Национальный исследовательский ядерный университет «МИФИ
advertisement

Национальный исследовательский ядерный университет «МИФИ»
Факультет Кибернетики и информационной безопасности
Кафедра «Компьютерные системы и технологии»
Пояснительная записка к дипломному проекту
(выпускной квалификационной работе)
на тему:
Разработка программы для шифрования/расшифрования данных по
алгоритму ГОСТ 28147-89 на основе технологии NVIDIA CUDA
Студент-дипломник:
/ Тычинин И. К.
/
Руководитель проекта:
/ Васильев Н.П.
/
Рецензент:
/ Литвинов А.Ю.
/
Заведующий кафедрой №12:
/ Иванов М.А.
/
Москва 2013
Аннотация
В техническом задании на дипломный проект требовалось разработать
программу шифрования по алгоритму ГОСТ 28147-89 на основе технологии
NVIDIA CUDA. Данный проект посвящён исследованию возможностей
ускорения операций зашифрования/расшифрования за счёт применения
гибридных вычислений.
В первой главе приведён обзор шифра, его основные компоненты и
основные шаги криптопреобразования. Также выполнен обзор технологии
NVIDIA CUDA, дано описание её особенностей и отличий от традиционного
метода программирования. Кроме того, проведено краткое сравнение и
представлен краткий обзор существующих на сегодняшний день технологий
гибридных вычислений.
Во второй главе разработаны алгоритмы шифрования с учётом
возможностей и потребностей NVIDIA CUDA. Помимо этого выполнена
разработка типов данных и структур для ключевой информации.
В третьей главе описана непосредственно реализация алгоритмов на
CUDA, разработанных во втором разделе, а также описаны методы отладки
реализованной программы. Кроме того, приведены замеры скорости
полученной программы.
Записка состоит из 3х глав, содержит 37 рисунков, 17 листингов, 3
формулы, 3 таблицы. Приложение содержит фрагмент кода на CUDA C с
реализацией режимов работы алгоритма ГОСТ 28147-89.
2
3
4
Оглавление
Введение......................................................................................................... 9
Глава 1. Обзорная часть.............................................................................. 12
1.1 Структура шифра ГОСТ 28147-89 .................................................. 12
1.1.1 Формат блоков данных .............................................................. 12
1.1.2 Основной шаг криптопреобразования ..................................... 12
1.1.3 Базовые циклы криптопреобразования ГОСТа 28147-89 ...... 14
1.1.4 Режим простой замены шифра ГОСТ 28147-89 ..................... 14
1.1.5 Режим гаммирования шифра ГОСТ 28147-89 ........................ 15
1.1.6 Режим гаммирования с обратной связью шифра ГОСТ 2814789 ..................................................................................................................... 16
1.1.7 Режим выработки имитовставки шифра ГОСТ 28147-89...... 16
1.2 Технология NVIDIA CUDA ............................................................. 17
1.2.1 История развития гибридных вычислений ............................. 17
1.2.2 Основные отличия GPU и CPU ................................................ 18
1.2.3 Структура CUDA процессора ................................................... 20
1.2.4 Структура памяти на CUDA процессоре ................................. 22
1.2.5 Конфигурируемая общая память и кэш ................................... 24
1.2.6 ECC .............................................................................................. 24
1.2.7Улучшения Fermi, относительно ранних архитектур ............. 24
1.2.8 Программная архитектура CUDA ............................................ 24
5
1.2.9 Программирование на CUDA ................................................... 26
1.2.10 Альтернативы CUDA............................................................... 28
1.2.11 Достоинства CUDA ................................................................. 29
1.2.12 Недостатки CUDA ................................................................... 29
2. Разработка программы для зашифрования/расшифрования данных по
алгоритму ГОСТ 28147-89 ................................................................................... 31
2.1 Архитектура программы .................................................................. 31
2.2 Формат ключевой информации и блоков данных в программе... 35
2.2.1 Функции проверки ключевой информации ............................ 35
2.2.2 Формат блоков данных .............................................................. 36
2.3 Разработка шифрования на GPU ..................................................... 37
2.3.1 Разработка базового цикла 32-З, 32-Р и режима простой
замены на GPU .............................................................................................. 37
2.3.2 Разработка алгоритма гаммирования, для исполнения на GPU
......................................................................................................................... 39
2.3.3 Разработка алгоритма гаммирования с обратной связью, для
исполнения на GPU ....................................................................................... 41
2.3.4
Разработка
алгоритма
выработки
имитовставки
для
исполнения на GPU ....................................................................................... 42
2.3.5 Общая схема шифрования на CUDA ....................................... 43
2.4 Интерфейс прикладного программирования ................................. 44
2.4.1 Тип данных, используемый для хранения внутренней
информации ................................................................................................... 47
6
2.5 Функция выработки количества блоков и потоков ....................... 47
2.6 Методика тестирования и отладки программы ............................. 48
3. Реализация и сравнение производительности программы для
зашифрования и расшифрования по алгоритму ГОСТ 28147-89..................... 51
3.1 Реализация программы ..................................................................... 51
3.1.1 Реализация программы в среде Microsoft Visual Studio 2010
Professional ..................................................................................................... 52
3.1.2 Типы данных и структуры, используемые в программе ....... 55
3.1.3 Реализация алгоритмов на CUDA ............................................ 56
3.1.4 Тестирование и отладка разработанной программы .............. 60
3.1.5 Выбор реализации программы шифрования по ГОСТ 2814789 на CPU ....................................................................................................... 63
3.1.6 Ключевые данные, используемые для работы программы ... 65
3.1.7 Сравнение функций шифрования GPU и CPU ....................... 66
3.2 Сравнение производительности шифрования на CPU и GPU ..... 69
3.2.1 Сравнение производительности шифрования в режиме
простой замены на CPU и GPU.................................................................... 70
3.2.2 Сравнение производительности шифрования в режиме
гаммирования на CPU и GPU....................................................................... 71
3.2.3 Сравнение производительности шифрования в режиме
гаммирования с обратной связью на CPU и GPU ...................................... 72
3.2.4 Сравнение производительности выработки имитовставки на
CPU и GPU ..................................................................................................... 73
7
3.2.5 Результаты сравнения производительности ........................... 74
Заключение .................................................................................................. 76
Список использованных источников: ....................................................... 79
Приложение 1. Фрагмент кода на CUDA C ............................................. 82
8
Введение
В настоящее время во всем мире происходит бурный рост объёмов
информации, как обрабатываемой, так хранимой и передаваемой по
различным каналам связи. По данным компании Cisco, ежегодный прирост
объёмов мирового сетевого трафика составляет приблизительно 50% в год.
График на рисунке 1 [19][20][21][22][23] показывает фактический рост
мирового трафика за 2006 – 2011 года, а на 2012 – 2016 года дан прогноз по
росту трафика:
120
100
80
60
40
20
0
2006
2007
IP трафик
4,234
PB/месяц
6,577
2008
2009
2010
2011
2012
2013
2014
2015
2016
10,174 14,686 20,151 30,734 43,441 54,812 69,028 87,331 110,282
Рисунок 1 Рост трафика по данным компании CISCO. Показатели с
2012 года – предположение компании по росту трафика.
Рост
объёмов
передаваемой
информации
означает
увеличение
количества хранимых и обрабатываемых данных, и о масштабности этого
роста можно судить по приведённым на графике показателям. На
сегодняшний день большая часть данных, которые ранее существовали
только в бумажном виде, перешли в электронный. Исходя и вышесказанного,
можно сделать вывод, что задача обеспечения защиты информации
становится все более актуальной.
Защита информации подразумевает выполнение трёх основных задач:
• Соблюдение конфиденциальности информации;
• Сохранение целостности информации;
9
• Обеспечение доступности информации.
Алгоритм ГОСТ 28147-89 служит, прежде всего, для обеспечения
конфиденциальности
информации,
несанкционированного
доступа
т.е.
защиты
посредством
информации
от
зашифрования
и
расшифрования.
Объектом данного дипломного проекта является ГОСТ 28147-89 –
блочный симметричный алгоритм шифрования. Размер блока в ГОСТ 2814789 – 64 бита. По стандарту ГОСТ 28147-89 можно производить шифрование в
нескольких режимах и создавать имитовставку. Стандарт создан и
официально введён в качестве стандарта в 1989 году, и используется до сих
пор.
По ГОСТ 28147-89 на текущий момент работают все государственные
предприятия, а также его используют множество систем передачи данных в
России. Более того, его использование закреплено законодательно. И это даёт
основания полагать, что данный шифр будет использоваться в течение
длительного времени. Всё это позволяет говорить об актуальности данного
проекта.
Предметом
данного
дипломного
проекта
является
реализация
основных операций ГОСТ 28147-89 с использованием технологии CUDA
(Compute Unified Device Architecture). Она представляет собой платформу
для параллельных вычислений и программную модель. CUDA позволяет
писать программы для исполнения на GPU (другими словами, на видеокарте,
установленной на компьютере или сервере). Кроме того, она предоставляет
разработчику набор средств управления памятью на GPU, написания
ассемблерного кода для исполнения на GPU и множество других средств
разработки
программ,
сопроцессора.
используя
Основные
отличия
GPU
CPU
в
качестве
параллельного
(центрального
процессора
компьютера или сервера) от GPU, о которых важно знать для ускорения
процессов, – это отличия в работе с процессами (или нитями, на GPU). На
CUDA устройстве, в отличие от CPU, используется огромное количество
10
нитей, которые можно запускать параллельно. Также, каждая нить должна
быть относительно «лёгкой», в сравнении с потоком на процессоре. CUDA
программа выполняется не только на GPU, она также задействует в своей
работе
CPU,
поэтому
такие
программы
называются
гибридными.
Фактически, в случае программы, написанной на CUDA, GPU работает как
сопроцессор. Однако компанией NVIDIA планируется выпуск GPU с ядром
CPU на плате, что превратит её в полноценную вычислительную систему, и,
возможно, позволит полностью выполнять программы на гибридном
устройстве.
Целью дипломного проекта является анализ возможностей повышения
скорости шифрования по алгоритму ГОСТ 28147-89 за счёт использования
гибридной
архитектуры
и
реализация
алгоритмов,
выработанных
в
исследовании, с использованием технологии NVIDIA CUDA.
Для достижения поставленной цели необходимо решить следующие
задачи:
1. Провести обзор шифра ГОСТ 28149-89.
2. Провести обзор технологии NVIDIA CUDA.
3. Разработать архитектуру программы.
4. Разработать
алгоритмы
зашифрования
и
расшифрования
по
алгоритму ГОСТ 28147-89.
5. Разработать тесты для программы.
6. Произвести отладку и тестирование программы.
7. Произвести исследование эффективности реализации ГОСТ 2814989 на CUDA.
8. Разработать интерфейс прикладного программирования (API) для
возможности интеграции с внешними программами.
11
Глава 1. Обзорная часть
1.1 Структура шифра ГОСТ 28147-89
ГОСТ 28147-89 является отечественным блочным шифром, стандартом
симметричного шифрования, а также является стандартом некоторых стран
СНГ. У ГОСТа (здесь и далее ГОСТ употребляется в значении ГОСТ 2814789) есть несколько основных режимов работы: режим простой замены,
гаммирования, гаммирования с обратной связью и выработки имитовставки.
1.1.1 Формат блоков данных
Ключевая информация состоит из двух элементов: ключ и таблица
замен. Ключ представляет собой 32-х байтный массив, состоящий из 8ми 32разрядных элементов. Таблица замен представляет собой группу из восьми
одномерных массивов, состоящих из 16ти 4-битных элементов от 0 до 15,
расположенных в произвольном порядке. Отсюда размер таблицы замен
равен 512 битам или 64 байтам. Также, для режима гаммирования
используется синхропосылка: 64-битная последовательность, призванная
синхронизировать ГПСЧ для выработки гаммы.
1.1.2 Основной шаг криптопреобразования
ГОСТ является классическим итерационным блочным шифром
Фейстеля.[1. С. 110]. Основной шаг преобразования, используемый в ГОСТе,
представлен на рисунке 1. Краткая расшифровка алгоритма: загружается 64битное число d(t) и ключ X, далее d(t) разбивается на 2 равные половины: L –
младшая, R – старшая, которые обрабатываются отдельно. Половина R
становится на место L выходного и, одновременно, вместе с ключом X,
подаётся на вход функции f(рис. 1.1 [1. С. 112]). L входное складывается по
модулю 2 (XOR) с выходным значением функции f и подаётся на выход как R
выходное. L и R выходное объединяются в 64-битное число, которое и
является d(t+1).
12
Рисунок 1.1 Общая схема основного шага криптопреобразования
Краткая расшифровка функции f: на вход поступает ключ X и 32битное число R, они складываются друг с другом по модулю 232, далее R
разбивается на 8 4-битных блоков, которые заменяются по таблице замен.
Замены происходят по следующей схеме: в качестве замены выбирается
элемент из строки, равной номеру нашего элемента, а номер столбца
равняется значению самого заменяемого элемента. В конце происходит
циклический сдвиг на 11 разрядов и результат подаётся на выход (рис 1.2 [1.
C. 112]).
13
Рисунок 1.2 Детализация функции f
1.1.3 Базовые циклы криптопреобразования ГОСТа 2814789
В ГОСТе используются 3 базовых цикла: алгоритмы зашифрования 32З и 16-З и алгоритм расшифрования 16-З.[1. С. 110] В названии цикла цифра
означает количество повторений, а буква – расшифрование и зашифрование
соответственно.
Все
три
цикла
построены
на
базовом
шаге
криптопреобразования. Фактически, циклы отличаются только порядком
использования ключа. Порядки использования ключа для циклов:
• 32-З: (k0, k1, …, k7, k0, k1, …, k7, k0, k1, …, k7, k7, k6, …, k1);
• 32-Р: (k0, k1, …, k7, k7, k6, …, k1, k7, k6, …, k1, k7, k6, …, k1);
• 16-З: (k0, k1, …, k7, k0, k1, …, k7).
1.1.4 Режим простой замены шифра ГОСТ 28147-89
Режим простой замены является наименее сложным в реализации среди
всех режимов ГОСТа. Данные для зашифрования разбиваются на блоки
длиной 64 бита, которые поочерёдно обрабатываются на базовом цикле 32-З.
Для расшифрования таким же образом используется цикл 32-Р.
Особенности данного режима напрямую вытекают из его реализации.
Т.к. блоки шифруются по одинаковому алгоритму, это означает, что
одинаковые исходные блоки будут преобразованы в одинаковые блоки
шифротекста. Вторая важная особенность заключается в том, что при
использовании этого режима нужно, чтобы данные были кратны 64м битам.
