Руководство пользователя SAP Predictive Analysis
advertisement

Руководство пользователя SAP Predictive Analysis
■ SAP Predictive Analysis 1.0.8
2013-01-31
Авторские
права
© 2012 SAP AG. Все права защищены.SAP, R/3, SAP NetWeaver, Duet, PartnerEdge, ByDesign,
SAP BusinessObjects Explorer, StreamWork, SAP HANA и другие упомянутые здесь продукты и
услуги SAP, а также соответствующие им логотипы, являются товарными знаками или
зарегистрированными товарными знаками SAP AG в Германии и в ряде других стран. Business
Objects и логотип Business Objects, BusinessObjects, Crystal Reports, Crystal Decisions, Web
Intelligence, Xcelsius и другие упомянутые в настоящем документе продукты и услуги Business
Objects, а также соответствующие им логотипы являются товарными знаками или
зарегистрированными товарными знаками Business Objects Software Ltd. Business Objects
Software Ltd. принадлежит к SAP Group. Sybase and Adaptive Server, iAnywhere, Sybase 365,
SQL Anywhere и другие упомянутые в настоящем документе продукты и услуги Sybase, а также
соответствующие им логотипы являются товарными знаками или зарегистрированными товарными
знаками Sybase, Inc. Sybase Inc. принадлежит к SAP Group. Crossgate, m@gic EDDY, B2B 360°,
B2B 360° Services являются товарными знаками Crossgate AG, зарегистрированными на
территории Германии и других стран. Crossgate принадлежит к SAP Group. Все другие указанные
продукты и услуги являются товарными знаками соответствующих компаний. Данные, содержащиеся
в настоящем документе, предназначены только для информационных целей. Возможны различные
варианты спецификаций продуктов для разных стран. Эти материалы могут быть изменены без
предварительного уведомления. Материалы предоставлены компанией SAP AG и ее дочерними
компаниями ("SAP Group") исключительно в информационных целях, без предоставления
каких-либо гарантий. SAP Group не несет ответственности за ошибки или пропуски в настоящих
материалах. Гарантии, если таковые предоставляются, в отношении продуктов и услуг SAP Group
содержатся исключительно в документах, которые прилагаются к соответствующим продуктам
и услугам. Ничто, изложенное в настоящем документе, не должно трактоваться как предоставление
дополнительных гарантий.
2013-01-31
Содержание
3
Глава 1
Об этом руководстве.............................................................................................................7
1.1
1.2
Содержание руководства.......................................................................................................7
Глава 2
Обзор приложения SAP Predictive Analysis.........................................................................9
Глава 3
Установка приложения SAP Predictive Analysis................................................................11
3.1
3.2
3.3
3.4
3.4.1
3.4.2
3.5
Предварительные требования к установке...........................................................................11
Глава 4
Установка и настройка библиотеки R с открытым исходным кодом................................15
4.1
4.2
Установка среды R-2.15.1 и обязательных пакетов..............................................................15
Глава 5
Начало работы с приложением SAP Predictive Analysis...................................................17
5.1
5.2
5.3
5.3.1
5.3.2
5.4
Основные понятия в приложении SAP Predictive Analysis...................................................17
Глава 6
Построение анализа............................................................................................................23
6.1
6.1.1
6.1.2
Создание анализа.................................................................................................................23
Целевая аудитория..................................................................................................................7
Установка SAP Predictive Analysis с помощью программы установки..................................12
Удаление приложения SAP Predictive Analysis ...................................................................12
Важные рекомендации по работе с SAP HANA...................................................................12
Настройка учетной записи _SYS_REPO для пользователя SAP Predictive Analysis............13
Поддерживаемые показатели OLAP ....................................................................................14
Важные рекомендации по работе с юниверсами SAP BusinessObjects..............................14
Настройка среды R...............................................................................................................15
Запуск приложения SAP Predictive Analysis........................................................................18
Общие сведения о приложении SAP Predictive Analysis......................................................18
Представление дизайнера....................................................................................................19
Представление результатов..................................................................................................19
Работа с приложением SAP Predictive Analysis...................................................................20
Импорт данных из источника данных....................................................................................23
Подготовка данных для анализа............................................................................................25
2013-01-31
Содержание
4
6.1.3
6.1.4
6.2
6.3
6.4
Применение алгоритмов.......................................................................................................25
Глава 7
Анализ данных.....................................................................................................................31
7.1
7.1.1
7.1.2
7.1.3
7.1.4
7.1.5
7.1.6
7.1.7
Диаграммы............................................................................................................................31
Глава 8
Работа с моделями..............................................................................................................39
8.1
8.2
8.3
8.4
8.5
8.6
Создание модели..................................................................................................................39
Глава 9
Свойства компонентов........................................................................................................43
9.1
9.1.1
9.1.2
9.1.3
9.1.4
9.1.5
9.1.6
9.1.7
9.1.8
9.2
9.2.1
9.2.2
9.2.3
9.2.4
9.3
Алгоритмы.............................................................................................................................43
Сохранение результатов анализа.........................................................................................27
Выполнение анализа.............................................................................................................28
Сохранение анализа.............................................................................................................28
Просмотр результатов..........................................................................................................29
Точечная матричная диаграмма............................................................................................32
Диаграмма статистической сводки.......................................................................................32
Параллельные координаты....................................................................................................33
Дерево принятия решений....................................................................................................34
Диаграмма регрессии...........................................................................................................35
Диаграмма временных рядов................................................................................................36
Кластерная диаграмма..........................................................................................................36
Просмотр сведений о модели...............................................................................................40
Экспорт модели в формате PMML.......................................................................................40
Экспорт модели в SPAR-файл..............................................................................................40
Импорт модели......................................................................................................................41
Удаление модели..................................................................................................................41
Регрессия..............................................................................................................................43
Посторонние значения.........................................................................................................54
Временные ряды...................................................................................................................56
Деревья принятия решений...................................................................................................62
Нейронная сеть.....................................................................................................................68
Кластеризация......................................................................................................................72
Связь.....................................................................................................................................75
Классификация.....................................................................................................................79
Компоненты подготовки данных...........................................................................................80
Формула................................................................................................................................80
Выборка................................................................................................................................86
Определение типа данных....................................................................................................89
Фильтр..................................................................................................................................90
Модули записи данных.........................................................................................................95
2013-01-31
Содержание
5
9.3.1
9.3.2
9.3.3
9.4
Модуль записи CSV..............................................................................................................95
Приложение A
Дополнительная информация.............................................................................................99
Модуль записи JDBC...........................................................................................................96
Модуль записи HANA...........................................................................................................97
Сохраненные модели............................................................................................................97
2013-01-31
Содержание
6
2013-01-31
Об этом руководстве
Об этом руководстве
1.1 Содержание руководства
В этом руководстве представлены следующие сведения:
• Обзор приложения SAP Predictive Analysis
• Установка и настройка приложения SAP Predictive Analysis
• Алгоритмы и компоненты, доступные в приложении SAP Predictive Analysis
• Создание анализов и моделей
• Анализ данных с использованием способов визуализации упреждающего анализа
В данное руководство не входит следующее:
• Импорт данных из различных источников
• Управление данными, их очистка, а также операции семантического пополнения в панели
Подготовка
• Общий доступ к диаграммам и наборам данных
Примечание:
В приложении SAP Predictive Analysis используются унаследованные функции импорта и
управления данными приложения SAP Visual Intelligence. Сведения о соответствующих рабочих
процессах не рассматриваются в этом документе и приводятся в руководстве пользователя SAP
Visual Intelligence, доступном по адресу http://help.sap.com/vi. Для полного понимания рабочего
процесса, лежащего в основе алгоритмов упреждающего анализа данных, рекомендуется
ознакомиться с руководствами пользователя по приложениям SAP Visual Intelligence и SAP
Predictive Analysis.
1.2 Целевая аудитория
Это руководство ориентировано на специалистов по анализу данных, бизнес-аналитиков и
дизайнеров информации, которые используют приложение SAP Predictive Analysis для анализа
и визуализации данных с помощью упреждающих алгоритмов.
Примечание:
Для работы с приложением SAP Predictive Analysis требуется знание алгоритмов статистического
анализа и сбора данных, а также основ их практического применения.
7
2013-01-31
Об этом руководстве
8
2013-01-31
Обзор приложения SAP Predictive Analysis
Обзор приложения SAP Predictive Analysis
SAP Predictive Analysis – это решение для статистического анализа и сбора данных,
предназначенное для построения прогнозных моделей, выявляющих скрытые закономерности
и взаимосвязи в данных, на основе которых можно прогнозировать результаты будущих событий.
В приложении SAP Predictive Analysis доступны различные методы анализа данных, в том числе
прогноз на основе временных рядов, обнаружение посторонних значений, анализ трендов,
классификационный анализ, сегментный анализ и анализ аффинитивности. В этом приложении
поддерживаются различные способы визуализации результатов анализа, в том числе точечные
матричные диаграммы, параллельные координаты, кластерные диаграммы и деревья принятия
решений.
В приложении SAP Predictive Analysis реализован широкий диапазон алгоритмов упреждающего
анализа с использованием языка статистического анализа с открытым исходным кодом R и
функций сбора данных в памяти для эффективной обработки больших объемов данных.
Примечание:
В приложении SAP Predictive Analysis используются унаследованные функции импорта и
управления данными приложения SAP Visual Intelligence. SAP Visual Intelligence – это инструмент
для визуализации данных и управления ими. Приложение SAP Visual Intelligence поддерживает
соединение с различными источниками данных, включая плоские файлы, реляционные базы
данных, базы данных в памяти и юниверсы SAP BusinessObjects. Оно обеспечивает работу с
любыми объемами данных, начиная с небольших матриц в CSV-файлах и заканчивая огромными
наборами SAP HANA, а также функции выбора, очистки данных и управления ими.
9
2013-01-31
Обзор приложения SAP Predictive Analysis
10
2013-01-31
Установка приложения SAP Predictive Analysis
Установка приложения SAP Predictive Analysis
3.1 Предварительные требования к установке
Перед установкой SAP Predictive Analysis убедитесь, что выполнены следующие требования:
•
•
•
•
На компьютере установлена операционная система Microsoft Windows 7. Приложение SAP
Predictive Analysis может работать как на 32-, так и на 64-разрядных компьютерах.
Перед установкой SAP Predictive Analysis необходимо удалить с компьютера ранее
установленное приложение SAP Visual Intelligence.
Для установки приложения SAP Predictive Analysis на компьютер требуются права администра
тора.
На следующих ресурсах должен быть доступен соответствующий объем свободного
пространства:
Требуемый объем
пространства
Ресурс
•
Диск, на котором размещается пользовательская папка данных
приложения
2,5 ГБ
Временная папка пользователя (\AppData\Local\Temp)
200 МБ
Диск, на котором размещается каталог установки
500 МБ
Должны быть доступны следующие порты:
Порт
Предназначение
6401
База данных Sybase IQ
Любой номер порта в диапазоне от 4520 до
4539
Установка приложения SAP Predictive Analysis
Полный список поддерживаемых сред и требований к оборудованию см. в матрице доступности
продуктов по адресу http://service.sap.com/pam
11
2013-01-31
Установка приложения SAP Predictive Analysis
3.2 Установка SAP Predictive Analysis с помощью программы установки
1. Запустите файл setup.exe.
Откроется диалоговое окно контроля учетных записей с предупреждением.
2. Нажмите кнопку Да в окне подтверждения.
3. Укажите папку, в которую требуется установить приложение SAP Predictive Analysis.
• Чтобы использовать предлагаемую по умолчанию папку, нажмите кнопку Далее .
• Чтобы выбрать другую папку для установки приложения SAP Predictive Analysis, нажмите
кнопку Обзор. Выберите папку и нажмите кнопку Далее.
Откроется страница «Лицензионное соглашение».
4. Ознакомьтесь с лицензионным соглашением, выберите пункт Я принимаю условия
лицензионного соглашения и нажмите кнопку Далее.
5. Чтобы начать установку, нажмите кнопку Далее.
По окончании установки откроется страница «Завершение установки».
6. Чтобы завершить установку, нажмите кнопку Готово.
3.3 Удаление приложения SAP Predictive Analysis
1. Выберите Пуск > Панель управления > Программы.
2. Выберите Удаление программ.
3. Щелкните правой кнопкой мыши приложение SAP Predictive Analysis и выберите пункт
Удалить.
Откроется мастер установки приложения SAP Predictive Analysis.
4. На странице Подтверждение удаления нажмите кнопку Далее .
5. Чтобы завершить удаление, нажмите кнопку Готово .
3.4 Важные рекомендации по работе с SAP HANA
В этом разделе приводятся важные рекомендации и требования по использованию приложения
SAP Predictive Analysis с базой данных SAP HANA.
12
2013-01-31
Установка приложения SAP Predictive Analysis
Требования системы безопасности при публикации в SAP HANA
Для публикации контента в SAP HANA пользователям необходимо назначить определенные
привилегии и роли. Эти же роли и привилегии требуются для получения данных из SAP HANA.
Для назначения пользователям ролей и привилегий используется приложение SAP HANA Studio.
Дополнительные сведения об администрировании базы данных SAP HANA и использовании
приложения SAP HANA Studio см. в руководстве по администрированию базы данных SAP HANA.
Дополнительные сведения о безопасности пользователей см. в руководстве по системе
безопасности SAP HANA (включая систему безопасности базы данных SAP HANA).
Учетной записи пользователя, которая используется для входа в систему HANA из приложения
SAP Predictive Analysis, должна быть назначена роль SAP HANA «MODELING».
Примечание:
Это действие может выполнить только пользователь с привилегиями ROLE_ADMIN на базу
данных SAP HANA.
Для входа пользователя SAP Predictive Analysis в систему SAP HANA внутренняя учетная запись
_SYS_REPO должна иметь:
•
•
привилегии SELECT SQL;
выбранный параметр Предоставляются другим для пользовательской схемы (SAP Predictive
Analysis).
3.4.1 Настройка учетной записи _SYS_REPO для пользователя SAP Predictive
Analysis
Если в системе SAP HANA уже определена учетная запись пользователя SAP Predictive Analysis:
1. Из соединения с системой в окне SAP HANA Studio Навигатор перейдите в раздел Каталог
> Авторизация > Пользователи.
2. Дважды щелкните учетную запись _SYS_REPO.
3. На вкладке Привилегии SQL щелкните значок +, введите имя пользовательской схемы и
нажмите кнопку ОК.
4. Выберите SELECT и щелкните Да в соответствующем разделе Предоставляются другим.
5. Щелкните Развернуть или Сохранить.
Примечание:
Также можно открыть редактор SQL в SAP HANA Studio и выполнить следующий оператор
SQL:
GRANT SELECT ON SCHEMA <user_account_name> TO _SYS_REPO WITH GRANT OPTION
13
2013-01-31
Установка приложения SAP Predictive Analysis
3.4.2 Поддерживаемые показатели OLAP
SAP HANA поддерживает только следующие показатели агрегирования в источниках данных
OLAP:
•
•
•
•
SUM
MIN
MAX
COUNT
Если набор данных содержит агрегирование по показателю, не перечисленному выше, система
SAP HANA при публикации будет игнорировать агрегирование, которое не будет включено в
результаты публикации.
3.5 Важные рекомендации по работе с юниверсами SAP BusinessObjects
•
•
При импорте данных из юниверсов на платформе BI 4.0 убедитесь, что сервер Web Intelligence
работает.
Также убедитесь, что платформа Business Intelligence имеет версию BI 4.0 с пакетом
обновления 2 (SP2) и пакетом исправлений 14 или более позднюю.
Примечание:
Кроме того, поддерживается импорт данных из юниверсов на платформе BI 4.0 с пакетами
обновления 3 и 4 (SP3 и SP4).
14
2013-01-31
Установка и настройка библиотеки R с открытым исходным кодом
Установка и настройка библиотеки R с открытым
исходным кодом
4.1 Установка среды R-2.15.1 и обязательных пакетов
Чтобы использовать в анализе алгоритмы R с открытым исходным кодом, необходимо установить
среду R и настроить ее для работы с приложением SAP Predictive Analysis.
В приложении SAP Predictive Analysis реализована специальная функция установки среды R
2.15.1 со всеми обязательными пакетами. В процессе установки R требуется соединение с
Интернетом.
Чтобы установить среду R со всеми обязательными пакетами, выполните следующие действия:
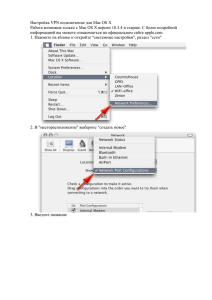
1. Запустите приложение SAP Predictive Analysis.
2. В меню Файл выберите Установить и настроить R.
3. Выберите Установить R.
4. Ознакомьтесь с лицензионным соглашением среды R с открытым исходным кодом и важными
инструкциями, после чего выберите Я соглашаюсь установить R с помощью скрипта.
5. Выберите ОК.
