КРИПТОГРАФИЧЕСКИЕ МЕТОДЫ ЗАЩИТЫ ИНФОРМАЦИИ
advertisement

ФЕДЕРАЛЬНОЕ АГЕНТСТВО ПО ОБРАЗОВАНИЮ
СИБИРСКИЙ ФЕДЕРАЛЬНЫЙ УНИВЕРСИТЕТ
Е.А. Новиков, Ю.А. Шитов
КРИПТОГРАФИЧЕСКИЕ МЕТОДЫ
ЗАЩИТЫ ИНФОРМАЦИИ
Учебное пособие
Красноярск
2008
2
Введение................................................................................................................................... 5
Глава 1. ИСТОРИЯ КРИПТОГРАФИИ ...................................................................................... 9
Шифр Атбаш.......................................................................................................................... 10
Квадрат Полибия ................................................................................................................... 11
Шифр Сцитала ....................................................................................................................... 11
Шифр Цезаря ......................................................................................................................... 12
Шифр Тритемия..................................................................................................................... 14
Квадрат Виженера ................................................................................................................. 15
Шифрующие таблицы........................................................................................................... 16
Шифр Плейфера .................................................................................................................... 18
Двойной квадрат.................................................................................................................... 19
Глава 2. ПРИНЦИПЫ ПОСТРОЕНИЯ БЛОЧНЫХ ШИФРОВ ............................................. 20
ШИФР DES ................................................................................................................................ 22
Формирование ключей ......................................................................................................... 24
Алгоритм вычисления функции шифрования .................................................................... 26
Режимы работы алгоритма DES .......................................................................................... 30
Режим «Электронная кодовая книга» ................................................................................. 32
Режим «Сцепление блоков шифра»..................................................................................... 32
Режим «Обратная связь по шифру»..................................................................................... 34
Режим "Обратная связь по выходу" .................................................................................... 35
Алгоритм шифрования данных IDEA ................................................................................. 36
Отечественный стандарт шифрования ................................................................................ 40
Режим простой замены ......................................................................................................... 42
Дешифровка зашифрованных данных в режиме простой замены ................................... 47
Режим гаммирования ............................................................................................................ 48
3.1. Шифрование данных в режиме гаммирования............................................................ 50
3.2. Расшифровывание зашифрованных данных в режиме гаммирования ..................... 52
4. Режим гаммирования с обратной связью........................................................................ 53
4.2. Расшифровывание в режиме гаммирования с обратной связью ............................... 55
5. Режим выработки имитовставки...................................................................................... 56
ШИФР AES ................................................................................................................................ 58
Формат блоков данных и число раундов ............................................................................ 58
Пример представления блока в виде матрицы 4•Nb .......................................................... 60
Функции шифрования........................................................................................................... 62
Функции расшифровывания................................................................................................. 63
Функция обратной расшифровки......................................................................................... 63
Функция прямой расшифровки............................................................................................ 64
Алгоритм выработки ключей (Key Schedule) ..................................................................... 66
Расширение (планирование) ключа ..................................................................................... 67
Выбор раундового ключа ..................................................................................................... 68
Раундовое преобразование ................................................................................................... 68
Замена байтов ........................................................................................................................ 69
Сдвиг строк ............................................................................................................................ 71
Перемешивание столбцов.................................................................................................... 74
Добавление раундового ключа AddRoundKet().................................................................. 76
Основные особенности AES................................................................................................. 76
Глава 3. ХЭШ-ФУНКЦИЯ ......................................................................................................... 77
Алгоритм MD5...................................................................................................................... 78
Алгоритм MD5 для вычисления хэш-функции ................................................................. 80
Алгоритм SHA-1................................................................................................................... 84
3
Алгоритм SHA-1 для вычисления хэш-функции .............................................................. 86
Алгоритм RIPEMD-160 ........................................................................................................ 88
Алгоритм RIPEMD-160 для вычисления хэш-функции ................................................... 92
ГОСТ Р34.11-94. Функция хеширования .............................................................................. 95
Алгоритм ГОСТ для вычисления хэш-функции ............................................................... 97
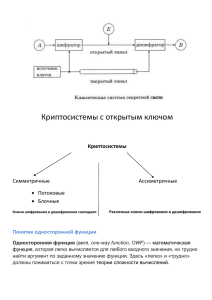
Глава 4. КРИПТОГРАФИЯ С ОТКРЫТЫМ КЛЮЧОМ ...................................................... 101
СХЕМА ДИФФИ-ХЭЛЛМАНА ................................................................................................ 103
Протокол формирования общего ключа по открытому каналу связи............................ 103
Протокол взаимной аутентификации ................................................................................ 103
КРИПТОСИСТЕМА RSA .......................................................................................................... 105
Формирование системы RSA ............................................................................................. 106
Алгоритм шифрования........................................................................................................ 107
Алгоритм дешифрования.................................................................................................... 107
Цифровая подпись .................................................................................................................. 107
СХЕМА ЭЛЬ-ГАМАЛЯ............................................................................................................. 111
Алгоритм формирования схемы Эль-Гамаля ................................................................... 111
Алгоритм формирования цифровой подписи................................................................... 111
Проверка подписи ............................................................................................................... 112
Алгоритм расшифрования 1 ............................................................................................... 112
Алгоритм расшифрования 2 ............................................................................................... 112
СХЕМА ШНОРРА .................................................................................................................... 113
Алгоритм формирования схемы Шнорра ......................................................................... 113
Алгоритм формирования цифровой подписи................................................................... 113
Проверка подписи ............................................................................................................... 113
Протокол аутентификации ................................................................................................. 114
Задача о рюкзаке.................................................................................................................. 115
Алгоритм формирования криптографической системы.................................................. 119
Схема шифрования текста .................................................................................................. 123
Схема дешифрования текста .............................................................................................. 126
Глава 5. ЭЛЕКТРОННЫЕ ЦИФРОВЫЕ ПОДПИСИ............................................................ 128
Стандарт электронной цифровой подписи DSS.............................................................. 130
Формирование системы DSS.............................................................................................. 130
Формирование подписи DSS............................................................................................. 131
Алгоритм проверки подписи DSS..................................................................................... 131
Глава 6. ПРОТОКОЛ ................................................................................................................ 132
Атака на протокол ............................................................................................................... 133
Примеры протоколов .......................................................................................................... 133
Формирование системы Шнорра ....................................................................................... 134
Схема аутентификации Шнорра ........................................................................................ 134
Протокол игры в «орел, решка»......................................................................................... 134
Протоколы распределения ключей.................................................................................... 136
Схемы протоколов передачи ключей ................................................................................ 137
Глава 7. ГЕНЕРАТОРЫ ПСЕВДОСЛУЧАЙНЫ ПОСЛЕДОВАТЕЛЬНОСТЕЙ (ПСП) . 139
Конгруэнтные генераторы ПСП ........................................................................................ 141
Генератор ПСП Блюм-Блюма-Шуба (BBS) ...................................................................... 142
Генератор последовательностей RSA ............................................................................... 142
Регистры сдвигов с обратной связью ................................................................................ 143
Глава 8. СРАВНЕНИЯ.............................................................................................................. 144
Свойства сравнений ............................................................................................................ 145
Модулярная арифметика .................................................................................................... 148
4
Вычисление ax mod n.......................................................................................................... 148
Вычисление наименьшего общего делителя ................................................................... 149
Классы .................................................................................................................................. 150
Полная и приведенная система вычетов ........................................................................... 152
Функция Эйлера .................................................................................................................. 153
Сравнения первой степени ................................................................................................. 159
Квадратичные вычеты......................................................................................................... 164
Алгоритм вычисления символа Якоби.............................................................................. 170
Китайская теорема об остатках.......................................................................................... 173
5
Введение
Как передать нужную информацию нужному адресату втайне от
других? Каждый человек в разное время и с разными целями наверняка
пытался решить для себя эту практическую задачу задачей тайной передачи.
Выбрав подходящее решение, человек, скорее всего, повторяет изобретение
один из способов скрытой передачи информации. Есть три возможности
решения поставленной задачи:
1) создать абсолютно надежный, недоступный для других канал связи
между абонентами;
2) использовать общедоступный канал связи, но скрыть сам факт
передачи информации;
3) использовать общедоступный канал связи, но передавать по нему
нужную информацию в таком виде, чтобы восстановить ее мог только
адресат.
На современном уровне развития науки и техники сделать такой канал
связи между удаленными абонентами для неоднократной передачи больших
объемов информации практически нереально. Разработкой средств и методов
скрытия факта передачи сообщения занимается стеганография. Первые следы
стеганографических методов теряются в глубокой древности. Например,
известен такой способ скрытия письменного сообщения: голову раба брили,
на коже головы писали сообщение и после отрастания волос раба отправляли
к адресату. С помощью стеганографии можно прятать и предварительно
зашифрованные тексты. Однако стеганография и криптография –
принципиально различные направления в теории и практике защиты
информации. Хорошо известны различные способы тайнописи между строк
обычного, незащищенного текста – от молока до сложных химических
реактивов с последующей обработкой.
Разработкой методов преобразования (шифрования) информации с
целью ее защиты от незаконных пользователей занимается криптография.
Такие методы и способы преобразования информации называются шифрами.
Шифрование – это процесс применения шифра к защищаемой информации,
то есть преобразование открытого текста в шифрованное сообщение
(шифртекст, криптограмму) с помощью определенных правил, содержащихся
в шифре. Дешифрование – это обратный шифрованию процесс, то есть
преобразование шифрованного сообщения в читаемую информацию с
помощью определенных правил, содержащихся в шифре.
Задача шифрования возникает только для информации, которая
нуждается в защите. Обычно в таких случаях говорят, что данные содержат
тайну, являются приватными, конфиденциальными или секретными.
Криптография – прикладная наука, она использует самые последние
6
достижения фундаментальных наук и, в первую очередь, математики. С
другой стороны, все конкретные задачи криптографии существенно зависят
от уровня развития техники и технологии, от применяемых средств связи и
способов передачи информации. Для наиболее типичных, часто
встречающихся ситуаций такого типа, введены даже специальные понятия:
1) государственная тайна;
2) военная тайна;
3) коммерческая тайна;
4) юридическая тайна;
5) врачебная тайна и т.д.
Под защищаемыми данными будем понимать следующую информацию:
1) имеется какой-то определенный круг пользователей, которые имеют
право владеть этой информацией;
2) имеются незаконные пользователи, которые стремятся овладеть
этими данными.
Криптография в переводе с греческого означает «тайнопись». Смысл
этого термина подчеркивает основную задачу криптографии – защитить или
сохранить в тайне необходимые данные. Развитие средств защиты создал три
метода защиты информации:
1) физический способ защиты;
2) стеганографический способ защиты:
3) криптографический способ защиты.
Физическая защита – физическая защита носителей данных, защита от
перехвата, уничтожение носителей при угрозе захвата информации
(американский самолет), обнаружение «утечки».
Стеганография – сделать носитель невидимым (Грибоедов, Ришелье,
голова раба, невидимые чернила, микроточка).
Криптографический способ защиты. Этот способ защиты наиболее
распространен в наши дни. Подробно он будет обсуждаться ниже.
Итак, криптография есть способ защиты информации. Криптография
обеспечивает:
1) секретность данных, то есть защиту от несанкционированного
знакомства с содержанием;
2) аутентификацию данных, то есть подтверждение их подлинности,
подлинности сторон, времени создания;
3) невозможность отказа от авторства, то есть электронную подпись;
7
4) целостность данных, то есть защита от несанкционированного
изменения в содержание.
Криптографические методы защиты информации применяются в
следующих прикладных задачах:
1) Электронная Цифровая Подпись (ЭЦП);
2) электронные деньги;
3) электронная жеребьевка;
4) одновременное подписание контрактов;
5) защита ценных бумаг и документов от подделок;
6) электронное голосование.
Некоторые общие тезисы о защите информации:
1) криптография – одно из многих средств защиты;
2) надо защищать то, что дорого;
3) нельзя создать систему защиты данных раз и навсегда, нужно
отслеживать, совершенствовать и т.п.;
4) надо искать достижение к компромиссу между стоимостью защиты
(стоимостью шифрования) и требуемой степени безопасности – нельзя ловить
рыбу на золотой крючок;
5) проблемы надежно шифровать нет – важно, чтобы коммерческие
масштабы шифрование отвечали некоторым оптимальным требованиям цены
и скорости;
6) значительный процент угроз для информационной безопасности –
сотрудники, а так же сбой аппаратуры.
Условно развитие криптографии можно разбить на три периода:
1) донаучный. В этот период не было единого системного подхода к
криптографии – криптография не была объектом исследования определенной
области науки;
2) научный. Этот период начинается с работ Шенона «Теория связи в
секретных системах», которые он опубликовал в 1949 году;
3) современный. Этот период начался с работы двух математиков
Диффи У. и Хеллмана М. «Новые направления в криптографии»,
опубликованной в 1976 году. В 1978 году на основе концепции, которая была
изложена в этой работе, три математика Ривест, Шамир, Адлеман
предложили принципиально новый криптографический метод шифрования,
который в дальнейшем был назван RSA. Имя метода составлено из первых
букв фамилий этих ученых.
8
В донаучный период криптография не была объектом исследования
определенного направления, поэтому ею занимались на уровне ремесла или
увлечения специалисты разных профессий. Среди известных авторов
криптографических методов были полководцы, руководители государств,
священники, дипломаты, юристы и многие другие. Авторами
криптографических систем защиты были даже известные исторические
деятели, такие как римский император Юлий Цезарь, кардинал Ришелье,
американский президент Джефферсон. Начиная со средних веков, вопросы
криптографии все в большей степени включаются в сферу исследования
математиков.
Основным понятием в криптографии является шифр. Шифр – это
преобразование исходного секретного сообщения с целью его защиты. Выбор
конкретного преобразования открытого текста определяется
наиболее
секретной частью криптографической защиты – так называемым ключом
защиты. Здесь надо подчеркнуть разницу между шифрованием и
кодированием данных. Кодирование – это преобразование информации, в
котором отсутствует ключ. Оно используется не для достижения защиты
информации, а для представления данных в другом формате при выполнении
каких-либо технических задач. Например, азбука Морзе, различные
архиваторы, представление информации для реализации графического
изображения. В кодировании секретом является выбранный формат
представления данных, а также технические, теоретические и
алгоритмические детали, которые используются для реализации выбранного
представления. Архиватор на первых порах использовался для сокрытия
информации.
В 1883 Керкгоффс сформулировал шесть требований к системам
шифрования:
1) система должна быть не раскрываемой, если не теоретически, то хотя
бы практически;
2) компроментация системы не должна причинять неудобства ее
пользователям;
3) секретный ключ должен быть легко запоминаемым без каких либо
записей;
4) криптограмма должна быть представлена в такой форме, чтобы ее
можно было передать по телеграфу;
5) аппаратура шифрования должна быть портативной и такой, чтобы ее
мог обслуживать один человек;
6) система должна быть простой. Она не должна требовать ни
запоминания длинного перечня правил, ни большого умственного
напряжения.
9
Эти правила можно трактовать как некоторое условие сертификации
криптосистем того времени. Если проанализировать эти старые требования
шифрования, пожалуй, только пункты 3, 4 и 5 стали как бы несущественными
в современных криптографических системах. Они, можно сказать,
выполняются автоматически в современных информационных технологиях.
Пункт первый требований в современных условиях можно
интерпретировать как стойкость шифров от атак. Шестое требование можно
интерпретировать следующим образом: построение доступных по стоимости
криптографических систем – современная интерпретация простоты есть
стоимость. Однако фундаментальным и незыблемым требованием к
криптографическим системам остается второе требование. Данное условие
называется правилом Керкгоффса. Суть его состоит в том, что при
построении криптографической системы надо исходить из того, что
противнику известен алгоритм шифрования. Отметим, что стойкость
шифрование зависит только от ключа шифрования – пример Энигма.
Классы шифров:
1) простая замены – поточные и блочные шифры простой замены;
2) шифр Цезаря, квадрат Полибия, шифр Плейфера, двойной квадрат;
3) перестановки – сциталь Лесандра, табличные способы перестановки,
таблица с усложненными элементами;
4) шифры замены легко расшифровать, например, с использованием
частотного анализа. Этот недостаток нейтрализуют многоалфавитные
шифры замены – квадрат Виженера, шифр Грансфельда.
В 1949 году Шенон сформулировал два основных принципа для
формирования стойких шифров. Это принцип «перемешивания» и принцип
«рассеивания».
Принцип перемешивания заключается в том, что шифрование
незначительно различающихся текстов приводит к существенно разным
результатам.
Принцип «рассеивания» состоит в том, чтобы влияние одного символа
открытого текста распространялось на как можно большее количество
символов. Шеннон предложил и общую структуру таких шифров, как
суперпозицию простых преобразований блочных символов.
Глава 1. ИСТОРИЯ КРИПТОГРАФИИ
Под шифром понимают совокупность обратимых преобразований
множества открытых данных на множество зашифрованных данных. Эти
преобразования задаются
10
▪ алгоритмом криптографического преобразования,
▪ ключом криптографического преобразования;
Разработкой методов преобразования (шифрования) информации с
целью ее защиты занимается криптография. Криптография создает и изучает
методы
преобразования
информации,
которые
не
позволяют
несанкционированному пользователю в случае перехвата данных
воспользоваться этой информацией. Естественно, здесь предполагается, что
несанкционированный пользователь перехватил преобразованное –
зашифрованное, а значит защищенное – сообщение.
История криптографии насчитывает не одно тысячелетие. Она связана с
большим количеством государственных, военных, дипломатических,
коммерческих, юридических и личных тайн. Долгое время криптографией
занимались кустари-одиночки. Среди таких любителей криптографии не
профессионалов были государственные деятели,
дипломаты, ученые,
полководцы, исторические личности, священники, врачи, писатели. В этот
период криптография была некоторым побочным результатом деятельности
узкого круга образованных умельцев, которые занимались данным вопросом
по необходимости или из-за интереса. Поэтому данный этап развития
криптографии – этап ремесленничества – можно отнести скорее к искусству,
чем к науке. Продлился данный «ненаучный» период развития криптографии
довольно долго, вплоть до первой половины XX века, и, можно считать, что
завершился он в 1949 году, когда появилась работа К. Шеннона «Теория
связи в секретных системах». Приведем наиболее важные примеры,
иллюстрирующие этапы истории развития криптографии.
Шифр Атбаш
Один из известных древним шифром является – атбаш [1]. Если
перенумеровать символы некоторого алфавита (например, русского), то
способ шифрования заключался в замене символа с номером k на символ с
номером (n-k+1), где n – номер последнего символа алфавита или количество
символов в алфавите. Здесь надо иметь в виду, что в общем случае алфавит
может включать необязательно только буквы, а, например, все символы
клавиатуры компьютера.
Пример. Пусть дан русский алфавит:
А
1
Б
2
В
3
Г
4
Д
5
Е
6
Е
7
Ж
8
З
9
И
10
Й
11
К
12
Л
13
М
14
Н
15
О
16
П
17
Р
18
С
19
Т
20
У
21
Ф
22
11
Х
23
Ц
24
Ч
25
Ш
26
Щ
27
Ъ
28
Ы
29
Ь
30
Э
31
Ю
32
Я
33
Число букв в данном алфавите n= 33. Для представленного алфавита при
использовании шифра атбаш слово баба преобразуется (зашифровывается) в
слово юяюя.
Если проанализировать шифр атбаш, то фактически он представляет
собой некоторое раз и навсегда зафиксированное новое обозначение букв
алфавита. Поэтому с большой натяжкой этот способ преобразования можно
отнести к шифрованию. В этом методе отсутствует ключ, который должен
обязательно присутствовать при любом преобразовании текста. Для данного
способа преобразования этот ключ единственный и нет возможности
заменить его от текста к тексту. Лучше сказать, что в данном алгоритме
отсутствует множество ключей, что является необходимым признаком любой
криптографической системы.
Квадрат Полибия
Один из древних способов шифрования был предложен греческим
государственным деятелем и историком Полибием за 200 лет до н.э.
Латинский алфавит, который состоял из 26 букв, располагался в таблицу
(квадрат) размером 5×5 клеток. При этом буква I отождествлялась с буквой J.
Шифруемая буква заменялась координатами квадрата, в котором она была
записана. Всевозможные модификации шифра Полибия широко применяли и
использовали в средние века.
Шифр Сцитала
Шифр Сцитала – это один из первых физических приборов, который
явился родоначальником целого класса шифров перестановки. Эти шифры
формируются за счет перестановки букв текста, который необходимо
шифровать. Шифр Сцитала был изобретен в Спарте в V век до н.э.
Для
шифрования
текста
использовался
цилиндр
заранее
обусловленного диаметра. На цилиндр наматывалась узкая лента из
пергамента, и открытый текст записывался вдоль оси цилиндра. Затем лента
сматывалась и отправлялась по назначению. Получатель сообщения
наматывал ленту на цилиндр того же диаметра и затем считывал его.
Заметим, что ключом данного метода шифрования является размер
радиуса цилиндра. Метод взлома данного шифра приписывается Аристотелю
[1]. Методика взлома заключалась в следующем. На длинный конус
наматывалась лента, а затем эту ленту начинали сдвигать по конусу. Там где
12
буквы текста формировали слова или слоги диаметр конуса совпадал с
диаметром цилиндра.
Шифр Сцитала является представителем класса шифров перестановки.
В общем случае этот класс шифров можно описать следующим образом.
Пусть число k определяет последовательность 1, 2, …, k-1, k чисел от 1 до k.
Зададим произвольную перестановку этих чисел α1, α2, …, αk. Число k и
зафиксированная перестановка α1, α2, …, αk являются секретным ключом
системы. Далее преобразование открытых данных происходит так. Открытый
текст разбивается на группы, в каждую из которых входит k букв. В каждой
группе буквы переставляют согласно выбранной перестановки α1, α2, …, αk.
Пример. Пусть дан текст: «Встречай одиннадцатого марта». Выберем k
= 6. Определим перестановку для чисел от 1 до 6 следующим образом: 3, 5,
1, 6, 2, 4. Разбиваем текст на группы по шесть символов
«Встреч, ай_оди, ннадца, того_м, арта.!»
Символ ‘_’ в тексте означает пробел. Теперь третья буква каждой группы
ставится на первое место, пятая – на второе место, первая – на третье место,
шестая – на четвертое место, вторая – на пятое место, четвертое – на шестое
место. Если в последней группе букв меньше k, то текст надо дополнить. В
нашем случае были добавлены символы «.» и «!», потому что они не меняют
смысл открытого текста. В результате открытый текст преобразовывается в
следующий
«Тевчср, _даийо, ацнанд, г_тмоо, т.а!ка».
Если отбросить запятые, расставленные между группами букв для удобства
объяснения, то окончательно получаем такое шифрованное сообщение:
Тевчср_даийоацнандг_тмоот.а!ка
Дешифрование выполняется в обратном порядке, а именно: первый
символ группы из шести букв зашифрованного текста становится третьим,
второй – пятым и т.д. согласно зафиксированной перестановке.
Заметим, что на компьютере подобное преобразование реализуется в
виде программы очень просто, несмотря на то, что ручное шифрование по
данному алгоритму трудоемко.
Шифру Сциталя можно дать иную трактовку, удобную для ручного
шифрования. Эта трактовка, о которой будет рассказано позже, приводит к
так называемым шифрующим таблицам или шифрованию по «маршруту».
Шифр Цезаря
13
Шифр Цезаря является хрестоматийным примером шифра. Он
определяется следующим образом. Занумеруем буквы алфавита. Пусть a
обозначает номер буквы открытого текста, n число букв в алфавите, k, k<n, –
некоторое число. Тогда по номеру буквы a открытого текста определяется
буква (код) шифрованного текста по формулам:
c = a + k,
c = a + k – n,
если c ≤ n,
если c > n.
Здесь число k называется ключом криптографической системы.
Смысл шифра Цезаря состоит в том, что любая буква открытого текста
заменяется k-й буквой относительно себя.
П р и м е р. Пусть ключ k равен 7, тогда слово баба шифром Цезаря
преобразуется в слово зжзж. Код буквы б равен 2, а код буквы а равен 1.
Буквы з и ж сдвинуты относительно б и а на семь позиций. Тогда коды букв
шифрованной записи определяются следующим образом:
б+k = 2+7 = 9 – соответствует букве з,
а + k = 1+7 = 8 – соответствует букве ж.
Заметим, что расшифровка происходит по формуле a = c – k.
Шифр Цезаря является представителем класса шифров, которые
называются шифрами простой замены. Для шифра Цезаря можно
использовать более удобную табличную форму. Если n – число букв в
алфавите, а k – ключ, то в прямоугольной таблице с k столбцами и t = n/k
строками записываем алфавит. В случае необходимости число строк можно
увеличить, если n/k не является целым числом. В свободные квадраты
таблицы, которые появляются при увеличении количества строк, можно,
например, заполнить знаками препинания или буквами латинского или
какого-нибудь другого алфавита.
Алгоритм шифрования в этом случае черезвычайно прост. Буква
открытого текста заменяется символом из того же столбца, но который
находится ниже данной буквы. Если буква открытого текста находится в
последней строке, то она заменяется верхней буквой того же столбца.
Пример. Пусть дана таблица:
А
Е
Й
О
У
Ш
Э
Б
Е
К
П
Ф
Щ
Ю
В
Ж
Л
Р
Х
Ъ
Я
Г
З
М
С
Ц
Ы
,
Д
И
Н
Т
Ч
Ь
.
14
Тогда для фразы
Я мыл раму.
получается шифровка
В с,р хесшд
Заметим, что ключом в данном случае является размер таблицы и
расположение в этой таблицы букв. В общем случае буквы в таблице можно
располагать случайным образом.
Предложенная схема шифрования при помощи таблицы можно описать,
например, следующим способом. Если буква открытого текста имеет
координаты в таблице (i, j), где i – номер строки, а j – номер столбца, то она
переходит в букву с координатами (i+1, j) или в букву с координатами (1, j),
если i совпадает с номером последней строки.
Шифр Тритемия
В шифре простой замены для фиксированного ключа k любая буква
алфавита, где бы она не встретилась в открытом тексте, она всегда
преобразуется в одну и ту же букву этого же или другого алфавита. По сути
дела происходит простое переобозначение букв алфавита. Поэтому шифр
простой замены легко взломать, вычислив частоту появления символов
зашифрованного текста. В любом языке различные буквы встречаются с
разной частотой. Преобразование символа α по формуле
γ=α+k
автоматически «переносит» частоту появления буквы α на частоту появления
символа γ.
В XVI веке аббат Иоганнес Тритемий предложил метод шифрования,
который породил класс шифров многоалфавитной замены. Тритемий
придумал таблицу – так называемую «таблица Тритемия». Для русского
алфавита она выглядит следующим образом (без букв Й и Е):
А
Б
В
Г
Д
Е
Ж
З
И
К
Л
М
Б
В
Г
Д
Е
Ж
З
И
К
Л
М
Н
В Г Д Е Ж З И К Л М
Г Д Е Ж З И К Л М Н
Д Е Ж З И К Л М Н О
Е Ж З И К Л М Н О П
Ж З И К Л М Н О П Р
З И К Л М Н О П Р С
И К Л М Н О П Р С Т
К Л М Н О П Р С Т У
Л М Н О П Р С Т У Ф
М Н О П Р С Т У Ф Х
Н О П Р С Т У Ф Х Ц
О П Р С Т У Ф Х Ц Ч
Н О П Р С Т У Ф Х Ц Ч Ш Щ Ъ Ы Ь Э Ю
О П Р С Т У Ф Х Ц Ч Ш Щ Ъ Ы Ь Э Ю Я
П Р С Т У Ф Х Ц Ч Ш Щ Ъ Ы Ь Э Ю Я А
Р С Т У Ф Х Ц Ч Ш Щ Ъ Ы Ь Э Ю Я А Б
С Т У Ф Х Ц Ч Ш Щ Ъ Ы Ь Э Ю Я А Б В
Т У Ф Х Ц Ч Ш Щ Ъ Ы Ь Э Ю Я А Б В Г
У Ф Х Ц Ч Ш Щ Ъ Ы Ь Э Ю Я А Б В Г Д
Ф Х Ц Ч Ш Щ Ъ Ы Ь Э Ю Я А Б В Г Д Е
Х Ц Ч Ш Щ Ъ Ы Ь Э Ю Я А Б В Г Д Е Ж
Ц Ч Ш Щ Ъ Ы Ь Э Ю Я А Б В Г Д Е Ж З
Ч Ш Щ Ъ Ы Ь Э Ю Я А Б В Г Д Е Ж З И
Ш Щ Ъ Ы Ь Э Ю Я А Б В Г Д Е Ж З И К
Я
А
Б
В
Г
Д
Е
Ж
З
И
К
Л
15
Н О П Р С Т У Ф Х Ц Ч Ш Щ Ъ Ы Ь Э Ю Я А Б В Г Д Е Ж З И К Л М
О П Р С Т У Ф Х Ц Ч Ш Щ Ъ Ы Ь Э Ю Я А Б В Г Д Е Ж З И К Л М Н
П Р С Т У Ф Х Ц Ч Ш Щ Ъ Ы Ь Э Ю Я А Б В Г Д Е Ж З И К Л М Н О
Р С Т У Ф Х Ц Ч Ш Щ Ъ Ы Ь Э Ю Я А Б В Г Д Е Ж З И К Л М Н О П
С Т У Ф Х Ц Ч Ш Щ Ъ Ы Ь Э Ю Я А Б В Г Д Е Ж З И К Л М Н О П Р
Т У Ф Х Ц Ч Ш Щ Ъ Ы Ь Э Ю Я А Б В Г Д Е Ж З И К Л М Н О П Р С
У Ф Х Ц Ч Ш Щ Ъ Ы Ь Э Ю Я А Б В Г Д Е Ж З И К Л М Н О П Р С Т
Ф Х Ц Ч Ш Щ Ъ Ы Ь Э Ю Я А Б В Г Д Е Ж З И К Л М Н О П Р С Т У
Х Ц Ч Ш Щ Ъ Ы Ь Э Ю Я А Б В Г Д Е Ж З И К Л М Н О П Р С Т У Ф
Ц Ч Ш Щ Ъ Ы Ь Э Ю Я А Б В Г Д Е Ж З И К Л М Н О П Р С Т У Ф Х
Ч Ш Щ Ъ Ы Ь Э Ю Я А Б В Г Д Е Ж З И К Л М Н О П Р С Т У Ф Х Ц
Ш Щ Ъ Ы Ь Э Ю Я А Б В Г Д Е Ж З И К Л М Н О П Р С Т У Ф Х Ц Ч
Щ Ъ Ы Ь Э Ю Я А Б В Г Д Е Ж З И К Л М Н О П Р С Т У Ф Х Ц Ч Ш
Ъ Ы Ь Э Ю Я А Б В Г Д Е Ж З И К Л М Н О П Р С Т У Ф Х Ц Ч Ш Щ
Ы Ь Э Ю Я А Б В Г Д Е Ж З И К Л М Н О П Р С Т У Ф Х Ц Ч Ш Щ Ъ
Ь Э Ю Я А Б В Г Д Е Ж З И К Л М Н О П Р С Т У Ф Х Ц Ч Ш Щ Ъ Ы
Э Ю Я А Б В Г Д Е Ж З И К Л М Н О П Р С Т У Ф Х Ц Ч Ш Щ Ъ Ы Ь
Ю Я А Б В Г Д Е Ж З И К Л М Н О П Р С Т У Ф Х Ц Ч Ш Щ Ъ Ы Ь Э
Я А Б В Г Д Е Ж З И К Л М Н О П Р С Т У Ф Х Ц Ч Ш Щ Ъ Ы Ь Э Ю
Первая строка таблицы является строкой букв для открытого текста. Далее
первая буква открытого текста шифруется по первой строке таблицы, вторая
буква – по второй строке, третья – по третьей строке и так далее. Если буква
открытого текста имеет координату в первой строке (1, j), то в строке i она
заменяется буквой с координатами (i, j). Иначе говоря, буква с номером j в
первой строке заменяется буквой с номером j в i-той строке. После того как
последняя строка была использована, осуществляется возвращение к первой
строке. При этом способе шифрования одна и та же буква открытого текста
может преобразовываться в разные буквы. Так слово «мама» при такой схеме
шифрования преобразуется в слово «мбог».
Заметим, что в описанном варианте шифрования отсутствует ключ. В
дальнейшем усложнение шифра пошло по произвольному порядку букв
исходного алфавита и по более сложному выбору порядка строк при
шифровании.
Квадрат Виженера
Квадрат Виженера состоит – как и таблица Тритемия – из циклически
сдвигаемых алфавитов. Первая строка есть строка алфавита, а i-ая строка
получается из строки (i-1) циклическим сдвигом на один символ влево.
Первая строка может быть алфавитом с произвольным порядком образующих
его букв. Первая строка используется для букв открытого текста, а первый
столбец этой таблицы служит для алфавита ключа.
Правило шифрования следующее. Если буква открытого текста имеет
координату (1, j), а буква ключа – (i, 1), то символом шифра будет буква,
которая находится на пересечении i-й строки и j-го столбца. Здесь
предполагается, что каждой букве открытого текста соответствует некоторая
16
буква ключа. Естественно, алфавит может состоять из любых существующих
символов и букв разных языков.
Дешифруется текст по следующей схеме. Координата ключа (i, 1)
определяет номер строки, а координата буквы шифра из этой строки (i, j)
определяет номер столбца, по которому определяется буква открытого текста
с координатой (1, j).
Шифрующие таблицы
Шифру Сциталя, как говорилось ранее, можно дать несколько другую
трактовку. Возьмем таблицу из n строк и m столбцов так, чтобы число n× m
равнялось количеству букв открытого текста. Если определить некоторый
порядок считывания текста из таблицы, то получим зашифрованный текст.
Ключом в такой схеме шифрования является структура таблицы, в данном
случае ее размер и «маршрут» считывания. Шифр Сциталя соответствует
считыванию текста по столбцам.
Пример. Рассмотрим таблицу из 4 строк и 4 столбцов.
1
2
3
4
1
2
3
4
П
3
α
Т
P
Ж
Ш
О
И
A
Е
Г
Е
Ю
С
О
Символ α используется для пробела. В эту таблицу занесен текст
Приезжаю шестого
Первый маршрут считывания осуществляется по номерам столбцов.
Столбцы нумеруются по порядку. В этом случае получают следующий текст
Пзαтржшоиаегеюсо
Легальный пользователь записывает полученный текст по столбцам и читает
сообщение по строкам.
Второй маршрут считывания осуществляется по номерам столбцов.
Столбцы пронумерованы случайным образом, то есть номера столбцов
образуют некоторую перестановку. В этом случае таблица имеет вид
3
1
4
2
1
2
П
3
P
Ж
И
A
Е
Ю
17
3
4
α
Т
Ш
О
Е
Г
С
О
В результате получается следующий шифрованный текст
Ржшоеюсопзαтиаег
Третий маршрут считывания определяется номерами строк, которые
пронумерованы случайным образом, а затем номерами столбцов, которые
тоже пронумерованы случайным образом.
2
3
4
1
3
1
4
2
П
3
α
Т
P
Ж
Ш
О
И
A
Е
Г
Е
Ю
С
О
В этом случае предварительно строки располагаются в порядке нумерации. В
результате получаем таблицу
1
2
3
4
3
1
4
2
Т
П
3
α
О
P
Ж
Ш
Г
И
A
Е
О
Е
Ю
С
Затем выписываем текст по столбцам в порядке нумерации. Получаем
следующий текст
Оржшоеюстпзαгиае
Четвертый маршрут считывания можно определить для любой ранее
приведенной таблицы. Он заключается в следующем – считывать от любой
угловой буквы по диагоналям матрицы.
На самом деле маршрутов считывания можно определить много. Здесь
мы перечислили некоторые из них. Во всех случаях расшифровка
преобразованного текста происходит
в обратном порядке. Все эти
преобразования по таблицам относятся к шифрам перестановки.
В заключении приведем пример шифрующей таблицы, которая по
утверждению авторов из [15] настолько надежна, что ее можно использовать
для оперативного и надежного шифрования информации небольшого объема
в режиме повседневной работы. В предлагаемой шифрующей таблице,
18
помимо случайной нумерации столбцов, не используются некоторые поля для
записи букв. Такой подход значительно увеличивает в этом методе число
всевозможных ключей, которые помимо размера таблицы и порядка
нумерации столбцов, усиливаются числом и положением неиспользуемых
полей. Пример такой таблице приведен ниже.
3
1
2
3
4
5
6
7
8
10
4
2
9
8
Ф И Р М ♦ А
Р ♦ С α С К
β О Б О Н ♦
♦ Т И Т С Я
α
В Ы ♦ Д А
Т
Е β
К Р Е
ω ♦ ♦ ♦ .