Это порождает дополнительную задачу: как заполнить последние биты
открытого текста, чтобы не упростить криптоаналитику задачу подбора
ключевой информации. Эта задача трудноразрешима, поэтому этот режим
ГОСТа в качестве шифрования данных практически не используется. В
ГОСТе этот режим определён для шифрования синхропосылки, длинна
которой, по условию ГОСТа, 64 бита.
14
1.1.5 Режим гаммирования шифра ГОСТ 28147-89
Режим гаммирования заключается в наложении на открытые данные
псевдослучайной гаммирующей последовательности.[1, С. 117] Для этого
открытые данные разбиваются на 64-разрядные блоки и зашифровываются,
поразрядно суммируясь с гаммой по модулю 2. Гаммирование решает
проблемы, возникающие при использовании режима простой замены.
Основная проблема с кратностью данных решается простым отбрасыванием
«хвоста» данных, если он есть. А проблема с одинаковыми блоками
шифротекста, решается тем, что гамма на каждом 64-разрядном блоке разная.
Гамма вырабатывается блоками по 64 бита. Генератор гаммы имеет
двухступенчатую структуру: сначала производится выработка выходной
последовательности (для старших и младших 32х разрядов производится
отдельно). После генерации последовательности она шифруется в режиме
простой замены. Зашифрованная последовательность и является гаммой.
Счётчик обеспечивает период, близкий к максимально возможному значению
264.
Генератор последовательности является рекуррентным. Генерация
гаммы для старшей и младшей части идёт по формулам 1.1:
𝑄𝐿 (𝑡 + 1) = (𝑄𝐿 (𝑡) + 𝐶1 )𝑚𝑜𝑑 232 , где C1 = 01010101h
(1.1)
�
𝑄𝐻 (𝑡 + 1) = (𝑄𝐻 (𝑡) + 𝐶2 − 1)𝑚𝑜𝑑 (232 − 1) + 1, где C2 = 01010104h
Для выработки одинаковых выходных последовательностей на стороне
получателя и отправителя используется синхропосылка. Она представляет
собой 64х разрядный набор данных, который сначала шифруется с помощью
режима простой замены, а потом составляет начальное заполнение QL(0) и
QH(0).
Особенности режима гаммирования: идентичные блоки, в отличие от
режима простой замены, дадут разные выходные результаты. Это не даст
возможности криптоаналитику делать выводы об их идентичности. Нет
проблем с шифрованием последнего блока данных, когда его размер меньше
64 бит. Конец гаммы можно просто отбросить. Появляется новый элемент,
15
требуемый для передачи: синхропосылка. Однако есть один недостаток:
возможность внесения в открытый текст предсказуемых изменений. Т.к.
биты не зависят друг от друга, изменение бита шифротекста на
противоположное значение приведёт к такому же изменению бита в
открытом тексте.
1.1.6 Режим гаммирования с обратной связью шифра
ГОСТ 28147-89
Данный режим похож на режим гаммирования. Основное отличие это
зацепка блоков, которая создаётся благодаря изменённому алгоритму
выработки гаммы: в качестве последующего элемента гаммы берётся
преобразование по циклу 32-З предыдущего блока шифротекста. Поэтому
каждый блок шифротекста зависит от своего и всех предыдущих блоков
открытого
текста.
Первый
блок
гаммы
вырабатывается,
как
и
в
гаммировании: синхропосылка преобразовывается по циклу 32-З и мы
получаем первый блок гаммы.
Зацепление позволяет избавиться от главного недостатка режима
гаммирования: возможности внесения предсказуемых изменений в открытый
текст. Теперь, при внесении изменений в один бит шифротекста, блок, в
который внесены изменения, будет содержать предсказуемые изменения, а
блок, идущий до него, будет содержать искажёнными все биты с
вероятностью 1/2 на бит. Однако выявлять непредсказуемые изменения
данный режим не позволяет. Это является его основным недостатком.
1.1.7 Режим выработки имитовставки шифра ГОСТ 2814789
Имитовставка – добавляемая к зашифрованным данным контрольная
комбинация, зависящая от открытых данных и ключевой информации.[1, C.
122]
Поскольку при внесении изменений обнаружить их не представляется
возможным, для этого был придуман этот режим. При разработке
16
руководствовались
двумя
следующими
критериями:
для
противника
неразрешима операция вычисления имитовставки для открытого текста и
неразрешима операция подбора открытых данных под определённую
имитовставку. Обычно, используется 32-разрядная имитовставка.
Имитовставка формируется следующим образом: на начальном этапе
она обнуляется, после чего начинается цикл: временная имитовставка
складывается с текущим элементом открытого текста по модулю 2 и
шифруется по алгоритму 16-З. Результат зашифрования является временной
имитовставкой. Конечная имитовставка формируется после повторения
цикла для всех блоков открытого текста.
1.2 Технология NVIDIA CUDA
CUDA представляет собой программно-аппаратную архитектуру,
позволяющую производить параллельные вычисления на GPU независимо от
CPU. Главной особенностью CUDA является возможность производить
множество параллельных вычислений без использования CPU.
1.2.1 История развития гибридных вычислений
В программных графических движках вся цепочка рендеринга писалась
разработчиком игры, куда можно было включать собственные эффекты. При
появлении видеоускорителей весь набор эффектов стал ограничиваться теми,
какие были заложены в архитектуру видеокарты. Через какое-то время стало
ясно, что исключительно аппаратно-заложенных эффектов мало для
успешной реализации задумок разработчиков. И первым средством для
разработки собственных эффектов стали шейдеры. Шейдеры представляют
собой программу для визуального определения поверхности объекта. Это
может быть описание освещения, текстурирования, постобработки и т.п. Т.е.
перед рендерингом над каждым объектом можно выполнить набор операций,
что позволяет более гибко накладывать эффекты на итоговое изображение.
Первые
шейдеры
были
очень
ограничены
по
функциональным
17
возможностям. Но, с развитием шейдеров, они становились всё более
гибкими и удобными для использования.
Следующим шагом стало появление GPGPU вычислений. Для этого
появились
некоторые
дополнительные
библиотеки,
позволявшие
производить вычисления на видеокартах, но, всё осложнялось тем, что
программистам требовалось знать как свою область разработки, так и
детально разбираться в работе с графикой, чтобы использовать эти
мощности, поскольку кроме как работать с графикой видеокарта ничего не
умела.
В конце 2006го года NVIDIA выпустила новый графический процессор
G80, одним из существенных отличий от предыдущих моделей которого
стала поддержка программно-аппаратной архитектуры CUDA, позволяющей
вычислять на видеокарте без дополнительных знаний DirectX и умения
работать с графикой. С этого момента GPGPU вычисления стали активно
развиваться и развиваются по сей день.
1.2.2 Основные отличия GPU и CPU
Основная задача при создании CPU заключается в максимально
быстрой обработке сложных однопоточных вычислений. Поскольку задачи
производить параллельные вычисления при разработке архитектуры x86 не
стояло, то методов параллельных вычислений на CPU практически нет. Под
этот принцип попадали и создаваемые программы, поэтому для увеличения
производительности железа проще всего было наращивать частоту. На
сегодняшний день увеличение частоты процессора практически невозможно.
Современные процессоры подобрались к максимально возможным для них
частотам. Фактически, рост частоты CPU остановлен приблизительно с 2005
года. Дальнейшее увеличение частоты нецелесообразно, поскольку приводит
к многократному росту тепловыделения, сложности изготовления устройств,
увеличению брака и росту потребления энергии. Фактически современные
CPU могут обрабатывать параллельные команды. Наборы инструкций MMX
18
и SSE позволяют это делать. Все современные производители CPU уже
начали
изготавливать
многоядерные
процессоры
(«цена»
таких
многоядерных CPU гораздо ниже, чем аналогичных по производительности
одноядерных), которые также позволяют выполнять несколько команд за
такт.
Основной задачей при создании GPU требовалось производить
множество небольших вычислений над набором плоскостей (пикселей, при
растеризации). В ходе усложнения графических приложений вычисления
стало нужно производить не только над плоскостями, но и над физикой,
светом/тенью и т.п., но при этом основа, параллельность вычислений,
осталась.
Основное отличие CPU и GPU кроется в количестве параллельно
выполняемых команд. Если для CPU это число ограничено десятками, то для
GPU это число варьируется от нескольких сотен (старые модели), до тысяч и
выше. Для обработки такого количества данных требуются большие
мощности, поэтому сама структура GPU процессора значительно отличается
от CPU. Большая часть транзисторов на GPU процессоре работает на
обработку данных (рис 1.3 [6 С. 3]).
Рисунок 1.3 Сравнение распределения транзисторов по их назначению.
Исходя из такого распределения, пиковая мощность вычислений на
GPU тоже должна быть выше. По графикам производительности (рис 1.4 [6.
С. 2]) видно, что так и есть.
19
Рисунок 1.4 Сравнение производительности разных моделей GPU и
CPU.
Однако стоит понимать, что достичь пиковой производительности на
CPU намного проще, чем на GPU, а просто переведя исполняться программу
на GPU, мы не получим какого-либо прироста. Поскольку сильная сторона
CUDA – это параллелизм.
1.2.3 Структура CUDA процессора
Как и любое вычислительное устройство, GPU состоит из множества
компонентов.
Основной
вычислительной
мультипроцессор(Streaming
единицей
Multiprocessor
или
является
SM).
Как
потоковый
видно
из
схематичного изображения (рис. 1.5), один SM состоит из множества CUDA
ядер (здесь и далее рассматривается архитектура Fermi и здесь 32 ядра).
Следующее поколение после Fermi (Kepler) имеет усовершенствованный SM,
называемый SMX. Основные отличия: количество компонентов на SM и
часто̀ты работы.
20
Каждый CUDA процессор (рис.
1.6) имеет на борту конвейерное АЛУ
(INT unit) и алу для операций с
плавающей точкой (FP unit), которое
может работать с числами стандарта
1985 и 2008 года. За один такт каждое
ядро может произвести одну операцию
умножения-сложения
(умножение
с
накоплением) над числами одинарной
точности с плавающей точкой. За 2
такта – аналогичную операцию над
числами с двойной точностью. АЛУ
для
работы
полностью
с
целыми
32-битное.
числами
Также
оно
оптимизировано для поддержки 64битных инструкций.
Рисунок
1.5
Мультипроцессора
Структура
В каждом SM
есть
16
блоков
LD/ST (Load Store
units). Их предназначение – высчитывать адрес источника
и назначения, для 16 потоков/такт. Они могут работать
как с кэшем, так и с глобальной памятью.
Рисунок
1.6
CUDA ядро
SFU – Special Function Unit, блок для вычисления специальных
инструкций, таких как sin, cos, exp, квадратный корень, вычисления
обратного числа и т.п..
SM обрабатывает набор сгруппированных SIMD потоков (до 48, в
большинстве случаев до 32), называемых Warp. Каждый из SM содержит в
себе 2 Warp Scheduler и 2 Instruction Dispatch Unit. Warp Scheduler выделяет 2
Warp, которые направляются на одну из групп CUDA Core, одну из 2х
16ядерных групп, SFU или LD/ST. Наличие 2х планировщиков на ядро
21
позволяет эффективнее использовать имеющиеся ресурсы CUDA ядра. Это
происходит, потому что большинство инструкций может быть обработано
параллельно на одном ядре, и часть ядра простаивает.
1.2.4 Структура памяти на CUDA процессоре
Изначально устройство GPU не было ориентировано на работу с
пользовательскими (т.е. неграфическими) данными. Поэтому количество
видов памяти на GPU и их взаимодействие достаточно запутанно. Общая
схема потока данных с использованием CUDA изображена на рисунке 1.7.
Global
Memory
являющаяся
самой
установленных
на
–
память,
медленной
GPU.
из
Фактически
работает, как оперативная память на ПК.
Используется
объёмов
для хранения
данных,
внешних
больших
поступающих
устройств.
от
Рекомендуется
использовать в крайних случаях, когда
нужно
Рисунок
1.7
Схема
потоков данных
обрабатывать
большой
объем
данных, которые не помещаются в более
быструю память. Идеальный вариант
работы с памятью: данные считываются,
обрабатываются на процессорах и пишутся в память обратно. Но часто
требуется записывать промежуточные результаты.
Представляет собой набор (для FERMI – 6) банков памяти с
параллельным доступом по 64х битной шине к каждому банку (суммарно
384битная шина).
Shared Memory, Cache L1 – быстрая память, расположена на SM,
используется для минимизации обращений к глобальной памяти, хранения
промежуточных результатов. В
пределах
одного блока
вычислений
адресация памяти одинакова. Тем самым удобно использовать память для
22
обмена данными. И Shared Memory и Cache являются одним устройством
хранения памяти, они разделены и могут быть разного объёма в зависимости
от нужд. Суммарный объём – 64кБ. Может разделяться на соотношения
16/48, 48/16 и 32/32 (только архитектура Kepler).
Constant Memory – память констант. Быстрая память в пределах GPU,
данные с неё возможно только считывать. Отсюда и название. Распределяет
данные компилятор.
Texture memory – память текстур, главным образом, предназначена для
работы с текстурами; в основном, она требуется для обработки изображений.
Она имеет специфическую адресацию.
Register memory – регистровая память, самая быстрая из имеющихся на
GPU. Особенностью является то, что компилятор сам распределяет по ней
данные. Явных способов работы с ней в CUDA нет.
L2 Memory cache – кэш для считывания из глобальной памяти
размером 768КБ. Введён для уменьшения задержек считывания из памяти.
Также есть возможность синхронизации между WARP`ами, поскольку
данные, хранящиеся в L1 кэше SM, не видны для другого SM, то L2 кэш
виден со всех SM, а доступ к нему осуществляется с меньшими задержками
чем доступ к глобальной памяти (в GT200 было только 256кб кэша, работал
он только как кэш глобальной памяти, и обмен данными через него был
невозможен).
Одним из существенных минусов работы с памятью является её
высокая
латентность.
Поэтому
работать
с
глобальной
памятью
рекомендуется по минимуму. В Fermi впервые введён кэш для считывания из
памяти. До этого считывание было некэшированным. Задержки при
считывании из глобальной памяти составляют порядка 1300 циклов, из кэша
– порядка 18 циклов.
23
1.2.5 Конфигурируемая общая память и кэш
Общая память (далее SMem), как и кэш, расположена прямо на
кристалле. Память установлена на SM. Использование общей памяти
помогает
программам
взаимодействовать,
способствует
повторному
использованию данных, хранящихся на чипе, и уменьшает трафик данных
извне (кристалла). На чипе установлено по 64КБ SMem на SM, которая
может быть сконфигурирована, как 16КБ кэша и 48КБ общей памяти, или как
16КБ памяти и 48КБ кэша (сделано для поддержки старых программ, где
было доступно 16 кб разделяемой памяти).
1.2.6 ECC
Одной из отличительных особенностей стала поддержка ECC. ECC
поддерживается для register files, shared memories, L1 and L2 cache и DRAM.