Примечание:
Если вы уже ранее установили среду R 2.15.x, вы можете выполнить эту процедуру для установки
обязательных пакетов R.
4.2 Настройка среды R
После установки среды R необходимо настроить поддержку ее алгоритмов в приложении. Если
вы уже установили версию R-2.11.1 или R-2.15.1 со всеми обязательными пакетами, вы можете
пропустить этап установки и перейти непосредственно к настройке среды R.
Примечание:
Прежде чем настраивать библиотеку R-2.11.1, необходимо задать некоторые переменные среды.
Например, если установка была выполнена в каталог C:\Program Files\R\R-2.11.1,
необходимо задать следующие переменные среды:
• R_HOME= C:\Program Files\R\R-2.11.1
15
2013-01-31
Установка и настройка библиотеки R с открытым исходным кодом
•
•
R_LIBS = C:\Program Files\R\R-2.11.1\library
Path = существующий_путь; C:\Program Files\R\R-2.11.1\library\rJava\jri;
C:\Program Files\R\R-2.11.1\bin
Чтобы настроить конфигурацию среды R, выполните следующие действия:
1. Запустите приложение SAP Predictive Analysis.
2. В меню Файл выберите Установить и настроить R.
3. На вкладке Конфигурация выберите Разрешить алгоритмы R с открытым исходным
кодом.
4. Нажмите кнопку Обзор и выберите каталог установки R.
5. Нажмите кнопку ОК.
Откроется диалоговое окно контроля учетных записей с предупреждением.
6. Нажмите кнопку Да в окне подтверждения.
16
2013-01-31
Начало работы с приложением SAP Predictive Analysis
Начало работы с приложением SAP Predictive
Analysis
5.1 Основные понятия в приложении SAP Predictive Analysis
Компонент
Компонент – это базовый блок обработки в приложении SAP Predictive Analysis. Каждый компонент
содержит входные и выходные точки привязки (точки соединения). Применение точек привязки
позволяет соединять компоненты с помощью коннекторов. Такой механизм обеспечивает передачу
данных между компонентами.
В состав приложения SAP Predictive Analysis входят следующие компоненты:
• Подготовка данных
• Алгоритмы
• Модули записи данных
Компоненты доступны в представлении дизайнера панели Прогноз. Состояние компонентов,
добавленных в редактор анализа, определяется с помощью соответствующих значков состояния.
Поддерживаются следующие состояния компонентов:
•
(не настроено). Отображается при перетаскивании компонента в редактор анализа. Это
состояние свидетельствует о необходимости настроить компонент перед выполнением
анализа.
•
(настроено). Отображается после настройки всех необходимых свойств компонента.
•
(успех). Отображается после успешного выполнения анализа.
•
(сбой). Отображается в том случае, если компонент стал причиной сбоя анализа.
Анализ
Анализ представляет собой последовательность соединенных коннекторами компонентов,
определяющих направление потока данных.
17
2013-01-31
Начало работы с приложением SAP Predictive Analysis
Модель
Модель представляет собой многократно используемый компонент, создаваемый посредством
обучения алгоритма с использованием исторических данных.
В базе данных
Режим выполнения анализа, при котором обработка данных осуществляется в базе с
использованием функций сбора данных. В этом режиме данные не извлекаются из базы для
обработки, что позволяет существенно повысить производительность. Этот режим часто
применяется для обработки крупных наборов данных. SAP HANA поддерживает сбор данных в
базе данных посредством интеграции библиотек R и Predictive Analysis (PAL).
В области обработки
Режим выполнения анализа, при котором данные извлекаются из базы в область обработки
Predictive Analysis для последующей обработки. Также может называться режимом обработки
вне базы данных.
5.2 Запуск приложения SAP Predictive Analysis
Чтобы запустить приложение SAP Predictive Analysis, выберите Пуск > Все программы > SAP
Business Intelligence > SAP Predictive Analysis > SAP Predictive Analysis.
5.3 Общие сведения о приложении SAP Predictive Analysis
При запуске SAP Predictive Analysis открывается домашняя страница приложения. На ней
представлены инструкции по началу работы с SAP Predictive Analysis.
Прежде чем приступить к анализу данных в приложении SAP Predictive Analysis, необходимо
установить соединение с источником и импортировать данные для анализа. После импорта
данных с ними можно выполнять следующие операции:
• Подготовка данных к анализу с использованием функций управления и очистки.
• Обработка данных с использованием алгоритмов сбора и статистического анализа.
• Предоставление общего доступа к наборам данных и диаграммам внешним пользователям.
Примечание:
В этом руководстве описывается анализ данных с использованием алгоритмов сбора и
статистического анализа. Дополнительные сведения об импорте, подготовке данных и общем
доступе к наборам данных см. в руководстве пользователя SAP Visual Intelligence, доступном по
адресу http://help.sap.com/vi.
Чтобы выполнить анализ данных, после их импорта перейдите в панель Прогноз.
18
2013-01-31
Начало работы с приложением SAP Predictive Analysis
5.3.1 Представление дизайнера
Представление дизайнера предназначено для разработки и выполнения анализа, а также для
создания прогнозных моделей.
5.3.2 Представление результатов
В представлении результатов доступны различные способы визуализации и интуитивно понятные
диаграммы, обеспечивающие наглядное представление данных и результатов анализа.
19
2013-01-31
Начало работы с приложением SAP Predictive Analysis
5.4 Работа с приложением SAP Predictive Analysis
В этом разделе приводится обзор процесса, позволяющего построить диаграмму на основе
набора данных. Это нелинейный процесс, этапы которого можно выполнять в произвольной
последовательности.
Этапы по работе с данными
Соединение с источником
данных.
Примечание:
Дополнительные сведения
о соединении с источником
данных см. в разделе Соединение с источником
данныхруководства пользователя SAP Visual
Intelligence.
Просмотрите и упорядочьте столбцы и атрибуты.
Примечание:
Дополнительные сведения
о просмотре столбцов и
атрибутов см. в разделе
Подготовка данныхруководства пользователя SAP
Visual Intelligence.
20
Описание
Тип источника данных:
• Реляционная СУБД – введите учетные данные, соединитесь
с сервером базы данных, перейдите к источнику данных и выберите его. Например, при соединении с источником SAP HANA
необходимо выбрать представление и куб, на основе которых
будет построена диаграмма.
• Плоский файл – выберите столбцы, которые требуется импортировать, вырезать, показать или скрыть.
• Юниверс – введите учетные данные юниверса, соединитесь с
репозиторием центрального сервера управления и выберите
юниверс, на основе которого будет построена диаграмма.
Импортированные данные могут быть представлены в виде
столбцов или аспектов. При необходимости можно выполнить
следующие действия, чтобы упорядочить данные, отображаемые
на диаграмме, для более удобного восприятия:
• Создайте фильтры и скройте ненужные столбцы.
• Создайте показатели, иерархии времени и географии.
• Очистите и упорядочьте данные в столбцах с использованием
различных инструментов манипулирования.
• Создайте столбцы с формулами, используя доступные функции.
2013-01-31
Начало работы с приложением SAP Predictive Analysis
Этапы по работе с данными
Выполните анализ данных
с использованием алгоритмов упреждающего анализа.
Примечание:
В этом руководстве рассматривается анализ данных с использованием алгоритмов упреждающего
анализа.
Сохранение анализа
21
Описание
После импорта необходимых данных в панели "Подготовка" откройте панель "Прогноз", на которой можно выполнить анализ
данных в поисках моделей и получить прогноз будущих результатов.
В панели "Прогноз" можно выполнить следующие действия:
• Создание анализа
• Построение прогнозных моделей
• Просмотр результатов анализа
• Просмотр визуализаций моделей
• Построение диаграмм
Примечание:
Дополнительные сведения о построении диаграмм см. в разделе Визуализация данныхруководства пользователя SAP
Visual Intelligence.
Присвойте имя анализу, который содержит диаграммы, и сохраните его. Анализ сохраняется в документе с расширением SViD
в каталоге "Документы" по заданному для вашего профиля пути.
2013-01-31
Начало работы с приложением SAP Predictive Analysis
22
2013-01-31
Построение анализа
Построение анализа
6.1 Создание анализа
Приложение SAP Predictive Analysis обеспечивает сбор данных и статистический анализ
посредством прогона данных через последовательность компонентов. Используемые компоненты
должны быть соединены коннекторами, которые определяют направление потока данных. Этот
процесс называется анализом. В процессе анализа можно считывать данные из источника,
анализировать их с помощью функций управления данными, алгоритмов сбора данных и
статистического анализа, а также сохранять результаты анализа.
Для создания анализа выполните следующие действия:
1. Импорт данных из источника.
2. (Необязательно) Подготовка данных для анализа, например, с использованием фильтров.
3. Применение алгоритмов.
4. (Необязательно) Сохранение результатов для использования в других анализах.
См. также
• Импорт данных из источника данных
• Подготовка данных для анализа
• Применение алгоритмов
• Сохранение результатов анализа
6.1.1 Импорт данных из источника данных
1. Нажмите кнопку Создать документ, расположенную в левом верхнем углу домашней страницы.
2. Установите соединение с источником данных или перейдите к нему.
Поддерживается импорт данных из следующих источников:
23
2013-01-31
Построение анализа
Источник данных
Описание
Файл CSV
Вы можете импортировать данные из файлов
со значениями, разделенными запятыми, и
выполнять их анализ в области обработки с
применением алгоритмов SAP и библиотеки
R.
Произвольный SQL
Вы можете создать собственный поставщик
данных, вручную введя код SQL целевого
источника, и выполнить его анализ в области
обработки с применением алгоритмов SAP
и библиотеки R.
Автономные источники данных SAP HANA
Вы можете импортировать данные из таблиц,
представлений или представлений анализа
SAP HANA и выполнять их анализ в области
обработки с применением алгоритмов SAP
и библиотеки R.
Интерактивные источники данных SAP HANA
Вы можете импортировать данные из таблиц,
представлений или представлений анализа
SAP HANA и выполнять их анализ в базе
данных с применением алгоритмов HANA
PAL.
MS Excel
Вы можете импортировать данные из электронных таблиц Microsoft Excel и выполнять
их анализ в области обработки с применением алгоритмов SAP и библиотеки R.
Юниверсы версии 3.x
Вы можете импортировать данные из юниверсов SAP BusinessObjects, размещающихся
на платформе XI 3.x, и выполнять их анализ
в области обработки с применением алгоритмов SAP и библиотеки R.
Юниверсы версии 4.x
Вы можете импортировать данные из юниверсов SAP BusinessObjects, размещающихся
на платформе BI 4.x, и выполнять их анализ
в области обработки с применением алгоритмов SAP и библиотеки R.
3. Щелкните Импортировать или Выбрать.
Столбцы отображаются в области "Данные", а атрибуты и показатели – в области "Семантика"
слева. Теперь можно приступать к построению анализа. В панели Прогноз в редактор анализа
добавляется настроенный компонент модуля чтения данных. Чтобы просмотреть результаты
компонента модуля чтения, можно выполнить анализ.
24
2013-01-31
Построение анализа
Примечание:
Дополнительные сведения о соединении с конкретным источником данных см. в руководстве
пользователя SAP Visual Intelligence, доступном по адресу http://help.sap.com/vi.
6.1.2 Подготовка данных для анализа
Это необязательное действие.
В большинстве случаев необработанные данные источника не подходят для анализа. Для
получения наиболее точных результатов перед выполнением анализа требуется подготовить и
обработать данные. Функции управления данными представлены в панели Подготовка, а функции
подготовки – в панели Прогноз.
На этапе подготовки обычно выполняются проверка данных на точность и отсутствие необходимых
полей, их фильтрация по диапазонам, выборка подмножества данных для исследования, а также
различные задачи по управлению ими. Для обработки данных применяются компоненты
подготовки.
1. Дважды щелкните нужный компонент подготовки на вкладке Подготовка данных панели
Прогноз.
Выбранный компонент подготовки добавляется в редактор анализа и автоматически
соединяется с компонентом чтения данных.
2. Щелкните компонент подготовки данных правой кнопкой мыши и выберите Настроить
свойства.
3. В диалоговом окне "Свойства компонента" введите значения свойств компонента подготовки.
4. Нажмите Сохранить и закрыть.
5. Чтобы просмотреть результаты компонентов чтения и подготовки данных, выберите
.
См. также
• Компоненты подготовки данных
6.1.3 Применение алгоритмов
После получения релевантных данных для анализа необходимо применить соответствующие
алгоритмы, позволяющие выявить присутствующие в них модели.
Определение подходящего алгоритма в каждом конкретном случае может быть очень непростой
задачей. Нередко для анализа данных применяется сочетание целого ряда алгоритмов. Например,
сначала можно использовать алгоритмы временных рядов для сглаживания данных, а затем –
регрессионные алгоритмы для поиска трендов в них.
25
2013-01-31
Построение анализа
В следующей таблице приводятся рекомендации по выбору алгоритма в соответствии со стоящими
перед вами задачами.
Прогнозирование по времени
Алгоритмы временных рядов
•
•
•
•
Тройное экспоненциальное сглаживание
Алгоритм однократного экспоненциального
сглаживания (R)
Алгоритм двойного экспоненциального
сглаживания (R)
Алгоритм тройного экспоненциального
сглаживания (R)
Прогнозирование последовательных перемен- Регрессионные алгоритмы
ных на основании значений других переменных
• Линейная регрессия
набора
• Экспоненциальная регрессия
• Геометрическая регрессия
• Логарифмическая регрессия
• Алгоритм множественной линейной регрессии HANA
• Алгоритм линейной регрессии (R)
• Алгоритм экспоненциальной регрессии (R)
• Алгоритм геометрической регрессии (R)
• Алгоритм логарифмической регрессии (R)
• Алгоритм множественной линейной регрессии (R)
Поиск распространенных моделей наборов
Ассоциативные алгоритмы
элементов в крупных транзакционных наборах
• Априорный алгоритм HANA
данных для создания правил ассоциации
• Априорный алгоритм (R)
Кластеризация наблюдений в группы схожих
наборов элементов
26
Алгоритмы кластеризации
•
•
Алгоритм K-средних HANA
Алгоритм K-средних
2013-01-31
Построение анализа
Классификация и прогнозирование одной или Деревья принятия решений
нескольких дискретных переменных на основе
• Алгоритм HANA C 4.5
значений других переменных набора
• Дерево CNR (R)
Обнаружение посторонних значений в наборе Алгоритмы обнаружения посторонних значений
данных
• Межквартильный размах
• Алгоритм обнаружения посторонних значений по методу ближайшего соседа
Прогнозирование, классификация и распозна- Алгоритмы нейронной сети
вание статистических моделей
• Нейронная сеть на основе алгоритма нейронной сети NNet (R)
• Нейронная сеть на основе алгоритма монотонного многослойного перцептрона (R)
1. Откройте панель Прогноз и дважды щелкните нужный компонент алгоритма на вкладке
Алгоритмы.
Выбранный компонент добавляется в редактор и соединяется с предыдущим компонентом
анализа.
2. Щелкните компонент алгоритма правой кнопкой мыши и выберите Настроить свойства.
3. В диалоговом окне "Свойства компонента" введите значения свойств компонента алгоритма.
4. Нажмите Сохранить и закрыть.
5. Чтобы просмотреть результаты компонентов чтения и подготовки данных, а также алгоритма,
выберите
.
См. также
• Алгоритмы
6.1.4 Сохранение результатов анализа
Это необязательное действие.
Результаты анализа можно сохранять с помощью компонентов записи данных в плоских файлах
или базах данных.
1. Дважды щелкните нужный компонент на вкладке Модули записи данных панели Прогноз.
Выбранный компонент добавляется в редактор и соединяется с предыдущим компонентом
анализа.
27
2013-01-31
Построение анализа
2. Щелкните компонент записи данных правой кнопкой мыши и выберите Настроить свойства.
3. В диалоговом окне "Свойства компонента" введите значения свойств компонента записи
данных.
4. Нажмите Сохранить и закрыть.
5. Чтобы просмотреть результаты компонентов чтения, подготовки и записи данных, а также
алгоритма, выберите
.
См. также
• Модули записи данных
6.2 Выполнение анализа
Чтобы выполнить анализ, выберите
в панели инструментов редактора анализа, либо щелкните
правой кнопкой мыши последний компонент анализа и выберите пункт Запуск анализа.
При работе с крупным анализом повышенной сложности можно последовательно выполнять все
входящие в его состав компоненты. Чтобы выполнить отдельный компонент анализа, выберите
в панели инструментов редактора анализа, либо щелкните правой кнопкой мыши компонент,
на котором требуется остановить выполнение, и выберите Выполнить до этого места.
6.3 Сохранение анализа
Созданный анализ можно сохранить для дальнейшего использования. В приложении SAP Predictive
Analysis для этого требуется сохранить соответствующий анализу документ. Документы
сохраняются в формате SViD. В сохраненном документе находятся импортированный из источника
набор данных (компонент чтения данных) и созданный анализ.