Н
♦ К ♦ ♦ О В
1
α
О
♦
ω
В
Д
О
.
6
7
5
Б А
♦ Р
К Р
α Н
А ♦
И Т
В И
α
β
♦
О
О
Е
Т
А
♦
♦
Символы α и β в данном сообщении играют роль пробелов, символ ω точки, а символ ♦ обозначает поле, которое не используется в таблице для
записи символа. Передаваемое сообщение будет следующим:
αОωВДО.МαОТКФРβαТωРСБИЫβООЕТАБК
αАИВαАРРНТИβАКЯАЕНВСНСДР.ОИОТВЕК
Получив сообщение легальный пользователь, зная структуру таблицы,
начинает заполнять ее по столбцам, соблюдая последовательность
нумерации. Затем считывает сообщение по строкам. О назначении символов
α, β и ω можно заранее не договариваться, оно будет ясно из контекста.
Все рассматриваемые выше методы преобразования открытого текста
попадают под одну общую схему. Любой метод определял некоторую
функцию преобразования E, и каждый символ α открытого текста определял
символ γ = E(α). Такая схема посимвольного преобразования текста
формирует класс поточных шифров.
Помимо рассмотренных поточных шифров существуют еще блочные
системы шифрования. Блочные системы производят преобразование блоков
символов фиксированной длины. В современной криптографии подобная
классификация сохраняет силу. Рассмотрим некоторые блочные
криптографические системы, которые существовали задолго до современных
криптографических подходов.
Шифр Плейфера
19
Для шифра Плейфера формируется таблица размером N = n × m. Здесь n
– число строк, m – число столбцов. Число N должно совпадать с числом
символов в алфавите. Символы алфавита в таблице располагаются случайным
образом. Размер таблицы и расположение символов в ней является ключом
данной криптографической системы.
Далее алгоритм шифрования состоит в следующем.
▪ Открытый текст разбивается на блоки по два символа в каждом. Такой
блок называют биграмой. Если в последнем блоке оказался один символ, то
он либо отбрасывается (если это возможно), либо добавляется один символ,
который не влияет на содержание открытого текста.
▪ Пусть символы ab являются некоторой биграмой открытого текста.
▪ Определяются координаты символа a и символа b в таблице. Пусть
координаты символа а будут числа (i, j), а координаты символа b – (t, q).
▪ В этом случае если:
▪ i≠ t и j≠ q (буквы биграмы находятся в разных строках и разных
столбцах таблицы), то символ a биграмы переходит в символ
таблицы с координатами (i, q), а символ b – в символ с координатами
(t, j);
▪ i=t и j≠ q (буквы биграмы находятся в одной строке, но разных
столбцах таблицы), то символ a биграмы переходит в символ
таблицы с координатами (i, j+1), а символ b – в символ с
координатами (t,q+1). Если j=m или q=m, то координаты новых
символов соответственно будут равны (i, 1) или (t, 1);
▪ i≠ t и j= q (буквы биграмы находятся в разных строках, но одном
столбце таблицы), то символ a биграмы переходит в символ таблицы
с координатами (i+1, j), а символ b – в символ с координатами
(t+1,q). Если i=n или t=n, то координаты новых символов
соответственно будут равны (1, j) или (1, q). Две одинаковые буквы с
координатами (i, j) преобразуются в две одинаковые буквы с
координатами (i+1, j);
Расшифровка текста происходит точно так же. Преобразованный текст
разбивается на блоки по два символа. Затем по координатам зашифрованных
символов в той же последовательности определяются символы открытого
текста.
Двойной квадрат
Для двойного квадрата формируются две таблицы размером N = n × m.
Здесь n – число строк, m – число столбцов. Число N должно совпадать с
числом символов в алфавите. Символы алфавита в таблицах располагаются
случайным образом. Лучше, если порядок символов в таблицах не совпадает
с алфавитом. Размеры таблиц и расположение символов в них являются
20
ключом данной криптографической системы. Одну таблицу принято называть
левой - пусть ей будет соответствовать номер 1, другую правой - пусть ее
номер будет равен 2.
Далее алгоритм шифрования состоит в следующем.
▪ Открытый текст разбивают на блоки по два символа в каждом. Такой
блок называют биграмой. Если в последнем блоке оказался один символ, то
он либо отбрасывается (если это возможно), либо добавляется один символ,
который не влияет на содержание открытого текста.
▪ Пусть символы ab являются некоторой биграмой открытого текста.
▪ Первый символ биграмы a располагают в первой таблице. Пусть пара
чисел (i, j) являются координатами этого символа в первой таблице.
▪ Второй символ биграмы b располагают во второй таблице. Пусть пара
чисел (t, q) являются координатами этого символа в первой таблице.
▪ В этом случае если:
▪ i≠ t (номера строк букв биграм не совпадают, а номера
столбцов, в которых находятся буквы биграм, произвольный), то
символ a биграмы переходит в символ второй таблицы с
координатами (i, q), а символ b – в символ первой таблицы с
координатами (t, j);
▪ i=t и j≠ q (буквы биграмы находятся в строках с одинаковыми
номерами, но с разными номерами столбцов таблиц) то символ a
биграмы переходит в символ второй таблицы с координатами (i, j), а
символ b – в символ первой таблицы с координатами (t, q).
▪ i= t и j= q (буквы биграмы находятся в строках и столбцах с
одинаковыми номерами), то символы a и b биграмы переставляются.
Расшифровка текста происходит по тем же правилам с той лишь
разницей, что первая буква биграмы шифрованного текста располагается в
правой (во второй) таблице, а вторая буква биграмы располагается в первой
(левой) таблице.
Криптографическая система двойной квадрат весьма устойчивый к
взлому [12]. Его просто реализовать в виде программы на компьютере. В этом
случае в символы алфавита можно включить все символы клавиатуры.
Глава 2. ПРИНЦИПЫ ПОСТРОЕНИЯ БЛОЧНЫХ ШИФРОВ
Блочными называют шифры, которые предназначены для шифрования
некоторого блока открытого текста. После преобразования этого блока
получают блок шифрованного текста такой же длины. В современных
блочных шифрах обычно используют битовое представление текста, то есть
открытый и шифрованный тексты представляет собой некоторый набор из
нулей и единиц фиксированной длины. Шеннон сформулировал общие
принципы построения блочных шифров.
21
Во-первых, он предложил реализовывать сложные преобразования в виде
суперпозиции нескольких простых отображений [1]. Шеннон предложил
реализовывать блочные шифры путем многократного применения к блокам
открытого текста некоторых базовых преобразований, которые просто
реализуемы, и при небольшом числе повторений обеспечивают сложные
преобразования.
Во-вторых, Шеннон потребовал, чтобы эти преобразования
данных
обеспечивали реализацию двух криптографических принципов –
«рассеивание» и «перемешивание». Задача «рассеивания» состоит в том,
чтобы распространять влияние одного символа открытого текста на как
можно большее число знаков шифрованного текста. Это позволяет скрыть
статистическую зависимость между символами открытого текста.
Цель «перемешивания» состоит в том, чтобы зависимость между ключом и
зашифрованным текстом сделать как можно более сложной. Иными словами,
преобразование должно быть таким, чтобы нельзя было обнаружить связь
между открытым и зашифрованным текстом. Данным требованиям
удовлетворяет шифр Фейстеля. На рис. 1 показана структура одного раунда
данного шифра.
Li-1
Ri-1
f
Li-1
ki-1
Li-1
Рис. 1. Шифр Файстеля (один раунд)
Первый блочный шифр, который обладал свойствами рассеивания и
перемешивания, был создан на фирме IBM в 60-х годах прошлого столетия.
На базе данного шифра была спроектирована система шифрования Люцифер
(Lucifer) [1]. Система Люцифер основана на комбинировании (чередовании)
22
методов подстановки и перестановки. В ней использовался ключ длиной 128
бит, управлявший состояниями блоков перестановки и подстановки. Система
Люцифер оказалась весьма сложной для практической реализации из-за
относительно малой скорости шифрования – 2190 байт/сек. при программной
реализация и 96970 байт/сек. при аппаратной реализации.
ШИФР DES
Одним из первых широко распространенным и используемым
стандартом шифрования данных был DES (Data Encryption Standard). Этот
стандарт был опубликован в Америке в 1977г. Стандарту DES
предшествовала система Люцифер фирмы IBM. Более того, алгоритм
шифрования DES
в сильной степени напоминает алгоритм, который
использовался в Люцифере (Lucifer) [3,6]. Заметим также, что стандарт DES
является представителем, точнее, обобщением шифра Фейстеля.
В самом общем виде алгоритм DES является блочным шифром, то есть
шифром, который одновременно преобразует данные фиксированного
размера в n бит (для системы DES значение n равно 64). Поэтому перед
шифрованием алгоритмом DES открытый текст надо разбить его на блоки по
64 бита (8 байтов). Далее, каждый i-й (i = 1, 2, .., N, где N – число блоков
открытого текста) блок открытого текста делят на две равные части – левую
Li и правую Ri части по 32 бита каждая. Затем для каждого блока
выполняются 16 раундов преобразований по структуре шифра Фейстеля. В
каждом раунде преобразования используется свой ключ.
Расшифровка текста принципиально ничем не отличается от
шифрования. Применяется тот же самый алгоритм с той лишь разницей, что
на вход подается блок в 64 бита шифрованного текста, а ключи используются
в обратном порядке. Перейдем к более детальному представлению алгоритма
DES. На рис. 2 приведена общая схема алгоритма DES.
Перечислим основные этапы алгоритма DES.
1. Генерируется случайная последовательность Q из 56 бит.
2. В последовательность Q, для контроля четности, добавляются восемь
контрольных битов в позиции 8, 16, 24, …, 64. Получается блок U размером в 64
бита.
3. Для удаления контрольных битов из блока U и формирования ключа K для
шифрования, блок U преобразуют с использованием функции G(U). Функция G
определяется в виде стандартной таблицы, которую надо применять в неизменном
виде. В результате преобразования получают блок K=G(U) размером 56 бит. Блок K
разбивают на две половины C0 и D0 по 28 бит.
4. Используя C0 и D0, последовательно определяются Ci и Di , i = 1, 2, …,
16. Для формирования Ci и Di применяют операции циклического сдвига влево на
один или два бита. Величина сдвига определяется стандартной таблицей. Операции
сдвига для Ci и Di выполняются независимо. Последовательность C5 получается из
23
C4 посредством циклического сдвига влево на 2 бита, а D5 – посредством
циклического сдвига влево на 2 бита D4 (см. табл. 1 сдвигов для вычисления ключа).
В результате четвертого этапа формируется 16 ключей для 16 раундов алгоритма
DES.
Исходный текст
Начальная перестановка
ключ
Шифрование
16 раз
Конечная перестановка
Шифртекст
Рис. 2. Общая схема алгоритма DES
5. Используя перестановку H, которая задается стандартной таблицей, каждый
ключ размером в 56 бит преобразуется в блок, состоящий из 48 бит. Данным
преобразованием завершается этап формирования ключей.
6. Текущий блок открытого текста размером в 64 бит, представленный в виде
двух 32 битовых блоков L0 и R0, преобразуется начальной перестановкой IP, которая
задается фиксированной стандартной таблицей.
7. Выполняется 16 раундов преобразований по следующим формулам
Li = Ri-1,
R i = L i _ f(R i-1 , Ki ),
i = 1, 2, …, 16.
Функция f(R i-1, Ki ) представляет собой некоторую суперпозицию простых
преобразований, детальное описание которых будет дано ниже. Отметим, что
функция f(R i-1, Ki ) является нелинейной. Нелинейность функции f(Ri-1, K i )
обеспечивается S-блоками.
8. Результат шестнадцатого раунда (L16R16 ) подвергается преобразованию,
которое представляет собой перестановку IP-1, обратную к перестановке IP
24
шестого этапа данной схемы. Это преобразование и будет заключительным
этапом шифрования блока открытого текста алгоритмом DES.
З а м е ч а н и е. Все таблицы, которые используются в DES, являются
стандартными и должны включаться в реализацию алгоритма DES в
неизменном виде. Таблицы разработаны таким образом, чтобы максимально
затруднить процесс расшифровки путем подбора ключа.
Таблица 1
Функция G
Функция G первоначальной подготовки ключа
57
1
10
19
63
7
14
21
49
58
2
11
55
62
6
13
41
50
59
3
47
54
61
5
33
42
51
60
39
46
53
28
25
34
43
52
31
38
45
20
17
26
35
44
23
30
37
12
9
18
27
36
15
22
29
4
Перейдем к детальному представлению отдельных этапов алгоритма DES.
Формирование ключей
Формирование ключей в общей схеме алгоритма включает в себя 5 шагов. К
ключу размером в 56 бит добавляются биты в позиции 8, 16, 24, …, 64 таким
образом, чтобы каждый байт содержал нечетное число единиц. Этот факт
используется для обнаружения ошибок при обмене и хранении ключей [1]. В
результате такого преобразования получаем блок U размером в 64 бита. Для
удаления из блока U контрольных битов и формирования начального значения
ключа K0 размером в 56 бит к блоку U применяется функция G, которая
предназначена для первоначальной подготовки ключа. Функция G задается в виде
таблицы 1.
Согласно функции G первыми битами ключа K0 = G(U) будут, соответственно,
биты 57, 49, 41 и т. д. блока U. Последним 56 битом K0 будет четвертый бит блока U.
Заметим, что при формировании ключа K0 не используются биты из позиций 8, 16,
24, …, 64 блока U, потому что контрольные биты при формировании K0
отбрасываются. Функция G при преобразовании блока U использует только 56 бит
этого блока. В итоге преобразование определяет первоначальный ключ K0 размером
56 бит, который представляется в виде двух равных частей по 28 бит каждая. Левая
часть первоначального ключа обозначается через C0, а правая – через D0. Результат
преобразования можно записать в виде формулы
K0 = G(U) = C0D0.
25
Зная C0 и D0 , последовательно определяем шестнадцать блоков Ci и Di, i = 1,
…, 16. Для этого используется таблица сдвигов для вычисления ключа. Операции
циклического сдвига влево выполняются для блоков Ci и Di независимо. Например,
последовательность C9 получается из C8 посредством циклического сдвига влево на
один бит, а D9 – посредством циклического сдвига D8 влево на один бит.
Таблица 2
Таблица сдвигов для вычисления ключа
(первая строка – номер раунда, вторая строка – число сдвигов)
1
1
2
1
3
2
4
2
5
2
6
2
7
2
8
2
9
1
10
2
11
2
12
2
13
2
14
2
15
2
16
1
Формирования ключа Ki для каждого раунда i, i = 1, …, 16, завершается, если
каждый блок Ci и Di размером в 56 бит преобразован с использованием функции
перестановки H, которая задается стандартной таблицей. Функция H преобразует
блок CiDi, i = 1, …, 16, размером в 56 бит в ключ Ki, i = 1, …, 16, размером в 48 бит.
Заметим, что функция H при преобразовании блока CiDi, i = 1, …, 16, размером в 56
бит не использует биты 9,18, 22, 25, 34, 35, 38, 43 этого блока. Данным
преобразованием завершается этап формирования шестнадцати ключей для
шестнадцати раундов алгоритма DES. В табл. 3 приведена функция Н,
завершающая обработку ключа.
Таблица 3
Функция Н
14 17 11
3
28 15
23 19 12
16 7 27
41 52 31
30 40 51
44 49 39
46 42 50
24
6
4
20
37
45
56
36
1
5
21 10
26
8
13
2
47 55
33 48
34 53
29 32
Перейдем непосредственно к детальному описанию процесса шифрования
открытого текста, который разбит на N блоков по 64 бита. Каждый блок открытого
текста Ti, i = 1, …, N, подвергается начальной перестановке IP, которая задается
стандартной таблицей. Биты входного блока переставляются в соответствии с
матрицей IP. Матрица начальной перестановки приведена в табл. 4.
Таблица 4
Матрица начальной перестановки IP
58
50
42
34
26
18
10
2
26
60
62
64
57
59
61
63
52
54
56
49
51
53
55
44
46
48
41
43
45
47
36
38
40
33
35
37
39
28
30
32
25
27
29
31
20
22
24
17
19
21
23
12
14
16
9
11
13
15
4
6
8
1
3
5
7
Бит 58 входного блока Тi становится первым битом преобразованного
блока, бит 50 – вторым битом и т.д. Эту перестановку можно описать
выражением
Wi= IP(Ti).
Полученная последовательность
последовательности
битов
Wi
разделяется
на
две
Lо – левые или старшие биты,
Ro – правые или младшие биты.
Последовательности Lо и Ro содержат по 32 бита. Далее для блока Wi
выполняется 16 раундов преобразований по следующим формулам
Li = Ri-1,
R i = L i _ f(R i-1 , Ki ),
i = 1.2, …, 16.
Здесь:
i – номер раунда;
Ki – ключ раунда;
– сложение по модулю 2 (операция XOR);
f() – функция шифрования.
Алгоритм вычисления функции шифрования
▪ К блоку Ri-1 применяют функцию расширения E(Ri-1), которая 32
битовый блок Ri-1 преобразовывает в блок R´ = E(Ri-1) размером в 48 бит.
Функция E(Ri-1) определяется стандартной таблицей 5. Заметим, что при
формирования блока R´ по два раза используются биты 1, 4, 5, 8, 9, 12, 13, 16,
17, 20, 21, 24, 25, 28, 29, 32.
Таблица 5
Функция расширения E
32
1
2
3
4
5
27
4
8
12
16
20
24
28
5
6
9 10
13 14
17 18
21 22
25 26
29 30
7
11
15
19
23
27
31
8
12
16
20
24
28
32
9
13
17
21
25
29
1
▪ Вычисляется новый блок размером в 48 бит по формуле:
B = E(Ri-1)
Ki.
▪ Блок B размером в 48 бит разбивается на восемь блоков Bj, j = 1, 2, …,
8, по шесть битов каждый
B = B1B2B3B4B5B6B7B8.
▪ Каждый блок Bj размером в шесть бит, используя свою функцию Sj ,
преобразуют в блок Sj(Bj) размером в четыре бита. В результате получаем
блок, размером в 32 бита
B′ = S1(B1) S2(B2) S3(B3) S4(B4) S5(B5) S6(B6) S7(B7) S8(B8)
▪ Алгоритм преобразования блока Bj размером в шесть бит в блок Sj(Bj)
размером в четыре бита следующий. Каждая функция Sj представляет собой
стандартную таблицу, которая состоит из четырех строк с номерами 0, 1, 2, 3
и шестнадцати столбцов с номерами 0, 1, 2, …, 15. Пусть, например,
некоторый блок имеет вид
Bj = b1 b2 b3 b4 b5 b6 = 110010,
j = 1, 2, …, 8.
Тогда биты b1b6 = 10 (число 10 записано в двоичной системе, оно совпадает с
числом 2 в десятичной системе) формируют номер столбца 10 (= 2) таблицы Sj,
а биты b2b3b4b5 = 1001 (число 1001 записано в двоичной системе, оно
совпадает с числом 9 в десятичной системе) формируют номер строки 1001 (=
9) таблицы Sj. Блок Bj = b1b2b3b4b5b6 = 110010 заменяют двоичным значением
числа таблицы Sj, которое находится на пересечение строки с номером b1b6 =
10 (=2) со столбцом с номером b2b3b4b5 = 1001 (=9). Преобразуя каждое Bj, j =
1, 2, …, 8, из блока B, получим новый блок B´ размером в 32 бита. В табл. 6
приведены функции преобразования Sj, j = 1, 2, …, 8.
28
Таблица 6
Функции преобразования S1, S2, …, S8
н
о
м
е
р
с
т
р
о
к
и
0
1
2
3
0
1
2
3
0
1
2
3
0
1
2
3
0
1
2
3
0
1
2
3
0
1
2
3
0
1
2
3
0
14
0
4
15
15
3
0
13
10
13
13
1
7
13
13
3
2
14
4
11
12
10
9
4
4
13
1
6
13
1
7
2
1
4
15
1
12
1
13
14
8
0
7
6
10
13
8
6
15
12
11
2
8
1
15
14
3
11
0
4
11
2
15
11
1
2
13
7
4
8
8
4
7
10
9
0
4
13
14
11
9
0
4
2
1
12
10
4
15
2
2
11
11
13
8
13
4
14
3
1
4
8
2
14
7
11
1
14
9
9
0
3
5
0
6
1
12
11
7
15
2
5
12
14
7
13
8
4
8
1
7
4
5
2
14
13
4
6
15
10
3
6
3
6
3
8
6
0
6
12
10
7
4
10
1
9
7
2
9
15
4
12
1
6
5
15
2
6
9
11
2
4
15
3
4
15
9
6
15
11
1
10
7
13
14
2
12
8
5
0
9
3
4
15
3
12
10
Номер столбца
6 7 8 9
11 8 3 10
13 1 10 6
2 11 15 12
1 7 5 11
3 4 9 7
8 14 12 0
13 1 5 8
4 2 11 6
15 5 1 13
6 10 2 8
3 0 11 1
8 7 4 15
9 10 1 2
0 3 4 7
7 13 15 1
13 8 9 4
11 6 8 5
13 1 5 0
7 8 15 9
2 13 6 15
6 8 0 13
9 5 6 1
12 3 7 0
15 10 11 14
8 13 3 12
1 10 14 3
7 14 10 15
10 7 9 5
11 1 10 9
7 4 12 5
14 2 0 6
8 13 15 12
10
6
12
9
3
2
1
12
7
12
5
2
14
8
2
3
5
3
15
12
0
3
13
1
0
14
12
3
15
5
9
5
6
11
12
11
4
14
13
10
6
12
7
14
12
3
5
12
14
11
15
10
5
9
4
14
10
7
7
12
8
15
14
11
13
0
12
5
9
3
10
12
6
9
0
11
12
5
11
11
1
5
12
13
3
6
10
14
0
1
6
10
14
5
0
15
3
2
5
13
9
5
10
0
0
9
3
5
4
11
10
5
12
10
2
7
4
0
9
3
4
7
11
13
0
10
15
5
2
0
14
3
14
0
3
5
6
5
11
2
14
2
15
14
2
4
14
8
2
14
8
0
5
5
3
1
8
6
8
9
3
12
9
5
11
Полученный блок
B´ = S1(B1) S2(B2) S3(B3) S4(B4) S5(B5) S6(B6) S7(B7) S8(B8)
15
7
8
0
13
10
5
15
9
8
1
7
12
15
9
4
14
9
6
14
3
11
8
6
13
1
6
2
12
7
2
8
6
S1
S2
S3
S4
S5
S6
S7
S8
29
размером в 32 бита преобразуется с помощью функции перестановки P(B′) в
блок размером в 32 бита. Функция P(B′) определяется стандартной табл. 7.
Таблица 7
Функция перестановки P
16 7
29 12
1 15
5 18
2
8
32 27
19 13
22 11
20 21
28 1 7
23 26
31 10
24 14
3
9
30 6
4 25
Завершается шифрование конечной перестановкой битов в блоке (L16, R16),
который является результатом преобразования в шестнадцатом раунде.
Перестановка определяется функцией IP-1, которая задается стандартной
табл. 8.
Таблица 8
-1
Матрица обратной перестановки IP
40
39
38
37
36
35
34
33
8
7
6
5
4
3
2
1
48
47
46
45
44
43
42
41
16
15
14
13
12
11
10
9
56
55
54
53
52
51
50
49
24
23
22
21
20
19
18
17
64
63
62
61
60
59
58
57
32
31
30
29
28
27
26
25
Заметим, что для L16 и R16 справедливы формулы:
L16 = R15,
R16 = L15 ⊕ f(R 15 , K16 ).
На основании этих формул легко организовать расшифровку блока. Так как
R15 известно и равно L16 и, зная ключ K 16 , легко вычислить значение
f(R 15, K16 ). Отсюда, зная
R16 = L15 ⊕ f(R 15 , K16 ) и f(R 15 , K 16 ),
30
легко определить L15 по формуле
R16 ⊕ f(R 15 , K 16 ) = L15 ⊕ f(R 15 , K 16 ) ⊕ f(R 15 , K 16 ) = L15.
Так как результат операции ⊕ (XOR) для двух одинаковых значений равен 0,
то имеет место соотношение
f(R 15 , K16 ) ⊕ f(R 15 , K 16 ) = 0.
Теперь, зная
L15 = R16 ⊕ f(R 15 , K16 ),
определяем R 14 = L15. Затем вычисляем f(R 14 , K 15 ) и из следующего
равенства
R15 ⊕ f(R 14 , K 15 ) = L14 ⊕ f(R 14 , K 15 ) ⊕ f(R 14 , K 15 ) = L14
определяем L14. И так далее, пока не опустимся до блоков Lо и Ro.
Одно время DES являлся наиболее распространенным алгоритмом,
используемым в системах защиты коммерческой информации. Более того,
реализация алгоритма DES в таких системах было признаком хорошего тона
[1]. Основные достоинства алгоритма DES [1] заключаются в следующем
▪ используется только один ключ длиной 56 бит;
▪ зашифровав сообщение с помощью одного пакета программ, для
расшифровки можно использовать любой другой пакет программ,
соответствующий стандарту DES;
▪ относительная простота алгоритма обеспечивает высокую скорость
обработки;
▪ достаточно высокая стойкость алгоритма.
Общая схема алгоритма DES представлена на рис. 3.
Режимы работы алгоритма DES
Для решения разнообразных криптографических задач алгоритмом
DES были разработаны несколько схем (режимов) его реализации. В
стандарте DES рекомендуется использовать следующие основные
режимы работы:
▪ электронная кодовая книга ECB (Electronic Code Book);
▪ сцепления блоков шифра CBC (Cipher Block Chaining);
▪ обратная связь по шифруемому тексту CFB (Cipher Feed Back);
▪ обратная связь по выходу OFB (Output Feed Back);
31
Входная последовательность
битов
Начальная перестановка IР
L0
R0
K1
f
R1=L1 f(R0,K1)
L1=R0
K2
f
L2=R1
R2=L1 f(R1,K2)
K15
f
R15=L14
L15=R14
f(R14,K15)
f
R15=L14
L2=R1
f(R14,K15)
Начальная перестановка IР-1
Выходная последовательность
битов (шифртекст)
Рис. 3. Общая схема алгоритма DES
K16
32
Режим «Электронная кодовая книга»
Сообщение разбивается на блоки по 64 бита (8 байтов). Каждый из
этих блоков шифруют независимо с использованием одного и того же
ключа шифрования. Данный режим можно представить в виде следующих
формул
Ci = Ek(Mi),
Mi = Dk(Ci),
где
Mi, Ci – соответственно, i-е блоки входной и зашифрованной
информации;
Ek, Dk – соответственно, алгоритм шифрования и дешифрования DES с
ключом k.
Схема режима «Электронная кодовая книга» представлена на рис. 4.
Рис. 4. Схема режима «Электронная кодовая книга»
Режим «Сцепление блоков шифра»
Режим сцепления блоков шифра (CBC) можно представить в виде
следующих формул
Ci = Ek(Mi ⊕ Ci-1),
33
Mi = Ci-1 ⊕Dk(Ci),
где
Mi, Ci – соответственно, i-е блоки входной и зашифрованной
информации;
Ek, Dk – соответственно, алгоритм шифрования и дешифрования DES с
ключом k;
С0 – некоторый начальный вектор;
⊕ – операция сложения по модулю 2.
В этом режиме – как и в режиме ECB – исходный файл М разбивается на
64-битовые блоки Mi, i = 1, 2, …, n, n – число блоков. Первый блок M1
складывается по модулю 2 с 64-битовым начальным блоком С0, который
можно менять ежедневно и держать в секрете. Полученная сумма затем
шифруется алгоритмом DES с использованием ключа k. Полученный в
результате шифрования 64-битовый блок С1 складывается по модулю 2 со
вторым блоком текста, результат шифруется и т.д. Процедура повторяется до
тех пор, пока не будут обработаны все блоки текста. Схема режима
«Сцепление блоков шифра» представлена на рис. 5.
IV
M1
64
64
M1 64
DES шифрование
M1
64
IV
64
M2
M1
64
64
M3
M1
64
64
DES шифрование
M1
64
DES шифрование
С1
M1
64
64
C2
M1
64
64
C3
M1
64
64
С1
64
C2
64
C3
64
DES расшифрование
M1
64
DES расшифрование
M2
64
DES расшифрование
M3
64
Рис. 5. Схема алгоритм DES в режиме сцепления блоков шифра
34
Режим «Обратная связь по шифру»
Режим обратной связи по шифру (CFB) можно представить в виде
следующих формул:
Ci = Mi ⊕ Ek(Ci-1),
Mi = Ci ⊕ Dk(Ci-1),
где
Mi, Ci – соответственно i-е блоки входной и зашифрованной
информации;
Ek, Dk – соответственно алгоритм шифрования и дешифрования DES с
ключом k;
С0 – некоторый начальный вектор;
⊕ – операция сложения по модулю 2.
В этом режиме размер блока может отличаться от 64 бит. Файл, подлежащий
шифрованию (расшифровыванию), считывается последовательными блоками
длиной t, t =1, ..., 64, битов. Входной блок, 64-битовый накопитель, вначале
содержит вектор инициализации, выровненный по правому краю. Схема
режима «Обратной связью по шифру» представлена на рис. 6.
Шифрование
Расшифрование
Сдвиг
Вх.
блок
Сдвиг
64 - k
64 - k
k
1
k
DESшифрование
Вых.
k
блок 1
k
Обратная
связь
k бит
Обратная
связь
k бит
1
Открытый текст
1
k
64 - k
k
1
1
k
DESшифрование
64 - k
Шифртекст
Вх.
блок
k
k
Вых.
блок
Шифртекст
k
1
k
Открытый текст
1
Рис. 6. Схема алгоритма DES в режиме обратной связи по шифру
k
35
Режим "Обратная связь по выходу"
Режим обратной связи по выходу (OFB) использует переменный
размер блоков и сдвиговый регистр, инициализируемый как в режиме CFB.
Входной блок вначале содержит вектор инициализации C0, выровненный
по правому краю (рис. 7). Для каждого сеанса шифрования данных
необходимо использовать новое начальное состояние регистра, которое
должно пересылаться по каналу открытым текстом.
Расшифрование
Шифрование
Сдвиг
Вх.
блок
Сдвиг
64 - k
64 - k
k
1
k
DESшифрование
Вых.
k
блок 1 k
Обратная
связь
k бит
1
Обратная
связь
k бит
64 - k
k
1
Шифртекст
k
DESшифрование
64 - k
1
Вх.
блок
k
k
Вых.
блок
Шифртекст
k
1
k
Открытый текст
1
k
Открытый текст
1
Рис. 7. Схема алгоритма DES в режиме обратной связи по выходу
Режим OFB можно представить в виде следующих формул:
Ci = Mi ⊕ Pi,
Pi = Ek(Ci-2Ci-1 >> t),
где
Mi, Ci – соответственно i-е блоки входной и зашифрованной
информации;
Ek, Dk – соответственно алгоритм шифрования и дешифрования DES с
ключом k;
С0 – некоторый начальный вектор;
k
36
⊕ – операция сложения по модулю 2.
Через Ci-1 >> t обозначается сдвиг на t разрядов влево, при этом старшие t
разрядов помещаются на место младших разрядов. Схема режима «Обратной
связью по выходу» представлена на рис. 7.
Алгоритм шифрования данных IDEA
Алгоритм IDEA (International Data Encryption Algorithm) является
блочным шифром. Он шифрует 64-битовые блоки открытого текста.
Алгоритм IDEA использует ключ длиной в 128 бит. Для шифрования и
дешифрования используется один и тот же алгоритм.
В алгоритме IDEA используются следующие математические
операции:
▪ операция сложения по модулю 2, данная операция обозначается
символом ;
▪ операция сложения без знаковых целых по модулю 216 (модуль
65536), данная операция обозначается символом ;
▪ операция умножения без знаковых целых по модулю (216+1) (модуль
65537), данная операция обозначается символом . В этом случае блок,
который состоит из одних нулей, интерпретируется как 216. Например,
000000000000000
100000000000000 = 1000000000000001,
потому что
216 × 216 mod (216 +1) = 215 + 1.
Эти операции обеспечивают в алгоритме комплексное преобразование
открытого текста. Заметим, что DES, в отличии от IDEA, базируется исключительно на операции сложения по модулю 2. Данные операции выполняются
над блоками длиной в 16 бит и эти операции не удовлетворяют ассоциативному и дистрибутивному закону, например:
a (b c) ≠ (a b) c,
a (b c) ≠ (a b) (a c).
В алгоритме IDEA выполняются девять раундов. В восьми раундах
выполняются четырнадцать шагов преобразований вводимой информации. В
последнем девятом раунде – четыре шага. Очередной блок X длиной в 64 бит
открытого текста, который надо зашифровать, делится на четыре 16-битовых
блока Xj, j = 1, 2, 3, 4. Эти четыре блока становятся входом в первый раунд
алгоритма. Для каждого раунда по определенному правилу формируются
шесть ключей размером в 16 бит. Эти ключи формируются из начального
37
ключа размером в 128 битов – вдвое длиннее ключа в DES. Всего в алгоритме
формируются 52 ключа – по шесть для каждого из восьми раундов и четыре
для преобразования выхода. Между раундами второй и третий блоки
меняются местами. Для каждого раунда i, i = 1, …, 8, выполняется следующая
последовательность операций:
ОДИНАКОВЫЕ СИМВОЛЫ ДЛЯ РАЗНЫХ ОПЕРАЦИЙ! (здесь даётся
последовательность шагов каждого раунда и в разных шагах используются
одинаковые операции, но с разными частями данных)
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
⊕
– умножение блока Х 1 и первого ключа Z 1 (i) .
– сложение блока Х2 и второго ключа Z 2 (i) .
– сложение блока Х3 и третьего ключа Z 3 (i) .
– умножение блока Х4 и четвертого ключа Z 4 (i) .
– сложение результатов шагов (1) и (3).
– сложение результатов шагов (2) и (4).
– умножение результата шага (5) и пятого ключа Z 5 (i) .
– сложение результатов шагов (6) и (7).
– умножение результата шага (8) с шестым ключом Z 6 (i) .
– сложение результатов шагов (7) и (9).
– сложение результатов шагов (1) и (9).
– сложение результатов шагов (3) и (9).
– сложение результатов шагов (2) и (10).
– сложение результатов шагов (4) и (10).
Здесь i, i = 1, …, 8, – номер раунда. Выходом цикла являются четыре блока,
которые получают как результаты выполнения шагов 11, 12, 13 и 14. В
завершение раунда переставляют местами два внутренних блока, за
исключением последнего раунда. В результате формируется входные данные
для следующего раунда. После восьмого раунда выполняются следующая
последовательность операций:
1.
2.
3.
4.
– умножение блока Х 1 и первого ключа Z 1 (9) .
– сложение блока Х2 и второго ключа Z 2 (9) .
– сложение блока Х3 и второго ключа Z 3 (9) .
– умножение блока Х4 и первого ключа Z 4 (9) .
Полученные в результате преобразования четыре блока по 16 бит каждый Xj,
j = 1, 2, 3, 4, образуют зашифрованный текст.
Для представленного алгоритма требуется 52 ключа длиной в 16 бит
каждый. Формирование ключей происходит по следующей схеме:
1. Генерируется случайным образом ключ k длиной 128 бит.
38
2. Ключ k делится на 8 ключей по 16 бит каждый.
3. Значения ключа шага 2 преобразуется в новое значение. Для этого
происходит циклический сдвиг 128 бит влево на 25 бит.
4. Шаги 2 и 3 повторяется до тех пор пока не будут сформированы
необходимые для алгоритма 52 ключа размером в 16 бит каждый.
Первые шесть сформированных таким образом ключей, используются
для первого раунда, вторые шесть ключей – для второго раунда и т.д.
Расшифровка осуществляется по представленному алгоритму, за
исключением того, что ключи немного изменяются. Значения некоторых
ключей при расшифровке представляют собой обратные значения ключей
при шифровании по отношению к операциям либо сложения, либо
умножения. Эти вычисления обратных значений надо выполнить для каждого
ключа один раз. Здесь надо помнить, что обратное значение нуля
относительно умножения по модулю 216 + 1 равно нулю. В алгоритме IDEA
блок, состоящий из одних нулей, равен 216=-1 [4]. Значения ключей
расшифровки представлены в табл. 9.