Включённый ECC ухудшает характеристики памяти за счёт добавляемых для
контроля за ошибками данных.
1.2.7Улучшения Fermi, относительно ранних архитектур
Fermi получила полную поддержку C++, виртуальных функций,
указателей на функции, конструкции try-catch. Для универсализации,
адресное пространство для каждой нити было объединено в единую область
памяти (как собственную память мультипроцессора, так и видимую
глобальную память). Стало возможным одновременно выполнять несколько
CUDA функций одного приложения (поскольку одна может не полностью
загрузить устройство). Подобное исполнение позволяет скрыть медленное
время передачи данных по шине PCI-e, т.к. GPU может больше не
останавливаться для обмена данными с компьютером, а параллельно
исполнять другие блоки программы.
1.2.8 Программная архитектура CUDA
CUDA представляет собой программно-аппаратную архитектуру,
позволяющую производить параллельные вычисления на GPU независимо от
24
CPU. Главной особенностью CUDA является возможность производить
множество параллельных вычислений без использования CPU.
Концепция
CUDA
отводит
GPU
роль
массивно-параллельного
сопроцессора. В литературе о CUDA основная система к которой
подключается GPU, для краткости называется хост (host), аналогично сам
GPU по отношению к хосту часто называется просто устройством (device).
[2. С. 21] GPU должно успешно справляться с тем, что CPU даётся с трудом,
однако CUDA программа работает как с CPU так и с GPU. На CPU
выполняются последовательные участки кода, тогда как на GPU –
параллельные.
Между потоками CPU и нитями GPU есть некоторые различия: нить на
GPU очень «лёгкая», её содержимое минимально, а регистры распределяются
заранее (при компиляции). Для эффективного использования GPU программе
нужно задействовать тысячи отдельных нитей, тогда как на многоядерном
CPU такая эффективность достигается с числом потоков равном, или в
несколько раз большем, чем количество ядер. В общем, работа с нитями
проходит в соответствии с принципом SIMD.
Warp – представляет собой «пучок» нитей, которые физически
одновременно исполняются на Single Multiprocessor. Отсюда вытекает, что у
них общие на всех ресурсы одного SM. Также они могут взаимодействовать
друг с другом через Shared Memory. Нити различных варпов могут
находиться на разных стадиях выполнения программы. Управление работой
варпов происходит на аппаратном уровне. Для удобства можно формировать
2х и 3х мерные массивы варпов и нитей. Общая иерархия нитей и варпов
представлена на рисунке 1.8:
25
Рисунок
1.8
Иерархия
нитей,
блоков
и
массивов
блоков
и
взаимодействия их с памятью
1.2.9 Программирование на CUDA
Изначально CUDA являлась расширением стандарта C99. Расширения,
вводимые в C:
• специификаторы функций, показывающие, где она может
выполняться и откуда будет вызвана;
• спецификаторы
переменных,
задающие
тип
памяти,
используемый для хранения данных;
• директива для запуска ядра, задающая как данные, так и
иерархию нитей;
• встроенные переменные, содержащие информацию о текущем
потоке;
• runtime, включающий в себя дополнительные типы данных.
26
В CUDA объявляются следующие спецификаторы:
• __device__ – выполняется и вызывается с GPU;
• __global__ – выполняется на GPU, вызывается из хоста;
• __host__ – выполнятеся и вызывается на хосте.
Спецификатор __global__ означает ядро. Обязательно возвращает
тип void.
На функции, выполняющиеся на GPU, накладываются следующие
ограничения:
• нельзя брать их адрес (за исключением __global__);
• не поддерживаются static – переменные внутри функции;
• не поддерживается переменное число входных аргументов.
Для
размещения
в
памяти
GPU
используются
следуюущие
спецификаторы: __device__, __constant__ и __shared__. Ограничения:
• спецификаторы не могут быть применены к полям структуры
(struct или union);
• соответствующие переменные могут быть использвоанны только
в пределах одного файла, запрещается объединение их как extern;
• запись в переменные типа __constant__ может осуществляться
только CPU при помощи специальных функций.
__shared__ переменные не могут инициализироваться при объявлении.
Добавляемые переменные:
• gridDim - размер grid'а (имеет тип dim3)
• blockDim - размер блока (имеет тип dim3)
• blockIdx - индекс текущего блока в grid'е (имеет тип uint3)
• threadIdx - индекс текущей нити в блоке (имеет тип uint3)
• warpSize - размер warp'а (имеет тип int)
Директива
запуска
ядра
имеет
следующий
вид:
kernelName
<<<Dg,Db,Ns,S>>> ( args ). Где kernelName это имя (адрес) __global__
функции, Dg – значение, задающие размерность массива в блоках, Db – это
27
размерность одного варпа в нитях, Ns – переменная (или значение) типа
size_t, задающая требуемый дополнительный объем shared-памяти, которая
должна быть выделена, S – переменная (или значение) типа cudaStream_t
задает поток (CUDA stream), в котором должен произойти вызов, по
умолчанию используется поток 0, args – это аргументы вызова функции
kernelName.
На текущий момент существуют и развиваются дополнительные
средства для работы на GPU на других языках: OpenCL, Fortran, Python,
Haskel, Java, Perl, Ruby, .NET, Matlab, Mathematica и т.п..
1.2.10 Альтернативы CUDA
На аппаратном уровне CUDA конкурирует фактически только с
технологией APP Acceleration от AMD[14]. Общий подход в ней аналогичен
рассматриваемой выше архитектуре. Соответствующие разработки есть и у
Intel (Intel Xeon Phi coprocessor [15], на данный момент является серверным
решением), в планах выпуска процессоры с GPU на едином кристалле с CPU
(CPU с интегрированным GPU уже выпущен). Ведутся разработки
компилятора C++(Intel SPMD Program Compiler), активно использующего
SIMD инструкции процессора.
Программно,
кроме
CUDA,
существует
также
язык
OpenCL,
базирующийся на языке C99. Данный проект был создан в качестве
дополнения к OpenAL и OpenGL, которые являются открытыми отраслевыми
стандартами для трёхмерной компьютерной графики и звука. Для создания
языка была создана рабочая группа из Apple, NVIDIA, AMD, IBцM, Intel,
ARM, Motorola и др., которая разработала и начала развивать язык. Данный
язык поддерживается AMD и с недавних пор NVIDIA поддерживает его
тоже. Это делает его довольно удобным и гибким инструментом для
написания программ. Но учитывая то, что в состав группы разработки входит
NVIDIA, маловероятно, что язык получит сильное и действительно активное
развитие для видеокарт NVIDIA, но поскольку AMD использует этот язык
28
как основной для своей архитектуры, то для использования с GPU AMD он
будет основным и хорошо заточенным инструментом. Но уже в сравнении с
CUDA у него есть несколько недостатков: отсутствие поддержки рекурсии,
указателей на функцию, массивов переменной длинны; многие из этих
недостатков уже исправлены в CUDA с выходом FERMI.
1.2.11 Достоинства CUDA
Основным достоинством данной архитектуры является высокая
производительность и ускорение при грамотной реализации многих задач: по
информации из проспектов NVIDIA ускорение, получаемое в медицинских
задачах до 146 раз, в задачах молекулярной динамики – до 36 раз, в
перекодировании видео – до 18 раз, в компьютерных вычислениях
(программа Matlab) – до 50 раз, астрофизике – до 100 раз, финансовом
моделировании – до 150 раз, линейной алгебре – до 47 раз, трёхмерной
ультразвуковой технике – до 20 раз, квантовой химии – до 130 раз, расчёте
генетической последовательности – до 130 раз. По информации NVIDIA это
реальные ускорения, полученные в разных программах, институтах и
лабораториях. Так что очевидно, что использование вычислений на этой
архитектуре значительно ускоряет скорость выполнения программ.
1.2.12 Недостатки CUDA
В технологии есть несколько существенных недостатков. Fermi
является третьей по счёту архитектурой, позволяющей производить
вычисления общего назначения. В первых двух архитектурах фактически
вычисления общего назначения были «приятным дополнением» к самой
видеокарте. Т.е. не было конкретной заточенности под вычисления, а была
некая попытка прощупать рынок и выйти на него, то с появлением Fermi
начали исправляться некоторые недостатки, призванные раскрыть потенциал
вычислений. Отсюда вытекает первый недостаток – «сырость» архитектуры.
Видеокарты не способны работать с вычислениями над большими
объёмами данных, это возникает из-за большой латентности памяти и шины
29
pci-e. На текущий момент это один из самых существенных недостатков
технологии, с которым активно борются разработчики.
Программы
необходимо
распараллеливать,
что
является
очень
трудоёмкой и сложной задачей. Некоторые программы просто не поддаются
распараллеливанию, что делает невыгодным выполнение их на видеокарте.
30
2.
Разработка
программы
для
зашифрования/расшифрования данных по алгоритму ГОСТ
28147-89
2.1 Архитектура программы
Программа CUDA GOST написана на языке C, с использованием
компилятора CUDA. Программа может быть использована в качестве
самостоятельного продукта для зашифрования/расшифрования, так и в
качестве части программы или программного комплекса.
Программа обеспечивает зашифрование/расшифрование данных по
алгоритму ГОСТ 28147-89, производя вычисления на видеокарте. Также в
рамках данной программы можно зашифровывать/расшифровывать данные
на CPU.
Для работы программы требуется:
• IBM совместимый компьютер;
• CUDA совместимая видеокарта NVIDIA;
• операционная система семейства Windows: Vista, 7 и выше;
• последняя версия видеодрайверов;
• Microsoft Visual C++ 2010 Redistributable Package или Microsoft
Visual Studio 2010 Professional.
Программа имеет консольный интерфейс. Для загрузки/сохранения
файлов используется Win API, поэтому принципиально, что программа
работает только на ОС семейства Windows, но если использовать свои
функции
загрузки/сохранения
или
пользоваться
только
функциями
программы, то Win API не требуется. В конце работы программы можно
сохранить файлы, которые были созданы. Схема взаимодействия модулей
программы представлена на рисунке 2.1:
31
Вывод
Ввод с
клавиатуры
Пользовательский
интерфейс
Выбор модуля
Выбранный модуль
Зашифрование/
расшифрование
Файлы
Рисунок 2.1 Схема взаимодействия модулей программы
Схема работы программы представлена на рисунке 2.2:
32
Ключевые
данные
Подготовк
а данных
Выбор модуля
обработчика
Открытые/
закрытые
данные
Выбранный модуль
обработки:
Зашифрование/
расшифрование/
имитовставка
Запись в файл
обработанных
данных
Рисунок 2.2 Схема работы программы
Схема функционирования программы представлена на рисунке 2.3:
33
Начало
1
Ввод данных и
их подготовка
Загрузка данных на
Хост
Выбор режима работы
программы
Передача
завершена
успешно?
Передача данных на
GPU
Передача
завершена
успешно?
Да
Обработка
данных на GPU
Зашифрование/
расшифрование/
имитовставка
Нет
Да
Нет
Сохранение данных
в файл
Вывод сообщения
об ошибке
Вывод сообщения об
ошибке
1
Конец
Рисунок 2.3 Схема функционирования программы.
Основные функции работы программы:
• функции загрузки, проверки и преобразования во внутренний
формат данных ключевой информации;
• функции генерирования тестовой ключевой информации;
• функция загрузки/сохранения файлов;
• функция режима простой замены на CPU;
• функция режима простой замены на GPU;
• функция гаммирования на CPU;
34
• функция гаммирования на GPU;
• функция гаммирования с обратной связью на CPU;
• функция гаммирования с обратной связью на GPU;
• функция выработки имитовставки на GPU;
• функция выработки имитовставки на CPU.
2.2 Формат ключевой информации и блоков данных в
программе
Таблица замен состоит из 4-битных элементов, а минимальный размер
типа данных составляет 8 бит (char). Исходя из этого, чтобы не вводить
дополнительные операции обработки при считывании и записи таблицы
замен, которые вытекают из-за отсутствия 4-битных типов данных в C, было
решено использовать следующий формат данных: для хранения в файле
используются 8-битные поля, при этом четыре старших бита должны быть
нулевыми.
Для того чтобы избежать трудностей, связанных с использованием 8битных полей при работе с таблицей замен, она была модифицирована.
Поскольку запросы идут последовательно, по строкам, соседние строки
можно объединить, перечислив все возможные сочетания их элементов,
которых будет 256. Теоретически, можно объединить все строки в одну, что
позволит избавиться от множества операций замен в основном шаге
криптопреобразования, но это чревато огромным объёмом требуемой памяти:
168
8∗1024∗1024∗1024
= 0,5гб, что делает такой способ упрощения практически
нереализуемым (на текущий момент).
В структуре ключа также присутствует булево поле, показывающее,
создан ключ или нет, что повышает удобство работы с ключом.
2.2.1 Функции проверки ключевой информации
При загрузке таблицы замен происходят следующие этапы проверки:
проверяется диапазон значений, поскольку в файле диапазон хранится в
35
байтовых переменных, то значения первых 4х бит должны быть нулевыми.
Также проверяется уникальность значений в таблице замен.
Общий алгоритм представлен на рисунке 2.4:
Начало
Проверка на наличие уже
загруженного ключа
Открытие и
загрузка ключа
Нет
Загрузка успешна?
Да
Преобразование таблицы
замен к байтовому виду и
проверка на корректность
Вывод сообщения об
ошибке
Проверка
успешна?
Нет
Вывод сообщения об
ошибке
Да
Конец
Рисунок 2.4 Функция загрузки и проверки ключевой информации
2.2.2 Формат блоков данных
Поскольку при обработке информации, загруженной с компьютера,
используются поделённые на старшую и младшую части 64-битные блоки
данных, для работы удобнее всего использовать массив из 32-битных чисел.
36
Учитывая эту особенность, отдельно стоит отметить тот факт, что размер
файла в памяти должен выделяться с округлением вверх до 64х бит. Размер
же файла должен быть равен округлённому количеству 64-битных слов,
которые нужно шифровать.
2.3 Разработка шифрования на GPU
При подробном рассмотрении алгоритмов шифрования на GPU,
становится очевидно, что распараллелить возможно только 2 вида
шифрования: режим простой замены и гаммирование. Подробно остановимся
на этих типах шифрования.
2.3.1 Разработка базового цикла 32-З, 32-Р и режима
простой замены на GPU
Эти циклы являются «сердцем» режима простой замены, шифрования
гаммированием и гаммированием с обратной связью. При ближайшем
рассмотрении видно, что распараллелить цикл изнутри не получится.
Подробно сам алгоритм рассмотрен в главе 1.1.2.