Чтобы сохранить анализ в документе, выполните следующие действия:
1. Выберите Файл > Сохранить.
2. Введите имя документа.
3. Выберите Сохранить.
Все анализы, созданные на основе одного и того же набора данных, сохраняются в одном
документе. Для доступа к анализам в документе используется раскрывающийся список Изменить.
28
2013-01-31
Построение анализа
Чтобы добавить в документ новый анализ, выберите
в панели инструментов анализа. Чтобы
переименовать анализ, выберите
и введите новое имя. Чтобы удалить существующий анализ
из документа, выберите
.
Примечание:
Результаты выполнения компонентов не сохраняются вместе с анализами. Чтобы просмотреть
результаты компонента, необходимо выполнить анализ повторно.
6.4 Просмотр результатов
Чтобы просмотреть результаты компонентов после выполнения анализа, щелкните нужный
компонент правой кнопкой мыши и выберите Просмотр результатов. Откроется представление
Результаты.
29
2013-01-31
Построение анализа
30
2013-01-31
Анализ данных
Анализ данных
После успешного выполнения анализа результаты каждого его компонента представляются с
использованием различных диаграмм.
Чтобы провести анализ данных, выполните следующие действия:
1. После выполнения анализа нажмите кнопку Результаты в панели инструментов, чтобы
перейти в представление "Результаты".
2. Чтобы просмотреть визуализацию компонента анализа, выберите его в области Селектор
компонентов.
По умолчанию результаты компонента отображаются в области Сетка. Чтобы просмотреть
результаты компонента на соответствующей диаграмме, перейдите в область Диаграммы.
Кроме того, в области Визуализация вы можете строить собственные диаграммы.
В следующей таблице описываются компоненты и поддерживаемые ими диаграммы визуализации.
Компоненты
Диаграммы
Модули чтения и подготовки данных
Точечная матричная диаграмма, диаграмма статистической сводки
и параллельные координаты
Алгоритмы кластеризации
Кластерная диаграмма и сводка алгоритма
Деревья принятия реше- Дерево принятия решений и сводка алгоритма
ний
Алгоритмы временных
рядов
Диаграмма временных рядов и сводка алгоритма
Регрессионные алгорит- Диаграмма регрессии и сводка алгоритма
мы
7.1 Диаграммы
31
2013-01-31
Анализ данных
7.1.1 Точечная матричная диаграмма
Точечная матричная диаграмма представляет собой матрицу диаграмм (n*n диаграмм, где n –
число выбранных атрибутов), которая используется для сравнения данных разных измерений.
По умолчанию для анализа выбирается четыре последовательных атрибута, начиная с первого
атрибута в источнике данных. В этом случае строится матрица размером 4*4 диаграммы. При
необходимости можно выбрать нужные атрибуты в параметре Настройки и обновить
визуализацию с помощью кнопки Применить.
Примечание:
В параметре Настройки можно выбрать не более четырех последовательных атрибутов.
7.1.2 Диаграмма статистической сводки
Содержит сводную информацию по последовательным атрибутам в источнике данных. В сводную
информацию включаются сведения о числе, минимальном и максимальном значениях, отклонении,
среднеквадратическом отклонении, сумме, среднем значении, диапазоне и числе записей. Для
каждого атрибута строится гистограмма.
32
2013-01-31
Анализ данных
7.1.3 Параллельные координаты
Способ, используемый для визуализации многомерных данных и многомерных моделей в данных
анализа.
На этой диаграмме по умолчанию отображаются первые пять атрибутов в виде разнесенных по
вертикали параллельных осей. Чтобы выбрать подмножество атрибутов для отображения на
диаграмме, используйте параметр Настройки. Каждой оси присваивается ярлык, содержащий
имя атрибута, а также его минимальные и максимальные значения. Каждое наблюдение
представляется последовательностью соединенных точек вдоль параллельных осей. Для
фильтрации данных по значениям категорий можно выбрать соответствующий параметру цвет.
Примечание:
В параметре Настройки можно выбрать до семи последовательных атрибутов.
33
2013-01-31
Анализ данных
7.1.4 Дерево принятия решений
Способ визуализации, при котором обеспечивается классификация наблюдений по группам и
прогнозирование будущих событий на основе набора правил принятия решений.
Это представление применяется при анализе с использованием дерева принятия решений. В
этом случае двоичное дерево принятия решений строится посредством разбиения наблюдений
на более мелкие подгруппы до тех пор, пока не будет достигнут критерий остановки. Концевой
узел соответствует классифицированным данным. Для увеличения дерева принятия решений
используйте кнопку "Увеличить масштаб".
Примечание:
•
•
При наличии более 32 значений категорий для зависимого столбца дерево принятия решений
не отображается.
Внешний вид дерева принятия решений определяется поставщиком алгоритма. Так, деревья,
при построении которых используются алгоритмы дерева CNR (R) и HANA C4.5, будут иметь
различный вид.
Каждый узел дерева принятия решений представляет классификацию данных на соответствующем
уровне. Чтобы просмотреть контент узла, щелкните соответствующий ему элемент
.
34
2013-01-31
Анализ данных
7.1.5 Диаграмма регрессии
Диаграмма регрессии используется для визуализации корреляции между зависимыми и
независимыми переменными. В режиме тренда можно оценить эффективность алгоритма,
сравнив фактические значения зависимых переменных с прогнозными. При этом зависимые
переменные будут представлены гистограммой, а прогнозные значения – линейной диаграммой.
В режиме заполнения алгоритм заполняет отсутствующие значения и выводит результаты в
виде линейной диаграммы.
При очень большом размере набора данных диаграмма может содержать слишком общее
представление данных. Для большей наглядности при работе с крупными наборами данных
следует выбрать отдельный диапазон с помощью селектора "Диапазон". В редакторе визуализации
будут отображаться данные выбранной области.
35
2013-01-31
Анализ данных
7.1.6 Диаграмма временных рядов
Используется для визуализации данных временных рядов в сравнении с расчетными или
прогнозными значениями алгоритма. На этой диаграмме можно просмотреть прогнозные данные
за определенный период. В режиме тренда зависимая переменная представляется в виде
гистограммы, а значения тренда – в виде линейной диаграммы. В режиме прогноза зависимая
переменная представляется в виде гистограммы, а прогнозные значения – в виде линейной
диаграммы.
При очень большом размере набора данных диаграмма может содержать слишком общее
представление данных. Для большей наглядности при работе с крупными наборами данных
следует выбрать отдельный диапазон с помощью селектора "Диапазон". В редакторе визуализации
будут отображаться данные выбранной области.
7.1.7 Кластерная диаграмма
Способ визуализации, при котором сведения о кластерах, в том числе о размере, плотности
кластеров и расстоянии между ними, а также сведения о сравнении переменных и кластеров,
представляются с использованием разных диаграмм.
Примечание:
При кластеризации наблюдений с использованием алгоритма K-средних HANA на диаграммах
могут быть представлены только данные о размере кластера и сравнении переменных кластера.
36
2013-01-31
Анализ данных
Размер кластера
Число элементов в каждом кластере, представленное в виде горизонтальной гистограммы. Кроме
того, для визуализации сведений о размере кластера можно использовать круговые диаграммы
и вертикальные гистограммы.
Плотность кластеров и расстояние между ними
Сведения о расстоянии между кластерами и их плотности представляются с помощью сетевых
диаграмм. Каждый узел сети представляет отдельный кластер и его размер. Плотность кластеров
представлена цветом узлов. Чтобы увеличить сетевую диаграмму, выберите
.
Сравнение переменных кластеров
Сравнение общего распределения по всем кластерам с распределением по отдельным кластерам,
представленное в виде гистограммы. В раскрывающемся списке переменных можно выбрать
нужный атрибут кластера. Для изменения кластера используйте регулятор.
Сравнение кластеров
Алгоритм K-средних (R) вычисляет центральные точки для каждого входного атрибута в каждом
кластере. Данные сравнения центральных точек и кластеров представляются в виде радиальной
диаграммы. Чтобы просмотреть диаграмму с нормализованными данными, выберите параметр
"Нормализовать результат". В режиме нормализации данные будут представлены значениями
в диапазоне от 0 до 1.
37
2013-01-31
Анализ данных
38
2013-01-31
Работа с моделями
Работа с моделями
Модель представляет собой сохраненный экземпляр многократно используемого компонента,
создаваемого посредством обучения алгоритма с использованием исторических данных.
Чаще всего модели создаются для выполнения следующих задач:
• Общий доступ к вычисляемым бизнес-правилам, которые могут применяться к схожим наборам
данных.
• Быстрый анализ результатов без применения исторических данных с использованием
"обученного" экземпляра алгоритма.
8.1 Создание модели
Чтобы создать модель, необходимо сохранить состояние алгоритма.
1. Импортируйте данные из нужного источника.
Компонент источника данных добавляется в панель Прогноз редактора анализа.
2. В панели Прогноз дважды щелкните нужный компонент алгоритма.
3. Щелкните компонент алгоритма правой кнопкой мыши и выберите Настроить свойства.
4. Настройте свойства алгоритма в диалоговом окне.
a. Введите необходимые значения свойств алгоритма.
b. В разделе Сведения о модели выберите Сохранить модель.
c. Введите имя и описание модели.
d. Если требуется перезаписать существующую модель новой, выберите Перезаписывать,
если существует.
e. Нажмите Сохранить и закрыть.
5. Выберите
.
Созданная модель добавляется на вкладку Сохраненные модели. После этого вы можете
выбирать ее при создании анализа, как и любой другой компонент.
Примечание:
Имена независимых столбцов, используемых при оценке и создании модели должны совпадать.
39
2013-01-31
Работа с моделями
8.2 Просмотр сведений о модели
В сведениях о модели указываются:
• Сведения о столбцах, которые использовались при создании модели
• Сводка алгоритма
Эти сведения помогают аналитиками лучше понять структуру модели.
Чтобы просмотреть сведения о модели, выполните следующие действия:
1. В панели Прогноз дважды щелкните нужную модель на вкладке Сохраненные модели.
При наличии сохраненных моделей в репозитории откроется вкладка Сохраненные модели.
2. Щелкните модель правой кнопкой мыши и выберите Просмотр информации о модели.
Отображается визуализация алгоритма, выбранного при создании модели.
8.3 Экспорт модели в формате PMML
Сведения о модели можно экспортировать в локальный файл стандартного отраслевого формата
PMML для дальнейшего использования в совместимых приложениях при анализе схожих данных.
Чтобы экспортировать модель в формате PMML, выполните следующие действия.:
1. Создайте модель.
2. В панели Прогноз дважды щелкните нужную модель на вкладке Сохраненные модели.
3. Щелкните модель правой кнопкой мыши и выберите Экспортировать в формате PMML.
4. Введите имя файла.
5. Выберите нужный тип файла (PMML или XML).
6. Выберите Сохранить.
8.4 Экспорт модели в SPAR-файл
Модель, созданную в виде документа в формате SVID, можно экспортировать в SPAR-файл для
последующего импорта в другой документ SVID.
Чтобы экспортировать модель, выполните следующие действия:
1. Создайте модель.
2. Щелкните модель правой кнопкой мыши и выберите Экспорт модели.
40
2013-01-31
Работа с моделями
3. Введите имя SPAR-файла.
4. Выберите Сохранить.
8.5 Импорт модели
Модель, созданную в виде документа в формате SVID, можно импортировать в другой документ
SVID из SPAR-файла.
Чтобы импортировать модель, выполните следующие действия:
1. Запустите приложение SAP Predictive Analysis.
2. В панели Прогноз выберите команду Импорт модели.
3. Выберите допустимый SPAR-файл и нажмите кнопку Открыть.
Модель импортируется и отображается на вкладке Сохраненные модели.
8.6 Удаление модели
Очень внимательно подходите к использованию этой функции, поскольку при удалении модели
возможна утрата работоспособности анализа, который содержит ссылки на нее.
Чтобы удалить модель, выполните следующие действия:
1. В панели Прогноз откройте вкладку Сохраненные модели.
2. Щелкните нужную модель правой кнопкой мыши и выберите Удалить.
41
2013-01-31
Работа с моделями
42
2013-01-31
Свойства компонентов
Свойства компонентов
9.1 Алгоритмы
Алгоритмы используются для сбора и статистического анализа данных. Например, с помощью
алгоритмов можно определять тренды и модели в данных.
В приложении SAP Predictive Analysis реализованы встроенные алгоритмы, в том числе на основе
регрессии, временных рядов и посторонних значений. Кроме того, в нем поддерживаются
алгоритмы на основе деревьев принятия решений, k-средних, нейронных сетей, временных
рядов и регрессии, представленные в библиотеке R с открытым исходным кодом. Также вы
можете выполнять анализ в базе данных с использованием алгоритмов библиотеки Predictive
Analysis (PAL) для SAP HANA.
9.1.1 Регрессия
9.1.1.1 Экспоненциальная регрессия
Этот алгоритм используется для обнаружения трендов в данных. Этот алгоритм используется
для одномерного регрессионного анализа. В его рамках определяется влияние одной переменной
на другую с использованием экспоненциальной функции по методу наименьших квадратов.
Примечание:
Тип данных столбцов, используемых при оценке модели должен совпадать с типом столбцов,
выбранных при ее построении.
43
2013-01-31
Свойства компонентов
Свойства экспоненциальной регрессии
Режим вывода
Выберите режим, в котором будут отображаться выходные данные.
Возможные значения:
• Заполнение – заполнение отсутствующих значений в целевом
столбце.
• Тренд – прогнозирование значений в зависимом столбце и
добавление дополнительного столбца для выходных данных, в
котором будут представлены прогнозные значения.
Независимый столбец Выберите исходный столбец ввода, для которого будет выполняться
регрессия.
Зависимый столбец
Выберите целевой столбец для выполнения регрессии.
Отсутствующие
значения
Выберите способ обработки отсутствующих значений.
Сохранить модель
Выберите этот параметр, чтобы сохранить состояние модели. При
этом требуется ввести имя и описание модели.
Возможные значения:
• Удалить – алгоритм пропускает записи независимого или
зависимого столбца, содержащие отсутствующие значения.
• Сохранить – отсутствующие значения сохраняются.
• Остановить – при отсутствии значения в независимом или
зависимом столбце выполнение алгоритма прекращается.
Имя столбца прогноза Введите имя создаваемого столбца, который содержит прогнозные
значения.
9.1.1.2 Геометрическая регрессия
Этот алгоритм используется для обнаружения трендов в данных. Этот алгоритм используется
для одномерного регрессионного анализа. В его рамках определяется влияние одной переменной
на другую с использованием геометрической функции по методу наименьших квадратов.
Примечание:
Тип данных столбцов, используемых при оценке модели должен совпадать с типом столбцов,
выбранных при ее построении.
44
2013-01-31
Свойства компонентов
Свойства геометрической регрессии
Режим вывода
Выберите режим, в котором будут отображаться выходные данные.
Возможные значения:
• Заполнение – заполнение отсутствующих значений в целевом
столбце.
• Тренд – прогнозирование значений в зависимом столбце и
добавление дополнительного столбца для выходных данных, в
котором будут представлены прогнозные значения.
Независимый столбец Выберите исходный столбец ввода, для которого будет выполняться
регрессия.
Зависимый столбец
Выберите целевой столбец для выполнения регрессии.
Отсутствующие
значения
Выберите способ обработки отсутствующих значений.
Сохранить модель
Выберите этот параметр, чтобы сохранить состояние модели. При
этом требуется ввести имя и описание модели.
Возможные значения:
• Удалить – алгоритм пропускает записи независимых или зависимых
столбцов, содержащие отсутствующие значения.
• Сохранить – отсутствующие значения сохраняются.
• Остановить – при отсутствии значения в независимом или
зависимом столбце выполнение алгоритма прекращается.
Имя столбца прогноза Введите имя создаваемого столбца, который содержит прогнозные
значения.
9.1.1.3 Алгоритм множественной линейной регрессии HANA
Этот алгоритм используется для обнаружения взаимосвязей между зависимой и одной или
несколькими независимыми переменными.
Свойства алгоритма множественной линейной регрессии HANA
Режим вывода
Выберите режим, в котором будут отображаться выходные данные.
Возможные значения:
• Заполнение – заполнение отсутствующих значений в целевом
столбце.
• Тренд – прогнозирование значений в зависимом столбце и
добавление дополнительного столбца для выходных данных, в
котором будут представлены прогнозные значения.
45
2013-01-31
Свойства компонентов
Независимые столбцы Выберите исходные столбцы ввода, для которых будет выполняться
регрессия.
Зависимый столбец
Выберите целевой столбец для выполнения регрессии.
Отсутствующие
значения
Выберите способ обработки отсутствующих значений.
Число потоков
Введите число потоков, которые можно использовать при выполнении.
Сохранить модель
Выберите этот параметр, чтобы сохранить состояние алгоритма. При
этом требуется ввести имя и описание модели.
Имя столбца прогноза
Введите имя создаваемого столбца, который содержит прогнозные
значения.