Таблица 9
Подключи шифрования и дешифрования алгоритма IDEA
Цикл
Подключи шифрования
Подключи дешифрования
1
Z1(1) Z2(1) Z3(1) Z4(1) Z5(1) Z6(1)
2
Z1(2) Z2(2) Z3(2) Z4(2) Z5(2) Z6(2)
3
Z1(3) Z2(3) Z3(3) Z4(3) Z5(3) Z6(3)
Z5
(4)
Z5
(5)
Z5
(6)
Z5
(7)
8
Z1
Z2
Z4
Z5
Преобразование Z1(9) Z2(9) Z3(9) Z4(9)
выхода
(8)
4
5
6
7
Z1
(4)
Z1
(5)
Z1
(6)
Z1
(7)
(8)
Z2
(4)
Z3
(4)
Z2
(5)
Z3
(5)
Z2
(6)
Z3
(6)
(7)
Z3
(7)
Z2
(8)
Z3)(8
Z4
(4)
Z4
(5)
Z4
(6)
Z4
(7)
(8)
Z6
(4)
Z6
(5)
Z6
(6)
Z6
(7)
Z6
(8)
Z1(9)- -
1
Z1
(8)- -
Z1
(7)- -
Z1
(6)- -
1
1
1
Z1(5)- -
1
Z1(4)- -
1
Z1(3)- -
1
Z1(2)- -
1
Z1(1)- -
1
-Z2(9) -Z3(9)
-Z3(8) -Z2(8)
-Z3(7) -Z2(7)
-Z3
(6)
-Z3
(5)
-Z3
(4)
-Z3
(3)
-Z3
(2)
-Z2
(6)
-Z2
(5)
-Z2
(4)
-Z2
(3)
-Z2
(2)
-Z2(1) -Z2(1)
Z4(9)- -
1
Z4
(8)- -
Z4
(7)- -
Z4
(6) --
1
1
1
Z4(5)- -
1
Z4(4)- -
1
Z4(3)- -
1
Z4(2)- -
1
Z5(8) Z6(8)
Z5(7) Z6(7)
Z5(6) Z6(6)
Z5(5) Z6(5)
Z5(4) Z6(4)
Z5(3) Z6(3)
Z5(2) Z6(2)
Z5(1) Z6(1)
Z4(1)- -
1
В табл. 9 выражение Zs(i) означает значение ключа размером в 16 бит в раунде
i, i = 1, 2, …,9, где s (s= 1,2, …, 6 пометка не понятна!) – номер ключа в
раунде i.
39
Схема алгоритма IDEA представлена на рис. 8. Алгоритм IDEA может
работать в любом режиме блочного шифра, предусмотренном для алгоритма
DES. Алгоритм IDEA обладает рядом преимуществ перед алгоритмом DES.
Он значительно безопаснее, поскольку 128-битовый ключ алгоритма IDEA
вдвое больше ключа DES. Внутренняя структура алгоритма IDEA
обеспечивает лучшую устойчивость к криптографическому анализу.
Существующие программные реализации алгоритма IDEA примерно вдвое
быстрее реализаций алгоритма DES.
X1
Z1
X3
X2
X4
Z3
Z2
Z4
Z5
Z6
MA
W11
W14
W12
W13
Рис. 8. Схема алгоритма IDEA
40
Отечественный стандарт шифрования
В алгоритме отечественном стандарте шифрования согласно ГОСТа
используются:
ключевое запоминающее устройство (КЗУ) на 256 бит, состоящее из
восьми 32-разрядных накопителей
Х0, Х1, Х2, Х3, Х4, Х5, Х6, Х7;
четыре 32-разрядных накопителя
N1, N2, N3, N4;
два 32-разрядных накопителя (N5, N6) с записанными в них постоянными
С2 и С1;
два 32-разрядных сумматора по модулю
232 (СМ1, СМ3);
один 32-разрядный сумматор поразрядного суммирования по модулю 2
(СМ2)
один 32-разрядный сумматор по модулю
(232-1) (СМ4);
сумматор по модулю 2 (СМ5), ограничения на разрядность сумматора
СМ5 не накладывается;
блок подстановки К;
регистр циклического сдвига R на одиннадцать шагов в сторону
старшего разряда.
Блок подстановки K состоит из восьми узлов замены
K1, K2, K3, K4, K5, K6, K7, K8.
Длина каждого узла Ki, i = 1, 2, …, 8, равна 64 битам. Этот блок представляет
собой таблицу (матрицу) размером 8×16. Элементом такой таблицы является
число kij (четырехразрядный вектор) размером в 4 бита. Поступающий на блок
подстановки 32-разрядный вектор V разбивается на восемь последовательно
идущих четырехразрядных векторов
V1, V2, V3, V4, V5, V6, V7, V8.
41
Четыре бита каждого вектора Vi, i = 1, 2, …, 8, равны некоторому числу αi.
Каждый из Vi, i = 1, 2, …, 8, заменяется соответствующим числом kij из
таблицы K. В этом режиме замены Vi на kij индекс i, который определяет
номер строки блока K, соответствует индексу Vi. Номер столбца j элемента kij
равен числу αi, j = αi, которое определяют 4 бита вектора Vi. В результате 32разрядный вектор V1, V2, V3, V4, V5, V6, V7, V8 заменяется на 32-разрядный
вектор
k1j1, k2j2, k3j3, k4j4, k5j5, k1j6, k7j7, k8j8,
где
k1j1 – число из 1-ой строки и столбца с номером j1 таблицы перестановки K;
k2j2 – число из 2-ой строки и столбца с номером j2 таблицы перестановки K;
…;
k8j8 – число из 8-ой строки и столбца с номером j8 таблицы перестановки K;
Выше дано объяснение как определяются номера столбцов j1, j2, …, j8 (эти
номер определяется четырёх битовым значением соответствующего Vi).
При сложении и циклическом сдвиге двоичных векторов старшими
разрядами считаются разряды накопителей с большими номерами.
При записи ключа
W1, W2, …, W256,
Wq лежит в интервале {0,1}, q=1÷256. В КЗУ значение W1 вводится в первый
разряд накопителя X0, значение W2 вводится во второй разряд накопителя X0,
…, значение W32 вводится в 32-й разряд накопителя Х0; значение W33 вводится
в первый разряд накопителя Х1, значение W34 вводится во второй разряд накопителя Х1, …, значение W64 вводится в 32-й разряд накопителя X1; значение
W65 вводится в первый разряд накопителя Х2 и т.д. Значение W256 вводится в
32-й разряд накопителя Х7.
При перезаписи информации содержимое р-го разряда одного
накопителя (сумматора) переписывается в р-й разряд другого накопителя
(сумматора). Значения постоянных (констант) заполнений С1 и С2 накопителей N6 и N5 приведены в приложении 2. Ключи, определяющие
заполнения КЗУ и таблиц блока подстановки K, являются секретными
элементами и поставляются в установленном порядке. Заполнение таблиц
блока подстановки К является долговременным ключевым элементом, общим
для сети ЭВМ.
В криптографической схеме предусмотрены четыре вида работы:
42
▪ шифровка (расшифровка) данных в режиме простой замены;
▪ шифровка (расшифровка) данных в режиме гаммирования;
▪ шифровка (расшифровка) данных в режиме гаммирования с обратной
связью;
▪ режим выработки имитовставки.
Режим простой замены
Открытые данные, подлежащие шифрованию, разбиваются на блоки TN
по 64 бита в каждом, где N – число блоков в открытом тексте. Если через j
обозначить номер блока открытого текста, а через a(j) и b(j) значение битов
этого текста, то ввод любого блока
Tj = ( a1(j), а2(j),..., a31(j), а32(j), b1(j), b2(j),..., b32(j) )
двоичной информации в накопители N1 и N2 производится так, что значение
а1(j) вводится в первый разряд N1, значение а2(j) вводится во второй разряд N1
и т.д.; значение а32(j) вводится в 32-й разряд N1; значение b1(j) вводится в
первый разряд N2, значение b2(j) вводится во второй разряд N2 и т.д.; значение
b32(j) вводится в 32-й разряд N2. В результате получают состояние
a32(s), a31(j),..., а2(j), а1(j)
накопителя N1 и состояние
b32(j), b31(j),...,b1(j)
накопители N2.
В КЗУ вводятся 256 бит ключа. Содержимое восьми 32-разрядных
накопителей
Х0, Х1, ..., Х7
имеют вид
X0=(W32, W31, …, W2, W1)
X1=(W64, W63, …, W34, W33)
…
X7=(W256, W255, …, W226, W225)
Алгоритм шифрования 64-разрядного блока открытых данных в режиме
простой замены состоит из 32 циклов. В первом цикле начальное заполнение
накопителя N1 суммируется по модулю 232 в сумматоре СM1 с заполнением
накопителя X0, при этом заполнение накопителя N0 сохраняется. Результат
суммирования преобразуется в блоке подстановки K и полученный вектор
поступает на вход регистра R, где циклически сдвигается на одиннадцать
шагов в сторону старших разрядов. Результат сдвига суммируется поразрядно
43
по модулю 2 в сумматоре СМ3 с 32-разрядным заполнением накопителя N2.
Полученный в СМ2 результат записывается в N1, при этом старое заполнение
N1 переписывается в N2. Первый цикл заканчивается.
Последующие циклы осуществляются аналогично, при этом во втором
цикле из КЗУ считывается заполнение Х1, в третьем цикле из КЗУ
считывается заполнение Х2 и т.д., в восьмом цикле из КЗУ считывается
заполнение Х7. В циклах с девятого по шестнадцатый, а также в циклах с
семнадцатого по 24-й заполнения из КЗУ считываются в том же порядке
X0, X1, X2, X3, X4, X5, X6, X7.
В последних восьми циклах с 25-го по 32-й порядок считывания
заполнений КЗУ обратный
X7, X6, X5, X4, X3, X2, X1, X0.
Таким образом, при шифровании в 32 циклах осуществляется
следующий порядок выбора заполнений накопителей:
X0, X1, X2, X3, X4, X5, X6, X7, (не понятна ПОМЕТКА!!!)
X0, X1, X2, X3, X4, X5, X6, X7,
X0, X1, X2, X3, X4, X5, X6, X7,
X7, X6, X5, X4, X3, X2, X1, X0.
В 32 цикле результат из сумматора СМ2 вводится в накопитель N2, а в
накопителе N1, сохраняется старое заполнение. Полученные данные после 32го цикла шифрования заполнений накопителей N1 и N2 являются блоком
зашифрованных данных, соответствующим блоку открытых данных.
Алгоритм шифрования в режиме простой замены можно записать в
виде следующих формул:
a(j)=( a(j-1)*X(j-1) (mod 8)) KR+b(j-1),
b(j)=a(j-1)
при j = 1÷24;
a(j)=(a(j-1)*X(32-j))KR+b(j-1),
b(j)=a(j-1)
при j=25÷31;
44
a(32)=a(31),
b(32)=( a(31)*X0 ) KR+b(31)
при j=32, где
а(0) = (а32(0), а31(0), ..., а1,(0)) – начальное заполнение N1 перед первым
циклом шифрования;
b(0) = (b32(0), b31(0), ..., b1(0)) – начальное заполнение N2 перед первым
циклом шифрования;
при j = 1÷32 имеем
a(j) = (a32(j), a31(j), ..., a1(j)) – заполнение N1 после j-го цикла
шифрования;
b(j) = (b32(j), b31(j), …, b1(j)) – заполнение
N2 после j-го цикла
шифрования.
45
Тш(i-1)
Тш(i) (Т0(i))
Т0(i) (Тш(i))
CM5
32...
Гш(i)
...1
C1
N6
CM4
C1
N5
CM5
N4
N3
N2
N1
32...
X0
X1
X2
X3
X4
...1
CM1
КЗУ
K0
K1
K6
K5
X5
X6
X7
R
CM2
Рис. 9. Схема алгоритма IDEA
K4
K3
K2
K1
46
Т0
Тш
N2
N1
32...
...1
КЗУ
X0
X1
X2
X3
X4
K0
K1
K6
K5
K4
K3
K2
K1
X5
X6
X7
R
CM2
Рис. 10. Криптосхема алгоритма шифрования в режиме простой вставки
Знак + означает поразрядное суммирование 32-разрядных векторов по
модулю 2.
Знак * означает суммирование 32-разрядных векторов по модулю 232.
Два целых числа a, b (0 ≤ a, b ≤ 232-1) суммируются по модулю 232 по
следующему правилу:
a*b = a + b, если a + b < 232,
a*b = a + b - 232, если a + b ≥ 232,
приведены в приложении 4;
R – операция циклического сдвига на одиннадцать шагов в сторону
старших разрядов, т.е.
R(r32, r31, r30, r29, r28, r27, r26, r25, r24, r23, r22, r21, r20, …, r2, r1)=
47
=(r21, r20, …, r2, r1, r32, r31, r30, r29, r28, r27, r26, r25, r24, r23, r22).
64-разрядный блок зашифрованных данных Tш выводится из
накопителей N1 и N2 в следующем порядке: из 1-го, 2-го ,..., 32-го разрядов
накопителя N1, затем из 1-го, 2-го, ..., 32-го разрядов накопителя Nl, т.e.
Tш=(а1(32), а2(32), ..., а32(32), b1(32), b2(32), ..., b32(32)).
Остальные блоки открытых данных в режиме простой замены
зашифровываются аналогично.
Дешифровка зашифрованных данных в режиме простой замены
Криптографическая схема, реализующая алгоритм дешифровки в режиме
простой замены, имеет тот же вид, что и при шифровании (см. рис. 10). В
КЗУ вводятся 256 бит того же ключа, на котором осуществлялось
шифрование. Зашифрованные данные, подлежащие дешифровки, разбиты на
блоки по 64 бита в каждом. Ввод любого блока
Tш=(a1(32), a2(32), ..., a32(32), b1(32), b2(32), ..., b32(32))
в накопители N1 и N2 производятся таким образом, что значение a1(32)
записывается в первый разряд N1, значение а2(32) записывается во второй
разряд N1 и т.д., значение а32 (32) записывается в 32-й разряд N1; значение
b1(32) вводится в первый разряд N2 и т.д., значение b32(32) записывается в 32й разряд N2.
Шифрование осуществляется
по тому же
алгоритму, что и
шифрование открытых данных с тем изменением, что заполнение
накопителей Х0, X1,..., X7 считываются из КЗУ в циклах шифрования в
следующем порядке:
X0, X1, X2, X3, X4, X5, X6, X7,
X7, X6, X5, X4, X3, X2, X1, X0,
X7, X6, X5, X4, X3, X2, X1, X0,
X7, X6, X5, X4, X3, X2, X1, X0,
Алгоритм дешифровки в режиме простой замены можно записать в виде
следующих формул:
a(32-j)=(a(32-j+1)*Xj-1)KR+b(32-j+1),
b(32-j)=a(32-j+1)
48
при j = 1÷8;
a(32-j)=(a(32-j+1)*X(32-j) (mod 8))KR+b(32-j+1),
b(32-j)=a(32-j+1)
при j = 9÷31;
a(0)=a(1),
b(0)=(a(1)*X0)KR+b(1)
при j=32.
Полученные после 32 циклов работы заполнения накопителей N1 и N2
составляют блок открытых данных
T0=(a1(0), a2(0), ..., a32(0), b1(0), b2(0), ..., b32(0)),
соответствующий блоку зашифрованных данных.
Значение a1(0) блока T0 соответствует содержимому первого разряда N1,
значение a2(0) соответствует содержимому второго разряда N1 и т.д., значение
a32(0) соответствует содержимому 32-го разряда N1.
Точно также значение b1(0) соответствует содержимому первого
разряда N2, значение b2(0) соответствует содержимому второго разряда N2 и
т.д., значение b32(0) соответствует содержимому 32-го разряда N2. Аналогично
расшифровываются остальные блоки зашифрованных данных.
!!!!!!(Более чётко обозначить мысль) В дальнейшем алгоритм
шифрования в режиме простой замены 64-битового блока T0 обозначается
через A, т. е.
A(T0) = Tш.
Режим гаммирования
Криптографическая схема, которая реализует алгоритм шифрования в
режиме гаммирования, имеет вид, указанный на рис. 11. Открытые данные,
разбитые на 64-разрядные блоки
Т0(1), Т0(2)..., Т0(М-1), Т0(М),
шифруются в режиме гаммирования путем поразрядного суммирования по
модулю 2 в сумматоре СМ5 с гаммой шифра Гш, которая вырабатывается
блоками по 64 бита, т.е.
49
Гш=(Гш(1), Гш(2), …, Гш(М-1), Гш(М)),
где М — определяется объемом шифруемых данных.
Гш – i-й 64-разрядный блок, i=1÷M. Число двоичных разрядов в блоке
(M)
T0 может быть меньше 64, при этом неиспользованная для шифрования
часть гаммы шифра из блока Гш(М) отбрасывается.
В КЗУ вводятся 256 бит ключа. В накопители N1 и N2 вводится 64разрядные двоичные последовательности (синхропосылки)
S=(S1, S2,..., S64),
Которые являются исходным заполнением этих
последующей выработки М блоков гаммы шифра.
Тш(i-1)
Тш(i) (Т0(i))
Т0(i) (Тш(i))
CM5
32...
накопителей
Гш(i)
...1
C1
N6
CM4
C1
N5
CM5
N4
N3
N2
N1
32...
X0
X1
X2
X3
X4
...1
CM1
КЗУ
K0
K1
K6
X5
X6
X7
R
CM2
K5
K4
K3
K2
K1
для
50
Рис. 11. Криптографическая схема алгоритма дешифровки в режиме простой замены
Синхропосылка вводится в N1 и N2 следующим образом.
Значение S1 вводится в первый разряд N1, значение S2 вводится во
второй разряд N1 и т.д.
Значение S32 вводится в 32-й разряд N1, значение S33 вводится в первый
разряд N2, значение S34 вводится по второй разряд N2 и т.д.
Значение S64 вводится в 32-й разряд N2.
3.1. Шифрование данных в режиме гаммирования
Исходное заполнение накопителей N1 и N2 (синхропосылка S)
зашифровывается в режиме простой замены. Результат шифрования А(S) =
(Y0, Z0) переписывается в 32-разрядные накопители N3 и N4 так, что
заполнение N1 переписывается в N3, а заполнение N2 переписывается в N4.
Заполнение накопителя N4 суммируется по модулю (232-1) в сумматоре
СМ4 с 32-разрядной константой C1 из накопителя N6, результат записывается
в N4. В приложении 4. Два целых числа a, b (0 ≤ a, b ≤ 232-1) суммируются по
модулю 232 - 1 по следующему правилу:
a*b = a + b, если a + b < 232,
a*b = a + b - 232 + 1, если a + b ≥ 232,
Заполнение накопителя N3 суммируется по модулю 232 в сумматоре СM3
в 32-разрядной константой C2 из накопителя N5, результат записывается в N3.
Константы C1 и C2 имеют следующие значения:
C1 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 0 0 0 0 1 0 0;
C2 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1.
Порядок разрядов накопителей N6 и N5 в которые заносятся константы C1 и
C2 следующий:
N6 (C1) 32 31 30 29 28 27 … 1;
N5 (C2) 32 31 30 29 28 27 … 1.
Заполнение N3 переписывается в N1, а заполнение N4 переписывается и
N2, при этом заполнение N3 и N4 сохраняется.
Заполнение N1 и N3 зашифровывается в режиме простой замены в
соответствии с требованиями алгоритма. Полученное в результате
шифрования заполнение N1 и N2 образует первый 64-разряднын блок гамма
51
шифра Гш(1), который суммируется поразрядно по модулю 2 в сумматоре CМ5
с первым 64-разрядным блоком открытых данных
Т0(1)=(t1(1), t2(1), …, t63(1), t64(1)).
В результате суммирования получается 64-разрядный блок зашифрованных данных
Tш(1)=(τ1(1), τ2(1), …, τ63(1), τ64(1)).
Значение τ1(1) блока Тш(1) является результатом суммирования по
модулю 2 в СМ5 значения t1(1) из блока T0(1) со значением первого разряда N1.
Значение τ2(1) блока Tш(1) является результатом суммирования по
модулю 2 в СМ5 значения t2(1) из блока T0(1) со значением второго разряда N1 и
т.д.
Значение τ64(1) блока Tш(1) является результатом суммирования по
модулю 2 В СМ5 значения t64(1) из блока Т0(1) со значением 32-го разряда N2.
Для получения следующего 64-разрядного блока гаммы шифра Гш(2)
заполнение N4 суммируется по модулю (232–1) в сумматоре СМ4 с константой
C1 из N6.
Заполнение N3 суммируется но модулю 232 в сумматоре СМ3 с
константой С2 из N5. Новое заполнение N3 переписывается в N1, а новое
заполнение N4 переписывается в N2, при этом заполнение N3 и N4 сохраняется.
Заполнение N1 и N2 зашифровывается в режиме простой замены в
соответствии с требованиями алгоритма. Полученное в результате
шифрования заполнение N1, N2 образует второй 64-разрядный блок гамма
шифра Гш(2), который суммируется поразрядно по модулю 2 в сумматоре CМ5
со вторым блоком открытых данных Т0(2). Аналогично вырабатываются
блоки гамма шифра
Гш(3), Гш(4), …, Гш(М)
и зашифровываются блоки открытых данных
Т0(3), Т0(4), …, Т0(М).
Если длина последнего М-го блока открытых данных Т0(М)' меньше 64 бит, то
из последнего M-го блока гамма шифра Гш(М) для шифрования используется
только соответствующее число разрядов гамма шифра. Остальные разряды
отбрасываются.
В канал связи или памяти ЭВМ передаются синхропосылка S и
блоки зашифрованных данных
Тш(1), Тш(2), …, Тш(М).
52
Алгоритм шифрования в режиме гаммирования можно записать в виде
следующих формул:
Тш(i)=A(Yi-1*C2, Zi-1\*C1)+T0(i)=Гш(i)+T0(i),
i=1…M,
где
\* –суммирование 32-разрядных заполнений по модулю (232-1);
* – поразрядное суммирование двух заполнений по модулю 2;
Уi – содержимое накопителя N3 после шифрования i-го блока открытых
данных T0(i);
Zi – содержимое накопителя N4 после шифрования i-ro блока открытых
данных Т0(i)',
(Y0, Z0)=A(S).
Расшифровывание зашифрованных данных в режиме гаммирования
При расшифровывании криптографическая схема имеет тот же вид, что
и при шифровании (см. рис. 11). В КЗУ вводятся 256 бит ключа, с помощью
которого осуществлялось шифрование данных
Т0(1), Т0(2), ..., Т0(М).
Синхропосылка S вводится в накопители N1 и N2 и аналогично шифрованию в
режиме гаммирования с обратной связью осуществляется процесс выработки
M блоков гаммы шифра
Гш(1), Гш(2) ,...., Гш(М).
Блоки зашифрованных данных
Тш(1), Тш(2),..., Тш(М)'
суммируются поразрядно по модулю 2 в сумматоре СМ5 с блоками гаммы
шифра, в результате получаются блоки открытых данных
Т0(1), Т0(2),..., Т0(М),
при этом Т0(М) может содержать меньше 64 разрядов.
Уравнение расшифровывания имеет вид:
Т0(i)=A(Yi-1*C2, Zi-1\*C1)+Tш(i)=Гш(i)+Tш(i),
i=1÷M.
53
Режим гаммирования с обратной связью
Шифрование открытых данных в режиме гаммирования с обратной
связью.
Криптографическая схема, реализующая алгоритм шифрования в
режиме гаммирования с обратной связью, имеет указанный на рис. 12 вид.
Открытые данные, разбитые на 64-разрядные блоки
Т0(1), ..., Т0(М),
шифруются в режиме гаммирования с обратной связью путем поразрядного
суммирования по модулю 2 в сумматоре CM5 с гаммой шифра Гш, которая
вырабатывается блоками по 64 бита, т.е. имеет место
Гш=(Гш(1), Гш(2), …, Гш(М)),
где М определяется объемом открытых данных, Гш(i) – i-й 64-разрядпый блок,
i = 1, …, M. Число двоичных разрядов в блоке Т0(М) может быть меньше 64.
В КЗУ вводятся 256 бит ключа. Синхропосылка
S= (S 1, S 2, ..., S 65)
из 64 бит вводится в N1 и N2 аналогично режиму гаммирования.
Исходное заполнение N1 и N2 зашифровывается в режиме простой
замены. Полученное в результате шифрования заполнение N1 и N2 образует
первый 64-разрядный блок гаммы шифра Гш(1)= A(S), который суммируется
поразрядно по модулю 2 в сумматоре СМ5 с первым 64-разрядным блоком
открытых данных
Т0(1) = (t1(1), t2(1), …, t64(1) ).
В результате получается 64-разрядный блок зашифрованных данных
Tш(1) = (τ1(1), τ2(1), …, τ 63(1), τ64(1))
Блок зашифрованных данных Tш(1) одновременно является также
исходным состоянием N1 и N2 для выработки второго блока гаммы шифра
Гш(2) и по обратной связи записывается в указанные накопители по
следующему правилу.
Значение τ1(1) вводится в 1-й разряд N1, значение τ2(1) вводится во 2-й
разряд N1 и т.д. Далее значение τ32(1) вводится в 32-й разряд N1; значение τ33(1)
54
вводится В 1-Й разряд N2, значение τ34(1)вводится по 2-й разряд N2 и т.д.,
значение τ64(1) вводится в 32-й разряд N2.
Заполнение N1 и N2 зашифровывается в режиме простой замены.
Полученное в результате шифрования заполнение N1 и N2 образует второй
64-разрядный блок гаммы шифра Гш(2), который суммируется поразрядно по
модулю 2 в сумматоре СМ5 со вторым блоком открытых данных Т0(2).
Выработка последующих блоков гамма шифра Гш(i) и шифрование
соответствующих блоков открытых данных Т0(i), i=3, …, M, производится
аналогично. Если длина последнего М-гo блока открытых данных Т0(М)
меньше 64 разрядов, то из Гш(М), используется только соответствующее число
разрядов гамма шифра, остальные разряды отбрасываются.
Тш(i-1)
Т0(i) (Тш(i) )
CM5
Гш(i)
N1
N2
32…
…1
32…
…1
X0
X1
X2
X3
K0
K1
K6
K3
K4
K3
K2
K1
X4
X5
X6
R
X7
32…
…1
32…
…1
CM2
32…
…1
Рис. 12. Криптосхема алгоритма шифрования в режиме гаммирования с обратной связью
55
Уравнения шифрования в режиме гаммирования с обратной связью
имеют вид:
Тш(1)=А(S)+T0(1)=Гш(1)+Т0(1)
Тш(i)=A(Tш(i-1))+T0(i)=Гш(i)+T0(i),
i=2÷M.
В канал связи или память ЭВМ передаются синхропосылка S и блоки
зашифрованных данных
Tш(1) , Tш(2) ,…, Tш(M) .
4.2. Расшифровывание в режиме гаммирования с обратной связью
При расшифровывании криптосхема имеет тот же вид, что и при
шифровании (см. рис. 12). В КЗУ вводятся 256 бит того же ключа, на
котором осуществлялось шифрование
T0(1) , T0(2) ,…, T0(М).
Синхропосылка S вводится в N1 и N2 аналогично расшифрованию в режиме
гаммирования.
Исходное заполнение N1 и N2 (синхропосылка S) зашифровывается в
режиме простой замены. Полученное в результате шифрования заполнение
N1 и N2 образует первый блок гамма шифра Гш(1)=A(S), который суммируется
поразрядно по модулю 2 в сумматоре СМ5 с блоком зашифрованных данных
Тш(1). В результате получается первый блок открытых данных T0(1).
Блок зашифрованных данных Тш(1) является исходным заполнением N1 и
N2 для выработки второго блока гаммы шифра Гш(2). Блок Тш(1) записывается в
N1 и N2 по тем же правилам как и при шифровании в режиме гаммирования с
обратной связью. Полученное заполнение N1 и N2 зашифровывается в режиме
простой замены. Полученный в результате блок Гш(2) суммируется поразрядно
по модулю 2 в сумматоре СМ5 со вторым блоком зашифрованных данных
Тш(2). В результате получается блок открытых данных Тш(2).
Аналогично в N1 и N2 последовательно записываются блоки зашифрованных данных
Тш(2), Тш(3), …, Тш(M-1) ,
из которых в режиме простой замены вырабатываются блоки гамма шифра
Гш(3), Гш(4), …, Гш(M).
Блоки гаммы шифра суммируются поразрядно по модулю 2 в сумматоре СМ5
с блоками зашифрованных данных
56
Тш(3), Тш(4), …, Тш(M),
в результате получаются блоки открытых данных
Т0(3), Т0(4), …, Т0(M),
при этом длина последнего блока открытых данных Т0(М) может содержать
меньше 64 разрядов.
Уравнения расшифровывания в режиме гаммирования с обратной
связью имеют вид
T0(1)=A(S)+Tш(1)=Гш(1)+Тш(1)
T0(i)=A(Tш(i-1))+Tш(i)=Гш(i)+Тш(i),
i=2÷M.
Режим выработки имитовставки
Для обеспечения имитозащиты открытых данных, состоящих из М 64разрядных блоков
T0(1), T 0(2) ,…, T 0(M),
M ≥ 2,
вырабатывается дополнительный блок из одного бита (имитовставка Иl). Процесс выработки имитовставки единообразен для всех режимов шифрования.
Первый блок открытых данных
Т0(1)=(t1(1), t2(1), …, t64(1))=
=( a1(1)(0), a2(1)(0), …, a32(1)(0), b1(1)(0), b2(1)(0), …, b32(1)(0) )
записывается в накопители N1 и N2.
Значение t1(1)=a1(1)(0) вводится в первый разряд N1, значение t2(1)=а2(1)(0)
вводится во второй разряд N1 и т.д.
Значение t32(1) = а32(1)(0) вводится в 32-й разряд N1; значение t33(1)=b1(1)(0)
вводится в первый разряд N2 и т.д.
Значение t64(1) = b32(1) (0) вводится в 32-й разряд N2.
Заполнение N1 и N2 подвергается преобразованию, соответствующему
первым 16 циклам алгоритма шифрования в режиме простой замены. В КЗУ
при этом находится тот же ключ, которым зашифровываются блоки открытых
данных
T0(1), T 0(2) ,…, T ш(M)
57
в соответствующие блоки зашифрованных данных
T ш(1) , T ш(2) ,…, T ш(M).
Полученное после 16 циклов работы заполнение N1 и N2, имеющие вид
( a1(1)(16), a 2(1)(16), …, a 32(1)(16),
b1(1)(16), b 2(1)(16), …, b 32(1)(16) ),
суммируется в СМ5 по модулю 2 со вторым блоком
Т0(2) =( t1(2), t 2(2), …, t 64(2)).
Результат суммирования
(a1(1)(16) + t1(2), a 2(1)(16) + t 2(2), …, a 32(1)(16) + t 32(2),
b 1(1)(16) + t 33(2), b 2(1)(16) + t 34(2), …, b 32(1)(16) + t 64(2))=
=( a 1(2)(0), a 2(2)(0), …, a 32(2)(0),
b1(2)(0), b 2(2)(0), …, b 32(2)(0))
заносится в N1 и N2 и подвергается преобразованию, соответствующему
первым 16 циклам алгоритма шифрования в режиме простой замены.
Полученное заполнение N1 и N2 суммируется с помощью СМ5 по модулю 2 с третьим блоком T0(3) и т.д. Последний блок
T0(М)=(t1(М), t 2(М), …, t 64(М)),
дополненный при необходимости до полного 64-разрядного блока нулями,
суммируется в СМ5 по модулю 2 с заполнением N1 и N2
(a1(M-1)(16) , a 2(M -1)(16), …, a 32(M -1)(16),
b 1(M -1)(16), b 2(M -1)(16) , …, b32(M -1)(16))
Результат суммирования
(a 1(M -1)(16)+t1(M), a2(M -1)(16)+ t 2(M), …, a 32(M -1)(16)+ t 32(M),
b1(M -1)(16)+ t 33(M), b 2(M -1)(16)+ t 34(M), …, b 32(M -1)(16)+ t 64(M))=
=(a 1(M)(0), a 2(M)(0), …, a 32(M)(0),
b 1(M)(0), b 2(M)(0), …, b 32(M)(0))
заносится в N1 и N2, а затем шифруется в режиме простой замены по первым
16 циклам работы алгоритма.
Из полученного заполнения накопителей N1 и N2
58
a1(M)(16), a 2(M)(16), …, a 32(M)(16),
b 1(M)(16), b 2(M)(16), …, b32(M)(16))
выбирается отрезок Иl (имитовставка) длиной l бит:
Иl=[ a 32-l+1(M)(16), a 32-l+2(M)(16), …, a32(M)(16) ].
Имитовставка Иi передается по каналу связи или в памяти ЭВМ в конце
зашифрованных данных, т.е.
Tш(1), Tш(2), …, Tш(M), Иl.
Поступившие зашифрованные данные
Tш(1), Tш(2), …, Tш(M)
расшифровываются из полученных блоков открытых данных
T0(1), T 0(2), …, T 0(M)
аналогично режиму шифрования. Сначала вырабатывается имитовставка Иl,
которая затем сравнивается с имитовставкой Иl, которая получена вместе с
зашифрованными данными из канала связи или из памяти ЭВМ. В случае
несовпадения имитовставок полученные блоки открытых данных T0(1),
T0(2),…, T0(M) считают ложными.
Выработка имитовставки Иl [И´l] может производиться перед
шифрованием (после расшифровки) всего сообщения или параллельно с
шифрованием (расшифровыванием) по блокам. Первые блоки открытых
данных, которые участвуют в выработке имитовставки, могут содержать
служебную информацию – адресную часть, отметку времени, синхропосылку
и др. и не зашифровываться.
Значение параметра – число двоичных разрядов в имитовставке –
определяется действующими криптографическими требованиями, при этом
учитывается, что вероятность навязывания ложных данных равна 2-1.
ШИФР AES
Формат блоков данных и число раундов
RIJNDAEL – это симметричный блочный шифр, оперирующий блоками
данных размером 128 бит и длиной ключа 128, 192 или 256 бит – название
стандарта соответственно “AES–123”, “ AES–192” и “ AES–256”.
59
Введем следующие обозначения:
Nb – число 32-битных слов, содержащихся во входном блоке, Nb=4;
Nk – число 32-битных слов, содержащихся в ключе шифрования, Nk=4,
6, 8;
Nr – число раундов шифрования, как функция от Nb и Nk, Nr=10, 12, 14.
Входные (input), промежуточные (state) и выходные(output) результаты
преобразований, выполняемых в рамках криптографического алгоритма,
называются состояниями (State). Состояние можно представить в виде
матрицы 4•Nb, элементами которой являются байты (четыре строки по Nb
байт) в следующем порядке
S00, S10, S20, S30, S01, S11, S21, S31, … .
Рис. 13 демонстрирует такое представление, носящее название архитектуры
«Квадрат».
60
Input
in0
in4
in8
in12
in0
in0
in0
in0
in0
in0
in0
in0
State
s0,0
s0,1
s0,2
s0,2
s1,0
s1,1
s1,2
s1,3
s2,0
s2,1
s2,2
s2,3
s3,0
s3,1
s3,2
s3,3
Output
out0
out4
out8
out12
out1
out5
out9
out13
out2
out6
out10
out14
out3
out7
out11
out15
Рис.13. Архитектура «квадрат»
Пример представления блока в виде матрицы 4•Nb
На старте процессов шифрования и дешифрования массив входных
данных
in0, in1, … , in15
61
преобразуется в массив State по правилу
S[r, c]=in[r+4c],
где 0≤r<4 и 0≤c<Nb. В конце действия алгоритма выполняется обратное
преобразование
out[r+4c]=s[r, c],
где 0≤r<4 и 0≤c<Nb. Выходные данные получаются из байтов состояния в том
же порядке.
Четыре байта в каждом столбце состояния представляют собой 32битное слово. Если r – номер строки состояния, то одновременно он является
индексом каждого байта в этом слове. Следовательно, состояние можно
представить как одномерный массив 32-битных слов
w0, … , wNb,
где номер столбца состояния c есть индекс в этом массиве. Тогда состояние
можно представить следующим образом
w0=s0,0, s1,0, s2,0, s3,0 w2=s0,2, s1,2, s2,2, s3,2
w1=s0,1, s1,1, s2,1, s3,2 w3=s0,3, s1,3, s2,3, s3,3
Ключ шифрования, как и массив State, представляется в виде
прямоугольного массива с четырьмя строками. Число столбцов этого массива
равно Nk.
Для алгоритма AES число раундов Nr определяется на старте в
зависимости от значения Nk.
Таблица 12
Зависимость значения Nr от Nk и Nb
Nk
AES-128 4
AES -192 6
AES -256 8
Nb
4
4
4
Nb
10
12
14
62
Функции шифрования
Введем следующие обозначения:
SubBytes() – замена байтов. Побайтовая нелинейная подстановка в Stateблоках (S-Box) с использованием фиксированной таблицы замен
размерностью 8x256 (affain map table);
ShiftRows() – сдвиг строк. Циклический сдвиг строк массива State на
различное количество байт;
MixColumns() – перемешивание столбцов. Умножение столбцов
состояния, рассматриваемых как многочлены над GF(28);
AddRoundKey() – сложение с раундовым ключом. Поразрядное XOR –
операция содержимого State с текущим фрагментом развернутого ключа.