Этот цикл в рамках режима простой замены можно выполнять каждой
нитью над своим 64-битным блоком данных. Таким образом, режим простой
замены получается хорошо распараллеленным. В идеальном варианте время,
требуемое только на шифрование всего файла (исключая передачу данных),
будет равно времени шифрования одного блока данных, что теоретически
должно дать большой прирост. Прирост будет увеличиваться в зависимости
от увеличения размера файла. Алгоритм блочного шифрования по циклу 32-Р
представлен на рисунке 2.5:
37
Начало
Загрузка
данных на
видеокарту
Нет
Загрузка прошла
успешно?
Да
…..
…..
Обработка
блока 1
…..
Обработка
блока N-1
Обработка
блока N
…..
…..
Вывод сообщения
об ошибке
Считывание
данных с GPU
И запись на
хост
Конец
Рисунок 2.5 Алгоритм обработки группы блоков, базовым циклом 32-З
Обработка блоков производится в соответствии с алгоритмами,
указанными на рисунках 1.1 и 1.2.
Поскольку каких-либо дополнительных инструментов для обработки
при зашифровании/расшифровании не требуется, рисунок 2.3 иллюстрирует
работу шифрования тоже.
38
2.3.2
Разработка
алгоритма
гаммирования,
для
исполнения на GPU
Алгоритм гаммирования (в общем виде), удобный для рассмотрения,
можно представить в виде, изображённом на рисунке 2.6:
Начало
Выработка гаммы для
младшей и старшей
части генератора
гаммы
Шифрование
гаммы
алгоритмом 32-З
Сложение по модулю
2 с получившейся
гаммой
Конец
Рисунок 2.6 Алгоритм шифрования гаммированием.
Исходя из этого, можно сделать следующий вывод: шаг 2 уже
распараллелен, шаг 3 можно распараллелить по данным, складывая отдельно
каждый блок. Задача оптимизации стоит только перед шагом 1.
Рассмотрим подробнее алгоритм выработки гаммы для старшей и
младшей частей по отдельности (см. формулу 1.1 на странице 15).
Видно, что младшая часть алгоритма фактически представляет собой
прибавление константы к каждому блоку гаммы. Отсюда очевидно, что для
m-го блока формула будет иметь вид:
𝑄𝐿 (𝑚) = (𝑆 + 𝐶1 ∙ 𝑚)𝑚𝑜𝑑 232 , где C1 = 01010101h (2.1)
39
Рассмотрим старшую часть (см. формулу 1.1 на странице 15).
Для более понятного вида, составим несколько уравнений для ряда
членов гаммы:
𝑄𝐻 (1) = (𝑆 + 𝐶2 − 1)𝑚𝑜𝑑 (232 − 1) + 1, где S
− соответствующая часть синхропосылки
𝑄𝐻 (2) = (𝑄𝐻 (1) + 𝐶2 − 1)𝑚𝑜𝑑(232 − 1) + 1
= ��(𝑆 + 𝐶2 − 1)𝑚𝑜𝑑 (232 − 1) + 1� + C2 − 1� 𝑚𝑜𝑑(232 − 1) + 1
= �(𝑆 + 2 ∙ 𝐶2 − 1)𝑚𝑜𝑑(232 − 1)� + 1
𝑄𝐻 (3) = (𝑄𝐻 (2) + 𝐶2 − 1)𝑚𝑜𝑑(232 − 1) + 1
= ��(𝑆 + 2 ∙ 𝐶2 − 1)𝑚𝑜𝑑(232 − 1)� + 1 + 𝐶2 − 1� 𝑚𝑜𝑑(232 − 1)
+ 1 = (𝑆 + 3 ∙ 𝐶2 − 1)𝑚𝑜𝑑(232 − 1) + 1
И так далее. Отсюда видно, что формула для m-го элемента гаммы
будет: 𝑄𝐻 (𝑚) = (𝑆 + 𝑚 ∙ 𝐶2 − 1)𝑚𝑜𝑑(232 − 1) + 1 (2.2)
Таким образом, мы распараллелили все операции в гаммировании.
Общий алгоритм представлен на рисунке 2.5:
40
Начало
…..
…..
Выработка
гаммы для
блока 1
…..
…..
…..
…..
…..
32-З над
блоком 1
гаммы
…..
…..
…..
…..
…..
XOR над
блоком 1
гаммы и
текста
…..
Выработка
гаммы для
блока N-1
Выработка
гаммы для
блока N
32-З над
блоком N-1
гаммы
32-З над
блоком N
гаммы
XOR над
блоком N-1
гаммы и
текста
XOR над
блоком N
гаммы и
текста
…..
…..
Конец
Рисунок 2.5 Общий алгоритм шифрования гаммированием
2.3.3 Разработка алгоритма гаммирования с обратной
связью, для исполнения на GPU
Алгоритм гаммирования фактически не поддаётся распараллеливанию.
Также для оптимизации времени выполнения ключевая информация
загружалась
в
shared
memory
и
проводилось
сравнение
скоростей
41
выполнения с загрузкой и без. Алгоритм, использованный на GPU, выглядит
следующим образом (рис. 2.6):
Начало
Шифрование
синхропосылки по
алгоритму 32-З
Шифрование
гаммы
алгоритмом 32-З
Сложение по модулю
2 с получившейся
гаммой
Конец файла
достигнут?
Нет
Переход к
следующему
блоку
Да
Конец
Рисунок 2.6 Алгоритм шифрования гаммированием с обратной связью
2.3.4 Разработка алгоритма выработки имитовставки для
исполнения на GPU
Алгоритм
выработки
имитовставки,
так
же
как
и
алгоритм
гаммирования с обратной связью, не поддаются распараллеливанию.
Аналогично, для выяснения влияния на скорость ключевая информация была
загружена в shared memory. Ниже представлен алгоритм, по которому
42
разрабатывались функции программы для выработки имитовставки (рис.
2.7):
Начало
Установка указателей на первый
блок файла.
Обнуление
переменной S
Текущий блок
файла XOR S
Шифрование
текущего блока
Достигнут конец
файла?
Нет
Сдвиг указателя на
одну позицию
Да
Конец
Рисунок 2.7 Алгоритм выработки имитовставки
После завершения данного алгоритма в переменной S будет находиться
имитовставка.
2.3.5 Общая схема шифрования на CUDA
Для единообразия и облегчения отладки и понимания текста программ
все алгоритмы разрабатываются в следующем виде (рис 2.8):
43
Начало
Данные, требуемые для
выбранного типа
шифрования готовы?
Выделение памяти
под вычисляемые
данные
Память
выделена
успешно?
Загрузка
требуемых
данных на GPU
1
При выполнении
предыдущего действия
были ли ошибки?
Загрузка
данных на
хост
Удаление
данных с GPU
Конец
Обработка по
выбранному
алгоритму
шифрования
1
Рисунок 2.8 Общий алгоритм шифрования
2.4 Интерфейс прикладного программирования
Для работы с программами в качестве внешнего файла подходят все
функции шифрования. Для простоты они приведены к единообразному виду.
Для работы всех функций шифрования требуется входной файл, длинна
входного файла, ключ и выходной файл. Также есть переменные параметры,
которые зависят от типа шифрования, такие как синхропосылка, количество
44
нитей/блоков, переменная для подробного вывода и т.п.. Параметры
сгруппированы следующим образом: сначала идёт ключевая информация,
потом файлы и длина, дальше необязательные параметры. Пример
объявления функции гаммирования на листинге 2.3:
crypt_file_gamma (KeyInfo * GKF, SynchroInfo * GSF, SynchroInfo * GCSF, word32 * OF,
word32 * CRF, int OFL, bool debug=0, unsigned int threads = 0, unsigned int blocks =
0)
Листинг 2.3 Пример объявления функции для API
Также для совместимости в функциях режима простой замены и
гаммирования дана возможность устанавливать собственные значения
количества нитей и блоков. При нулевых значениях числа устанавливаются
автоматически. Ограничения, прописанные в функции: 65535 блоков и 1024
потока в блоке. Если видеокарта не позволяет работать с такими
параметрами, или наоборот, позволяет работать с большим количеством
блоков/потоков, то рекомендуется использовать собственные функции
выработки
количества
блоков/потоков
или
переписать
имеющиеся
ограничения.
Все функции шифрования работают по принципу, представленному на
рисунке 2.8. Это накладывает ряд ограничений и требований на работу с
функциями:
• Структуры, указатели на которые передаются в функцию,
должны в точности соответствовать описанным выше (глава 2.2).
• Память под данные (как открытые, так и закрытые) должна быть
выделена заранее и в полном объёме.
• Все требуемые к загрузке данные должны быть загружены в
память до вызова функции и должны быть неизменны всё время
работы функции.
• Память, которая используется для выгрузки зашифрованных
данных, не должна использоваться какими-либо другими
программами для записи данных в неё.
45
• Размер памяти, выделенной под данные файла должен быть
округлён вверх до 64х бит. Алгоритм расчёта размера в 64битных блоках файла на рисунке 2.9:
Начало
R=Размер
файла в
байтах.
R64=R/8
Остаток от деления
R/8 Равен 0?
R64=R64+1
Конец
Рисунок 2.9 Алгоритм расчёта длины файла в 64-битных блоках
Для примера, файл размером 100 байт в памяти будет занимать
64 * 13 бит, т.е. 104 байта, где 4 байта и есть округление вверх.
• Длина, передаваемая в функцию, должна показывать не
истинную длину файла, а минимальное количество 64-битных
слов, в которое умещается файл.
46
• Память на видеокарте должна быть свободной. Объём памяти,
как минимум, 2 объёма файла, округлённого вверх до 64х бит,
плюс суммарный объём используемых в данном методе
шифрования ключевых данных.
• Файлы для зашифрования/расшифрования в режиме простой
замены должны быть кратны 64м битам.
2.4.1 Тип данных, используемый для хранения внутренней
информации
В программе используются несколько основных типов данных.
Основной
формат
хранения
данных
это
32-битное
целочисленное
беззнаковое число. Оно требуется, в частности, для хранения исходного и
зашифрованного файла. Также в этом виде хранятся элементы ключа и
синхропосылка.
Также
для
хранения
элементов
таблицы
замен
используется
переменная размером 8 бит.
2.5 Функция выработки количества блоков и потоков
Учитывая ограниченность ресурсов видеокарты по количеству блоков
и то, что оптимальная загруженность возникает при количестве нитей,
большем, чем может обработать блок параллельно, была написана
следующая функция, алгоритм которой представлен на рисунке 2.10:
47
Начало
Потоки=128
Блоки=1
Нет
Длина
файла < 128
Да
Длина
файла%Потоки >0
Потоки=длина
файла
Нет
Да
Блоки = Блоки+1
Блоки=(длина
файла/Потоки) + 1
Блоки>65535 И
Потоки< 1024
Нет
Блоки<=65535 И
Потоки<=1024
Нет
Вывод сообщения
об ошибке
Да
Потоки=Потоки*2
Конец
Блоки=Длина
файла/Потоки
Рисунок 2.10 Функция выработки количества блоков и потоков.
2.6 Методика тестирования и отладки программы
Целями тестирования программы является поиск и устранение
неисправностей, скоростное и нагрузочное тестирование программы.
Поскольку код программы известен, то тестирование будет проходить
по методу белого ящика [24 с 107]. Некоторые модули будут протестированы
пошагово. Основной задачей тестирования будет являться проход по каждой
48
ветке алгоритма (где это возможно) и проверка корректности отработки
программы во всех пройдённых ветках. Также для выявления ошибок
необходимо исследовать работу программы при граничных значениях
переменных, таких как маленький и большой размер файла и запуск
программы при не загруженном в память файле. Также, по возможности,
должно быть проведено тестирование отдельных модулей программы.
Для
проверки
использована
алгоритмов
свободно
зашифрования\расшифрования
распространяемая
программа
была
HashTab[17],
подсчитывающая результаты хеширования по алгоритмам CRC-32, MD5,
SHA-1[4 Глава 18]. Пример работы показан на рисунке 2.11
Рисунок 2.11 Пример работы программы расчёта результата хэшфункций.
Сверялись файлы, расшифрованные и зашифрованные на GPU, с
файлами на CPU. Также сверялись файлы после зашифрования и
расшифрования с оригиналом, дабы понять, верно ли работают функции,
поскольку при визуальном сравнении файлов можно пропустить ошибки.
49
Для целей нагрузочного тестирования были выбран набор файлов
размерами от нескольких байт до 300+ мегабайт, которые прогонялись через
все из имеющихся функций шифрования. Минимальный файл, с которым
проводилась работа, был размером 80байт.
50
3.
Реализация
и
сравнение
производительности
программы для зашифрования и расшифрования по алгоритму
ГОСТ 28147-89
3.1 Реализация программы
Для реализации алгоритмов с использованием CUDA, во первых
следует убедиться, поддерживает ли видеокарта работу с CUDA. На
сегодняшний день эту технологию поддерживают видеокарты компании
NVIDIA, при этом чип, установленный на видеокарте, должен быть не
младше чипа G80 (модели серии 8000 и более поздние). Для точной
уверенности
можно
проверить,
используя
программу
GPU-Z
(или
аналогичную). Пример проверки на рисунке 3.1:
Рисунок 3.1 Пример работы программы GPU-Z
Из этого нас интересует флажок CUDA в нижнем поле Computing. Если
он установлен – это значит, что видеокарта поддерживает работу с
вычислениями. Если он снят – это значит, что текущая видеокарта не имеет
51
поддержки технологии CUDA, и для работы с разрабатываемой программой
видеокарту нужно заменить.
Также для реализации были установлены следующие программы:
• Microsoft Visual Studio 2010 Professional;
• NVIDIA CUDA Toolkit;
• NVIDIA CUDA SDK Computing;
• NVIDIA Nsight Visual Studio Edition 2.2;
• родные драйвера на видеокарту последней версии.
Также при вычислениях на видеокарте, которые занимают длительное
время, может возникнуть ошибка, при которой Windows перезапустит
драйвер видеокарты, и программа не выполнится до конца. Пример
сообщения, которое может появиться, приведен на рисунке 3.2 [16]:
Рисунок 3.2. Сообщение ОС при аварийном перезапуске драйвера
Чтобы иметь возможность спокойно вычислять и не встречать
подобной ошибки, нужно прописать следующие значения в реестр: в ветку
[HKLM\System\CurrentControlSet\Control\GraphicsDrivers] добавить значение
типа dword, назвать его: "TdrLevel" без кавычек и присвоить значение 0 и
после этого перезагрузить компьютер. Подробное описание этой особенности
Windows описано в [16].
3.1.1 Реализация программы в среде Microsoft Visual Studio
2010 Professional
Для реализации программы нам потребуется выполнить следующие
действия:
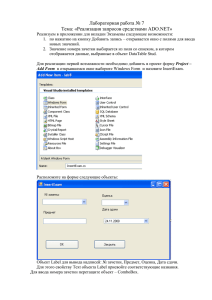
1. Запустить программу Microsoft Visual Studio 2010 Professional.