Возможные значения:
• Удалить – алгоритм пропускает записи независимых или зависимых
столбцов, содержащие отсутствующие значения.
• Сохранить – отсутствующие значения сохраняются.
• Остановить – при отсутствии значения в независимом или
зависимом столбце выполнение алгоритма прекращается.
9.1.1.4 Линейная регрессия
Этот алгоритм используется для обнаружения трендов в данных. Этот алгоритм используется
для одномерного регрессионного анализа. В его рамках определяется влияние одной переменной
на другую по методу наименьших квадратов.
Примечание:
Тип данных столбцов, используемых при оценке модели должен совпадать с типом столбцов,
выбранных при ее построении.
Свойства алгоритма линейной регрессии
Режим вывода
Выберите режим, в котором будут отображаться выходные данные.
Возможные значения:
• Заполнение – заполнение отсутствующих значений в целевом
столбце.
• Тренд – прогнозирование значений в зависимом столбце и
добавление дополнительного столбца для выходных данных, в
котором будут представлены прогнозные значения.
Независимый столбец Выберите исходный столбец ввода, для которого будет выполняться
регрессия.
Зависимый столбец
46
Выберите целевой столбец для выполнения регрессии.
2013-01-31
Свойства компонентов
Отсутствующие
значения
Выберите способ обработки отсутствующих значений.
Сохранить модель
Выберите этот параметр, чтобы сохранить состояние модели. При
этом требуется ввести имя и описание модели.
Возможные значения:
• Удалить – алгоритм пропускает записи независимых или зависимых
столбцов, содержащие отсутствующие значения.
• Сохранить – отсутствующие значения сохраняются.
• Остановить – при отсутствии значения в независимом или
зависимом столбце выполнение алгоритма прекращается.
Имя столбца прогноза Введите имя создаваемого столбца, который содержит прогнозные
значения.
9.1.1.5 Логарифмическая регрессия
Этот алгоритм используется для обнаружения трендов в данных. Этот алгоритм используется
для одномерного регрессионного анализа. В его рамках определяется влияние одной переменной
на другую с использованием логарифмической функции по методу наименьших квадратов.
Примечание:
Тип данных столбцов, используемых при оценке модели должен совпадать с типом столбцов,
выбранных при ее построении.
Свойства алгоритма логарифмической регрессии
Режим вывода
Выберите режим, в котором будут отображаться выходные данные.
Возможные значения:
• Заполнение – заполнение отсутствующих значений в целевом
столбце.
• Тренд – прогнозирование значений в зависимом столбце и
добавление дополнительного столбца для выходных данных, в
котором будут представлены прогнозные значения.
Независимый столбец Выберите исходный столбец ввода, для которого будет выполняться
регрессия.
Зависимый столбец
47
Выберите целевой столбец для выполнения регрессии.
2013-01-31
Свойства компонентов
Отсутствующие
значения
Выберите способ обработки отсутствующих значений.
Сохранить модель
Выберите этот параметр, чтобы сохранить состояние модели. При
этом требуется ввести имя и описание модели.
Возможные значения:
• Удалить – алгоритм пропускает записи независимых или зависимых
столбцов, содержащие отсутствующие значения.
• Сохранить – отсутствующие значения сохраняются.
• Остановить – при отсутствии значения в независимом или
зависимом столбце выполнение алгоритма прекращается.
Имя столбца прогноза Введите имя создаваемого столбца, который содержит прогнозные
значения.
9.1.1.6 Алгоритм экспоненциальной регрессии (R)
Этот алгоритм используется для обнаружения трендов в данных. Этот алгоритм используется
для одномерного регрессионного анализа. В его рамках определяется влияние одной переменной
на другую с использованием экспоненциальной функции из библиотеки R с открытым исходным
кодом.
Примечание:
Тип данных столбцов, используемых при оценке модели должен совпадать с типом столбцов,
выбранных при ее построении.
Свойства алгоритма экспоненциальной регрессии (R)
Режим вывода
Выберите режим, в котором будут отображаться выходные данные.
Возможные значения:
• Заполнение – заполнение отсутствующих значений в целевом
столбце.
• Тренд – прогнозирование значений в зависимом столбце и
добавление дополнительного столбца для выходных данных, в
котором будут представлены прогнозные значения.
Независимый столбец Выберите исходный столбец ввода, для которого будет выполняться
регрессия.
Зависимый столбец
48
Выберите целевой столбец для выполнения регрессии.
2013-01-31
Свойства компонентов
Отсутствующие
значения
Выберите способ обработки отсутствующих значений.
Возможные значения:
• Удалить – алгоритм пропускает записи независимых или зависимых
столбцов, содержащие отсутствующие значения.
• Сохранить – отсутствующие значения сохраняются.
• Остановить – при отсутствии значения в независимом или зависимом
столбце выполнение алгоритма прекращается.
Разрешить
Логическое значение. Если установлено значение true, в матрице
сингулярный подбор ковариации коэффициентов игнорируются неоднородные
коэффициенты. Если установлено значение false, при обработке модели
с неоднородными коэффициентами возвращается ошибка.
Наличие неоднородных коэффициентов в модели свидетельствует о
том, что квадратная матрица x*x является сингулярной.
Контрасты
Выберите контрасты для множителей, используемых в модели в
качестве переменных.
Сохранить модель
Выберите этот параметр, чтобы сохранить состояние модели. При
этом требуется ввести имя и описание модели.
Имя столбца прогноза Введите имя создаваемого столбца, который содержит прогнозные
значения.
9.1.1.7 Алгоритм геометрической регрессии (R)
Этот алгоритм используется для обнаружения трендов в данных. Этот алгоритм используется
для одномерного регрессионного анализа. В его рамках определяется влияние одной переменной
на другую с использованием геометрической функции из библиотеки R с открытым исходным
кодом.
Примечание:
Тип данных столбцов, используемых при оценке модели должен совпадать с типом столбцов,
выбранных при ее построении.
49
2013-01-31
Свойства компонентов
Свойства алгоритма геометрической регрессии (R)
Режим вывода
Выберите режим, в котором будут отображаться выходные данные.
Возможные значения:
• Заполнение – заполнение отсутствующих значений в целевом
столбце.
• Тренд – прогнозирование значений в зависимом столбце и
добавление дополнительного столбца для выходных данных, в
котором будут представлены прогнозные значения.
Независимый столбец Выберите исходный столбец ввода, для которого будет выполняться
регрессия.
Зависимый столбец
Выберите целевой столбец для выполнения регрессии.
Отсутствующие
значения
Выберите способ обработки отсутствующих значений.
Возможные значения:
• Удалить – алгоритм пропускает записи независимых или зависимых
столбцов, содержащие отсутствующие значения.
• Сохранить – отсутствующие значения сохраняются.
• Остановить – при отсутствии значения в независимом или зависимом
столбце выполнение алгоритма прекращается.
Разрешить
Логическое значение. Если установлено значение true, в матрице
сингулярный подбор ковариации коэффициентов игнорируются неоднородные
коэффициенты. Если установлено значение false, при обработке модели
с неоднородными коэффициентами возвращается ошибка.
Наличие неоднородных коэффициентов в модели свидетельствует о
том, что квадратная матрица x*x является сингулярной.
Контрасты
Выберите контрасты для множителей, используемых в модели в
качестве переменных.
Сохранить модель
Выберите этот параметр, чтобы сохранить состояние модели. При
этом требуется ввести имя и описание модели.
Имя столбца прогноза Введите имя создаваемого столбца, который содержит прогнозные
значения.
9.1.1.8 Алгоритм линейной регрессии (R)
Этот алгоритм используется для обнаружения трендов в данных. Этот алгоритм используется
для одномерного регрессионного анализа. В его рамках определяется влияние одной переменной
на другую с использованием функций библиотеки R с открытым исходным кодом.
50
2013-01-31
Свойства компонентов
Примечание:
Тип данных столбцов, используемых при оценке модели должен совпадать с типом столбцов,
выбранных при ее построении.
Свойства алгоритма линейной регрессии (R)
Режим вывода
Выберите режим, в котором будут отображаться выходные данные.
Возможные значения:
• Заполнение – заполнение отсутствующих значений в целевом
столбце.
• Тренд – прогнозирование значений в зависимом столбце и
добавление дополнительного столбца для выходных данных, в
котором будут представлены прогнозные значения.
Независимый столбец Выберите исходный столбец ввода, для которого будет выполняться
регрессия.
Зависимый столбец
Выберите целевой столбец для выполнения регрессии.
Отсутствующие
значения
Выберите способ обработки отсутствующих значений.
Возможные значения:
• Удалить – алгоритм пропускает записи независимых или зависимых
столбцов, содержащие отсутствующие значения.
• Сохранить – отсутствующие значения сохраняются.
• Остановить – при отсутствии значения в независимом или зависимом
столбце выполнение алгоритма прекращается.
Разрешить
Логическое значение. Если установлено значение true, в матрице
сингулярный подбор ковариации коэффициентов игнорируются неоднородные
коэффициенты. Если установлено значение false, при обработке модели
с неоднородными коэффициентами возвращается ошибка.
Наличие неоднородных коэффициентов в модели свидетельствует о
том, что квадратная матрица x*x является сингулярной.
Контрасты
Выберите контрасты для множителей, используемых в модели в
качестве переменных.
Сохранить модель
Выберите этот параметр, чтобы сохранить состояние модели. При
этом требуется ввести имя и описание модели.
Имя столбца прогноза Введите имя создаваемого столбца, который содержит прогнозные
значения.
9.1.1.9 Алгоритм логарифмической регрессии (R)
51
2013-01-31
Свойства компонентов
Этот алгоритм используется для обнаружения трендов в данных. Этот алгоритм используется
для одномерного регрессионного анализа. В его рамках определяется влияние одной переменной
на другую с использованием логарифмической функции из библиотеки R с открытым исходным
кодом.
Примечание:
Тип данных столбцов, используемых при оценке модели должен совпадать с типом столбцов,
выбранных при ее построении.
Свойства алгоритма логарифмической регрессии (R)
Режим вывода
Выберите режим, в котором будут отображаться выходные данные.
Возможные значения:
• Заполнение – заполнение отсутствующих значений в целевом
столбце.
• Тренд – прогнозирование значений в зависимом столбце и
добавление дополнительного столбца для выходных данных, в
котором будут представлены прогнозные значения.
Независимый столбец Выберите исходный столбец ввода, для которого будет выполняться
регрессия.
Зависимый столбец
Выберите целевой столбец для выполнения регрессии.
Отсутствующие
значения
Выберите способ обработки отсутствующих значений.
Возможные значения:
• Удалить – алгоритм пропускает записи независимых или зависимых
столбцов, содержащие отсутствующие значения.
• Сохранить – отсутствующие значения сохраняются.
• Остановить – при отсутствии значения в независимом или зависимом
столбце выполнение алгоритма прекращается.
Разрешить
Логическое значение. Если установлено значение true, в матрице
сингулярный подбор ковариации коэффициентов игнорируются неоднородные
коэффициенты. Если установлено значение false, при обработке модели
с неоднородными коэффициентами возвращается ошибка.
Наличие неоднородных коэффициентов в модели свидетельствует о
том, что квадратная матрица x*x является сингулярной.
Контрасты
Выберите контрасты для множителей, используемых в модели в
качестве переменных.
Сохранить модель
Выберите этот параметр, чтобы сохранить состояние модели. При
этом требуется ввести имя и описание модели.
Имя столбца прогноза Введите имя создаваемого столбца, который содержит прогнозные
значения.
52
2013-01-31
Свойства компонентов
9.1.1.10 Алгоритм множественной линейной регрессии (R)
Этот алгоритм используется для обнаружения взаимосвязей между зависимой и одной или
несколькими независимыми переменными.
Примечание:
Тип данных столбцов, используемых при оценке модели должен совпадать с типом столбцов,
выбранных при ее построении.
Свойства алгоритма множественной линейной регрессии (R)
Режим вывода
Выберите режим, в котором будут отображаться выходные данные.
Возможные значения:
• Заполнение – заполнение отсутствующих значений в целевом
столбце.
• Тренд – прогнозирование значений в зависимом столбце и
добавление дополнительного столбца для выходных данных, в
котором будут представлены прогнозные значения.
Независимые столбцы
Выберите исходные столбцы ввода, для которых будет выполняться
регрессия.
Зависимый столбец
Выберите целевой столбец для выполнения регрессии.
Отсутствующие
значения
Выберите способ обработки отсутствующих значений.
Возможные значения:
• Удалить – алгоритм пропускает записи независимых или
зависимых столбцов, содержащие отсутствующие значения.
• Сохранить – отсутствующие значения сохраняются.
• Остановить – при отсутствии значения в независимом или
зависимом столбце выполнение алгоритма прекращается.
Степень достоверности Введите степень достоверности алгоритма.
Сохранить модель
Выберите этот параметр, чтобы сохранить состояние модели. При
этом требуется ввести имя и описание модели.
Имя столбца прогноза
Введите имя создаваемого столбца, который содержит прогнозные
значения.
9.1.1.11 Алгоритм множественной линейной регрессии HANA (R)
53
2013-01-31
Свойства компонентов
Этот алгоритм используется для обнаружения взаимосвязей между зависимой и одной или
несколькими независимыми переменными.
Примечание:
Тип данных столбцов, используемых при оценке модели должен совпадать с типом столбцов,
выбранных при ее построении.
Свойства алгоритма множественной линейной регрессии HANA (R)
Режим вывода
Выберите режим, в котором будут отображаться выходные данные.
Возможные значения:
• Заполнение – заполнение отсутствующих значений в целевом
столбце.
• Тренд – прогнозирование значений в зависимом столбце и
добавление дополнительного столбца для выходных данных, в
котором будут представлены прогнозные значения.
Независимые столбцы
Выберите исходные столбцы ввода, для которых будет выполняться
регрессия.
Зависимый столбец
Выберите целевой столбец для выполнения регрессии.
Отсутствующие
значения
Выберите способ обработки отсутствующих значений.
Возможные значения:
• Удалить – алгоритм удаляет записи независимых или зависимых
столбцов, содержащие отсутствующие значения.
• Сохранить – отсутствующие значения сохраняются.
• Остановить – при отсутствии значения в независимом или
зависимом столбце выполнение алгоритма прекращается.
Степень достоверности Введите степень достоверности алгоритма.
Сохранить модель
Выберите этот параметр, чтобы сохранить состояние модели. При
этом требуется ввести имя и описание модели.
Имя столбца прогноза
Введите имя создаваемого столбца, который содержит прогнозные
значения.
9.1.2 Посторонние значения
54
2013-01-31
Свойства компонентов
9.1.2.1 Межквартильный размах
Этот алгоритм используется для обнаружения посторонних значений на основе статистического
распределения между первым и третьим квартилем.
Примечание:
Во входных данных этого алгоритма должны содержаться как минимум 4 строки.
Свойства алгоритма межквартильного размаха
Режим вывода
Выберите режим, в котором будут отображаться выходные данные.
Возможные значения:
• Показать выбросы – добавляет к входным данным столбец
логического типа, в котором определяется, является ли
соответствующее значение посторонним (выбросом).
• Удалить выбросы – удаляет посторонние значения из входных
данных.
Независимый столбец Выберите исходный столбец ввода.
Отсутствующие
значения
Выберите способ обработки отсутствующих значений.
Ограничивающий
коэффициент
Введите отклонение допустимых значений от межквартильного
размаха.
Возможные значения:
• Удалить – алгоритм пропускает записи независимых или зависимых
столбцов, содержащие отсутствующие значения.
• Сохранить – отсутствующие значения сохраняются.
• Остановить – при отсутствии значения в независимом или
зависимом столбце выполнение алгоритма прекращается.
9.1.2.2 Посторонние значения по методу ближайшего соседа
Этот алгоритм обнаруживает посторонние значения на основе числа соседних элементов (N) и
среднего расстояния до значений по сравнению с их ближайшими N соседями.
55
2013-01-31
Свойства компонентов
Свойства алгоритма обнаружения посторонних значений по методу ближайшего
соседа
Режим вывода
Выберите режим, в котором будут отображаться выходные данные.
Возможные значения:
• Показать выбросы – добавляет к входным данным столбец
логического типа, в котором определяется, является ли
соответствующее значение посторонним (выбросом).
• Удалить выбросы – удаляет посторонние значения из входных
данных.
Независимый столбец
Выберите исходный столбец ввода.
Отсутствующие
значения
Выберите способ обработки отсутствующих значений.
Число соседних
элементов
Введите отклонение допустимых значений от межквартильного
размаха.
Число выбросов
Введите число посторонних значений, которые требуется удалить.
Имя столбца прогноза
Введите имя нового столбца, который содержит прогнозные значения.
Возможные значения:
• Удалить – алгоритм пропускает записи независимых или
зависимых столбцов, содержащие отсутствующие значения.
• Сохранить – отсутствующие значения сохраняются.