На псевдокоде операция шифрования выглядит следующим образом:
Cipher (byte in [4*Nb], byte out [4*Nb], word w [Nb*(Nr+1)])
begin
byte state [4,Nb]
state=in
AddRoundKey (state, w[0, Nb-1])
for round=1 step 1 to Nr-1
Subbytes (state)
ShiftRows(state)
MixColumns (state)
AddRoundKey (state, w[round*Nb, (round+1)*Nb-1])
end for
SubBytes (state)
ShiftRows(state)
AddRoundKey (state, w[Nr*Nb, (Nr+1)*Nb-1])
out=state
end
Рис.14. Операция шифрования, реализованная на псевдокоде
После заполнения массива State элементами входных данных к нему
применяется преобразование AddRoundKey(). Далее, в зависимости от
величины Nk , массив State подвергается раундовой трансформации 10, 12, 14
раз, причем финальный раунд является несколько укороченным – в нем
отсутствует преобразование MixColumns(). Выходными данными описанной
последовательности операций является шифротекст – результат действия
функции шифрования AES.
63
Функции расшифровывания
В спецификации алгоритма AES предлагаются два вида реализаций
функции расшифровывания, которые отличаются друг от друга
последовательностью
Приложения
преобразований
обратных
преобразованиям
функции
шифрования
и
последовательностью
планирования ключей (см. ниже).
Введем следующие обозначения:
InvSubBytes() – обратная SubBytes замена байтов – побайтовая
нелинейная подстановка в State-блоках с использованием фиксированной
таблицы замен размерностью 8x256 (inverse affain map);
InvShiftrows() – обратный сдвиг строк, ShiftRows() – циклический
сдвиг строк массива State на различное количество байт;
InvMixColumns() – восстановление значений столбцов. Умножение
столбцов состояния, рассматриваемых как многочлены над GF (28).
Функция обратной расшифровки
Если вместо SubBytes(), ShiftRows(), MixColumns и AddRoundKey() в
обратной последовательности выполнить инверсные им преобразования,
можно построить функцию обратного расшифровывания. Порядок
использования раундовых ключей является обратным по отношению к тому,
который используется при шифровании. На псевдокоде процесс
расшифровывания выглядит следующим образом:
64
InvCipher (byte in[4*Nb], byte out [4*Nb], word
w[Nb*(Nr+1)])
begin
byte state [4, Nb]
state=in
AddRoundKey (state, dw [Nr*Nb, (Nr+1)*Nb-1])
for round=Nr-1 step -1 downto 1
InvShiftRows (state)
InvSubBytes (state)
AddRoundKey (state, w [round*Nb, (round+1)*Nb-1])
InvMixColumns (state)
end for
InvShiftRows (state)
InvSubBytes (state)
AddRoundKey (state, w [0, Nb-1])
out=state
end
Рис. 14. Операция прямого расшифровывания на псевдокоде
Функция прямой расшифровки
65
EqInvCipher (byte in [4*Nb], byte out [4*Nb], word dw [Nb*
(Nr+1)])
begin
byte state [4, Nb]
state=in
AddRoundKey (state, dw [Nr*Nb, (Nr+1)*Nb-1])
for round=Nr-1 step -1 downto 1
InvSubBytes (state)
InvShiftRows (state)
InvMixColumns (state)
AddRoundKey (state, dw [round*Nb, (round+1)*Nb-1])
end for
InvSubBytes (state)
InvShiftRows (state)
AddRoundKey (state, dw [0, Nb-1])
out state
end
Рис. 15. Операция прямой дешифровки на псевдокоде
Описанный выше алгоритм обратного расшифровывания имеет порядок
приложения операций-функций, обратный порядку операций в алгоритме
прямого шифрования, но использует те же параметры развернутого ключа.
Изменив определенным образом последовательность планирования ключа,
можно построить еще один алгоритм – алгоритм прямого расшифровывания
(рис. 15). Два следующих свойства позволяют алгоритм прямого
расшифровывания:
▪ Порядок приложения функций SubBytes() и ShiftRows() не играет роли.
То же самое верно для операций InvSubBytes() и InvShiftRows(). Это
происходит потому, что функции SubBytes() и InvSubBytes() работают с
байтами, а операции ShiftRows() и InvShiftRows() сдвигают целые байты, не
затрагивая их значений.
▪ Операция MixColumns() является линейной относительно входных
данных, что означает
MixColumns() (State XOR roundKey)==
66
==MixColumns() (State) XOR MixColumns() (RoundKey)
Эти свойства алгоритма шифрования позволяют изменить порядок
применения функций InvSubBytes() и IntShiftRows(). Функции AddRoundKey()
и InvMixColumns() также могут быть применены в обратном порядке, но при
условии,
что
столбцы
(32-битные
слова)
развернутого
ключа
расшифровывания предварительно обработаны функцией InvMixColumns().
Таким образом, можно реализовать более эффективный способ
расшифровывания с тем же порядком приложения функций, как и в
алгоритме шифрования.
Алгоритм выработки ключей (Key Schedule)
Введем следующие обозначения:
Rcon[] – массив 32-битных раундовых констант;
RotWord() – операция циклической перестановки входного 4-байтного
слова в выходное по следующему правилу
[a0, a1, a2, a3] → [a1, a2, a3, a0];
SunWord() – операция замены в 4-байтном слове с помощью S-Box
каждого байта;
○ – операция исключающего или XOR.
Раундовые ключи получаются из ключа шифрования посредством
алгоритма выработки ключей. Он содержит два компонента – расширение
ключа (Key Expansion) и выбор раундового ключа (Round Key selection).
Основополагающие принципы алгоритма выглядят следующим образом:
▪ общее число битов раундовых ключей равно умноженной на число
раундов длине блока плюс 1;
▪ ключ шифрования расширяется в расширенный ключ (Expansion Key);
▪ раундовые ключи берутся из расширенного ключа следующим
образом: первый раундовый ключ содержит первые Nb слов, второй –
следующие Nb слов и т.д.
KeyExpansion (byte key [4*nk], word w [Nb, *(Nr+1)], Nk)
begin
word temp
i=0
while (i<Nk)
67
w[i]=word (key [4+i], key [4*i+1}, key [4*i+2], key [4*i+3])
end while
i=Nk
while (i<Nb*(Nr-1)]
temp=w[i+1]
if (i mod Nk=0)
temp=SubWord (RotWord (temp)) xor Rcon [i/Nk]
else if (Nk>6 and I mod Nk=4)
temp=Subword(temp)
end if
w[i]=w[i-Nk] xor temp
i=i+1
end while
end
Рис. 16. Операция расширения ключа на псевдокоде
Расширение (планирование) ключа
Расширенный ключ (рис. 17) представляет собой линейный массив
w[i], состоящий из 4(Nr+1) байтных слов, i=0,4(Nr+1).
w0 w1 w2 w3 w4 w5 w6 w7 w8 w9 w10 w11 w12 w13 w14 …
Раундовый
ключ 0
Раундовый
ключ 1
Раундовый
ключ 2
Рис.17. Процедуры расширения и выборки раундового ключа для Nk=4.
На рис. 17 светло-серым цветом выделены слова расширенного ключа,
которые формируются без использования функций SubWord() и RotWord().
Темно-серым цветом выделены слова расширенного ключа, при вычислении
которых используются преобразования SubWord() и RotWord()).
Первые Nk слов содержат ключ шифрования.. Каждое последующее
слово w[i] получается посредством XOR–преобразования предыдущего слова
w[i-1] и слова на Nk позиций ранее, т.е.
68
[i-Nk]: w[i]=w[i-1]○w[i-Nk].
Для слов, позиция которых кратна Nk, перед XOR–преобразованием
применяется преобразование к w[i-1], а затем еще прибавляется раундовая
константа Rcon[i]. Преобразование реализуется с помощью с помощью двух
дополнительных функций SubWord() и RotWord(). Значение Rcon[j] равно 2j-1.
Значение w[i] в этом случае определяется выражением
w[i]=SubWord (RotWord (w[i-1]))○w[i-Nk].
Выбор раундового ключа
i-й раундовый ключ выбирается из слов массива расширенного ключа
в промежутке от W[Nb• i] до W[Nb• (i+1)]. Для функции шифрования
расширенный ключ генерируется алгоритмом, приведенном на рис. 18. Для
функции расширенного обратного расшифровывания используется этот же
ключ, но в обратной последовательности, начиная с последнего раундового
подключа шифрования.
Для функции прямого расшифровывания используется несколько
модифицированный алгоритм планирования ключа. При формировании
развернутого ключа в процедуру планирования необходимо добавить в конце
дополнительное преобразование (рис. 18), причем расширенный ключ
используется при прямом расшифровывании в той же последовательности,
что и при шифровании.
for i=0 step 1 to (Nr+1)*Nb-1
dw [i]=w[i]
end for
for round =1 step 1 to Nr-1
InvMixColumns (dw[round*Nb, (round+1)*Nb-1])
end for
Рис. 18. Дополнительное преобразование расширенного ключа для функции прямого
расшифровывания
Раундовое преобразование
Раундовое преобразование состоит из последовательного применения к
массиву State ряда трансформаций, математическое описание которых
приводилось в главе 2. Сейчас обсудим детали его реализации.
69
Замена байтов
Как было отмечено в главе 2, нелинейная замена байтов массива
состояния посредством SubBytes() имеет вид:
λ(f)≡( (X4+ X3+ X2+ X+1)·f+ X6+ X5+ X+1) mod (X8+1).
Многократное вычисление в процессе шифрования данного выражения
оказывало бы неоправданную вычислительную нагрузку на исполняющую
систему, поэтому для практической реализации наиболее приемлемым
решением является использование предварительно вычисленной таблицы SBox. Логика работы S-Box при преобразовании байта {xy} отражена в
шестнадцатеричном виде в табл. 13.
Таблица 13
Таблица S-Box замены байтов
0
1
2
3
4
5
6
7
8
9
a
b
c
d
e
f
0
63
ca
b7
04
09
53
d0
51
cd
60
e0
e7
ba
70
e1
8c
1
7c
82
Fd
c7
83
d1
Ef
a3
0c
81
32
c8
78
3e
f8
a1
2
77
c9
93
23
2c
00
aa
40
13
4f
3a
37
25
b5
98
89
3
7b
7d
26
C3
1a
Ed
Fb
8f
Ec
dc
0a
6d
2e
66
11
0d
4
f2
Fa
36
18
1b
20
43
92
5f
22
49
8d
1c
48
69
bf
5
6b
59
3f
96
6e
fc
4d
9d
97
2a
06
d5
a6
03
d9
e6
6
6f
47
f7
o5
5a
b1
33
38
44
90
24
4e
b4
f6
8e
42
7
c5
f0
cc
9a
a0
5b
85
f5
17
88
5c
a9
c6
0e
94
68
8
30
ad
34
07
52
6a
45
bc
c4
46
c2
6c
e8
61
9b
41
9
01
d4
a5
12
3b
Cb
f9
b6
a7
Ee
d3
56
Dd
35
1e
99
A
67
A2
E5
80
D6
be
02
da
7e
B8
ac
F4
74
57
87
2d
b
2b
af
f1
e2
b3
39
7f
21
3d
14
62
ea
1f
b9
e9
0f
c
fe
9c
71
eb
29
4a
50
10
64
de
91
65
4b
86
ce
b0
d
d7
a4
d8
27
e3
4c
3c
ff
5d
5e
95
7a
bd
c1
55
54
e
ab
72
31
b2
2f
58
9f
f3
19
0b
e4
ae
8b
1d
28
bb
f
76
c0
15
75
84
cf
a8
d2
73
db
79
08
8a
9e
df
16
Использование табл. 13 сводит операцию SubBytes() к простейшей выборке
байта из массива λ(f)=Sbox[f].
В функции расшифровывания применяется операция, обратная
SubBytes() и Inv SubBytes(), математическая интерпретация которой
выражается следующей формулой
λ(f)≡( (X4+ X3+ X2+ X+1)·f+ X6+ X5+ X+1) mod (X8+1),
70
но реализуется так же просто, как и предыдущая посредством инверсной табS-Box – λ-1(f)=InvSbox[f]. Логика ее работы при преобразовании байта {xy}
отражена в шестнадцатеричном виде в табл. 14.
Таблица 14
Таблица S-Box инверсной замены байтов
0
1
2
3
4
5
6
7
8
9
a
b
c
d
e
f
0
52
7c
54
08
72
6c
90
d0
3a
96
47
fc
1f
60
a0
17
1
09
e3
7b
2e
f8
70
d8
2c
91
ac
f1
56
dd
51
e0
2b
2
6a
39
94
a1
f6
48
ab
1e
11
74
1a
3e
a8
7f
3b
04
3
d5
82
32
66
64
50
00
8f
41
22
71
4b
33
a9
4d
7e
4
30
9b
a6
28
86
fd
8c
ca
4f
e7
1d
c6
88
19
ae
ba
5
36
2f
c2
d9
68
ed
bc
3f
67
ad
29
d2
07
b5
2a
76
6
a5
ff
23
24
98
b9
d3
0f
dc
35
c5
79
c7
4a
f5
d6
7
38
87
3d
b2
16
da
0a
02
ea
85
89
20
31
0d
b0
26
8
bf
34
ee
76
d4
5e
f7
c1
97
e2
6f
9a
b1
2d
c8
e1
9
40
8e
4c
5b
a4
15
e4
af
f2
f9
b7
db
12
e5
eb
69
a
a3
43
95
a2
5c
46
58
bd
cf
37
62
c0
10
7a
bb
14
B
9e
44
0b
49
Cc
57
05
03
Ce
e8
0e
Fe
59
9f
3c
63
c
81
c4
42
6d
5d
a7
b8
01
f0
1c
aa
78
27
93
83
55
d
f3
de
fa
8b
65
8d
b3
13
b4
75
18
cd
80
c9
53
21
e
d7
e9
c3
d1
b6
9d
45
8a
e6
df
be
5a
ec
9c
99
0c
F
fb
cb
4e
25
92
84
06
6b
73
6e
1b
f4
5f
ef
61
7d
Рис. 19 иллюстрирует применение преобразования замены байтов к
состоянию в функциях шифровки и дешифровки.
S-Box
S0,0
S0,1
S0,2
S0,3
S0,0
S0,1
S0,2
S0,3
S1,0
Sr,c
S1,2
S1,3
S1,0
S1,1
S1,2
S1,3
S2,0
S2,1
S2,2
S2,3
S2,0
S2,1
S2,2
S2,3
S3,0
S3,1
S3,2
S3,3
S3,0
S3,1
S3,2
S3,3
Рис.19. Преобразование состояния посредством таблицы замены S-Box
71
Сдвиг строк
В преобразовании сдвига строк (ShiftRows) последние три строки
состояния циклически сдвигаются ВЛЕВО на различное число байтов. Строка
1 сдвигается на C1 байт, строка 2 на C2 байт и строка 3 на C3 байт. Значение
сдвигов C1, C2 и C3 в Rijndael зависят от длины блока Nb. Их величины
приведены в табл. 14.
Таблица 14
Величина сдвига строк для разной длины блоков
Nb shift (0, Nb)=c shift (0, Nb)=c shift (0, Nb)=c shift (0, Nb)=c
4
6
8
0
0
0
1
1
1
2
2
3
3
3
4
AES
В стандарте AES, где определен единственный размер блока, равный 128
битам, имеем C1=1, C2 =2 и C3=3.
Операция сдвига содержимого состояния может быть представлена
следующим выражением
Sr,c’=Sr,(c+shift(r,Nb)) mod Nb
для 0<r<4 и 0≤с<Nb, где значение shift (r, Nb) зависит от номера строки r. Рис.
20 показывает влияние преобразования Shiftrows() на состояние.
72
ShiftRows()
sr,0
sr,1
sr,2
sr,3
s´r,0
s´r,1
S
s´r,2
s´r,3
S´
s0,0
s0,1
s0,2
s0,3
s0,0
s0,1
s0,2
s0,3
s1,0
s1,1
s1,2
s1,3
s1,0
s1,1
s1,2
s1,3
s2,0
s2,1
s2,2
s2,3
s2,0
s2,1
s2,2
s2,3
s3,0
s3,1
s3,2
s3,3
s3,0
s3,1
s3,2
s3,3
Рис. 20. Преобразование сдвига строк в функции дешифровки
В преобразовании обратного сдвига строк InvshiftRows последние три
строки состояния циклически сдвигаются вправо на различное число байтов.
Строка 1 сдвигается на C1 байт, строка 2 – на C2 байт, строка 3 – на C3 байт.
Значения сдвигов C1, C2 и C3 зависят от длины блока Nb. Их величины
соответствуют значениям, приведенным в табл. 3.2. Операция обратного
сдвига InvshiftRows() содержимого состояния представлена выражением
Sr, (c+shift(r, nb)) mod Nb = Sr,c
для 0<r<4 и 0≤c<Nb, где значение shift(r, Nb) зависит от номера строки r. Рис
21 иллюстрирует преобразования обратного сдвига строки состояния.
73
ShiftRows()
sr,0
sr,1
sr,2
sr,3
s´r,0
s´r,1
S
s´r,2
s´r,3
S´
s0,0
s0,1
s0,2
s0,3
s0,0
s0,1
s0,2
s0,3
s1,0
s1,1
s1,2
s1,3
s1,0
s1,1
s1,2
s1,3
s2,0
s2,1
s2,2
s2,3
s2,0
s2,1
s2,2
s2,3
s3,0
s3,1
s3,2
s3,3
s3,0
s3,1
s3,2
s3,3
Рис. 20. Преобразование обратного сдвига строк в функции дешифровки
ShiftRows()
sr,0
sr,1
sr,2
sr,3
s´r,0
s´r,1
S
s´r,2
s´r,3
S´
s0,0
s0,1
s0,2
s0,3
s0,0
s0,1
s0,2
s0,3
s1,0
s1,1
s1,2
s1,3
s1,0
s1,1
s1,2
s1,3
s2,0
s2,1
s2,2
s2,3
s2,0
s2,1
s2,2
s2,3
s3,0
s3,1
s3,2
s3,3
s3,0
s3,1
s3,2
s3,3
74
Рис. 21. Преобразование обратного сдвига строк в функции дешифровки
Перемешивание столбцов
В преобразовании перемешивания столбцов (Mixcolumns) столбцы
состояния рассматриваются как многочлены над GF(28). Они подвергаются
преобразованию
μ(g)=с·g mod (Y4+1),
где c=(X, 1, 1, X+1), т.е. они умножаются по модулю x4+1 на многочлен c(x),
выглядящий, как
c(x)={03}x3+{01}x+{02}.
Это преобразование может быть представлено в матричном виде следующим
образом:
⎧ s0′ c ⎫ ⎧02 03 01 01 ⎫
⎪ s′ ⎪ ⎪
⎪
⎪ 1c ⎪ ⎪01 02 03 04 ⎪
⎨ ⎬=⎨
⎬,
⎪ s2′ c ⎪ ⎪01 01 02 03 ⎪
⎩⎪ s3′c ⎭⎪ ⎩⎪03 01 01 02 ⎭⎪
0≤c≤c, где c – номер столбца массива State. В результате такого умножения
байты столбца s0c, s1c, s2c и s3c заменяются соответственно на байты
s´0, c = ( {02}· s0, c ) ○ ( {03}· s1, c )○ s2, c ○ s3, c,
s´1 c = s0, c ○( {02}· s1, c ) ○ ( {03}· s2, c ) ○ s3, c,
s´2, c = s0, c ○ s1, c ○( {02}· s2, c )○( {03} )· s3, c ),
s´3, c = ( {03}· s0, c )○ s1, c ○ s2, c ○( {02}}· s3, c ).
Применение этой операции ко всем четырем столбцам состояния
обозначается, как MixColumns(State). Рис. 22 демонстрирует преобразования
MixXolumns() к столбцу состояния.
75
ixColums()
S0,0
S0,1
S0,c
S0,3
S0,0
S0,c
S0,2
S0,3
S1,0
Sr,c
S1,c
S1,3
S1,0
S1,c
S1,2
S1,3
S2,0
S2,1
S2,c
S2,3
S2,0
S2,c
S2,2
S2,3
S3,0
S3,1
S3,c
S3,3
S3,0
S3,c
S3,2
S3,3
Рис. 22. Операция перемешивания действует на столбцы состояния
В обратном преобразовании InvMixColumns столбцы состояния
рассматриваются как многочлены над GF(28), но, естественно, подвергаются
обратному преобразованию
v(g)=μ-1(g) = mod (Y4+1),
гдe
d=(X3+ X2+ X, X3+ 1,X3+ X2+ 1, X3+ X+1),
т.е. умножаются по модулю (x4+1) на многочлен d(x), выглядящий
следующим образом
d(x)={0b}x3+{0d}x2+{09}x+{0e}.
Это может быть представлено в матричном виде следующим образом:
⎧ s0′ c ⎫ ⎧0e
⎪ s′ ⎪ ⎪
⎪ 0 c ⎪ ⎪ 0e
⎨ ⎬=⎨
⎪ s0′ c ⎪ ⎪0e
⎪⎩ s0′ c ⎪⎭ ⎩⎪0e
0b 0d 09 ⎫
0b 0d 09 ⎪⎪
⎬,
0b 0d 09 ⎪
0b 0d 09 ⎭⎪
0≤с≤3, где с – номер столбца массива State. В результате на выходе
получаются следующие байты:
s´0c=({0e}· s´0c)○({0b}· s´1c)○({0d}· s´2c)○({09}· s´3c),
s´1c=({09}· s´0c)○({0e}· s´1c)○({0b}· s´2c)○({0d}· s´3c),
s´2c=({0d}· s´0c)○({09}· s´1c)○({0e}· s´2c)○({0b}· s´3c),
s´3c=({0b}· s´0c)○({0d}· s´1c)○({09}· s´2c)○({0e}· s´3c).
76
Добавление раундового ключа AddRoundKet()
В данной операции раундовый ключ добавляется к состоянию
посредством поразрядного XOR-преобразования. Длина ключа в 32разрядных словах равна длине блока Nb. Преобразование, содержащее
добавление раундового ключа к состоянию представляется выражением
[s0, c, s1, c, s2, c, s3, c]=[ s0, c, s1, c, s2, c, s3, c]○[wr(Nb+c)],
где 0≤с≤Nb и 0≤r≤Nr. Рис. 23 иллюстрирует действие данной операции на
состояние. Это преобразование обозначается как AddRoundKey(State,
RoundKey).
wl
+
wl+c
wl+2
wl+2
l=r·Nb
S0,0
S0,1
S0,c
S0,3
S0,0
S0,c
S0,2
S0,3
S1,0
Sr,c
S1,c
S1,3
S1,0
S1,c
S1,2
S1,3
S2,0
S2,1
S2,c
S2,3
S2,0
S2,c
S2,2
S2,3
S3,0
S3,1
S3,c
S3,3
S3,0
S3,c
S3,2
S3,3
Рис. 23. AbbRoundKey(State, RoundKey) действует на столбцы состояния
Основные особенности AES
В заключении главы сформулируем основные особенности AES.
▪ новая архитектура»Квадрат» обеспечивает быстрое рассеивание и
перемешивание информации, при этом за один раунд преобразованию
подвергается весь входной блок;
▪ байт ориентированная структура удобна для реализации на
восьмиразрядных микроконтроллерах;
77
▪ все раундовые преобразования - суть операции в конечных полях,
допускающие эффективную аппаратную и программную реализацию на
различных платформах.
Глава 3. ХЭШ-ФУНКЦИЯ
Хэш-функция h – это такая функция, которая определена на битовых
строках произвольной длины со значениями на битовых строках
фиксированной длины. Иными словами, сообщение произвольной длины
хэш-функция преобразует («сжимает») в сообщение фиксированной длины.
Хэш-функции имеют различные применения. Например, для поиска
сообщения из большого списка сообщений разной длины удобнее
сравнивать не сами длинные сообщения, а их одинаковые по длине хэшзначения. Результаты хэш-функции могут играть роль контрольных сумм.
Криптографические хэш-функции отличаются от стандартных
функций тем, что они должны быть односторонними функциями. Более
того, от криптографических функций требуют, чтобы по значению H=h(M)
невозможно было восстановить сообщение M. Помимо вышесказанного,
криптографические хэш-функции должны удовлетворять следующим
требованиям:
▪ для любого сообщения M1 невозможно найти такое сообщение M2,
M1 ≠ M2, что имеет место h(M1) = h(M2);
▪ невозможно найти такую пару значений M1 и M2, M1 ≠ M2, что
h(M1) = h(M2);
▪ при случайном выборе значений аргументов (сообщений) значения
хэш-функций должны быть равномерно распределены.
▪ при значениях аргументов M1 и M2 мало отличающих друг от друга
их хэш значения не должны быть близки.
В криптографии хэш-функции применяются для решения следующих
задач [1]:
▪ построение систем контроля целостности данных при их передачи и
хранении;
▪ в процедурах аутентификации;
▪ при формировании цифровой подписи.
Принцип проектирования хэш-функции заключается в том, что ее
значения должны производить лавинообразный эффект – небольшое
изменение в аргументе сильно влияет на значение хэш-функции. Как
правило [1], хэш-функции строят на основе одношаговых сжимающих
функций
y=f(u,v)
78
двух переменных. Здесь u, v – двоичные векторы длины L, а y – двоичный
вектор, длина которого определяется фиксированной длиной значений хэшфункции. Если дано сообщение M, то для вычисления H=h(M)
предварительно M разбивают на N блоков
M 1 , M 2 , …,MN
длины L. Если длина M не кратна L, то последний блок по определенному
правилу дополняют до длины L. Затем к полученным блокам применяют
следующую последовательность вычислений:
H 0 = M0 ,
Hi = f(Mi,Hi-1), i = 1, …, N,
h(M) = HN ,
где H0 - начальное значение хэш-функции, M0 - константа метода. Общая
схема вычисления хэш-функции демонстрируется на рис. 1
M1
M2
H2
H1
M0
f
MN
HN-
f
HN
f
Рис.1. Общая схема вычисления хэш-функции.
Чтобы значения хэш-функции были свободны от повторений, их длина
должна быть не меньше 128 бит, однако предпочтительней является длина
в 160 битов [6].
Алгоритм MD5
Алгоритм использует в качестве входных данных сообщение
произвольной длины и выдает на выходе 128-битовое значение. Вводимые
данные последовательно разбиваются на блоки по 512 бит.
В алгоритме MD5 используются:
▪ Массив значений T [i], i = 1, 2, …, 64,
Т[1] = D76AA478
Т[2] = Е8С7В756
Т[3] - 242070DB
Т[17] = F61E2562
Т[18] = С040В340
Т[19] = 265Е5А51
Т[33]= FFFA3942
Т[34] = 8771F681
Т[35] = 699D6122
Т[49] = F4292244
Т[50] = 432AFF97
Т[51] = АВ9423А7
79
Т[4] = C1BDCEEE
Т[5] = F57COFAF
Т[6] = 4787С62А
Т[7] = А8304613
Т[8] = FD469501
Т[9] = 698098D8
Т[10] = 8B44F7AF
Т[11] = FFFF5BB1
Т[12] = 895CD7BE
Т[13] = 6В901122
Т[14] = FD987193
Т[15] = А679438Е
Т[1б] = 49В40821
Т[20] = Е9В6С7А
Т[21] = D62F105D
Т[22] = 02441453
Т[23] = D8A1E681
Т[24] = E7D3FBC8
Т[25] = 21E1CDE6
Т[26] = C33707D6
Т[27] = F4D50D87
Т[28] = 455A14ED
Т[29] = А9ЕЗЕ905
Т[ЗО] = FCEFA3F8
Т[31] = 676F02D9
Т[32] = 8D2A4C8A
T[36] = FDE5380C
Т[37] = А4ВЕЕА44
Т[38] = 4BDECFA9
Т[39] = F6BB4B60
Т[40] = BEBFBC70
Т[41] = 289В7ЕС6
T[42] = EAA127FA
Т[43] = D4EF3085
Т[44] = 04881D05
Т[45] = D9D4D039
Т[46] = E6DB99E5
Т[47] = 1FA27CF8
T[48] = С4АС5665
Т[52] = FC93A039
Т[53] = 655B59СЗ
Т[54] = 8FOCCC92
Т[55] = FFEFF47D
Т[56] = 85845DD1
Т[57] = 6FA87E4F
Т[58] = FE2CE6EO
Т[59] = А3014314
Т[60] = 4E0811A1
Т[61] = F7537E82
Т[62] = BD3AF235
Т[63] = 2AD7D2BB
Т[64] = EBE6D391
Элемент T [i] равен целой части числа
232 × abs(sin(i)),
где i соответствует значению угла в радианах.
▪ Четыре переменных A, B, C, D размером в 32 бита каждая. Эти
переменные называются переменными сцепления, и они инициализируются
следующими значениями:
А
В
С
D
= 0x6745012301,
= 0xEFCDAB89,
= 0x98BADCFE,
= 0x10325476.
Эти данные сохраняются в формате прямого порядка записи байтов, когда
наименее значимый байт слова находится в позиции с младшим адресом. Так
32-битовые строки значения инициализации будут иметь вид
А: 01 23 45 67,
В: 89 АВ CD EF,
C: FE DC BA 98,
D: 76 54 32 10.
▪ Четыре функции:
1. F(b, c, d)= (b ^ c) ∨ ( b ∧d);
2. G(b, c, d)= (b ∧ d) ∨ (c∧ d ) ;
3. H(b, c, d)= b⊕ c⊕ d;
4. I(b, c, d) = c ⊕ (b ∨ d ).
80
Каждая функция три 32-битовые переменные b, c и d преобразует в одно 32битовое значение.
Алгоритм MD5 для вычисления хэш-функции
Шаг 1. Добавляются биты к исходному сообщению. Сообщение
дополняют так, чтобы его общая длина в битах была сравнима со значением
448 по модулю 512. Пусть L есть длина сообщения, тогда для L должна
выполняться формула
L ≡ 448 mod 512.
Это означает, что длина дополненного сообщения в битах должна быть на
64 бита меньше ближайшего кратного целого числа 512. Операция
дополнения выполняется всегда, даже если сообщение оказывается
требуемой длины [5]. Если длина сообщения равна 448 битам, то к
сообщению добавляется еще 512 битов, в результате чего длина дополненного
сообщения оказывается равной 960 битам [5]. Это означает, что число
добавляемых битов может лежать в пределах от 1 до 512. НЕПОНЯТНАЯ
ФРАЗА! Структура дополнения следующая: первый бит, дополняемого
значения, равен 1, а остальные равны 0.
Шаг 2. К сообщению из шага 1 добавляется значение длины исходного
сообщения. К результату шага 1 добавляется 64-битовое значение длины
исходного сообщения, т.е. длины сообщения до шага 1. Наименее значимый
байт длины записывается первым. Если длина исходного сообщения
превосходит 264, то используются только младшие 64 бита значения длины.
Таким образом, соответствующее поле для длины сообщения будет содержать
длину исходного сообщения по модулю 264.
Шаг 3. Результат шага 2 разбивается на блоки по 512 бит
M1, M2 …, MK ,
где K число таких блоков (L= K ⊕ 512). В свою очередь каждый блок Mi, i = 1,
2, …, K, разбивают на 16 подблоков по 32 бита
X[0], X[1], …, X[k],
k= 0, 1, …, 15.
Шаг 4. Для записи промежуточных значений в 128 бит при вычислении
хэш-функции используются буфер H, который состоит из четырех переменных
a, b, c и d размером в 32 бита каждая. Эти переменные соответственно,
инициализируются ранее определенными константами A, B, C и D.
Шаг 5. Преобразуются блоки Mi, i = 1, 2, …, K, в 512 бит в профиль H i
длиной в 128 бит. Напомним, что блок Mi разбит на 16 подблоков по 32 бита
81
X[0], X[1], …, X[k],
k= 0, 1, …, 15.
Функция сжатия (преобразования) ⊕ в H i состоит из четырех раундов по 16
шагов каждый. Общее число шагов функции сжатия равно 64. Введем
обозначения
a, b, c, d – переменные в 32 бита каждая, образующие буфер H;
+ – сложение по модулю 232;
X[k], k = 0, 1, …, 15, k-ый блок сообщения M i , i = 1, 2, …, K;
j, j = 1, 2, …, 64, – текущий шаг в функции сжатия;
<<< sj – циклический сдвиг влево на sj разрядов для текущего шага j;
T[j] – значение элемента массива T [64] для текущего шага j;
F(b, c, d), G(b, c, d), H(b, c, d), I(b, c, d) – ранее определенные функции.
Тогда на каждом шаге j используются следующие операции:
первый раунд:
a=b+ ((a+F(b,c,d)+X[k]+T[j]) <<< sj,
j=1, …, 16;
второй раунд:
a=b+ ((a+G(b,c,d)+X[k]+T[j]) <<< sj,
j=17, …, 32;
третий раунд
a=b+ ((a+H(b,c,d)+X[k]+T[j]) <<< sj,
j=33, …, 48;
четвертый раунд:
a=b+ ((a+I(b,c,d)+X[k]+T[j]) <<< sj,
j=49, …, 64.
Обозначим операции каждого раунда следующим образом, соответственно
F(abcd k j s),
G(abcd k j s),
H(abcd k j s),
I(abcd k j s).
Тогда четыре раунда по 16-ть шагов выглядят следующим образом
Раунд 1:
F (abcd 0 1 7)
F (dabc 1 2 12)
F (cdab 2 3 17)
F (bcda 3 4 22)
82
F (abcd
F (dabc
F (cdab
F (bcda
F (abcd
F (dabc
F (cdab
F (bcda
F (abcd
F (dabc
F (cdab
F (bcda
4
5
6
7
8
9
10
11
12
13
14
15
5
6
7
8
9
10
11
12
13
14
15
16
7)
12)
17)
22)
7)
12)
17)
22)
7)
12)
17)
22)
G (abcd
G (dabc
G (cdab
G (bcda
G (abcd
G (dabc
G (cdab
G (bcda
G (abcd
G (dabc
G (cdab
G (bcda
G (abcd
G (dabc
G (cdab
G (bcda
1
6
11
0
5
10
15
4
9
14
3
8
13
2
7
12
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
5)
9)
14)
20)
5)
9)
14)
20)
5)
9)
14)
20)
5)
9)
14)
20)
H (abcd
H (dabc
H (cdab
H (bcda
H (abcd
H (dabc
H (cdab
H (bcda
H (abcd
H (dabc
H (cdab
H (bcda
5
8
11
14
1
4
7
10
13
0
3
6
33
34
35
36
37
38
39
40
41
42
43
44
4)
11)
16)
23)
4)
11)
16)
23)
4)
11)
16)
23)
Раунд 2:
Раунд 3:
83
H (abcd
H (dabc
H (cdab
H (bcda
9
12
15
2
45
46
47
48
4)
11)
16)
23)
Раунд 4:
I (abcd
I (dabc
I (cdab
I (bcda
I (abcd
I (dabc
I (cdab
I (bcda
I (abcd
I (dabc
I (cdab
I (bcda
I (abcd
I (dabc
I (cdab
I (bcda
0
7
14
5
12
3
10
1
8
15
6
13
4
11
2
9
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
6)
10)
15)
21)
6)
10)
15)
21)
6)
10)
15)
21)
6)
10)
15)
21)
В каждом раунде на вход подается текущий 512-битовый блок Mi и 128-битовое
значение буфера abcd. После каждого шага алгоритма происходит
обновление содержимого буфера, который состоит из переменных a, b, c, d. В
каждом раунде используется также четвертая часть ранее определенного
массива T [64].
!!!! НЕ ПОНЯТНО ПОМЕТКА !!!!
При завершении (i+1) шага выходное значение четвертого раунда
добавляется к входному значению первого раунда (в наших обозначениях Hi), в
результате чего получается результат (i+1) шага (в наших обозначениях Hi+1).
Ниже на рис. 25 дана схема одного раунда.
84
A
B
+
+
+
C
D
fj
X[k]
T[i]
rol10
CLS4
+
A
B
C
D
Рис. 25. Элементарная операция MD5 (один шаг раунда)
Шаг 6. После обработки всех Mi, i = 1,2, … K, 512-битовых блоков на
выходе обработки получается 128-битовый профиль сообщения.