2. Выбрать пункт «Создать проект…» (рисунок 3.3).
52
Рисунок 3.3 Создание проекта
3. В открывшемся окне надо выбрать версию CUDA Runtime, которая
требуется для разработки (в данном случае выбрана 5.0), в поле
«Имя» надо ввести название проекта, а в поле «Расположение» надо
выбрать папку, в которой будет расположен проект. Папка, как и
название проекта, должна содержать только английские символы,
иначе проект не будет работать. После ввода всех данных надо
нажать кнопку Ok (рис 3.4).
Рисунок 3.4 Создание проекта CUDA в MS Visual Studio 2010
53
4. Будет создан проект с программой, создаваемой по умолчанию. В
окне с текстом проекта нужно набрать требуемые функции. Пример
на рисунке 3.5:
Рисунок 3.5 Проект с набранным текстом программы
5. Для компиляции и запуска готового проекта используются кнопки
F5 – запуск с отладкой и Ctrl+F5 – запуск без отладки. Пример
запущенного проекта на рисунке 3.6:
54
Рисунок 3.6 Запуск проекта
3.1.2
Типы
данных
и
структуры,
используемые
в
программе
Поскольку основной целочисленный тип данных unsigned int зависит от
разрядности платформы и компилятора и может быть различной длины в
битах, а типов данных с фиксированной длиной в 32 бита язык не имеет,
было решено объявить собственный тип данных, который избавляет от
проблем, связанных с изменением разрядности программы (листинг 3.1):
typedef unsigned __int32 word32;
Листинг 3.1 Объявление типа данных word32
Оно объявляет беззнаковое 32-битное целое число, как тип word32.
Таким образом, можно смело использовать word32 в качестве 32-битного
поля данных.
Также для удобства программирования и улучшения читабельности
кода была добавлена байтовая переменная. Объявление на листинге 3.2.
55
typedef unsigned char byte;
Листинг 3.2 Объявление типа данных byte
Для
хранения
ключевой
информации
используется
следующая
структура, описанная в главе 2.2 пояснительной записки, реализация которой
представлена на листинге 3.3:
struct KeyInfo
{
word32 k[8]; //Ключ
byte k87[256]; //Таблица замен для работы с байтовой адресацией.
byte k65[256];
byte k43[256];
byte k21[256];
bool greated;
};
Листинг 3.3 Структура ключевой информации
3.1.3 Реализация алгоритмов на CUDA
Пример реализации алгоритма, описанного в главе 2.3.1, а конкретно –
базового цикла 32-Р, можно увидеть на листинге 3.4:
56
word32 n1, n2;
word32 tmp=0;
int i, j;
unsigned int ind64=(threadIdx.x+(blockIdx.x*threads));
if (ind64<=len)
{
n1=d[2*ind64];
n2=d[2*ind64+1];
for(i=0; i<=6; i+=2)
{
tmp=n1+c->k[i];
tmp = c->k87[tmp >> 24 & 255] << 24 | c->k65[tmp >> 16 & 255]
16 | c->k43[tmp >> 8 & 255] << 8 | c->k21[tmp & 255];
n2 ^= tmp << 11 | tmp >> (32-11);
tmp=n2+c->k[i+1];
tmp = c->k87[tmp >> 24 & 255] << 24 | c->k65[tmp >> 16 & 255]
16 | c->k43[tmp >> 8 & 255] << 8 | c->k21[tmp & 255];
n1 ^= tmp << 11 | tmp >> (32-11);
};
for(j=0; j<3; ++j)
{
for(i=7; i>=1; i-=2)
{
tmp=n1+c->k[i];
tmp = c->k87[tmp >> 24 & 255] << 24 | c->k65[tmp >> 16
255] << 16 | c->k43[tmp >> 8 & 255] << 8 | c->k21[tmp & 255];
n2 ^= tmp << 11 | tmp >> (32-11);
tmp=n2+c->k[i-1];
tmp = c->k87[tmp >> 24 & 255] << 24 | c->k65[tmp >> 16
255] << 16 | c->k43[tmp >> 8 & 255] << 8 | c->k21[tmp & 255];
n1 ^= tmp << 11 | tmp >> (32-11);
};
}
d_out[2*ind64] = n2;
d_out[2*ind64+1] = n1;
}
<<
<<
&
&
Листинг 3.4 Реализация алгоритма 32-Р на CUDA
Здесь, для краткости, представлена версия с циклами. В программе
циклы частично развёрнуты, поскольку реализация с меньшим количеством
циклов выполняется быстрее.
Реализация шага 32-З аналогична шагу 32-Р. Она представлена в
дополнении к записке.
Реализация шага 16-З представлена на листинге 3.5:
57
{
word32 n1, n2;
word32 tmp=0;
int Иj;
n1=d[0];
n2=d[1];
for(j=0; j<2; ++j)
{
tmp=n1+c->k[0];
tmp = c->k87[tmp >> 24 & 255] << 24 | c->k65[tmp >> 16 & 255] <<
16 | c->k43[tmp >> 8 & 255] << 8 | c->k21[tmp & 255];
n2 ^= tmp << 11 | tmp >> (32-11);
tmp=n2+c->k[1];
tmp = c->k87[tmp >> 24 & 255] << 24 | c->k65[tmp >> 16 & 255] <<
16 | c->k43[tmp >> 8 & 255] << 8 | c->k21[tmp & 255];
n1 ^= tmp << 11 | tmp >> (32-11);
<… пропущена часть кода …>
tmp=n1+c->k[6];
tmp = c->k87[tmp >> 24 & 255] << 24 | c->k65[tmp >> 16 & 255] <<
16 | c->k43[tmp >> 8 & 255] << 8 | c->k21[tmp & 255];
n2 ^= tmp << 11 | tmp >> (32-11);
tmp=n2+c->k[7];
tmp = c->k87[tmp >> 24 & 255] << 24 | c->k65[tmp >> 16 & 255] <<
16 | c->k43[tmp >> 8 & 255] << 8 | c->k21[tmp & 255];
n1 ^= tmp << 11 | tmp >> (32-11);
}
d[0] = n2;
d[1] = n1;
};
Листинг 3.5 Реализация шага 32-З на CUDA
При режиме простой замены, на GPU не выполняется больше ничего.
При гаммировании же, выполняется другие функции (листинг 3.6 3.7):
word32 ind32,ind64;
ind64=(threadIdx.x+(blockIdx.x*threads));
ind32=2*ind64;
ind32+=2;
if(ind32<GLen)
{
asm(".reg
.u32 tmp;"
"mul.lo.u32 tmp, %2, %3;"
"add.u32 %0, %1, tmp;" : "=r"(Gamm[ind32]) : "r"(SF[0]), "r"(GPU_C[0]),
"r"(ind64+1));
}
Листинг 3.6 Вычисление гаммы для младшей части блока на CUDA
58
word32 ind32,ind64;
ind64=(threadIdx.x+(blockIdx.x*threads));
ind32=2*ind64+1;
ind32+=2;
if(ind32<GLen)
{
Gamm[ind32] = ( ( SF[ 1 ] + ((ind64+1) * GPU_C[1]) - 1 ) % 4294967295 ) + 1;
}
Листинг 3.7 Вычисление гаммы для старшей части блока на CUDA
На листингах 3.6 и 3.7 показано вычисление чётной и нечётной части
гаммы на GPU соответственно. Также при гаммировании происходит
шифрование каждого блока гаммы на базовом цикле 32-З и операция
складывания по модулю 2 (XOR) файла с гаммой, в тексте записки функция
не представлена, поскольку почти полностью дублирует листинг 3.4.
В функции гаммирования реализована загрузка ключа в shared memory
для ускорения работы. Реализация функции гаммирования с обратной связью
на GPU показана на листинге 3.8
word32 gamm_decr[2];
word32 gamm_cr[2];
gamm_decr[0]=s->s[0];
gamm_decr[1]=s->s[1];
__shared__ KeyInfo sc;
for (unsigned int i=0; i<256; ++i)
{
sc.k87[i]=c->k87[i];
sc.k65[i]=c->k65[i];
sc.k43[i]=c->k43[i];
sc.k21[i]=c->k21[i];
}
sc.k[0]=c->k[0]; sc.k[1]=c->k[1];
sc.k[2]=c->k[2]; sc.k[3]=c->k[3];
sc.k[4]=c->k[4]; sc.k[5]=c->k[5];
sc.k[6]=c->k[6]; sc.k[7]=c->k[7];
for (unsigned int i=0; i<Len64; ++i)
{
GPU_gostcrpt_gout(&sc, gamm_decr, gamm_cr);
f_out[ 2 * i ]=f_in[ 2 * i ]
^ gamm_cr[ 0 ];
f_out[ 2 * i + 1 ]=f_in[ 2 * i + 1 ]
^ gamm_cr[ 1 ];
gamm_decr[0]=f_in[ 2 * i ];
gamm_decr[1]=f_in[ 2 * i + 1 ];
}
Листинг 3.8 Реализация функции с обратной связью на CUDA
Функция GPU_gostcrpt_gout фактически является функцией режима
простой замены.
59
В функции выработки имитовставки также используется shared memory
для хранения ключа. Функция, вырабатывающая имитовставку, представлена
на листинге 3.9:
word32 S[2]={0, 0};
__shared__ KeyInfo sc;
for (unsigned int i=0; i<256; ++i)
{
sc.k87[i]=c->k87[i];
sc.k65[i]=c->k65[i];
sc.k43[i]=c->k43[i];
sc.k21[i]=c->k21[i];
}
sc.k[0]=c->k[0];
sc.k[1]=c->k[1];
sc.k[2]=c->k[2];
sc.k[3]=c->k[3];
sc.k[4]=c->k[4];
sc.k[5]=c->k[5];
sc.k[6]=c->k[6];
sc.k[7]=c->k[7];
for (unsigned int i=0; i<Len64; ++i)
{
S[0]=S[0]^f_in[2*i];
S[1]=S[1]^f_in[2*i+1];
GPU_16_P_par(&sc, S);
}
f_out[0]=S[0];
f_out[1]=S[1];
Листинг 3.9 Функция выработки имитовставки
3.1.4 Тестирование и отладка разработанной программы
Для упрощения отладки программы и более точного выявления места
ошибок в параметры функций была добавлена необязательная переменная
“debug”, которая выводит некоторую системную информацию, позволяющую
легче находить ошибочную функцию и место в ней.
Все функции выделения памяти на GPU обрамлены в конструкции,
пример которой показан на листинге 3.10:
cudaStatus = cudaMalloc((void**)&GOF, (sizeof(word32)*(intOFL)));
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaMalloc failed! Errcode %d",cudaStatus);
ret = 7;
goto error;
}
Листинг 3.10 Конструкции, используемые для выделения памяти на GPU
При выделении считывается возвращаемое значение и по нему
ориентируемся, выделилась ли память. В случае ошибки выдаётся
60
сообщение, меняется возвращаемое значение и выполняется аварийное
завершение программы с очищением памяти. После этого выполняется
переход на ссылку, по которой очищается вся выделенная память в этой
функции.
Протокол тестирования представлен на таблице 3.1:
Таблица 3.1 Протокол тестирования
Что тестируется
Результат
тестирования
Причина ошибки
Меню программы, в
качестве функций –
Успешно
—
Успешно
—
Успешно
—
заглушки
Функция
считывания файла
Функция записи в
файл
Функция работы с
Проблема с именем
файлом на Win Api
окна
При генерации
Функция генерации
тестового ключа
значение, которое
генерируется,
заполняет только 16
бит
Была проблема с типом текста,
задающего имя окна. Тип
исправлен.
Алгоритм генерации ключа
усовершенствован, чтобы
старшая половина не была
нулевой.
Функция
считывания
ключевой
Успешно
—
Успешно
—
информации
Функция
считывания
61
синхропосылки
Функция
шифрования
простой замены на
GPU
Ошибка при работе
с файлами большого
размера
Ошибка при распределении
количества потоков и блоков.
Внесены ограничения на
количество.
Функция
шифрования
Успешно
—
синхропосылки
Возникла ошибка, связанная с
Функция выработки
гаммы на GPU
некорректным заполнением
Неуспешно
первого блока гаммы на GPU.
Заполнение было выделено в
отдельную функцию.
Функция
гаммирования на
GPU
Возникает ошибка
Возникала ошибка при
при работе с
выделении памяти. Изменён код
файлами большого
выделения памяти. Подробное
размера
описание решения под таблицей.
Успешно
—
Успешно
—
Функция
шифрования
гаммирования с
обратной связью на
GPU
Функция выработки
имитовставки на
GPU
Проблема с функцией гаммирования на GPU: при работе с файлом
большого размера память не могла выделиться, поскольку в ОЗУ не было
достаточно места для непрерывного участка памяти. Поскольку выделять
память не вектором для работы с CUDA нельзя, да и это, скорее всего,
62
приведёт к падению скорости, было решено поставить обработчик ошибок на
функцию выделения памяти. Пример исправленного кода представлен на
листинге 3.11:
try
{
}
{
}
CRF[0]=new word32[intOFL];
catch (std::bad_alloc& ba)
fprintf (stderr, "bad_alloc caught: %s\n", ba.what());
printf("Error while allocated memory for crypted file\n");
delete CRF[0];
return 1;
Листинг 3.11 Конструкция для работы с выделением памяти на компьютере
Также выделение памяти под файл-приёмник было сделано до начала
шифрования и вырабатывания зашифрованного файла, что позволило
прервать исполнение программы функции, не начиная расчёты. Однако
программа не прерывается и можно освободить память под выходные данные
и продолжить работу без потери данных.
