t∈T Φ,Θ Похожи ли модели PLSA и word2vec? Похожи ли модели PLSA и word2vec? I Определим «псевдо-документы»: пусть документ d, порожденный словом w содержит все слова, встречающиеся в окнах ширины k = 10 каждого вхождения слова w в коллекцию. I Тогда обе модели задаются максимизацией правдоподобия: XX L= ndw log p(w |d) → max d I Но в PLSA: p(w |d) = w P p(w |t)p(t|d), t а в word2vec: p(w |d) = exp(hw ,di) PD d=1 exp(hw ,di) Модель GloVe Обозначим pij = p(wj |wi ). I word2vec максимизирует кросс-энтропию: E =− V X V X nij log pij = − i=1 j=1 I V X i=1 ni V X p̂ij log pij = j=1 V X ni H(p̂i , pi ) i=1 GloVe максимизирует L2 норму: X E= f (nij )( wi , wj0 − log nij )2 , i,j где f (nij ) понижает веса для частых слов. Subsampling в q −5 word2vec: отбросить слово с вероятностью 1 − 10ni Jeffrey Pennington, Richard Socher, and Christopher D. Manning – GloVe: Global Vectors for Word Representation, 2014. SGNS: Skip-gram Negative Sampling Будем предсказывать, встречается ли пара wj , wi в корпусе: p = σ( wi , wj0 ) = 1 D E 1 + exp − wi , wj0 Хотим предсказывать большую вероятность для положительных примеров и маленькую для отрицательных: X L= nij log σ( wi , wj0 ) + k Ep(wk ) log σ(− wi , wk0 ), i,j где p(wk ) = nk N или p 3/4 (wk ). SGNS как разложение shifted PMI-матрицы Зависимость функционала от одной пары wj , wi : nj l = nij log σ( wi , wj0 ) + k ni log σ(− wi , wj0 ) → max N Максимум достигается при: nij N − log k wi , wj0 = log ni nj Т.е. SGNS раскладывает shifted PMI-матрицу. I SVD-разложение для PMI-матрицы, SGNS, GloVe дают похожие результаты при правильном подборе параметров. Levy et al. – Neural Word Embedding as Implicit Matrix Factorization, 2014; Improving Distributional Similarity with Lessons Learned from Word Embeddings, 2015. Направления работы: I Построение тематической модели на «псевдо-документах»: I I I I Как будут отличаться темы от обычной модели? Вероятностная интерпретация матрицы W 0 . Нужна ли регуляризация для такой задачи? Нужна ли регуляризация в модели SGNS? I Включение в модель двух типов документов аналогично мультимодальной тематической модели. I Эксперименты на коротких документах: выделение этно-нагруженных тем по сообщениям Вконтакте. I Включение pPMI-информации в виде регуляризатора когерентности, эффективная реализация на E-шаге. Задача построения тематической модели – это задача матричного разложения: Проблема: матричное разложение неединственно: ΦΘ = (ΦS)(S −1 Θ) = Φ0 Θ0 Подход аддитивной регуляризации: учесть дополнительные требования к задаче в виде аддитивных слагаемых. Направления работы: I Построение тематической модели на «псевдо-документах»: I I I I Как будут отличаться темы от обычной модели? Вероятностная интерпретация матрицы W 0 . Нужна ли регуляризация для такой задачи? Нужна ли регуляризация в модели SGNS? I Включение в модель двух типов документов аналогично мультимодальной тематической модели. I Эксперименты на коротких документах: выделение этно-нагруженных тем по сообщениям Вконтакте. I Включение pPMI-информации в виде регуляризатора когерентности, эффективная реализация на E-шаге. Мультимодальная тематическая модель Мультимодальная тематическая модель для каждой темы находит распределение на словах p(w |t), Мультимодальная тематическая модель Мультимодальная тематическая модель для каждой темы находит распределение на словах p(w |t), авторах p(a|t), временных метках p(y |t), Мультимодальная тематическая модель Мультимодальная тематическая модель для каждой темы находит распределение на словах p(w |t), авторах p(a|t), временных метках p(y |t), объектах на изображениях p(o|t), Мультимодальная тематическая модель emphМультимодальная тематическая модель для каждой темы находит распределение на словах p(w |t), авторах p(a|t), временных метках p(y |t), объектах на изображениях p(o|t), ссылках p(d 0 |t), Мультимодальная тематическая модель Мультимодальная тематическая модель для каждой темы находит распределение на словах p(w |t), авторах p(a|t), временных метках p(y |t), объектах на изображениях p(o|t), ссылках p(d 0 |t), рекламных баннерах p(b|t), Мультимодальная тематическая модель Мультимодальная тематическая модель для каждой темы находит распределение на словах p(w |t), авторах p(a|t), временных метках p(y |t), объектах на изображениях p(o|t), ссылках p(d 0 |t), баннерах p(b|t), пользователях p(u|t), Мультимодальная тематическая модель Мультимодальная тематическая модель для каждой темы находит распределение на словах p(w |t), авторах p(a|t), временных метках p(y |t), объектах на изображениях p(o|t), ссылках p(d 0 |t), баннерах p(b|t), пользователях p(u|t). Мультимодальная тематическая модель X m∈M λm X X d∈D w ∈Wm ndw ln X t∈T ϕwt θtd + n X τi Ri (Φ, Θ) → max i=1 где λm > 0, τi > 0 – коэффициенты регуляризации. Φ,Θ, Направления работы: I Построение тематической модели на «псевдо-документах»: I I I I Как будут отличаться темы от обычной модели? Вероятностная интерпретация матрицы W 0 . Нужна ли регуляризация для такой задачи? Нужна ли регуляризация в модели SGNS? I Включение в модель двух типов документов аналогично мультимодальной тематической модели. I Эксперименты на коротких документах: выделение этно-нагруженных тем по сообщениям Вконтакте. I Включение PMI-информации в виде регуляризатора когерентности, эффективная реализация на E-шаге. Этно-нагруженные темы (русские): русский, князь, россия, татарин, великий, царить, царь, иван, император, империя, грозить, государь, век, московская, екатерина, москва, (русские): акция, организация, митинг, движение, активный, мероприятие, совет, русский, участник, москва, оппозиция, россия, пикет, протест, проведение, националист, поддержка, общественный, проводить, участие, (сирийцы): сирийский, асад, боевик, район, террорист, уничтожать, группировка, дамаск, оружие, алесио, оппозиция, операция, селение, сша, нусра, турция, (американцы): американский, американка, война, россия, военный, страна, вашингтон, америка, армия, конгресс, сирия, союзный, российский, обама, войска, русский, оружие, операция, (китайцы): китайский, россия, производство, китай, продукция, страна, предприятие, компания, технология, военный, регион, производить, производственный, промышленность, российский, экономический, кнр, (норвежцы): дитя, ребенок, родиться, детский, семья, воспитанный, право, возраст, отец, воспитание, норвежский, родительский, родить, мальчик, взрослый, опека, сын, (канадцы): команда, игра, игрок, канадский, сезон, хоккей, сборная, играть, болельщик, победа, кубок, счет, забирать, хоккейный, выигрывать, хоккеист, чемпионат, шайба, (немцы): армия, война, войска, советский, военный, дивизия, немец, фронт, немецкий, генерал, борт, операция, оборона, русский, бог, победа Тематическая модель для коротких текстов I Каждое слово представляется вектором из PMI-оценок. Составляется матрица из косинусных расстояний между такими векторами. I Производится симметричное неотрицательное матричное разложение (SNMF) методом ALS. I Подбирается матрица описания документов, соответсвующая найденной матрице описания слов. Xiaohui Yan et al. – Learning Topics in Short Texts by Non-negative Matrix Factorization on Term Correlation Matrix, 2015. Направления работы: I Построение тематической модели на «псевдо-документах»: I I I I Как будут отличаться темы от обычной модели? Вероятностная интерпретация матрицы W 0 . Нужна ли регуляризация для такой задачи? Нужна ли регуляризация в модели SGNS? I Включение в модель двух типов документов аналогично мультимодальной тематической модели. I Эксперименты на коротких документах: выделение этно-нагруженных тем по сообщениям Вконтакте. I Включение PMI-информации в виде регуляризатора когерентности, эффективная реализация на E-шаге. Когерентность темы: тема хорошая, если ее слова статистически часто встречаются «рядом». TCPMI = j 10 X X j=2 i=1 log nij N , ni nj где суммирование ведется по всем парам в топ-10 слов темы. Регуляризация локального контекста: p̃tdw = ptdw nd 1 X ndw i=1 X ∂Rdi ∂Rdi [wi = w ] 1 + − psdw ∂ptdw ∂psdw s∈T Эксперимент: модель PLSA на коллекции пресс-релизов Тематическая сегментация последовательного текста по p(t|d, w ) I PLSA предполагает, что тема встречается равномерно по ходу документа. Невозможно обнаружить смены тем. I Общая лексика относится к наиболее вероятным темам дкоумента. Поэтому ключевая терминология зашумляется. Улучшение сегментации регуляризацией локального контекста I Ослабление влияния Θ – тематического профиля документа (например, сглаживанием). I Использование локальных контекстов, чтобы настроить p(t|d, w ) и фильтрация слов, не вписывающихся в контекст, в фоновые темы. Сравнение LDA и модели локальных контекстов Phi Theta contrast purity 1400 1600 0.4 1000 800 600 w 10 w 100 doc 10 5 10 15 20 Iterations count contrast purity 800 0.0 600 1.8 1.6 1.4 1.2 1.0 0.8 0.6 0.4 0.2 0.0 0 1.0 0.8 0.6 0.4 1000 0.2 30 Theta 1200 doc 100 25 Phi 1400 Coherence Coherence 0.8 0.6 1200 1.8 1.6 1.4 1.2 1.0 0.8 0.6 0.4 0.2 0.0 0 1800 Sparsity Perplexity Perplexity 1600 1.0 Sparsity 1800 0.2 0.0 w 10 5 w 100 10 doc 10 15 20 Iterations count doc 100 25 30 Gaussian LDA: другой способ комбинирования LDA и word2vec I I Тема – многомерное нормальное распределение над векторными представлениями слов. Документ – мультиномиальное распределение над темами. Rajarshi Das, Manzil Zaheer, Chris Dyer — Gaussian LDA for Topic Models with Word Embeddings, 2015.