Алгоритм SHA-1
Алгоритм SHA-1 сообщение произвольной длины преобразовывает в
160-битовое значение. Сообщение разбивается на блоки по 512 бит
M1, M2 …, MK,
где K число таких блоков (L= K × 512). Алгоритм последовательно
преобразовывает блоки M1, M2 …, MK и состоит из четырех раундов по 20
шагов каждый. Обозначим через t, 0 ≤ t ≤ 79, текущий шаг алгоритма. Тогда
распределение шагов по раундам следующее.
▪ для первого раунда 0 ≤ t ≤ 19;
▪ для второго раунда 20 ≤ t ≤ 39;
▪ для третьего раунда 40 ≤ t ≤ 59;
▪ для четвертого раунда 60 ≤ t ≤ 79.
85
В свою очередь каждый блок Mi, i = 1, 2, …,K, разбивают на 16
подблоков по 32 бита
X[0], X[1], …, X[k],
k= 0, 1, …, 15.
Далее из 16 блоков X[0], …, X[k], k=0,1, …, 15, формируют 80 блоков Wt,
0 ≤ t ≤ 79, по 32 бита по следующим формулам
Wt = Mt,
для значений 0 ≤ t ≤ 15;
Wt = (Wt-3 ⊕ Wt-8 ⊕ Wt-14 ⊕ Wt-16) <<< 1,
для значений 16 ≤ t ≤ 79. Здесь выражение вида “ <<< 1 ” означает
циклический сдвиг слова на 1 бит.
В алгоритме SHA-1 используются:
▪ Четыре константы:
Kt = 0x5A827999,
для первого раунда (0 ≤ t ≤ 19);
Kt = 0x6ED9EBA1,
для второго раунда (20 ≤ t ≤ 39);
Kt = 0x8F1BBCDC,
для третьего раунда (40 ≤ t ≤ 59);
Kt = 0xCA62C1D6
для четвертого раунда (60 ≤ t ≤ 79).
▪ Пять переменных A, B, C, D и E размером в 32 бита каждая. Эти
переменные называются переменными сцепления, и они инициализируются
следующими значениями:
А = 0x67452301,
В = 0xEFCDAB89,
С = 0x98BADCFE,
D =0x10325476,
Е = 0xC3D2E1F0.
Первые четыре значения совпадают со значениями, используемыми в MD5.
Однако, в отличие от MD5, в SHA-1 эти значения сохраняются в формате
86
обратного порядка следования байтов. Это значит, что наиболее значимый
байт слова хранится в младшей адресной позиции [5].
▪ Четыре функции:
ft (b,c,d)= (b^c) ∨ ( b ^d),
для 1-го раунда (0 ≤ t ≤ 19);
ft (b,c,d)= b ⊕ c ⊕ d,
для 2-го раунда (20 ≤ t ≤ 39);
ft (b,c,d)= (b ∧ c) ∨ (b ∧ d) ∨ (c ∧ d),
для 3-го раунда (40 ≤ t ≤ 59);
ft (b,c,d)= b ⊕ c ⊕ d,
для 4-го раунда (60 ≤ t
⊕
69).
Каждая функция три 32-битовые переменные b, c и d преобразует в одно
32-битовое значение.
Алгоритм SHA-1 для вычисления хэш-функции
Шаг 1. Добавление битов заполнителя. Сообщение дополняется так,
чтобы его общая длина в битах была сравнима со значением 448 по
модулю 512, т.е. длина=448 mod 512. Операция дополнения выполняется
всегда, даже если сообщение уже оказывается требуемой длины. Поэтому
число добавляемых битов должно быть от 1 до 512. Структура битов
заполнителя следующая - первый бит равен 1, а все остальные равны 0.
Шаг 2. К сообщению из шага 1 добавляется значение длины. К
результату шага 1 добавляется 64-битовое значение длины исходного
сообщения, т.е. длины сообщения до шага 1. Наименее значимый байт длины
записывается первым. Если длина исходного сообщения превосходит 264, то
используются только младшие 64 бита значения длины. Таким образом,
соответствующее поле для длины сообщения будет содержать длину исходного
сообщения по модулю 264.
Шаг 3. Результат шага 2 разбивается на блоки по 512 бит
M1, M2 …, MK ,
87
где K число таких блоков, L= K × 512. В свою очередь каждый блок M i , i = 1,
2, …, K, разбивают на 16 подблоков по 32 бита
X[0], X[1], …, X[k],
k= 0, 1, …, 15.
Шаг 4. Для записи промежуточных значений в 160 бит при вычислении
хэш-функции используются буфер H, который состоит из пяти переменных a, b,
c, d и e размером в 32 бита каждая. Эти переменные соответственно
инициализируются ранее определенными константами A, B, C, D и E.
Шаг 5. Обработка сообщения происходит 512-битовыми блоками.
Логику модуля функции сжатия алгоритма можно представить в виде
следующего цикла
Hi=Hi-1+H
Цикл от t=0 до t=79 шаг 1
Начало цикла
H= (a <<< 5) + ft (b, c, d) + e + Wt + Kt
e=d
d=c
c = b <<< 30
b=a
a=H
Конец цикла
Hi+1=Hi+H
Здесь
ft (b, c, d), Wt , Kt – функции, 32-битовые блоки и константы, которые
определялись ранее. Заметим, что Wt формируется из текущего входного
блока Mi.
Hi – промежуточные значения результата вычисления хэш-функции.
+ –операция сложения по модулю 232.
Ниже на рис. 26 дана схема функции сжатия
88
A
B
C
D
ft
E
+
S5
+
+
Wt
+
30
S
+
A
B
C
D
Kt
E
Рис. 26. Элементарная операция SHA (один шаг раунда)
Шаг 6. После обработки всех Mi, i = 1,2, … K, 512-битовых блоков на
выходе обработки получается 160-битовый профиль сообщения.
Алгоритм RIPEMD-160
Алгоритм RIPEMD-160 сообщение произвольной длины преобразует в
160-битовое значение. Сообщение разбивается на блоки по 512 бит
M1, M2 …, MK ,
где K число таких блоков, L= K × 512. Алгоритм последовательно преобразует
блоки M1, M2 …, MK и состоит из 5 раундов по 16 шагов каждый. Обозначим
через t, 0 ≤ t ≤ 79, текущий шаг алгоритма. Тогда распределение шагов по
раундам следующее:
▪ для первого раунда
▪ для второго раунда
▪ для третьего раунда
▪ для четвертого раунда
▪ для пятого раунда
0 ≤ t ≤ 15;
16 ≤ t ≤ 31;
32 ≤ t ≤ 47;
48 ≤ t ≤ 63.
63 ≤ t ≤ 79.
89
В каждом раунде существуют две идентичные по структуре функции
сжатия
f1(Mi, Hi) и f2(Mi,Hi)
текущего блока Mi, i = 1, 2, …, K. По завершении пятого раунда результат
сжатия очередного блока Mi формируется из двух результатов
преобразований значения Mi
Hi = f1(Mi, Hi-1), Hi´= f2(Mi, Hi-1)
и предыдущего значения блока сцепления
Hi-1= (ai-1, bi-1, ci-1, di-1, ei-1).
В свою очередь каждый блок Mi, i = 1, 2, …, K, разбивают на 16 подблоков
по 32 бита
X[0], X[1], …, X[k],
k= 0, 1, …, 15.
Один из шестнадцати блоков X[j], 0 ≤ j ≤ 15, используется на каждом шаге t,
0 ≤ t ≤ 79, функциями сжатия f1(M1, Hi) и f2(Mi, Hi), причем для каждой
функции применяется свой блок. Перечислим порядок использования
блоков X[k] по раундам для функций f1(Mi, Hi) и f2(Mi,Hi).
Порядок использования блоков X[k]:
Раунд 1 (шаги t, 0 ≤ t ≤ 15) для функции f1 :
j = 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15
Раунд 1 (шаги t, 0 ≤ t ≤ 15) для функции f2 :
j = 5, 14, 7, 0, 9, 2, 11, 4, 13, 6, 15, 8, 1, 10, 3, 12
Раунд 2 (шаги t, 16 ≤ t ≤ 31) для функции f1:
j=
Раунд 2 (шаги t, 16 ≤ t ≤ 31) для функции f2 :
j=
90
Раунд 3 (шаги t, 32 ≤ t ≤ 47) для функции f1:
j=
Раунд 3 (шаги t, 32 ≤ t ≤ 47) для функции f2 :
j=
Раунд 4 (шаги t, 48 ≤ t ≤ 63) для функции f1:
j=
Раунд 4 (шаги t, 48 ≤ t ≤ 63) для функции f2 :
j=
Раунд 5 (шаги t, 64 ≤ t ≤ 79) для функции f1:
j=
Раунд 5 (шаги t, 64 ≤ t ≤ 79) для функции f2:
j=
В алгоритме RIPEMD-160 используются:
▪ Десять констант:
Kt = 0x00000000,
Kt´= 0x50A28BE6
для 1-го раунда (0 ≤ t ≤ 19);
Kt = 0x5A827999,
Kt´= 0x5C4DD124
для 2-го раунда (16 ≤ t ≤ 31);
Kt = 0x6ED9EBA1, Kt´= 0x6В703EF3
для 3-го раунда (32 ≤ t ≤ 47);
Kt = 0x8F1BBCDC, Kt´= 0x7A6D76E9
для 4-го раунда (48 ≤ t ≤ 63);
91
Kt = 0XA953FD4E, Kt´= 0x00000000
для 4-го раунда (64 ≤ t ≤ 79).
З а м е ч а н и е. Константы Kt и Kt´ используются соответственно в
функциях сжатия f1( M i , Hi) и f2( M i ,Hi).
▪ Пять переменных A, B, C, D и E размером в 32 бита каждая. Эти
переменные называются переменными сцепления, и они инициализируются
следующими значениями:
А = 0x67452301,
В = 0xEFCDAB89,
С = 0x98BADCFE,
D =0x10325476,
Е = 0xC3D2E1F0.
Как и в MD5, эти значения сохраняются в формате прямого порядка
следования байтов.
▪ Пять функций, которые применяются в функции сжатия f1:
ft (b,c,d)= b ⊕ c ⊕ d,
для первого раунда (0 ≤ t ≤ 15);
ft (b,c,d)= (b^c) ∨ ( b ^d),
для второго раунда (16 ≤ t ≤ 31);
ft (b,c,d)=(b ∨ c ) ⊕ d,
для третьего раунда (32 ≤ t ≤ 47);
ft (b,c,d)= (b ∧ d) ∨ (c ∧ d ),
для 4-го раунда (48 ≠ t ≤ 63);
ft (b,c,d)= b ⊕ (c ∨ d ),
для 5-го раунда (64 ≤ t ≤ 79);
92
З а м е ч а н и е. Функция сжатия f2 использует те же самые функции,
только в обратном порядке, т.е. в первом раунде функция f2 использует пятую
функцию и т.д.
Алгоритм RIPEMD-160 для вычисления хэш-функции
Шаг 1. Добавление битов заполнителя. Сообщение дополняется так,
чтобы его общая длина в битах была сравнима со значением 448 по
модулю 512 (т.е. длина=448 mod 512). Операция дополнения выполняется
всегда, даже если сообщение уже оказывается требуемой длины. Поэтому
число добавляемых битов должно быть от 1 до 512. Структура битов
заполнителя следующая – первый бит равен 1, а все остальные равны 0.
Шаг 2. К сообщению из шага 1 добавляется значение длины. К
результату шага 1 добавляется 64-битовое значение длины исходного
сообщения, т.е. длины сообщения до шага 1. Наименее значимый байт длины
записывается первым. Если длина исходного сообщения превосходит 264, то
используются только младшие 64 бита значения длины. Таким образом,
соответствующее поле для длины сообщения будет содержать длину исходного
сообщения по модулю 264. Заметим, что в отличии от SHA-1 в алгоритме
RIPEMD-160, подобно как и в MD5, предусмотрен прямой порядок
следования байтов .
Шаг 3. Для записи промежуточных значений в 160 бит при вычислении
хэш-функции используются два буфера H[5] и H’[5], которые состоят
соответственно из пяти переменных
a, b, c, d, e и
a´, b´, c´, d´, e´
размером в 32 бита каждая. Эти переменные соответственно инициализируются
ранее определенными константами A, B, C, D, E.
Шаг 5. Обработка сообщения происходит 512-битовыми блоками.
Логику модуля функции сжатия алгоритма можно представить в виде
следующего цикла [5]:
a=H[0] b= H[1] c= H[2] d= H[3] e= H[4]
a´=H[0] b´= H[1] c´= H[2] d´= H[3] e´= H[4]
Цикл от t=0 до t=79 шаг 1
Начало цикла
R1= (a+ ft (b,c,d)) <<< s[j] + X[j] + Kt + e
a=e
e=d
d = c <<< 10
c=b
b = R1
93
R2 =(a´+ ft (b´, c´, d´)) <<< s’[j] + X[j] + Kt´+ e
A´ = e´
E´ = d´
D´ = c´ <<< 10
C´ = b´
B´ = R2
Конец цикла
Hi+1 [0] = Hi[1]+c+d´
Hi+1[1] = Hi[2]+d+e´
Hi+1 [2] = Hi[3]+e+a´
Hi+1 [3] = Hi[4]+a+b´
Hi+1[4] = Hi[0]+b+c´
Здесь
i – порядковый номер блока сообщения Mi размером в 512 бит.
(a+ ft (b, c, d)) <<< s[j] + X[j] + Kt + e – функция сжатия f1.
(a´+ ft (b´, c´, d´)) <<< s’[j] + X[j] + Kt´+ e – функция сжатия f2 .
ft (b, c, d), X[j], Kt , Kt´ – функции, 32-битовые блоки и константы,
которые определялись ранее в соответствии со значением текущего шага t.
Hi – промежуточные значения результата вычисления хэш-функции.
+ – означает операцию сложения по модулю 232.
<<< – циклический сдвиг.
s[j], s’[j] – величина сдвига.
Величины сдвигов s[j] и s’[j] для каждого раунда однозначно определяются
номером блока X[j], который участвует в функции сжатия на текущем шаге t,
0 ≤ t × 79. Значения этих величин сдвига в зависимости от раунда и порядкового
номера блока X[j] даны в табл. 1. На рис. 27 дана схема функции сжатия
Таблица 1
Циклический сдвиг влево слов сообщения (обе линии обработки)
Раун
д
1
2
3
4
5
x0 x1 x2 X3 x4 x5 x6 x7 X x9 x10 x11 x12 x13 x14 x15
11
12
13
14
15
14
13
15
11
12
15
11
14
12
13
12
15
11
14
13
5
6
7
8
9
8
9
7
6
5
7
9
6
5
8
9
7
8
5
6
8
11
12
13
14
15
13
15
14
12
11
14
11
13
15
12
15
13
12
14
11
6
7
5
9
8
7
8
5
9
6
9
7
6
8
5
8
7
9
6
5
94
CVq
Yq
Yq
f1, K1, Xi
16 шагов
A B
C В
F5, K´1, Xi
16 шагов
E
A´ B´ C´ В´ E´
F2, K2, Xρ(i)
16 шагов
A B
C В
F4, K´2, Xρ(i)
16 шагов
E
A´ B´ C´ В´ E´
F2, K2, Xρ2(i)
16 шагов
A B
C В
F3, K´2, Xρ2(i)
16 шагов
E
A´ B´ C´ В´ E´
F2, K2, Xρ3(i)
16 шагов
A B
C В
F2, K´2, Xρ3(i)
16 шагов
E
A´ B´ C´ В´ E´
F2, K2, Xρ4(i)
16 шагов
F1, K´2, Xρ4(i)
16 шагов
+
+
+
+
CVq+1
Рис. 27. Схема функции сжатия
Шаг 6. После обработки всех Mi, i = 1,2, … K, 512-битовых блоков на
выходе обработки получается 160-битовый профиль сообщения.
95
A
B
+
C
D
E
D
E
fj
+
Xi
Ki
+
rol10
rola(j)
+
A
B
C
Рис. 28. Элементарная операция RIPEMD160 (один шаг раунда)
ГОСТ Р34.11-94. Функция хеширования
Алгоритм ГОСТ сообщение произвольной длины преобразует в 256битовое значение. Сообщение разбивается на блоки по 256 бит
X1, X2 …, XN,
где N число таких блоков, L= N × 256. Алгоритм последовательно
преобразовывает блоки X1, X2 …, XK согласно общей схеме, представленной
на рис. 1. В процессе вычислении значения хэш-функции каждый блок Xi, i =
1, 2, …, K, интерпретируется следующим образом:
▪ совокупность четырех блоков xj , j=1, 2, 3, 4, по 64 бита
Xi = x4 || x3 || x2 || x1
▪ совокупность 16 блоков hj , j = 1, 2, …, 16, по 16 бит
Xi = η16 || η15 || … ||η1
96
▪ совокупность 32 блоков e j , j = 1, 2, …, 32, по 8 бит
Xi = e32 || e31 || … || e1.
Далее будем использовать следующие обозначения:
| X | – длину слова X в битах;
А ⊕ В - побитное сложение слов А и В по mod 2;
А В - сложение слов А и В по mod 2256 .
В алгоритме ГОСТ используются:
▪ Функция
A(X) = A(x4 || x3 || x2 || x1) = (x1 ⊕ x2) || x4 || x3 || x2.
▪ Функция
Ψ(X) = Ψ( η16 || η15 || … ||η1) =
=η1 ⊕ η2 ⊕ η3 ⊕ η4 ⊕ η13 ⊕ η16 ||η16|| η15 ||…||η2.
▪ Функция ϕ(j), которая преобразовывает множество индексов j=1, 2,
…, 32 в некоторые значения ϕ (j) из этого же множества, 1 ≤ ϕ (j) ≤ 32.
Функция ϕ () определяется следующим образом:
ϕ ( i+1+4(k-1) ) = 8i + k,
i = 0, 1, 2, 3; k = 1, 2, 3, 4, 5, 6, 7, 8.
Непосредственно вычисляя ϕ (j), т.е. перебирая все i и k, получаем
ϕ (1)=9,
ϕ (5)=2,
ϕ (9)=3,
ϕ (13)=4,
ϕ (17)=5,
ϕ (21)=6,
ϕ (25)=7,
ϕ (29)=8,
ϕ (2)=9,
ϕ (6)=10,
ϕ (10)=11,
ϕ (14)=10,
ϕ (18)=13,
ϕ (22)=14,
ϕ (26)=15,
ϕ (30)=16,
ϕ (3)=17,
ϕ (7)=18,
ϕ (11)=19,
ϕ (15)=20,
ϕ (19)=21,
ϕ (23)=22,
ϕ (27)=23,
ϕ (31)=24,
ϕ(4)=25,
ϕ (8)=26,
ϕ (12)=27,
ϕ (16)=28,
ϕ (20)=29,
ϕ (24)=30,
ϕ (28)=31,
ϕ (32)=32.
Функция
P(X)=P(e32 || e31 || … || e1) =
97
=eϕ(32) || eϕ(31) || eϕ(30) ||… ||eϕ(1) .
▪ Криптографическая система ГОСТ, которую будем обозначать через
EK(h), где
E – алгоритм шифрования;
K – ключ шифра;
h – блок в 64 бита исходного сообщения.
▪ Три константы C2 ,C3 ,C4, размером в 256 бита каждая. Эти переменные
инициализируются следующими значениями:
C2=0x00000000000000000000000000000000,
C3=0xF0FF000FF00F0FF00F0F0F0FF0F0F0F0,
C4=0x00000000000000000000000000000000.
▪ Переменная L – для длины обработанного сообщения.
▪ Переменная Σ – для контрольной суммы.
Алгоритм ГОСТ для вычисления хэш-функции
Шаг 1. Инициализируем буфер h в 256 бит для значения хэш-функции.
В отличие от алгоритмов MD5, SHA-1 и RIPEMD-160, начальное
значение буфера h0 – произвольное слово в 256 бит. Если значение h0
заранее неизвестно, то оно должно передаваться вместе с сообщением с
гарантией целостности.
Шаг 2. Исходное сообщение разбивается на блоки по 256 бит
M1, M2 …, MN ,
где N число таких блоков.
Шаг 3. Добавляются биты к исходному сообщению. Если последний
блок сообщения MN не равен 256 бит, то его дополняют нулями до 256 бит.
Предварительно биты последнего блока сдвигают вправо на число
добавляемых нулей. Структура дополнения представлена на рис. 30.
|Ml|
M1
M2
···
M -l
00…
Ml
{0}256-
98
Рис. 30. Структура дополнения
Шаг 4. На каждом шаге i генерируются ключи для шифрования
предыдущего значения буфера hi.
Алгоритм генерации четырех ключей K1, K2, K3, K4 на шаге i.
1.
2.
3.
4.
5.
Определяем переменные U, V и W в 256 бит.
Инициализируем U=Mi и V=hi-1.
Вычисляем W=U⊕V.
Определяем ключ K1=P(W), где функция P определенна ранее.
Цикл от t=2 до t= 4
Начало цикла
Вычисляем U=A(U)⊕Ct,
Вычисляем V=A(A(V)) ,
Вычисляем W=U⊕V,
Вычисляем Kt=P(W) ,
Конец цикла
Выход: значения ключей K1, K2, K3, K4
Здесь A, P, C2, C3, C4 – определенные ранее функции и константы алгоритма.
Шаг 5. Шифрующее преобразование. На шаге i в предлагаемом
алгоритме шифруется значение буфера hi-1. В этом случае hi-1 представляется
как объединение четырех блоков по 64 бита каждый
hi-1 = h4 || h3 || h2 || h1.
Далее используя алгоритм шифрования ГОСТ в режиме простой замены
s1=EK1(h1),
s2=EK2(h2),
s3=EK3(h3),
s4=EK4 (h4),
si = s4 || s3 || s2 || s1
Шаг
6.
Перемешивающее
преобразование.
Перемешивающее
преобразование χ(M, h), где M, h – блоки по 256 бит, имеет вид:
hi=χ(Mi, hi-1)=Ψ 61( hi-1⊕Ψ(Mi⊕Ψ12 (si)) ),
где Ψ n – n-я степень преобразования Ψ, которое определенно выше. (где
приведеноΨ? СТР 90) Схема перемешивающего преобразования дана на
рис. 31.
99
Mi
Si
Ψ12
Ψ
Ψ61
hi-1
hi
Рис. 31. Перемешивающее преобразование ГОСТ
Шаг 7. Вычисление переменных L и Σ. После каждого шага i алгоритм
ГОСТ вычисляет переменные L (длина сообщения) и Σ (контрольная сумма)
по формулам
Li=Li-1 + |Mi| (mod 2256),
Σi = Σi-1 ⊗ Mi,
где символ ⊗ означает операцию по правилам
Σi-1 + Mi mod 2n,
n=|Σi-1| = | Mi |,
где Mi длина блока.
Шаг 8. Завершающее преобразование. Обозначим через M´N последний
блок сообщения. Если |M´N| < 256, через MN его дополнение до 256 бит.
Тогда, завершающее преобразование сводится к следующим шагам:
L=L+M´N mod 2256,
Σ=Σ⊗MN ,
h´=χ(MN, hN-1) ,
h´=χ(L, h´),
hитог = χ(Σ, h´ ).
Шаг 9. После обработки всех Mi, i = 1,2, … N, 256-битовых
блоков на выходе обработки получается 256-битовый профиль сообщения
hитог.
100
Сформулируем кратко алгоритм вычисления хэш-функции по ГОСТ.
Вход: сообщение M, начальное значение h0.
1. Инициализация переменных h= h0, Σ = 0, L= 0.
2. Функция сжатия сообщения M пока |M| > 256:
h=χ(Mi, h) ,
L= L+ 256 mod 2256,
Σ = Σ ⊗ Mi .
3. Завершающее преобразование.
L=L+M´N mod 2256,
Σ=Σ⊗MN,
h´=χ(MN, hN-1) ,
h´=χ(L, h´ ) ,
hитог = χ(Σ, h´ ).
Ниже на рис. 32 дана схема дана блок-схема алгоритма ГОСТ.
I
h1
H*
{0}25
{0}25
∑1
∑2
L
L
(256
(256
Функция
набив
h
H*
∑
L
h2
H*
H*
H*
h
101
Рис. 32 Общая схема функции хэширования по ГОСТ Р 34.11 - 94
Глава 4. КРИПТОГРАФИЯ С ОТКРЫТЫМ КЛЮЧОМ
Идея криптографии с открытыми ключами была опубликована в 1976г.
в работе Диффи и Хеллмана «Новые направления в криптографии». Эта идея
базируется на построении функции F, при помощи которой, зная значение
аргумента x, можно эффективно вычислить
y = F(x).
В то же время по значению y невозможно за приемлемый промежуток
времени решить обратную задачу, т.е. по y определить аргумент x. Функции с
такими свойствами называются односторонними.
О п р е д е л е н и е 1. Функция F: X → Y называется односторонней,
если она обладает двумя свойствами:
▪ существует полиномиальный алгоритм вычисления значения y = F(x);
▪ не существует полиномиального алгоритма для решения обратной
задачи, т.е. определения значения x по y.
Решение обратной задачи для односторонней функции одинаково
невыполнимо как для санкционированного, так и не санкционированного
решения. Для разрешения данной коллизии Диффи и Хеллман ввели понятие
односторонней функции с секретом (one-way trapdoor function).
О п р е д е л е н и е 2. Функция
FK : X → Y,
которая зависит от параметра K, называется односторонней с сектретом K,
если она обладает тремя свойствами
▪ при любом параметре K существует полиномиальный алгоритм
вычисления значения
y = FK (x);
▪ при неизвестном K не существует полиномиального алгоритма для
решения обратной задачи, т.е. определения значения x по y;
102
▪ при известном K существует полиномиальный алгоритм для решения
обратной задачи, т.е. определения значения x по y.
Решение обратной задачи для односторонней функции с секретом
становится выполнимой для санкционированного решения, но невыполнимо
для не санкционированного решения.
Для практических целей в криптографии при построении функций,
которые исполняют роль односторонних, используют сложные задачи из
теории чисел, например, следующие
▪ Разложить на множители число n.
▪ Определить, является ли число n простым.
▪ Найти простое число больше n.
▪ Найти число x из уравнения
x2 ≡ a mod n.
▪ Найти число x из уравнения
ax ≡ b mod n.
Последнее время развивается криптографические методы с открытыми
ключами, которые базируются на теории эллиптических кривых. Суть
криптографии с открытым ключом заключается в следующем. В
криптографической системе существуют два разных ключа. Расшифровать и
зашифровать может только тот, кто владеет этими двумя ключами. При таком
подходе можно разрабатывать различные схемы использования открытых
ключей, например, следующие
▪ есть пользователь, который владеет двумя ключами;
▪ нет пользователей, которые владеют одновременно двумя ключами.
В зависимости от разработанной схемы можно выполнять различные
криптографические процедуры: аутентификацию, электронную подпись,
формирования общего ключа, криптографические протоколы, которые в свою
очередь решают различные задачи, связанные с обменом информации и т.д. В
предложенных выше схемах с открытыми ключами в качестве примера их
использования будут предлагаться алгоритмы цифровой подписи и
аутентификации. Определим данные понятия.
Аутентификация – процедура (функция) проверка подлинности.
Аутентификация может относиться ко всем аспектам взаимодействия при
передаче информации – сеансу связи, передаваемому сообщению, источнику
сообщения и т.д.
103
Электронная цифровая подпись (ЭЦП) – процедура, которая
обеспечивает невозможность отказа от переданного и подписанного
сообщения.
Справедливости ради, следует заметить, что первые результаты по
криптографии с открытым ключом были ранее получены британскими
учеными, но они не были опубликованы [6].
СХЕМА ДИФФИ-ХЭЛЛМАНА
Протокол формирования общего ключа по открытому каналу связи
1. Есть два пользователя (абонента) A и B.
2. Дано простое число p, которое известно пользователям A и B.
3. Выбирается общее число g, g < p-1.
4. Абоненты A и B независимо друг от друга выбирают соответственно
секретные ключи a, 0 < a < p-1 и b, 0 < b < p-1.
5. Абонент A посылает абоненту B сообщение
ga mod p.
6. Абонент B посылает абоненту A сообщение
gb mod p.
7. Абонент A вычисляет общий ключ
k=[gb]a mod p.
8. Абонент B вычисляет общий ключ
k= [ga]b mod p.
Протокол взаимной аутентификации
Существует несколько схем аутентификации источника данных ([1],
[7]). Приведем условия и алгоритм реализации одной из них.
1. Есть два абонента A и B.
2. Даны простое число p и число g, g < p-1, которые известны
абонентам A и B.
3. Абоненты A и B владеют, соответственно, открытыми функциями
шифрования EA и EB и закрытыми функциями дешифрования D A и DB ,
которые обладают свойствами
104
DAEA (M)=M, DBEB (M)=M.
Здесь М – передаваемое сообщение, равенства не зависит от порядка
применения функций.
4. Абоненты A и B независимо друг от друга выбирают соответственно
секретные ключи a, 0 < a < p-1 и b, 0 < b < p-1.
5. Абонент A посылает абоненту B сообщение
ga mod p.
6. Абонент B:
▪ вычисляет общий ключ
k= [ga]b mod p;
▪ используя закрытую функцию DB, создает подпись (сообщение)
DB (ga mod p, gb mod p);
▪ используя ключ k, шифрует подпись
EK (DB (ga mod p, gb mod p) ),
где EK есть общая функция шифрования;
▪ отправляет абоненту A сообщение
gb mod p, EK (DB (ga mod p, gb mod p)).
7. Абонент A:
▪ вычисляет общий ключ
k= [gb]a mod p;
▪ используя закрытую функцию DA, создает подпись, то есть передает
сообщение
DA (ga mod p, gb mod p);
▪ используя ключ k, шифрует подпись
EK (DA (ga mod p, gb mod p));
▪ отправляет абоненту B сообщение
105
EK (DA (ga mod p, gb mod p));
▪ проверяет подпись B, вычисляя
EB (DK (EK (DB (ga mod p, gb mod p)))) =
= ga mod p, gb mod p,
где DK есть общая функция дешифрования.
8. Абонент B проверяет подпись A, вычисляя
EA (DK (EK (DA (ga mod p, gb mod p)))) =
= ga mod p, gb mod p.
КРИПТОСИСТЕМА RSA
Алгоритм RSA является первым алгоритмом шифрования с открытым
ключом. Название система RSA происходит от первых букв фамилий ее
авторов (Р. Ривест, А. Шамир и Л. Адлеман). Система базируется на
следующих фактах:
▪ вычисление по составному модулю n числа
a ≡ bd mod n
является простой задачей;
▪ вычисление по составному модулю n числа b из уравнения
a ≡ bd mod n
является трудной задачей;
▪ если известно, что p и q простые числа и n = pq, то вычислить n легко,
а найти разложение n на простые множители является трудной задачей;
▪ если известно разложение n=pq на простые множители, то задача
вычисления числа b из уравнения
a≡bd mod n
выполнима.
Теоретической основой криптосистемы RSA является теорема Эйлера из
теории чисел.
Т е о р е м а (Эйлер). Для любых натуральных и взаимно простых чисел
n и a справедливо равенство
106
aϕ
(n)
≡ 1 mod n.
Здесь φ(n) есть функция Эйлера – количество взаимно простых с n
натуральных чисел от 1 до n.
Из теории чисел известно, что если p и q простые числа, а n=pq, то
φ(n)=(p-1)(q-1).
Кроме того, из теоремы Эйлера следует, что если некоторое число
взаимнопросто с φ(n), то уравнение
e
de ≡ 1 mod φ(n)
или иначе
de=k φ(n) + 1
однозначно решается относительно
расширенным алгоритмом Евклида.
d.
Решение
легко
определяется
Итак, если известно, что
de ≡ 1 mod φ(n),
а x – передаваемая информация, то справедливо равенство
(xe)d mod n ≡ (xkϕ (n)+1) mod n ≡
≡ (xϕ (n)) k x mod n ≡ x.
Фактически, последнее равенство является основой для формулировки системы
RSA.
Формирование системы RSA
1. Выбираем два различных простых числа p и q.
2. Вычисляем n = pq и
φ(n)= (p-1) (q-1).
107
3. Выбираем число e взаимнопростое с φ(n).
4. Вычисляем число d из уравнения
de ≡ 1 mod φ(n).
5. Определяем открытые ключи e и n.
6. Определяем закрытые ключи d, p, q и φ(n).
Алгоритм шифрования
1. Дан текст сообщения М.
2. Шифротекст C вычисляется по формуле
C=E k (M)=M e mod n.
Алгоритм дешифрования
1. Дан шифротекст C.
2. Текст сообщения M вычисляется по формуле
M=D k (C)=C d mod n=(M e ) d mod n= M.
Цифровая подпись
1. Есть абонент A и текст для подписи M.
2. Определяются закрытые ключи системы RSA, а именно d, p, q, φ(n)
3. Определяются открытые ключи e и n.
4. Закрытым ключом вычисляется
C=Md mod n.
Сообщение C рассматривается как подпись абонента A, потому что закрытый ключ d
известен только ему.
5. Проверка подписанного документа вычисляется по формуле
C e = (Md)e mod n=M,
используя открытый ключ e.
З а м е ч а н и е. Схема подписи усложняется [10], если абоненты A и B имеет
систему RSA с эксклюзивными модулями nA и nB , соответственно. Если абонент A
желает свое подписанное сообщение
C = M d mod nA
108
зашифровать открытым ключом абонента B, т.е. вычислить
С1= Ceβ mod nB,
чтобы M было доступно только абоненту B, то значение
C1 d mod nB
B
не всегда будет равно сообщению
C= M d mod nA.
Для этого надо, чтобы выполнялось неравенство nA < nB. Чтобы в подобном режиме
пересылки информации разрешить представленную коллизию, надо пользователям
договориться о некотором пороге T и создавать два набора параметров – один с
модулем меньшим T, другой с модулем большим T. В этом случае отправитель
использует свой меньший модуль для подписи, а больший модуль получателя – для
шифрования [10].
П р и м е р [1]. Зашифруем аббревиатуру RSA. Пусть p=17 и q=31.
Т о г д а п = p q = 5 2 7 , причем имеет место
φ(n) =(p-1)(q-1)= 480.
Выберем число e=7, взаимно простое с φ(n). Решая уравнение
de ≡ 1 mod φ(n)
относительно d с помощью алгоритма Евклида, найдем число d=343. Поскольку
-137 = 343 mod 480,
то выполняется равенство d = 343 .
Проверка:
7· 343 = 2401 ≡ 1 mod 480.
Представим
сообщение RSA в виде последовательности чисел,
содержащихся в интервале [0, 526]. Для этого буквы R, S и А закодируем
пятимерными двоичными векторами, воспользовавшись двоичной записью
их порядковых номеров в английском алфавите
R = 18 = (10010), S = 19 = (10011),
109
А = 1 = (00001).
Тогда
RSA = (100101001100001).
Укладываясь в заданный
представление кода
интервал [0, 526], получаем следующее
RSA = (100101001), (100001) = (М1 = 297, М2 = 33).
Далее последовательно шифруем М1 и М2
С1 = Ек (М 1 ) = M 1e ≡ 297 7 mod 527 = 474.
При этом мы воспользовались тем, что
297 7 = ( (297 2 ) 3 297) mod 527 =
= (2003 ( mod 527 ) 297 ) mod 527,
С2 = Ек (М2) = Мe2 ≡ ЗЗ7 mod 527 = 407.
В итоге получаем шифртекст y1 = 474 и у2 = 407.
При
расшифровании
нужно
выполнить
следовательность действий. Во-первых, вычислить
следующую
D k (C 1 ) 3 43 = (C 1 ) 3 4 3 mod 527.
Отметим, что при возведении в степень удобно воспользоваться тем, что
343 = 256 + 64 + 16 + 4 + 2 + 1.
На основании этого представления получаем
474 2 ≡ 174 mod 527,
4748 mod 527 ≡ 307,
47432 mod 527 ≡ 205,
474128 mod 527) ≡ 307,
474 4 mod 527 ≡
47416 mod 527 ≡
47464 mod 527 ≡
474256 mod 527 ≡
237,
443,
392,
443,
в силу чего имеет место
474 343(mod 527) ≡
≡ (443 · 392 · 443 · 237 · 174 · 474) mod 527 ≡ 297.
по-
110
Аналогично
407343 mod 527 ≡ 33.
Возвращаясь к буквенной записи, получаем после расшифрования RSA.
Следуя [1], проанализируем вопрос о стойкости системы RSA. Можно
показать, что сложность нахождения секретного ключа системы RSA
определяется сложностью разложения числа п на простые множители. В связи
с этим нужно выбирать числа р и q таким образом, чтобы задача
разложения числа п была достаточно сложна в вычислительном плане. Для
этого рекомендуются следующие требования:
1) числа р и q должны быть достаточно большими, не слишком сильно
отличаться друг от друга и в то же время быть не слишком близкими друг
другу;
2) числа р и q должны быть такими, чтобы наибольший общий
делитель чисел (р-1) и (q-1) был небольшим; желательно, чтобы
наибольший общий делитель имел вид (p-1, q-1) = 2;
3) р и q должны быть сильно простыми числами;
Определение. Простое число p называется сильно простым, если
выполняются условия:
p ≡ 1 mod r,
p ≡ s-1 mod s,
r ≡ 1 mod t,
где p, r, s, t – большие простые числа.