• Остановить – при отсутствии значения в независимом или
зависимом столбце выполнение алгоритма прекращается.
9.1.3 Временные ряды
9.1.3.1 Тройное экспоненциальное сглаживание
Этот алгоритм применяется для сглаживания исходных данных и поиска сезонных трендов в
них.
56
2013-01-31
Свойства компонентов
Свойства алгоритма тройного экспоненциального сглаживания
Режим вывода
Выберите режим, в котором будут отображаться выходные данные.
• Тренд – отображение исходных данных вместе с прогнозными
значениями для выбранного набора данных.
• Прогноз – отображение прогнозных значений за указанный
период.
Зависимый столбец
Выберите столбец ввода для прогноза.
Учитывать столбец даты Этот параметр определяет, используется ли столбец даты.
Столбец даты
Введите имя столбца, который содержит значения даты.
Отсутствующие значения Выберите метод обработки отсутствующих записей.
• Удалить – алгоритм пропускает записи независимого или
зависимого столбца, содержащие отсутствующие значения.
• Остановить – при отсутствии значения в независимом или
зависимом столбце выполнение алгоритма прекращается.
57
Период
Выберите период прогнозирования.
Периодов в году
Выберите периоды прогнозирования. Этот параметр доступен
только при выборе пользовательского периода.
Начальный год
Введите год, начиная с которого должны учитываться данные
наблюдений. Например, 2009, 1987, 2019.
Начальный период
Введите период, начиная с которого должны учитываться данные
наблюдений.
Периоды прогноза
Введите число периодов прогнозирования.
Сохранить модель
Выберите этот параметр, чтобы сохранить состояние модели. При
этом требуется ввести имя и описание модели.
Имя столбца прогноза
Введите имя создаваемого столбца, который содержит прогнозные
значения.
Значения года
Введите имя нового столбца, который содержит значения года.
Значения квартала
Введите имя нового столбца, который содержит значения квартала.
Значения месяца
Введите имя нового столбца, который содержит значения месяца.
Значения периода
Введите имя нового столбца, который содержит значения периода.
Альфа
Введите сглаживающую постоянную для сглаживающих
наблюдений (базисные параметры). Диапазон: 0-1.
Бета
Введите сглаживающую постоянную для параметров поиска тренда.
Диапазон: 0-1.
Гамма
Введите сглаживающую постоянную для параметров поиска тренда.
Диапазон: 0-1.
2013-01-31
Свойства компонентов
9.1.3.2 Алгоритм двойного экспоненциального сглаживания (R)
Этот алгоритм применяется для сглаживания исходных данных и поиска трендов в них.
Свойства алгоритма двойного экспоненциального сглаживания (R)
58
Режим вывода
Выберите режим, в котором будут отображаться выходные
данные.
• Тренд – отображение исходных данных вместе с прогнозными
значениями для выбранного набора данных.
• Прогноз – отображение прогнозных значений за указанный
период.
Зависимый столбец
Выберите столбец ввода для прогноза.
Период
Выберите период прогнозирования.
Периодов в году
Выберите периоды прогнозирования. Этот параметр доступен
только при выборе пользовательского периода.
Начальный год
Введите год, начиная с которого должны учитываться данные
наблюдений. Например, 2009, 1987, 2019.
Начальный период
Введите период, начиная с которого должны учитываться данные
наблюдений.
Периоды прогноза
Введите число периодов прогнозирования.
Имя столбца прогноза
Введите имя создаваемого столбца, который содержит
прогнозные значения.
Значения года
Введите имя нового столбца, который содержит значения года.
Значения квартала
Введите имя нового столбца, который содержит значения
квартала.
Значения месяца
Введите имя нового столбца, который содержит значения месяца.
Значения периода
Введите имя нового столбца, который содержит значения
периода.
Альфа
Введите сглаживающую постоянную для сглаживающих
наблюдений (базисные параметры). Диапазон: 0-1.
Бета
Введите сглаживающую постоянную для параметров поиска
тренда. Диапазон: 0-1.
Степень достоверности
Введите степень достоверности алгоритма.
Число периодических
наблюдений
Введите число периодических наблюдений, необходимое для
начала вычисления.
2013-01-31
Свойства компонентов
Уровень
Введите начальное значение уровня (a[0]) (l.start). Например:
0,4.
Тренд
Введите начальное значение для поиска параметров тренда
(b[0]) (b.start). Например: 0,4.
Входные данные
оптимизатора
Введите начальные значения альфы, беты и гаммы для
оптимизатора. Например: 0,3; 0,1; 0,1.
9.1.3.3 Алгоритм однократного экспоненциального сглаживания (R)
Этот алгоритм применяется для сглаживания исходных данных.
Свойства алгоритма однократного экспоненциального сглаживания (R)
59
Режим вывода
Выберите режим, в котором будут отображаться выходные
данные.
• Тренд – отображение исходных данных вместе с прогнозными
значениями для выбранного набора данных.
• Прогноз – отображение прогнозных значений за указанный
период.
Зависимый столбец
Выберите столбец ввода для прогноза.
Период
Выберите период прогнозирования.
Периодов в году
Выберите период прогнозирования. Этот параметр доступен
только при выборе пользовательского периода.
Начальный год
Введите год, начиная с которого должны учитываться данные
наблюдений. Например, 2009, 1987, 2019.
Начальный период
Введите период, начиная с которого должны учитываться данные
наблюдений.
Периоды прогноза
Введите число периодов прогнозирования.
Имя столбца прогноза
Введите имя создаваемого столбца, который содержит
прогнозные значения.
Значения года
Введите имя нового столбца, который содержит значения года.
Значения квартала
Введите имя нового столбца, который содержит значения
квартала.
Значения месяца
Введите имя нового столбца, который содержит значения
месяца.
Значения периода
Введите имя нового столбца, который содержит значения
периода.
2013-01-31
Свойства компонентов
Альфа
Введите сглаживающую постоянную для сглаживающих
наблюдений (базисные параметры). Диапазон: 0-1.
Степень достоверности
Введите степень достоверности алгоритма.
Число периодических
наблюдений
Введите число периодических наблюдений, необходимое для
начала вычисления.
Уровень
Введите начальное значение уровня (a[0]) (l.start). Например:
0,4.
9.1.3.4 Алгоритм тройного экспоненциального сглаживания (R)
Этот алгоритм применяется для сглаживания исходных данных и поиска сезонных трендов в
них.
Свойства алгоритма тройного экспоненциального сглаживания (R)
60
Режим вывода
Выберите режим, в котором будут отображаться выходные данные.
• Тренд – отображение исходных данных вместе с прогнозными
значениями для выбранного набора данных.
• Прогноз – отображение прогнозных значений за указанный
период.
Зависимый столбец
Выберите столбец ввода для прогноза.
Период
Выберите период прогнозирования.
Периодов в году
Выберите период прогнозирования. Этот параметр доступен только
при выборе пользовательского периода.
Начальный год
Введите год, начиная с которого должны учитываться данные
наблюдений. Например, 2009, 1987, 2019.
Начальный период
Введите период, начиная с которого должны учитываться данные
наблюдений.
Периоды прогноза
Введите число периодов прогнозирования.
Имя столбца прогноза
Введите имя создаваемого столбца, который содержит прогнозные
значения.
Значения года
Введите имя нового столбца, который содержит значения года.
Значения квартала
Введите имя нового столбца, который содержит значения квартала.
Значения месяца
Введите имя нового столбца, который содержит значения месяца.
Значения периода
Введите имя нового столбца, который содержит значения периода.
2013-01-31
Свойства компонентов
Альфа
Введите сглаживающую постоянную для сглаживающих
наблюдений (базисные параметры). Диапазон: 0-1.
Бета
Введите сглаживающую постоянную для параметров поиска
тренда. Диапазон: 0-1.
Гамма
Введите сглаживающую постоянную для параметров поиска
тренда.
Сезонная
Выберите тип алгоритма экспоненциального сглаживания
Хольта-Винтерса.
Степень достоверности
Введите степень достоверности алгоритма.
Число периодических
наблюдений
Введите число периодических наблюдений, необходимое для
начала вычисления.
Уровень
Введите начальное значение уровня (a[0]) (l.start). Например: 0,4.
Тренд
Введите начальное значение для поиска параметров тренда (b[0])
(b.start). Например: 0,4.
Сезон
Введите начальные значения для поиска сезонных параметров
(s.start). Это значение зависит от выбранного столбца. Например,
если в качестве периода выбран квартал, необходимо ввести
четыре значения типа double.
Входные данные
оптимизатора
Введите начальные значения альфы, беты и гаммы для
оптимизатора. Например: 0,3; 0,1; 0,1.
9.1.3.5 Алгоритм тройного экспоненциального сглаживания HANA (R)
Этот алгоритм применяется для сглаживания исходных данных и поиска сезонных трендов в
них.
Свойства алгоритма тройного экспоненциального сглаживания HANA (R)
61
Режим вывода
Выберите режим, в котором будут отображаться выходные данные.
• Тренд – отображение исходных данных вместе с прогнозными
значениями для выбранного набора данных.
• Прогноз – отображение прогнозных значений за указанный
период.
Зависимый столбец
Выберите столбец ввода для выполнения анализа временных
рядов.
Период
Выберите период прогнозирования.
Периодов в году
Выберите период прогнозирования. Этот параметр доступен только
при выборе пользовательского периода.
2013-01-31
Свойства компонентов
Начальный год
Введите год, начиная с которого должны учитываться данные
наблюдений. Например, 2009, 1987, 2019.
Начальный период
Введите период, начиная с которого должны учитываться данные
наблюдений.
Периоды прогноза
Введите число периодов прогноза. Это значение используется
только в режиме вывода "Прогноз".
Имя столбца прогноза
Введите имя создаваемого столбца, который содержит прогнозные
значения.
Значения года
Введите имя нового столбца, который содержит значения года.
Значения квартала
Введите имя нового столбца, который содержит значения квартала.
Значения месяца
Введите имя нового столбца, который содержит значения месяца.
Значения периода
Введите имя нового столбца, который содержит значения периода.
Альфа
Введите сглаживающую постоянную для сглаживающих
наблюдений (базисные параметры). Диапазон: 0-1.
Бета
Введите сглаживающую постоянную для параметров поиска тренда.
Диапазон: 0-1.
Гамма
Введите сглаживающую постоянную для параметров поиска тренда.
Сезонная
Выберите тип алгоритма экспоненциального сглаживания
Хольта-Винтерса.
Степень достоверности
Введите степень достоверности алгоритма.
Число периодических
наблюдений
Введите число периодических наблюдений, необходимое для
начала вычисления.
Уровень
Введите начальное значение уровня (a[0]) (l.start). Например: 0,4.
Тренд
Введите начальное значение для поиска параметров тренда (b[0])
(b.start). Например: 0,4.
Сезон
Введите начальные значения для поиска сезонных параметров
(s.start). Это значение зависит от выбранного столбца. Например,
если в качестве периода выбран квартал, необходимо ввести
четыре значения типа double.
Входные данные
оптимизатора
Введите начальные значения альфы, беты и гаммы для
оптимизатора. Например: 0,3; 0,1; 0,1.
9.1.4 Деревья принятия решений
62
2013-01-31
Свойства компонентов
9.1.4.1 Алгоритм HANA C 4.5
Этот алгоритм используется для классификации наблюдений по группам и прогнозирования
одной или нескольких дискретных переменных на основе значений других переменных.
Свойства алгоритма HANA C 4.5
Режим вывода
Выберите режим, в котором будут отображаться выходные данные.
Возможные значения:
• Тренд – прогнозирование значений в зависимом столбце и
добавление дополнительного столбца для выходных данных,
в котором будут представлены прогнозные значения.
• Заполнение – заполнение отсутствующих значений в целевом
столбце.
Независимые столбцы
Выберите исходные столбцы ввода.
Зависимый столбец
Выберите целевой столбец.
Отсутствующие значения Выберите способ обработки отсутствующих значений.
Возможные значения:
• Удалить – алгоритм пропускает записи независимых или
зависимых столбцов, содержащие отсутствующие значения.
• Сохранить – отсутствующие значения сохраняются.
• Остановить – при отсутствии значения в независимом или
зависимом столбце выполнение алгоритма прекращается.
Процентное соотношение Введите долю данных, которые будут обрабатываться при анализе.
Число потоков
Введите число потоков, которые можно использовать при
выполнении.
Имя столбца
Введите имя независимого столбца, содержащего числовые
значения.
Введите диапазоны
интервала
Введите диапазоны интервала.
9.1.4.2 Дерево CNR (R)
63
2013-01-31
Свойства компонентов
Этот алгоритм используется для классификации наблюдений по группам и прогнозирования
одной или нескольких дискретных переменных на основе значений других переменных. Кроме
того, этот алгоритм можно использовать для поиска трендов в данных.
Примечание:
•
•
•
Пакет "rpart" из состава библиотеки R 2.15 не поддерживает имена столбцов, содержащие
пробелы или специальные символы. Пакет "rpart" поддерживает только те имена столбцов
ввода, формат которых поддерживается кадром данных R.
Имена независимых столбцов, используемых при оценке и создании модели должны совпадать.
Имена столбцов, содержащие пробелы или любые другие специальные символы, за
исключением точки (.), не поддерживаются.
Свойства дерева CNR (R)
Режим вывода
Выберите режим, в котором будут отображаться выходные данные.
Возможные значения:
• Тренд – прогнозирование значений в зависимом столбце и
добавление дополнительного столбца для выходных данных, в
котором будут представлены прогнозные значения.
• Заполнение – заполнение отсутствующих значений в целевом
столбце.
Независимые
столбцы
Выберите исходные столбцы ввода.
Зависимый столбец
Выберите целевой столбец.
Отсутствующие
значения
Выберите способ обработки отсутствующих значений.
Метод
Выберите тип правила расщепления.
Возможные значения:
• Рекурсивное разбиение – алгоритм удаляет все наблюдения, для
которых отсутствует зависимый столбец. Тем не менее, наблюдения,
для которых отсутствуют один или несколько независимых столбцов,
сохраняются.
• Удалить – алгоритм пропускает записи независимого или зависимого
столбца, содержащие отсутствующие значения.
• Сохранить – отсутствующие значения сохраняются.
• Остановить – при отсутствии значения в независимом или зависимом
столбце выполнение алгоритма прекращается.
Возможные значения:
• Классификация – этот метод используется при наличии в зависимой
переменной значений категорий.
• Регрессия – этот метод используется при наличии в зависимом
столбце последовательных значений.
64
2013-01-31
Свойства компонентов
Минимальное
расщепление
Введите минимальное число наблюдений для разделения узла.
Критерий разделения Выберите критерий расщепления для узла.
Возможные значения:
• Коэффициент Джини – коэффициент расслоения Джини.
• Информация – накопление информации.
Сохранить модель
Выберите этот параметр, чтобы сохранить состояние модели. При этом
требуется ввести имя и описание модели.
Имя столбца
прогноза
Введите имя создаваемого столбца, который содержит прогнозные
значения.
Параметр сложности Введите параметр сложности, который позволит уменьшить время
вычисления, запрещая расщепления, которые не улучшают подбор.
Максимальная
глубина
Введите максимальный уровень узла в конечном дереве (корневой узел
имеет уровень 0).
Примечание:
Если значение максимальной глубины превышает 30, алгоритм может
возвращать неточные результаты (на 32-разрядных компьютерах).
65
Перекрестная
проверка
Введите число перекрестных проверок. С увеличением числа
перекрестных проверок возрастает время вычисления, однако
повышается точность результатов.
Априорная
вероятность
Введите вектор априорных вероятностей.
Использовать
суррогат
Введите суррогат, используемый в процессе разделения.
Возможные значения:
• Только показывать – наблюдение с отсутствующим значением для
первичного правила разделения не передается на нижележащие
уровни дерева.
• Использовать суррогат – разделение субъектов, для которых
отсутствует первичная переменная. Если отсутствуют все суррогаты,
наблюдение не разделяется.
• Останавливать при отсутствии – при отсутствии всех суррогатов
наблюдение передается в доминирующем направлении.
2013-01-31
Свойства компонентов
Стиль суррогата
Введите стиль, определяющий порядок выбора лучшего суррогата.
Возможные значения:
• Использовать полностью корректную классификацию – алгоритм
использует для поиска потенциальной переменной-суррогата общее
число корректных классификаций.
• Использовать процент распознанных случаев – алгоритм использует
для поиска потенциального суррогата заданный процент
классифицированных случаев.
Максимальный
суррогат
Введите максимальное число суррогатов, которые будут храниться для
каждого узла дерева.
9.1.4.3 Дерево CNR HANA (R)
Этот алгоритм используется для классификации наблюдений по группам и прогнозирования
одной или нескольких дискретных переменных на основе значений других переменных. Кроме
того, этот алгоритм можно использовать для поиска трендов в данных.
Примечание:
•
•
•
Пакет "rpart" из состава библиотеки R 2.15 не поддерживает имена столбцов, содержащие
пробелы или специальные символы. Пакет "rpart" поддерживает только те имена столбцов
ввода, формат которых поддерживается кадром данных R.