3.1.5 Выбор реализации программы шифрования по ГОСТ
28147-89 на CPU
Для сравнения скоростей шифрования было решено написать
программную реализацию для шифрования по ГОСТ на CPU. В качестве
эталона для написания программы был выбран исходный код из книги Брюса
Шнайера. В книге «Прикладная криптография» приведён код программы,
зашифрования и расшифрования по базовым циклам 32-Р и 32-З. Цикл 32-Р
из книги приведён на листинге 3.12 [4 часть 5.4]:
63
void gostcrypt(gost_ctx *c, word32 *d)
register word32 n1, n2;
n1 = d[0]; n2 = d[1];
n2 ^= f(c, n1 + c->k[0]); n1 ^=
n2 ^= f(c, n1 + c->k[2]); n1 ^=
n2 ^= f(c, n1 + c->k[4]); n1 ^=
n2 ^= f(c, n1 + c->k[6]); n1 ^=
n2 ^= f(c, n1 + c->k[0]); n1 ^=
n2 ^= f(c, n1 + c->k[2]); n1 ^=
n2 ^= f(c, n1 + c->k[4]); n1 ^=
n2 ^= f(c, n1 + c->k[6]); n1 ^=
n2 ^= f(c, n1 + c->k[0]); n1 ^=
n2 ^= f(c, n1 + c->k[2]); n1 ^=
n2 ^= f(c, n1 + c->k[4]); n1 ^=
n2 ^= f(c, n1 + c->k[6]); n1 ^=
n2 ^= f(c, n1 + c->k[7]); n1 ^=
n2 ^= f(c, n1 + c->k[5]); n1 ^=
n2 ^= f(c, n1 + c->k[3]); n1 ^=
n2 ^= f(c, n1 + c->k[1]); n1 ^=
d[0] = n2; d[1] = n1;
}
{
f(c,
f(c,
f(c,
f(c,
f(c,
f(c,
f(c,
f(c,
f(c,
f(c,
f(c,
f(c,
f(c,
f(c,
f(c,
f(c,
n2
n2
n2
n2
n2
n2
n2
n2
n2
n2
n2
n2
n2
n2
n2
n2
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
c->k[1]);
c->k[3]);
c->k[5]);
c->k[7]);
c->k[1]);
c->k[3]);
c->k[5]);
c->k[7]);
c->k[1]);
c->k[3]);
c->k[5]);
c->k[7]);
c->k[6]);
c->k[4]);
c->k[2]);
c->k[0]);
Листинг 3.12 Функция зашифрования по алгоритму 32-З
В функции f(…) происходит работа с таблицей замен, показанная на
рисунке 1.2.
Поскольку в исходном коде у Шнайера была произведена операция
зашифрования/рашифрования
одного
64-битного
блока
данных,
для
полноценной реализации шифрования требовалось дописать часть функций,
основываясь на шаге 32-З. Шаг 16-З был сделан путём преобразования
исходного
кода,
представленного
на
листинге
3.10.
В
процессе
преобразования были убраны лишние для этого цикла части и порядок
перебора ключей был приведён к правильному виду.
Реализация гаммирования на CPU (листинг 3.13):
64
word32 gamm_decr[2];//Гамма до зашифрования
word32 gamm_cr[2];//Гамма зашифрованная
gamm_decr[0]=s->s[0];
gamm_decr[1]=s->s[1];
CPU_gostcrpt_gout(k, gamm_decr, gamm_decr); //Шифрование синхропосылки
gamm_decr[ 0 ] =gamm_decr[ 0 ] + 0x1010101;
gamm_decr[ 1 ] = ( ( gamm_decr[ 1 ] + 0x1010104 - 1) % 4294967295 ) + 1;
for (unsigned int i=0; i<Len64; ++i)
{
CPU_gostcrpt_gout(k, gamm_decr, gamm_cr);
f_out[ 2 * i ] = f_in[ 2 * i ] ^ gamm_cr[ 0 ];
f_out[ 2 * i + 1 ] = f_in[ 2 * i + 1 ] ^ gamm_cr[ 1 ];
gamm_decr[ 0 ] =gamm_decr[ 0 ] + 0x1010101;
gamm_decr[ 1 ] = ( ( gamm_decr[ 1 ] + 0x1010104 - 1) % 4294967295 ) + 1;
}
return 0;
Листинг 3.13 Реализация режима гаммирования на CPU
Реализация гаммирования с обратной связью (листинг. 3.14):
word32 gamm_decr[2];
word32 gamm_cr[2];
gamm_decr[0]=s->s[0];
gamm_decr[1]=s->s[1];
for (unsigned int i=0; i<Len64; ++i)
{
CPU_gostcrpt_gout(k, gamm_decr, gamm_cr);
gamm_decr[0]=f_in[ 2 * i ]
^ gamm_cr[ 0 ];
gamm_decr[1]=f_in[ 2 * i + 1 ]
^ gamm_cr[ 1 ];
f_out[ 2 * i ]
= gamm_decr[0];
f_out[ 2 * i + 1 ] = gamm_decr[1];
}
return 0;
Листинг 3.14 Реализация режима гаммирования с обратной связью на CPU
Реализация выработки имитовставки (листинг 3.15):
int ret = 0;
register word32 S[2]={0, 0};
for (unsigned int i=0; i<Len64; i++)
{
S[0]=S[0]^f_in[2*i];
S[1]=S[1]^f_in[2*i+1];
CPU_16_P(k, S);
}
f_out[0]=S[0];
f_out[1]=S[1];
return ret;
Листинг 3.15 Реализация выработки имитовставки на CPU
3.1.6
Ключевые
данные,
используемые
для
работы
программы
Для работы с программой потребуется ключевая информация и таблица
замен. Ключ был выработан случайным образом, таблица замен взята из
65
книги Шнайера [2 Раздел 14-1, таблица 14-2], в которой утверждается, что
этой таблицей пользуется ЦБ РФ. Ключевая информация в 16-ричном виде
представлена на листинге 3.16:
78
F8
04
0E
05
07
06
04
0D
01
7B
C5
0A
0B
08
0D
0C
0B
0B
0F
B0
77
09
04
01
0A
07
0A
04
0D
10
9B
02
0C
0D
01
01
00
01
00
68
A8
0D
06
0A
00
05
07
03
05
72
81
08
0D
03
08
0F
02
0F
07
11
25
00
0F
04
09
0D
01
05
0A
32
AE
0E
0A
02
0F
08
0D
09
04
08
88
06
02
0E
0E
04
03
00
09
3C
95
0B
03
0F
04
0A
06
0A
02
57
E7
01
08
0C
06
09
08
0E
03
FA
D7
0C
01
07
0C
0E
05
07
0E
38
08
07
00
06
0B
00
09
06
06
A4
EE
0F
07
00
02
03
0C
08
0B
62
60
05
05
09
05
0B
0F
02
08
D8
56
03
09
0B
03
02
0E
0C
0C
Листинг 3.16 Ключ и таблица замен, используемая для шифрования в
16-ричном виде.
3.1.7 Сравнение функций шифрования GPU и CPU
Поскольку функция режима простой замены работает с файлами
размера, кратного 64м битам, то для теста требуется такой файл. Для этого с
помощью программы редактора файлов можно дополнить любой из тестовых
файлов, что и было сделано. Результат сравнения зашифрованных файлов на
GPU и CPU на рисунке 3.7:
66
Рисунок 3.7 Результат сравнения, файлов зашифрованных на GPU и
CPU
Как
видно,
файлы
идентичны.
Также
тест
на
сравнение
расшифрованного файла с исходным. Результат на рисунке 3.8:
Рисунок 3.8 Результат сравнения файлов, зашифрованных на GPU и
CPU
67
Для остальных методов шифрования были проведены аналогичные
сравнения. Результаты можно видеть на рисунках 3.9 – 3.11 ниже.
Гаммирование:
Рисунок
3.9
Результат
сравнения
файлов,
зашифрованных
гаммированием на GPU и CPU
Гаммирование с обратной связью рисунок 3.10:
Рисунок
3.10
Результат
сравнения
файлов,
зашифрованных
гаммированием с обратной связью на GPU и CPU
68
Выработка имитовставки рисунок 3.11:
Рисунок 3.11 Результат сравнения имитовставок, выработанных на
GPU и CPU
Для
проверки
корректности
реализации
подобные
сравнения
проводились на каждом этапе разработки и при внесении изменений в
функции шифрования.
3.2 Сравнение производительности шифрования на CPU и
GPU
Для сравнения производительности проводилось тестирование на
файлах разного размера. Для большей «естественности» тестирования было
принято решение не формировать файлы вручную, а использовать готовые
файлы, которые подвергались зашифрованию. Для этого были отобраны
несколько файлов: текстовый, размером 80 байт, 2 файла pdf размером 2.9 и
115 мб, аудио файл mp3 размером 6.3 мб и видео файл mkv, размером 321мб.
Все файлы поочерёдно шифровались на каждом из алгоритмов шифрования.
Расшифрование и зашифрование занимает приблизительно равное время,
поэтому измерения для расшифрования не показаны. Также проводилось
отдельное измерение функций с загрузкой ключа в shared memory для всего
набора файлов.
69
Также во время отладки было замечено, что зачастую время
выполнения отличается. При более детальном анализе стало ясно, что это
происходит при переходе видеокарты в режим энергосбережения. Т.к. явных
способов его выключить не нашлось, все измерения производились в режиме
анализа активности NVIDIA Parallel Nsight[25]. Он выключал режим
энергосбережения, и в нём результаты были самыми стабильными и не
изменялись при многократном запуске.
3.2.1
Сравнение
производительности
шифрования
в
режиме простой замены на CPU и GPU
25000
Время шифрования
20000
15000
10000
5000
0
80
3 056 428
6 631 243
121 097 812
337 166 183
GPU ms
0,8222
6,8776
12,6542
196,013
576,6179
CPU ms
0
180
403
7140
20020
Рисунок 3.12 Производительность шифрования в режиме простой
замены
70
Из графика очевидно, что использование шифрования в режиме
простой замены выгодно для скорости вычисления. Результат шифрования
самого большого файла на GPU не превысил и секунды.
3.2.2
Сравнение
производительности
шифрования
в
режиме гаммирования на CPU и GPU
25000
Время шифрования
20000
15000
10000
5000
0
80
3 056 428
6 631 243
121 097 812
337 166 183
GPU ms
1,9451
9,0411
16,1256
231,8658
641,7645
CPU ms
0
180
392
7146
19901
Рисунок 3.13 Производительность шифрования в режиме гаммирования
Ситуация с гаммированием аналогична ситуации с режимом простой
замены. Благодаря распараллеливанию вычислений, использовать GPU
намного выгоднее, чем CPU, особенно на больших файлах. Скорость
шифрования из-за дополнительных операций стала ниже, но даже на файле
максимального размера время шифрования меньше секунды.
71
3.2.3
Сравнение
производительности
шифрования
в
режиме гаммирования с обратной связью на CPU и GPU
4000000
3500000
Время шифрования
3000000
2500000
2000000
1500000
1000000
500000
0
80
3 056 428
6 631 243
121 097
812
337 166
183
GPU ms
1,6521
31219,0625
67722,25
1236226,375
3441918
GPU SM ms
2,695
24657,0449
53480,3477
976183,875
2718007,52
0
180
394
7150
20046
CPU ms
Рисунок
3.14
Производительность
шифрования
в
режиме
гаммирования с обратной связью
Из-за того что шифрование гаммированием с обратной связью не
распараллеливается, картина, наблюдаемая
в этом режиме,
обратна
предыдущим двум ситуациям. На этот раз отставание из-за вычислений в
один поток значительное, и использовать гибридные вычисления для
шифрования в этом режиме неоправданно. Использование shared memory для
72
хранения ключа на время вычислений позволило немного уменьшить время
шифрования, но оно всё равно слишком велико для использования.
3.2.4
Сравнение
производительности
выработки
имитовставки на CPU и GPU
1800000
1600000
1400000
Время шифрования
1200000
1000000
800000
600000
400000
200000
0
80
3 056 428
6 631 243
121 097
812
337 166
183
GPU ms
1,5782
14633,2959
31715,877
578750,375
1611361,5
CPU ms
0
100
200
3610
10075
GPU SM
2,3059
11342,0078
24589,943
448629,125
1249092,875
Рисунок 3.15 Производительность выработки имитовставки
Ситуация с выработкой имитовставки аналогична гаммированию с
обратной связью. Имитовставку лучше вырабатывать на компьютере.
73
Ситуация
с
использованием
shared
memory
полностью
аналогична
гаммированию с обратной связью.
3.2.5 Результаты сравнения производительности
Результаты сравнения производительности шифрования на GPU и CPU
для режимов гаммирования и простой замены представлены на таблице 3.2:
Таблица 3.2 Результаты сравнения производительности в режиме
гаммирования и простой замены
Простая замена
Гаммирование
Размер файлов,
байт
GPU ms CPU ms Прирост раз GPU ms CPU ms Прирост раз
80
0,822
0
1,945
0
нет
нет
3056428
6,878
180
9,041
180
26,18
19,91
6631243
12,654 403
16,126 392
31,85
24,31
121097812 196,013 7140
231,866 7146
36,43
30,82
337166183 576,618 20020
641,765 19901
34,72
31,01
Как видно из представленной таблицы, при работе есть значительный
прирост в 36 раз (на файле размером 121097812 байт) для режима простой
замены и в 31 (на файле размером 337166183 байт) для режима
гаммирования.
Результаты сравнения производительности шифрования на GPU и CPU
режимов гаммирования с обратной связью и выработки имитовставки
представлены на таблице 3.3:
Таблица 3.3 Результаты сравнения производительности в режиме
выработки имитовставки и гаммирования с обратной связью
Гаммирование с обратной связью Выработка имитовставки
Падение
Падение
GPU ms CPU ms
GPU ms CPU ms
раз
раз
80
2,695
0
2,306
0
3056428
24657,045
180
11342,008
100
136,98
113,42
6631243
53480,348
394
24589,943
200
135,74
122,95
121097812 976183,875 7150
448629,125 3610
136,53
124,27
337166183 2718007,520 20046
135,59 1249092,875 10075 123,98
Из представленного сравнения видно, что падение производительности
Размер
файлов, байт
для режима гаммирования с обратной связью доходит до 136 раз, а для
режима выработки имитовставки до 124 раз.
74
Таким образом, было опытным путём получено, что такие режимы
работы алгоритма ГОСТ, как режим простой замены и гаммирования,
целесообразно реализовывать с помощью GPU-вычислений; при этом
производительность по сравнению с CPU-версией увеличивается в несколько
десятков раз. В то же время остальные режимы ГОСТ распараллеливаются
плохо, и их GPU-реализация работает значительно медленнее, нежели CPUверсия, а значит, эти режимы реализовывать в виде GPU-программ
нецелесообразно.
75
Заключение
В настоящем дипломном проекте была разработана программа для
зашифрования/расшифрования данных по алгоритму ГОСТ 28147-89 на
основе технологии NVIDIA CUDA. Программа выполнена в полном объёме в
соответствии с техническим заданием.
Программа предназначена для зашифрования/расшифрования данных
по алгоритму ГОСТ 28147-89 на основе технологии NVIDIA CUDA. С
помощью данной программы, имеющей в своей основе гибридную
архитектуру, можно зашифровывать и расшифровывать данные различного
размера. На основании проведённых замеров можно сделать вывод, что
алгоритмы шифрования в режиме простой замены и гаммирования на файлах
больших размеров работают быстрее, чем аналогичная реализация на CPU, а
алгоритмы гаммирования с обратной связью и выработки имитовставки –
медленнее, чем реализация на CPU.
В процессе выполнения дипломного проекта был проведён обзор
технологии гибридного вычисления NVIDIA CUDA, произведено сравнение
с другими технологиями, также выполнен обзор криптографического шифра
ГОСТ 28147-89.