В случае когда не выполнено хотя бы одно из указанных условий,
имеются эффективные алгоритмы разложения п на простые множители (см.,
например, [8-9]).
В настоящее время самые большие простые числа вида п = p·q,
которые удается разложить на множители известными методами, содержат
в своей записи 140 десятичных знаков. Поэтому согласно указанным
рекомендациям числа р и q в системе RSA должны содержать не менее 100
десятичных знаков.
Следует подчеркнуть необходимость соблюдения осторожности в
выборе модуля RSA (числа п) для каждого из корреспондентов сети. В связи
с этим можно сказать следующее. Читатель может самостоятельно
убедиться в том, что, зная одну из трех величин р, q или φ(n), можно легко
найти секретный ключ RSA. Известно также, что зная секретную экспоненту
расшифрования d, можно легко разложить модуль п на множители. В этом
случае удается построить вероятностный алгоритм разложения п. Отсюда
111
следует, что каждый корреспондент сети, в которой для шифрования используется система RSA, должен иметь свой уникальный модуль.
В самом деле, если в сети используется единый для всех модуль n, то
такая организация связи не обеспечивает конфиденциальности, несмотря на
то, что базовая система RSA может быть стойкой. Выражаясь другими
словами, говорят о несостоятельности протокола с общим модулем.
Несостоятельность следует из того, что знание произвольной пары
экспонент (ei, di) позволяет, как было отмечено, разложить п на множители.
Поэтому любой корреспондент данной сети имеет возможность найти
секретный ключ любого другого корреспондента. Более того, это можно
сделать даже без разложения п на множители (см., например, [8]).
Как отмечалось ранее, системы шифрования с открытыми ключами
работают сравнительно медленно. Для повышения скорости шифрования
RSA на практике используют малую экспоненту зашифрования e [1].
СХЕМА ЭЛЬ-ГАМАЛЯ
Алгоритм формирования схемы Эль-Гамаля
1. Выбираем простое число p.
2. Выбираем два случайных числа g, g < p и x, x <p.
3. Вычисляем
y = g x mod p.
Открытым ключом схемы Эль-Гамаля являются числа y, g и p, закрытым
ключом – число x.
Алгоритм формирования цифровой подписи
1. Дано сообщение M, которое надо подписать.
2. Выбираем случайное число k, k < p взаимно простое с p-1.
3. Вычисляем
a = g k mod p.
4. Из уравнения
M = (xa+kb) mod (p-1)
определяем b по формуле
b= (M-xa) k
−1
mod (p-1).
5. Формируем подпись. Подписью является пара чисел (a, b).
112
Число k является секретным ключом.
З а м е ч а н и е. При формировании цифровой подписи на четвертом
шаге вместо значения M можно использовать значение μ=H(M), где H –
некоторая хэш-функция.
Проверка подписи
1. Дано сообщение M и подпись (a, b).
2. Вычисляем
a
yaab mod p= [g x ] a b = g xa g kb =
=g
3. Вычисляем gM mod p.
Если значение
совпало с
xa + kb
= gM mod p.
yaab mod p
gM mod p,
то подпись верна.
Алгоритм расшифрования 1
1. Дано сообщение M.
2. Выбираем случайное число k, k < p взаимно простое с p-1.
3. Вычисляем
a = g k mod p.
4. Шифруем сообщение по формуле
b = ykM mod p = gkxM mod p.
Пара сообщений (a, b) является шифротекстом. Заметим, что шифротекст при
таком способе шифрования длинее исходного текста.
Алгоритм расшифрования 2
1. Вычисляем
ax ≡ gkx mod p.
2. Тогда
M = b/ax ≡ gkxM / gkx mod p.
113
СХЕМА ШНОРРА
Алгоритм формирования схемы Шнорра
1. Выбираем два простых числа p и q, так, чтобы q было множителем
(p-1).
2. Выбираем значение a такое, что a ≠ 1 и
aq ≡ 1 mod p.
3. Выбираем случайное число s, s < q .
4. Вычисляем
y = a-s mod p.
Открытым ключом схемы Шнорра являются числа p, q и a. Закрытым ключом
– число y.
Алгоритм формирования цифровой подписи
1. Дано сообщение M и хеш-функция H(M).
2. Выбираем случайное число r, r < q.
3. Вычисляем
r
x = a mod p.
4. Присоединяем к сообщению M значение x и вычисляем
e=H(M, x) mod q.
5. Вычисляем значение
v=(r+se) mod q
6. Формируем подпись. Подписью является пара чисел (e, v).
З а м е ч а н и е. Число r – секретное число.
Проверка подписи
1. Дано сообщение M и подпись (e, v).
2. Вычисляется значение
x 1 = avye mod p,
где
avye = a(r+se) mod q a-se mod q = aγ.
3. Присоединяем к сообщению M значение x 1 и вычисляем:
114
e 1 =H(M, x 1 ) mod q.
4. Если e 1 = e, то подпись считается верной.
З а м е ч а н и е. Числа r и s, которые используются в пункте 2 –
закрытые ключи. Они используются только для проверки выкладки.
Протокол аутентификации
1. Есть отправитель A и получатель B.
2. Пользователь A выбирает случайное число r, r < q и вычисляет
x = armod p.
3. Пользователь A отсылает B число x.
4. Пользователь B выбирает случайно число e из диапозона
[0, 2 t - 1].
5. Пользователь B отсылает A число e.
6. Пользователь A вычисляет
v = (r+se) mod q.
7. Пользователь A отсылает B число v.
8. Пользователь B вычисляет
x 1 = avye mod p,
где
avye = a
( r + se ) mod q
a − se mod q = aγ.
9. Если x 1 = x, то доказательство аутентификации принимается.
З а м е ч а н и е 1. При протоколе аутентификации случайное число e –
в отличии от цифровой подписи – определяет получатель B.
З а м е ч а н и е 2. От параметра t зависит безопсность алгоритма
аутентификации. Шнорр [2, 4] предлагает использовать значение p порядка
512 битов, q – 140 битов, а значение числа t равное 72.
115
Задача о рюкзаке
Рассмотрим задачу о рюкзаке, и на основании этой задачи построим
криптографическую систему с открытым ключом.
З а д а ч е о р ю к з а к е. Задан набор (вектор)
A = (a 1 , a 2 , ..., a n )
из п положительных целых чисел и одно положительное целое число V.
Требуется найти такие числа a i , i = 1, 2, …, k, если это возможно, сумма
которых равна V. В простейшем случае V указывает размер рюкзака, а каждое
из чисел a i , i = 1, 2, …, k, указывает размер предмета, который может быть
упакован в рюкзак. Задачей является нахождение такого набора предметов,
чтобы рюкзак был полностью заполнен.
В качестве иллюстрации приведем пример из [8]. Рассмотрим число
3231 и набор из 10 чисел
43, 129, 215, 473, 903, 302, 561, 1165, 697, 1523 .
Заметим, что
3231 = 129 + 473 + 903 + 561 + 1165.
В результате нашли искомое решение.
В принципе, решение всегда может быть найдено полным перебором
подмножеств А и проверкой, какая из их сумм равна V. В нашем случае это
означает перебор 210 = 1024 подмножеств, включая при этом и пустое
множество. Это вполне осуществимо.
Однако, если n =300, то в этом случае надо сделать перебор среди 2300
подмножеств, что является проблематичной задачей. Поиск среди 2300
подмножеств не поддается обработке.
Используя вектор А размерности n, можно определить функцию f(x)
следующим образом. Заметим, что любое число х в интервале 0 ≤ х ≤2п-1
может быть задано двоичным представлением из n разрядов, где при
необходимости для чисел, меньших (2п-1), в старшие разряды добавляются
начальные нули.
Итак, пусть двоичная запись числа х из интервала 0 ≤ x ≤ 2п-1 имеет
следующий вид
x = x 1 x 2 ...x n ,
где xi ∈ {0,1} и i = 1, 2, …, n. Тогда каждому значению x ставится в
соответствие число S по следующей формуле
116
f(x) = x 1 a 1 + x 2 a 2 + … + x n a n = S.
Используя скалярное произведение двух векторов, можно записать
v r
f(x) = A x
r
r
где
A и x - векторы размерностью n. Используя введенную функцию f(x) =
v r
A x , предыдущее равенство
3231 = 129 + 473 + 903 + 561 + 1165
может быть записано в виде
0*43+1*129+0* 215+1*473+1* 903+0*302+
+1*561+1*1165+0*697+0*1523=
= f(0101101100) =
=f(364) = 129 + 473 + 903 + 561 + 1165 = 3231,
потому что двоичное число 0101101100 представимо в виде
0101101100 = 0*109+1*108+0*107+1*106+
+1*105+0*104+1*103+1*102+0*101+ 0*100 =
=0*29+1*28+0*27+1*26+1*25+0*24+1*23+1*22+
0*21+ 0*20 =0+1*256+0+1*64+1*32+0+8+4+0+0 =
=256 +64 + 32 +8 +4 = 364.
Заметим, что определить х по значению f(x) сложно. Однако если мы сумели
востановить x по f(x), то по двоичному представлению числа x можно
определить компоненты набора A, которые входят в сумму для f(х). С другой
стороны, вычислить f(x) по х легко. Отсюда следует вывод, что задача о
рюкзаке является хорошим кандидатом для односторонней функции.
Конечно, надо потребовать, чтобы число n было достаточно большим,
скажем, не менее 200. Ниже будет показано, как используя функцию f(х)
можно определить аналог односторонней функции с секретом. Тем самым
построить некоторую криптографическую систему с открытым ключем.
Сначала рассмотрим, как "рюкзачные векторы" А могут быть использованы в качестве основы криптосистемы. Или иначе, как применяя
последовательность A перобразовать исходный текст в зашифрованный текст.
В рамках поставленной задачи можно сформулировать следующую схему
шифрования.
1. Определяется последовательность
117
A = (a 1 , a 2 , ..., a n ).
2. Исходный текст преобразуется в бинарную последовательность.
3. Бинарная последовательность разбивается на блоки длиной по n бит,
где n – число элементов в наборе A.
4. Текущий блок исходного текста
x 1 x 2 ... x n
из n бит шифруется по формуле
C = x1a1 + x2a2 + … + xnan,
где C – шифр текущего блока исходного текста x 1 x 2 ...x n .
Заметим, что если для шифрования использовать компьютеры, то в
памяти компьютера вся водимая информация представляется автоматически в
виде бинарной последовательности. Поэтому представление информации в
виде бинарной последовательности не требует никаких дополнительных
преобразований.
Идея построения криптосистемы с открытым ключом на базе задачи о
рюкзаке заключается в построении некоторого класса задач о рюкзаке,
которые решаются легко. При этом для данного класса легких задач
существуют некоторые преобразования параметров, которые модифицируют
эти легкие задачи под общий случай. Параметры класса легких задач при
таком построении определяют секретный ключ криптографической системы,
а параметры модифицированной задачи определяют открытый ключ. В
качестве легко решаемой задачи в 1978г. была предложена задача о рюкзаке с
быстровозрастающей последовательностью A = (a 1 , a 2 , ..., a n ).
О п р е д е л е н и е. Набор (последовательность) из n чисел называется
быстровозрастающей, если для всех j, 0 ≤ j ≤ n имеет место
aj > a1 + a2 + … + aj-1.
Задача о рюкзаке с быстровозрастающим набором чисел несравненно
проще. Для поиска решения в данном случае достаточно просмотреть набор
A один раз справа налево, а не осуществлять полный перебор вариантов
решений. Алгоритм поиска решения в этом случае можно описать
следующим образом.
Для заданного V – размера рюкзака или зашифрованного набора x и
значения индекса j = n сначала проверяем неравенство V < аj. Если V < аj, то
aj не может входить в искомую сумму. Если же V > аj, то aj должно входить в
сумму. Это следует из того факта, что сумма остальных ai меньшее V. Данное
118
рассуждение можно свести к следующим вычислительным формулам. Для
заданного V и индекса j определим xj по формулам
xj = 1, если V ≥ aj
xj = 0, если V < aj.
Далее вычисляем новое значение V и j следующим образом
V = V - xj*aj, j = j-1.
Затем повторяем данную процедуру для j = n-1, n-2, …, 1.
Теперь можно сформулировать алгоритм решения задачи о рюкзаке с
быстровозрастающей последовательностью.
1. Определяем быстровозрастающий набор
A = (a 1 , a 2 , ..., a n )
и число V.
2. Для j = n, n-1, …, 1 выполняем шаги 3 - 5.
3. Если V ≥ aj, то xj = 1, иначе xj = 0.
4. Вычисляем
V = V – xj*aj.
5. Полагаем j равным (j-1).
6. Переходим к шагу 2.
Сформулированный алгоритм показывает, что для любого V задача рюкзака
имеет не более одного решения при условии, что A является
быстровозрастаюшей последовательностью.
Итак, если A – быстровозрастающая последовательность, то по любой
бинарной последовательности легко вычислить значение V. Легко решить
обратную задачу – по значению V определить бинарную последовательность.
Отсюда следует вывод, что если быстровозрастающий набор A открыт, то для
нелегального пользователя расшифровать текст будет так же легко, как и для
легального. Поэтому, чтобы избежать этого, надо модифицировать набор
в некоторый набор
A = (a 1 , a 2 , ..., a n )
B = (b 1 , b 2 , ..., b n )
таким
образом,
чтобы
последовательность
B
не
являлась
быстровозрастающей, и выглядела как произвольный вектор рюкзака. При
этом набор B должен обладать еще тем свойством, что текст, зашифрованный
119
с применением набора B, можно было расшифровать при помощи
быстровозрастающей последовательности A. Алгоритм формирования такого
набора B по быстровозрастающему набору A существует,
и он
формулируется следующим образом.
Алгоритм формирования криптографической системы
1. Определяем быстровозрастающий набор
A = (a 1 , a 2 , ..., a n ).
2. Выбираем модуль m таким образом, чтобы выполнялось неравенство
m > S = a 1 + a 2 + ... + a n .
3. Выбираем целое случайное число (множитель) t, взаимно простое с
m.
4. Вычисляем число t-1 обратное к t, т.е. имеет место
tt-1 ≡ 1 mod m.
5. По набору A = (a 1 , a 2 , ..., a n ) вычисляем набор
B=(b 1 , b 2 , ..., b n )
по формуле
b j =ta j , 0 ≤ j ≤ n.
Таким образом, определённый набор B как бы «маскирует»
быстровозрастающий набор A, который является определяющим для
криптографической системы на базе задачи о рюкзаке.
Открытым ключом данной криптографической системы,
которая основана на задаче о рюкзаке, является последовательность
B=(b 1 , b 2 , ..., b n ). При помощи вектора B шифруют исходный текст
сообщения. Секретным ключом системы являются параметры, в
которые входят быстровозрастающий набор A = (a 1 , a 2 , ..., a n ),
модуль m и число t(t - 1 ).
Замечание.
Для
увеличения
надежности
построенной
криптографической системы набор A предварительно можно преобразовать,
используя некоторую случайно выбранную перестановку элементов
последовательности. В этом случае выбранная случайным образом
перестановка является параметром, который включается в секретный ключ.
Итак, пусть
120
C = c1 + c2 + … + cn
есть блок зашифрованного текста, где
c i = x i b i , 0 ≤ i ≤ n.
Выберем C по следующему правилу
C = x1b1 + x2b2 + … + xnbn ≡
≡ x 1 ta 1 + x 2 ta 2 + … + x n ta n .
Тогда алгоритм дешифровки формулируется следующим образом.
1. Вычисляется число V
V mod m ≡ t - 1 C mod m ≡
≡ t - 1 c 1 + t - 1 c 2 + … + t - 1 c n mod m ≡
≡ x 1 t - 1 ta 1 + x 2 t - 1 ta 2 + … + x n t - 1 ta n mod m ≡
≡x 1 a 1 + x 2 a 2 + … + x n a n mod m.
2. Для определения значения V решаем задачу рюкзака для
быстровозрастающего набора A = (a 1 , a 2 , ..., a n ).
Пример [8]. Формирование криптографической системы, которая
базируется на задаче о рюкзаке.(В чем задача?)
1. Определяем быстровозрастающий набор
A = (1, 3, 5, 11, 21, 44, 87, 175, 349, 701).
2. Вычисляем
S = 1+3+5+11+21+44+87+175+349+701=
= 1397.
3. Выбираем модуль m, m = 1590 > S =1397.
4. Выбираем целое случайное число t = 43, взаимно простое с m.
5. Вычисляем число t-1, обратное к t, т.е. tt-1 ≡ 1 mod m.
Решение сравнения 43x ≡ 1 mod 1590 определяется формулой
где
x ≡ t-1 ≡ (-1)k-1Pk -1 mod 1590,
121
k – число шагов в расширенном алгоритме Евклида при разложении
дроби m/a в последовательность подходящих дробей. В нашем случае a = 43 и
m = 1590;
Pk-1 – числитель предпоследней подходящей дроби в разложении дроби
a/m при помощи расширенного алгоритма Евклида.
Напомним, что числители подходящих дробей в алгоритме Евклида
вычисляются по формуле
Pi = qi×Pi-1 + Pi-2,
i = 1, 2, …, k,
где
P0 = 1, P1 = q1 – начальные значения Pi;
qi – частные в алгоритме Евклида при вычислении НОД для чисел a и
m. В нашем случае a = 43 и m = 1590.
Итак, для решения сравнения
43x ≡ 1 mod 1590
делаем следующие шаги.
▪ Определяем q1 как частное от деления a=43 и m = 1590. Получаем
q1=36. Значение остатка от деления r2=42. Тогда по определению P0=1, P1=q1=
36.
▪ Вычисляем частное q2 и остаток r3 от деления числа a = 43 на
предыдущий остаток r2 = 42. Получаем q2=1 и r3=1. Тогда, по определению
P2 = q2P1 + P0 = 1×36 + 1 = 37.
▪ Вычисляем частное q3 и остаток r4 от деления предыдущего частного
q2=1 на остаток r3 = 1. Получаем q3 = 1, а остаток r4 = 0.
▪ Т.к. остаток r4 = 0, то процесс вычисления по расширенному
алгоритму Эвклида завершается. В свою очередь это позволяет по формуле
x ≡ t-1 ≡ (-1)k-1Pk -1 mod 1590
определить решение сравнения
43x ≡ 1 mod 1590,
оно равно
x ≡ t-1 ≡ (-1)k-1Pk -1 mod 1590 ≡ (-1)237 mod 1590 ≡ 37 mod 1590.
122
Действительно, 43×37 = 1591 ≡ 1 mod 1590.
Таким образом, задав параметр t=43, и определив обратный элемент к
нему t-1= 37, продолжим формировать криптографическую систему, которая
использует задачу о рюкзаке. Для этого нам надо перейти к 5-му шагу
алгоритма формирования криптографической системы и вычислить вектор B,
который «маскирует» быстровозрастающий вектор A = (1, 3, 5, 11, 21, 44,
87, 175, 349, 701).
5. (ЧТО ТАКОЕ 5? )Вычисляем набор B
B=(b 1 , b 2 , ..., b n ),
который маскирует быстровозрастающий вектор A по формуле:
b j ≡ta j mod 1590, 0 ≤ j ≤ n.
Получаем:
b 1 ≡ 43•1 mod 1590 ≡
≡ 43,
b 2 ≡ 43•3 mod 1590 ≡
≡ 129,
b 3 ≡ 43•5 mod 1590 ≡
≡ 215,
b 4 ≡ 43•11 mod 1590 ≡
≡ 473,
b 5 ≡ 43•21 mod 1590 ≡
≡ 903,
b 6 ≡ 43•44 mod 1590≡ ≡ 1892≡(1590+ 302) mod 1590 ≡
≡ 302,
b 7 ≡ 43•87 mod 1590≡ 3741≡(2•1590+ 561) mod 1590 ≡
≡ 561,
b 8 ≡ 43•175 mod 1590≡7525≡(4•1590+ 1165) mod 1590 ≡
≡ 1165,
b 9 ≡ 43•349 mod 1590≡150007≡(9•1590+ 697) mod 1590 ≡
≡ 697,
b 1 0 ≡43•701 mod 1590≡30143≡(18•1590+1523) mod 1590 ≡
≡ 1523.
В результате получили следующий набор B
B = (43, 129, 215, 473, 903, 302, 561, 1165, 697, 1523).
123
Итак, нами сформирована криптографическая система на базе задачи о
рюкзаке с открытым набором B=(43, 129, 215, 473, 903, 302, 561, 1165, 697,
1523) для шифрования информации
и секретными параметрами для
расшифровки текста. В эти секретные параметры входят
▪ быстровозрастающий набор
A = (1, 3, 5, 11, 21, 44, 87, 175, 349, 701);
▪ модуль m=1590;
▪ множитель t=43 и обратный к множителю число t-1=37;
Схема шифрования текста
Пусть дано сообщение
Добро ори клон
которое надо зашифровать. Предположим, что символы, которые входят в
сообщение, имеют следующие двоичные коды длиной в пять бит
СИМВОЛ
Пробел
Д
О
Б
Р
И
К
Л
Н
КОД
00000
10011
00001
10101
01110
00100
01000
00101
01100.
Для данных кодов исходное сообщение преобразуется в следующую
бинарную последовательность
1001100001 1010101110 0000100000
0000101110 0010000000 0100000101
0000101100.
Бинарую последовательность разбиваем на семь блоков по 10 разрядов:
1001100001
1010101110
124
0000100000
0000101110
0010000000
0100000101
0000101100
Число разрядов определяется числом элементов в наборе B. Каждый блок
фактически представляет собой
шифр двух символов сообщения и
соответствует следующим десятичным числам
1001100001=
= 1*2 +0*2 +0*2 +1*26+1*25+0*24+0*23+0*22+0*2+1*20=
512+0+0+64+32+0+0+0+0+1=
= 609,
9
8
7
1010101110=
1*2 +0*2 +1*2 +0*2 +1*25+0*24+1*23+1*22+1*2+0*20=
512+0+128+0+32+0+8+4+2+0=
= 686,
9
8
7
6
0000100000=
= 0*2 +0*2 +0*2 +0*26+1*25+0*24+0*23+0*22+0*2+0*20=
0+0+0+0+32+0+0+0+0+0=
= 32,
9
8
7
0000101110=
= 0*2 +0*2 +0*2 +0*26+1*25+0*24+1*23+1*22+1*2+0*20=
0+0+0+0+32+0+8+4+2+0=
= 46,
9
8
7
0010000000=
= 0*2 +0*2 +1*2 +0*26+0*25+0*24+0*23+0*22+0*2+0*20=
0+0+128+0+0+0+0+0+0+0=
= 128
9
8
7
0100000101=
= 0*2 +1*2 +0*2 +0*26+0*25+0*24+0*23+1*22+0*2+1*20=
0+256+0+0+0+0+0+4+0+1=
= 261,
9
8
7
0000101100=
= 0*2 +0*2 +0*2 +0*26+1*25+0*24+1*23+1*22+0*2+0*20=
0+0+0+0+32+0+8+4+0+0=
9
8
7
125
= 44.
Шифруем предложенное сообщение, используя
предложенную ранее схему шифрования, получаем:
набор
B
f(609)=
1*43+0*129+0*215+1*473+1*903+0*302+0*561+0*1165+0*697+1*1523=
43+473+903+1523=
=2942.
f(686)=
1*43+0*129+1*215+0*473+1*903+0*302+1*561+1*1165+1*697+0*1523=
43+215+903+561+1165+697=
=3584,
f(32)=
0*43+0*129+0*215+0*473+1*903+0*302+0*561+0*1165+0*697+0*1523=
=903,
f(46)=
0*43+0*129+0*215+0*473+1*903+0*302+1*561+1*1165+1*697+0*1523=
903+561+1165+697=
=3326,
f(128)=
0*43+0*129+1*215+0*473+0*903+0*302+0*561+0*1165+0*697+0*1523=
=215,
f(261)=
0*43+1*129+0*215+0*473+0*903+0*302+0*561+1*1165+0*697+1*1523=
129+1165+1523=
=2817,
f(44)=
0*43+0*129+0*215+0*473+1*903+0*302+1*561+1*1165+0*697+0*1523=
903+561+1165=
=2629.
Итак, предложенное сообщение
Добро ори клон
шифруется в следующий набор C
и
126
C=(2942, 3584, 903, 3326, 215, 2817, 2629).
Схема дешифрования текста
1. Вычисляется число V
V mod m ≡ t - 1 C mod m ≡ 37*С mod m ≡
≡ (37•2942, 37•3584, 37•903, 37•3326,
37•215, 37•2817, 37•2629) mod m,
где m=1590.
Проведем вычисления. Получаем:
37*2942 = 108854 = (68*1590+734) mod 1590 = 734,
37*3584 = 132608 =(83*1590+638) mod 1590 = 638,
37*903 = 33411 = (21*1590+21) mod 1590 = 21,
37*3326 = 123062 =(77*1590+632) mod 1590 = 632,
37*215 = 7955 =(5*1590+5) mod 1590 = 5,
37*2817 = 104229 = (65*1590+879) mod 1590 = 879,
37*2629 = 97273 =(61*1590+283) mod 1590 = 283.
В результате вычисления получили набор
V = (734, 638, 21, 632, 5, 879, 283).
Для кажого элемента этого набора решаем
быстровозрастающей последовательностью
задачу
о
рюкзаке
с
A =(1, 3, 5, 11, 21, 44, 87, 175, 349, 701).
Для числа 734 получаем:
включаем 701, потому что 701<734. Порядковый индекс компоненты i,
i=1;
находим разность 734-701= 33;
включаем 21, потому что 21 < 33). Порядковый индекс компоненты i,
i=6;
находим разность 33-21= 12;
включаем 11, потому что 11 < 12. Порядковый индекс компоненты i,
i=7;
находим разность 12-11= 1;
включаем 1. Порядковый индекс компоненты i, i = 10;
находим разность 1-1= 0;
Бинарный код для шифра 734 имеет вид
127
1001100001.
Для числа 638 получаем:
включаем 349, потому что 349 < 638. Порядковый индекс компоненты i,
i=2;
находим разность 638-349=289;
включаем 175, потому что 175 < 289. Порядковый индекс компоненты i,
i=3;
находим разность 289-175= 114;
включаем 87, потому что 87 < 114. Порядковый индекс компоненты i,
i=4;
находим разность 114-87= 27;
включаем 21, потому что 21 < 27. Порядковый индекс компоненты i,
i=6;
находим разность 27-21= 6;
включаем 5, потому что 5 < 6. Порядковый индекс компоненты i, i = 8;
находим разность 6-5= 1;
включаем 1. Порядковый индекс компоненты i, i = 10;
находим разность 1-1= 0;
Бинарный код для шифра 638 имеет вид
1010101110.
Для числа 21 получаем:
включаем 21, потому что 21=21. Порядковый индекс компоненты i, i=6;
находим разность 21-21=0;
Бинарный код для шифра 21 имеет вид
0000100000.
Для числа 632 получаем:
включаем 349, потому что 349 < 632. Порядковый индекс компоненты i,
i=2;
находим разность 632-349=283;
включаем 175, потому что 175 < 283. Порядковый индекс компоненты i,
i=3;
находим разность 283-175= 108;
включаем 87, потому что 87 < 105). Порядковый индекс компоненты i,
i=4;
находим разность 108-87= 21;
включаем 21, потому что 21=21). Порядковый индекс компоненты i,
i=6;
находим разность 21-21=0;
Бинарный код для шифра 632 имеет вид
128
0000101110
для числа 5:
включаем 5 (т.к. 5=5) (порядковый индекс компоненты i = 8);
находим разницу 5-5=0;
бинарный код для шифра 21 имеет следующий вид 0010000000
для числа 879:
включаем 701 (т.к. 701 < 879) (порядковый индекс компоненты i = 1);
находим разницу 879-701= 178;
включаем 175 (т.к. 175 < 178); (порядковый индекс компоненты i = 3);
находим разницу 178-175= 3;
включаем 3; (порядковый индекс компоненты i = 9);
находим разницу 3-3= 0;
бинарный код для шифра 879 имеет следующий вид 0100000101;
для числа 283:
включаем 175 (т.к. 175 < 283) (порядковый индекс компоненты i = 3);
находим разницу 283-175= 108;
включаем 87 (т.к. 87 < 108); (порядковый индекс компоненты i = 4);
находим разницу 108-87=21;
включаем 21; (порядковый индекс компоненты i = 6);
находим разницу 21-21= 0;
бинарный код для шифра 283 имеет следующий вид 00000101100;
В результате дешифрования получили бинарный код исходного сообщения.
Глава 5. ЭЛЕКТРОННЫЕ ЦИФРОВЫЕ ПОДПИСИ
Электронная цифровая подпись (ЭЦП) позволяет решить следующие
три задачи [1]:
▪ осуществить аутентификацию источника сообщения,
▪ установить целостность сообщения,
▪ обеспечить невозможность отказа от факта подписи конкретного
сообщения.
Схема цифровой подписи состоит из следующих компонентов [7]:
▪ Множество сообщений.
▪ Множество подписей.
▪ Множество ключей подписи.
129
▪ Эффективный алгоритм генерации ключа.
▪ Эффективный алгоритм подписи.
▪ Эффективный алгоритм проверки подписи.
Свойство перемешивания, которое должно присутствовать в надежных
алгоритмах шифрования, необходимо и в схемах цифровых подписей.
Алгоритм подписи должен равномерно распределять цифровые подписи по
всему множеству подписей.
Важным моментом при формировании ЭЦП является невозможность ее
подделки без знания секретного ключа. При формировании подписи можно
использовать следующую дополнительную информацию:
▪ дата подписи;
▪ срок окончания действия ключа данной подписи;
▪ идентификацию лица, которое подписывает информацию;
▪ и т.д. согласно алгоритму подписи.
Формально, схема цифровой подписи состоит из двух преобразований:
▪ алгоритм вычисления цифровой подписи,
▪ алгоритм проверки цифровой подписи.
Естественно, алгоритм формирования подписи строго регламентирует
структуру, порядок, временные характеристики и другие параметры,
необходимые для формирования и проверки цифровой подписи. Главные
требования к этим алгоритмам заключаются в исключении возможности
получения подписи без использования секретного ключа и гарантировании
возможности проверки подписи без знания какой-либо секретной
информации.
Как видно из общей схемы ЭЦП для ее реализации необходимы два
алгоритма – алгоритм вычисления подписи и алгоритм ее проверки.
Надежность схемы цифровой подписи определяется сложностью следующих
трех задач [1]:
▪ подделка подписи, то есть нахождения значения подписи под
заданным документом лицом, не являющимся владельцем секретного
ключа;
▪ создания подписанного сообщения, то есть нахождения хотя бы
одного сообщения с правильным значением подписи;
▪ подмены сообщения, то есть подбор двух различных сообщений с
одинаковыми значениями подписи.
130
Имеется
множество
различных
схем
цифровой
подписи,
обеспечивающих тот или иной уровень стойкости. Основные подходы к их
построению будут рассмотрены ниже.
В алгоритме проверки электронной цифровой подписи главная трудность
состоит в вопросе, каким открытым ключам можно доверять. Возникает
проблема идентификации открытого ключа с конкретным лицом.
Проверяющий подпись должен быть абсолютно уверен, что ключ, который
он использует для проверки, принадлежит адресату A, а не некоторому
адресату X или Y. Поэтому принципиальной сложностью, возникающей при
использовании цифровой подписи на практике, является проблема создания
инфраструктуры открытых ключей [1]. Для проверки подписи
необходима некоторая открытая информация, которая связанная с
возможностью проверки подписи. Для исключения подделки этой
открытой информации должна быть создана инфраструктура, которая
состоит из центров сертификации открытых ключей. Эта структура должна
обеспечивать возможность
▪ подтверждения достоверности данного
заявленному владельцу,
▪ обнаружения подлога открытого ключа.
открытого
ключа
В разделе криптографии с открытыми ключами приводятся две схемы
цифровых подписей, которые базируются на методе RSA и Эль-Гамаля. Ниже
рассматриваются два стандарта цифровых подписей – американский DSS и
российский ГОСТ.
Стандарт электронной цифровой подписи DSS
Алгоритм цифровой подписи DSS был предложен в США в 1991г.
Формирование системы DSS
1. Выбрать простое число p, 2512 < p < 21024, битовая длина которого
кратна 64.
2. Выбрать простое число q длиной 160 бит, причем q должно быть
делителем p-1 (q | p-1).
3. Выбрать целое число h такое, что 0 < h < p-1 и
h(p-1)/q mod p > 1.
4. Вычислить
g = h(p-1)/q mod p.
131
5. Выбрать целое число x, 0 < x < q, где x – секретный ключ.
6. Вычислить число
y=gx mod p.
7. Выбрать однонаправленную хэш-функцию H(M). Сообщение M – это
число в диапазоне 0 < M < q. Стандарт определяет в качестве функции H
использовать алгоритм SHA.
В результате формирования системы DSS для пользователей сети
определяются три открытых параметра p, q и g. Закрытым ключом в данной
схеме является число x, а открытым – y.
Формирование подписи DSS
Дано сообщение M, которое надо подписать. Для подписи требуется
выполнить следующую последовательность действий:
1. Абонентом выбирается число k, 0 < k < q. Число k является
секретным.
2. Вычисляется число
r = (gk mod p) mod q.
3. Вычисляется число
s = k -1(H(M) + xr) mod q.
Цифровой подписью абонента A является пара чисел (r, s).
Алгоритм проверки подписи DSS
1. Извлечь открытый ключ (p, q, g, y).
2. Проверить, что 0 < r < q и 0 < s < q. Если неравенства
выполняются, то подпись не принимается.
3. Вычислить H(M).
4. Вычислить
w = s-1 mod q.
5. Вычислить
u1 = w h(m) mod q, u2 = r w mod q.
6. Вычислить
v = (gu1 yu2 mod p) mod q.
7. Принять подпись в том и только в том случае, если v = r.
не
132
Глава 6. ПРОТОКОЛ
О п р е д е л е н и е. Протокол – это алгоритм процедуры
взаимодействия между двумя (или более) сторонами (участниками) [13].
Криптографическим протоколом называют протокол, в реализации
которого используют криптографию. Обычно криптография в протоколе
используется для выполнения криптографических функций, т.е. для
обеспечения безопасности задач, которые решаются при использовании
протокола.
Криптографические протоколы применяются [13]:
▪ в электронных платежах;
▪ в электронном обмене данных;
▪ в электронной коммерции;
▪ в электронном голосовании;
▪ в играх по телефону с применением компьютерных сетей.
Безопасность протокола выражается в обеспечении гарантий некоторых
задач защиты информации, например, конфиденциальность, целостность,
аутентификации и др. В настоящее время понятие безопасности систем
отождествляется со степенью надежности функций безопасности. Концепции
функций безопасности изложены в международном стандарте. Перечислим
некоторые из них [13]:
▪ аутентификация источника данных – обеспечивает проверку
достоверности источника;
▪ аутентификация сторон – обеспечивает проверку достоверности
сторон;
▪ конфиденциальность данных – обеспечивает защиту от
несанкционированного доступа к информации;
▪ невозможность отказа – обеспечивает невозможность отказа сторон от
участия в информационном обмене;
▪ обеспечения целостности данных – обеспечивает защиту информации
от несанкционированной модификации;
▪ разграничение доступа – обеспечивает защиту системы от
несанкционированного доступа к ресурсам.
Криптографические протоколы можно классифицировать по разным
признакам. Дадим классификацию протоколов по функциям, которые они
выполняют [13]:
▪ протокол аутентификации сообщений;
▪ протокол цифровой подписи;
133
▪ протокол идентификации;
▪ протокол конфиденциальной передачи;
▪ протокол обмена секретами;
▪ протокол распределения ключей.
Кратко охарактеризуем назначение перечисленных протоколов.
Протокол аутентификации сообщений предназначен для обеспечения
целостности передаваемых данных между участниками обмена информацией.
Протокол цифровой подписи обеспечивает невозможность отказа
сторон от участия в информационном обмене.
Протокол идентификации обеспечивает проверку подлинности сторон,
которые участвуют в обмене информацией.
Протокол конфиденциальной передачи обеспечивает защиту от
несанкционированного доступа при обмене информации.
В случае прерывания обмена данными протокол обмена секретами не
предоставляет преимуществ какой-либо стороне, участвующей в обмене
информацией.