Имена независимых столбцов, используемых при оценке и создании модели должны совпадать.
Имена столбцов, содержащие пробелы или любые другие специальные символы, за
исключением точки (.), не поддерживаются.
Свойства дерева CNR HANA (R)
Режим вывода
Выберите режим, в котором будут отображаться выходные данные.
Возможные значения:
• Тренд – прогнозирование значений в зависимом столбце и
добавление дополнительного столбца для выходных данных, в
котором будут представлены прогнозные значения.
• Заполнение – заполнение отсутствующих значений в целевом
столбце.
66
Независимые
столбцы
Выберите исходные столбцы ввода.
Зависимый столбец
Выберите целевой столбец.
2013-01-31
Свойства компонентов
Отсутствующие
значения
Выберите способ обработки отсутствующих значений.
Метод
Выберите тип правила расщепления.
Возможные значения:
• Удалить – алгоритм пропускает записи независимого или зависимого
столбца, содержащие отсутствующие значения.
• Сохранить – отсутствующие значения сохраняются.
• Остановить – при отсутствии значения в независимом или зависимом
столбце выполнение алгоритма прекращается.
Возможные значения:
• Классификация – этот метод используется при наличии в зависимой
переменной значений категорий.
• Регрессия – этот метод используется при наличии в зависимом
столбце последовательных значений.
Минимальное
расщепление
Введите минимальное число наблюдений для разделения узла.
Критерий разделения Выберите критерий расщепления для узла.
Возможные значения:
• Коэффициент Джини – коэффициент расслоения Джини.
• Информация – накопление информации.
Сохранить модель
Выберите этот параметр, чтобы сохранить состояние модели. При
этом требуется ввести имя и описание модели.
Имя столбца прогноза Введите имя создаваемого столбца, который содержит прогнозные
значения.
Параметр сложности
Введите параметр сложности, который позволит уменьшить время
вычисления, запрещая расщепления, которые не улучшают подбор.
Максимальная
глубина
Введите максимальный уровень узла в конечном дереве (корневой
узел имеет уровень 0).
Примечание:
Если значение максимальной глубины превышает 30, алгоритм может
возвращать неточные результаты (на 32-разрядных компьютерах).
67
Перекрестная
проверка
Введите число перекрестных проверок. С увеличением числа
перекрестных проверок возрастает время вычисления, однако
повышается точность результатов.
Априорная
вероятность
Введите вектор априорных вероятностей.
2013-01-31
Свойства компонентов
Использовать
суррогат
Введите суррогат, используемый в процессе разделения.
Стиль суррогата
Введите стиль, определяющий порядок выбора лучшего суррогата.
Возможные значения:
• Только показывать – наблюдение с отсутствующим значением для
первичного правила разделения не передается на нижележащие
уровни дерева.
• Использовать суррогат – разделение субъектов, для которых
отсутствует первичная переменная. Если отсутствуют все суррогаты,
наблюдение не разделяется.
• Останавливать при отсутствии – при отсутствии всех суррогатов
наблюдение передается в доминирующем направлении.
Возможные значения:
• Использовать полностью корректную классификацию – алгоритм
использует для поиска потенциальной переменной-суррогата общее
число корректных классификаций.
• Использовать процент распознанных случаев – алгоритм использует
для поиска потенциального суррогата заданный процент
классифицированных случаев.
Максимальный
суррогат
Введите максимальное число суррогатов, которые будут храниться
для каждого узла дерева.
9.1.5 Нейронная сеть
9.1.5.1 Нейронная сеть на основе алгоритма монотонного многослойного
перцептрона (R)
Этот алгоритм применяется для прогнозирования, классификации и распознавания статистических
моделей с использованием функций библиотеки R.
Примечание:
Библиотека R не поддерживает хранение нейронной сети на основе алгоритма монотонного
многослойного перцептрона в формате PMML.
68
2013-01-31
Свойства компонентов
Свойства нейронной сети на основе алгоритма монотонного многослойного перцептрона
(R)
Режим вывода
Выберите режим, в котором будут отображаться выходные
данные.
Возможные значения:
• Тренд – прогнозирование значений в зависимом столбце
и добавление дополнительного столбца для выходных
данных, в котором будут представлены прогнозные
значения.
• Заполнение – заполнение отсутствующих значений в
целевом столбце.
Независимые столбцы
Выберите исходные столбцы ввода.
Зависимый столбец
Выберите целевой столбец.
Нейроны скрытого слоя 1
Введите число узлов или нейронов на первом скрытом
слое (hidden1).
Сохранить модель
Выберите этот параметр, чтобы сохранить состояние
модели. При этом требуется ввести имя и описание
модели.
Имя столбца прогноза
Введите имя создаваемого столбца, который содержит
прогнозные значения.
Передаточная функция скрытого Выберите функцию активации для скрытого слоя (Th).
слоя
69
Передаточная функция
выходного слоя
Выберите функцию активации для выходного слоя (To).
Производная передаточной
функции скрытого слоя
Выберите производную для функции активации скрытого
слоя (Th.prime).
Производная передаточной
функции выходного слоя
Выберите производную для функции активации выходного
слоя (To.prime).
Нейроны скрытого слоя 2
Введите число узлов или нейронов на втором скрытом
слое (hidden2).
Максимальное число итераций
Введите максимальное число итераций для алгоритма
оптимизации (iter.max).
Монотонные столбцы
Введите индексы столбцов, к которым требуется применить
ограничение монотонности (monotone).
Обучающие итерации
Введите число обучающих итераций, после которого
прекращается вычисление функции стоимости
(iter.stopped).
Начальные веса
Введите начальный вектор весов (init.weights).
2013-01-31
Свойства компонентов
Максимальное число исключений Введите максимальное число исключений для операции
оптимизации (max.exceptions).
Масштабировать зависимый
столбец
Чтобы масштабировать зависимые столбцы до нулевого
отклонения и единичной дисперсии перед выполнением
подбора, выберите True (scale.y).
Требуется использовать метод
случайных подвыборок
Чтобы использовать метод случайных подвыборок (bag),
выберите True.
Число испытаний для исключения Введите число повторных испытаний для исключения
локальных минимумов
локальных минимумов (n.trials).
Число элементов совокупности
Введите число членов совокупности для подбора
(n.ensemble).
9.1.5.2 Нейронная сеть на основе алгоритма нейронной сети NNet (R)
Этот алгоритм применяется для прогнозирования, классификации и распознавания статистических
моделей с использованием функций библиотеки R.
Свойства нейронной сети на основе алгоритма нейронной сети NNet (R)
Режим вывода
Выберите режим, в котором будут отображаться выходные данные.
Возможные значения:
• Тренд – прогнозирование значений в зависимом столбце и
добавление дополнительного столбца для выходных данных, в
котором будут представлены прогнозные значения.
• Заполнение – заполнение отсутствующих значений в целевом
столбце.
Независимые столбцы
Выберите исходные столбцы ввода.
Зависимый столбец
Выберите целевой столбец.
Отсутствующие значения Выберите способ обработки отсутствующих значений.
Возможные значения:
• Удалить – алгоритм пропускает записи независимых или
зависимых столбцов, содержащие отсутствующие значения.
• Сохранить – отсутствующие значения сохраняются для
обработки.
• Остановить – при отсутствии значения в независимом или
зависимом столбце выполнение алгоритма прекращается.
Нейроны скрытого слоя Введите число узлов или нейронов на скрытом слое.
70
2013-01-31
Свойства компонентов
Имя столбца прогноза
Введите имя создаваемого столбца, который содержит прогнозные
значения.
Тип
Выберите тип анализа, который будет выполнен с применением
этого алгоритма.
Пропуск скрытого слоя
Чтобы добавить прямые связи между входом и выходом, выберите
True.
Линейный выход
Чтобы получить линейный выход, выберите True. Если выбран тип
анализа "Классификация", этот атрибут должен иметь значение
true.
Использовать софтмакс Чтобы использовать лог-линейную модель и подбор условного
максимального правдоподобия, выберите True.
Атрибуты linout, entropy, softmax и censored являются
взаимоисключающими.
Использовать энтропию Чтобы использовать подбор условного максимального
правдоподобия, выберите True. По умолчанию этот алгоритм
использует метод наименьших квадратов.
Возможные значения:
• True – используется подбор условного максимального
правдоподобия.
• False – используется метод наименьших квадратов.
Использовать
цензурированную
функцию
Для софтмакса строка (0,1,1) определяет по одному экземпляру
классов 2 и 3, однако для цензурированной функции эта строка
определяет один экземпляр класса 2 или 3.
Диапазон
Введите начальный диапазон случайных весов [-rang, rang]. Если
входные данные имеют небольшой объем, используйте значение
0,5. Для объемных входных данных диапазон вычисляется по
формуле rang * max(|x|) <= 1
Уменьшение веса
Введите значение для вычисления новых весов (decay).
Максимальное число
итераций
Введите максимально допустимое число итераций.
Требуется матрица Гессе Чтобы получить показатель Гессе на основе лучшего набора весов,
выберите True.
Максимальные веса
Введите максимально допустимое число весов для вычисления.
Максимальное число весов не ограничивается в коде, однако с его
ростом возможно существенное увеличение длительности подбора.
Абсолютный допуск
71
Введите значение, определяющее точный подбор (abstol).
2013-01-31
Свойства компонентов
Относительный допуск
Работа алгоритма завершается, если оптимизатору не удается
уменьшить критерий подбора на величину "1 - относительный
допуск".
Контрасты
Введите список контрастов для переменных множителей,
используемых в модели.
Сохранить модель
Выберите этот параметр, чтобы сохранить состояние модели. При
этом требуется ввести имя и описание модели.
9.1.6 Кластеризация
9.1.6.1 Алгоритм K-средних HANA
Этот алгоритм используется для кластеризации связанных наблюдений в группы при отсутствии
априорных сведений о взаимоотношениях между ними. При его использовании наблюдения
кластеризуются в k групп, где значение k предоставляется в виде параметра ввода. Далее каждое
наблюдение относится к соответствующему кластеру на основании его близости к среднему
значению кластера. Процесс продолжается до тех пор, пока не будет достигнуто схождение
кластеров.
Примечание:
•
•
При каждом выполнении алгоритма K-средних HANA число кластеров может изменяться. Тем
не менее, число наблюдений в каждом кластере остается одинаковым
Создание моделей на основе алгоритма K-средних HANA не поддерживается.
Свойства алгоритма K-средних HANA
72
Режим вывода
Выберите режим, в котором будут отображаться выходные
данные.
Независимые столбцы
Выберите исходные столбцы ввода.
2013-01-31
Свойства компонентов
Отсутствующие значения
Выберите способ обработки отсутствующих значений.
Возможные значения:
• Удалить – алгоритм пропускает записи независимых или
зависимых столбцов, содержащие отсутствующие значения.
• Игнорировать – при вычислении алгоритма пропускаются
записи, содержащие отсутствующие значения. Тем не менее,
эти записи остаются в таблице результатов.
• Остановить – при отсутствии значения в независимом или
зависимом столбце выполнение алгоритма прекращается.
Число кластеров
Введите число групп для кластеризации.
Имя кластера
Введите имя создаваемого столбца, в котором содержится имя
кластера.
Максимальное число
итераций
Введите допустимое число итераций при поиске кластеров.
Метод вычисления центра Выберите метод вычисления начальных центров кластера.
Нормализация
Чтобы выполнить нормализацию данных, выберите True.
Число потоков
Введите число потоков, которые можно использовать при
выполнении.
Порог выхода
Введите пороговое значение для выхода из итераций.
9.1.6.2 Алгоритм K-средних (R)
Этот алгоритм используется для кластеризации связанных наблюдений в группы при отсутствии
априорных сведений о взаимоотношениях между ними. При его использовании наблюдения
кластеризуются в k групп, где значение k предоставляется в виде параметра ввода. Далее каждое
наблюдение относится к соответствующему кластеру на основании его близости к среднему
значению кластера. Процесс продолжается до тех пор, пока не будет достигнуто схождение
кластеров.
Примечание:
•
•
При каждом выполнении алгоритма K-средних (R) число кластеров может изменяться. Тем
не менее, число наблюдений в каждом кластере остается одинаковым
Создание моделей с использованием алгоритма K-средних (R) не поддерживается.
Свойства алгоритма K-средних (R)
73
Режим вывода
Выберите режим, в котором будут отображаться выходные
данные.
Независимые столбцы
Выберите исходные столбцы ввода.
2013-01-31
Свойства компонентов
Число кластеров
Введите число групп для кластеризации.
Имя кластера
Введите имя создаваемого столбца, в котором содержится
имя кластера.
Максимальное число итераций Введите допустимое число итераций при поиске кластеров.
Число начальных наборов
Введите число задаваемых случайным образом начальных
наборов для кластеризации (nstart).
Алгоритм
Выберите тип алгоритма для кластеризации по методу
K-средних.
9.1.6.3 Алгоритм K-средних HANA (R)
Этот алгоритм используется для кластеризации связанных наблюдений в группы при отсутствии
априорных сведений о взаимоотношениях между ними. При его использовании наблюдения
кластеризуются в k групп, где значение k предоставляется в виде параметра ввода. Далее каждое
наблюдение относится к соответствующему кластеру на основании его близости к среднему
значению кластера. Процесс продолжается до тех пор, пока не будет достигнуто схождение
кластеров.
Примечание:
•
•
При каждом выполнении алгоритма K-средних (R) число кластеров может изменяться. Тем
не менее, число наблюдений в каждом кластере остается одинаковым
Создание моделей на основе алгоритма K-средних HANA (R) не поддерживается.
Свойства алгоритма K-средних HANA (R)
Режим вывода
Выберите режим, в котором будут отображаться выходные
данные.
Независимые столбцы
Выберите исходные столбцы ввода.
Число кластеров
Введите число групп для кластеризации.
Имя кластера
Введите имя создаваемого столбца, в котором содержится
имя кластера.
Максимальное число итераций Введите допустимое число итераций при поиске кластеров.
74
Число начальных наборов
Введите число задаваемых случайным образом начальных
наборов для кластеризации (nstart).
Алгоритм
Выберите тип алгоритма для кластеризации по методу
K-средних.
2013-01-31
Свойства компонентов
9.1.7 Связь
9.1.7.1 Априорный алгоритм HANA
Этот алгоритм позволяет обнаруживать частотные модели наборов элементов в крупных
транзакционных наборах данных для создания правил ассоциации. С его помощью можно
определить, какие продукты и услуги клиенты предрасположены покупать одновременно.
Анализируя тренды, наблюдающиеся в покупательских предпочтениях клиентов, посредством
ассоциативного анализа, можно прогнозировать их поведение в будущем.
Например, сведения о том, что клиенты склонны одновременно покупать обувь и носки, можно
представить в виде правила ассоциации с заданными минимальными значениями поддержки и
достоверности: Обувь=> Носки [поддержка = 0,5, достоверность= 0,1]
Свойства априорного алгоритма HANA
Столбцы элементов
Выберите столбцы, содержащие элементы, к которым требуется
применить алгоритм.
Столбец ид. транзакций
Выберите столбец, содержащий идентификаторы транзакций, к
которым требуется применить алгоритм.
Отсутствующие значения Выберите способ обработки отсутствующих значений.
Возможные значения:
• Удалить – алгоритм пропускает записи независимых или
зависимых столбцов, содержащие отсутствующие значения.
• Сохранить – отсутствующие значения сохраняются для
обработки.
Поддержка
Введите минимальное значение поддержки для элемента.
Достоверность
Введите значение минимальной достоверности правил или
ассоциации.
Предварительное правило Введите имя нового столбца, который содержит первый операнд
(LHS) априорного правила для указанного набора данных.
75
Пост-правило
Введите имя нового столбца, который содержит второй операнд
(RHS) априорного правила для указанного набора данных.
Значения поддержки
Введите имя нового столбца, который содержит значения
поддержки для соответствующих правил.
2013-01-31
Свойства компонентов
Значения достоверности
Введите имя нового столбца, который содержит значения
достоверности для соответствующих правил.
Значения подъема
Введите имя нового столбца, который содержит значения подъема
для соответствующих правил.
Число потоков
Введите число потоков, которые можно использовать при
выполнении.
9.1.7.2 Априорный алгоритм (R)
Этот алгоритм позволяет обнаруживать частотные модели наборов элементов в крупных
транзакционных наборах данных для создания правил ассоциации с использованием пакета
"arules" библиотеки R. С его помощью можно определить, какие продукты и услуги клиенты
предрасположены покупать одновременно. Анализируя тренды покупательских предпочтений
клиентов с помощью ассоциативного анализа можно спрогнозировать их поведение в будущем.
Например, сведения о том, что клиенты склонны одновременно покупать обувь и носки, можно
представить в виде правила ассоциации с заданными минимальными значениями поддержки и
достоверности: Обувь=> Носки [поддержка = 0,5, достоверность= 0,1]
Свойства априорного алгоритма (R)
76
Режим вывода
Выберите режим, в котором будут отображаться выходные
данные.