Во время работы было использовано следующее программное
обеспечение:
• Microsoft Visual Studio 2010 professional;
• NVIDIA CUDA Toolkit;
• NVIDIA CUDA SDK;
• NVIDIA Nsight Visual Studio Edition 2.2
При
программы
измерении
в
производительности,
качестве
рабочего
места
тестировании
использовалось
и
отладке
следующее
оборудование:
76
Персональный компьютер на базе процессора Intel Core I7 (2.66 ГГц,
ОЗУ 6Гб), видеокарта серии GeForce GTX 660 (ОЗУ 2 ГБ GDDR5),
операционная система Microsoft Windows Ultimate x64;
С помощью вышеперечисленных программных средств были решены
следующие задачи:
1. Разработана архитектура программы.
2. Разработаны алгоритмы зашифрования, расшифрования по всем
описанным в ГОСТе методам.
3. Разработан алгоритм выработки имитовставки.
4. Произведено тестирование и отладка программы.
5. Произведено исследование эффективности реализации ГОСТ 2814789 на CUDA.
6. Разработан интерфейс прикладного программирования.
В результате, можно утверждать, что разработанная программа
обеспечивает значительный прирост производительности при шифровании
по следующим алгоритмам шифрования:
• режим простой замены – прирост до 35 раз;
• гаммирование – прирост до 31 раза.
Реализация остальных алгоритмов, описанных в ГОСТе, показывает,
что их практически невозможно распараллелить, и на текущий момент
реализовывать их на гибридной архитектуре нецелесообразно. Однако
возможно проведение дополнительных исследований реализации ГОСТа
после появления гибридных вычислительных блоков на одной плате
(NVIDIA, архитектура Maxwell).
Разработанная программа может успешно применяться для ускорения
работы с алгоритмом ГОСТ 28147-89 следующим образом:
1. Шифрование
алгоритмом
простой
замены
файлов
больших
размеров.
2. Шифрование гаммированием.
77
3. Выработка псевдослучайной последовательности, с использованием
описанного в ГОСТе алгоритма генерации псевдослучайных чисел.
Область применения разработанной программы распространяется от
электронных учебников и пособий до систем передачи и защиты данных, а
также других систем, работающих с шифрованием по алгоритму ГОСТ
28147-89.
Таким образом, можно сделать вывод, что задачи, поставленные во
введении, выполнены, а цель дипломного проекта (анализ возможностей
повышения скорости шифрования по алгоритму ГОСТ 28147-89 за счёт
использования гибридной архитектуры) полностью была достигнута.
78
Список использованных источников:
1 Иванов М.А Криптографические методы защиты информации в
компьютерных системах и сетях М.: «Кудиц-образ», 2001 – 368с.
2 ГОСТ 28147 – 89 Алгоритм криптографического преобразования –
26
С.
[Электронный
техническому
ресурс]:
регулированию
Федеральное
и
агентство
метрологии
по
URL:
http://protect.gost.ru/v.aspx?control=8&baseC=-1&page=0&month=1&year=-1&search=&RegNum=1&DocOnPageCount=15&id=131282
Дата посещения 26.01.2013
3 Боресков А. В. и др. Параллельные вычисления на GPU.
Архитектура и программная модель CUDA. М.: Издательство
Московского университета, 2012. – 336 с.
4 Брюс Шнайер. Прикладная криптография. Протоколы, алгоритмы,
исходные тексты на языке Си. - М.: "Триумф", 2002 816 с.
5 Сандерс ДЖ., Кэндрот Э. Технология CUDA в примерах: введение в
программирование графических процессоров. М.: ДМК пресс, 2011.
– 232 с.
6 NVIDIA CUDA Toolkit, CUDA_C_Programming_guide, 2012 – 175 с.
7 NVIDIA CUDA Toolkit, CUDA_Getting_Started_Windows, 2012. – 15
c.
8 NVIDIA CUDA Toolkit, CUDA C Best Practices Guide, 2012. – 80 c.
9 NVIDIA CUDA Toolkit, CUDA Developer Guide for NVIDIA Optimus
Platforms, 2010. – 11 c.
10 NVIDIA CUDA Toolkit, Using_Inline_PTX_Assembly_In_CUDA,
2011. - 9 с.
11 NVIDIA CUDA Toolkit, CUDA API Reference Manual, 2012. – 548 c.
12 NVIDIA CUDA Toolkit, PARALLEL THREAD EXECUTION ISA,
2012. – 230 с.
79
13 Боресков А.В., Харламов А.А., Основы работы с технологией
CUDA. – М.: ДМК Пресс, 2010. – 232 с.
14 AMD App Acceleration [Электронный ресурс]: Официальный сайт
компании
AMD
URL:
http://www.amd.com/ru/products/technologies/amdapp/Pages/eyespeed.aspx Дата посещения 26.01.2013
15 Intel® Xeon Phi™ Coprocessor: Parallel Processing [Электронный
ресурс]:
Официальный
сайт
компании
Intel
URL:
http://www.intel.com/content/www/us/en/high-performancecomputing/high-performance-xeon-phi-coprocessor-brief.html
Дата
посещения 26.01.2013
16 Timeout Detection and Recovery of GPUs (TDR) (Windows Drivers)
[Электронный
ресурс]:
Официальный
сайт
Microsoft.
URL:
http://msdn.microsoft.com/enus/library/windows/hardware/ff570088.aspx
Дата
посещения
26.01.2013
17 HashTab tool to quickly find file hash information [Электронный
ресурс]:
Официальный
сайт
Implbits
Software
http://www.implbits.com/HashTab/HashTabWindows.aspx
LLC
URL:
Дата
посещения 26.01.2013
18 TechPowerUp GPU-Z v0.6.7 | techPowerUp [Электронный ресурс]:
официальный
сайт
программы:
http://www.techpowerup.com/downloads/2198/TechPowerUp_GPUZ_v0.6.7.html Дата посещения 26.01.2013
19 Cisco Visual Networking Index: Forecast and Methodology, 2011–2016
[Электронный
ресурс]:
http://www.cisco.com/en/US/solutions/collateral/ns341/ns525/ns537/ns7
05/ns827/white_paper_c11-481360.pdf Дата посещения 26.01.2013
20 Cisco Visual Networking Index: Forecast and Methodology, 2010–2015
[Электронный
ресурс]:
80
http://www.df.cl/prontus_df/site/artic/20110602/asocfile/2011060211363
7/white_paper_c11_481360_1_.pdf Дата посещения 26.01.2013
21 Cisco Visual Networking Index: Forecast and Methodology, 2009–2014
[Электронный
ресурс]:
http://large.stanford.edu/courses/2010/ph240/abdulkafi1/docs/white_paper_c11-481360.pdf Дата посещения 26.01.2013
22 Cisco Visual Networking Index: Forecast and Methodology, 2008–2013
[Электронный
ресурс]:
http://www.cisco.com/web/BR/assets/docs/whitepaper_VNI_06_09.pdf
Дата посещения 26.01.2013
23 Cisco Visual Networking Index: Forecast and Methodology, 2007–2012
[Электронный
ресурс]:
http://www.nextgenweb.org/wp-
content/uploads/2008/06/cisco-visual-networking-index-white-paper.pdf
Дата посещения 26.01.2013
24 Г. Майерс Искусство тестирования программ/Пер. с англ. под ред. Б.
А. Позина. – М.: Финансы и статистика, 1982. – 176 с., ил.
25 NVIDIA Nsight Visual Studio Edition | NVIDIA Developer Zone
[Электронный
ресурс]:
Официальный
сайт
https://developer.nvidia.com/nvidia-nsight-visual-studio-edition
NVIDIA
Дата
посещения 26.01.2013
81
Приложение 1. Фрагмент кода на CUDA C
__device__ void GPU_16_P_par(KeyInfo *c, word32 *d)
{
word32 n1, n2;
word32 tmp=0;
int j;
n1=d[0];
n2=d[1];
//16 циклов вычислений
for(j=0; j<2; ++j)
{
// считаем n2 ^= f(c, n1 + c->k[0..6]);
tmp=n1+c->k[0];
tmp = c->k87[tmp >> 24 & 255] << 24 | c->k65[tmp >> 16 & 255] <<
16 | c->k43[tmp >> 8 & 255] << 8 | c->k21[tmp & 255];
n2 ^= tmp << 11 | tmp >> (32-11);
//считаем n1 ^= f(c, n2 + c->k[1..7]);
tmp=n2+c->k[1];
tmp = c->k87[tmp >> 24 & 255] << 24 | c->k65[tmp >> 16 & 255] <<
16 | c->k43[tmp >> 8 & 255] << 8 | c->k21[tmp & 255];
n1 ^= tmp << 11 | tmp >> (32-11);
// считаем n2 ^= f(c, n1 + c->k[0..6]);
tmp=n1+c->k[2];
tmp = c->k87[tmp >> 24 & 255] << 24 | c->k65[tmp >> 16 & 255] <<
16 | c->k43[tmp >> 8 & 255] << 8 | c->k21[tmp & 255];
n2 ^= tmp << 11 | tmp >> (32-11);
//считаем n1 ^= f(c, n2 + c->k[1..7]);
tmp=n2+c->k[3];
tmp = c->k87[tmp >> 24 & 255] << 24 | c->k65[tmp >> 16 & 255] <<
16 | c->k43[tmp >> 8 & 255] << 8 | c->k21[tmp & 255];
n1 ^= tmp << 11 | tmp >> (32-11);
// считаем n2 ^= f(c, n1 + c->k[0..6]);
tmp=n1+c->k[4];
tmp = c->k87[tmp >> 24 & 255] << 24 | c->k65[tmp >> 16 & 255] <<
16 | c->k43[tmp >> 8 & 255] << 8 | c->k21[tmp & 255];
n2 ^= tmp << 11 | tmp >> (32-11);
//считаем n1 ^= f(c, n2 + c->k[1..7]);
tmp=n2+c->k[5];
tmp = c->k87[tmp >> 24 & 255] << 24 | c->k65[tmp >> 16 & 255] <<
16 | c->k43[tmp >> 8 & 255] << 8 | c->k21[tmp & 255];
n1 ^= tmp << 11 | tmp >> (32-11);
// считаем n2 ^= f(c, n1 + c->k[0..6]);
tmp=n1+c->k[6];
tmp = c->k87[tmp >> 24 & 255] << 24 | c->k65[tmp >> 16 & 255] <<
16 | c->k43[tmp >> 8 & 255] << 8 | c->k21[tmp & 255];
n2 ^= tmp << 11 | tmp >> (32-11);
//считаем n1 ^= f(c, n2 + c->k[1..7]);
tmp=n2+c->k[7];
tmp = c->k87[tmp >> 24 & 255] << 24 | c->k65[tmp >> 16 & 255] <<
16 | c->k43[tmp >> 8 & 255] << 8 | c->k21[tmp & 255];
n1 ^= tmp << 11 | tmp >> (32-11);
}
82
//Запись с переворачиванием
d[0] = n2;
d[1] = n1;
};
__global__ void GPU_imitoinsert(KeyInfo * c, word32 * f_in, word32 * f_out, unsigned
int Len64)
{
word32 S[2]={0, 0};
__shared__ KeyInfo sc;
for (unsigned int i=0; i<256; ++i)
{
sc.k87[i]=c->k87[i];
sc.k65[i]=c->k65[i];
sc.k43[i]=c->k43[i];
sc.k21[i]=c->k21[i];
}
sc.k[0]=c->k[0];
sc.k[1]=c->k[1];
sc.k[2]=c->k[2];
sc.k[3]=c->k[3];
sc.k[4]=c->k[4];
sc.k[5]=c->k[5];
sc.k[6]=c->k[6];
sc.k[7]=c->k[7];
for (unsigned int i=0; i<Len64; ++i)
{
S[0]=S[0]^f_in[2*i];
S[1]=S[1]^f_in[2*i+1];
GPU_16_P_par(&sc, S);
}
f_out[0]=S[0];
f_out[1]=S[1];
};
__device__ void GPU_gostcrpt_gout(KeyInfo *c, word32 *d, word32 * d_out)
{
word32 n1, n2;
word32 tmp=0;
int i, j;
//Проверка на выход за массив значиний для зашифрования
n1=d[0];
n2=d[1];
//первые 24 циклов вычислений
for(j=0; j<3; ++j)
{
for(i=0; i<=6; i+=2)//длится 4! цикла
{
// считаем n2 ^= f(c, n1 + c->k[0..6]);
tmp=n1+c->k[i];
tmp = c->k87[tmp >> 24 & 255] << 24 | c->k65[tmp >> 16 & 255] <<
16 | c->k43[tmp >> 8 & 255] << 8 | c->k21[tmp & 255];
83
n2 ^= tmp << 11 | tmp >> (32-11);
//считаем n1 ^= f(c, n2 + c->k[1..7]);
tmp=n2+c->k[i+1];
tmp = c->k87[tmp >> 24 & 255] << 24 | c->k65[tmp >> 16 & 255] <<
16 | c->k43[tmp >> 8 & 255] << 8 | c->k21[tmp & 255];
n1 ^= tmp << 11 | tmp >> (32-11);
};
}
//Последние 8 циклов.