Протокол
распределения
ключей
обеспечивает
защиту
от
несанкционированного доступа к ключам, которые распределяются между
участниками обмена информацией.
Атака на протокол
Так как протоколы защищают информацию при обмене между
участниками, естественно, существуют злоумышленники, которые пытаются
нарушить работу протокола или вмешаться в последовательность его
действий для того, чтобы получить передаваемые данные. Такие попытки
вмешаться в процесс обмена данными между санкционированными
сторонами называются атаками на протокол. Перечислим некоторые виды
атак на криптографические протоколы ([1], [5], [7], [13]).
▪ Нарушитель выдает себя за одну из сторон обмена – подмена легального
пользователя несанкционированным пользователем.
▪ Нарушитель навязывает повторное сообщение.
▪ Нарушитель задерживает передачу сообщения.
▪ Нарушитель открывает несколько параллельных сеансов обмена для
манипулирования сообщениями из разных сеансов.
Примеры протоколов
134
Будем предполагать, что в рассматриваемых протоколах обмена
информацией
участвуют два легальных или санкционированных
пользователя A и B.
Формирование системы Шнорра
Схема Шнорра основана на сложности задачи дискретного
логарифмирования. Для реализации схемы Шнорра [2, 4] выбираются два
таких простых чисел p и q, что имеет место (q|p-1) – q делит p-1. В
дальнейшем из множества чисел, которые принадлежат классу вычетов по
модулю p, p ∈Zp, выбираем число g такое, что
gq = 1 mod p.
Числа q, p, g являются открытыми параметрами схемы Шнорра. Для
закрытого ключа схемы выбирается произвольное целое число x, 1 ≤ x ≤ q-1,
и вычисляется число (открытый ключ)
y = g-x.
Схема аутентификации Шнорра
Шаг 1. Пользователь A выбирает число k, 1 ≤ k ≤ q-1, и вычисляет
r = gk mod p.
Шаг 2. Участник A пересылает число r пользователю B.
Шаг 3. Участник B выбирает число e, 0 ≤ e ≤ 2t-1, где t – некоторый
параметр, и пересылает это число стороне A.
Шаг 4. Пользователь A посылает B число s, которое вычисляет по
формуле:
s = k + xe.
Шаг 5. Участник B вычисляет число
r´= gsye mod p.
Если число r´ совпало с числом r из первого шага, то B доверяет участнику A,
в противном случае B отвергает участника A.
Протокол игры в «орел, решка»
135
Протоколы игры подбрасывание монеты по телефоны создаются по
следующей общей схеме.
▪ Определяется односторонняя функция f(x);
▪ Выбирается случайное целое число x. Если x – четное, то f(x) означает
«орел», в противном случае считают, что f(x) соответствует «решке».
Далее определяются следующие шаги протокола подбрасывания
монеты.
Шаг 1. Сторона A выбирает число x. Затем вычисляет и отправляет
своему противнику B значение
y1=f(x).
Шаг 2. Участник B сообщает стороне A свою догадку о выбранном им
числе («четное», «нечетное») или («орел», «решка»).
Шаг 3. Сторона A пересылает противнику B значение числа x.
Шаг 4. Участник B вычисляет значение
y2=f(x).
Если y1 ≠ y2, то раунд игры не принимается. В противном случае B
определяет (без участия стороны A) свой проигрыш или выигрыш в
соответствующем раунде игры.
Ясно, что при таком подходе, конкретные протоколы подбрасывания
монеты могут отличаться друг от друга только выбором функции f(x).
Подбрасывание монеты по телефону можно организовывать, используя
криптографию с открытым ключом. Рассмотрим систему Шнорра. В рамках
данной системы протокол подбрасывания монеты определяется следующим
образом [2].
Шаг 1. Участник A выбирает число x из класса чисел Zq, вычисляет
y=gx mod p
и посылает y противнику B.
Шаг 2. Участник B выбирает случайное число k из класса чисел Zq, и
случайный бит b, вычисляет число
r=ybgk mod p
и отсылает число r противнику A.
Шаг 3. Участник A выбирает случайный бит α и посылает его B.
136
Шаг 4. Участник B посылает противнику A выбранные ранее бит b и
число k.
Шаг 5. Участник A вычисляет число
r1= ybgk mod p.
Если r1=r, то A определяет свой выигрыш или проигрыш.
Рассмотрим систему RSA. В рамках данной системы протокол
подбрасывания монеты определяется следующим образом [4].
Шаг 1. Участники игры A и B генерируют каждый свою пару ключей
EA, DA и EB, DB (открытый и закрытый).
Шаг 2. Участник A формирует два сообщения M1 и M2. Одно указывает
на орел, второе – на решку. Сообщения шифруются открытым ключом
игрока A. В случайном порядке сообщения EA(M1) и EA(M2) отправляются
противнику B.
Шаг 3. Участник B выбирает одно из сообщений (идентифицирует его с
понятием «орла» или «решки») и шифрует своим открытым ключом
EB(EA(Mi)),
где i равно 1 или 2, и отправляет полученный результат игроку A.
Шаг 4. Участник A дешифрует сообщение, вычисляя значение
DA(EB(EA(Mi))) = EB(Mi),
где i равно 1 или 2. Результат EB(Mi) отправляется противнику B.
Шаг 5. Игрок B дешифрует сообщение
DB(EB(Mi)) = Mi,
определяет свой выигрыш или проигрыш и результат отправляет своему
противнику A.
Шаг 6. Если полученное сообщение совпало с M1 или M2, игрок A
определяет свой выигрыш или проигрыш.
Шаг 7. После завершения игры участники открывают пары своих
ключей, чтобы каждая сторона убедилась в честности партнера.
Протоколы распределения ключей
Протоколы распределения ключей (ПРК) разделяют на следующие [1]:
137
▪ протоколы передачи (сгенерированных) ключей;
▪ протоколы совместной выработки общего ключа;
▪ протоколы предварительного распределения ключей.
Схемы протоколов передачи ключей
Рассмотрим протоколы, которые реализованы с применением
симметричного шифрования. Пусть пользователи A и B владеют общим
секретным ключом kab, который применяется в симметричном шифровании.
Тогда для передачи нового ключа k от пользователя A к пользователю B
можно использовать следующую схему [1]:
A→ B: Ekab(k, t, B),
где E – алгоритм шифрования, k – новый ключ, t – метка времени, B –
идентификатор участника протокола B.
Если требуется односторонняя аутентификация, то приемлема
следующая схема протокола:
Шаг 1. Участник B генерирует случайное число rb и пересылает его
стороне A.
Шаг 2. Участник A пересылает B сообщение:
Ekab(k, t, rb, B).
Если требуется двусторонняя аутентификация, то можно использовать
следующую схему протокола:
Шаг 1. Участник B генерирует случайное число rb и пересылает его
стороне A.
Шаг 2. Участник A генерирует случайное число ra и пересылает
B сообщение
Ekab(k, t, ra, rb, B).
Шаг 3. Участник A пересылает B сообщение Ek(ra).
Третий шаг позволит участнику A убедиться в том, имеет ли он дело с
участником B и получил ли он правильное значение ключа k.
Последний протокол можно модифицировать таким образом, чтобы в
формировании
нового ключа
принимал участие пользователь A и
пользователь B [1]. Пример такого протокола дан ниже.
138
Шаг 1. Участник B генерирует случайное число rb и пересылает его
стороне A.
Шаг 2. Участник A генерирует случайное число ra, ключ ka и
пересылает B сообщение
Ekab(ka, t, ra, rb, B).
Шаг 3. Участник B генерирует ключ kb и пересылает B сообщение
Ekab(kb, t, ra, rb, A).
После обмена по протоколу каждый участник по некоторой функции
вычисляет общий ключ
k = f(ka, kb).
Теперь перейдем к протоколам, которые используют асимметричное
шифрование. В протоколах с открытыми ключами каждая сторона владеет
двумя ключами открытым и закрытым. Обозначим через E алгоритм
шифрования, который использует открытый ключ. Тогда возможен
следующий протокол NSPK [13] обмена информацией:
Шаг 1. Участник A пересылает напарнику B сообщение
EB (ka, IDA),
где ka – новая ключевая переменная, IDA – идентификатор пользователя A.
Шаг 2. Участник B пересылает A сообщение
EA (ka, kb),
где kb – новая ключевая переменная.
Шаг 3. Участник A пересылает B сообщение EB (kb).
В этом протоколе участники обмениваются новыми ключами. После
обмена каждый участник по некоторой односторонней функции может
вычислить общий ключ
k = f(ka, kb),
либо использовать эти ключи при шифровании автономно (самостоятельно).
Заметим, что второй и третий шаги протокола обеспечивают дополнительно
аутентификацию сторон.
Рассмотрим протокол Oakley Conservative [13], который имеет
следующую структуру.
139
Шаг 1. Участник A пересылает напарнику B сообщение:
IDA, IDB, EB (ka),
где ka – новая ключевая переменная, IDA и IDB
идентификаторы пользователей A и B.
Шаг 2. Участник B пересылает A сообщение:
–
соответственно,
EA (ka, kb), IDA, IDB,
где kb – новая ключевая переменная.
Шаг 3. Участник A пересылает B сообщение:
hk (IDA, IDB),
где hk – хэш-функция. Ключ k – это значение хэш-функции при нулевом
ключе от значений ka, kb, т.е.
k=h0(ka, kb).
Третий шаг в алгоритме NSPK изменен для того, чтобы при его
выполнении нельзя было выполнить атаку на извлечении ключа kb.
Глава 7. ГЕНЕРАТОРЫ ПСЕВДОСЛУЧАЙНЫ
ПОСЛЕДОВАТЕЛЬНОСТЕЙ (ПСП)
Стойкость криптосистемы обуславливается отсутствием каких-либо
закономерностей
в
зашифрованной
информации.
Отсутствие
закономерностей при шифровании обуславливается выполнением некоторых
требований. Одним из таких требованием является случайность ключа.
Обычно случайность ключа обеспечивают генераторы псевдослучайных
последовательностей (ПСП).
Генераторы случайных чисел встроены в любой персональный
компьютер. Однако использовать данные генераторы для нужд криптографии
нельзя, потому что подобные генераторы оказываются не слишком
«случайными». В большинстве приложений, которые не связаны с
криптографией, случайные числа используются мало. Поэтому «не
случайность» случайных чисел не будет заметна. Однако для задач
криптографии, где последовательность случайных чисел используется часто,
подобные встроенные генераторы являются неприемлемы. На самом деле,
при помощи компьютера невозможно сформировать абсолютно случайную
последовательность. Число состояний, в которых может находиться
140
компьютер, велико, но ограничено. Отсюда следует, что любой генератор на
компьютере периодичен. Все что периодично может быть предсказано.
Поэтому основная задача при создании генераторов псевдослучайных
последовательностей заключается в том, чтобы создать случайную
последовательность, период повторения которой достаточно велик. Генератор
последовательностей можно считать псевдослучайным [4], если он проходит
все статистические тесты, которые созданы для этой цели. Все генераторы,
созданные на компьютере, периодичны. Однако если их период не менее 2256
бит, то подобные генераторы можно использовать в криптографических
приложениях [4].
Псевдослучайные последовательности используются для решения
следующих задач [14]:
▪ генерация гаммирующих последовательностей, т.е. при построении
синхронных поточных шифров;
▪ хеширования информации;
▪ формирования ключевой информации, которая обеспечивает
стойкость криптографических алгоритмов;
▪ формирования случайных запросов при реализации большого числа
криптографических протоколов, например протоколов выработки общего
секретного ключа, разделения секрета, подбрасывания монеты, привязки к
биту, аутентификации, электронной подписи и др.;
▪ внесения неопределенности в работу защищаемых аппаратнопрограммных средств.
Генератор псевдослучайных последовательностей должен
удовлетворять следующим требованиям [14]:
▪ криптографическая стойкость;
▪
хорошие
статистические
свойства,
псевдослучайная
последовательность по своим статистическим свойствам не должна
отличаться от истинно случайной последовательности;
▪ большой период формируемой последовательности;
▪ эффективная аппаратная и программная реализация.
Генераторы
псевдослучайных
последовательностей
можно
классифицировать по методу их реалиции. Для реализации генераторов
можно использовать криптографические и некриптогафические методы.
Генераторы на криптографических методах используют:
▪ поточные шифры;
▪ блочные шифры;
▪ односторонние функции;
141
▪ шифры с открытыми ключами.
Генераторы на не криптографических методах строятся на базе:
▪ конгруэнтных генераторов;
▪ регистров сдвигов с обратной связью.
Конгруэнтные генераторы ПСП
Линейным
конгруэнтным
генератором
(ЛКГ)
называются
генераторы псевдослучайных последовательностей следующего вида:
xn+1 = (axn + b) mod m,
где xn+1 и xn соответственно (n+1)-й и n-й члены последовательности, a –
множитель, b – приращение, m – модуль. Для формирования какой-либо
последовательности надо задать некоторое начальное число x0. Справедливо
следующее утверждение [14].
Т е о р е м а. Линейная конгруэнтная последовательность,
определенная числами m, a, b, x0 имеет период длиной m тогда и только тогда,
когда
▪ числа m и b – взаимно простые;
▪ (a-1) кратно каждому простому p, которое является делителем m;
▪ (a-1) кратно четырем, если m кратно четырем.
К преимуществам ЛКГ можно отнести быстродействие. Однако
использовать их в криптографии нельзя [4], поскольку существуют методы,
по которым можно предсказать их выходное значение. Помимо линейных
генераторов
существуют
полиномиальные
генераторы,
например,
квадратичный
xn+1 = (axn2 + bxn + с) mod m
и кубический
xn+1 = (axn3 + bxn2 + cxn + d) mod m.
генераторы.
В настоящее время разработаны методы вскрытия любого
полиномиального генератора [4]. Из этого следует, что использовать
конгруэнтные генераторы в криптографии нельзя.
142
Генератор ПСП Блюм-Блюма-Шуба (BBS)
Генератор BBS создан на базе трудной задачи из теории чисел, а
именно – найти число x из уравнения
x2 ≡ a mod n.
Для формирования генератора BBS надо:
▪ выбрать два простых числа p и q, для которых выполняются равенства
p ≡ 3 mod 4,
q ≡ 3 mod 4,
т.е. p и q сравнимы с 3 по модулю 4.
▪ определить число n=pq, которое называется целым числом Блюма;
▪ выбрать случайное число x, взаимно простое с n;
▪ из уравнения
x0 = x2 mod n
вычисить x0.
Искомой псевдослучайной последовательностью длиной (m+1) будет являтся
последовательность
b0b1…bm,
где bi, i ≤ m, – младший бит числа xi, которое определяется из уравнения:
xi = xi-12 mod n.
Для тех, кто знает разложение числа n на множители, значение xi можно
вычислить по формуле:
xi = x0α mod n,
где
α = 2i mod (p-1)(q-1).
Генератор последовательностей RSA
Предположим, что сформирована криптосистема RSA, т.е. выбран
аналог односторонней функции с секретом. Напомним, что система RSA
определяется следующими параметрами:
▪ простыми числами p, q и числом n=pq;
143
▪ числом e, взаимнопростым с ϕ (n), где
ϕ (n) = (p-1)(q-1);
▪ числом d, которое определяется из уравнения
ed=1 mod n.
Искомой псевдослучайной последовательностью длиной m+1 будет являтся
последовательность
b0b1…bm,
где bi, i ≤ m, – младший бит числа xi, которое определяется из уравнения:
xi = xi-1e mod n.
Регистры сдвигов с обратной связью
Один из способов генерации псевдослучайной последовательности
основан на регистре сдвигов с обратной связью. Регистр сдвига с обратной
связью это набор ячеек памяти, в каждой из которых содержит значение
одного бита – 0 или 1. На каждом шаге формирования бита псевдослучайной
последовательности содержимое определенных ячеек памяти, которые
называются отводами, преобразуются функцией обратной связи. Пусть в
регистре, который содержит N ячеек памяти, число отводов равно k. Если
a1, a2, …, ak
значение битов ячеек памяти, которые являются отводами, то обратная связь
есть некоторая функция
F( a1, a2, …, ak)
от k переменных, которая вычисляет значение бита
β = F( a1, a2, …, ak).
Заметим, что здесь нижние индексы i у значений ai, i = 1, 2,…, k, не
соответствуют номерам ячеек регистра, а являются порядковым номерами
отводов. Значение этого бита, которая вычисляет функция, записывается в
левую ячейку регистра, предварительно сдвигая остальные биты на одну
позицию вправо. Самый правый бит, который выводится из регистра сдвига,
является
очередным
значением
элемента
псевдослучайной
последовательности. Заметим, что и самая правая ячейка регистра может
144
быть ячейкой отвода. Другими словами, значение бита самой правой ячейки
памяти является не только очередным значением псевдослучайной
последовательности, но и являться аргументом для функции F( a1, a2, …, ak).
Ориентация «самая левая ячейка» и «самая правая ячейка» взята для
определенности, что общности рассуждений не нарушает.
В качестве функций обратной связи надежнее использовать нелинейные
функции, но на практике это сложно реализовать. Поэтому в настоящее время
широко используются и иследуются регистры сдвига с линейной обратной
связью LSFR (Linear Feedback Shift Register). Регистры сдвига с линейной
обратной связью LSFR не являются криптостойкими. Поэтому они
применяются как блоки для проектирования генераторов псевдослучайной
последовательности [14].
Свойства LSFR связаны со свойствами двоичного многочлена
Φ(x) = aN xN + aN-1xN-1 + … + a1x + 1,
где N – число ячеек в регистре, а значения ai , 1 ≤ i ≤ N, и x равны 1 или 0.
Числа ai, которые не равны нулю, соответствуют тем номерам ячеек
регистра, которые являются отводами. Если рассмотреть конкретный
многочлен, например, следующий
Φ(x) = x8 + x7 + x5 + x3 + 1,
то этот многочлен соответствует регистру из восьми ячеек. Отводами у этого
регистра являются ячейки с номерами 3, 5, 7, 8. В качестве функции
можно выбрать следующую
F(a8, a7, a5, a3)
F(a8, a7, a5, a3) = a8 + a7 + a5 + a3 ,
где a8, a7, a5 и a3 есть значения в ячейках регистра с соответствующими
номерами.
Наибольший период у псевдослучайной последовательности, которая
генерируется
LSFR, будет в том случае, если генератору будет
соответствовать примитивный многочлен [14]. В этом случае период
псевдослучайной последовательности будет равен (2N -1).
Глава 8. СРАВНЕНИЯ
Возьмем натуральное целое число m, которое будем называть модулем.
145
О п р е д е л е н и е 1. Целые числа a и b называются сравнимыми по
модулю m, если разность (a – b) делится на m (m | a - b).
Это соотношение между a, b и m для краткости записывается следующим
образом:
a ≡ b(mod m),
где a и b будем называть соответственно левой и правой частями сравнения.
Из определения 1 следует, что если a делится на m, то
a ≡ 0 mod m.
Т е о р е м а 1. Число a сравнимо с b тогда и только тогда, когда a и b
имеют одинаковые остатки при делении на модуль m.
Д о к а з а т е л ь с т в о. Пусть
a ≡ b mod m.
Представим a и b в виде
a=mq 1 + r 1 , b=mq 2 + r 2 ,
где 0 ≤ r 1 < m, 0 ≤ r 2 < m. Из этих представлений получаем
a-b=m(q 1 - q 2 ) + r 1 - r 2 .
Так как (m | a – b), то m должно делить (r 1 - r 2 ). Однако имеет место
–m<r 1 -r 2 <m.
Отсюда следует, что r 1 -r 2 = 0, т.е. r 1 = r 2 .
Обратно. Пусть остатки от деления a и b на m равны, т.е. имеет место
a=mq 1 + r, b=mq 2 + r.
Тогда
a-b=m(q 1 - q 2 ),
т.е. m | a – b.
На основании теоремы 1 можно дать следующее определения
сравнимости чисел a и b.
О п р е д е л е н и е 2. Целые числа a и b называются сравнимыми по
модулю m, если остатки от деления этих чисел на m равны.
Свойства сравнений
Т е о р е м а 2. Отношения сравнимости рефлексивно, т.е.
146
a ≡ a mod m.
Доказательство следует из того, что левая и правая часть сравнения
имеют равные остатки.
Т е о р е м а 3. Отношения сравнимости симметрично, т.е. если
a ≡ b mod m,
то
b ≡ a mod m.
Д о к а з а т е л ь с т в о. Если a и b имеют одинаковые остатки при
делении на m, то остатки от деления b и a на m также равны.
Т е о р е м а 4. Отношения сравнимости транзитивно, т.е. если
a ≡ b(mod m), b ≡ c(mod m),
то
a ≡ c(mod m).
Д о к а з а т е л ь с т в о. Если у чисел a и b, а также у чисел b и c
остатки от деления на m равны, то a и c имеют одинаковые остатки при
делении на m.
Т е о р е м а 5. Если
a ≡ b(mod m)
и k произвольное целое число, то
ka ≡ kb(mod m).
Д о к а з а т е л ь с т в о. Если a ≡ b(mod m), то m|a-b. Тогда
m|k(a-b) или m|ka-kb.
Следовательно ka ≡ kb(mod m).
О п р е д е л е н и е 2. Пусть a и b целые числа, причем b ≠ 0. Число b
называется делителем a, если существует целое число k, такое, что a=kb.
О п р е д е л е н и е 3. Общим делителем двух чисел a и b называется
любое целое k, такое, что k|a и k|b.
О п р е д е л е н и е 4. Наибольшим общим делителем (НОД) двух
чисел a и b называется такой положительный общий делитель k, который
делится на любой другой общий делитель этих чисел. Наибольший общий
делитель чисел a и b обозначается следующим образом:
(a, b) = k.
147
О п р е д е л е н и е 5. Числа a и b называются взаимно простыми, если
наибольший общий делитель этих чисел равен 1, т.е. (a,b)=1.
Т е о р е м а 6. Если
ka≡kb(mod m)
и (k,m)=1, то
a≡b(mod m).
Д о к а з а т е л ь с т в о. Если ka ≡ kb(mod m), то m|ka-kb, т.е. m|k(a-b).
Так как по условию вышеприведенных теорем наибольший общий делитель
равен 1, то из условия m|k(a-b) следует, что m|a-b.
Т е о р е м а 7. Если
a≡b(mod m)
и k – произвольное целое натуральное число, то
ka≡kb(mod km).
Д о к а з а т е л ь с т в о. Если m|a-b, то km|ka-kb. Отсюда следует, что
ka ≡ kb(mod km).
Т е о р е м а 8. Если
a≡b(mod m), c≡d(mod m),
то
a+c≡(b+d) mod m, a-c≡(b-d) mod m.
Д о к а з а т е л ь с т в о. Если m|a-b и m|c-d, то m|(a-b) ± (c-d). Отсюда
получаем
m|(a ± c)-(b ± d).
Т е о р е м а 9. Если
a≡b(mod m), c≡d(mod m),
то
ac≡bd(mod m).
Д о к а з а т е л ь с т в о. Если a ≡ b(mod m) и c ≡ d(mod m),
теоремы 5 следует
ac≡bc(mod m) и cb≡db(mod m).
то
Тогда из свойства транзитивности сравнений получим, что ac ≡ bd(mod m).
Т е о р е м а 10. Если
a≡b(mod m),
из
148
то при любом целом n ≥ 0 имеет место
an ≡ bn (mod m).
Д о к а з а т е л ь с т в о. Применяя n раз теорему 9 для сравнений
a ≡ b(mod m) и a ≡ b(mod m) получим доказательство теоремы 10.
Пусть n – любое положительное целое число, p(x) – многочлен степени
n с целыми коэффициентами. Тогда из теорем 2 – 10, следует
Т е о р е м а 11. Если
a≡b(mod m),
то
p(a) ≡ p(b)(mod m).
Модулярная арифметика
Модулярная арифметика или арифметика остатков является основой
современной криптографии. Эта арифметика заключается в том, что у любого
выражения, в котором используются только целые числа, требуется
вычислить не значение этого выражения, а остаток от деления этого значения
на некоторое целое число n. Арифметика остатков во многом совпадает с
обычной арифметикой. Она коммутативна, ассоциативна и дистрибутивна.
Кроме того, вычисление промежуточного результата по модулю n дает такой
же результат, что и выполнение всего вычисления с последующим
вычислением остатка, т.е. справедливы формулы:
(a+b) mod n≡ ( (a mod n)+(b mod n) ) mod n
(a-b) mod n≡ ( (a mod n) - (b mod n) ) mod n
(a*b) mod n≡ ( (a mod n) * (b mod n) ) mod n
( c(a+b) ) mod n≡ ( ((ca) mod n)+((cb) mod n) ) mod n
Пока при составлении арифметических выражений можно использовать
только операции сложения, умножения и вычитания. В дальнейшем мы
научимся вычислять обратный элемент, логарифм числа и квадратный корень
по модулю n.
Вычисление ax mod n
В случае, когда показатель степени x является степенью 2, для
вычисления
ax mod n
можно использовать формулу, которая для x=16 имеет следующий вид
149
a 16 mod n = ( ( (a 2 mod n) 2 mod n ) 2 mod n ) 2 mod n
Если показатель x не является степенью 2, то записав этот показатель в
двоичной системе счисления можно представить x в виде суммы степеней 2,
что позволяет значительно уменьшить число операций умножений.
Вычисление наименьшего общего делителя
Одним из самых древних методов вычисления наибольшего общего
делителя является алгоритм Евклида. Итак, пусть даны два положительных
целых числа a и b. Предположим, что a > b. В этом случае существуют такие
целые числа q ≠ 0 и r, 0 ≤ r < b, что имеет место соотношение
a = bq + r.
(1)
Здесь q – частное, а r – остаток от деления числа a на число b. Алгоритм
Евклида вычисления наибольшего общего делителя (НОД) базируется на
следующем факте. Если существует делитель d чисел a и b, то из (1) следует,
что d|r, т.е. справедлива формула:
НОД(a,b) = НОД(b, r) = НОД(b, a mod b).
(2)
Используя формулу (2) определить наибольший общий делитель можно
последующей схеме:
a = bq1 + r1,
b = r1q2 + r2,
r1= r2q3 + r3,
…
rk-1 = rkqk+1 + rk+1,
rk = rk+1qk+2 + rk+2,
где
b > r1> r2> … > 0.
Процесс завершается после того, как на некотором шаге i остаток от деления
r i станет равным нулю. В этом случае будет справедливо равенство
ri-2= ri-1qi,
из которого следует, что ri-1 является наибольшим делителем чисел a и b.
150
Классы
О п р е д е л е н и е 6. Классом вычетов по модулю n называется
множество всех целых чисел, которые сравнимы с некоторым данным целым
числом a. Такой класс обозначается через [a] n .
Условимся, что если значение модуля однозначно определенно, индекс
в обозначении класса будем опускать. Множество всех классов вычетов по
модулю n обозначим через Z / n. Заметим, что в определении не исключается
случай, когда число a больше модуля n.
Т е о р е м а 12. Класс чисел, сравнимых с a по модулю n, совпадает с
множеством чисел вида a + nk, где k – произвольное целое число.
Д о к а з а т е л ь с т в о. Если целое число x ∈ [a], то
x≡a(mod n),
т.е. x - a = nk или x = a + nk, где k – любое целое число. В то же время при
любом значении k имеем
a + nk ≡a(mod n).
Откуда следует, что множество чисел a + nk совпадает с классом [a].
Из теоремы 12 следует, что каждый класс содержит бесконечно
множество чисел.
П р и м е р. Пусть модуль n=7. В этом случае класс [9] состоит из
чисел:
…, -12, -5, 2, 9, 16, 23, …,
Т е о р е м а 13. [a] = [b] тогда и только тогда, когда
a≡b mod n.
Д о к а з а т е л ь с т в о. Если a≡b mod n, то для любого x ∈ [a] следует
соотношение
x≡a(mod n).
Из транзитивности сравнения вытекает, что
x≡b(mod n),
т.е. x ∈ [b]. В силу симметрии a и b следует, что для любого x ∈ [b] имеет
место x ∈ [a]. Таким образом, классы [a] и [b] совпадают.
Обратно. Если [a] = [b], то это означает, что
151
a≡b mod n.
Т е о р е м а 14. Если два класса имеют хотя бы один общий элемент, то
они совпадают.
Д о к а з а т е л ь с т в о. Если x ∈ [a] и x ∈ [b], то
x≡a(mod n), x≡b(mod n),
то по свойству транзитивности
a ≡ b(mod n).
Тогда из теореме 13 следует, что [a] = [b]
Т е о р е м а 15. Если какое-то число класса по модулю n имеет при
делении на n остаток равный r, то все числа класса имеют при делении на n
остаток r.
Д о к а з а т е л ь с т в о. Пусть
x = nk +r, 0 ≤ r < n.
Тогда по теореме 12 все числа из класса, которому принадлежит x, имеют
вид:
x + nt = n(k+t) + r = ns + r,
где s = k+t – любое целое число.
Т е о р е м а 16. Число классов по модулю n конечно и равно n.
Д о к а з а т е л ь с т в о. По теореме 15 все числа одного класса имеют
при делении на n один и тот же остаток. Поэтому классы по модулю n
взаимно однозначно соответствуют остаткам. Остатками при делении на n
являются числа 0, 1, 2, …, n-1.
О п р е д е л е н и е 7. Вычетом класса называется любое из чисел,
которое принадлежит данному классу.
Среди неотрицательных (положительных) вычетов класса обязательно
есть наименьшее, которое называется наименьшим положительным вычетом
класса.
Т е о р е м а 17. Наименьший неотрицательный вычет класса [a] по
модулю n равен остатку от деления a на n.
Д о к а з а т е л ь с т в о. Пусть r – остаток от деления a на n, т.е.
a = nq + r.
Тогда
a ≡r(mod n)
152
и [a] = [r]. В этом случае, если c ∈ [a], то
c = r + nt.
Если t < 0, то
r + nt ≤ r – m < 0. В
результате имеем, что c > 0, если t = 0.
Т е о р е м а 18. Множество классов по данному модулю представляют
собой аддитивную группу, т.е. множество с одной операцией сложения,
нулевым и противоположным элементом.
Т е о р е м а 19. Множество классов по данному модулю представляет
собой коммутативное кольцо.
Полная и приведенная система вычетов
О п р е д е л е н и е 8. Полной системой вычетов по некоторому
модулю называется система чисел, взятых по одному из каждого класса по
этому модулю.
Если из каждого класса по некоторому модулю взять любое число
получается полная система вычетов.
П р и м е р. Числа 12, -23, 2, 63, -2, 5 образуют полную систему
вычетов по модулю 6.
З а м е ч а н и е. Остаток от деления -23 на 6 равен –5 по правилам
обычной арифметики. Чтобы определить класс, которому принадлежит число
-23, надо к остатку -5 прибавить модуль 6. Получим, что число -23
принадлежит классу, который соответствует остатку 1. Аналогичный
результат получаем, если при делении будем добиваться положительного
остатка. В этом случае частное от деления -23 на 6 будет равен -4, а остаток
равен 1.
Обычно в качестве представителей классов берут наименьшее
неотрицательное число из каждого класса. Отсюда следует, что системой
наименьших неотрицательных вычетов по модулю n являются следующие
числа:
1, 2, 3, …, n.
Т е о р е м а 20. Если (a, n) = 1 (a, n – взаимно просты), b –
произвольное целое число, а x пробегает полную систему вычетов по модулю
n, то числа ax+b также принимают значения, которые образуют полную
систему вычетов по этому модулю.
О п р е д е л е н и е 9. Приведенной системой вычетов по некоторому
модулю называется система чисел, которые взяты по одному из каждого
класса, взаимно простого с модулем.
153
Функция Эйлера
О п р е д е л е н и е 10. Число классов по модулю n, взаимно простых с
этим модулем, называется функцией Эйлера φ(n).
Так как число классов взаимно простых с модулем n равно числу целых
чисел, не превосходящих n и взаимно простых с n, то можно дать следующее
эквивалентное определение функции Эйлера.
О п р е де л е н и е 11. Число натуральных чисел, взаимно простых с n и
не превосходящих n, называется функцией Эйлера φ(n).
П р и м е р. Для модуля n = 1 значение функции Эйлера φ(1) = 1. Для
модуля n = 12 в приведенной системе вычетов
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11
только четыре числа
1, 5, 7, 11
являются взаимно простыми с модулем 12. Поэтому φ(12) = 4.
О п р е де л е н и е 12. Функция f(n), определенная на множестве
натуральных чисел, называется мультипликативной, если для любых взаимно
простых натуральных чисел a и b имеет место
f(a, b) = f(a)f(b).
Т е о р е м а 21. Функция Эйлера мультипликативная, т.е. имеет место
соотношение
φ(ab) = φ(a) φ(b),
если числа a и b взаимно просты, т.е. наибольший общий делитель равен 1
или (a, b) = 1.
Т е о р е м а 22. Пусть p – простое число и α - любое натуральное,
тогда
φ(pα) = pα - 1(p-1).
Заметим, что для простого p функция Эйлера φ(p) = p-1.
Т е о р е м а 23. Пусть
m =p1α1p2α2…pkαk,
где pi – простые числа и α, i ≤ k, – любые натуральные числа. Тогда
φ( p1α1p2α2…pkαk) =
=p1α1-1(p1-1) p2α2-1(p1-1)… p1αk-1(pk-1).
П р и м е р ы. Пусть для модуля n=2 и n=3 соответственно
154
φ(2)=1, φ(3) = 2.
Тогда
φ(6)= φ(2×3) = φ(2)φ(3) = 2.
В тоже время
φ(18)= φ(3×6)≠ φ(3) φ(6),
потому что числа 3 и 6 не взаимно просты, наибольший общий делитель
этих чисел равен трем (3,6)=3. Однако имеет место
φ(18) = φ(2×9) = φ(2×32) =
=(2-1) 32-1(3-1) =3×2=6.
Т е о р е м а (Ферма). Для любого простого p и любого a, a ≥ 1, которое
не делится на p, справедливо сравнение
ap-1 ≡ 1 mod p,
или
ap ≡ a mod p.
Заметим, что p-1 для простого p совпадет с функцией Эйлера
φ(p) = p-1.
Поэтому доказываемое сравнение теоремы Ферма можно записать в виде
ap-1 = aϕ (p) ≡ 1 mod p.
Оказывается, что последнее сравнение справедливо для любого модуля m,
взаимно простого с числом a, a ≥ 1. Последний факт подтверждается
следующей теоремой Эйлера.
Т е о р е м а (Эйлер). Для любого модуля m и любого a ≥ 1, взаимно
простого с m, справедливо сравнение
aϕ (m) ≡ 1 mod m.
Теоремы Ферма и Эйлера позволяют находить остатки от деления на
модуль больших степеней заданного числа. Если надо найти остаток от
деления an на модуль m, где (a, m) = 1 (общий делитель a и m равен 1), и
φ(m)<n, то число n можно представить в виде
155
n = qφ(m) + r,
где 0 ≤ r < φ(m). Тогда
an = a qϕ (m) + r = ( aϕ (m) )q ar ≡ ar mod m.
Если существует наибольший общий делитель d у чисел a и m, т.е. (m, a) = d,
то m = m1d и a = a1d, где (m1, a1) = 1. Обозначим через r остаток от деления an
на m. Тогда:
an = an-1a = an-1a1d ≡ r mod m ≡ r mod m1d.
По свойству сравнений можно написать r = r1d. Поэтому
an-1a1d ≡ r mod m ≡ r1d mod m1d
или
an-1a1 ≡ r1 mod m1.
Вычисления остатка r1 от деления an на m сводится к вычислению остатков от
деления чисел a1 и an-1 на модуль m1.
П р и м е р. Найти остаток от деления 1712147 на 52. Для определения
остатка от деления выполним следующие шаги.
1. Определяем значение функции Эйлера для модуля 52, то есть
φ(52) = φ(4×13) = φ(22×13) =
= 22-1(2-1)×(13-1) = 2×12 = 24;
2. Определяем результат деления степени 2147 на значение функции
Эйлера от модуля 52, имеем φ(52) = 24. Частное от деления равно q=89, а
остаток r равен 11. Поэтому можно записать
2147 = q× φ(52) + r = 89×24 + 11;
3. Имеем
17189×24 + 11 = 17189×2417111=
(17124)8917111 = ( 171ϕ (52) )8917111.
По теореме Эйлера 171ϕ (52) = 1. По свойству сравнений, если основание
степени a > m, m – модуль, и
a = qm + r,
156
где q – частное, а r – остаток от деления a на m, то
an mod m ≡ (qm + r)n mod m ≡ rn mod m.