Формат входных данных
Выберите формат входных данных.
Столбцы элементов
Выберите столбцы, содержащие элементы, к которым требуется
применить алгоритм.
Столбец ид. транзакций
Выберите столбец, содержащий идентификаторы транзакций,
к которым требуется применить алгоритм.
Поддержка
Введите минимальное значение поддержки для элемента.
Достоверность
Введите значение минимальной достоверности правил или
ассоциации.
Сохранить модель
Выберите этот параметр, чтобы сохранить состояние модели.
При этом требуется ввести имя и описание модели.
Правила
Введите имя нового столбца, который содержит априорные
правила для указанного набора данных.
Значения поддержки
Введите имя нового столбца, который содержит значения
поддержки для соответствующих правил.
Значения достоверности
Введите имя нового столбца, который содержит значения
достоверности для соответствующих правил.
2013-01-31
Свойства компонентов
Значения подъема
Введите имя нового столбца, который содержит значения
подъема для соответствующих правил.
Ид. транзакции
Введите имя нового столбца, который содержит ид. транзакции.
Элементы
Введите имя нового столбца, который содержит имена
элементов.
Сопоставляемые правила
Введите имя нового столбца, который содержит
сопоставляемые правила.
Элементы слева
Введите разделенный запятыми список ярлыков элементов,
которые будут отображаться слева от правил или наборов
элементов.
Элементы справа
Введите разделенный запятыми список ярлыков элементов,
которые будут отображаться справа от правил или наборов
элементов.
Элементы с обеих сторон
Введите разделенный запятыми список ярлыков элементов,
которые будут отображаться с обеих сторон от правил или
наборов элементов.
Невключаемые элементы
Введите разделенный запятыми список ярлыков элементов,
которые не будут отображаться в правилах или наборах
элементов.
Внешний вид по умолчанию Введите параметр внешнего вида, который будет применяться
к правилам по умолчанию при отсутствии явного выбора.
Сортировать элементы
Выберите способ сортировки элементов по их частоте.
Фильтровать элементы
Введите числовое значение, определяющее порядок
фильтрации неиспользуемых элементов транзакций.
Представление "Дерево"
Выберите True, чтобы упорядочить транзакции в виде
префиксного дерева.
Использовать
Чтобы использовать пирамидальную сортировку вместо
пирамидальную сортировку быстрой сортировки транзакций, выберите True.
Минимальная загрузка
памяти
Чтобы уменьшить загрузку памяти за счет снижения
производительности, выберите True.
Загрузить транзакции
Чтобы загрузить транзакции в память, выберите True.
9.1.7.3 Априорный алгоритм HANA (R)
Этот алгоритм позволяет обнаруживать частотные модели наборов элементов в крупных
транзакционных наборах данных для создания правил ассоциации с использованием пакета
"arules" библиотеки R. С его помощью можно определить, какие продукты и услуги клиенты
77
2013-01-31
Свойства компонентов
предрасположены покупать одновременно. Анализируя тренды покупательских предпочтений
клиентов с помощью ассоциативного анализа можно спрогнозировать их поведение в будущем.
Например, сведения о том, что клиенты склонны одновременно покупать обувь и носки, можно
представить в виде правила ассоциации с заданными минимальными значениями поддержки и
достоверности: Обувь=> Носки [поддержка = 0,5, достоверность= 0,1]
Свойства априорного алгоритма HANA (R)
78
Режим вывода
Выберите режим, в котором будут отображаться выходные
данные.
Формат входных данных
Выберите формат входных данных.
Столбцы элементов
Выберите столбцы, содержащие элементы, к которым требуется
применить алгоритм.
Столбец ид. транзакций
Выберите столбец, содержащий идентификаторы транзакций,
к которым требуется применить алгоритм.
Поддержка
Введите минимальное значение поддержки для элемента.
Достоверность
Введите значение минимальной достоверности правил или
ассоциации.
Сохранить модель
Выберите этот параметр, чтобы сохранить состояние модели.
При этом требуется ввести имя и описание модели.
Правила
Введите имя нового столбца, который содержит априорные
правила для указанного набора данных.
Значения поддержки
Введите имя нового столбца, который содержит значения
поддержки для соответствующих правил.
Значения достоверности
Введите имя нового столбца, который содержит значения
достоверности для соответствующих правил.
Значения подъема
Введите имя нового столбца, который содержит значения
подъема для соответствующих правил.
Ид. транзакции
Введите имя нового столбца, который содержит ид. транзакции.
Элементы
Введите имя нового столбца, который содержит имена
элементов.
Сопоставляемые правила
Введите имя нового столбца, который содержит
сопоставляемые правила.
Элементы слева
Введите разделенный запятыми список ярлыков элементов,
которые будут отображаться слева от правил или наборов
элементов.
Элементы справа
Введите разделенный запятыми список ярлыков элементов,
которые будут отображаться справа от правил или наборов
элементов.
2013-01-31
Свойства компонентов
Элементы с обеих сторон
Введите разделенный запятыми список ярлыков элементов,
которые будут отображаться с обеих сторон от правил или
наборов элементов.
Невключаемые элементы
Введите разделенный запятыми список ярлыков элементов,
которые не будут отображаться в правилах или наборах
элементов.
Внешний вид по умолчанию Введите параметр внешнего вида, который будет применяться
к правилам по умолчанию при отсутствии явного выбора.
Сортировать элементы
Выберите способ сортировки элементов по их частоте.
Фильтровать элементы
Введите числовое значение, определяющее порядок
фильтрации неиспользуемых элементов транзакций.
Представление "Дерево"
Выберите True, чтобы упорядочить транзакции в виде
префиксного дерева.
Использовать
Чтобы использовать пирамидальную сортировку вместо
пирамидальную сортировку быстрой сортировки транзакций, выберите True.
Минимальная загрузка
памяти
Чтобы уменьшить загрузку памяти за счет снижения
производительности, выберите True.
Загрузить транзакции
Чтобы загрузить транзакции в память, выберите True.
9.1.8 Классификация
9.1.8.1 Компонент HANA KNN
Этот компонент используется для классификации данных на основе выборки данных обучения.
При работе с компонентом KNN объекты классифицируются по большинству голосов соседних
элементов.
Свойства компонента HANA KNN
Независимые столбцы
Выберите исходные столбцы ввода.
Число соседних элементов Введите число соседних элементов, которое будет учитываться
при поиске расстояний.
Тип голосования
79
Выберите тип голосования.
2013-01-31
Свойства компонентов
Отсутствующие значения
Выберите способ обработки отсутствующих значений.
• Удалить – алгоритм пропускает записи независимых или
зависимых столбцов, содержащие отсутствующие значения.
• Сохранить – отсутствующие значения учитываются при
обработке.
• Остановить – при отсутствии значения в независимом или
зависимом столбце выполнение алгоритма прекращается.
Имя схемы
Введите имя схемы, содержащей данные обучения.
Имя таблицы
Введите имя таблицы, содержащей данные обучения.
Независимые столбцы
Укажите столбцы ввода, которые будут использоваться при
создании данных обучения.
Зависимый столбец
Укажите столбец выходных данных, который будут
использоваться при создании данных обучения.
Число потоков
Введите число потоков, которые можно использовать при
выполнении.
Имя столбца прогноза
Введите имя нового столбца, который содержит значения
классификации.
9.2 Компоненты подготовки данных
Эти компоненты применяются при подготовке данных к анализу. Они являются необязательными.
9.2.1 Формула
Этот компонент позволяет добавить предопределенные функции и операторы для работы с
данными. Все функции и выражения, за исключением функций управления данными, создают
новый столбец, содержащий результаты вычисления формулы.
Примечание:
•
•
80
При вводе строкового литерала одинарные кавычки необходимо предварять символами
обратной косой черты. Например, строку 'О'Генри' необходимо вводить как 'О\'Генри'.
При вводе имени столбца квадратные скобки также необходимо предварять символами
обратной косой черты. Например, имя [Клиент[Возраст]] необходимо вводить как
[Клиент\[Возраст\]].
2013-01-31
Свойства компонентов
Свойства формул
Имя
Введите имя столбца, создаваемого при применении формулы.
Выражение
Введите применяемую формулу. Например, Average([Возраст]).
Пример: Вычисление среднего возраста сотрудников
Таблица сотрудников:
Ид. сотрудни- Имя сотрудни- Дата рождека
ка
ния
Возраст
Дата поступле- Дата подтверния
ждения
1
Лора
11/11/1986
25
12/9/2005
27/11/2005
2
Дейзи
12/5/1981
30
24/6/2000
10/7/2000
3
Алекс
30/5/1978
33
10/10/1998
24/12/1998
4
Джон
6/6/1979
32
2/12/1999
20/12/1999
1. Перетащите компонент Формула в редактор анализа.
2. Введите имя формулы в представлении свойств.
Например, Average_Age.
3. В поле Выражение введите следующую формулу: AVERAGE([Возраст])
4. Выберите Проверить и применить, чтобы проверить синтаксис формулы.
Таблица выходных данных.
81
2013-01-31
Свойства компонентов
Ид. сотруд- Имя сотруд- Дата рожденика
ника
ния
Возраст
Дата поступ- Дата подления
тверждения Average_Age
1
Лора
11/11/1986
25
12/9/2005
27/11/2005
30
2
Дейзи
12/5/1981
30
24/6/2000
10/7/2000
30
3
Алекс
30/5/1978
33
10/10/1998
24/12/1998
30
4
Джон
6/6/1979
32
2/12/1999
20/12/1999
30
Поддерживаемые функции
Категория
Функция (функция, применяемая к таблице сотрудников)
Описание
Дата
DAYSBETWEEN
Возвращает количество дней между двумя
датами.
CURRENTDATE
Возвращает текущую системную дату.
MONTHSBETWEEN
Возвращает количество месяцев между
двумя датами.
Например, при применении функции
MONTHSBETWEEN([Дата присоединения],[Дата подтверждения]) к таблице сотрудников возвращается столбец, содержащий следующие значения: 2,0,2,0.
DAYNAME
Возвращает название дня в строковом
формате.
Например, при применении функции
DAYNAME([Дата поступления]) к таблице
сотрудников возвращается столбец, содержащий следующие значения: Понедельник, Суббота, Суббота, Четверг.
DAYNUMBEROFMONTH
Возвращает номер дня в указанном месяце.
Например, для строки "12/11/1980" возвращается значение "12".
DAYNUMBEROFWEEK
Возвращает номер дня в неделе.
Например, воскресенье=1, понедельник=2.
82
2013-01-31
Свойства компонентов
Категория
Функция (функция, применяемая к таблице сотрудников)
Описание
DAYNUMBEROFYEAR
Возвращает номер дня в году.
Например, 1-е января=1, 1-е февраля=32,
3-е февраля=34.
LASTDATEOFWEEK
Возвращает дату последнего дня недели.
Например, для строки "12/9/2005" возвращается значение "17/9/2005".
LASTDATEOFMONTH
Возвращает дату последнего дня в месяце.
Например, для строки "12/9/2005" возвращается значение "30/9/2005".
MONTHNUMBEROFYEAR
Возвращает номер месяца в дате.
Например, январь=1, февраль=2, март=3.
WEEKNUMBEROFYEAR
Возвращает номер недели в году.
Например, для строки "12/9/2005" возвращается значение "38".
QUARTERNUMBEROFDATE
Возвращает номер квартала в дате.
Например, для строки "12/9/2005" возвращается значение "3".
Строка
Параметр CONCAT
Соединяет две строки.
Например, функция CONCAT('США', 'Австралия') возвращает следующую строку:
СШААвстралия.
INSTRING
Возвращает значение true, если в исходной строке найдена поисковая строка.
Например, функция INSTRING('США', 'СШ')
возвращает следующее значение: true.
SUBSTRING
Возвращает подстроку исходной строки.
Например, выражение SUBSTRING('США',
1,2) возвращает значение "СШ".
STRLEN
83
Возвращает число символов в исходной
строке. Например, выражение
STRLEN('Австралия') возвращает значение 9.
2013-01-31
Свойства компонентов
Категория
Функция (функция, применяемая к таблице сотрудников)
Описание
Матема- MAX
тические
функции
MIN
Возвращает минимальное значение в
столбце.
COUNT
Возвращает число значений в столбце.
SUM
Возвращает сумму значений в столбце.
AVERAGE
Возвращает среднее по всем значениям
столбца.
Управле- @REPLACE
ние данными
84
Возвращает максимальное значение в
столбце.
Замещает строку на месте.
Например, функция @REPLACE([страна],'США', 'АМЕРИКА') замещает все значения "США" в столбце "страна" строками
"Америка".
2013-01-31
Свойства компонентов
Категория
Функция (функция, применяемая к таблице сотрудников)
Описание
@BLANK
Замещает пустые значения указанным.
Например, функция @BLANK([страна],
'США') замещает все пустые значения в
столбце "страна" строками "США".
@SELECT
Выбирает строки, удовлетворяющие заданному условию. Для определения условия
можно использовать любой условный
оператор.
Например, функция @SELECT([страна]=='США') выбирает строки, для которых
в столбце "страна" содержится значение
"США".
Условное IF(условие) THEN(строковое выражевыраже- ние/математическое выражение/условное
ние
выражение) ELSE(строковое выражение/математическое выражение/условное
выражение)
Возвращает разные значения, если проверяемое условие имеет значение 'true' или
'false'.
Например, IF([Дата присоединения]>12/9/2005) THEN ('Сотрудник присоединился к компании после 12 сентября
2005 года') ELSE ('Сотрудник присоединился к компании до 12 сентября 2005 года')
Примечание:
Математические выражения, которые содержат функции, возвращающие числовые значения,
не поддерживаются. Например, выражение DAYNUMBEROFMONTH(CURRENTDATE())+2
возвращает числовое выражение и, соответственно, не поддерживается.
Математические операторы
Математические операторы используются для создания формул, содержащих числовые столбцы
и/или числа. Например, выражение [Возраст] + 1 создает новый столбец со следующими
значениями: 26, 31, 34, 33.
85
Математические операторы
Описание
+
Оператор сложения
-
Оператор вычитания
*
Оператор умножения
/
Оператор деления
()
Круглые скобки
2013-01-31
Свойства компонентов
Математические операторы
Описание
^
Оператор возведения в степень
%
Оператор модуля
E
Экспоненциальный оператор
Условные операторы
С помощью условных операторов можно создавать выражения IF THEN ELSE и SELECT.
Условные операторы
Описание
==
Равно
!=
Не равно
<
Меньше
>
Больше
<=
Меньше или равно
>=
Больше или равно
Логические операторы
Логические операторы позволяют сравнить два условия, возвращая значение 'true' или 'false'.
Например, выражение IF([Дата присоединения]>12/9/2005 && [Возраст] >=25 ) THEN ('True') ELSE
('False') создает новый столбец со следующими значениями: True, False, False, False.
Логические операторы
Описание
&&
И
||
ИЛИ
9.2.2 Выборка
Этот компонент применяется для выбора подмножества данных из крупных наборов.
Поддерживаются следующие типы выборок:
• Первые N – выбор первых N записей в наборе данных.
• Последние N – выбор последних N записей в наборе данных.
• Каждые N – выбор каждой N-ой записи в наборе данных (N – интервал). Например, при N=2
будут выбраны 2-я, 4-я, 6-я, 8-я и последующие четные записи.
86
2013-01-31
Свойства компонентов
•
•
Простая случайная выборка – случайная выборка записей (N – размер выборки или процентная
доля записей в наборе данных).
Систематическая случайная выборка – выборка на основе заданного интервала или размера
сегмента. При таком подходе случайным образом выбирается N-я запись из первого и каждого
последующего сегмента.
Свойства компонента "Выборка"
Тип выборки
Укажите тип выборки.
Критерий ограничения строк
Выберите метод ограничения строк.
Число строк
Введите число строк, которые требуется выбрать.
Доля строк в процентах
Введите долю строк в процентах, которые требуется
выбрать.
Размер сегмента
Введите размер сегмента, в котором будет выбрана
случайная строка.
Интервал
Введите интервал выборки строк.
Максимальное число строк
Введите максимальное число строк, которые требуется
выбрать.