for(i=7; i>=1; i-=2)//Длится 4! цикла
{
// считаем n2 ^= f(c, n1 + c->k[7..1]);
tmp=n1+c->k[i];
tmp = c->k87[tmp >> 24 & 255] << 24 | c->k65[tmp >> 16 & 255] << 16 | c>k43[tmp >> 8 & 255] << 8 | c->k21[tmp & 255];
n2 ^= tmp << 11 | tmp >> (32-11);
//считаем n1 ^= f(c, n2 + c->k[6..0]);
tmp=n2+c->k[i-1];
tmp = c->k87[tmp >> 24 & 255] << 24 | c->k65[tmp >> 16 & 255] << 16 | c>k43[tmp >> 8 & 255] << 8 | c->k21[tmp & 255];
n1 ^= tmp << 11 | tmp >> (32-11);
};
//Запись с переворачиванием
d_out[0] = n2;
d_out[1] = n1;
};
__global__ void GPU_gostcrypt_gamma_back(KeyInfo * c, SynchroInfo * s, word32 * f_in,
word32 * f_out, unsigned int Len64)
{
word32 gamm_decr[2];//Гамма до зашифрования
word32 gamm_cr[2];//Гамма зашифрованная
gamm_decr[0]=s->s[0];
gamm_decr[1]=s->s[1];
__shared__ KeyInfo sc;
for (unsigned int i=0; i<256; ++i)
{
sc.k87[i]=c->k87[i];
sc.k65[i]=c->k65[i];
sc.k43[i]=c->k43[i];
sc.k21[i]=c->k21[i];
}
sc.k[0]=c->k[0];
sc.k[1]=c->k[1];
sc.k[2]=c->k[2];
sc.k[3]=c->k[3];
sc.k[4]=c->k[4];
sc.k[5]=c->k[5];
sc.k[6]=c->k[6];
sc.k[7]=c->k[7];
for (unsigned int i=0; i<Len64; ++i)
{
GPU_gostcrpt_gout(&sc, gamm_decr, gamm_cr); //Шифрование гаммы
84
};
}
gamm_decr[0]=f_in[ 2 * i ]
^ gamm_cr[ 0 ];
gamm_decr[1]=f_in[ 2 * i + 1 ] ^ gamm_cr[ 1 ];
//Заполнение файла
f_out[ 2 * i ]
= gamm_decr[0];
f_out[ 2 * i + 1 ] = gamm_decr[1];
__global__ void GPU_gostdecrypt_gamma_back(KeyInfo * c, SynchroInfo * s, word32 *
f_in, word32 * f_out, unsigned int Len64)
{
word32 gamm_decr[2];//Гамма до зашифрования
word32 gamm_cr[2];//Гамма зашифрованная
gamm_decr[0]=s->s[0];
gamm_decr[1]=s->s[1];
__shared__ KeyInfo sc;
for (unsigned int i=0; i<256; ++i)
{
sc.k87[i]=c->k87[i];
sc.k65[i]=c->k65[i];
sc.k43[i]=c->k43[i];
sc.k21[i]=c->k21[i];
}
sc.k[0]=c->k[0];
sc.k[1]=c->k[1];
sc.k[2]=c->k[2];
sc.k[3]=c->k[3];
sc.k[4]=c->k[4];
sc.k[5]=c->k[5];
sc.k[6]=c->k[6];
sc.k[7]=c->k[7];
for (unsigned int i=0; i<Len64; ++i)
{
GPU_gostcrpt_gout(&sc, gamm_decr, gamm_cr); //Шифрование гаммы
};
}
//Заполнение файла
f_out[ 2 * i ]=f_in[ 2 *
f_out[ 2 * i + 1 ]=f_in[
//Продление гаммы
gamm_decr[0]=f_in[ 2 * i
gamm_decr[1]=f_in[ 2 * i
i ]
2 * i + 1 ]
^ gamm_cr[ 0 ];
^ gamm_cr[ 1 ];
];
+ 1 ];
__global__ void base_32_CR_Synchro(word32 * d, KeyInfo *c, int len) //оптимизация:
убрать лишние вычисления!
{
word32 n1, n2;
word32 tmp=0;
int i, j;
tmp=threadIdx.x;
//Проверка на выход за массив значиний для зашифрования
if (tmp<=len)
{
n1=d[2*tmp];
n2=d[2*tmp+1];
85
//первые 24 циклов вычислений
for(j=0; j<3; ++j)
{
for(i=0; i<=6; i+=2)//длится 4! цикла
{
// считаем n2 ^= f(c, n1 + c->k[0..6]);
tmp=n1+c->k[i];
tmp = c->k87[tmp >> 24 & 255] << 24 | c->k65[tmp >> 16 &
255] << 16 | c->k43[tmp >> 8 & 255] << 8 | c->k21[tmp & 255];
n2 ^= tmp << 11 | tmp >> (32-11);
//считаем n1 ^= f(c, n2 + c->k[1..7]);
tmp=n2+c->k[i+1];
tmp = c->k87[tmp >> 24 & 255] << 24 | c->k65[tmp >> 16 &
255] << 16 | c->k43[tmp >> 8 & 255] << 8 | c->k21[tmp & 255];
n1 ^= tmp << 11 | tmp >> (32-11);
};
}
//Последние 8 циклов.
for(i=7; i>=1; i-=2)//Длится 4! цикла
{
// считаем n2 ^= f(c, n1 + c->k[7..1]);
tmp=n1+c->k[i];
tmp = c->k87[tmp >> 24 & 255] << 24 | c->k65[tmp >> 16 & 255] <<
16 | c->k43[tmp >> 8 & 255] << 8 | c->k21[tmp & 255];
n2 ^= tmp << 11 | tmp >> (32-11);
//считаем n1 ^= f(c, n2 + c->k[6..0]);
tmp=n2+c->k[i-1];
tmp = c->k87[tmp >> 24 & 255] << 24 | c->k65[tmp >> 16 & 255] <<
16 | c->k43[tmp >> 8 & 255] << 8 | c->k21[tmp & 255];
n1 ^= tmp << 11 | tmp >> (32-11);
};
};
//Запись с переворачиванием
tmp=threadIdx.x;
d[2*tmp] = n2;
d[2*tmp+1] = n1;
}
__global__ void base_32_CR_block(KeyInfo *c, word32 * d, word32 * d_out, unsigned int
len, unsigned int threads) //оптимизация: убрать лишние вычисления + попробовать
разную память (ключ - константная итп). Поиграться с циклами и ветвлениями!
{
word32 n1, n2;
word32 tmp=0;
int j;
unsigned int ind64=(threadIdx.x+(blockIdx.x*threads));
if (ind64<=len)
//Проверка на выход за массив значиний для зашифрования
{
n1=d[2*ind64];
n2=d[2*ind64+1];
//первые 24 циклов вычислений
for(j=0; j<3; ++j)
{
//for(i=0; i<=6; i+=2)//длится 4! цикла
{
// считаем n2 ^= f(c, n1 + c->k[0..6]);
tmp=n1+c->k[0];
tmp = c->k87[tmp >> 24 & 255] << 24 | c->k65[tmp >> 16 &
255] << 16 | c->k43[tmp >> 8 & 255] << 8 | c->k21[tmp & 255];
86
n2 ^= tmp << 11 | tmp >> (21);
//считаем n1 ^= f(c, n2 + c->k[1..7]);
tmp=n2+c->k[0+1];
tmp = c->k87[tmp >> 24 & 255] << 24 | c->k65[tmp >> 16 &
255] << 16 | c->k43[tmp >> 8 & 255] << 8 | c->k21[tmp & 255];
n1 ^= tmp << 11 | tmp >> (21);
tmp=n1+c->k[2];
tmp = c->k87[tmp >> 24 & 255] << 24 | c->k65[tmp >> 16 &
255] << 16 | c->k43[tmp >> 8 & 255] << 8 | c->k21[tmp & 255];
n2 ^= tmp << 11 | tmp >> (21);
//считаем n1 ^= f(c, n2 + c->k[1..7]);
tmp=n2+c->k[2+1];
tmp = c->k87[tmp >> 24 & 255] << 24 | c->k65[tmp >> 16 &
255] << 16 | c->k43[tmp >> 8 & 255] << 8 | c->k21[tmp & 255];
n1 ^= tmp << 11 | tmp >> (21);
tmp=n1+c->k[4];
tmp = c->k87[tmp >> 24 & 255] << 24 | c->k65[tmp >> 16 &
255] << 16 | c->k43[tmp >> 8 & 255] << 8 | c->k21[tmp & 255];
n2 ^= tmp << 11 | tmp >> (21);
//считаем n1 ^= f(c, n2 + c->k[1..7]);
tmp=n2+c->k[4+1];
tmp = c->k87[tmp >> 24 & 255] << 24 | c->k65[tmp >> 16 &
255] << 16 | c->k43[tmp >> 8 & 255] << 8 | c->k21[tmp & 255];
n1 ^= tmp << 11 | tmp >> (21);
255]
255]
16 |
16 |
tmp=n1+c->k[6];
tmp = c->k87[tmp >> 24 & 255] << 24 | c->k65[tmp >> 16 &
<< 16 | c->k43[tmp >> 8 & 255] << 8 | c->k21[tmp & 255];
n2 ^= tmp << 11 | tmp >> (21);
//считаем n1 ^= f(c, n2 + c->k[1..7]);
tmp=n2+c->k[6+1];
tmp = c->k87[tmp >> 24 & 255] << 24 | c->k65[tmp >> 16 &
<< 16 | c->k43[tmp >> 8 & 255] << 8 | c->k21[tmp & 255];
n1 ^= tmp << 11 | tmp >> (21);
};
}
//Последние 8 циклов.
//for(i=7; i>=1; i-=2)//Длится 4! цикла
{
// считаем n2 ^= f(c, n1 + c->k[7..1]);
tmp=n1+c->k[7];
tmp = c->k87[tmp >> 24 & 255] << 24 | c->k65[tmp >> 16 & 255] <<
c->k43[tmp >> 8 & 255] << 8 | c->k21[tmp & 255];
n2 ^= tmp << 11 | tmp >> (21);
//считаем n1 ^= f(c, n2 + c->k[6..0]);
tmp=n2+c->k[7-1];
tmp = c->k87[tmp >> 24 & 255] << 24 | c->k65[tmp >> 16 & 255] <<
c->k43[tmp >> 8 & 255] << 8 | c->k21[tmp & 255];
n1 ^= tmp << 11 | tmp >> (21);
tmp=n1+c->k[5];
tmp = c->k87[tmp >> 24 & 255] << 24 | c->k65[tmp >> 16 & 255] <<
16 | c->k43[tmp >> 8 & 255] << 8 | c->k21[tmp & 255];
n2 ^= tmp << 11 | tmp >> (21);
//считаем n1 ^= f(c, n2 + c->k[6..0]);
tmp=n2+c->k[5-1];
tmp = c->k87[tmp >> 24 & 255] << 24 | c->k65[tmp >> 16 & 255] <<
16 | c->k43[tmp >> 8 & 255] << 8 | c->k21[tmp & 255];
n1 ^= tmp << 11 | tmp >> (21);
87
tmp=n1+c->k[3];
tmp = c->k87[tmp >> 24 & 255] << 24 | c->k65[tmp >> 16 & 255] <<
16 | c->k43[tmp >> 8 & 255] << 8 | c->k21[tmp & 255];
n2 ^= tmp << 11 | tmp >> (21);
//считаем n1 ^= f(c, n2 + c->k[6..0]);
tmp=n2+c->k[3-1];
tmp = c->k87[tmp >> 24 & 255] << 24 | c->k65[tmp >> 16 & 255] <<
16 | c->k43[tmp >> 8 & 255] << 8 | c->k21[tmp & 255];
n1 ^= tmp << 11 | tmp >> (21);
tmp=n1+c->k[1];
tmp = c->k87[tmp >> 24 & 255] << 24 | c->k65[tmp >> 16 & 255] <<
16 | c->k43[tmp >> 8 & 255] << 8 | c->k21[tmp & 255];
n2 ^= tmp << 11 | tmp >> (21);
//считаем n1 ^= f(c, n2 + c->k[6..0]);
tmp=n2+c->k[1-1];
tmp = c->k87[tmp >> 24 & 255] << 24 | c->k65[tmp >> 16 & 255] <<
16 | c->k43[tmp >> 8 & 255] << 8 | c->k21[tmp & 255];
n1 ^= tmp << 11 | tmp >> (21);
};
//Запись с переворачиванием
d_out[2*ind64] = n2;
d_out[2*ind64+1] = n1;
}
};
__global__ void base_32_ENCR_block(KeyInfo *c, word32 * d, word32 * d_out, unsigned
int len, unsigned int threads)
{
word32 n1, n2;
word32 tmp=0;
int i, j;
unsigned int ind64=(threadIdx.x+(blockIdx.x*threads));
//Проверка на выход за массив значиний для расшифрования
if (ind64<=len)
{
n1=d[2*ind64];
n2=d[2*ind64+1];
for(i=0; i<=6; i+=2)//длится 4! цикла
{
// считаем n2 ^= cuda_f(c, n1 + c->k[0..6]);
tmp=n1+c->k[i];
tmp = c->k87[tmp >> 24 & 255] << 24 | c->k65[tmp >> 16 & 255] <<
16 | c->k43[tmp >> 8 & 255] << 8 | c->k21[tmp & 255];
n2 ^= tmp << 11 | tmp >> (32-11);
//считаем n1 ^= cuda_f(c, n2 + c->k[1..7]);
tmp=n2+c->k[i+1];
tmp = c->k87[tmp >> 24 & 255] << 24 | c->k65[tmp >> 16 & 255] <<
16 | c->k43[tmp >> 8 & 255] << 8 | c->k21[tmp & 255];
n1 ^= tmp << 11 | tmp >> (32-11);
};
//24 цикла вычислений
for(j=0; j<3; ++j)
{
//8 циклов
for(i=7; i>=1; i-=2)//Длится 4! цикла
{
//считаем n2 ^= cuda_f(c, n1 + c->k[7..1]);
tmp=n1+c->k[i];
88
tmp = c->k87[tmp >> 24 & 255] << 24 | c->k65[tmp >> 16 &
255] << 16 | c->k43[tmp >> 8 & 255] << 8 | c->k21[tmp & 255];
n2 ^= tmp << 11 | tmp >> (32-11);
//считаем n1 ^= cuda_f(c, n2 + c->k[6..0]);
tmp=n2+c->k[i-1];
tmp = c->k87[tmp >> 24 & 255] << 24 | c->k65[tmp >> 16 &
255] << 16 | c->k43[tmp >> 8 & 255] << 8 | c->k21[tmp & 255];
n1 ^= tmp << 11 | tmp >> (32-11);
};
}
//Запись с переворачиванием
d_out[2*ind64] = n2;
d_out[2*ind64+1] = n1;
}
};
__global__ void base_32_Gamm_make_OPT_even(word32 * Gamm, int GLen, word32 * SF, int
threads) //Вычисление гаммы для чётных чисел запускать суммарное количество нитей =
32битная длинна\2+1. или 64битная длинна.
{
word32 ind32,ind64;
ind64=(threadIdx.x+(blockIdx.x*threads));//Чтобы не затрагивать нулевой
элемент.
ind32=2*ind64;
ind32+=2;
if(ind32<GLen)
{
asm(".reg
.u32 tmp;"
"mul.lo.u32 tmp, %2, %3;"
"add.u32 %0, %1, tmp;" : "=r"(Gamm[ind32]) : "r"(SF[0]),
"r"(GPU_C[0]), "r"(ind64+1));
}
};
__global__ void base_32_Gamm_make_OPT_odd(word32 * Gamm, int GLen, word32 * SF, int
threads) //Вычисление гаммы для нечётных чисел
{
word32 ind32,ind64;
ind64=(threadIdx.x+(blockIdx.x*threads));//Чтобы не затрагивать нулевой
элемент.
ind32=2*ind64+1; //Нечётные элементы 1, 3, 5
ind32+=2;
if(ind32<GLen)
{
Gamm[ind32] = ( ( SF[ 1 ] + ((ind64+1) * GPU_C[1]) - 1 ) % 4294967295 )
+ 1; //Быстрее работает
}
};
__global__ void base_32_Gamm_synchro_load(word32 * gamm, word32 * SF) //Заполнение
{
gamm[blockIdx.x]=SF[blockIdx.x];
};
89