Так как основание степени 171 больше модуля 52, то можно записать
171 = 3×52 + 15,
где 3 – частное от деления числа 171 на модуль 52, а 15 – остаток. Учитывая
проведенные выкладки, получаем
(171ϕ (52))8917111 mod 52 ≡ (1)891511 mod 52 ≡
≡ 1511 mod 52 ≡ 158153 mod 52.
Используя формулу для возведения в степень
a8 mod n = ((a 2 mod n) 2 mod n) 2 mod n,
получаем
152 mod 52 ≡ 225 mod 52 ≡ 17 mod 52.
Далее имеем
172 mod 52 ≡ 289 mod 52 ≡ 29 mod 52.
Теперь можно записать
158 mod 52 ≡ ((152 mod 52)2 mod 52)2 mod 52 ≡
≡ 292 mod 52 ≡ 841 mod 52.
Окончательно получим
158 mod 52 ≡ 841 mod 52 ≡ 9 mod 52.
По свойству сравнений имеем
158153 mod 52 ≡
≡ (158 mod 52) (152 mod 52) (15 mod 52) ≡
≡ (9×17×15) mod 52.
Далее запишем
(9×17×15) mod 52 ≡ (9×17 mod 52) ×15 mod 52 ≡
≡ (153 mod 52) ×15 mod 52 ≡ (49 mod 52)×(15 mod 52) ≡
≡ (49×15) mod 52 ≡ 735 mod 52≡7 mod 52.
157
Окончательно получим
1712147 ≡ (171ϕ (52))8917111 mod 52 ≡ 17111 mod 52 ≡
≡1511 mod 52 ≡ 7 mod 52.
Задача вычисления остатка от деления 1712147 на 52 завершена.
П р и м е р. Найти остаток от деления 1261020 на 138. Заметим, что
основание степени 126 и модуль 138 имеет наибольший общий делитель
равный 6. Для определения остатка от деления делаем следующие шаги.
1. Преобразуем степень и модуль следующим образом
1261020 = 1261019 × 126 = 1261019 × 21×6,
138 = 23×6.
Тогда,
1261020 mod 138 ≡ 1261019 × 21×6 mod (23×6) ≡
≡1261019 × 21 mod 23;
2. Определяем значение функции Эйлера для модуля 23. Т.к. 23 –
простое число, то
φ(23) = 23 – 1 = 22;
3. Определяем результат деления степени 1019 на значение функции
Эйлера от модуля 23, то есть φ(23) = 22. Частное от деления равно q=46, а
остаток r равен r=7, поэтому можно записать
1019 = q× φ(23) + r = 22×46 + 7;
4. Имеет место соотношение
1261019 × 21 mod 23 ≡ (12622×46 + 7 × 21) mod 23 ≡
≡ ( (12622)46 126 7 × 21) mod 23.
Так как по теореме Эйлера можно записать
126ϕ (23) mod 23 ≡ 12622 mod 23 ≡ 1 mod 23,
то в итоге получаем
1261020 mod 138 ≡ 126 7 × 21 mod 23.
158
Учитывая, что остаток от деления числа 126 на модуль 23 равен 11, по
свойствам сравнений можно записать
126 7 × 21 mod 23 ≡ (126 mod 23) 7 × 21 mod 23 ≡
≡117 mod 23 × 21 mod 23.
Вычислим
117 mod 23.
Можно записать
117 mod 23 ≡ 116+1 mod 23 ≡ (116×11) mod 23 ≡
≡116 mod 23 ×11 mod 23.
Далее имеем
116 mod 23 ≡ (112 mod 23)3 mod 23 ≡
≡ (121 mod 23 )3 mod 23.
Учитывая, что остаток от деления числа 121 на модуль 23 равен 6, получаем
(121 mod 23 )3 mod 23 ≡ (6 mod 23)3 mod 23.
Используя свойства сравнений, имеем
(6 mod 23)3 mod 23 ≡ 63 mod 23 ≡ 216 mod 23 ≡ 9 mod 23.
Итак, в результате запишем
117 mod 23 ≡ 9 mod 23×11 mod 23 ≡
≡ (9×11) mod 23 ≡ 7 mod 23
Далее получаем
1261020 mod 138 ≡ 7 mod 23 ×21 mod 23 ≡ (7×21) mod 23 ≡
≡ 147 mod 23≡9 mod 23.
Окончательно имеем
1261020 mod 138 ≡ 6×1 (261019 × 21 mod 23) ≡
≡ 6×9 mod 138 ≡ 54 mod 138.
Таким образом, остаток от деления числа 1261020 на 138 равен 54. Задача
вычисления остатка от деления 1261020 на 138 завершена.
159
Результаты Ферма и Эйлера, которые были получены соответственно в
1640г. и 1760г., явились фундаментом для формирования криптографической
системы RSA c открытым ключом. В 1977 году три американских ученых
Ривест Р., Шамир А. и Адлеман Л. практически одновременно предложили
эту принципиально новую и важную для современных информационных
технологий систему. Фактически же система RSA полностью базируется на
теореме Эйлера.
Сравнения первой степени
Пусть a и b – целые числа. Обозначим через целое m модуль для
вычисления сравнений. Тогда, выражение
ax ≡ b mod m
называется сравнением первой степени с одним неизвестным.
Решить сравнение – значит найти все значения x, которые
удовлетворяют данному сравнению.
Т е о р е м а 24. Если (a, m) = d, т.е. число a и модуль m имеет общий
делитель d, причем число d не делит b, то сравнение
ax ≡ b mod m
не имеет решений.
Т е о р е м а 25. Если (a, m) = 1, т.е. числа a и m взаимно просты, то
сравнение
ax ≡ b mod m
имеет одно и только одно решение.
Т е о р е м а 26. Если (a, m) = 1, т.е числа a и b взаимно простые, то
решением сравнения
ax ≡ b mod m
является класс
x ≡ baϕ (m)-1 mod m,
где φ(m) – значение функции Эйлера для модуля m.
П р и м е р. Решить сравнение
3x ≡ 4 mod 34.
160
Заметим, что (3,4) = 1, т.е. числа 3 и 4 взаимно просты. Тогда решение
определяется формулой
x ≡ 4×3ϕ (34)-1 mod 34.
Вычислим
φ(34) = φ(2×17) = (2-1)×(17-1) = 16.
Тогда значение решения определяется по формуле
x ≡ 4×316-1 ≡ 4×315 mod 34.
Вычислим значение 315 mod 34, используя свойство сравнений. Имеем
315 = (34)3×33 mod 34 ≡ (81 mod 34)3 ×27 mod 34 ≡
≡ (13 mod 34)3×27 mod 34 ≡(133 mod 34)×27 mod 34 ≡
(2197 mod 34)×27 mod 34 ≡ mod (21 mod 34)×27 mod 34 ≡
(21×27) mod 34 ≡ 567 mod 34 ≡ 23 mod 34.
Окончательно для решения сравнения получаем следующее значение для x
x ≡ 4×23 mod 34 ≡ 92 mod 34 ≡ 24 mod 34.
Проверка. Для проверки полученного решения
x = 24 mod 34
подставим x в исходное сравнение
3x ≡ 4 mod 34.
Тогда получим
(3× 24) mod 34 ≡ 72 mod 34 ≡ 4 mod 34,
потому что при делении числа 72 на модуль 34 частное равно 2, а остаток 4.
Отсюда видим, что найденное решение x удовлетворяет данному сравнению.
Задача решения сравнения 3x ≡ 4 mod 34 завершена.
Если число m достаточно большое, то разложить его на простые
множители, чтобы вычислить значение функции Эйлера φ(m) для модуля m и
для того чтобы найти решение сравнения
ax ≡ b mod m
по формуле
x ≡ baϕ (m)-1 mod m,
161
может оказаться сложной задачей. Обычно для определения решения
сравнения используют формулу
где
x ≡ (-1)k-1bPk-1 mod m,
k – число подходящих дробей разложения m/a в цепную дробь;
Pk-1 – знаменатель предпоследней подходящей дроби разложения m/a в
цепную дробь.
Напомним, что из теории цепных дробей известно, что любую дробь
m/a, можно разложить в последовательность подходящих дробей
Pi/Qi , i = 0, 1, …, k.
При этом m/a = Pk/Qk, причем для вычисления Pi и Qi, i = 0, 1, …, k,
справедливы рекуррентные соотношения
Pi = qiPi-1 + Pi-2,
Qi = qiQi-1 + Qi-2,
где qi – частные в алгоритме Евклида при вычислении наименьшего общего
делителя, а начальные значения P0, P1 и Q0, Q1 задаются следующим образом
P0 = 1, Q0 = 0, P1 = q1, Q1 = 1.
З а м е ч а н и е. Первым шагом алгоритма считается результат деления
модуля m на левую часть сравнения, т.е на число a.
П р и м е р. Решить сравнение
37x ≡ 25 mod 107.
Для решения данного сравнения выполним следующие шаги.
1. Вычисляем частное q1 и остаток r2 от деления модуля сравнения
m=107 на число a = 37. Получаем q1 = 2 и остаток r2 = 33. Тогда по
определению имеем P1 = q1 = 2.
2. Вычисляем частное q2 и остаток r3 от деления числа a = 37 на остаток
r2 = 33. Получаем q2 = 1 и остаток r3 = 4. Вычисляем P2 по формуле
P2 = q2P1 + P0 = 1×2 + 1 = 3.
3. Вычисляем частное q3 и остаток r4 от деления числа r2 = 33 на остаток
r3 = 4. Получаем q3 = 8 и остаток r4 = 1. Вычисляем P3 по формуле
162
P3 = q3P2 + P1 = 8×3 + 2 = 26.
4. Вычисляем частное q4 и остаток r5 от деления числа r3 = 4 на остаток
r3 = 1. Получаем q4 = 4 и остаток r5 = 0. Вычисляем P4 по формуле
P4 = q4P3 + P2 = 4×26 + 3 = 107.
Наконец, определяем решение сравнения 37x ≡ 25 mod 107 по формуле
x ≡ (-1)k-1bPk-1 mod m ≡
≡ (-1)3× 26 × 25 mod 107 ≡ -650 mod 107
или
x ≡ -8 mod 107 ≡ 99 mod 107.
Проверка решения x ≡ 99 mod 107 для сравнения 37x ≡ 25 mod 107:
(99×37) mod 107 ≡ 3663 mod 107 ≡
≡ (34×107 + 25) mod 107 ≡ 25 mod 107.
Задача решения сравнения 37x ≡ 25 mod 107 завершена.
Формулу
x ≡ (-1)k-1bPk-1 mod m
для решения сравнения
ax ≡ b mod m
можно использовать для определения обратного значения a-1 к элементу a в
смысле модулярной арифметике. Для вычисления a-1 надо определить x,
решая сравнение
ax ≡ 1 mod m.
В этом случае
a-1 ≡ x ≡ (-1)k-1Pk-1 mod m.
П р и м е р. Решить сравнение
1181x ≡ 1 mod 1290816.
Для решения данного сравнения выполним следующие шаги.
163
1. Вычисляем частное q1 и остаток r2 от деления модуля сравнения
m=1290816 на число a = 1181. Получаем q1 = 1092 и остаток r2 = 1164. Тогда
по определению P1 = q1 = 1092.
2. Вычисляем частное q2 и остаток r3 от деления числа a = 1181 на
остаток r2 = 1164. Получаем q2 = 1 и остаток r3 = 17. Вычисляем P2 по
формуле
P2 = q2P1 + P0 = 1×1092 + 1 = 1093.
3. Вычисляем частное q3 и остаток r4 от деления числа r2 = 1164 на
остаток r3 = 17. Получаем q3 = 68 и остаток r4 = 8. Вычисляем P3 по формуле
P3 = q3P2 + P1 = 68×1093 + 1092 = 75416.
4. Вычисляем частное q4 и остаток r5 от деления числа r3 = 17 на
остаток r4 = 8. Получаем q4 = 2 и остаток r5 = 1. Вычисляем P4 по формуле
P4 = q4P3 + P2 = 2×75416 + 1093 = 151925.
5. Вычисляем частное q5 и остаток r6 от деления числа r4 = 8 на остаток
r5 = 1. Получаем q5 = 8 и остаток r6 = 0. Вычисляем P5 по формуле
P5 = q5P4 + P3 = 8×151925 + 75416 = 1290816.
Наконец, определяем решение сравнения 1181x ≡ 1 mod 1290816 по формуле
x ≡ (-1)k-1Pk-1 mod m ≡ (-1)4× 151925 mod 1290816 ≡
≡ 151925 mod 1290816.
Проверка решения x ≡ 151925 mod 1290816 для сравнения 1181x ≡ 1
mod 1290816. Можно записать
(1181×151925) mod 1290816 ≡
≡ 179423425 mod 1290816 ≡
(139×1290816 + 1) mod 1290816 ≡
≡ 1 mod 1290816.
Задача решения сравнения 1181x ≡ 1 mod 1290816 завершена.
Т е о р е м а 27. Если (a, m) = d, т.е. число a и модуль m имеет общий
делитель d и число d делит b (d|b), то сравнение
ax ≡ b mod m
имеет d решений.
164
Квадратичные вычеты
Пусть p – нечетное простое число.
О п р е д е л е н и е 1. Целое число a называется квадратичным
вычетом по модулю p, если сравнение
x2 ≡ a mod p
имеет решение.
О п р е д е л е н и е 2. Целое число a называется квадратичным
невычетом по модулю p, если сравнение x2 ≡ a mod p не имеет решение.
Свойство целого числа a быть или не быть квадратичным вычетом по
модулю p определяется только свойствами остатка от деления числа a на
число p. Поэтому существуют класс чисел, которые удовлетворяют
определению 1 и 2. Данные числа соответственно называются классом
квадратичных вычетов и невычетов по модулю p.
Т е о р е м а 1. Число a является квадратичным вычетом по простому
модулю p, p>2, p не делит a, тогда и только тогда, когда справедливо
сравнение
a(p-1)/2 ≡ 1 mod p.
Т е о р е м а 2. Число a является квадратичным невычетом по простому
модулю p, p>2, p не делит a, тогда и только тогда, когда справедливо
сравнение
a(p-1)/2 ≡ -1 mod p.
Т е о р е м а 3. Числа
12, 22, …, [(p-1)/2]2
образуют систему представителей всех классов квадратичных вычетов по
простому модулю p (p > 2).
П р и м е р. Рассмотрим число p = 7. Тогда:
12 = 1 ≡ 1 mod 7,
22 = 4 ≡ 4 mod 7,
32 = 9 ≡ 2 mod 7,
42 = 16 ≡ 2 mod 7,
52 = 25 ≡ 4 mod 7,
62 = 36 ≡ 1 mod 7.
Из приведенных соотношений видно, что для p=7 только числа
165
1, 2, 4
являются представителями класса квадратичных вычетов. Эти вычеты
определяются уже для чисел 12, 22, 32.(НЕ ПОНЯТНО ПОЧЕМУ
ВЫДЕЛЕНО) Заметим, что числа
3, 5, 6
являются квадратичными невычетами, так что следующие уравнения:
x2 ≡ 3 mod 7,
x2 ≡ 5 mod 7,
x2 ≡ 6 mod 7
не имеют решения.
О п р е д е л е н и е 3. Пусть a – целое число и p, p > 2 – простое число.
Символом Лежандра L(a, p) определяется равенством
0, если a ≡ 0 mod p
L(a, p) = 1, если a – квадратичный вычет по модулю p,
-1, если a – квадратичный невычет по модулю p.
Иными словами, L(a, p) =1, если сравнение x2 ≡ a mod p имеет решение,
и L(a, p) = -1, если сравнение x2 ≡ a mod p имеет решение.(НЕ ПОНЯТНО
ПОЧЕМУ ВЫДЕЛЕНО) В литературе
символ Лежандра часто обозначается следующим образом:
⎛a⎞
L(a, p) = ⎜⎜ ⎟⎟ .
⎝ p⎠
Далее будем рассматривать случай, когда p не делит a, т.е. L(a, p) ≠ 0.
П р и м е р ы.
L(3, 11) = 1, так как сравнение
x2 ≡ 3 mod 11
имеет два решения
x1 ≡ 5 mod 11 и x2 ≡ -5 mod 11.
L(6, 7) = -1, так как сравнение
x2 ≡ 6 mod 7
166
не имеет решений.
Приведем основные свойства символа Лежандра.
1. Если a ≡ b mod p, то L(a, p) = L(b, p).
2. L(a1×a2×…× ak) = L(a1, p)×L(a2, p)× … ×L(ak, p).
3. L(a2, p) = 1.
4. L(1, p) = 1.
5. L(a, p) = a(p-1)/2 mod p (критерий Эйлера).
6. L(-1, p) = (-1)(p-1)/2
mod p.
2
( p -1)/8
7. L(2, p) = (-1)
.
[(p-1)/2][(q-1)/2]
8. L(q, p) = -1
L(p, q) – закон взаимности. Этот закон можно
записать в виде
L(q, p)L(p, q) = -1[(p-1)/2][(q-1)/2].
На основании перечисленных свойств заметим, что если
то
a = a1α1 … akαk,
L(a, p) = L(a1, p)α1 … L(ak, p)αk.
В данном равенстве, учитывая свойство 3, можно отбросить множители, у
которых показатель αj, j ≤ k, является четным числом. Если же некоторое aj =
2, j ≤ k, то свойство 7 позволяет вычислить значение
L(aj, p)αj = L(2, p)αj.
Вышесказанное позволяет сформулировать алгоритм вычисления символа
Лежандра.
1. Если число a отрицательное, то выделяем множитель L(-1, p);
2. Заменяем число a на остаток от деления числа a на p;
3. Раскладываем число a в произведение в простых сомножителей
a = a1α1a2α2 … akαk;
если число на простые множители не разлагается, то переходим на шаг 7.
4. Переходим к разложению
L(a, p) = L(a1, p)α1 … L(ak, p)αk;
5. Отбрасываем множители с четным значением показателя αj, j ≤ k,;
6. Вычисляем символ Лежандра L(aj, p)αj для aj = 2;
167
7. Если все символы Лежандра в выражении
L(a, p) = L(a1, p)α1 … L(ak, p)αk
вычислены, то алгоритм вычисления L(a, p) завершен. В противном случае
для множителей L(aj, p)αj, у которых aj ≠ 2, применяем закон взаимности
L(p, q) = -1[(p-1)/2][(q-1)/2]L(q, p).
В формуле для L(p, q) полагается p = aj.
8. переходим к шагу 1.
Замечание. На каждом шаге процесс вычисления символа Лежандра
может быть завершен. Это произойдет в том случае, если на каком-то шаге
алгоритма все числа αj, j ≤ k, окажутся равными 1, 2 или –1.
П р и м е р. Вычислить L(68, 113). Здесь a = 68, а p = 113 есть простое
число.
Алгоритм вычисления L(68, 113).
1. Так как a > 0, то множитель L(-1, 113) отсутствует;
2. Так как 68 < 113, то остаток равен самому числу;
3. Разлагаем число a = 68 на простые множители 68 = 22×17;
4. Имеем:
L(68, 113)=L(22×17, 113)=L(22, 113)L(17, 113)=
= [L(2, 113)]2L(17, 113);
5. Так как L(22, 113) = 1 (см. свойство 3), то в разложении:
L(68, 113)= [L(2, 113)]2L(17, 113)
отбрасываем множитель [L(2, 113)]2;
6. После выполнения шага 5 получаем
L(68, 113) = L(17, 113).
В полученном разложении отсутствует множитель L(2, 113);
7. Для множителя L(17, 113), применяя закон взаимности для a=17 и
p=113, получаем:
L(17, 113) = (-1)8×56L(113, 17) = L(113, 17).
8. В итоге получаем
L(68, 113) = L(113, 17).
168
Далее переходим на шаг 1 и начинаем вычислять L(113, 17), здесь a = 113, а p
= 17 есть простое число.
Алгоритм вычисления L(113, 17).
1. Так как a > 0, то множитель L(-1, 17) отсутствует;
2. Остаток от деления числа 113 на 17 равен 11, поэтому получаем:
L(113, 17) = L(11, 17);
3. Число 11 – простое на множители не разлагается;
4. Так как 11 число простое, то переходим к шагу 7;
7. Для множителя L(11, 17), применяя закон взаимности для a=11 и
p=17, получаем:
L(11, 17) = (-1)5×8L(17, 11) = L(17, 11).
8. В итоге имеем
L(113, 17) = L(17, 11).
Далее переходим на шаг 1 и начинаем вычислять L(17, 11), здесь a = 17,
p = 11 – простое число.
Алгоритм вычисления L(17, 11).
1. Так как a > 0, то множитель L(-1, 11) отсутствует;
2. Остаток от деления числа 17 на 11 равен 6;
3. Разлагаем число 6 на простые множители 6 = 2×3;
4. Имеем
L(6, 11) = L(2,11)L(3,11)
5. В разложении множители с четным значением показателей
отсутствуют, поэтому переходим к шагу 6;
6. Вычисляем значение L(2,11):
L(2,11) = [-1](α-1)/8 = [-1]15 = -1,
где
α = p2 = 112 = 121;
7. Для множителя L(3, 11), применяя закон взаимности для a=3 и
p=11, получаем:
L(3, 11) = (-1)1×5L(11, 3) = -L(11, 3).
8. В итоге получаем:
169
L(17, 11) = (-1)×[-L(11, 3)] = L(11,3).
Далее переходим на шаг 1 и начинаем вычислять L(11, 3), здесь a = 11, p = 3 –
простое число.
Алгоритм вычисления L(11, 3).
1. Так как a > 0, то множитель L(-1, 3) отсутствует;
2. Остаток от деления числа 11 на 3 равен 2, поэтому получаем:
L(11, 3) = L(2, 3)
3. Число 2 – простое, на множители не разлагается;
4. Имеем
L(11, 3) = L(2,3)
5. В разложении множители с четным значением показателей
отсутствуют, поэтому переходим к шагу 6;
6. вычисляем значение L(2,3)
L(2, 3) = [-1](α-1)/8 = [-1]1 = -1,
где
α = p2 = 32 = 9.
Окончательно получаем, что
L(68, 113) = -1.
Тем самым вычисление символа Лежандра L(68, 113) завершено. Значение
символа Лежандра L(68, 13) = -1 позволяет сделать вывод, что сравнение
x2 ≡ 68 mod 113
не имеет решений.
О п р е д е л е н и е 4. Пусть нечетное число p имеет следующее
разложение на простые множители
p = p1p2…pk,
где pj, j ≤ k, – простые числа, среди которых могут быть одинаковые. Символ
Якоби J(a, p) определяется равенством:
J(a, p) = L(a, p1) L(a, p2)… L(a, pk).
Заметим, что символ Лежандра является частным случаем символа Якоби.
Более того, если число p – простое, то символ Якоби по определению
170
является символом Лежандра. Вместе с тем символ Якоби J(a, p) может
равняться 1, то есть
J(a, p) = 1,
а сравнение
x2 ≡ a mod p
не имеет решений.
П р и м е р. Определим символ Якоби J(2, 15). По определению
J(2, 15) = L(2,3)L(2,5).
Вычислим L(2, 3)
L(2, 3) = [-1](α-1)/8 = [-1]1 = -1 (α = p2 = 32 = 9)
и L(2, 5)
L(2, 5) = [-1](α-1)/8 = [-1]3 = -1 (α = p2 = 52 = 25).
Окончательно получаем
J(2, 15) = L(2,3)L(2,5) = (-1)(-1) =1.
Итак, J(2, 15) = 1, а сравнение
x2 ≡ 2 mod 15
не имеет решений.
Приведем основные свойства символа Якоби.
1. Если a ≡ b mod p, то J(a, p) = J(b, p).
2. J(a1×a2×…× ak) = J(a1, p)×J(a2, p)× … ×J(ak, p).
3. J(a2, p) = 1.
4. J(1, p) = 1.
5. J(-1, p) = (-1)(p-1)/2
mod p.
2
( p -1)/8
6. J(2, p) = (-1)
.
[(p-1)/2][(q-1)/2]
L(p,q) – закон взаимности. Этот закон можно
7. J(q, p) = -1
еще записать в виде
J(q, p)J(p, q) = -1[(p-1)/2][(q-1)/2].
Алгоритм вычисления символа Якоби.
1. Если число a отрицательно, то выделяем множитель J(-1, p);
2. Заменяем число a на остаток от деления числа a на p;
3. Если число a четно, то представляем его в виде
где a1 – нечетное число.
a = 2ta1,
171
4. Переходим к разложению
J(a, p) = J(2, p)t J(a1, p);
5. Отбрасываем множитель J(2, p)t, если t – четное число;
6. Если t нечетно, то вычисляем символ Лежандра J(2, p)t;
7. Применяем к J(q, p) закон взаимности
L(q, p) = -1[(p-1)/2][(q-1)/2]L(p,q),
где полагается q = a1.
8. Переходим к шагу 1.
П р и м е р. Вычислить J(506, 1103), здесь a = 506, p = 1103 – простое
число. Так как 1103 – простое число, то значение символа Якоби равно
значению символу Лежандра, т.е.
J(506, 1103) = L(506, 1103).
Вычисление символа Якоби упрощается за счет того, что при составном
числе a можно применять закон взаимности. При рассмотрении символов
Лежандра составное число a надо раскладывать на произведение простых
множителей, что является не простой задачей.
Алгоритм вычисления J(506, 1103).
1.Так как a > 0, то множитель J(-1, 1103) отсутствует;
2. Так как 506 < 1103, то остаток равен самому числу;
3. Число a = 506 представляем в виде 506 = 2×253;
4. Переходим к разложению
J(506, 1103) = J(2, 1103)J(253, 1103);
5. Показатель степени t = 1 множителя J(2, 1103) нечетно, поэтому
переходим к шагу 6 (НЕ ПОНЯТНО ПОЧЕМУ ВЫДЕЛЕНО);
6. Вычисляем
J(2, 1103) = [-1](α-1)/8 = [-1]152076 = 1,
где α = p2 = 11032;
7. Для множителя J(253, 1103), применяя закон взаимности при
a=253 и p=1103. Получаем
J(253, 1103) = (-1)126×551J(1103, 253) =
= J(1103, 253).
172
8. В итоге имеем
J(506, 1103) = J(1103, 253).
Далее переходим на шаг 1 и начинаем вычислять J(1103, 253), здесь a = 1103,
p = 253;
Алгоритм вычисления J(1103, 253).
1. Так как a > 0, то множитель J(-1, 253) отсутствует;
2. Остаток от деления числа 1103 на 253 равен 91, поэтому
J(1103, 253) = J(91, 253);
3. Число a = 91 – нечетное, переходим на шаг 7;
4. Не выполняется;
5. Не выполняется;
6. Не выполняется;
7. Для символа Якоби J(91,253), применяя закон взаимности для
a=91 и p=253. Получаем
J(91, 253) = (-1)45×126J(253,91) = J(253, 91).
8. В итоге имеем J(1103, 253) = J(253, 91). Далее переходим на шаг 1 и
начинаем вычислять J(253, 91), здесь a = 253, p = 91;
Алгоритм вычисления J(253, 51).
1. Так как a > 0, то множитель J(-1, 91) отсутствует;
2. Остаток от деления числа 253 на 91 равен 71, поэтому
J(253, 91) = J(71, 91);
3. Число a = 71 – нечетное, переходим на шаг 7;
4. Не выполняется;
5. Не выполняется;
6. Не выполняется;
7. Для символа Якоби J(71, 91), применяя закон взаимности для a=71
и p=91. Имеем
J(71, 91) = (-1)35×45J(91, 71) = -J(91, 71).
8. В итоге получаем J(253, 91) = -J(91, 71). Далее переходим на шаг 1 и
начинаем вычислять J(91, 71), здесь a = 91, p = 71;
Алгоритм вычисления J(91, 71).
173
1. Так как a = 91 > 0, то множитель J(-1, 71) отсутствует;
2. Остаток от деления числа 91 на 71 равен 20, поэтому
J(91, 71) = J(20, 71);
3. Число a = 20 представим в виде a = 22×5;
4. Переходим к разложению
J(20, 71) = J(2, 71)2J(5, 71) :
5. Показатель степень у множителя J(2, 71) t=2 четный, поэтому
J(2, 71)2 = 1.
Переходим к шагу 7;
6. Не выполняется;
7. Для символа Якоби J(5, 71), применяя закон взаимности для a=5 и
p=71. Имеем
J(5, 71) = (-1)2×35J(71, 5) = J(71, 5).
8. В итоге получаем -J(91, 71) = -J(71, 5). Далее переходим на шаг 1 и
начинаем вычислять -J(71, 5), где a = 71, p = 5;
Алгоритм вычисления J(71, 5).
1. Так как a = 71 > 0, то множитель J(-1, 71) отсутствует;
2. Остаток от деления числа 71 на 5 равен 1, поэтому
J(71, 5) = J(1, 5);
3. Число a = 1 – нечетное, переходим на шаг 7;
4. Не выполняется;
5. Не выполняется;
6. Не выполняется;
7. Вычисляем символ Якоби J(1, 5) =1;
8. В итоге получаем -J(71, 5) = -1. Вычисление символа Якоби
J(1103,253) завершен. Окончательно получаем J(1103, 253) = -1. Значение
символа Якоби J(506,1103) = -1 позволяет сделать вывод, что сравнение
x2 ≡ 506 mod 1103
не имеет решений.
Китайская теорема об остатках
174
Одним из важных результатов теории чисел является так называемая
китайская теорема об остатках (KTO). По существу, эта теорема утверждает,
что можно восстановить целое число по множеству его остатков от деления
на числа из некоторого набора попарно взаимно простых чисел. Эта теорема
была доказана приблизительно в 100 году до н.э. Существуют несколько
формулировок китайской теоремы об остатках. Представим здесь некоторые
из них.
Обозначим через Zn кольцо вычетов по модулю n.
Т е о р е м а (КТО). Если
n = n1n2…nk,
где ni, 1≤ i≤k, – взаимно простые числа, то кольцо Zn является прямой суммой
колец Z ni.
Т е о р е м а (КТО). Пусть
ni, 1 ≤ i ≤ k,
взаимно простые числа, и пусть ai – целые числа. Тогда существует такое
число x, что имеет место
x ≡ a1 mod n1,
x ≡ a2 mod n2,
…
x ≡ ak mod nk.
Пусть дана система сравнений:
x ≡ a1 mod n1,
x ≡ a2 mod n2,
…
x ≡ ak mod nk.
Т е о р е м а (КТО). Пусть модули системы линейных сравнений
являются взаимно простыми. Это означает, что общий делитель двух чисел ni
и nj равен единице, то есть (ni, nj) = 1 при 1≤i, j≤k. В этом случае существует
класс вычетов Zni, который удовлетворяет условию
Zni ≡ 0 mod nj.
И, наконец, рассмотрим еще одну формулировку теоремы, которую
будем использовать в дальнейшем в этом пособии.
Т е о р е м а (КТО). Пусть mi, 1≤ i≤k, – взаимно простые числа, и
M=m1m2…mk.
175
Пусть
ai, 0 ≤ ai ≤ mi,
целые числа. Введем обозначение Mi = M/mi. Пусть Ni число, которое
удовлетворяет сравнению
MiNi ≡ 1 mod mi.
При этих условиях сравнение
x ≡ ai mod mi
имеет на интервале [0, M-1] единственное решение, которое определяется
формулой
x = a1N1M1 + a2N2M2 + … + akNkMk.
В рамках условий теоремы китайская теорема об остатках утверждает,
что существует взаимно однозначное соответствие между целыми числами и
некоторым наборами целых чисел. Другими словами, для каждого целого
числа B найдется соответствующий ему единственный набор чисел
b1, b2, …, bk,
и, наоборот, для каждого набора чисел (b1, b2, …, bk) найдется единственное
соответствующему этому набору число B.
П р и м е р. Решить систему сравнений
x ≡ a1 mod 4,
x ≡ a2 mod 5,
x ≡ a3 mod 7,
где m1 = 4, m2 = 5, m3 = 7. Определим число
Вычислим
M = m1m2m3 = 4×5×7 = 140.
M1 = M/m1 = 140/4 = 35,
M2 = M/m2 = 140/5 = 28,
M3 = M/m3 = 140/7 = 20.
Вычислим N1, N2, и N3 из следующих сравнений
N1M1 = 35N1 ≡ 1 mod 4,
N2M2 = 28N2 ≡ 1 mod 5,
176
N3M3 = 20N3 ≡ 1 mod 7.
Решаем 1-ое сравнение
35N1 ≡ 1 mod 4.
Определяем функцию Эйлера
ϕ (4) = ϕ (22) = 22-1(2-1) = 2.
Тогда из теоремы Ферма следует
N1 = 35ϕ (4) -1 mod 4 = 352-1 mod 4 = 35 mod 4 = 3.
Проверка решения 1-го сравнения 35N1 ≡ 1 mod 4. Подставляем
значение N1 = 3 в сравнение
35N1 ≡ 1 mod 4,
получаем
35×3 mod 4 ≡ 105 mod 4 ≡ 1 mod 4.
Решаем 2-ое сравнение
28N2 ≡ 1 mod 5.
Определяем функцию Эйлера φ(5) = 5-1 = 4. Тогда из теоремы Ферма
следует
N2 = 28ϕ (5) -1 mod 5 = 284-1 mod 4 =
=283 mod 5 = 112 mod 5 = 2 mod 5.
Проверка решения 2-го сравнения 28N2 ≡ 1 mod 5. Подставляем
значение N2 = 2 в сравнение
получаем
28N2 ≡ 1 mod 5,
28×2 mod 5 ≡ 56 mod 5 ≡ 1 mod 5.
Решаем 3-е сравнение
20N3 ≡ 1 mod 7.
Определяем функцию Эйлера φ(7)=7-1=6. Тогда из теоремы Ферма следует
N3 = 20ϕ (7) -1 mod 7 = 206-1 mod 7 =
= 205 mod 7 = 20 mod 7 = 6 mod 7 .
177
Проверка решения 3-его сравнения 20N3 ≡ 1 mod 7. Подставляем
значение N3 = 6 в сравнение
20N2 ≡ 1 mod 7,
имеем
20×6 mod 7 ≡ 120 mod 7 ≡ 1 mod 7.
Окончательно получаем, что решение системы сравнений
определяется формулой:
x ≡ a1 mod 4,
x ≡ a2 mod 5,
x ≡ a3 mod 7,
x = (a1N1M1 + a2N2M2 + a3N3M3 =
=(35×3a1 + 28×2a2 + 20×6a3) mod 140.
БИБЛИОГРАФИЧЕСКИЙ СПИСОК
1. А.П. Алферов, А.Ю. Зубков, А.С. Кузьмин, А.В. Черёмушкин. Основы
Криптографии./ Алфёров, А. П.. М.: «Гелиос АРВ», 2001. 480 с.
2. Введение в криптографию. Под редакцией В.В. Ященко./ Под общ. ред.
В.В. Ященко. М.: МЦНМО, «ЧеРо.», 1998. 272 с.
3. М.А. Иванов. Криптографические методы защиты информации в
компьютерных системах и сетях. / Иванов, М. А. М.: «Кудиц-образ», 2001.
368 с.
4. Брюс Шнайер. Прикладная криптография. Протоколы, алгоритмы,
исходные тексты на языке Си./ Шнайер, Брюс. М.: Триумф, 2003. 816 с.
5. Вильям Столлингс. Криптография и защита сетей: принципы и практика/
Столлингс, Вильям. М.: «Вильямс». 2001. 672 с.
6. Н. Смарт. Криптография. / Смарт, Н. М.: Техносфера. 2005. 528 с.
178
7. Венбо Мао. Современная криптография: теория и практика. / Мао, Венбо.
М.: «Вильямс», 2005. 768 с.
8. Саломаа А. Криптография с открытым ключём./ Саломаа А. М.: «Мир»,
1996. 318 с.
9. В. И. Нечаев. Элементы криптографии. Основы теории защиты
информации./ Нечаев В. И. М.: Высш. шк., 1999. 109 с.
10. Х. К. А. ван Тилборг. Основы криптологии. Профессиональное
руководство и интерактивный учебник. / Тилборг ван Х. К. А. М.: Мир, 2006.
471 с.
11. Л. Дж. Хоффман. Современные методы защиты информации./ Хоффман
Л. М.: Сов. Радио, 1980. 264 с.
12. Жельников В. Криптография от папируса до компьютера. / Жельников,
Владимир. М.: АВF, 1996. 336 с.
13. Черёмушкин А.В. Криптографические протоколы. Основные свойства и
уязвимости./ М., 2007, 254 с.
14. М.А. Иванов, И.В. Чугунков. Теория, применение и оценка качества
генераторов псевдослучайных последовательностей./ М., КУДИЦ-ОБРАЗ,
2003, 240 с.
15. В.А. Герасименко, А.А. Малюк. Основы защиты информации. /
Герасименко В.А.: М., ООО «Инкомбук», 1997, 537 с.