Пример: Выбор подмножества набора данных
Ид. сотрудника
Имя сотрудника
Дата рождения
Возраст
1
Лора
11/11/1986
25
2
Дейзи
12/5/1981
30
3
Алекс
30/5/1978
33
4
Джон
6/6/1979
32
5
Тед
4/7/1987
24
6
Том
30/6/1970
41
7
Анна
24/6/1965
46
8
Вэлери
6/7/1990
21
9
Мэри
19/9/1985
26
10
Мартин
21/11/1986
25
1. Первые N (N=5)
87
2013-01-31
Свойства компонентов
Ид. сотрудника
Имя сотрудника
Дата рождения
Возраст
1
Лора
11/11/1986
25
2
Дейзи
12/5/1981
30
3
Алекс
30/5/1978
33
4
Джон
6/6/1979
32
5
Тед
4/7/1987
24
Ид. сотрудника
Имя сотрудника
Дата рождения
Возраст
7
Анна
24/6/1965
46
8
Вэлери
6/7/1990
21
9
Мэри
19/9/1985
26
10
Мартин
21/11/1986
25
2. Последние N (N=4)
3. Каждые N (интервал=3)
Ид. сотрудника
Имя сотрудника
Дата рождения
Возраст
3
Алекс
30/5/1978
33
6
Том
30/6/1970
41
9
Мэри
19/9/1985
26
4. Простая случайная выборка (число строк=2)
В результатах могут возвращаться любые две строки.
Ид. сотрудника
Имя сотрудника
Дата рождения
Возраст
7
Анна
24/6/1965
46
8
Вэлери
6/7/1990
21
5. Систематическая случайная выборка (размер сегмента=4)
88
2013-01-31
Свойства компонентов
Ид. сотрудника
Имя сотрудника
Дата рождения
Возраст
2
Дейзи
12/5/1981
30
6
Том
30/6/1970
41
10
Мартин
21/11/1986
25
Ид. сотрудника
Имя сотрудника
Дата рождения
Возраст
1
Лора
11/11/1986
25
5
Тед
4/7/1987
24
9
Мэри
19/9/1985
26
или
9.2.3 Определение типа данных
С помощью этого компонента можно изменить имя, тип данных и формат даты исходного столбца.
Эффективное определение типа данных позволяет подготовить их для дальнейшего
использования в анализе.
Пример.
• Например, имя столбца "Пред" в источнике данных во время анализа может вызывать
сомнения. Если изменить его на "Предназначение", то конечные пользователи легко поймут,
для какой цели он используется.
• Значения даты, хранящиеся в формате ммддгг без разделителя (например, 120201), могут
интерпретироваться системой как целочисленные. С помощью компонента "Определение
типа данных" можно выбрать любой поддерживаемый формат даты, например, мм/дд/гггг
или дд/мм/гггг.
Чтобы изменить имя, тип данных и формат даты исходного столбца, выполните следующие
действия:
1. Добавьте в анализ компонент "Определение типа данных".
2. Щелкните компонент правой кнопкой мыши и выберите Настроить свойства.
3. Чтобы изменить имя столбца, введите псевдоним соответствующего исходного столбца.
4. Чтобы изменить тип данных столбца, выберите соответствующий тип для исходного столбца.
89
2013-01-31
Свойства компонентов
9.2.4 Фильтр
Этот компонент используется для фильтрации строк и столбцов в соответствии с заданным
условием.
Примечание:
•
•
Компонент фильтра в базе данных не поддерживает функции и расширенные выражения.
Если после настройки компонента фильтра изменить источник данных, в этом компоненте
будут сохранены ранее определенные фильтры строк.
Свойства фильтра
Выделенные столбцы
Выберите столбцы для анализа.
Условие фильтра
Введите условие фильтра.
Пример: Например, можно отфильтровать столбец исходных данных "Магазин" с
применением условия "Прибыль >2000".
Магазин
Доход
Прибыль
Контрольное значение
10 000
1000
Спенсер
20000
4500
Сох
25000
8000
1. Отмените выбор столбца "Магазин" в разделе "Выделенные столбцы".
2. Выберите столбец "Прибыль" в области Фильтр строк.
3. В параметре Диапазон выбора введите значение 2000 в поле От. Поле До необходимо
оставить пустым.
4. Нажмите кнопку ОК.
5. Нажмите Сохранить и закрыть.
6. Выполните анализ.
Доход
Прибыль
20000
4500
25000
8000
Примечание:
Компонент фильтра поддерживает только выражения, возвращающие результаты логического
типа.
90
2013-01-31
Свойства компонентов
В качестве примера рассмотрим следующую таблицу сотрудников:
Ид. сотрудни- Имя сотрудни- Дата рождека
ка
ния
Возраст
Дата поступле- Дата подтверния
ждения
1
Лора
11/11/1986
25
12/9/2005
27/11/2005
2
Дейзи
12/5/1981
30
24/6/2000
10/7/2000
3
Алекс
30/5/1978
33
10/10/1998
24/10/1998
4
Джон
6/6/1979
32
2/12/1999
20/12/1999
•
•
Выражение DAYSBETWEEN([Дата поступления],[Дата подтверждения]) возвращает числовое
значение и не может использоваться в фильтре. Корректный пример использования выражения
DAYSBETWEEN в фильтре: DAYSBETWEEN([Дата поступления],[Дата подтверждения]) ==
14. Это выражение выбирает строки, в которых разница между значениями атрибутов "Дата
поступления" и "Дата подтверждения" составляет 14 дней. В приведенной выше таблице
выбирается третья строка.
Выражение DAYNAME([Дата присоединения]) == 'Суббота' выбирает вторую и третью строки
таблицы сотрудников.
Примечание:
•
•
При вводе строкового литерала одинарные кавычки необходимо предварять символами
обратной косой черты. Например, строку 'О'Генри' необходимо вводить как 'О\'Генри'.
При вводе имени столбца квадратные скобки также необходимо предварять символами
обратной косой черты. Например, имя [Клиент[Возраст]] необходимо вводить как
[Клиент\[Возраст\]].
Поддерживаемые функции
Примечание:
Компонент фильтра не поддерживает функции управления данными.
91
2013-01-31
Свойства компонентов
Категория
Функция (функция, применяемая к таблице сотрудников)
Описание
Дата
DAYSBETWEEN
Возвращает количество дней между двумя
датами.
CURRENTDATE
Возвращает текущую системную дату.
MONTHSBETWEEN
Возвращает количество месяцев между
двумя датами.
Например, при применении функции
MONTHSBETWEEN([Дата присоединения],[Дата подтверждения]) к таблице сотрудников возвращается столбец, содержащий следующие значения: 2,0,2,0.
DAYNAME
Возвращает название дня в строковом
формате.
Например, при применении функции
DAYNAME([Дата поступления]) к таблице
сотрудников возвращается столбец, содержащий следующие значения: Понедельник, Суббота, Суббота, Четверг.
DAYNUMBEROFMONTH
Возвращает номер дня в указанном месяце.
Например, для строки "12/11/1980" возвращается значение "12".
DAYNUMBEROFWEEK
Возвращает номер дня в неделе.
Например, воскресенье=1, понедельник=2.
DAYNUMBEROFYEAR
Возвращает номер дня в году.
Например, 1-е января=1, 1-е февраля=32,
3-е февраля=34.
LASTDATEOFWEEK
Возвращает дату последнего дня недели.
Например, для строки "12/9/2005" возвращается значение "17/9/2005".
LASTDATEOFMONTH
Возвращает дату последнего дня в месяце.
Например, для строки "12/9/2005" возвращается значение "30/9/2005".
92
2013-01-31
Свойства компонентов
Категория
Функция (функция, применяемая к таблице сотрудников)
Описание
MONTHNUMBEROFYEAR
Возвращает номер месяца в дате.
Например, январь=1, февраль=2, март=3.
WEEKNUMBEROFYEAR
Возвращает номер недели в году.
Например, для строки "12/9/2005" возвращается значение "38".
QUARTERNUMBEROFDATE
Возвращает номер квартала в дате.
Например, для строки "12/9/2005" возвращается значение "3".
Строка
Параметр CONCAT
Соединяет две строки.
Например, функция CONCAT('США', 'Австралия') возвращает следующую строку:
СШААвстралия.
INSTRING
Возвращает значение true, если в исходной строке найдена поисковая строка.
Например, функция INSTRING('США', 'СШ')
возвращает следующее значение: true.
SUBSTRING
Возвращает подстроку исходной строки.
Например, выражение SUBSTRING('США',
1,2) возвращает значение "СШ".
Матема- MAX
тические
функции
93
Возвращает максимальное значение в
столбце.
MIN
Возвращает минимальное значение в
столбце.
COUNT
Возвращает число значений в столбце.
2013-01-31
Свойства компонентов
Категория
Функция (функция, применяемая к таблице сотрудников)
Описание
SUM
Возвращает сумму значений в столбце.
AVERAGE
Возвращает среднее по всем значениям
столбца.
Условное IF(условие) THEN(строковое выражевыраже- ние/математическое выражение/условное
ние
выражение) ELSE(строковое выражение/математическое выражение/условное
выражение)
Возвращает разные значения, если проверяемое условие имеет значение 'true' или
'false'.
Например, IF([Дата присоединения]>12/9/2005) THEN ('Сотрудник присоединился к компании после 12 сентября
2005 года') ELSE ('Сотрудник присоединился к компании до 12 сентября 2005 года')
Примечание:
Математические выражения, которые содержат функции, возвращающие числовые значения,
не поддерживаются. Например, выражение DAYNUMBEROFMONTH(CURRENTDATE())==2
возвращает числовое выражение и, соответственно, не поддерживается.
Математические операторы
Математические операторы используются для создания формул, содержащих числовые столбцы
и/или числа. Например, выражение [Возраст] + 1 создает новый столбец со следующими
значениями: 26, 31, 34, 33.
Математические операторы
Описание
+
Оператор сложения
-
Оператор вычитания
*
Оператор умножения
/
Оператор деления
()
Круглые скобки
^
Оператор возведения в степень
%
Оператор модуля
E
Экспоненциальный оператор
Условные операторы
С помощью условных операторов можно создавать выражения IF THEN ELSE и SELECT.
94
2013-01-31
Свойства компонентов
Условные операторы
Описание
==
Равно
!=
Не равно
<
Меньше
>
Больше
<=
Меньше или равно
>=
Больше или равно
Логические операторы
Логические операторы позволяют сравнить два условия, возвращая значение 'true' или 'false'.
Например, выражение IF([Дата присоединения]>12/9/2005 && [Возраст] >=25 ) THEN ('True') ELSE
('False') создает новый столбец со следующими значениями: True, False, False, False.
Логические операторы
Описание
&&
И
||
ИЛИ
9.3 Модули записи данных
С помощью этих модулей можно сохранить результаты анализа в плоском файле или базе данных
для последующего использования.
9.3.1 Модуль записи CSV
Этот компонент используется для записи данных в плоские файлы в формате CSV, TXT и DAT.
Свойства модуля записи CSV
95
Имя файла
Выберите csv, dat или txt-файл.
Перезаписать
Выберите этот параметр, чтобы перезаписать существующий
файл.
Разделитель столбцов
Выберите символ, который используется в файле для
разделения маркеров данных на столбцы.
Символ кавычки
Выберите символ, добавляемый при записи данных.
2013-01-31
Свойства компонентов
Включить заголовки столбцов Выберите этот параметр, чтобы использовать первую строку
в качестве строки заголовков столбцов.
Кодировка
Выберите кодировку текста, которая будет использоваться
при записи данных.
Десятичный разделитель
Выберите символ, определяющий десятичное представление
группировки разрядов.
Разделитель групп
Выберите символ-разделитель тысяч.
Формат чисел
Введите формат, который будет применяться к числовым
данным.
Формат даты и времени
Выберите формат, который будет применяться к датам.
9.3.2 Модуль записи JDBC
Этот компонент используется для записи данных в реляционные базы данных, такие как MySQL,
MS SQL Server, DB2, Oracle, SAP MaxDB и SAP HANA.
Свойства модуля записи JDBC
Тип базы данных
Выберите тип базы данных.
Путь к драйверу базы данных Укажите местоположение драйвера JDBC. Например, для
записи в базу данных Oracle необходимо указать
местоположение jar-файла Oracle JDBC (C:\ojdbc6.jar).
96
Имя компьютера
Введите имя компьютера, на котором установлена база
данных.
Номер порта
Введите номер порта, используемый базой данных или
службой.
Имя базы данных
Введите имя базы данных.
Имя пользователя
Введите имя пользователя базы данных.
Пароль
Введите пароль пользователя базы данных.
Тип таблицы
Укажите тип таблицы. Это свойство используется при записи
в базу данных SAP HANA.
Имя таблицы
Введите имя таблицы.
Перезаписать
Выберите этот параметр, чтобы перезаписывать
существующие таблицы.
2013-01-31
Свойства компонентов
9.3.3 Модуль записи HANA
Этот компонент используется для записи данных в таблицы базы данных SAP HANA.
Компонент модуля записи HANA
Имя схемы
Введите имя схемы.
Тип таблицы
Выберите тип таблицы, в которую будут записываться
данные.
Имя таблицы
Введите имя таблицы.
Перезаписать
Выберите этот параметр, чтобы перезаписывать
существующие таблицы.
9.4 Сохраненные модели
Модели, создаваемые при сохранении состояния алгоритмов, перечислены на вкладке
Сохраненные модели. В приложении SAP Predictive Analysis отсутствуют предопределенные
модели. Соответственно, при первом запуске приложения вкладка Сохраненные модели не
отображается.
Дополнительные сведения о создании новых моделей см. в подразделе "Создание модели"
раздела Работа с моделями.
97
2013-01-31
Свойства компонентов
98
2013-01-31
Дополнительная информация
Дополнительная информация
Источник информации
Местоположение
Информация о продуктах SAP
BusinessObjects
http://www.sap.com
Перейдите к http://help.sap.com/businessobjects/ и на боковой панели
«BusinessObjects Overview» выберите All Products.
Справочный портал SAP предоставляет доступ к актуальной документации по всем продуктам SAP BusinessObjects и их развертыванию. Можно загрузить документы в формате PDF или устанавливаемые HTML-библиотеки.
Справочный портал SAP
Некоторые руководства находятся на веб-сайте SAP Service
Marketplace и недоступны на справочном портале SAP. На данном
портале перечислены эти руководства и даны соответствующие
ссылки на SAP Service Marketplace. Клиенты, заключившие соглашение о техническом обслуживании, получают идентификатор авторизованного пользователя для доступа к этому веб-сайту. Для получения идентификатора обратитесь к представителю службы поддержки
пользователей.
http://service.sap.com/bosap-support > Документация
•
•
SAP Service Marketplace
99
Руководства по установке: https://service.sap.com/bosap-instguides
Примечания к выпуску: http://service.sap.com/releasenotes
На веб-сайте SAP Service Marketplace содержатся некоторые руководства по установке, модернизации, миграции и развертыванию,
а также примечания к версия и документация по поддерживаемым
платформам. Клиенты, заключившие соглашение о техническом
обслуживании, получают идентификатор авторизованного пользователя для доступа к этому веб-сайту. Для получения идентификатора
обратитесь к представителю службы поддержки пользователей.
Если вас перенаправили на веб-сайт SAP Service Marketplace со
справочного портала SAP, с помощью меню в навигационной панели
слева перейдите в категорию, содержащую нужные вам документы.
2013-01-31
Дополнительная информация
Источник информации
Местоположение
https://cw.sdn.sap.com/cw/community/docupedia
Docupedia
Docupedia предоставляет дополнительные ресурсы документации,
объединенную среду для создания контента и интерактивный канал
обратной связи.
https://boc.sdn.sap.com/
Ресурсы разработчика
https://www.sdn.sap.com/irj/sdn/businessobjects-sdklibrary
Статьи SAP BusinessObjects в
сети сообщества SAP
https://www.sdn.sap.com/irj/boc/businessobjects-articles
Подобные статьи ранее назывались технической документацией.
https://service.sap.com/notes
Примечания
Эти примечания ранее назывались статьями базы знаний.
Форумы в сети сообщества SAP
https://www.sdn.sap.com/irj/scn/forums
http://www.sap.com/services/education
Обучение
Мы можем предложить обучающий пакет, соответствующий вашим
потребностям и предпочтительным формам обучения – от классических занятий в классах до специализированных курсов eLearning.
http://service.sap.com/bosap-support
Интерактивная служба поддержки пользователей
100
На портале службы поддержки SAP представлены сведения о программах и услугах поддержки. Здесь также содержатся ссылки на
самую разнообразную техническую информацию и множество
файлов для загрузки. Клиенты, заключившие соглашение о техническом обслуживании, получают идентификатор авторизованного
пользователя для доступа к этому веб-сайту. Для получения идентификатора обратитесь к представителю службы поддержки пользователей.
2013-01-31
Дополнительная информация
Источник информации
Местоположение
http://www.sap.com/services/bysubject/businessobjectsconsulting
Консалтинговые услуги
101
Наши консультанты готовы оказывать вам поддержку на всех этапах
– от начального анализа до развертывания системы. Советы экспер
тов можно найти, например, в темах, посвященных относительным
и многомерным базам данных, возможностям подключения, сред
ствам разработки баз данных и технологии встраивания с индивиду
альными настройками.
2013-01-31
Дополнительная информация
102
2013-01-31
![[ВВЕДИТЕ НАЗВАНИЕ ДОКЛАДА]](http://s1.studylib.ru/store/data/000320758_1-3a3b08d0faac59fef5ecc65da37995bb-300x300.png)